1. Introduction
In a machinery system, diagnostics and prognostics usually involve two kinds of problems, a fault-type classification and a remaining useful life (RUL) prediction problem. In particular, prognostics has been applied to the field of machinery maintenance as it allows industries to better plan logistics, as well as save cost by conducting maintenance only when needed [
1]. Various approaches have been proposed in each problem and they can be divided into three categories: Physics-based, data-driven, and hybrid-based approaches. Physics-based approaches incorporate prior system-specific knowledge from an expert, as shown in previous studies, of fault-type classification [
2,
3,
4,
5] and RUL prediction [
6,
7,
8,
9] problems. Alternatively, data-driven approaches are based on statistical-/machine-learning techniques using the historical data (see example studies about fault-type classification [
10,
11,
12,
13,
14] and RUL estimation [
15,
16,
17,
18]). Hybrid-based approaches attempt to utilize the strengths of both approaches, if applicable, by combining knowledge related to the physical process and information obtained from the observed data (see example studies about fault-type classification [
19,
20,
21,
22] and RUL prediction [
23,
24,
25,
26]). However, physics-based and hybrid-based approaches are limited in practice because the underlying physical models are not available in most real systems. Therefore, data-driven approaches have become increasingly popular along with recent advancements in sensor systems and data storage/analysis techniques.
From a review of the data-driven approaches, we noticed that many different types of learning methods and data pre-processing algorithms have been employed. For example, the fisher discriminative analysis and the support vector machine were used for feature extraction and classification, respectively, to diagnose seven failure modes of three different polymer electrolyte membrane fuel cell systems in a previous study [
10]. Another study applied a single hidden-layer feedforward neural network combined with an extreme learning machine technology to identify the offset, stuck, and noise faults in induction motor drive systems [
11]. A multi-classification model based on the recurrent neural network was established to classify ten different fault-types of a wind power generation system [
27]. A deep convolutional neural network and a random forest ensemble were employed to diagnose faults of a reliance electric motor and a rolling mill [
28]. In [
29], a genetic algorithm-based optimal feature subset selection and a
K-nearest-neighbor classifier were applied to distinguish between normal and crack conditions of a spherical tank. Various approaches have also been tried for the RUL prediction. A previous study presented a new deep feature learning method for the RUL estimation of a bearing through a multiscale convolutional neural network [
18]. A support vector machine was applied to predict the RUL of a Li-ion battery [
30] and a microwave component [
31]. Another study investigated the applicability of the Kalman filter to fuse the estimates of the RUL from five learning methods such as generalized linear models, neural networks,
K-nearest neighbors, random forests, and support vector machines, using the field data of an aircraft bleed valve [
15].
This literature review indicated that the process of developing data-driven diagnostics and prognostics methods involved some fundamental subtasks such as data rebalancing, feature extraction, dimension reduction, and machine-learning in the fault-type and/or RUL prediction problems. In addition, the best performing algorithm in each subtask was varied across the characteristics of the given dataset. Moreover, each algorithm required appropriate specification of a number of hyper-parameters. Therefore, it is always challenging to develop a general diagnostics/prognostics framework that can automatically identify the best subtask algorithms and optimize the involved parameters for a given dataset. Although such a general framework does not produce the prediction function that can be common to different systems, it can save the costs in developing diagnostic or prognostic functions by re-executing it. The most straightforward approaches for this purpose are the exhaustive grid search [
32], which examines a subset of parameters with a constant interval, and the experience-based manual selection [
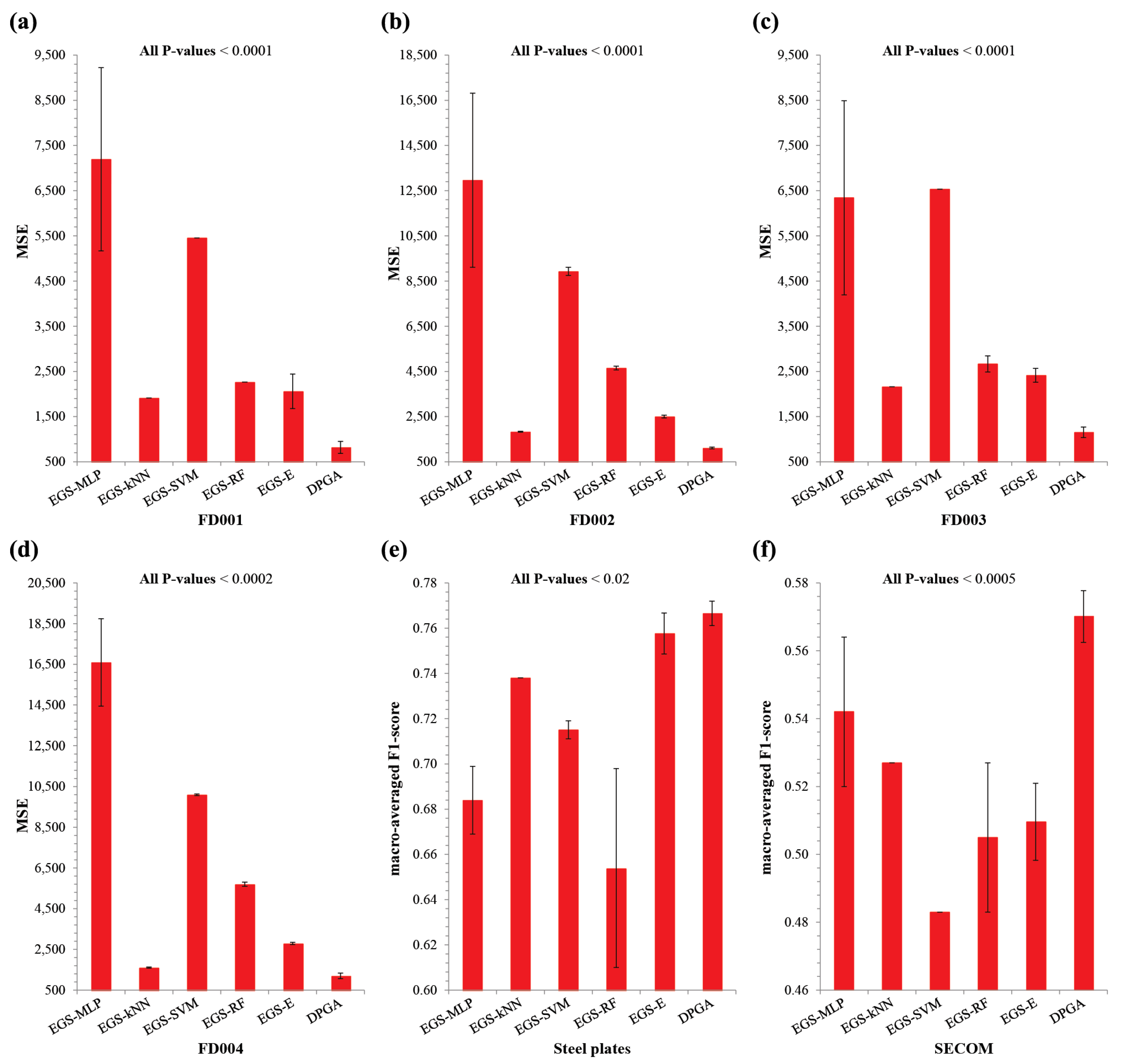
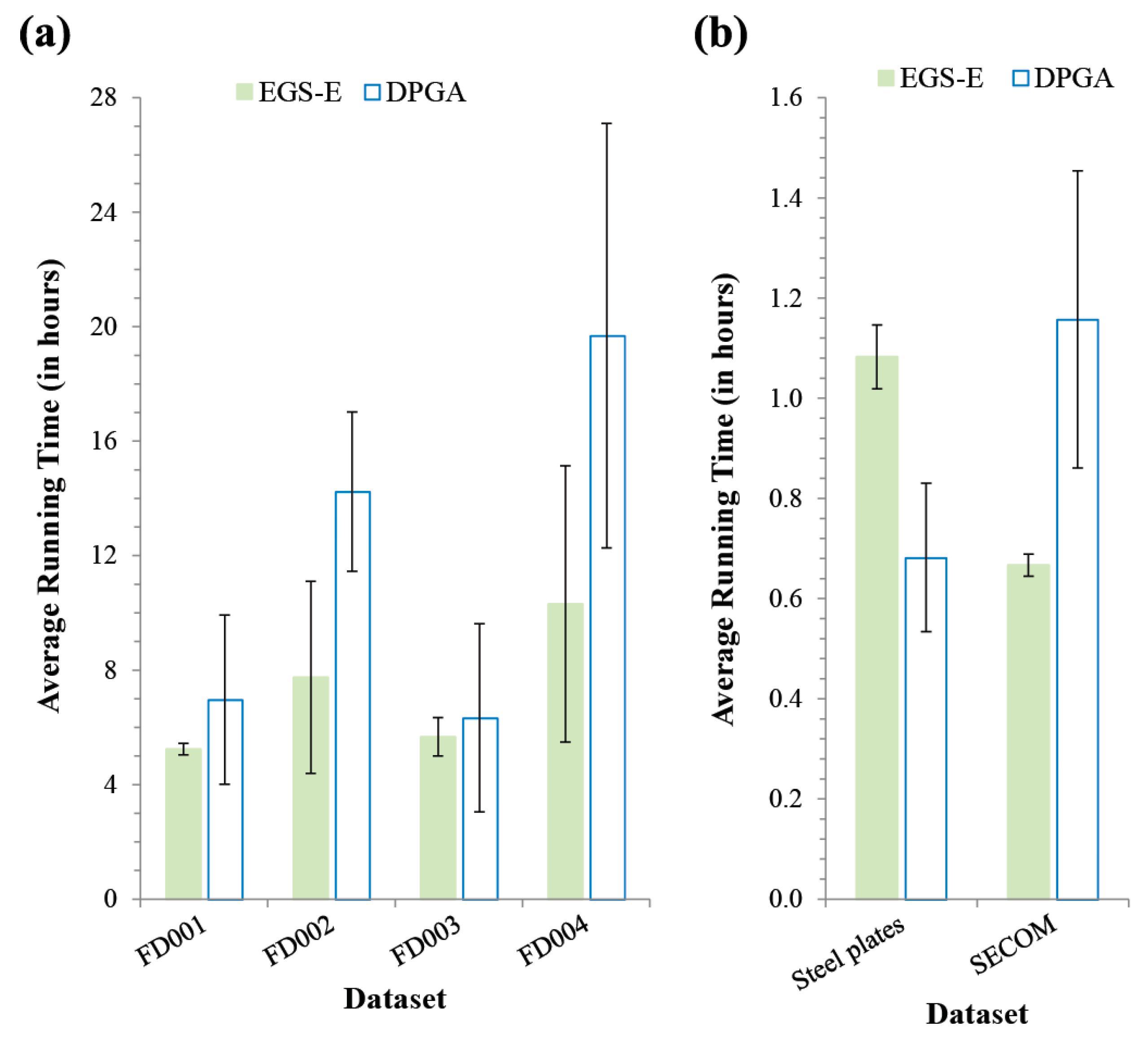
33], where a human expert specifies the parameter values based on their experience. However, the former can be inefficient due to the expensive computational cost, and the latter is dependent on the expert’s knowledge, which is not general to various datasets. In this regard, there is a pressing need to develop an efficient and data-independent approach, so we propose a new framework to develop a diagnostics and prognostics method based on an ensemble of genetic algorithms (GAs) that can be applied for both the fault-type classification and RUL prediction problems. Our framework handles four subtasks such as the data rebalancing, feature extraction, feature reduction, and machine-learning. Accordingly, our GA tries to select the optimal algorithm for each subtask and specify the optimal parameter values involved in the selected algorithm. In addition, the proposed method constructs an ensemble of the prediction models that are found by the GAs combined with various machine-learning methods. To verify the usefulness of our approach, we compared it to a traditional grid-search over three benchmark datasets of the fault-type classification (the steel plates faults and SECOM datasets) and the RUL prediction (NASA commercial modular aero-propulsion system simulation (C-MAPSS) dataset) problems. Our method showed a significantly better and more robust performance than the latter, with a practically acceptable running time.
The remainder of this paper is organized as follows.
Section 2 introduces the backgrounds on the diagnostics and prognostics problem and the performance evaluation metrics.
Section 3 explains the details of our approach and
Section 4 presents the experimental results along with discussion.
Section 5 includes the concluding remarks and suggestions for future work.
2. Backgrounds
In the fault-type classification and RUL prediction problems, data-preprocessing has a great impact on the performance of machine-learning methods and it is usually implemented by the rebalancing (in a classification problem), filtering, and dimension-reduction methods. They are introduced in the following subsections, and the last subsection explains the performance evaluation metric used in the study.
2.1. Data Rebalancing Methods
In the practical fault-type classification problem, the proportion of samples of the minority class is often severely lower than that of the majority class, which restricts the learning performance. To resolve this problem, the data rebalancing methods are commonly used. They can be classified into the over-sampling method, which adds samples of the minority class, and the under-sampling method, which reduces samples of the majority class. In general, the resampling process is repeated until the balancing ratio, which is defined by the ratio of the number of samples in the minority class over that in the majority class, is equal to or greater than a threshold parameter value . In the following, we introduce some representative rebalancing methods that were included in our framework.
2.1.1. Over-Sampling Methods
2.1.2. Under-Sampling Methods
Under-sampling methods eliminate the samples of the majority class. This might cause the loss of information of the data, which led the under-sampling method to be less popular than the over-sampling of Batista et al. [
38].
2.2. Filtering Methods
A filtering method is employed to remove noise from an original signal, and we herein introduce five well-known filtering methods. Let be the value of the feature at time in the following.
Simple moving average (SMA)—SMA is the unweighted average of values over the past time points as follows.
where
is the number of past time-points.
Central moving average (CMA)—SMA causes a shift in a trend because it considers only the past samples. On the other hand, CMA is the unweighted average of values over both the past and future time points as follows.
where
is an odd number specifying the number of time points to be averaged.
Exponential moving average (EMA)—EMA, which is also known as an exponentially weighted moving average (EWMA), is a type of infinite impulse response filter with an exponentially decreasing weighting factor. The EMA of a time-series of the feature
is recursively calculated as follows.
where, given the total number of observations
,
is a constant factor.
Exponential smoothing (ES)—Similar to EMA, ES is another weighted recursive combination of signals with a constant weighting factor
as follows.
Linear Fourier smoothing (LFS)—LFS is based on the Fourier transform, which decomposes a signal into its frequency components. By suppressing the high-frequency components, one can achieve a denoising effect.
where
and
denote the forward and inverse Fourier transform, respectively, and
is the characteristic function of the set
(
is the cut-off frequency parameter). We used the standard fast Fourier transform algorithm to compute the one-dimensional discrete Fourier transform of a real-valued feature
.
2.3. Dimensionality Reduction Methods
A reduction method is used to reduce the -dimensional input space into a lower -dimensional feature space ().
Principal component analysis (PCA) [
41,
42,
43]—PCA extracts
principal components by using a linear transformation of the singular value decomposition (SVD) to maintain most of the variability in input data.
Latent semantic analysis (LSA) [
44]—Contrary to the PCA, LSA performs the linear dimensionality reduction by means of the truncated SVD.
Feature agglomeration (FAG) [
45]—FAG uses the Ward hierarchical clustering, which groups features that look very similar to each other. Specifically, it recursively merges a pair of features in a way to increase the total within-cluster variance as less as possible. The recursion stops when the remaining number of features is reduced to
.
Gaussian random projection (GRP) [
41]—GRP projects the high-dimensional input space onto a lower dimensional subspace using a random matrix whose components are drawn from the normal distribution
.
Sparse random projection (SRP) [
46]—SRP reduces the dimensionality by projecting the original input space using a sparsely populated random matrix introduced in [
47]. The sparse random matrix is an alternative to a dense Gaussian random projection matrix to guarantee a similar embedding quality while saving computational cost.
2.4. Performance Evaluation Metrics
In this paper, we used the F1-score and the mean-squared error to evaluate the performance of the fault-type classification and the RUL prediction, respectively.
2.4.1. F1-Score
For a classification task, the precision and the recall with respect to a given class
are defined as
and
, respectively, where TP, FP, and FN denote true positives, false positives, and false negatives, respectively. The macro-averaged F1-score is the average of the harmonic means of precision and recall of each class, as follows:
where
is the set of all classes.
2.4.2. Mean Squared Error (MSE)
MSE is a general performance measure used in RUL prediction problems. It is defined as follows:
where
and
are the observed and the predicted RUL values of the
-th sample among a total of
samples, respectively.
3. The Proposed Method
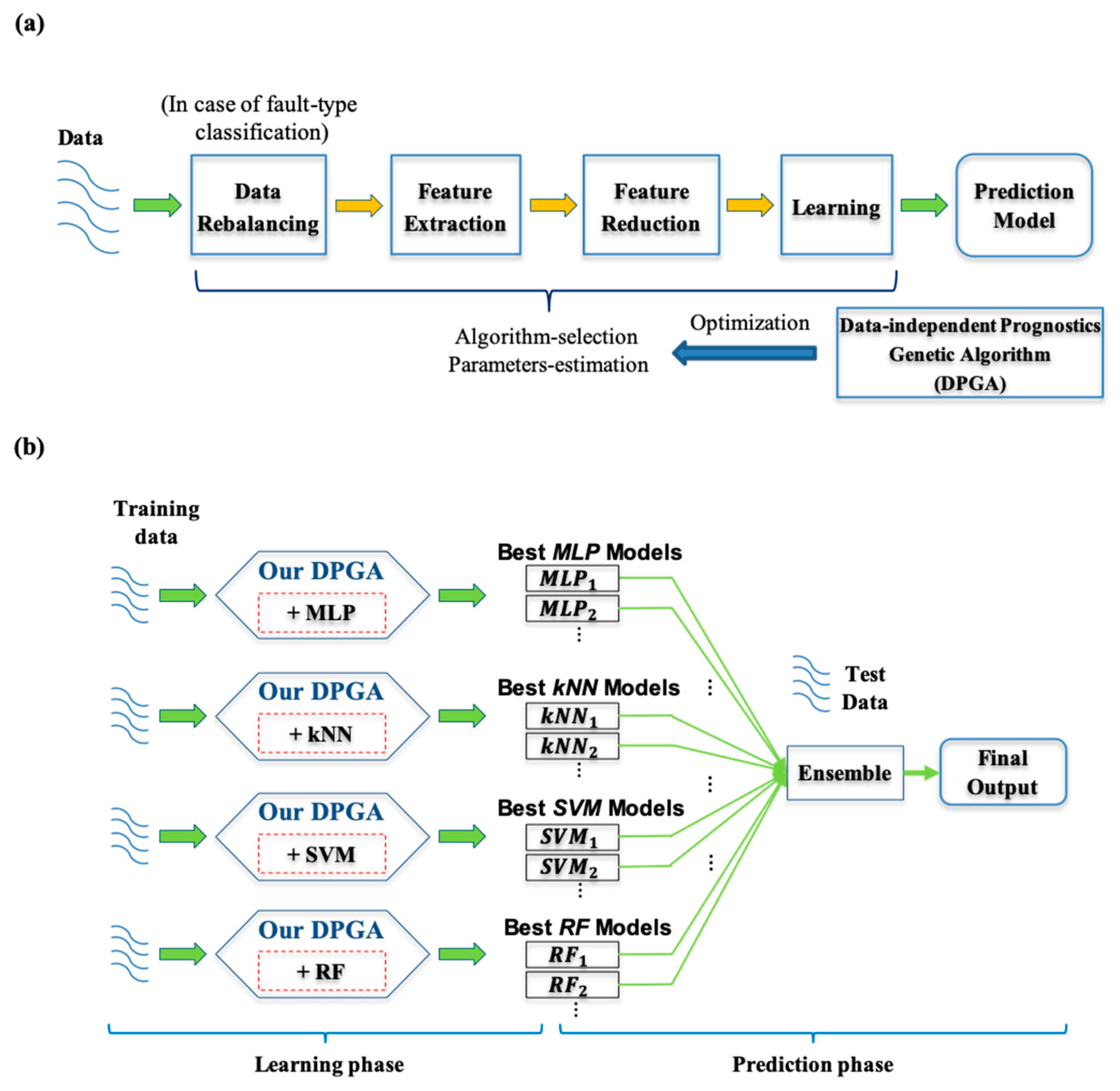
In this work, we propose a novel problem-independent framework for both the fault-type classification and the RUL prediction based on a GA. As we mentioned, the GA was employed to select the close-to-optimal set of data-processing algorithms and optimize the involved parameters in a robust way for a given dataset. As shown in
Figure 1a, we first outlined the general process of the data-driven diagnostics and prognostics, which consists of four subtasks of data rebalancing (for classification problems), feature extraction, feature reduction, and learning. We did not explicitly include a feature selection in our framework, although it is a frequently used technique [
48]. In fact, an implicit feature selection was already employed in the feature extraction stage because the inclusion and exclusion of created features are dynamically determined by a chromosome in the genetic algorithm (see the
Section 3.1.1 for more details). As we explained in
Section 2, a variety of algorithms in each subtask can be considered, and the diagnostics/prognostics performance is likely to be highly dependent on the selected algorithm and the specified parameter values. In this regard, it is necessary to select the optimal data preprocessing algorithms and specify the optimal parameter values involved by those algorithms. Hence, we propose a data-independent diagnostic/prognostic genetic algorithm (DPGA) to resolve it. In addition, our DPGA can be easily extended to generate an ensemble result [
49,
50] because it runs along with various learning methods, as shown in
Figure 1b. We note that four representative machine-learning methods such as the multi-layer perceptron network (MLP),
k-nearest neighbor (kNN), support vector machine (SVM), and random forest (RF) were employed in this study. As shown in
Figure 1b, our DPGA runs to search the optimal data-processing algorithms for data rebalancing, feature extraction, and feature reduction subtasks and the relevant parameter values over the training dataset for each learning method in the learning phase. Then, a set of best solutions found by each DPGA are integrated into an ensemble to predict the fault-type or the RUL value over the test dataset in the prediction phase. In the following subsections, we explain the details of DPGA and the employed ensemble approach.
3.1. DPGA
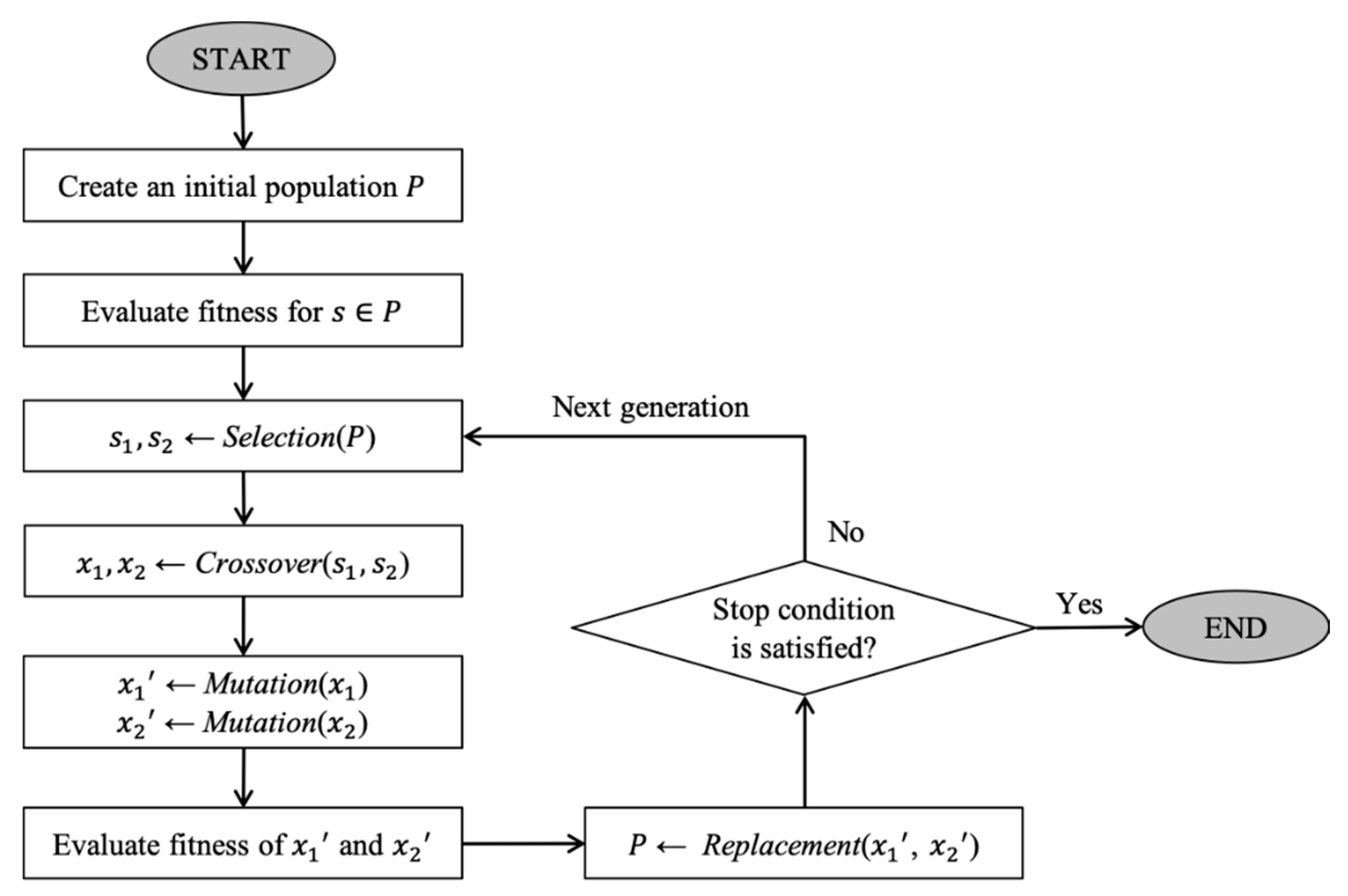
DPGA is a steady-state genetic algorithm, and the overall framework is depicted in
Figure 2. It first creates a random initial population of solutions,
, and evaluates the fitness of each solution. It selects two parent solutions
and
among the population according to the fitness values and generates two offspring solutions
and
by a crossover operation. These new solutions can be mutated with a low probability. After evaluating the fitness values of the offspring solutions, the GA replaces some old solutions in the population with them. This process is repeated until a stopping condition is satisfied. The specified values of parameters of the GA are summarized in
Table 1. In the following subsections, we introduce the details of each part in DPGA.
3.1.1. Chromosome Representation
In a GA, a solution is represented by a chromosome.
Table 2 shows a chromosome in DPGA, which is implemented by a one-dimensional list consisting of categorical and continuous variables to represent algorithm-selection and parameter-specification. Specifically, it is composed of four parts corresponding to data rebalancing, feature extraction, feature reduction, and learning subtasks as follows:
Data rebalancing—This part is only applicable in the fault-types classification. As explained in
Section 2.1, the ‘DR algo.’ field in a chromosome indicates one among five over-sampling and two under-sampling algorithms, or none of them. In addition, the ‘DR para.’ field represents the threshold parameter of the rebalancing ratio (see
Section 2.1 for details).
Feature extraction—To generate latent features, our GA employed two groups of approaches, filtering-based (available only for time-series datasets, see
Section 2.2) and reduction-based (see
Section 2.3) approaches. The ‘FFE algo.’ field represents the subset of five filtering-based feature extraction algorithms (SMA, CMA, EMA, ES, and LFS). In addition, the ‘FFE para.’ field includes the corresponding parameters that are necessary to run the selected feature extraction algorithms (for example, the number of time points in SMA or CMA). Similar to filtering-based feature extraction, the ‘RFE algo.’ and ‘RFE para.’ fields represent the combinatorial selection among five reduction-based feature extraction algorithms (PCA, LSA, FAG, GRP, and SRP) and the corresponding parameters (for example, the number of principal components), respectively. We note that if none are selected in ‘FFE algo.’ and ‘RFE algo.,’ only the original variables are used as input variables in the learning algorithm.
Dimension-reduction by PCA—Before executing the learning method, the dimension of the input space consisting of all of the newly constructed features and the original variables can be finally reduced by the PCA [
41,
42,
43]. The ‘PCA flag’ and ‘PCA para.’ represent whether PCA is applied or not, and the threshold parameter (
) with respect to the desirable explained variance, respectively. In other words, when the ‘PCA flag’ turns on, the set of highest-order principal components that account for more than
of the data variability are selected as the final input variables to be fed into a learning method.
Learning method: As explained before, we employed four machine-learning algorithms in this study. Therefore, the ‘LM para.’ field represents the corresponding parameters that are necessary to run the learning method as follows:
- -
MLP: The MLP of a single hidden layer is assumed and
denotes the number of hidden nodes. In addition, the type of the activation function (
) is selected between the hyperbolic tan function (“tanh”) and the rectified linear unit function (“relu”). The solver for weight optimization (
) is also selected between an optimizer in the family of quasi-Newton methods (“lbfgs”) [
51] and a stochastic gradient-based optimizer (“adam”) [
52].
- -
kNN: denotes the number of nearest neighbors. In addition, the weight function () is selected between “uniform” and “distance.” In the former, the neighbors are weighted equally, whereas the neighbors are weighted by the inverse of the distance to the query in the latter.
- -
SVM: denotes the penalty parameter for the misclassification.
- -
RF: denotes the number of trees in the forest.
3.1.2. Fitness Calculation
To evaluate a chromosome
, the F1-score and MSE measures (see
Section 2.4 for details) are used for the fault-type classification and the RUL prediction, respectively, as follows.
where
and
are the results by the leaning method using the algorithms and the parameter values included in
. In addition,
denotes a constant large enough to make the fitness a positive real value. Consequently, the higher the fitness value, the better the solution in both the fault-type classification and the RUL prediction problems. To avoid the over-fitting, we used
-fold cross-validation in computing the fitness over the training data. More specifically, the whole training dataset was randomly divided into
disjoint subsets. Then, each subset was held out for evaluation while the rest
of the subsets were used as the training data. For a more stable fitness evaluation, we repeated the cross-validation
times. Accordingly, the fitness of
is the average over
trials. In this work, we set
to 5 and
to 3.
3.1.3. Selection
To choose a parent solution from the population
, we employed the roulette wheel selection where the selection probability of a chromosome
is proportional to the fitness value of
as follows:
3.1.4. Crossover
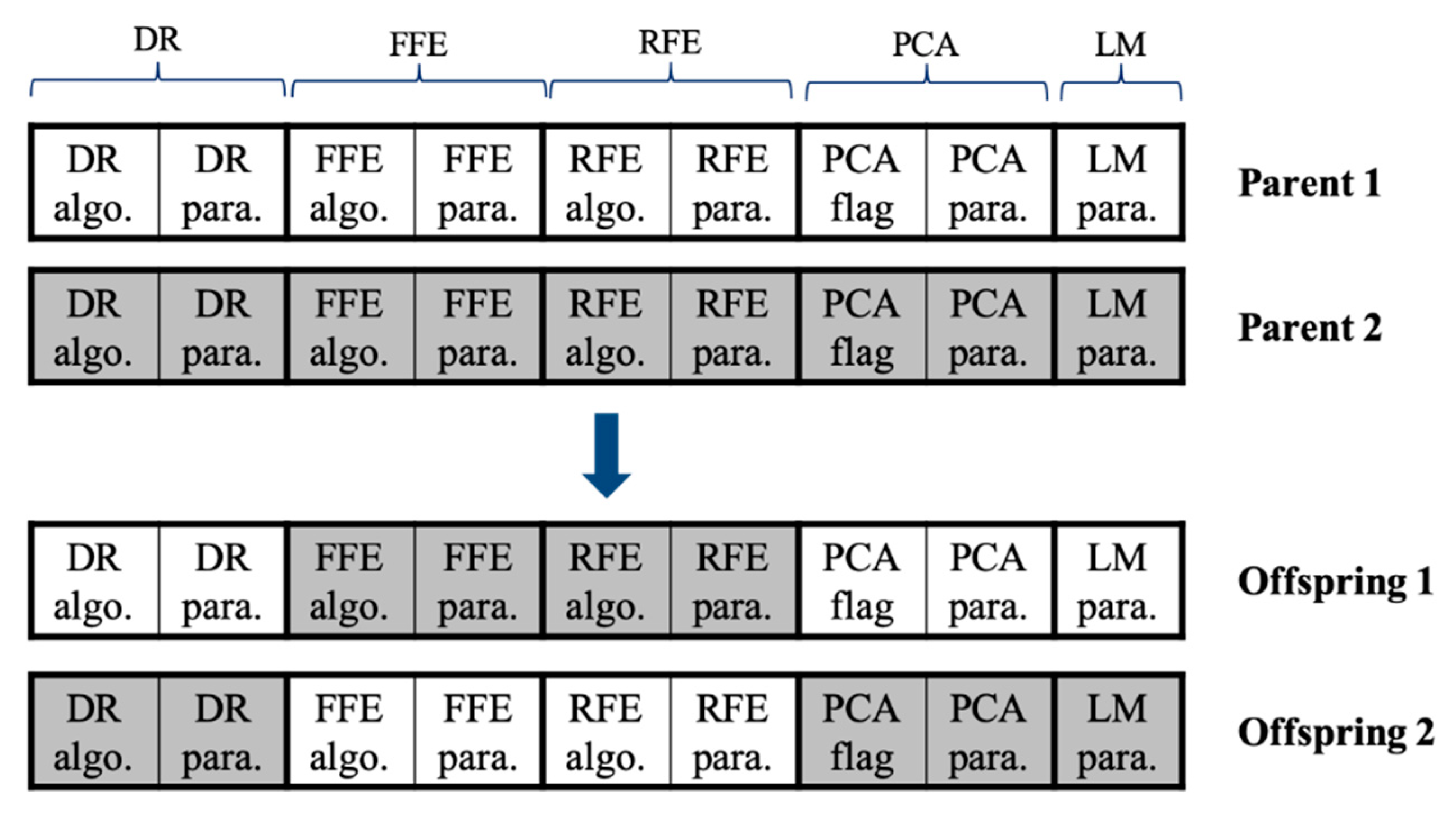
Two new offspring solutions are generated by a crossover with a probability
, or they are duplicated from the parent solutions with a probability
. The employed crossover is a block-wise uniform crossover, as shown in
Figure 3. Specifically, there are five blocks such as ‘DR,’ ‘FFE,’ ‘RFE,’ ‘PCA,’ and ‘LM,’ all of which, except for the last block, consist of ‘algo. (or flag)’ and ‘para.’ fields, as explained in
Section 3.1.1. For each block, the first offspring chromosome is inherited from one of two parent chromosomes uniformly at random and the second offspring chromosome is inherited from the remaining parent chromosome. For example, the first offspring inherited DR, PCA, and LM blocks from the first parent, whereas FFE and RFE blocks were inherited from the second parent in
Figure 3.
3.1.5. Mutation
The offspring chromosome created by the block-wise crossover is mutated with a small probability , whereas the offspring created by the duplication is surely mutated to create a new chromosome that is not identical to the parent chromosome. Only one among four blocks, ‘DR,’ ‘FFE,’ ‘RFE,’ and ‘PCA,’ in the offspring is randomly selected, and it is mutated by one of the following two ways:
Algorithm-change mutation—The selected algorithm is changed. In other words, the current choice in the ‘DR algo.’, ‘FFE algo.’, ‘RFE algo.’, or ‘PCA flag’ field is replaced with an alternative uniformly at random.
Parameter-change mutation—The parameter value specified for the corresponding algorithm is mutated. In other words, the ‘DR para.’, ‘FFE para.’, ‘RFE para.’, or ‘PCA para’ field is replaced with a new value.
In this work, the parameter-change mutation probability was set to a larger value (0.7) than the algorithm-change mutation probability (0.3) considering that the range of values in the former case is much wider than that in the latter case.
3.1.6. Replacement and Stop Criterion
When the offspring solution is better than the worst solution in the population, the latter is replaced with the former. For an efficient stopping criterion, we set a patience parameter . Our GA stops when the best solution in the population is not improved during the past consecutive generations.
3.2. Ensemble Methods
As explained in
Figure 1b, the DPGA can produce many prediction models, which can constitute an ensemble of solutions. Herein, we employed the voting ensemble and the Kalman filter ensemble [
53] for the fault-type classification and the RUL prediction, respectively. For the former case, we applied a soft voting rule to achieve the combined results of multiple optimal classifiers. The voting ensemble is based on the sums of the predicted probabilities from well-calibrated classifiers. The Kalman filter ensemble can provide a mechanism for fusing multiple model predictions over time for a stable and high prediction performance.
5. Conclusions
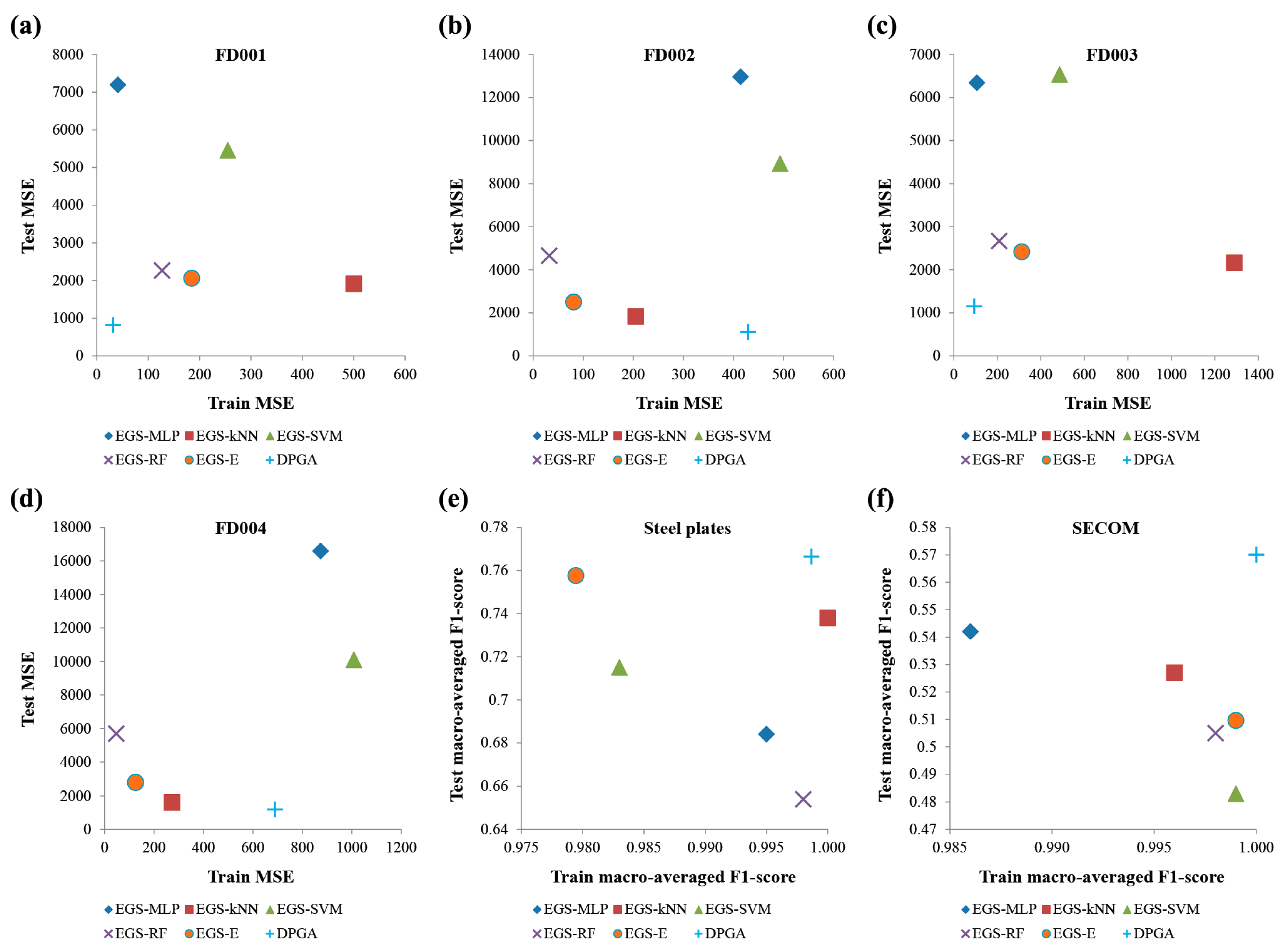
In this study, we proposed a DPGA, which is a novel framework to predict the RUL and fault-types. It is a self-adaptive method to select the close-to-optimal set of data-preprocessing algorithms and optimize the involved parameters in each subtask of data rebalancing, feature extraction, feature reduction, and learning. Although DPGA used four machine-learning methods such as the multi-layer perceptron network, k-nearest neighbor, support vector machine, and random forest in this study, it can be easily extended to combine other kinds of machine-learning methods. In addition, our method seems robust because it can generate an ensemble of prediction models. Through the performance comparison of DPGA with the traditional grid-search framework over three benchmark datasets, the former showed significantly better accuracies than the latter in a comparable running time. This implies that our genetic search was efficient in solving the large-scaled diagnostics and prognostics problems. It was interesting that the best solutions found by DPGA involve many filtering- or reduction-based feature extraction algorithms to generate various feature variables. As shown in the results, it is advantageous that DPGA can be applicable to other machinery systems without a priori knowledge about the most proper machine-learning method or a feature processing algorithm. In a future study, a parallel and distributed version of the DPGA method can be developed to reduce the execution time. It is also promising to further validate the usefulness of our approach by employing other kinds of the machine-learning models such as the recurrent neural network. Finally, it will be another interesting future study to design a more robust ensemble approach than what was employed in DPGA.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
