1. Introduction
The importance of cyberspace security has become more and more significant. However, cyberspace is facing a serious threat of invasion. The root cause of most cyber-attacks is vulnerabilities. Vulnerabilities exploited by attackers compromise the confidentiality, integrity, and availability of information systems. For instance, the ransomware Wannacry which exploited a vulnerability in Windows server message block protocol has swept the world [
1]. Early detection of vulnerability is an effective way to reduce the loss. Despite the efforts of experts and scholars, vulnerabilities remain a huge problem and will continue to exist in the long term. This can be justified by the fact that an increasing number of vulnerabilities are published every year [
2].
Vulnerability detection is a method to discover vulnerabilities in software. Traditional vulnerability detection includes static and dynamic methods [
3]. Static methods, such as data flow analysis [
4,
5], symbol execution [
6], and theorem proving [
7], analyze source code or executable code without running software. Static methods have high coverage and can be deployed in the early stage of software development. However, it suffers from a high false positive rate. Dynamic methods, such as fuzzy test [
8] and dynamic symbol execution [
9], verify or discover the nature of software by running the program. Dynamic methods have a low false positive rate and simple deployment, but their dependence on the coverage of test cases incurs a low recall. Therefore, realizing automatic and intelligent vulnerability detection is the trend of research. This can be justified by the organization of DARPA’s Cyber Grand Challenge [
10].
The development of machine learning technology provides new methods to alleviate the bottlenecks of traditional methods. Intelligent vulnerability detection methods which operate on source code are one of the main research directions. It can be categorized into 3 types: using software engineering metrics, anomaly detection, and vulnerable pattern learning [
11]. In the early stages, software engineering metrics, such as software complexity [
12], developer activities [
13], and code commits [
14] are explored to train a machine learning model. The inspiration for this approach is that the more complex the software is, the more vulnerable it is. Software engineering metrics methods have the advantages of speediness and easily acquired datasets, but its effectiveness in accuracy and recall is still to be improved. Anomaly detection and vulnerable pattern learning both try to improve the detection effect by utilizing the syntactic and semantic information in the code [
15]. Anomaly detection learns the legal programming pattern from mature software codes. The similarity or association between the candidates and the learned rules is used to detect vulnerabilities [
16]. Anomaly detection has the advantage of discovering unknown vulnerabilities. However, the false positive and false negative is high. The vulnerable pattern learning method learns vulnerable patterns from vulnerable and clean samples [
17]. Compared with anomaly detection, this method has a better performance on the accuracy, but highly dependent on the quality of the dataset.
The intelligent vulnerability detection methods leverage software syntax and semantic information to improve detection performance, but there are several problems that compromise the effect of existing intelligent methods: (1) long-term dependency between code elements. In a vulnerable sample, the dependency between context can be long. For example, variables defined at the beginning of a program may be used at the end. This may cause the machine learning algorithm to ignore the correlation between context when detecting the vulnerability; (2) out-of-vocabulary (OoV) issue. Program language allows users to customize identifiers, such as variable name, function name, and class name, and every programmer has his own style when naming identifiers. This leads to the lack of a common vocabulary to cover all possible identifiers. Hence, there is always an out-of-vocabulary issue during vulnerability detection. This will weaken the effect of vulnerability detection; (3) coarse detection granularity. A coarse detection granularity, such as a component, function or file, cannot properly represent vulnerability information. For example, a vulnerability might cross the boundary of a function or a file. A coarse detection granularity may incur noise when detecting vulnerabilities. In addition, coarse detection granularity provides imprecise information to assist developers to patch. Thus a considerable human effort is still required to pinpoint the vulnerable code fragments; (4) lack of vulnerability dataset. The quantity and quality of training data determine the effectiveness of intelligent vulnerability detection methods. However, due to the particularity of vulnerability, the lack of a general and authoritative vulnerability dataset for training and testing still limits the performance of intelligent methods.
To overcome these challenges, we proposed a framework that detects software vulnerabilities in four stages: pre-processing, pre-training, representation learning, and classifier training. In the pre-processing stage, our method transforms the samples in the form of raw source code into the minimum intermediate representations through dependency analysis, program slicing, tokenization, and serialization. The length of dependencies between context is reduced by eliminating irrelevant code. The samples used in the next three stages are pre-processed respectively. In the pre-training stage, considering the lack of vulnerability samples, we conduct unsupervised learning on an extended corpus. The purpose of this process is to learn the common syntax features of program language and alleviate the OoV issue through distributed embedding. The result of the pre-training stage will serve as the parameters of the embedding layer in the next two stages. In the representation learning stage, three concatenated convolutional neural networks are utilized to obtain high-level features from a vulnerability dataset. In order to train this network, two dense layers are added in this stage. In the classifier training stage, the vulnerability dataset is transformed into high-level features using the learned network in the last stage, and a classifier is trained for vulnerability detection by the learned high-level features. Finally, test samples will be classified by the trained model. The empirical study shows that compared with the traditional methods and state-of-the-art intelligent methods, our method has made significant improvements in false positive rate, false negative rate, precision, recall, and F1 metrics.
The remainder of this paper is organized as follows: We introduce the related work in
Section 2. In
Section 3 motivating examples and hypotheses are introduced. Our method for automated vulnerability detection in source code is presented in
Section 4. We introduce the experiments and discuss the results in
Section 5. Finally, we conclude this paper in
Section 6.
4. Proposed Approach
4.1. Overview
Our study aims to automatically detect vulnerabilities in the software while providing precise information to assist developers to audit. Our method selects an inter-procedural slice as the detection granularity.
Figure 3 shows an overview of our proposed method. The black arrow represents the data flow during the pre-training stage. The red arrow represents the data flow during the representation learning stage. The blue arrow represents the data flow during the classifier training stage. Although the arrows in the pre-processing phase are black, the data in the other three stages will flow through this stage. As shown in
Figure 3, the inputs are in the form of source code. In the pre-processing stage, through dependency analysis, security slicing, tokenization, and serialization, we obtain a sequential minimum intermediate representation of the sample. In the pre-training stage, we learn a distributed embedding from an extended corpus. The output of this stage is used as the parameters of the embedding layer in the next two stages. In the representation learning stage, three concatenated convolutional neural networks are used to learn high-level features. The trained model is reused in the next stage. In the classifier training stage, a machine learning classifier is trained using the outputs of the convolutional layer. Finally, test samples will be detected by the trained model in the last stage to predict whether they are vulnerable or not.
4.2. Pre-Processing
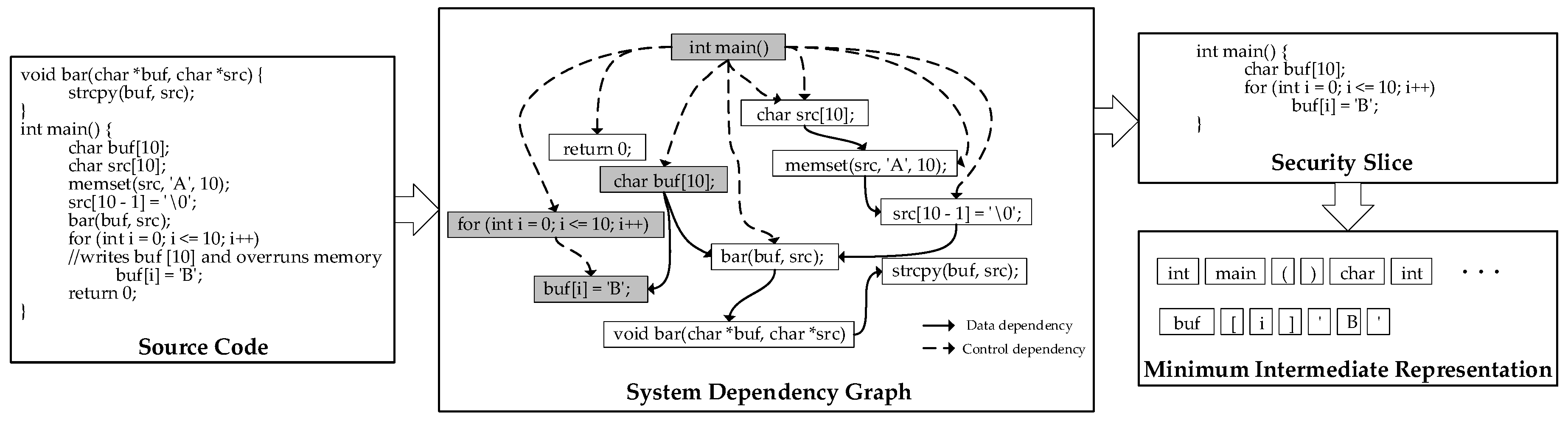
A fine-granularity detection method can not only eliminate extraneous features in the analysis process but also provide detailed information to audit. Different from file-level and function-level granularity in many papers, our method chooses the subset of code related to vulnerabilities as detection granularity. We define minimum intermediate representation (MIR) as a sequence of tokens which are serialized from an inter-procedural program slice that takes a security-critical operation as a criterion. The order between tokens represents dependencies.
As shown in
Figure 4, the samples in the form of the source code are converted to minimum intermediate representations by static analysis in the pre-processing stage. First samples in the form of source code are converted into program dependency graphs by control dependency and data dependency analysis.
Control dependency between statement i and statement j satisfies that , (1) ; (2) i is not post-dominate by j.
Data dependency between statement i and statement j satisfies that , (1) and ; (2) , . denotes the set of variables in a program. denotes the set of variables defined at statement i, and denote the set of variables referenced at statement j.
In this paper, a program dependence graph (PDG) is a directed graph . S is the set of the vertex in the program dependency graph that denotes the statements. The E is the set of edges that represents the control dependency and data dependency. Given many vulnerabilities are inter-procedural, we generated the system dependence graph (SDG) by adding the invocation between procedures to the program dependency graph.
Next, all the critical operations in the system dependency graph are located according to the characteristics of the vulnerability to be detected. A backward program slice is conducted on every critical operation. Then, we replace the call and declaration statements of the custom functions with a data dependency between the arguments to the parameters and a data dependency between the return values to the call points. We serialize the results of slicing in the order the code executes. So far, the basic unit is still a statement. Therefore, lexical analysis is performed to turn the slice into tokens. In the example shown in
Figure 4, ”buf[i] = ’B’” is a critical operation for buffer overflow vulnerability. This is because its misuse can cause data to be written out of the buffer. The relevant statements are pinpointed by dependency analysis in the SDG. They are statements {” for (int i = 0; i <= 10; i++)”, “char buf[10];”, ”int main()”}. We serialize the critical operation and its associated statements in the executed order. Finally, by a custom lexical analysis, we obtain the MIR: {“int”, “main”, “(“, “)”, “{“, “char”, “buf”, “[“, “10”, ”]”, “;”, “for”, “(“, “int”, “i”, ”=”, “0”, ”;”, “i”, “<=”, “10”, “;”, “i”, “++”, “)”, “buf”, “[“, “i”, “]”, “=”, “’”, “B”, ”’”}. As a result, the source code is transformed into a form similar to natural language.
4.3. Pre-Training
Machine learning models take real value vectors as inputs. Therefore the minimum intermediate representations should be mapped to real value vectors. Based on Hypothesis 1, we distributedly represent each token with its context. Compared with traditional encoding methods, such as one-hot, term frequency–inverse document frequency (TF-IDF), n-gram, distributed representation is denser. Semantically similar identifiers will be mapped to similar vector representations due to their similar context.
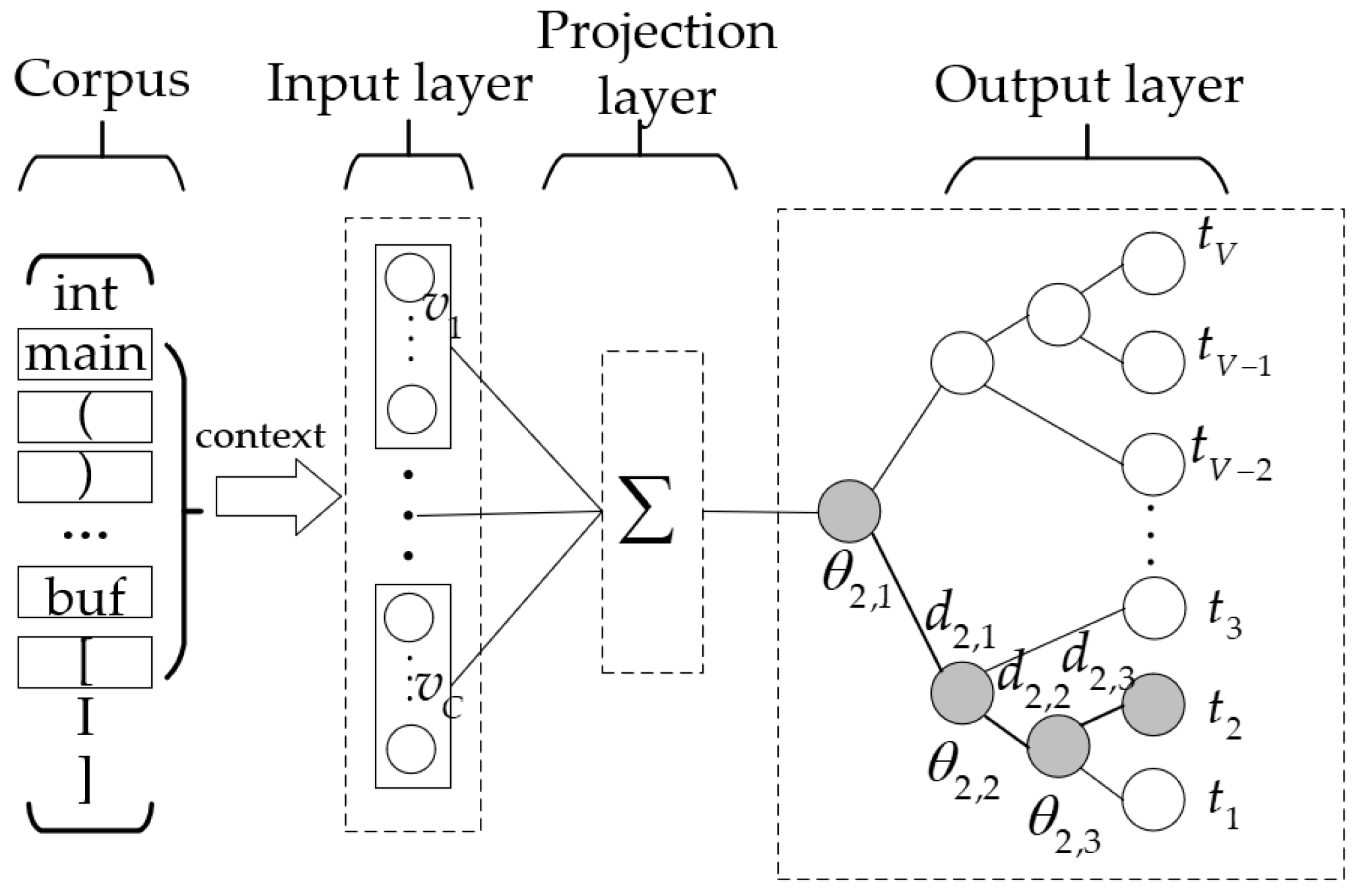
In the pre-training stage, the Continuous Bag-of-Words (CBOW) model is leveraged to obtain distributed vector representations. As illustrated in
Figure 5, the CBOW model is a simplified neural network with three layers. The input of the CBOW model is the vector representation of context. Therefore, the size of the input layer is
, where
is the size of the context and
is the dimension of vector representation. The projection layer summates the vector representations, and the output is:
where
is the initial vector representation of token
. The output layer is a Huffman tree, whose leaf nodes represent the tokens in the vocabulary. Therefore, the number of leaf nodes is
and the number of the inner nodes is
. In a Huffman tree, there is a unique path
from the root node to the target leaf node
. In the path, the
j-th node is represented as
.
represents the vector of
, and
denotes the encoding value of the node
. The probability of going left or right at the inner node
is:
Therefore, in the CBOW model, the probability of target token
appearing in a context is:
where
denotes the context of the target token
. Then, the objective function is:
This is an unsupervised learning method that enables us to learn programing patterns from an unlabeled dataset. Therefore, we utilize a transfer learning method to learn distributed embedding from an extended dataset. Tool word2vec [
37] is used to implement the CBOW language model. The learned vector representations are used as the parameters of the embedding layer in the representation learning stage and classifier training stage.
4.4. High-Level Feature Learning
According to Hypothesis 2, the vulnerable programming pattern of a sample is hidden in the context. We leverage a representation learning method to obtain high-level features from the serialized tokens. Convolutional neural networks have been successfully used in many tasks such as computer vision and natural language processing. It proves the ability of the convolutional neural network to learn the spatial structure in input data.
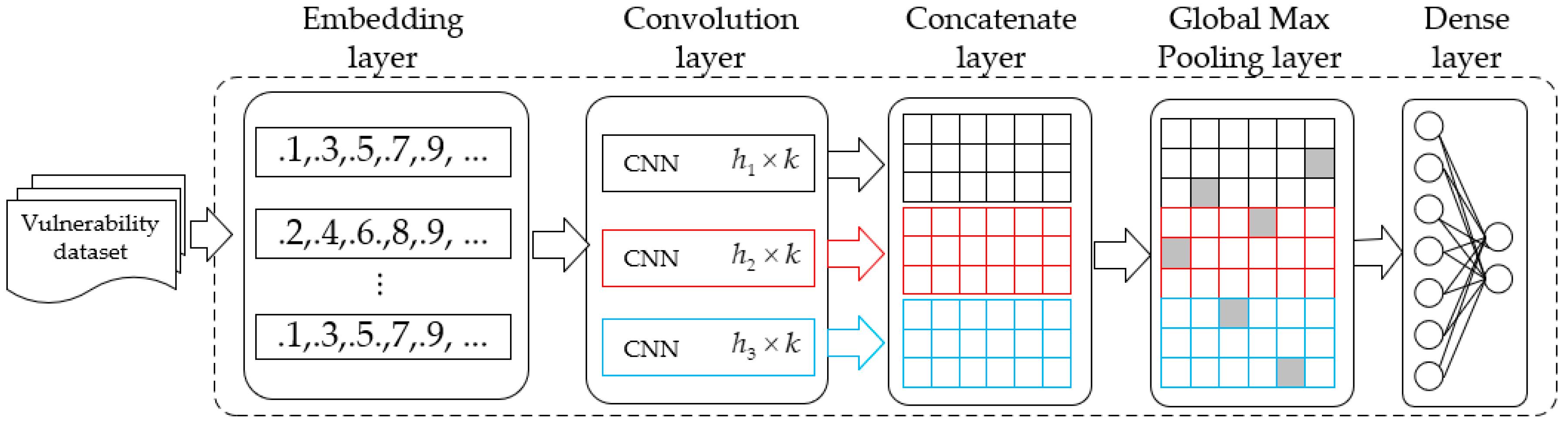
Inspired by the n-gram model in natural language processing, we use three parallel 1-dimensional convolutional neural networks to extract different features. As shown in
Figure 6, the representation learning stage consists of five layers. The embedding layer map for the MIR is obtained through static analysis to a form of vector. Let
be the vector representation corresponding to the
token in a MIR. A MIR
of length
represented as
where
j is the order of the sample in the dataset and
denotes the concatenate operator. In the convolution layer, let
be the filter, and the window of the filter is
,
. A new feature
is generated by
where
is the bias, and
is an activation function.
denotes the value involved in the convolution. There are
filters for each type. Therefore, the output of each convolution operation with a window
is
. After performing a concatenation operation on
, all features are mapped to a 2-dimensional tensor
. The global-max-pooling operation is conducted on the second dimension of
. This will pick out the most important feature while retaining the structure information. As a result, we obtain a high-level feature
. In order to complete the network, two dense layers are added after the global max pooling layer, and the dense layers have
and two nodes, respectively. The convolutional layer is reused in the classifier training phase.
4.5. Building Models and Performing Vulnerability Detection
We obtain the high-level features of the vulnerability dataset by reusing the trained convolutional neural networks. The high-level features are utilized to train a classifier for predicting whether a sample is vulnerable or not.
Finally, we get the vulnerability detection model. It leverages the pre-processing method in
Section 4.3 to obtain the minimum intermediate representations of the test samples. The word vectors obtained in
Section 4.4 are used as parameters of the embedding layer. The convolutional neural networks trained in the representation learning stage of
Section 4.5 are used to obtain high-level features. The classifier trained in the last stage is used to predict whether the test samples are vulnerable or not.
5. Experiments and Results
5.1. Evaluation Metrics
Let True Positive (TP) denote the number of correctly classified vulnerable samples, False Positive (FP) denotes the number of falsely classified clean samples, False Negative (FN) denotes the number of falsely classified vulnerable samples, and Ture Negative (TN) denotes the number of correctly classified clean samples. To measure vulnerability detection results, five metrics were used. denotes the proportion of falsely classified clean samples in all clean samples. , denotes the proportion of falsely classified vulnerable samples in all vulnerable samples. Precision (P) = TP/(TP + FP), denotes the proportion of correctly classified vulnerable samples in all samples that are classified as vulnerable. , represents the ability of a classifier to discover vulnerabilities from all vulnerable samples. measure the ability of both Precision and Recall. In the experimental results, the classifiers with low FPR, FNR and high P, R and F1 metrics have excellent performance.
5.2. Experimental Setup
The dataset used in this paper comes from the Software Assurance Reference Dataset (SARD) [
38] and the National Vulnerability Database (NVD) [
39]. SARD comes from the Software Assurance Metrics And Tool Evaluation (SAMATE) project of the National Institute of Standards and Technology (NIST). SARD aims to serve as a standard dataset to evaluate the effectiveness of vulnerability detection tools with known software security errors and fixes for them. The samples in the dataset come in two forms: artificially designed vulnerabilities, and vulnerabilities found in software products. The NVD is the U.S. government repository that collects vulnerabilities and their patches in software products. We choose the buffer overflow vulnerabilities (CWE-119) and resource management error vulnerabilities (CWE-399) on SARD and NVD as the samples for learning vulnerable programming patterns. Other samples in C language on SARD were selected to extend the dataset for pre-training. Statistics on training data and pre-training data are summarized in
Table 1. These datasets have been preliminarily processed by [
25]. We set train data:test data = 7:3, and used 10-fold cross validation to choose super parameters. In our experiment, buffer overflow vulnerability was selected as the main detection object (except
Section 5.5). This is because the buffer overflow vulnerability is the most significant vulnerability [
35]. Therefore, the detection of this type of vulnerability has practical significance. In addition, abundant samples of the buffer overflow vulnerability are available. It should be noted that our approach also applies to other vulnerabilities caused by the misuse of data processing and control logic.
The neural networks are implemented by Keras (version 2.2.5). The Random Forest, Gradient Boosting Decision Tree, SVM, Logistic Regression and Naive Bayesian algorithm were provided by the Scikit-learn (version 0.21.3). The distributed embedding is implemented by Word2vec provided by genism (version 3.0.1). Our algorithm was run on Google Colaboratory with Tesla T4 GPU.
In the representation learning stage, the parameters we used are shown in
Table 2.
5.3. Comparison of Different Neural Networks
In order to select the best model for representation learning, we adopted a 10-fold cross validation on train data. We compared six neural networks. Sequential CNN has three sequentially connected convolutional neural networks (CNN). Each convolutional neural network has 128 filters, and the size of filters is 3, 5, 7, respectively. Sequential LSTM has two long short-term memory neural networks (LSTM). Each LSTM has a 128-dimensional output. BiLSTM is composed of a forward LSTM and a backward LSTM, and it has a 128-dimensional output. In CNN + BiLSTM, the output of CNN with 128 5-dimensional filters is the input of LSTM with 128 output. CNN + BiLSTM + Attention has an extra self-attention layer in addition to CNN + BiLSTM. Concatenated CNN has an output that concatenates the output of three convolutional neural networks. Each neural network is connected to a dense layer for training. The comparison results are showed in
Table 3.
We observe that although BiLSTM achieves the best results on FNR and Recall, it has the worst results on P. Compared with other models, Concatenated CNN has balanced performance and achieves the best results in FPR, P, and F1. Therefore, in the representation learning stage, we chose Concatenated CNN as the final model to learn high-level features.
In order to compare the effects of different classifiers at the stage of vulnerability detection, we used the learned high-level features to train six classifiers: Logistic Regression (LR), Naive Bayesian (NB), Support Vector Machine (SVM), Multi-Layer Perceptron (MLP), Gradient Boosting Decision Tree (GBDT), Random Forest (RF).
Table 4 shows the comparison results. Among the six classifiers, SVM had the best performance on FPR and P metrics, while RF achieved the best performance on FNR, R, and F1 metrics. Therefore, RF has a more balanced performance.
5.4. Effectiveness of Pre-Training
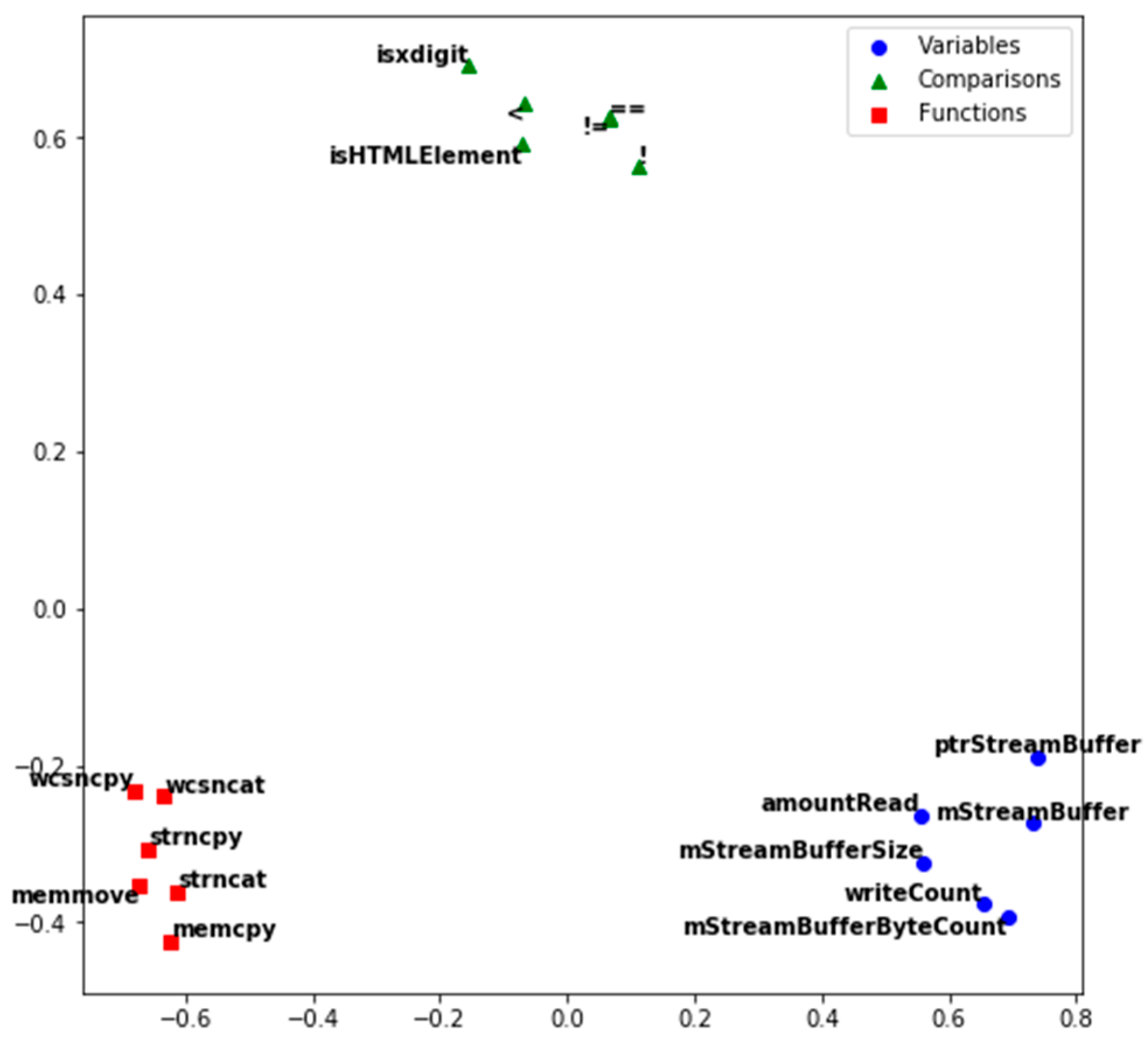
In order to validate the effectiveness of pre-training, we projected the 200-dimensional embeddings to 2-dimensional vectors. Three types of tokens with different semantics were picked out. They are memory manipulation functions, logical comparisons and custom identifiers. The projected embeddings are shown in
Figure 7.
As can be seen from
Figure 7, different types of tokens were grouped into separable clusters. This proves that through the pre-training on the extended corpus, our method can learn the common semantic information. In addition, custom identifiers with similar semantics have similar positions. This proves the ability of our method to alleviate the OoV problem.
In addition, we compared the effectiveness of our method with four different embedding methods. A random forest is used as a classifier in all five methods. The first three methods that use Vocabulary, N-Gram, IT-IDF language models respectively were performed on the same dataset (CWE-119). Their classifiers are trained using the real value vectors encoded respectively. The last two methods both use the CBOW language model as the embedding method, and a representation learning is performed to obtained high-level features. The difference is that the former uses the same dataset (CWE-119) for pre-training, representation learning, and classifier training. The latter is our approach that utilizes an extended corpus for pre-training and vulnerability dataset (CWE-119) for representation learning and classifier training.
Table 5 summarizes the experimental results. The first three methods have approximate performances. A significant improvement over the first three methods is achieved by the fourth method. This shows that the application of pre-training can improve the effectiveness of vulnerability detection. The last result is achieved by our method that has the best performance. This is because, through pre-training from a large database, the common syntax of a programming language is learned, and every token is represented by its context. Even if tokens are unique in a different program, it will eventually be represented as a similar vector as long as the identifier has a similar context. By using this transfer learning approach, we mitigate the impact of the OoV issue. The results validate Hypothesis 1.
5.5. Ability to Detect Different Vulnerabilities
In order to verify the detection ability of our method for different types of vulnerability, we conduct experiments on two datasets: CWE-119 and CWE-399. CWE-119 was the dataset of buffer overflow vulnerability. CWE-399 was the dataset of resource management error vulnerability. The two experiments were performed with the same super parameters and experimental procedures. The results are summarized in
Table 6.
As shown in
Table 6, our proposed method carried out effective detection on both two datasets. This validates that our detection method can be applied to different types of vulnerability. In comparison, the detection effect of CWE-399 was better than that of CWE-119. This is because buffer overflow vulnerability has more complex forms than resource management error vulnerability, such as complex data and control dependencies and various sanitization methods. As a result, this makes it difficult for machine learning algorithms to learn vulnerability patterns from samples.
The execution time and memory space of our proposed method are summarized in
Table 7. In the pre-training stage, our method took 216.5 s and used 278.0 MB of memory space. In the representation learning stage, the execution time of CWE-119 was 301.1 s and the execution time of CWE-399 was 137.4 s. The memory space was 2356.6 MB and 2341.9 MB, respectively. In the classifier training stage, execution time was 7.0 s and 4.2 s, respectively, and the memory space was 39.0 MB and 20.6 MB respectively. In general, the execution time and memory space of our proposed method were within the acceptable range.
5.6. Comparative Analysis
In order to examine the effectiveness of the proposed method in vulnerability detection, we performed a comparative experiment with state-of-the-art methods. We chose open-source static analysis tool Flawfinder [
4] and commercial static analysis tool Checkmarx [
5]. They represent traditional vulnerability detection methods based on static analysis. VUDDY [
19] was chosen to represent the similarity-based method. VulDeePecker and our methods detect vulnerabilities based on learning vulnerable programming patterns. The difference is that VulDeePecker [
25] has no representation learning stage, and it uses one dataset through the entire method. All the results in
Table 8 are based on the same dataset. The results of Checkmarx and VulDeePecker are from the paper [
25]. This because we are not able to access the commercial tool Checkmarx and VulDeePecker is not an open-source tool.
It can be seen from
Table 6 that our method outperforms the state-of-the-art methods. Specifically, traditional static analysis methods incur high FNR and FPR. The result of Checkmarx was relatively superior to Flawfinder. This is because the former applies efficient data flow analysis algorithms. VUDDY has a low FPR (3.5%), but has a poor performance on FNR (91.3%), P (47.0%), R (8.7%), and F1 (14.7%). This means that most vulnerabilities are not detected. This is because the similarity-based method is suitable for detecting vulnerabilities caused by code cloning, and is not adept at detecting general vulnerabilities. VulDeePecker and our method outperform other methods in most indicators. This indicates that the vulnerable pattern-based method excels at detecting general vulnerabilities. Compared with VulDeePecker, our method improved by 1.4% in FPR, 8.4% in FNR, 4.0% in P, 7.6% in R, and 6.4% in F1. This indicates that compared with training classifier directly, the application of transfer learning and representation learning can effectively improve the effect of vulnerability detection.
The above experimental results show that our method has a fine granularity and representation ability by transforming the sample into the minimum intermediate representation. This facilitates audits and alleviates long-term dependency issues. By applying transfer learning, unlabeled data can be utilized to improve the effectiveness of vulnerability detection. By using the representation learning approach, our approach is able to learn the features of vulnerabilities from context. The comparative experiment results show that our method outperforms state-of-the-art methods. Compared with the traditional static analysis method, our method has a better performance. This is because traditional static analysis methods rely on expert-defined vulnerable patterns, which are laborious and error-prone due to the diversity of programming patterns. Compared with the similarity-based method, our method learns common vulnerability patterns from training samples and can be applied to a wide range of detection scenarios. Moreover, our method excels with other pattern-based methods because of the application of transfer learning and presentation learning. This proves our hypotheses.
6. Conclusions
This paper presents a novel solution to detect vulnerability in source code by learning vulnerable programming patterns automatically, which aimed to improve the effectiveness of vulnerability detection. The granularity of our proposed method is a minimum intermediate representation that extracts vulnerability relevant information based on dependency analysis. It covers not only intra-procedural but also inter-procedural vulnerabilities, and it alleviates the long-term dependency issue and provides precise vulnerability information. We transfer the common language features in an unlabelled dataset to the task of specific vulnerability detection. Representation learning is leveraged to abstract high-level features. It mitigates the impact of the OoV and the lack of vulnerability dataset issues. We implemented a prototype and performed systematic experiments to validate the effectiveness of our method. The experimental results show that our method has an obvious improvement over the state-of-the-art methods.
The proposed approach has several limitations which can be further investigated. First, the problem of long-term dependency is merely alleviated by eliminating the irrelevant code in the pre-processing stage. This is an inherent deficiency of the sequential structure. To improve this limitation, the graph embedding method can be applied. By transforming the source code into a graph structure, the element is connected directly to its context. Second, the method in this paper does not clean out the mislabeled samples in the dataset. Mislabeled samples will interfere with the learning of vulnerable programming patterns. Therefore, sample selection could be conducted in further research. Finally, our method falls into the category of static analysis. It means that our method cannot be applied to detect vulnerability in compiled software. This can be solved by transforming the compiled software into a common intermediate representation, such as the intermediate representation of Low Level Virtual Machine (LLVM).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}