Toward Scalable Video Analytics Using Compressed-Domain Features at the Edge



Abstract
1. Introduction
- Introduction of a compressed-domain moving object detection method that can be applied in numerous surveillance applications.
- Design of an edge-to-cloud computing system for surveillance video analytics that applies the proposed method at edge devices to minimize the transfer of video data from surveillance camera feeds to the cloud.
- Implementation and evaluation of the proposed method with an edge-cloud system. The implementation is lightweight and easy to deploy at any edge devices.
2. Background
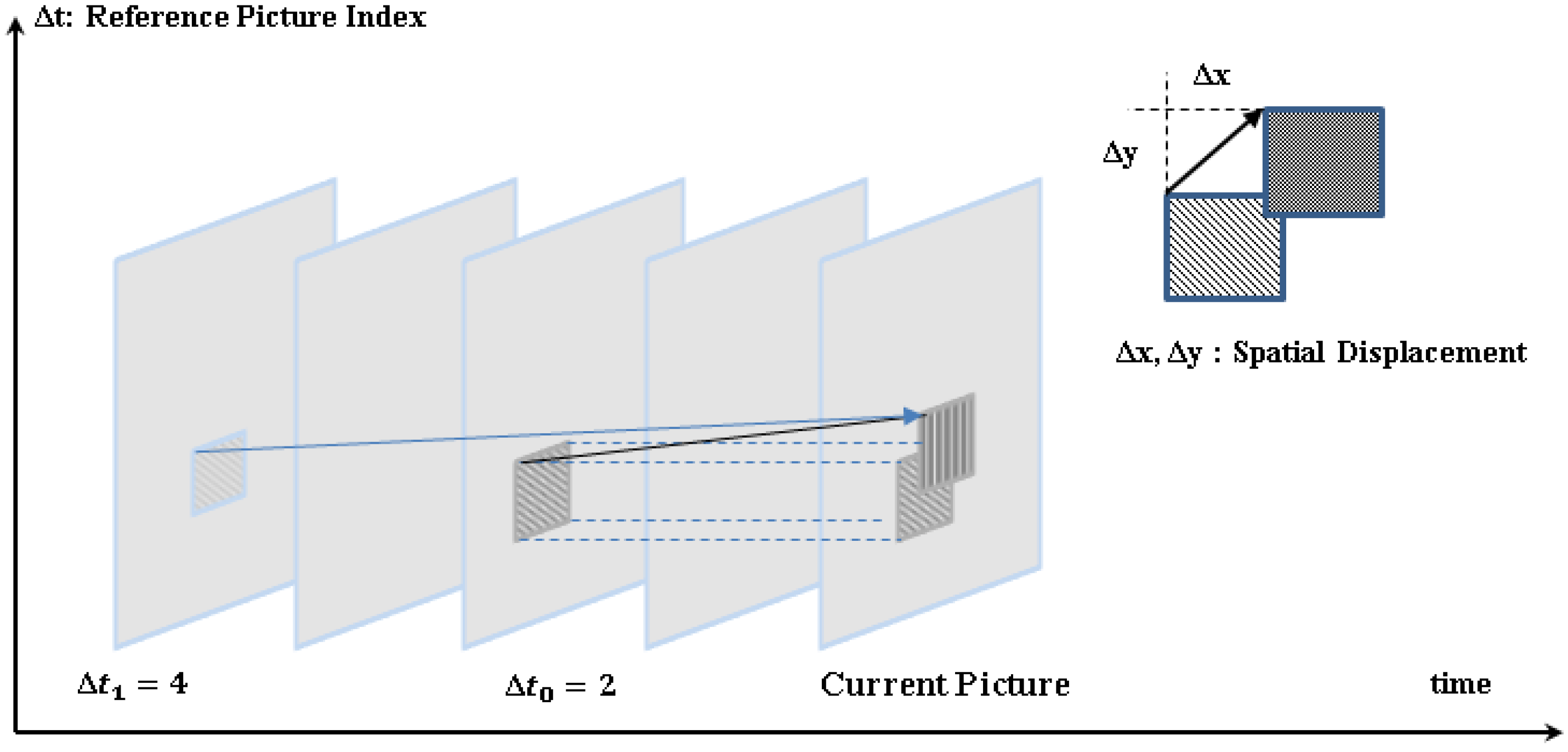
2.1. Compressed-Domain-Based Moving Object Detection
2.2. Pixel-Domain-Based Moving Object Detection
2.2.1. Hybrid Model of Background Subtraction and Object Classification-Based Moving Object Detection
2.2.2. Deep Learning-Based Moving Object Detection
- R-CNN, Fast R-CNN, Faster R-CNN
- You only look once (YOLO)
- Single shot detectors (SSDs)
3. Methodology
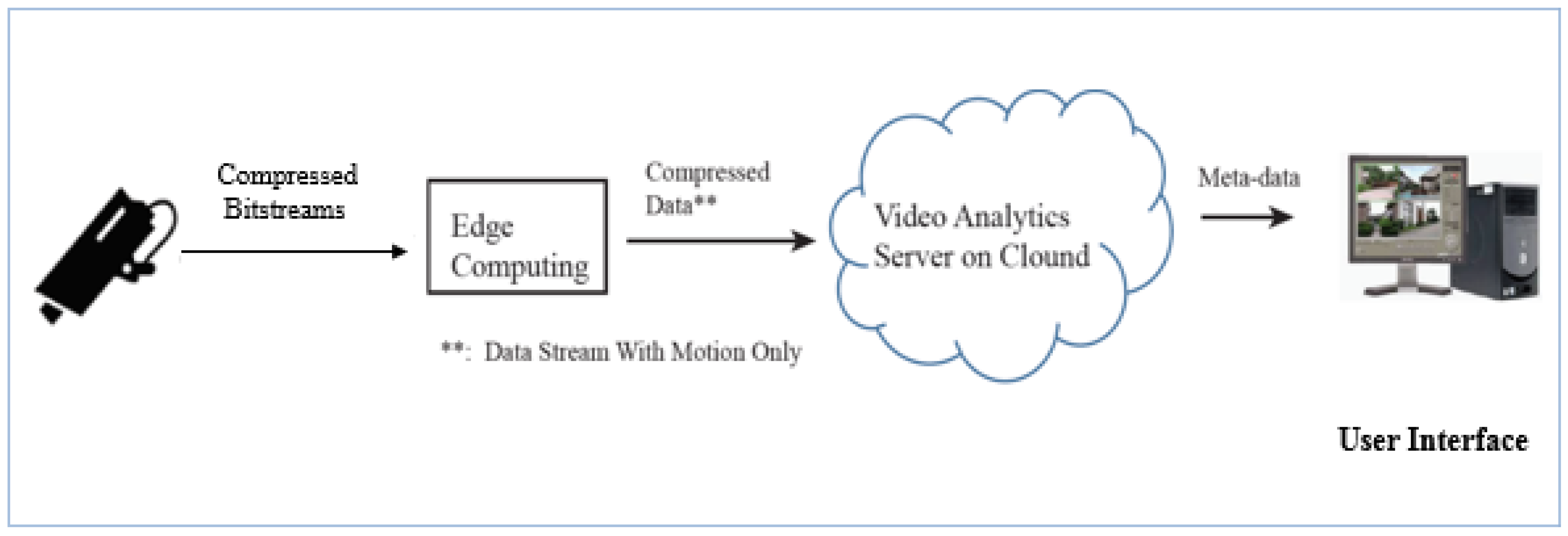
3.1. The Edge-to-Cloud System Model for Surveillance Camera-Based Applications
- Camera source node: The camera node periodically generates video tasks, divides each video task into a number of video chunks, compresses the video chunks at certain compression ratios, and then, assigns the compressed video chunks among all edge nodes as per scheduling policies.
- Edge node: The edge has computational ability and storage capacity and helps preprocess video chunks. Moreover, edge nodes can form cooperative groups based on the specific group formation policy and receive compressed video chunks as per the video load assignment policy.
- Cloud server: The cloud server collects the preprocessing results from edge nodes, which has abundant computational abilities, and performs additional video analysis.
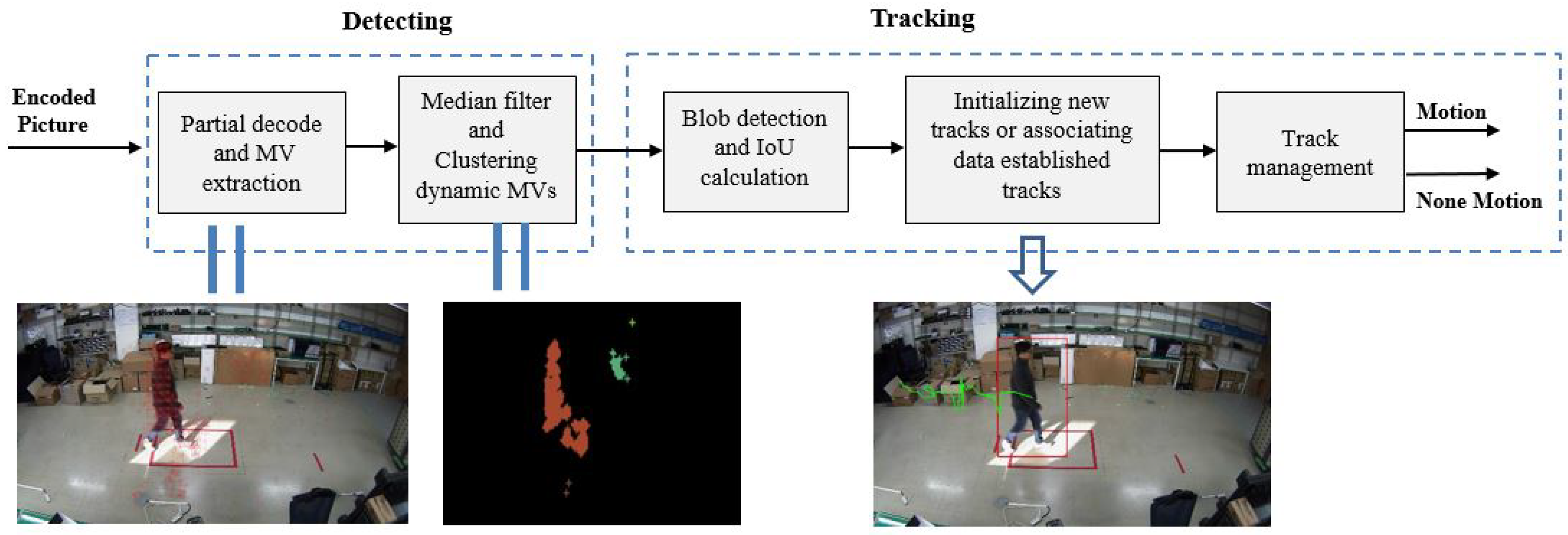
3.2. Light-Weight Runtime Moving Object Detection in the Video Compressed-Domain
3.2.1. Median Filter and Moving Object Detection
- For each , find all the neighboring points within spatial distance .
- Cluster all the MV points that are density reachable or density connecting [39] and label them.
- Terminate the process after all the MV points are checked. The output is a set of clusters of dynamic points.
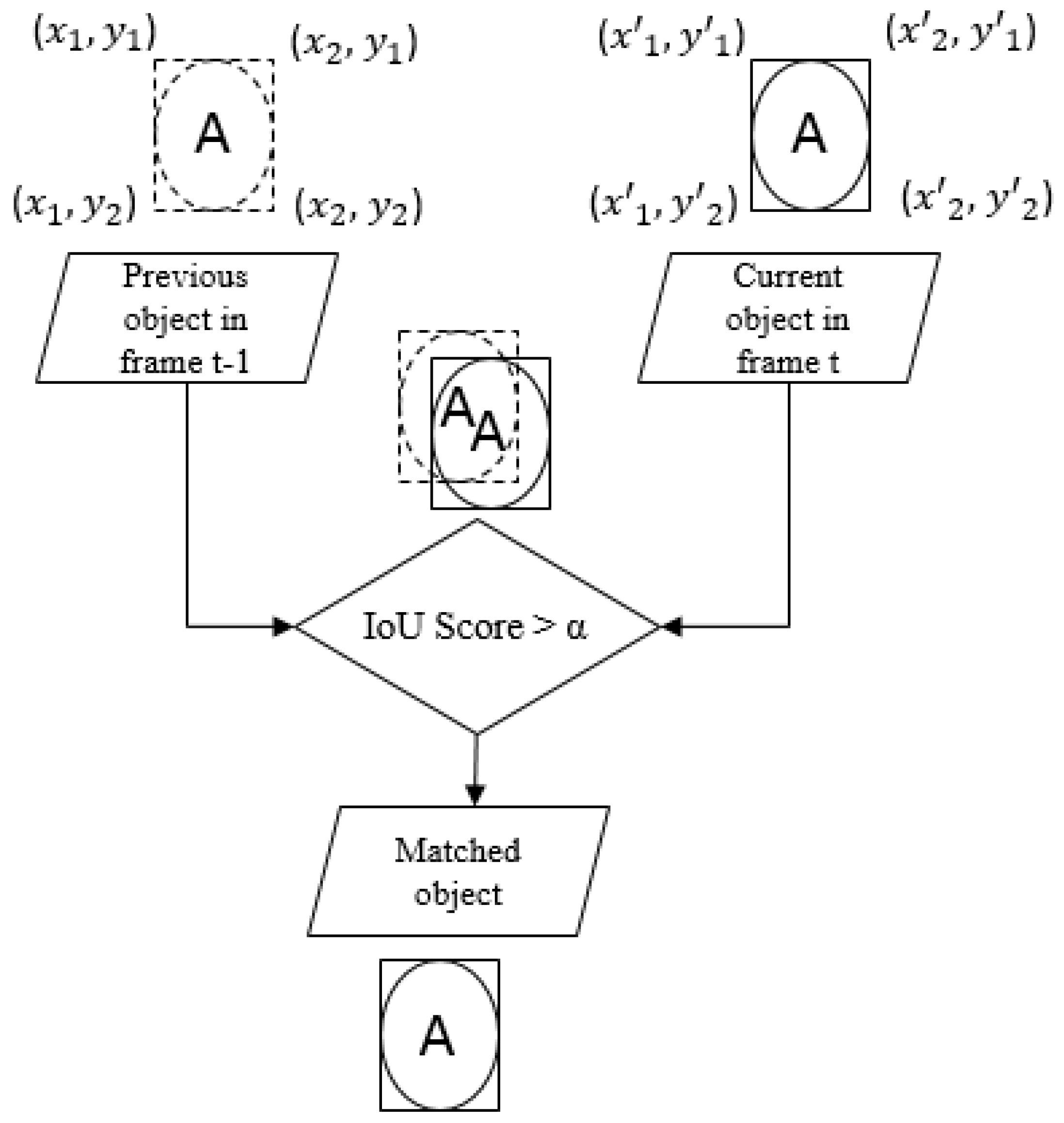
3.2.2. IoU-Based Moving Objects Tracking
| Algorithm 1 IoU for two bounding boxes. |
Data: Corners of the two bounding boxes. - First bounding box: - Second bounding box:
where . Calculation: IoU value - The area of the first bounding box: - The area of the second bounding box: - The area of overlap: - |
3.3. Performance Evaluation Model
4. Implementation and Performance Evaluation
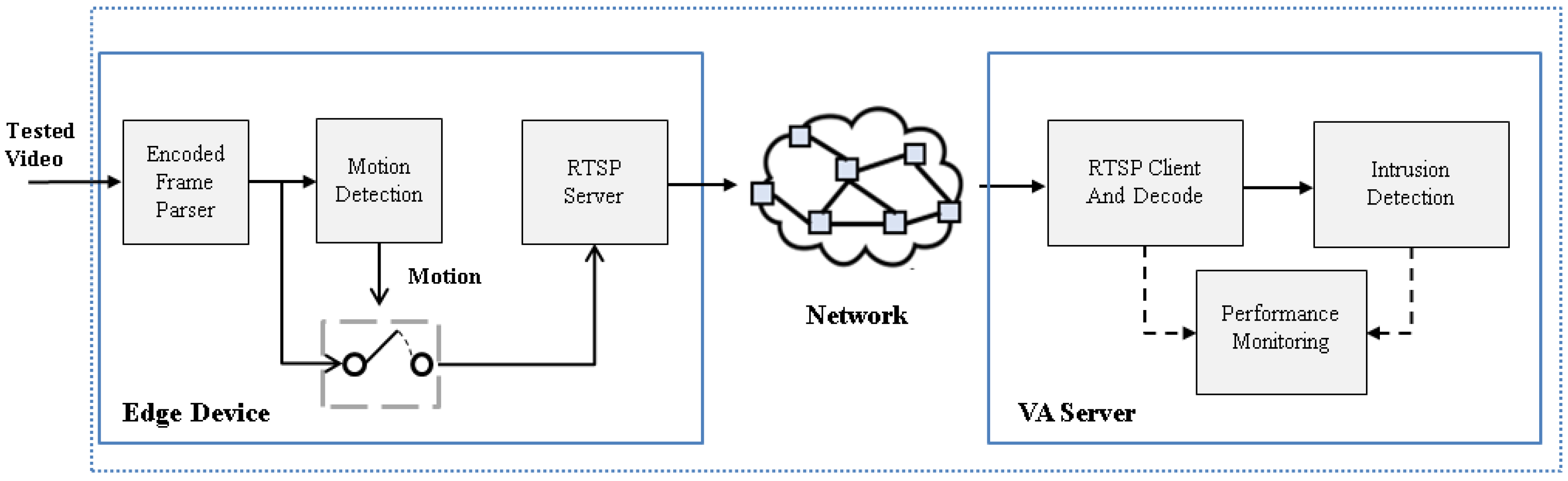
- Edge node implementation: The streaming data from the camera sources are parsed, and the proposed method is applied to detect moving objects in the current frame. If the encoded frame includes the motion, it will be forwarded to a cloud node using its own real-time streaming protocol (RTSP) server. To avoid decoding inaccuracies at the cloud node, all frames from the start time to the end time of the motion are continuously delivered in a connection session. Each session will start with an intra-coded frame.
- Cloud node implementation: receiving the forwarded encoded frame with the motion from the edge node over the network and then decoding and placing the output images into the intrusion detection module, which uses YOLO to detect humans.
4.1. Scenario Setup
- Testbed: We built a testbed comprised of a single edge device node and a single video analytics server that runs as a cloud node, as shown in Figure 12. The edge device node involves the moving object detection and runs on a low computation device called the Raspberry Pi 4, and the video analytics server is executed on NVIDIA Jetson Xavier because it is a GPU that supports running YOLO. The hardware specifications of the edge node and video analytics server are listed in Table 1. Note that the two devices are directly connected to a router using a wired cable.
- Video test sequence: Experiments were conducted on the two video datasets. The VIRAT video dataset [42] was collected in natural scenes showing people performing normal actions for video surveillance domains. The second dataset was previously recorded from our surveillance camera and uploaded [43]. The details of our video test sequence and the ground-truth motion time are listed in Table 2 and Table 3.
4.2. Light-weight Runtime Moving Object Detection in the Video Compressed-Domain
4.3. Performance Evaluation Results
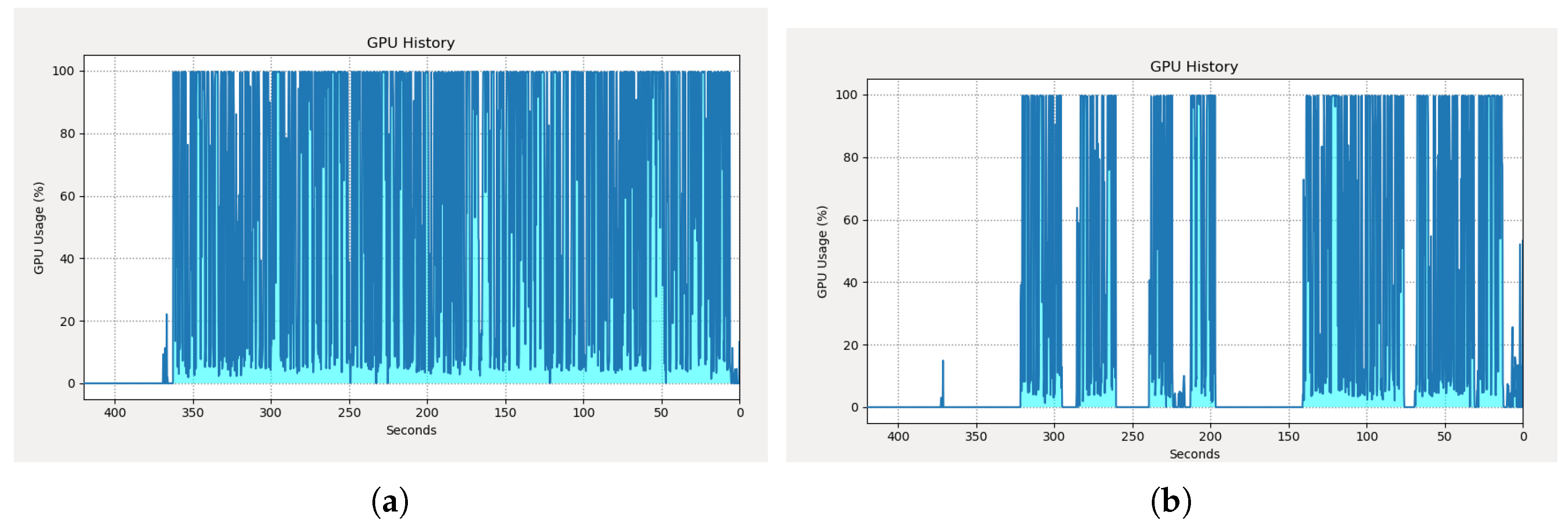
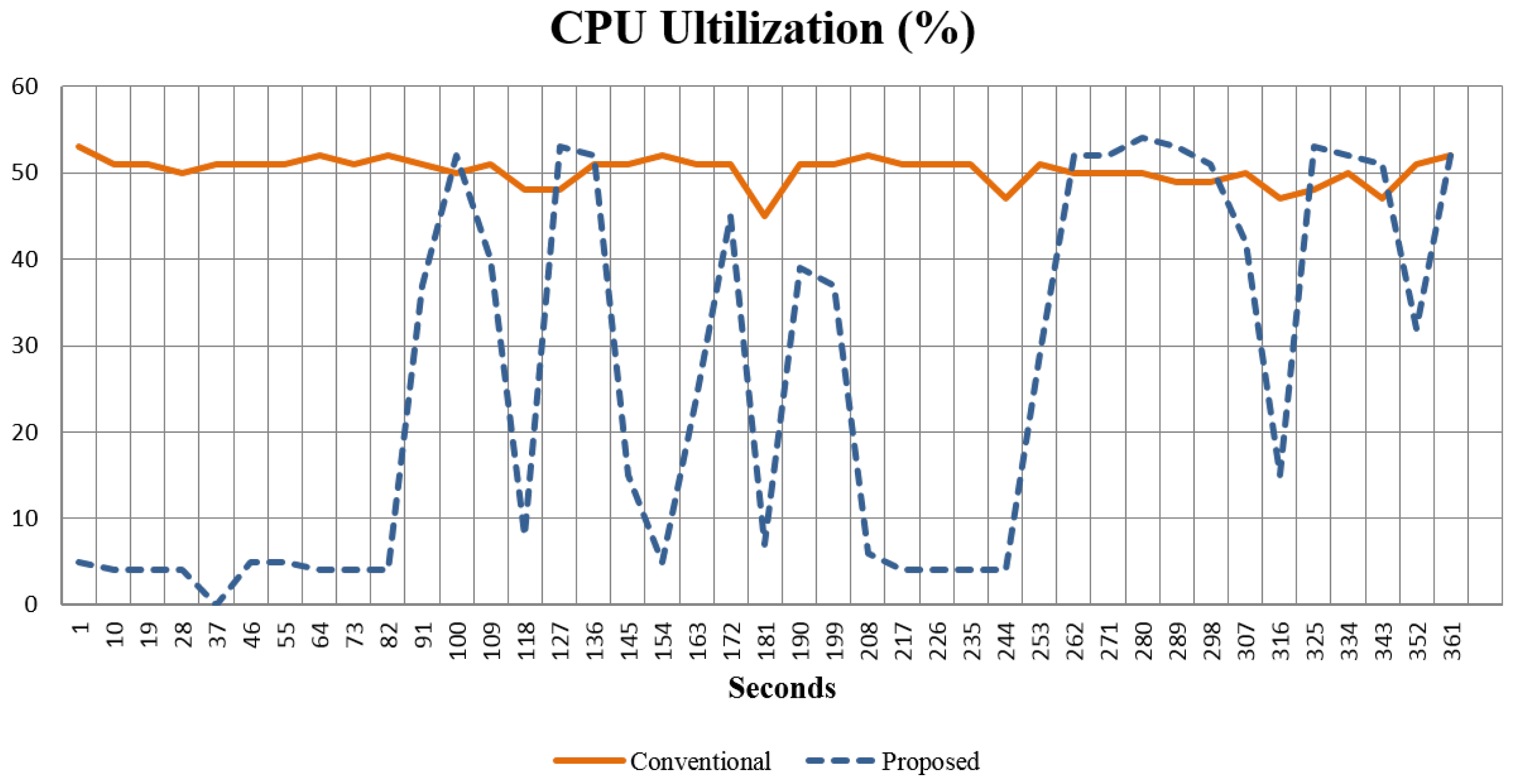
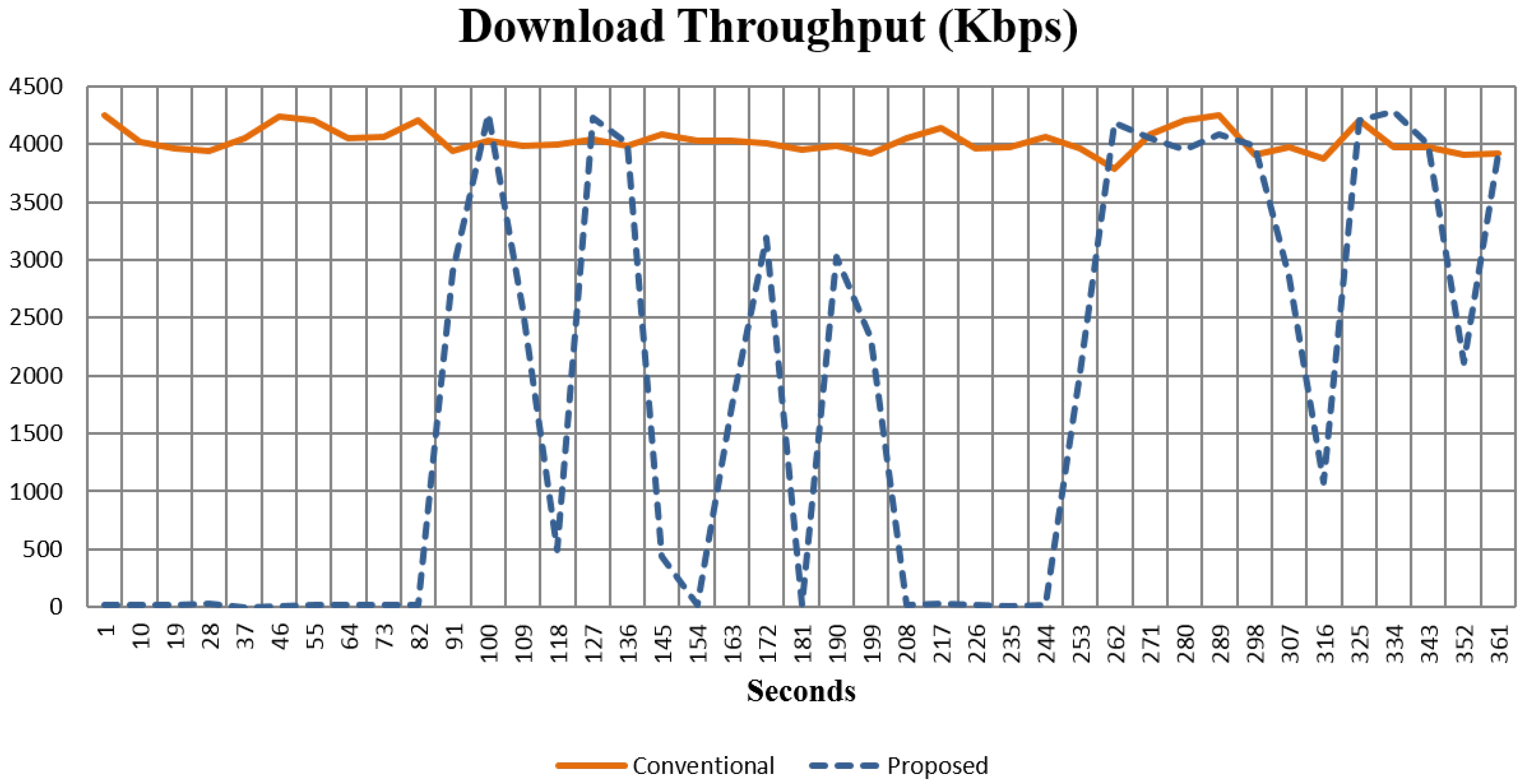
Computing Resource Consumption
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ananthanarayanan, G.; Bahl, V.; Cox, L.; Crown, A.; Nogbahi, S.; Shu, Y. Demo: Video Analytics-Killer App for Edge Computing. In ACM MobiSys; Association for Computing Machinery: Seoul, Korea, 2019. [Google Scholar]
- Philippou, O. Video Surveillance Installed Base Report—2019. 2020. Available online: https://technology.informa.com/607069/video-surveillance-installed-base-report-2019 (accessed on 3 September 2020).
- Stone, T.; Stone, N.; Jain, P.; Jiang, Y.; Kim, K.H.; Nelakuditi, S. Towards Scalable Video Analytics at the Edge. In Proceedings of the 2019 16th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), Boston, MA, USA, 10–13 June 2019; pp. 1–9. [Google Scholar]
- Lu, X.; Izumi, T.; Takahashi, T.; Wang, L. Moving vehicle detection based on fuzzy background subtraction. In Proceedings of the 2014 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Beijing, China, 20–24 August 2014; pp. 529–532. [Google Scholar]
- Kumar, S.; Yadav, J.S. Segmentation of moving objects using background subtraction method in complex environments. Radioengineering 2016, 25, 399–408. [Google Scholar] [CrossRef]
- Gujrathi, P.; Priya, R.A.; Malathi, P. Detecting moving object using background subtraction algorithm in FPGA. In Proceedings of the IEEE 2014 Fourth International Conference on Advances in Computing and Communications, Kerala, India, 27–29 August 2014; pp. 117–120. [Google Scholar]
- Wang, Z.; Sun, X.; Diao, W.; Zhang, Y.; Yan, M.; Lan, L. Ground moving target indication based on optical flow in single-channel SAR. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1051–1055. [Google Scholar] [CrossRef]
- Favalli, L.; Mecocci, A.; Moschetti, F. Object tracking for retrieval applications in MPEG-2. IEEE Trans. Circuits Syst. Video Technol. 2000, 10, 427–432. [Google Scholar] [CrossRef]
- Yoneyama, A.; Nakajima, Y.; Yanagihara, H.; Sugano, M. Moving object detection and identification from MPEG coded data. In Proceedings of the IEEE 1999 International Conference on Image Processing (Cat. 99CH36348), Piscataway, NJ, USA, 24–28 October 1999; Volume 2, pp. 934–938. [Google Scholar]
- Dong, L.; Zoghlami, I.; Schwartz, S.C. Object tracking in compressed video with confidence measures. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006; pp. 753–756. [Google Scholar]
- Achanta, R.; Kankanhalli, M.; Mulhem, P. Compressed domain object tracking for automatic indexing of objects in MPEG home video. In Proceedings of the IEEE International Conference on Multimedia and Expo, Lausanne, Switzerland, 26–29 August 2002; Volume 2, pp. 61–64. [Google Scholar]
- Laroche, G.; Jung, J.; Pesquet-Popescu, B. RD optimized coding for motion vector predictor selection. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1247–1257. [Google Scholar] [CrossRef]
- Jiang, X.; Song, T.; Katayama, T.; Leu, J.S. Spatial Correlation-Based Motion-Vector Prediction for Video-Coding Efficiency Improvement. Symmetry 2019, 11, 129. [Google Scholar] [CrossRef]
- Bross, B.; Helle, P.; Lakshman, H.; Ugur, K. Inter-picture prediction in HEVC. In High Efficiency Video Coding (HEVC); Springer: Berlin/Heidelberg, Germany, 2014; pp. 113–140. [Google Scholar]
- Bombardelli, F.; Gül, S.; Becker, D.; Schmidt, M.; Hellge, C. Efficient Object Tracking in Compressed Video Streams with Graph Cuts. In Proceedings of the 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), Vancouver, BC, Canada, 29–31 August 2018; pp. 1–6. [Google Scholar]
- Khatoonabadi, S.H.; Bajic, I.V. Video object tracking in the compressed domain using spatio-temporal Markov random fields. IEEE Trans. Image Process. 2012, 22, 300–313. [Google Scholar] [CrossRef] [PubMed]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef]
- Zeng, D.; Zhu, M. Background subtraction using multiscale fully convolutional network. IEEE Access 2018, 6, 16010–16021. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, J.; Zhu, B.; Tang, M.; Lu, H. Pixel-wise deep sequence learning for moving object detection. IEEE Trans. Circuits Syst. Video Technol. 2017, 29, 2567–2579. [Google Scholar] [CrossRef]
- Babaee, M.; Dinh, D.T.; Rigoll, G. A deep convolutional neural network for video sequence background subtraction. Pattern Recognit. 2018, 76, 635–649. [Google Scholar] [CrossRef]
- Wang, Y.; Luo, Z.; Jodoin, P.M. Interactive deep learning method for segmenting moving objects. Pattern Recognit. Lett. 2017, 96, 66–75. [Google Scholar] [CrossRef]
- Patil, P.W.; Murala, S. Msfgnet: A novel compact end-to-end deep network for moving object detection. IEEE Trans. Intell. Transp. Syst. 2018, 20, 4066–4077. [Google Scholar] [CrossRef]
- Ou, X.; Yan, P.; Zhang, Y.; Tu, B.; Zhang, G.; Wu, J.; Li, W. Moving object detection method via ResNet-18 with encoder–decoder structure in complex scenes. IEEE Access 2019, 7, 108152–108160. [Google Scholar] [CrossRef]
- Lee, J.; Park, M. An adaptive background subtraction method based on kernel density estimation. Sensors 2012, 12, 12279–12300. [Google Scholar] [CrossRef]
- Stauffer, C.; Grimson, W.E.L. Adaptive background mixture models for real-time tracking. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), Collins, CO, USA, 23–25 June 1999; Volume 2, pp. 246–252. [Google Scholar]
- Lu, N.; Wang, J.; Wu, Q.; Yang, L. An Improved Motion Detection Method for Real-Time Surveillance. IAENG Int. J. Comput. Sci. 2008, 35, 1. [Google Scholar]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar]
- Jarrett, K.; Kavukcuoglu, K.; Ranzato, M.A.; LeCun, Y. What is the best multi-stage architecture for object recognition? In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; pp. 2146–2153. [Google Scholar]
- Lee, H.; Grosse, R.; Ranganath, R.; Ng, A.Y. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Proceedings of the ACM 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 609–616. [Google Scholar]
- Hussain, M.; Bird, J.J.; Faria, D.R. A Study on CNN Transfer Learning for Image Classification. In UK Workshop on Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2018; pp. 191–202. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; Citeseer: College Park, MD, USA, 2009. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; IEEE: Hoboken, NJ, USA, 2015; Volume 39, pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv, 2018; arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. Kdd 1996, 96, 226–231. [Google Scholar]
- Sheu, R.K.; Pardeshi, M.; Chen, L.C.; Yuan, S.M. STAM-CCF: Suspicious Tracking Across Multiple Camera Based on Correlation Filters. Sensors 2019, 19, 3016. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Xing, Q.; Ma, Z. HKSiamFC: Visual-Tracking Framework Using Prior Information Provided by Staple and Kalman Filter. Sensors 2020, 20, 2137. [Google Scholar] [CrossRef] [PubMed]
- The VIRAT Video Dataset. Available online: https://viratdata.org (accessed on 3 September 2020).
- Recorded Video Test Sequence. Available online: https://youtu.be/v24ldT1AGRw (accessed on 3 September 2020).
- Motion Vector Extraction Source Code. Available online: https://github.com/diennv/MotionVectorAnalysis (accessed on 3 September 2020).
- The Conventional Method. Available online: https://www.youtube.com/watch?v=Cz_zxr_ElTU (accessed on 3 September 2020).
- The Proposed Method. Available online: https://www.youtube.com/watch?v=-fRc36HAduI&feature=youtu.b (accessed on 3 September 2020).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specifications | Edge Device | Video Analytics Server |
|---|---|---|
| Device Name | Raspberry Pi 4 | NVIDIA Jetson Xavier |
| Operating System | Ubuntu 18.04, 64 bits | Ubuntu 18.04, 64 bits |
| GPU | Not supported | NVIDIA Maxwell architecture with NVIDIA CUDA cores |
| CPU | Quad-core ARM Cortext-A72 | Quad-core ARM Cortext-A57 MPCore processor |
| RAM | 4 GB | 8 GB |
| Tested Video Information | |
|---|---|
| Resolution | 1920 × 1080 |
| Length | 6 min |
| Codec | H264 |
| Group of picture (GOP) | 30 |
| Frame rate | 25 |
| Time | Duration (Seconds) |
|---|---|
| 00:00:50 00:01:10 | 20 |
| 00:01:25 00:01:45 | 20 |
| 00:02:12 00:01:10 | 5 |
| 00:02:39 00:02:45 | 6 |
| 00:03:50 00:04:48 | 58 |
| 00:05:00 00:05:35 | 35 |
| 00:05:40 00:06:00 | 20 |
| Total | 164 |
| Video Test Sequence | Scenario | IoU Average | |
|---|---|---|---|
| Camera Position | Moving Speed | ||
| Our recorded test video | Near | Normal | 0.75 |
| Our recorded test video | Near | Fast | 0.26 |
| Video test from VIRAT | Far | Normal | 0.6 |
| Frame Size | ST-MRF[16] | Graph Cuts[15] | Proposed Method |
|---|---|---|---|
| 1280 × 720 | 64 ms (16 FPS) | 62 ms (17 FPS) | 39 ms (26 FPS) |
| 1920 × 1080 | N/A | N/A | 69 ms (14 FPS) |
| Computing Resources | Conventional Method | Proposed Method | Performance Ratio |
|---|---|---|---|
| GPU Utilization (%) | 65.61 | 33.73 | 0.51 |
| CPU Utilization (%) | 50.24 | 25.9 | 0.51 |
| Download Throughput (Kbps) | 4028 | 1808.2 | 0.45 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, D.V.; Choi, J. Toward Scalable Video Analytics Using Compressed-Domain Features at the Edge. Appl. Sci. 2020, 10, 6391. https://doi.org/10.3390/app10186391
Nguyen DV, Choi J. Toward Scalable Video Analytics Using Compressed-Domain Features at the Edge. Applied Sciences. 2020; 10(18):6391. https://doi.org/10.3390/app10186391
Chicago/Turabian StyleNguyen, Dien Van, and Jaehyuk Choi. 2020. "Toward Scalable Video Analytics Using Compressed-Domain Features at the Edge" Applied Sciences 10, no. 18: 6391. https://doi.org/10.3390/app10186391
APA StyleNguyen, D. V., & Choi, J. (2020). Toward Scalable Video Analytics Using Compressed-Domain Features at the Edge. Applied Sciences, 10(18), 6391. https://doi.org/10.3390/app10186391