Improved Photoacoustic Imaging of Numerical Bone Model Based on Attention Block U-Net Deep Learning Network



Abstract
1. Introduction
- The CNN for PA bone imaging was first analyzed in this study.
- A modified U-Net architecture was proposed by embedding attention modules for PA bone imaging.
- The relationship between bone structure and reconstruction quality of the CNN was analyzed in this study.
2. Principles and Methods
2.1. Photoacoustic Image Reconstruction
2.2. Deep Learning for Photoacoustic Image Reconstruction
2.3. Attention Block U-Net Deep Learning Network
2.3.1. AB-U-Net Architecture
2.3.2. Attention Module
2.3.3. Loss Function
2.3.4. Evaluation for Reconstructed PA Image
- Peak Signal to Noise Ratio (PSNR)Based on the error between corresponding pixels, PSNR is the most widely used objective evaluation index of images. It implies the small distortion at a high value, formulated as:where is the maximum value of image color, and if each sampling point is represented by 8 bits, the maximum value is 255. is the mean square error of a predicted image X and ground truth image Y, defined as
- Structural Similarity (SSIM)Structural similarity is used to evaluate the structural information of the image object, based on the strong correlation between adjacent pixels. compared with PSNR, this SSIM index is more proper to evaluate the trabecular reconstruction of bone PA signals. Given the predicted image x and ground truth image y, SSIM is computed as:where , are local means of x and y respectively, , are standard deviations, is the cross-covariance for x and y. and are constants with values of 6.50 and 58.52 respectively, to avoid errors when denominator is close to 0. , and a high value represents small image distortion.
2.3.5. Networks for Comparison
3. Experiments
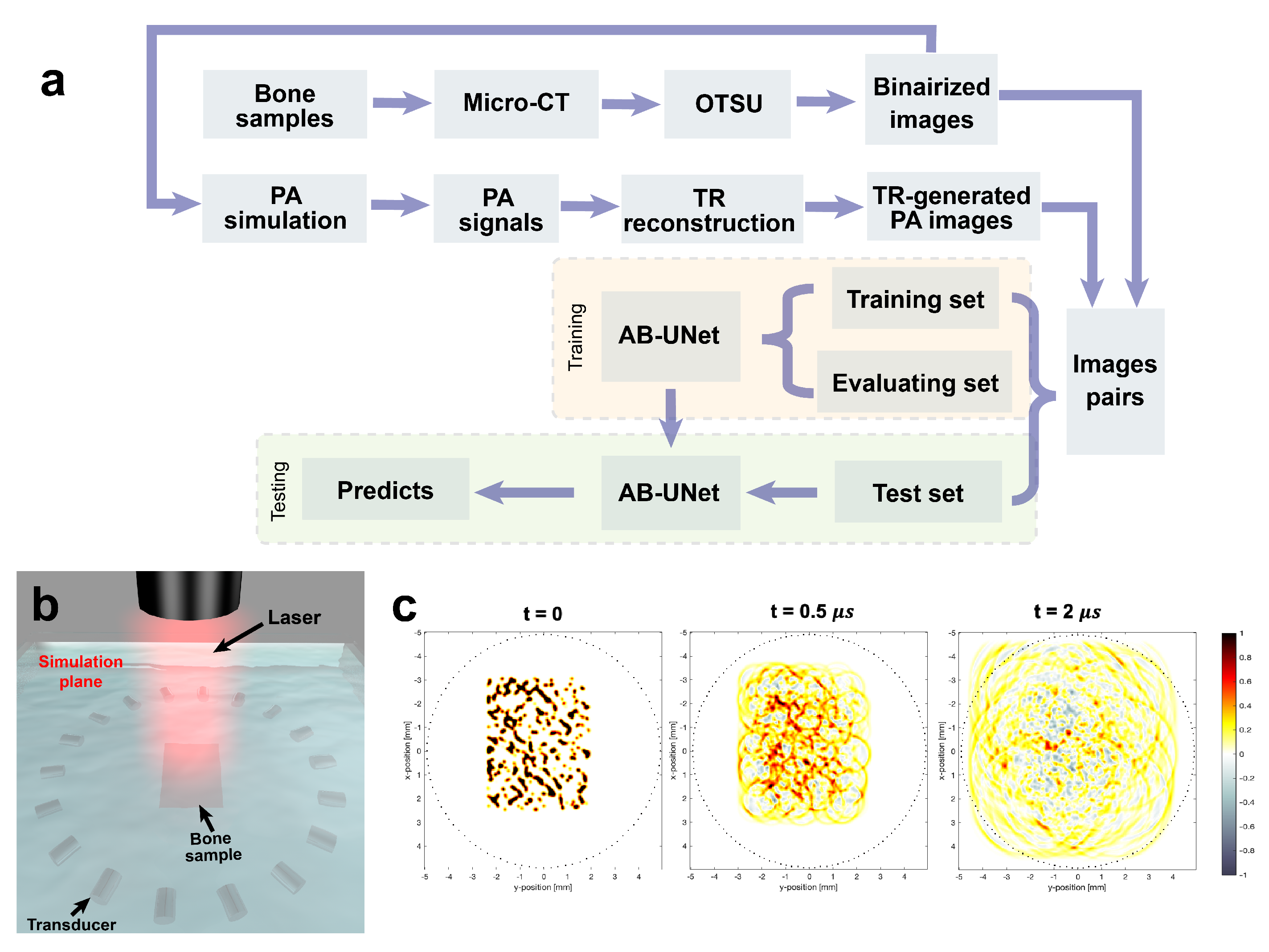
3.1. Dataset Generation
3.2. Training on Simulation Data
4. Results
4.1. Reconstruction Results of Examples
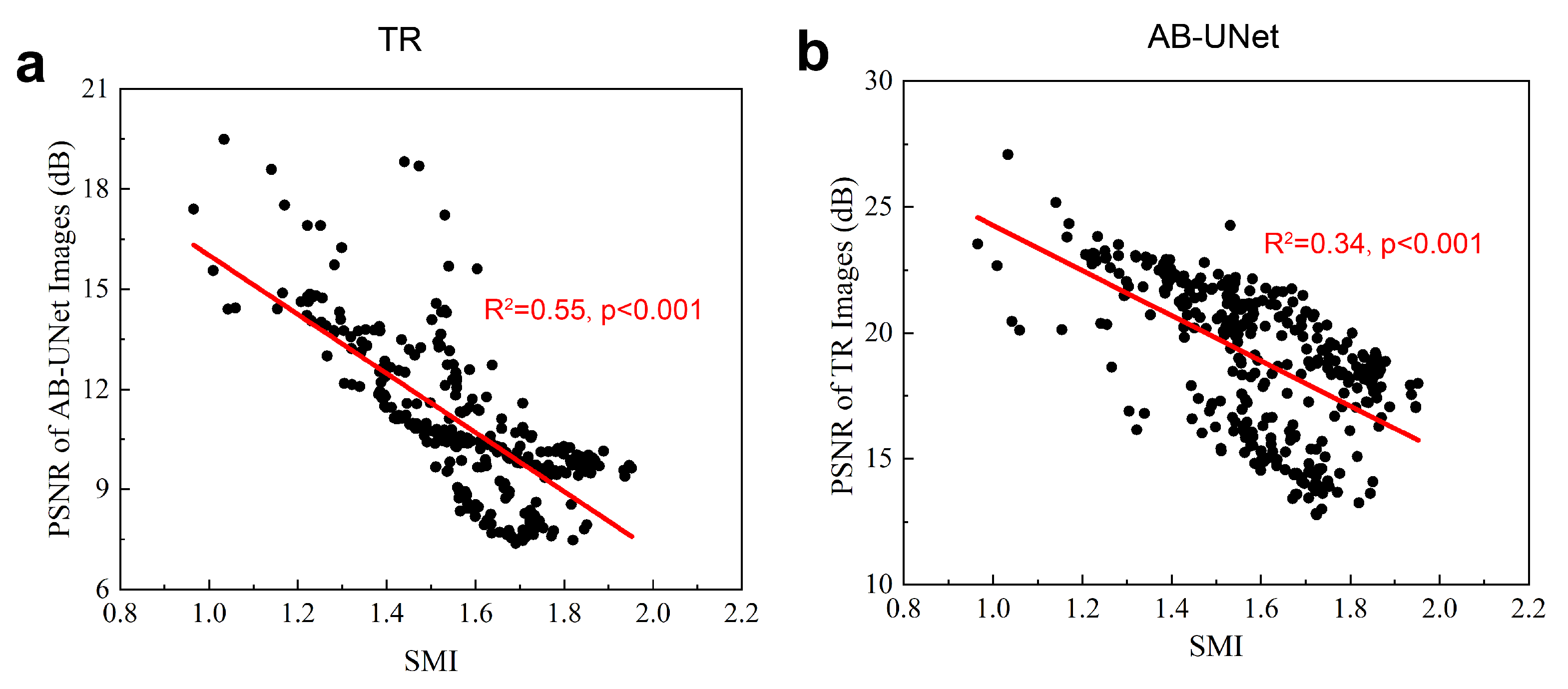
4.2. Results of Global Test Set
4.3. Statistical Significance Tests on the Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| PA | photoacoustic |
| CNN | convolution neural network |
| AB-U-Net | attention block U-Net |
| CBAM | convolutional block attention module |
| PSNR | peak signal to noise ratio |
| SSIM | structural similarity |
| DXA | dual-energy X-ray absorptiometry |
| BMD | bone mineral density |
| CT | computerized tomography |
| QUS | quantitative ultrasound |
| SOS | speed of sound |
| BUA | broadband ultrasound attenuation |
| MRI | magnetic resonance imaging |
| TR | time reversal |
References
- Griffith, J.F.; Yeung, D.K.; Antonio, G.E.; Lee, F.K.; Hong, A.W.; Wong, S.Y.; Lau, E.M.; Leung, P.C. Vertebral bone mineral density, marrow perfusion, and fat content in healthy men and men with osteoporosis: Dynamic contrast-enhanced MR imaging and MR spectroscopy. Radiology 2005, 236, 945–951. [Google Scholar] [CrossRef]
- Harvey, N.; Dennison, E.; Cooper, C. Osteoporosis: Impact on health and economics. Nat. Rev. Rheumatol. 2010, 6, 99. [Google Scholar] [CrossRef]
- Sim, L.; Van Doorn, T. Radiographic measurement of bone mineral: Reviewing dual energy X-ray absorptiometry. Australas. Phys. Eng. Sci. Med. 1995, 18, 65. [Google Scholar]
- Blake, G.M.; Fogelman, I. Technical principles of dual energy x-ray absorptiometry. In Seminars in Nuclear Medicine; Elsevier: Amsterdam, The Netherlands, 1997; Volume 27, pp. 210–228. [Google Scholar]
- Pisani, P.; Renna, M.D.; Conversano, F.; Casciaro, E.; Muratore, M.; Quarta, E.; Di Paola, M.; Casciaro, S. Screening and early diagnosis of osteoporosis through X-ray and ultrasound based techniques. World J. Radiol. 2013, 5, 398. [Google Scholar] [CrossRef] [PubMed]
- Laugier, P.; Haïat, G. Bone Quantitative Ultrasound; Springer: Berlin/Heidelberg, Germany, 2011; Volume 576. [Google Scholar]
- Fratzl, P.; Gupta, H.; Paschalis, E.; Roschger, P. Structure and mechanical quality of the collagen–mineral nano-composite in bone. J. Mater. Chem. 2004, 14, 2115–2123. [Google Scholar] [CrossRef]
- Genant, H.; Engelke, K.; Prevrhal, S. Advanced CT bone imaging in osteoporosis. Rheumatology 2008, 47, iv9–iv16. [Google Scholar] [CrossRef] [PubMed]
- Njeh, C.; Boivin, C.; Langton, C. The role of ultrasound in the assessment of osteoporosis: A review. Osteoporos. Int. 1997, 7, 7–22. [Google Scholar] [CrossRef] [PubMed]
- Kaufman, J.J.; Einhorn, T.A. Ultrasound assessment of bone. J. Bone Miner. Res. 1993, 8, 517–525. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Dong, R.; Li, B.; Li, Y.; Xu, F.; Ta, D.; Wang, W. Ultrasonic backscatter characterization of cancellous bone using a general Nakagami statistical model. Chin. Phys. B 2019, 28, 024302. [Google Scholar] [CrossRef]
- Liu, C.; Li, B.; Li, Y.; Mao, W.; Chen, C.; Zhang, R.; Ta, D. Ultrasonic Backscatter Difference Measurement of Bone Health in Preterm and Term Newborns. Ultrasound Med. Biol. 2020, 46, 305–314. [Google Scholar] [CrossRef]
- Li, Y.; Li, B.; Li, Y.; Liu, C.; Xu, F.; Zhang, R.; Ta, D.; Wang, W. The ability of ultrasonic backscatter parametric imaging to characterize bovine trabecular bone. Ultrason. Imaging 2019, 41, 271–289. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Ta, D.; Fujita, F.; Hachiken, T.; Matsukawa, M.; Mizuno, K.; Wang, W. The relationship between ultrasonic backscatter and trabecular anisotropic microstructure in cancellous bone. J. Appl. Phys. 2014, 115, 064906. [Google Scholar] [CrossRef]
- Wear, K.A. Mechanisms of Interaction of Ultrasound With Cancellous Bone: A Review. IEEE Trans. Ultrason. Ferroelectr. Freq. Control. 2019, 67, 454–482. [Google Scholar] [CrossRef]
- Chaffaı, S.; Peyrin, F.; Nuzzo, S.; Porcher, R.; Berger, G.; Laugier, P. Ultrasonic characterization of human cancellous bone using transmission and backscatter measurements: Relationships to density and microstructure. Bone 2002, 30, 229–237. [Google Scholar] [CrossRef]
- Liu, C.; Li, B.; Diwu, Q.; Li, Y.; Zhang, R.; Ta, D.; Wang, W. Relationships of ultrasonic backscatter with bone densities and microstructure in bovine cancellous bone. IEEE Trans. Ultrason. Ferroelectr. Freq. Control. 2018, 65, 2311–2321. [Google Scholar] [CrossRef]
- Guillaume, R.; Pieter, K.; Didier, C.; Pascal, L. In vivo ultrasound imaging of the bone cortex. Phys. Med. Biol. 2018, 63, 125010. [Google Scholar]
- Xu, M.; Wang, L.V. Photoacoustic imaging in biomedicine. Rev. Sci. Instruments 2006, 77, 041101. [Google Scholar] [CrossRef]
- Beard, P. Biomedical photoacoustic imaging. Interface Focus 2011, 1, 602–631. [Google Scholar] [CrossRef]
- Cao, F.; Qiu, Z.; Li, H.; Lai, P. Photoacoustic imaging in oxygen detection. Appl. Sci. 2017, 7, 1262. [Google Scholar] [CrossRef]
- Feng, T.; Zhu, Y.; Morris, R.; Kozloff, K.; Wang, X. Functional Photoacoustic and Ultrasonic Assessment of Osteoporosis: A Clinical Feasibility Study. Biomed. Eng. Front. 2020, 2020, 15. [Google Scholar]
- Wang, L.V.; Hu, S. Photoacoustic tomography: In vivo imaging from organelles to organs. Science 2012, 335, 1458–1462. [Google Scholar] [CrossRef] [PubMed]
- Hoelen, C.; De Mul, F.; Pongers, R.; Dekker, A. Three-dimensional photoacoustic imaging of blood vessels in tissue. Opt. Lett. 1998, 23, 648–650. [Google Scholar] [CrossRef] [PubMed]
- Jansen, K.; Van Der Steen, A.F.; van Beusekom, H.M.; Oosterhuis, J.W.; van Soest, G. Intravascular photoacoustic imaging of human coronary atherosclerosis. Opt. Lett. 2011, 36, 597–599. [Google Scholar] [CrossRef] [PubMed]
- Kruger, R.A.; Lam, R.B.; Reinecke, D.R.; Del Rio, S.P.; Doyle, R.P. Photoacoustic angiography of the breast. Med. Phys. 2010, 37, 6096–6100. [Google Scholar] [CrossRef]
- Mallidi, S.; Luke, G.P.; Emelianov, S. Photoacoustic imaging in cancer detection, diagnosis, and treatment guidance. Trends Biotechnol. 2011, 29, 213–221. [Google Scholar] [CrossRef]
- Rao, A.P.; Bokde, N.; Sinha, S. Photoacoustic imaging for management of breast cancer: A literature review and future perspectives. Appl. Sci. 2020, 10, 767. [Google Scholar] [CrossRef]
- Lashkari, B.; Mandelis, A. Coregistered photoacoustic and ultrasonic signatures of early bone density variations. J. Biomed. Opt. 2014, 19, 036015. [Google Scholar] [CrossRef]
- Feng, T.; Kozloff, K.M.; Tian, C.; Perosky, J.E.; Hsiao, Y.S.; Du, S.; Yuan, J.; Deng, C.X.; Wang, X. Bone assessment via thermal photo-acoustic measurements. Opt. Lett. 2015, 40, 1721–1724. [Google Scholar] [CrossRef]
- Gu, C.; Katti, D.R.; Katti, K.S. Microstructural and photoacoustic infrared spectroscopic studies of human cortical bone with osteogenesis imperfecta. JOM 2016, 68, 1116–1127. [Google Scholar] [CrossRef]
- Wang, X.; Feng, T.; Cao, M.; Perosky, J.E.; Kozloff, K.; Cheng, Q.; Yuan, J. Photoacoustic measurement of bone health: A study for clinical feasibility. In Proceedings of the 2016 IEEE International Ultrasonics Symposium (IUS), Tours, France, 18–21 September 2016; pp. 1–4. [Google Scholar]
- Wang, X.; Chamberland, D.L.; Jamadar, D.A. Noninvasive photoacoustic tomography of human peripheral joints toward diagnosis of inflammatory arthritis. Opt. Lett. 2007, 32, 3002–3004. [Google Scholar] [CrossRef]
- Yang, L.; Lashkari, B.; Tan, J.W.; Mandelis, A. Photoacoustic and ultrasound imaging of cancellous bone tissue. J. Biomed. Opt. 2015, 20, 076016. [Google Scholar] [CrossRef] [PubMed]
- Merrill, J.A.; Wang, S.; Zhao, Y.; Arellano, J.; Xiang, L. Photoacoustic microscopy for bone microstructure analysis. In Proceedings of the Biophotonics and Immune Responses XV. International Society for Optics and Photonics, Bellingham, WA, USA, 1–6 February 2020; Volume 11241, p. 112410H. [Google Scholar]
- Syahrom, A.; bin Mohd Szali, M.A.F.; Harun, M.N.; Öchsner, A. Cancellous bone. In Cancellous Bone; Springer: Berlin/Heidelberg, Germany, 2018; pp. 7–20. [Google Scholar]
- Shim, V.; Yang, L.; Liu, J.; Lee, V. Characterisation of the dynamic compressive mechanical properties of cancellous bone from the human cervical spine. Int. J. Impact Eng. 2005, 32, 525–540. [Google Scholar] [CrossRef]
- Hans, D.; Wu, C.; Njeh, C.; Zhao, S.; Augat, P.; Newitt, D.; Link, T.; Lu, Y.; Majumdar, S.; Genant, H. Ultrasound velocity of trabecular cubes reflects mainly bone density and elasticity. Calcif. Tissue Int. 1999, 64, 18–23. [Google Scholar] [CrossRef] [PubMed]
- Haiat, G.; Lhemery, A.; Renaud, F.; Padilla, F.; Laugier, P.; Naili, S. Velocity dispersion in trabecular bone: Influence of multiple scattering and of absorption. J. Acoust. Soc. Am. 2008, 124, 4047–4058. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Wang, L.V. Effects of acoustic heterogeneity in breast thermoacoustic tomography. IEEE Trans. Ultrason. Ferroelectr. Freq. Control. 2003, 50, 1134–1146. [Google Scholar] [PubMed]
- Haltmeier, M. Sampling conditions for the circular radon transform. IEEE Trans. Image Process. 2016, 25, 2910–2919. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhao, Z.; Song, J.; Chen, G.; Nie, Z.; Liu, Q.H. Reducing the effects of acoustic heterogeneity with an iterative reconstruction method from experimental data in microwave induced thermoacoustic tomography. Med. Phys. 2015, 42, 2103–2112. [Google Scholar] [CrossRef] [PubMed]
- Jin, X.; Wang, L.V. Thermoacoustic tomography with correction for acoustic speed variations. Phys. Med. Biol. 2006, 51, 6437. [Google Scholar] [CrossRef]
- Zhang, J.; Anastasio, M.A. Reconstruction of speed-of-sound and electromagnetic absorption distributions in photoacoustic tomography. In Photons Plus Ultrasound: Imaging and Sensing 2006: The Seventh Conference on Biomedical Thermoacoustics, Optoacoustics, and Acousto-optics; International Society for Optics and Photonics: Bellingham, WA, USA, 2006; Volume 6086, p. 608619. [Google Scholar]
- Rui, W.; Liu, Z.; Tao, C.; Liu, X. Reconstruction of Photoacoustic Tomography Inside a Scattering Layer Using a Matrix Filtering Method. Appl. Sci. 2019, 9, 2071. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Li, Q.; Cai, W.; Wang, X.; Zhou, Y.; Feng, D.D.; Chen, M. Medical image classification with convolutional neural network. In Proceedings of the 2014 13th International Conference on Control Automation Robotics & Vision (ICARCV), Singapore, 10–12 December 2014; pp. 844–848. [Google Scholar]
- Chan, T.H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A simple deep learning baseline for image classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Yu, S.; Jia, S.; Xu, C. Convolutional neural networks for hyperspectral image classification. Neurocomputing 2017, 219, 88–98. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Higaki, T.; Nakamura, Y.; Tatsugami, F.; Nakaura, T.; Awai, K. Improvement of image quality at CT and MRI using deep learning. Jpn. J. Radiol. 2019, 37, 73–80. [Google Scholar] [CrossRef]
- Urase, Y.; Nishio, M.; Ueno, Y.; Kono, A.K.; Sofue, K.; Kanda, T.; Maeda, T.; Nogami, M.; Hori, M.; Murakami, T. Simulation Study of Low-Dose Sparse-Sampling CT with Deep Learning-Based Reconstruction: Usefulness for Evaluation of Ovarian Cancer Metastasis. Appl. Sci. 2020, 10, 4446. [Google Scholar] [CrossRef]
- Liang, D.; Cheng, J.; Ke, Z.; Ying, L. Deep magnetic resonance image reconstruction: Inverse problems meet neural networks. IEEE Signal Process. Mag. 2020, 37, 141–151. [Google Scholar] [CrossRef]
- Kovács, P.; Lehner, B.; Thummerer, G.; Mayr, G.; Burgholzer, P.; Huemer, M. Deep learning approaches for thermographic imaging. J. Appl. Phys. 2020, 128, 155103. [Google Scholar] [CrossRef]
- Ramzi, Z.; Ciuciu, P.; Starck, J.L. Benchmarking MRI Reconstruction Neural Networks on Large Public Datasets. Appl. Sci. 2020, 10, 1816. [Google Scholar] [CrossRef]
- Yang, C.; Lan, H.; Gao, F.; Gao, F. Deep learning for photoacoustic imaging: A survey. arXiv 2020, arXiv:2008.04221. [Google Scholar]
- Hauptmann, A.; Cox, B. Deep Learning in Photoacoustic Tomography: Current approaches and future directions. J. Biomed. Opt. 2020, 25, 112903. [Google Scholar] [CrossRef]
- Manwar, R.; Li, X.; Mahmoodkalayeh, S.; Asano, E.; Zhu, D.; Avanaki, K. Deep learning protocol for improved photoacoustic brain imaging. J. Biophotonics 2020, 13, e202000212. [Google Scholar] [CrossRef]
- Allman, D.; Reiter, A.; Bell, M.A.L. Photoacoustic source detection and reflection artifact removal enabled by deep learning. IEEE Trans. Med. Imaging 2018, 37, 1464–1477. [Google Scholar] [CrossRef] [PubMed]
- Davoudi, N.; Deán-Ben, X.L.; Razansky, D. Deep learning optoacoustic tomography with sparse data. Nat. Mach. Intell. 2019, 1, 453–460. [Google Scholar] [CrossRef]
- Hariri, A.; Alipour, K.; Mantri, Y.; Schulze, J.P.; Jokerst, J.V. Deep learning improves contrast in low-fluence photoacoustic imaging. Biomed. Opt. Express 2020, 11, 3360–3373. [Google Scholar] [CrossRef]
- Hauptmann, A.; Lucka, F.; Betcke, M.; Huynh, N.; Adler, J.; Cox, B.; Beard, P.; Ourselin, S.; Arridge, S. Model-based learning for accelerated, limited-view 3-d photoacoustic tomography. IEEE Trans. Med. Imaging 2018, 37, 1382–1393. [Google Scholar] [CrossRef]
- Jin, K.H.; McCann, M.T.; Froustey, E.; Unser, M. Deep convolutional neural network for inverse problems in imaging. IEEE Trans. Image Process. 2017, 26, 4509–4522. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Treeby, B.E.; Cox, B.T. k-Wave: MATLAB toolbox for the simulation and reconstruction of photoacoustic wave fields. J. Biomed. Opt. 2010, 15, 021314. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 fourth international conference on 3D vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Andrew, G.; Gao, J. Scalable training of L 1-regularized log-linear models. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 33–40. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man, Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Aula, A.; Töyräs, J.; Hakulinen, M.; Jurvelin, J. Effect of bone marrow on acoustic properties of trabecular bone-3d finite difference modeling study. Ultrasound Med. Biol. 2009, 35, 308–318. [Google Scholar] [CrossRef]
- Antholzer, S.; Haltmeier, M.; Nuster, R.; Schwab, J. Photoacoustic image reconstruction via deep learning. In Proceedings of the Photons Plus Ultrasound: Imaging and Sensing 2018. International Society for Optics and Photonics, San Diego, CA, USA, 19–23 August 2018; Volume 10494, p. 104944U. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]
- Rehman, A.; Rostami, M.; Wang, Z.; Brunet, D.; Vrscay, E.R. SSIM-inspired image restoration using sparse representation. EURASIP J. Adv. Signal Process. 2012, 2012, 16. [Google Scholar] [CrossRef]
- Mishra, P.; Pandey, C.M.; Singh, U.; Gupta, A.; Sahu, C.; Keshri, A. Descriptive statistics and normality tests for statistical data. Ann. Card. Anaesth. 2019, 22, 67. [Google Scholar] [PubMed]
- Trawiński, B.; Smętek, M.; Telec, Z.; Lasota, T. Nonparametric statistical analysis for multiple comparison of machine learning regression algorithms. Int. J. Appl. Math. Comput. Sci. 2012, 22, 867–881. [Google Scholar] [CrossRef]
- Xu, Y.; Feng, D.; Wang, L.V. Exact frequency-domain reconstruction for thermoacoustic tomography. I. Planar geometry. IEEE Trans. Med. Imaging 2002, 21, 823–828. [Google Scholar]
- Xu, M.; Wang, L.V. Time-domain reconstruction for thermoacoustic tomography in a spherical geometry. IEEE Trans. Med. Imaging 2002, 21, 814–822. [Google Scholar]
- Xu, Y.; Wang, L.V. Time reversal and its application to tomography with diffracting sources. Phys. Rev. Lett. 2004, 92, 033902. [Google Scholar] [CrossRef]
- Xu, M.; Wang, L.V. Universal back-projection algorithm for photoacoustic computed tomography. Phys. Rev. E 2005, 71, 016706. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, Y.; Zhang, W.; Liao, P.; Li, K.; Zhou, J.; Wang, G. Low-dose CT via convolutional neural network. Biomed. Opt. Express 2017, 8, 679–694. [Google Scholar] [CrossRef]
- Lee, D.; Yoo, J.; Tak, S.; Ye, J.C. Deep residual learning for accelerated MRI using magnitude and phase networks. IEEE Trans. Biomed. Eng. 2018, 65, 1985–1995. [Google Scholar] [CrossRef]
- Arlot, M.E.; Burt-Pichat, B.; Roux, J.P.; Vashishth, D.; Bouxsein, M.L.; Delmas, P.D. Microarchitecture influences microdamage accumulation in human vertebral trabecular bone. J. Bone Miner. Res. 2008, 23, 1613–1618. [Google Scholar] [CrossRef]
- Zhao, T.; Wu, X. Pyramid feature attention network for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3085–3094. [Google Scholar]
- Cheng, P.M.; Malhi, H.S. Transfer learning with convolutional neural networks for classification of abdominal ultrasound images. J. Digit. Imaging 2017, 30, 234–243. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Test Set (760 Samples) | |
|---|---|---|
| PSNR (dB) | SSIM | |
| Time Reversal | 12 ± 2.16 | 0.65 ± 0.09 |
| U-Net | 15.6 ± 1.97 | 0.81 ± 0.00 |
| Attention U-Net | 15.67 ± 1.95 | 0.81 ± 0.00 |
| AB-U-Net | 15.83 ± 2.04 | 0.82 ± 0.00 |
| Models | Params (M) | FLOPs (G) | Training Time (100 Epochs) | Testing Time (Single Image) |
|---|---|---|---|---|
| U-Net | 31 | 184 | 23 h | 3 s |
| Attention U-Net | 34 | 266 | 1 d 8 h | 3 s |
| AB-U-Net | 95 | 329 | 2 d 20 h | 5 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P.; Liu, C.; Feng, T.; Li, Y.; Ta, D. Improved Photoacoustic Imaging of Numerical Bone Model Based on Attention Block U-Net Deep Learning Network. Appl. Sci. 2020, 10, 8089. https://doi.org/10.3390/app10228089
Chen P, Liu C, Feng T, Li Y, Ta D. Improved Photoacoustic Imaging of Numerical Bone Model Based on Attention Block U-Net Deep Learning Network. Applied Sciences. 2020; 10(22):8089. https://doi.org/10.3390/app10228089
Chicago/Turabian StyleChen, Panpan, Chengcheng Liu, Ting Feng, Yong Li, and Dean Ta. 2020. "Improved Photoacoustic Imaging of Numerical Bone Model Based on Attention Block U-Net Deep Learning Network" Applied Sciences 10, no. 22: 8089. https://doi.org/10.3390/app10228089
APA StyleChen, P., Liu, C., Feng, T., Li, Y., & Ta, D. (2020). Improved Photoacoustic Imaging of Numerical Bone Model Based on Attention Block U-Net Deep Learning Network. Applied Sciences, 10(22), 8089. https://doi.org/10.3390/app10228089