
Contextualized Small Target Detection Network for Small Target Goat Face Detection


Abstract
Simple Summary
Abstract
1. Introduction
- (a)
- The image resolution is too low, lacking sufficient feature information for recognition, and environmental factors can easily affect the detection effect;
- (b)
- The number of positive samples for small targets is small and, when the boundary between the Anchor set by the model and the small target is large, the number of positive training samples for small targets will be much smaller than the number of positive samples for large targets; the model is prone to ignore the detection of small targets, especially when the target object spans a large scale;
- (c)
- When performing feature fusion, the small target information is easily lost due to the small target features, which are easily overwhelmed by background noise.
- (i)
- A Contextual Information Detection Module (CIDM) was proposed, which can provide more background information and further contextual information about the target, which can help in the detection of small targets;
- (ii)
- A Feature Complementary Module (FCM) was proposed to fuse the information of each scale while eliminating noise and interference, thus improving the reliability and anti-interference abilities of the feature target;
- (iii)
- WH-CIoU was proposed on the basis of CIoU, which can calculate the difference between the predicted frame width and height relative to their true values. The loss function is more biased to the change in the prediction frame size, which is more favorable to the regression of the prediction frame.
2. Materials and Methods
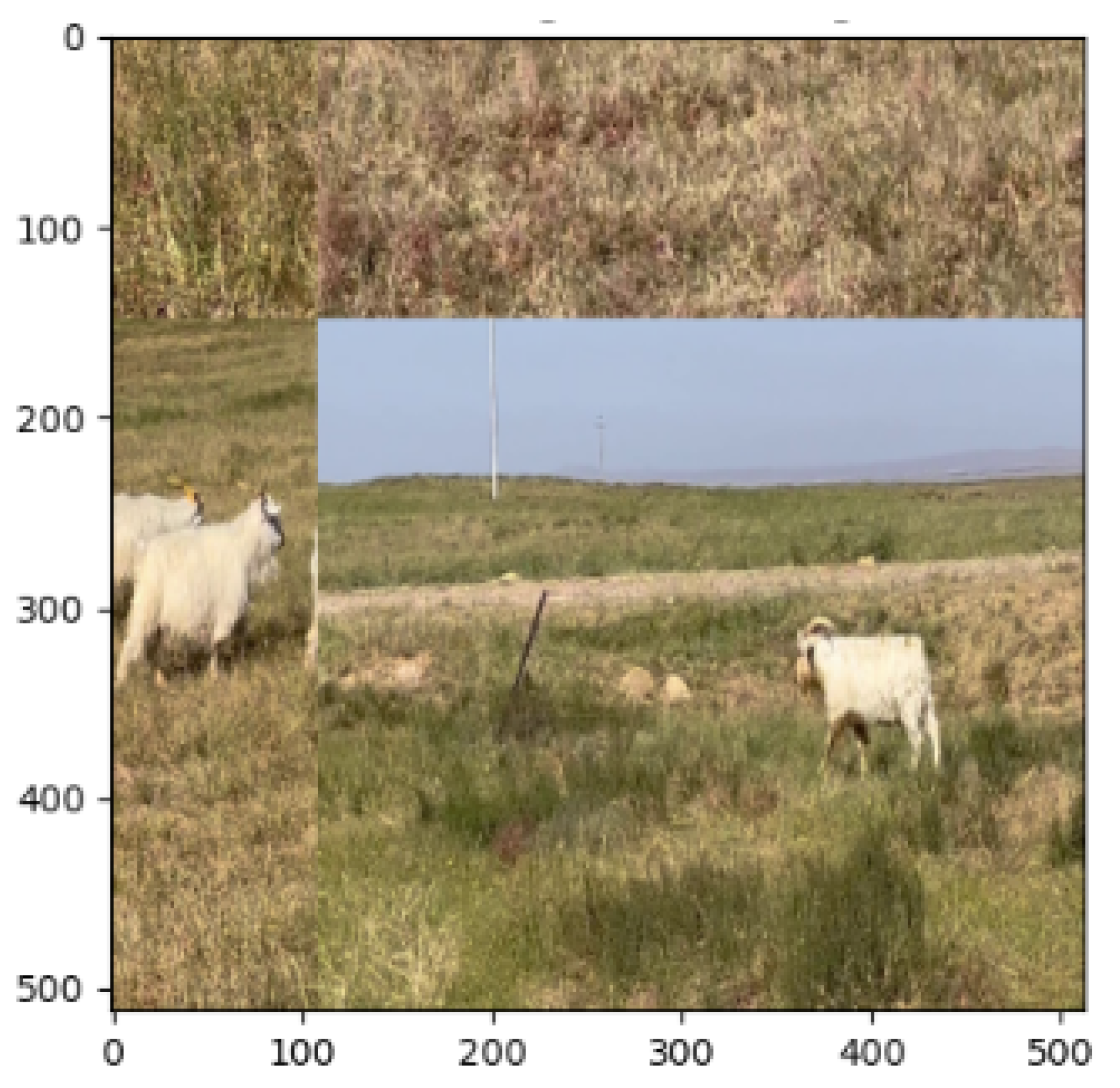
2.1. Small Target Definition
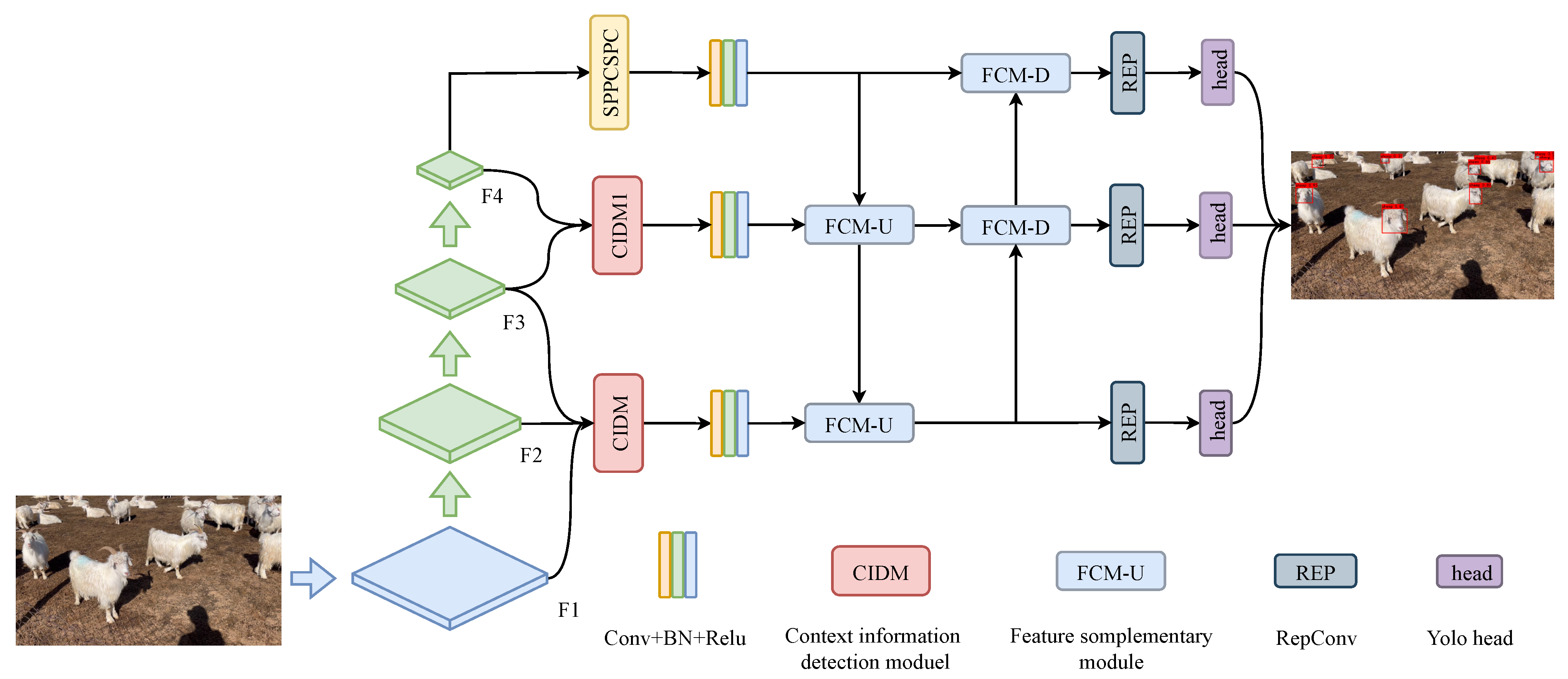
2.2. Network Architecture Design
2.2.1. YOLOV7-Based Network Architecture
2.2.2. Network Structure
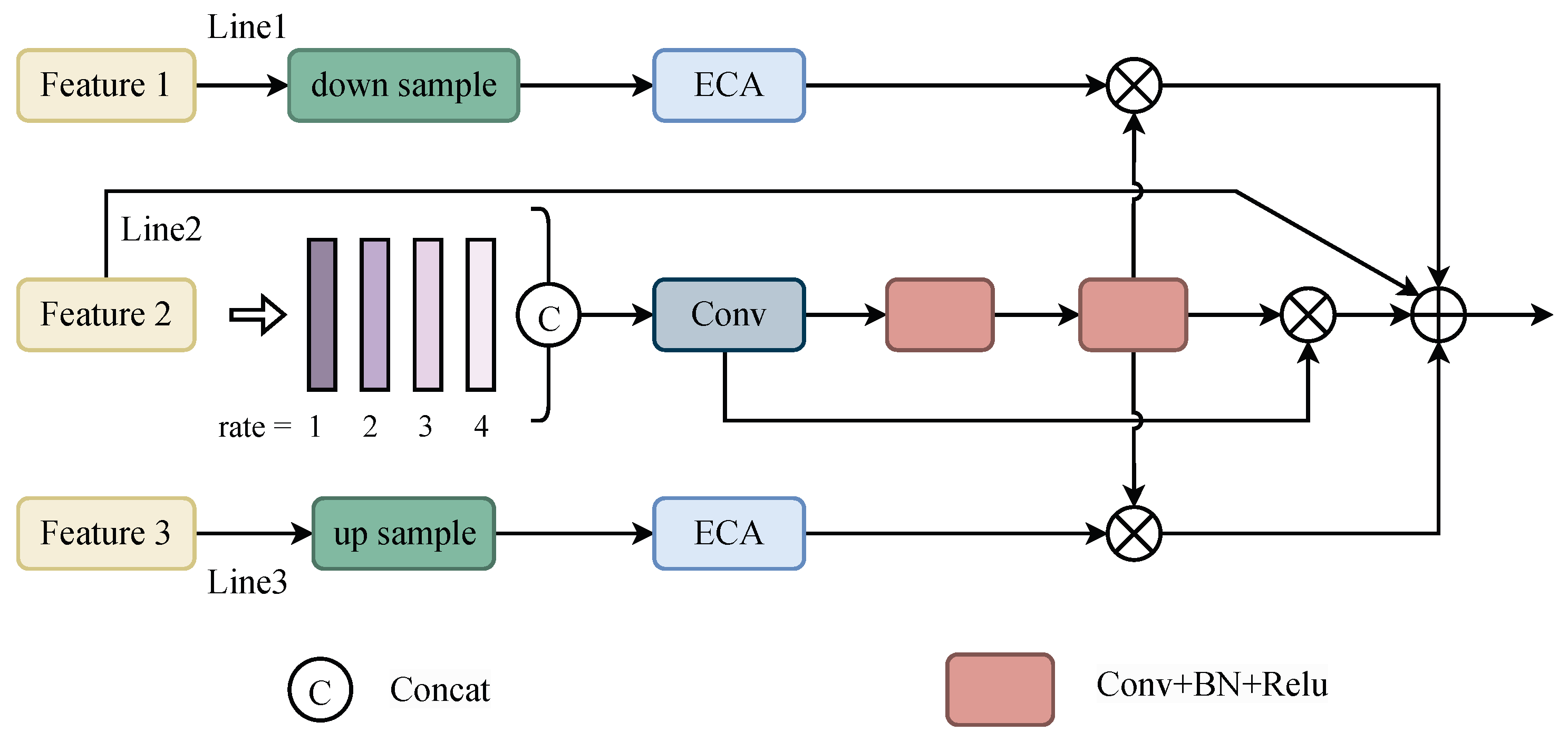
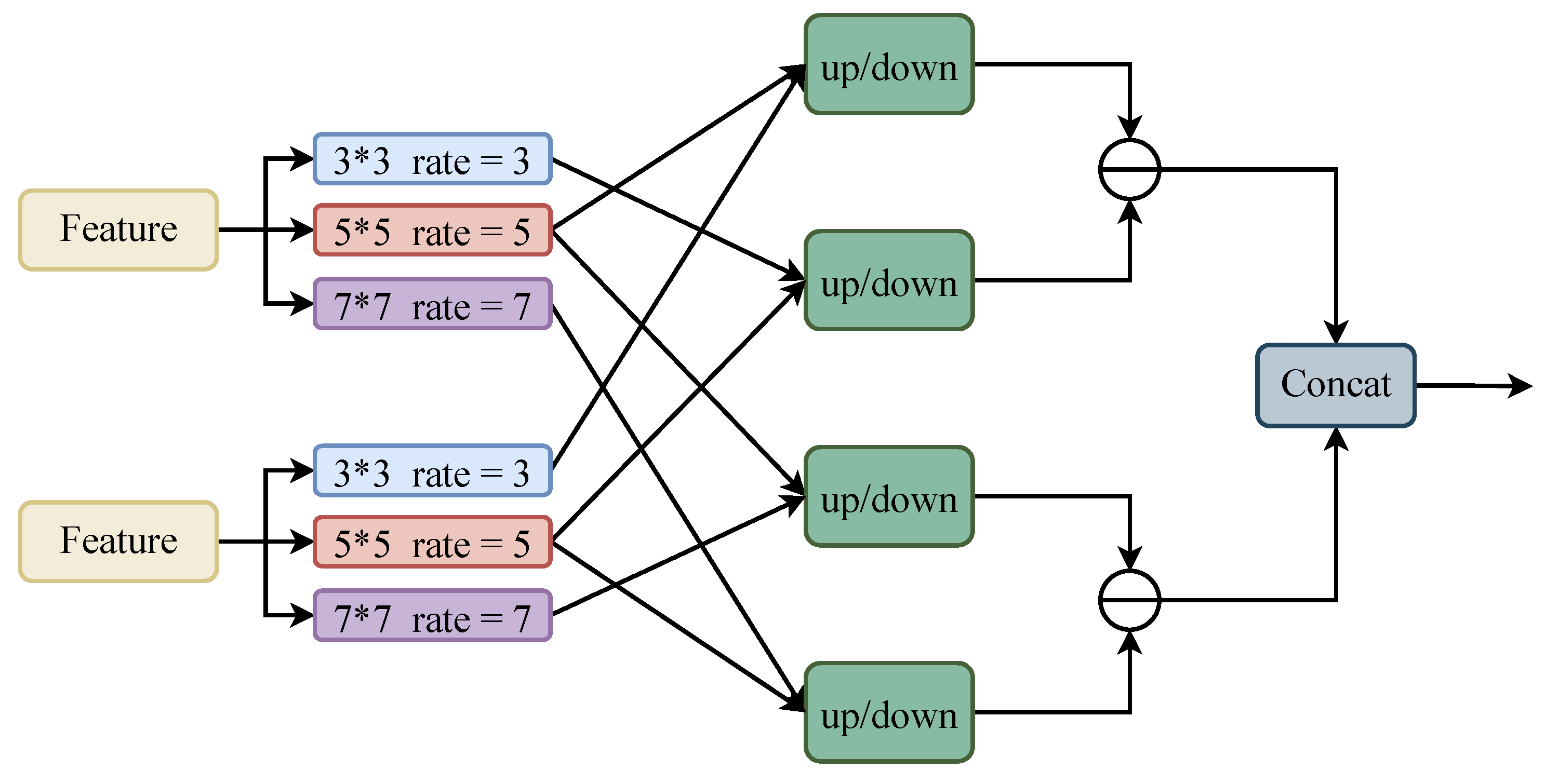
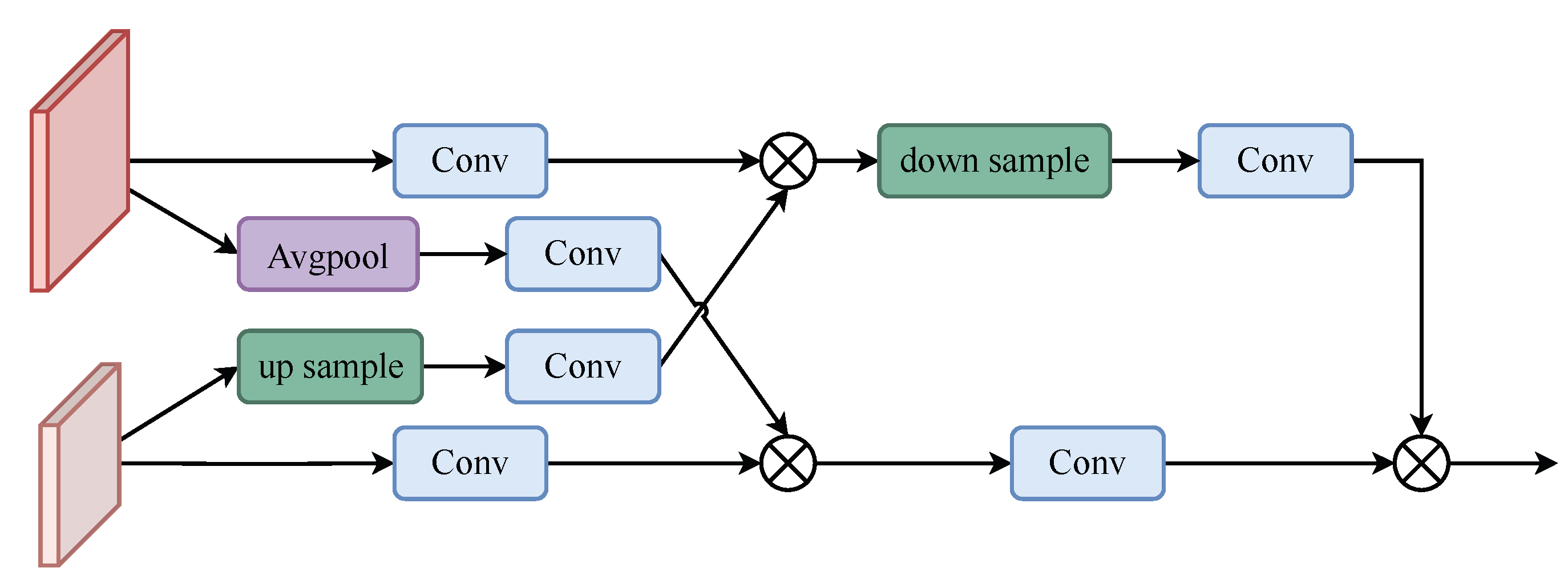
2.3. Context Information Detection Module
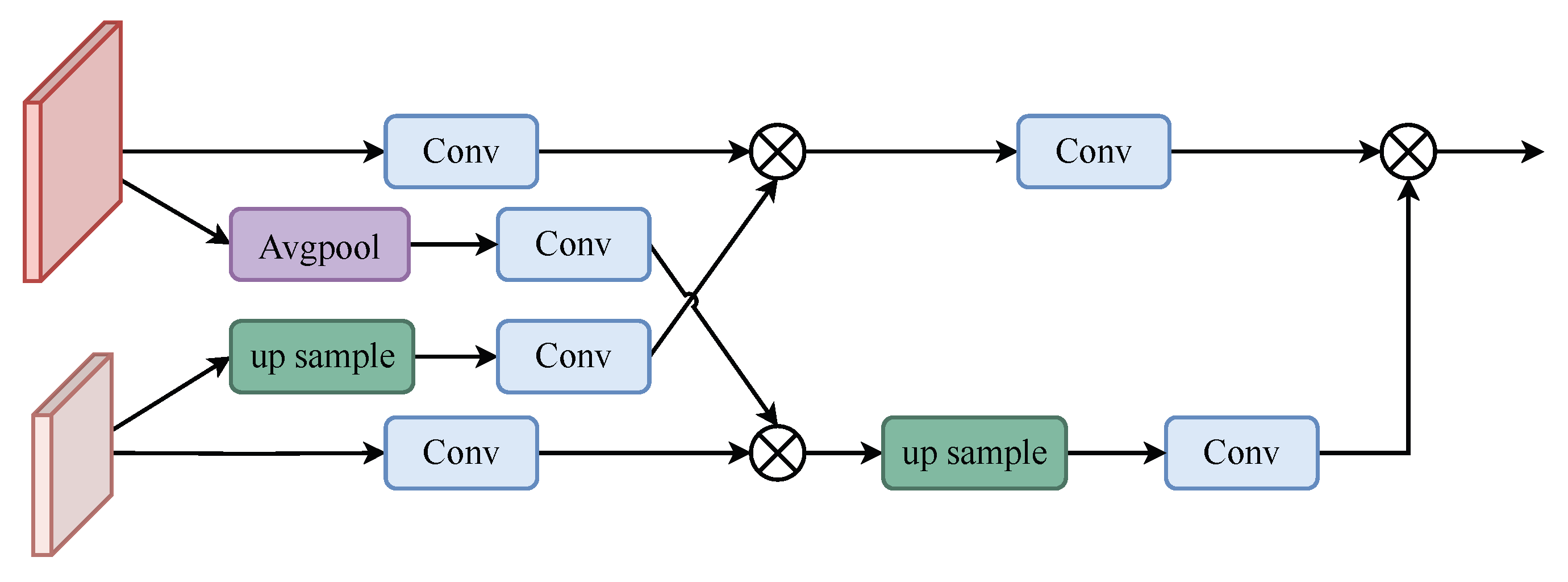
2.4. Feature Complementary Module
2.5. Small-Target Detection Head and Loss Function
3. Experiments
3.1. Goat Face Image Dataset
3.2. Experimental Evaluation Metrics
- Precision (P): This indicator describes the proportion of positive samples detected by the model that are actually positive. The larger the value, the higher the accuracy rate, which would ideally be 1:1:
- Recall (R): This indicator describes the proportion of correct positive samples detected by the model among all positive samples:
- F1-Score: This indicator combines precision and recall and takes a balanced value for a comprehensive assessment of:
- AP: AP is the average precision, which is the area under the precision–recall curve:where is the number of samples that are actually positive and predicted to be positive, is the number of samples that are actually negative but predicted to be positive, and is the number of samples that are actually positive but predicted to be negative.
3.3. Test Environment and Network Parameter Settings
3.4. Comparison Experiments
3.5. Ablation Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Neethirajan, S. The role of sensors, big data and machine learning in modern animal farming. Sens. Bio-Sens. Res. 2020, 29, 100367. [Google Scholar] [CrossRef]
- Nobrega, L.; Tavares, A.; Cardoso, A.; Goncalves, P. Animal monitoring based on IoT technologies. In Proceedings of the 2018 IoT Vertical and Topical Summit on Agriculture—Tuscany (IOT Tuscany), Tuscany, Italy, 8–9 May 2018; pp. 1–5. [Google Scholar]
- Guo, Y.; He, D.; Chai, L. A Machine Vision-Based Method for Monitoring Scene-Interactive Behaviors of Dairy Calf. Animals 2020, 10, 190. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Dong, J.; Song, X.; Nie, L.; Zhang, S.; Liu, M. Research on Goat Health Management System. In Proceedings of the International Workshop on Intelligent Systems & Applications, Wuhan, China, 28–29 May 2011. [Google Scholar]
- He, D.; Liu, D.; Zhao, K. Review of perceiving animal information and behavior in precision livestock farming. Trans. Chin. Soc. Agric. Mach. 2016, 47, 231–244. [Google Scholar]
- Guo, S.; Xu, P.; Miao, Q.; Shao, G.; Chapman, C.A.; Chen, X.; He, G.; Fang, D.; Zhang, H.; Sun, Y.; et al. Automatic identification of individual primates with deep learning techniques. Iscience 2020, 23, 101412. [Google Scholar] [CrossRef] [PubMed]
- Hitelman, A.; Edan, Y.; Godo, A.; Berenstein, R.; Lepar, J.; Halachmi, I. Biometric identification of sheep via a machine-vision system. Comput. Electron. Agric. 2022, 194, 106713. [Google Scholar] [CrossRef]
- Li, X.; Xiang, Y.; Li, S. Combining convolutional and vision transformer structures for sheep face recognition. Comput. Electron. Agric. 2023, 205, 107651. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. The role of context in object recognition. Trends Cogn. Sci. 2007, 11, 520–527. [Google Scholar] [CrossRef] [PubMed]
- Leng, J.; Ren, Y.; Jiang, W.; Sun, X.; Wang, Y. Realize Your Surroundings: Exploiting Context Information for Small Object Detection. Neurocomputing 2021, 433, 287–299. [Google Scholar] [CrossRef]
- Lim, J.S.; Astrid, M.; Yoon, H.; Lee, S.I. Small Object Detection using Context and Attention. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 13–16 April 2021; pp. 181–186. [Google Scholar]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual Generative Adversarial Networks for Small Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1951–1959. [Google Scholar]
- Liu, G.; Han, J.; Rong, W. Feedback-driven loss function for small object detection. Image Vis. Comput. 2021, 111, 104197. [Google Scholar] [CrossRef]
- Robicquet, A.; Sadeghian, A.; Alahi, A.; Savarese, S. Learning Social Etiquette: Human Trajectory Understanding in Crowded Scenes; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Wang, J.; Yang, W.; Guo, H.; Zhang, R.; Xia, G.S. Tiny Object Detection in Aerial Images. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. WIDER FACE: A Face Detection Benchmark. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5525–5533. [Google Scholar]
- Ji, Z.; Kong, Q.; Wang, H.; Pang, Y. Small and Dense Commodity Object Detection with Multi-Scale Receptive Field Attention. In Proceedings of the 27th ACM International Conference, Nice, France, 21–25 October 2019. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Yifu, Z.; Wong, C.; Montes, D.; et al. Ultralytics/YOLOv5: V7. 0-YOLOv5 SOTA Realtime Instance Segmentation; Zenodo: Geneva, Switzerland, 2022. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 9–11 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Du, S.; Zhang, B.; Zhang, P.; Xiang, P. An improved bounding box regression loss function based on CIOU loss for multi-scale object detection. In Proceedings of the 2021 IEEE 2nd International Conference on Pattern Recognition and Machine Learning (PRML), Chengdu, China, 16–18 July 2021; pp. 92–98. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. arXiv 2020, arXiv:1710.09412. [Google Scholar]
- Zhang, X.; Xuan, C.; Xue, J.; Chen, B.; Ma, Y. LSR-YOLO: A High-Precision, Lightweight Model for Sheep Face Recognition on the Mobile End. Animals 2023, 13, 1824. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection; 2019. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6569–6578. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 6569–6578. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | P (%) | R (%) | F1 | AP (%) |
|---|---|---|---|---|
| CenterNet [31] | 88.02 | 52.36 | 0.66 | 71.51 |
| EfficientDet [32] | 95.55 | 22.0 | 0.36 | 39.77 |
| SSD [33] | 89.45 | 47.42 | 0.57 | 57.28 |
| FASSD [11] | 98.41 | 21.9 | 0.35 | 36.36 |
| FCOS [34] | 84.80 | 63.56 | 0.73 | 74.69 |
| RetinaNet [35] | 94.37 | 17.55 | 0.30 | 31.40 |
| YOLOV5 [21] | 84.47 | 51.22 | 0.63 | 63.45 |
| YOLOV7 [20] | 85.71 | 69.13 | 0.77 | 77.9 |
| Ours | 90.42 | 75.93 | 0.83 | 85.97 |
| Module | P | R | F1 | AP | Average |
|---|---|---|---|---|---|
| CenterNet [31] | 3 | 4 | 4 | 4 | 3.75 |
| SSD [33] | 2 | 6 | 6 | 6 | 5 |
| FCOS [34] | 5 | 3 | 3 | 3 | 3.5 |
| YOLOV5 [21] | 6 | 5 | 5 | 5 | 5.25 |
| YOLOV7 [20] | 4 | 2 | 2 | 2 | 2.5 |
| Ours | 1 | 1 | 1 | 1 | 1 |
| Module | P (%) | R (%) | F1 | AP (%) |
|---|---|---|---|---|
| CenterNet [31] | 88.62 | 53.70 | 0.67 | 72.83 |
| EfficientDet [32] | 95.60 | 24.57 | 0.39 | 42.13 |
| SSD [33] | 88.02 | 49.48 | 0.63 | 71.73 |
| FASSD [11] | 92.41 | 31.17 | 0.46 | 48.52 |
| FCOS [34] | 93.02 | 90.03 | 0.92 | 94.04 |
| RetinaNet [35] | 94.69 | 19.85 | 0.33 | 33.79 |
| YOLOV5 [21] | 90.76 | 76.73 | 0.83 | 86.51 |
| YOLOV7 [20] | 95.13 | 89.47 | 0.94 | 95.72 |
| Ours | 94.52 | 88.75 | 0.92 | 94.59 |
| Module | P | R | F1 | AP | Average |
|---|---|---|---|---|---|
| CenterNet [31] | 6 | 5 | 5 | 5 | 5.25 |
| SSD [33] | 5 | 6 | 6 | 6 | 5.75 |
| FCOS [34] | 3 | 1 | 2.5 | 3 | 2.375 |
| YOLOV5 [21] | 4 | 4 | 4 | 4 | 4 |
| YOLOV7 [20] | 1 | 2 | 1 | 1 | 1.25 |
| Ours | 2 | 3 | 2.5 | 2 | 2.375 |
| Module | P(%) | R(%) | F1 | AP(%) |
|---|---|---|---|---|
| backbone | 85.71 | 69.13 | 0.77 | 77.9 |
| backbone + CIDM | 88.78 | 73.17 | 0.8 | 81.42 |
| backbone + FCM | 88.84 | 74.22 | 0.82 | 83.63 |
| backbone + CIDM + FCM | 90.42 | 75.93 | 0.83 | 85.97 |
| Module | P | R | F1 | AP | Average |
|---|---|---|---|---|---|
| backbone | 4 | 4 | 4 | 4 | 4 |
| backbone + CIDM | 3 | 3 | 3 | 3 | 3 |
| backbone + FCM | 2 | 2 | 2 | 2 | 2 |
| backbone + CIDM + FCM | 1 | 1 | 1 | 1 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Han, D.; Wang, L.; Guo, Y.; Du, H. Contextualized Small Target Detection Network for Small Target Goat Face Detection. Animals 2023, 13, 2365. https://doi.org/10.3390/ani13142365
Wang Y, Han D, Wang L, Guo Y, Du H. Contextualized Small Target Detection Network for Small Target Goat Face Detection. Animals. 2023; 13(14):2365. https://doi.org/10.3390/ani13142365
Chicago/Turabian StyleWang, Yaxin, Ding Han, Liang Wang, Ying Guo, and Hongwei Du. 2023. "Contextualized Small Target Detection Network for Small Target Goat Face Detection" Animals 13, no. 14: 2365. https://doi.org/10.3390/ani13142365
APA StyleWang, Y., Han, D., Wang, L., Guo, Y., & Du, H. (2023). Contextualized Small Target Detection Network for Small Target Goat Face Detection. Animals, 13(14), 2365. https://doi.org/10.3390/ani13142365