Automated Code-Smell Detection in Microservices Through Static Analysis: A Case Study




Abstract
1. Introduction
2. Related Work
3. Microservice Code Smell Catalogue
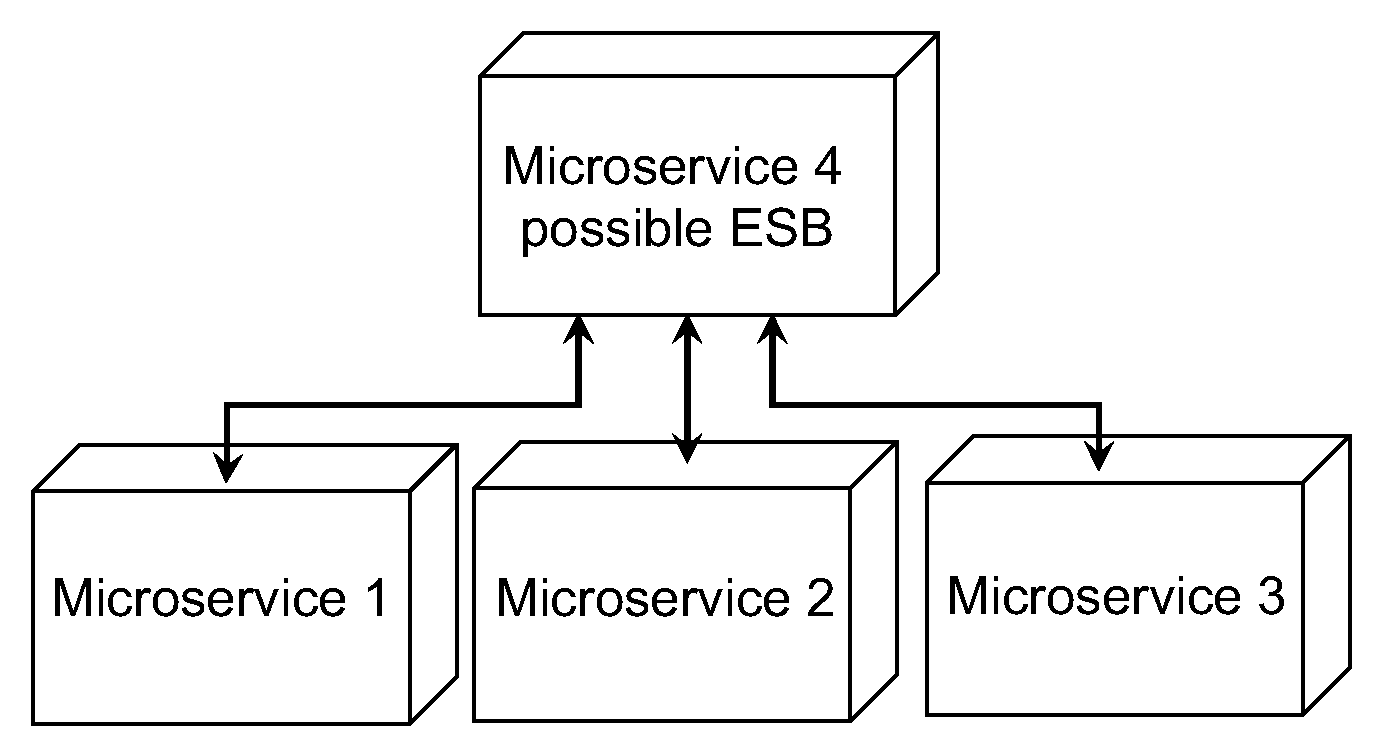
- ESB Usage (EU): An Enterprise Service Bus (ESB) [2] is a way of message passing between modules of a distributed application in which one module acts as a service bus for all of the other modules to pass messages on. There are pros and cons to this approach. However, in microservices, it can become an issue of creating a single point of failure, and increasing coupling, so it should be avoided. An example is displayed in Figure 1.
- Too Many Standards (MS): Given the distributed nature of the microservice application, multiple discrete teams of developers often work on a given module, separate from the other teams. This can create a situation where multiple frameworks are used when a standard should be established for consistency across the modules.
- Wrong Cuts (WC): This occurs when microservices are split into their technical layers (presentation, business, and data layers). Microservices are supposed to be split by features, and each fully contains their domain’s presentation, business, and data layers.
- Not Having an API Gateway (NAG): The API gateway pattern is a design pattern for managing the connections between microservices. In large, complex systems, this should be used to reduce the potential issues of direct communication.
- Hard-Coded Endpoints (HCE): Hardcoded IP addresses and ports are used to communicate between services. By hardcoding the endpoints, the application becomes more brittle to change and reduces the application’s scalability.
- API Versioning (AV): All Application Programming Interfaces (API) should be versioned to keep track of changes properly.
- Microservice Greedy (MG): This occurs when microservices are created for every new feature, and, oftentimes, these new modules are too small and do not serve many purposes. This increases complexity and the overhead of the system. Smaller features should be wrapped into larger microservices if possible.
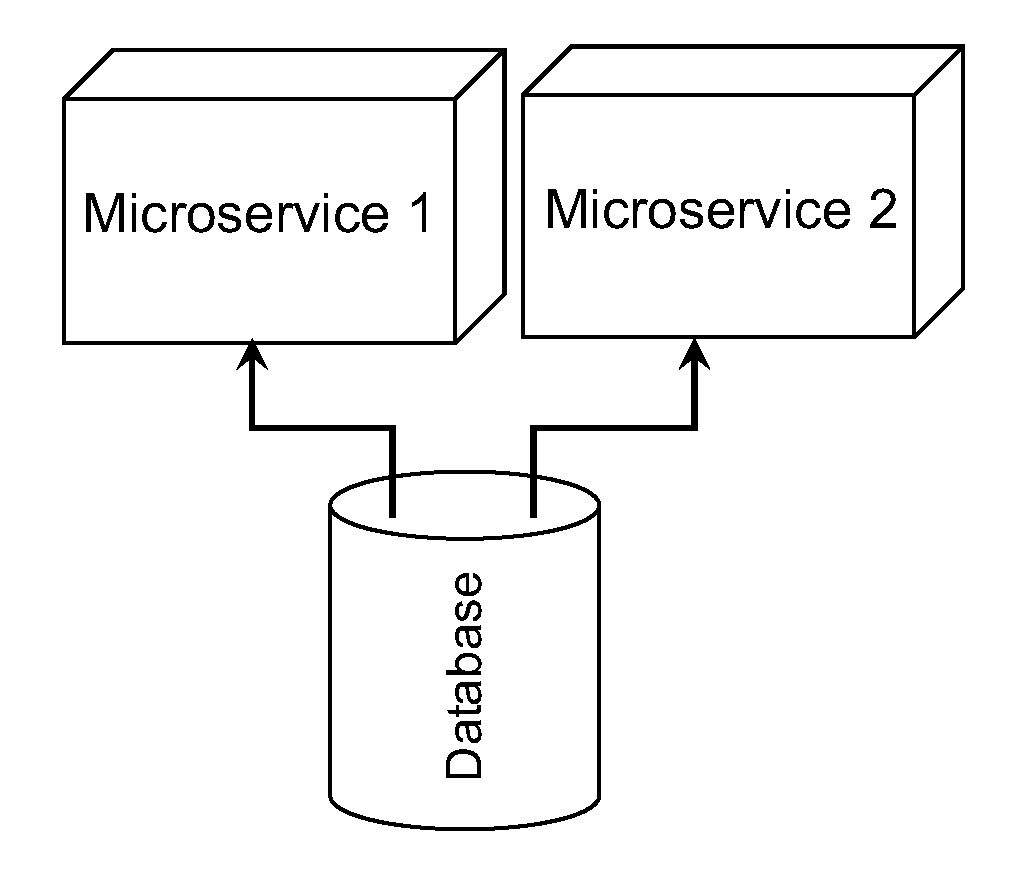
- Shared Persistency (SP): When two microservice application modules access the same database, it breaks the microservice definition. Each microservice should have autonomy and control over its data and database. An example is provided in Figure 2.
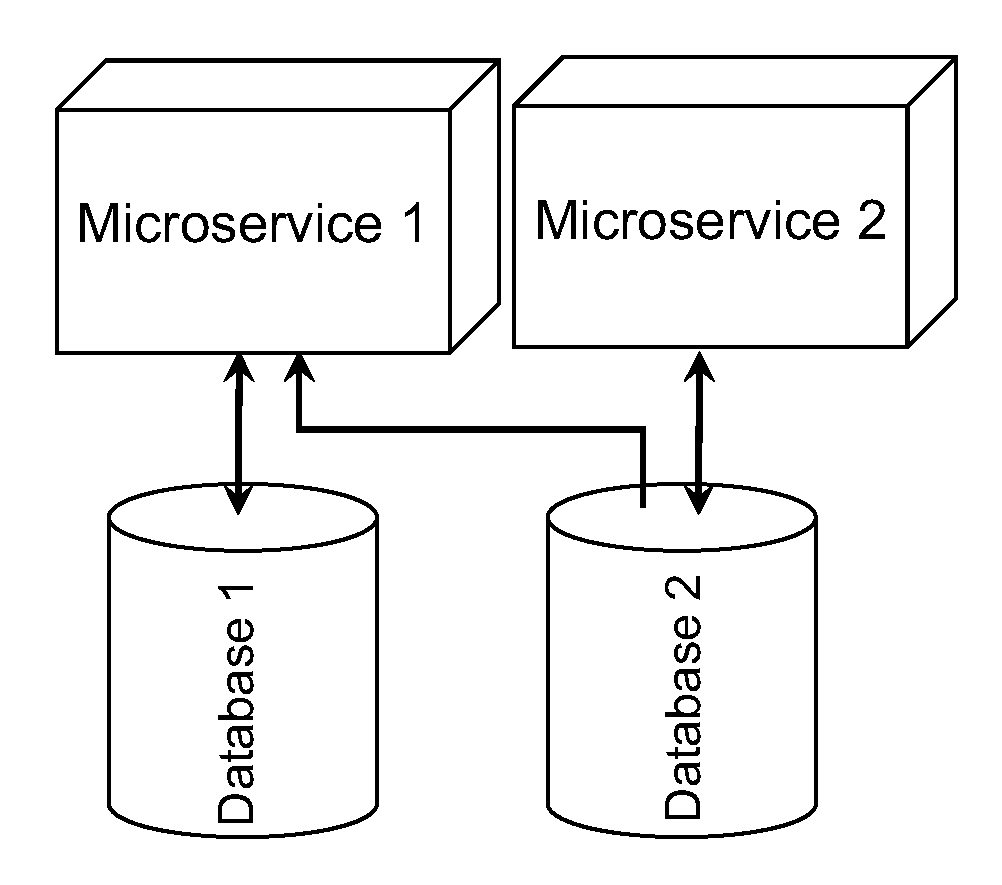
- Inappropriate Service Intimacy (ISI): One module requesting private data from a separate module also breaks the microservice definition. Each microservice should have control over its private data. An example is given in Figure 3.
- Shared Libraries (SL): If microservices are coupled with a common library, that library should be refactored into a separate module. This reduces the fragility of the application by migrating the shared functionality behind a common, unchanging interface. This will make the system resistant to ripples from changes within the library.
- Cyclic Dependency (CD): This occurs when there is a cyclic connection between calls to different modules. This can cause repetitive calls and also increase the complexity of understanding call traces for developers. This is a poor architectural practice for microservices.
4. Code Analysis and Extension for Enterprise Architectures
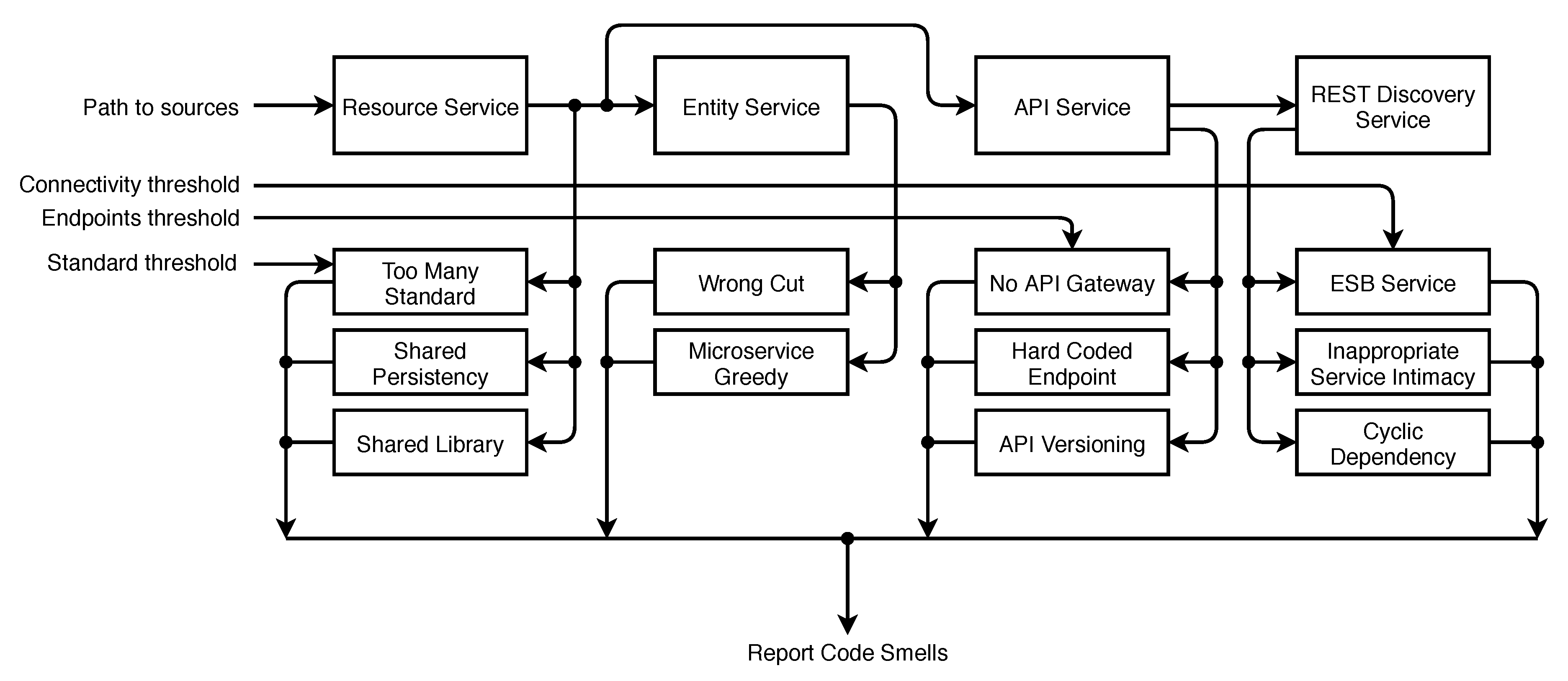
5. Proposed Solution to Detect Code Smells
5.1. ESB Usage
5.2. Too Many Standards
5.3. Wrong Cuts
5.4. Not Having an API Gateway
5.5. Shared Persistency
5.6. Inappropriate Service Intimacy
5.7. Shared Libraries
5.8. Cyclic Dependency
5.9. Hard-Coded Endpoints
5.10. API Versioning
5.11. Microservice Greedy
6. Case Study
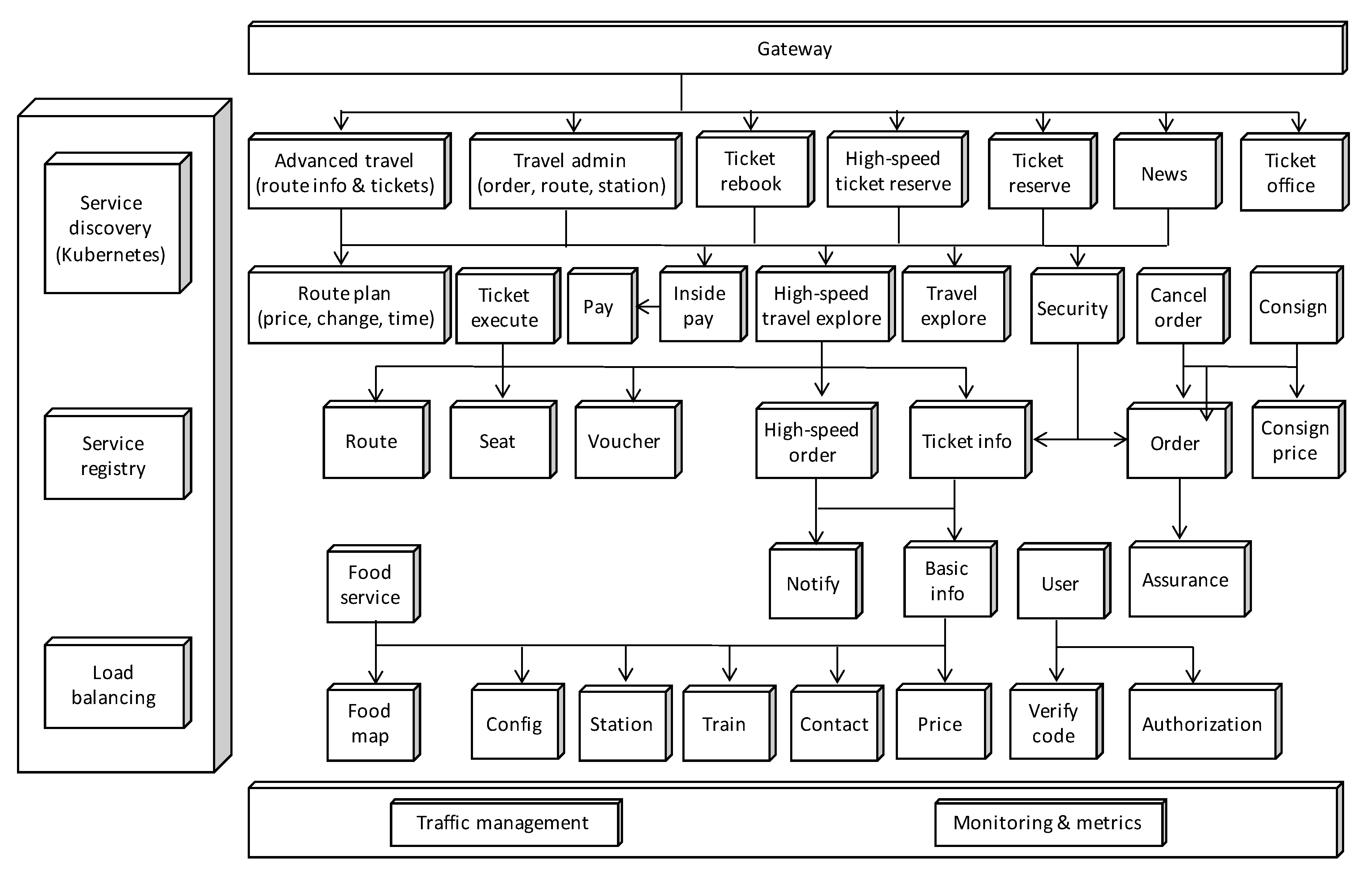
6.1. Train Ticket
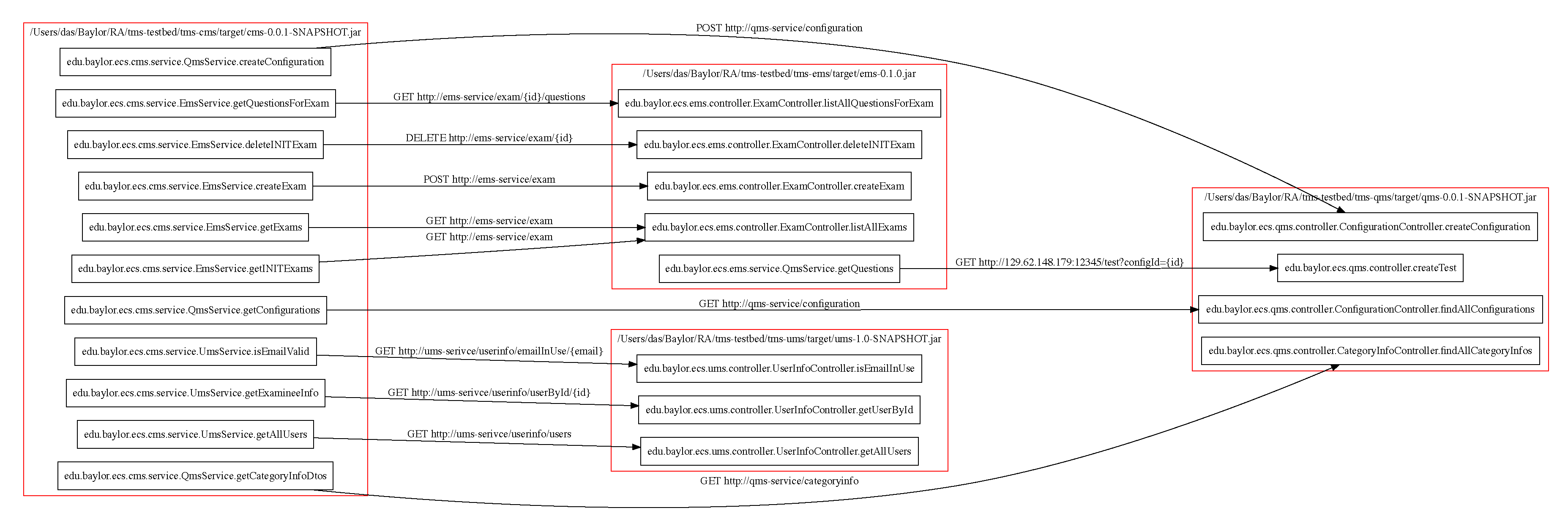
6.2. Teacher Management System
6.3. Validity threats
6.3.1. Internal Threats
6.3.2. External Threats
7. Future Trends
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- NGINX, Inc. The Future of Application Development and Delivery Is Now Containers and Microservices Are Hitting the Mainstream. 2015. Available online: https://www.nginx.com/resources/library/app-dev-survey/ (accessed on 27 March 2020).
- Cerny, T.; Donahoo, M.J.; Trnka, M. Contextual Understanding of Microservice Architecture: Current and Future Directions. SIGAPP Appl. Comput. Rev. 2018, 17, 29–45. [Google Scholar] [CrossRef]
- Walker, A.; Cerny, T. On Cloud Computing Infrastructure for Existing Code-Clone Detection Algorithms. SIGAPP Appl. Comput. Rev. 2020, 20, 5–14. [Google Scholar] [CrossRef]
- Fowler, M. Refactoring: Improving the Design of Existing Code; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2018. [Google Scholar]
- Yamashita, A.; Moonen, L. Do developers care about code smells? An exploratory survey. In Proceedings of the 2013 20th Working Conference on Reverse Engineering (WCRE), Koblenz, Germany, 14–17 October 2013; pp. 242–251. [Google Scholar]
- DeMichiel, L.; Shannon, W. JSR 366: Java Platform, Enterprise Edition 8 Spec. 2016. Available online: https://jcp.org/en/jsr/detail?id=342 (accessed on 27 March 2020).
- DeMichiel, L.; Keith, M. JSR 220: Enterprise JavaBeans Version 3.0. Java Persistence API. 2006. Available online: http://jcp.org/en/jsr/detail?id=220 (accessed on 27 March 2020).
- Bernard, E. JSR 303: Bean Validation. 2009. Available online: http://jcp.org/en/jsr/detail?id=303 (accessed on 27 March 2020).
- DeMichiel, L. JSR 317: JavaTM Persistence API, Version 2.0. 2009. Available online: http://jcp.org/en/jsr/detail?id=317 (accessed on 27 March 2020).
- Hopkins, W. JSR 375: JavaTM EE Security API. Available online: https://jcp.org/en/jsr/detail?id=375 (accessed on 27 March 2020).
- Fontana, F.A.; Zanoni, M. On Investigating Code Smells Correlations. In Proceedings of the 2011 IEEE Fourth International Conference on Software Testing, Verification and Validation Workshops, Berlin, Germany, 21–25 March 2011; pp. 474–475. [Google Scholar]
- Suryanarayana, G.; Samarthyam, G.; Sharma, T. Refactoring for Software Design Smells: Managing Technical Debt, 1st ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2014. [Google Scholar]
- Tufano, M.; Palomba, F.; Bavota, G.; Oliveto, R.; Di Penta, M.; De Lucia, A.; Poshyvanyk, D. When and Why Your Code Starts to Smell Bad. In Proceedings of the 2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, Florence, Italy, 16–24 May 2015; Volume 1, pp. 403–414. [Google Scholar]
- Gupta, V.; Kapur, P.; Kumar, D. Modelling and measuring code smells in enterprise applications using TISM and two-way assessment. Int. J. Syst. Assur. Eng. Manag. 2016, 7. [Google Scholar] [CrossRef]
- Yamashita, A.; Moonen, L. Exploring the impact of inter-smell relations on software maintainability: An empirical study. In Proceedings of the 2013 35th International Conference on Software Engineering (ICSE), San Francisco, CA, USA, 18–26 May 2013; pp. 682–691. [Google Scholar]
- Moonen, L.; Yamashita, A. Do Code Smells Reflect Important Maintainability Aspects? In Proceedings of the 2012 IEEE International Conference on Software Maintenance (ICSM), Trento, Italy, 23–28 September 2012; pp. 306–315. [Google Scholar] [CrossRef]
- Yamashita, A.; Counsell, S. Code smells as system-level indicators of maintainability: An empirical study. J. Syst. Softw. 2013, 86, 2639–2653. [Google Scholar] [CrossRef]
- Macia, I.; Garcia, J.; Daniel, P.; Garcia, A.; Medvidovic, N.; Staa, A. Are automatically-detected code anomalies relevant to architectural modularity? An exploratory analysis of evolving systems. In Proceedings of the AOSD’12—11th Annual International Conference on Aspect Oriented Software Development, Potsdam, Germany, 25–30 March 2012. [Google Scholar] [CrossRef]
- Counsell, S.; Hamza, H.; Hierons, R.M. The ‘deception’ of code smells: An empirical investigation. In Proceedings of the ITI 2010—32nd International Conference on Information Technology Interfaces, Cavtat/Dubrovnik, Croatia, 21–24 June 2010; pp. 683–688. [Google Scholar]
- Sehgal, R.; Nagpal, R.; Mehrotra, D. Measuring Code Smells and Anti-Patterns. In Proceedings of the 2019 4th International Conference on Information Systems and Computer Networks (ISCON), Mathura, India, 21–22 November 2019; pp. 311–314. [Google Scholar]
- Sae-Lim, N.; Hayashi, S.; Saeki, M. How Do Developers Select and Prioritize Code Smells? A Preliminary Study. In Proceedings of the 2017 IEEE International Conference on Software Maintenance and Evolution (ICSME), Shanghai, China, 17–22 September 2017; pp. 484–488. [Google Scholar]
- Peters, R.; Zaidman, A. Evaluating the Lifespan of Code Smells using Software Repository Mining. In Proceedings of the 2012 16th European Conference on Software Maintenance and Reengineering, Szeged, Hungary, 27–30 March 2012; pp. 411–416. [Google Scholar]
- Oliveira, R. When More Heads Are Better than One? Understanding and Improving Collaborative Identification of Code Smells. In Proceedings of the 2016 IEEE/ACM 38th International Conference on Software Engineering Companion (ICSE-C), Austin, TX, USA, 14–22 May 2016; pp. 879–882. [Google Scholar]
- Tufano, M.; Palomba, F.; Bavota, G.; Oliveto, R.; Penta, M.D.; De Lucia, A.; Poshyvanyk, D. When and Why Your Code Starts to Smell Bad (and Whether the Smells Go Away). IEEE Trans. Softw. Eng. 2017, 43, 1063–1088. [Google Scholar] [CrossRef]
- Tahir, A.; Dietrich, J.; Counsell, S.; Licorish, S.; Yamashita, A. A large scale study on how developers discuss code smells and anti-pattern in Stack Exchange sites. Inf. Softw. Technol. 2020, 125, 106333. [Google Scholar] [CrossRef]
- Van Emden, E.; Moonen, L. Java Quality Assurance by Detecting Code Smells. In Proceedings of the Ninth Working Conference on Reverse Engineering (WCRE’02), Richmond, VA, USA, 28 October–1 November 2002; p. 97. [Google Scholar]
- Alikacem, E.H.; Sahraoui, H.A. A Metric Extraction Framework Based on a High-Level Description Language. In Proceedings of the 2009 Ninth IEEE International Working Conference on Source Code Analysis and Manipulation, Edmonton, AB, Canada, 20–21 September 2009; pp. 159–167. [Google Scholar]
- Marinescu, R.; Ratiu, D. Quantifying the quality of object-oriented design: The factor-strategy model. In Proceedings of the 11th Working Conference on Reverse Engineering, Delft, The Netherlands, 8–12 November 2004; pp. 192–201. [Google Scholar]
- Rao, A.; Reddy, K. Detecting Bad Smells in Object Oriented Design Using Design Change Propagation Probability Matrix. In Lecture Notes in Engineering and Computer Science; Newswood Limited: Hong Kong, China, 2008; Volume 2168. [Google Scholar]
- Moha, N. Detection and correction of design defects in object-oriented designs. In Proceedings of the OOPSLA ’07, Montreal, QC, USA, 21–25 October 2007. [Google Scholar]
- Moha, N.; Guéhéneuc, Y.G.; Meur, A.F.; Duchien, L.; Tiberghien, A. From a Domain Analysis to the Specification and Detection of Code and Design Smells. Form. Asp. Comput. 2010, 22. [Google Scholar] [CrossRef]
- Moha, N.; Guéhéneuc, Y.G.; Meur, A.F.L.; Duchien, L. A Domain Analysis to Specify Design Defects and Generate Detection Algorithms. In Proceedings of the 11th International Conference on Fundamental Approaches to Software Engineering, Budapest, Hungary, 29 March–6 April 2008; Lecture Notes in Computer Science. Springer International Publishing: Berlin/Heidelberg, Germany, 2008; Volume 4961, pp. 276–291. [Google Scholar] [CrossRef]
- Moha, N.; Gueheneuc, Y.; Duchien, L.; Le Meur, A. DECOR: A Method for the Specification and Detection of Code and Design Smells. IEEE Trans. Softw. Eng. 2010, 36, 20–36. [Google Scholar] [CrossRef]
- Khomh, F.; Di Penta, M.; Gueheneuc, Y. An Exploratory Study of the Impact of Code Smells on Software Change-proneness. In Proceedings of the 2009 16th Working Conference on Reverse Engineering, Lille, France, 13–16 October 2009; pp. 75–84. [Google Scholar]
- Moha, N.; Gueheneuc, Y.; Leduc, P. Automatic Generation of Detection Algorithms for Design Defects. In Proceedings of the 21st IEEE/ACM International Conference on Automated Software Engineering (ASE’06), Tokyo, Japan, 18–22 September 2006; pp. 297–300. [Google Scholar]
- Marinescu, R. Measurement and quality in object-oriented design. In Proceedings of the 21st IEEE International Conference on Software Maintenance (ICSM’05), Budapest, Hungary, 26–29 September 2005; pp. 701–704. [Google Scholar]
- SpotBugs. 2019. Available online: https://spotbugs.github.io (accessed on 27 March 2020).
- Pugh, B. FindBugs. 2015. Available online: http://findbugs.sourceforge.net (accessed on 27 March 2020).
- CheckStyle. 2019. Available online: https://checkstyle.sourceforge.io (accessed on 27 March 2020).
- PMD: An Extensible Cross-Language Static Code Analyzer. 2019. Available online: https://pmd.github.io (accessed on 27 March 2020).
- Mathew, A.P.; Capela, F.A. An Analysis on Code Smell Detection Tools. In Proceedings of the 17th SC@ RUG 2019–2020, Groningen, The Netherlands, 17 May 2020; p. 57. [Google Scholar]
- Azadi, U.; Arcelli Fontana, F.; Taibi, D. Architectural Smells Detected by Tools: A Catalogue Proposal. In Proceedings of the 2019 IEEE/ACM International Conference on Technical Debt (TechDebt), Montreal, QC, Canada, 26–27 May 2019; pp. 88–97. [Google Scholar]
- Taibi, D.; Lenarduzzi, V. On the Definition of Microservice Bad Smells. IEEE Softw. 2018, 35, 56–62. [Google Scholar] [CrossRef]
- Pigazzini, I.; Fontana, F.A.; Lenarduzzi, V.; Taibi, D. Towards Microservice Smells Detection. In Proceedings of the 42nd International Conference on Software Engineering, Seoul, Korea, 24 June–16 July 2020. [Google Scholar]
- Logarix. AI Reviewer. Available online: http://aireviewer.com (accessed on 21 September 2020).
- Le, D.M.; Behnamghader, P.; Garcia, J.; Link, D.; Shahbazian, A.; Medvidovic, N. An Empirical Study of Architectural Change in Open-Source Software Systems. In Proceedings of the 2015 IEEE/ACM 12th Working Conference on Mining Software Repositories, Florence, Italy, 16–17 May 2015; pp. 235–245. [Google Scholar]
- Sharma, T. Designite—A Software Design Quality Assessment Tool. In Proceedings of the 2016 IEEE/ACM 1st International Workshop on Bringing Architectural Design Thinking Into Developers’ Daily Activities (BRIDGE), Austin, TX, USA, 17 May 2016. [Google Scholar] [CrossRef]
- Mo, R.; Cai, Y.; Kazman, R.; Xiao, L. Hotspot Patterns: The Formal Definition and Automatic Detection of Architecture Smells. In Proceedings of the 2015 12th Working IEEE/IFIP Conference on Software Architecture, Montreal, QC, Canada, 4–8 May 2015; pp. 51–60. [Google Scholar]
- Dietrich, J. Upload Your Program, Share Your Model. In Proceedings of the 3rd Annual Conference on Systems, Programming, and Applications: Software for Humanity, Tucson, AZ, USA, , 19–26 October 2012; Association for Computing Machinery: New York, NY, USA; pp. 21–22. [Google Scholar] [CrossRef]
- von Zitzewitz, A. Mitigating Technical and Architectural Debt with Sonargraph. In Proceedings of the 2019 IEEE/ACM International Conference on Technical Debt (TechDebt), Montreal, QC, Canada, 26–27 May 2019; pp. 66–67. [Google Scholar]
- Bugan IT Consulting UG. STAN. Available online: http://stan4j.com (accessed on 21 September 2020).
- Headway Software Technologies Ltd. Structure101. Available online: https://structure101.com (accessed on 21 September 2020).
- Cerny, T.; Svacina, J.; Das, D.; Bushong, V.; Bures, M.; Tisnovsky, P.; Frajtak, K.; Shin, D.; Huang, J. On Code Analysis Opportunities and Challenges for Enterprise Systems and Microservices. IEEE Access 2020. [Google Scholar] [CrossRef]
- Kumar, K.S.; Malathi, D. A Novel Method to Find Time Complexity of an Algorithm by Using Control Flow Graph. In Proceedings of the 2017 International Conference on Technical Advancements in Computers and Communications (ICTACC), Kochi, India, 22–24 August 2017; pp. 66–68. [Google Scholar] [CrossRef]
- Ribeiro, J.C.B.; de Vega, F.F.; Zenha-Rela, M. Using Dynamic Analysis Of Java Bytecode For Evolutionary Object-Oriented Unit Testing. In Proceedings of the 25th Brazilian Symposium on Computer Networks and Distributed Systems (SBRC), Belem, Brazil, June 2007. [Google Scholar]
- Syaikhuddin, M.M.; Anam, C.; Rinaldi, A.R.; Conoras, M.E.B. Conventional Software Testing Using White Box Method. Kinet. Game Technol. Inf. Syst. Comput. Netw. Comput. Electron. Control 2018, 3, 65–72. [Google Scholar] [CrossRef]
- Roy, C.K.; Cordy, J.R.; Koschke, R. Comparison and Evaluation of Code Clone Detection Techniques and Tools: A Qualitative Approach. Sci. Comput. Program. 2009, 74, 470–495. [Google Scholar] [CrossRef]
- Selim, G.M.K.; Foo, K.C.; Zou, Y. Enhancing Source-Based Clone Detection Using Intermediate Representation. In Proceedings of the 2010 17th Working Conference on Reverse Engineering, Beverly, MA, USA, 13–16 October 2010; pp. 227–236. [Google Scholar] [CrossRef]
- Albert, E.; Gómez-Zamalloa, M.; Hubert, L.; Puebla, G. Verification of Java Bytecode Using Analysis and Transformation of Logic Programs. In Practical Aspects of Declarative Languages; Hanus, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 124–139. [Google Scholar]
- Keivanloo, I.; Roy, C.K.; Rilling, J. SeByte: Scalable clone and similarity search for bytecode. Sci. Comput. Program. 2014, 95, 426–444. [Google Scholar] [CrossRef]
- Keivanloo, I.; Roy, C.K.; Rilling, J. Java Bytecode Clone Detection via Relaxation on Code Fingerprint and Semantic Web Reasoning. In Proceedings of the 6th International Workshop on Software Clones, Zurich, Switzerland, 4 June 2012; IEEE Press: Piscataway, NJ, USA, 2012; pp. 36–42. [Google Scholar]
- Lau, D. An Abstract Syntax Tree Generator from Java Bytecode. 2018. Available online: https://github.com/davidlau325/BytecodeASTGenerator (accessed on 27 March 2020).
- Chatley, G.; Kaur, S.; Sohal, B. Software Clone Detection: A review. Int. J. Control Theory Appl. 2016, 9, 555–563. [Google Scholar]
- Gabel, M.; Jiang, L.; Su, Z. Scalable Detection of Semantic Clones. In Proceedings of the 30th International Conference on Software Engineering, Leipzig, Germany, 10–18 May 2008; ACM: New York, NY, USA, 2008; pp. 321–330. [Google Scholar] [CrossRef]
- Su, F.H.; Bell, J.; Harvey, K.; Sethumadhavan, S.; Kaiser, G.; Jebara, T. Code Relatives: Detecting Similarly Behaving Software. In Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering, Seattle, WA, USA, 13–18 November 2016; ACM: New York, NY, USA, 2016; pp. 702–714. [Google Scholar] [CrossRef]
- Makai, M. Object-Relational Mappers (ORMs). 2019. Available online: https://www.fullstackpython.com/object-relational-mappers-orms.html (accessed on 27 March 2020).
- Walker, A.; Svacina, J.; Simmons, J.; Cerny, T. On Automated Role-Based Access Control Assessment in Enterprise Systems. In Information Science and Applications; Kim, K.J., Kim, H.Y., Eds.; Springer: Singapore, 2020; pp. 375–385. [Google Scholar]
- Trnka, M.; Svacina, J.; Cerny, T.; Song, E.; Hong, J.; Bures, M. Securing Internet of Things Devices Using the Network Context. IEEE Trans. Ind. Inform. 2020, 16, 4017–4027. [Google Scholar] [CrossRef]
- Svacina, J.; Simmons, J.; Cerny, T. Semantic Code Clone Detection for Enterprise Applications. In Proceedings of the 35th ACM/SIGAPP Symposium On Applied Computing, Brno, Czech Republic, 30 March–3 April 2020. [Google Scholar]
- Torres, A.; Galante, R.; Pimenta, M.S. Towards a uml profile for model-driven object-relational mapping. In Proceedings of the 2009 XXIII Brazilian Symposium on Software Engineering, Fortaleza, Brazil, 5–9 October 2009; pp. 94–103. [Google Scholar]
- Cerny, T.; Cemus, K.; Donahoo, M.J.; Song, E. Aspect-driven, data-reflective and context-aware user interfaces design. ACM SIGAPP Appl. Comput. Rev. 2013, 13, 53–66. [Google Scholar] [CrossRef]
- Rademacher, F.; Sachweh, S.; Zündorf, A. A Modeling Method for Systematic Architecture Reconstruction of Microservice-Based Software Systems. In Enterprise, Business-Process and Information Systems Modeling; Nurcan, S., Reinhartz-Berger, I., Soffer, P., Zdravkovic, J., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 311–326. [Google Scholar]
- Alshuqayran, N.; Ali, N.; Evans, R. Towards Micro Service Architecture Recovery: An Empirical Study. In Proceedings of the 2018 IEEE International Conference on Software Architecture (ICSA), Seattle, WA, USA, 30 April–4 May 2018; pp. 47–4709. [Google Scholar]
- Granchelli, G.; Cardarelli, M.; Di Francesco, P.; Malavolta, I.; Iovino, L.; Di Salle, A. Towards Recovering the Software Architecture of Microservice-Based Systems. In Proceedings of the 2017 IEEE International Conference on Software Architecture Workshops (ICSAW), Gothenburg, Sweden, 5–7 April 2017; pp. 46–53. [Google Scholar]
- Tarjan, R. Depth-first search and linear graph algorithms. In Proceedings of the 12th Annual Symposium on Switching and Automata Theory (SWAT 1971), East Lansing, MI, USA, 13–15 October 1971; pp. 114–121. [Google Scholar]
- Márquez, G.; Astudillo, H. Identifying Availability Tactics to Support Security Architectural Design of Microservice-Based Systems. In Proceedings of the 13th European Conference on Software Architecture, Paris, France, 9–13 September 2019; pp. 123–129. [Google Scholar] [CrossRef]
- Aderaldo, C.M.; Mendonça, N.C.; Pahl, C.; Jamshidi, P. Benchmark Requirements for Microservices Architecture Research. In Proceedings of the 1st International Workshop on Establishing the Community-Wide Infrastructure for Architecture-Based Software Engineering, Buenos Aires, Argentina, 22 May 2017; pp. 8–13. [Google Scholar]
- Zhou, X.; Peng, X.; Xie, T.; Sun, J.; Xu, C.; Ji, C.; Zhao, W. Benchmarking microservice systems for software engineering research. In Proceedings of the 40th International Conference on Software Engineering: Companion Proceeedings, Gothenburg, Sweden, 27 May–3 June 2018; Chaudron, M., Crnkovic, I., Chechik, M., Harman, M., Eds.; ACM: New York, NY, USA, 2018; pp. 323–324. [Google Scholar] [CrossRef]
- Smid, A.; Wang, R.; Cerny, T. Case Study on Data Communication in Microservice Architecture. In Proceedings of the Conference on Research in Adaptive and Convergent Systems, Chongqing, China, 24–27 September 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 261–267. [Google Scholar] [CrossRef]
- Mantyla, M.; Vanhanen, J.; Lassenius, C. A taxonomy and an initial empirical study of bad smells in code. In Proceedings of the International Conference on Software Maintenance, Amsterdam, The Netherlands, 22–26 September 2003; pp. 381–384. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tools / Smell | 1 EU | 2 MS | 3 WC | 4 NAG | 5 HCE | 6 AV | 7 MG | 8 SP | 9 ISI | 10 SL | 11 CD |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AI Reviewer [45] | X | ||||||||||
| ARCADE [46] | X | ||||||||||
| Arcan [44] | X | X | X | ||||||||
| Designite [47] | X | ||||||||||
| Hotspot Detector [48] | X | ||||||||||
| Massey Architecture Explorer [49] | X | ||||||||||
| MSA Nose | X | X | X | X | X | X | X | X | X | X | X |
| Sonargraph [50] | X | ||||||||||
| STAN [51] | X | ||||||||||
| Structure 101 [52] | X |
| Smell | Manual | MSANose | Time (ms) |
|---|---|---|---|
| ESB Usage | No | No | 1 |
| Too Many Standards | No | No | 213 |
| Wrong Cuts | 0 | 2 | 1487 |
| Not Having an API Gateway | No | No | 1 |
| Hard-Coded Endpoints | 28 | 28 | 1 |
| API Versioning | 76 | 76 | 1981 |
| Microservice Greedy | 0 | 0 | 2093 |
| Shared Persistency | 0 | 0 | 123 |
| Inappropriate Service Intimacy | 1 | 1 | 1617 |
| Shared Libraries | 4 | 4 | 237 |
| Cyclic Dependency | No | No | 1 |
| Total | 7755 |
| Smell | Manual | MSANose | Time (ms) |
|---|---|---|---|
| ESB Usage | No | No | 1 |
| Too Many Standards | No | No | 66 |
| Wrong Cuts | 0 | 0 | 279 |
| Not Having an API Gateway | Yes | No | 1 |
| Hard-Coded Endpoints | 2 | 2 | 1 |
| API Versioning | 62 | 62 | 546 |
| Microservice Greedy | 0 | 0 | 271 |
| Shared Persistency | 0 | 0 | 60 |
| Inappropriate Service Intimacy | 0 | 0 | 1 |
| Shared Libraries | 2 | 2 | 47 |
| Cyclic Dependency | No | No | 1 |
| Total | 1074 |
| bolean isCyclic() { |
| // Mark all the vertices as not visited |
| // and not part of recursion stack |
| boolean[] visited = new boolean[V]; |
| boolean[] recStack = new boolean[V]; |
| // Call the recursive helper function to |
| // detect cycle in different DFS trees |
| for (int i = 0; i < V; i++) |
| if (isCyclicUtil(i, visited, recStack)) |
| return true; |
| return false; |
| } |
| boolean isCyclicUtil(int i, |
| boolean[] visited, |
| boolean[] recStack) { |
| // Mark the current node as visited |
| // and part of recursion stack |
| if (recStack[i]) |
| return true; |
| if (visited[i]) |
| return false; |
| visited[i] = true; |
| recStack[i] = true; |
| List<Integer> children = adjList.get(i); |
| for (Integer c: children) |
| if (isCyclicUtil(c,visited,recStack)) |
| return true; |
| recStack[i] = false; |
| return false; |
| } |
| @RestController |
| @RequestMapping("/api/v1/users") |
| public class UserController{ |
| @Autowired |
| private UserService userService; |
| @Autowired |
| private TokenService tokenService; |
| @PostMapping("/login") |
| public ResponseEntity<?> getToken(...){ |
| return ResponseEntity.ok(...); |
| } |
| ... |
| } |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Walker, A.; Das, D.; Cerny, T. Automated Code-Smell Detection in Microservices Through Static Analysis: A Case Study. Appl. Sci. 2020, 10, 7800. https://doi.org/10.3390/app10217800
Walker A, Das D, Cerny T. Automated Code-Smell Detection in Microservices Through Static Analysis: A Case Study. Applied Sciences. 2020; 10(21):7800. https://doi.org/10.3390/app10217800
Chicago/Turabian StyleWalker, Andrew, Dipta Das, and Tomas Cerny. 2020. "Automated Code-Smell Detection in Microservices Through Static Analysis: A Case Study" Applied Sciences 10, no. 21: 7800. https://doi.org/10.3390/app10217800
APA StyleWalker, A., Das, D., & Cerny, T. (2020). Automated Code-Smell Detection in Microservices Through Static Analysis: A Case Study. Applied Sciences, 10(21), 7800. https://doi.org/10.3390/app10217800