Innovative Approaches in Sports Science—Lexicon-Based Sentiment Analysis as a Tool to Analyze Sports-Related Twitter Communication


Abstract
1. Introduction
2. Methods
2.1. Dataset
2.2. Manual Annotation
2.3. Preprocessing of Data
- -
- Removing all URLs (“https://t.co/hSizQPxVFy”) and mentions (“@CardiffCityFC”)
- -
- Removing emoticons not analyzable as provided by the Twitter API in R (“<U+009F>”)
- -
- Removing punctuation characters and digits
- -
- Removing tabs, line breaks and unnecessary spaces
- -
- Removing any non-ascii character
- -
- Changing text to lower case
- -
- Replacing contractions with full forms (“wouldn’t” → “would not”)
- -
- Replacing acronyms with full forms (“omg” → “oh my god”)
- -
- Correcting and doubling intentionally misspelled words that express some sort of intensification (“niiiiiiiiiiiiiiiice” → “nice nice”)
2.4. Algorithmic Evaluation
2.5. Negation Handling
2.6. Accuracy Measures
3. Results
3.1. Manual Annotation
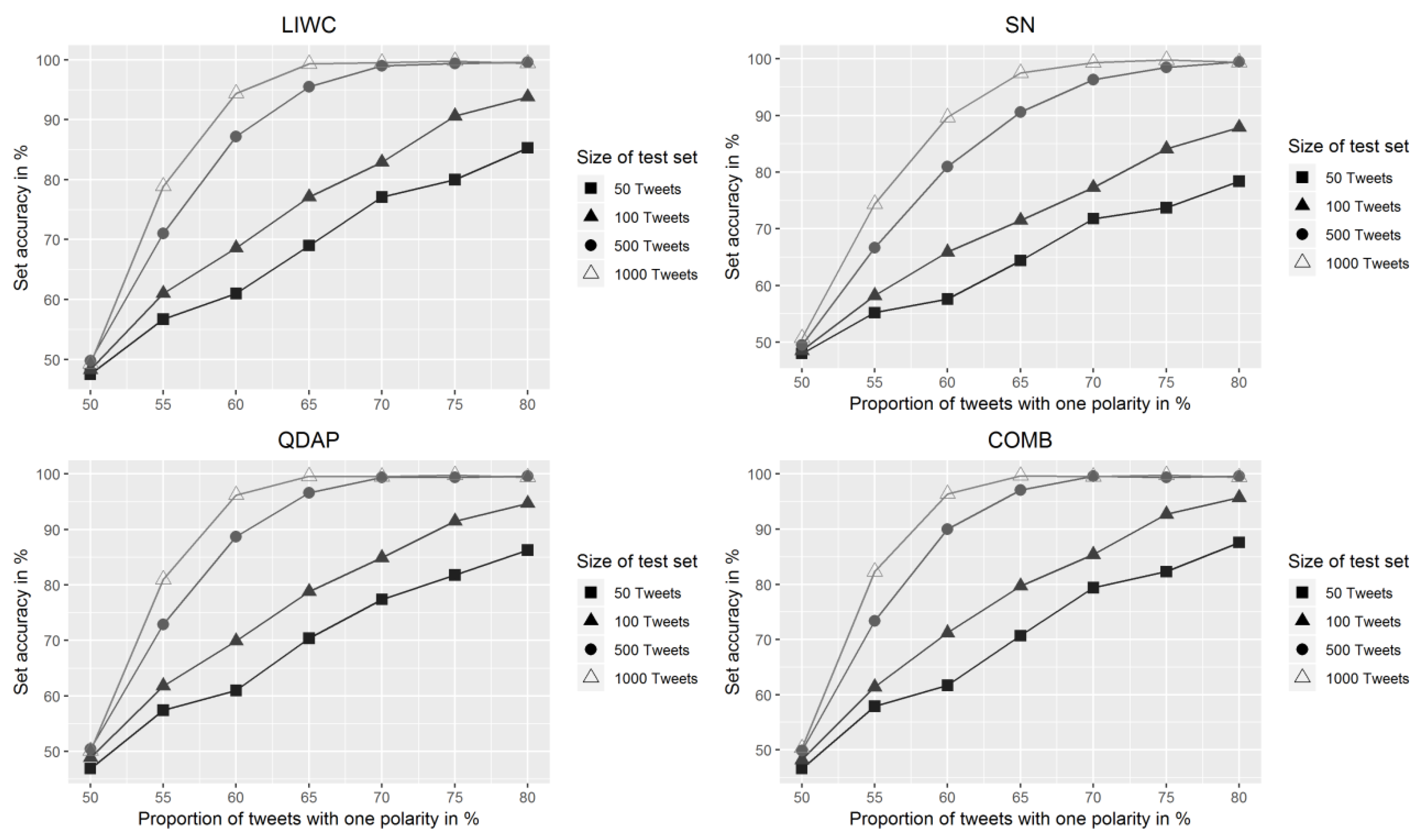
3.2. Accuracy Measures
3.3. Qualitative Observations
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mauro, A.D.; Greco, M.; Grimaldi, M. What Is Big Data? A Consensual Definition and a Review of Key Research Topics; AIP Publishing LLC: Melville, NY, USA, 2015; pp. 97–104. [Google Scholar]
- Memmert, D.; Lemmink, K.; Sampaio, J. Current Approaches to Tactical Performance Analyses in Soccer Using Position Data. Sports Med. 2017, 47, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Wei, X.; Lucey, P.; Morgan, S.; Sridharan, S. Sweet-spot: Using spatiotemporal data to discover and predict shots in tennis. In Proceedings of the 7th Annual MIT Sloan Sports Analytics Conference, Boston, MA, USA, 6–7 March 2013. [Google Scholar]
- Lucey, P.; Bialkowski, A.; Carr, P.; Yue, Y.; Matthews, I. How to get an open shot: Analyzing team movement in basketball using tracking data. In Proceedings of the 8th Annual MIT SLOAN Sports Analytics Conference, Boston, MA, USA, 30 April 2014. [Google Scholar]
- Ginsberg, J.; Mohebbi, M.H.; Patel, R.S.; Brammer, L.; Smolinski, M.S.; Brilliant, L. Detecting influenza epidemics using search engine query data. Nature 2009, 457, 102–104. [Google Scholar] [CrossRef] [PubMed]
- D’Amuri, F.; Marcucci, J. The predictive power of Google searches in forecasting US unemployment. Int. J. Forecast. 2017, 33, 801–816. [Google Scholar] [CrossRef]
- Gayo-Avello, D.A. Meta-Analysis of State-of-the-Art Electoral Prediction From Twitter Data. Soc. Sci. Comput. Rev. 2013, 31, 649–679. [Google Scholar] [CrossRef]
- Huberty, M. Can we vote with our tweet. On the perennial difficulty of election forecasting with social media. Int. J. Forecast. 2015, 31, 992–1007. [Google Scholar] [CrossRef]
- Bollen, J.; Mao, H.; Zeng, X.J. Twitter mood predicts the stock market. J. Comput. Sci. 2011, 2, 1–8. [Google Scholar] [CrossRef]
- Kramer, A.D.I.; Guillory, J.E.; Hancock, J.T. Experimental evidence of massive-scale emotional contagion through social networks. Proc. Natl. Acad. Sci. USA 2014, 111, 8788–8790. [Google Scholar] [CrossRef]
- Piryani, R.; Madhavi, D.; Singh, V.K. Analytical mapping of opinion mining and sentiment analysis research during 2000–2015. Inf. Process. Manag. 2017, 53, 122–150. [Google Scholar] [CrossRef]
- Mäntylä, M.V.; Graziotin, D.; Kuutila, M. The evolution of sentiment analysis—A review of research topics, venues, and top cited papers. Comput. Sci. Rev. 2018, 27, 16–32. [Google Scholar] [CrossRef]
- Mohammad, S.; Bravo-Marquez, F.; Salameh, M.; Kiritchenko, S. Semeval-2018 task 1: Affect in tweets. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 1–17. [Google Scholar]
- Basile, V.; Bosco, C.; Fersini, E.; Nozza, D.; Patti, V.; Rangel, F.; Rosso, P.; Sanguinetti, M. Semeval-2019 task 5: Multilingual detection of hate speech against immigrants and women in twitter. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 54–63. [Google Scholar]
- Dunne, D.M.; Lefevre, C.; Cunniffe, B.; Tod, D.; Close, G.L.; Morton, J.P.; Murphy, R. Performance Nutrition in the digital era—An exploratory study into the use of social media by sports nutritionists. J. Sports Sci. 2019, 30, 54–63. [Google Scholar] [CrossRef]
- Hendricks, S.; Jones, A. European Journal of Sport Science gears up its social media. Eur. J. Sports Sci. 2014, 14, 519–520. [Google Scholar] [CrossRef] [PubMed]
- Sheffer, M.L.; Schultz, B. Paradigm Shift or Passing Fad. Twitter and Sports Journalism. Int. J. Sport Commun. 2010, 3, 472–484. [Google Scholar] [CrossRef]
- Hambrick, M.E.; Simmons, J.M.; Greenhalgh, G.P.; Greenwell, T.C. Understanding Professional Athletes’ Use of Twitter. A Content Analysis of Athlete Tweets. Int. J. Sport Commun. 2010, 3, 454–471. [Google Scholar] [CrossRef]
- Witkemper, C.; Lim, C.H.; Waldburger, A. Social Media and Sports Marketing. Examining the Motivations and Constraints of Twitter Users. Sport Mark. Q. 2012, 21, 170–183. [Google Scholar]
- Schumaker, R.P.; Jarmoszko, A.T.; Labedz, C.S. Predicting wins and spread in the Premier League using a sentiment analysis of twitter. Decis. Support Syst. 2016, 88, 76–84. [Google Scholar] [CrossRef]
- Brown, A.; Rambaccussing, D.; Reade, J.J.; Rossi, G. Forecasting with social media. Evidence from tweets on soccer matches. Econ. Inq. 2017, 20, 1363. [Google Scholar] [CrossRef]
- Godin, F.; Zuallaert, J.; Vandersmissen, B.; De Neve, W.; van de Walle, R. Beating the bookmakers. leveraging statistics and Twitter microposts for predicting soccer results. In Proceedings of the KDD Workshop on Large-Scale Sports Analytics, New York, NY, USA, 6 June 2014. [Google Scholar]
- Twitter Inc. 2019. Available online: https://twitter.com/ (accessed on 30 August 2019).
- Twitter API. 2019. Available online: https://developer.twitter.com/ (accessed on 30 August 2019).
- Kearney, M.W. rtweet: Collecting Twitter Data. 2019. Available online: https://CRAN.R-project.org/package=rtweet (accessed on 30 August 2019).
- Agarwal, A.; Xie, B.; Vovsha, I.; Rambow, O.; Passonneau, R. Sentiment Analysis of Twitter Data. In Proceedings of the Workshop on Languages in Social Media, Oregon, Portland, 23 June 2011. [Google Scholar]
- Angiani, G.; Ferrari, L.; Fontanini, T.; Fornacciari, P.; Iotti, E.; Magliani, F.; Manicardi, S. A Comparison between Preprocessing Techniques for Sentiment Analysis in Twitter. KDWeb. 2016. Available online: https://pdfs.semanticscholar.org/09c0/136d4e3d9defc50a72253a967180e86be244.pdf?_ga=2.120249992.1431766548.1578324939-1266920968.1578324939 (accessed on 16 August 2019).
- Kharde, V.A.; Sonawane, S.S. Sentiment Analysis of Twitter Data: A Survey of Techniques. Int. J. Comput. Appl. 2016, 139, 5–15. [Google Scholar] [CrossRef]
- Taboada, M.; Brooke, J.M.; Voll, K.M. Lexicon-Based Methods for Sentiment Analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; Boyd, R.L.; Jordan, K.K. The Development and Psychometric Properties of LIWC2015; University of Texas at Austin: Austin, TX, USA, 2015. [Google Scholar]
- Feuerriegel, S.; Proellochs, N. SentimentAnalysis: Dictionary-Based Sentiment Analysis. 2019. Available online: https://CRAN.R-project.org/package=SentimentAnalysis (accessed on 30 August 2019).
- R Core Team. R: A Language and Environment for Statistical Computing. 2017. Available online: https://www.R-project.org/ (accessed on 30 August 2019).
- Rinker, T.W. qdapDictionaries: Dictionaries to Accompany the qdap Package; University at Buffalo: Buffalo, NY, USA, 2013. [Google Scholar]
- Rinker, T.W. Lexicon Data; Buffalo: Buffalo, NY, USA, 2018. [Google Scholar]
- Cambria, E.; Poria, S.; Bajpai, R.; Schuller, B. SenticNet 4: A Semantic Resource for Sentiment Analysis Based on Conceptual Primitives. In Proceedings of the 26th International Conference on Computational Linguistics: Technical Papers, COLING 2016, Osaka, Japan, 11–16 December 2016; pp. 2666–2677. [Google Scholar]
- Turney, P.D. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Pennsylvania, PA, USA, 7–12 July 2002; pp. 417–424. [Google Scholar]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorial data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef]
- Fleiss, J.L.; Levin, B.; Paik, M.C. Statistical Methods for Rates and Proportions, 3rd ed.; Wiley: Hoboken, NJ, USA, 2003. [Google Scholar]
- Feldman, R. Techniques and applications for sentiment analysis. Commun. ACM 2013, 56, 82. [Google Scholar] [CrossRef]
- Cambria, E.; Schuller, B.; Xia, Y.; Havasi, C. New Avenues in Opinion Mining and Sentiment Analysis. IEEE Intell. Syst. 2013, 28, 15–21. [Google Scholar] [CrossRef]
- Furnham, A. Response bias, social desirability and dissimulation. Personal. Individ. Differ. 1986, 7, 385–400. [Google Scholar] [CrossRef]


{kind=link}
| Discipline | Research Question |
|---|---|
| Sports ethics | How do fans think about ethical questions related to sports such as corruption in sports, criticism on Olympic Games, use of performance-enhancing drugs? How does public opinion change over time or after important events? |
| Sports economics | How do fans think about clubs and athletes? How can clubs or athletes optimize their online image in order to improve sponsoring value? Can social media content be valuable in sports forecasting? (i.e., in-play match forecasting, forecasting of individual player success) |
| Sports psychology | Which kind of moods or emotions of fans come up during sport competitions? What focus of attention do fans have when they watch, discuss or reflect sport games? |
| Computer Science in Sports | How can sports-related online content be efficiently extracted? What is the validity of sentiment analysis methods when analyzing sports-related content? Are there improvements in sentiment analysis methods considering the special characteristics of sports-related content? |
| Sports journalism | How do consumers react to media coverage of sports? What are current and relevant topics discussed by sports fans? |
| Date | Match | Competition | Hashtag | Number of Tweets |
|---|---|---|---|---|
| 20 February 2019 | Atletico Madrid vs. Juventus Turin | Champions League | #AtletiJuve | 5121 |
| 24 February 2019 | Manchester United vs. Liverpool | Premier League | #MUNLIV | 30,044 |
| 7 March 2019 | Chelsea vs. Dynamo Kiev | Europa League | #CHEDYN | 3262 |
| 31 March 2019 | Cardiff City vs. Chelsea | Premier League | #CARCHE | 13,114 |
| 31 March 2019 | FC Liverpool vs. Tottenham Hotspur | Premier League | #LIVTOT | 17,503 |
| 10 April 2019 | Ajax Amsterdam vs. Juventus Turin | Champions League | #AJAJUV | 2213 |
| 16 April 2019 | FC Barcelona vs. Manchester United | Champions League | #FCBMUN | 3615 |
| 1 May 2019 | FC Barcelona vs. FC Liverpool | Champions League | #FCBLIV | 3603 |
| 25 May 2019 | RB Leipzig vs. Bayern Munich | German Cup | #RBLFCB | 1252 |
| 29 May 2019 | Chelsea vs. Arsenal | Europa League | #UELfinal | 5096 |
| Category | Tweet |
|---|---|
| Positive | “Messi is anything but human. #FCBLIV” |
| “What a save @Alissonbecker #MUNLIV #pl #lfc” | |
| “C’mon United. #GGMU #MUNLIV” | |
| Negative | “Stupidity from Ole for putting Lingard instead of Sanchez #MUNLIV” |
| “Never a pen, minimal contact outside box on Costa, Atletico lucky to get a free kick #AtletiJuve #ucl” | |
| “Liverpool BATTERED #lfc #FCBLIV @btsportfootball” | |
| Neutral | “VAR overrules ref. Freekick rather a pen #AtletiJuve” |
| “Bit surprised Klopp has broken up the Milner/Henderson/Wijnaldum midfield that’s played in most of the big games this season if it is Milner at right back today #MUNLIV” | |
| “Barcelona vs. Liverpool: Messi scores two goals in seven minutes #FCBLIV https://t.co/sZWqueaNlL” | |
| Nonsense | “Looking for professional business flyer designer? Please contact following link. Messi #MUNLIV #AtikuIsWinning HOLD THE DATE #SundayMorning #FelizDomingo https://t.co/jvMrrxjN4D” |
| “INVIOLABLE LE BUT DE TER STEGEN #FCBLIV” | |
| “@TheSportsman The Savior has emerged... Imam #Ahmedalhasan (as). The Messenger from Imam Mahdi (as). The Mahdi (as) that is born during the end of time... The Messenger from Jesus (as). The Messenger from Elijah (as) #AtletiJuve #skamfrance https://t.co/Qq8eA54ESE https://t.co/6bGIO6DNEw” |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wunderlich, F.; Memmert, D. Innovative Approaches in Sports Science—Lexicon-Based Sentiment Analysis as a Tool to Analyze Sports-Related Twitter Communication. Appl. Sci. 2020, 10, 431. https://doi.org/10.3390/app10020431
Wunderlich F, Memmert D. Innovative Approaches in Sports Science—Lexicon-Based Sentiment Analysis as a Tool to Analyze Sports-Related Twitter Communication. Applied Sciences. 2020; 10(2):431. https://doi.org/10.3390/app10020431
Chicago/Turabian StyleWunderlich, Fabian, and Daniel Memmert. 2020. "Innovative Approaches in Sports Science—Lexicon-Based Sentiment Analysis as a Tool to Analyze Sports-Related Twitter Communication" Applied Sciences 10, no. 2: 431. https://doi.org/10.3390/app10020431
APA StyleWunderlich, F., & Memmert, D. (2020). Innovative Approaches in Sports Science—Lexicon-Based Sentiment Analysis as a Tool to Analyze Sports-Related Twitter Communication. Applied Sciences, 10(2), 431. https://doi.org/10.3390/app10020431