1. Introduction
There is growing pressure on marine ecosystems due to human use, especially near coasts where interactions between terrestrial and marine drivers have the potential to generate large cumulative impacts [
1]. Coastal ecosystems provide many important goods and services to both coastal and inland inhabitants [
2,
3,
4]. Therefore, it is often necessary to balance competing demands from stakeholders with the sustainable management of marine resources and ecology [
5]. Marine spatial planning (MSP) is a framework by which this can be accomplished [
6]. Using MSP, local maps of ecology are analyzed alongside those of human use to identify overlaps and conflicts. This spatial information is used to implement management plans for the current and future use of the marine system [
6]. Maps are, therefore, key components to such management initiatives as the primary means of conveying spatial information.
Seafloor substrate maps are particularly useful for determining the distribution of coastal marine biota. Substrate composition can be a strong predictor of benthic biodiversity [
7]. The presence of hard substrata, for example, can provide attachment surfaces for sessile animals, marine algae, and the grazers that feed on them, while soft sediments provide habitat for many infaunal invertebrates [
7]. Substrate composition also determines seabed complexity by providing structure and shelter for marine fauna—factors that correlate with biodiversity [
8]. Substrate maps can therefore inform on the distributions of single species or biodiversity—both of which may be important components of a given management framework.
A variety of methods for producing seabed sediment maps have been explored (e.g., [
9,
10,
11]). Surficial sediment maps were traditionally produced by manual interpretation of ground-truth data in the context of local geomorphology and often, sonar data (e.g., Todd et al. [
12]) but modern methods increasingly rely on automated objective approaches [
13]. These have recently become feasible thanks to the widespread accessibility of digital data, powerful geographic information system (GIS) tools and high-performance computing – they allow for mapping a range of substrate characteristics. Grab sample and core data, for example, have been used to predict sediment grain size [
10,
14] and particulate organic carbon content in unconsolidated sediments [
15], while the presence of rock or hard substrates has been predicted from underwater video [
16,
17]. There are now a variety of approaches to choose from for a given mapping application and it is important to select those that fit the given geographic and dataset characteristics.
Coupled with high-resolution acoustic mapping, automated statistical methods are among the most promising recent approaches to mapping seabed sediments. They perform well compared to other methods [
9,
18] and are objective—providing several advantages over manual or subjective approaches [
19]. In supervised modelling, ground-truth sediment samples (e.g., grabs, cores, video observations) are used to train a statistical model based on environmental data (e.g., depth, seabed morphology, acoustic seabed properties). Statistical relationships between sediment samples (response variable) and environmental data at the sample location (explanatory variables) are used to predict sediment characteristics at unsampled locations. With spatially continuous remotely sensed environmental data, it is therefore possible to produce full-coverage seabed sediment maps from relatively sparse sediment samples.
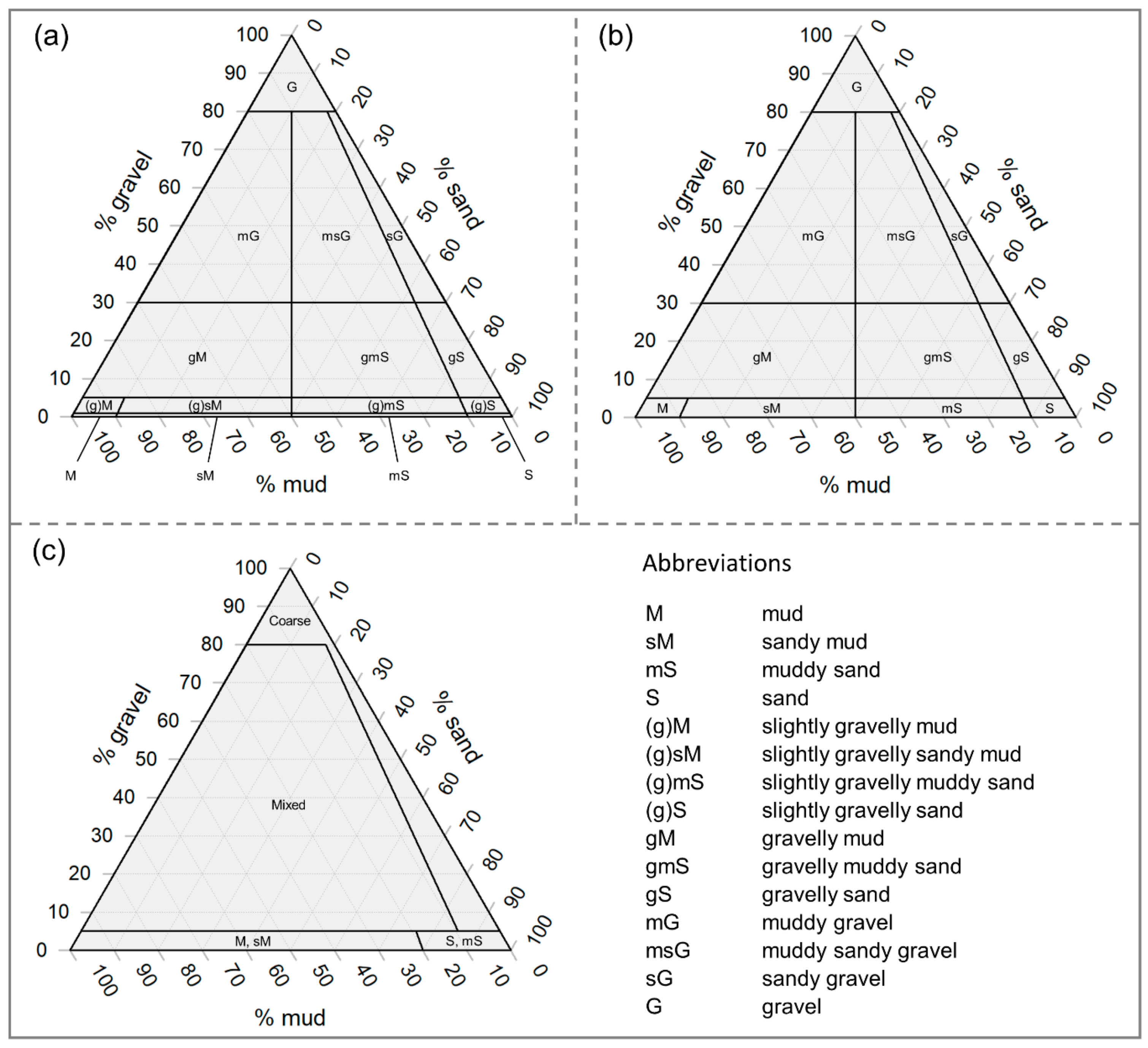
For producing classified (thematic) maps of sediment grain size, several common textural classification schemes, such as Folk [
20], place grain size samples on a ternary diagram according to the ratio of sand:mud and the percentage of gravel (
Figure 1a). Similar textural schemes coarsen the thematic resolution of Folk’s by aggregating to fewer classes, such as the British Geological Survey (BGS) modification for small-scale (1:1,000,000) maps, which eliminates the “slightly gravelly” classes (
Figure 1b; [
21]). To account for substrate types used in the European Nature Information System (EUNIS) habitat classification, a further simplified version of Folk’s classification with only four classes has been suggested and is widely used [
21,
22] (
Figure 1c). Among other criteria, the selection of a classification scheme may be for compatibility with regional management systems (e.g., EUNIS [
23,
24]), for alignment with existing literature [
25] or for matching with ground-truth data.
Using a supervised modelling approach, ground-truth sediment data are commonly treated in two ways to produce classified maps of seabed sediment according to schemes such as those described in
Figure 1:
1. Quantitative measures of a substrate property, such as grain size fraction (e.g., percent mud, sand, and gravel), are used to predict quantitative gradational values across the full environmental data coverage (e.g., [
26]). These predictions are useful for management or further modelling but some applications require classified or thematic maps, which can be produced by classifying the quantitative predictions according to some scheme (e.g.,
Figure 1). This is useful for summarizing sediment composition in a single map or for ensuring compatibility with regional management plans or similar research (see Strong et al. [
25] for discussion of classification and compatibility).
2. Ground-truth data are aggregated according to a classification scheme prior to modelling, thereby treating them as categorical variables (e.g., [
27]). It may also be the case that inherited data (e.g., from the literature, online databases, legacy data) are already classified and the quantitative data are unavailable or that datasets consist of sediment classes derived from visual assessment. In these cases, the options available to the modeler are limited and the categorical classification approach may be the logical choice. Using this approach, a model can predict the occurrence of the observed classes over the full extent of the environmental data.
Here we will refer to these as “quantitative” and “categorical” modelling approaches. While the quantitative approach is also known as “continuous” or “regression” modelling and categorical is commonly referred to as “classification,” we use the terms “quantitative” and “categorical” to reduce confusion, since the other terms also have other meanings that are relevant here (e.g., “classified” maps can be produced from either approach and all predictions are “spatially continuous”).
Each of these broad approaches contain numerous individual modelling techniques with their own intricacies, many of which have been compared in the ecological and conservation management literature (e.g., presence-absence models [
28], regression models [
29], machine learning [
30], geostatistical and hybrid methods [
18,
31]). Among machine learning techniques, Random Forest [
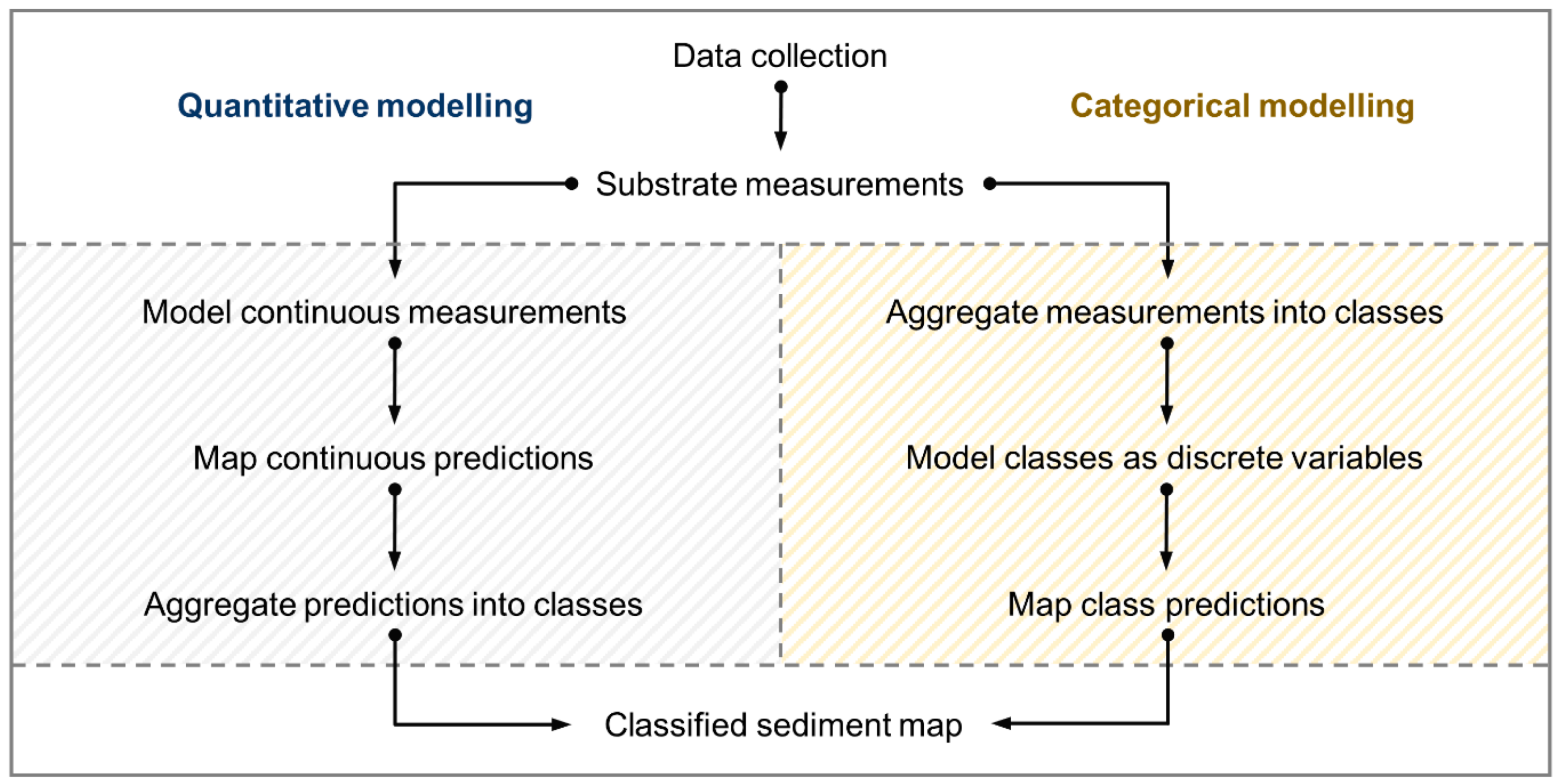
32] is a particularly flexible and accurate method that is capable of both quantitative and categorical modelling. This flexibility, coupled with widespread availability via popular statistical and GIS software (e.g., R, ArcGIS), has made Random Forest popular for seabed mapping. Given the goal of producing a classified (i.e., “thematic”) seabed map using continuous sediment data, Random Forest could be applied using either quantitative or categorical approaches (
Figure 2) at the discretion of the user.
There are apparent advantages and disadvantages to both quantitative and categorical sediment modelling approaches for producing classified maps. Unclassified quantitative predictions on their own constitute a useful result for further modelling and mapping and are flexible once produced—it is easy to classify and reclassify quantitative values as necessary. The modelling process can be complex though, potentially involving data transformations such as additive log-ratios for compositional data [
33], multiple models for different log-ratios [
26] and multiple corresponding tuning and variable selection procedures. On the other hand, the categorical modelling procedure can be more straightforward, requiring little data manipulation once ground-truth measurements have been aggregated into classes and explanatory variables have been selected. Class labels can be predicted to new data relatively easily. Once produced though, classes are more static compared to quantitative predictions. It may be possible to simply aggregate mapped classes to a more general scheme (e.g., Folk to simplified Folk;
Figure 1) but it may also be necessary to re-classify the ground-truth, select new variables and re-tune model parameters for a new classification, especially if the original scheme is a poor match for the data.
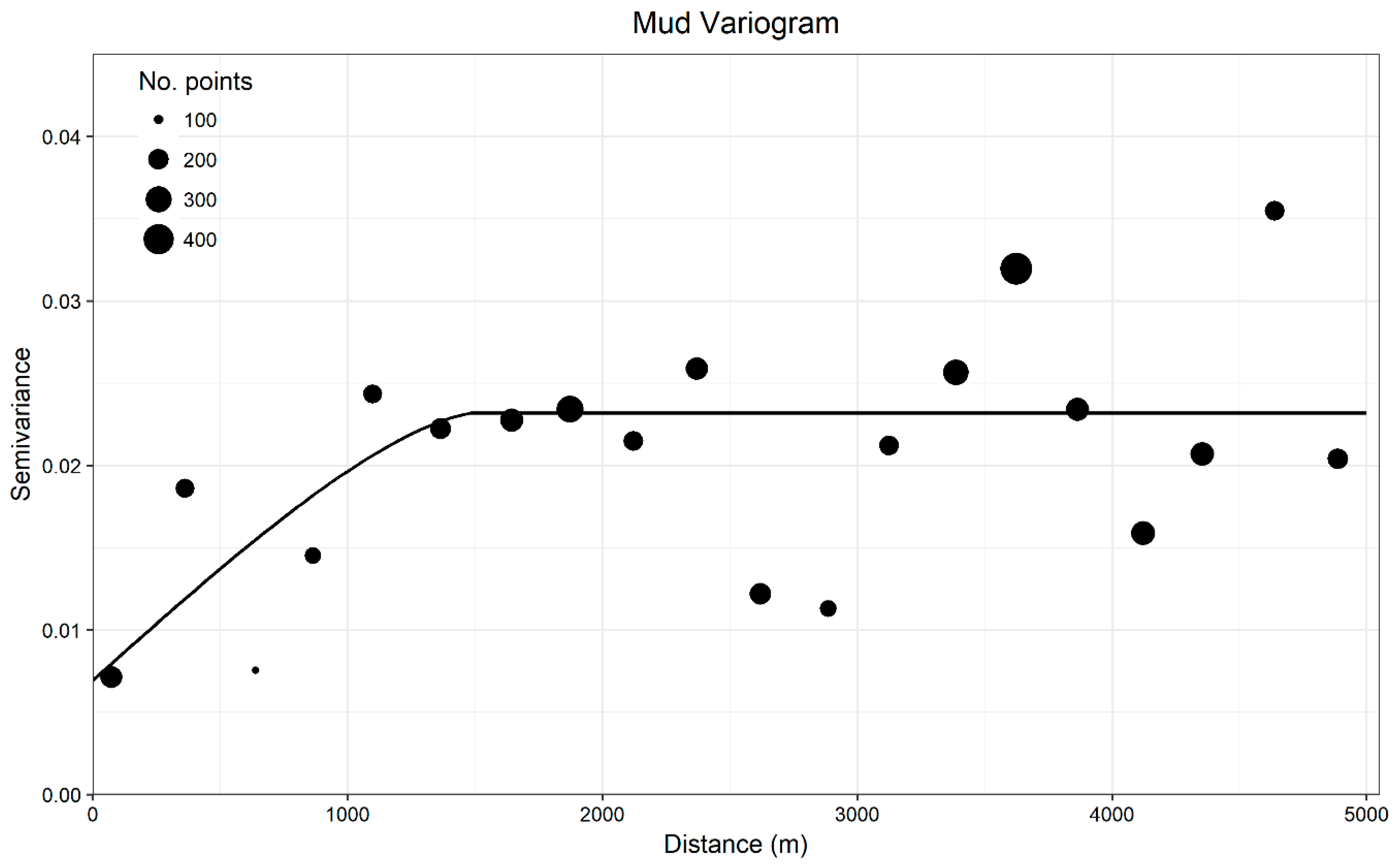
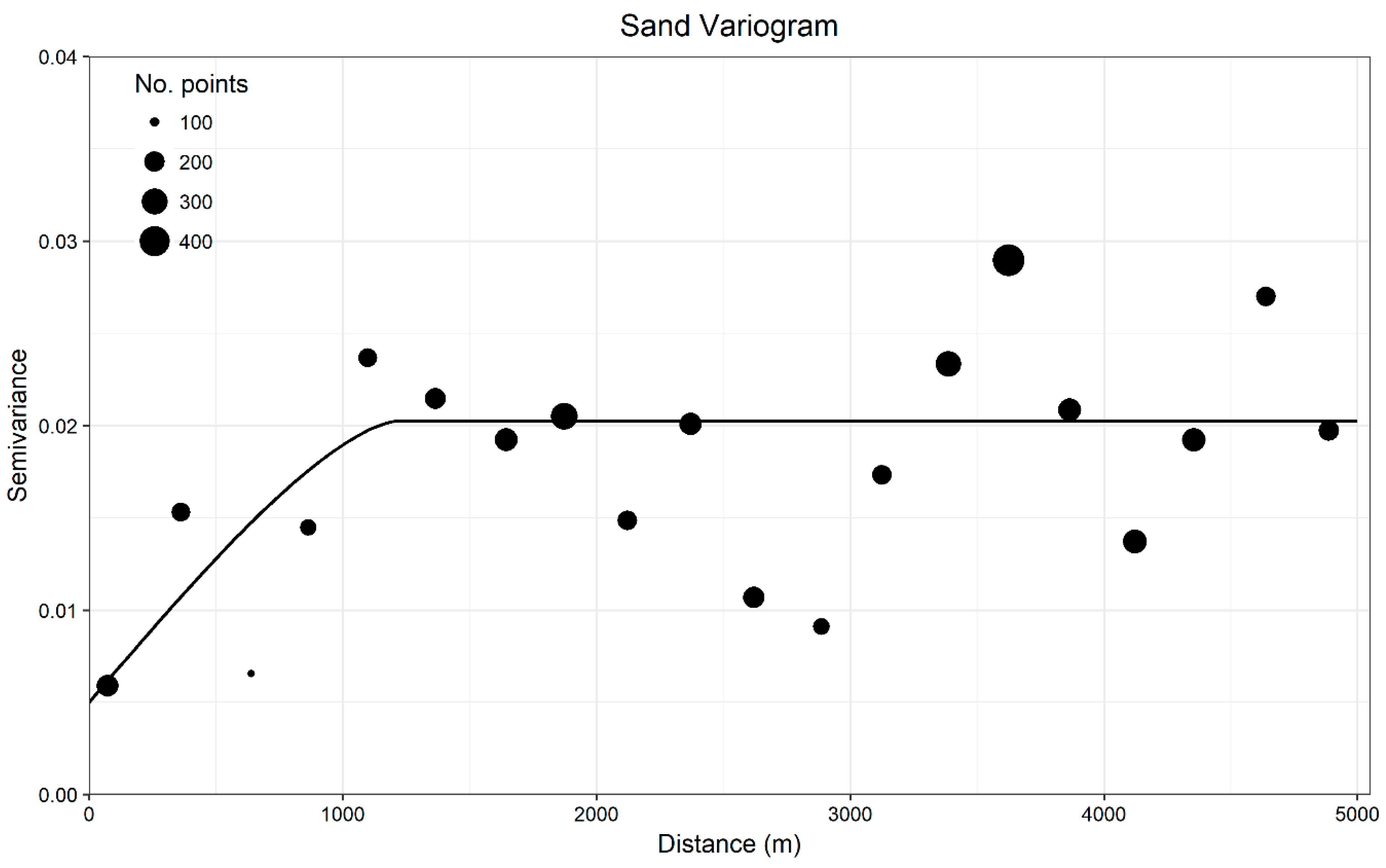
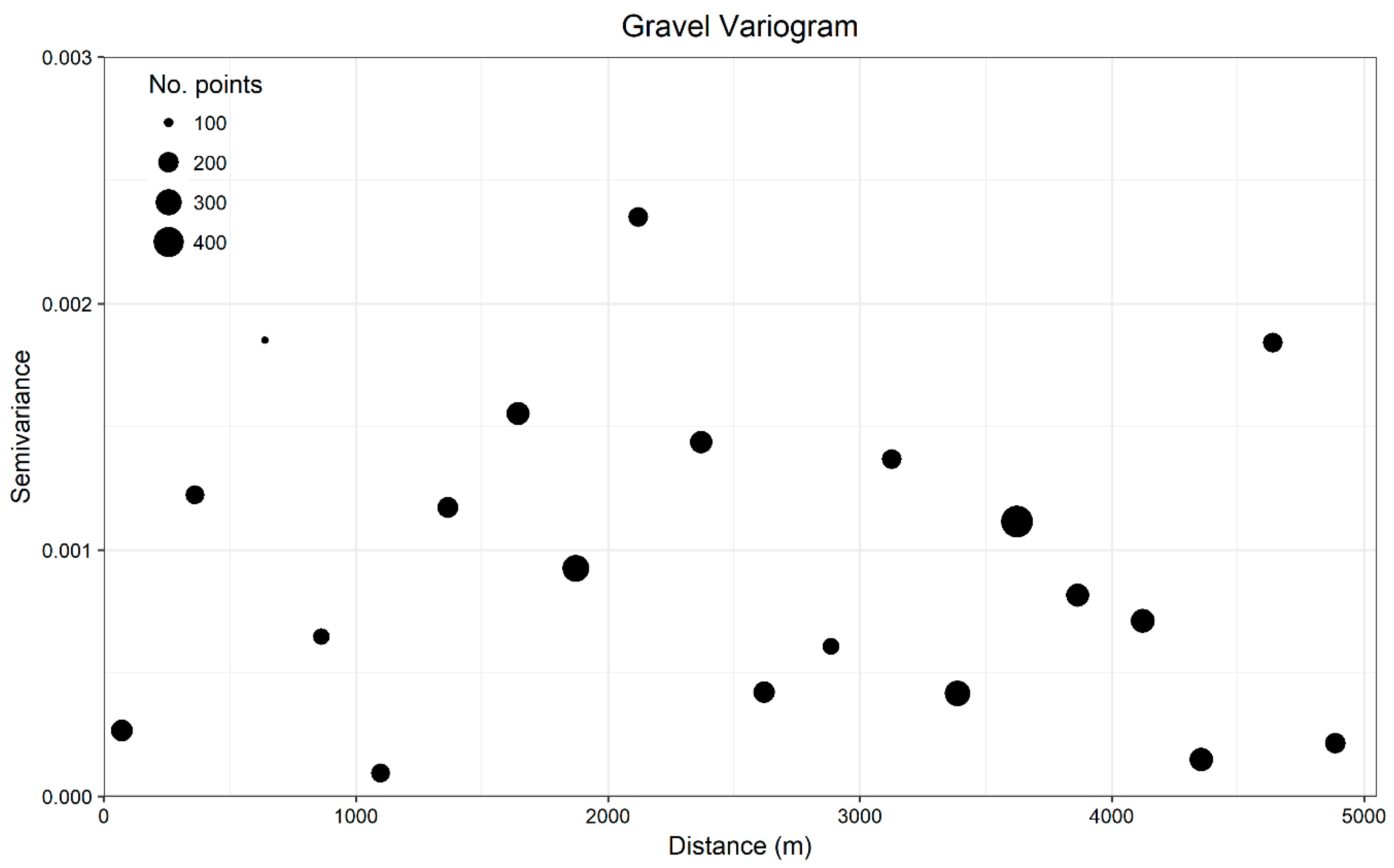
Otherwise, characteristics of the ground-truth data and the type of prediction required by the models may be important qualities for determining the suitability of modelling approaches. For example, sample size, distribution and bias, class prevalence and spatial dependence are known to have profound effects on the performance of distribution models [
29,
34,
35] and particularly Random Forest [
36]. These and other dataset characteristics might influence the appropriateness of the approach selected for producing classified maps. For instance, rare classes may be difficult to model using a categorical approach when they have been sampled few times but may cause less of an issue when modelled as quantitative variables. In some cases, clustered or uneven sampling may create spatial dependence in the response data [
37], violating assumptions of independence [
38]. This could have unintended consequences for prediction and apparent model accuracy, especially when extrapolating to new locations [
37,
39] and these could depend partly on the modelling approach. Here we refer to extrapolation in a spatial sense as predictions outside of the sampled area, whereas interpolation occurs between sample locations. An implicit assumption then, is that interpolation operates within the sampled environmental conditions, while extrapolation may predict outside of them.
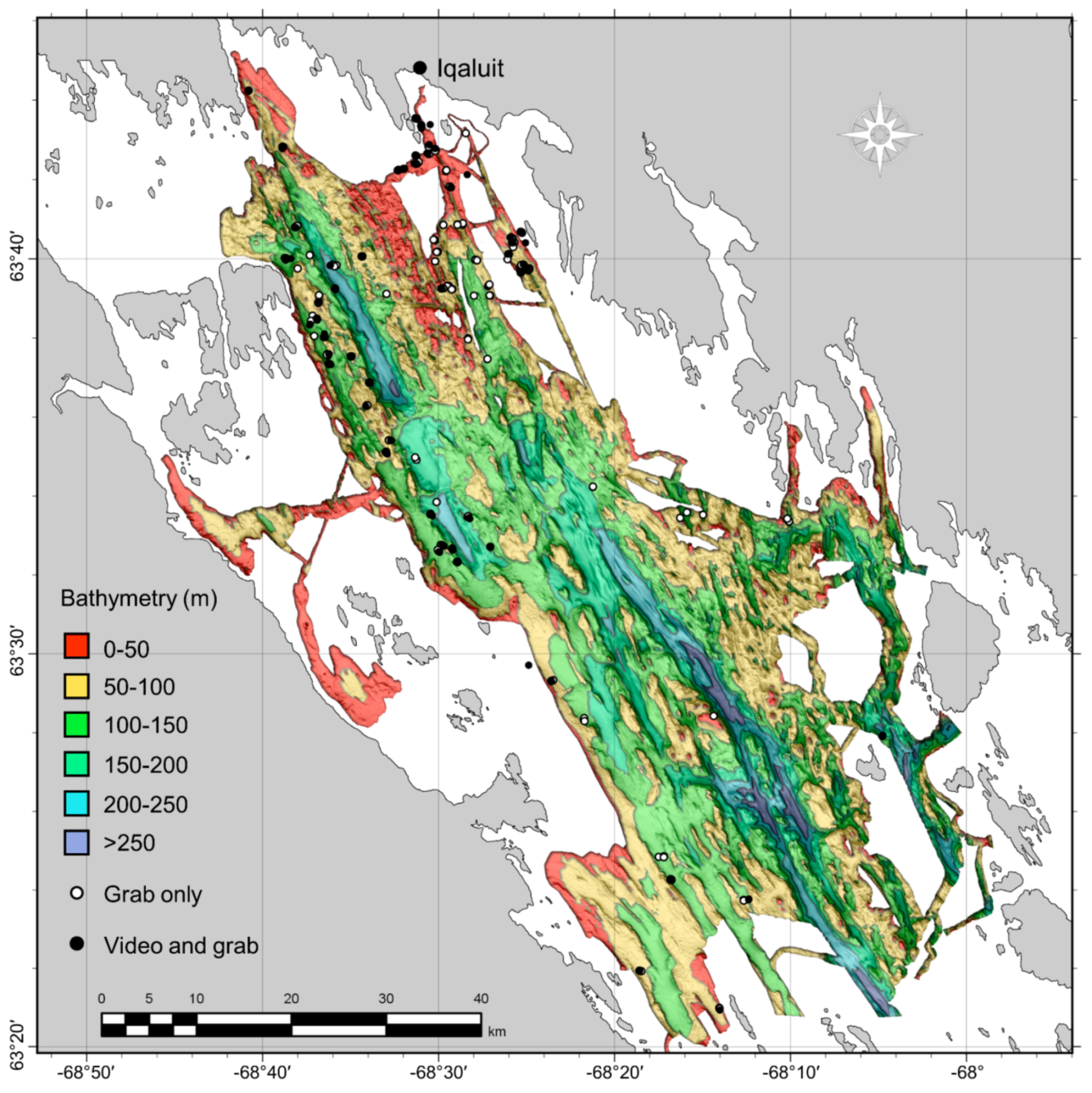
The primary goal of this study was to create a classified seabed sediment map for inner Frobisher Bay, Nunavut, Canada from grab samples and underwater video using the Random Forest statistical modelling algorithm. Ground-truth characteristics, however, suggested that spatial dependence might be an issue when extrapolating seabed sediment characteristics to unsampled locations and evaluating these predictions. We therefore undertook a spatially explicit investigation of the qualities of the two modelling approaches—quantitative and categorical (
Figure 2) —for predicting sediment grain size classes from grab samples using Random Forest. Coarse substrates that were not adequately represented in grab samples were modelled separately using underwater video data and the two predictions were subsequently combined to produce a single map of surficial sediment distribution.
Specifically, when evaluating the quantitative and categorical Random Forest models for producing classified maps, we investigated: (1) their performance when extrapolating grain size predictions to new locations and if this was affected by spatial autocorrelation; (2) the appropriateness of three levels of classification based on the relative proportions of grain size measurements; and (3) if the two approaches produced similar maps. Because the observations of coarse sediment from video transects were likely to be spatially autocorrelated, we investigated if the proximity of these samples: (1) inflated the apparent accuracy of coarse substrate predictions; and (2) caused overfitting in model training. The results of these investigations informed the selection of modelling approach, while also providing spatially explicit accuracy estimates. Based on the results, we provide recommendations on the utility and potential pitfalls of these approaches in a spatial context.
4. Discussion
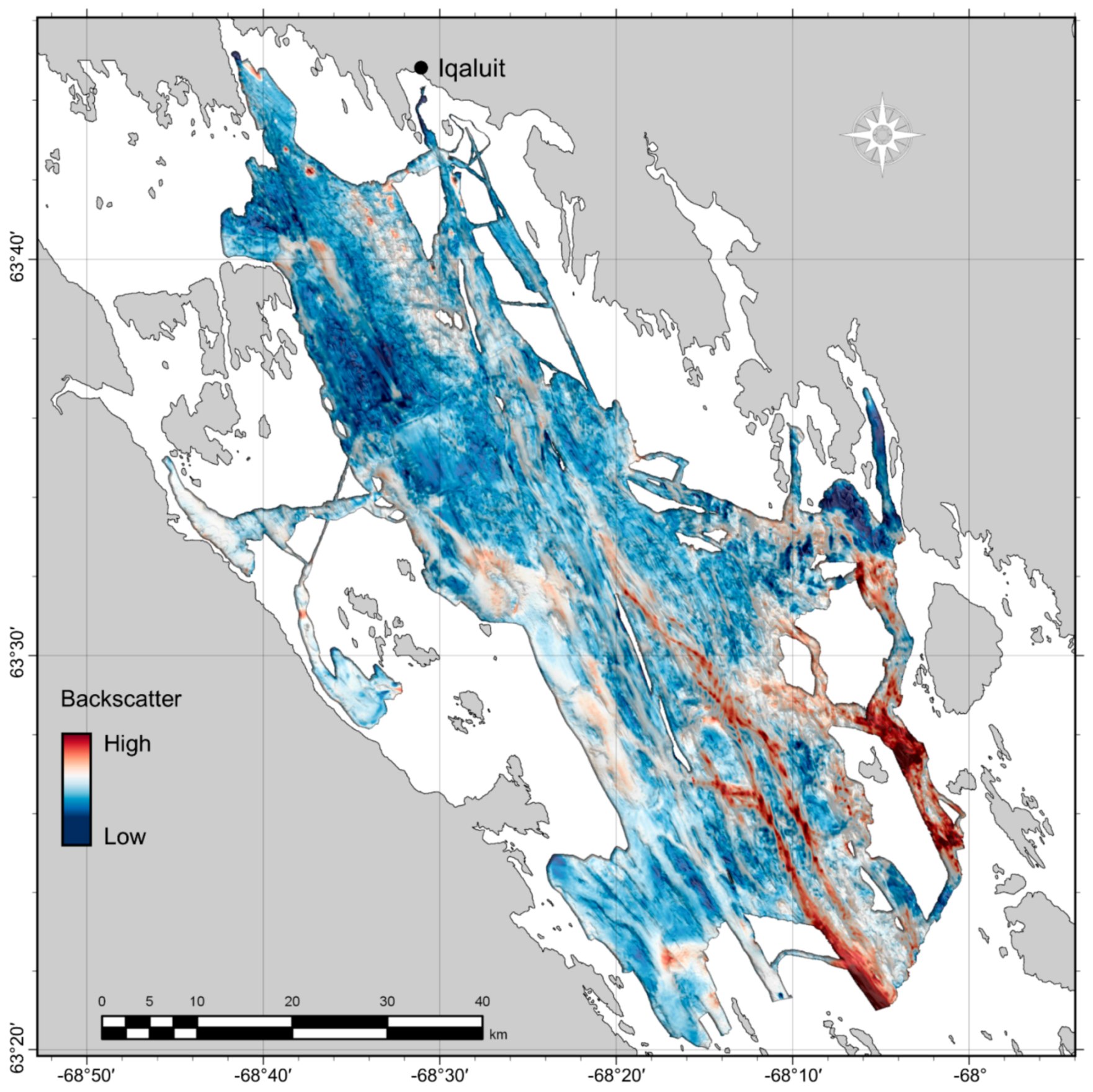
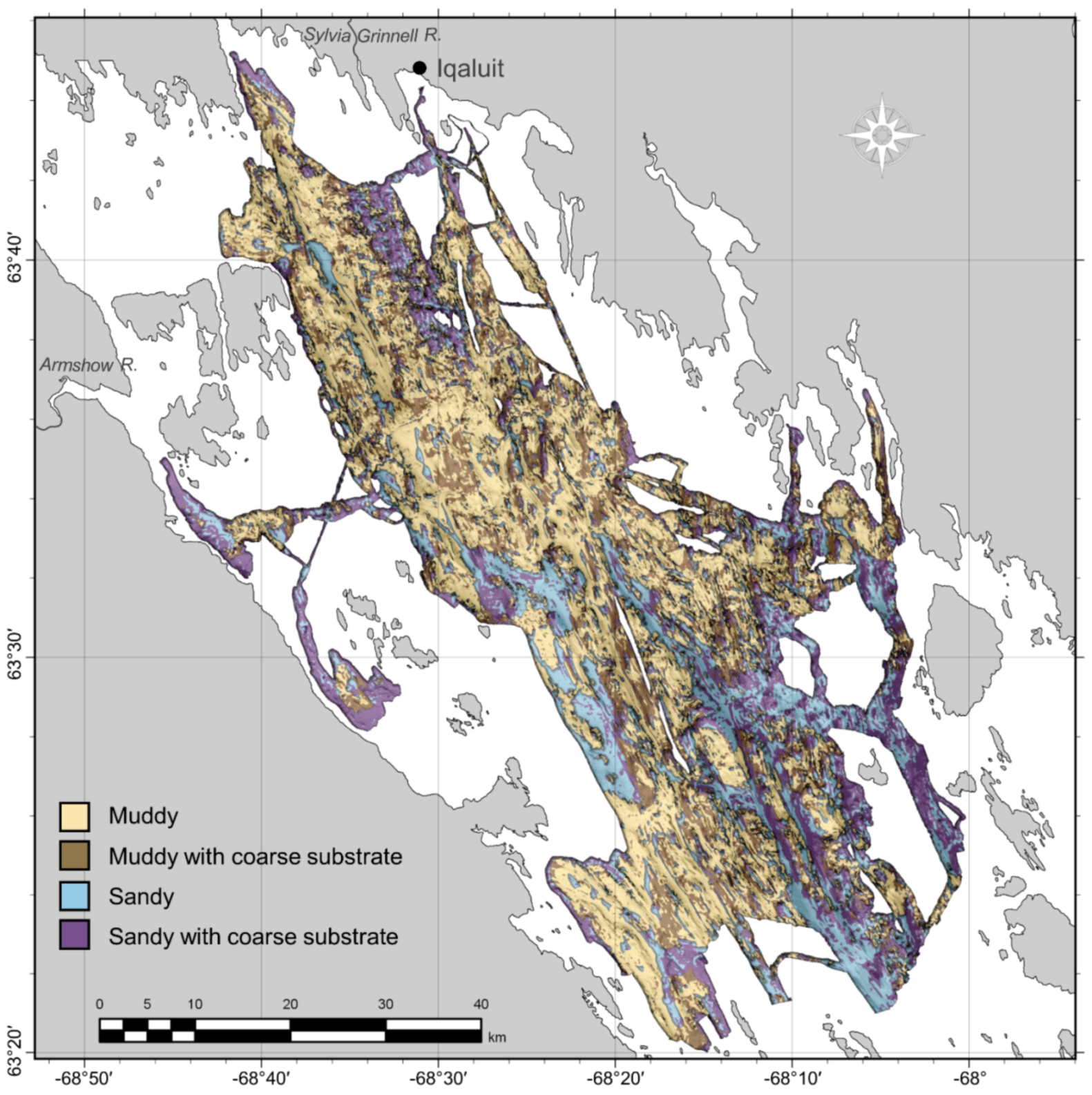
The predicted seabed sediment classes generally agreed with expectation given the geomorphology of the bay, yet particular locations without ground-truth data require further investigation. The majority of the low-relief seabed was classified as “muddy,” which is not surprising given what was observed in grab samples and underwater video (e.g.,
Figure 6 and
Figure 7a). Sandy sediments predicted south and southwest of Iqaluit may be partially attributable to sediment input from the Sylvia Grinnell River, directly west of the city. This is also an area of distinct sea-ice scouring [
42] with higher acoustic backscatter than the surrounding seabed (
Figure 5) and several distinctly reflective features that were classified as “sandy with coarse substrate.” This class was also predicted at several locations along the coast, fining to muddier grain sizes with increasing distance and depth. Otherwise, exposed coarse substrates predicted along the flanks of steep topographic features may be attributable to current winnowing of unstable fine sediments [
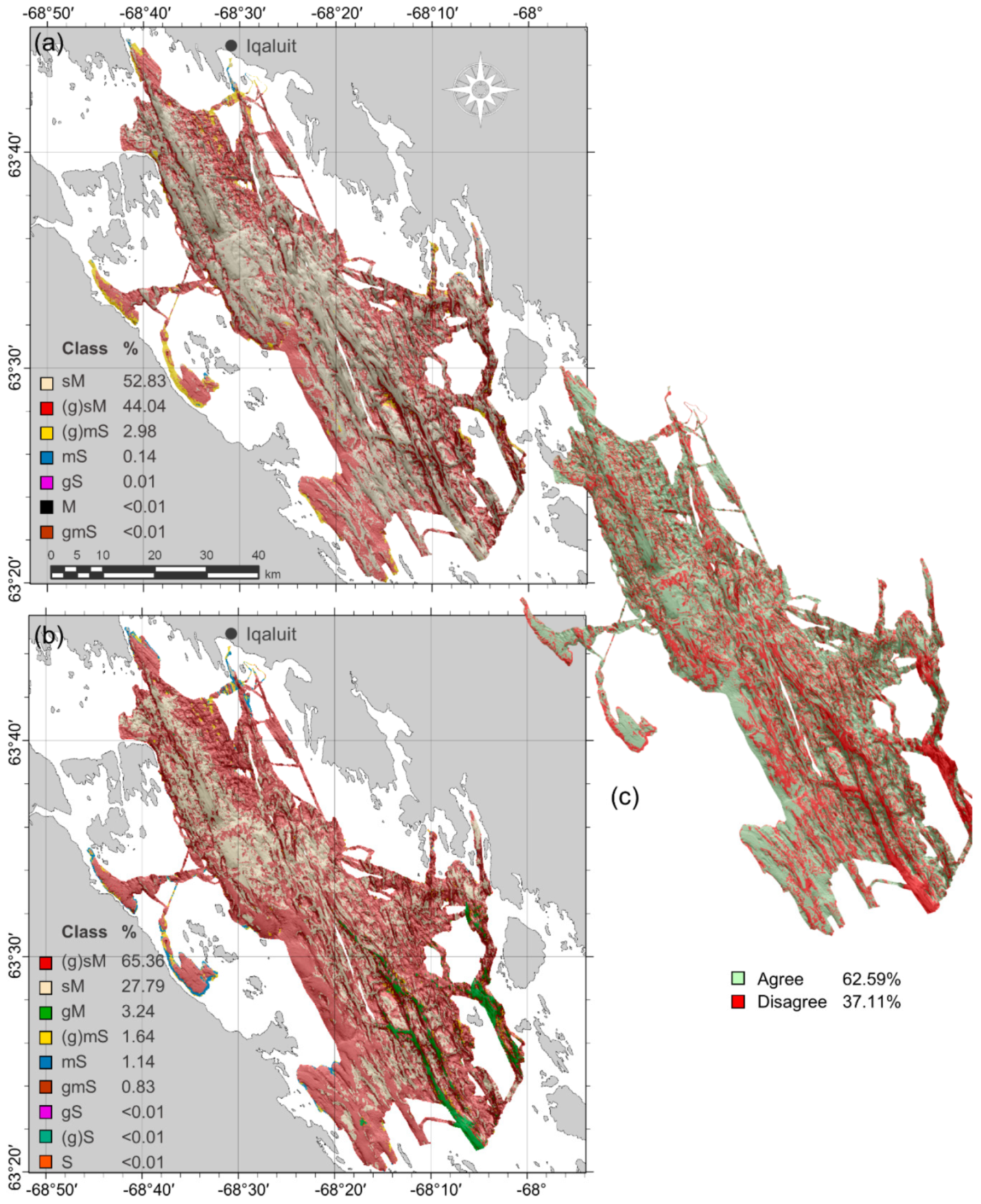
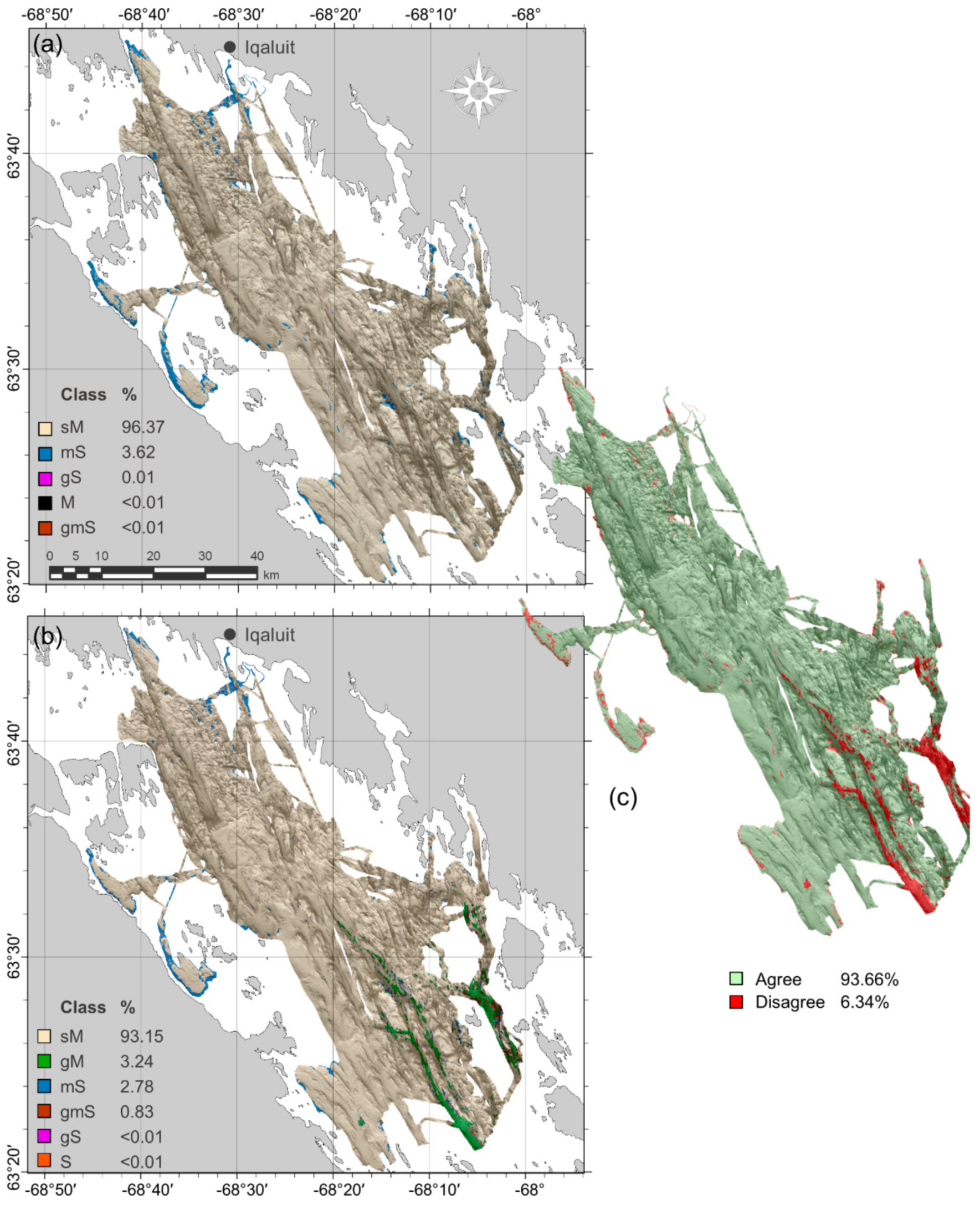
69]. This is likely the case in the high-relief, deep southeastern channels, where coarse substrates were predicted extensively. Further investigation is necessary in these deep channels though—this was an unsampled area of high disagreement between the categorical and quantitative models (
Figure 8 and
Figure 9). One might expect a muddier composition at the bottoms of these deep channels, yet sandier grain sizes were predicted, likely as a product of the high backscatter response (
Figure 5).
4.1. Model Comparison
There was little difference in accuracy between quantitative and categorical Random Forest approaches when using spatially explicit cross-validation methods but their maps differed substantially. Using a two-class scheme, it was possible to tune the threshold of occurrence for the probabilistic output of the categorical model to obtain a higher accuracy than the quantitative model and this was selected for the final map. The most noticeable difference between maps was that the quantitative approach predicted extensive patches of sediment classes that were not observed in the ground-truth data, where the categorical approach predicted the most commonly observed classes. The predicted proportions and distributions of the classes also differed between approaches.
Although the quantitative Random Forest approach failed at extrapolation in this study, it has several characteristics that may be otherwise desirable. Because classification of quantitative predictions is done
post hoc, this method might avoid some of the difficulty associated with predicting unbalanced classes—one of the major shortcomings of the categorical approach. Furthermore, as demonstrated here, predictions are not constrained to the classes that were sampled. Thus, if the model were fit well, it may be possible to predict rare and unsampled classes at new locations, while this is not feasible with the categorical approach. This may be a particularly useful quality if unsampled areas are expected to contain different sediment characteristics than the sample sites, yet it requires a high degree of confidence in the modelled relationships between grain size composition and the explanatory variables. The spatial leave-one-out CV error matrices for classified quantitative predictions (
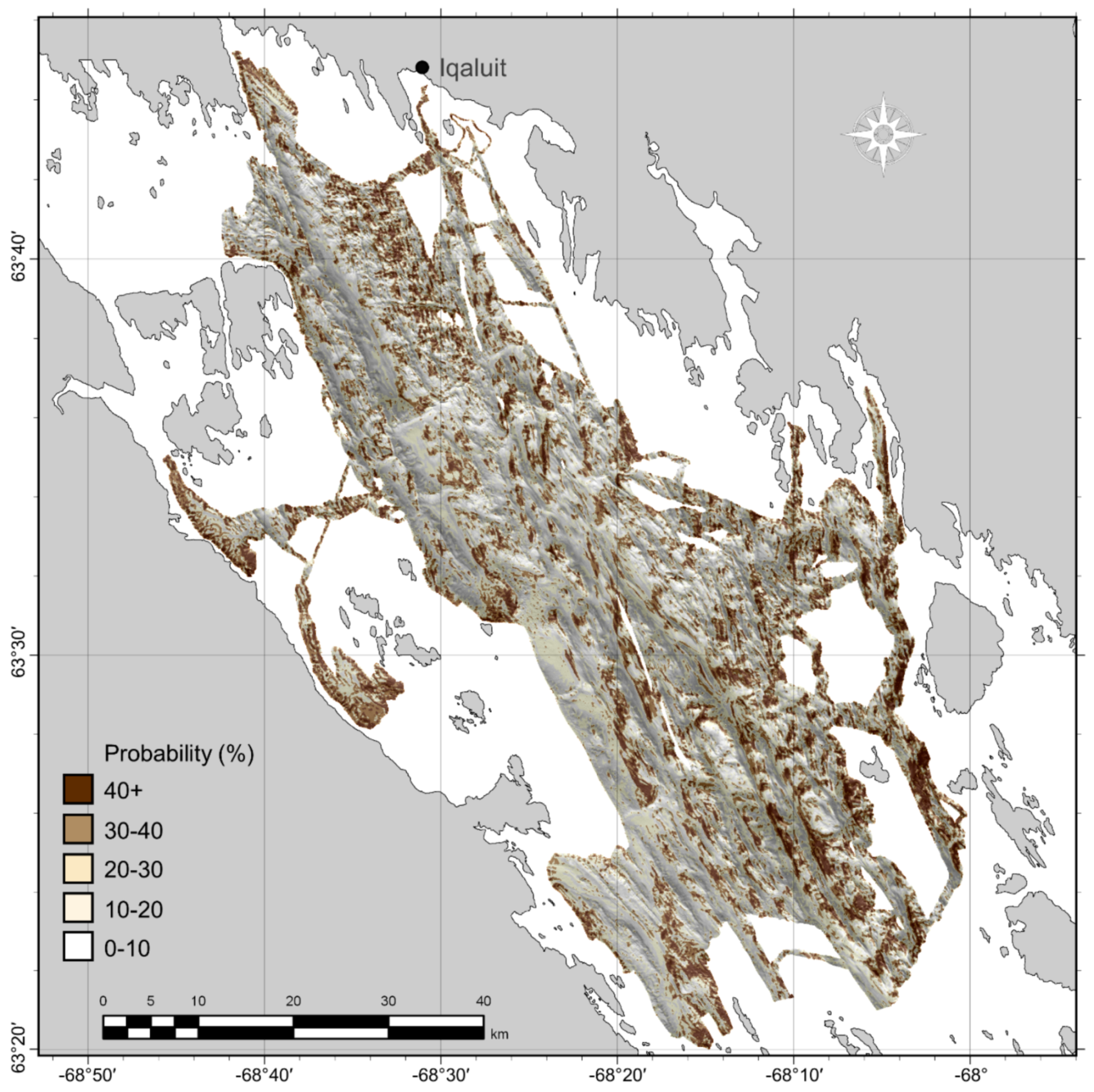
Appendix D) failed to indicate that the model could successfully predict rare classes in this study and we did not have the confidence to adopt predictions of unobserved classes in unsampled areas. It is quite possible that these areas do actually contain different sedimentary characteristics though, as their morphology and backscatter characteristics were unique but there is no way to confirm this. Sampling these areas would be a priority in future work.
It is also worth considering characteristics of the unclassified quantitative predictions of mud, sand, and gravel, which may offer some advantages over classification. These predictions represent gradational changes in sediment composition, which are more realistic and potentially more desirable than discrete classes. If classes are required, quantitative predictions are completely flexible with regards to classification scheme. Because the quantitative values remain the same, it is not necessary to run through the model fitting procedure to test different classifications – the class boundaries simply need to be adjusted. Other methods could also be used to optimize the classification of quantitative predictions to produce relevant and distinct classes, such as multivariate clustering. This way, it is possible to define an appropriate number of classes with boundaries that are most relevant to a given study area.
The qualities of the categorical Random Forest approach ultimately made it more suitable for this study but one major difficulty was assessing whether rare classes were predicted correctly. Because the data were spatially autocorrelated, samples of rare classes were likely to occur close to one another. Using a spatial CV approach, in which samples proximal to the test data are omitted from model training (as in S-LOO CV) or proximal samples are not allowed for either training or testing (as in SR-LOO CV), can potentially remove most or all other samples of a rare class, making it impossible to assess if it was predicted accurately. Selecting a classification scheme that matches the data facilitates the estimation of accuracy by ensuring an adequate number of samples for training and testing each class. Here, the Folk and simplified Folk schemes each contained several classes with very few observations (< 5) and the success in predicting these could not be confidently determined. The muddy/sandy classification better fit the data, providing adequate samples of each class to evaluate predictive success.
Though the muddy/sandy classification was a good fit given these data (
Figure 6), the class prevalence was still unbalanced. Another solution afforded by the categorical approach is that the threshold of occurrence can be optimized. Setting this threshold to maximize the sum of sensitivity + specificity equally weights the success in predicting each class and this produced higher extrapolative (i.e., S-LOO CV) accuracy than the quantitative approach, especially after removing superfluous variables. Another common approach used to predict rare classes is to subsample the dataset to ensure equal class representation but that requires enough samples of the rarest class to allow a reasonable subsample size. Furthermore, some research has suggested that the proportions of classes in the training data should be representative of the actual proportions of these classes [
36].
4.2. Spatial Assessment
Spatial autocorrelation inflated estimates of predictive accuracy regardless of the modelling approach or classification scheme for both grain size and coarse substrate models, hindering the ability to determine whether the models could successfully extrapolate grain size classes at unsampled locations. Similar to LOO CV, many common model validation techniques (e.g., sample partitioning, k-fold CV) have no spatial component. For this study, non-spatial techniques failed to correctly estimate the model’s ability to extrapolate. If LOO CV were used in isolation to evaluate the categorical simplified Folk predictions for example, the percent correctly classified and values (85.50%; 0.52) would suggest the model is highly accurate and reliable. In reality though, it fails to extrapolate beyond the sphere of spatial autocorrelation influence, with predictions no better than random.
The SR-LOO CV for the coarse substrate model suggested not only that spatial autocorrelation inflated estimates of accuracy but also that Random Forest was spatially overfitting, hindering extrapolation. This is an important issue for severely autocorrelated datasets that is not necessarily solved by other spatial validation approaches that allow for proximal training samples such as S-LOO CV or spatial blocking. Though SR-LOO CV shows promise for reducing overfitting and providing non-biased estimates of accuracy, we note that the computational effort may not always be realistic. One hundred random samples of each spatially-buffered leave-one-out sample set (n = 324) yielded 32,400 sub-samples and corresponding Random Forest models for one SR-LOO CV run. Furthermore, the “embarrassingly parallel” qualities of Random Forest were leveraged to implement SR-LOO CV here, which is not characteristic of most other modelling methods. Simpler alternatives could involve aggregating sample transects to a single point and adjusting the raster resolution, yet this may be less attractive if a high resolution is desired. How such methods compare with the SR-LOO CV remains to be explored.
4.3. Spatial Prediction
It is important to distinguish between interpolating a well-sampled area and extrapolating to unsampled locations [
67]. Though it is becoming standard practice to report predictive accuracy, it is less common to differentiate between these predictive spatial qualities, which are partly determined by sample distribution and intensity. Again, if interpolation is the goal, with somewhat uniform and well-distributed sampling, then standard non-spatial model evaluation methods may be appropriate (e.g., LOO CV,
k-fold CV, partitioning). If samples are clustered, with parts of the study area unsampled, then it is necessary to evaluate for extrapolation, which may require a spatially explicit approach, as was the case here. This also may affect the appropriateness of categorical and quantitative approaches – if extrapolating to a potentially new sedimentary environment is the goal and if there is confidence in the modelled relationships between sediment and explanatory variables, then a quantitative approach may be useful for identifying unsampled or rare sediment classes. Here, we found that the flexibility of the threshold of occurrence using a categorical Random Forest approach resulted in superior extrapolative performance compared to a quantitative approach for a binary classification scheme. Given a set of classification requirements (e.g., regional compatibility) and a desire to maximize predictive accuracy of predetermined classes, it may be desirable to test both approaches where feasible – our results do not suggest the consistent superiority of one method over the other.
Recently there have been calls for greater transparency in reporting map quality, including uncertainty and error, to determine whether thematic maps are fit for purpose (e.g., [
70,
71]). This becomes especially important when providing maps as tools for management, where end-users may lack the technical understanding to critically evaluate a map [
72]. The spatial component of distribution modelling is a potential source of data error [
71] that is commonly neglected [
52], yet which can be exacerbated due to marine sampling constraints. Here we have demonstrated the necessity of spatially explicit analysis for comparing the error and predictions between two seabed sediment mapping approaches and the potential pitfalls of neglecting to do so. Though many approaches have been tested and compared in the seabed mapping literature, these qualities are often ignored. The SR-LOO CV approach used here to model the presence of coarse substrates is similar to the variable scale selection procedure used by Holland et al. [
68] but uses “embarrassingly parallel” Random Forests so that no samples are fully omitted. This is the first application of the approach in this context to our knowledge. Though the SR-LOO CV method was well-suited to modelling video transect data in this study, we acknowledge several other useful strategies [
67] and tools [
73] that are worth considering to address spatial sampling bias. Geostatistical methods may also be a preferable alternative for handling spatially dependent data depending on the modelling goals. The focus of this study was on modelling seabed sediments but the findings are relevant to other similar benthic distribution models including those of species and biotopes.

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











