Variable Compliance Control for Robotic Peg-in-Hole Assembly: A Deep-Reinforcement-Learning Approach

 and
and 
Abstract
Featured Application
Abstract
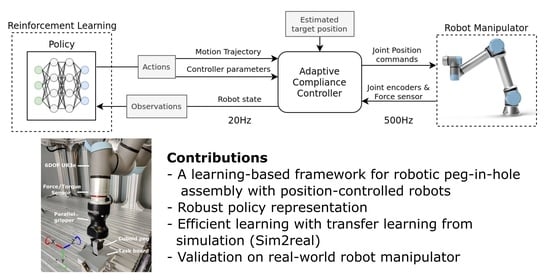
1. Introduction
- A robust policy representation based on time convolutional neural networks (TCNs).
- Faster learning of control policies via domain transfer-learning techniques (sim2real) to greatly improve the training efficiency in real robots.
- Improved generalization capabilities of the learned control policies via domain randomization during the training phase in simulations. Although the effects of domain randomization have been researched [25,26], to the best of our knowledge, we are the first to study the effects of sim2real with domain randomization on contact-rich, real-robot applications with position-controlled robots.
Problem Statement
- The manipulated object was already firmly grasped. However, slight changes of object orientation within the gripper were possible during manipulation.
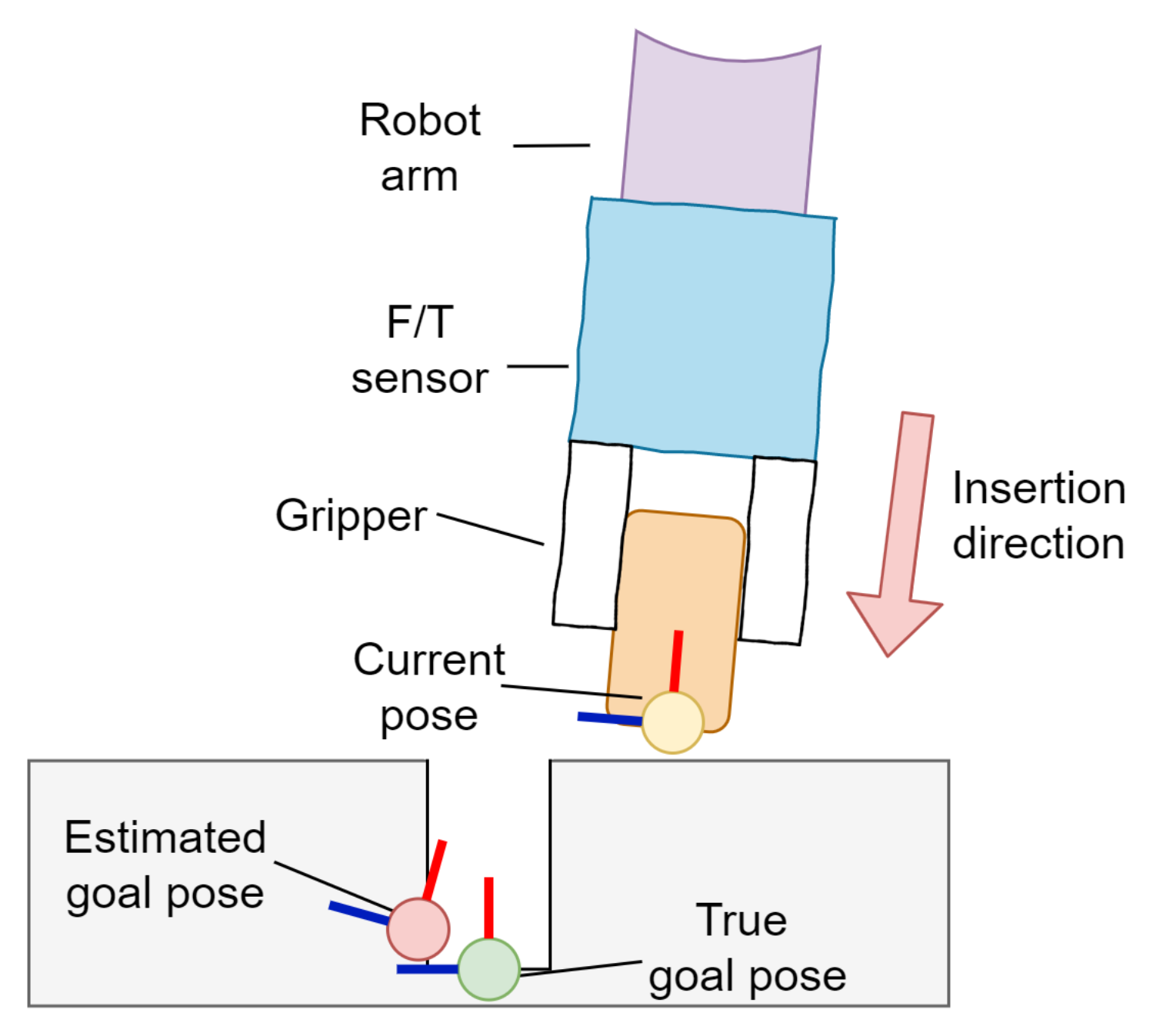
- There was access to imperfect prediction of the target end-effector pose (as shown in Figure 1) or a reference trajectory and its degree of uncertainty.
- The manipulated object was inserted in a direction parallel to the gripper’s orientation.
2. Materials and Methods
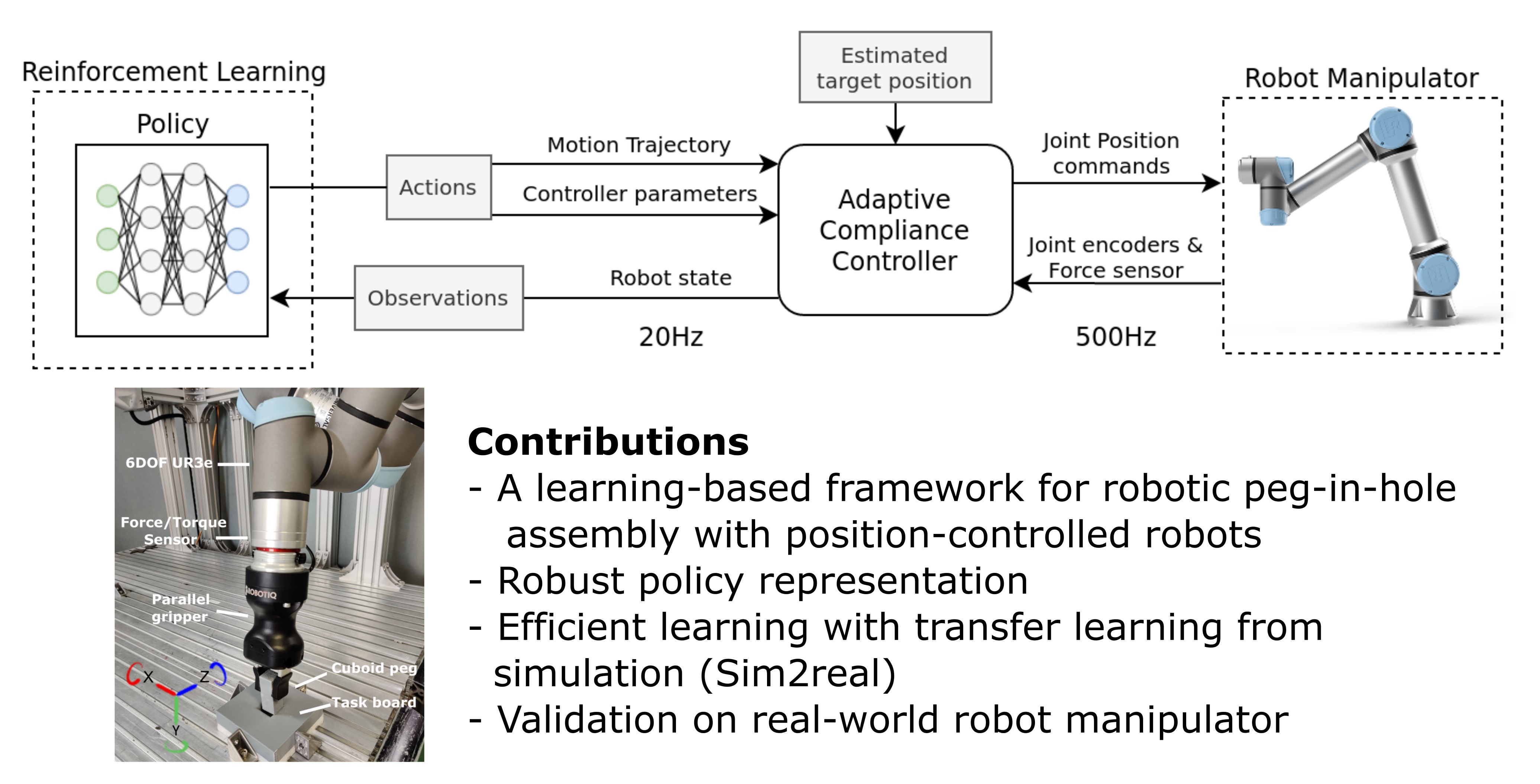
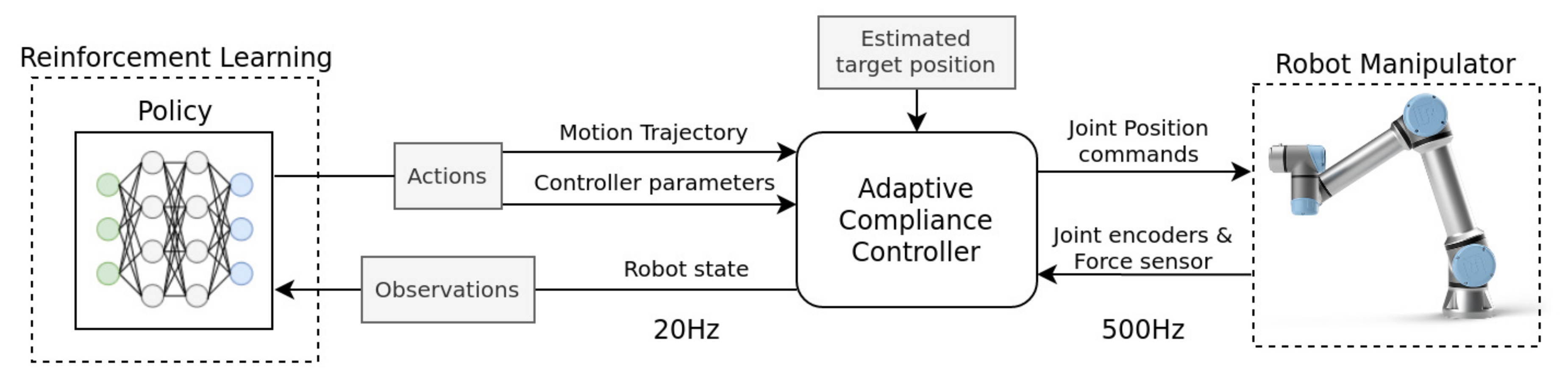
2.1. System Overview
2.2. Learning Adaptive-Compliance Control
2.2.1. Reinforcement-Learning Algorithm
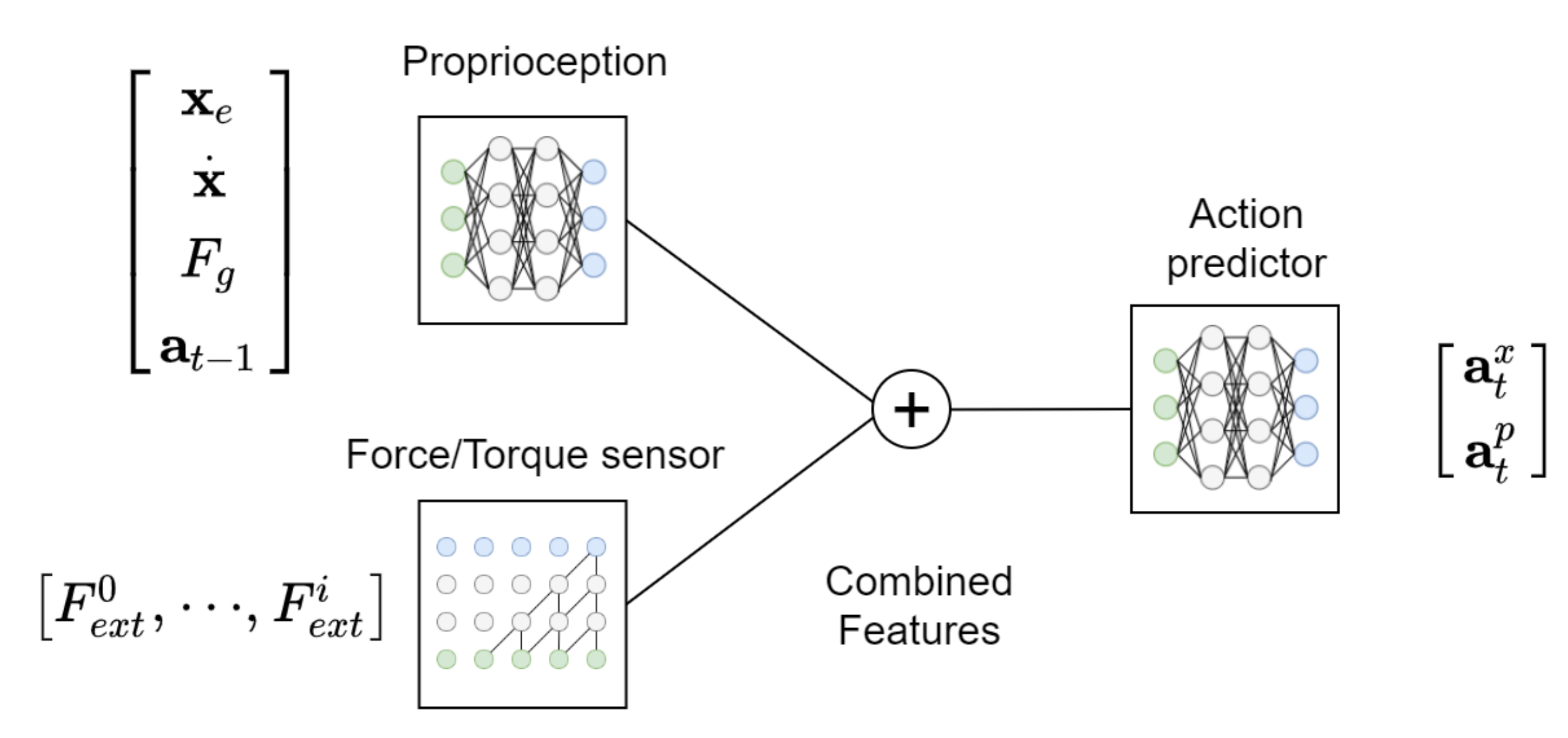
2.2.2. Multimodal Policy Architecture
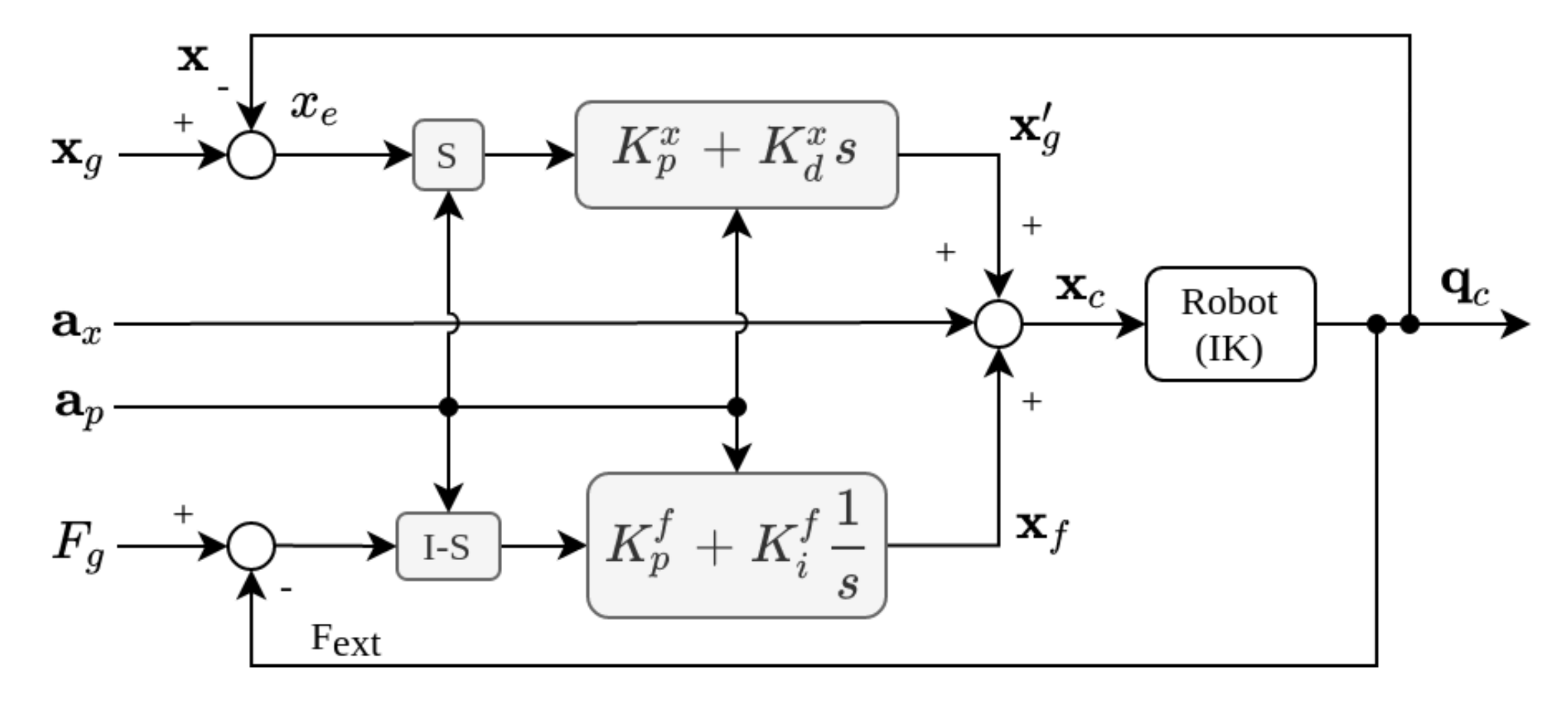
2.2.3. Compliance Control in Task Space
2.3. A Task’s Reward Function
2.4. Speeding up Learning
2.4.1. Residual Reinforcement Learning
2.4.2. Sim2real
- Initial/goal end-effector position: Having random initial/goal positions helps the RL algorithm to find policies that generalize to a wide range of initial-position conditions.
- Object-surface stiffness: The RL agent also needs to learn to fine-tune the force-controller parameters to obtain a proper response to the contact force. Therefore, randomizing the stiffness of the manipulated objects helps it find policies that adapt to different dynamic conditions.
- Uncertainty error of goal pose prediction: On a real robot, the prediction of the target pose comes from noisy sensory information, either from a vision-detection system or from known prior manipulations (grasp and regrasp). Thus, during training on the simulation, we emulated this error by using normal Gaussian distribution with mean zero and standard deviation of a maximal distance error (for position and orientation).
- Desired insertion force: For different insertion tasks, a specific contact force is necessary for insertion to succeed. As we considered insertion force an input to the policy, during training, we randomized this value for each episode.
3. Experiments and Results
3.1. Experiment Setup
3.2. Training
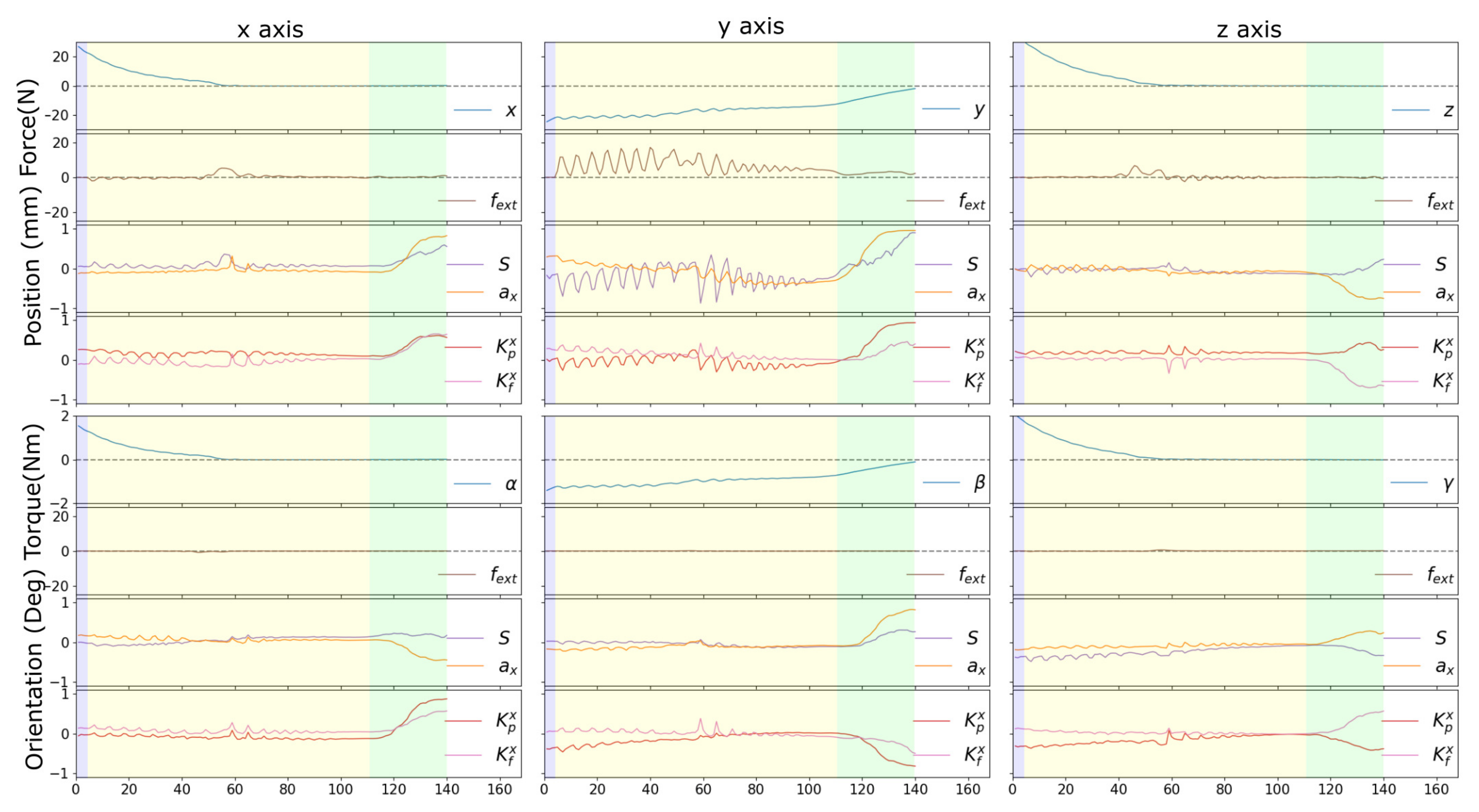
3.3. Evaluation
3.4. Generalization
3.4.1. Varying Degrees of Uncertainty Error
3.4.2. Varying Environment Stiffness
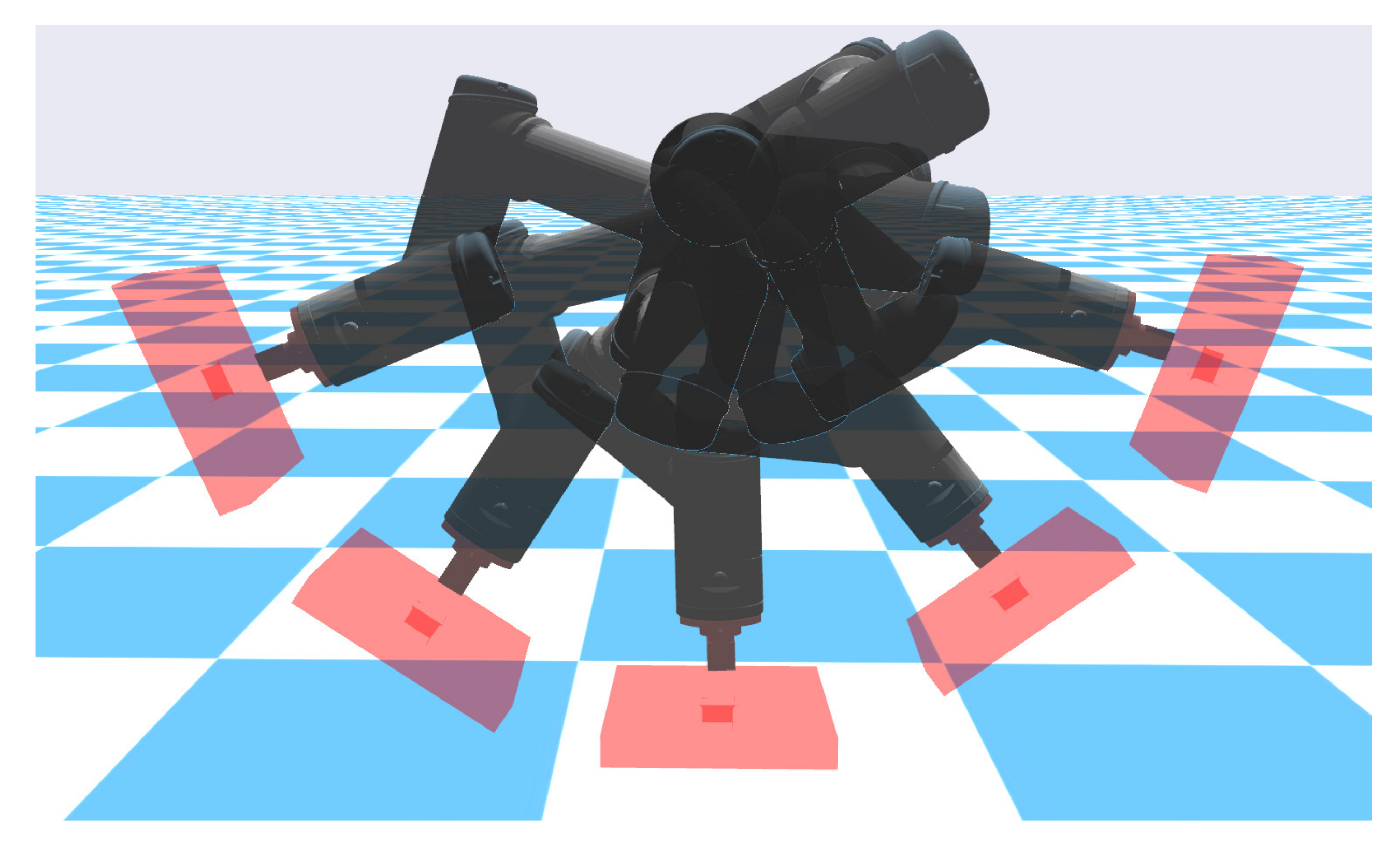
3.4.2.1. Varying Insertion Tasks
3.5. Ablation Studies
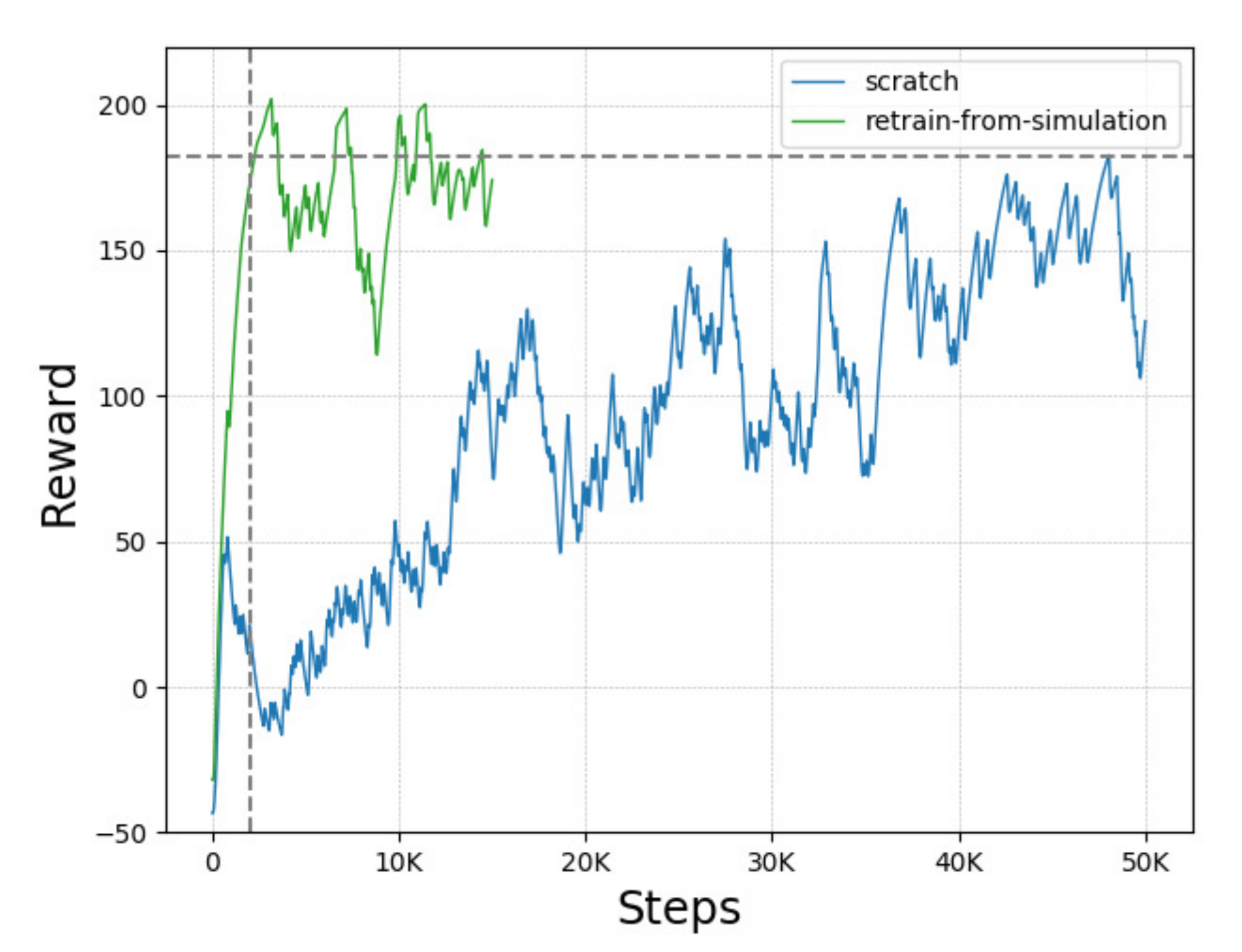
3.5.1. Learning from Scratch vs. Sim2real
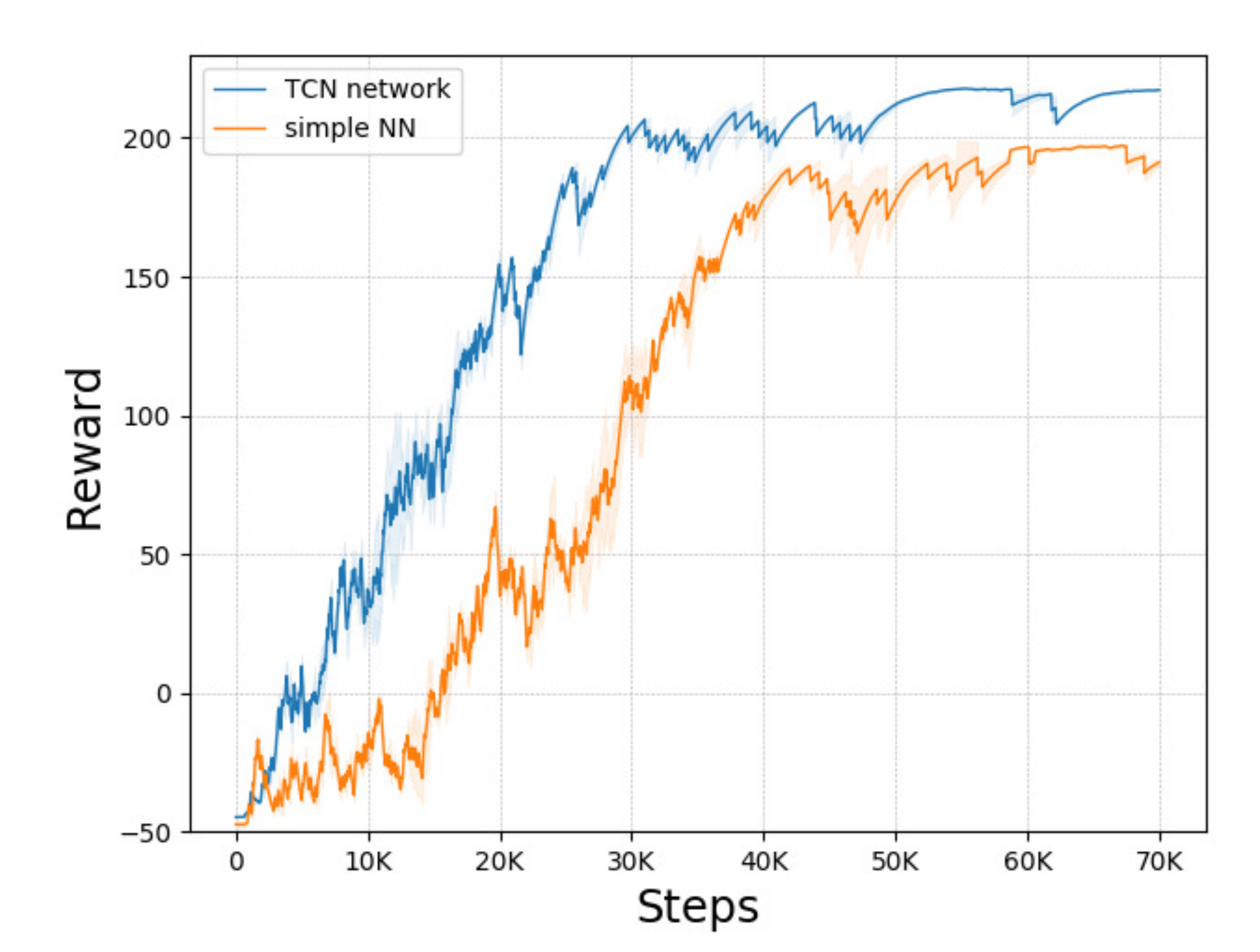
3.5.2. Policy Architecture
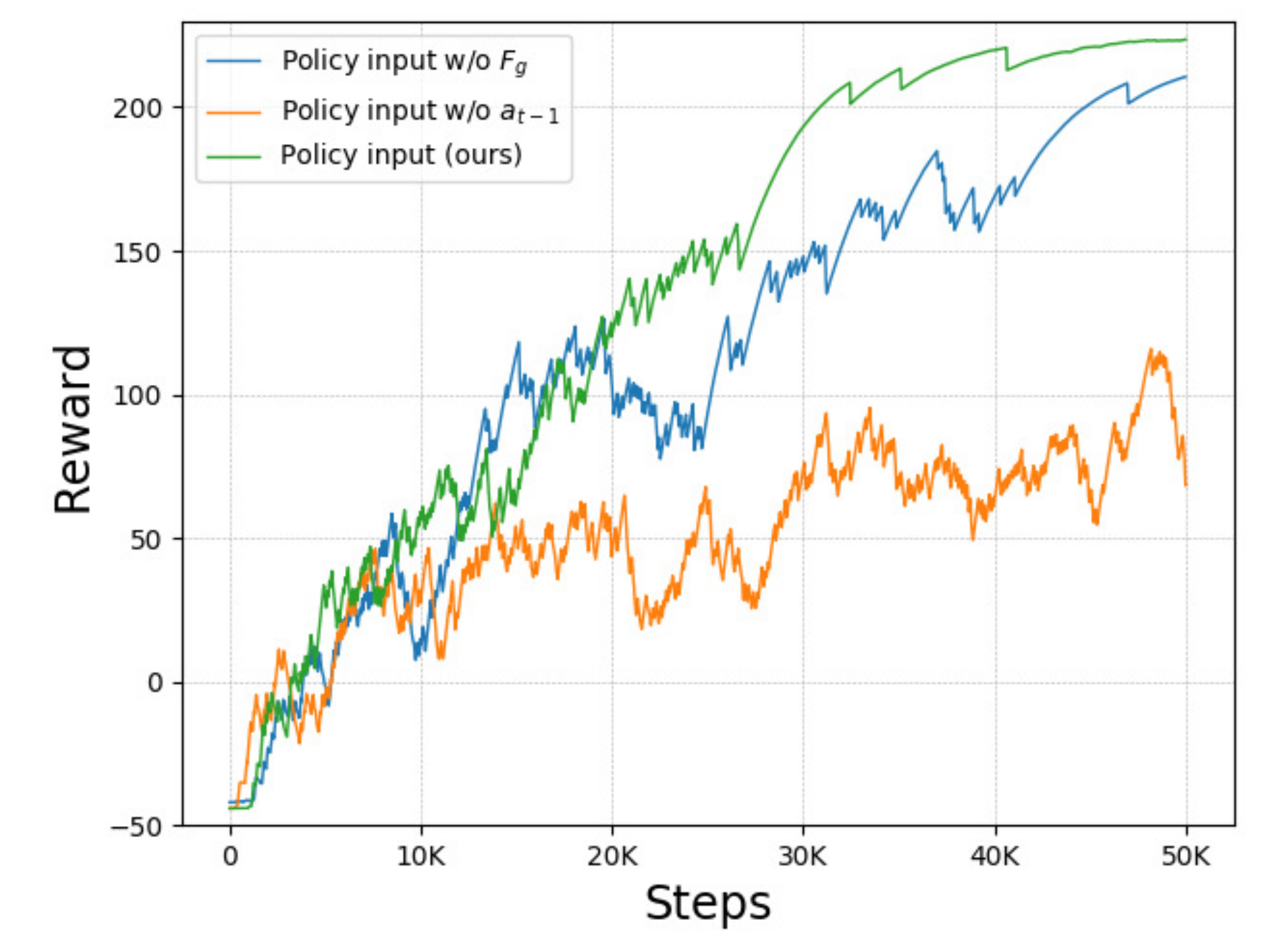
3.5.3. Policy Inputs
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Kroemer, O.; Niekum, S.; Konidaris, G. A review of robot learning for manipulation: Challenges, representations, and algorithms. arXiv 2019, arXiv:1907.03146. [Google Scholar]
- Whitney, D.E. Quasi-Static Assembly of Compliantly Supported Rigid Parts. J. Dyn. Syst. Meas. Control. 1982, 104, 65–77. [Google Scholar] [CrossRef]
- Tsuruoka, T.; Fujioka, H.; Moriyama, T.; Mayeda, H. 3D analysis of contact in peg-hole insertion. In Proceedings of the 1997 IEEE International Symposium on Assembly and Task Planning (ISATP’97)-Towards Flexible and Agile Assembly and Manufacturing, Marina del Rey, CA, USA, 7–9 August 1997; pp. 84–89. [Google Scholar]
- Zhang, K.; Shi, M.; Xu, J.; Liu, F.; Chen, K. Force control for a rigid dual peg-in-hole assembly. Assem. Autom. 2017, 37, 200–207. [Google Scholar] [CrossRef]
- Fukumoto, Y.; Harada, K. Force Control Law Selection for Elastic Part Assembly from Human Data and Parameter Optimization. In Proceedings of the 2018 IEEE-RAS 18th International Conference on Humanoid Robots (Humanoids), Beijing, China, 6–9 November 2018; pp. 1–7. [Google Scholar]
- Kyrarini, M.; Haseeb, M.A.; Ristić-Durrant, D.; Gräser, A. Robot learning of industrial assembly task via human demonstrations. Auton. Robots 2019, 43, 239–257. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Yang, C.; Zeng, C.; Cong, Y.; Wang, N.; Wang, M. A learning framework of adaptive manipulative skills from human to robot. IEEE Trans. Ind. Inform. 2018, 15, 1153–1161. [Google Scholar] [CrossRef]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robot. Res. 2018, 37, 421–436. [Google Scholar] [CrossRef]
- Pinto, L.; Gupta, A. Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours. In Proceedings of the 2016 IEEE international conference on robotics and automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 3406–3413. [Google Scholar]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the 2017 IEEE international conference on robotics and automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar]
- Nuttin, M.; Van Brussel, H. Learning the peg-into-hole assembly operation with a connectionist reinforcement technique. Comput. Ind. 1997, 33, 101–109. [Google Scholar] [CrossRef]
- Inoue, T.; De Magistris, G.; Munawar, A.; Yokoya, T.; Tachibana, R. Deep reinforcement learning for high precision assembly tasks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 819–825. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Xu, J.; Hou, Z.; Wang, W.; Xu, B.; Zhang, K.; Chen, K. Feedback deep deterministic policy gradient with fuzzy reward for robotic multiple peg-in-hole assembly tasks. IEEE Trans. Ind. Inform. 2018, 15, 1658–1667. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M.A. Deterministic Policy Gradient Algorithms. In Proceedings of the International Conference on Machine Learning, Beijing, China, 22–24 June 2014. [Google Scholar]
- Fan, Y.; Luo, J.; Tomizuka, M. A learning framework for high precision industrial assembly. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 811–817. [Google Scholar]
- Levine, S.; Koltun, V. Guided policy search. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1–9. [Google Scholar]
- Luo, J.; Solowjow, E.; Wen, C.; Ojea, J.A.; Agogino, A.M. Deep reinforcement learning for robotic assembly of mixed deformable and rigid objects. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2062–2069. [Google Scholar]
- Ren, T.; Dong, Y.; Wu, D.; Chen, K. Learning-based variable compliance control for robotic assembly. J. Mech. Robot. 2018, 10, 061008. [Google Scholar] [CrossRef]
- Buchli, J.; Stulp, F.; Theodorou, E.; Schaal, S. Learning variable impedance control. Int. J. Robot. Res. 2011, 30, 820–833. [Google Scholar] [CrossRef]
- Lee, M.A.; Zhu, Y.; Srinivasan, K.; Shah, P.; Savarese, S.; Fei-Fei, L.; Garg, A.; Bohg, J. Making sense of vision and touch: Self-supervised learning of multimodal representations for contact-rich tasks. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8943–8950. [Google Scholar]
- Abu-Dakka, F.J.; Nemec, B.; Jørgensen, J.A.; Savarimuthu, T.R.; Krüger, N.; Ude, A. Adaptation of manipulation skills in physical contact with the environment to reference force profiles. Auton. Robot. 2015, 39, 199–217. [Google Scholar] [CrossRef]
- Beltran-Hernandez, C.C.; Petit, D.; Ramirez-Alpizar, I.G.; Nishi, T.; Kikuchi, S.; Matsubara, T.; Harada, K. Learning Force Control for Contact-rich Manipulation Tasks with Rigid Position-controlled Robots. IEEE Robot. Autom. Lett. 2020, 5, 5709–5716. [Google Scholar] [CrossRef]
- Chebotar, Y.; Handa, A.; Makoviychuk, V.; Macklin, M.; Issac, J.; Ratliff, N.; Fox, D. Closing the sim-to-real loop: Adapting simulation randomization with real world experience. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8973–8979. [Google Scholar]
- Andrychowicz, O.M.; Baker, B.; Chociej, M.; Jozefowicz, R.; McGrew, B.; Pachocki, J.; Petron, A.; Plappert, M.; Powell, G.; Ray, A.; et al. Learning dexterous in-hand manipulation. Int. J. Robot. Res. 2020, 39, 3–20. [Google Scholar] [CrossRef]
- Sharma, K.; Shirwalkar, V.; Pal, P.K. Intelligent and environment-independent peg-in-hole search strategies. In Proceedings of the 2013 International Conference on Control, Automation, Robotics and EMbedded Systems (CARE), Jabalpur, India, 16–18 December 2013; pp. 1–6. [Google Scholar]
- Zakharov, S.; Shugurov, I.; Ilic, S. Dpod: 6d pose object detector and refiner. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 1941–1950. [Google Scholar]
- Peng, S.; Liu, Y.; Huang, Q.; Zhou, X.; Bao, H. Pvnet: Pixel-wise voting network for 6dof pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4561–4570. [Google Scholar]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes. Robot. Sci. Syst. (RSS) 2018, 2018. [Google Scholar] [CrossRef]
- Hodan, T.; Haluza, P.; Obdržálek, Š.; Matas, J.; Lourakis, M.; Zabulis, X. T-LESS: An RGB-D dataset for 6D pose estimation of texture-less objects. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 880–888. [Google Scholar]
- Harada, K.; Nakayama, K.; Wan, W.; Nagata, K.; Yamanobe, N.; Ramirez-Alpizar, I.G. Tool exchangeable grasp/assembly planner. In Proceedings of the International Conference on Intelligent Autonomous Systems; Springer: Berlin/Heidelberg, Germany, 2018; pp. 799–811. [Google Scholar]
- Masehian, E.; Ghandi, S. ASPPR: A new Assembly Sequence and Path Planner/Replanner for monotone and nonmonotone assembly planning. Comput.-Aided Des. 2020, 123, 102828. [Google Scholar] [CrossRef]
- Nair, A.; McGrew, B.; Andrychowicz, M.; Zaremba, W.; Abbeel, P. Overcoming exploration in reinforcement learning with demonstrations. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 6292–6299. [Google Scholar]
- Gupta, A.; Kumar, V.; Lynch, C.; Levine, S.; Hausman, K. Relay Policy Learning: Solving Long-Horizon Tasks via Imitation and Reinforcement Learning. In Proceedings of the Conference on Robot Learning (CoRL) 2019, Osaka, Japan, 30 October–1 November 2019. [Google Scholar]
- Wang, Y.; Harada, K.; Wan, W. Motion planning of skillful motions in assembly process through human demonstration. Adv. Robot. 2020, 1–15. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv 2018, arXiv:1801.01290. [Google Scholar]
- Horgan, D.; Quan, J.; Budden, D.; Barth-Maron, G.; Hessel, M.; van Hasselt, H.; Silver, D. Distributed Prioritized Experience Replay. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Chiaverini, S.; Sciavicco, L. The parallel approach to force/position control of robotic manipulators. IEEE Trans. Robot. Autom. 1993, 9, 361–373. [Google Scholar] [CrossRef]
- Johannink, T.; Bahl, S.; Nair, A.; Luo, J.; Kumar, A.; Loskyll, M.; Ojea, J.A.; Solowjow, E.; Levine, S. Residual Reinforcement Learning for Robot Control. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6023–6029. [Google Scholar] [CrossRef]
- Silver, T.; Allen, K.R.; Tenenbaum, J.B.; Kaelbling, L.P. Residual Policy Learning. arXiv 2018, arXiv:1812.06298. [Google Scholar]
- Bellegarda, G.; Byl, K. Training in Task Space to Speed Up and Guide Reinforcement Learning. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 2693–2699. [Google Scholar]
- Koenig, N.; Howard, A. Design and use paradigms for gazebo, an open-source multi-robot simulator. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sendai, Japan, 28 September–2 October 2004; Volume 3, pp. 2149–2154. [Google Scholar]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; Volume 3, p. 5. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Condition | Value Range | |
|---|---|---|
| Initial position (relative to goal) | Position (mm) | [−400, 400] |
| Orientation () | [−10, 10] | |
| Uncertainty error | Position (mm) | [−2, 2] |
| Orientation () | [−5, 5] | |
| Desire insertion force (N) | [0, 10] | |
| Stiffness (in Gazebo: surface/friction/ode/kp) | [7.0 × 10−4, 1.0 × 10−5] | |
| Method | Success Rate | Avg. Time Steps | Avg. Time (sec) |
|---|---|---|---|
| Scratch | 100% | 109.6 | 5.48 |
| Sim2real | 95% | 75.3 | 3.77 |
| Ours | 100% | 65.6 | 3.28 |
| Estimation Error/Success Rate | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Position | Orientation | ||||||||||
| Method | 1 mm | 2 mm | 3 mm | 4 mm | 5 mm | 1° | 2° | 3° | 4° | 5° | Random |
| Scratch | 90% | 90% | 70% | 55% | 35% | 100% | 90% | 80% | 80% | 50% | 80% |
| Sim2real | 90% | 85% | 75% | 60% | 40% | 100% | 90% | 80% | 80% | 30% | 75% |
| Ours | 100% | 100% | 95% | 65% | 60% | 100% | 100% | 100% | 100% | 100% | 90% |
| Method/Stiffness | High | Medium | Low |
|---|---|---|---|
| Scratch | 100% | 70% | 40% |
| Sim2real | 95% | 100% | 100% |
| Ours | 100% | 100% | 100% |
| Task | Success Rate | Insertion Force |
|---|---|---|
| Ring | 80% | 5N |
| Electric Outlet (x) | 75% | 10N |
| Electric Outlet (y) | 75% | 10N |
| LAN port (x) | 55% | 5N |
| LAN port (y) | 60% | 5N |
| USB | 80% | 8N |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Beltran-Hernandez, C.C.; Petit, D.; Ramirez-Alpizar, I.G.; Harada, K. Variable Compliance Control for Robotic Peg-in-Hole Assembly: A Deep-Reinforcement-Learning Approach. Appl. Sci. 2020, 10, 6923. https://doi.org/10.3390/app10196923
Beltran-Hernandez CC, Petit D, Ramirez-Alpizar IG, Harada K. Variable Compliance Control for Robotic Peg-in-Hole Assembly: A Deep-Reinforcement-Learning Approach. Applied Sciences. 2020; 10(19):6923. https://doi.org/10.3390/app10196923
Chicago/Turabian StyleBeltran-Hernandez, Cristian C., Damien Petit, Ixchel G. Ramirez-Alpizar, and Kensuke Harada. 2020. "Variable Compliance Control for Robotic Peg-in-Hole Assembly: A Deep-Reinforcement-Learning Approach" Applied Sciences 10, no. 19: 6923. https://doi.org/10.3390/app10196923
APA StyleBeltran-Hernandez, C. C., Petit, D., Ramirez-Alpizar, I. G., & Harada, K. (2020). Variable Compliance Control for Robotic Peg-in-Hole Assembly: A Deep-Reinforcement-Learning Approach. Applied Sciences, 10(19), 6923. https://doi.org/10.3390/app10196923