Classification-Based Regression Models for Prediction of the Mechanical Properties of Roller-Compacted Concrete Pavement

 ,
,  ,
,  and
and
Abstract
1. Introduction
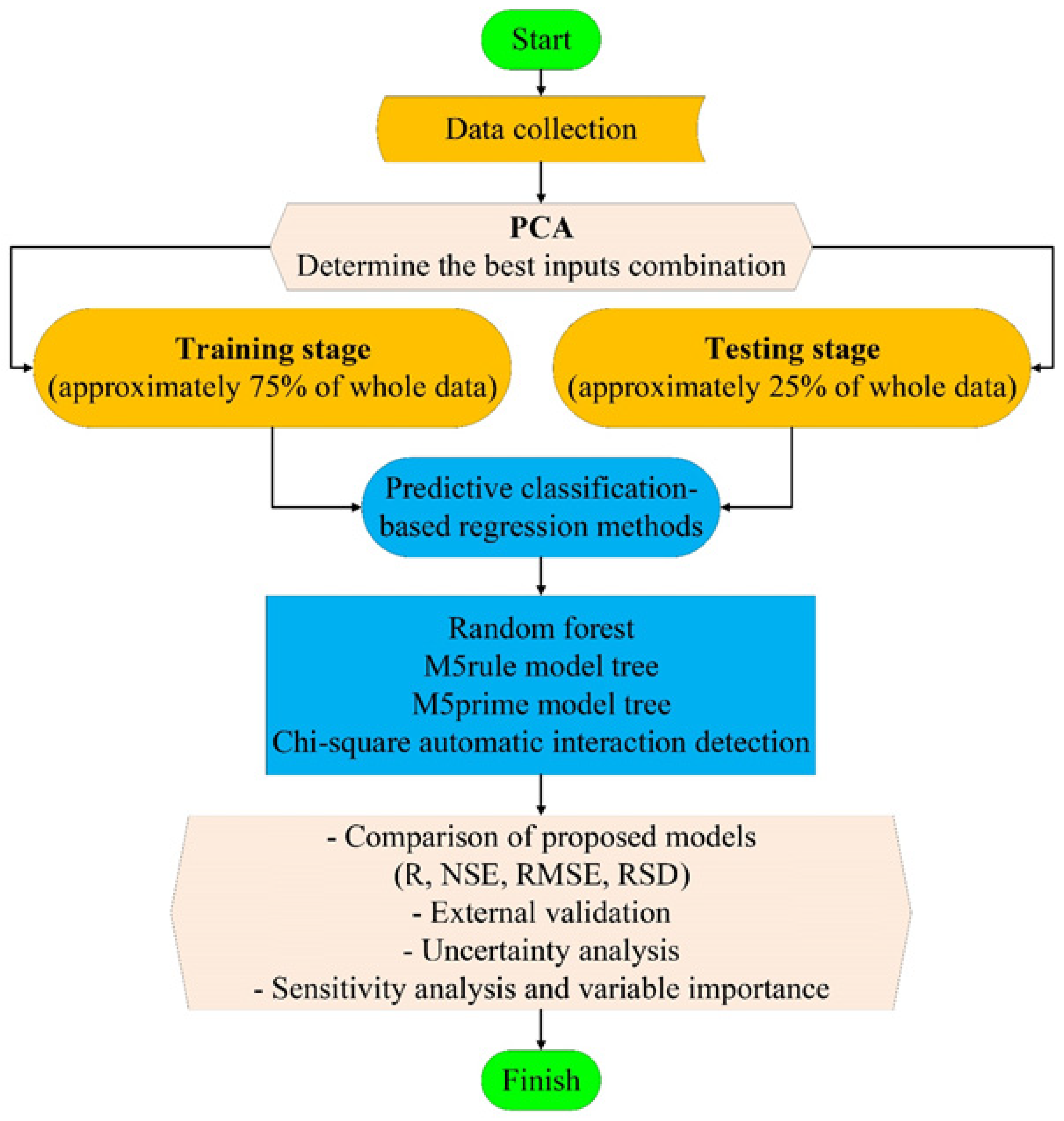
2. Materials and Methods
2.1. Theoretical Background and Data Description
2.2. Random Forest
- (a)
- Based on the dataset, draw an instance that is chosen randomly with substitution.
- (b)
- Using the bootstrap instance, evolve a tree with these modifications: for each node, select the best randomized subset of m try descriptors (i.e., the number of predictors tried per each node). M try here has the role of a tuning a parameter in the RF algorithm. The tree is generated to its maximum size without pruning it.
- (c)
- Stage (b) is iterated until the user-manual numbers of trees (ntree) are grown on the basis of the bootstrap instance of observations. The final prediction values are determined by combining all individual tree outcomes [61]. After growing K trees {Tk(x)}, the regression explanatory variables in RF is stated by the following formula:
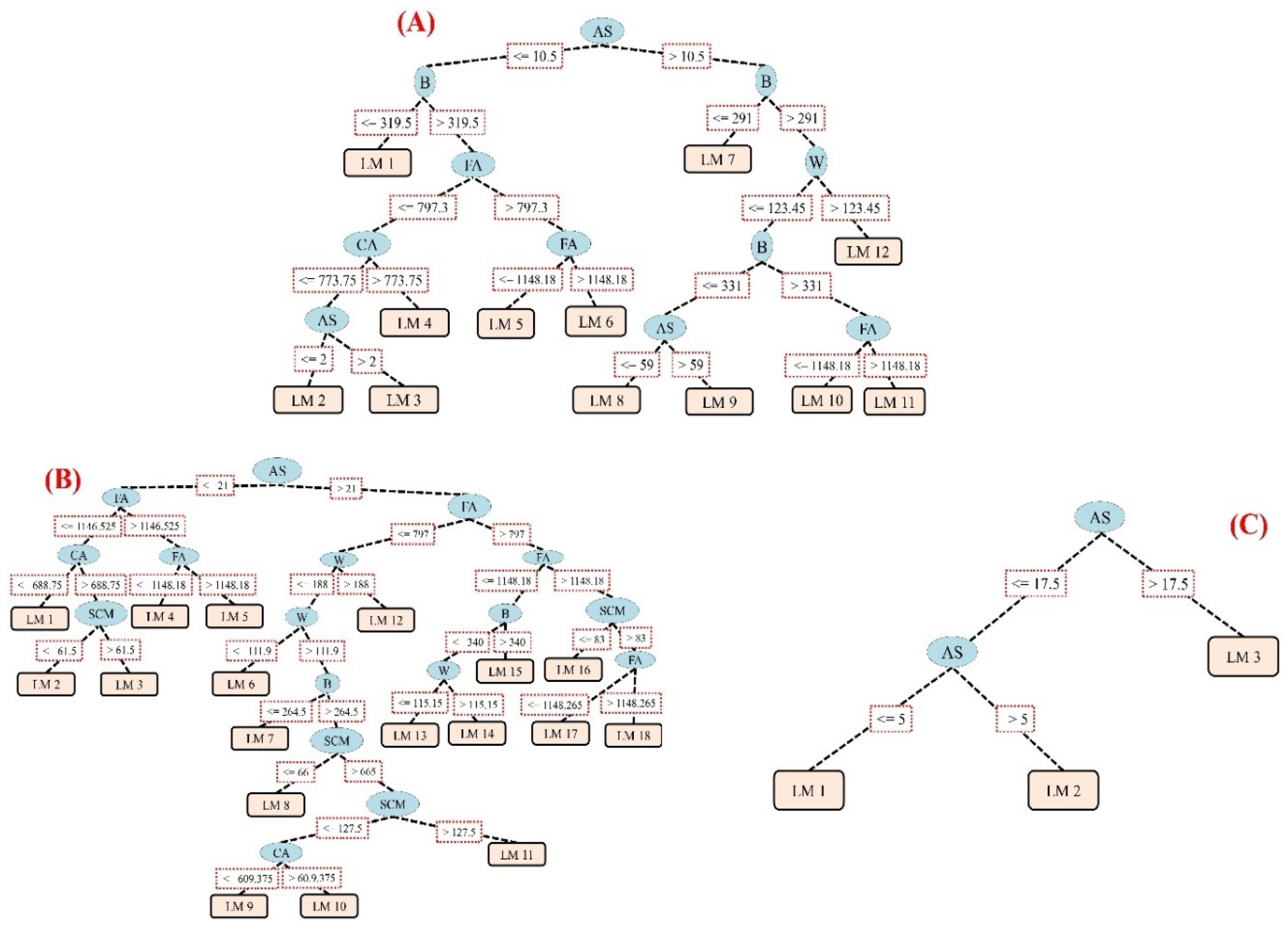
2.3. M5 Rule Model Tree
2.4. M5 Prime Model Tree
2.5. Chi-Square Automatic Interaction Detector
2.6. Principal Component Analysis
2.7. Statistical Criteria
3. Application Results and Discussion
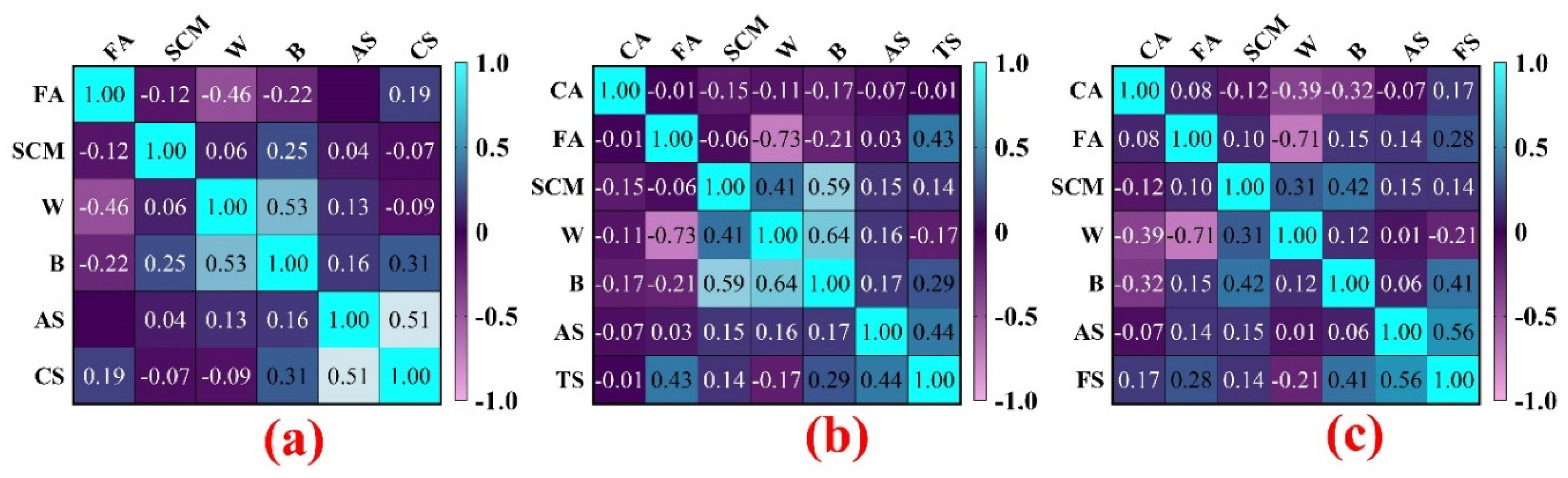
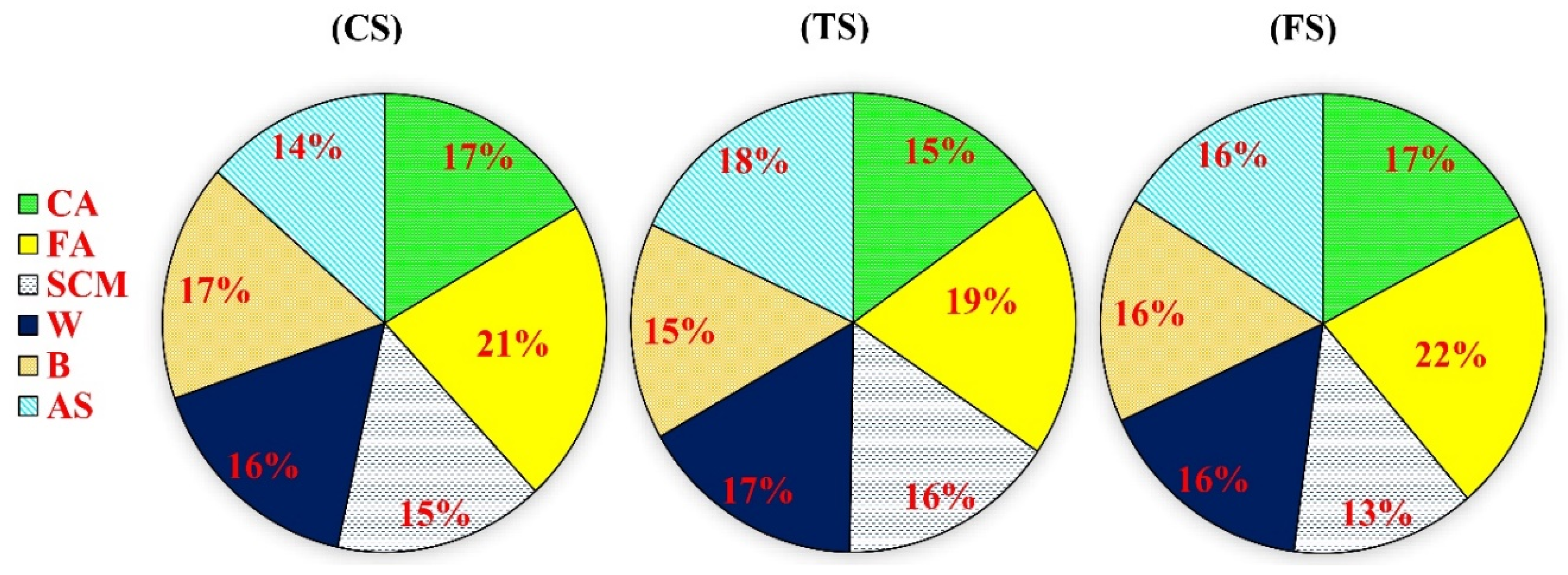
3.1. Selection of the Input Variables Using the PCA Technique
3.2. Estimation of RCCP Mechanical Characteristics Using Classification-Based Regression Methods
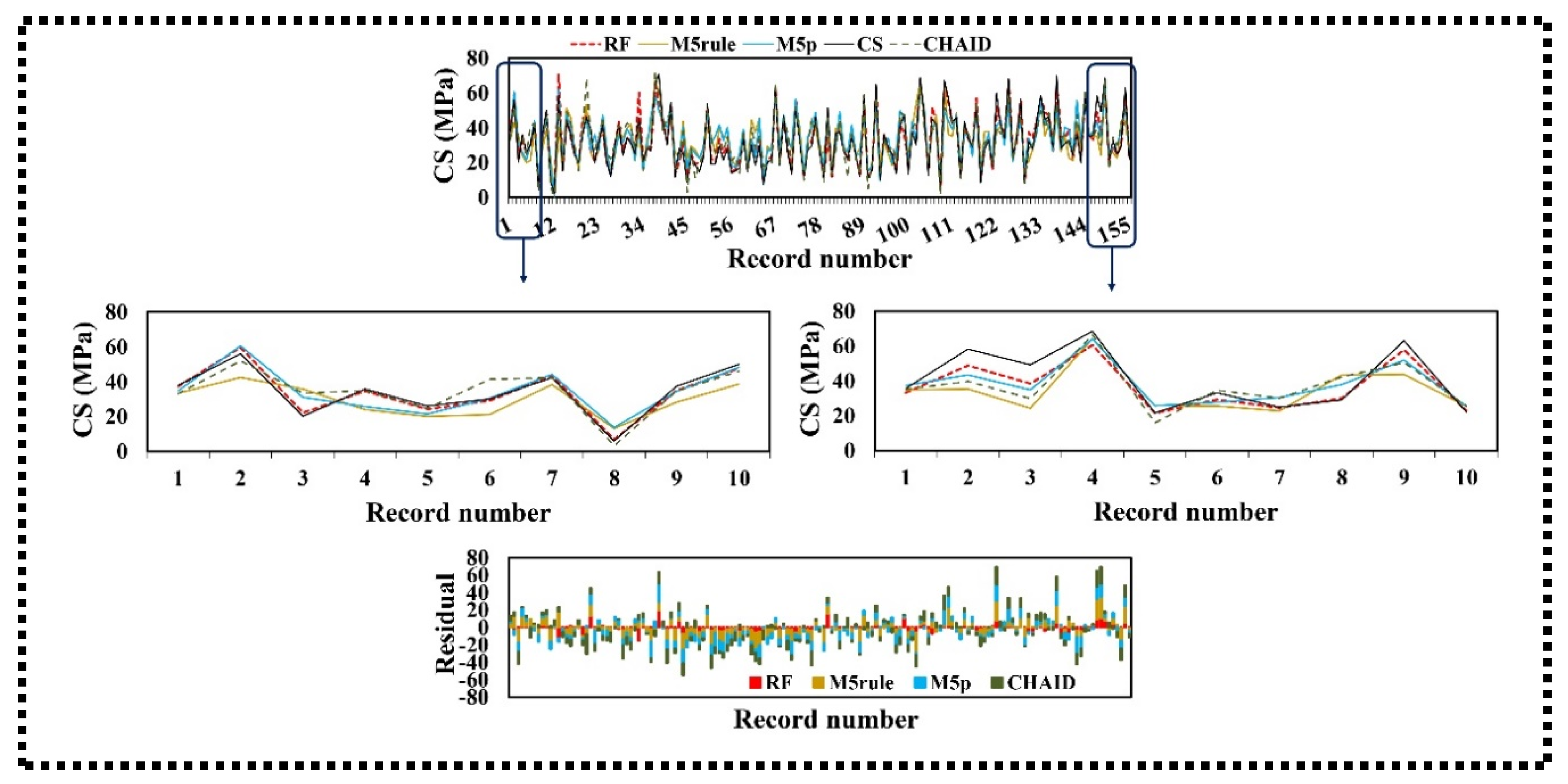
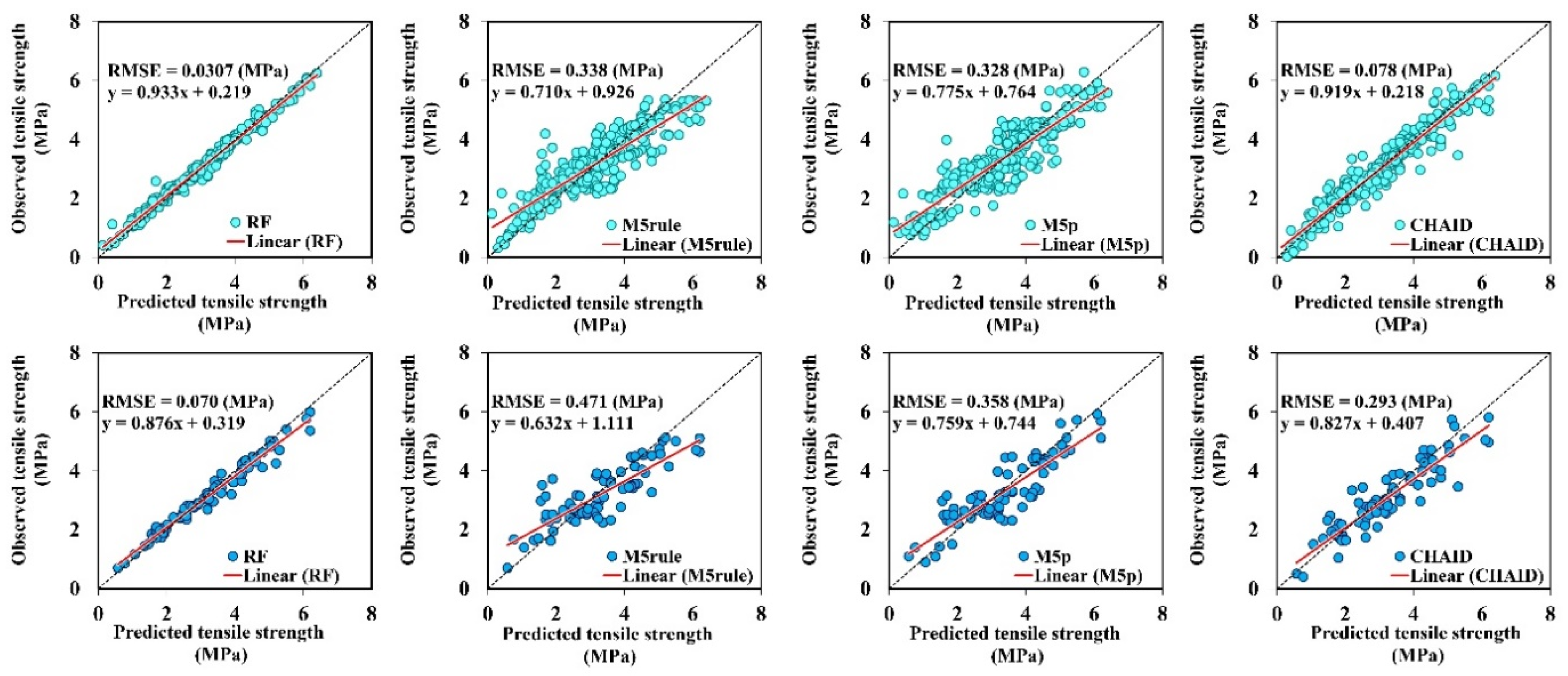
3.2.1. Compressive Strength
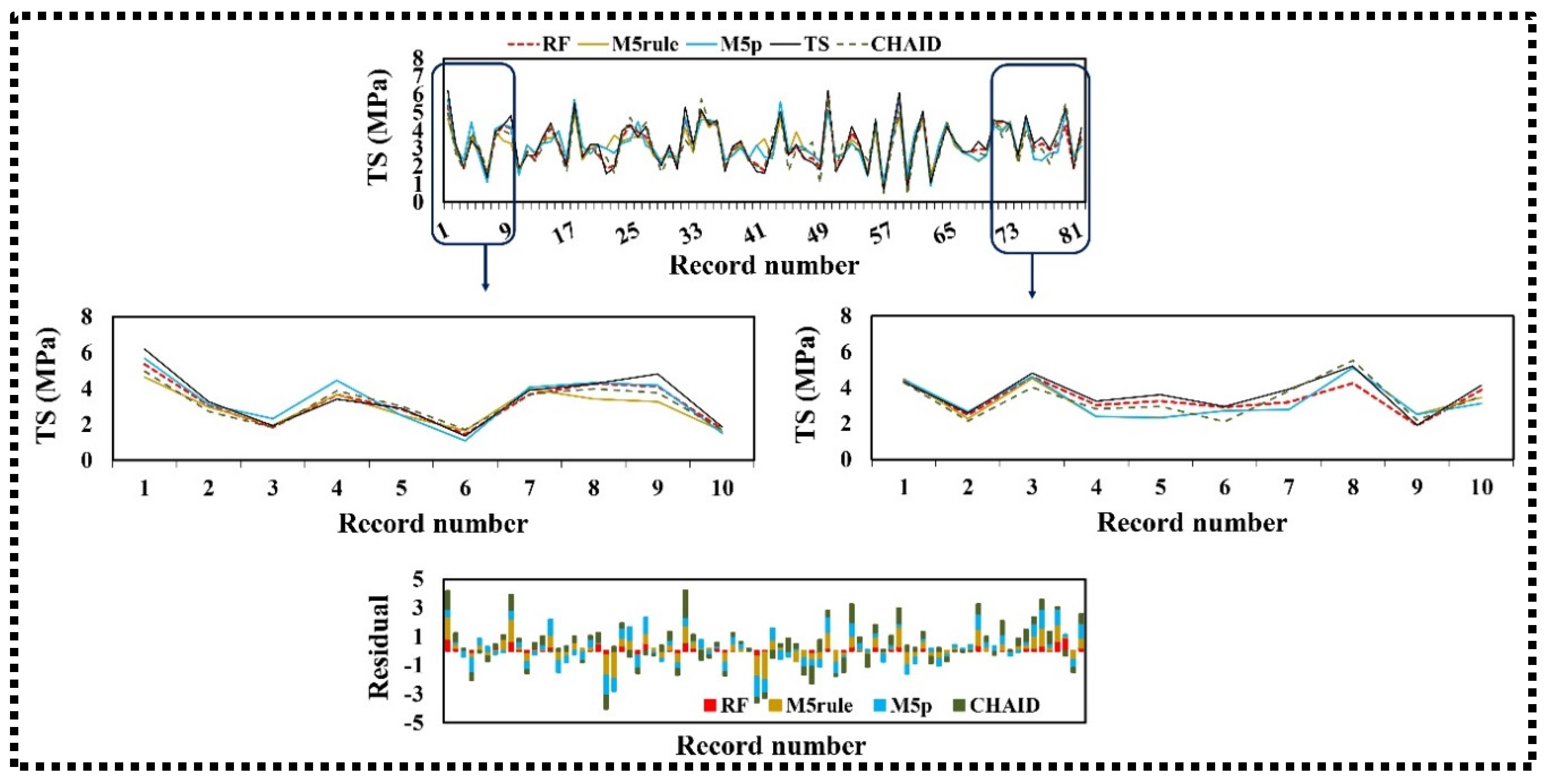
3.2.2. Tensile Strength
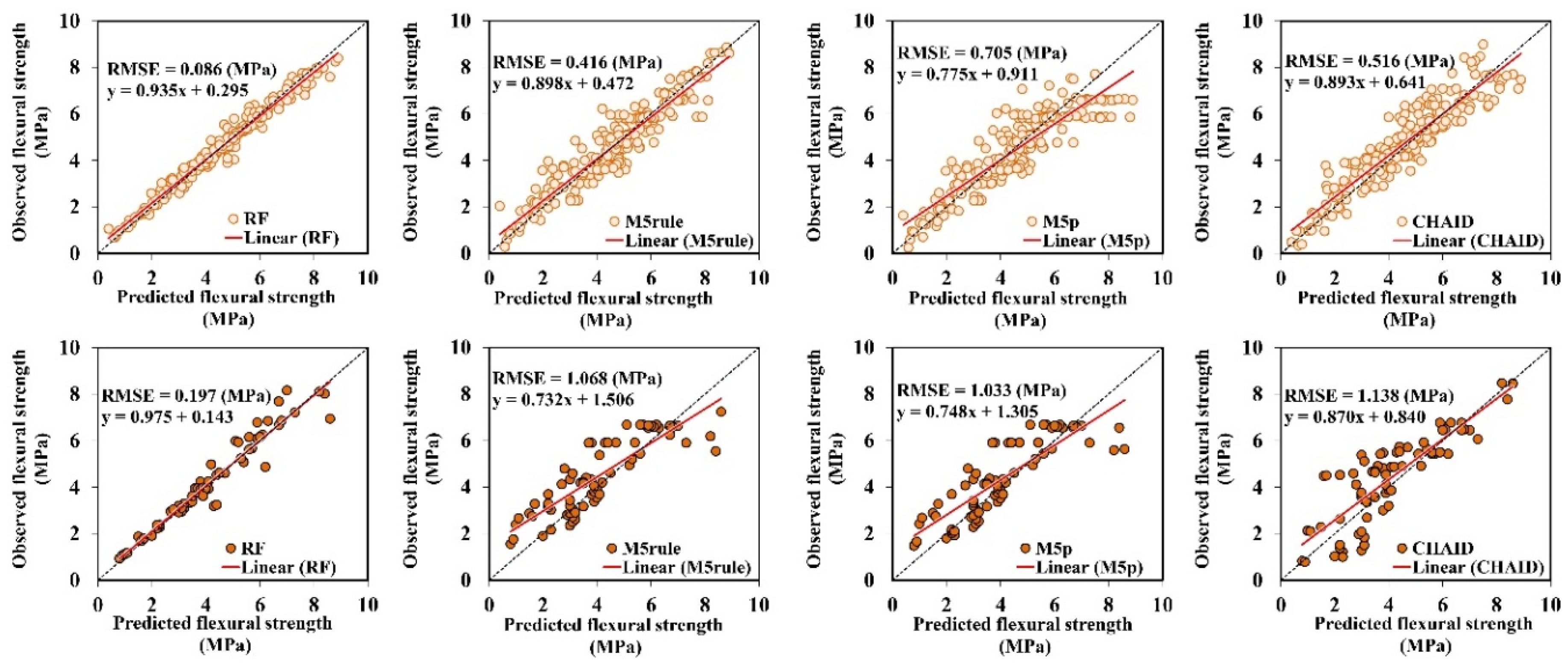
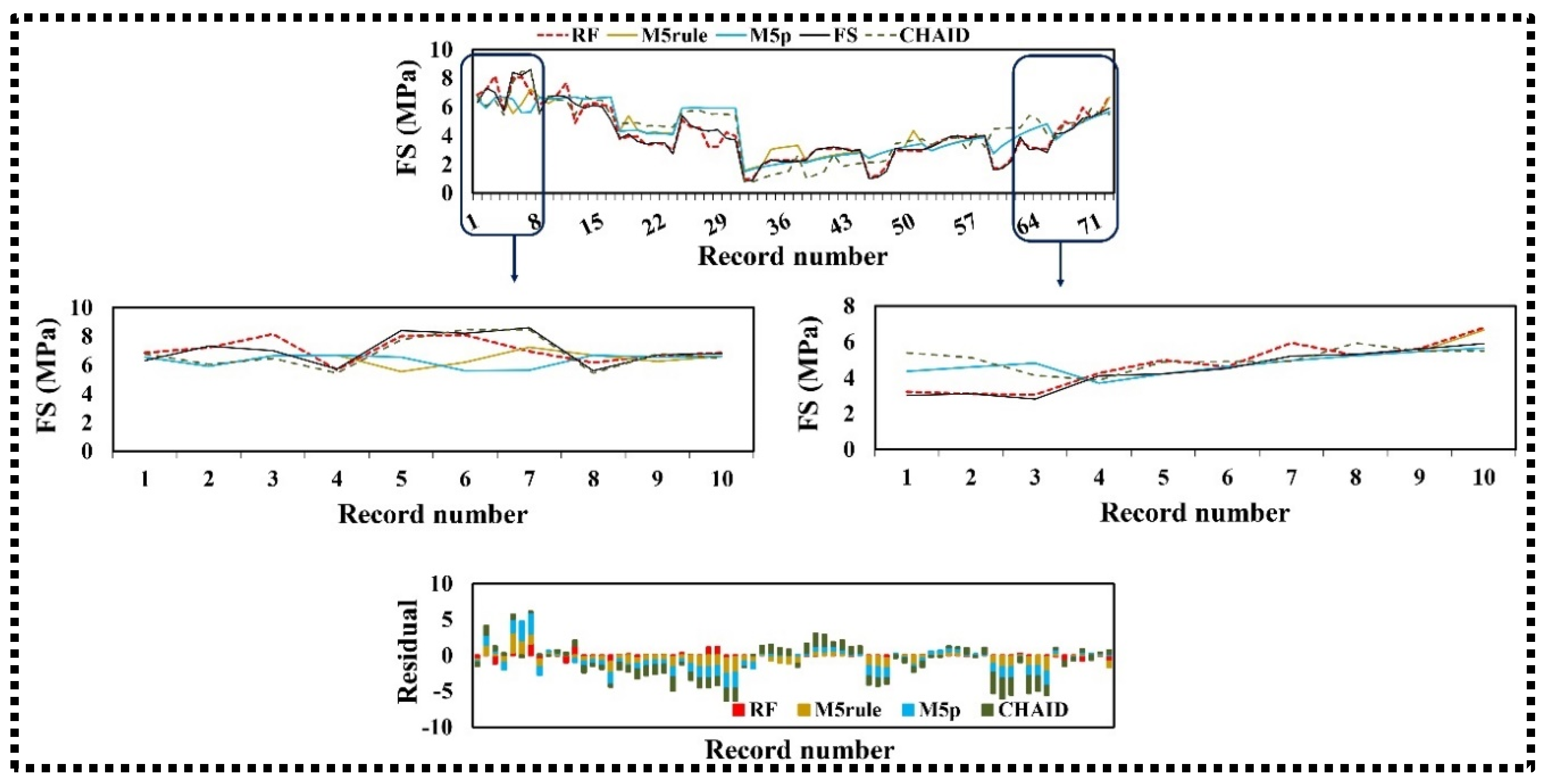
3.2.3. Flexural Strength
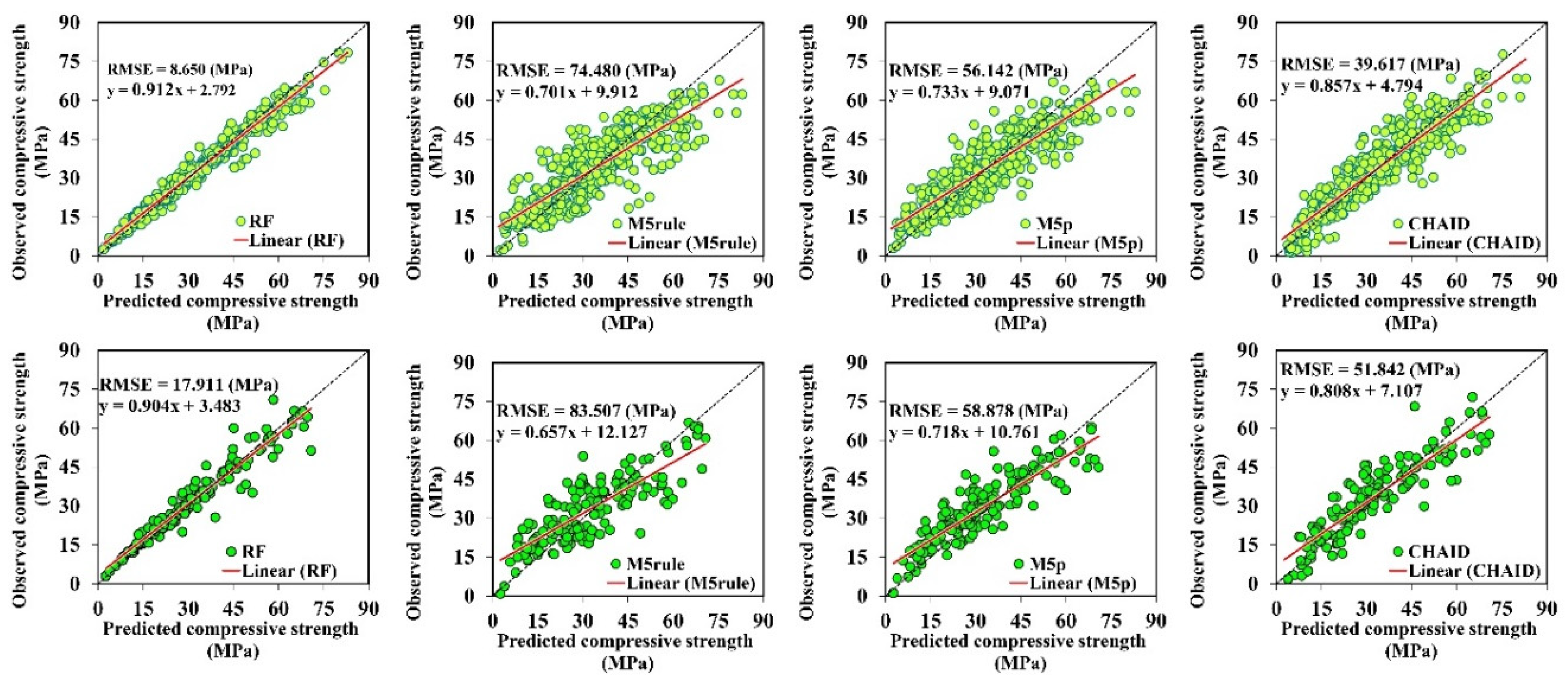
3.3. Model Validity
3.4. Sensitivity Analysis and Variable Importance
4. Conclusions
- Developing models based on RF, M5rule, M5p, and CHAID revealed that the CS, TS, and FS of RCCP are mainly related to the six inputs of CA, FA, SCM, W, B, and AS, as determined by PCA.
- The presented CS, TS, and FS-simulated values indicate that the RF method has greater precision compared with the other three tree-based techniques, with respect to R, NSE, RMSE, and RSD measures for the training and testing phases.
- The proposed RF and CHAID models met all of the required criteria of external validation.
- The Monte-Carlo uncertainty investigation of the implemented tree-based methods validated their robustness. Moreover, sensitivity analysis of variable importance revealed fine aggregate content to be the most important predictor influencing the mechanical characteristics of RCCP.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Linear Model | Coefficient | ||||||
|---|---|---|---|---|---|---|---|
| CA | FA | SCM | W | B | AS | X | |
| LM1 | 0.000 | 0.005 | −0.043 | −0.067 | 0.113 | 1.543 | −11.878 |
| LM2 | 0.010 | 0.002 | −0.039 | −0.078 | 0.082 | 1.681 | −8.495 |
| LM3 | 0.010 | 0.002 | −0.042 | −0.078 | 0.082 | 1.6815 | −7.7941 |
| LM4 | 0.010 | −0.001 | −0.024 | −0.084 | 0.0819 | 0.7478 | −2.6946 |
| LM5 | 0.005 | −0.013 | −0.048 | −0.220 | 0.265 | 1.068 | −23.049 |
| LM6 | 0.112 | −0.023 | −0.081 | −0.149 | 0.148 | 1.317 | −68.118 |
| LM7 | −0.016 | 0.001 | −0.072 | −0.100 | 0.251 | 0.104 | −4.059 |
| LM8 | 0.002 | −0.004 | −0.003 | 0.345 | 0.066 | 0.059 | −15.986 |
| LM9 | 0.002 | −0.004 | −0.003 | 0.293 | 0.066 | 0.058 | −5.490 |
| LM10 | 0.007 | −0.006 | −0.003 | 0.055 | 0.086 | 0.114 | 16.015 |
| LM11 | 0.009 | −31.824 | −0.003 | 0.055 | 0.086 | 0.074 | 36.545 |
| LM12 | −0.012 | −0.0003 | 0.049 | −0.236 | 0.083 | 0.116 | 50.6158 |
| Linear Model | Coefficient | ||||||
|---|---|---|---|---|---|---|---|
| CA | FA | SCM | W | B | AS | X | |
| LM1 | −0.004 | 0.0005 | −0.002 | −0.002 | −0.029 | 0.213 | 7.607 |
| LM2 | 0.001 | 0.0003 | −0.006 | −0.0008 | 0.002 | 0.015 | 0.004 |
| LM3 | 0.0004 | 0.0003 | 0.003 | 0.0003 | 0.002 | 0.174 | −0.0899 |
| LM4 | 0.000 | −0.006 | −0.004 | −0.003 | 0.003 | 0.125 | 9.550 |
| LM5 | 0.000 | −0.008 | −0.007 | −0.003 | 0.003 | 0.107 | 12.874 |
| LM6 | −0.0001 | 0.000 | −0.003 | −0.016 | 0.004 | 0.002 | 3.923 |
| LM7 | −0.0002 | 0.000 | −0.004 | −0.010 | 0.005 | 0.002 | 2.984 |
| LM8 | 0.0001 | −0.001 | −0.003 | −0.016 | 0.004 | 0.002 | 5.166 |
| LM9 | −0.0005 | 0.000 | −0.004 | −0.011 | 0.004 | 0.002 | 4.006 |
| LM10 | −0.0005 | 0.000 | −0.004 | −0.011 | 0.004 | 0.002 | 3.982 |
| LM11 | −0.0004 | 0.000 | −0.004 | −0.011 | 0.004 | 0.001 | 3.902 |
| LM12 | 0.0004 | −0.0003 | −0.002 | −0.002 | 0.003 | 0.004 | 2.258 |
| LM13 | 0.001 | 0.001 | 0.0009 | 0.011 | 0.006 | 0.005 | −1.933 |
| LM14 | 0.001 | 0.001 | 0.0009 | 0.002 | 0.006 | 0.010 | −1.058 |
| LM15 | 0.003 | 0.001 | 0.001 | 0.002 | 0.007 | 0.003 | −1.188 |
| LM16 | 0.001 | 0.0004 | 0.001 | 0.0005 | 0.004 | 0.004 | 1.367 |
| LM17 | 0.001 | 0.0006 | −0.001 | 0.0005 | 0.004 | 0.003 | 1.295 |
| LM18 | 0.001 | 0.0006 | −0.001 | 0.0005 | 0.004 | 0.003 | 1.195 |
| Linear Model | Coefficient | ||||||
|---|---|---|---|---|---|---|---|
| CA | FA | SCM | W | B | AS | X | |
| LM1 | 0.001 | 0.0001 | −0.009 | −0.003 | 0.011 | 0.283 | −1.899 |
| LM2 | 0.002 | 0.0001 | −0.001 | −0.013 | 0.015 | 0.037 | −1.207 |
| LM3 | 0.003 | 0.0001 | −0.0003 | −0.0008 | 0.017 | 0.012 | −3.863 |
References
- Hashemi, M.; Shafigh, P.; Bin Karim, M.R.; Atis, C.D. The effect of coarse to fine aggregate ratio on the fresh and hardened properties of roller-compacted concrete pavement. Constr. Build. Mater. 2018, 169, 553–566. [Google Scholar] [CrossRef]
- Modarres, A.; Hesami, S.; Soltaninejad, M.; Madani, H. Application of coal waste in sustainable roller compacted concrete pavement-environmental and technical assessment. Int. J. Pavement Eng. 2016, 19, 748–761. [Google Scholar] [CrossRef]
- Lam, M.N.-T.; Le, D.-H.; Jaritngam, S. Compressive strength and durability properties of roller-compacted concrete pavement containing electric arc furnace slag aggregate and fly ash. Constr. Build. Mater. 2018, 191, 912–922. [Google Scholar] [CrossRef]
- Chhorn, C.; Kim, Y.K.; Hong, S.J.; Lee, S.W. Evaluation on compactibility and workability of roller-compacted concrete for pavement. Int. J. Pavement Eng. 2017, 20, 905–910. [Google Scholar] [CrossRef]
- Adamu, M.; Mohammed, B.; Shafiq, N.; Liew, M.S. Durability performance of high volume fly ash roller compacted concrete pavement containing crumb rubber and nano silica. Int. J. Pavement Eng. 2018, 1–8. [Google Scholar] [CrossRef]
- Adamu, M.; Mohammed, B.; Liew, M.S. Mechanical properties and performance of high volume fly ash roller compacted concrete containing crumb rubber and nano silica. Constr. Build. Mater. 2018, 171, 521–538. [Google Scholar] [CrossRef]
- Ashrafian, A.; Gandomi, A.H.; Rezaie-Balf, M.; Emadi, M. An evolutionary approach to formulate the compressive strength of roller compacted concrete pavement. Measurement 2020, 152. [Google Scholar] [CrossRef]
- Taheri Amiri, M.J.; Ashrafian, A.; Haghighi, F.R.; Javaheri Barforooshi, M. Prediction of the Compressive Strength of Self-compacting Concrete containing Rice Husk Ash using Data Driven Models. Modares Civ. Eng. J. 2019, 19, 196–206. [Google Scholar]
- Rezaie-Balf, M.; Maleki, N.; Kim, S.; Ashrafian, A.; Babaie-Miri, F.; Kim, N.W.; Chung, I.-M.; Alaghmand, S. Forecasting Daily Solar Radiation Using CEEMDAN Decomposition-Based MARS Model Trained by Crow Search Algorithm. Energies 2019, 12, 1416. [Google Scholar] [CrossRef]
- Ashrafian, A.; Taheri, A.M.J.; Haghighi, F. Modeling the Slump Flow of Self-Compacting Concrete Incorporating Metakaolin Using Soft Computing Techniques. J. Syst. Control Eng. 2019, 5–20. [Google Scholar] [CrossRef]
- Amlashi, A.T.; Abdollahi, S.M.; Goodarzi, S.; Ghanizadeh, A.R. Soft computing based formulations for slump, compressive strength, and elastic modulus of bentonite plastic concrete. J. Clean. Prod. 2019, 230, 1197–1216. [Google Scholar] [CrossRef]
- Gholampour, A.; Gandomi, A.H.; Ozbakkaloglu, T. New formulations for mechanical properties of recycled aggregate concrete using gene expression programming. Constr. Build. Mater. 2017, 130, 122–145. [Google Scholar] [CrossRef]
- Asteris, P.G.; Armaghani, D.J.; Hatzigeorgiou, G.D.; Karayannis, C.G.; Pilakoutas, K. Predicting the shear strength of reinforced concrete beams using Artificial Neural Networks. Eng. Struct. 2019, 24, 469–488. [Google Scholar]
- Ly, H.B.; Pham, B.T.; Dao, D.V.; Le, V.M.; Le, L.M.; Le, T.T. Improvement of ANFIS Model for Prediction of Compressive Strength of Manufactured Sand Concrete. Appl. Sci. 2019, 9, 3841. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, J.; Gu, Y.; Huang, Y.; Sun, Y.; Ma, G. Prediction of permeability and unconfined compressive strength of pervious concrete using evolved support vector regression. Constr. Build. Mater. 2019, 207, 440–449. [Google Scholar] [CrossRef]
- Ashrafian, A.; Shokri, F.; Amiri, M.J.T.; Yaseen, Z.M.; Rezaie-Balf, M. Compressive strength of Foamed Cellular Lightweight Concrete simulation: New development of hybrid artificial intelligence model. Constr. Build. Mater. 2020, 230, 117048. [Google Scholar] [CrossRef]
- Deng, F.; He, Y.; Zhou, S.; Yu, Y.; Cheng, H.; Wu, X. Compressive strength prediction of recycled concrete based on deep learning. Constr. Build. Mater. 2018, 175, 562–569. [Google Scholar] [CrossRef]
- Karballaeezadeh, N.; Zaremotekhases, F.; Shamshirband, S.; Mosavi, A.; Nabipour, N.; Csiba, P.; Várkonyi-Kóczy, A.R. Intelligent Road Inspection with Advanced Machine Learning; Hybrid Prediction Models for Smart Mobility and Transportation Maintenance Systems. Energies 2020, 13, 1718. [Google Scholar] [CrossRef]
- Shahmansouri, A.A.; Bengar, H.A.; Jahani, E. Predicting compressive strength and electrical resistivity of eco-friendly concrete containing natural zeolite via GEP algorithm. Constr. Build. Mater. 2019, 229, 116883. [Google Scholar] [CrossRef]
- Feng, D.-C.; Liu, Z.-T.; Wang, X.-D.; Chen, Y.; Chang, J.-Q.; Wei, D.-F.; Jiang, Z. Machine learning-based compressive strength prediction for concrete: An adaptive boosting approach. Constr. Build. Mater. 2020, 230, 117000. [Google Scholar] [CrossRef]
- Iqbal, M.F.; Liu, Q.-F.; Azim, I.; Zhu, X.; Yang, J.; Javed, M.F.; Rauf, M. Prediction of mechanical properties of green concrete incorporating waste foundry sand based on gene expression programming. J. Hazard. Mater. 2020, 384, 121322. [Google Scholar] [CrossRef]
- Asteris, P.G.; Ashrafian, A.; Rezaie-Balf, M. Prediction of the compressive strength of self-compacting concrete using surrogate models. Comput. Concr. 2019, 24, 137–150. [Google Scholar]
- Golafshani, E.M.; Behnood, A.; Arashpour, M. Predicting the compressive strength of normal and High-Performance Concretes using ANN and ANFIS hybridized with Grey Wolf Optimizer. Constr. Build. Mater. 2020, 232, 117266. [Google Scholar] [CrossRef]
- Yoon, J.Y.; Kim, H.; Lee, Y.-J.; Sim, S.-H. Prediction Model for Mechanical Properties of Lightweight Aggregate Concrete Using Artificial Neural Network. Materials 2019, 12, 2678. [Google Scholar] [CrossRef] [PubMed]
- Van Dao, D.; Ly, H.-B.; Trinh, S.H.; Le, T.-T.; Pham, B.T. Artificial Intelligence Approaches for Prediction of Compressive Strength of Geopolymer Concrete. Materials 2019, 12, 983. [Google Scholar] [CrossRef]
- Sun, L.; Koopialipoor, M.; Armaghani, D.J.; Tarinejad, R.; Tahir, M.M. Applying a meta-heuristic algorithm to predict and optimize compressive strength of concrete samples. Eng. Comput. 2019, 1–13. [Google Scholar] [CrossRef]
- Moayedi, H.; Kalantar, B.; Foong, L.K.; Bui, T.; Motevalli, A.; Bui, D.T. Application of Three Metaheuristic Techniques in Simulation of Concrete Slump. Appl. Sci. 2019, 9, 4340. [Google Scholar] [CrossRef]
- Hassan, M.; Khalil, A.; Kaseb, S.; Kassem, M. Exploring the potential of tree-based ensemble methods in solar radiation modeling. Appl. Energy 2017, 203, 897–916. [Google Scholar] [CrossRef]
- Fan, J.; Yue, W.; Wu, L.; Zhang, F.; Cai, H.; Wang, X.; Lu, X.; Xiang, Y. Evaluation of SVM, ELM and four tree-based ensemble models for predicting daily reference evapotranspiration using limited meteorological data in different climates of China. Agric. For. Meteorol. 2018, 263, 225–241. [Google Scholar] [CrossRef]
- Behnood, A.; Olek, J.; Glinicki, M.A. Predicting modulus elasticity of recycled aggregate concrete using M5′ model tree algorithm. Constr. Build. Mater. 2015, 94, 137–147. [Google Scholar] [CrossRef]
- Behnood, A.; Behnood, V.; Gharehveran, M.M.; Alyamaç, K.E. Prediction of the compressive strength of normal and high-performance concretes using M5P model tree algorithm. Constr. Build. Mater. 2017, 142, 199–207. [Google Scholar] [CrossRef]
- Han, Q.; Gui, C.; Xu, J.; Lacidogna, G. A generalized method to predict the compressive strength of high-performance concrete by improved random forest algorithm. Constr. Build. Mater. 2019, 226, 734–742. [Google Scholar] [CrossRef]
- Mohamed, O.A.; Ati, M.; Najm, O.F. Predicting Compressive Strength of Sustainable Self-Consolidating Concrete Using Random Forest. In Key Engineering Materials; Trans Tech Publications: New York, NY, USA, 2017; Volume 744, pp. 141–145. [Google Scholar] [CrossRef]
- Ashrafian, A.; Amiri, M.J.T.; Rezaie-Balf, M.; Ozbakkaloglu, T.; Lotfi-Omran, O. Prediction of compressive strength and ultrasonic pulse velocity of fiber reinforced concrete incorporating nano silica using heuristic regression methods. Constr. Build. Mater. 2018, 190, 479–494. [Google Scholar] [CrossRef]
- Gholampour, A.; Mansouri, I.; Kisi, O.; Ozbakkaloglu, T. Evaluation of mechanical properties of concretes containing coarse recycled concrete aggregates using multivariate adaptive regression splines (MARS), M5 model tree (M5Tree), and least squares support vector regression (LSSVR) models. Neural Comput. Appl. 2018, 32, 295–308. [Google Scholar] [CrossRef]
- AzariJafari, H.; Amiri, M.J.T.; Ashrafian, A.; Rasekh, H.; Barforooshi, M.J.; Berenjian, J. Ternary blended cement: An eco-friendly alternative to improve resistivity of high-performance self-consolidating concrete against elevated temperature. J. Clean. Prod. 2019, 223, 575–586. [Google Scholar] [CrossRef]
- Ramezanianpour, A.A.; Mohammadi, A.; Dehkordi, E.R.; Chenar, Q.B. Mechanical properties and durability of roller compacted concrete pavements in cold regions. Constr. Build. Mater. 2017, 146, 260–266. [Google Scholar] [CrossRef]
- Kokubu, K.; Anzaki, Y. State of the Art Report on Roller Compacted Concrete Pavements. Concr. J. 1989, 27, 22–30. [Google Scholar] [CrossRef]
- Rao, S.K.; Sravana, P.; Rao, T.C. Strength and Compaction Characteristics of Fly Ash Roller Compacted Concrete. Int. J. Sci. Res. Knowl. 2015, 3, 260–269. [Google Scholar] [CrossRef]
- Mardani-Aghabaglou, A.; Ramyar, K. Mechanical properties of high-volume fly ash roller compacted concrete designed by maximum density method. Constr. Build. Mater. 2013, 38, 356–364. [Google Scholar] [CrossRef]
- Pavan, S.; Rao, S.K. Effect of Fly ash on Strength Characteristics of Roller Compacted Concrete Pavement. IOSR J. Mech. Civ. Eng. 2014, 11, 4–8. [Google Scholar] [CrossRef]
- Atiş, C.D.; Sevim, U.; Özcan, F.; Bilim, C.; Karahan, O.; Tanrikulu, A.; Eksi, A. Strength properties of roller compacted concrete containing a non-standard high calcium fly ash. Mater. Lett. 2004, 58, 1446–1450. [Google Scholar] [CrossRef]
- Tangtermsirikul, S.; Kaewkhluab, T.; Jitvutikrai, P. A compressive strength model for roller-compacted concrete with fly ash. Mag. Concr. Res. 2004, 56, 35–44. [Google Scholar] [CrossRef]
- Rao, S.K.; Sravana, P.; Rao, T.C. Experimental studies in Ultrasonic Pulse Velocity of roller compacted concrete pavement containing fly ash and M-sand. Int. J. Pavement Res. Technol. 2016, 9, 289–301. [Google Scholar] [CrossRef]
- Cao, C.; Sun, W.; Qin, H. The analysis on strength and fly ash effect of roller-compacted concrete with high volume fly ash. Cem. Concr. Res. 2000, 30, 71–75. [Google Scholar] [CrossRef]
- Rao, S.K.; Sravana, P.; Rao, T.C. Investigation on pozzolanic effect of Fly ash in Roller Compacted Concrete pavement. IRACST-Eng. Sci. Technol. Int. J. 2015, 5, 202–206. [Google Scholar]
- Ghahari, S.; Mohammadi, A.; Ramezanianpour, A. Performance assessment of natural pozzolan roller compacted concrete pavements. Case Stud. Constr. Mater. 2017, 7, 82–90. [Google Scholar] [CrossRef]
- Mohammed, B.S.; Adamu, M. Mechanical performance of roller compacted concrete pavement containing crumb rubber and nano silica. Constr. Build. Mater. 2018, 159, 234–251. [Google Scholar] [CrossRef]
- Debbarma, S.; Ransinchung, G.D.; Singh, S. Feasibility of roller compacted concrete pavement containing different fractions of reclaimed asphalt pavement. Constr. Build. Mater. 2019, 199, 508–525. [Google Scholar] [CrossRef]
- Fardin, H.E.; Santos, A.G. Roller Compacted Concrete with Recycled Concrete Aggregate for Paving Bases. Sustainability 2020, 12, 3154. [Google Scholar] [CrossRef]
- Lam, M.N.-T.; Jaritngam, S.; Le, D.-H. EAF Slag Aggregate in Roller-Compacted Concrete Pavement: Effects of Delay in Compaction. Sustainability 2018, 10, 1122. [Google Scholar] [CrossRef]
- Mohammadzadeh S., D.; Kazemi, S.-F.; Nasseralshariati, E.; Tah, J.H.M. Prediction of Compression Index of Fine-Grained Soils Using a Gene Expression Programming Model. Infrastructures 2019, 4, 26. [Google Scholar] [CrossRef]
- Shamsaei, M.; Aghayan, I.; Kazemi, K.A. Experimental investigation of using cross-linked polyethylene waste as aggregate in roller compacted concrete pavement. J. Clean. Prod. 2017, 165, 290–297. [Google Scholar] [CrossRef]
- Hesami, S.; Modarres, A.; Soltaninejad, M.; Madani, H. Mechanical properties of roller compacted concrete pavement containing coal waste and limestone powder as partial replacements of cement. Constr. Build. Mater. 2016, 111, 625–636. [Google Scholar] [CrossRef]
- Nabipour, N.; Karballaeezadeh, N.; Dineva, A.; Mosavi, A.; Mohammadzadeh S., D.; Shamshirband, S. Comparative Analysis of Machine Learning Models for Prediction of Remaining Service Life of Flexible Pavement. Mathematics 2019, 7, 1198. [Google Scholar] [CrossRef]
- Rao, S.K.; Sravana, P.; Rao, T.C. Abrasion resistance and mechanical properties of Roller Compacted Concrete with GGBS. Constr. Build. Mater. 2016, 114, 925–933. [Google Scholar] [CrossRef]
- Karballaeezadeh, N.; Mohammadzadeh S., D.; Moazami, D.; Nabipour, N.; Mosavi, A.; Reuter, U. Smart Structural Health Monitoring of Flexible Pavements Using Machine Learning Methods. Preprints 2020, 2020040029. [Google Scholar] [CrossRef]
- Karballaeezadeh, N.; Mohammadzadeh S., D.; Shamshirband, S.; Hajikhodaverdikhan, P.; Mosavi, A.; Chau, K.W. Prediction of remaining service life of pavement using an optimized support vector machine (case study of Semnan–Firuzkuh road). Eng. Appl. Comput. Fluid Mech. 2019, 13, 188–198. [Google Scholar]
- Sheikh Khozani, Z.; Sheikhi, S.; Mohtar, W.H.M.W.; Mosavi, A. Forecasting shear stress parameters in rectangular channels using new soft computing methods. PLoS ONE 2020, 15, e0229731. [Google Scholar] [CrossRef]
- Rashad, A.M. A preliminary study on the effect of fine aggregate replacement with metakaolin on strength and abrasion resistance of concrete. Constr. Build. Mater. 2013, 44, 487–495. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Adusumilli, S.; Bhatt, D.; Wang, H.; Bhattacharya, P.; Devabhaktuni, V. A low-cost INS/GPS integration methodology based on random forest regression. Expert Syst. Appl. 2013, 40, 4653–4659. [Google Scholar] [CrossRef]
- Zhou, J.; Shi, X.; Du, K.; Qiu, X.; Li, X.; Mitri, H. Feasibility of Random-Forest Approach for Prediction of Ground Settlements Induced by the Construction of a Shield-Driven Tunnel. Int. J. Géoméch. 2017, 17, 04016129. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Mitri, H. Comparative performance of six supervised learning methods for the development of models of hard rock pillar stability prediction. Nat. Hazards 2015, 79, 291–316. [Google Scholar] [CrossRef]
- Troncoso, A.; Salcedo-Sanz, S.; Casanova-Mateo, C.; Riquelme, J.C.; Prieto, L. Local models-based regression trees for very short-term wind speed prediction. Renew. Energy 2015, 81, 589–598. [Google Scholar] [CrossRef]
- Arnett, F.C.; Edworthy, S.M.; Bloch, D.A.; McShane, D.J.; Fries, J.F.; Cooper, N.S.; Healey, L.A.; Kaplan, S.R.; Liang, M.H.; Luthra, H.S.; et al. The american rheumatism association 1987 revised criteria for the classification of rheumatoid arthritis. Arthritis Rheum. 1988, 31, 315–324. [Google Scholar] [CrossRef]
- Quinlan, J.R. Learning with Continuous Classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence, Hobart, Tasmania, Australia, 16–18 November 1992. [Google Scholar]
- Mitchell, T.M. Machine learning and data mining. Commun. ACM 1999, 42, 30–36. [Google Scholar] [CrossRef]
- Abdelkader, S.S.; Grolinger, K.; Capretz, M.A. Predicting Energy Demand Peak Using M5 Model Trees. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 509–514. [Google Scholar]
- Attar, N.F.; Pham, Q.B.; Nowbandegani, S.; Rezaie-Balf, M.; Fai, C.M.; Ahmed, A.N.; Pipelzadeh, S.; Tran, D.D.; Nhi, P.T.T.; Dao, N.-K.; et al. Enhancing the Prediction Accuracy of Data-Driven Models for Monthly Streamflow in Urmia Lake Basin Based upon the Autoregressive Conditionally Heteroskedastic Time-Series Model. Appl. Sci. 2020, 10, 571. [Google Scholar] [CrossRef]
- Kass, G.V. An Exploratory Technique for Investigating Large Quantities of Categorical Data. J. R. Stat. Soc. Ser. C Appl. Stat. 1980, 29, 119. [Google Scholar] [CrossRef]
- Kamber, M.; Pei, J. Data Mining; Morgan Kaufmann: New York, NY, USA, 2006. [Google Scholar]
- Sharp, A. The Performance of Segmentation Variables: A Comparative Study. Ph.D. Thesis, University of Otago, Otago, New Zealand, 1998. [Google Scholar]
- Gallagher, C.A.; Monroe, H.M.; Fish, J.L. An Iterative Approach to Classification Analysis. J. Appl. Stat. 2000, 29, 256–266. [Google Scholar]
- Lungu, C.; Ersali, S.; Szefler, B.; Pîrvan-Moldovan, A.; Basak, S.; Diudea, M. Dimensionality of big data sets explored by Cluj descriptors. Studia Univ. Babeș-Bolyai Chem. 2017, 62, 197–204. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysis, 2nd ed.; Springer: New York, NY, USA, 2002; ISBN 978-0-387-95442-4. [Google Scholar]
- Gosav, S.; Praisler, M.; Birsa, L.M. Principal Component Analysis Coupled with Artificial Neural Networks—A Combined Technique Classifying Small Molecular Structures Using a Concatenated Spectral Database. Int. J. Mol. Sci. 2011, 12, 6668–6684. [Google Scholar] [CrossRef] [PubMed]
- Defernez, M.; Kemsley, E.K. Avoiding overfitting in the analysis of high-dimensional data with artificial neural networks (ANNs). Analyst 1999, 124, 1675–1681. [Google Scholar] [CrossRef]
- Golbraikh, A.; Tropsha, A. Beware of q2! J. Mol. Graph. Model. 2002, 20, 269–276. [Google Scholar] [CrossRef]
- Sattar, A.M.A. Gene Expression Models for the Prediction of Longitudinal Dispersion Coefficients in Transitional and Turbulent Pipe Flow. J. Pipeline Syst. Eng. Pr. 2014, 5, 04013011. [Google Scholar] [CrossRef]
- Roy, P.P.; Roy, K. On Some Aspects of Variable Selection for Partial Least Squares Regression Models. QSAR Comb. Sci. 2008, 27, 302–313. [Google Scholar] [CrossRef]
- Landau, D.P. An Introduction To Monte Carlo Methods in Statistical Physics; World Scientific Pub Co Pte Ltd.: Singapore, 2005; pp. 53–91. [Google Scholar]
- Newcombe, R.G. Two-sided confidence intervals for the single proportion: Comparison of seven methods. Stat. Med. 1998, 17, 857–872. [Google Scholar] [CrossRef]
- Abessi, O.; Eshtehardian, E.; Haghighi, F.; Taheri, M.J. Optimization of Time, Cost, and Quality in Critical Chain Method Using Simulated Annealing (RESEARCH NOTE). Int. J. Eng. 2017, 30, 627–635. [Google Scholar]
- Kuncheva, L.I.; Whitaker, C. Measures of Diversity in Classifier Ensembles and Their Relationship with the Ensemble Accuracy. Mach. Learn. 2003, 51, 181–207. [Google Scholar] [CrossRef]
- Zhang, H.; Zhou, J.; Armaghani, D.J.; Tahir, M.M.; Pham, B.T.; Huynh, V. A Combination of Feature Selection and Random Forest Techniques to Solve a Problem Related to Blast-Induced Ground Vibration. Appl. Sci. 2020, 10, 869. [Google Scholar] [CrossRef]










| Variable | PC1 | PC2 | PC3 | PC4 | PC5 | PC6 | PC8 | PC9 | PC10 |
|---|---|---|---|---|---|---|---|---|---|
| CA | 0.262 | −0.942 | 0.187 | 0.086 | −0.028 | −0.001 | 0.000 | 0.000 | 0.000 |
| FA | −0.959 | −0.244 | 0.054 | 0.113 | −0.065 | −0.007 | 0.000 | 0.000 | 0.000 |
| C | 0.011 | 0.168 | 0.777 | 0.151 | 0.108 | 0.007 | 0.003 | 0.000 | 0.001 |
| W/B | 0.000 | 0.000 | 0.000 | −0.001 | 0.000 | 0.007 | −0.113 | −0.993 | 0.019 |
| SCM | 0.046 | −0.043 | −0.546 | 0.600 | 0.069 | 0.004 | −0.002 | 0.000 | −0.002 |
| W | 0.072 | 0.082 | 0.081 | 0.187 | −0.971 | −0.056 | −0.003 | 0.000 | 0.001 |
| B | 0.057 | 0.125 | 0.231 | 0.750 | 0.178 | 0.011 | 0.001 | −0.001 | −0.001 |
| W/C | 0.000 | 0.000 | −0.003 | 0.001 | −0.004 | 0.001 | 0.986 | −0.115 | −0.117 |
| SCM/B | 0.000 | 0.000 | −0.002 | 0.001 | 0.000 | 0.000 | 0.118 | 0.006 | 0.993 |
| CA/FA | −0.003 | 0.000 | 0.000 | 0.000 | −0.058 | 0.998 | 0.000 | 0.007 | 0.000 |
| EV | 0.513 | 0.326 | 0.098 | 0.054 | 0.008 | 0.000 | 0.000 | 0.000 | 0.000 |
| CS | 0.513 | 0.839 | 0.937 | 0.991 | 1 | 1 | 1 | 1 | 1 |
| Variables | Mean | Standard Deviation | Median | Kurtosis | Skewness | Minimum | Maximum |
|---|---|---|---|---|---|---|---|
| CA | 1014.9 | 184.2 | 1095 | −0.68 | −0.62 | 585 | 1325 |
| FA | 855.87 | 225.7 | 807 | −0.13 | −0.22 | 272.5 | 1263 |
| SCM | 86.26 | 72.23 | 90 | −0.7 | 0.44 | 0 | 272.5 |
| W | 129.29 | 39.57 | 117 | 7.5 | 2.26 | 78 | 336.25 |
| B | 311.6 | 66.44 | 295 | 8.34 | 2.12 | 200 | 672.5 |
| AS | 35.54 | 42.55 | 28 | 2.25 | 1.6 | 1 | 180 |
| CS | 33.276 | 16.553 | 31.4 | −0.46 | 0.38 | 1.88 | 83 |
| TS | 3.1828 | 1.2761 | 3.2 | −0.25 | 0.08 | 0.14 | 6.4 |
| FS | 4.498 | 1.864 | 4.55 | −0.47 | 0.07 | 0.4 | 8.9 |
| Phase | Proposed Models | Performance Metrics | |||
|---|---|---|---|---|---|
| R | NSE | RMSE | RSD | ||
| Training | RF | 0.986 | 0.968 | 8.650 | 0.561 |
| M5rule | 0.855 | 0.731 | 74.480 | 5.460 | |
| M5p | 0.896 | 0.797 | 56.142 | 4.122 | |
| CHAID | 0.925 | 0.857 | 39.617 | 2.570 | |
| Testing | RF | 0.965 | 0.931 | 17.911 | 1.181 |
| M5rule | 0.828 | 0.680 | 83.507 | 6.499 | |
| M5p | 0.889 | 0.774 | 58.878 | 4.507 | |
| CHAID | 0.897 | 0.801 | 51.842 | 3.556 | |
| Phase | Proposed Models | Performance Metrics | |||
|---|---|---|---|---|---|
| R | NSE | RMSE | RSD | ||
| Training | RF | 0.991 | 0.981 | 0.030 | 0.025 |
| M5rule | 0.892 | 0.791 | 0.338 | 0.320 | |
| M5p | 0.895 | 0.798 | 0.328 | 0.294 | |
| CHAID | 0.975 | 0.951 | 0.078 | 0.024 | |
| Testing | RF | 0.984 | 0.955 | 0.070 | 0.062 |
| M5rule | 0.850 | 0.706 | 0.471 | 0.500 | |
| M5p | 0.882 | 0.776 | 0.358 | 0.328 | |
| CHAID | 0.912 | 0.817 | 0.293 | 0.255 | |
| Phase | Proposed Models | Performance Metrics | |||
|---|---|---|---|---|---|
| R | NSE | RMSE | RSD | ||
| Training | RF | 0.988 | 0.974 | 0.086 | 0.049 |
| M5rule | 0.937 | 0.878 | 0.416 | 0.234 | |
| M5p | 0.887 | 0.782 | 0.705 | 0.435 | |
| CHAID | 0.925 | 0.849 | 0.516 | 0.288 | |
| Testing | RF | 0.970 | 0.939 | 0.197 | 0.108 |
| M5rule | 0.853 | 0.673 | 1.068 | 0.689 | |
| M5p | 0.843 | 0.683 | 1.033 | 0.644 | |
| CHAID | 0.846 | 0.651 | 1.138 | 0.612 | |
| Model | K | K′ | m | n | Rm | |
|---|---|---|---|---|---|---|
| CS | RF | 0.995 | 0.990 | −0.071 | −0.071 | 0.691 |
| M5rule | 0.978 | 0.955 | −0.452 | −0.444 | 0.303 | |
| M5p | 0.971 | 0.984 | −0.254 | −0.261 | 0.436 | |
| CHAID | 0.986 | 0.983 | −0.238 | −0.240 | 0.552 | |
| TS | RF | 1.035 | 0.961 | −0.020 | −0.019 | 0.834 |
| M5rule | 1.038 | 0.927 | −0.358 | −0.328 | 0.354 | |
| M5p | 1.014 | 0.956 | −0.282 | −0.266 | 0.413 | |
| CHAID | 1.044 | 0.936 | −0.181 | −0.164 | 0.508 | |
| FS | RF | 0.984 | 1.006 | −0.060 | −0.061 | 0.716 |
| M5rule | 0.914 | 1.043 | −0.278 | −0.356 | 0.400 | |
| M5p | 0.934 | 1.018 | −0.355 | −0.402 | 0.353 | |
| CHAID | 0.910 | 1.043 | −0.324 | −0.380 | 0.370 | |
| Model | Se | Median | MAD | Uncertainty (%) | ||
|---|---|---|---|---|---|---|
| CS | RF | 0.174 | 8.765 | 34.181 | 11.302 | 33.065 |
| M5rule | −0.017 | 3.313 | 32.539 | 12.530 | 38.509 | |
| M5p | 0.221 | 6.533 | 33.789 | 12.374 | 36.622 | |
| CHAID | 0.499 | 7.527 | 33.724 | 11.210 | 33.240 | |
| TS | RF | 0.004 | 0.004 | 3.168 | 0.836 | 26.393 |
| M5rule | −0.038 | 0.361 | 3.091 | 0.973 | 31.507 | |
| M5p | −0.012 | 0.201 | 3.108 | 0.943 | 30.346 | |
| CHAID | 0.048 | 0.578 | 3.116 | 0.883 | 28.348 | |
| FS | RF | −0.026 | 0.905 | 4.586 | 1.377 | 30.026 |
| M5rule | 0.104 | 0.754 | 4.568 | 1.428 | 31.275 | |
| M5p | 0.008 | 0.338 | 4.563 | 1.455 | 31.896 | |
| CHAID | 0.188 | 0.798 | 4.806 | 1.447 | 30.119 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ashrafian, A.; Taheri Amiri, M.J.; Masoumi, P.; Asadi-shiadeh, M.; Yaghoubi-chenari, M.; Mosavi, A.; Nabipour, N. Classification-Based Regression Models for Prediction of the Mechanical Properties of Roller-Compacted Concrete Pavement. Appl. Sci. 2020, 10, 3707. https://doi.org/10.3390/app10113707
Ashrafian A, Taheri Amiri MJ, Masoumi P, Asadi-shiadeh M, Yaghoubi-chenari M, Mosavi A, Nabipour N. Classification-Based Regression Models for Prediction of the Mechanical Properties of Roller-Compacted Concrete Pavement. Applied Sciences. 2020; 10(11):3707. https://doi.org/10.3390/app10113707
Chicago/Turabian StyleAshrafian, Ali, Mohammad Javad Taheri Amiri, Parisa Masoumi, Mahsa Asadi-shiadeh, Mojtaba Yaghoubi-chenari, Amir Mosavi, and Narjes Nabipour. 2020. "Classification-Based Regression Models for Prediction of the Mechanical Properties of Roller-Compacted Concrete Pavement" Applied Sciences 10, no. 11: 3707. https://doi.org/10.3390/app10113707
APA StyleAshrafian, A., Taheri Amiri, M. J., Masoumi, P., Asadi-shiadeh, M., Yaghoubi-chenari, M., Mosavi, A., & Nabipour, N. (2020). Classification-Based Regression Models for Prediction of the Mechanical Properties of Roller-Compacted Concrete Pavement. Applied Sciences, 10(11), 3707. https://doi.org/10.3390/app10113707