
Linking Clusters of Micropollutants in Surface Water to Emission Sources, Environmental Conditions, and Substance Properties


Abstract
1. Introduction
2. Methods
2.1. Environmental Monitoring Data
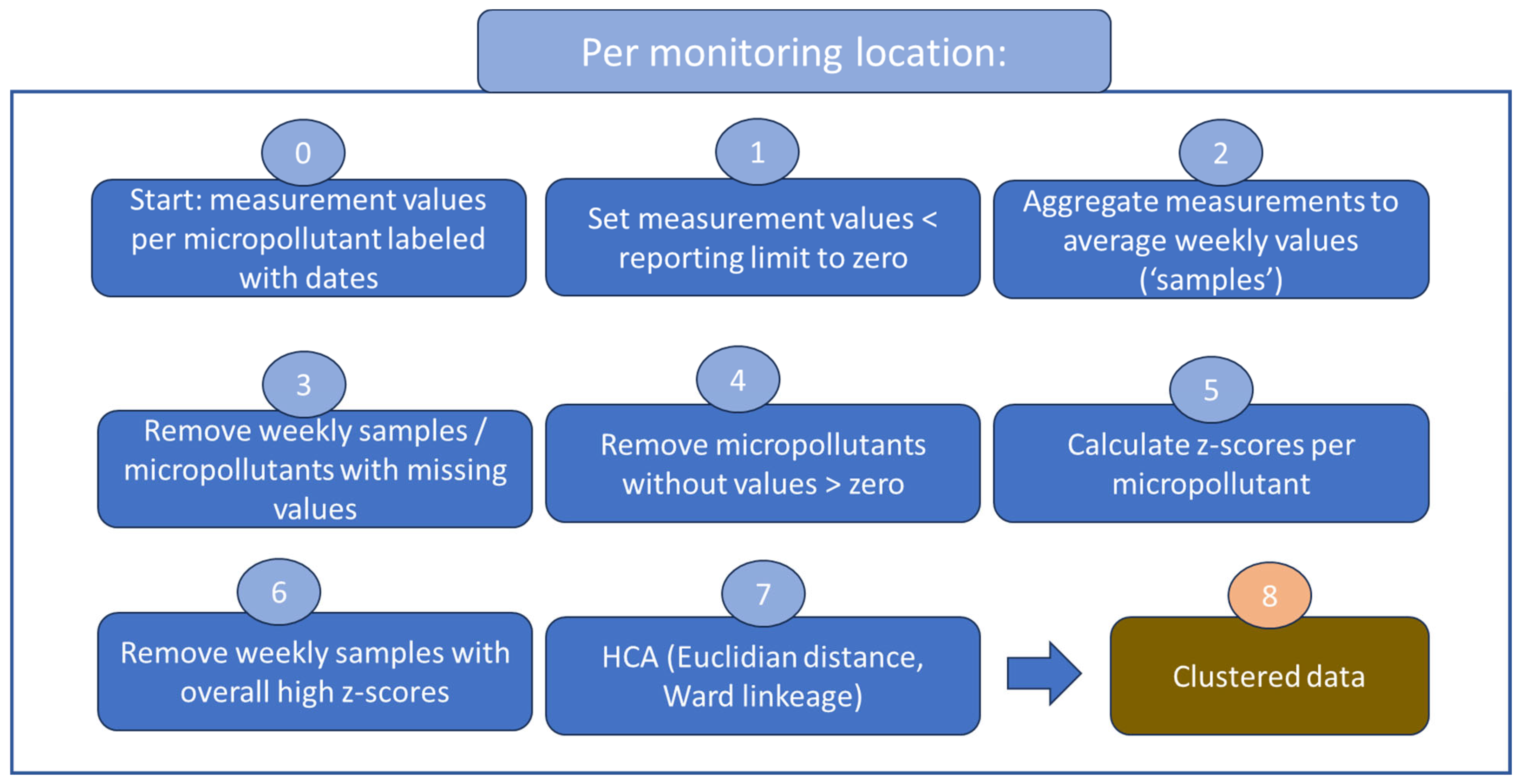
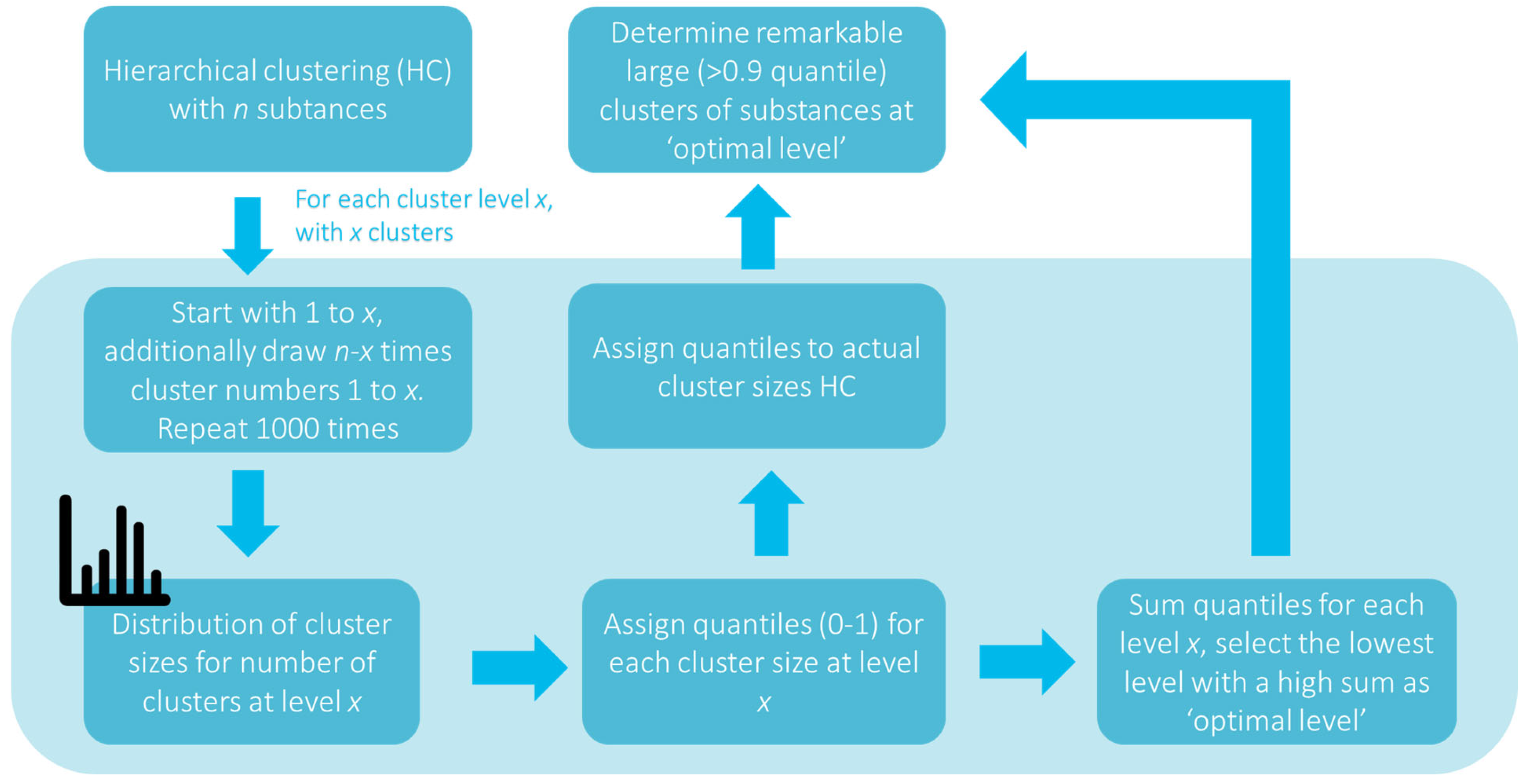
2.2. Cluster Analysis
2.3. Assigning Cluster Significance
2.4. Overlap of Clusters with Reference Lists
- M, the total number of relevant substances (in all reference lists and monitoring data);
- n, the substances in a reference substance list;
- N, the number of substances in a cluster;
- X, the number of substances in the overlap.
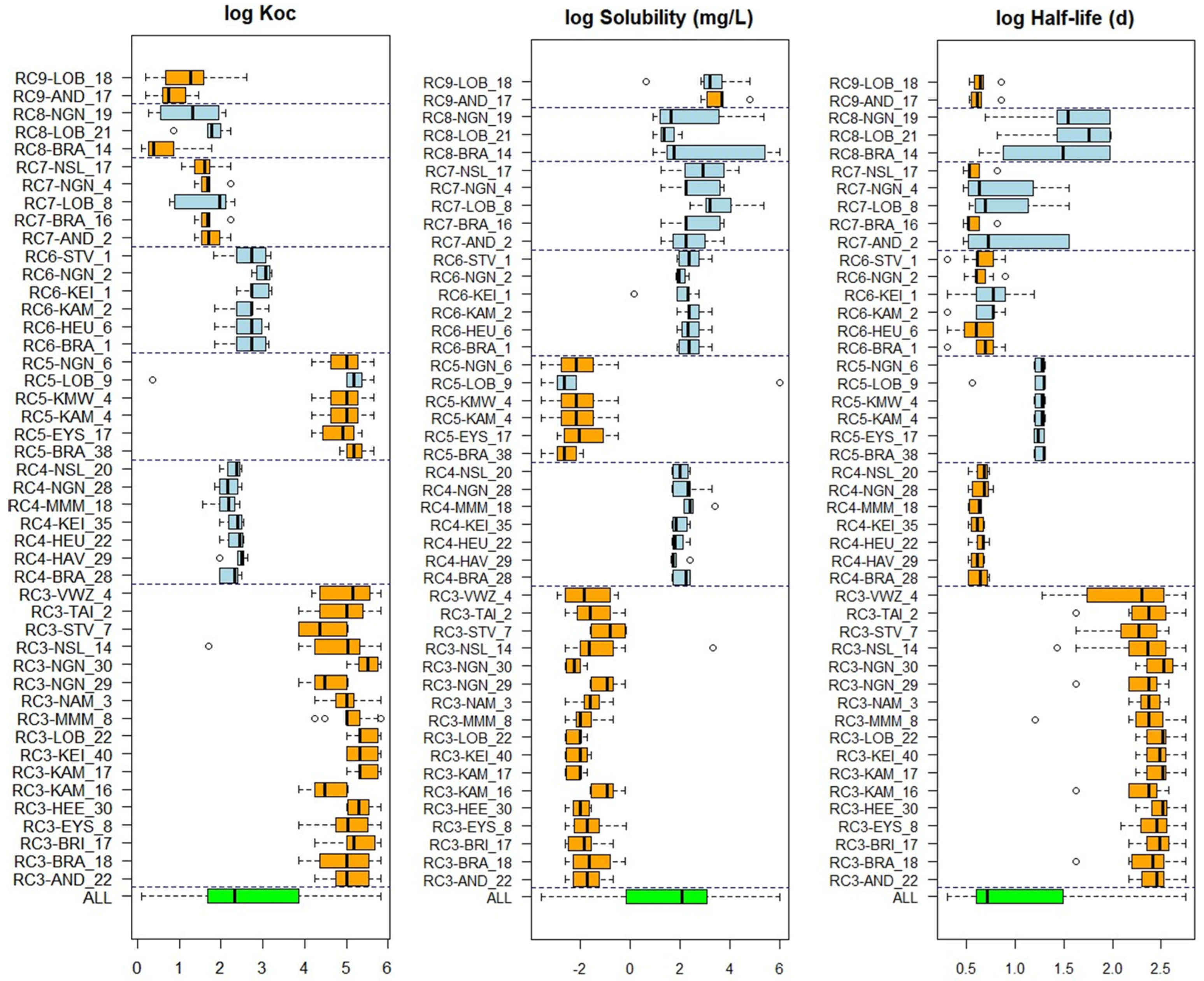
2.5. Linking Clusters to Substance Properties
2.6. Linking Clusters to Environmental Conditions
2.7. Identifying Significant Clusters That Are Recurring in Multiple Locations
3. Results
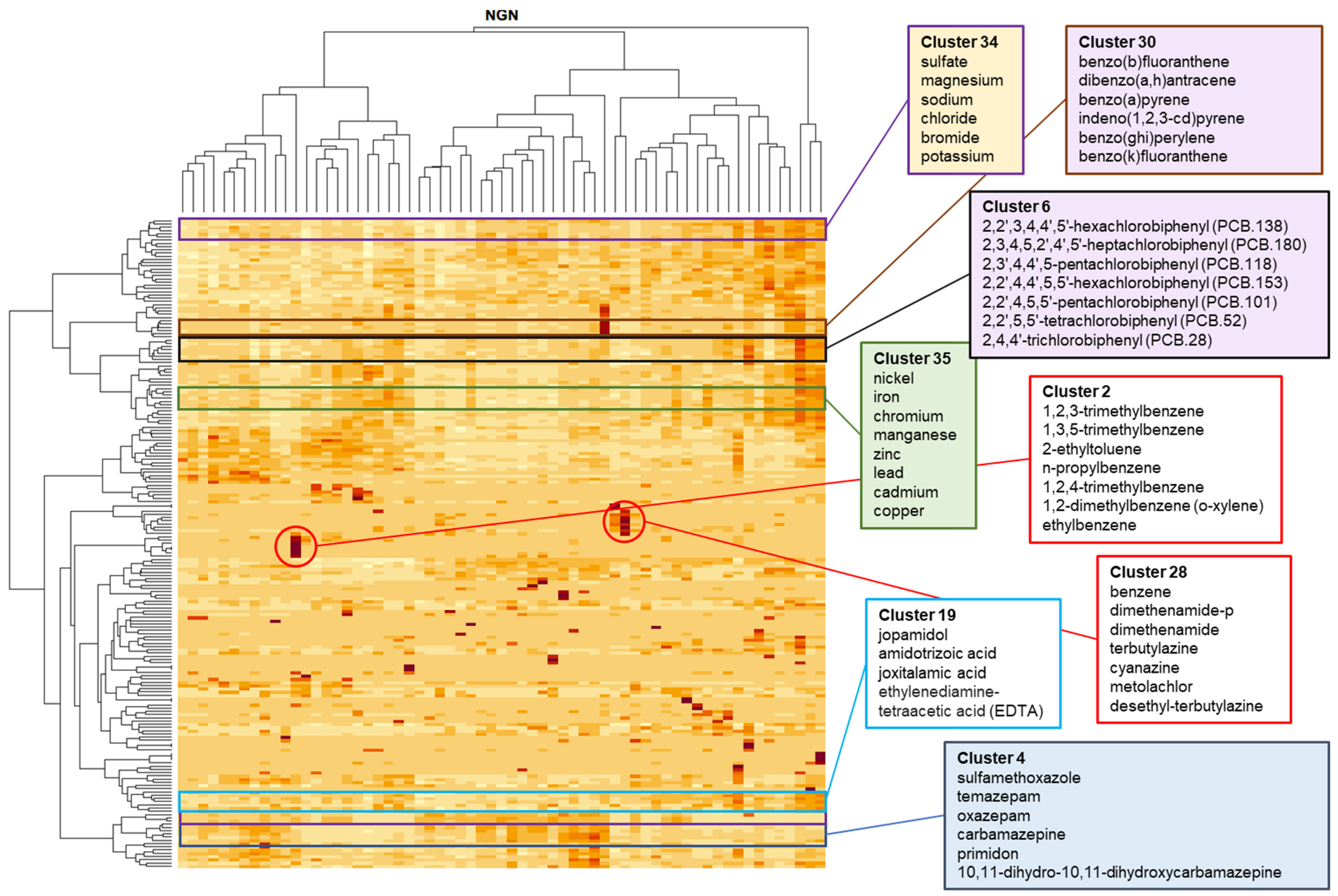
3.1. Clusters in Meuse and Rhine Locations
3.2. Overlap of Clusters with Reference Lists
3.3. Recurring Clusters of Pollution
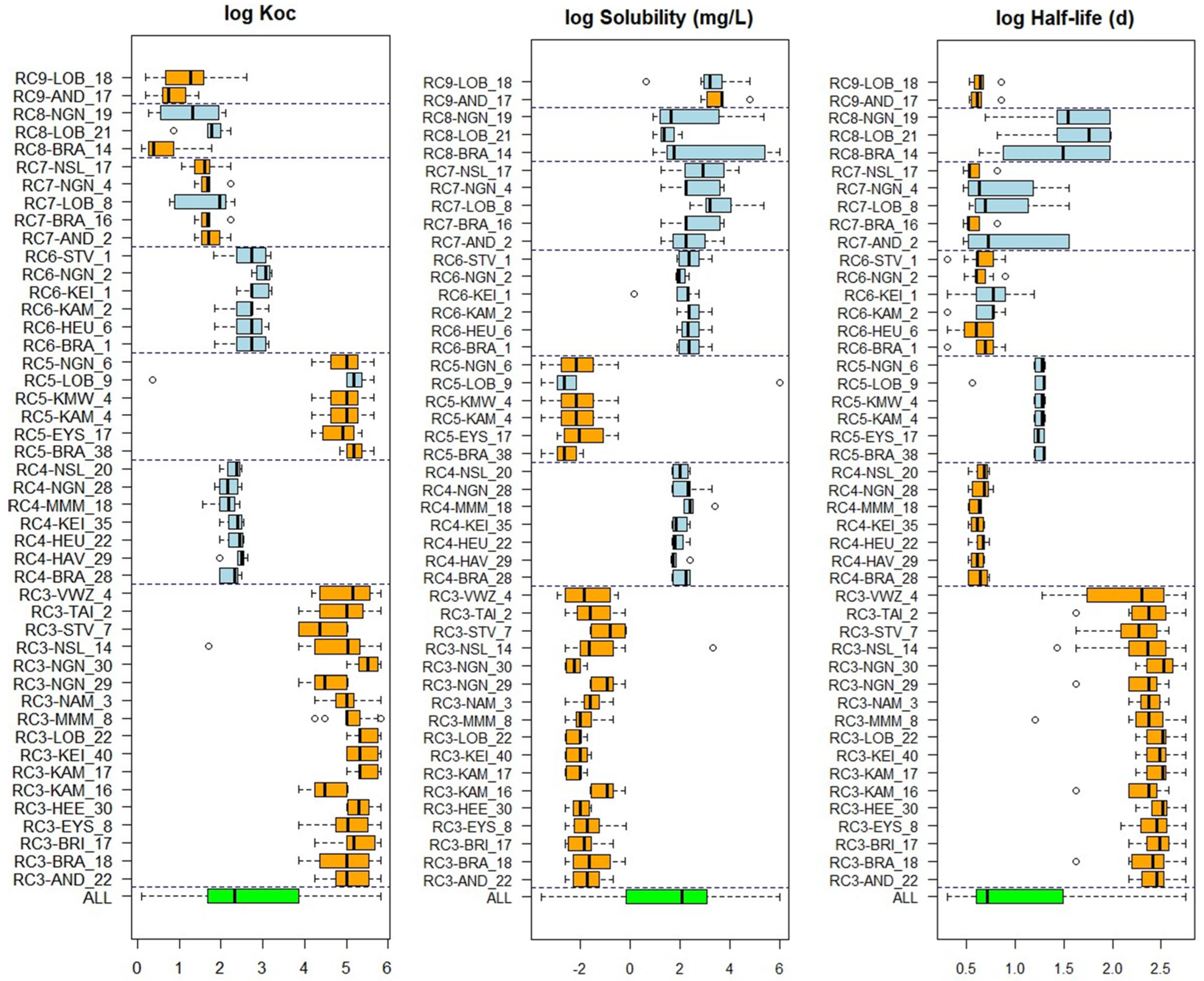
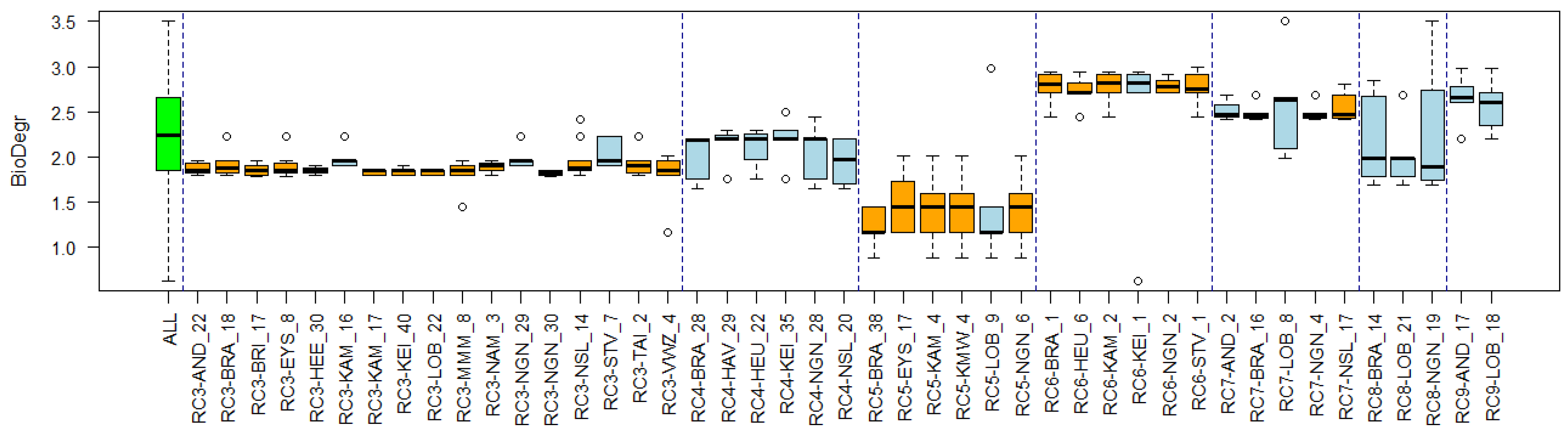
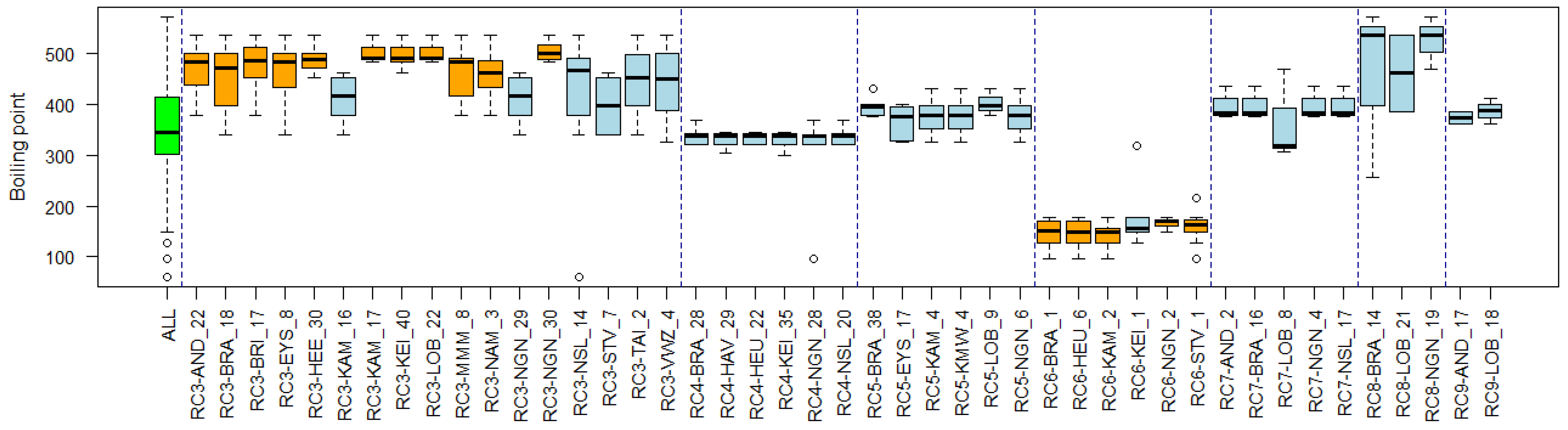
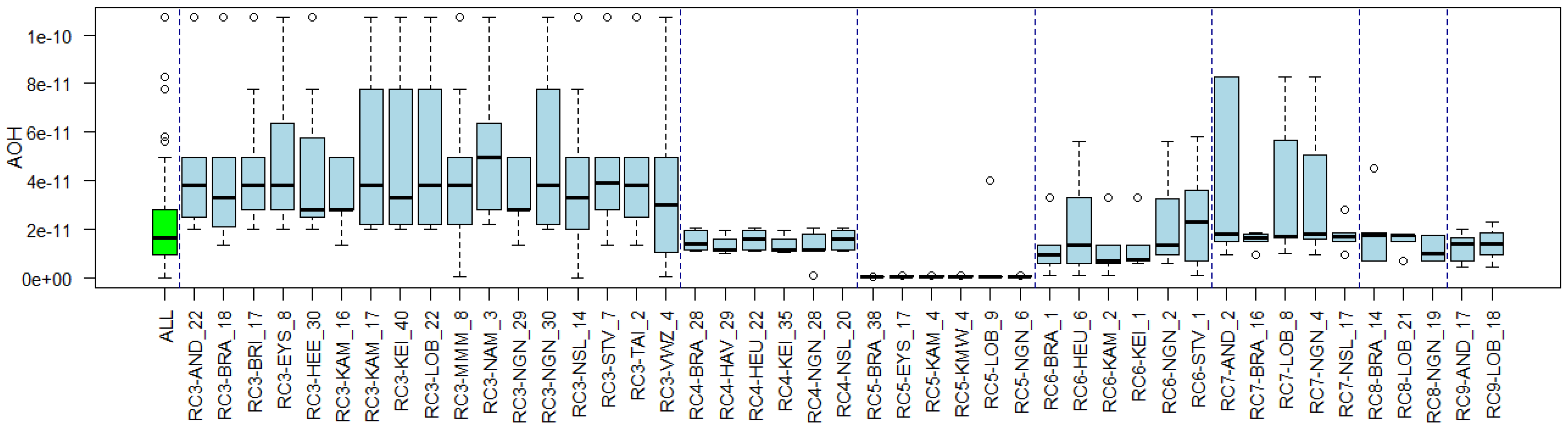
3.4. Substance Properties of Recurring Clusters
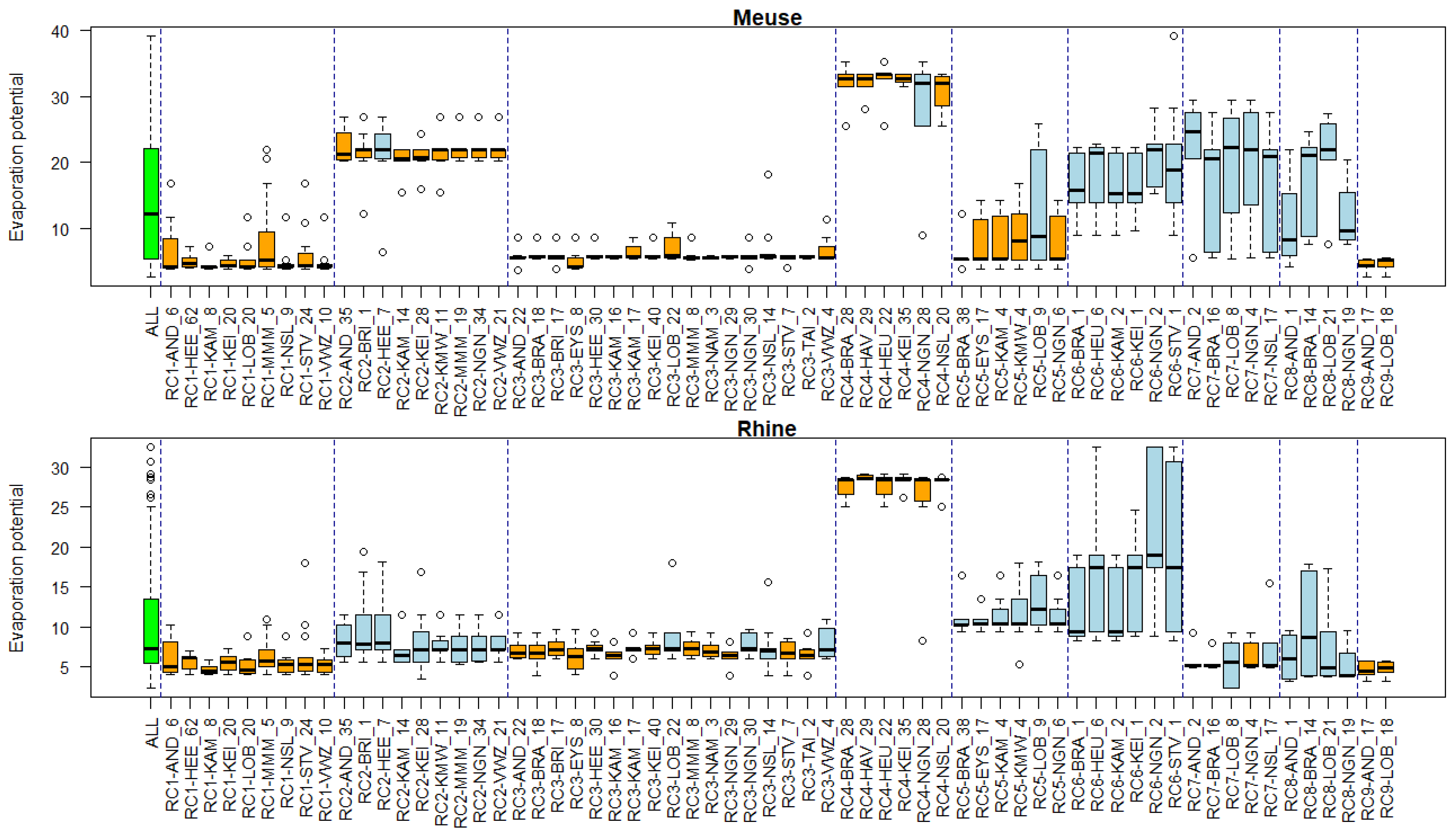
3.5. Associations of Environmental Conditions with Clusters
4. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Reference Substance Lists

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| List Source ID | List Source Name | Source | Sub-Lists | Sub-Stances |
|---|---|---|---|---|
| L1 | Substances used in various agriculture types | Centraal Bureau voor de Statistiek | 58 | 1715 |
| L2 | Substances measured near agriculture types | Landelijk Meetnet gewasbeschermingsmiddelen (data obtained from Deltares) | 8 | 63 |
| L3 | Sewage treatment plants | Watson database (data driven, substances found >0.1 μg/L in >25 sewages’ effluents) | 1 | 83 |
| L4 | Trans-border Meuse | RIWA database (data driven, substances in samples of location Eijsden on average >0.1 μg/L) | 2 | 47 |
| L5 | Trans-border Rhine | RIWA database (data driven, substances in samples of location Lobith on average >0.1 μg/L) | 2 | 71 |
| L6 | Biocides per product type | ECHA European Chemicals Agency database | 20 | 656 |
| L7 | Distinguished groups (diverse) | RIWA-Rijn | 89 | 1714 |
| L8 | Micropollutants as source and process indicators | [10] | 17 | 71 |
| L9 | EU emissions by industries | EEA Industries Reporting Database | 20 | 128 |
| L10 | Veterinary pharmaceuticals in manure slurries | [32] | 2 | 28 |
| L11 | Sources of PFAS in Dutch surface water | [33] | 11 | 13 |
| L12 | Typical substances in untreated wastewater | Watson database (data driven, substances found abundantly (>25 sewages’, at least 0.1 μg/L) in influent, not in effluent, and are well removed (>80%)) | 1 | 9 |
| L13 | Drug waste constituents | [34] | 1 | 62 |
| L14 | A list of substances in fertilizers | CompTox lists | 1 | 22 |
| L15 | Motor fuel leakage substances | CompTox lists | 1 | 27 |
| L16 | Natural toxins | CompTox lists | 1 | 90 |
| L17 | Veterinary drugs | CompTox lists | 1 | 124 |
| L18 | Cyanoginosins (from cyanobacteria) | CompTox lists | 1 | 7 |
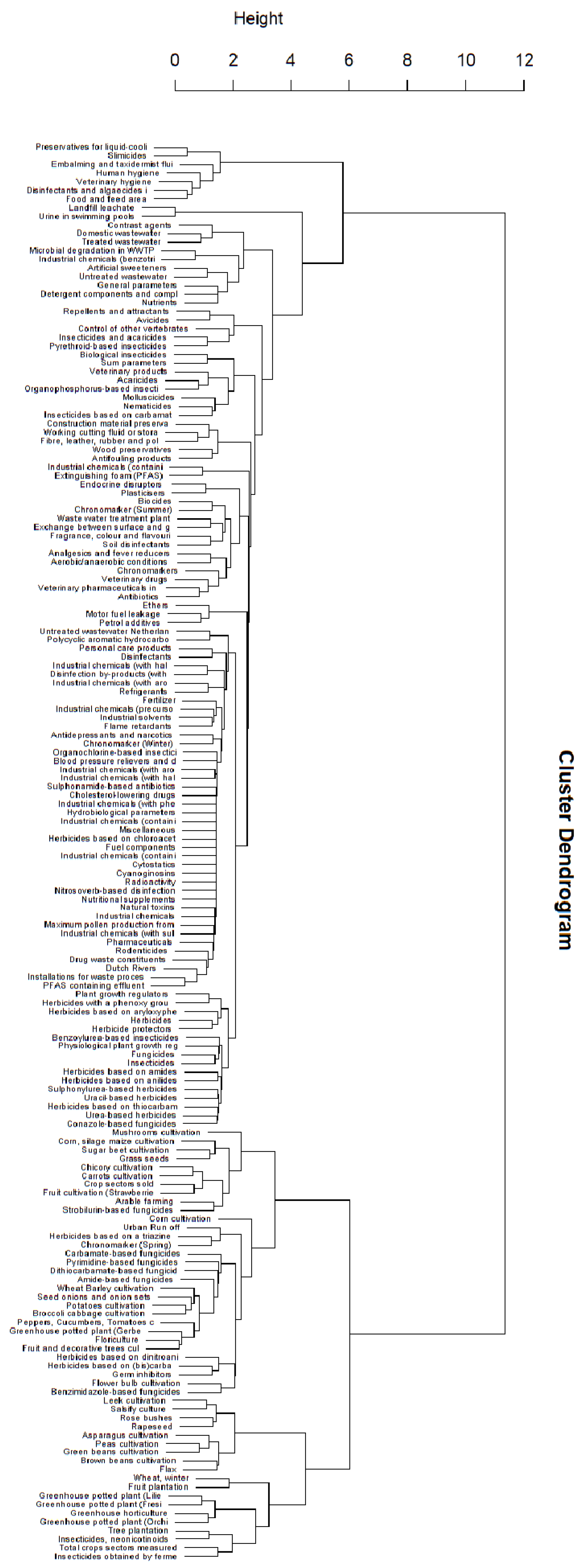
Appendix B. Substance Properties and Environmental Conditions per Cluster
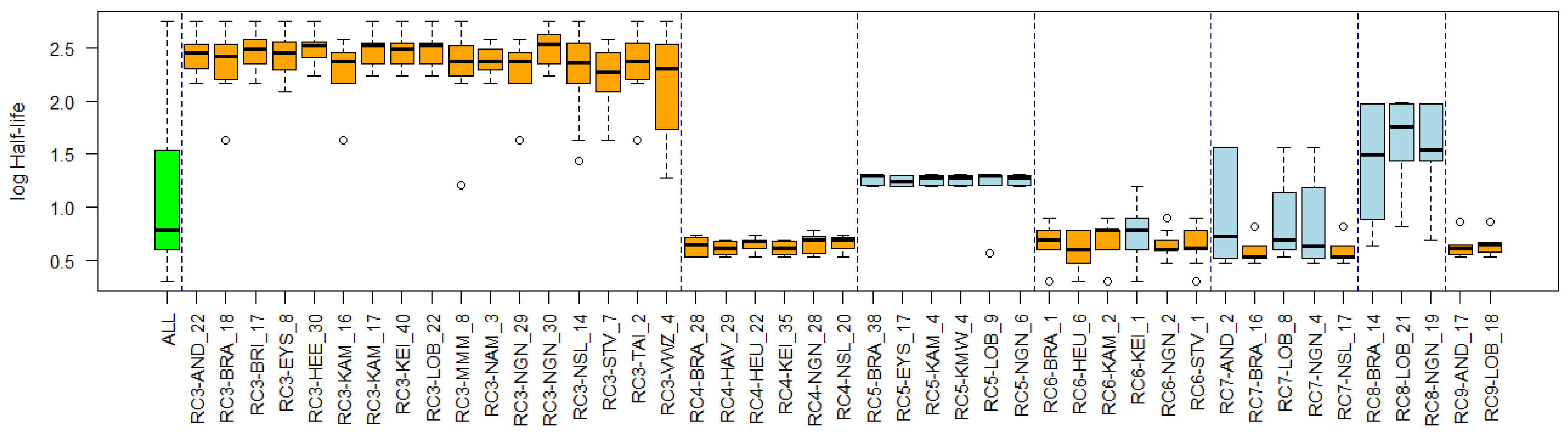
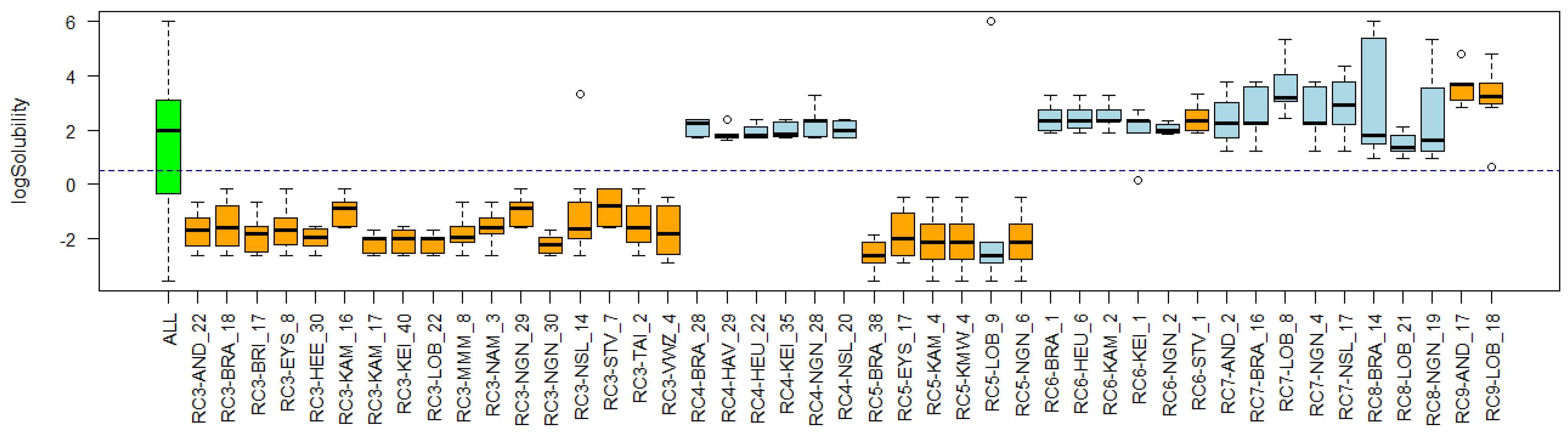

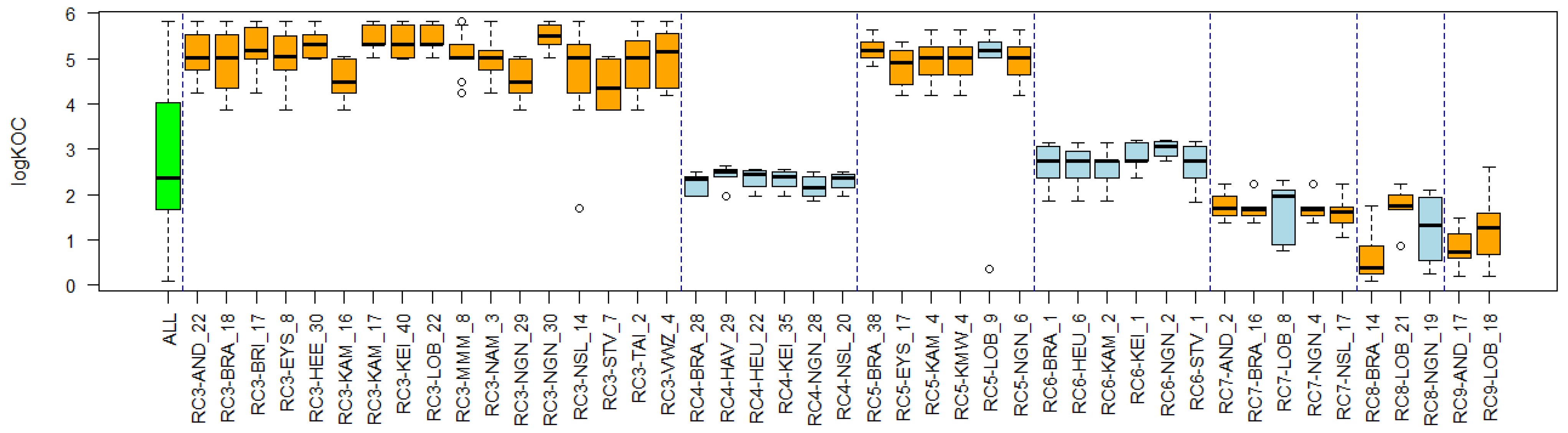
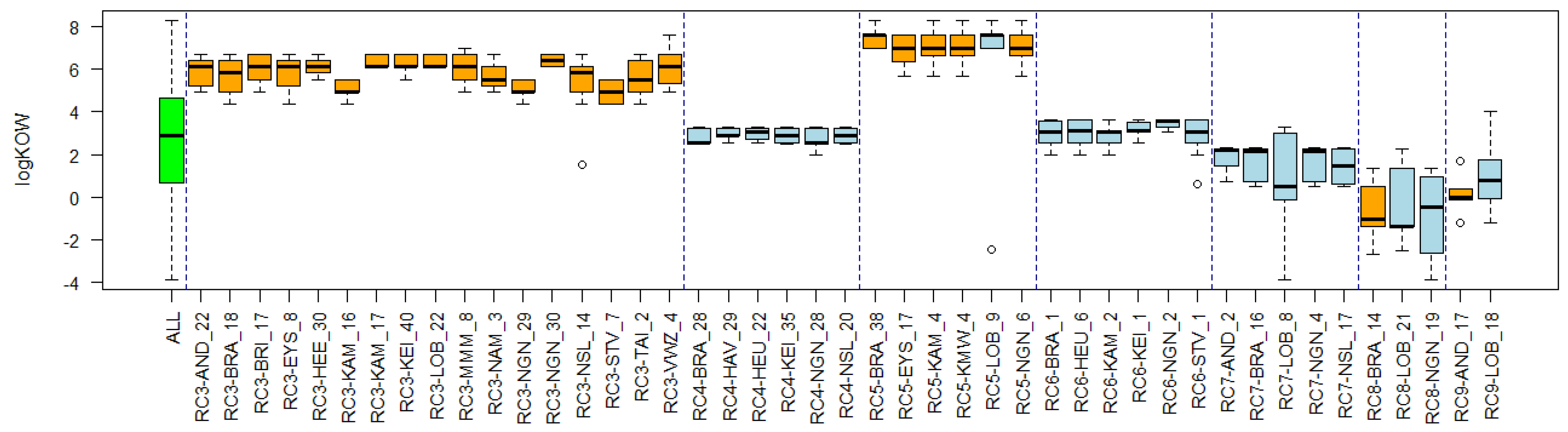

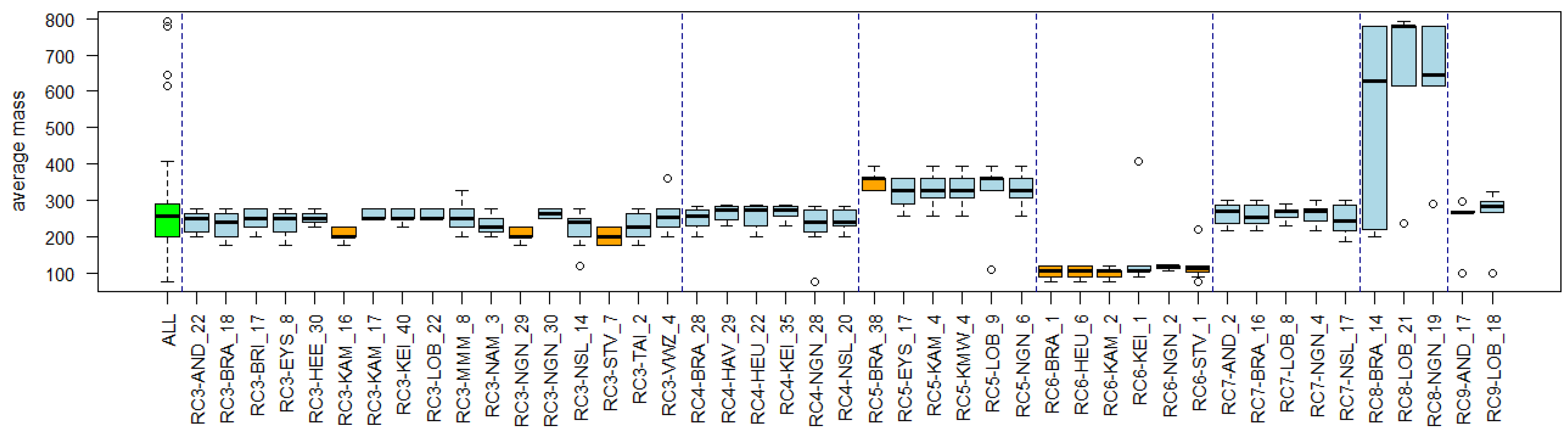

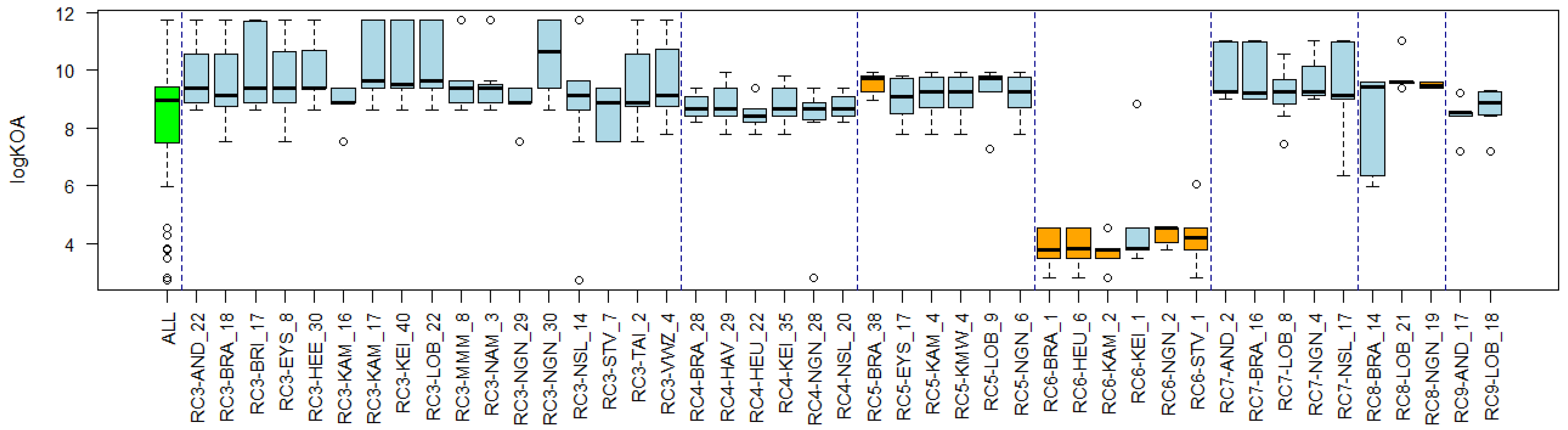

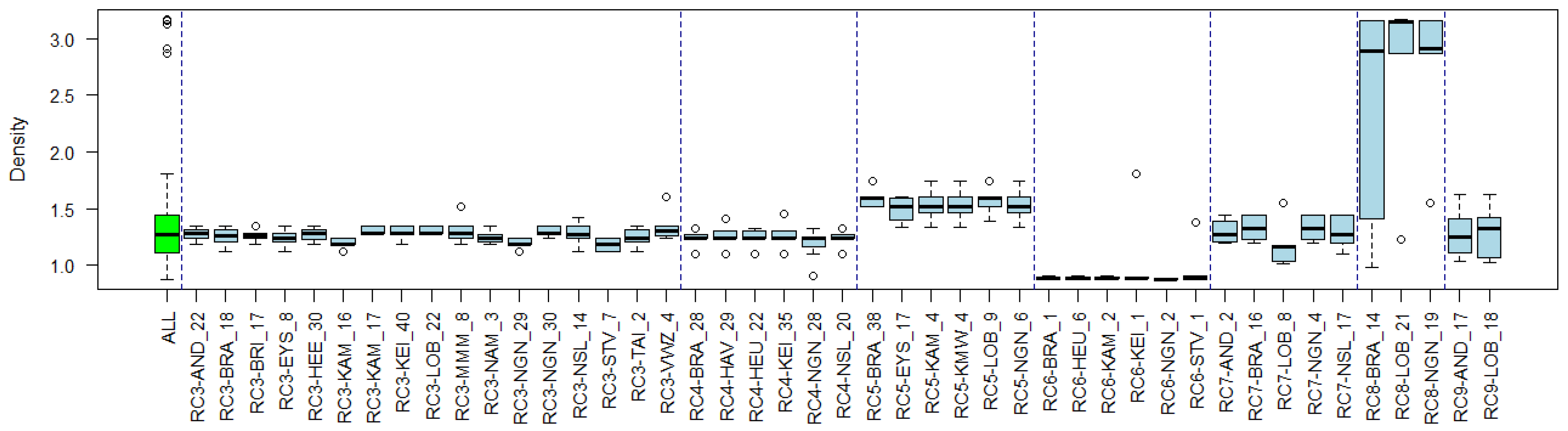

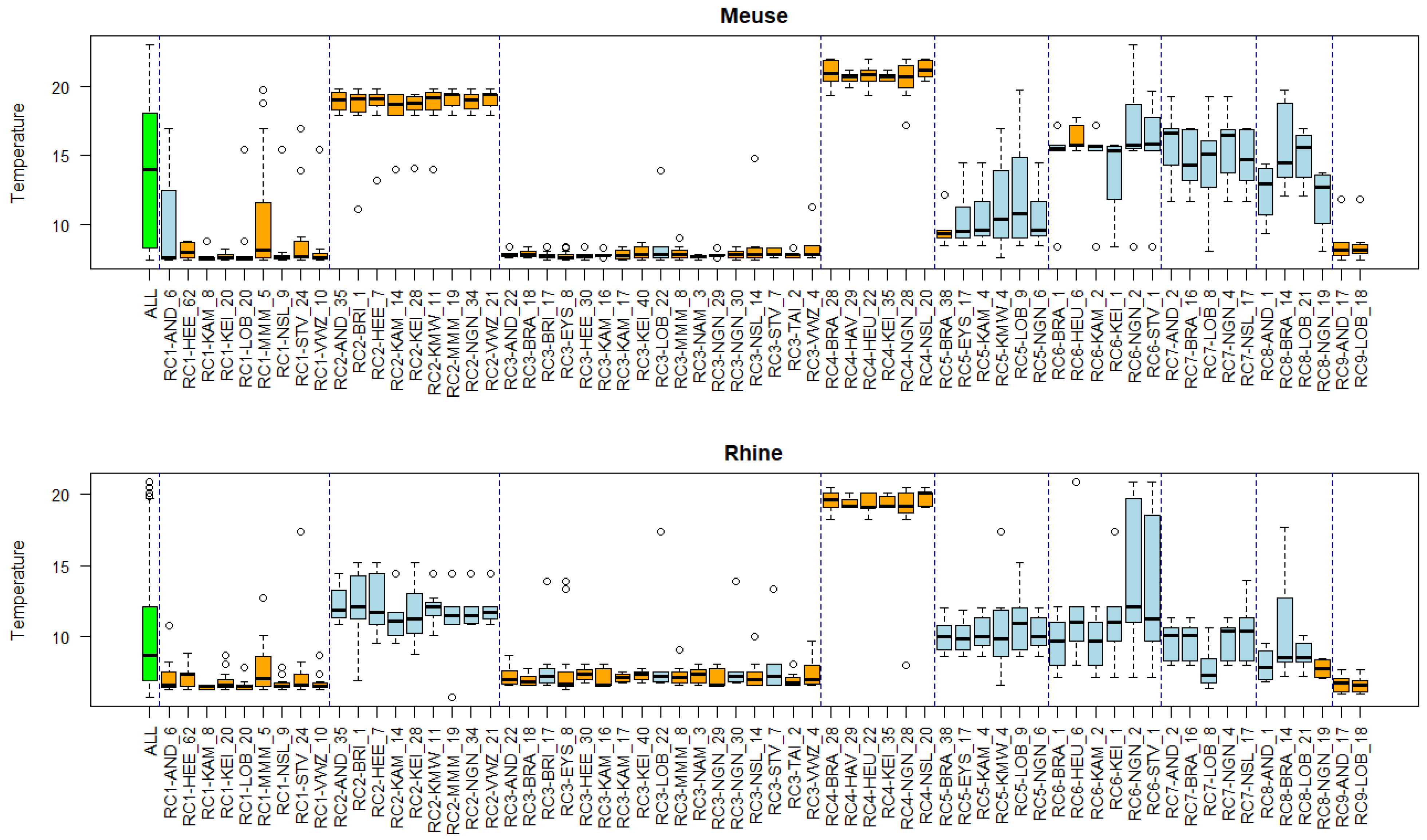
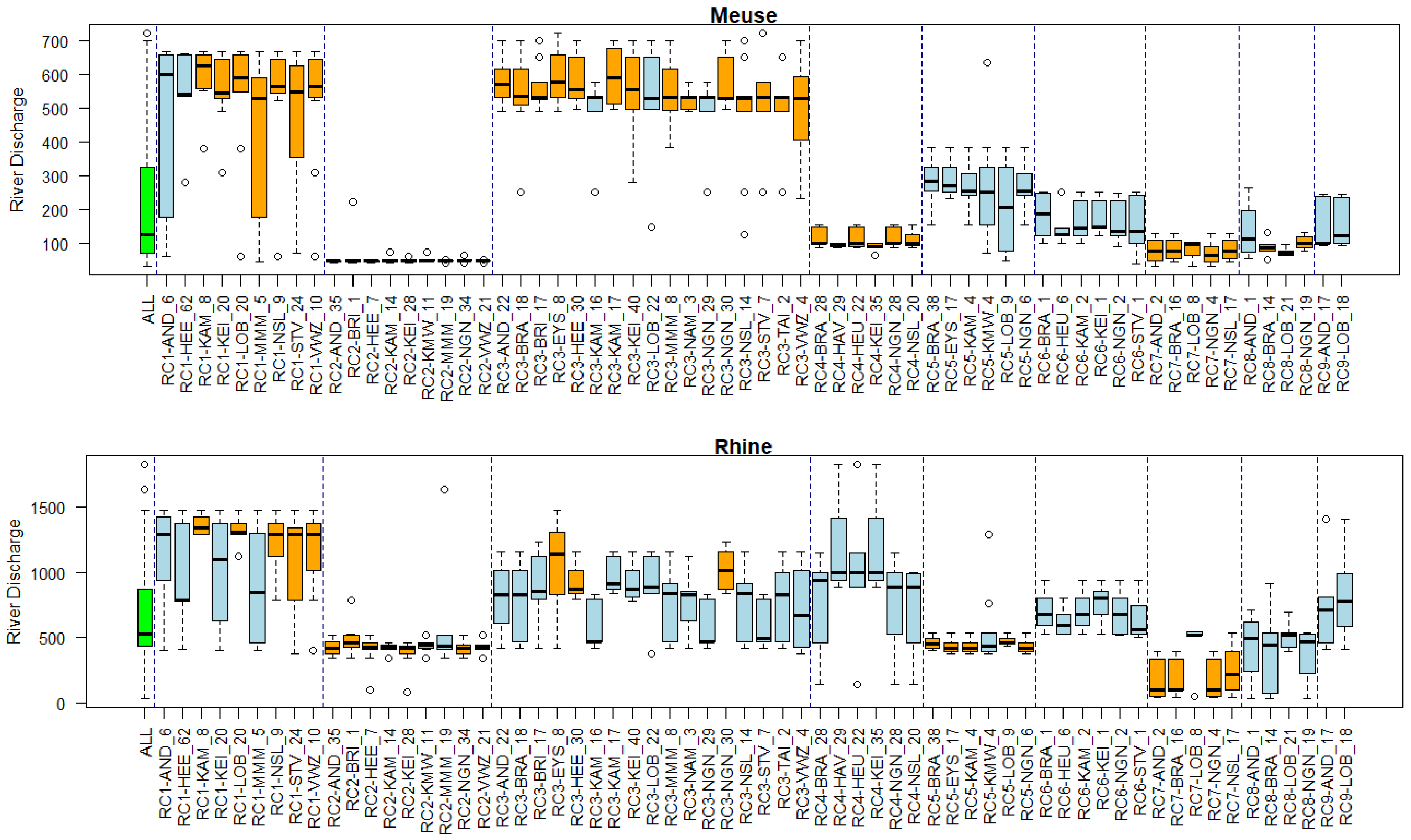
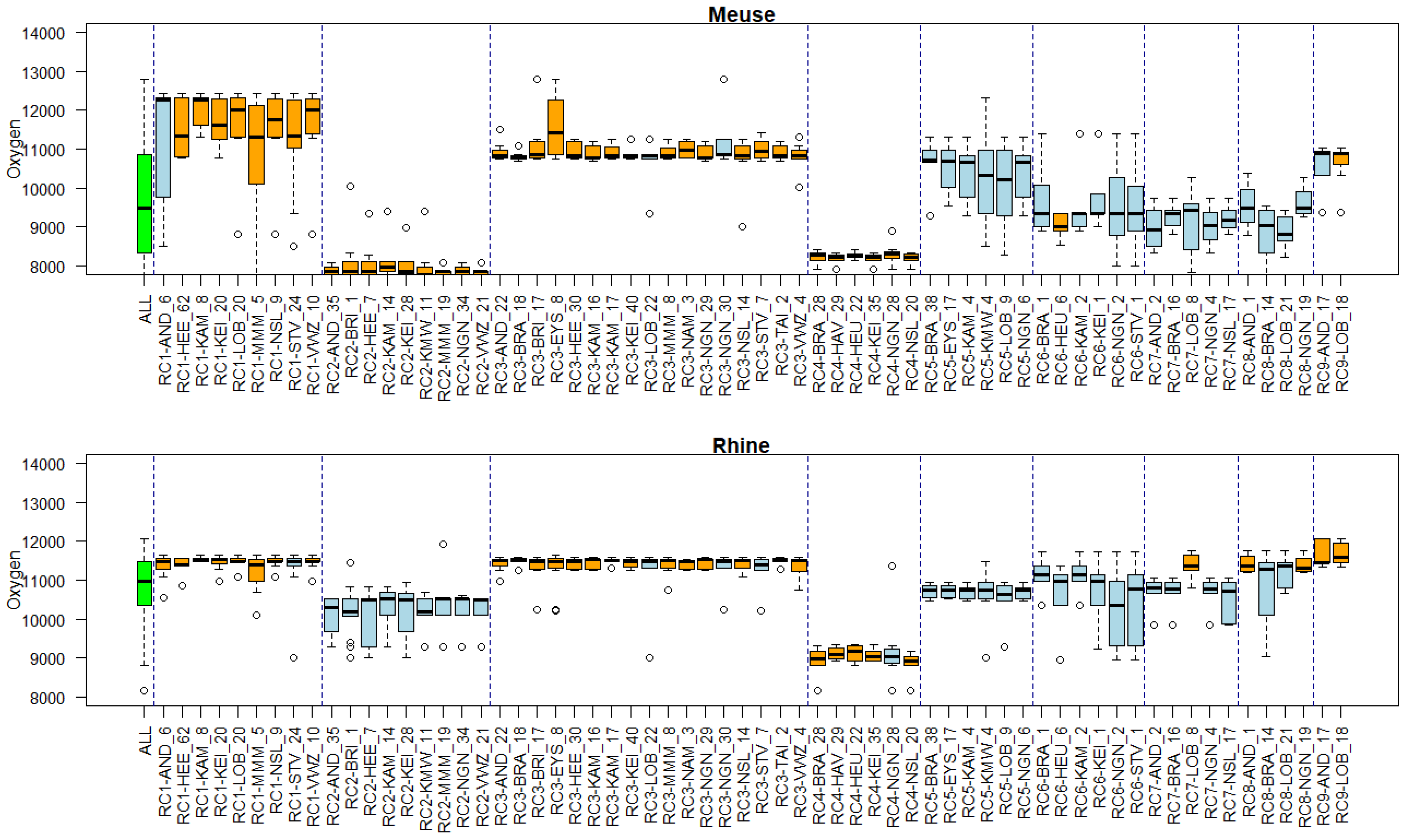

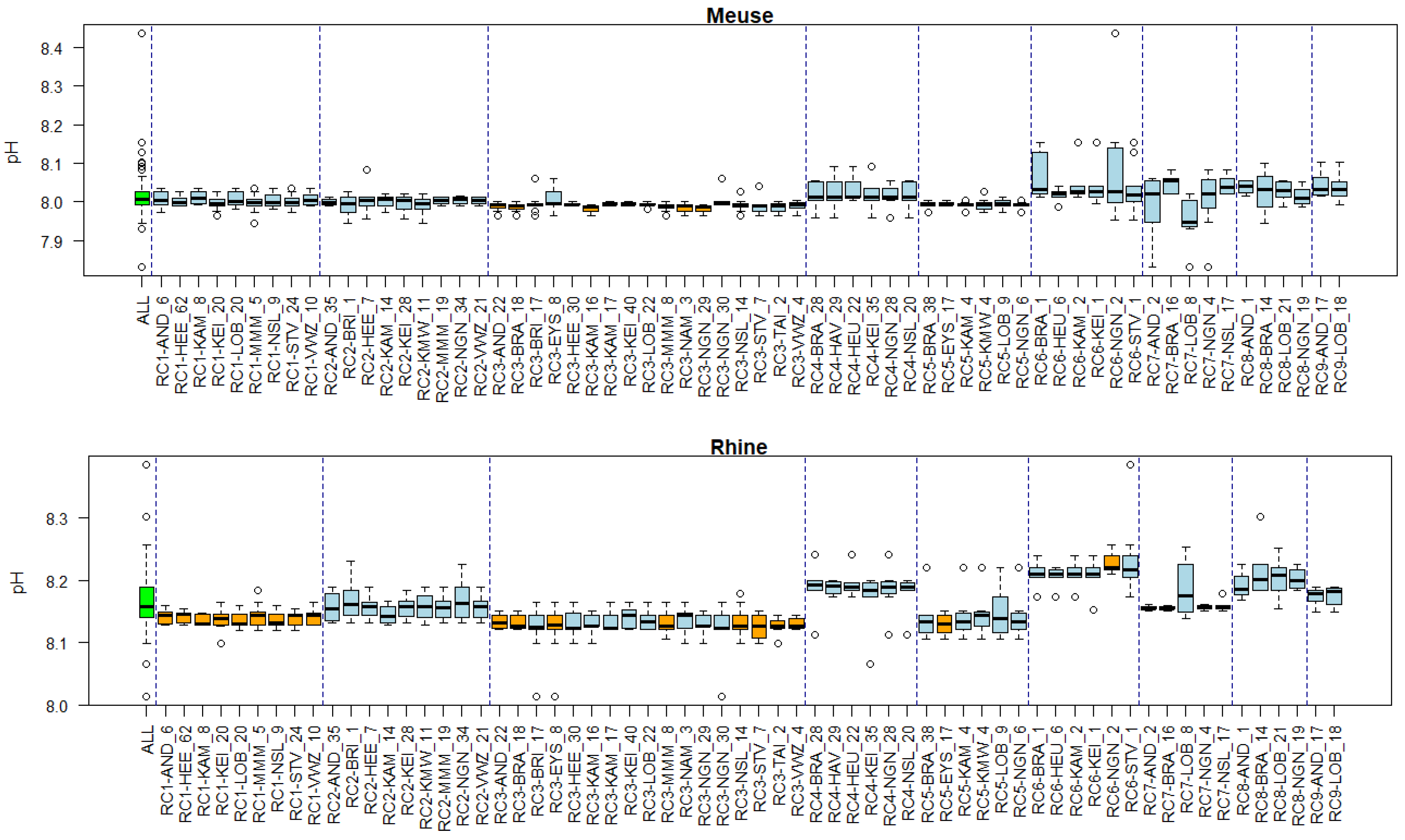
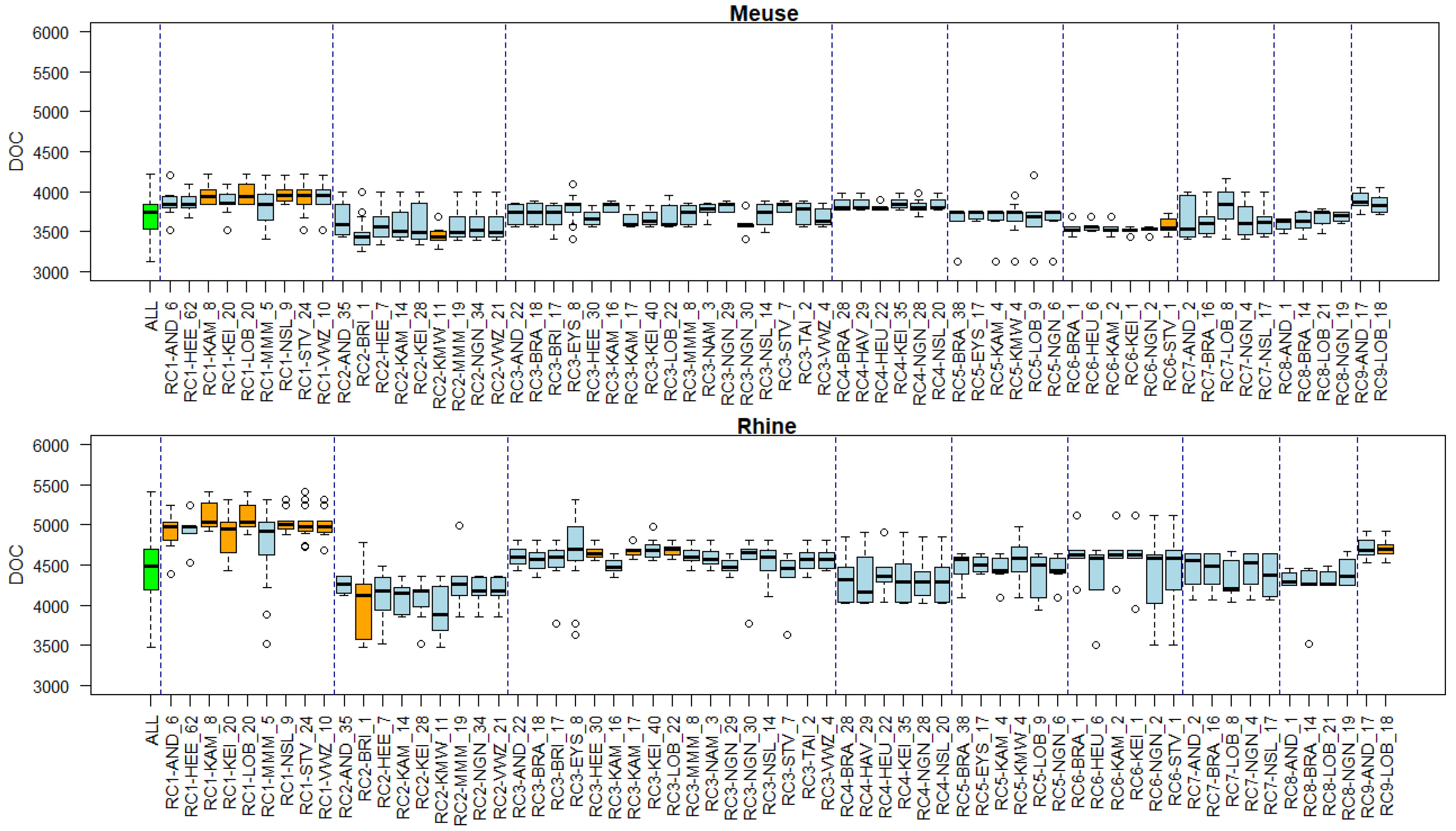
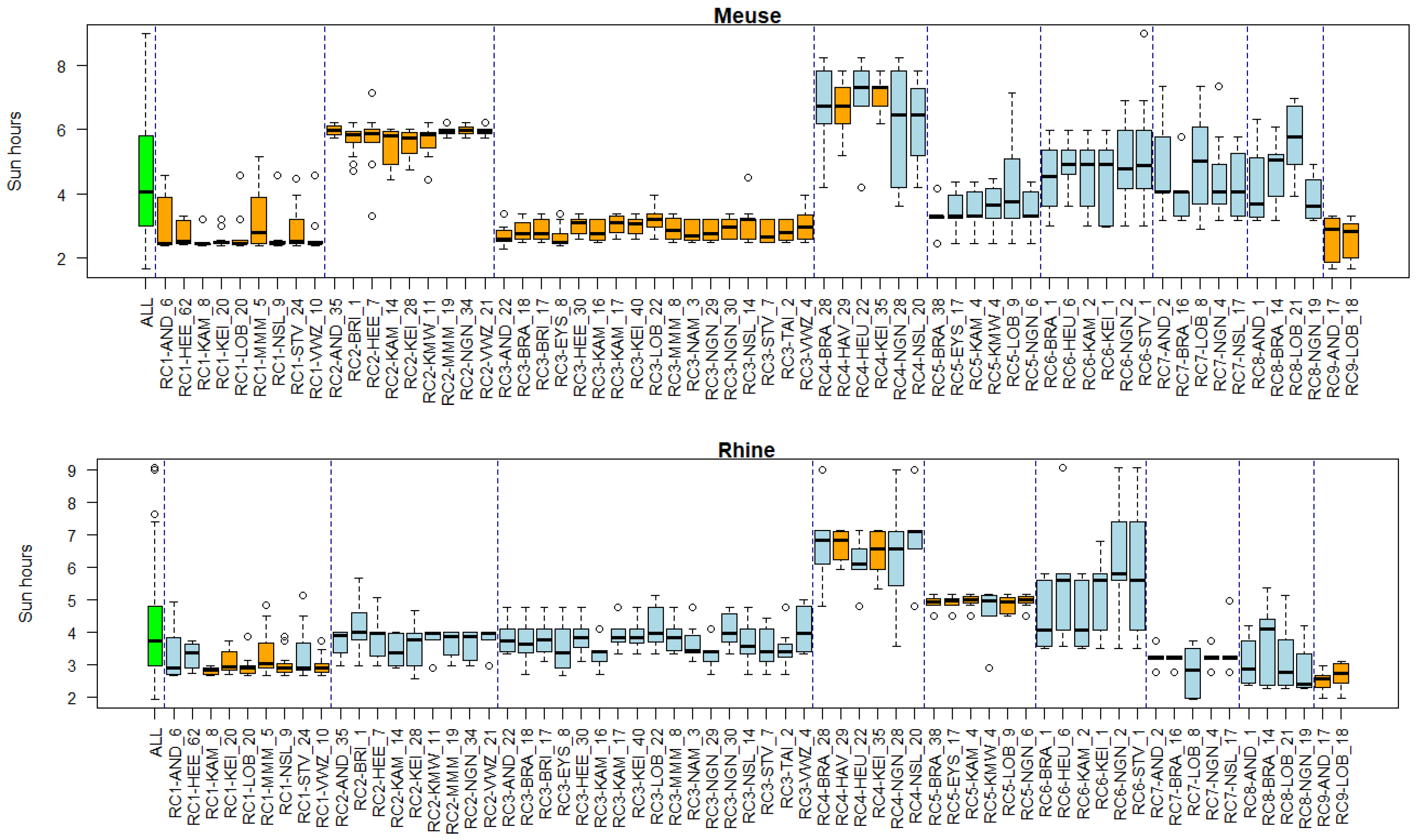
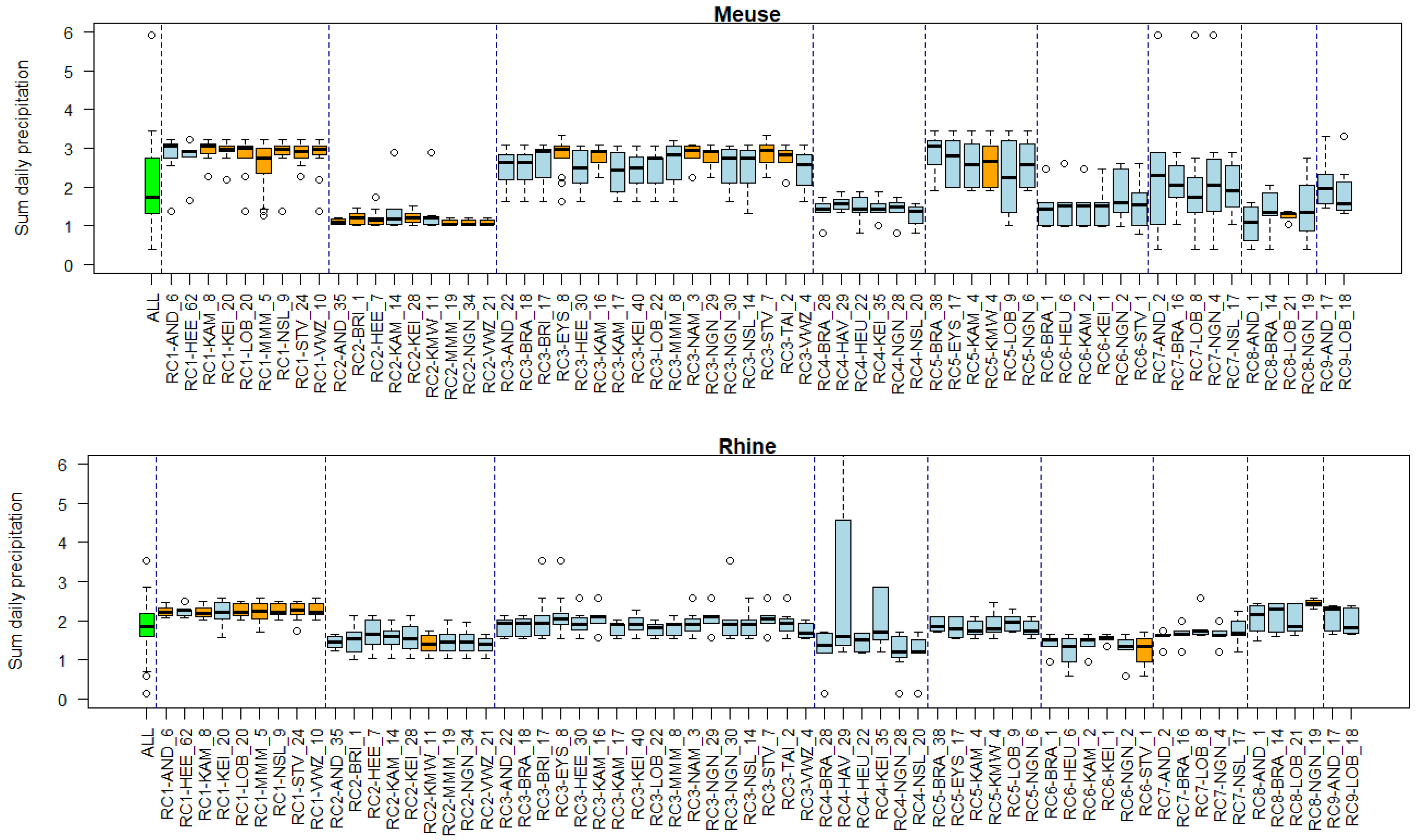
Appendix C. Cluster Significance

References
- Musolff, A.; Leschik, S.; Möder, M.; Strauch, G.; Reinstorf, F.; Schirmer, M. Temporal and spatial patterns of micropollutants in urban receiving waters. Environ. Pollut. 2009, 157, 3069–3077. [Google Scholar] [CrossRef]
- Baragaño, D.; Ratié, G.; Sierra, C.; Chrastný, V.; Komárek, M.; Gallego, J.R. Multiple pollution sources unravelled by environmental forensics techniques and multivariate statistics. J. Hazard. Mater. 2022, 424, 127413. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, L.; Huang, Q.-H.; Li, W.-Y.; Tang, Y.-J.; Zhao, J.-F. Source apportionment of polycyclic aromatic hydrocarbons (PAHs) in surface sediments of the Huangpu River, Shanghai, China. Sci. Total Environ. 2009, 407, 2931–2938. [Google Scholar] [CrossRef] [PubMed]
- Luo, T.; Hu, S.; Cui, J.; Tian, H.; Jing, C. Comparison of arsenic geochemical evolution in the Datong Basin (Shanxi) and Hetao Basin (Inner Mongolia), China. Appl. Geochem. 2012, 27, 2315–2323. [Google Scholar] [CrossRef]
- Cha, Y.; Kim, Y.M.; Choi, J.-W.; Sthiannopkao, S.; Cho, K.H. Bayesian modeling approach for characterizing groundwater arsenic contamination in the Mekong River basin. Chemosphere 2016, 143, 50–56. [Google Scholar] [CrossRef] [PubMed]
- Bonelli, M.G.; Ferrini, M.; Manni, A. Artificial neural networks to evaluate organic and inorganic contamination in agricultural soils. Chemosphere 2017, 186, 124–131. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.H.; Sthiannopkao, S.; Pachepsky, Y.A.; Kim, K.-W.; Kim, J.H. Prediction of contamination potential of groundwater arsenic in Cambodia, Laos, and Thailand using artificial neural network. Water Res. 2011, 45, 5535–5544. [Google Scholar] [CrossRef]
- Brückner, I.; Classen, S.; Hammers-Wirtz, M.; Klaer, K.; Reichert, J.; Pinnekamp, J. Tool for selecting indicator substances to evaluate the impact of wastewater treatment plants on receiving water bodies. Sci. Total. Environ. 2020, 745, 140746. [Google Scholar] [CrossRef]
- Jekel, M.; Dott, W.; Bergmann, A.; Dünnbier, U.; Gnirß, R.; Haist-Gulde, B.; Hamscher, G.; Letzel, M.; Licha, T.; Lyko, S.; et al. Selection of organic process and source indicator substances for the anthropogenically influenced water cycle. Chemosphere 2015, 125, 155–167. [Google Scholar] [CrossRef]
- Warner, W.; Licha, T.; Nödler, K. Qualitative and quantitative use of micropollutants as source and process indicators. A review. Sci. Total Environ. 2019, 686, 75–89. [Google Scholar] [CrossRef]
- Kahl, S.; Nivala, J.; van Afferden, M.; Müller, R.A.; Reemtsma, T. Effect of design and operational conditions on the performance of subsurface flow treatment wetlands: Emerging organic contaminants as indicators. Water Res. 2017, 125, 490–500. [Google Scholar] [CrossRef] [PubMed]
- Wolf, L.; Held, I.; Eiswirth, M.; Hötzl, H. Impact of Leaky Sewers on Groundwater Quality. Acta Hydrochim. Hydrobiol. 2004, 32, 361–373. [Google Scholar] [CrossRef]
- ter Laak, T.L.; Kooij, P.J.F.; Tolkamp, H.; Hofman, J. Different compositions of pharmaceuticals in Dutch and Belgian rivers explained by consumption patterns and treatment efficiency. Environ. Sci. Pollut. Res. Int. 2014, 21, 12843–12855. [Google Scholar] [CrossRef] [PubMed]
- Buttiglieri, G.; Peschka, M.; Frömel, T.; Müller, J.; Malpei, F.; Seel, P.; Knepper, T.P. Environmental occurrence and degradation of the herbicide n-chloridazon. Water Res. 2009, 43, 2865–2873. [Google Scholar] [CrossRef] [PubMed]
- Byer, J.D.; Struger, J.; Sverko, E.; Klawunn, P.; Todd, A. Spatial and seasonal variations in atrazine and metolachlor surface water concentrations in Ontario (Canada) using ELISA. Chemosphere 2011, 82, 1155–1160. [Google Scholar] [CrossRef] [PubMed]
- Harman, C.; Reid, M.; Thomas, K.V. In Situ Calibration of a Passive Sampling Device for Selected Illicit Drugs and Their Metabolites in Wastewater, And Subsequent Year-Long Assessment of Community Drug Usage. Environ. Sci. Technol. 2011, 45, 5676–5682. [Google Scholar] [CrossRef] [PubMed]
- Loraine, G.A.; Pettigrove, M.E. Seasonal Variations in Concentrations of Pharmaceuticals and Personal Care Products in Drinking Water and Reclaimed Wastewater in Southern California. Environ. Sci. Technol. 2006, 40, 687–695. [Google Scholar] [CrossRef]
- Seitz, W.; Winzenbacher, R. A survey on trace organic chemicals in a German water protection area and the proposal of relevant indicators for anthropogenic influences. Environ. Monit. Assess. 2017, 189, 244. [Google Scholar] [CrossRef]
- Pascual-Aguilar, J.; Andreu, V.; Picó, Y. An environmental forensic procedure to analyse anthropogenic pressures of urban origin on surface water of protected coastal agro-environmental wetlands (L’Albufera de Valencia Natural Park, Spain). J. Hazard. Mater. 2013, 263, 214–223. [Google Scholar] [CrossRef]
- Hermsen, S.A.B.; Pronk, T.E.; van den Brandhof, E.-J.; van der Ven, L.T.M.; Piersma, A.H. Transcriptomic analysis in the developing zebrafish embryo after compound exposure: Individual gene expression and pathway regulation. Toxicol. Appl. Pharmacol. 2013, 272, 161–171. [Google Scholar] [CrossRef]
- Pronk, T.E.; van Someren, E.P.; Stierum, R.H.; Ezendam, J.; Pennings, J.L.A. Unraveling toxicological mechanisms and predicting toxicity classes with gene dysregulation networks. J. Appl. Toxicol. 2013, 33, 1407–1415. [Google Scholar] [CrossRef] [PubMed]
- Mansouri, K.; Grulke, C.M.; Judson, R.S.; Williams, A.J. OPERA models for predicting physicochemical properties and environmental fate endpoints. J. Cheminformatics 2018, 10, 1–19. [Google Scholar] [CrossRef] [PubMed]
- US EPA. Estimation Programs Interface Suite™ for Microsoft® Windows; version 4.11; United States Environmental Protection Agency: Washington, DC, USA, 2023.
- Mamy, L.; Patureau, D.; Barriuso, E.; Bedos, C.; Bessac, F.; Louchart, X.; Martin-Laurent, F.; Miege, C.; Benoit, P. Prediction of the Fate of Organic Compounds in the Environment From Their Molecular Properties: A Review. Crit. Rev. Environ. Sci. Technol. 2015, 45, 1277–1377. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Gao, J.; Zheng, Q.; Thai, P.K.; Duan, H.; Mueller, J.F.; Yuan, Z.; Jiang, G. Effects of pH, Temperature, Suspended Solids, and Biological Activity on Transformation of Illicit Drug and Pharmaceutical Biomarkers in Sewers. Environ. Sci. Technol. 2021, 55, 8771–8782. [Google Scholar] [CrossRef] [PubMed]
- Echols, K.R.; Brumbaugh, W.G.; Orazio, C.E.; May, T.W.; Poulton, B.C.; Peterman, P.H. Distribution of Pesticides, PAHs, PCBs, and Bioavailable Metals in Depositional Sediments of the Lower Missouri River, USA. Arch. Environ. Contam. Toxicol. 2008, 55, 161–172. [Google Scholar] [CrossRef] [PubMed]
- Schneider, A.R.; Porter, E.T.; Baker, J.E. Polychlorinated Biphenyl Release from Resuspended Hudson River Sediment. Environ. Sci. Technol. 2007, 41, 1097–1103. [Google Scholar] [CrossRef] [PubMed]
- Brunsch, A.F.; ter Laak, T.L.; Rijnaarts, H.; Christoffels, E. Pharmaceutical concentration variability at sewage treatment plant outlets dominated by hydrology and other factors. Environ. Pollut. 2018, 235, 615–624. [Google Scholar] [CrossRef]
- Azuma, T.; Nakada, N.; Yamashita, N.; Tanaka, H. Synchronous Dynamics of Observed and Predicted Values of Anti-influenza drugs in Environmental Waters during a Seasonal Influenza Outbreak. Environ. Sci. Technol. 2012, 46, 12873–12881. [Google Scholar] [CrossRef]
- Mu, G.; Bian, D.; Zou, M.; Wang, X.; Chen, F. Pollution and Risk Assessment of Polycyclic Aromatic Hydrocarbons in Urban Rivers in a Northeastern Chinese City: Implications for Continuous Rainfall Events. Sustainability 2023, 15, 5777. [Google Scholar] [CrossRef]
- Helsel, D.R. More Than Obvious: Better Methods for Interpreting nondetect data. Environ. Sci. Technol. 2005, 39, 419–423. [Google Scholar] [CrossRef]
- Rakonjac, N.; van der Zee, S.E.; Wipfler, L.; Roex, E.; Kros, H. Emission estimation and prioritization of veterinary pharmaceuticals in manure slurries applied to soil. Sci. Total Environ. 2022, 815, 152938. [Google Scholar] [CrossRef]
- Jans, A.C.H.; Berbee, R.P.M. Sources of PFAS for Dutch Surface Waters. RWS Report. 2020. Available online: https://open.rijkswaterstaat.nl/publish/pages/135993/rws_information_sources_of_pfas_for_dutch_surface_waters.pdf (accessed on 2 January 2024).
- van Leerdam, R.C.; van Driezum, I.H.; Broekman, M.H. Type De Gevaren Van Dumpingen en Lozingen Van Drugsproductieafval Voor de Kwaliteit Van Drinkwaterbronnen. RIVM Report. 2022. Available online: https://rivm.openrepository.com/handle/10029/626320 (accessed on 2 January 2024).
- Suzuki, R.; Shimodaira, H. Pvclust: An R package for assessing the uncertainty in hierarchical clustering. Bioinformatics 2006, 22, 1540–1542. [Google Scholar] [CrossRef]
- Kimes, P.K.; Liu, Y.; Neil Hayes, D.; Marron, J.S. Statistical significance for hierarchical clustering. Biometrics 2017, 73, 811–821. [Google Scholar] [CrossRef]




| Rhine | Meuse | |
|---|---|---|
| Temporal spread | 2551 unique sampling dates over 5 years | 2323 unique sampling dates over 5 years |
| Spatial spread | 10 locations | 9 locations |
| Processed, weekly aggregated data (step 2, Figure 1) | 1128 weekly samples over 10 locations, 854 substances (with a CAS-number) | 2315 weekly samples over 9 locations, 1008 substances (with a CAS-number) |
| Location Code | Location Name | Weekly Samples | Substances | Clusters | Substances in Clusters | Average Cluster Size | River |
|---|---|---|---|---|---|---|---|
| AND | Andijk | 62 | 168 | 13 | 64 | 4.9 | Rhine |
| LOB | Lobith | 52 | 193 | 18 | 100 | 5.6 | Rhine |
| NGN | Nieuwegein | 63 | 201 | 22 | 102 | 4.6 | Rhine |
| NSL | Nieuwersluis | 64 | 139 | 10 | 68 | 6.8 | Rhine |
| BRI | Brienenoord | 62 | 121 | 8 | 52 | 6.5 | Rhine |
| KAM | Kampen | 64 | 109 | 10 | 53 | 5.3 | Rhine |
| KMW | Ketelmeer-West | 61 | 102 | 10 | 59 | 5.9 | Rhine |
| MMM | Markermeer-Midden | 60 | 94 | 8 | 51 | 6.4 | Rhine |
| VWZ | Vrouwezand (IJsselmeer) | 61 | 88 | 6 | 37 | 6.2 | Rhine |
| HAV | Stad aan ‘t Haringvliet | 53 | 166 | 11 | 67 | 6.1 | Rhine |
| BRA | Brakel | 53 | 164 | 16 | 75 | 4.7 | Meuse |
| HEE | Heel | 52 | 163 | 18 | 76 | 4.2 | Meuse |
| EYS | Eijsden | 60 | 111 | 6 | 48 | 8 | Meuse |
| HEU | Heusden | 60 | 62 | 6 | 26 | 4.3 | Meuse |
| NAM | Nameche | 64 | 40 | 3 | 20 | 6.7 | Meuse |
| TAI | Tailfer | 49 | 39 | 4 | 21 | 5.3 | Meuse |
| STV | Stevensweert | 62 | 114 | 10 | 75 | 7.5 | Meuse |
| KEI | Keizersveer | 54 | 177 | 13 | 68 | 5.2 | Meuse |
| LUI | Luik | 63 | 57 | 4 | 17 | 4.3 | Meuse |
| Reference Lists | Meuse Clusters | Rhine Clusters |
|---|---|---|
| ‘Dutch Rivers’ | 29 | 48 |
| ‘Wastewater treatment plant’ | 33 | 43 |
| ‘Installations for waste processing or landfills or refinery’ | 19 | 23 |
| ‘Polycyclic aromatic hydrocarbons (PAHs)’ | 12 | 17 |
| ‘Industrial substances (containing PCBs)’ | 4 | 12 |
| ‘Herbicides based on a triazine group’ | 9 | 9 |
| Recurring Cluster Number | Substances | 3 Example Clusters in Locations | Description |
|---|---|---|---|
| RC1 | Aluminum, barium, beryllium, cadmium, cesium, chromium, iron, cobalt, copper, mercury, lithium, lead, manganese, rubidium, thallium, tin, titanium, vanadium, zinc, nickel, arsenic | LOB_20 NGN_18 MMM_5 | Metals Sometimes combined with PAH substances |
| RC2 | Boron, calcium, chloride, potassium, lithium, magnesium, molybdenum, sodium, rubidium, strontium, sulfate, uranium, bromide, silicate as Si | NGN_34 BRI_1 KAM_14 | Salts and reactive (alkali) metals |
| RC3 | benzo(a)anthracene, benzo(a)pyrene, benzo(b)fluoranthene, benzo(ghi)perylene, benzo(k)fluoranthene, chrysene, dibenzo(a,h)anthracene, fluoranthene, indeno(1,2,3-cd)pyrene, pyrene, phenanthrene, anthracene | LOB_22 NGN_30 EYS_8 | Polycyclic aromatic hydrocarbons (PAHs) (fossil fuel burning) In some clusters together with PCBs like VWZ_4, HAV_21 |
| RC4 | Cyanazine, desethyl-terbutylazine, dimethenamide, dimethenamide-p, metolachlor, terbuthylazine, ethofumesate, metobromuron, linuron | NGN_28 NSL_20 BRA_28 | Herbicides |
| RC5 | 2,2′,3,4,4′,5′-hexachlorobiphenyl (PCB 138), 2,2′,4,4′,5,5′-hexachlorobiphenyl (PCB 153), 2,2′,4,5,5′-pentachlorobiphenyl (PCB 101), 2,2′,5,5′-tetrachlorobiphenyl (PCB 52), 2,3′,4,4′,5-pentachlorobiphenyl (PCB 118), 2,3,4,5,2′,4′,5′-heptachlorobiphenyl (PCB 180), 2,4,4′-trichlorobiphenyl (PCB 28) | NGN_6 KMW_4 BRA_38 | Polychlorinated Biphenyls (PCBs) (industrial and commercial applications) |
| RC6 | 1,2-dimethylbenzene (o-xylene), 1,2,4-trimethylbenzene, Benzene, Ethylbenzene, methylbenzene (toluene), 1,2,3-trimethylbenzene, 1,3,5-trimethylbenzene, 2-ethyltoluene, Ethenylbenzene, n-propylbenzene | KAM_2 NGN_2 KEI_1 | Aromatic hydrocarbons (petrol oil and fuel) |
| RC7 | 10,11-dihydro-10,11-dihydroxycarbamazepine, carbamazepine, oxazepam, primidone, sulfamethoxazole, temazepam | NGN_4 AND_2 BRA_16 | Pharmaceuticals |
| RC8 | Amidotrizoic acid, ethylenediaminetetraethanoic acid (EDTA), jopamidol, joxitalamic acid jopromide, johexol | LOB_21 NGN_19 BRA_14 | Contrast-agents |
| RC9 | Bisoprolol, guanylureum, sotalol, hydrochlorothiazide, atenolol, metoprolol | AND_17 BRA_21 LOB_18 | Beta blockers, diuretics |
| Cluster Name | Overlapping Reference Lists | Substance Properties | Environmental Conditions |
|---|---|---|---|
| RC1 Metals | Dutch Rivers/ Installations for waste processing or landfills or refinery/ Wastewater treatment plant/Untreated wastewater Netherlands | n.a. |
|
| RC2 Salts, reactive metals | Dutch Rivers/ Wastewater treatment plant/Installations for waste processing or landfills or refinery | n.a. |
|
| RC3 PAHs | Polycyclic aromatic hydrocarbons (PAHs)/Untreated wastewater Netherlands |
|
|
| RC4 Herbicides | Herbicides based on a triazine group/Herbicides based on amides |
|
|
| RC5 PCBs | Industrial substances (containing PCBs) |
|
|
| RC6 AHs | Petrol additives/Industrial solvents/Motor fuel leakage/Industrial substances |
|
|
| RC7 Pharmaceuticals | Pharmaceuticals/Wastewater treatment plant/Exchange between surface and groundwater/Domestic wastewater/Antidepressants and narcotics |
|
|
| RC8 Contrast agents | Contrast agents/Domestic wastewater/Dutch Rivers/Wastewater treatment plant |
|
|
| RC9 Beta blockers | Blood pressure relievers and diuretics/ Dutch Rivers/ Wastewater treatment plant |
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pronk, T.E.; Amato, E.D.; Kools, S.A.E.; Ter Laak, T.L. Linking Clusters of Micropollutants in Surface Water to Emission Sources, Environmental Conditions, and Substance Properties. Environments 2024, 11, 46. https://doi.org/10.3390/environments11030046
Pronk TE, Amato ED, Kools SAE, Ter Laak TL. Linking Clusters of Micropollutants in Surface Water to Emission Sources, Environmental Conditions, and Substance Properties. Environments. 2024; 11(3):46. https://doi.org/10.3390/environments11030046
Chicago/Turabian StylePronk, Tessa E., Elvio D. Amato, Stefan A. E. Kools, and Thomas L. Ter Laak. 2024. "Linking Clusters of Micropollutants in Surface Water to Emission Sources, Environmental Conditions, and Substance Properties" Environments 11, no. 3: 46. https://doi.org/10.3390/environments11030046
APA StylePronk, T. E., Amato, E. D., Kools, S. A. E., & Ter Laak, T. L. (2024). Linking Clusters of Micropollutants in Surface Water to Emission Sources, Environmental Conditions, and Substance Properties. Environments, 11(3), 46. https://doi.org/10.3390/environments11030046