Remote Sensing Scene Classification and Explanation Using RSSCNet and LIME



Abstract
1. Introduction
- In order to reduce model overfitting and to obtain models with a high generalization capability, we recommend a new CNN (convolutional neutral networks) architecture, i.e., RSSCNet (remote sensing scene classification network), integrated with the simultaneous use of a two-stage cyclical learning-rate training policy and the no-freezing transfer learning technology that requires only a small number of iterations. In this way, an excellent level of accuracy can be obtained.
- By using the LIME (local interpretable model, agnostic explanation) super-pixel explanation, the root causes of model classification errors were made clearer and a further understanding was obtained. After the image correction preprocessing on the misclassified cases in the WHU-RS19 [18] dataset, this correction procedure was found to improve the overall classification accuracy. We hope that readers can better understand the reasoning mechanism of AI models for remote sensing scene classification.
2. Datasets
2.1. UC Merced Land-Use Dataset
2.2. RSSCN7 Dataset
2.3. WHU-RS19 Dataset
3. Method
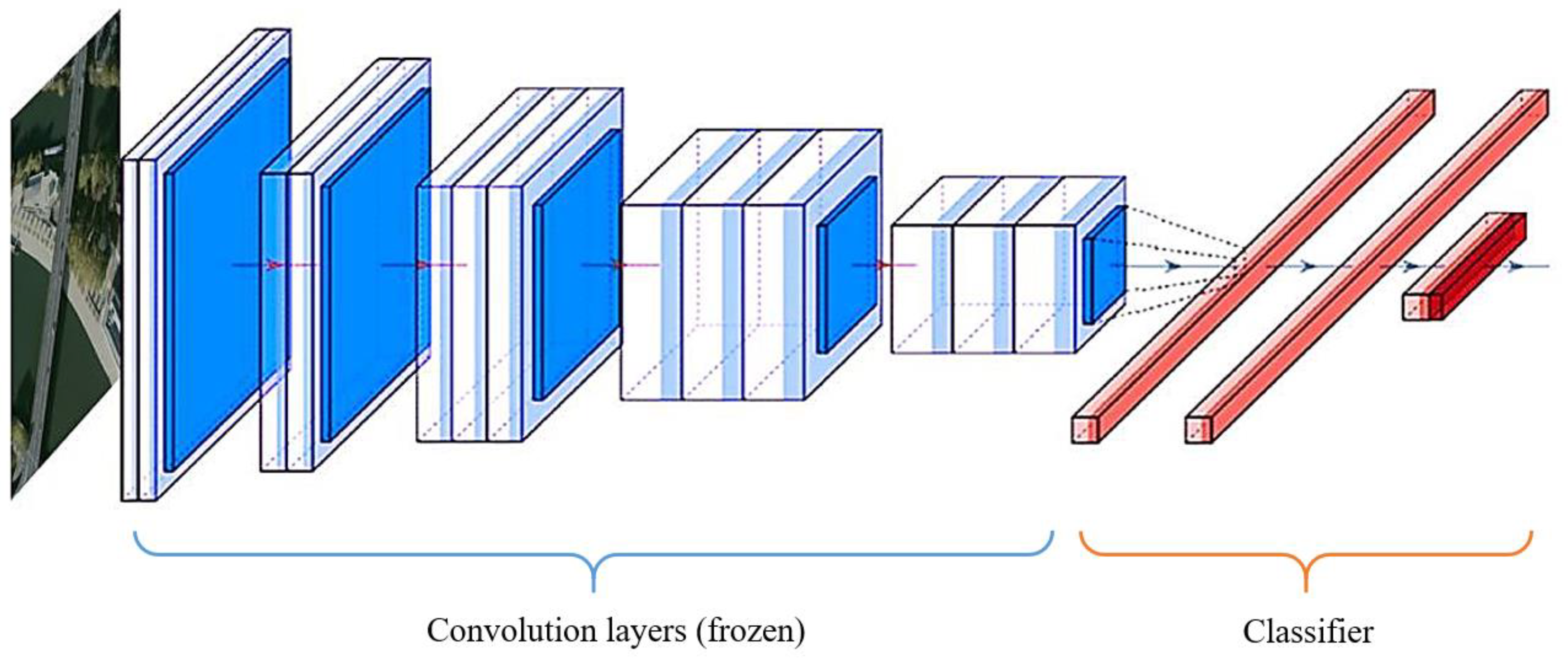
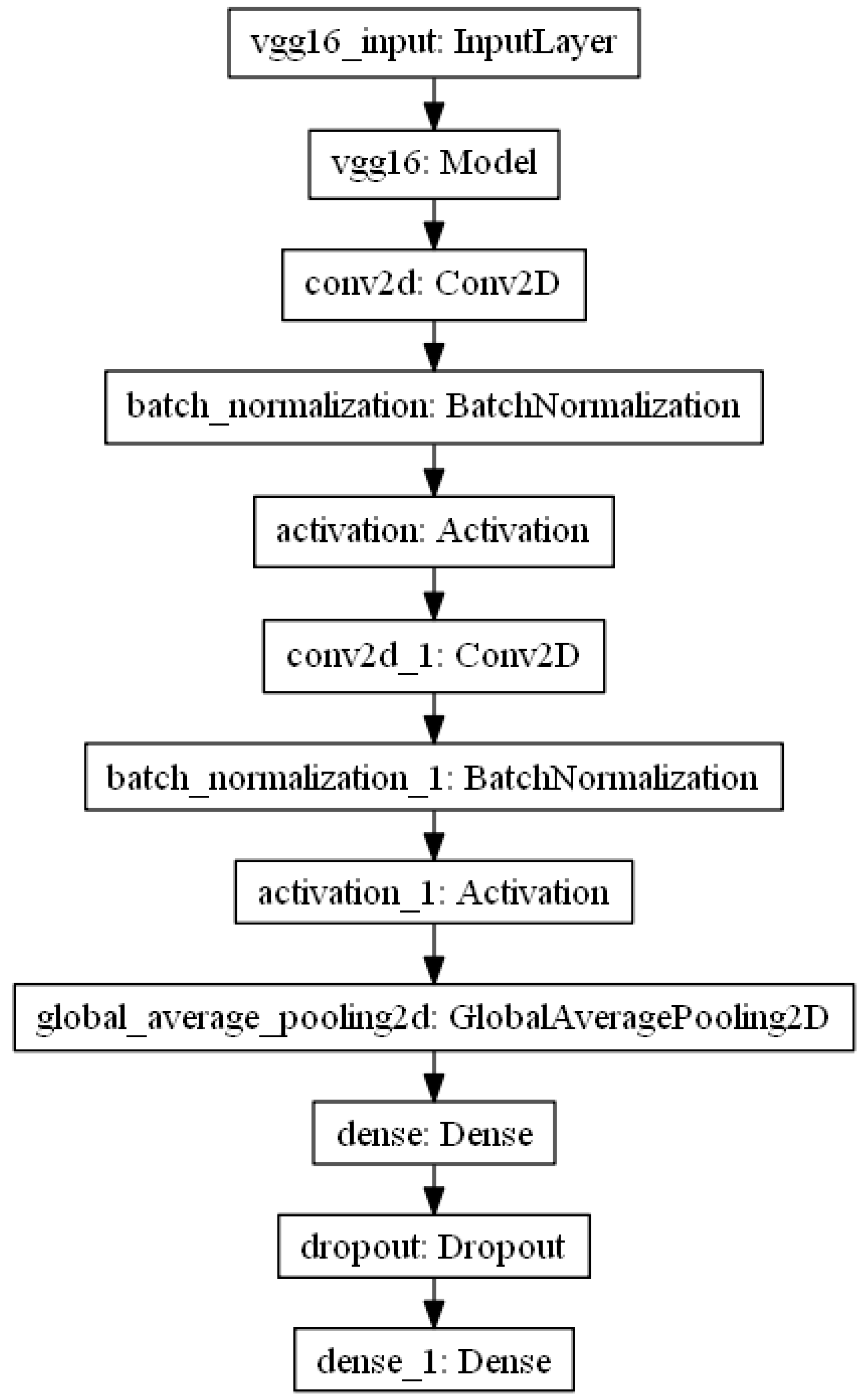
3.1. Convolutional Neural Network Model
3.2. Image Data Augmentation
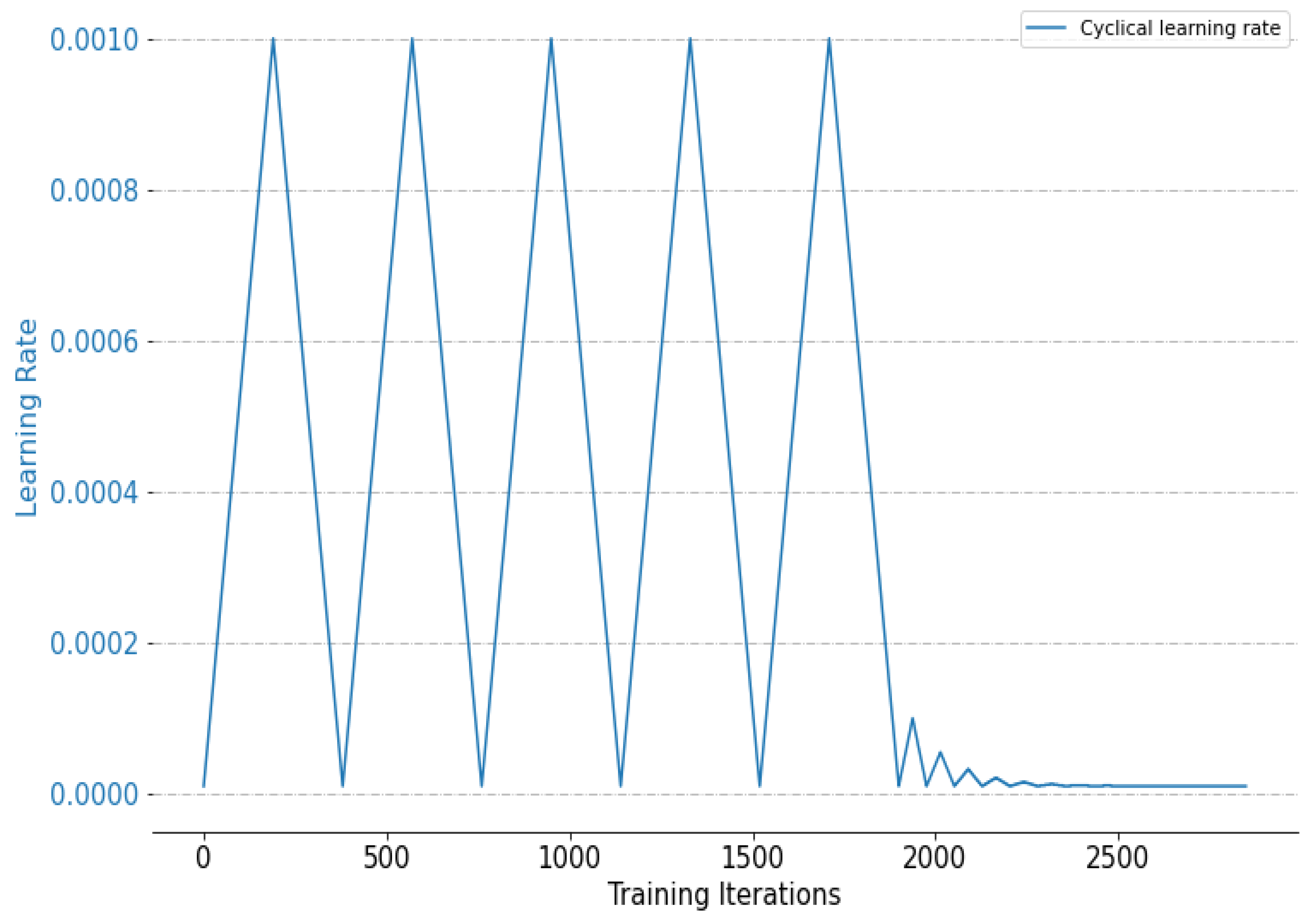
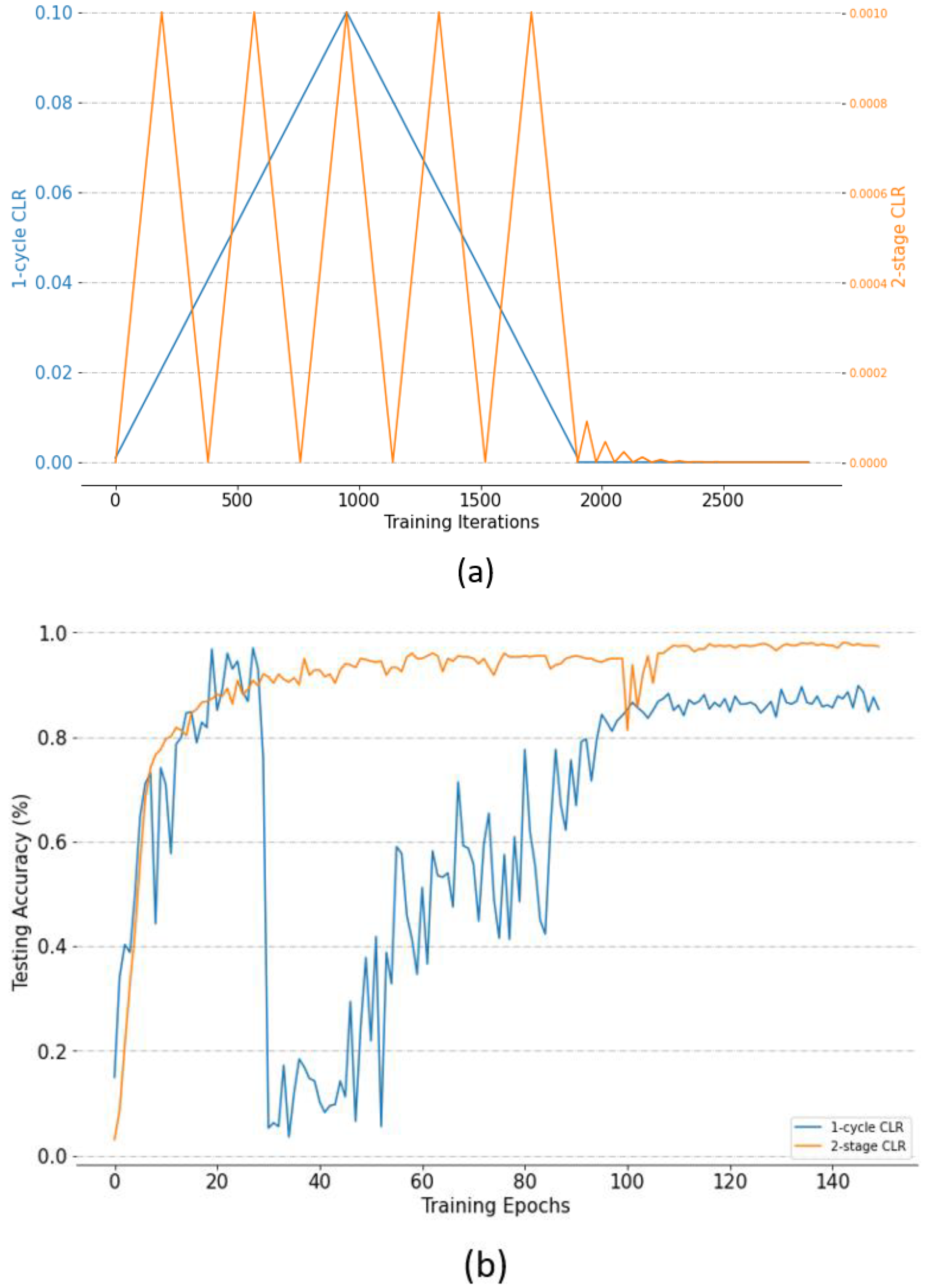
3.3. Cyclical Learning Rate
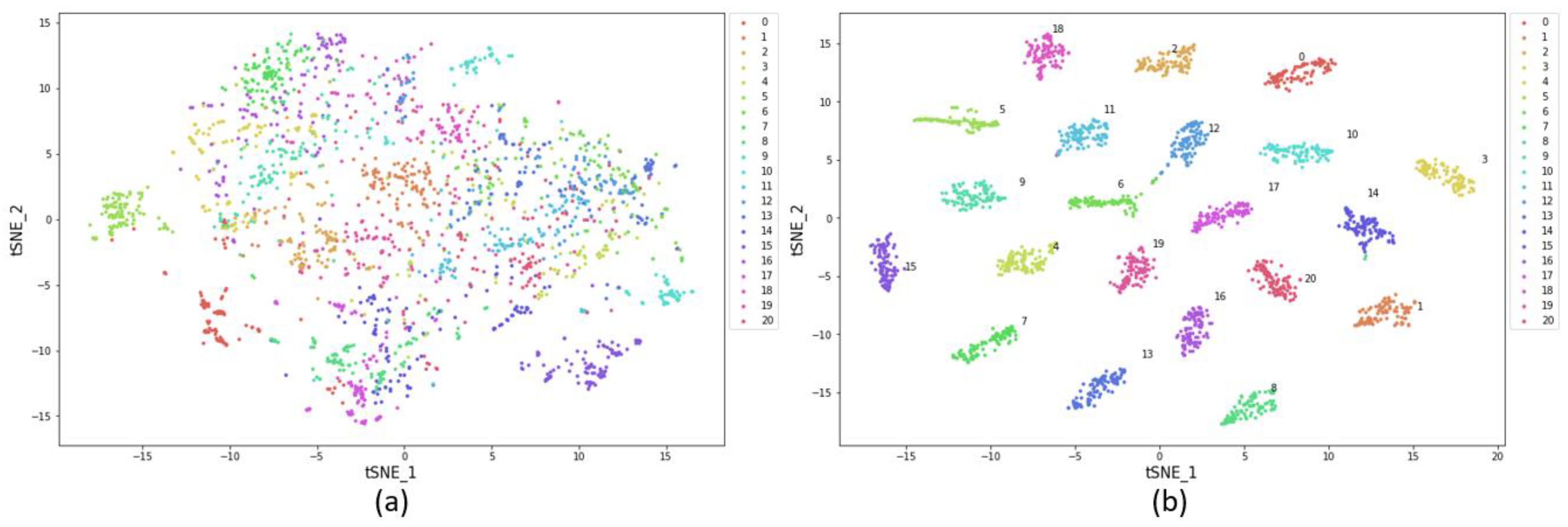
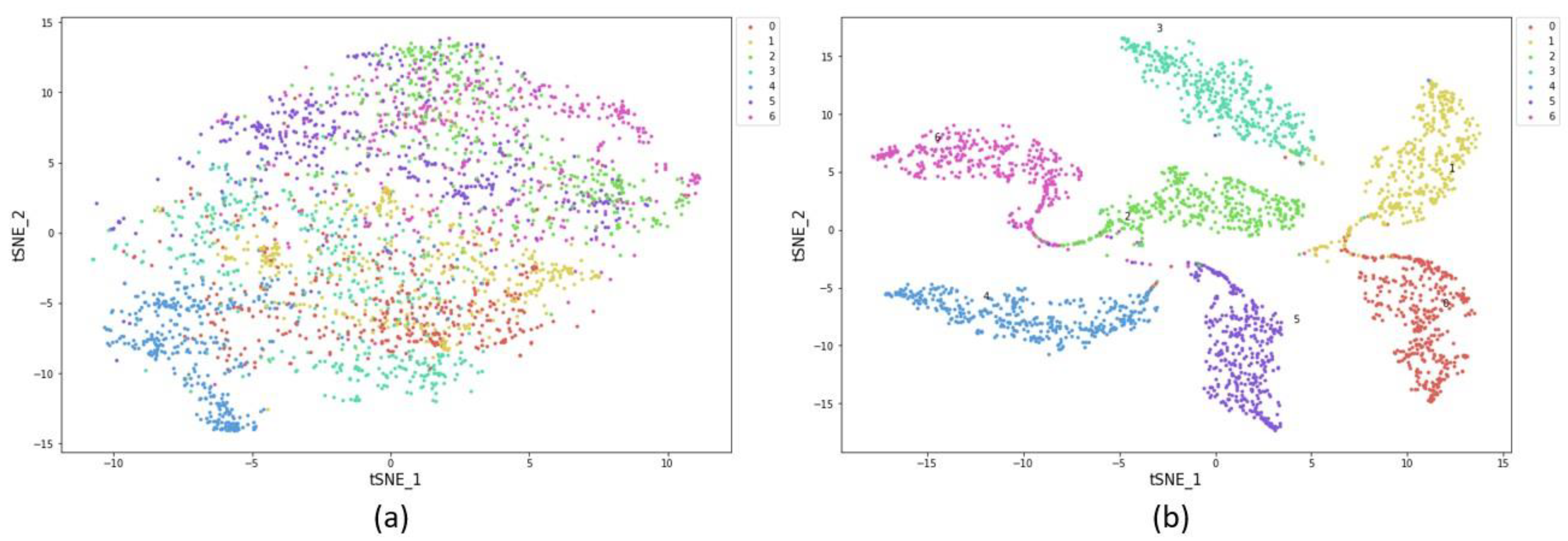
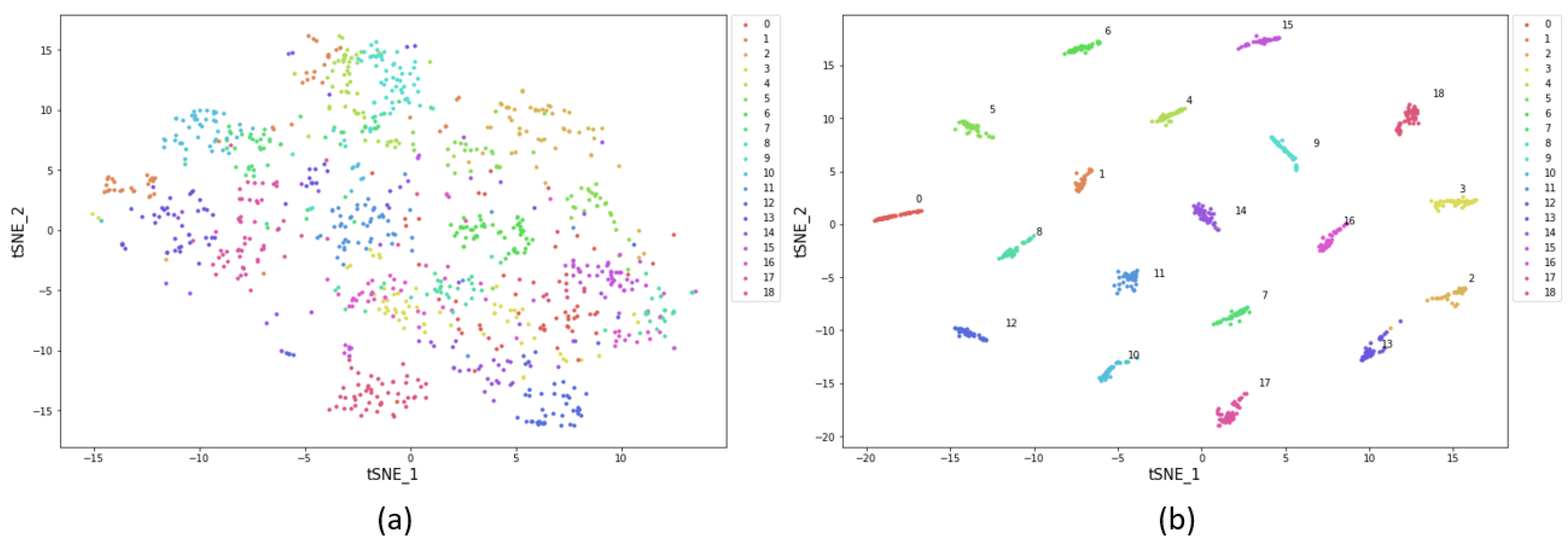
3.4. t-Distributed Stochastic Neighbor Embedding (t-SNE) Analysis Method
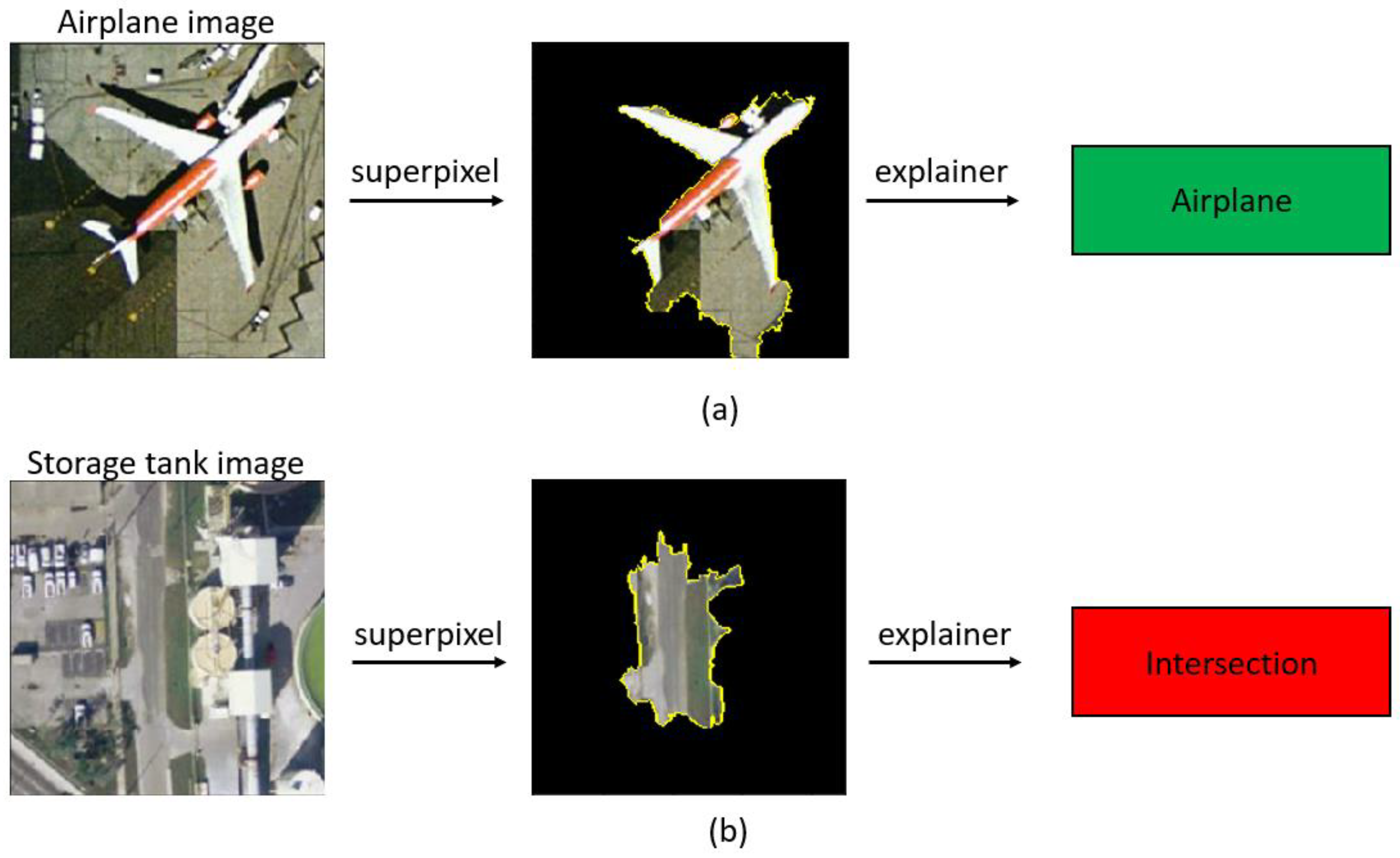
3.5. LIME Model Explanation Kit
4. Results and Analysis
4.1. Experimental Set-Ups
4.1.1. Implementation Details
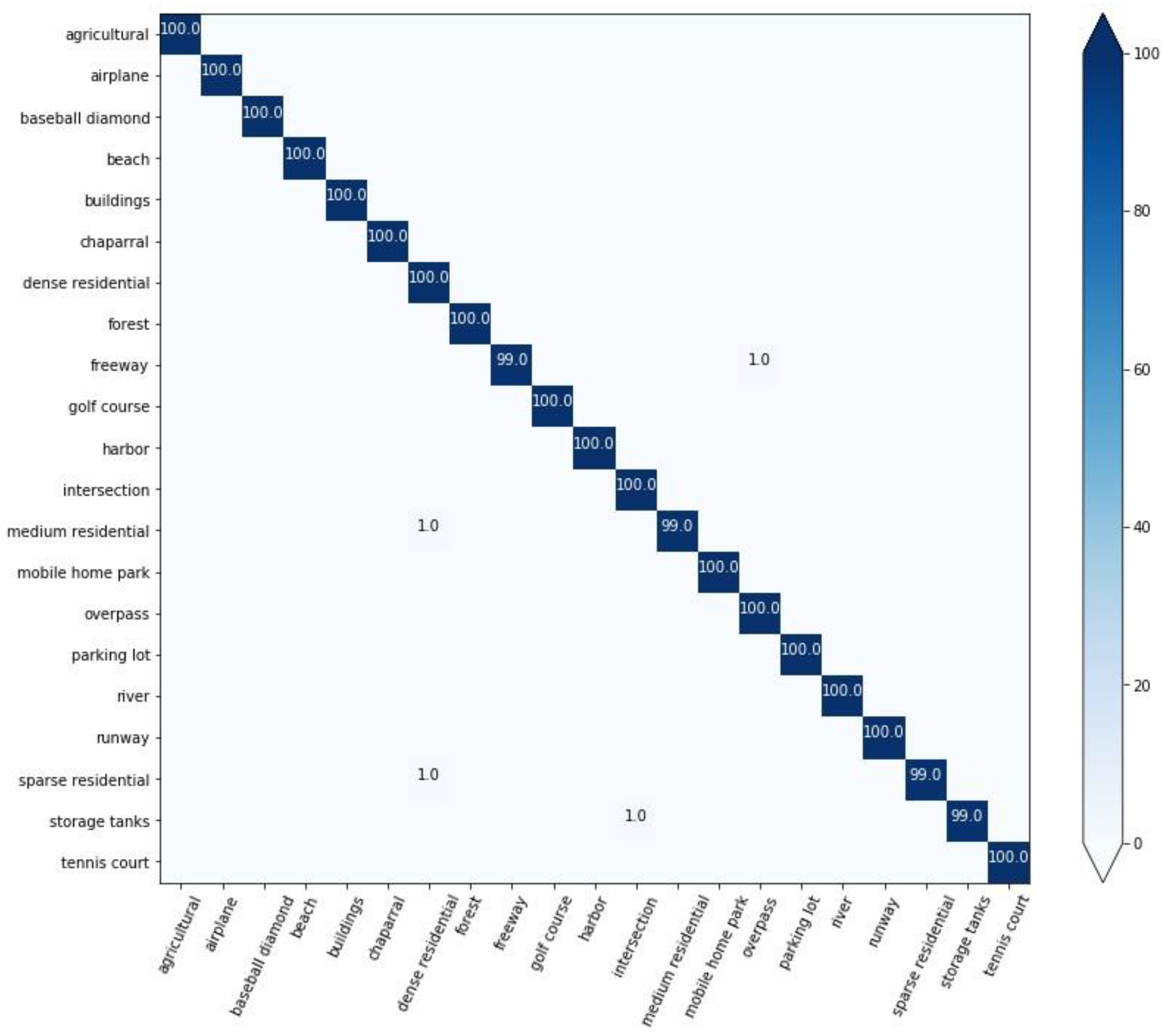
4.1.2. Evaluation Methods
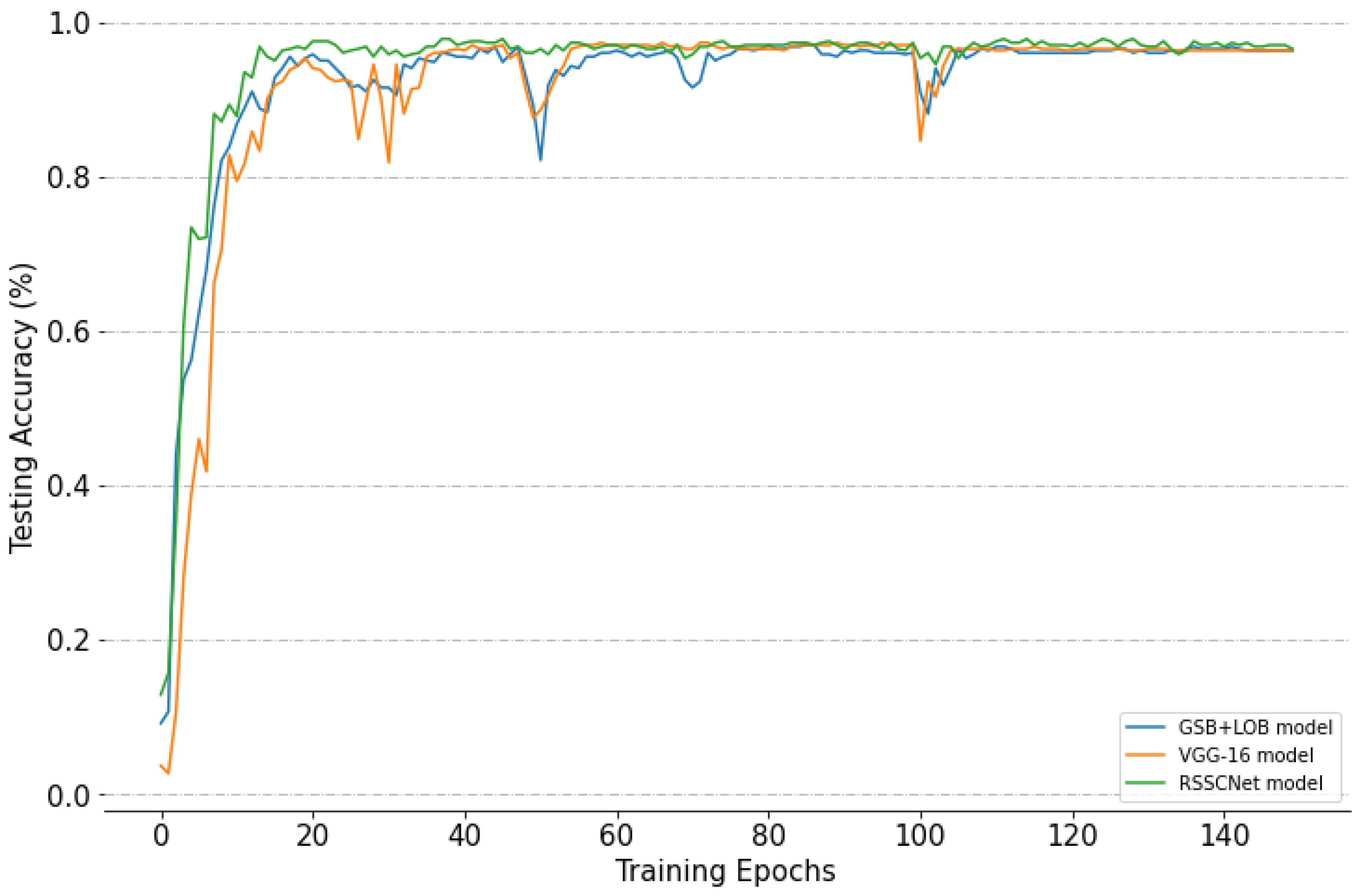
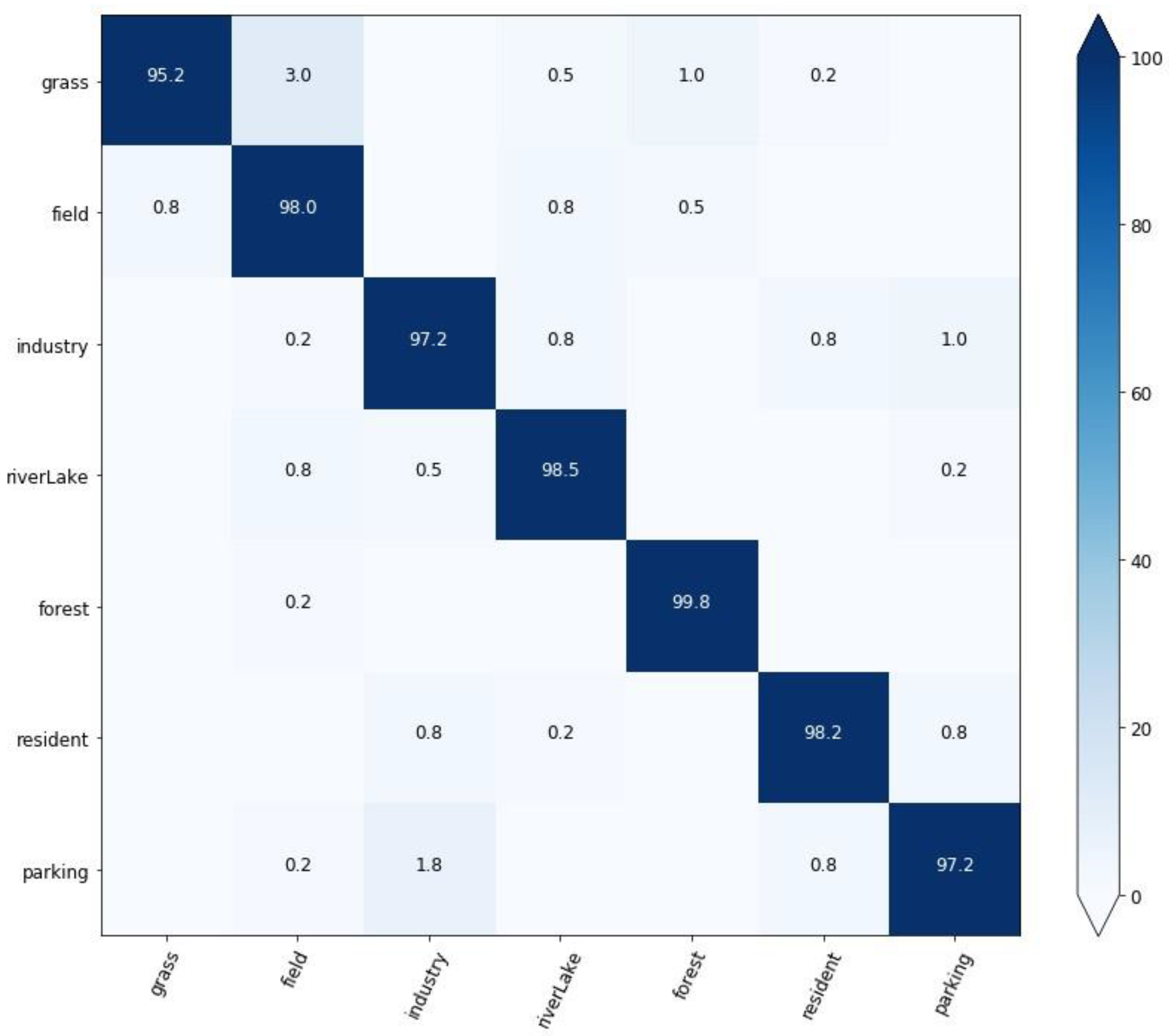
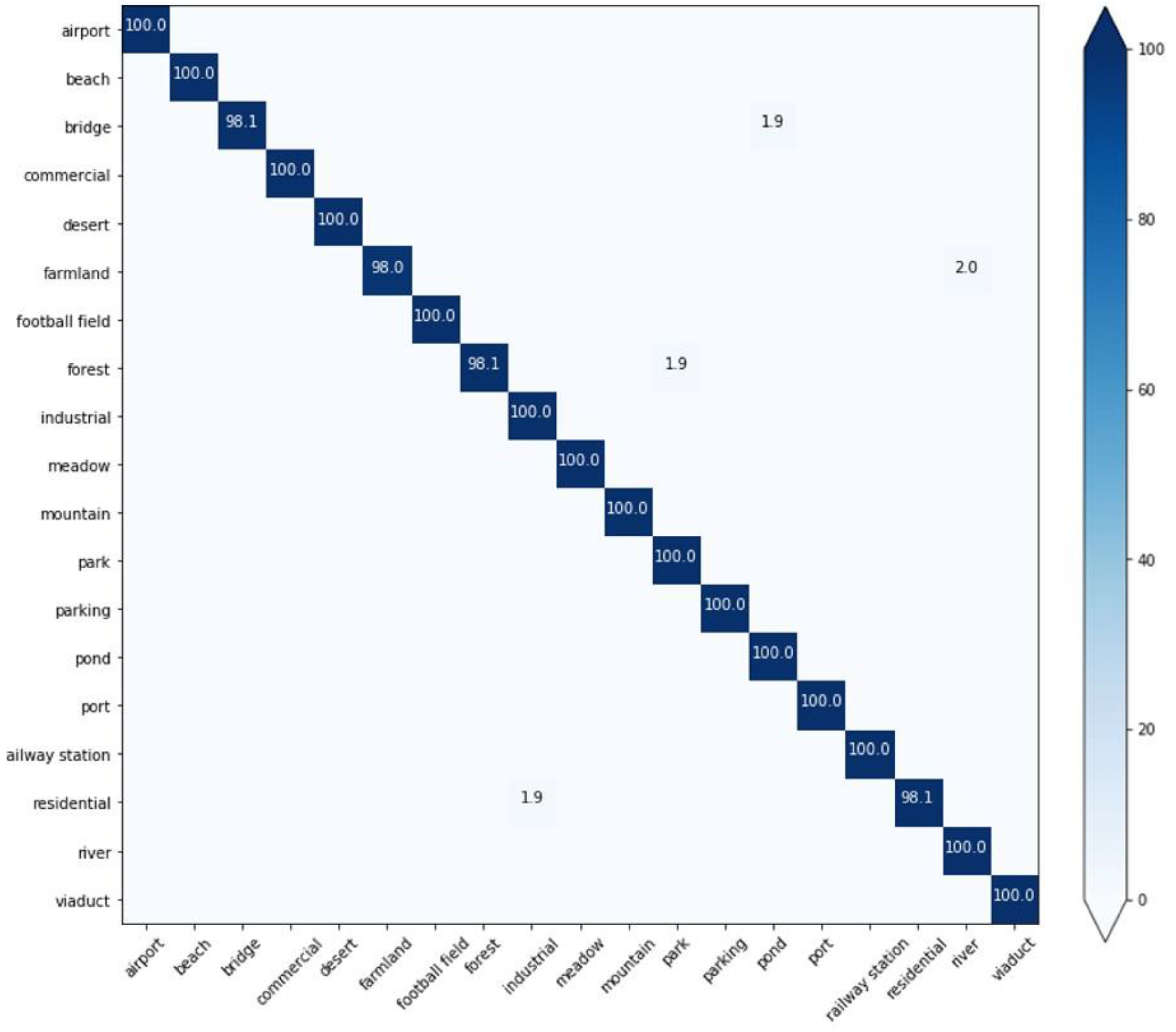
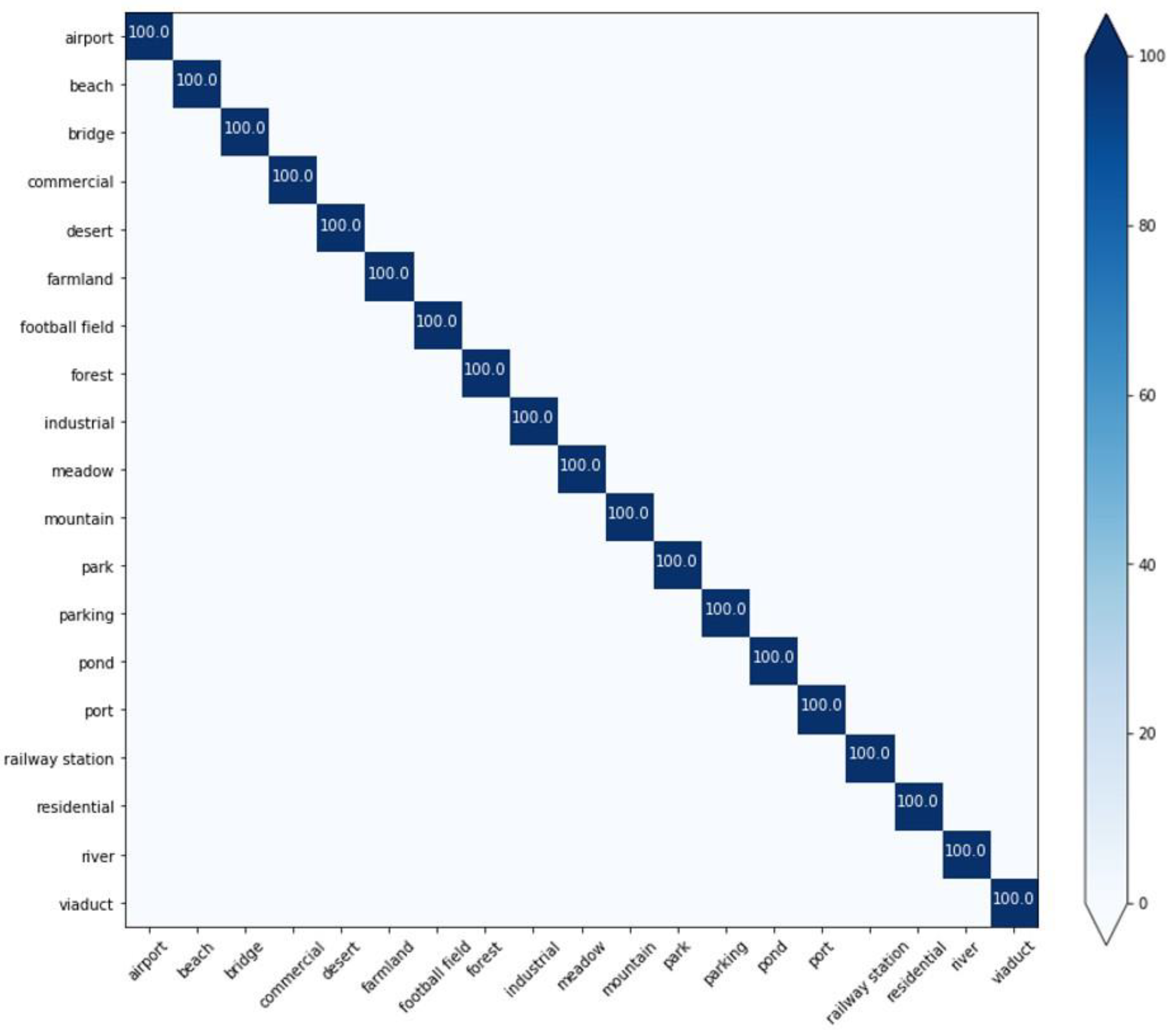
4.2. Results and Analysis
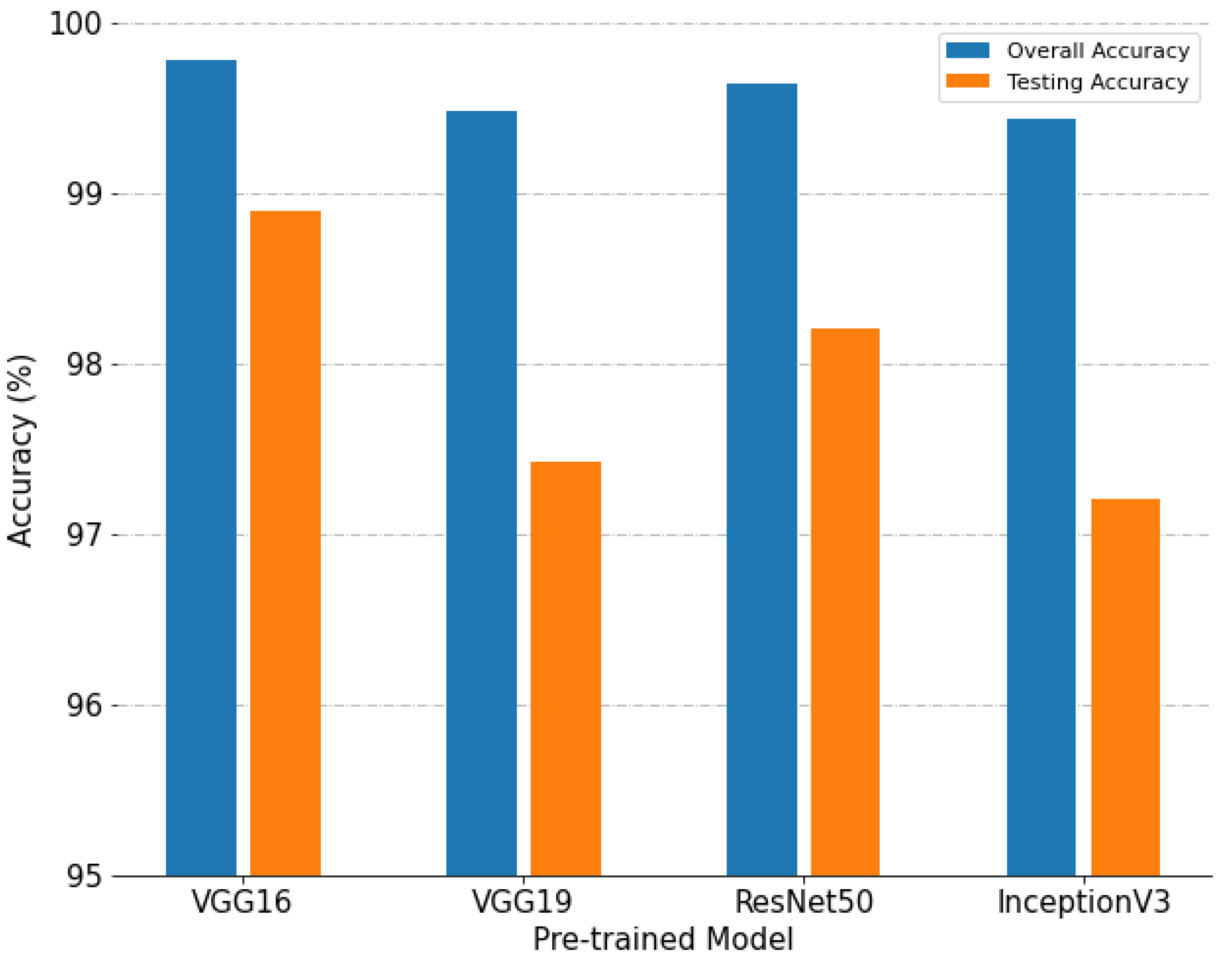
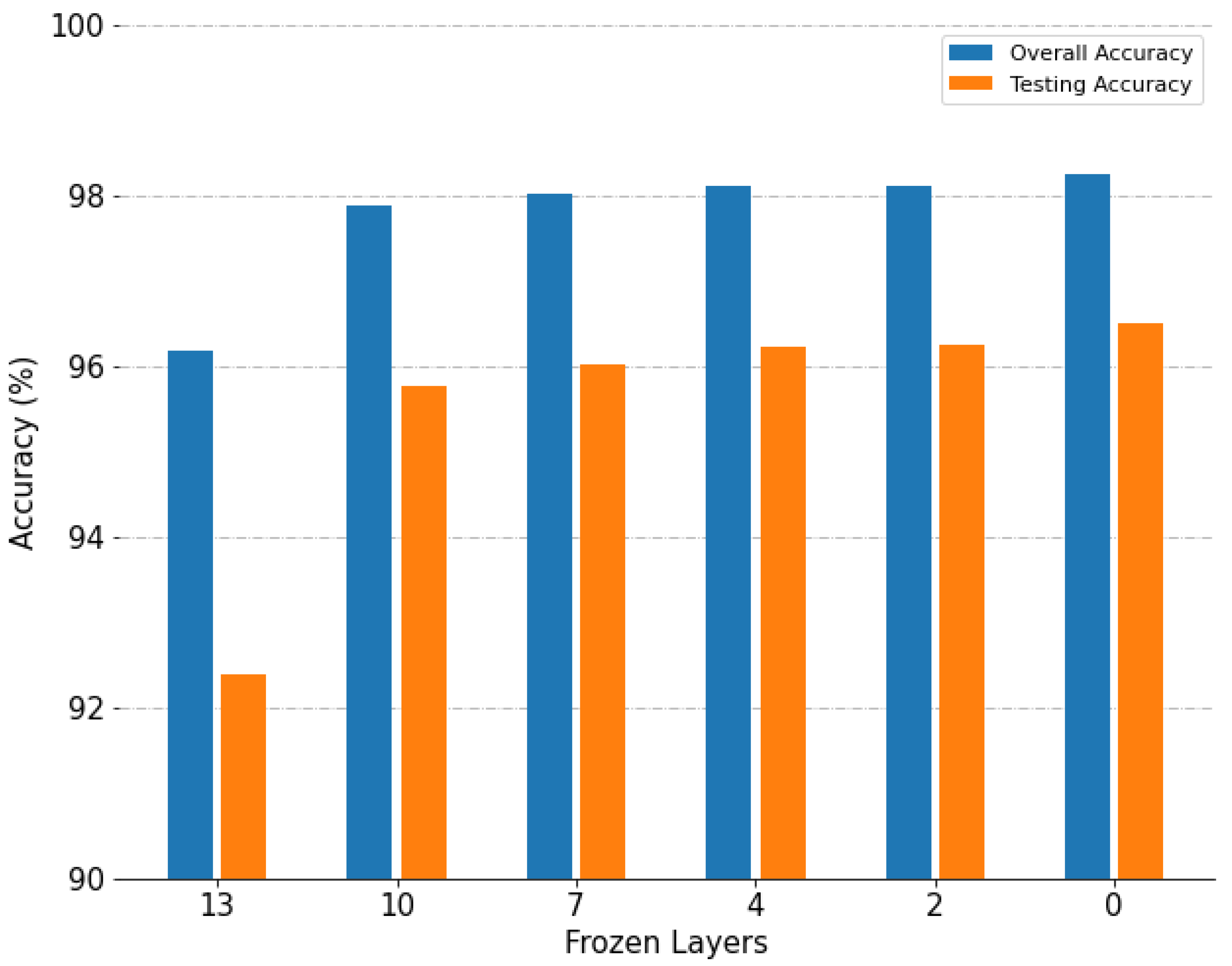
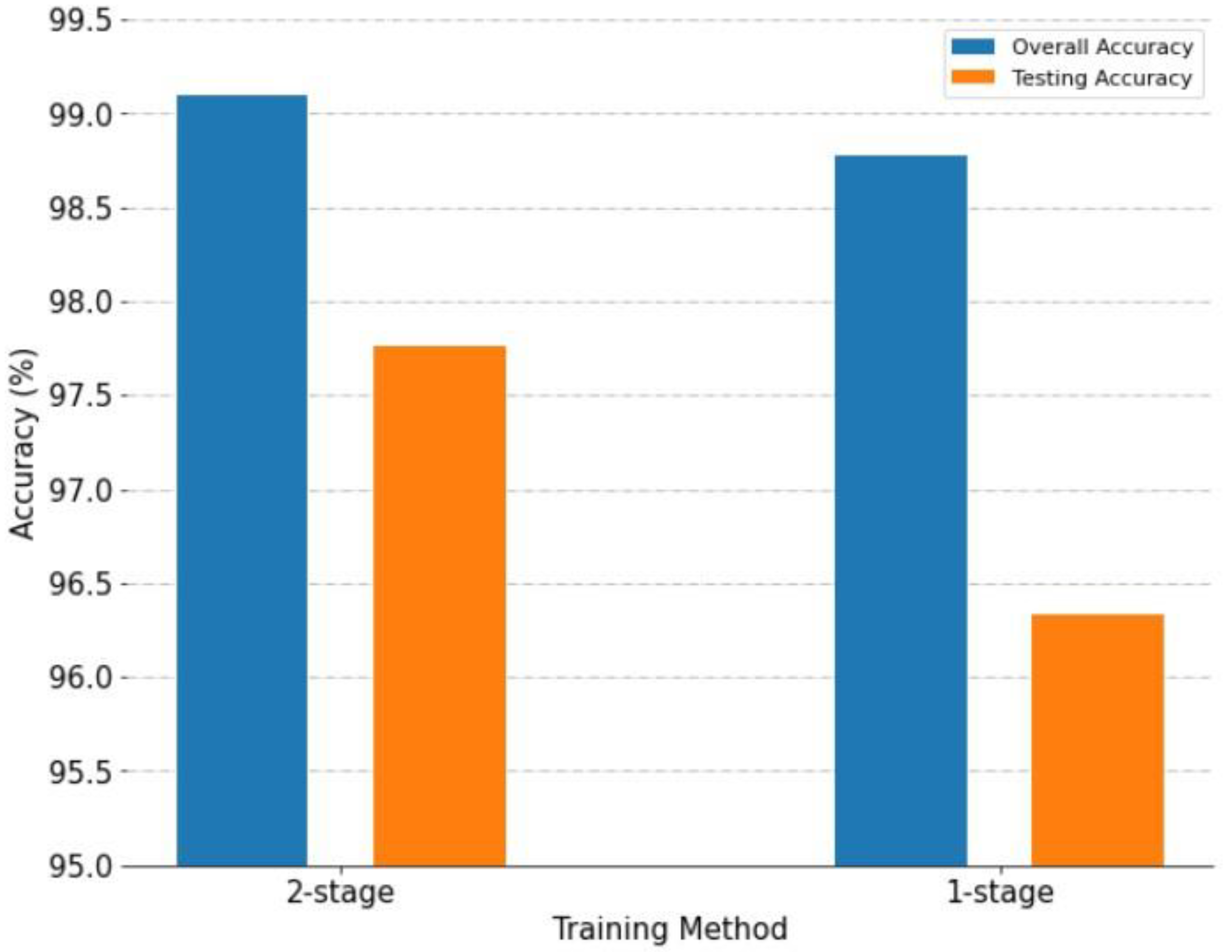
4.2.1. Analysis of Experimental Parameters
- 1.
- Different pre-trained CNN models
- 2.
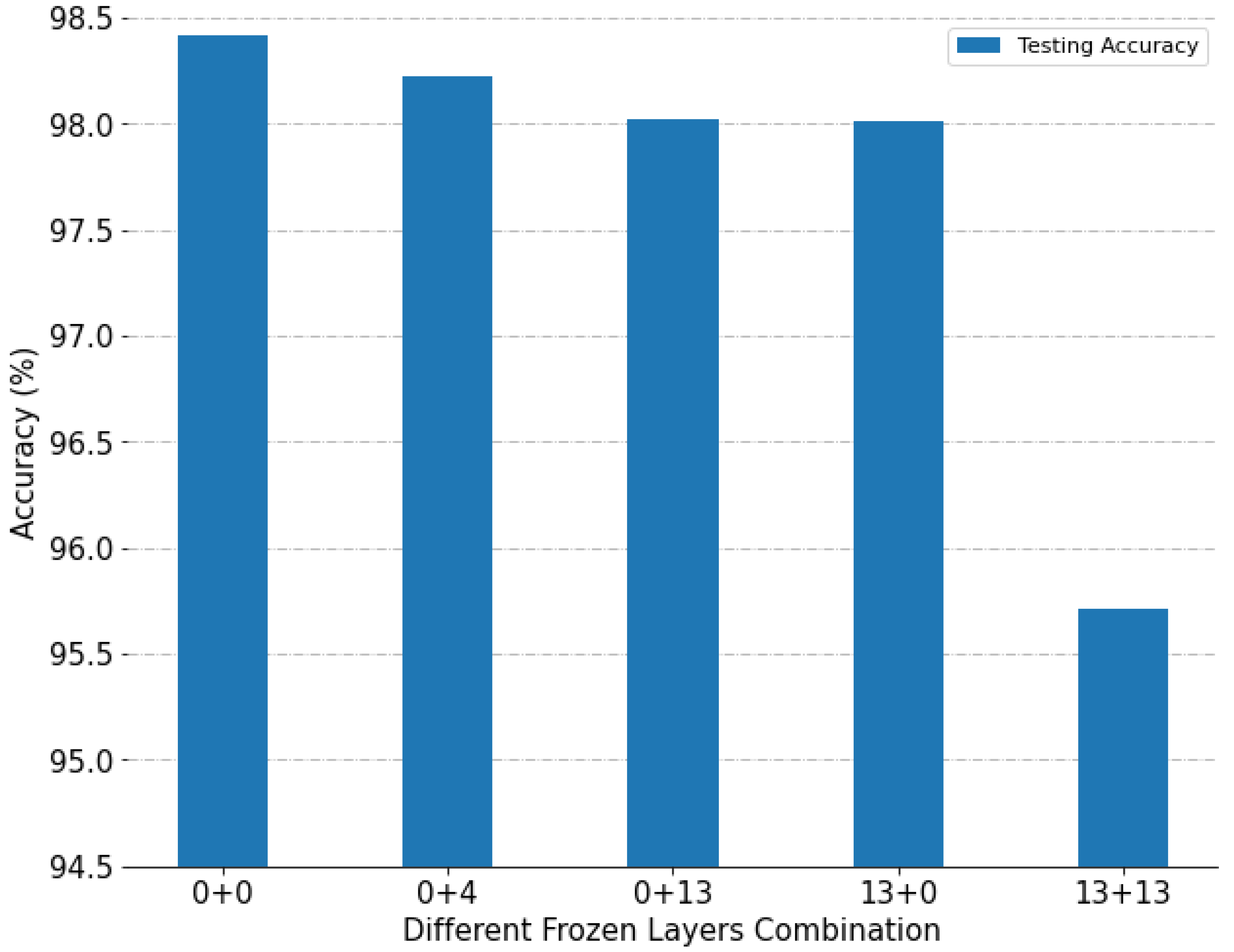
- Different numbers of fine-tuning layers during training
- 3.
- Different classification architectures
- 4.
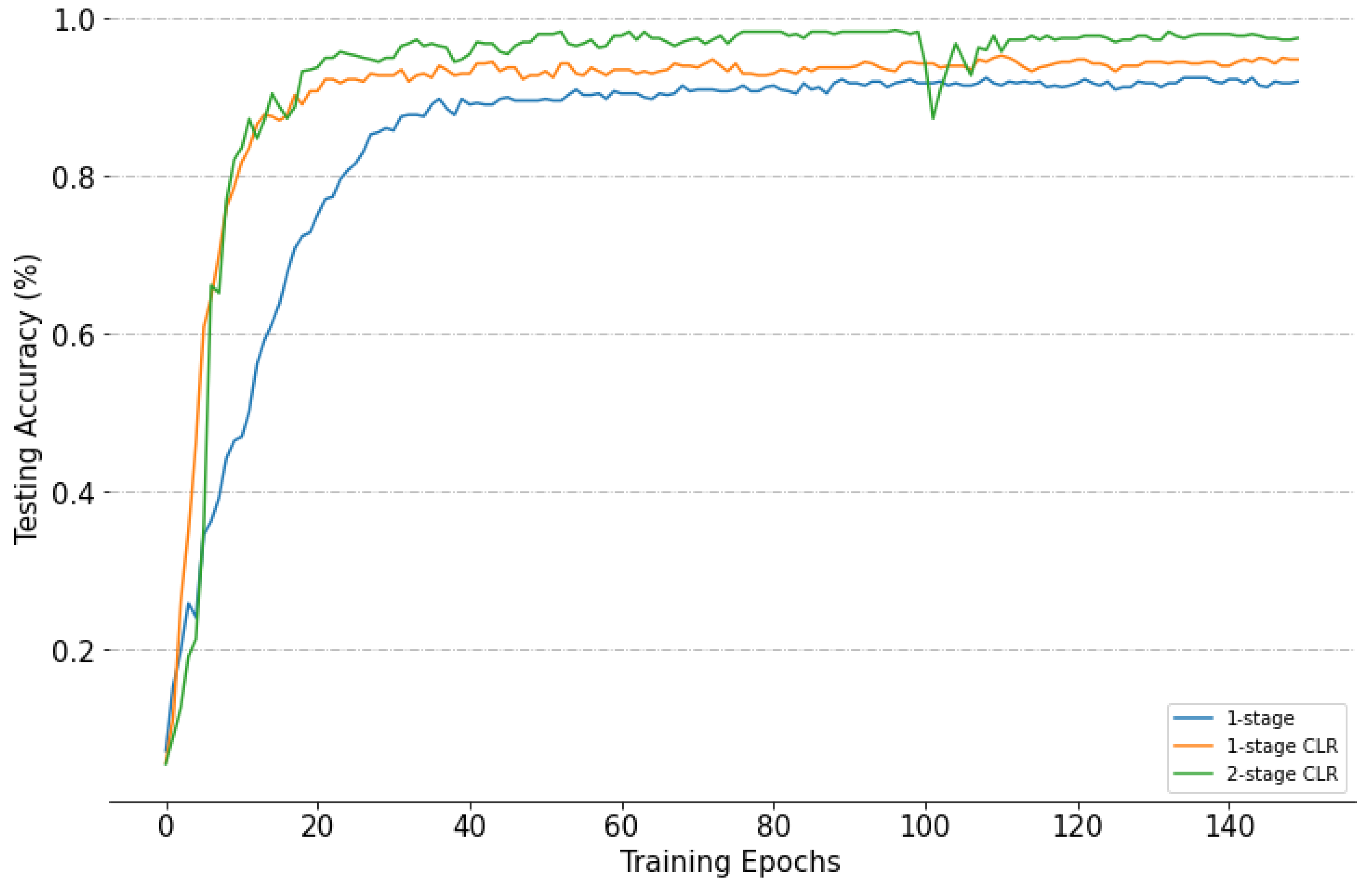
- Different cyclical learning-rate methods
4.2.2. Experimental Results
- 1.
- Classification of UC Merced land-use dataset
- 2.
- Classification of RSSCN7 dataset
- 3.
- Classification of WHU-RS19 dataset
4.2.3. Further Explanation and Discussion
- 1.
- The effectiveness of fine-tuning
- 2.
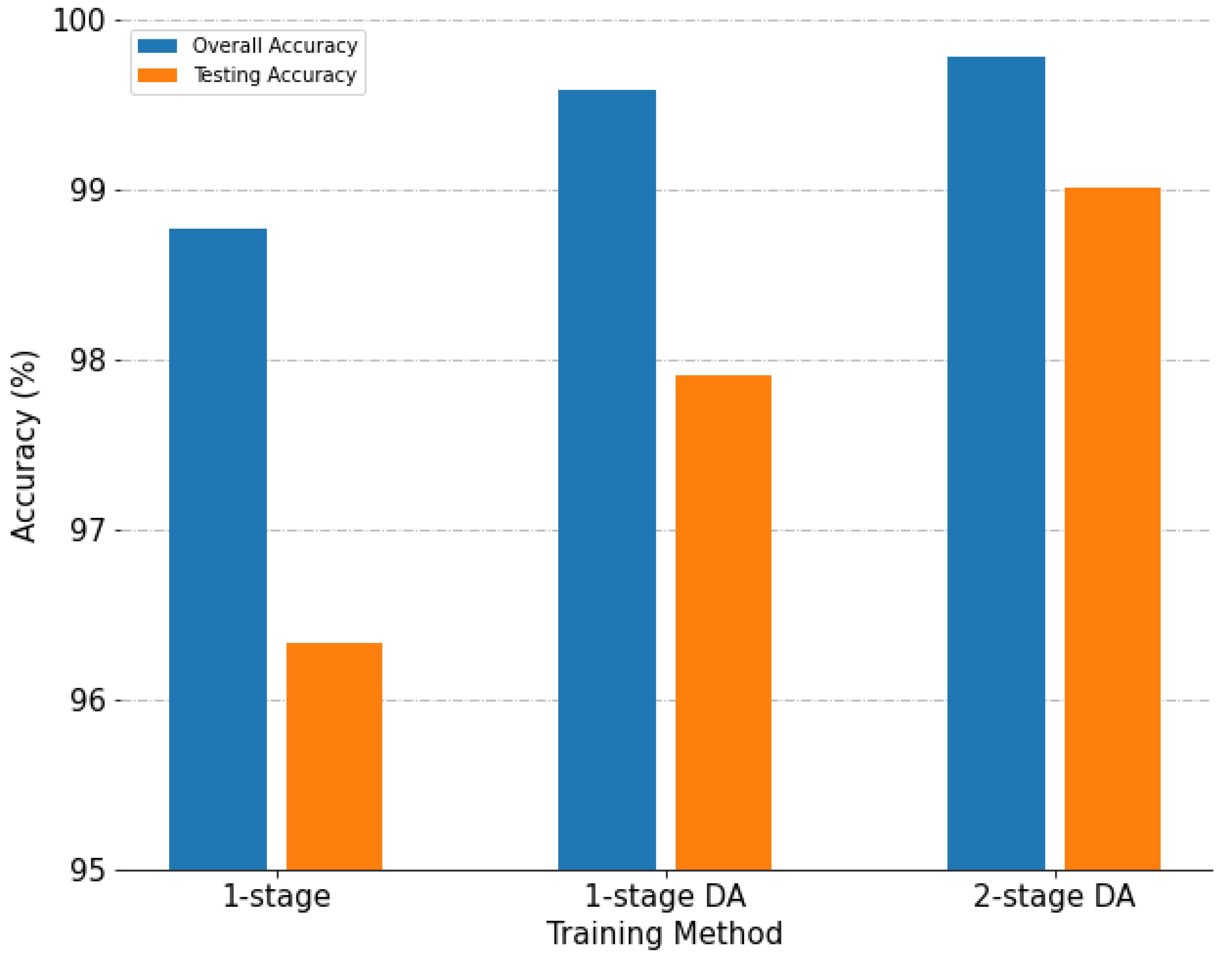
- Effectiveness of image data augmentation
- 3.
- Effectiveness of using a two-stage cyclical learning-rate method
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gu, Y.; Wang, Y.; Li, Y. A survey on deep learning-driven remote sensing image scene understanding: Scene classification, scene retrieval and scene-guided object detection. Appl. Sci. 2019, 9, 2110. [Google Scholar] [CrossRef]
- Scholl, V.M.; Cattau, M.E.; Joseph, M.B.; Balch, J.K. Integrating national ecological observatory network (neon) airborne remote sensing and in-situ data for optimal tree species classification. Remote Sens. 2020, 12, 1414. [Google Scholar] [CrossRef]
- Cheriyadat, A.M. Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 439–451. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Granger, J.E.; Mohammadimanesh, F.; Salehi, B.; Brisco, B.; Homayouni, S.; Gill, E.; Huberty, B.; Lang, M. Meta-analysis of wetland classification using remote sensing: A systematic review of a 40-year trend in north america. Remote Sens. 2020, 12, 1882. [Google Scholar] [CrossRef]
- Luus, F.P.S.; Salmon, B.P.; Van den Bergh, F.; Maharaj, B.T.J. Multiview deep learning for land-use classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2448–2452. [Google Scholar] [CrossRef]
- Maire, F.; Mejias, L.; Hodgson, A. A convolutional neural network for automatic analysis of aerial imagery. In Proceedings of the 2014 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Wollongong, New South Wales, Australia, 25–27 November 2014; pp. 1–8. [Google Scholar]
- Wang, T.; Thomasson, J.A.; Yang, C.; Isakeit, T.; Nichols, R.L. Automatic classification of cotton root rot disease based on uav remote sensing. Remote Sens. 2020, 12, 1310. [Google Scholar] [CrossRef]
- Tong, X.-Y.; Xia, G.-S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef]
- Zhang, Z.; Jiang, R.; Mei, S.; Zhang, S.; Zhang, Y. Rotation-invariant feature learning for object detection in vhr optical remote sensing images by double-net. IEEE Access 2019, 8, 20818–20827. [Google Scholar] [CrossRef]
- Zhong, Y.; Han, X.; Zhang, L. Multi-class geospatial object detection based on a position-sensitive balancing framework for high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2018, 138, 281–294. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.A.; dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef]
- Penatti, O.A.; Nogueira, K.; Dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar]
- Smith, L.N.; Topin, N. Super-convergence: Very fast training of neural networks using large learning rates. In Proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications, Baltimore, MD, USA, 10 May 2019; p. 1100612. [Google Scholar]
- Leclerc, G.; Madry, A. The two regimes of deep network training. arXiv 2020, arXiv:2002.10376. [Google Scholar]
- Caruana, R.; Lawrence, S.; Giles, C.L. Overfitting in neural nets: Backpropagation, conjugate gradient, and early stopping. In Proceedings of the Advances in Neural Information Processing Systems, Cambridge, MA, USA, 2001; pp. 402–408. [Google Scholar]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Perez, H.; Tah, J.H.; Mosavi, A. Deep learning for detecting building defects using convolutional neural networks. Sensors 2019, 19, 3556. [Google Scholar] [CrossRef] [PubMed]
- Clevert, D.-A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-sne. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Linderman, G.C.; Rachh, M.; Hoskins, J.G.; Steinerberger, S.; Kluger, Y. Fast interpolation-based t-sne for improved visualization of single-cell rna-seq data. Nat. Methods 2019, 16, 243–245. [Google Scholar] [CrossRef] [PubMed]
- Song, W.; Wang, L.; Liu, P.; Choo, K.-K.R. Improved t-sne based manifold dimensional reduction for remote sensing data processing. Multimed. Tools Appl. 2019, 78, 4311–4326. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Zeng, D.; Chen, S.; Chen, B.; Li, S. Improving remote sensing scene classification by integrating global-context and local-object features. Remote Sens. 2018, 10, 734. [Google Scholar] [CrossRef]
- Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. Aid: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Bian, X.; Chen, C.; Tian, L.; Du, Q. Fusing local and global features for high-resolution scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2889–2901. [Google Scholar] [CrossRef]
- Li, P.; Ren, P.; Zhang, X.; Wang, Q.; Zhu, X.; Wang, L. Region-wise deep feature representation for remote sensing images. Remote Sens. 2018, 10, 871. [Google Scholar] [CrossRef]
- Anwer, R.M.; Khan, F.S.; van de Weijer, J.; Molinier, M.; Laaksonen, J. Binary patterns encoded convolutional neural networks for texture recognition and remote sensing scene classification. ISPRS J. Photogramm. Remote Sens. 2018, 138, 74–85. [Google Scholar] [CrossRef]
- Liu, B.-D.; Xie, W.-Y.; Meng, J.; Li, Y.; Wang, Y. Hybrid collaborative representation for remote-sensing image scene classification. Remote Sens. 2018, 10, 1934. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F. A two-stream deep fusion framework for high-resolution aerial scene classification. Comput. Intell. Neurosci. 2018, 2018, 8639367. [Google Scholar] [CrossRef]
- Huang, H.; Xu, K. Combing triple-part features of convolutional neural networks for scene classification in remote sensing. Remote Sens. 2019, 11, 1687. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Remote sensing image scene classification using cnn-capsnet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef]
- Guo, Y.; Ji, J.; Shi, D.; Ye, Q.; Xie, H. Multi-view feature learning for vhr remote sensing image classification. Multimed. Tools Appl. 2020. [Google Scholar] [CrossRef]
- Wu, H.; Liu, B.; Su, W.; Zhang, W.; Sun, J. Deep filter banks for land-use scene classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1895–1899. [Google Scholar] [CrossRef]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 80% Training Ratio | 50% Training Ratio |
|---|---|---|
| GoogLeNet [33] | 94.31 ± 0.89 | 92.70 ± 0.60 |
| CaffNet [33] | 95.02 ± 0.81 | 93.98 ± 0.67 |
| VGG-16 [33] | 95.21 ± 1.20 | 94.14 ± 0.69 |
| salM3LBP-CLM [34] | 95.75 ± 0.80 | 94.21 ± 0.75 |
| CNN-R+VLAD with SVM [35] | 95.85 | NA |
| TEX-Net-LF [36] | 96.62 ± 0.49 | 95.89 ± 0.37 |
| VGG19+Hybrid-KCRC [37] | 96.33 | NA |
| Two-Stream Fusion [38] | 98.02 ± 1.03 | 96.97 ± 0.75 |
| CTFCNN [39] | 98.44 ± 0.58 | NA |
| GCFs + LOFs [32] | 99.00 ± 0.35 | 97.37 ± 0.44 |
| Inception-v3-CapsNet [40] | 99.05 ± 0.24 | 97.59 ± 0.16 |
| MVFLN+VGG-VD16 [41] | 99.52 ± 0.17 | NA |
| RSSCNet (this paper) | 99.81 ± 0.06 | 98.76 ± 0.19 |
| Method | 50% Training Ratio | 20% Training Ratio |
|---|---|---|
| DBN [20] | 77.00 | NA |
| GoogLeNet [33] | 85.84 ± 0.92 | 82.55 ± 1.11 |
| CaffNet [33] | 88.25 ± 0.62 | 85.57 ± 0.95 |
| VGG-16 [33] | 87.18 ± 0.94 | 83.98 ± 0.87 |
| Deep Filter Banks [42] | 90.4 ± 0.6 | NA |
| GCFs + LOFs [32] | 95.59 ± 0.49 | 92.47 ± 0.29 |
| RSSCNet (this paper) | 97.41 ± 0.27 | 93.51 ± 0.51 |
| Method | 60% Training Ratio | 40% Training Ratio |
|---|---|---|
| GoogLeNet [33] | 94.71 ± 1.33 | 93.12 ± 0.82 |
| CaffNet [33] | 96.24 ± 0.56 | 95.11 ± 1.20 |
| VGG-16 [33] | 96.05 ± 0.91 | 95.44 ± 0.60 |
| TEX-Net-LF [36] | 98.00 ± 0.52 | 97.61 ± 0.36 |
| Two-Stream Fusion [38] | 98.92 ± 0.52 | 98.23 ± 0.56 |
| RSSCNet (this paper) | 99.46 ± 0.21 | 98.54 ± 0.37 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hung, S.-C.; Wu, H.-C.; Tseng, M.-H. Remote Sensing Scene Classification and Explanation Using RSSCNet and LIME. Appl. Sci. 2020, 10, 6151. https://doi.org/10.3390/app10186151
Hung S-C, Wu H-C, Tseng M-H. Remote Sensing Scene Classification and Explanation Using RSSCNet and LIME. Applied Sciences. 2020; 10(18):6151. https://doi.org/10.3390/app10186151
Chicago/Turabian StyleHung, Sheng-Chieh, Hui-Ching Wu, and Ming-Hseng Tseng. 2020. "Remote Sensing Scene Classification and Explanation Using RSSCNet and LIME" Applied Sciences 10, no. 18: 6151. https://doi.org/10.3390/app10186151
APA StyleHung, S.-C., Wu, H.-C., & Tseng, M.-H. (2020). Remote Sensing Scene Classification and Explanation Using RSSCNet and LIME. Applied Sciences, 10(18), 6151. https://doi.org/10.3390/app10186151