In this section, several research questions on the BLSTM neural network for malicious JavaScript detection are proposed. This can help us objectively evaluate the effectiveness of the method proposed in this paper. To this end, we propose comprehensive experiments to answer these questions:
RQ2: How effective is the BLSTM neural network compared to other machine learning-based detection methods?
RQ3: What is the influence of obfuscation on the BLSTM neural network and other learning-based detection methods?
5.1. Dataset Preprocessing
We collected 60380 raw benign and malicious samples with a total size of more than 3.1 GB. To prevent duplication of data from multiple data sources, we calculated the MD5 of each sample to ensure that each sample is unique.
As for malicious samples, 29893 files (
Table 4) were collected from HynekPatrak [
48], geeksonsecurity [
49] and Wang Wei’s dataset [
50]. Most of these malicious samples are JavaScript files. For HTML files, we manually extracted the JavaScript code from the <script> tags and stored them as a JavaScript file. Almost all samples were obfuscated, e.g., through data obfuscation or encoding obfuscation.
As for benign samples, we collected JavaScript files in Alexa [
51] top sites. We believe that the JavaScript files from these sites are safe, because subjectively these sites have no motive to do evil, and objectively there are a large number of security engineers to protect these sites. For each website, we first visited their homepage, then visited the same domain link on the homepage to collect dynamically generated scripts. For inline scripts in HTML, we extracted the JavaScript code and stored it as a JavaScript file in the original order. In this way, we obtained 30487 unique benign samples. In order to ensure that these JavaScript files are benign, we checked them with anti-virus software. Skolka et al. [
52] indicate that more than 30% of developers obfuscate their scripts and more than 55% of third-party scripts are obfuscated. Therefore, there should also be a certain proportion of obfuscated scripts in our benign samples.
We constructed two new datasets, DB_DeOb and DB_Ob, based on the collected raw data (called DB_Raw). The dataset DB_DeOb contains only deobfuscated scripts. We combined deobfuscation tools and manual analysis to deobfuscate 1227 malicious samples and 1516 benign samples. It should be noted that there is currently no strict definition of obfuscated code and deobfuscated code, so we consider the code that meets the following two conditions to be successful in deobfuscating:
Condition 1: The variables and strings in the code are not encoded by Unicode, ASCII, etc.
Condition 2: Compared with before processing, the clarity of the processed code logic has been significantly improved.
The dataset DB_Ob consists only of obfuscated codes. In order to construct DB_Ob, we collected 9892 benign samples and 9721 malicious samples from DB_Raw with conspicuous feature of obfuscation.
Table 5 gives the details of these datasets.
5.2. Measurement Metrics
We leverage accuracy, precision, recall, and F1-score to evaluate the effectiveness of BLSTM neural network in detecting malicious JavaScript. In general, the effectiveness of a model is evaluated by the accuracy rate, i.e.,
where
represents the number of samples that predict correctly, and
represents the total number of samples in the dataset. However, it is not enough to evaluate the performance of the model based on accuracy alone, so we choose precision and recall as supplements. The precision refers to the ratio of true positive malicious JavaScript to the total number of samples detected as malicious, i.e.,
where
is the number of samples with malware JavaScript detected correctly, and
is the number of samples with false malicious JavaScript detected. The recall measures the ratio of true positive malware JavaScript to the entire population of malicious JavaScript samples, i.e.,
where
is the number of samples with true malicious JavaScript undetected. F1-score takes into account both precision and recall, that is:
Ideally, our detector should not miss any malicious code and not trigger false alarms, that is, it both has high precision and recall at the same time, but these two indicators are mutually exclusive in some scenarios. For example, if only one sample is taken, and the sample is also a positive sample, then the precision = 1.0, and recall may be lower (because there may be multiple samples in the dataset). As a comprehensive index, the F1-score is to evaluate a classifier comprehensively in order to balance the influence of precision and recall.
5.4. Runtime Performance
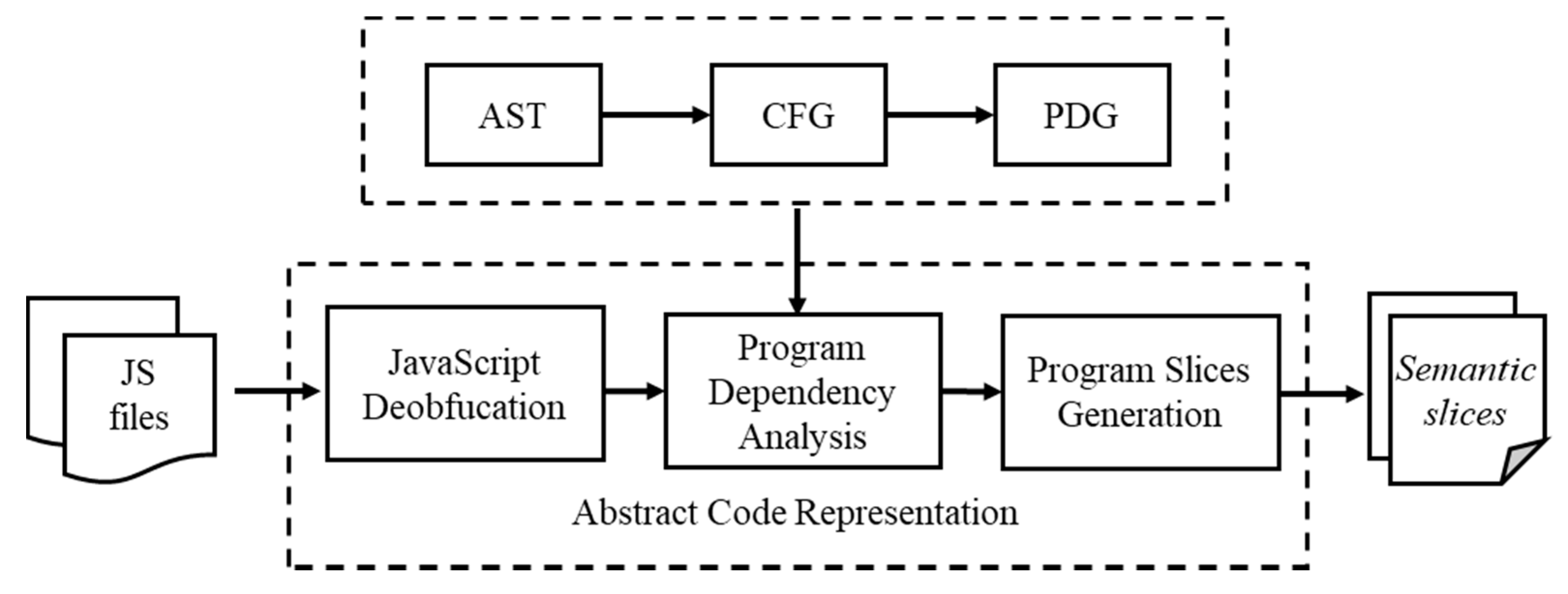
In order to comprehensively evaluate the performance of BLSTM neural network, we gather statistics on the time consumption in each of the stages. We randomly select 2000 unique samples, half of which are benign and half of which are malicious and that recorded the time consumption. As for abstract code representation,
Table 7 shows the minimum, maximum, average, and median time consumption at each stage, for one file. As we can see, deobfuscation takes the least amount of time, and a file takes only 18 ms on average. The generation of AST is divided into two steps, one is to parse JavaScript files with Esprima [
33], the other is to construct the AST, which makes the process take a little longer, with an average of 96 ms per file. The more time-consuming stage is to generate the PDG, which largely depends on the size of the AST, because we have to traverse it several times to add data dependencies. The generation of
semantic slices takes the most time, with an average of 233 ms, because this process requires traversing the PDG and finding the corresponding source code statements at the same time. In general, the more complex code representation causes higher overhead, but this also makes the code abstract representation preserve more semantic information.
Since the input vector dimensions of BLSTM neural networks are fixed, the time consumption per sample is similar.
Table 8 shows the average time of each stage of learning the BLSTM neural network, for one file. As we can see, in the learning phase, the model spends an average of 0.241 ms processing a file, and in the classification phase, the model spends an average of 2.765 ms process a file.
For one JavaScript sample, the detection time is approximately the sum of the average time for generating the abstract code representation (from deobfuscation to
semantic slice generation) and the average time for the classifier. Based on the data in
Table 7 and
Table 8, the detection time is 595 ms. Considering that the average size of JavaScript samples is 32KB, we think this overhead is reasonable.
5.5. Detection Performance
Answer to RQ1: As shown in
Table 9, the BLSTM neural network achieves a good performance. The accuracy of the BLSTM neural network reached 97.71%, which indicates that most malicious samples can be accurately found during the test. At the same time, the model also achieved a recall rate of 97.91%, which means that it caused very few false positives. The F1-score is the harmonic mean of the precision and recall, where an F1 score reaches its best value at 1. It is one of the most important measurements for evaluating a model’s performance. The F1-score of the BLSTM neural network reached a very high value of 98.29%, which means our model achieves higher rates of true positives with lower rates of false positives.
Therefore, we conclude that the BLSTM neural network is extremely effective in detecting malicious JavaScript.
Answer to RQ2: In order to compare with other malicious code detection approaches, we chose three widely used machine learning models, a malicious JavaScript detection tool and an antivirus software. As shown in
Table 9, although the Naive Bayes algorithm achieves a relatively high recall rate, its accuracy is very low, only 64.61%. This means that a large number of benign samples are misclassified. If the Naive Bayes model is used to detect malicious JavaScript on the Internet, then much manpower must be invested to manually audit the detection results of the model to reduce the impact on normal websites. Contrary to the Naive Bayes model, the accuracy rate of the Support Vector Machine (SVM) model is higher than the recall rate, and the F1-score of 81.68% seems to perform well. However, we noticed that the recall rate of the SVM model is only 72.39%, which means that 27.61% of the malicious JavaScript evade the detection of the model. Therefore, such a model is not capable of detecting malicious JavaScript. We consider that the reason for the poor performance of these two models is that the models are too simple to fully describe the malicious features. The performance of random forest is much better than the previous two models, but it is still worse than the BLSTM neural network with 7.7% lower accuracy, 5.88% lower recall rate, and 7.17% lower F1-Score. We need to emphasize that malicious JavaScript detection is different from other neural network applications, such as speech recognition and emotion classification. Undetected malicious JavaScript may cause huge losses to Internet users, such as the stealing of credit card information. Therefore, any increase in accuracy will protect more Internet users from attackers.
JaSt was proposed by Fass et al. [
13], which extracts features from the AST and uses the frequency analysis of specific patterns to detect malicious JavaScript. Since JsSt is open source, we use it to compare with our method.
Table 9 shows the experimental results, the perform of the BLSTM neural network is better than JaSt with 4.71% higher accuracy, 5.88% higher recall rate, and 4.25% higher F1-score. This means that the program slices can extract more semantic information than simply traversing the AST, and the increase in semantic information improves the performance. The results in
Table 9 are all experimentally obtained on the deobfuscated dataset. But we noticed that the authors of JaSt do not process the samples collected from the Internet, but directly use them to train the model. In order to demonstrate the robustness of our model, we use the same data processing method as JaSt to experiment again. The experimental results are shown in
Table 10. The accuracy rate of the BLSTM neural network is 2.26% higher than that of JaSt, the recall rate is 2.99% higher, and the F1-score is 1.08% higher. This means that even with unprocessed samples to train the model, the BLSTM neural network still performs better than JaSt.
In addition, in order to demonstrate that the performance of the learning-based method is better than the pattern-based method, we chose a traditional antivirus software for comparison. ClamAV [
54] is a famous open source antivirus software used in a variety of situations, including email scanning, web scanning, and endpoint security. We used the latest stable release version (0.102.2) of ClamAV to compare with our method. As shown in
Table 9, ClamAV has an accuracy of 84.21%, which is significantly lower than that of the BLSTM neural network and even lower than that of JaSt and random forest. ClamAV’s 68.3% recall rate means that 31.7% of malicious samples have not been found, which is lower than our expectations for antivirus software. Upon further analysis, we found that the precision of ClamAV reached 95.01%, combined with a low recall rate, which shows that ClamAV has very low false positives. This means that ClamAV may tend to classify the samples as benign to avoid the bad experience that false positives bring to users. In summary, learning-based detection methods perform better than pattern-based detection methods. This is because the learning-based method can capture high-level semantic information and describe attack vectors from hundreds of dimensions, while the pattern-based method can only define rules to describe syntactic-level features. Therefore, we conclude that the BLSTM neural network performs better than other methods in detecting malicious JavaScript.
Answer to RQ3: Many existing studies assume that neural networks can extract high-level semantic features of programs, so obfuscation techniques have no influence on neural network-based detectors. But they do not prove it experimentally. In order to study the influence of obfuscation techniques on the BLSTM neural network and other machine learning models, we experiment again on obfuscated dataset. As shown in
Table 9 and
Table 11, the performance of the BLSTM neural network decreases significantly on the obfuscation dataset, the accuracy, decrease from 97.71% to 92.01%, the recall rate decrease from 97.91% to 93.03%, and the F1-score decrease from 98.29% to 93.63%. These measurements decrease by an average of 5.08%. This means that the obfuscation techniques have a relatively significant negative impact on the BLSTM neural network. For the Naive Bayes model, SVM model, and random forest model, the accuracy decreases by an average of 2.32% and F1-socre decreases by an average of 2.4%. This means that deep learning models seem to be more sensitive to obfuscation than traditional machine learning models. This may be due to the obfuscation techniques make the semantic information in the
semantic slices incorrect. These errors continue to accumulate between different layers of the neural network, which ultimately leads to a decline in the performance of the BLSTM neural network.
For JaSt, obfuscation has little effect on it. The reason for this may be the choice of program features. JaSt extracts syntax units from JavaScript programs, which is a syntactic level of program features, and then uses them to train the model. This feature extraction method also captures the syntax changes caused by obfuscation. In other words, JaSt considers that obfuscation is one of the characteristics of malicious code. The author of JaSt also confirmed this in the paper. However, this features extracting method has obvious limitations. On the one hand, benign obfuscation is widely used to protect the intellectual property rights of program developers. Using obfuscation as a feature of malicious code leads to false positives. On the other hand, the syntactic level program features have limited expression power to malicious code. Experienced attackers can still evade the detection of JaSt by adjusting the syntax structure, which makes it difficult to improve JaSt’s performance.
In summary, the assumptions about the effects of obfuscation in existing studies are not entirely correct. The impact of obfuscation is related to the abstract representation of the program and the choice of model. Semantic level program features are more sensitive to obfuscation than syntactic level program features. Deep learning models are more sensitive to obfuscation than traditional machine learning models.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}