Digital Transformation of the Etymological Dictionary of Geographical Names


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
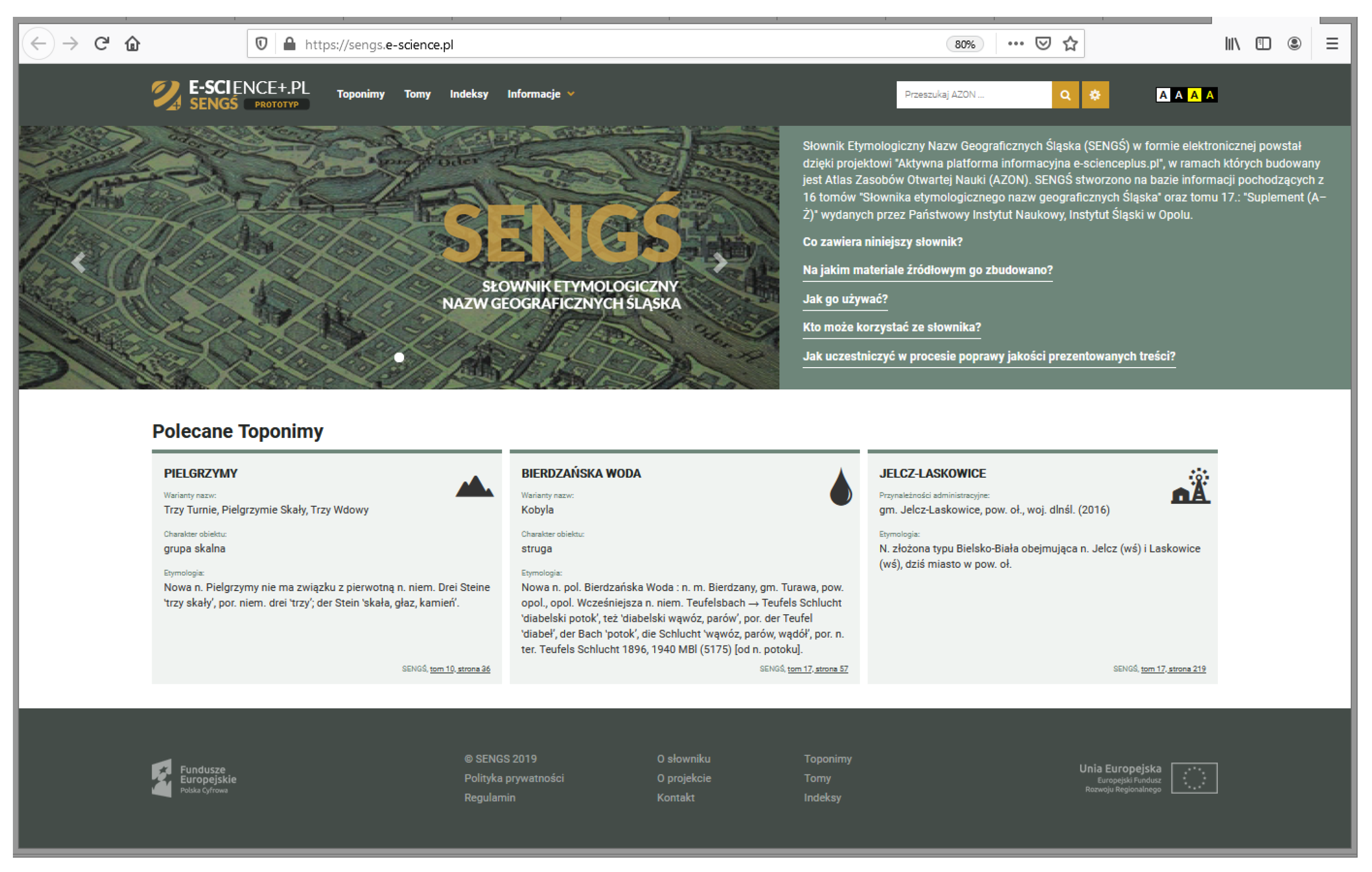
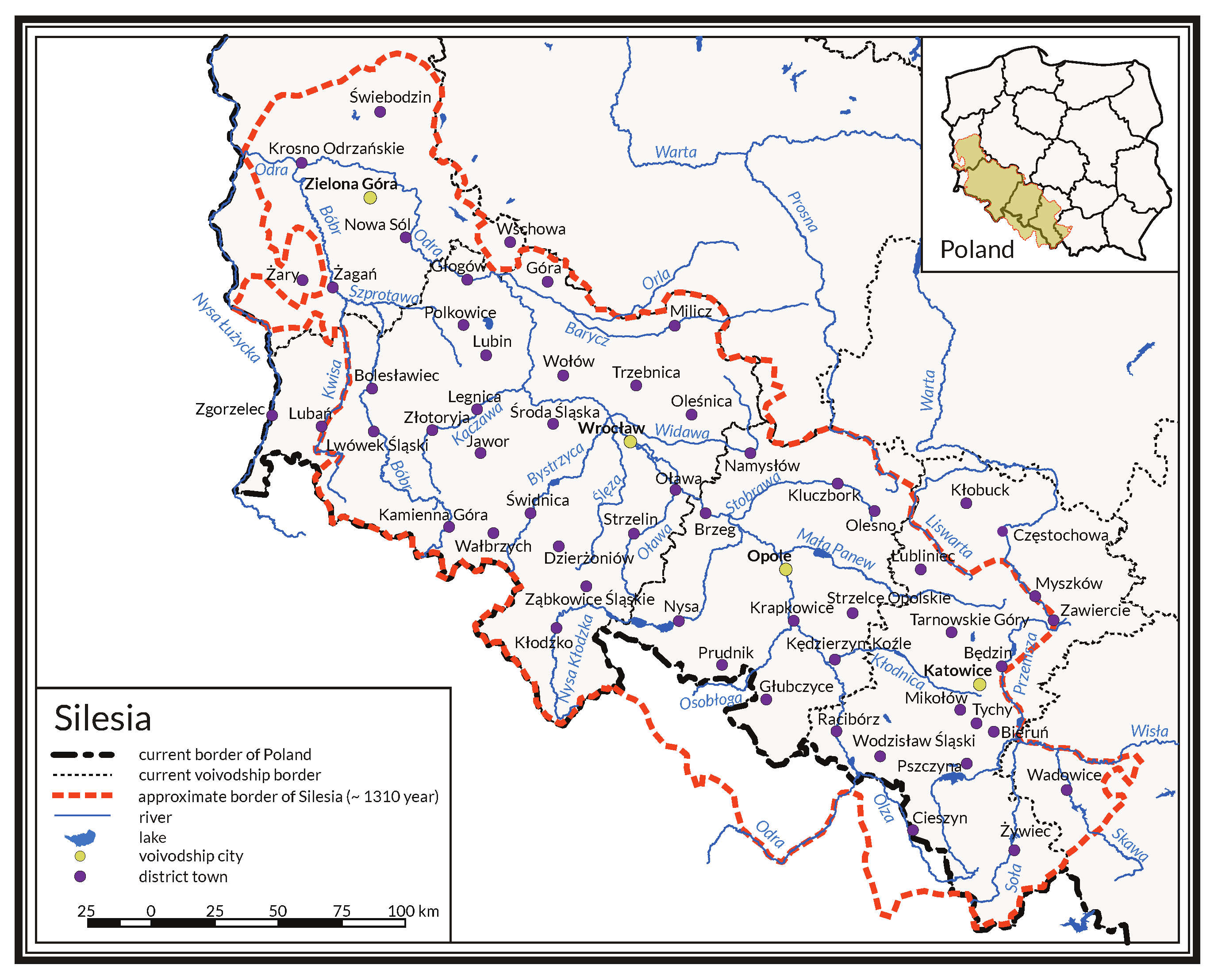
2. The Etymological Dictionary of the Geographical Names of Silesia
2.1. Scope of the Dictionary
2.2. Dictionary Evolution
2.3. Details of Entries
- Descriptive entries, with detailed descriptions of real objects;
- Referring entries, with labels of other entries listed for comparison.
- Lexical label—holds the name of the object or objects being described. By default, the lexical label opens the description of the first object. If there are more objects, their descriptions are given in enumerated sections (the second and the consecutive section are marked with numbers, and the use of a repetition character “” at the beginning is allowable). These sections can be mapped to the senseGroups, and the section number to the senseNumber [14]. The label can be marked with a character denoting a certainty qualifier: “∗” if the reconstructed name differs from the common form, “†” if the name was considered to be lost, and “?” if the reconstruction of the name is doubtful or unclear. All the names are given in the primary, reconstructed, and current forms (at the time of dictionary publication).
- Genitive ending (or endings)—if given, it represents the genitive of the Polish name (the second case in Polish grammar).
- Name variant (or variants)—one or more words representing a name variant. By assumption, the words placed in brackets are official names, and others are treated as unofficial names. In most cases, if a name was given in Polish, an official variant was in the German language.
- Physical characteristics of the object—these define the nature of the object (e.g., city, river, village).
- Location of the object—informs about the administrative affiliation of the object and/or about names of the associated river basin, river inflow, or mountain peak, depending on the object’s nature.
- Historical material—a chronologically ordered aggregation of: a transliterated form of the name (as mentioned in the historical source), year, and bibliographic reference to the historical source (usually an abbreviation of the name, followed by the volume, numbering, or position).
- Etymology—explains the origins of the name. This part appears at the end of the entry. Its paragraph without any annotations applies to all objects described, and annotation with numbers (or a range of numbers) applies to objects described in the relevant numbered sections.
- Source lexical label—contains the name used as a comparison source, sometimes assisted with a complement (additional text);
- Destination lexical labels—represent names (at least one) serving as comparison destinations, pointing at other descriptive or referring entries, sometimes assisted with complements (additional texts).
3. Model Design
- Parts of the entries that do not determine real objects can be treated as abstract toponyms. Because of the existence of two kinds of entries, the abstract toponyms can be divided into: explicated toponyms (which are abstract toponyms associated directly with detailed descriptions of real objects) and compared toponyms (which are abstract toponyms associated with the other abstract toponyms through the comparison list. The entry parts that are related to real objects (real places) can be treated as concrete toponyms. They are characterized by attributes such as: name, genitive, location, etymology, etc.
- There exists an association between concrete toponyms and explicated toponyms belonging to the same entry: the attributes shared among concrete toponyms, like part of the etymological description, are assigned to the corresponding explicated toponym.
- Each concrete toponym is affiliated with the proper administrative unit valid at the time of publication of the particular volume. However, adding the current administrative affiliation should also be possible.
- To facilitate advanced searching and linking, the following model extensions are required: classifying attributes for reasonable cross-sectioning, georeferenced location for positioning in the real world, external links to related Web resources, and references to historical materials managed in external systems.
- Ideally, all references appearing in the descriptive parts of the entries should be converted into hyperlinks. Therefore, the data types used to implement the relevant parts of the model should offer such a possibility.
- There should be some elements available to declare data certainty.
- The form of etymological description should be preserved, but its structuring should be considered. Based on these assumptions, two models were designed: an entity-relationship model and a graph model.
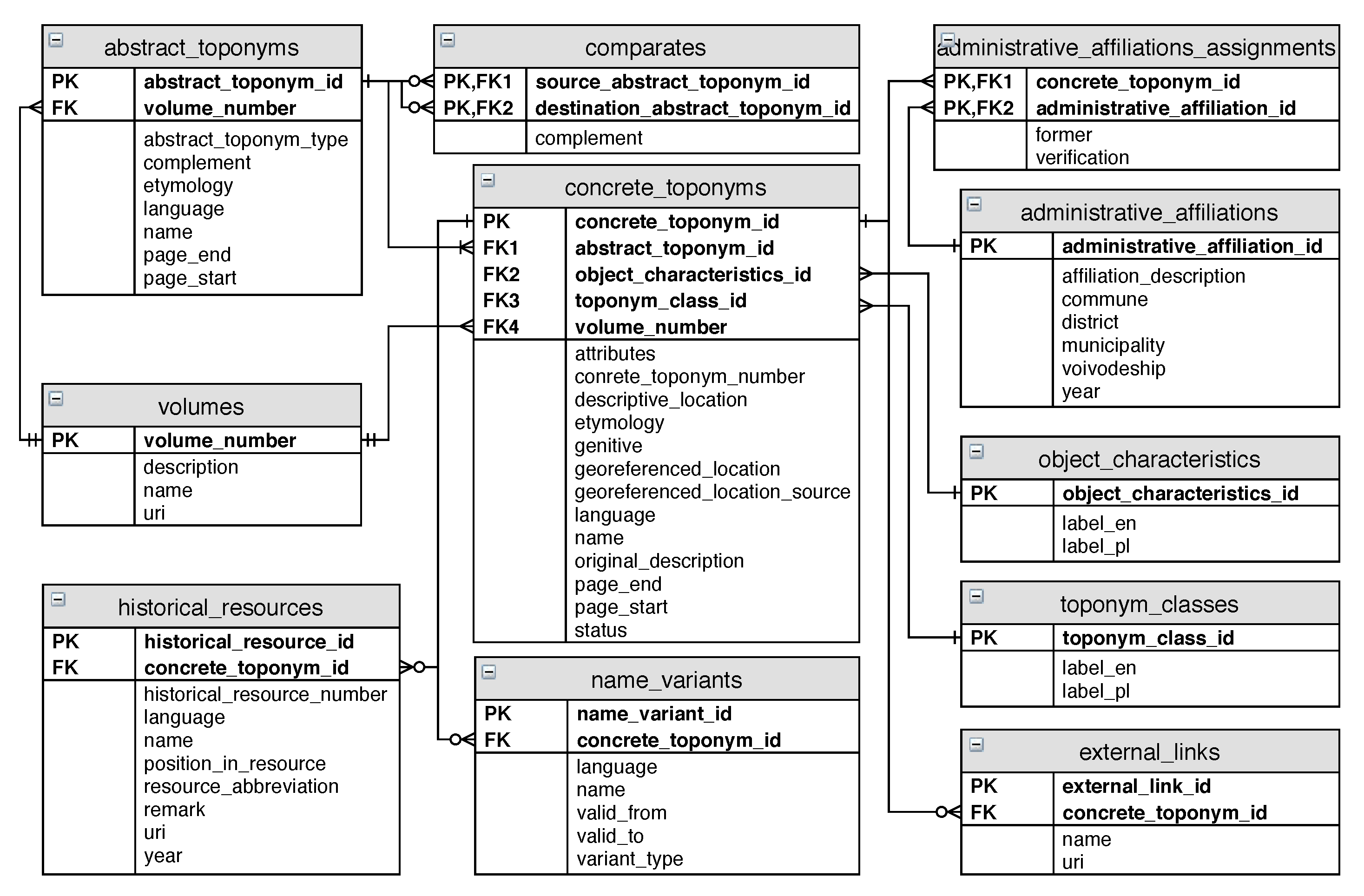
3.1. An Entity-Relationship Model
- concrete_toponym_id, abstract_toponym_id—primary and foreign keys;
- object_characteristics_id—a foreign key to the object_characteristics table that stores qualifiers as: city, town, village, etc. (over 370 such terms were identified);
- toponym_class_id—a foreign key that refers to the primary key in the table with terms representing toponym classes, like oikonym, hydronym, urbanonym, etc. (an extension introduced to facilitate qualification);
- attributes—a place for the specific information about objects being described (e.g., river length, mountain height, lake surface area);
- concrete_toponym_number—a number assigned to a concrete toponym;
- descriptive_location—a location expressed in natural language, applicable especially to rivers (descriptions of river courses, basins, and inflows) and mountains (descriptions of mountain peaks and ranges);
- etymology—a descriptive explanation of the name’s origin (potentially encoded with the use of markup language);
- genitive—a genitive ending (or endings);
- georeferenced_location—a location in the form of geometry represented as Well-Known Text (WKT) strings [26] (an extension introduced together with georeferenced_location_source to facilitate georeferencing);
- georeferenced_location_source—source of information stored in georeferenced_location;
- language—a language in which the name is given;
- name—a real object name;
- original_description—an original, textual description extracted from the dictionary (an extension introduced for data verification);
- volume_number, page_start, page_end—attributes used to represent the physical position of the description in the original dictionary (an extension introduced to preserve information about origins of data);
- status—a certainty qualifier.
- administrative_affiliation_id—a primary key;
- affiliation_description—an attribute merging all parts of administrative affiliation into one string (potentially encoded with the use of markup language) for display on the user interface;
- commune, district, municipality, and voivodeship—attributes used to represent names of administrative units at different levels of administrative division;
- year—an attribute indicating the year in which the administrative affiliation was valid (usually the year of the volume’s publication).
- historical_resource_id, concrete_toponym_id—primary and foreign keys;
- name—a historical name of a concrete toponym, often in a form presented in a historical source;
- language—the language of the source;
- historical_resource_number—a number representing a position in a chronological list;
- position_in_resource—a relative position of the quoted content (like page, sheet number, etc.);
- resource_abbreviation—an abbreviation assigned to the historical source;
- uri—a link to the record of the historical source deposited and published in AZON (an extension);
- year—year of appearance.
3.2. Graph Model
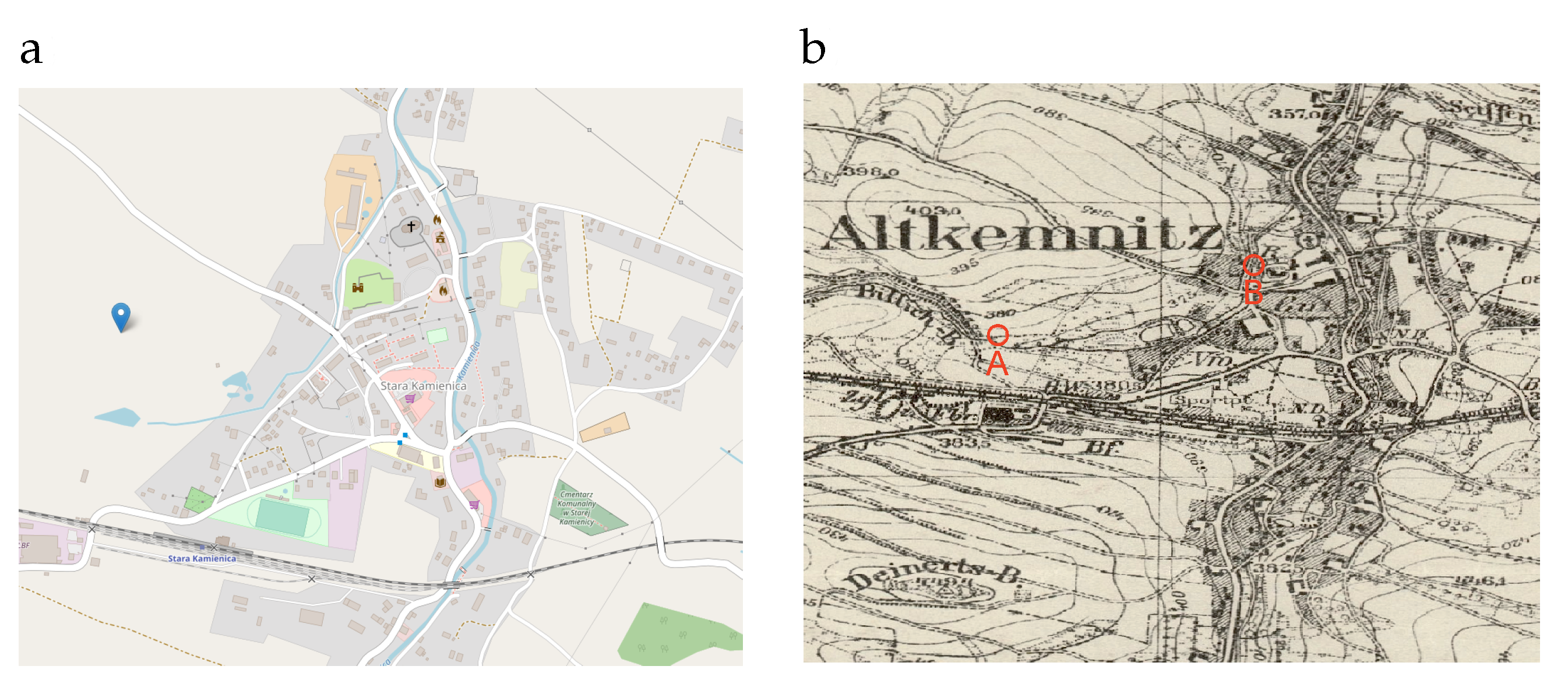
3.3. Georeferences
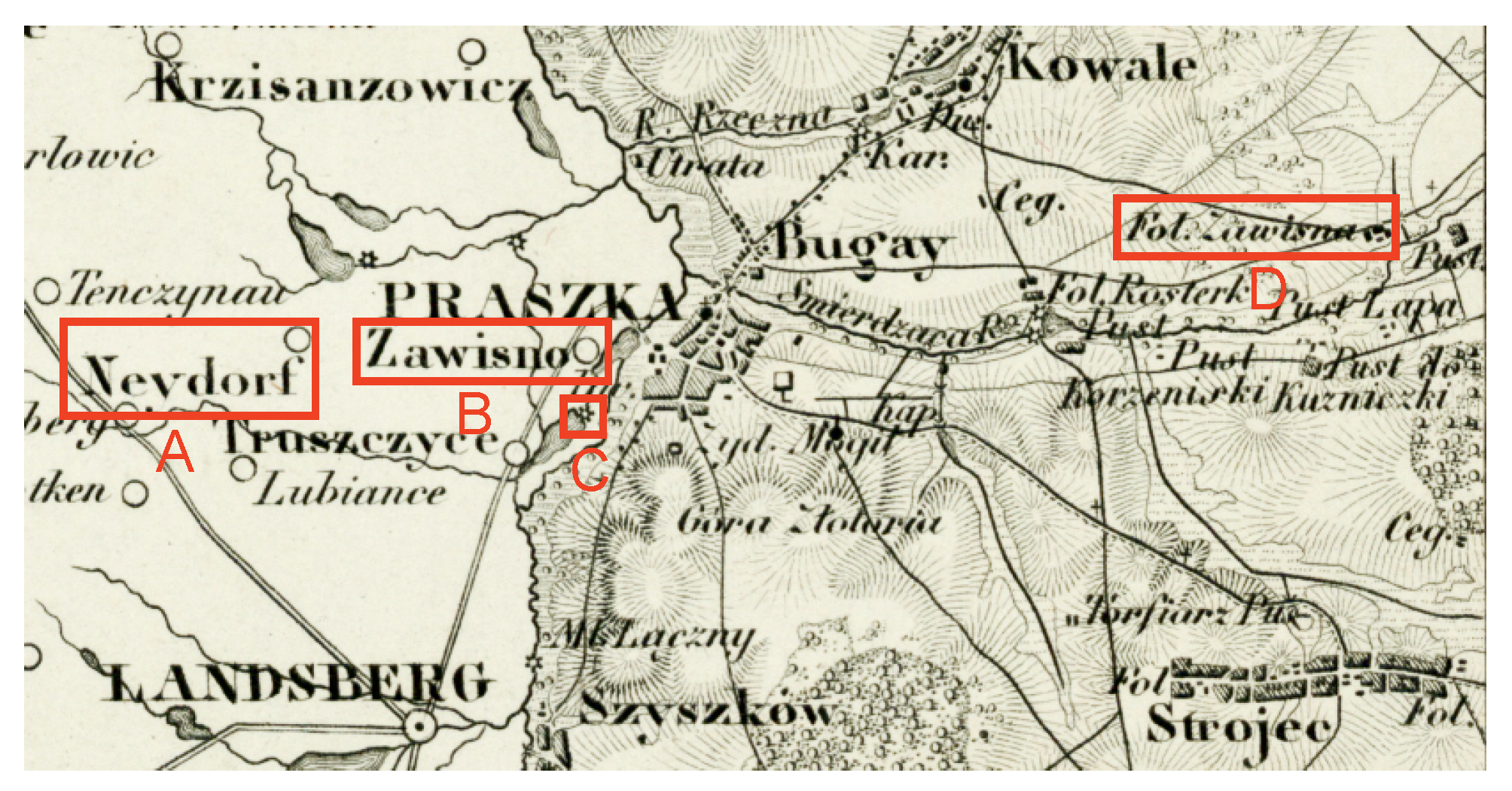
- Zawisna (1, vol. 4)—smelter and settlement, now part of the town of Praszka (name transferred from the name of the settlement)—with the oldest name dating back to 1845 according to the historical resources.
- Zawisna (Sowisna, Eichelhof) (1, vol. 16)—premises/buildings to Ciecierzyna, Byczyna municipality, Kluczbork district (pol. powiat), Opole voivodeship—with multiple name forms, of which the oldest one dates back to 1783. Etymology: eichelhof (ger.)—“oak mansion”.
- Zawisna (Grenzwiese) (2, vol. 16)—Part of Nowa Wieś Oleska, Gorzów Śląski municipality, Olesno district (pol. powiat), Opole voivodship—with multiple name forms, of which the oldest one dates back to 1834. Etymology: grenzwiese (ger.)—“border meadow”—an artificial German name from 1936;.
- Zawisna (Grenzmühle) (3, vol. 16)—carding mill with buildings to Zawisna, Olesno district (pol. powiat), Opole voivodship. Etymology: grenzmühle (ger.)—“border mill” (compare die Grenze (ger.)—“border”, die Mühle (ger.)—“mill”) has been replaced with the Polish name Zawisna. The historical resource list includes the map Messtischblatt 1:25,000 (symbol 4976) published in 1940.
- Krajowy Rejestr Urzędowy Podziału Terytorialnego Kraju (TERYT: “National Official Register of the Territorial Division of the Country”);
- Państwowy Rejestr Nazw Geograficznych (PRNG: “National Register of Geographical Names”);
- Państwowy Rejestr Granic (PRG: “National Register of Boundaries”);
- Baza Danych Obiektów Ogólnogeograficznych (BDOO: “General Geographic Database”);
- Baza Danych Obiektów Topograficznych (BDOT: “Database of Topographic Objects”);
- Komputerowa mapa podziału hydrograficznego Polski (“Computer map of hydrographic division of Poland”);
- The outcomes of institutions responsible for names standardization, such as Komisja Nazw Miejscowości i Obiektów Fizjograficznych (KNMIOF: “Commission on Names of Localities and Physiographic Objects”) and Komisja Standaryzacji Nazw Geograficznych poza Granicami Rzeczypospolitej Polskiej (KSNG: “Commission on Standardization of Geographical Names Outside the Republic of Poland”).
- Geonames (http://www.geonames.org/export/web-services.html);
- OpenStreetMap (OSM; https://gis-support.pl/openstreetmap-jak-pobrac-dane/);
- Getty Thesaurus of Geographic Names® Online (https://www.getty.edu/research/tools/vocabularies/tgn/);
- Mapster (http://igrek.amzp.pl/search.php?range=short);
- Wikipedia (https://www.wikipedia.org/).
- select ?l {
- ?a <https://pzgik.geoportal.gov.pl/ontologies/prng/nazwaGlowna>\linebreak "Stara Kamienica" .
- ?a <http://www.opengis.net/ont/geosparql#hasGeometry> ?g .
- ?g <http://www.opengis.net/ont/geosparql#asWKT> ?l} limit 10
4. Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ginsburg, R.; Khidekei, S.; Knyazeva, G.; Sankin, A. A Course in Modern English Lexicology (Revised and Enlarged, Second ed.); VYSŠAJA ŠKOLA: Moscow, Russia, 1979. [Google Scholar]
- Harpring, P. Introduction to Controlled Vocabularies: Terminology for Art, Architecture, and Other Cultural Works; Getty Research Institute: Los Angeles, CA, USA, 2010. [Google Scholar]
- Kubik, T. Role of Thesauri in the Information Management in the Web-Based Services and Systems. In Transactions on Computational Collective Intelligence III; Nguyen, N.T., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 25–49. [Google Scholar]
- INSPIRE Registry, Theme Register: Names, Definitions (From the INSPIRE Directive) and Descriptions (Based on the Data Specifications Technical Guidelines), 2020. Available online: http://inspire.ec.europa.eu/theme/gn (accessed on 2 October 2020).
- Hill, L.L. Georeferencing: The Geographic Associations of Information; MIT Press: Cambridge, MA, USA; London, UK, 2006. [Google Scholar]
- Cimiano, P.; Chiarcos, C.; McCrae, J.P.; Gracia, J. Linguistic Linked Open Data Cloud. In Linguistic Linked Data: Representation, Generation and Applications; Springer International Publishing: Cham, Switzerland, 2020; pp. 29–41. [Google Scholar]
- Berners-Lee, T. Linked-Data Design Issues. W3C Design Issue Document, 2009. Available online: http://www.w3.org/DesignIssues/LinkedData.html (accessed on 2 October 2020).
- Babczyński, T.; Kubik, T.; Ptak, R.; Strauchold, G. GIS as a tool to analyze the history of Silesia and the changes in its political (and cultural) geography. Stud. Geohistorica 2016, 4, 113–141. [Google Scholar]
- Sochacka, S. Słownik etymologiczny nazw geograficznych Śląska. Suplement A–Ż; Państwowy Instytut Naukowy, Instytut Śląski w Opolu: Opole, Poland, 2016. [Google Scholar]
- Semkowicz, W. Podstawy historyczno-geograficzne Śląska. In Historia Śląska od Najdawniejszych Czasów do Roku 1400; Spulera, B., Translator; Die Historisch-Geographischen Grundlagen Schlesiens: Berlin, Germany, 1935; Volume 1. [Google Scholar]
- Arnold, S. Terytoria Plemienne w Ustroju Administracyjnym Polski Piastowskiej (w. XII-XIII); Prace Komisji dla Atlasu Historycznego Akademii Umiejętności: Kraków, Poland, 1927. (In Polish) [Google Scholar]
- Hosák, L.; Šrámek, R. Místní jména na Moravě a ve Slezsku I, A–L, II, M–Ž; Academia, Tisk 2, Brno: Praha, Czech Republic, 1970–1980. [Google Scholar]
- Howard, J. Lexicography: An Introduction, 1st ed.; Routledge: London, UK; New York, NY, USA, 2002. [Google Scholar]
- ISO 1951:2007. Presentation/Representation of Entries in Dictionaries—Requirements, Recommendations and Information; International Organization for Standardization: Geneva, Switzerland, 2007. [Google Scholar]
- Pras, A.; Schoenwaelder, J. On the Difference between Information Models and Data Models. RFC 3444, IETF, 2003. Available online: http://tools.ietf.org/rfc/rfc3444.txt (accessed on 2 October 2020).
- Burnard, L.; Bauman, S. (Eds.) TEI P5: Guidelines for Electronic Text Encoding and Interchange. Version 3.6.0. Last updated on 16th July 2019; TEI Consortium, 2019; Available online: https://www.tei-c.org/release/doc/tei-p5-doc/en/html/DI.html (accessed on 2 October 2020).
- ISO 25964-1. Information and Documentation—Thesauri and Interoperability with Other Vocabularies—Part 1: Thesauri for Information Retrieval; Standard; International Organization for Standardization: Geneva, Switzerland, 2011. [Google Scholar]
- Miles, A.; Bechhofer, S. SKOS Simple Knowledge Organization System Reference. W3C recommendation, W3C, 2009. Available online: http://www.w3.org/TR/skos-reference (accessed on 2 October 2020).
- “About WordNet.” WordNet. Princeton University. 2010. Available online: http://wordnet.princeton.edu (accessed on 2 October 2020).
- Maziarz, M.; Piasecki, M.; Rudnicka, E.; Szpakowicz, S.; Kędzia, P. PlWordNet 3.0—A Comprehensive Lexical-Semantic Resource. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; Calzolari, N., Matsumoto, Y., Prasad, R., Eds.; ACL: Stroudsburg, PA, USA, 2016; pp. 2259–2268. [Google Scholar]
- McCrae, J.; de Cea, G.A.; Buitelaar, P.; Cimiano, P.; Declerck, T.; Pérez, A.G.; Gracia, J.; Hollink, L.; Montiel-Ponsoda, E.; Spohr, D.; et al. The Lemon Cookbook. 2012. Available online: https://lemon-model.net/lemon-cookbook/index.html (accessed on 2 October 2020).
- Rospond, S. Klasyfikacja Strukturalno-Gramatyczna Słowiańskich Nazw Geograficznych; Prace Wrocławskiego Towarzystwa Naukowego, Seria A, nr 58; Państwowy Wydawnictwo Naukowe: Wrocław, Poland, 1957. [Google Scholar]
- Szymanek, B. Compounding in Polish and the absence of phrasal compounding. In Further Investigations into the Nature of Phrasal Compounding; Trips, C., Kornfilt, J., Eds.; Language Science Press: Berlin, Germany, 2017; pp. 49–79. [Google Scholar]
- Codd, E.F. The Relational Model for Database Management: Version 2; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1990. [Google Scholar]
- Curé, O.; Blin, G. (Eds.) Chapter Two—Database Management Systems. In RDF Database Systems. Triples Storage and SPARQL Query Processing; Morgan Kaufmann: Boston, MA, USA, 2015; pp. 9–40. [Google Scholar] [CrossRef]
- ISO/IEC 13249-3:2016. Information Technology—Database Languages—SQL Multimedia and Application Packages—Part3: Spatial; Standard; International Organization for Standardization, International Electrotechnical Commission: Geneva, Switzerland, 2016. [Google Scholar]
- ISO/DIS 24613-3. Language Resource Management—Lexical Markup Framework (LMF)—Part 3: Etymological Extension; Working Draft; International Organization for Standardization: Geneva, Switzerland, 2019. [Google Scholar]
- Cyganiak, R.; Wood, D.; Lanthaler, M. RDF 1.1 Concepts and Abstract Syntax. W3C Recommendation, W3C, 2014. Available online: http://www.w3.org/TR/2014/REC-rdf11-concepts-20140225/ (accessed on 2 October 2020).
- Guha, R.; Brickley, D. RDF Schema 1.1. W3C Recommendation, W3C, 2014. Available online: http://www.w3.org/TR/rdf-schema/ (accessed on 2 October 2020).
- W3C OWL Working. OWL 2 Web Ontology Language. Document overview (Second Edition). W3C Recommendation, W3C, 2012. Available online: http://www.w3.org/TR/owl2-overview/ (accessed on 2 October 2020).
- ISO 21127:2014. Information and Documentation—A Reference Ontology for the Interchange of Cultural Heritage Information; Standard; International Organization for Standardization: Geneva, Switzerland, 2014. [Google Scholar]
- RDF 1.1 Semantics. W3C Recommendation, W3C, 2014. Available online: http://www.w3.org/TR/2014/REC-rdf11-mt-20140225/ (accessed on 2 October 2020).
- OWL 2 Web Ontology Language Mapping to RDF Graphs (Second Edition). W3C Recommendation, W3C, 2012. Available online: http://www.w3.org/TR/2012/REC-owl2-mapping-to-rdf-20121211/ (accessed on 2 October 2020).
- DCMI Usage Board. DCMI Metadata Terms. DCMI Recommendation, Dublin Core Metadata Initiative, 2020. Available online: https://www.dublincore.org/specifications/dublin-core/dcmi-terms/ (accessed on 2 October 2020).
- DCMI Usage Board. Using Dublin Core—Dublin Core Qualifiers. DCMI recommended resource, Dublin Core Metadata Initiative, 2005. Available online: https://www.dublincore.org/specifications/dublin-core/usageguide/qualifiers/ (accessed on 2 October 2020).
- Hogan, A.; Arenas, M.; Mallea, A.; Polleres, A. Everything you always wanted to know about blank nodes (but were afraid to ask). J. Web Semant. 2014, 27, 42–69. [Google Scholar] [CrossRef]
- Martínez, O. How archaeologists found the lost city of Troy. Natl. Geogr. Hist. Mag. 2018. Available online: https://www.nationalgeographic.com/history/magazine/2015/12/the-lost-city-of-troy/ (accessed on 2 October 2020).
- Rymut, K. The Polish Toponymic Guidelines, 1993. Available online: http://ksng.gugik.gov.pl/pliki/the_polish_toponymic_guidelines.pdf (accessed on 2 October 2020).
- Council of Ministers. Regulation of the Council of Ministers of 8 August 2000 Concerning the National Reference System (pol. Rozporządzenie Rady Ministrów z Dnia 8 sierpnia 2000 r. w Sprawie Państwowego Systemu Odniesień Przestrzennych. In Dz.U. 2000 nr 70, poz. 821. Available online: http://isap.sejm.gov.pl/isap.nsf/DocDetails.xsp?id=WDU20000700821 (accessed on 2 October 2020).








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kubik, T. Digital Transformation of the Etymological Dictionary of Geographical Names. Appl. Sci. 2021, 11, 289. https://doi.org/10.3390/app11010289
Kubik T. Digital Transformation of the Etymological Dictionary of Geographical Names. Applied Sciences. 2021; 11(1):289. https://doi.org/10.3390/app11010289
Chicago/Turabian StyleKubik, Tomasz. 2021. "Digital Transformation of the Etymological Dictionary of Geographical Names" Applied Sciences 11, no. 1: 289. https://doi.org/10.3390/app11010289
APA StyleKubik, T. (2021). Digital Transformation of the Etymological Dictionary of Geographical Names. Applied Sciences, 11(1), 289. https://doi.org/10.3390/app11010289