Quantitative Assessment of Epistemic Uncertainties in Tsunami Hazard Effects on Building Risk Assessments



Abstract
1. Introduction
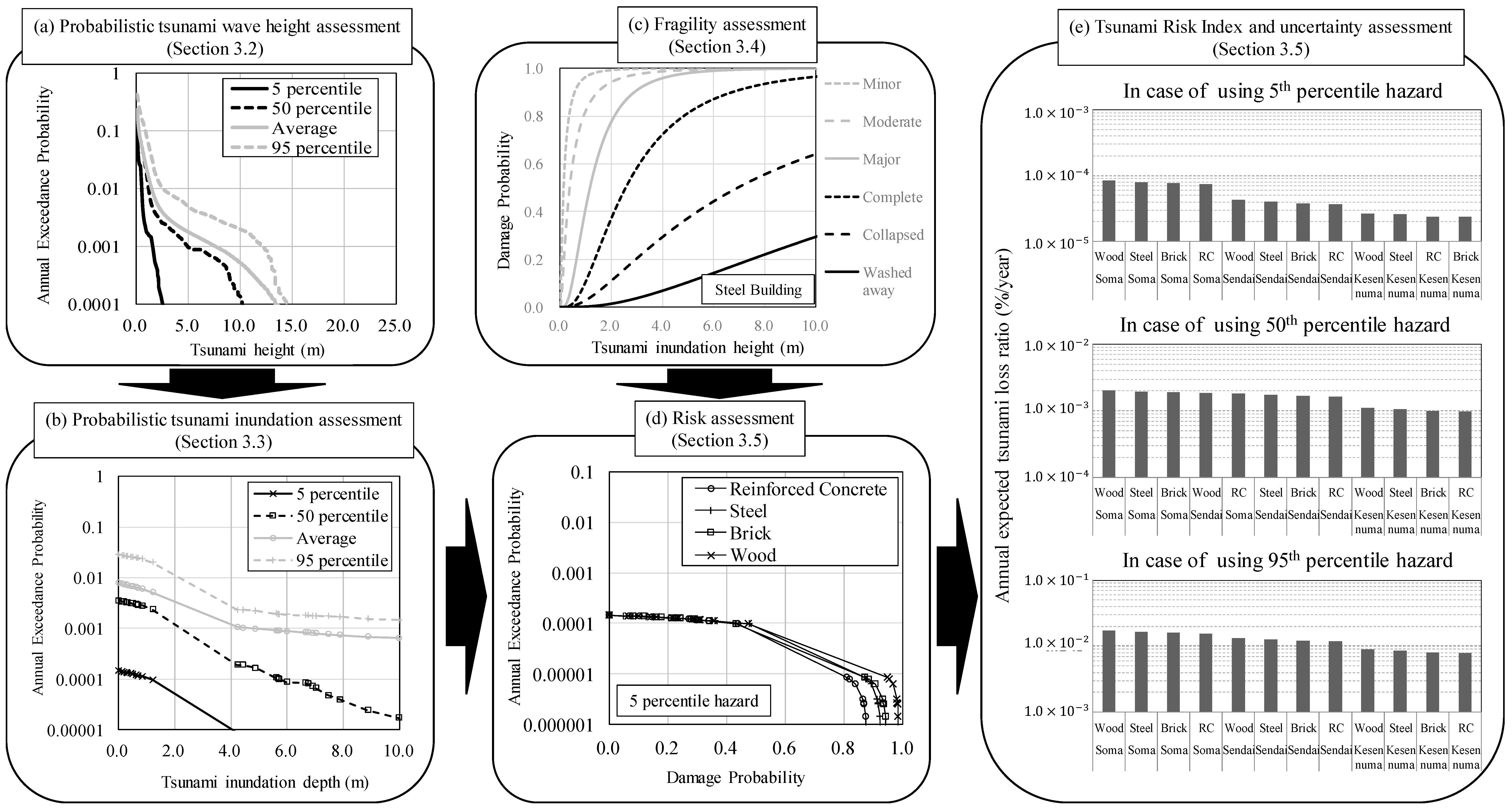
2. Methodology for the Tsunami Risk Assessment and Quantification of Hazard Uncertainty
3. Application to the Tohoku Area
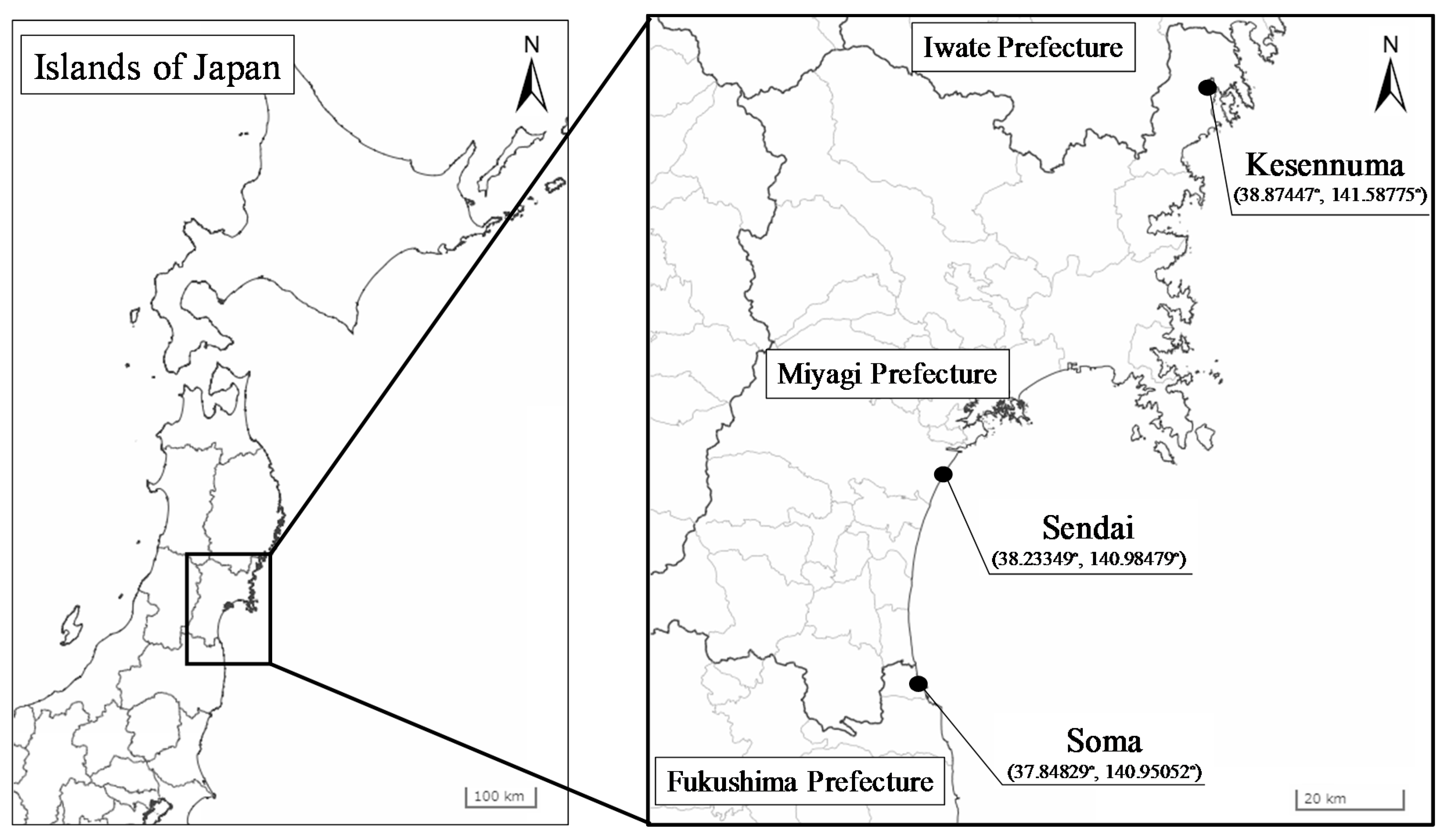
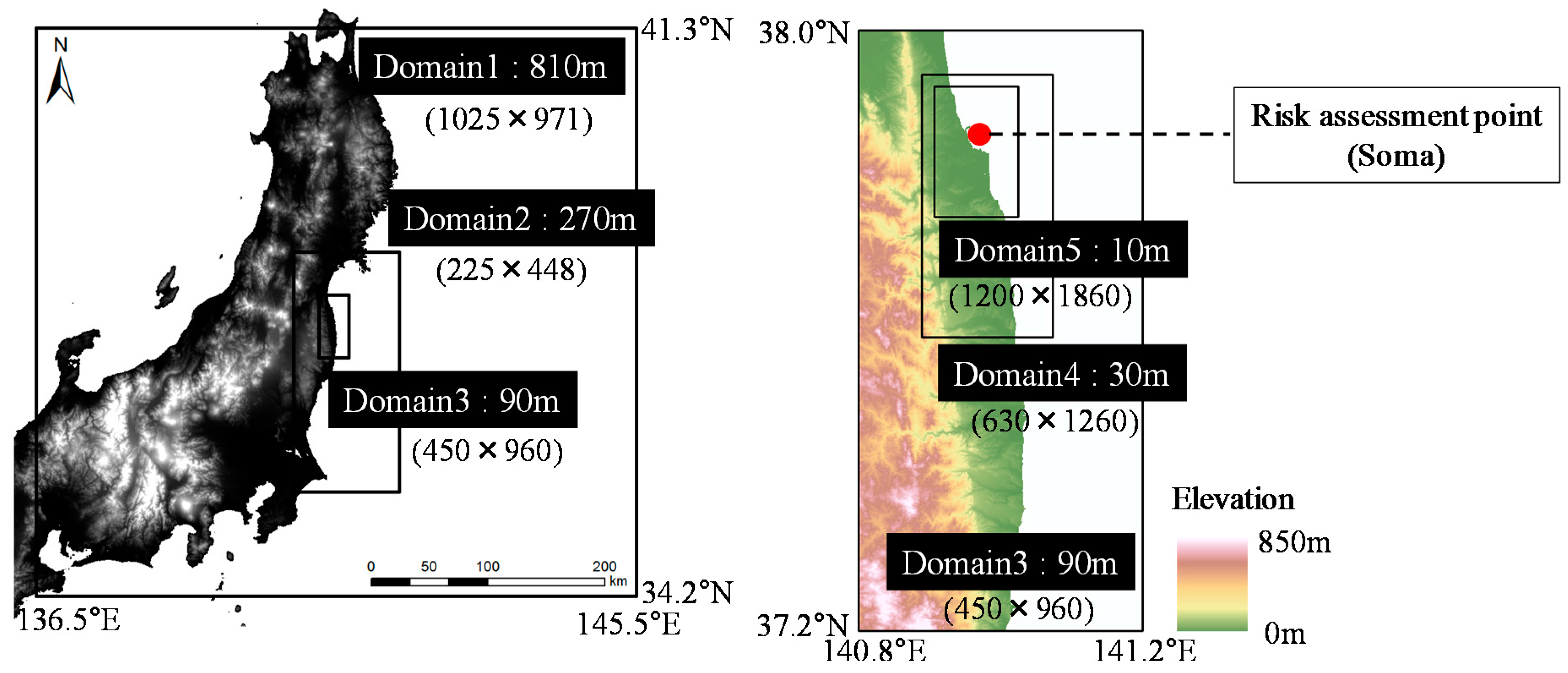
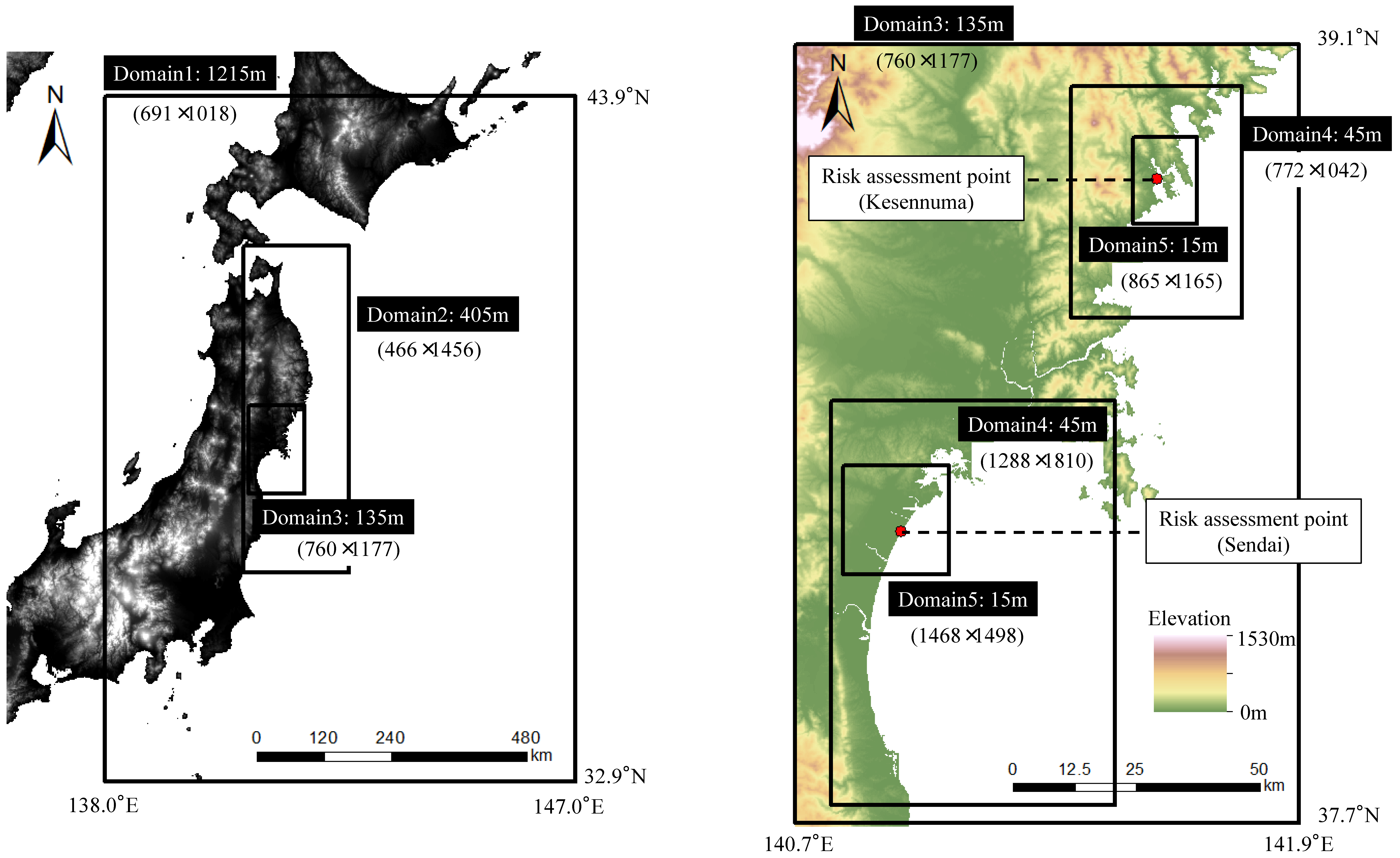
3.1. Assessment Targets
3.2. Probabilistic Tsunami Wave Height
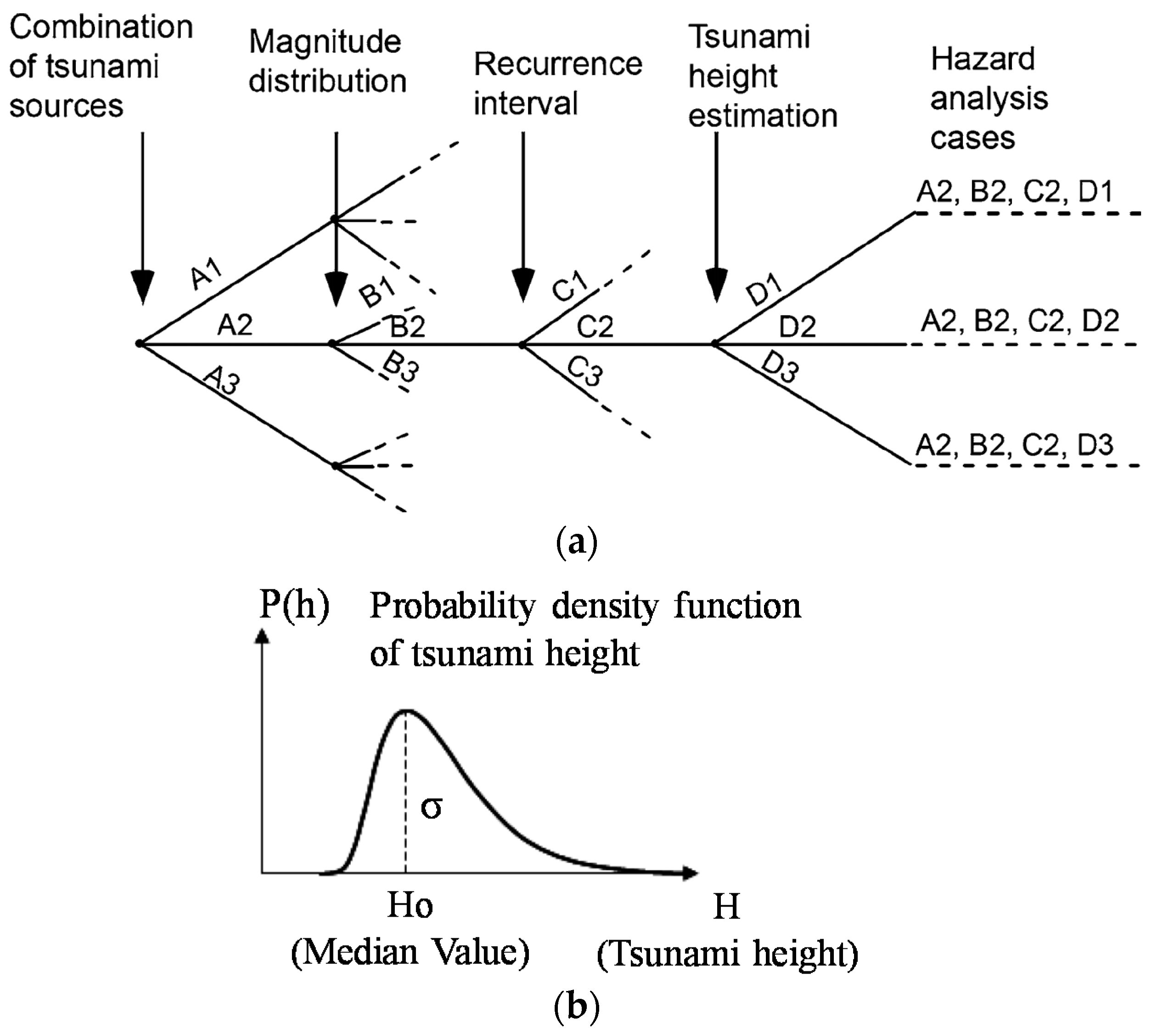
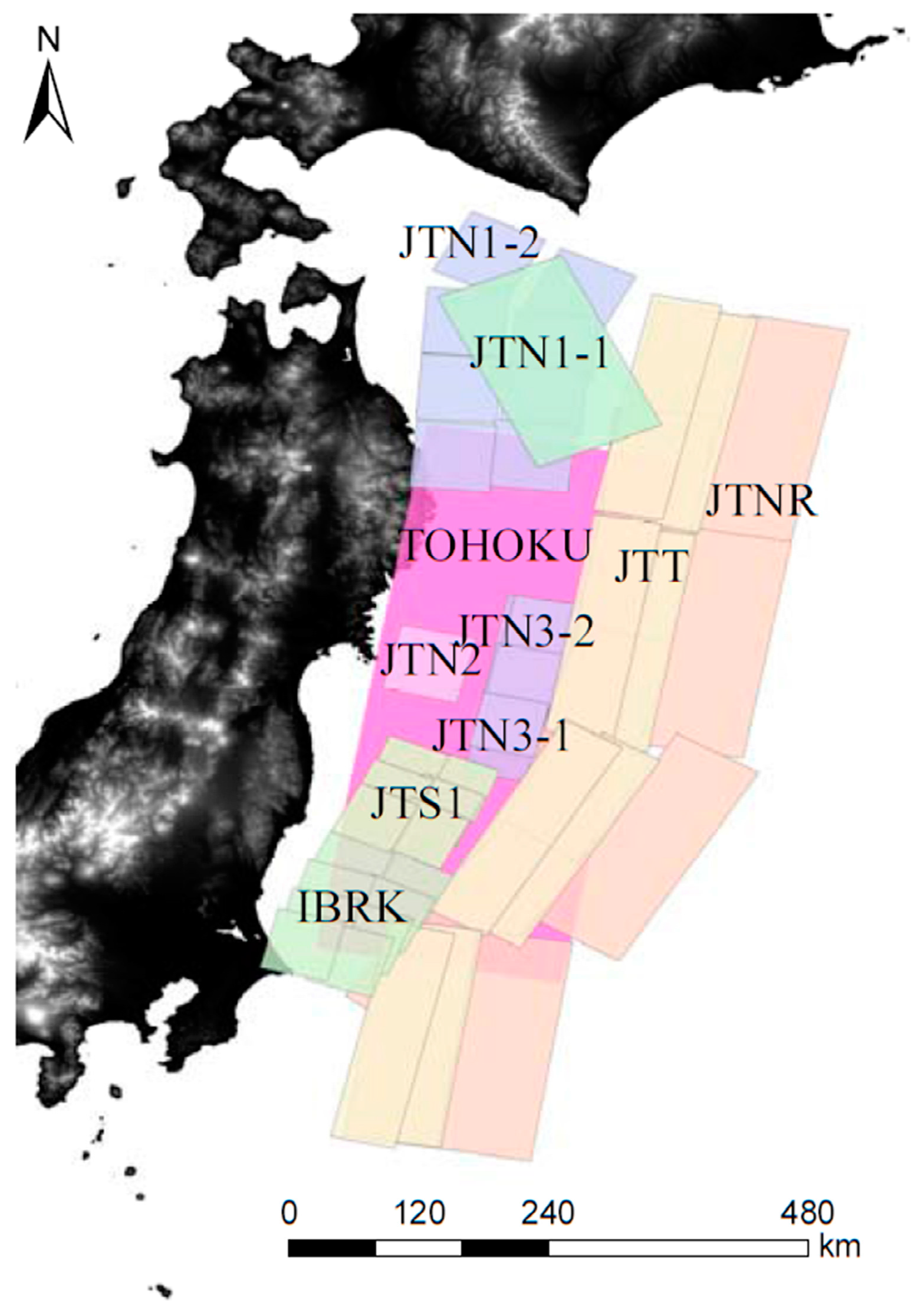
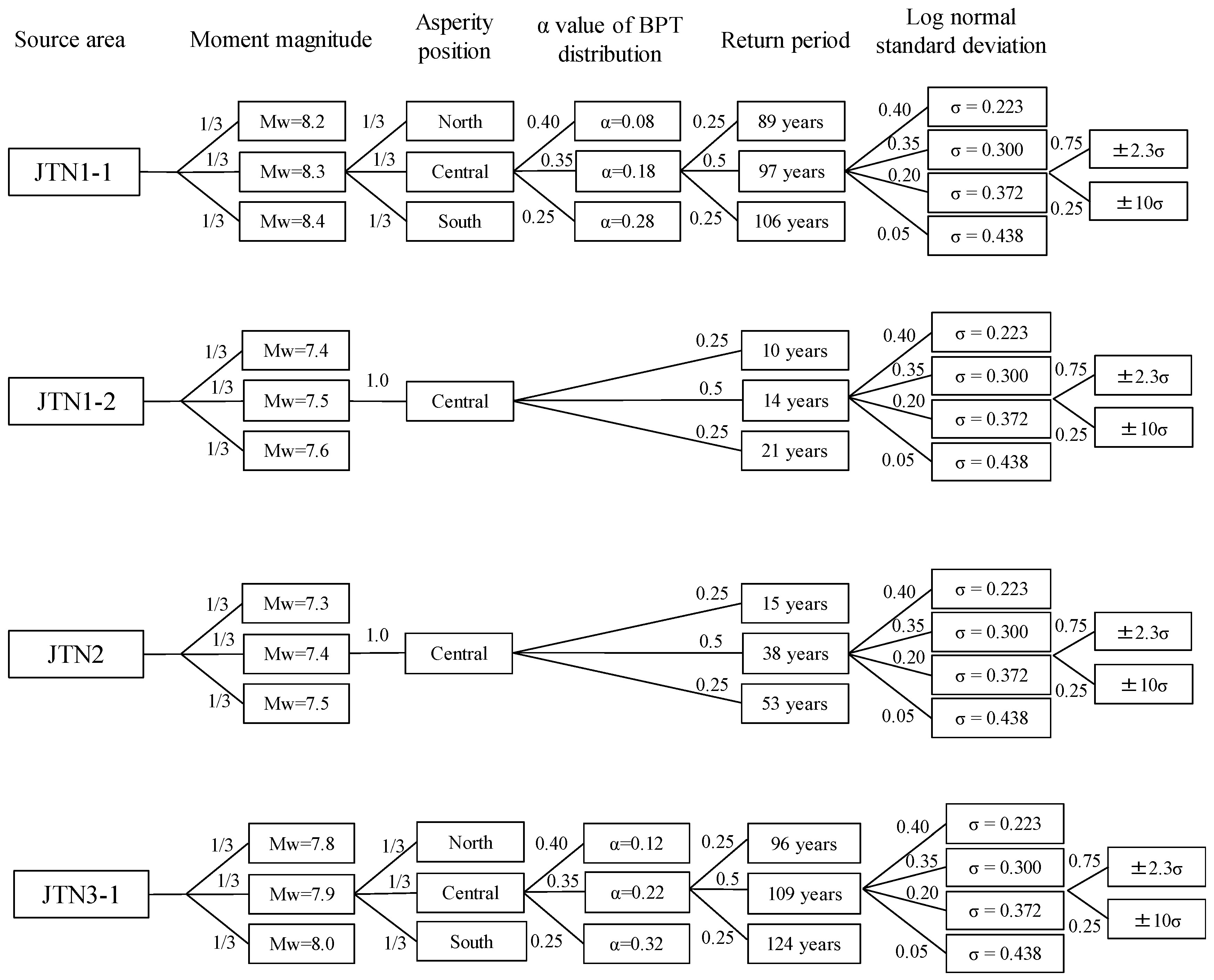
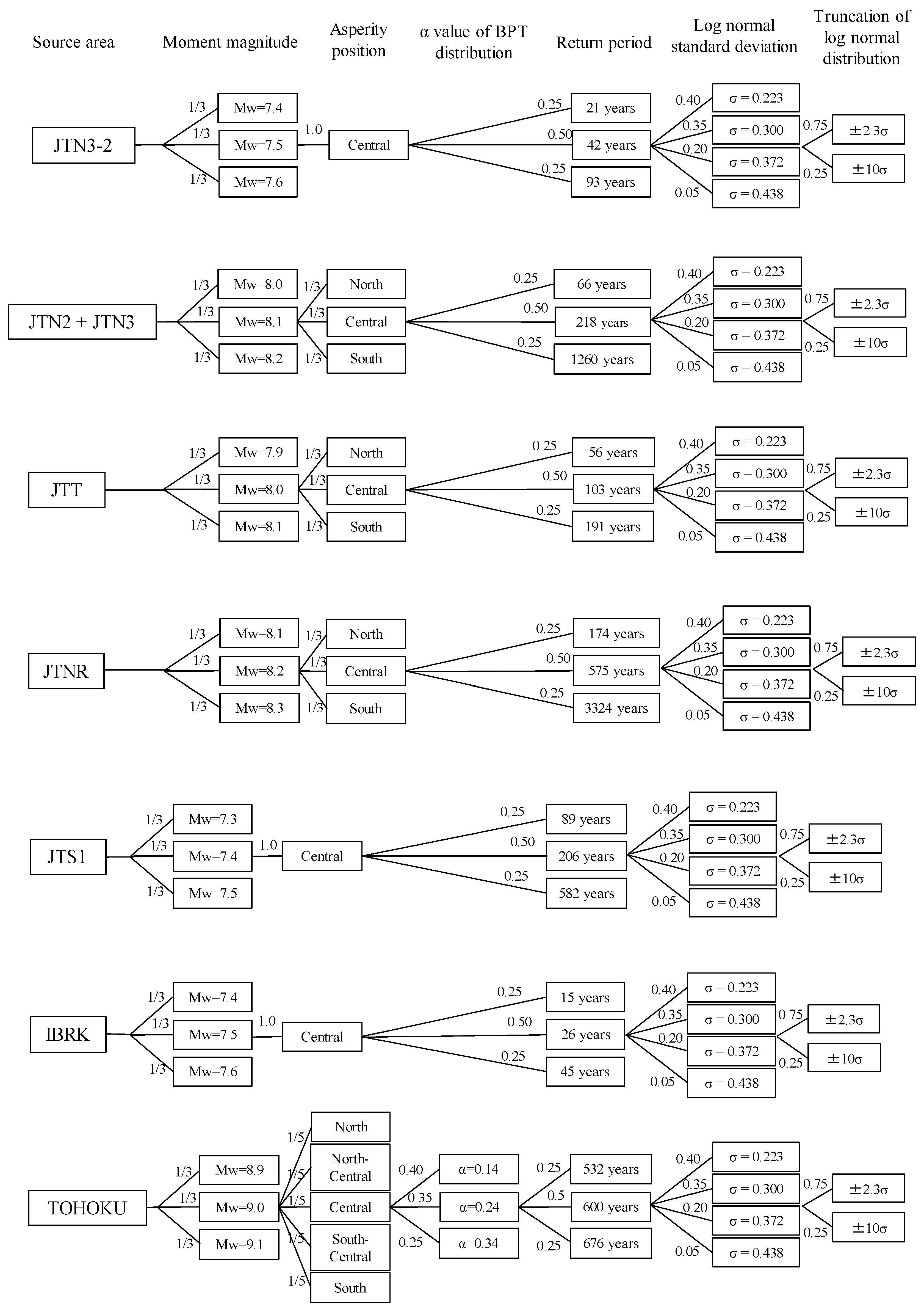
3.2.1. Construction of the Logic Trees
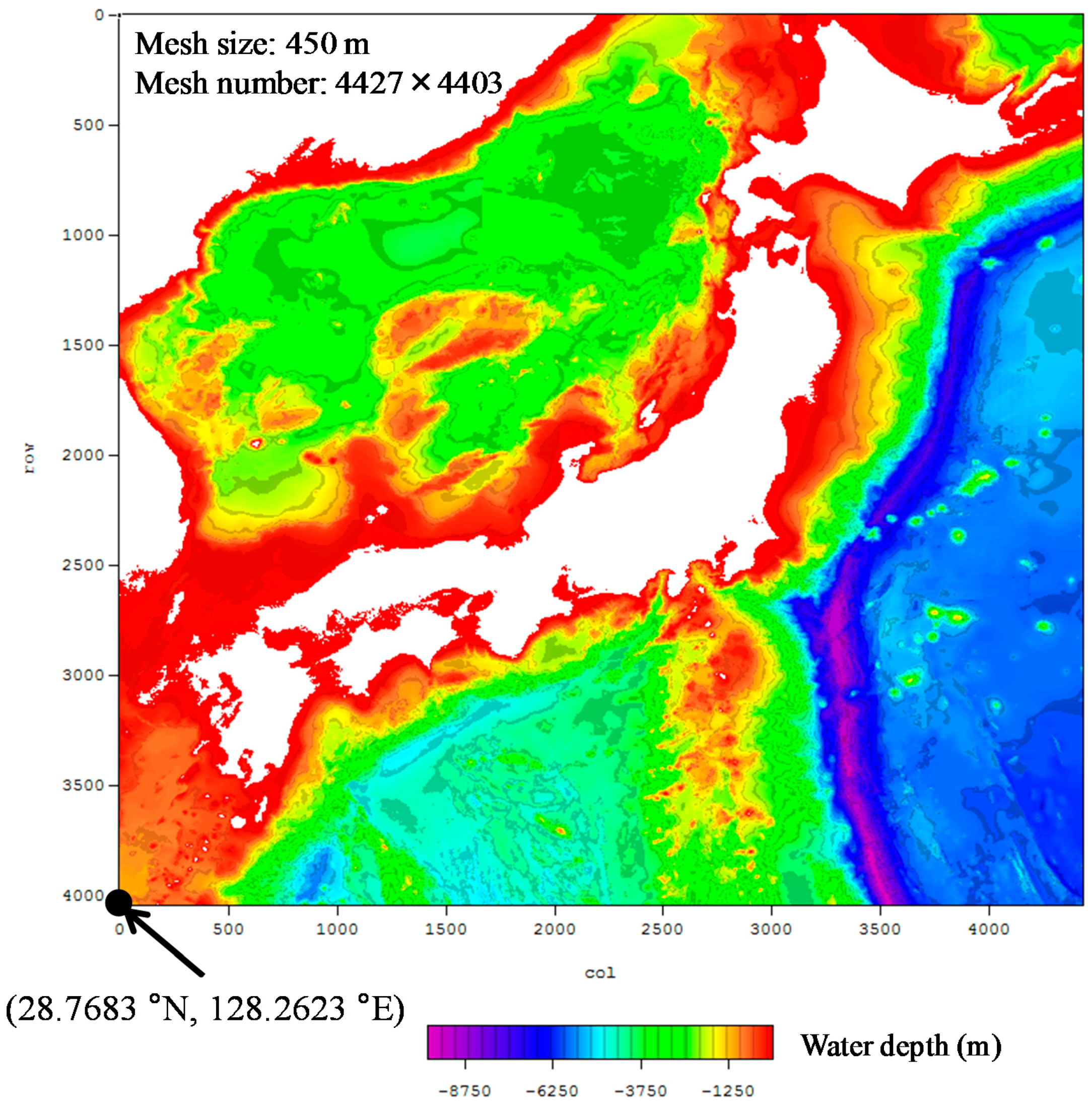
3.2.2. Tsunami Numerical Simulation
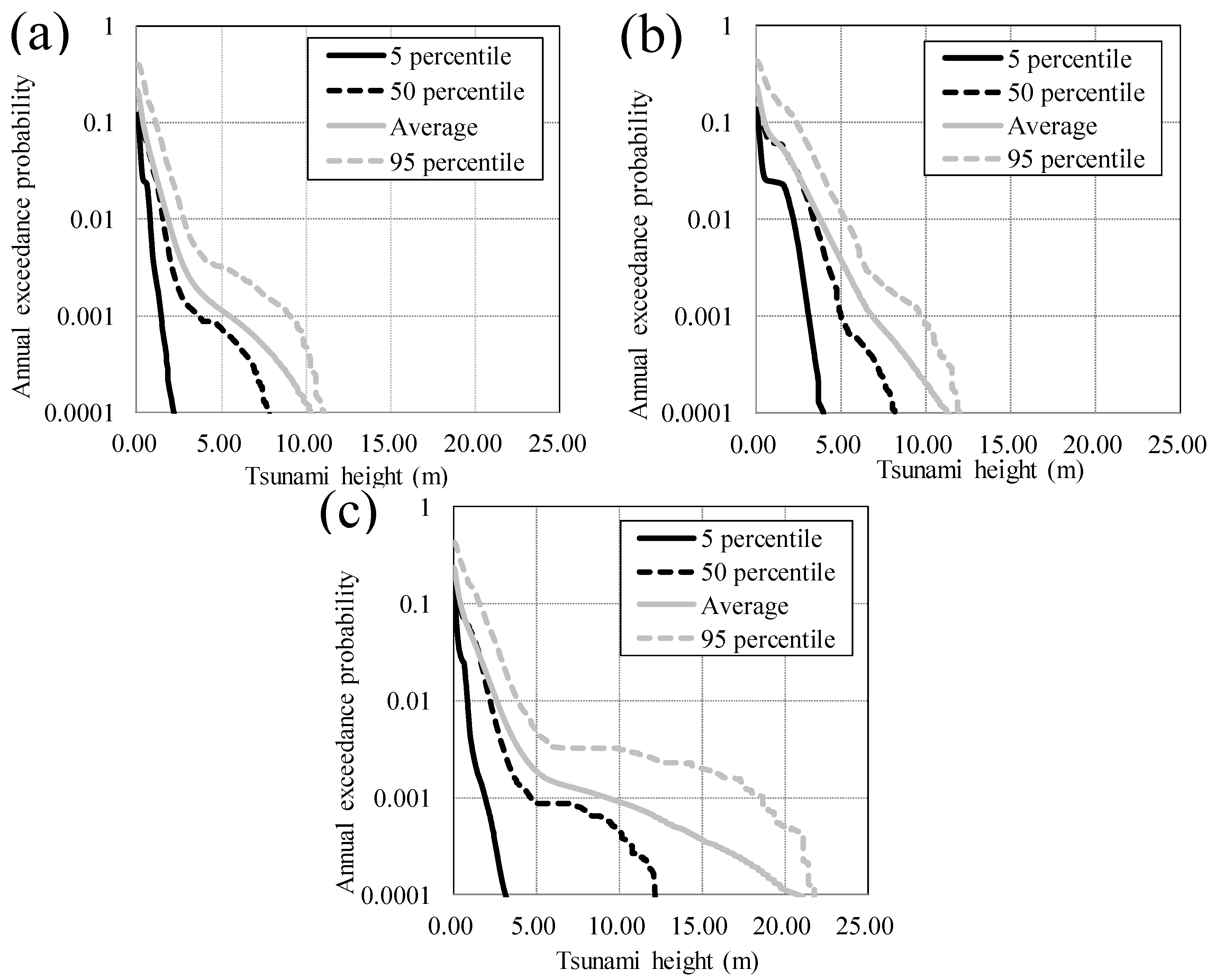
3.2.3. Tsunami Hazard Curves at the Offshore Points
3.3. Tsunami Inundation Assessment
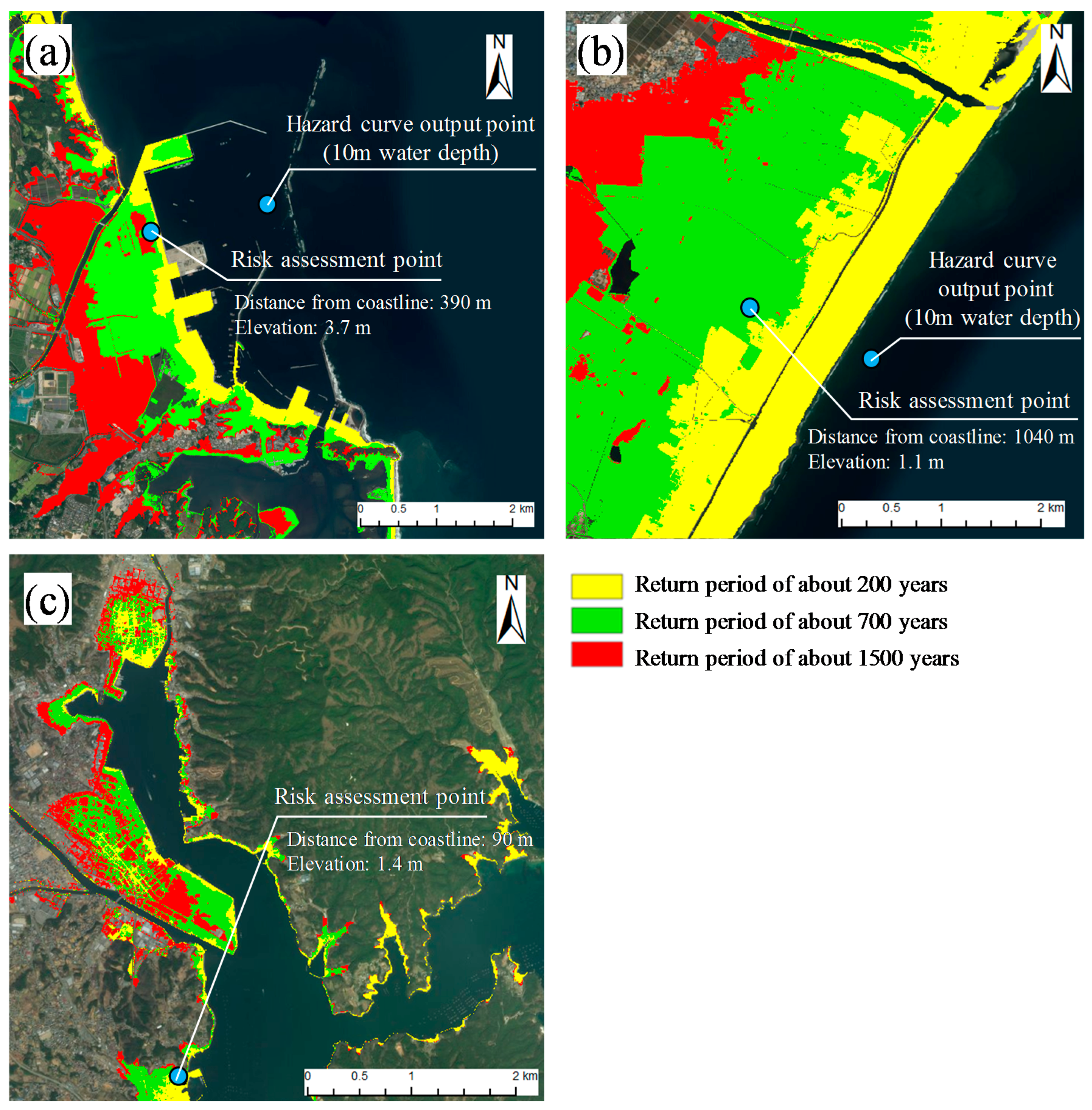
3.3.1. Probabilistic Tsunami Hazard Map
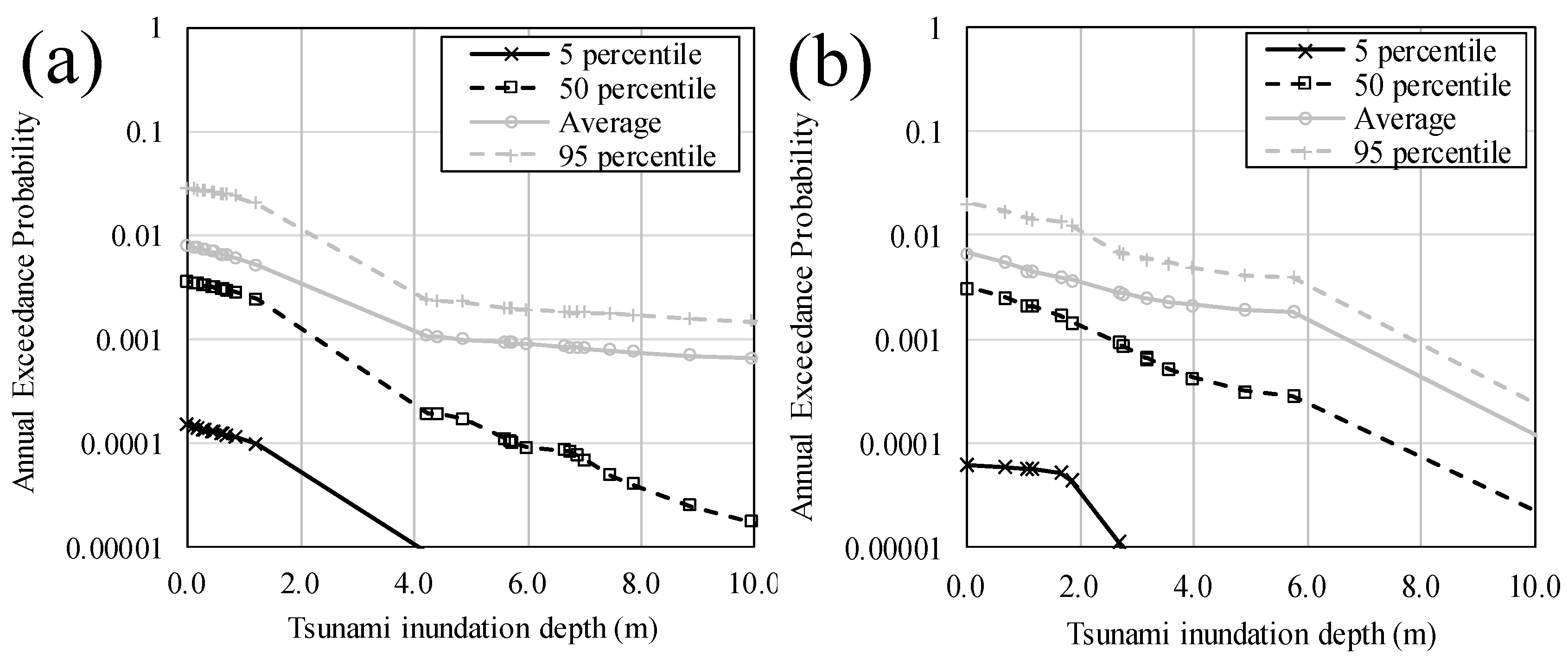
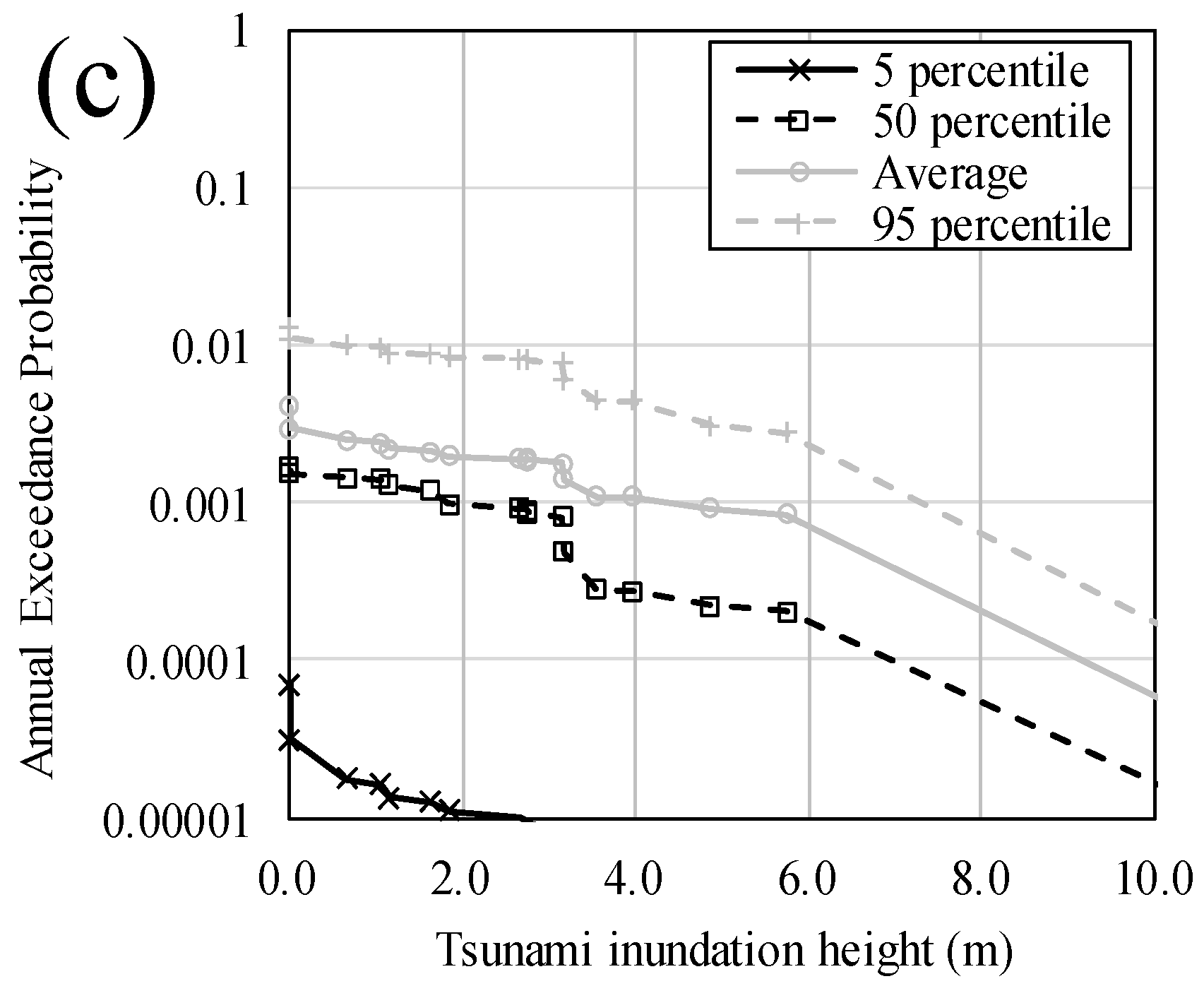
3.3.2. Tsunami Hazard Curves at Inland Points
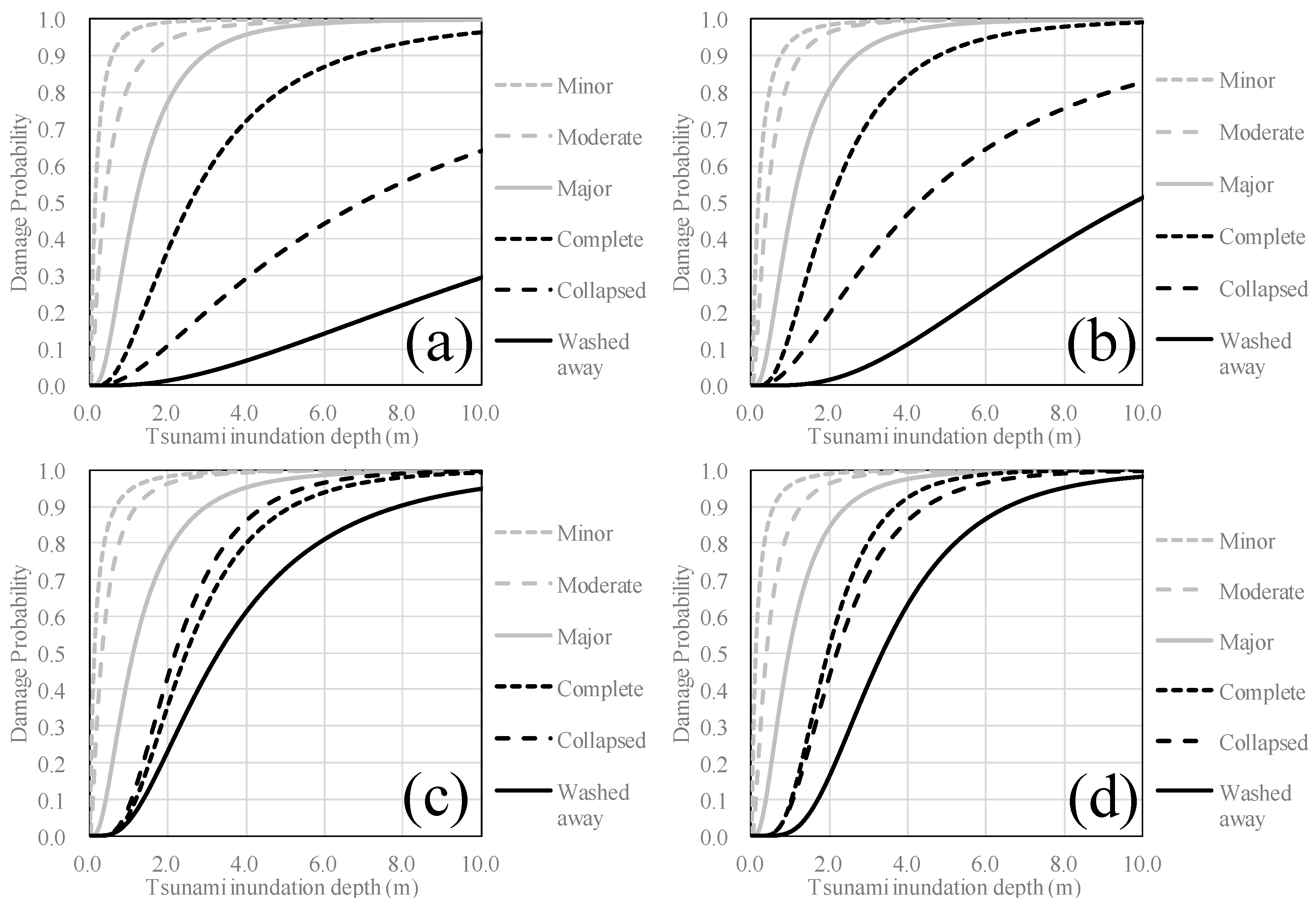
3.4. Fragility Assessment
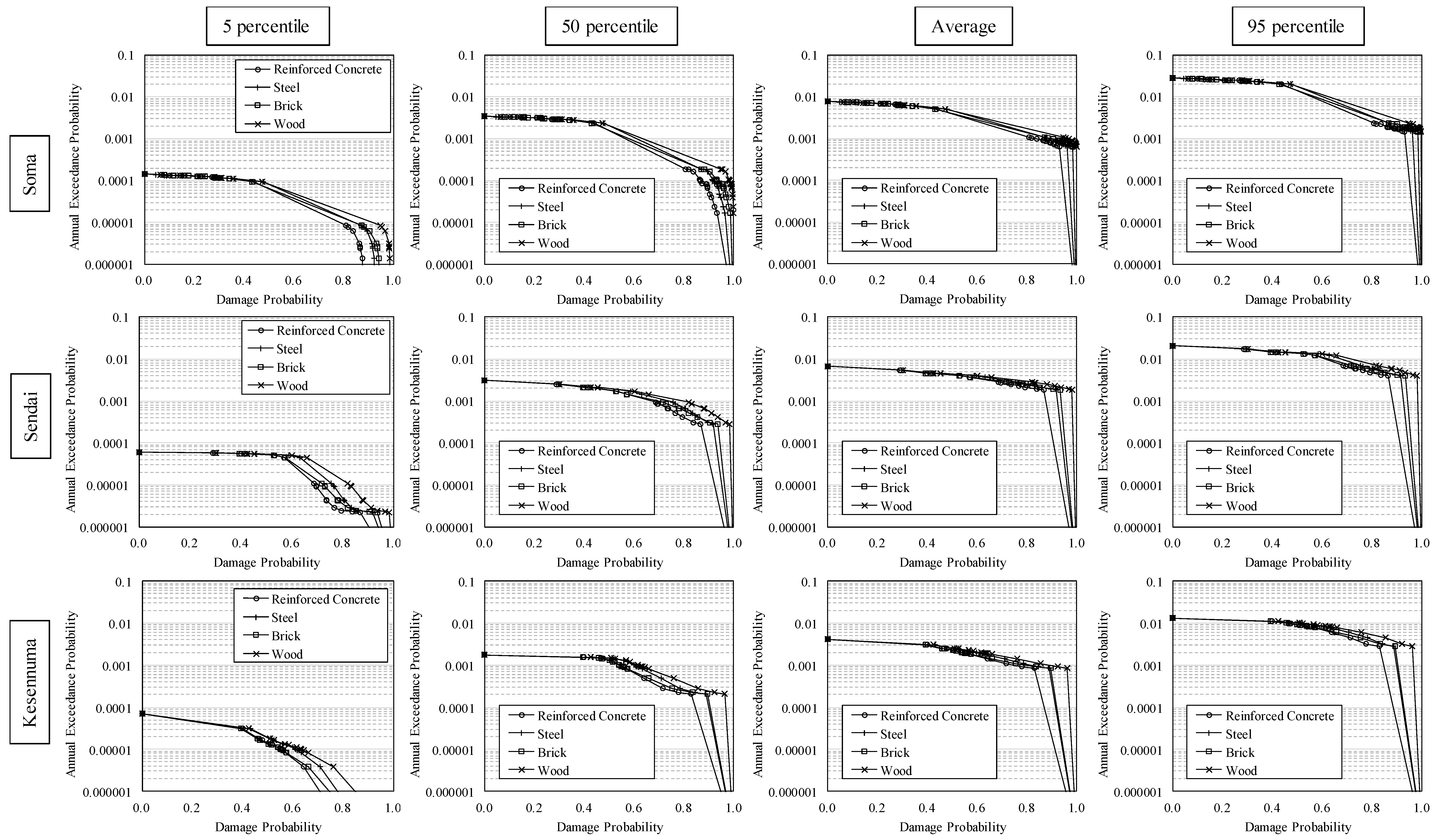
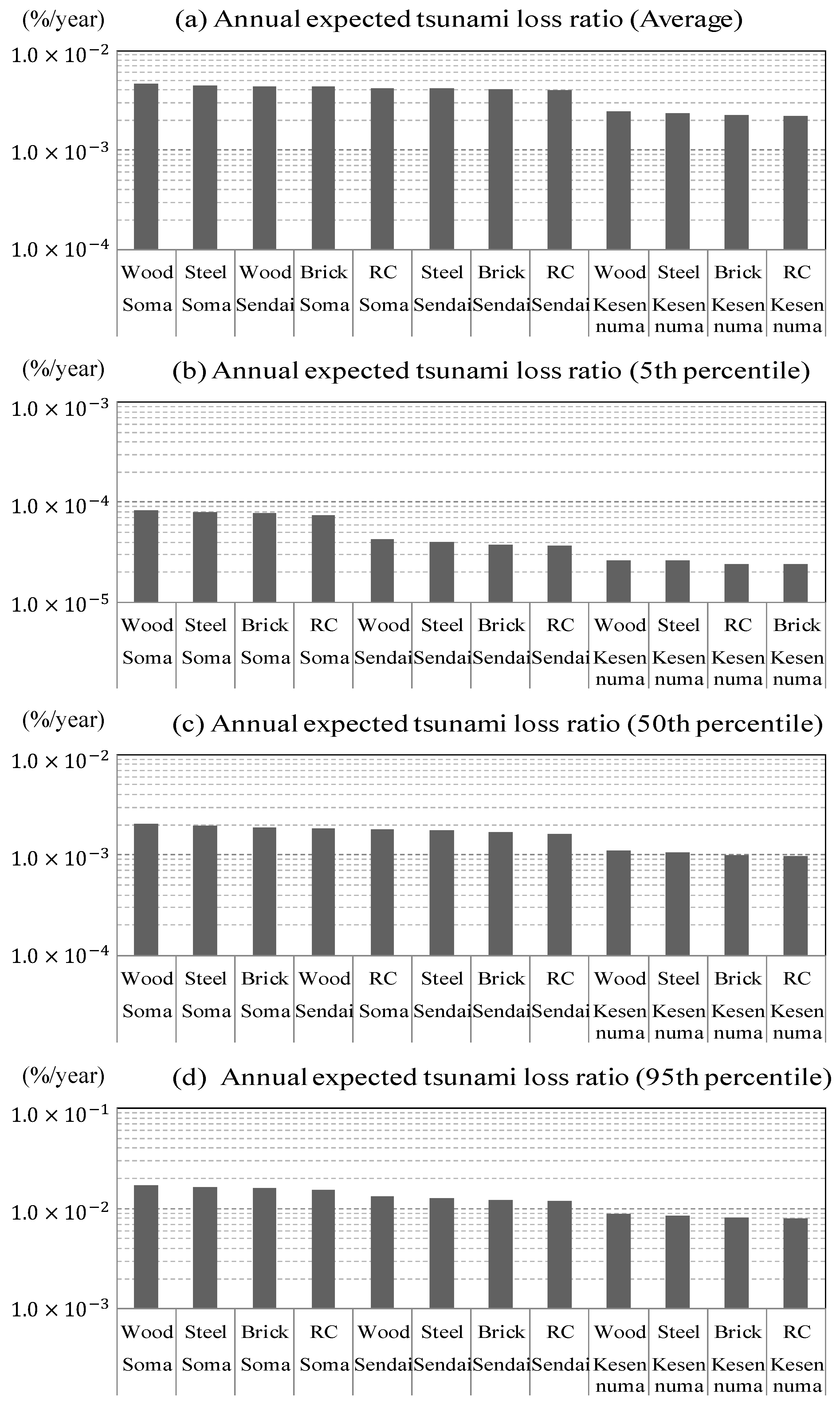
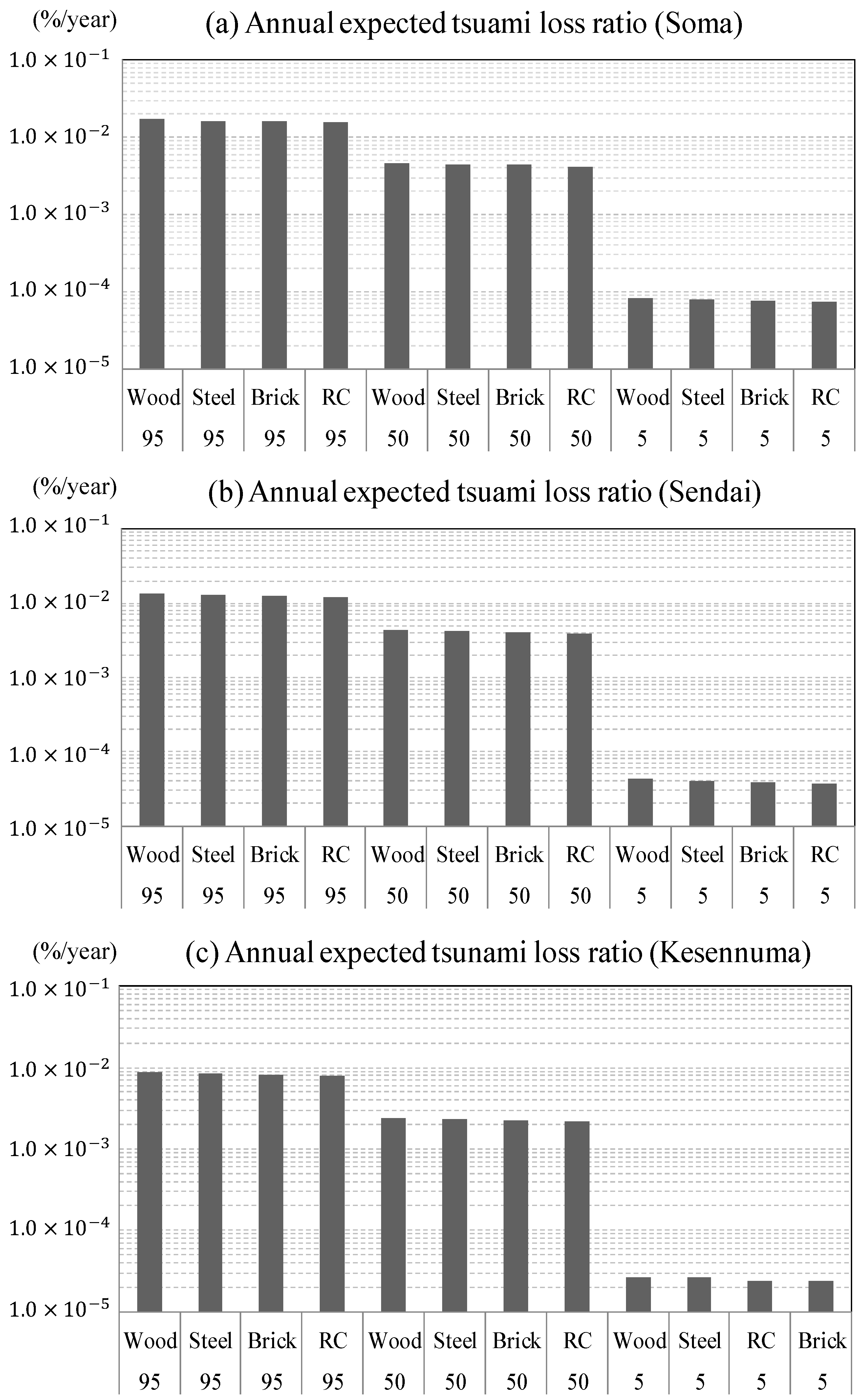
3.5. Risk Assessment and Quantitative Effects of the Hazard Assessment
3.6. Discussion
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N | ||
|---|---|---|
| 1.84 | 0 | 0 |
| 3.30 | 1 | 0.173 |
| 4.64 | 2 | 0.708 |
| 5.92 | 3 | 1.37 |
| 7.16 | 4 | 2.09 |
| 8.38 | 5 | 2.84 |
| 9.58 | 6 | 3.62 |
| 10.8 | 7 | 4.42 |
| 12.0 | 8 | 5.23 |
| 13.1 | 9 | 6.06 |
| 14.3 | 10 | 6.89 |
References
- United Nations Department of Humanitarian Affairs. Glossary: Internationally Agreed Glossary of Basic Terms Related to Disaster Management, Geneva, Switzerland. Available online: https://reliefweb.int/sites/reliefweb.int/files/resources/004DFD3E15B69A67C1256C4C006225C2-dha-glossary-1992.pdf (accessed on 28 September 2017).
- González, F.I.; Geist, E.L.; Jaffe, B.; Kânoğlu, U.; Mofjeld, H.; Synolakis, C.E.; Titov, V.V.; Arcas, D.; Bellomo, D.; Carlton, D.; et al. Probabilistic tsunami hazard assessment at seaside, Oregon, for near-and far-field seismic sources. J. Geophys. Res. Oceans 2009, 114, C11023. [Google Scholar] [CrossRef]
- Løvholt, F.; Pedersen, G.; Bazin, S.; Kuhn, D.; Bredesen, R.E.; Harbitz, C. Stochastic analysis of tsunami runup due to heterogeneous coseismic slip and dispersion. J. Geophys. Res. 2012, 117, C03047. [Google Scholar] [CrossRef]
- Goda, K.; Mai, P.M.; Yasuda, T.; Mori, N. Sensitivity of tsunami wave profiles and inundation simulations to earthquake slip and fault geometry for the 2011 Tohoku earthquake. Earth Planets Space 2014, 66, 105. [Google Scholar] [CrossRef]
- Park, H.; Cox, D.T. Probabilistic assessment of near-field tsunami hazards: Inundation depth, velocity, momentum flux, arrival time, and duration applied to Seaside, Oregon. Coast. Eng. 2016, 117, 79–96. [Google Scholar] [CrossRef]
- Thio, H.K.; Somerville, P.G.; Polet, J. Probabilistic Tsunami Hazard in California; College of Engineering, University of California: Los Angeles, CA, USA, 2010. [Google Scholar]
- Horspool, N.; Pranantyo, I.; Griffin, J.; Latief, H.; Natawidjaja, D.H.; Kongko, W.; Cipta, A.; Bustaman, B.; Anugrah, S.D.; Thio, H.K. A probabilistic tsunami hazard assessment for Indonesia. Nat. Hazards Earth Syst. Sci. 2014, 14, 3105–3122. [Google Scholar] [CrossRef]
- Davies, G.; Griffin, J.; Løvholt, F.; Glimsdal, S.; Harbitz, C.; Thio, H.K.; Lorito, S.; Basili, R.; Selva, J.; Geist, E.; et al. A global probabilistic tsunami hazard assessment from earthquake sources. Geol. Soc. Lond. Spec. Publ. 2017, 456, SP456-5. [Google Scholar] [CrossRef]
- Geist, E.L.; Parsons, T. Probabilistic analysis of tsunami hazards. Nat. Hazards 2006, 37, 277–314. [Google Scholar] [CrossRef]
- Annaka, T.; Satake, K.; Sakakiyama, T.; Yanagisawa, K.; Shuto, N. Logic-tree Approach for Probabilistic Tsunami Hazard Analysis and its Applications to the Japanese Coasts. Pure Appl. Geophys. 2007, 164, 577–592. [Google Scholar] [CrossRef]
- Cornell, C.A. Engineering Seismic Risk Analysis. Bull. Seism. Soc. Am. 1968, 58, 1583–1606. [Google Scholar]
- Suppasri, A.; Latcharote, P.; Bricker, J.D.; Leelawat, N.; Hayashi, A.; Yamashita, K.; Makinoshima, F.; Roeber, V.; Imamura, F. Improvement of Tsunami Countermeasures Based on Lessons from The 2011 Great East Japan Earthquake and Tsunami—Situation After Five Years. Coast. Eng. J. 2016, 58, 1640011. [Google Scholar] [CrossRef]
- Japan Society of Civil Engineers. A Method for Probabilistic Tsunami Hazard Analysis. The Tsunami Evaluation Subcommittee, The Nuclear Civil Engineering Committee, Japan Society of Civil Engineers: Tokyo, Japan. Available online: http://committees.jsce.or.jp/ceofnp/system/files/PTHA20111209_0.pdf (accessed on 28 September 2017). (In Japanese).
- National Research Institute for Earth Science and Disaster Resilience (NIED). Japan Seismic Hazard Information Station (JSHIS 2013). Available online: http://www.j-shis.bosai.go.jp/map/ (accessed on 28 September 2017).
- Fukutani, Y.; Suppasri, A.; Imamura, F. Stochastic analysis and uncertainty assessment of tsunami wave height using a random source parameter model that targets a Tohoku-type earthquake fault. Stoch. Environ. Res. Risk. Assess. 2015, 29, 1763–1779. [Google Scholar] [CrossRef]
- Headquarters for Earthquake Research Promotion, Probabilistic Seismic Hazard Maps for Japan. Available online: http://www.jishin.go.jp/evaluation/seismic_hazard_map/shm_report/ (accessed on 28 September 2017).
- Aida, I. Reliability of a tsunami source model derived from fault parameters. J. Phys. Earth 1978, 26, 57–73. [Google Scholar] [CrossRef]
- Okada, Y. Surface deformation due to shear and tensile faults in a half-space. Bull. Seism. Soc. Am. 1985, 75, 1135–1154. [Google Scholar]
- IUGG/IOC TIME Project. Numerical Method of Tsunami Simulation with the Leap-Frog Scheme; Intergovernmental Oceanographic Commission Manuals and Guides 35; UNESCO: Paris, France, 1997. [Google Scholar]
- Suppasri, A.; Mas, E.; Charvet, I.; Gunasekera, R.; Imai, K.; Fukutani, Y.; Abe, Y.; Imamura, F. Building damage characteristics based on surveyed data and fragility curves of the 2011 Great East Japan tsunami. Nat. Hazards 2013, 66, 319–341. [Google Scholar] [CrossRef]
- Charvet, I.; Macabuag, J.; Rossetto, T. Estimating Tsunami-Induced Building Damage through Fragility Functions: Critical Review and Research Needs. Front. Built Environ. 2017, 3, 36. [Google Scholar] [CrossRef]
- Weichert, D.H. Estimation of the earthquake recurrence parameters for unequal observation periods for different magnitudes. Bull. Seism. Soc. Am. 1980, 70, 1337–1356. [Google Scholar]


















| Target Location | Latitude (°) | Longitude (°) | Elevation (m) | Distance from Coastline (m) |
|---|---|---|---|---|
| Soma | 37.84829 | 140.95052 | 3.7 | 390 |
| Sendai | 38.23349 | 140.98479 | 1.1 | 1040 |
| Kesennuma | 38.87447 | 141.58775 | 1.4 | 90 |
| Abbreviation | Earthquake Name |
|---|---|
| JTN1-1 | Large interplate earthquakes in Northern Sanriku-Oki (repeating earthquakes) |
| JTN1-2 | Large interplate earthquakes in Northern Sanriku-Oki (other than repeating earthquakes) |
| JTN2 | Miyagi-ken-Oki earthquake (repeating earthquakes) |
| JTN3-1 | Earthquakes close to the offshore trenches in Southern Sanriku-Oki (repeating earthquakes) |
| JTN3-2 | Earthquakes close to the offshore trenches in Southern Sanriku-Oki (other than repeating earthquakes) |
| JTN2 + JTN3 | Miyagi-ken-Oki, earthquakes close to the offshore trenches in Southern Sanriku-Oki consolidated-type-earthquake |
| TOHOKU | Great East Japan Earthquake (2011 Tohoku-type earthquake) |
| JTT | Large interplate earthquakes close to the offshore trenches in the Sanriku-Oki to Boso-Oki regions (tsunami earthquakes) |
| JTNR | Large intraplate earthquakes close to the offshore trenches in the Sanriku-Oki to Boso-Oki regions (normal fault-type) |
| JTS1 | Interplate earthquakes in Fukushima-ken-Oki |
| IBRK | Interplate earthquakes in Ibaraki-ken-Oki (other than repeating earthquakes) |
| Earthquake Name (Abbreviation) | Model for Generation Interval of Earthquake | α Value of BPT Distribution | Average Return Period (Year) | Sample Period (Year) | Earthquake Generation Time | Lower Limit of Confidence Interval for the Return Period | Upper Limit of Confidence Interval for the Return Period |
|---|---|---|---|---|---|---|---|
| JTN1-1 | BPT | 0.08 | 97 | 412 | 4 | 93 | 101 |
| 0.18 | 97 | 412 | 4 | 89 | 106 | ||
| 0.28 | 97 | 412 | 4 | 84 | 112 | ||
| JTN2 | Poisson process | - | 38 | 110 | 4 | 15 | 53 |
| JTN3-1 | BPT | 0.12 | 109 | 220 | 3 | 102 | 117 |
| 0.22 | 109 | 220 | 3 | 96 | 124 | ||
| 0.32 | 109 | 220 | 3 | 91 | 131 | ||
| JTN2 + JTN3 | Poisson process | - | 218 | 218 | 1 | 66 | 1260 |
| JTT | Poisson process | - | 103 | 400 | 4 | 56 | 191 |
| JTNR | Poisson process | - | 575 | 575 | 1 | 174 | 3324 |
| JTN1-2 | Poisson process | - | 14 | 127 | 9 | 10 | 21 |
| JTN3-2 | Poisson process | - | 42 | 127 | 3 | 21 | 93 |
| JTS1 | Poisson process | - | 206 | 412 | 2 | 89 | 582 |
| IBRK | Poisson process | - | 26 | 127 | 5 | 15 | 45 |
| TOHOKU | BPT | 0.14 | 600 | 2400 | 4 | 559 | 644 |
| 0.24 | 600 | 2400 | 4 | 532 | 676 | ||
| 0.34 | 600 | 2400 | 4 | 506 | 711 |
| Earthquake Name (Abbreviation) | Moment Magnitude (Mw) | Number of Earthquake Faults | Earthquake Fault Parameter | Earthquake Moment Mo (Nm) | Shear Modulus μ (N/m2) | Average Slip (m) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Longitude (°) | Lattitude (°) | Depth (km) | Length (km) | Width (km) | Strike (°) | Rake (°) | Dip (°) | ||||||
| JTN1-1 | 8.2 | 1 | 143.096 | 41.603 | 9.0 | 170 | 100 | 156 | 90 | 20 | 2.51 × 1021 | 3.50 × 1010 | 3.30 |
| JTN2 | 7.6 | 1 | 142.388 | 38.454 | 30.8 | 60 | 60 | 194 | 90 | 22 | 2.72 × 1020 | 7.00 × 1010 | 1.10 |
| JTN3-1 | 7.9 | 1 | 143.203 | 38.74 | 16.8 | 50 | 165 | 191 | 90 | 10 | 9.43 × 1020 | 5.00 × 1010 | 3.30 |
| JTN2+JTN3 | 8.1 | 1 | The fault parameters were assumed as JTN2, JTN3-1 Consolidated Type Earthquake | 1.78 × 1021 | 5.00 × 1010 | 2.20 | |||||||
| TOHOKU | 9.0 | 1 | 144.139 | 39.9 | 4.1 | 500 | 200 | 193 | 90 | 13 | 3.98 × 1022 | Shallow part: 3.60 × 1010, Deep part: 5.20 × 1010 | Shallow part: 18.1, Deep part: 6.0 |
| JTT | 8.0 | 1 | 144.729 | 41.087 | 6.5 | 200 | 50 | 192 | 90 | 6 | 1.26 × 1021 | 3.50 × 1010 | 3.60 |
| 2 | 144.428 | 41.187 | 8.1 | 200 | 50 | 192 | 90 | 9 | 1.26 × 1021 | 3.50 × 1010 | 3.60 | ||
| 3 | 144.278 | 39.351 | 6.8 | 200 | 50 | 190 | 90 | 7 | 1.26 × 1021 | 3.50 × 1010 | 3.60 | ||
| 4 | 143.928 | 39.401 | 10.3 | 200 | 50 | 190 | 90 | 8 | 1.26 × 1021 | 3.50 × 1010 | 3.60 | ||
| 5 | 143.915 | 37.46 | 7.0 | 200 | 50 | 211 | 90 | 7 | 1.26 × 1021 | 3.50 × 1010 | 3.60 | ||
| 6 | 143.6 | 37.572 | 10.3 | 200 | 50 | 210 | 90 | 9 | 1.26 × 1021 | 3.50 × 1010 | 3.60 | ||
| 7 | 142.44 | 36.058 | 7.0 | 200 | 50 | 189 | 90 | 8 | 1.26 × 1021 | 3.50 × 1010 | 3.60 | ||
| 8 | 142.21 | 36.031 | 10.8 | 200 | 50 | 193 | 90 | 10 | 1.26 × 1021 | 3.50 × 1010 | 3.60 | ||
| JTNR | 8.3 | 1 | 144.706 | 41.088 | 0.0 | 200 | 100 | 192 | 270 | 45 | 3.55 × 1021 | 7.00 × 1010 | 2.50 |
| 2 | 144.226 | 39.353 | 0.0 | 200 | 100 | 190 | 270 | 45 | 3.55 × 1021 | 7.00 × 1010 | 2.50 | ||
| 3 | 143.856 | 37.458 | 0.0 | 200 | 100 | 211 | 270 | 45 | 3.55 × 1021 | 7.00 × 1010 | 2.50 | ||
| 4 | 142.407 | 36.058 | 0.0 | 200 | 100 | 189 | 270 | 45 | 3.55 × 1021 | 7.00 × 1010 | 2.50 | ||
| 5 | 145.486 | 40.988 | 0.0 | 200 | 100 | 192 | 270 | 45 | 3.55 × 1021 | 7.00 × 1010 | 2.50 | ||
| 6 | 145.006 | 39.253 | 0.0 | 200 | 100 | 190 | 270 | 45 | 3.55 × 1021 | 7.00 × 1010 | 2.50 | ||
| 7 | 144.736 | 37.358 | 0.0 | 200 | 100 | 211 | 270 | 45 | 3.55 × 1021 | 7.00 × 1010 | 2.50 | ||
| 8 | 143.186 | 35.958 | 0.0 | 200 | 100 | 189 | 270 | 45 | 3.55 × 1021 | 7.00 × 1010 | 2.50 | ||
| JTN1-2 | 7.5 | 1 | 143.717 | 41.43 | 17.5 | 60 | 60 | 206 | 90 | 13 | 2.24 × 1020 | 5.00 × 1010 | 1.50 |
| 2 | 142.966 | 41.726 | 34.4 | 60 | 60 | 207 | 90 | 17 | 2.24 × 1020 | 5.00 × 1010 | 1.50 | ||
| 3 | 143.405 | 41.099 | 19.3 | 60 | 60 | 185 | 90 | 14 | 2.24 × 1020 | 5.00 × 1010 | 1.50 | ||
| 4 | 142.658 | 41.304 | 35.4 | 60 | 60 | 184 | 90 | 19 | 2.24 × 1020 | 5.00 × 1010 | 1.50 | ||
| 5 | 143.313 | 40.654 | 20.1 | 60 | 60 | 184 | 90 | 14 | 2.24 × 1020 | 5.00 × 1010 | 1.50 | ||
| 6 | 142.605 | 40.754 | 35.4 | 60 | 60 | 184 | 90 | 19 | 2.24 × 1020 | 5.00 × 1010 | 1.50 | ||
| 7 | 143.222 | 40.194 | 21.3 | 60 | 60 | 186 | 90 | 14 | 2.24 × 1020 | 5.00 × 1010 | 1.50 | ||
| 8 | 142.556 | 40.2 | 34.9 | 60 | 60 | 185 | 90 | 20 | 2.24 × 1020 | 5.00 × 1010 | 1.50 | ||
| JTN3-2 | 7.4 | 1 | 143.267 | 38.727 | 16 | 50 | 50 | 192 | 90 | 10 | 1.58 × 1020 | 5.00 × 1010 | 1.30 |
| 2 | 143.121 | 38.332 | 16.5 | 50 | 50 | 191 | 90 | 10 | 1.58 × 1020 | 5.00 × 1010 | 1.30 | ||
| 3 | 142.997 | 37.922 | 16.9 | 50 | 50 | 193 | 90 | 10 | 1.58 × 1020 | 5.00 × 1010 | 1.30 | ||
| JTS1 | 7.4 | 1 | 142.804 | 37.298 | 17.3 | 50 | 50 | 204 | 90 | 10 | 1.58 × 1020 | 5.00 × 1010 | 1.30 |
| 2 | 142.372 | 37.445 | 23.4 | 50 | 50 | 201 | 90 | 15 | 1.58 × 1020 | 5.00 × 1010 | 1.30 | ||
| 3 | 141.948 | 37.564 | 34.6 | 50 | 50 | 204 | 90 | 23 | 1.58 × 1020 | 5.00 × 1010 | 1.30 | ||
| 4 | 142.556 | 36.877 | 15.7 | 50 | 50 | 212 | 90 | 13 | 1.58 × 1020 | 5.00 × 1010 | 1.30 | ||
| 5 | 142.12 | 37.036 | 24.6 | 50 | 50 | 205 | 90 | 16 | 1.58 × 1020 | 5.00 × 1010 | 1.30 | ||
| 6 | 141.697 | 37.149 | 35.3 | 50 | 50 | 207 | 90 | 22 | 1.58 × 1020 | 5.00 × 1010 | 1.30 | ||
| IBRK | 7.5 | 1 | 142.2 | 36.515 | 16 | 55 | 55 | 207 | 90 | 15 | 2.24 × 1020 | 5.00 × 1010 | 1.40 |
| 2 | 141.467 | 36.77 | 34.7 | 55 | 55 | 205 | 90 | 21 | 2.24 × 1020 | 5.00 × 1010 | 1.40 | ||
| 3 | 141.881 | 36.149 | 17.5 | 55 | 55 | 201 | 90 | 15 | 2.24 × 1020 | 5.00 × 1010 | 1.40 | ||
| 4 | 141.222 | 36.367 | 36.1 | 55 | 55 | 194 | 90 | 19 | 2.24 × 1020 | 5.00 × 1010 | 1.40 | ||
| 5 | 141.714 | 35.99 | 18.4 | 55 | 55 | 197 | 90 | 17 | 2.24 × 1020 | 5.00 × 1010 | 1.40 | ||
| 6 | 141.299 | 36.127 | 31.6 | 55 | 55 | 194 | 90 | 20 | 2.24 × 1020 | 5.00 × 1010 | 1.40 | ||
| Item | Calculation Condition |
|---|---|
| Governing equation | 2D non-linear shallow water equation (Tohoku University TUNAMI model) [19] |
| Numerical integration method | Staggered leap-frog differential method |
| Initial condition | Okada equation [18] |
| Boundary condition | Open boundary |
| Coordination system | Spherical coordinate system |
| Tidal setting | T.P. +0.0 m |
| Mesh size | 450 m |
| Time step | 0.9 s |
| Calculation time | 3 h |
| (a) | (b) | (c) | (d) | (e) | (f) | (g) | (h) |
|---|---|---|---|---|---|---|---|
| Earthquake Source | Moment Magnitude (Mw) | Position of Asperity | Tsunami Height (m) (10 m Water Depth Point) | Annual Exceedance Probability | Return Period (year) | Tsunami Inundation Height (m) (Risk Assessment Point) | Tsunami Inundation Depth (m) (Risk Assessment Point) |
| TOHOKU | 9.1 | Center | 8.58 | 0.000294 | 3405 | 13.63 | 9.96 |
| 9.1 | Between south and center | 7.84 | 0.000423 | 2363 | 10.33 | 6.66 | |
| 9.1 | South | 7.84 | 0.000425 | 2355 | 12.54 | 8.87 | |
| 9.0 | Center | 7.10 | 0.000579 | 1728 | 11.54 | 7.87 | |
| 9.1 | Between north and center | 6.78 | 0.000655 | 1526 | 10.56 | 6.89 | |
| 9.0 | South | 6.58 | 0.000702 | 1425 | 11.13 | 7.46 | |
| 9.1 | North | 6.51 | 0.000720 | 1388 | 10.68 | 7.01 | |
| 9.0 | Between south and center | 6.48 | 0.000725 | 1379 | 10.41 | 6.74 | |
| 9.0 | Between north and center | 5.49 | 0.000992 | 1008 | 9.38 | 5.71 | |
| 8.9 | Center | 5.44 | 0.001009 | 991 | 9.27 | 5.60 | |
| 9.0 | North | 5.42 | 0.001015 | 986 | 9.35 | 5.68 | |
| 8.9 | South | 5.28 | 0.001052 | 950 | 9.65 | 5.98 | |
| 8.9 | Between south and center | 4.93 | 0.001171 | 854 | 8.54 | 4.87 | |
| 8.9 | Between north and center | 4.40 | 0.001381 | 724 | 8.08 | 4.41 | |
| 8.9 | North | 4.08 | 0.001538 | 650 | 7.89 | 4.22 | |
| JTNR | 8.4 | North | 2.50 | 0.004316 | 232 | 4.30 | 0.63 |
| 8.4 | Center | 2.47 | 0.004464 | 224 | 3.97 | 0.30 | |
| 8.4 | South | 2.37 | 0.005014 | 199 | 3.84 | 0.17 | |
| JTN2 + JTN3 | 8.2 | South | 2.29 | 0.005459 | 183 | 4.51 | 0.84 |
| 8.2 | Center | 2.26 | 0.005667 | 176 | 4.36 | 0.69 | |
| JTT | 8.1 | Center | 2.25 | 0.005738 | 174 | 4.15 | 0.48 |
| 8.1 | North | 2.23 | 0.005885 | 170 | 4.10 | 0.43 | |
| 8.1 | Center | 2.23 | 0.005961 | 168 | 3.93 | 0.26 | |
| JTNR | 8.4 | South | 2.23 | 0.005961 | 168 | 4.28 | 0.61 |
| 8.4 | North | 2.20 | 0.006195 | 161 | 4.88 | 1.21 | |
| 8.4 | Center | 2.19 | 0.006275 | 159 | 4.35 | 0.68 | |
| JTT | 8.1 | North | 2.14 | 0.006612 | 151 | 3.78 | 0.11 |
| 8.0 | Center | 2.01 | 0.007986 | 125 | 0.00 | 0.00 | |
| 8.1 | South | 1.96 | 0.008441 | 118 | 0.00 | 0.00 | |
| 8.0 | Center | 1.96 | 0.008441 | 118 | 0.00 | 0.00 |
| (a) | (b) | (c) | (d) | (e) | (f) | (g) | (h) |
|---|---|---|---|---|---|---|---|
| Earthquake Source | Moment Magnitude (Mw) | Position of Asperity | Tsunami Height (m) (10 m Water Depth Point) | Annual Exceedance Probability | Return Period (year) | Tsunami Inundation Height (m) (Risk Assessment Point) | Tsunami Inundation Depth (m) (Risk Assessment Point) |
| TOHOKU | 9.1 | Center | 9.89 | 0.000220 | 4536 | 6.84 | 5.74 |
| 9.0 | Center | 8.50 | 0.000459 | 2177 | 5.97 | 4.87 | |
| 9.1 | Between north and center | 7.95 | 0.000603 | 1657 | 5.06 | 3.96 | |
| 9.1 | South | 7.58 | 0.000712 | 1404 | 4.66 | 3.56 | |
| 8.9 | Center | 6.82 | 0.001023 | 978 | 4.27 | 3.17 | |
| 9.0 | Between north and center | 6.78 | 0.001041 | 960 | 4.26 | 3.16 | |
| 9.1 | Between south and center | 6.64 | 0.001123 | 890 | 3.84 | 2.74 | |
| 9.0 | South | 6.52 | 0.001197 | 836 | 3.77 | 2.67 | |
| 9.1 | North | 6.38 | 0.001339 | 747 | 3.85 | 2.75 | |
| 8.9 | Between north and center | 5.62 | 0.002392 | 418 | 2.74 | 1.64 | |
| 9.0 | Between south and center | 5.56 | 0.002493 | 401 | 2.15 | 1.05 | |
| 9.0 | North | 5.52 | 0.002592 | 386 | 2.95 | 1.85 | |
| 8.9 | South | 5.30 | 0.003047 | 328 | 2.25 | 1.15 | |
| 8.9 | North | 4.49 | 0.005733 | 174 | 1.76 | 0.66 | |
| 8.9 | Between south and center | 4.30 | 0.006729 | 149 | 0.00 | 0.00 | |
| JTN2 + JTN3 | 8.2 | South | 4.16 | 0.007465 | 134 | 0.00 | 0.00 |
| 8.2 | Center | 4.04 | 0.008285 | 121 | 0.00 | 0.00 | |
| 8.2 | North | 3.79 | 0.010163 | 98 | 0.00 | 0.00 | |
| JTN3-1 | 8.0 | South | 3.76 | 0.010331 | 97 | 0.00 | 0.00 |
| 8.0 | Center | 3.61 | 0.011687 | 86 | 0.00 | 0.00 | |
| JTN2 + JTN3 | 8.1 | Center | 3.41 | 0.013891 | 72 | 0.00 | 0.00 |
| JTN3-1 | 8.0 | North | 3.36 | 0.014356 | 70 | 0.00 | 0.00 |
| JTN2 + JTN3 | 8.1 | South | 3.31 | 0.014959 | 67 | 0.00 | 0.00 |
| JTT | 8.1 | South | 3.16 | 0.017056 | 59 | 0.00 | 0.00 |
| JTN2 + JTN3 | 8.1 | North | 3.13 | 0.017479 | 57 | 0.00 | 0.00 |
| JTT | 8.1 | Center | 3.01 | 0.019274 | 52 | 0.00 | 0.00 |
| JTN3-1 | 7.9 | Center | 2.93 | 0.020564 | 49 | 0.00 | 0.00 |
| JTNR | 8.4 | South | 2.90 | 0.021068 | 47 | 0.00 | 0.00 |
| 8.4 | North | 2.87 | 0.021410 | 47 | 0.00 | 0.00 | |
| 8.4 | Center | 2.85 | 0.021757 | 46 | 0.00 | 0.00 |
| (a) | (b) | (c) | (d) | (e) | (f) | (g) | (h) |
|---|---|---|---|---|---|---|---|
| Earthquake Source | Moment Magnitude (Mw) | Position of Asperity | Tsunami Height (m) (10 m Water Depth Point) | Annual Exceedance Probability | Return Period (year) | Tsunami Inundation Height (m) (Risk Assessment Point) | Tsunami Inundation Depth (m) (Risk Assessment Point) |
| TOHOKU | 9.1 | Between north and center | 19.44 | 0.000132 | 7574 | 2.91 | 1.51 |
| 9.1 | Center | 17.01 | 0.000254 | 634 | 2.97 | 1.57 | |
| 9.0 | Between north and center | 15.66 | 0.000334 | 531 | 3.18 | 1.78 | |
| 9.0 | Center | 14.21 | 0.000444 | 440 | 3.16 | 1.76 | |
| 9.1 | Between south and center | 12.41 | 0.000616 | 416 | 2.73 | 1.33 | |
| 9.1 | North | 12.24 | 0.000627 | 405 | 6.08 | 4.68 | |
| 8.9 | Between north and center | 10.50 | 0.000853 | 327 | 3.26 | 1.86 | |
| 8.9 | Center | 10.48 | 0.000855 | 326 | 3.08 | 1.68 | |
| 9.0 | North | 10.11 | 0.000896 | 318 | 5.13 | 3.73 | |
| 9.0 | Between south and center | 9.30 | 0.000992 | 309 | 2.78 | 1.38 | |
| 9.1 | South | 9.13 | 0.001019 | 309 | 4.35 | 2.95 | |
| 8.9 | North | 7.82 | 0.001191 | 309 | 4.34 | 2.94 | |
| 9.0 | South | 6.85 | 0.001320 | 307 | 3.71 | 2.31 | |
| 8.9 | Between south and center | 6.44 | 0.001383 | 305 | 2.46 | 1.06 | |
| 8.9 | South | 4.92 | 0.001951 | 194 | 3.14 | 1.74 | |
| JTT | 8.1 | South | 3.63 | 0.004062 | 78 | 0.00 | 0.00 |
| 8.1 | South | 3.61 | 0.004093 | 77 | 0.00 | 0.00 | |
| 8.1 | Center | 3.56 | 0.004288 | 73 | 0.00 | 0.00 | |
| 8.1 | North | 3.46 | 0.004608 | 68 | 0.00 | 0.00 | |
| 8.1 | Center | 3.37 | 0.005007 | 61 | 0.00 | 0.00 | |
| JTNR | 8.4 | South | 3.27 | 0.005458 | 55 | 0.00 | 0.00 |
| 8.4 | North | 3.26 | 0.005506 | 55 | 0.00 | 0.00 | |
| JTT | 8.1 | North | 3.19 | 0.005808 | 51 | 0.00 | 0.00 |
| JTNR | 8.4 | Center | 3.18 | 0.005860 | 50 | 0.00 | 0.00 |
| JTN2 + JTN3 | 8.2 | North | 3.05 | 0.006667 | 44 | 0.00 | 0.00 |
| JTNR | 8.4 | South | 2.86 | 0.008003 | 35 | 0.00 | 0.00 |
| 8.4 | Center | 2.82 | 0.008243 | 34 | 0.00 | 0.00 | |
| JTT | 8.0 | South | 2.82 | 0.008325 | 34 | 0.00 | 0.00 |
| 8.0 | Center | 2.78 | 0.008662 | 32 | 0.00 | 0.00 | |
| 8.0 | South | 2.78 | 0.008662 | 32 | 0.00 | 0.00 |
| Item | Calculation Condition |
|---|---|
| Governing equation | 2D non-linear shallow water equation (Tohoku University TUNAMI model) [19] |
| Numerical integration method | Staggered leap-frog differential method |
| Initial condition | Okada equation [18] |
| Boundary condition | Run-up boundary |
| Coordinate system | Plane rectangular coordinate system IX |
| Tidal setting | T.P. +0.0 m |
| Mesh size | 810 m, 270 m, 90 m, 30 m, 10 m |
| Time step | 0.9 s, 0.3 s, 0.1 s, 0.03 s, 0.01 s |
| Calculation time | 3 h |
| Item | Calculation Condition |
|---|---|
| Governing equation | 2D non-linear shallow water equation (Tohoku University TUNAMI model) [19] |
| Numerical integration method | Staggered leap-frog differential method |
| Initial condition | Okada equation [18] |
| Boundary condition | Run-up boundary |
| Coordinate system | Plane rectangular coordinate system X |
| Tidal setting | T.P. +0.0 m |
| Mesh size | 1215 m, 405 m, 135 m, 45 m, 15 m |
| Time step | 0.9 s, 0.3 s, 0.1 s, 0.03 s, 0.01 s |
| Calculation time | 3 h |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fukutani, Y.; Suppasri, A.; Imamura, F. Quantitative Assessment of Epistemic Uncertainties in Tsunami Hazard Effects on Building Risk Assessments. Geosciences 2018, 8, 17. https://doi.org/10.3390/geosciences8010017
Fukutani Y, Suppasri A, Imamura F. Quantitative Assessment of Epistemic Uncertainties in Tsunami Hazard Effects on Building Risk Assessments. Geosciences. 2018; 8(1):17. https://doi.org/10.3390/geosciences8010017
Chicago/Turabian StyleFukutani, Yo, Anawat Suppasri, and Fumihiko Imamura. 2018. "Quantitative Assessment of Epistemic Uncertainties in Tsunami Hazard Effects on Building Risk Assessments" Geosciences 8, no. 1: 17. https://doi.org/10.3390/geosciences8010017
APA StyleFukutani, Y., Suppasri, A., & Imamura, F. (2018). Quantitative Assessment of Epistemic Uncertainties in Tsunami Hazard Effects on Building Risk Assessments. Geosciences, 8(1), 17. https://doi.org/10.3390/geosciences8010017