1. Introduction
Sport has always played an essential role in every culture in the past and still does in current times. Everybody knows conventional sports, such as football, volleyball, basketball, etc., but there are new sports appearing that are increasingly expanding in popularity. One of them is Electronic Sports, also known as eSports or e-sports [
1]. At the beginning of the 90s, the history of e-sport began. During this decade, it became more and more popular, and the number of players increased significantly [
2,
3,
4,
5]. E-sport is a type of sport in which players compete in computer games [
6,
7]. The players’ activities are only restrained from being placed in the virtual environment [
3]. E-sport is exciting entertainment for many fans, but it is also a source of income for the professional players and the whole e-sport organization. Professional players usually belong to different e-sport organizations and represent their teams competing in omnifarious tournaments, events, and international championship [
2,
3,
4,
8]. The competition takes place online or through so-called local networks (LAN). The most encounters take place in a LAN network, where both smaller and larger numbers of computers are connected in one building allowed for lower in-game latency between gamers [
2,
6,
8,
9,
10]. In e-sports, the viewership is crucial. The gameplay should be designed to attract and emotionally engage the participation of as many gameplay observers as possible.
E-sport is a lifestyle for computer gamers. It becomes a real career path from which you can start, develop, and build your future. People still consider e-sport very conservatively. They think of it as something trivial and frivolous. While some people do not take it seriously all the time, spectator count records, as well as prize pool records, are regularly updated during major tournaments, reaching millions watching Counter-Strike: Global Offensive (CS: GO) [
11]. It is full of opportunities, awards, travel, and also requires great sacrifice. It is incredibly demanding to reach a world-class level [
1]. Actually, it looks like a full-time job. Players usually train 8 hours a day or more. They use the computer as a tool to achieve success in a new field. To become a professional, people have to work hard without any excuses. A player is considered as professional when he is hired by an organization that pays for his work representing that entity by appearing at events, mostly official tournaments on a national or international level [
8]. E-sport has become an area that requires so much precision that even milliseconds determine whether to win or lose. Pointing out the importance of specialized skills, such as hand-eye coordination, muscle memory, or reaction time, as well as strategical or tactical in-game knowledge, increases achieving success in that area [
12]. Hand-eye coordination is the ability of the vision system to coordinate the information received through the eyes to control, guide, and direct the hands in the accomplishment of a given task, such as handwriting or catching a ball [
13]. The aim of e-sports is defeating other players. It could be done by neutralizing them, or just like in sports games, by racing as fast as possible to cross the finish line before your opponents. In addition, the win may be achieved by scoring the most points [
2,
3].
One of the most popular genres of eSports games is First-Person-Shooter (FPS) [
2,
6,
8,
14]. The virtual environment of the game is approached from the perspective of the avatar. The only thing visible of the avatars on the screen is the hands and the weapons they handle [
2]. Counter-Strike is an FPS multiplayer game created and released by Valve Corporation and Hidden Path Entertainment [
5,
6]. There were many other versions of the game, which did not achieve much success. Valve realized how popular e-sport had become and create the new Counter-Strike game we play today, wholly tailored for competition, known as CS: GO. The rules in CS: GO are uncomplicated. There are two teams in the game: terrorists (T) and counter-terrorists (CT). Each team aims to eliminate the opposing team or to perform a specific task. The first one’s target is to plant the bomb and let it explode, while the second’s is to prevent the bomb from being planted and/or exploding. Additionally, the game consists of 30 rounds, where each last about 2 min. After 15 rounds, players need to switch teams. Then, the team that first achieves 16 rounds is the winner. When the game does not end in 30 rounds, it goes to overtime. It consists of a best of six rounds, three on each side. The team that gets to 4 rounds wins. If there is another draw situation, the same rule applies until a winner is found [
4,
8]. The team’s economy is concerned with the amount of money that everybody on the team have pooled cooperatively in order to buy new weapons and equipment. Winning a round by eliminating the entire enemy team provides the winners with USD 3250 per player, plus USD 300 if the bomb is planted by a terrorist. Winning by time on the counter-terrorist’s side rewards players USD 3250, and winning the round with a defusal (CT) or detonation of the bomb (T) rewards USD 3500. However, if the terrorists run out of time before killing all the oponnents or planting the bomb, they will not come in for any cash prize. If a round is lost on the T-side, but they still manage to plant the bomb, the team will be awarded USD 800 in addition to the current round loss streak value. The money limit for each individual player in competitive matches is equal to USD 16.000 [
15].
For gamers, the foundation of e-sports is the glory of winning, the ability to evoke excitement in people, and the privilege of being perceived as one of the best players in the world [
2,
8]. In the past, players had to bring their equipment to LAN events, while having fun in a hermetically sealed society. They could then eventually win small cash prizes or gadgets. Now, these players are winning a prize pool of over USD 500 thousand, performing on big stages full of cameras and audience [
1]. The increase in popularity of e-sports was not only impressive but also forced many business people, large corporations, and television companies to become interested in this dynamically developing market [
8]. E-sport teams are often headed by traditional sports organizations and operated by traditional sports media. Tournaments are organized by conventional sports leagues highlighting the growing connections between classical sport and e-sport [
16].
In recent years, e-sport has become one of the fastest-growing forms of new media driven by the growing origins of games broadcasting technologies [
7,
17]. E-sport and computer gaming have entered the mainstream, transforming into a convenient way of entertainment. In 2019, 453.8 million people had been watching e-sport worldwide, which increased by about 15% compared to 2018. It consisted of 201 million regular and 252 million occasional viewers. Between 2019 and 2023, total e-sport viewership is expected to increase by 9% per year, from 454 million in 2019 to 646 million in 2023. In six years, the number of watchers will almost double, reaching 335 million in 2017. In the current economic situation, global revenues from e-sport may reach USD 1.8 billion by 2022, or even an optimistic USD 3.2 billion. Hamari in Reference [
3] claims that with the development of e-sport, classic sport is becoming a computer-based form of media and information technology. Therefore, e-sport is a fascinating subject of research in the field of information technology.
The accurate player ranking is a crucial issue in both classic [
18] and e-sport [
19,
20]. The result of a classification, calculated based on wins and losses in a competitive game, is often considered to be an indicator of a player’s skills [
20]. Each player’s position in the ranking is strictly determined by their abilities, predispositions, and talent in the field of represented discipline [
16]. However, there are more than just statistics to prove the player’s value and ability. Many professional players play a supporting role in their teams, and winning even a single round is a priority. What matters first and foremost is the team’s victory, unlike the ambitions of the individual units. The team members have to work collectively, like one organism, and everyone has to cooperate to achieve the team’s success and the best possible results [
21]. That is why the creation of accurate player ranking is a problematic issue.
In this paper, we identify the model to generate a ranking of players in the popular e-sport game, i.e., Counter-Strike: Global Offensive (CS: GO), using the Characteristic Objects METhod (COMET). The obtained ranking will be compared to Rating 2.0, which is the most popular for CS: GO game [
22,
23]. This study case facilitates the application of COMET in the new field of application. The COMET is a novel method of identifying a multi-criteria expert decision model to solve decision problems based on a rule set, using elements of the theory of fuzzy sets [
23,
24]. Unlike most available multi-criteria decision analysis (MCDA) methods, COMET is completely free of the rank reversal problem. The advantages of this technique are both an intuitive dialogue with the decision-maker and the identification of a complete model of the modeling area, which is a vital element in the application of the proposed approach in the methodological and algorithmic engine in the area of computer games and, more specifically, e-sport.
The most important methodological contribution is the analysis of the significance of individual inputs and outputs, which enables the analysis of the dependence of results on individual input data. Similarly, as in the Analytic Hierarchy Process (AHP) method, it is to serve as a possibility of extended decision analyzing in order to explain what influence particular aspects had on the final result. The Spearman correlation coefficient is used to measure the input-output dependencies, which extends the COMET technique to include new interpretative possibilities. It is important to note that this is significant as the COMET method itself does not apply any significance weights. The proposed approach makes it possible to estimate the significant weights.
The justification of the undertaken research has both theoretical and practical dimensions. MCDA methods themselves have proved to be powerful tools to solve different practical problems [
25,
26]. In particular, the construction of assessment models and rankings using MCDA methods is extensively discussed in the literature [
27,
28,
29,
30]. Examples of decision-making problems successfully solved with the usage of different multi-criteria methods include the assessment of environmental effects of marine transportation [
31], innovation [
32,
33], sustainability [
34,
35], evaluation of renewable energy sources (RES) investments [
36,
37] or a broad environmental investments assessment [
38], and industrial [
39], as well as personnel assessment [
40] of preventive health effects [
41] or even evaluation of medical therapy effects [
42,
43]. It is also worth noticing the additional motivation of the research that MCDA methods have already shown their utility in building assessment models in traditional sports. For instance, the MCDA-based evaluation of soccer players was conducted in Reference [
44], where Choquet method was used to evaluate the performance of sailboats [
45]. Preference ranking organization method for enrichment evaluation II (PROMETHEE II)-based evaluation model of football clubs was proposed in Reference [
46], while application of AHP/SWOT model in sport marketing was presented in Reference [
47]. MCDA-based, multi-stakeholder perspective was handled in the evaluation of national-level sport organizations in Reference [
48]. Both the examples provided and state of the art presented in Reference [
49] clearly show the critical role of MCDA methods in the area of building assessment models and rankings in the field of sport. When we analyze the area of the e-sport in addition to the dominant trends, including economic research [
50], sociological [
3,
51], psychological [
52] or conversion-oriented research, and user experience (UX) [
53], we observe attempts to use quantitative methods in the search for the algorithmic engines of digital products and games. For example, ex-post surveys and statistical-based approach were used to manage the health of the eSport athlete [
54]. Personal branding of eSports athletes was evaluated in Reference [
55]. In Reference [
56], streaming-based performance indicators were developed, and players’ behavior and performance were assessed. The research focused on win/live prediction in multi-player games was conducted in Reference [
57]. The study aimed to identify the biometric features contributing to the classification of particular skills of the players was presented in Reference [
58]. So, far, only one example of MCDA-based method usage in e-sport player selection and evaluation has been proposed [
58]. The authors indicate the appropriateness of fuzzy MCDA in the domain of e-sport player selection and assessment. The above literature studies show a distinct research gap, including the limited application of MCDA in e-sport domain. Besides, the paper addresses the following essential theoretical and practical research gaps:
extension of the COMET method by the stage of analyzing the significance of individual input data and decision-making sub-models to the final form of a ranking of decision-making options
transferring the methodological experience of using MCDA methods to the important and promising ground for building decision support systems in the area of eSports;
by identifying a domain-specific proper reflecting modeling domain (e-sport player evaluation), the form of which (both within the family of evaluation criteria and alternatives) is significantly different from that of classical sports; and
analysis and study of the adaptation and examination of MCDA methods usage as an algorithmic methodological engine of decision support system (potentially providing additional functionality to a range of available digital products and games).
The rest of the paper is organized as follows: MCDA foundations and simple comparison of MCDA techniques are presented in
Section 2.
Section 3 contains preliminaries of the fuzzy sets theory. The explanation of the definitions and algorithms of the multi-criteria decision-making method named COMET is given in
Section 4.
Section 5 introduces the results of the study, and, in
Section 6, the discussion about the differences in both rankings. In
Section 7, we present the conclusions and future directions.
2. MCDA Fundations
Multi-criteria decision support aims to achieve a solution for the most satisfactory decision-maker and at the same time to meet a sufficient number of often conflicting goals [
59]. The search for such solutions requires the consideration of many alternatives and their evaluation against many criteria, as well as the transfer of the subjectivity of evaluation (e.g., the relevance of the criteria by the decision-maker) into a target model. Multi-criteria Decision Analysis (MCDA) methods is dedicated to solving this class of decision problems. During many years of research, two schools of MCDA methods have been developed. First, American MCDA school is based on the assumption that the decision-maker’s preferences are expressed using two basic binary relations. When comparing the decision-making options, undifferentiated relations and preferences may occur. In the case of the European MCDA school, this set has been significantly extended by introducing the so-called “superiority relationship”. The relation of superiority, apart from the two basic relations mentioned above, introduces the relation of weak preference of one of the variants to another and the relation of incomparability of the decision options.
In the case of the American school methods, the result of the comparison of variants is determined for each criterion separately, and the effect of the aggregation of the grades is a single, synthesized criterion, with the order of variants being full. The methods of the American school of decision support in the vast majority using the function of value or utility. The best-known methods of the American school are Multi Attribute Utility Theory (MAUT), AHP, Analytic Network Process (ANP), Simple Multi-Attribute Rating Technique (SMART), UTA, Simple Multi-Attribute Rating Technique (MACBETH), or Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS).
In contrast to the American school (which is at the same time an accusation of “European School”-oriented researchers), the algorithms of the European School methods are strongly oriented on faithful reflection of the decision-maker’s preferences (including their imprecision). The aggregation of the assessment results in itself is done with the use of the relation of superiority, and the effect of aggregation in the vast majority of methods is a partial order of variants (the effect of using the relation of incomparability). The primary methods of the European School are ELimination Et Choice Translating REality (ELECTRE) and PROMETHEE [
60]. What is important, among them only the Promethee II method as a result of the aggregation of assessments provides a full order of decision options. Other methods belonging to the MCDA European School are, for example, ORESTE, REGIME, ARGUS, TACTIC, MELCHIOR or PAMSSEM. An important additional difference between the indicated schools is also the fact that there is a substitution of criteria in the methods using synthesis to one criterion. In contrast, the methods of the European School are considered non-compensatory [
61].
The third group of MCDA methods are based on decision-making rules. The formal basis of these methods is fuzzy set theory and approximate set theory. Algorithms of this group of methods consist in building decision rules and consequences, and, using these rules, variants are compared and evaluated, and the final ranking is generated. Examples of MCDA rules are DRSA (Dominance-based Rough Set Approach) or Characteristic Objects Method (COMET) [
24].
The COMET uses fuzzy triangular numbers to build criteria functions. A set of characteristic objects is created Using the core values of particular fuzzy numbers. So, it is a method based on fuzzy logic mechanisms. Additionally, it can also support problems with uncertain data.
Table 1 shows the comparison of the COMET method with other MCDA problems. The most important is that the COMET technique is working without knowing the criteria weights. The decision-maker’s task is to compare pairs of characteristic objects. Based on these comparisons, a model ranking is generated. The model variants are the base for building a fuzzy rule database. When the considered alternatives are given to the decision-making system, the appropriate rules are activated, and the aggregated evaluation of the variant is determined as the sum of the degree products in which the variants activate the individual rules [
62].
Additionally, the literature also indicates groups of so-called basic methods (e.g., lexicographic method, maximin method, or additive weighting method) and mixed methods, e.g., EVAMIX [
63] or QUALIFLEX, as well as Pairwise Criterion Comparison Approach (PCCA). Examples of the latter are methods: MAPPAC, PRAGMA, PACMAN, and IDRA [
64].
4. The Characteristic Objects Method
COMET (
Characteristic Objects Method) is a very simple approach, most commonly used in the field of sustainable transport [
34,
35,
62], interactive marketing [
65,
66], sport [
67], medicine [
68], in handling the uncertain data in decision-making [
69,
70], and banking [
71]. Carnero, in Reference [
72], suggests using COMET method as future work to improve her waste segregation model. The COMET is an innovative method of identifying a multi-criteria expert decision model to solve decision problems based on a rule set, using elements of the theory of fuzzy sets [
24,
68]. The COMET method distinguishes itself from other multiple-criteria decision-making methods by its resistance to the rank reversal paradox [
73]. Contrary to other methods, the assessed alternatives are not being compared here, and the result of the assessment is obtained only based on the model [
24].
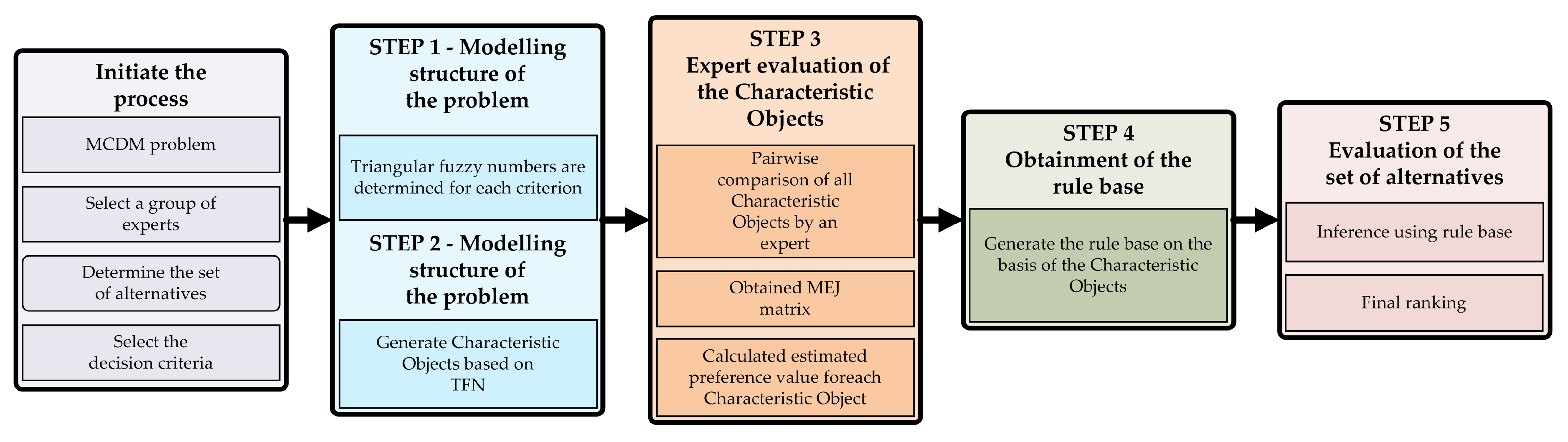
The whole decision-making process by using the COMET method is presented in
Figure 1. The formal notation of this method can be presented using the following five steps [
34]:
Step 1. Define the space of the problem – an expert determines dimensionality of the problem by selecting number
r of criteria,
. Subsequently, the set of fuzzy numbers for each criterion
is selected, i.e.,
. In this way, the following result is obtained:
where
are numbers of the fuzzy numbers for all criteria.
Step 2. Generate the characteristic objects—The characteristic objects (
) are obtained by using the Cartesian Product of fuzzy numbers cores for each criteria as follows:
As the result, the ordered set of all
is obtained:
where
t is a number of
:
Step 3. Rank the characteristic objects—the expert determines the Matrix of Expert Judgment (
). It is a result of pairwise comparison of the characteristic objects by the expert knowledge. The
structure is as follows:
where
is a result of comparing
and
by the expert. The more preferred characteristic object gets one point and the second object get zero points. If the preferences are balanced, the both objects get half point. It depends solely on the knowledge of the expert and can be presented as:
where
is an expert mental judgment function. Afterwards, the vertical vector of the Summed Judgments (
) is obtained as follows:
The last step assigns to each characteristic object an approximate value of preference. In the result, the vector P is obtained, where -th row contains the approximate value of preference for .
Step 4. The rule base—each characteristic object and value of preference is converted to a fuzzy rule as follows detailed form:
In this way, the complete fuzzy rule base is obtained, that approximates the expert mental judgement function
Step 5. Inference and final ranking—The each one alternative is a set of crisp numbers corresponding to criteria
. It can be presented as follows:
5. Results
The detailed steps of the research to identify players carried out according to the methodical framework is presented in
Figure 2. It is worth mentioning, once again, that algorithmic background and methodical approach provide COMET method.
The identified model creates a ranking, which is compared with Rating 2.0 that was proposed by Half-Life Television (HLTV). It is a news website that covers professional CS: GO news, tournaments, statistics, and rankings [
23]. The obtained ranking is more natural to interpret. Each player assessment has three additional parameters. Many parameters influence the player’s performance, including the evaluation of his skills and predispositions. For instance, with player’s age, the drop-off in reaction time makes it hard for them to compete and harder to aim the head of moving target. High percentage of headshots reflects the shooting skills and is a kind of prestige [
74]. There are plenty of criteria, which could be used to create an evaluation model. For instance, the damage per round given by grenades, the total number of rounds played by a player, which could inform us about the player’s experience or a high percentage of headshots, that was mentioned earlier. Other criteria have been chosen because of their greater impact on the assessment of the individual skills of each player. Especially important are the
and
criteria. They inform us that eliminating the player is smaller than the possibility that he will kill the enemies [
74].
Many parameters influence the player’s performance, including the assessment of his skills and predispositions. For instance, with player’s age, the drop-off in reaction time makes it hard for them to compete and harder to aim the head of moving target. Hight percentage of headshots reflects the shooting skills and is a kind of prestige. Therefore, the following six criteria have been selected [
22,
23]:
—Average kills per round, the average number of kills scored by the player during one round;
—Average damage per round, mean damage inflicted by a player during one round;
—Total kills, the total number of kills gained by the player;
—K/D Ratio, the number of kills divided by number of deaths;
—Average assists per round, the mean number of assists gained by the player during one round; and
—Average deaths per round, the average number of deaths of a player during one round.
There are plenty of criteria, which could be used to create an evaluation model. For instance, the damage per round given by grenades, the total number of rounds played by a player, which could inform us about the player’s experience or a high percentage of headshots, that was mentioned earlier. However, a set of six criteria have been chosen because of their greater impact on the assessment of the individual skills of each player. The collected data for all applied criteria and Rating 2.0 assessment are derived from the official HLTV website and dated June 2019. Especially important are the and criteria. They inform us that the chance to eliminate the player is smaller than the possibility that he will kill the enemies.
The economy of a player depends on how much he has spent on weapons and armor, the kill awards that have been received per elimination (based on weapon type), the status of bomb planting or defusing, and finally who won the round [
15]. Average kills per round (
) is always an important criterion because, by fragging (killing an enemy), you can eliminate first of all the threat from your opponent. For each elimination you get, depending on the weapon used, the amount of money needed to buy ammunition, equipment, grenades, and other utilities at a later stage of the game. For instance, elimination with a sniper rifle (AWP) is the least economically profitable and gives the player only USD 100, while almost any pistol gives 300 dollars reward, and shotguns, which are the most cost-effective, give even up to USD 900 in cash prize. Additionally, by killing enemies, they lose the weapons they acquired, thus losing all equipment, such as kevlar with a helmet or defuse kit (CT). Criterion
is a profit type criterion, where the value increase means the preference increase. Based on the information about players statistics from the HLTV database for best 40 professional players, for
, the lowest obtained value is 0.72, the highest 0.88, and the average value is equal to 0.78.
As the number of Average damage per round increases, the probability of killing an enemy increases, as well. Moreover, the player is more priceless and useful for a team when he deprives the enemy team of the precious health points and makes gaining frag much easier for his teammates. There was a situation during the PGL Major Kraków 2017 event when a professional player Mikhail "Dosia" Stolyarov from Gambit Esports during the grand final against Immortals team done some unbelievable action. His team (on CT side) was going to lose the round because there was not enough time to defuse the bomb versus three opponents. Dosia knew it was impossible to win, but he came up with an idea and threw a grenade to give some extra damage to players, who were saving their weapons. It was a few seconds before the detonation of the bomb, which takes many health points (HP) from players located in an area of the explosion. Doing it, he contributed to the death of two players, which lost precious weapons and equipment, forcing them to spent extra money in the next round. That was an example of the validity of this criterion on the professional field of CS: GO. Criterion is characterized by a positive correlation to player value. For criterion , the lowest result is 75.60, the highest 88.20, and the mean value is equal to 82.70.
Criterion determine the total number of kills scored by the player, which could signify that the player plays a lot and has a background in Counter-Strike, like the legendary player Christopher “GeT RiGhT” Alesund from Sweden or Filip “Neo” Kubski from Poland. When value increases, the player’s evaluation also improves. As the total number of kills increases, the player’s skill level and overall experience develop, as well, playing later against much better enemies. For criterion , the lowest result is 1516.00, the highest 4151.00, and the mean value is equal to 2514.90. Frankly, it is not the most critical parameter because players with much less number of frags could play as good or even better. It depends on individual predispositions and the innate potential of the gamer.
Criterion is probably the most prominent rate of players’ abilities in CS: GO. It is a profit type criterion, like the previous three criteria. It informs us that the chance to eliminate the player is smaller than the possibility that he will kill the enemies. If the total number of kills is more significant than the overall number of deaths, the player’s skill level is getting more superior, and the gamer improves every time he plays. For professional gamers, the criterion obtained the lowest result equal to 1.15, the highest 1.51, and the mean value is equal to 1.25. Even the worst K/D Ratio value in this set of players is a great result.
Obtaining assistance in team games is proof of successful and productive team play. In CS: GO, assists are also received in this way because it is an evident proof that the player was close to making an elimination on the opponent. However, something went wrong and only deprived him of most of the health points in the end without gaining a single frag. Then, he gives his teammates the opportunity for an easy kill, but he only got an assist instead of a full frag on his account. Often, players who play a supporting role get a significant amount of assists because they contribute to getting eliminations on the rival by, for example, blinding him with a flashlight, helping his colleagues. For criterion , the lowest result is 0.09, the highest 0.18, and the average value is equal to 0.13.
As it is known in FPS games, the most important thing is to eliminate your opponents instead of being killed. By analyzing the Average number of deaths per round, we can conclude which player loses the most shooting duels and has to observe the actions of his teammates only as an observer. It could show us the weakness of the player and skill shortages that will allow the best ones to be distinguished. It is a cost-type criterion, which means the value increase indicates the preference decrease. For criterion , the lowest result is 0.52, the highest 0.68, and the mean value is equal to 0.63.
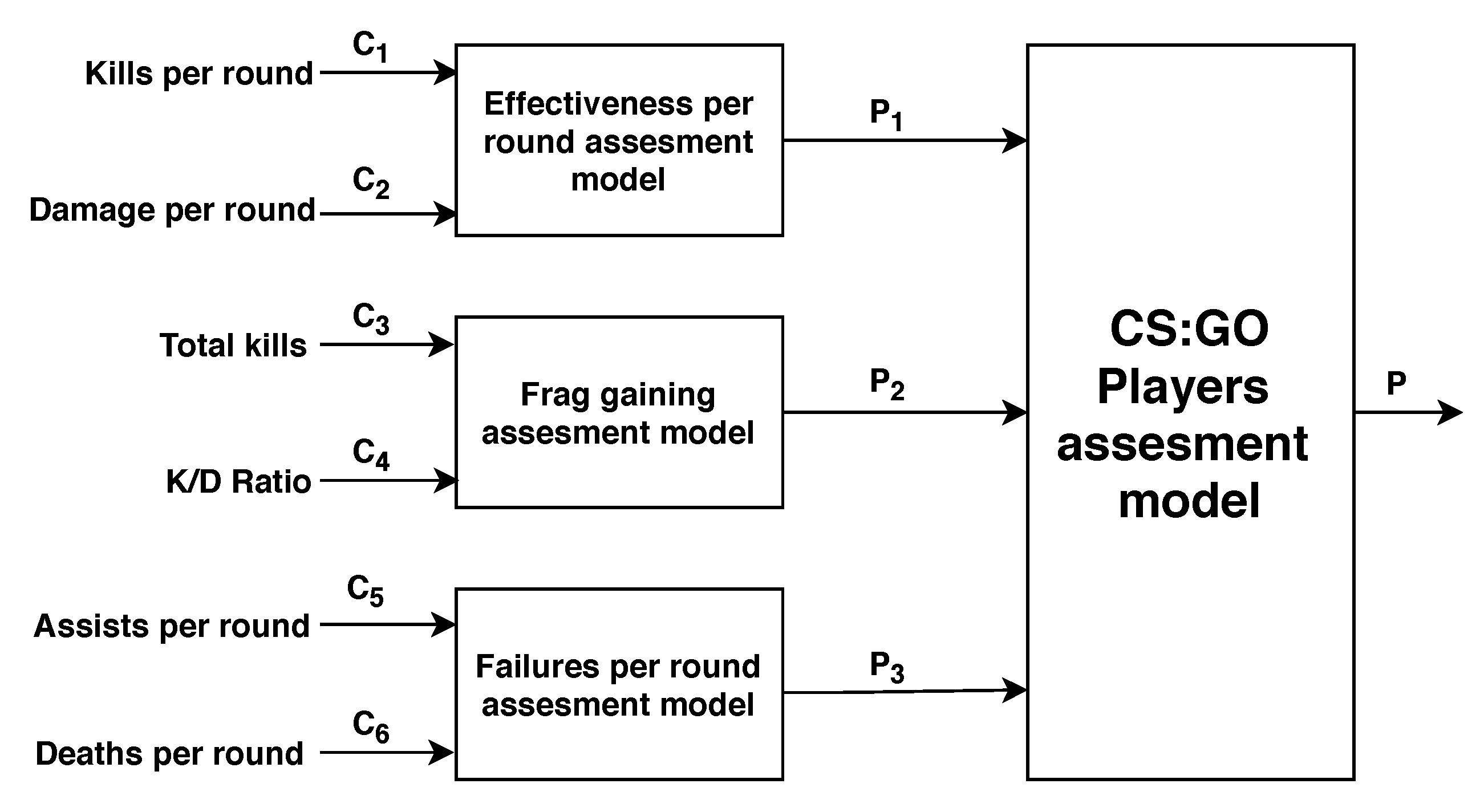
The values of selected criteria
–
, positions and names of alternatives are presented in the
Table 2. In this study case, the considered problem is simplified to a structure, which is presented in
Figure 3.
In that way, we have to identify three related models, where each one requires a lot smaller number of queries to the expert. The final decision model consists of three following models, where, for each one, nine characteristic objects and 36 pairwise comparisons are needed:
—Effectiveness per round assessment model with two inputs;
—Frag gaining assessment model with two inputs;
—Failures per round assessment model with two inputs.
In the Effectiveness per round assessment model (), we aggregate two essential criteria, like Average kills per round () and Average damage per round (), as input values. The output value is our player evaluation for model , and the lowest result is 0.23, the highest 0.88, and the mean value is equal to 0.45 for top 40 professional players in CS: GO. The input values of the Frag gaining assessment model () are two significant criteria, like Total kills () and K/D Ratio (). The outcome value is our player assessment for model , and the lowest result is 0.00, the highest 0.84, and the mean value is equal to 0.45. In the Failures per round assessment model (), we connect two crucial criteria, like Average assists per round () and Average deaths per round (). The output value is our player evaluation for model , and the lowest result is 0.25, the highest 0.78, and the mean value is equal to 0.44.
The model will be validated based on the results obtained from the official HLTV website for the top 10 professional CS: GO players for June 2019, which are presented in
Table 2. To identify the final model for players assessment, we have to determine the three following assessment models, i.e., Effectiveness per round, Frag gaining, and Failures per round.
5.1. Effectiveness per Round Assessment Model
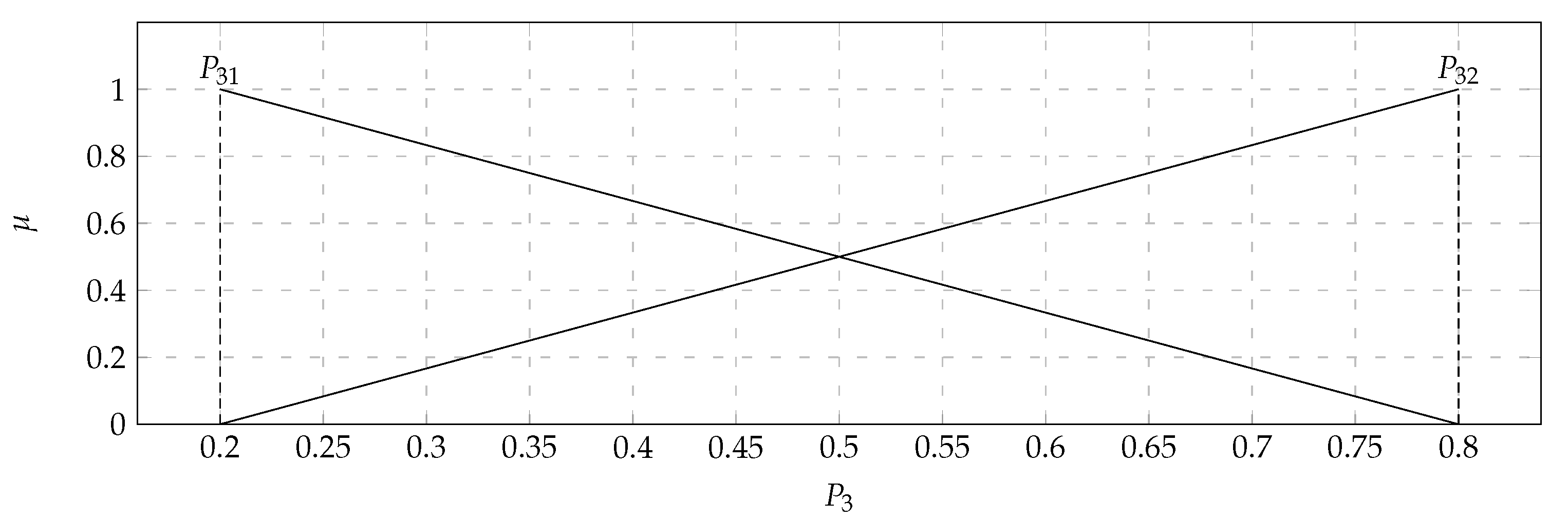
This model evaluates the efficiency in eliminating and injuring enemies, which is one of the essential elements of CS: GO. The expert identified two significant criteria for the Effectiveness per round assessment model: Average kills per round, which is the mean number of frags scored by the player pending one round, and Average damage per round, that is mean damage delivered by a player during one round. Both of them are a profit type criteria, where the value increase means the preference increase. In such complex problems, the relationship is sporadically linear.
Table 3 presents the values of the criteria
and
and the
assessment model. Based on the presented data, it can be determined that the best value of the criteria
was achieved by ‘
Simple’, which is equal to 0.88, while the worst result was obtained by ‘
dexter’ with the value equal to 0.72. In the case of the second criterion, the best score was given to ‘
huNter’ with 88.2, and the lowest score was received by ‘
xsepower’ with value equal to 75.6. Analyzing the results of the effectiveness per round assessment model (
), we can conclude that the highest score
was obtained by ‘
Simple’, and is equal to 0.8825. The triangular fuzzy numbers of criterium
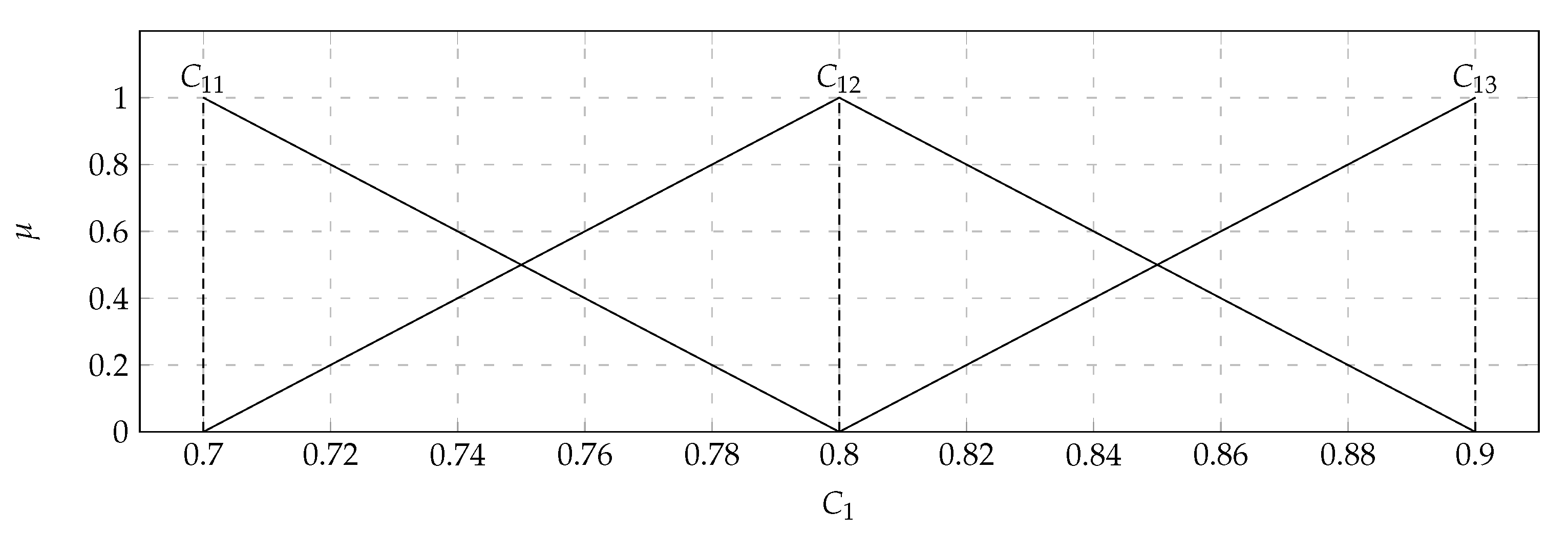
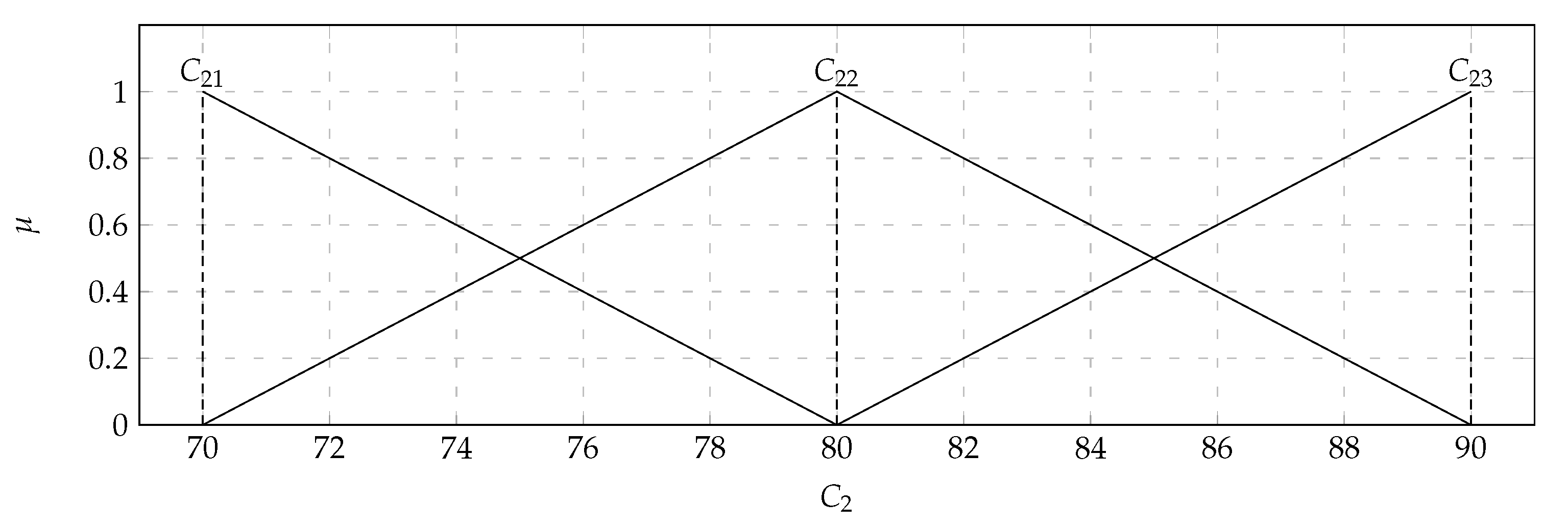
are presented in
Figure 4, while
is presented in
Figure 5.
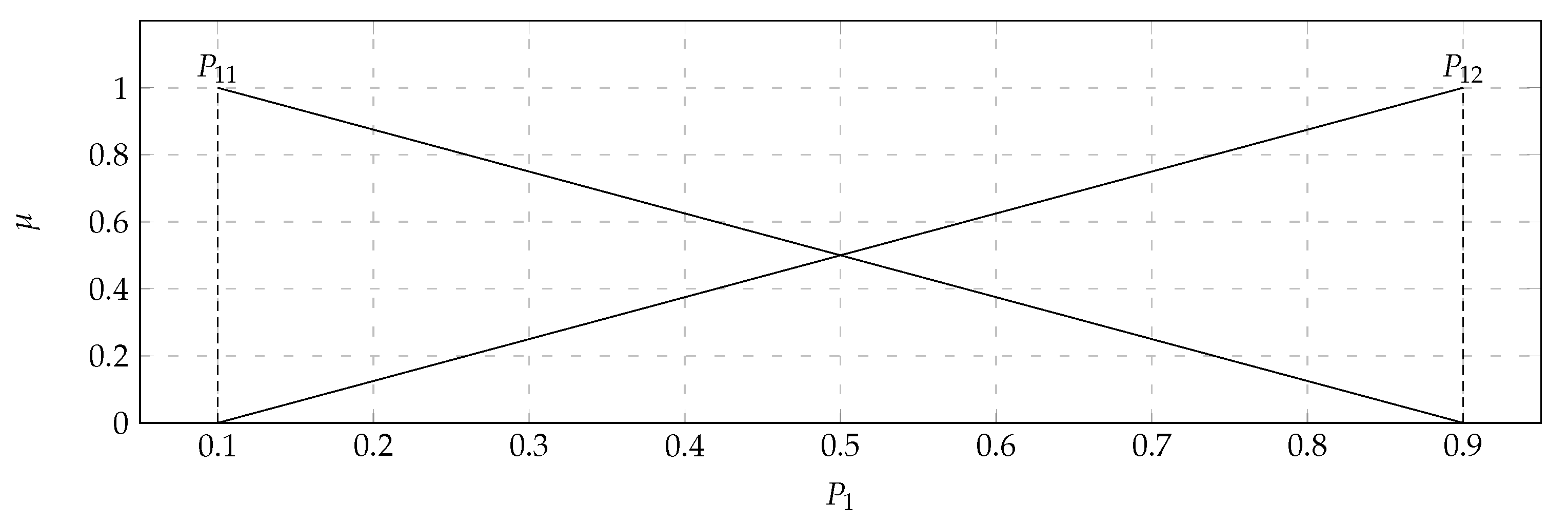
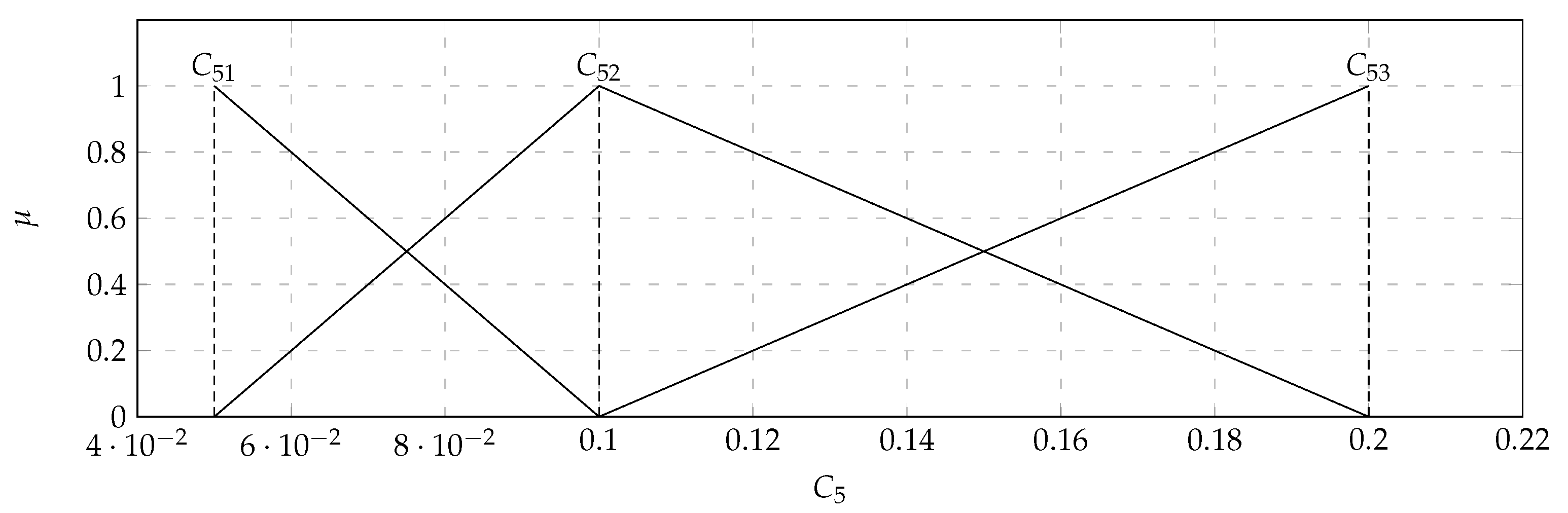
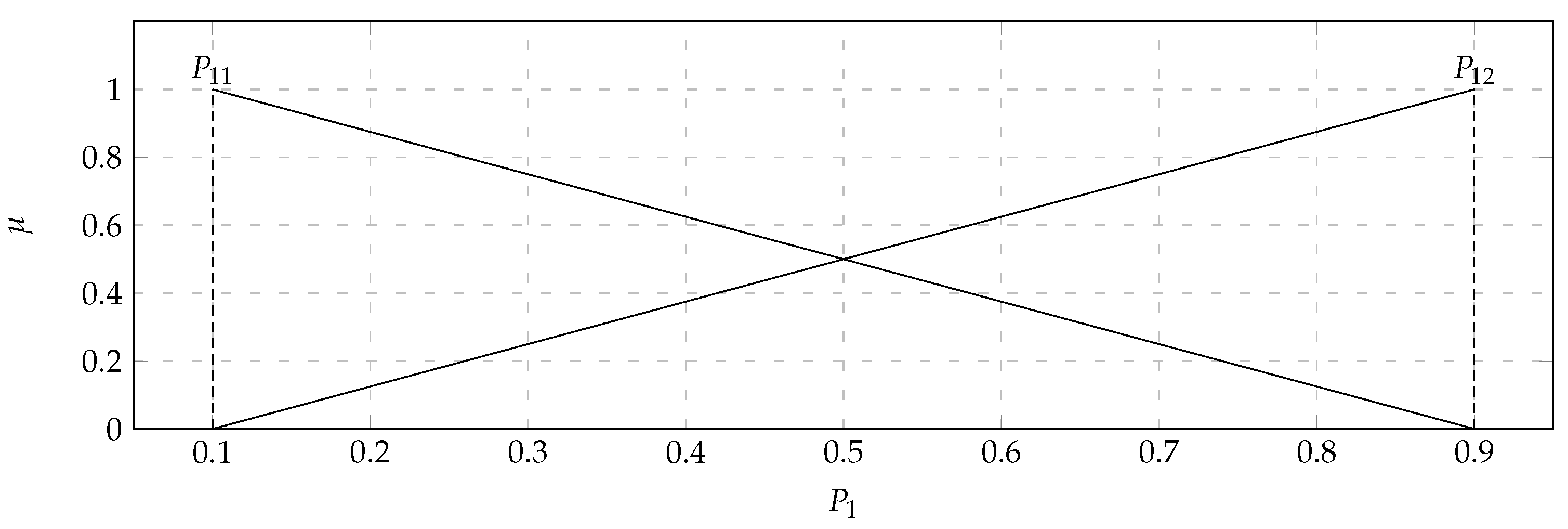
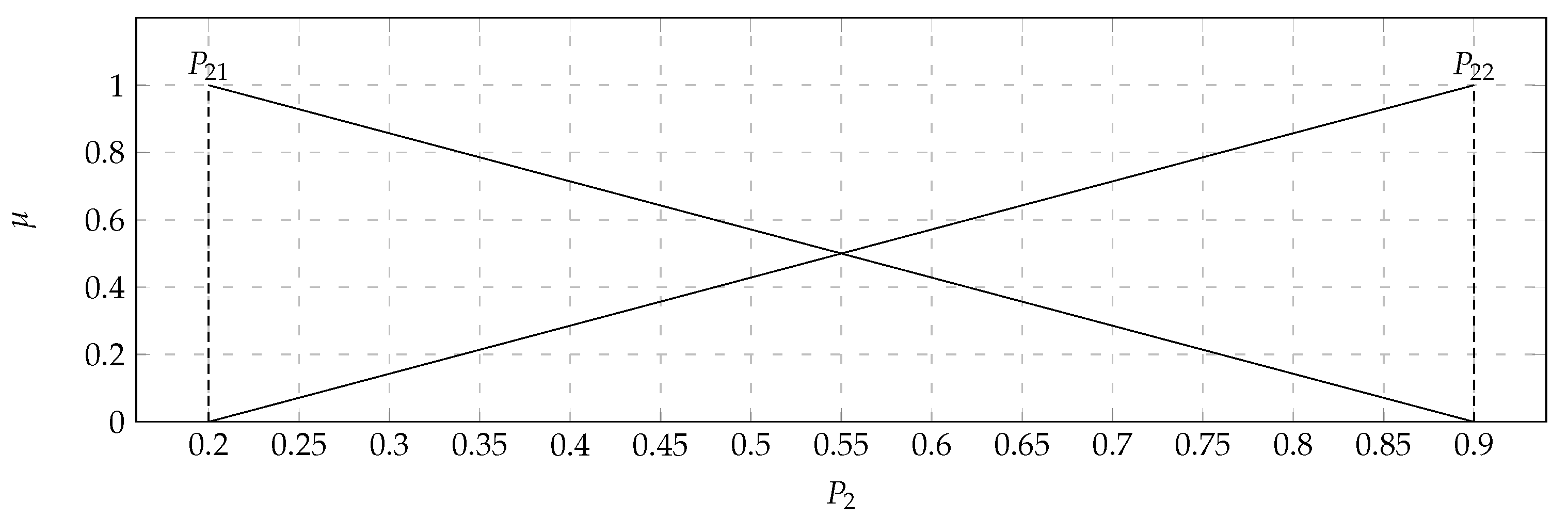
In the considered set of parameters, there were players with: Average kills per round (
) with the values of the support of the triangular fuzzy number from 0.7 (
) to 0.9 (
) and the core valued 0.8 (
); Average damage per round (
) with the values of the support of the triangular fuzzy number from 70 (
) to 90 (
) and the core valued 0.8 (
) health points. Based on the data presented in the
Table 4, it turned out that the output
takes values from 0.1 to 0.9. Therefore, the variable
will take two values. Both of them will also be determined as triangular fuzzy numbers. They were displayed in
Figure 6. The comparison of the 36 pairwise of the 9 characteristic objects were executed. Consequently, the Matrix of Expert Judgment (
) was defined as (
15), where each
value was calculated using Equation (
11).
As a result, the vector of the Summed Judgements (
) was calculated using Equation (
12), and it was employed to determine the values of preference (
), which are presented in
Table 3. The characteristic objects
–
presented in
Table 3 are generated using the Cartesian product of the fuzzy numbers’ cores of criteria
and
. The highest value of preference
received
with a triangular fuzzy number of criterion
valued 0.9 (
) and with a triangular fuzzy number of criterion
valued 90 (
). The lowest value of preference
fell to
with a triangular fuzzy number of criterion
valued 0.7 (
) and with a triangular fuzzy number of criterion
valued 70 (
). With an increase in the value of the criterion
, the preference increases more significantly than with an increase in the value of the criterion
. It means that
has a greater impact on the assessment of the
model than
.
For a better demonstration of the relevance of the criteria to the
assessment model, a
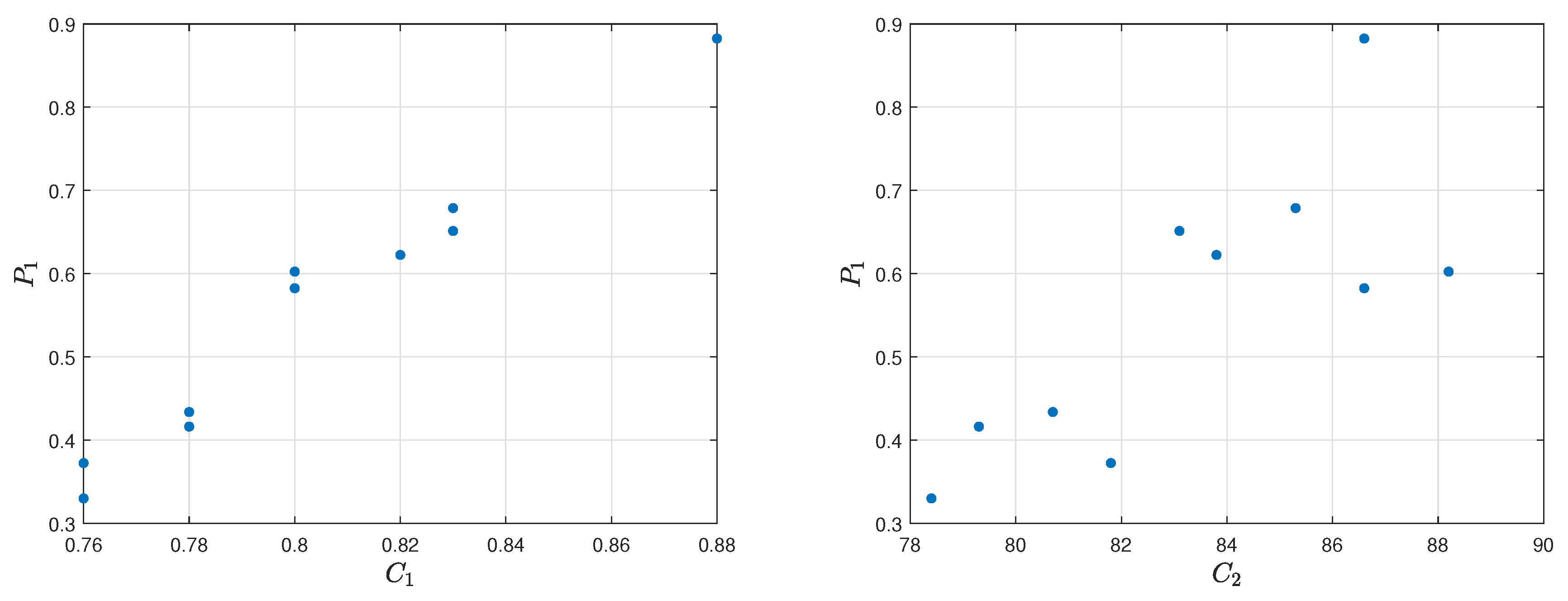
Spearman’s rank correlation coefficient was calculated.
Spearman’s rank correlation coefficient between the criteria
,
and reference ranking obtained by
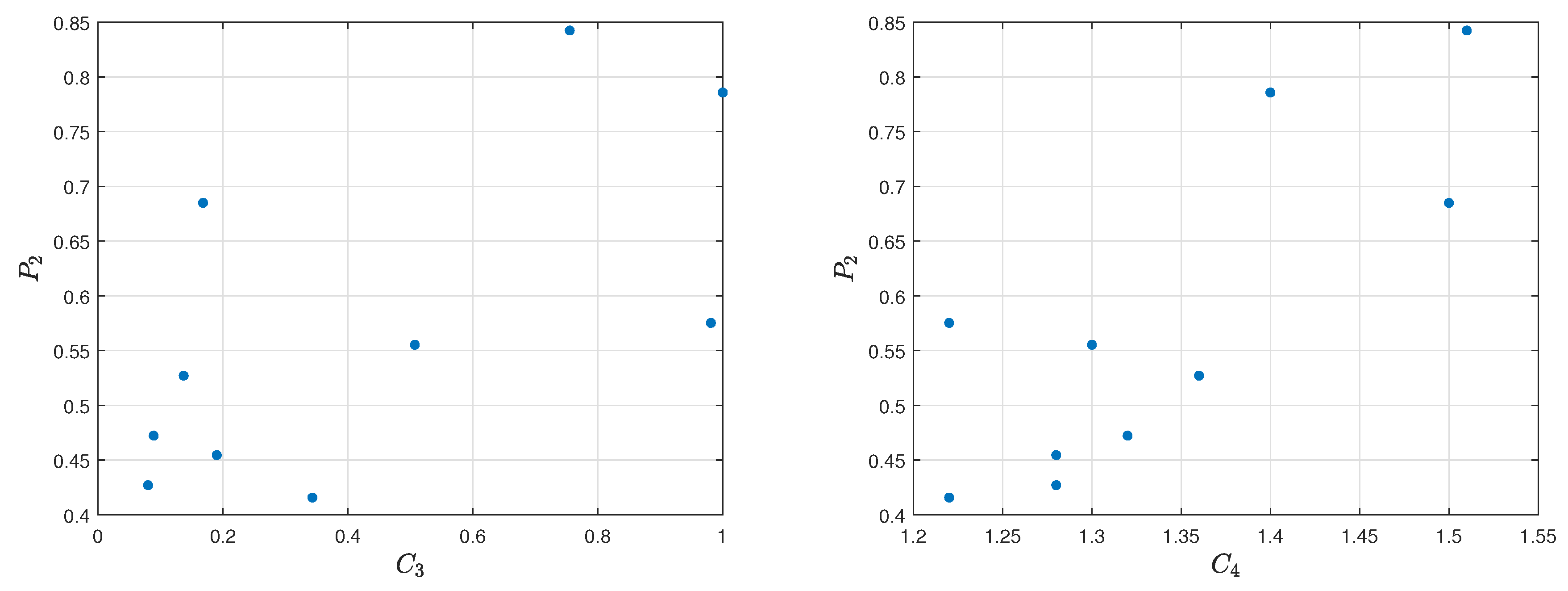
assessment model for top 10 players is equal to 0.9273 and 0.2970. The correlation between the first one is strong, while, in the second one, it is weak. The visualization of the relation diagram of Average kills per round (
) and
assessment model, as well as the relation diagram of Average damage per round (
) and
assessment model, is presented in
Figure 7.
5.2. Frag Gaining Assessment Model
The model verifies the probability of a player to get an elimination based on the number of kills he has obtained in official CS: GO matches and a specific factor, which shows that the player is superior. The expert identified two significant criteria for the Frag gaining assessment model. Total kills, which is the total number of frags delivered by the player, and K/D Ratio, that is the number of frags divided by the number of deaths. Both of them are profit type criteria, whereas it was mentioned earlier, with the increase in values, preference increases, too.
Table 5 shows the values of the criteria
and
and the
assessment model. Based on the presented data, it can be determined that the best value of the criteria
was achieved by ‘
ZywOo’, which is equal to 1.000, while the worst result was obtained by ‘
BnTeT’ with the value equal to 0. In the case of the second criterion, the best score was given to ‘
Jame’ with 1.51, and the lowest score was received by ‘
Texta’ with a value equal to 1.15. Analyzing the results of the Frag gaining assessment model (
), we can conclude that the highest score was obtained by ‘
Jame’, and is equal to 0.8423. The triangular fuzzy numbers of criterium
are presented in
Figure 8 and
in
Figure 9.
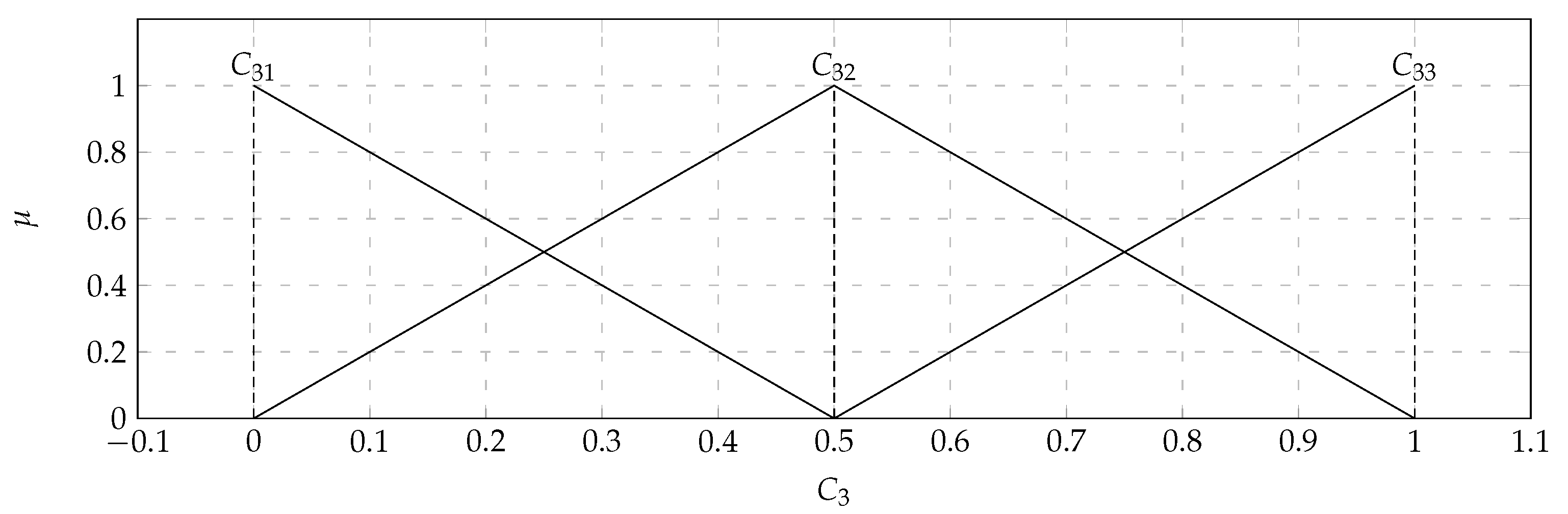
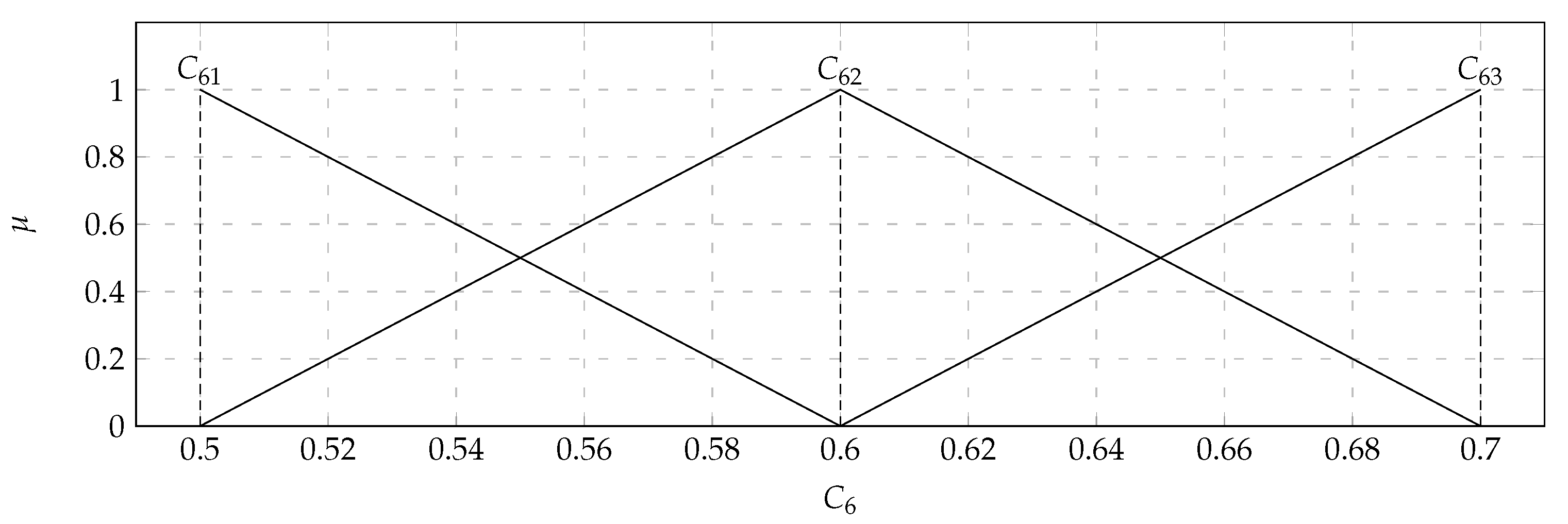
In the considered set of parameters, there were players with: total kills (
) with the values of the support of the triangular fuzzy number from 0 (
) to 1 (
) and the core valued 0.5 (
); K/D ratio (
) with the values of the support of the triangular fuzzy number from 1 (
) to 1.6 (
) and the core valued 1.25 (
). Based on the data presented in the
Table 6, it turned out that the output
takes values from 0.2 to 0.9. Therefore, the variable
will take two values. Both of them will also be saved as triangular fuzzy numbers. They are displayed in
Figure 10. The comparison of the 36 pairwise of the 9 characteristic objects was executed. Consequently, the Matrix of Expert Judgment (
) was defined (
16), where each
value was calculated using Equation (
11).
As a result, the vector of the Summed Judgements (
) was calculated using Equation (
12), and it was used to determine the values of preference (
), which are presented in
Table 5. The characteristic objects
–
presented in
Table 5 are generated using the Cartesian product of the fuzzy numbers’ cores of criteria
and
. The highest value of preference
received
with a triangular fuzzy number of criterion
valued 1 (
) and with a triangular fuzzy number of criterion
valued 1.6 (
). The lowest value of preference
fell to
with a triangular fuzzy number of criterion
valued 0 (
) and with a triangular fuzzy number of criterion
valued 1 (
). With an increase in the value of the criterion
, the preference increases more significantly than with an increase in the value of the criterion
. It means that
has a greater impact on the assessment of the
model than
.
For a better demonstration of the relevance of the criteria to the
assessment model, a
Spearman’s rank correlation coefficient was calculated.
Spearman’s rank correlation coefficient between the criteria
,
, and reference ranking obtained by
assessment model is equal to 0.5636 and 0.4910. The correlation between the first one and the reference ranking is moderately strong, while, in the second one, it is weak. The visualization of the relation diagram of total kills (
) and
assessment model, as well as the relation diagram of K/D ratio (
) and
assessment model, is shown in
Figure 11.
5.3. Failures per Round Assessment Model
This model evaluates the weaker side of the player by showing how often he has a decline in form and skill deficiencies, which are vital to maintaining himself at the top of the global e-sport scene. The expert identified two crucial criteria for the Failures per round assessment model. Average assists per round, which is the average number of assists scored by the player during one round and Average deaths per round, that is the average number of deaths of a player pending one round. The first one is a profit type criterion, which means that the value increase indicates the preference increase; however, the second one is a cost-type criterion, which means the value increase indicates the preference decrease.
Table 7 shows the values of the criteria
and
and the
assessment model. Based on the presented data, it can be determined that the best value of the criteria
was achieved by ‘
INS’, which is equal to 1.18, while the worst result was obtained by ‘
kNgV-’ with the value equal to 0.09. In the case of the second criterion, the best score was given to ‘
Jame’ with 0.52, and the worst score was received by ‘
roeJ’ with a value equal to 0.68. Analyzing the results of the Failures per round assessment model (
), we can conclude that the highest score was obtained by ‘
Jame’ and is equal to 0.7750. The triangular fuzzy numbers of criterium
are presented in
Figure 12 and
in
Figure 13.
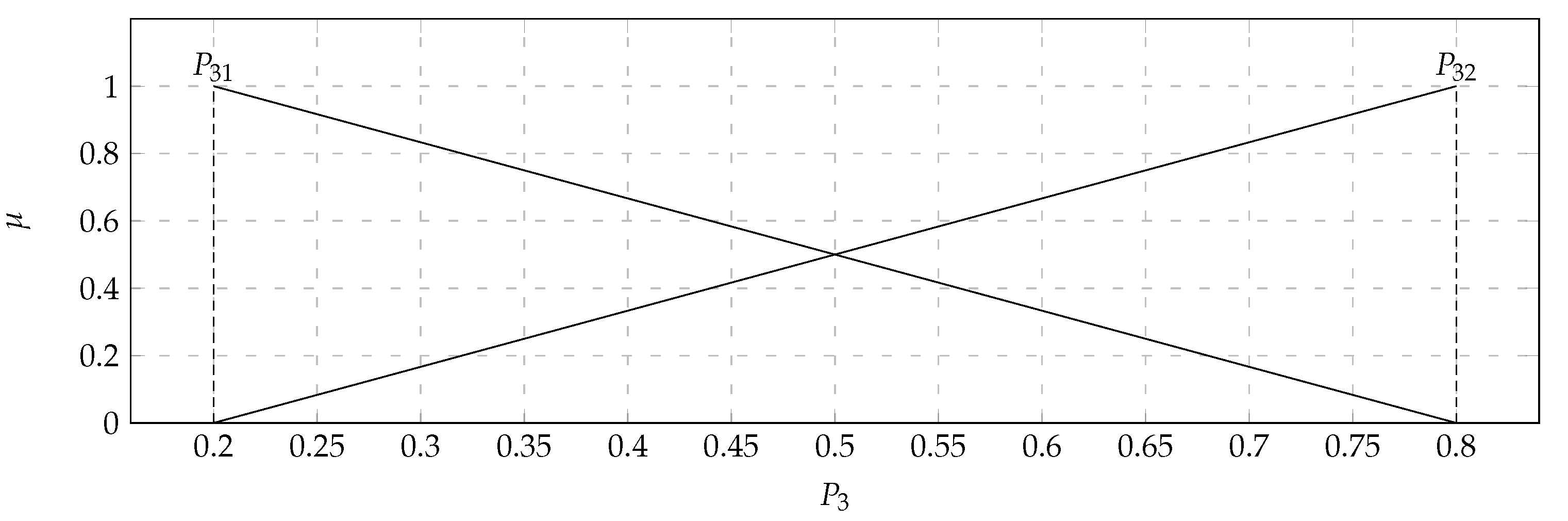
In the considered set of parameters there were players with: Average assists per round (
) with the values of the support of the triangular fuzzy number from 0.05 (
) to 0.2 (
) and the core valued 0.1 (
); Average deaths per round (
) with the values of the support of the triangular fuzzy number from 0.5 (
) to 0.7 (
) and the core valued 0.6 (
). Based on the data presented in the
Table 8, it turned out that the output
takes values from 0.2 to 0.8. Therefore, the variable
will take two values. Both of them will also be saved as triangular fuzzy numbers. They were displayed in
Figure 14. The comparison of the 36 pairwise of the 9 characteristic objects were executed. Consequently, the Matrix of Expert Judgment (
) was defined (
17), where each
value was calculated using Equation (
11).
As a result, the vector of the Summed Judgements (
) was calculated using Equation (
12), and it was employed to determine the values of preference (
), which are presented in
Table 7. The characteristic objects
–
presented in
Table 7 are generated using the Cartesian product of the fuzzy numbers’ cores of criteria
and
. The highest value of preference
received
with a triangular fuzzy number of criterion
valued 0.2 (
) and with a triangular fuzzy number of criterion
valued 0.5 (
). The lowest value of preference
fell to
with a triangular fuzzy number of criterion
valued 0.05 (
) and with a triangular fuzzy number of criterion
valued 0.7 (
). With a decrease in the value of the criterion
, the preference increases more significantly than with an increase in the value of the criterion
. It means that
has a greater impact on the assessment of the
model than
.
For a better demonstration of the relevance of the criteria to the
assessment model, a
Spearman’s rank correlation coefficient was calculated.
Spearman’s rank correlation coefficient between the criteria
,
, and reference ranking obtained by
assessment model is equal to 0.5273 and 0.1636. The correlation between the first one and the reference ranking is moderately strong, while, in the second one, it is weak. The visualization of the relation diagram of Average assists per round (
) and
assessment model, as well as the relation diagram of Average deaths per round (
) and
assessment model, is shown in
Figure 15.
5.4. Final Model
CS: GO Players assessment model finally determines the uniqueness of the Counter-Strike Global: Offensive player by placing him in the final ranking, based on previous partial assessments. The final model for the players’ assessment has three aggregated input variables. The output variable from the Effectiveness per round assessment, Frag gaining assessment, and the output variable from the Failures per round assessment were applied. The aggregated variables
and
are both profit type, whereas the
is cost type. The triangular fuzzy numbers of parameter
is presented in
Figure 16,
in
Figure 17, and
in
Figure 18.
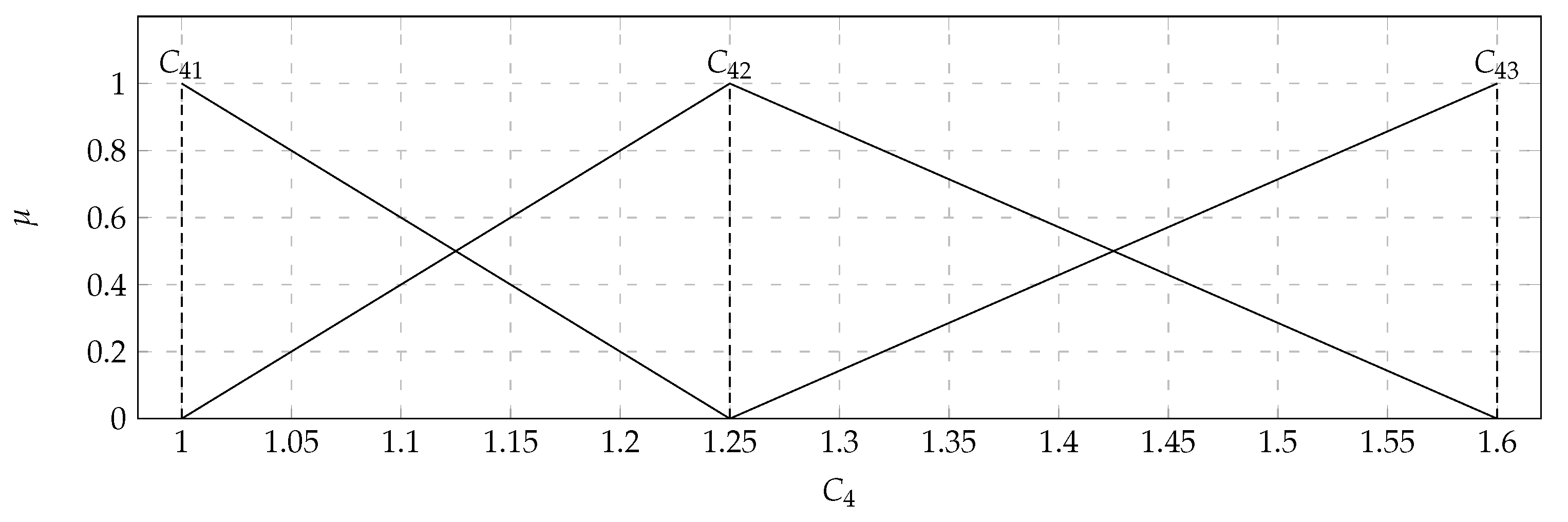
In the considered set of parameters there were players with: Effectiveness per round (
) with the values of the support of the triangular fuzzy number from 0.2 (
) to 1 (
), Frag gaining (
) with the values of the support of the triangular fuzzy number from 0.1 (
) to 0.9 (
), Failures per round (
) with the values of the support of the triangular fuzzy number from 0.2 (
) to 0.9 (
). The comparison of the 28 pairwise of the 8 characteristic objects were executed. Consequently, the Matrix of Expert Judgment (
) was defined as (
18), where each
value was calculated using Equation (
11).
As a result, the vector of the Summed Judgements (
) was calculated using Equation (
12), and it was employed to determine the final values of preference (
P), which are presented in
Table 9. The characteristic objects
–
presented in
Table 9 are generated using the Cartesian product of the fuzzy numbers’ cores of related models
,
, and
. The highest value of preference
P received
with a triangular fuzzy number of parameter
valued 0.9 (
), with a triangular fuzzy number of parameter
valued 0.9 (
), and with a triangular fuzzy number of parameter
valued 0.2 (
). The lowest value of preference
P fell to
with a triangular fuzzy number of parameter
valued 0.1 (
), with a triangular fuzzy number of parameter
valued 0.2 (
), and with a triangular fuzzy number of parameter
valued 0.8 (
). With an increase in the value of the parameter
, the preference increases more significantly than with an increase in the value of the parameters
and
. It means that
has the greatest impact on the assessment of the
P model compared to the other two parameters.
For a better demonstration of the relevance of the obtained parameters to the final assessment model
P, a
Spearman’s rank correlation coefficient was calculated.
Spearman’s rank correlation coefficient between the
,
, and
model and final ranking
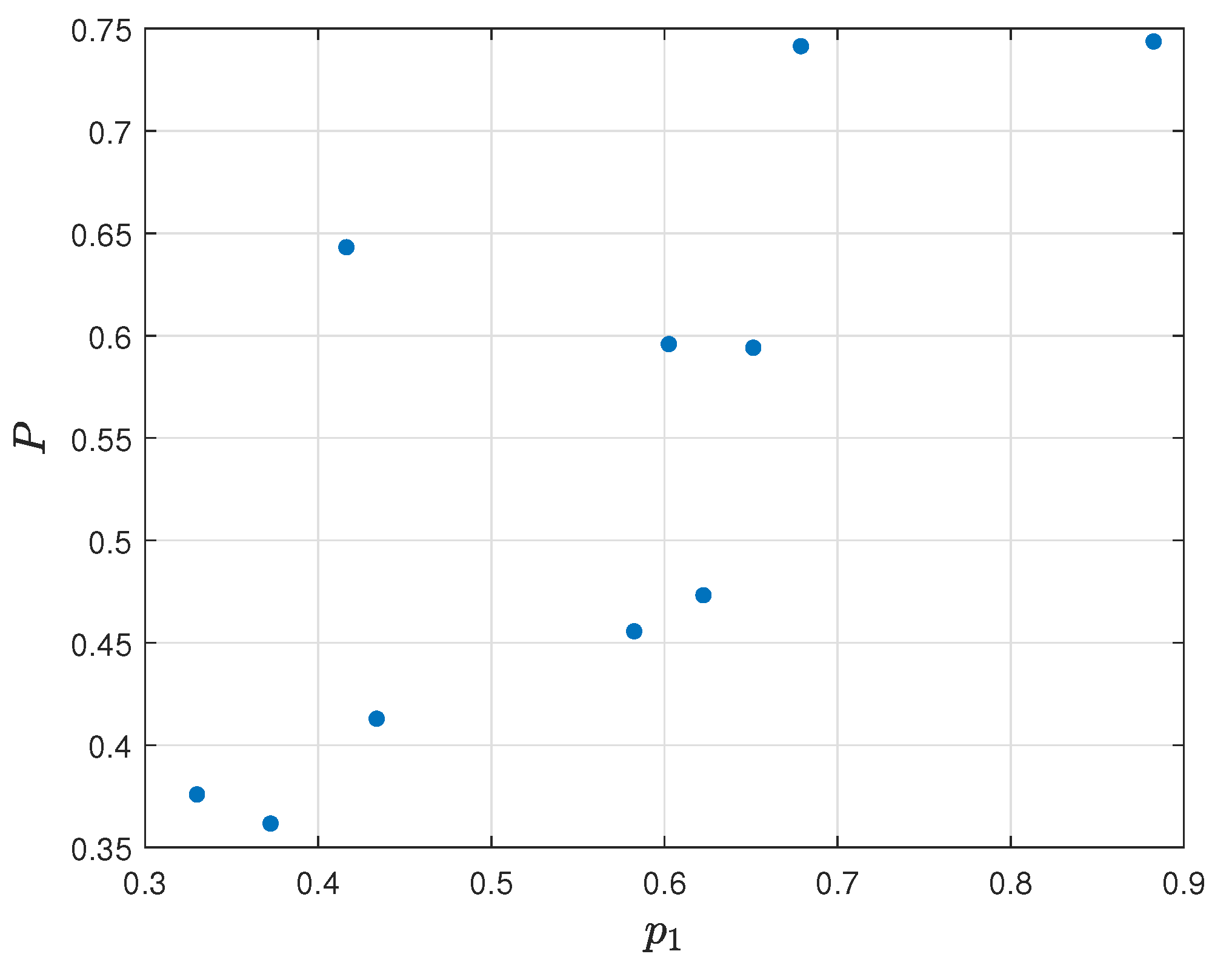
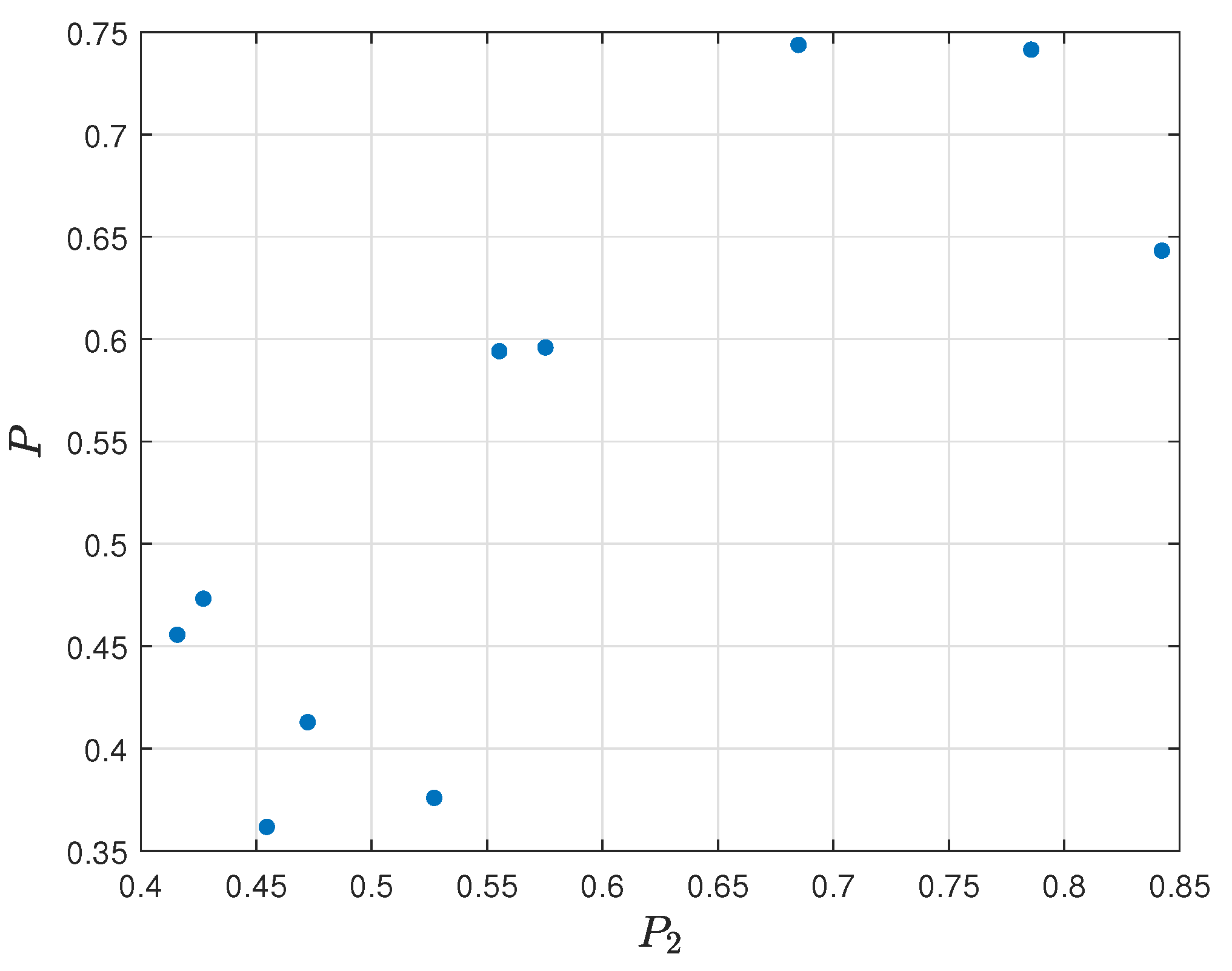
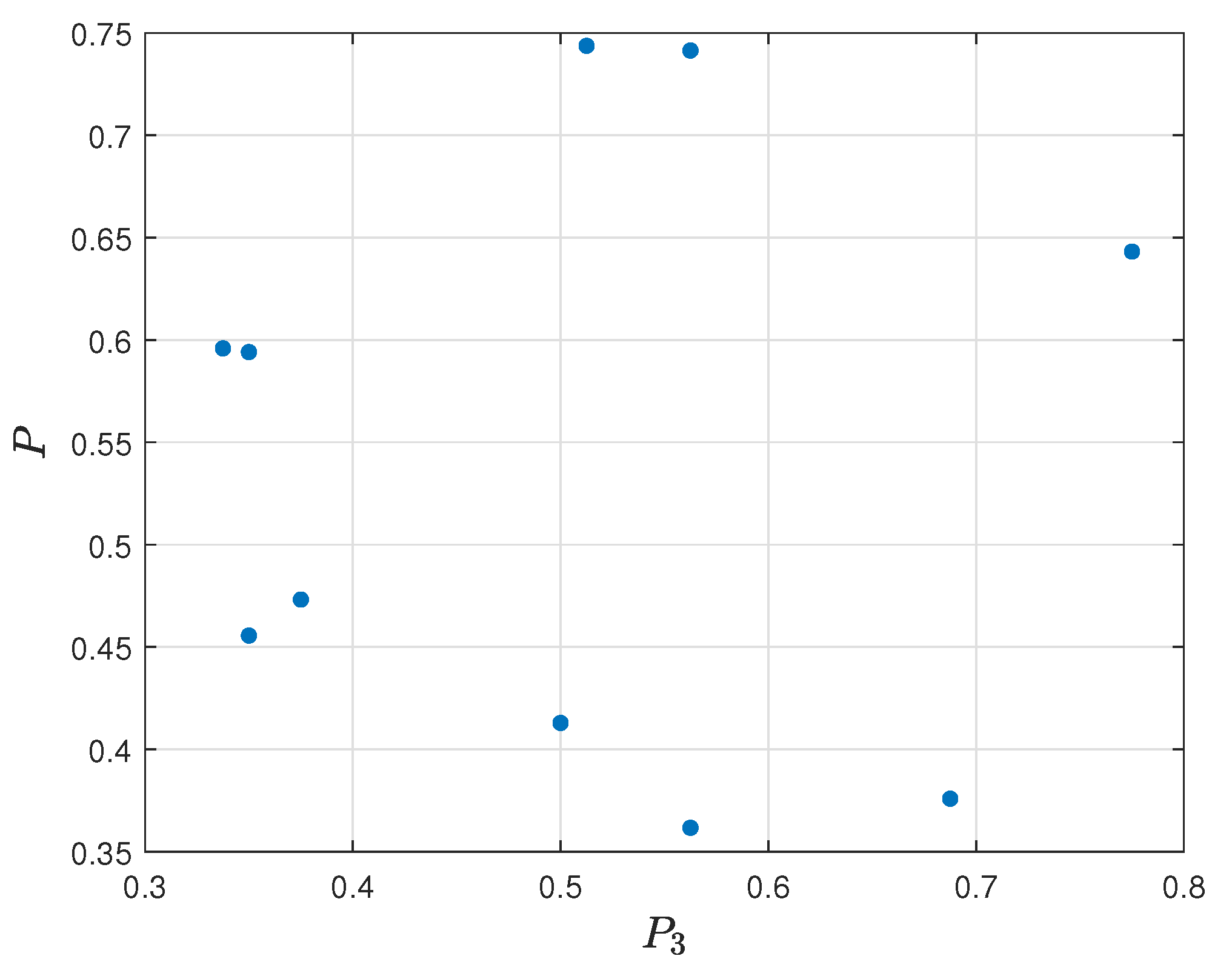
P is equal, respectively, to 0.5122, 0.6679, and 0.3182. The correlation between the first two models is moderately strong, and, in the case of the third model, the correlation is weak. The visualization of the relation diagram of effectiveness per round (
) and final assessment
P is shown in
Figure 19, the relation diagram of frag gaining (
) and final assessment
P is presented in
Figure 20, and the relation diagram of failures per round (
) and final assessment
P is presented in
Figure 21.
The sample data for the top 10 players is shown in
Table 10. The final decision assessment model identified ‘
Simple’ as the best player at all when the worst rating was given to
’Hatz’. Analyzing the results of the three related models, we can conclude that the highest score in the first model (
) was obtained by ‘
Simple’ again, and is equal to 0.8825. In the (
) and
models, the best outcome was acquired by ‘
Jame’ with the value 0.8423 as
and 0.7750 as
. The interesting fact is that ‘
ZywOo’, who placed the second position, even if he did not have the best score in any of the three models, was still better than Jame. ‘
ZywOo’ received a much better result in the first model and had a comparable score to ‘
Jame’ in the second model. Furthermore, ‘
huNter’ with the fourth result was close to beat ‘
Jame’ and take over his position. In comparison with ‘
Jame’, ‘
huNter’ had much higher assessment in
, getting average results at the rest of the models. It follows from this that the most critical models are
and
.
Spearman’s rank correlation coefficient between the , , and model and reference ranking is equal, respectively, to 0.7818, 0.7091, and 0.0061. The correlation between the first two models is moderately strong, and, in the case of the third model, there is no correlation. However, Spearman’s coefficient between the final model and reference ranking is equal to 0.9636, which means that both rankings are strongly correlated, and the proposed structure of the assessment model well defines the investigated relationships.
6. Practical Exploitation of the Identified Model
This section proposes and applies the own players’ assessment model using a hierarchical structure with the application of COMET method. It describes every related assessment model and shows the final summary and obtained results for the top 40 professional players in CS: GO game. The performance table is presented in
Table 11.
The performance table of the selected criteria
,
and assessment model
is presented in
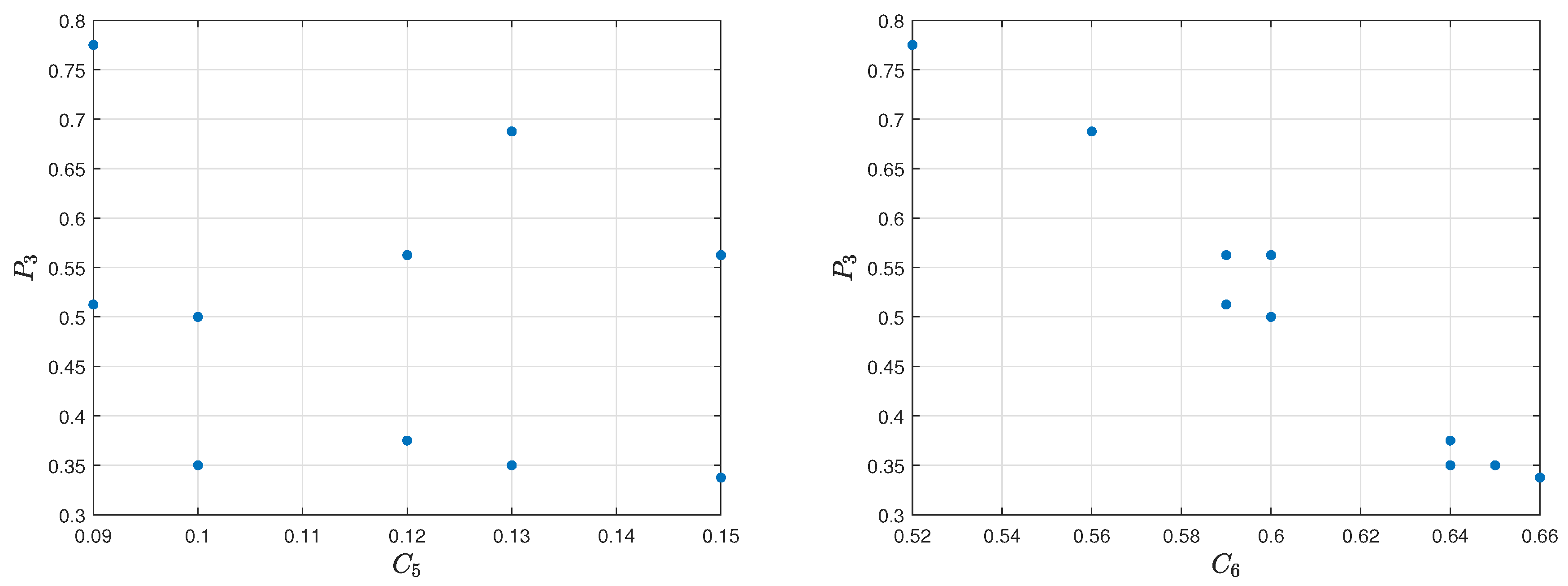
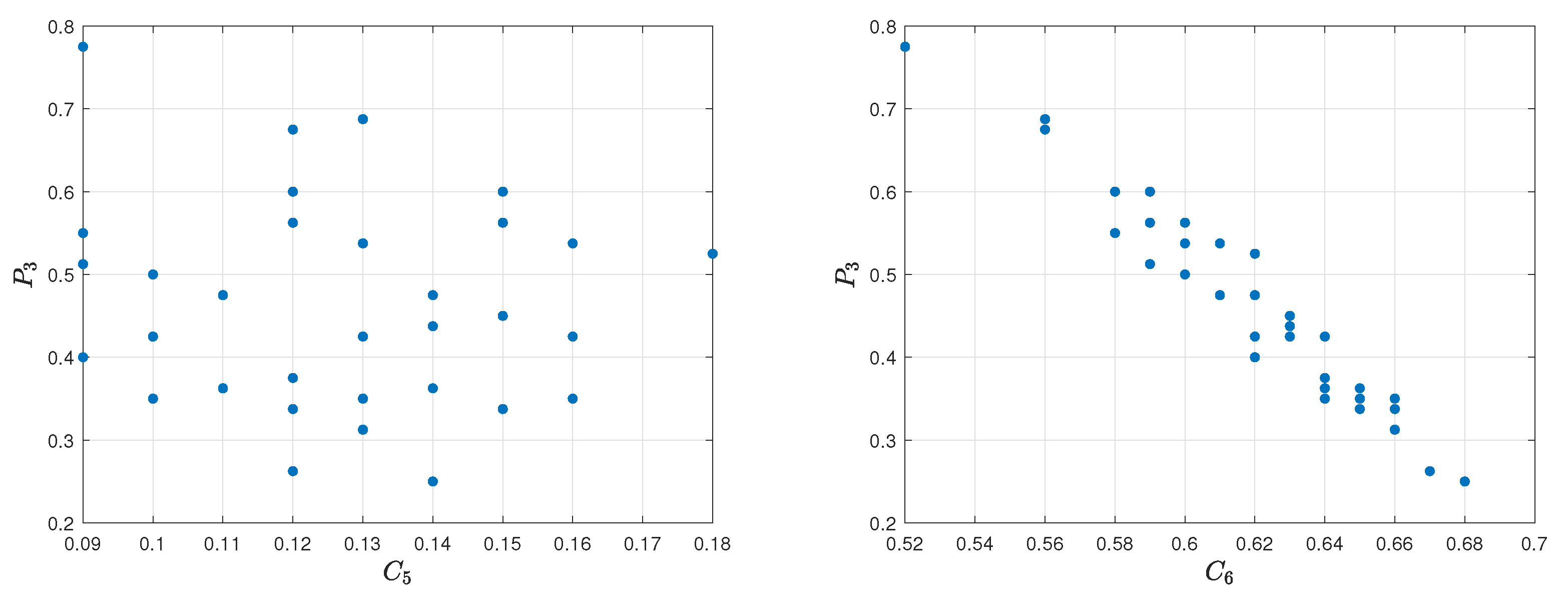
Table 12. For a better demonstration of the relevance of the criteria to the
assessment model, a
Spearman’s rank correlation coefficient was calculated.
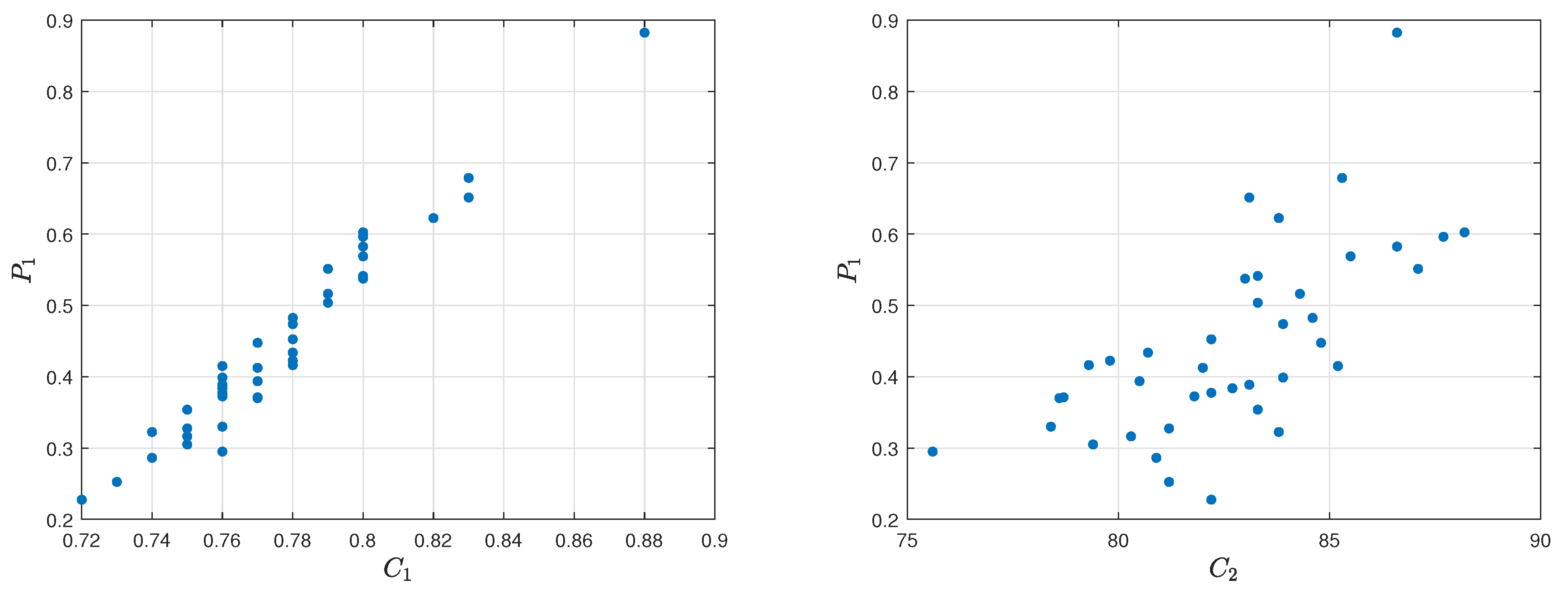
Spearman’s rank correlation coefficient between the criteria
,
and reference ranking obtained by
assessment model is equal to 0.6670 and 0.2420. The correlation between the first one is moderately strong, while, in the second one, it is weak. The visualization of the relation diagram of Average kills per round (
) and
assessment model, as well as the relation diagram of Average damage per round (
) and
assessment model, is presented in
Figure 22. The
and
models were analyzed, as well, and their results presented in an analogical way. The whole process can be found in
Appendix A.
The sample data for the top 40 players is shown in
Table 13. The final decision assessment model identified ‘
Simple’ as the best player at all with an excellent value equal to 0.7437, when the worst rating was given to ‘
BnTeT’, who received value equal to 0.1021. Analyzing the results of the three related models, we can conclude that the highest score in the first model
was obtained by ‘
Simple’ again, and is equal to 0.8825, while the lowest score received by
’NAF’ was only 0.2275. In the
and
models, the best outcome was acquired by ‘
Jame’ with the value 0.8423 as
and 0.7750 as
. The worst assessment in
was given to ‘
BnTeT’ with the value 0, and in the
model the lowest evaluation value was given to ‘
roeJ’ with the value 0.2500. The interesting fact is that ‘
ZywOo’, who placed the second position, even if he did not have the best score in any of the three models, was still better than Jame. ‘
ZywOo’ received a much better result in the first model and had a comparable score to ‘
Jame’ in the second model. Furthermore, ‘
huNter’ with the fourth result was close to beat ‘
Jame’ and take over his position. In comparison with ‘
Jame’, ‘
huNter’ had much higher assessment in
, getting average results at the rest of the models. It follows from this that the most critical models are
and
.
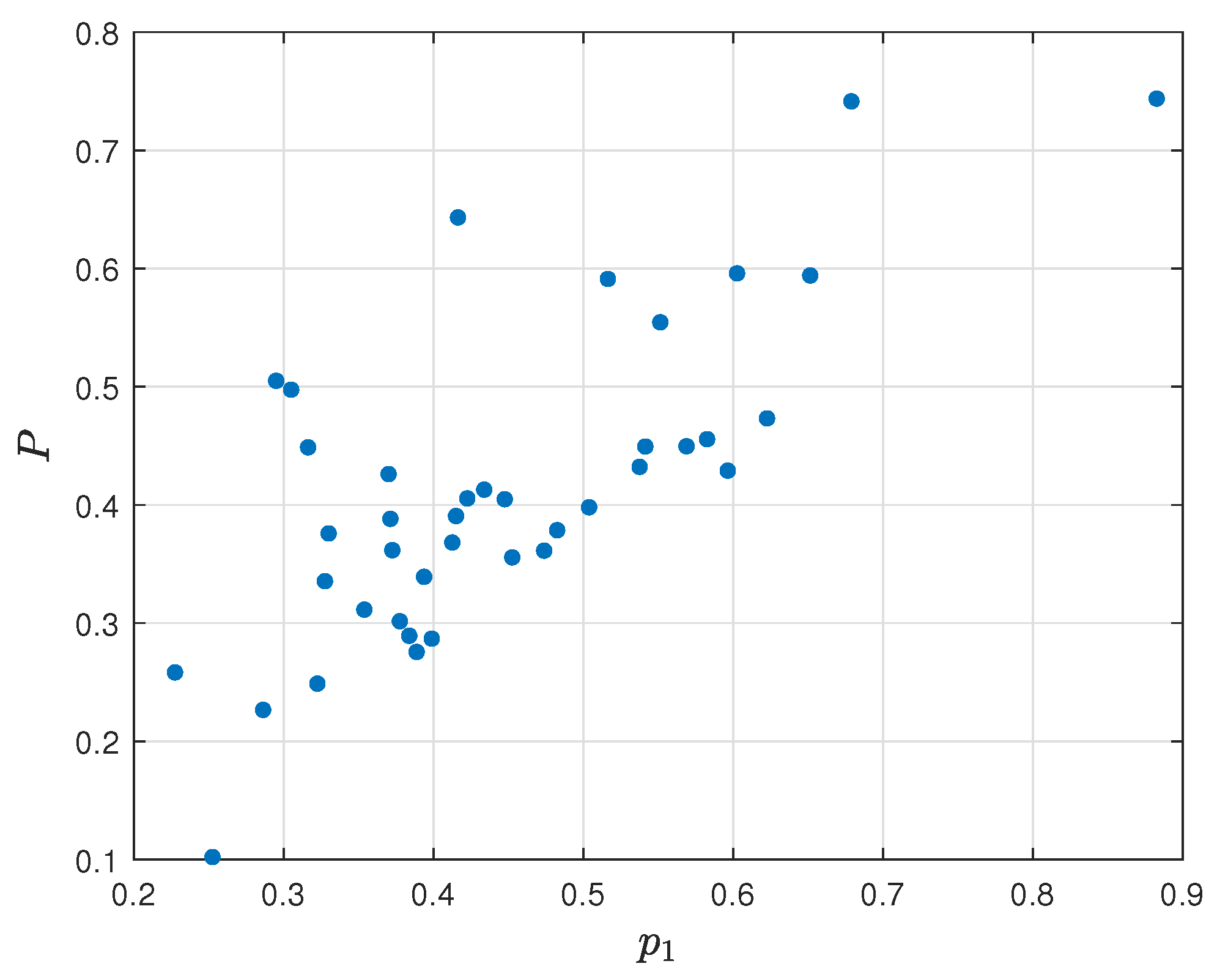
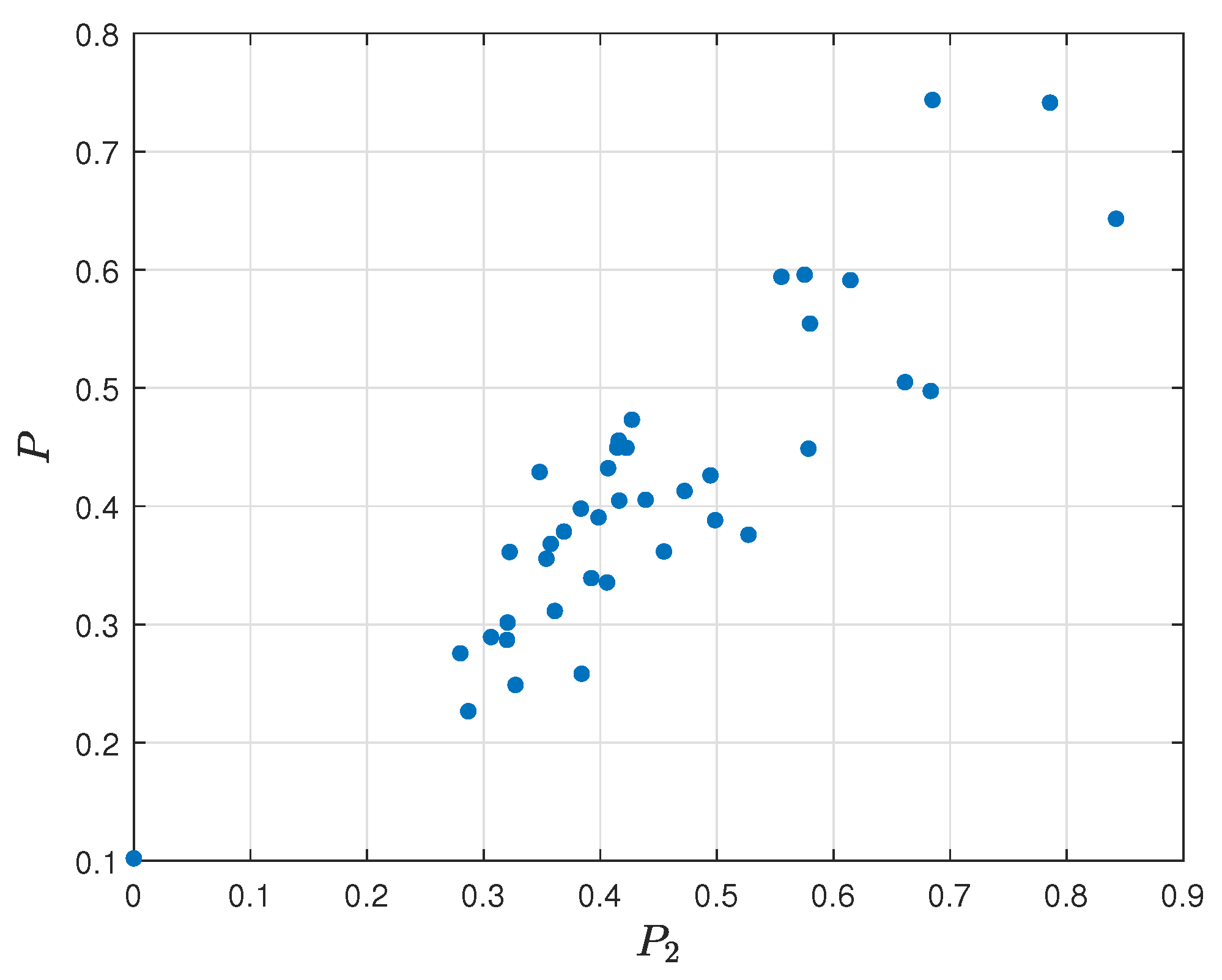
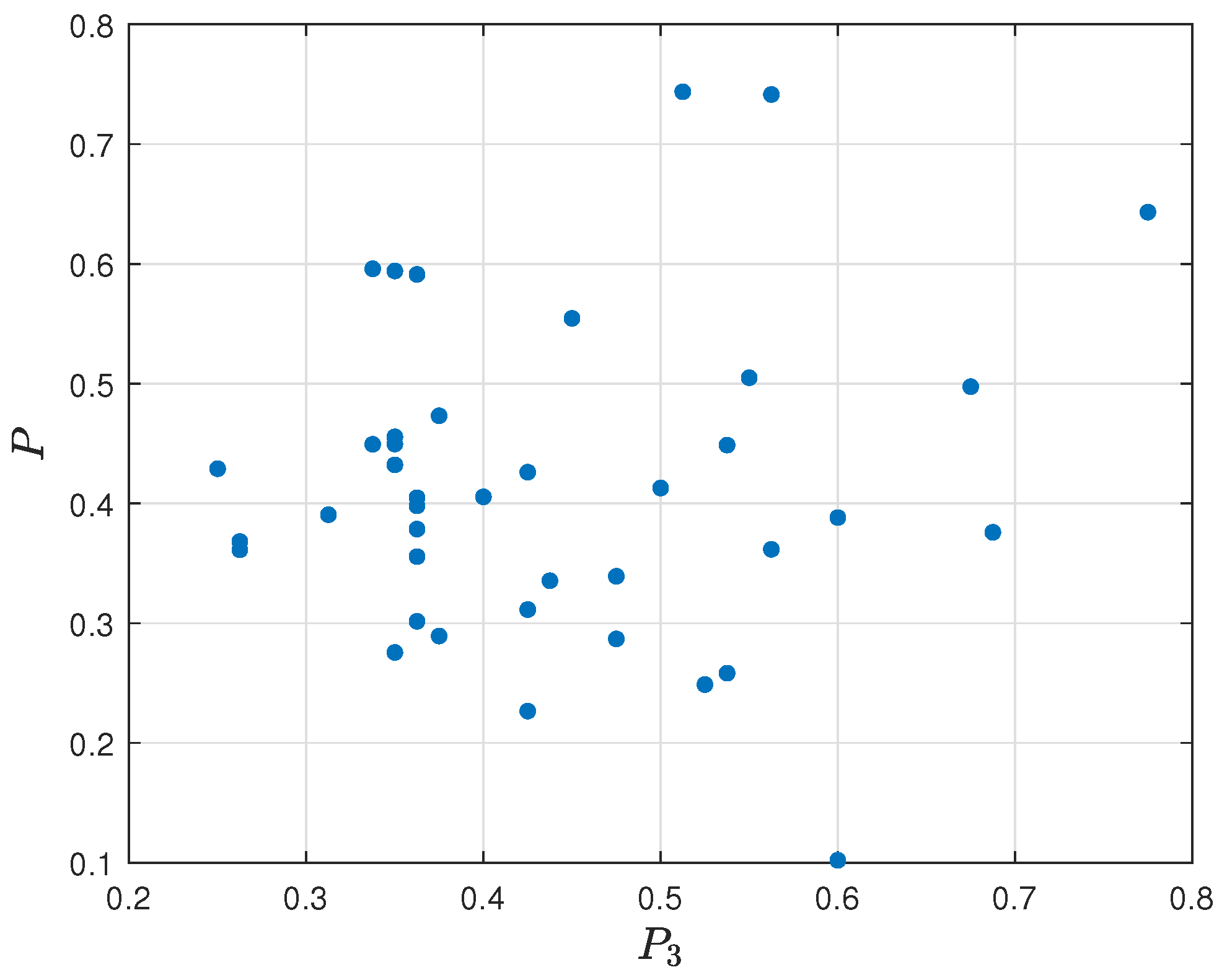
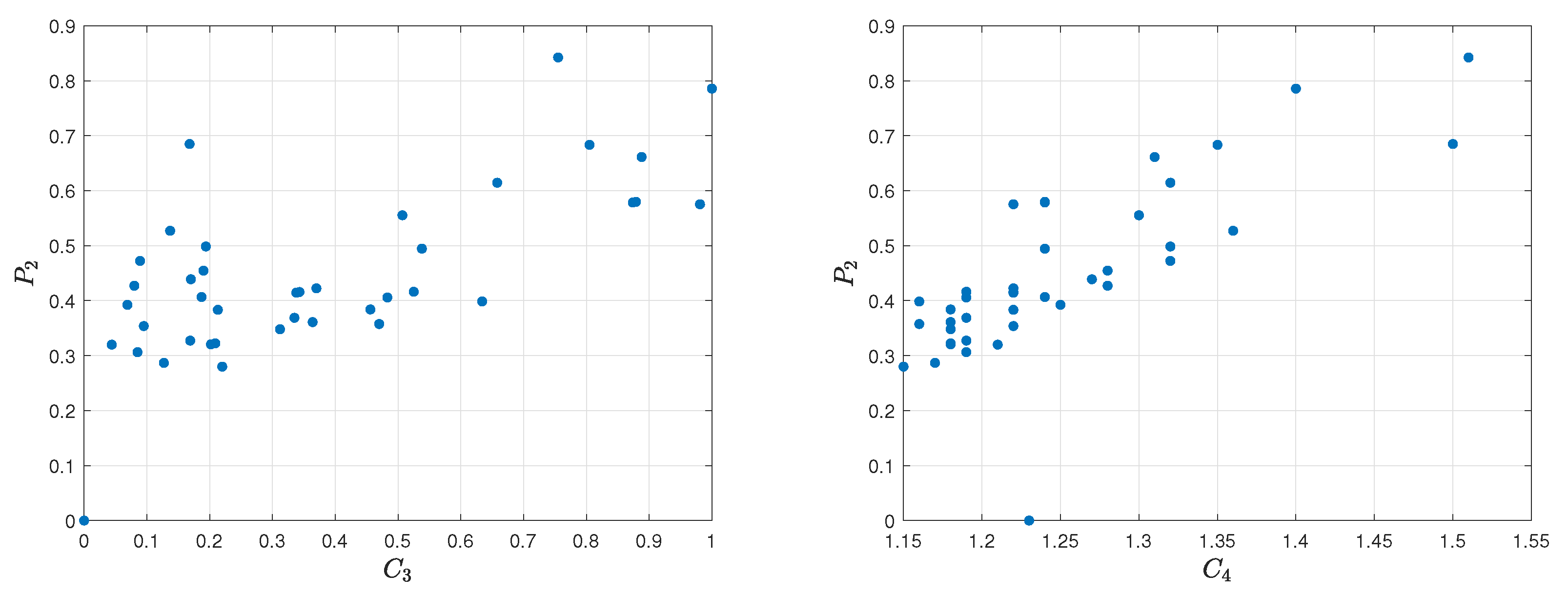
To show the relation of the obtained parameters with the final assessment model
P, a
Spearman’s rank correlation coefficient was calculated.
Spearman’s rank correlation coefficient between the
,
, and
model and final ranking
P is equal, respectively, to 0.5122, 0.6679, and 0.3182. The correlation between the first two models is moderately strong, and, in the case of the third model, the correlation is weak. The visualization of the relation diagram of effectiveness per round (
) and final assessment
P is shown in
Figure 23, the relation diagram of frag gaining (
) and final assessment
P is presented in
Figure 24, and the relation diagram of failures per round (
) and final assessment
P is presented in
Figure 25.
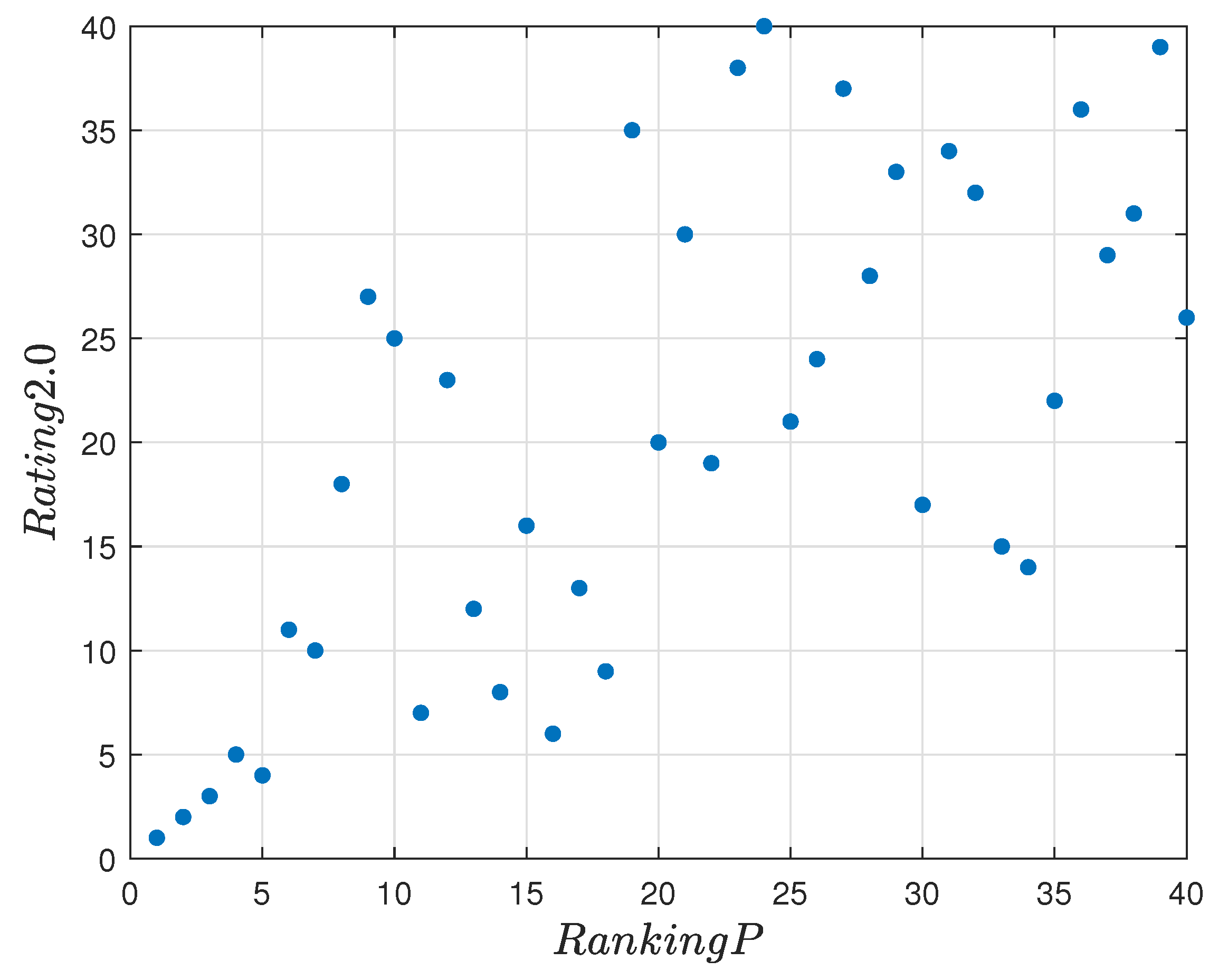
Spearman’s coefficient between the final model and reference ranking is equal to 0.5304, which means that both rankings are moderately correlated. The visualization of the relation diagram of final ranking
P and Rating 2.0 is presented in
Figure 26.
7. Conclusions
The objective of this work was an identification of the model to create a ranking of players in the popular e-sport game, i.e., Counter-Strike: Global Offensive (CS: GO), using the appropriate multi-criteria decision-making method. For verification purposes, the obtained ranking of players was compared to the existing ranking created by HLTV called Rating 2.0, which is the most prestigious for this game. It was decided to set a ranking for top 10 and, later, even for 40 players. The additional purpose of this paper is to familiarize people with the term of e-sport and to convince them that it is worthwhile and future-proof.
The main contribution of this work is a proposal of the CS: GO players assessment model with three related evaluation models. It was obligatory to choose the right method, build associated models for the players, and then to calculate the player’s assessments for their performances. Comet’s resistant to the rank reversal paradox is a significant feature. That’s not relevant which set of players will be applied, because each of them will always get the same value. The comparison of characteristic objects is easier than the players because the distance between them is bigger than the compared players. The identification of the CS: GO players assessment model additionally allows evaluating every set of players in the considered numerical space without involving the expert in the evaluation process again because the model is defined for a certain set of player characteristics. Another original feature of the COMET method is the employment of global criterion weights, which determine the average significance of a criterion for the final assessment. The linear weighting of non-linear problems reduces the accuracy of the results. That is the reason why the calculation procedure of this method has resigned from arbitrary weights for specific criteria. Therefore, the COMET method was chosen as the best approach to make an identification of the players’ assessment model.
The results demonstrate that the model could be utilized to evaluate the players and helps to generate the ranking and select the best CS: GO player. The positions of incorrectly classified players are quite close to each other. Spearman’s coefficient between the final model and reference ranking is equal to 0.5304, which means that both rankings are moderately correlated. Despite quite an average result, this ranking might be considered as sufficient, because the top positions of the classification are more fitted to reference ranking. The proposed structure of the assessment model satisfactorily defines the investigated relationships.
Further future work directions should concentrate on the improvement of model effectiveness. Perhaps adding a greater amount of input criteria, and thus increasing the number of related assessment models, could make the final ranking more reliable and appropriate to reflect some players real talent. Moreover, this should fix on the prospective empirical investigation for CS: GO game but also in other e-sport games.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



























