EmbeddedPigDet—Fast and Accurate Pig Detection for Embedded Board Implementations




Abstract
1. Introduction
- Individual pigs are detected with a low-cost embedded board, such as an NVIDIA Jetson Nano [50]. Although many pig detection methods have been proposed with typical PCs, an embedded board-based pig detection method is proposed here, to the best of our knowledge for the first time. Since low-cost embedded boards have more limited computing power than typical PCs, fast and accurate detection of individual pigs for low-cost pig monitoring applications is very challenging. Because this research direction for a light-weight pig detector is a kind of “on-device” AI [51,52,53,54,55], it can also contribute to the on-device AI community.
- For satisfying both execution speed and accuracy requirements with a low-cost embedded board, we first reduce the computational workload of 3 × 3 convolution of a deep learning-based object detector, in order to get a light-weight version of it. Then, with simple image preprocessing steps, we generate a three-channel composite image as an input image for the light-weight object detector, in order to improve the accuracy of the light-weight object detector. With this fast and accurate pig detector, we can integrate additional high-level vision tasks for continuous monitoring of individual pigs, in order to reduce the damage of a pig farm.
2. Background
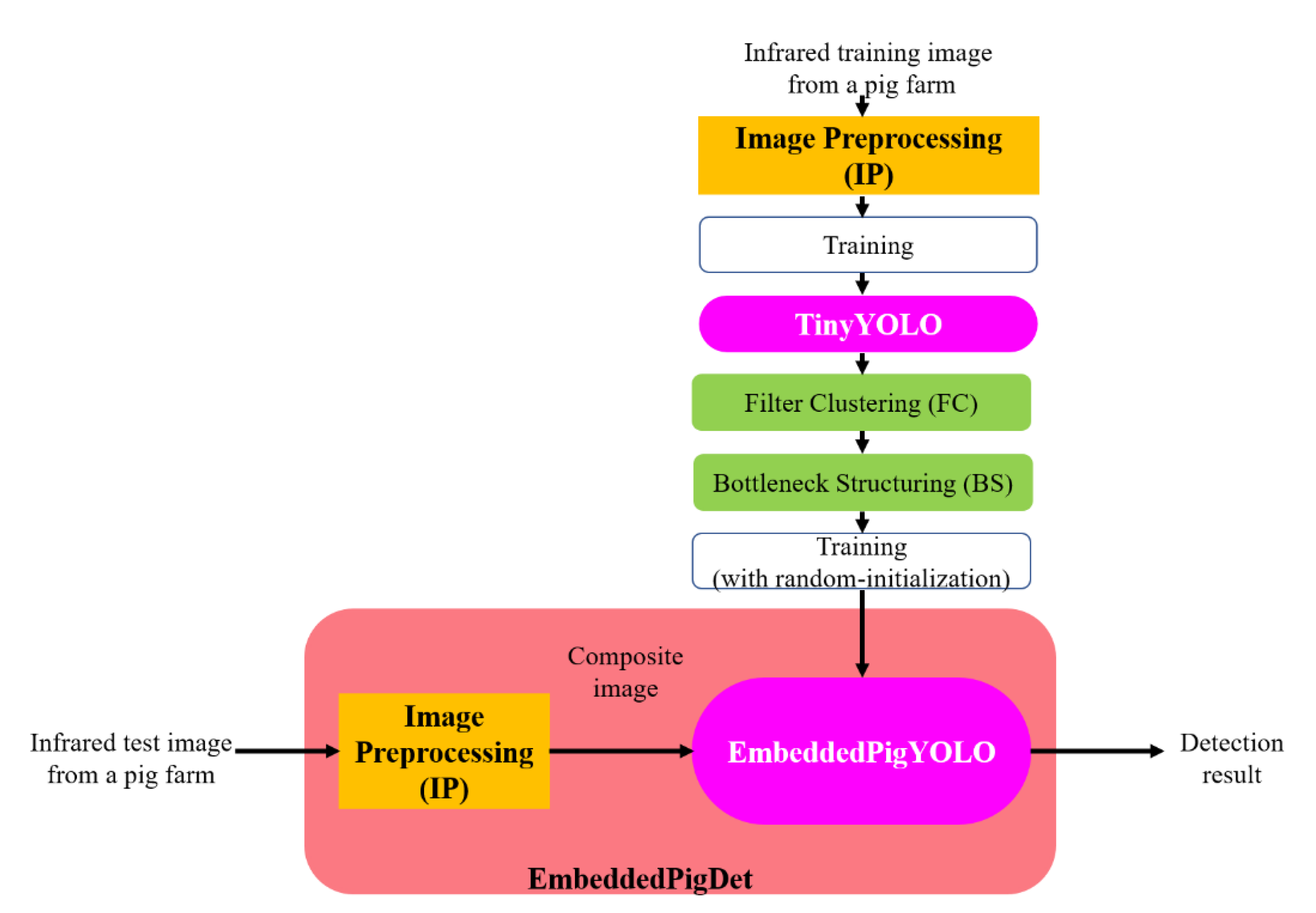
3. Proposed Method
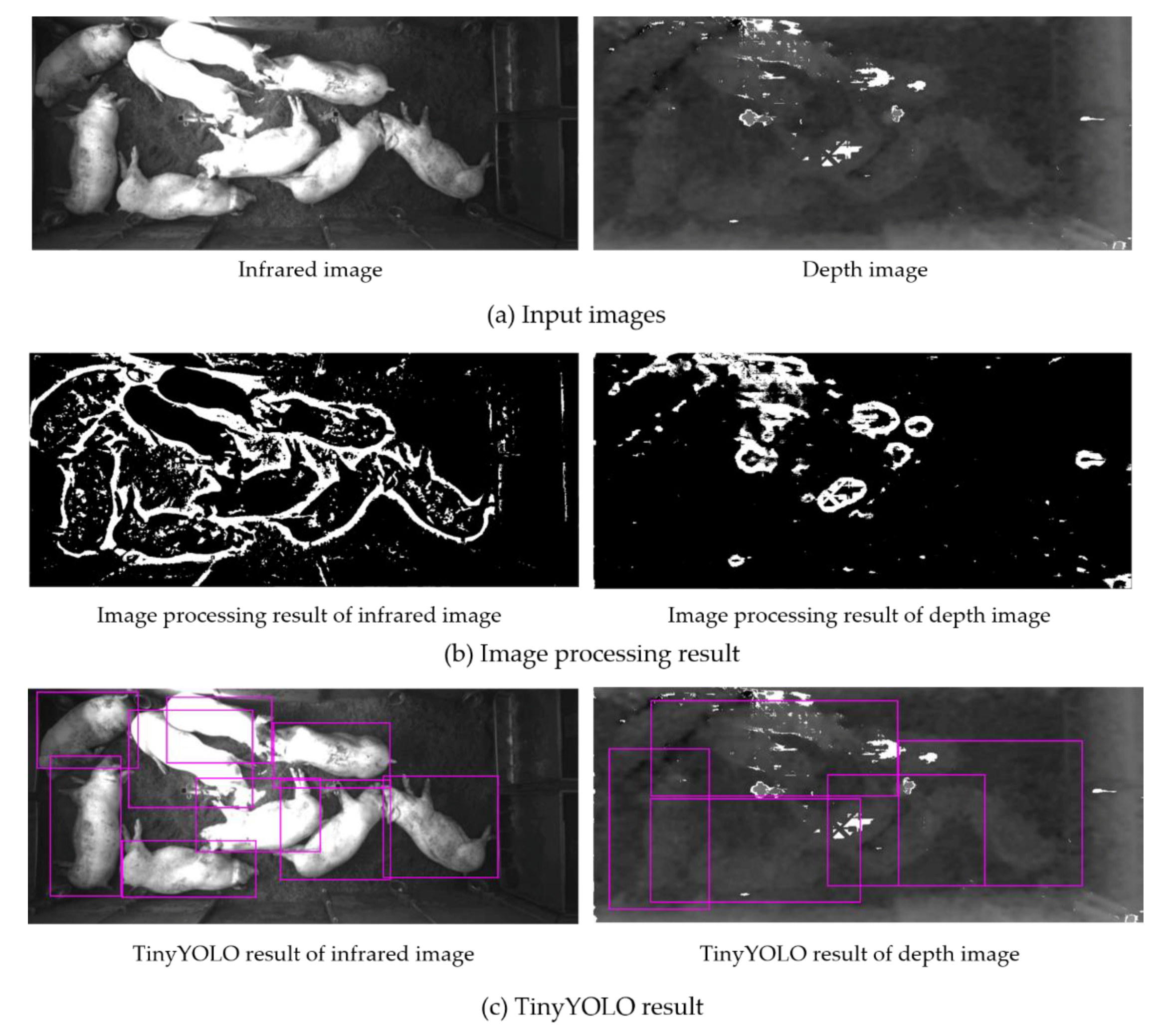
3.1. Image Preprocessing (IP) Module
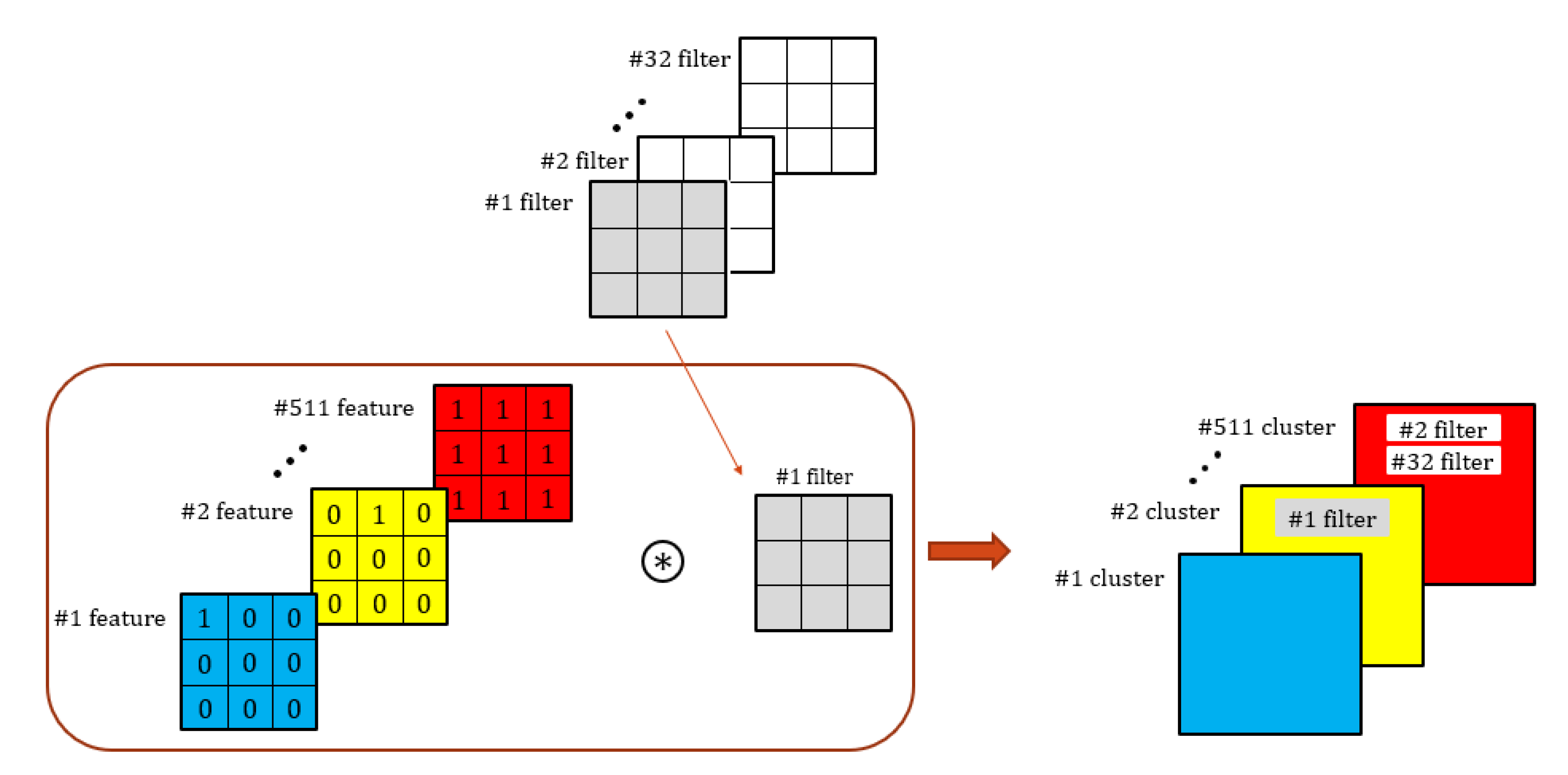
3.2. Filter Clustering (FC) Module
3.3. Bottleneck Structuring (BS) module
4. Experimental Results
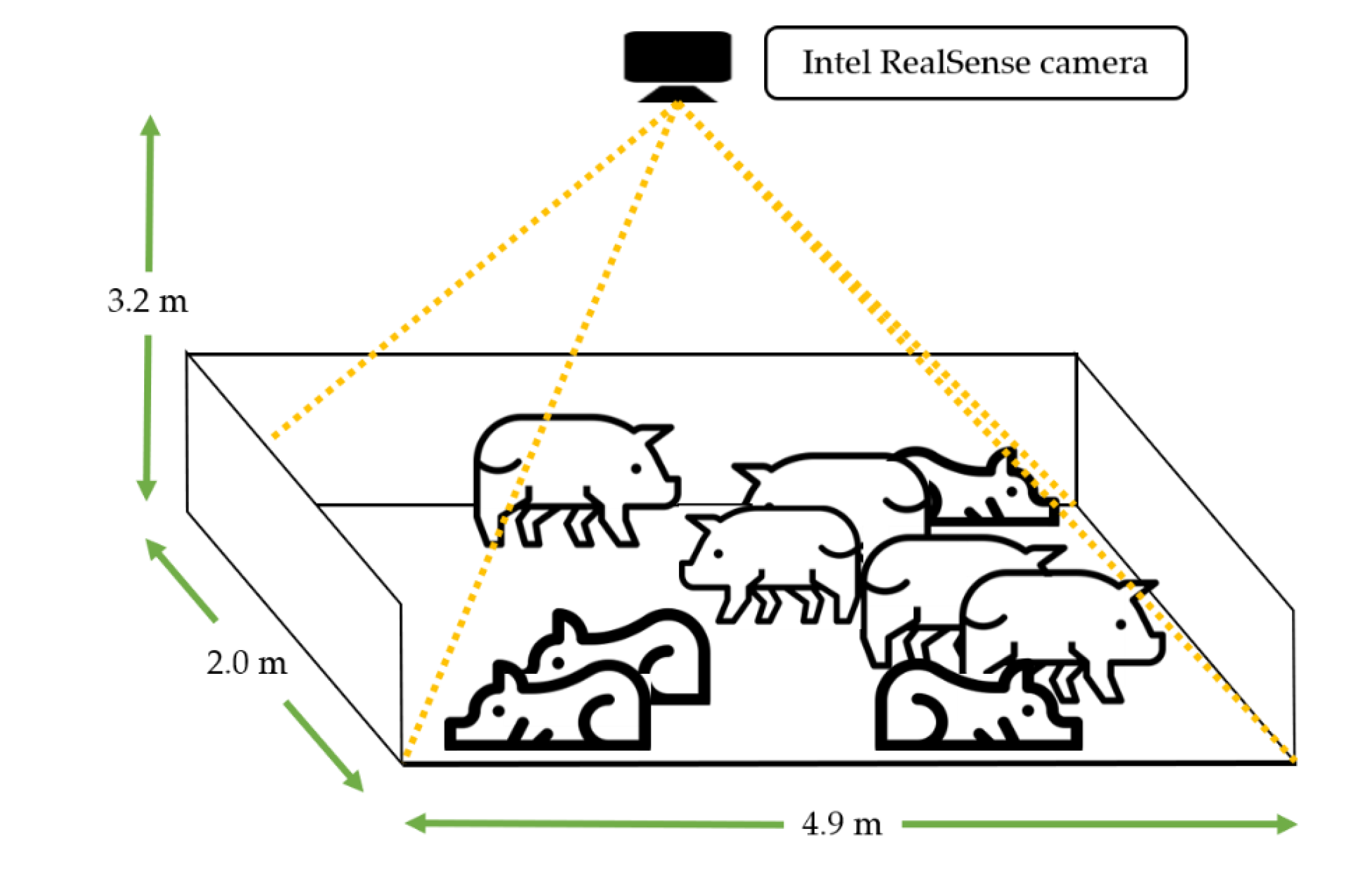
4.1. Experimental Setup and Resources for the Experiment
- PC: Intel Core i5-9400F 2.90 GHz (Intel, Santa Clara, CA, USA), NVIDIA GeForce RTX2080 Ti (NVIDIA, Santa Clara, CA, USA), 32 GB RAM.
- Jetson TX-2 [77]: dual-core Denver 2 64-bit CPU and quad-core ARM A57 complex, NVIDIA Pascal™ architecture with 256 NVIDIA CUDA cores, 8 GB 128-bit LPDDR4.
- Jetson Nano [50]: quad-core ARM A57 complex, NVIDIA Maxwell™ architecture with 128 NVIDIA CUDA cores, 4 GB 64-bit LPDDR4.
4.2. Evaluation of Detection Performance
4.3. Comparison of Detection Performance
4.4. Discussion
4.5. Dimensionality Reduction and Texture
4.6. Video and 3D
4.7. Other confidence methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Banhazi, T.; Lehr, H.; Black, J.; Crabtree, H.; Schofield, P.; Tscharke, M.; Berckmans, D. Precision Livestock Farming: An International Review of Scientific and Commercial Aspects. Int. J. Agric. Biol. 2012, 5, 1–9. [Google Scholar]
- Neethirajan, S. Recent Advances in Wearable Sensors for Animal Health Management. Sens. Bio-Sens. Res. 2017, 12, 15–29. [Google Scholar] [CrossRef]
- Tullo, E.; Fontana, I.; Guarino, M. Precision livestock farming: An overview of image and sound labelling. In Proceedings of the 6th European Conference on Precision Livestock Farming, Leuven, Belgium, 10–12 September 2013; pp. 30–38. [Google Scholar]
- Matthews, S.; Miller, A.; Clapp, J.; Plötz, T.; Kyriazakis, I. Early Detection of Health and Welfare Compromises through Automated Detection of Behavioural Changes in Pigs. Vet. J. 2016, 217, 43–51. [Google Scholar] [CrossRef] [PubMed]
- Tscharke, M.; Banhazi, T. A Brief Review of the Application of Machine Vision in Livestock Behaviour Analysis. J. Agric. Inform. 2016, 7, 23–42. [Google Scholar]
- Korean Government. 4th Industrial Revolution and Agriculture; Korean Government: Seoul, Korea, 2016. (In Korean)
- Han, S.; Zhang, J.; Zhu, M.; Wu, J.; Kong, F. Review of automatic detection of pig behaviours by using Image Analysis. In Proceedings of the International Conference on AEECE, Chengdu, China, 26–28 May 2017; pp. 1–6. [Google Scholar]
- Schofield, C. Evaluation of Image Analysis as A Means of Estimating the Weight of Pigs. J. Agric. Eng. Res. 1990, 47, 287–296. [Google Scholar] [CrossRef]
- Wouters, P.; Geers, R.; Parduyns, G.; Goossens, K.; Truyen, B.; Goedseels, V.; Van der Stuyft, E. Image-Analysis Parameters as Inputs for Automatic Environmental Temperature Control in Piglet Houses. Comput. Electron. Agric. 1990, 5, 233–246. [Google Scholar] [CrossRef]
- McFarlane, N.; Schofield, C. Segmentation and Tracking of Piglets in Images. Mach. Vis. Appl. 1995, 8, 187–193. [Google Scholar] [CrossRef]
- Cook, N.; Bench, C.; Liu, T.; Chabot, B.; Schaefer, A. The Automated Analysis of Clustering Behaviour of Piglets from Thermal Images in response to Immune Challenge by Vaccination. Animal 2018, 12, 122–133. [Google Scholar] [CrossRef]
- Brunger, J.; Traulsen, I.; Koch, R. Model-based Detection of Pigs in Images under Sub-Optimal Conditions. Comput. Electron. Agric. 2018, 152, 59–63. [Google Scholar] [CrossRef]
- Tu, G.; Karstoft, H.; Pedersen, L.; Jorgensen, E. Illumination and Reflectance Estimation with its Application in Foreground. Sensors 2015, 15, 12407–12426. [Google Scholar] [CrossRef]
- Tu, G.; Karstoft, H.; Pedersen, L.; Jorgensen, E. Segmentation of Sows in Farrowing Pens. IET Image Process. 2014, 8, 56–68. [Google Scholar] [CrossRef]
- Tu, G.; Karstoft, H.; Pedersen, L.; Jorgensen, E. Foreground Detection using Loopy Belief Propagation. Biosyst. Eng. 2013, 116, 88–96. [Google Scholar] [CrossRef]
- Nilsson, M.; Herlin, A.; Ardo, H.; Guzhva, O.; Astrom, K.; Bergsten, C. Development of Automatic Surveillance of Animal Behaviour and Welfare using Image Analysis and Machine Learned Segmentation Techniques. Animal 2015, 9, 1859–1865. [Google Scholar] [CrossRef]
- Kashiha, M.; Bahr, C.; Ott, S.; Moons, C.; Niewold, T.; Tuyttens, F.; Berckmans, D. Automatic Monitoring of Pig Locomotion using Image Analysis. Livest. Sci. 2014, 159, 141–148. [Google Scholar] [CrossRef]
- Oczak, M.; Maschat, K.; Berckmans, D.; Vranken, E.; Baumgartner, J. Automatic Estimation of Number of Piglets in a Pen during Farrowing, using Image Analysis. Biosyst. Eng. 2016, 151, 81–89. [Google Scholar] [CrossRef]
- Ahrendt, P.; Gregersen, T.; Karstoft, H. Development of a Real-Time Computer Vision System for Tracking Loose-Housed Pigs. Comput. Electron. Agric. 2011, 76, 169–174. [Google Scholar] [CrossRef]
- Khoramshahi, E.; Hietaoja, J.; Valros, A.; Yun, J.; Pastell, M. Real-Time Recognition of Sows in Video: A Supervised Approach. Inf. Process. Agric. 2014, 1, 73–82. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Hensel, O.; Edwards, S.; Sturm, B. Automatic Detection of Mounting Behaviours among Pigs using Image Analysis. Comput. Electron. Agric. 2016, 124, 295–302. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Hensel, O.; Edwards, S.; Sturm, B. A New Approach for Categorizing Pig Lying Behaviour based on a Delaunay Triangulation Method. Animal 2017, 11, 131–139. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Edwards, S.; Matheson, S.; Sturm, B. Using Automated Image Analysis in Pig Behavioural Research: Assessment of the Influence of Enrichment Subtrate Provision on Lying Behaviour. Appl. Anim. Behav. Sci. 2017, 196, 30–35. [Google Scholar] [CrossRef]
- Guo, Y.; Zhu, W.; Jiao, P.; Chen, J. Foreground Detection of Group-Housed Pigs based on the Combination of Mixture of Gaussians using Prediction Mechanism and Threshold Segmentation. Biosyst. Eng. 2014, 125, 98–104. [Google Scholar] [CrossRef]
- Guo, Y.; Zhu, W.; Jiao, P.; Ma, C.; Yang, J. Multi-Object Extraction from Topview Group-Housed Pig Images based on Adaptive Partitioning and Multilevel Thresholding Segmentation. Biosyst. Eng. 2015, 135, 54–60. [Google Scholar] [CrossRef]
- Buayai, P.; Kantanukul, T.; Leung, C.; Saikaew, K. Boundary Detection of Pigs in Pens based on Adaptive Thresholding using an Integral Image and Adaptive Partitioning. CMU J. Nat. Sci. 2017, 16, 145–155. [Google Scholar] [CrossRef]
- Lu, M.; Xiong, Y.; Li, K.; Liu, L.; Yan, L.; Ding, Y.; Lin, X.; Yang, X.; Shen, M. An Automatic Splitting Method for the Adhesive Piglets Gray Scale Image based on the Ellipse Shape Feature. Comput. Electron. Agric. 2016, 120, 53–62. [Google Scholar] [CrossRef]
- Lu, M.; He, J.; Chen, C.; Okinda, C.; Shen, M.; Liu, L.; Yao, W.; Norton, T.; Berckmans, D. An Automatic Ear Base Temperature Extraction Method for Top View Piglet Thermal Image. Comput. Electron. Agric. 2018, 155, 339–347. [Google Scholar] [CrossRef]
- Jun, K.; Kim, S.; Ji, H. Estimating Pig Weights from Images without Constraint on Posture and Illumination. Comput. Electron. Agric. 2018, 153, 169–176. [Google Scholar] [CrossRef]
- Kang, F.; Wang, C.; Li, J.; Zong, Z. A Multiobjective Piglet Image Segmentation Method based on an Improved Noninteractive GrabCut Algorithm. Adv. Multimed. 2018, 108876. [Google Scholar] [CrossRef]
- Yang, A.; Huang, H.; Zhu, X.; Yang, X.; Chen, P.; Li, S.; Xue, Y. Automatic Recognition of Sow Nursing Behavious using Deep Learning-based Segmentation and Spatial and Temporal Features. Biosyst. Eng. 2018, 175, 133–145. [Google Scholar] [CrossRef]
- Yang, Q.; Xiao, D.; Lin, S. Feeding Behavior Recognition for Group-Housed Pigs with the Faster R-CNN. Comput. Electron. Agric. 2018, 155, 453–460. [Google Scholar] [CrossRef]
- Kongsro, J. Estimation of Pig Weight using a Microsoft Kinect Prototype Imaging System. Comput. Electron. Agric. 2014, 109, 32–35. [Google Scholar] [CrossRef]
- Lao, F.; Brown-Brandl, T.; Stinn, J.; Liu, K.; Teng, G.; Xin, H. Automatic Recognition of Lactating Sow Behaviors through Depth Image Processing. Comput. Electron. Agric. 2016, 125, 56–62. [Google Scholar] [CrossRef]
- Stavrakakis, S.; Li, W.; Guy, J.; Morgan, G.; Ushaw, G.; Johnson, G.; Edwards, S. Validity of the Microsoft Kinect Sensor for Assessment of Normal Walking Patterns in Pigs. Comput. Electron. Agric. 2015, 117, 1–7. [Google Scholar] [CrossRef]
- Zhu, Q.; Ren, J.; Barclay, D.; McCormack, S.; Thomson, W. Automatic animal detection from kinect sensed images for livestock monitoring and assessment. In Proceedings of the International Conference on Computer and Information Technology, ICCCIT, Dhaka, Bangladesh, 21–23 December 2015; pp. 1154–1157. [Google Scholar]
- Kulikov, V.; Khotskin, N.; Nikitin, S.; Lankin, V.; Kulikov, A.; Trapezov, O. Application of 3D Imaging Sensor for Tracking Minipigs in the Open Field Test. J. Neurosci. Methods 2014, 235, 219–225. [Google Scholar] [CrossRef] [PubMed]
- Shi, C.; Teng, G.; Li, Z. An Approach of Pig Weight Estimation using Binocular Stereo System based on LabVIEW. Comput. Electron. Agric. 2016, 129, 37–43. [Google Scholar] [CrossRef]
- Matthews, S.; Miller, A.; Plötz, T.; Kyriazakis, I. Automated Tracking to Measure Behavioural Changes in Pigs for Health and Welfare Monitoring. Sci. Rep. 2017, 7, 17582. [Google Scholar] [CrossRef]
- Zheng, C.; Zhu, X.; Yang, X.; Wang, L.; Tu, S.; Xue, Y. Automatic Recognition of Lactating Sow Postures from Depth Images by Deep Learning Detector. Comput. Electron. Agric. 2018, 147, 51–63. [Google Scholar] [CrossRef]
- Lee, J.; Jin, L.; Park, D.; Chung, Y. Automatic Recognition of Aggressive Pig Behaviors using Kinect Depth Sensor. Sensors 2016, 16, 631. [Google Scholar] [CrossRef]
- Kim, J.; Chung, Y.; Choi, Y.; Sa, J.; Kim, H.; Chung, Y.; Park, D.; Kim, H. Depth-based Detection of Standing-Pigs in Moving Noise Environments. Sensors 2017, 17, 2757. [Google Scholar] [CrossRef]
- Chung, Y.; Kim, H.; Lee, H.; Park, D.; Jeon, T.; Chang, H. A Cost-Effective Pigsty Monitoring System based on a Video Sensor. KSII Trans. Internet Inf. Syst. 2014, 8, 1481–1498. [Google Scholar]
- Sa, J.; Choi, Y.; Lee, H.; Chung, Y.; Park, D.; Cho, J. Fast Pig Detection with a Topview Camera under Various Illumination Conditions. Symmetry 2019, 11, 266. [Google Scholar] [CrossRef]
- Zhang, L.; Gray, H.; Ye, X.; Collins, L.; Allinson, N. Automatic Individual Pig Detection and Tracking in Pig Farms. Sensors 2019, 19, 1188. [Google Scholar] [CrossRef] [PubMed]
- Nasirahmadi, A.; Sturm, B.; Olsson, A.; Jeppsson, K.; Muller, S.; Edwards, S.; Hensel, O. Automatic Scoring of Lateral and Sternal Lying Posture in Grouped Pigs Using Image Processing and Support Vector Machine. Comput. Electron. Agric. 2019, 156, 475–481. [Google Scholar] [CrossRef]
- Psota, E.; Mittek, M.; Perez, L.; Schmidt, T.; Mote, B. Multi-Pig Part Detection and Association with a Fully-Convolutional Network. Sensors 2019, 19, 852. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Liu, L.; Shen, M.; Sun, Y.; Lu, M. Group-Housed Pig Detection in Video Surveillance of Overhead Views using Multi-Feature Template Matching. Biosyst. Eng. 2019, 181, 28–39. [Google Scholar] [CrossRef]
- Lee, S.; Ahn, H.; Seo, J.; Chung, Y.; Park, D.; Pan, S. Practical Monitoring of Undergrown Pigs for IoT-Based Large-Scale Smart Farm. IEEE Access 2019, 7, 173796–173810. [Google Scholar] [CrossRef]
- NVIDIA. NVIDIA Jetson Nano. Available online: http://www.nvidia.com/object/embedded-systems-dev-kits-modules.html (accessed on 10 November 2019).
- Mahdavinejad, M.; Rezvan, M.; Barekatain, M.; Adibi, P.; Barnaghi, P.; Sheth, A. Machine Learning for Internet of Things Data Analysis: A Survey. Digit. Commun. Netw. 2018, 4, 161–175. [Google Scholar] [CrossRef]
- Ham, M.; Moon, J.; Lim, G.; Song, W.; Jung, J.; Ahn, H.; Woo, S.; Cho, Y.; Park, J.; Oh, S.; et al. NNStreamer: Stream Processing Paradigm for Neural Networks, Toward Efficient Development and Execution of On-Device AI Applications. arXiv 2019, arXiv:1901.04985. [Google Scholar]
- Nguyen, P.; Arsalan, M.; Koo, J.; Naqvi, R.; Truong, N.; Park, K. LightDenseYOLO: A Fast and Accurate Marker Tracker for Autonomous UAV Landing by Visible Light Camera Sensor on Drone. Sensors 2018, 18, 1703. [Google Scholar] [CrossRef]
- Xiao, J.; Wu, H.; Li, X. Internet of Things Meets Vehicles: Sheltering In-Vehicle Network through Lightweight Machine Learning. Symmetry 2019, 11, 1388. [Google Scholar] [CrossRef]
- Yang, T.; Howard, A.; Chen, B.; Zhang, X.; Go, A.; Sandler, M.; Sze, V.; Adam, H. Netadapt: Platform-aware neural network adaptation for mobile applications. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 285–300. [Google Scholar]
- Intel. Intel RealSense D435. Available online: https://click.intel.com/intelr-realsensetm-depth-camera-d435.html (accessed on 28 February 2018).
- Bradley, D.; Roth, G. Adaptive Thresholding using the Integral Image. J. Graph. Tools 2007, 12, 13–21. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vega, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Ott, S.; Moons, C.; Kashiha, M.; Bahr, C.; Tuyttens, F.; Berckmans, D.; Niewold, T. Automated video analysis of pig activity at pen level highly correlates to human observations of behavioural activities. Livest. Sci. 2014, 160, 132–137. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, W.; Steibel, J.; Siegford, J.; Wurtz, K.; Han, J.; Norton, T. Recognition of aggressive episodes of pigs based on convolutional neural network and long short-term memory. Comput. Electron. Agric. 2020, 169, 105166. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, W.; Liu, D.; Steibel, J.; Siegford, J.; Wurtz, K.; Norton, T. Detection of aggressive behaviours in pigs using a RealSence depth sensor. Comput. Electron. Agric. 2019, 166, 105003. [Google Scholar] [CrossRef]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- He, Y.; Kang, G.; Dong, X.; Fu, Y.; Yang, Y. Soft filter pruning for accelerating deep convolutional neural networks. arXiv 2018, arXiv:1808.06866. [Google Scholar]
- Yu, R.; Li, A.; Chen, C.; Lai, J.; Morariu, V.; Han, X.; Davis, L. Nisp: Pruning networks using neuron importance score propagation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9194–9203. [Google Scholar]
- Ding, X.; Ding, G.; Han, J.; Tang, S. Auto-balanced filter pruning for efficient convolutional neural networks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Lin, S.; Ji, R.; Li, Y.; Wu, Y.; Huang, F.; Zhang, B. Accelerating convolutional networks via global & dynamic filter pruning. In Proceedings of the International Joint Conferences on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 2425–2432. [Google Scholar]
- Peng, B.; Tan, W.; Li, Z.; Zhang, S.; Xie, D.; Pu, S. Extreme network compression via filter group approximation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 300–316. [Google Scholar]
- Zhuang, Z.; Tan, M.; Zhuang, B.; Liu, J.; Guo, Y.; Wu, Q.; Zhu, J. Discrimination-aware channel pruning for deep neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 875–886. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zuiderveld, K. Contrast Limited Adaptive Histogram Equalization; Academic Press Inc.: Cambridge, MA, USA, 1994. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- OpenCV. Open Source Computer Vision. Available online: http://opencv.org (accessed on 30 April 2019).
- NVIDIA. NVIDIA Jetson TX2. Available online: http://www.nvidia.com/object/embedded-systems-dev-kits-modules.html (accessed on 30 April 2019).
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Kwak, T.; Song, A.; Kim, Y. The Impact of the PCA Dimensionality Reduction for CNN based Hyperspectral Image Classification. Korean J. Remote Sens. 2019, 35, 959–971. [Google Scholar]
- Sun, L.; Liu, Y.; Chen, S.; Luo, B.; Li, Y.; Liu, C. Pig Detection Algorithm Based on Sliding Windows and PCA Convolution. IEEE Access 2019, 7, 44229–44238. [Google Scholar] [CrossRef]
- Kim, J.; Choi, Y.; Sa, J.; Ju, M.; Chung, Y.; Park, D.; Kim, H. Pig Detection Using Texture Information; The Institute of Electronics and Information Engineers: Seoul, Korea, 2016; pp. 403–406. (In Korean) [Google Scholar]
- Choi, Y.; Lee, J.; Park, D.; Chung, Y. Noise-Robust Porcine Respiratory Diseases Classification Using Texture Analysis and CNN. KIPS Trans. Softw. Data Eng. 2018, 7, 91–98. [Google Scholar]
- Mousas, C.; Anagnostopoulos, C. Learning motion features for example-based finger motion estimation for virtual characters. 3D Res. 2017, 8, 25. [Google Scholar] [CrossRef]
- Yuan, P.; Zhong, Y.; Yuan, Y. Faster r-cnn with region proposal refinement. Tech. Rep. 2017. [Google Scholar]
- Han, W.; Khorrami, P.; Paine, T.; Ramachandran, P.; Babaeizadeh, M.; Shi, H.; Huang, T. Seq-nms for video object detection. arXiv 2016, arXiv:1602.08465. [Google Scholar]
- Zhou, Y.; Li, Z.; Xiao, S.; He, C.; Huang, Z.; Li, H. Auto-conditioned recurrent networks for extended complex human motion synthesis. arXiv 2018, arXiv:1707.05363. [Google Scholar]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A. Multimodal deep learning. In Proceedings of the International Conference on Machine Learning, Washington, DC, USA, 28 June–2 July 2011. [Google Scholar]
- Chung, Y.; Oh, S.; Lee, J.; Park, D.; Chang, H.; Kim, S. Automatic detection and recognition of pig wasting diseases using sound data in audio surveillance systems. Sensors 2013, 13, 12929–12942. [Google Scholar] [CrossRef]
- Han, S.; Lee, S.; Sa, J.; Ju, M.; Kim, H.; Chung, Y.; Park, D. Pigs boundary detection using both color and depth information. Korean Inst. Smart Media 2015, 5, 168–170. [Google Scholar]
- Kim, H. Automatic identification of a coughing animal using audio and video data. In Proceedings of the Fourth International Conference on Information Science and Cloud Computing, Guangzhou, China, 18–19 December 2015; p. 264. [Google Scholar]
- Bai, J.; Zhang, H.; Li, Z. The generalized detection method for the dim small targets by faster R-CNN integrated with GAN. In Proceedings of the IEEE 3rd International Conference on Communication and Information Systems (ICCIS), Singapore, 28–30 December 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Choi, Y.; Lee, J.; Park, D.; Chung, Y. Enhanced Sound Signal Based Sound-Event Classification. Korea Inf. Process. Soc. 2019, 8, 193–204. (In Korean) [Google Scholar]
- Sailor, H.; Patil, H. Novel unsupervised auditory filterbank learning using convolutional RBM for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 2341–2353. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
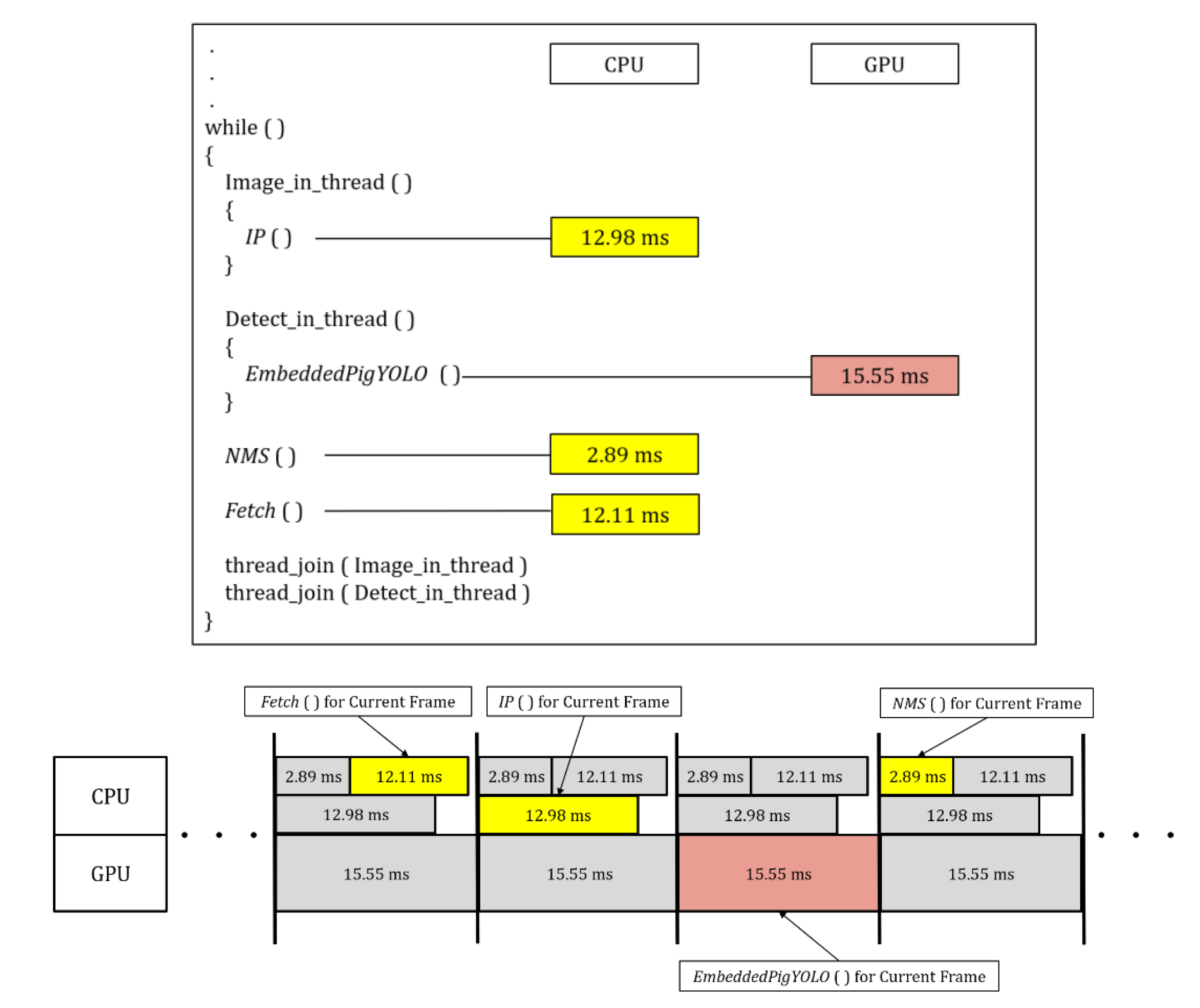{kind=link}
| Target Platform | Data Size | No. of Pigs in a Pen | Detection Technique | Individual Detection of Pigs | Execution Time (ms) | Reference |
|---|---|---|---|---|---|---|
| PC | Not Specified | Not Specified | Image Processing | No | Not Specified | [10] |
| 720 × 540 | 12 | Image Processing | Yes | 220 (PC) | [11] | |
| 768 × 576 | Not Specified | Image Processing | No | 1000 (PC) | [12] | |
| 768 × 576 | Not Specified | Image Processing | No | 500 (PC) | [13] | |
| 150 × 113 | Not Specified | Image Processing | No | 250 (PC) | [14] | |
| 640 × 480 | 9 | Learning | No | Not Specified | [15] | |
| 720 × 576 | 9 | Image Processing | Yes | Not Specified | [16] | |
| 1280 × 720 | 7–13 | Image Processing | Yes | Not Specified | [17] | |
| Not Specified | 3 | Image Processing | Yes | Not Specified | [18] | |
| 352 × 288 | Not Specified | Learning | No | 236 (PC) | [19] | |
| 640 × 480 | 22–23 | Image Processing | Yes | Not Specified | [20] | |
| 640 × 480 | 22 | Image Processing | Yes | Not Specified | [21] | |
| Not Specified | 17–20 | Image Processing | Yes | Not Specified | [22] | |
| 256 × 256 | Not Specified | Image Processing | No | Not Specified | [23] | |
| 1760 × 1840 | Not Specified | Image Processing | Yes | Not Specified | [24] | |
| 1280 × 720 | 23 | Image Processing | Yes | 971 (PC) | [25] | |
| Not Specified | 2–12 | Image Processing | Yes | Not Specified | [26] | |
| 320 × 240 | Not Specified | Image Processing | No | Not Specified | [27] | |
| 512 × 424 | Not Specified | Image Processing | No | Not Specified | [28] | |
| 1440 × 1440 | Not Specified | Image Processing | Yes | 1606 (PC) | [29] | |
| 960 × 540 | 1 | Deep Learning | No | Not Specified | [30] | |
| 2560 × 1440 | 4 | Deep Learning | Yes | Not Specified | [31] | |
| Not Specified | 1 | Image Processing | No | Not Specified | [32] | |
| 640 × 480 | Not Specified | Image Processing | No | Not Specified | [33] | |
| 512 × 424 | 1 | Image Processing | No | Not Specified | [34] | |
| 512 × 424 | Not Specified | Image Processing | No | Not Specified | [35] | |
| 512 × 424 | 1 | Image Processing | No | Not Specified | [36] | |
| 1294 × 964 | 1 | Image Processing | No | Not Specified | [37] | |
| 512 × 424 | 19 | Image Processing | Yes | 142 (PC) | [38] | |
| 512 × 424 | 1 | Deep Learning | No | 50 (PC) | [39] | |
| 512 × 424 | 22 | Image Processing | No | 56 (PC) | [40] | |
| 512 × 424 | 13 | Image Processing | No | 2 (PC) | [41] | |
| 640 × 480 | 22, 24 | Image Processing | No | 60 (PC) | [42] | |
| 1280 × 720 | 9 | Image Processing | No | 8 (PC) | [43] | |
| 1920 × 1080 | 9 | Deep Learning | Yes | 42 (PC) | [44] | |
| 960 × 720 | ~30 | Image Processing | Yes | Not Specified | [45] | |
| 1920 × 1080 | Not Specified | Deep Learning | Yes | 250 (PC) | [46] | |
| 1024 × 768 | 4 | Image Processing | Yes | 921 (PC) | [47] | |
| Not Specified | Not Specified | Deep Learning | Yes | 500 (PC) | [48] | |
| Embedded Board | 1280 × 720 | 9 | Image Processing Deep Learning | Yes | 29.08 * (Nano) | Proposed Method |
| TinyYOLOv2 [70] | EmbeddedPigYOLO(v2) | ||
|---|---|---|---|
| Filter | Filter with FC | Filter with FC+BS | |
| Conv1 | 3 × 3 (16) | 3 × 3 (16) | 3 × 3 (16) |
| Conv2 | 3 ×3 (32) | 3 × 3 (32) | 1 × 1 (8) 3 × 3 (8) 1 × 1 (32) |
| Conv3 | 3 × 3 (64) | 3 × 3 (61) | 1 × 1 (16) 3 × 3 (16) 1 × 1 (64) |
| Conv4 | 3 × 3 (128) | 3 × 3 (114) | 1 × 1 (29) 3 × 3 (29) 1 × 1 (116) |
| Conv5 | 3 × 3 (256) | 3 × 3 (197) | 1 × 1 (50) 3 × 3 (50) 1 × 1 (200) |
| Conv6 | 3 × 3 (512) | 3 × 3 (256) | 1 × 1 (64) 3 × 3 (64) 1×1 (256) |
| Conv7 | 3 × 3 (1024) | 3 × 3 (349) | 1 × 1 (88) 3 × 3 (88) 1 × 1 (352) |
| Conv8 | 3 × 3 (1024) | 3 × 3 (353) | 1 × 1 (89) 3 × 3 (89) 1 × 1 (356) |
| TinyYOLOv3 [71] | EmbeddedPigYOLO(v3) | ||
|---|---|---|---|
| Filter | Filter with FC | Filter with FC+BS | |
| Conv1 | 3 × 3 (16) | 3 × 3 (16) | 3 × 3 (16) |
| Conv2 | 3 × 3 (32) | 3 × 3 (31) | 1 × 1 (8) 3 × 3 (8) 1 × 1 (32) |
| Conv3 | 3 × 3 (64) | 3 × 3 (60) | 1 × 1 (15) 3 × 3 (15) 1 × 1 (60) |
| Conv4 | 3 × 3 (128) | 3 × 3 (115) | 1 × 1 (29) 3 × 3 (29) 1 × 1 (116) |
| Conv5 | 3 × 3 (256) | 3 × 3 (204) | 1 × 1 (51) 3 × 3 (51) 1 × 1 (204) |
| Conv6 | 3 × 3 (512) | 3 × 3 (261) | 1 × 1 (66) 3 × 3 (66) 1 × 1 (264) |
| Conv7 | 3 × 3 (1024) | 3 × 3 (335) | 1 × 1 (84) 3 × 3 (84) 1 × 1 (336) |
| Conv8 | 1 × 1 (256) | 1 × 1 (256) | 1 × 1 (256) |
| Conv9 | 3 × 3 (512) | 3 × 3 (234) | 1 × 1 (59) 3 × 3 (59) 1 × 1 (236) |
| Conv10 | 1 × 1 (128) | 1 × 1 (128) | 1 × 1 (128) |
| Conv11 | 3 × 3 (256) | 3 × 3 (148) | 1 × 1 (37) 3 × 3 (37) 1 × 1 (148) |
| Mean | Contrast | Entropy | ||||
|---|---|---|---|---|---|---|
| Input | Composite | Input | Composite | Input | Composite | |
| 2 AM | 52.76 | 92.43 | 0.27 | 0.41 | 4.44 | 5.23 |
| 8 AM | 74.94 | 103.82 | 0.28 | 0.40 | 4.53 | 5.30 |
| 2 PM | 54.25 | 95.12 | 0.22 | 0.40 | 4.40 | 5.25 |
| 8 PM | 41.19 | 87.75 | 0.18 | 0.38 | 4.06 | 5.16 |
| Method | Accuracy (AP) ↑ | Speed (fps) ↑ | Integrated Performance (AP × fps) ↑ | |
|---|---|---|---|---|
| YOLOv2 [75] | End-to-end deep learning for object detection | 98.41 | 6.86 | 675 |
| TinyYOLOv2 [75] | 96.96 | 24.94 | 2418 | |
| EmbeddedPigYOLO(v2) (Ours) | 95.60 | 56.91 | 5440 | |
| EmbeddedPigDet(v2) (Ours) | Combination of image processing and deep learning | 97.66 | 32.73 | 3196 |
| EmbeddedPigDetpipe(v2) (Ours) | 97.66 | 64.30 | 6279 (×9.3 than YOLO) (×2.5 than TinyYOLO) | |
| Method | Accuracy (AP) ↑ | Speed (fps) ↑ | Integrated Performance (AP × fps) ↑ | |
|---|---|---|---|---|
| YOLOv2 [75] | End-to-end deep learning for object detection | 98.41 | 3.91 | 384 |
| TinyYOLOv2 [75] | 96.96 | 12.78 | 1239 | |
| EmbeddedPigYOLO(v2) (Ours) | 95.60 | 21.19 | 2025 | |
| EmbeddedPigDet(v2) (Ours) | Combination of image processing and deep learning | 97.66 | 15.83 | 1545 |
| EmbeddedPigDetpipe(v2) (Ours) | 97.66 | 34.38 | 3357 (×8.7 than YOLO) (×2.7 than TinyYOLO) | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seo, J.; Ahn, H.; Kim, D.; Lee, S.; Chung, Y.; Park, D. EmbeddedPigDet—Fast and Accurate Pig Detection for Embedded Board Implementations. Appl. Sci. 2020, 10, 2878. https://doi.org/10.3390/app10082878
Seo J, Ahn H, Kim D, Lee S, Chung Y, Park D. EmbeddedPigDet—Fast and Accurate Pig Detection for Embedded Board Implementations. Applied Sciences. 2020; 10(8):2878. https://doi.org/10.3390/app10082878
Chicago/Turabian StyleSeo, Jihyun, Hanse Ahn, Daewon Kim, Sungju Lee, Yongwha Chung, and Daihee Park. 2020. "EmbeddedPigDet—Fast and Accurate Pig Detection for Embedded Board Implementations" Applied Sciences 10, no. 8: 2878. https://doi.org/10.3390/app10082878
APA StyleSeo, J., Ahn, H., Kim, D., Lee, S., Chung, Y., & Park, D. (2020). EmbeddedPigDet—Fast and Accurate Pig Detection for Embedded Board Implementations. Applied Sciences, 10(8), 2878. https://doi.org/10.3390/app10082878