
Cartesian Stiffness Shaping of Compliant Robots—Incremental Learning and Optimization Based on Sequential Quadratic Programming


Abstract
1. Introduction
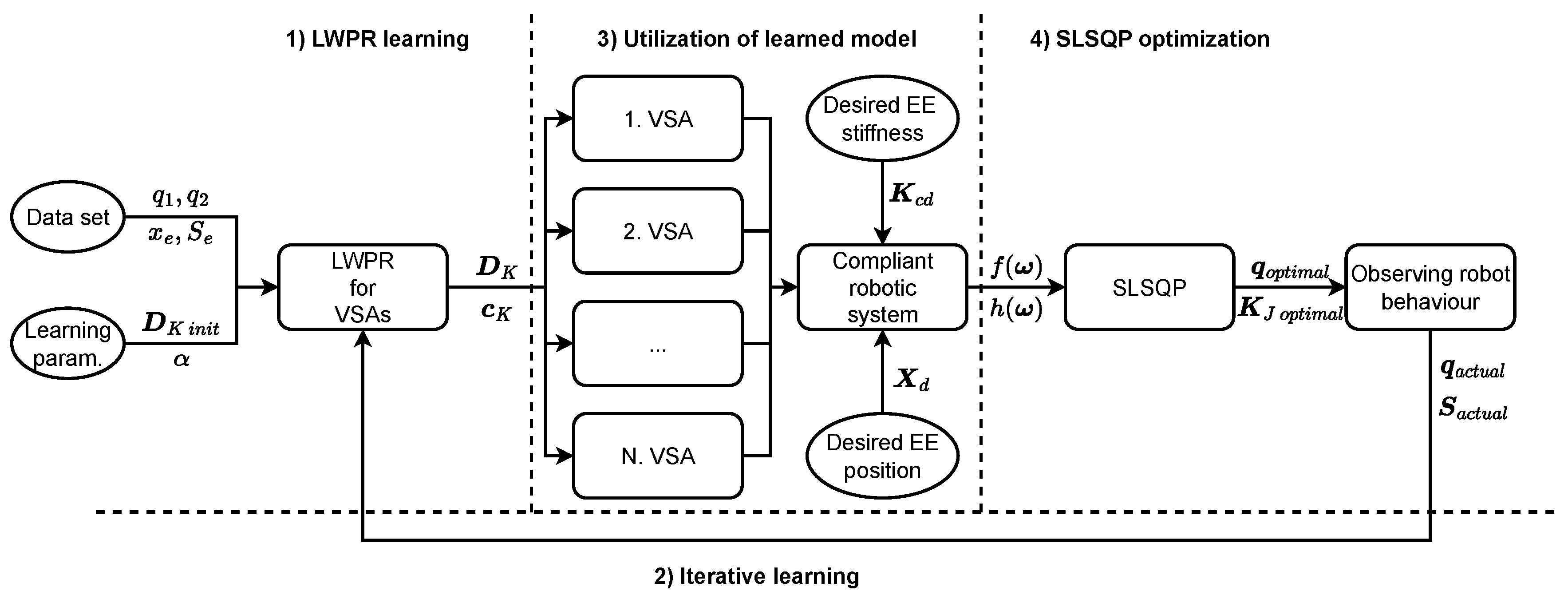
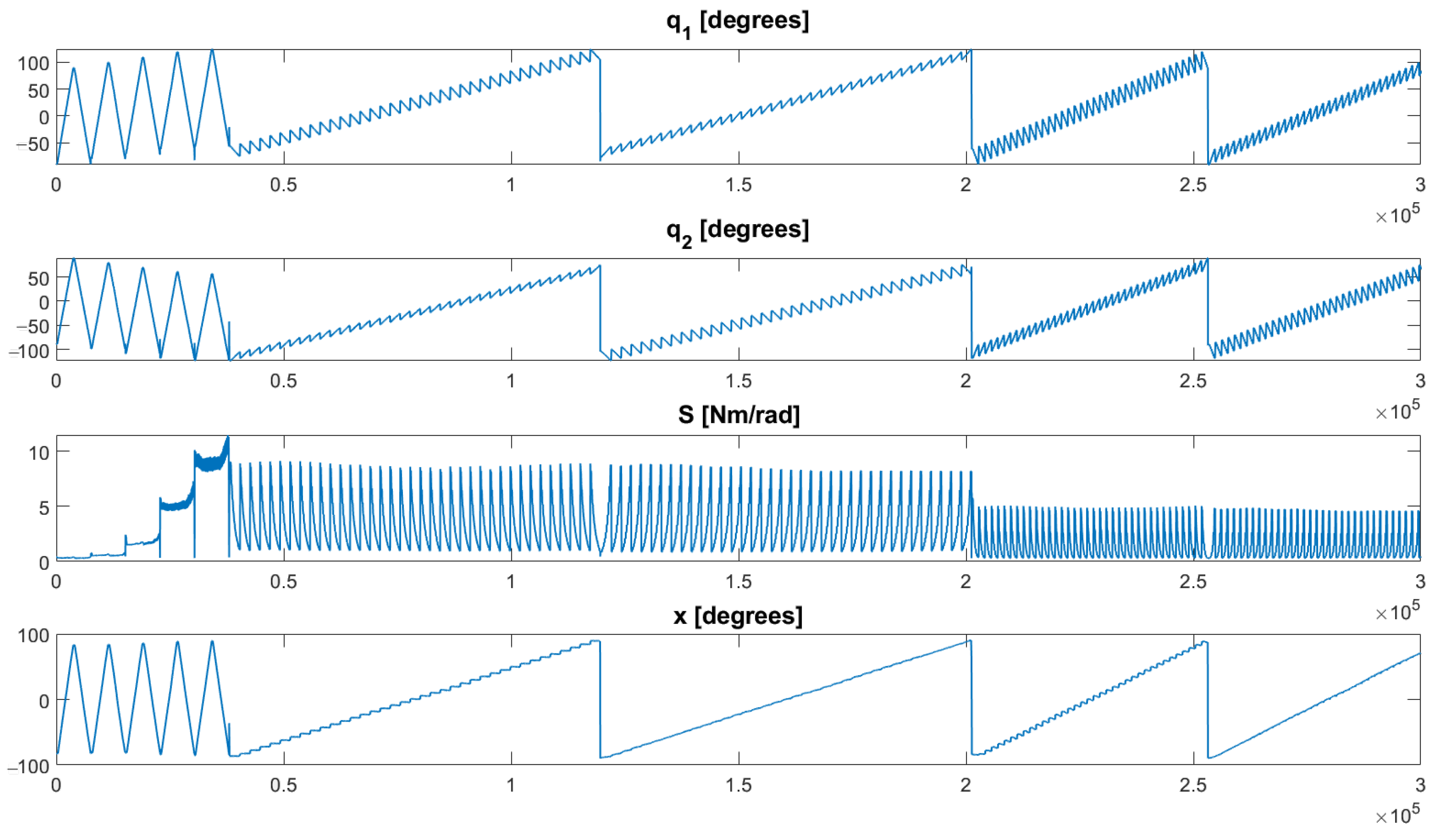
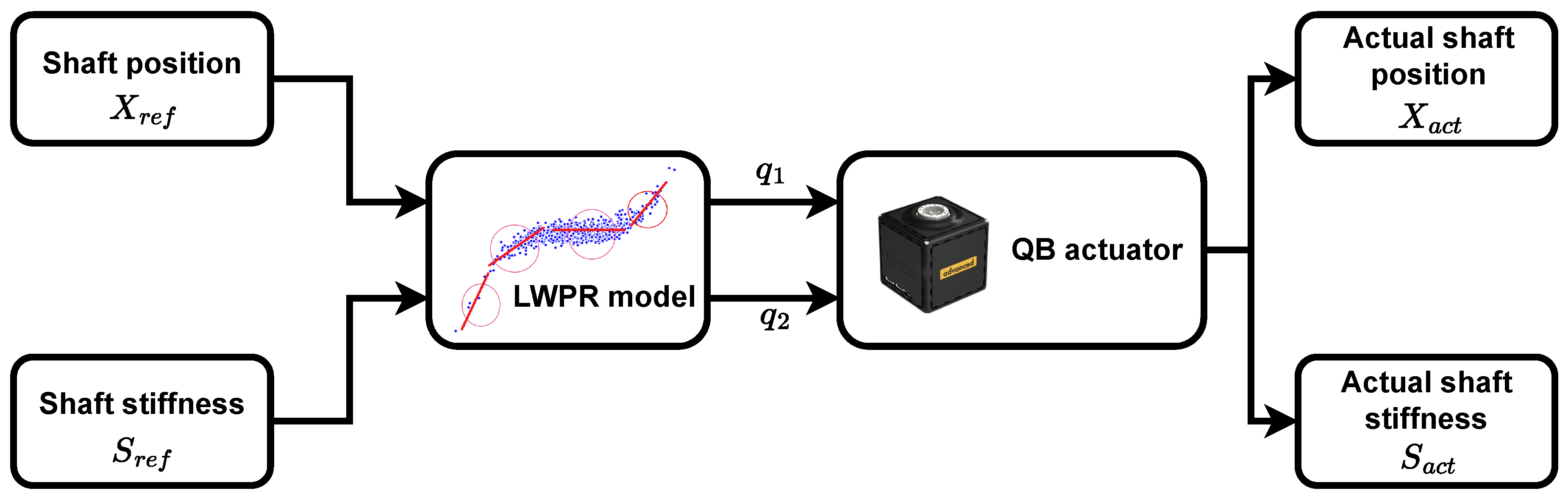
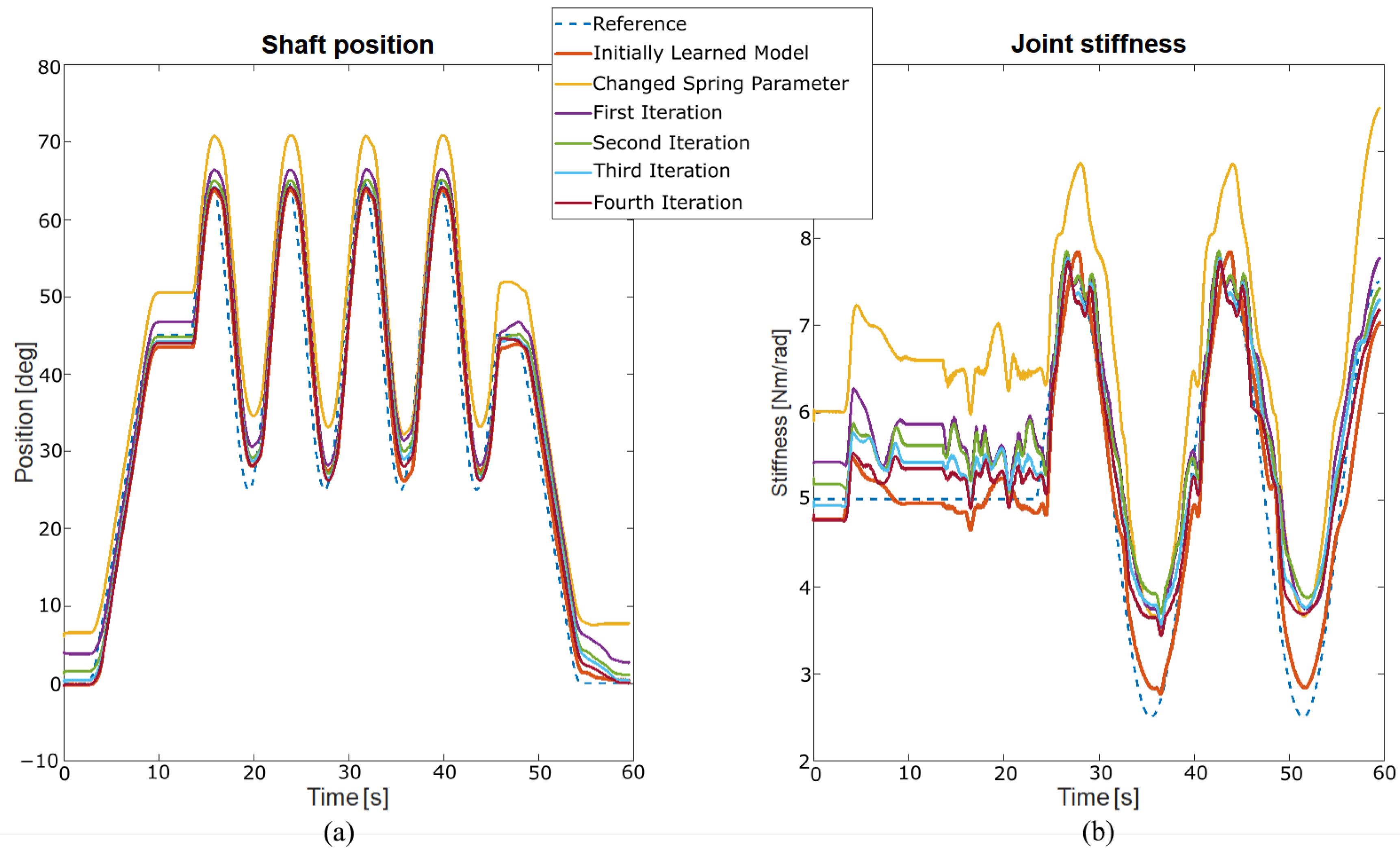
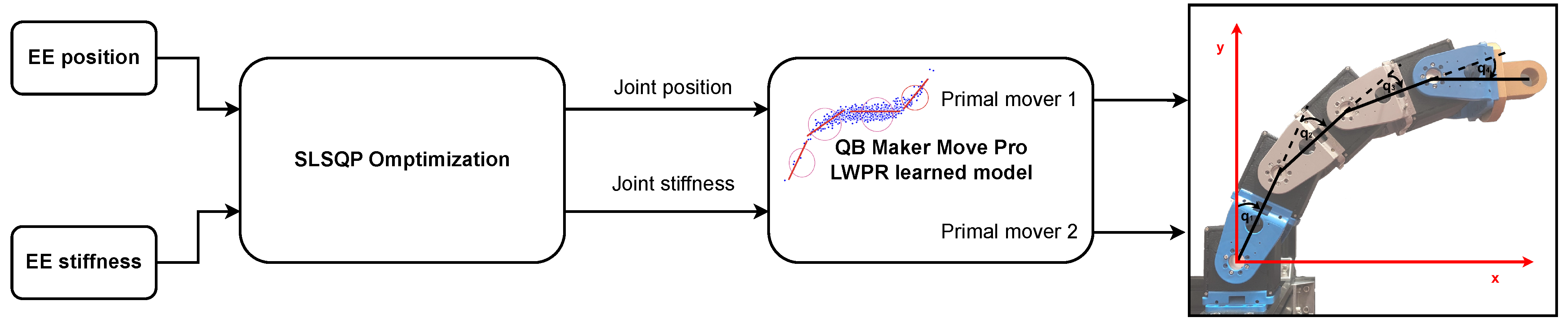
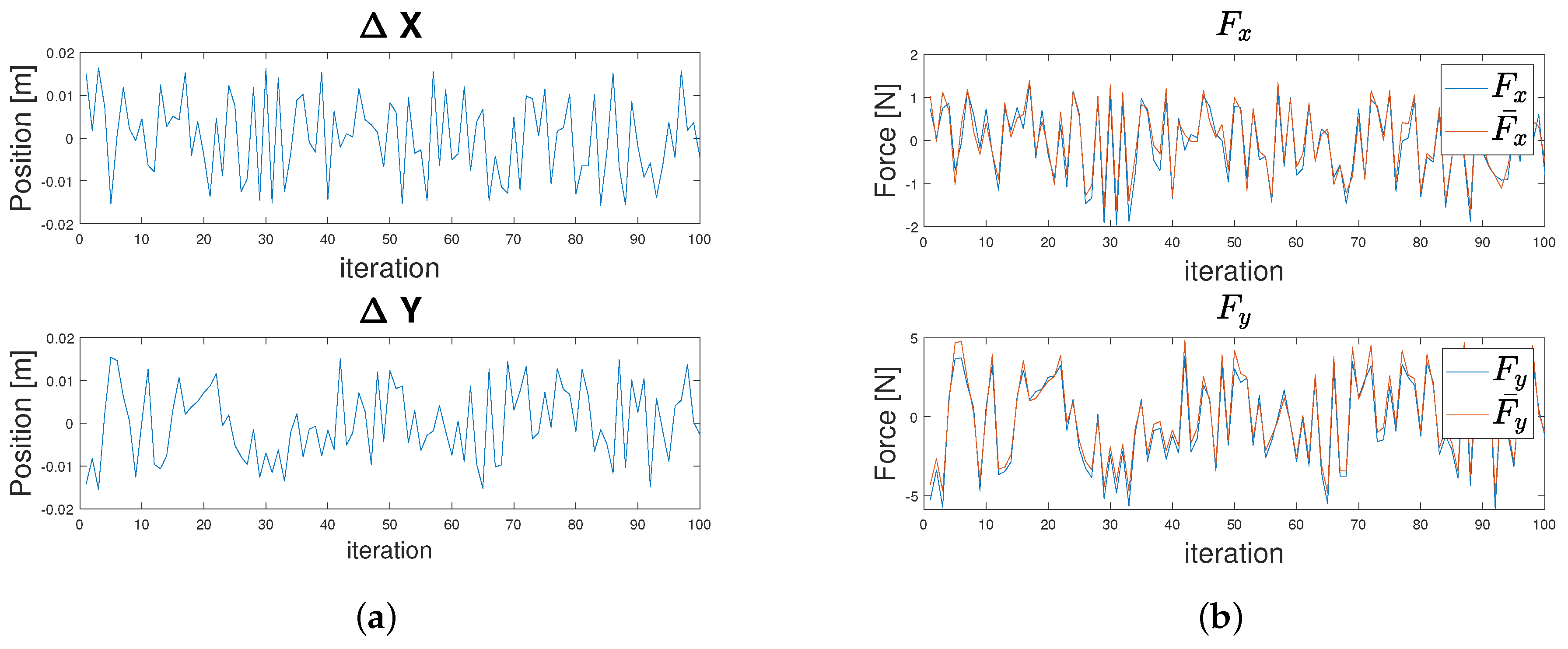
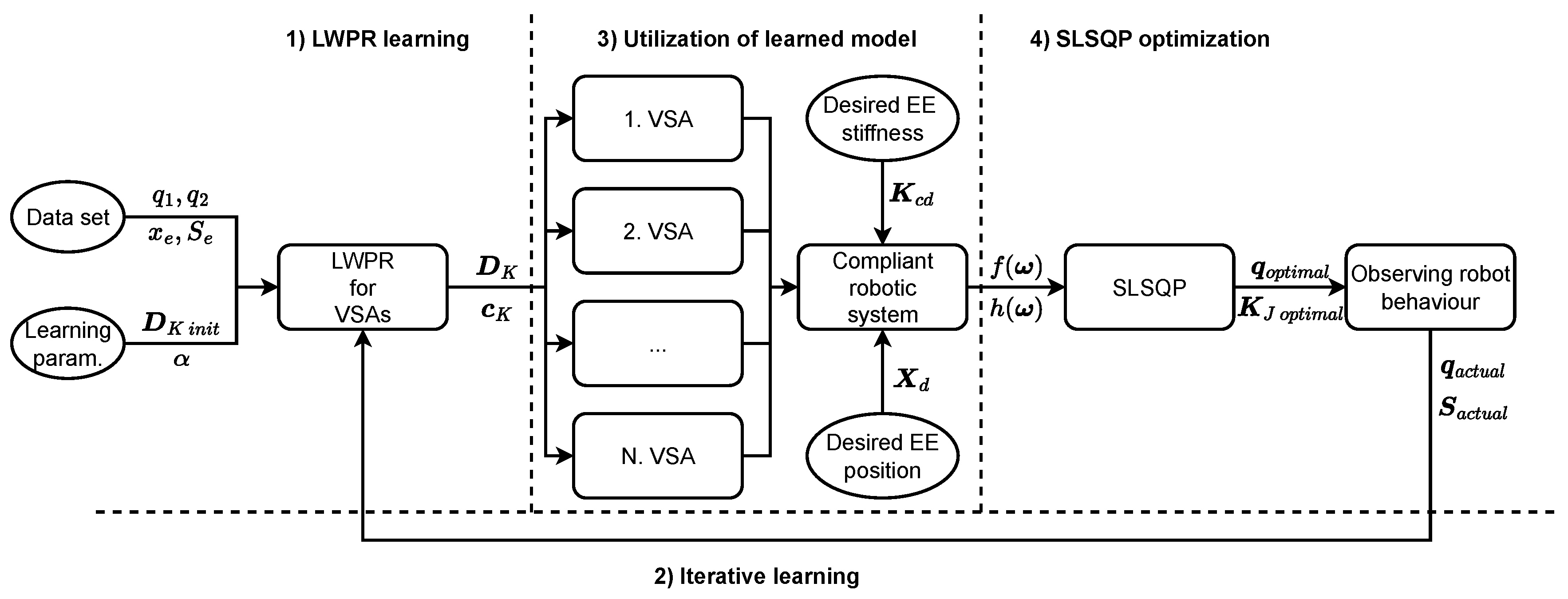
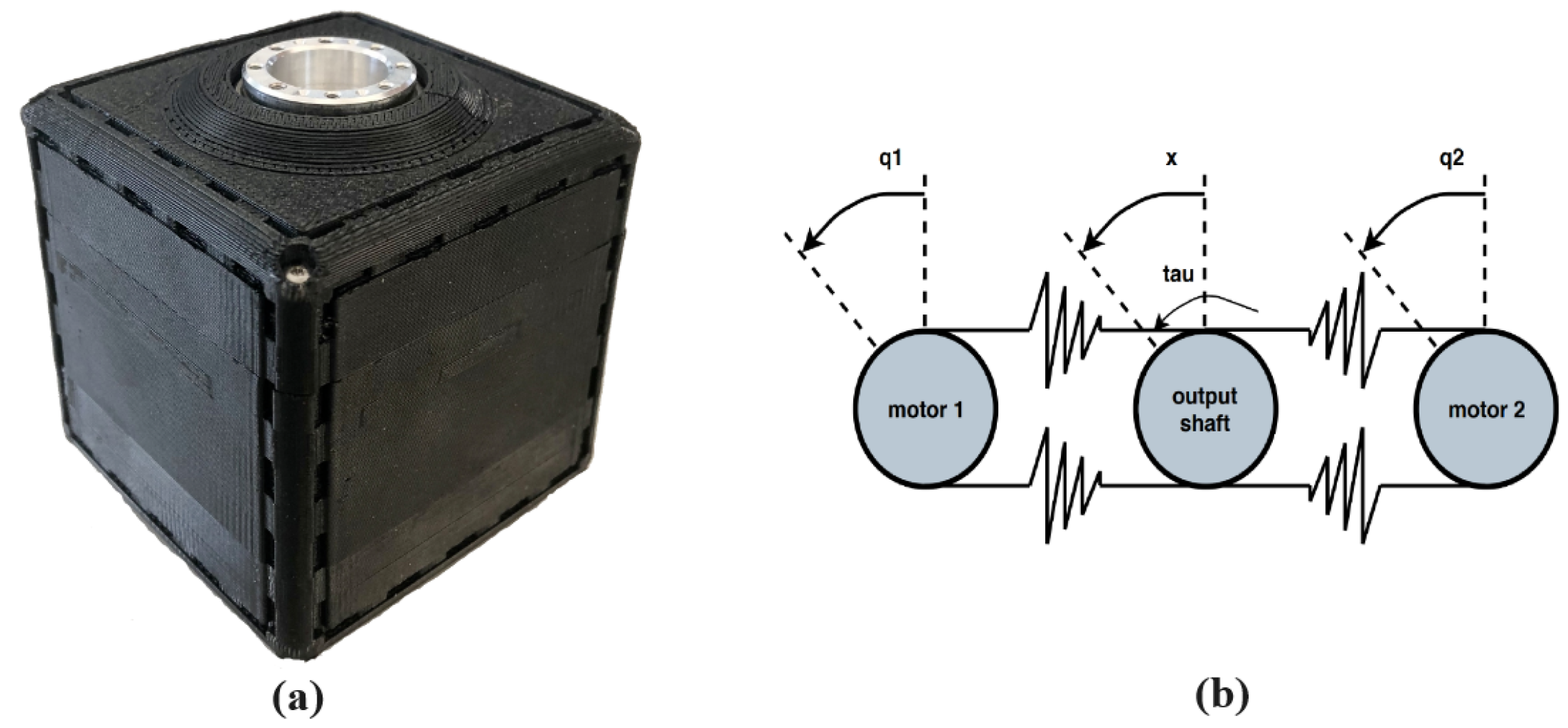
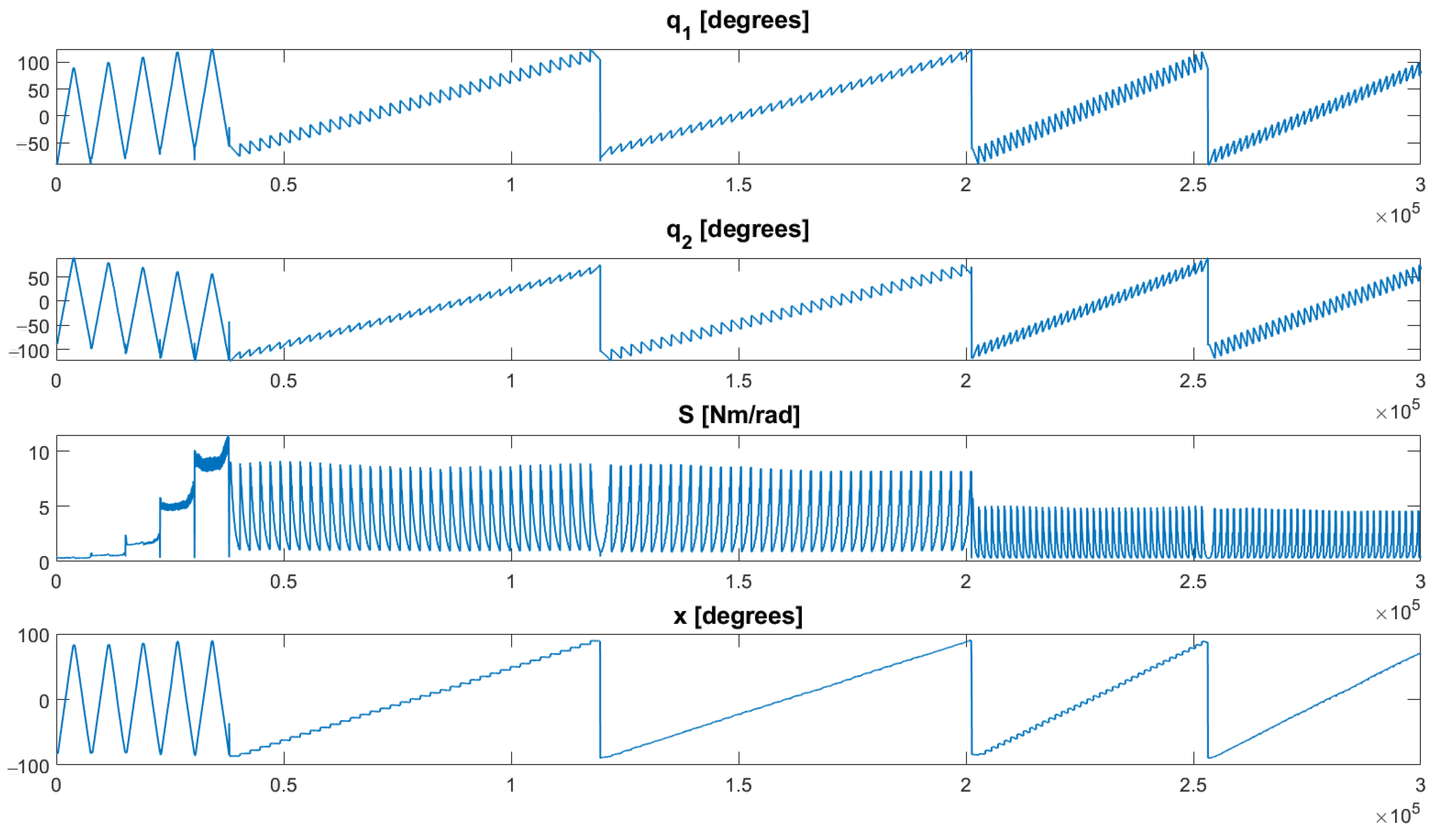
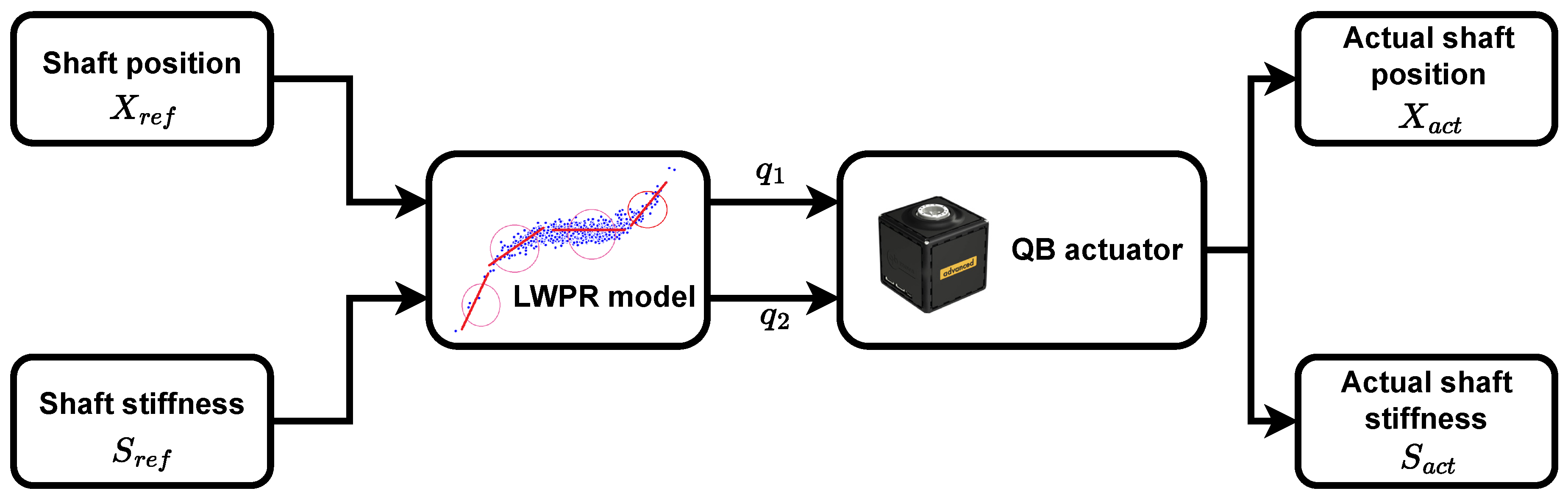
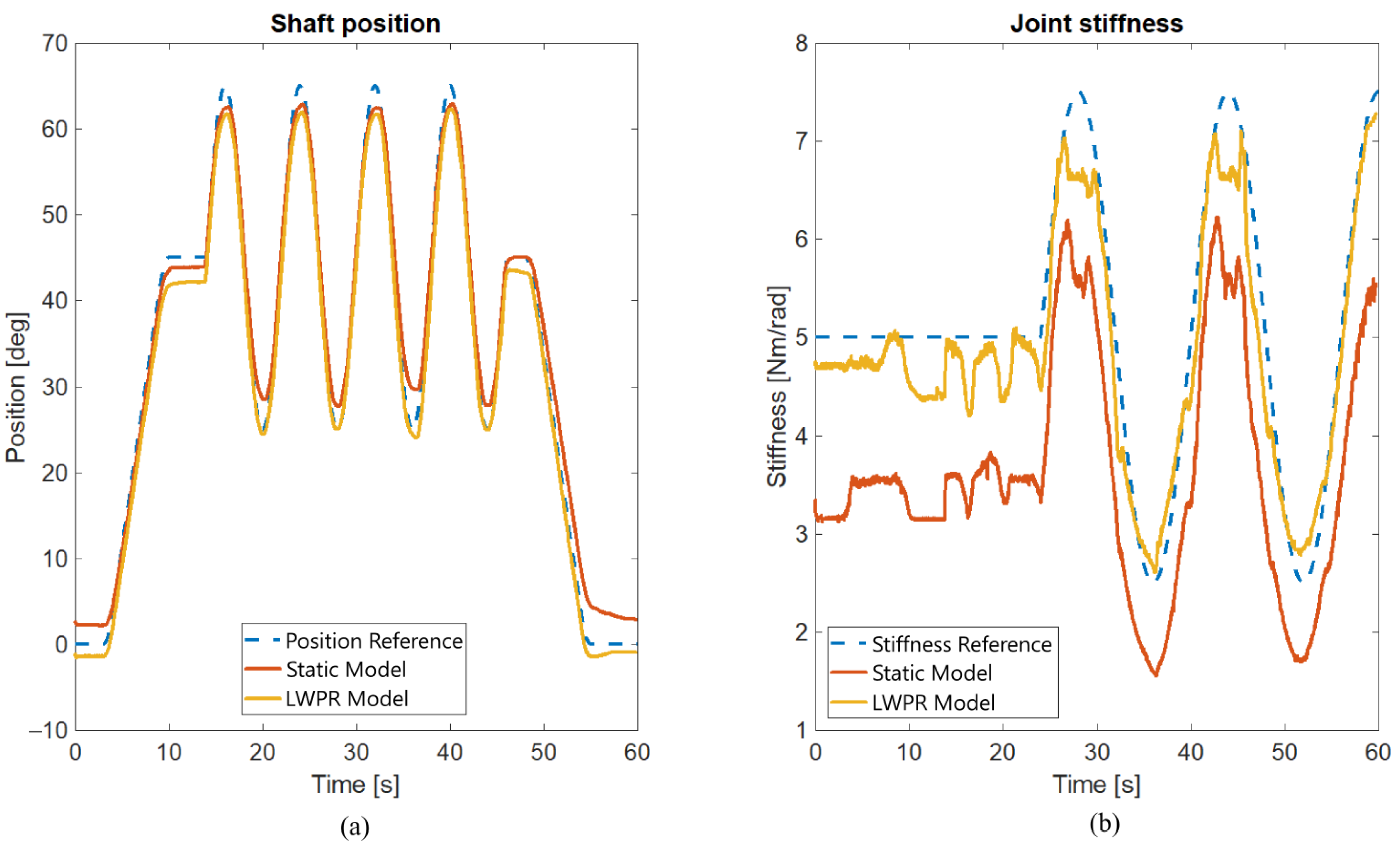
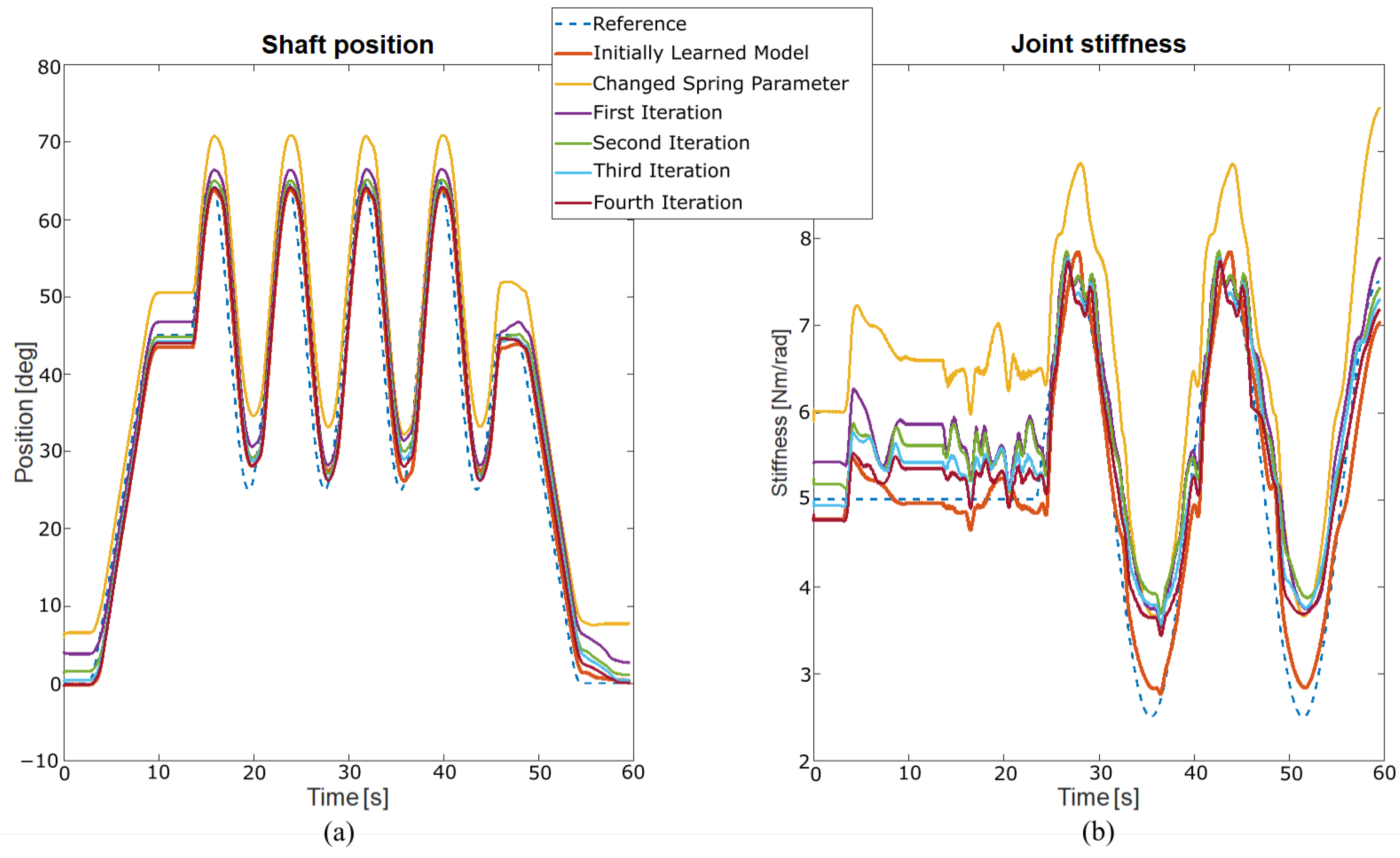
2. Learning a Variable Stiffness Actuator Model
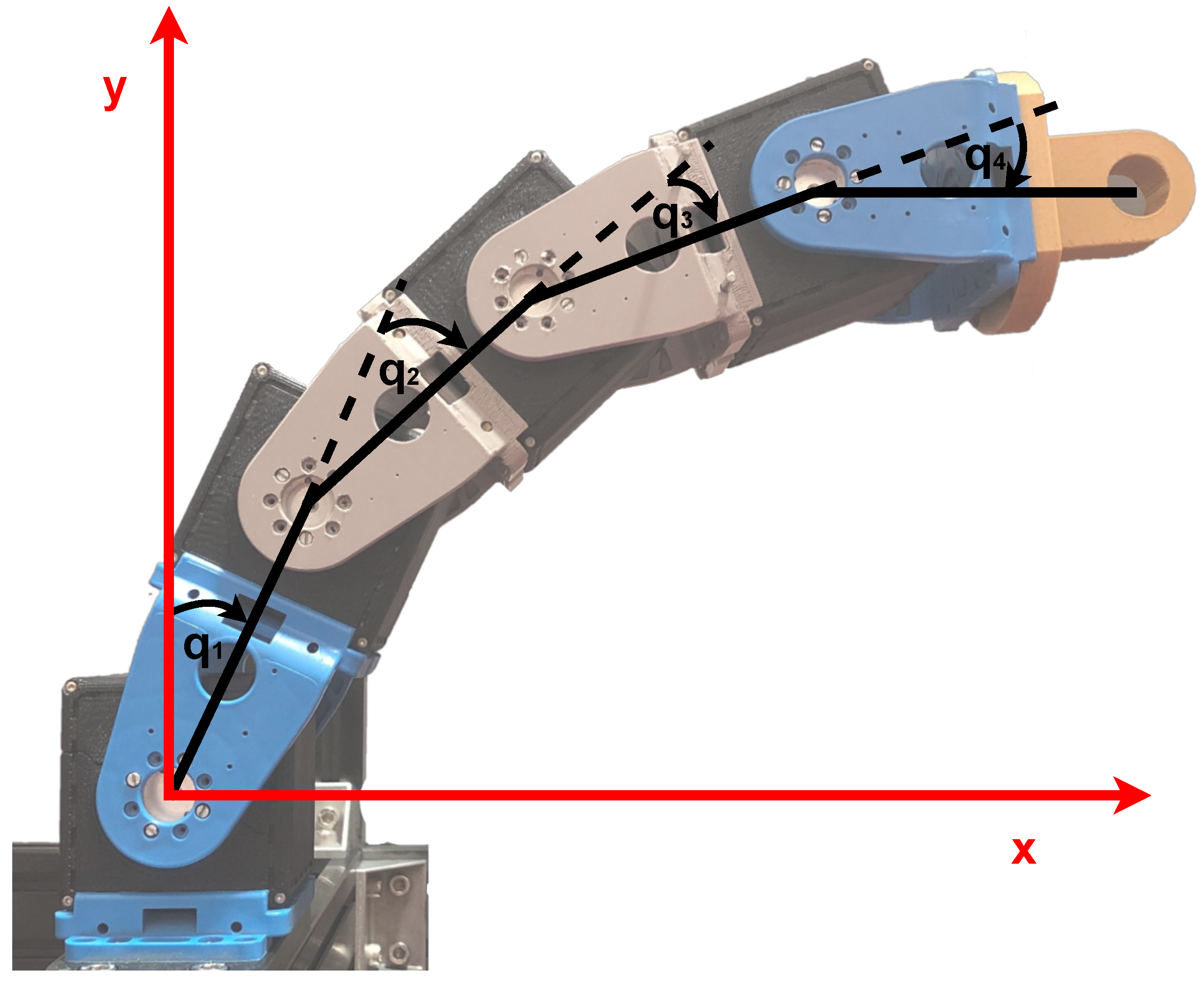
3. Planning End-Effector Cartesian Stiffness
3.1. Optimization over One Axis
3.2. Multiple Axis Optimization
3.3. Favoring One of the Axes
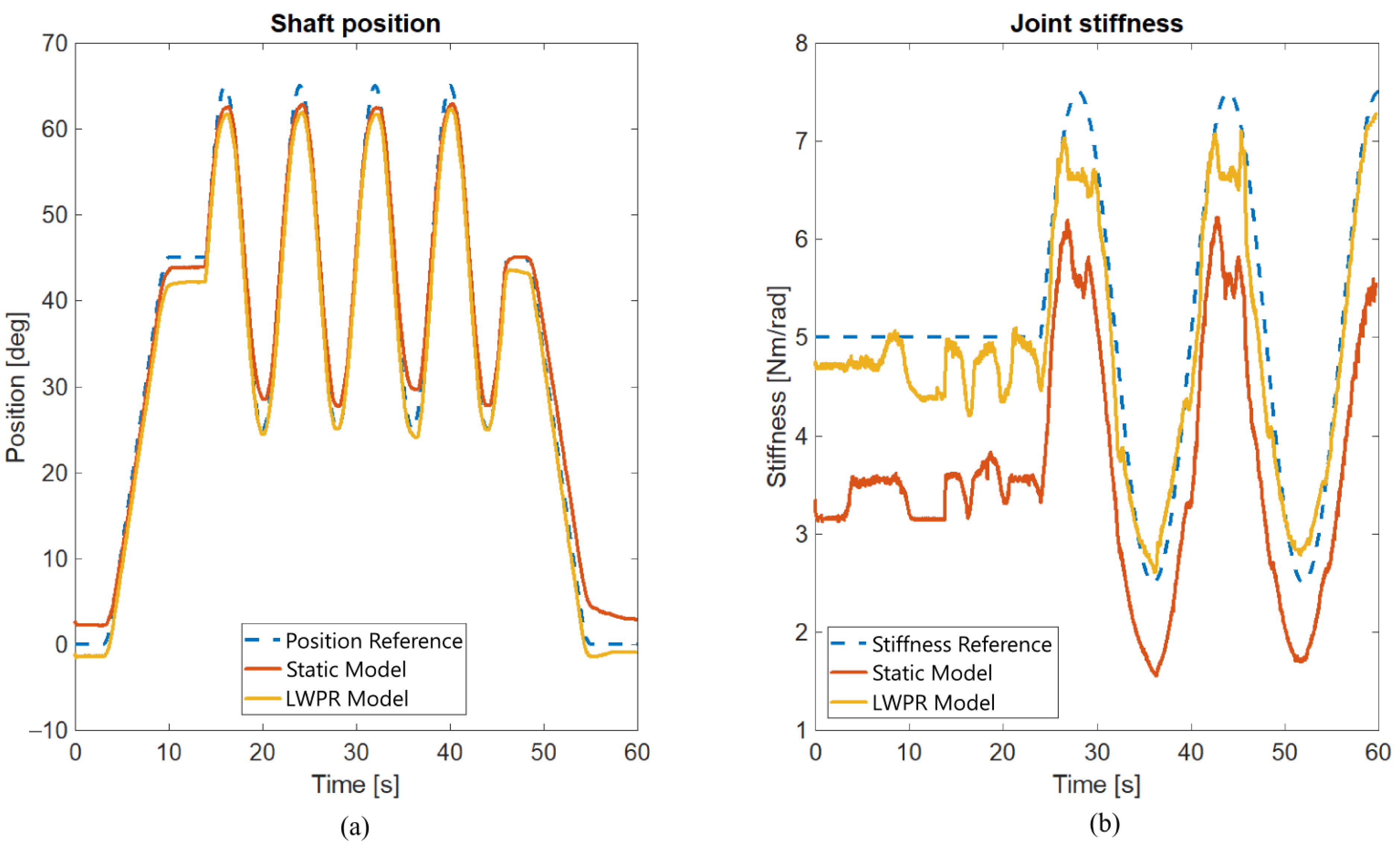
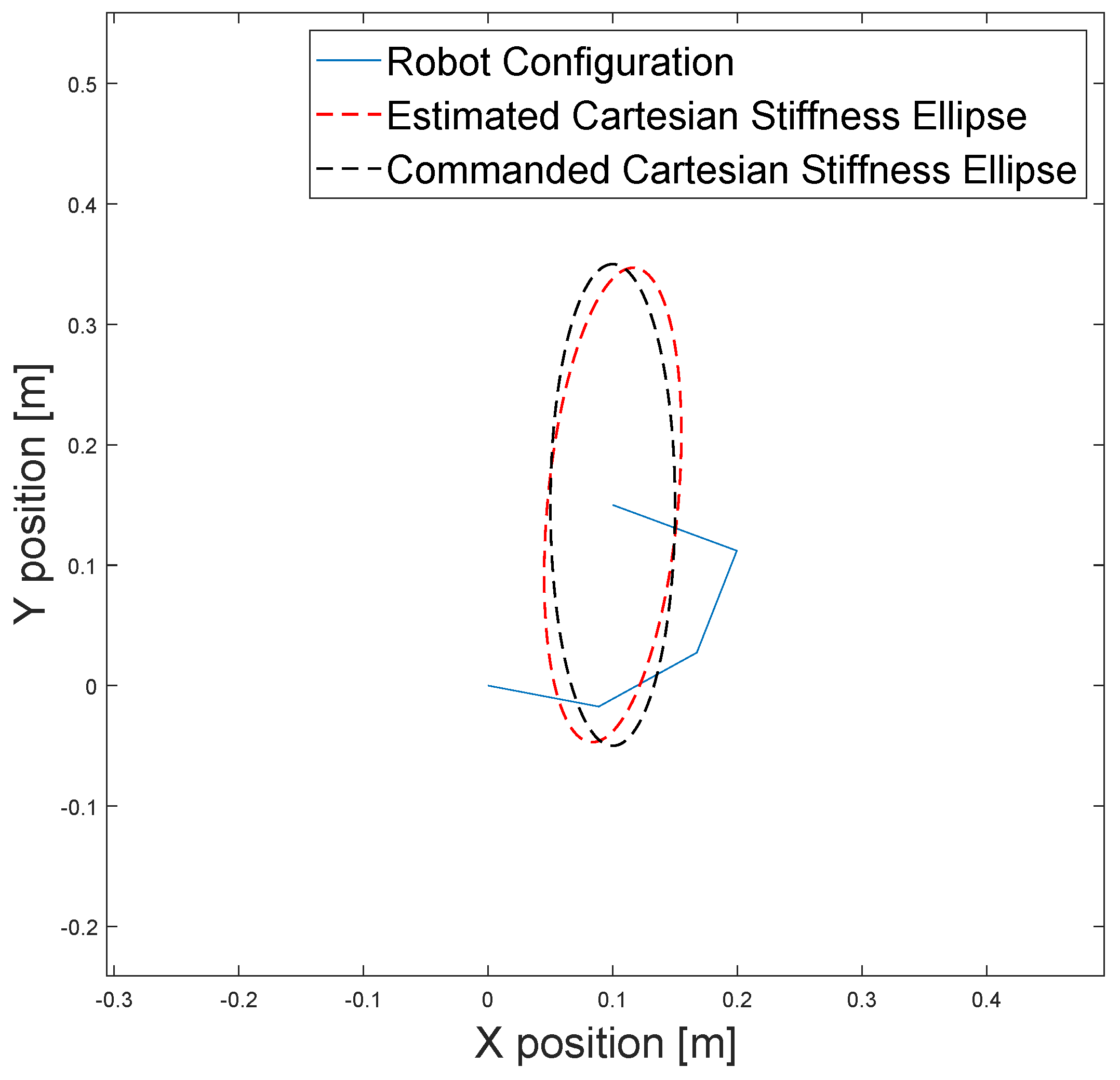
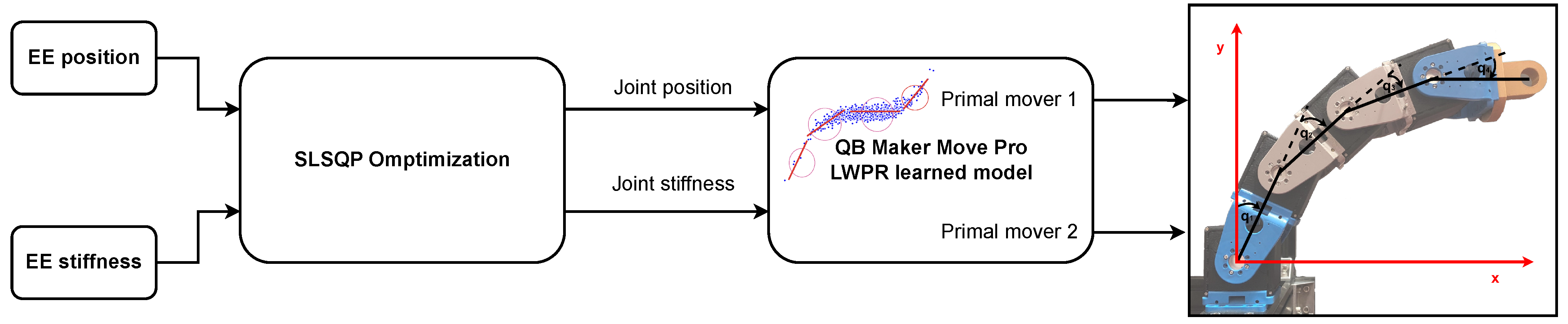
4. Experimental Validation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| VSA | Variable Stiffness Actuator |
| LWPR | Locally Weighted Projection Regression |
| DoF | Degrees of Freedom |
| EE | End Effector |
| SLSQP | Sequential Least Squares Programming |
References
- Peshkin, M.A.; Colgate, J.E.; Wannasuphoprasit, W.; Moore, C.A.; Gillespie, R.B.; Akella, P. Cobot architecture. IEEE Trans. Robot. Autom. 2001, 17, 377–390. [Google Scholar] [CrossRef]
- Haddadin, S.; Albu-Schaffer, A.; De Luca, A.; Hirzinger, G. Collision Detection and Reaction: A Contribution to Safe Physical Human-Robot Interaction. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 3356–3363. [Google Scholar] [CrossRef]
- Bicchi, A.; Tonietti, G.; Bavaro, M.; Piccigallo, M. Variable Stiffness Actuators for Fast and Safe Motion Control. In Robotics Research. The Eleventh International Symposium; Dario, P., Chatila, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 527–536. [Google Scholar]
- Visser, L.C.; Stramigioli, S.; Bicchi, A. Embodying Desired Behavior in Variable Stiffness Actuators. IFAC Proc. Vol. 2011, 44, 9733–9738. [Google Scholar] [CrossRef]
- Haddadin, S.; Weis, M.; Wolf, S.; Albu-Schäffer, A. Optimal Control for Maximizing Link Velocity of Robotic Variable Stiffness Joints. IFAC Proc. Vol. 2011, 44, 6863–6871. [Google Scholar] [CrossRef]
- Garabini, M.; Passaglia, A.; Belo, F.; Salaris, P.; Bicchi, A. Optimality principles in variable stiffness control: The VSA hammer. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 3770–3775. [Google Scholar] [CrossRef]
- Logozzo, S.; Malvezzi, M.; Achilli, G.; Valigi, M. Characterization of finger joints with underactuated modular structure. Mater. Res. Proc. 2022, 26, 201. [Google Scholar]
- Pratt, G.A.; Williamson, M.M. Series elastic actuators. In Proceedings of the 1995 IEEE/RSJ International Conference on Intelligent Robots and Systems. Human Robot Interaction and Cooperative Robots, Pittsburgh, PA, USA, 5–9 August 1995; Volume 1, pp. 399–406. [Google Scholar] [CrossRef]
- Junior, A.G.L.; de Andrade, R.M.; Filho, A.B. Series Elastic Actuator: Design, Analysis and Comparison. In Recent Advances in Robotic Systems; IntechOpen: Rijeka, Croatia, 2016; Chapter 10. [Google Scholar] [CrossRef]
- Petit, F.; Chalon, M.; Friedl, W.; Grebenstein, M.; Albu-Schäffer, A.; Hirzinger, G. Bidirectional antagonistic variable stiffness actuation: Analysis, design Implementation. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 4189–4196. [Google Scholar] [CrossRef]
- Buondonno, G.; De Luca, A. Efficient Computation of Inverse Dynamics and Feedback Linearization for VSA-Based Robots. IEEE Robot. Autom. Lett. 2016, 1, 908–915. [Google Scholar] [CrossRef]
- Trumić, M.; Jovanović, K.; Fagiolini, A. Decoupled nonlinear adaptive control of position and stiffness for pneumatic soft robots. Int. J. Robot. Res. 2021, 40, 277–295. [Google Scholar] [CrossRef]
- Palli, G.; Melchiorri, C.; De Luca, A. On the Feedback Linearization of Robots with Variable Joint Stiffness. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008; pp. 1753–1759. [Google Scholar] [CrossRef]
- Potkonjak, V.; Svetozarevic, B.; Jovanovic, K.; Holland, O. The Puller-Follower Control of Compliant and Noncompliant Antagonistic Tendon Drives in Robotic Systems. Int. J. Adv. Robot. Syst. 2011, 8, 69. [Google Scholar] [CrossRef]
- Lukić, B.; Jovanović, K.; Šekara, T.B. Cascade Control of Antagonistic VSA—An Engineering Control Approach to a Bioinspired Robot Actuator. Front. Neurorobot. 2019, 13, 69. [Google Scholar] [CrossRef]
- Weerasooriya, S.; El-Sharkawi, M. Identification and control of a DC motor using back-propagation neural networks. IEEE Trans. Energy Convers. 1991, 6, 663–669. [Google Scholar] [CrossRef]
- Ismeal, G.A.; Kyslan, K.; Fedák, V. DC motor identification based on Recurrent Neural Networks. In Proceedings of the 16th International Conference on Mechatronics–Mechatronika 2014, Brno, Czech Republic, 3–5 December 2014; pp. 701–705. [Google Scholar] [CrossRef]
- Rubaai, A.; Kotaru, R. Online identification and control of a DC motor using learning adaptation of neural networks. IEEE Trans. Ind. Appl. 2000, 36, 935–942. [Google Scholar] [CrossRef]
- Gautier, M.; Jubien, A.; Janot, A. New iterative learning identification and model based control of robots using only actual motor torque data. In Proceedings of the 2013 IEEE/ASME International Conference on Advanced Intelligent Mechatronics, Wollongong, NSW, Australia, 9–12 July 2013; pp. 1436–1441. [Google Scholar] [CrossRef]
- Ono, S.; Masuya, K.; Takagi, K.; Tahara, K. Trajectory tracking of a one-DOF manipulator using multiple fishing line actuators by iterative learning control. In Proceedings of the 2018 IEEE International Conference on Soft Robotics (RoboSoft), Livorno, Italy, 24–28 April 2018; pp. 467–472. [Google Scholar]
- Angelini, F.; Santina, C.D.; Garabini, M.; Bianchi, M.; Gasparri, G.M.; Grioli, G.; Catalano, M.G.; Bicchi, A. Decentralized Trajectory Tracking Control for Soft Robots Interacting With the Environment. IEEE Trans. Robot. 2018, 34, 924–935. [Google Scholar] [CrossRef]
- Angelini, F.; Mengacci, R.; Santina, C.D.; Catalano, M.G.; Garabini, M.; Bicchi, A.; Grioli, G. Time Generalization of Trajectories Learned on Articulated Soft Robots. IEEE Robot. Autom. Lett. 2020, 5, 3493–3500. [Google Scholar] [CrossRef]
- Della Santina, C.; Bianchi, M.; Grioli, G.; Angelini, F.; Catalano, M.; Garabini, M.; Bicchi, A. Controlling Soft Robots: Balancing Feedback and Feedforward Elements. IEEE Robot. Autom. Mag. 2017, 24, 75–83. [Google Scholar] [CrossRef]
- Huh, S.; Tonietti, G.; Bicchi, A. Neural Network based Robust Adaptive Control for a Variable Stiffness Actuator. In Proceedings of the 2008 16th Mediterranean Conference on Control and Automation, Ajaccio, France, 25–27 June 2008; pp. 1028–1034. [Google Scholar]
- Guo, Z.; Pan, Y.; Sun, T.; Zhang, Y.; Xiao, X. Adaptive Neural Network Control of Serial Variable Stiffness Actuators. Complexity 2017, 2017, 1–9. [Google Scholar] [CrossRef]
- Cremer, S.; Das, S.K.; Wijayasinghe, I.B.; Popa, D.O.; Lewis, F.L. Model-Free Online Neuroadaptive Controller with Intent Estimation for Physical Human–Robot Interaction. IEEE Trans. Robot. 2020, 36, 240–253. [Google Scholar] [CrossRef]
- Buchli, J.; Stulp, F.; Theodorou, E.; Schaal, S. Learning variable impedance control. Int. J. Robot. Res. 2011, 30, 820–833. [Google Scholar] [CrossRef]
- Thuruthel, T.G.; Falotico, E.; Renda, F.; Laschi, C. Model-Based Reinforcement Learning for Closed-Loop Dynamic Control of Soft Robotic Manipulators. IEEE Trans. Robot. 2019, 35, 124–134. [Google Scholar] [CrossRef]
- Yang, Q.; Dürr, A.; Topp, E.A.; Stork, J.A.; Stoyanov, T. Variable Impedance Skill Learning for Contact-Rich Manipulation. IEEE Robot. Autom. Lett. 2022, 7, 8391–8398. [Google Scholar] [CrossRef]
- Kronander, K.; Billard, A. Online learning of varying stiffness through physical human-robot interaction. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 1842–1849. [Google Scholar] [CrossRef]
- Keemink, A.Q.; van der Kooij, H.; Stienen, A.H. Admittance control for physical human–robot interaction. Int. J. Robot. Res. 2018, 37, 1421–1444. [Google Scholar] [CrossRef]
- Sadeghian, H.; Villani, L.; Keshmiri, M.; Siciliano, B. Task-Space Control of Robot Manipulators With Null-Space Compliance. IEEE Trans. Robot. 2014, 30, 493–506. [Google Scholar] [CrossRef]
- Guo, Y.; Dong, H.; Ke, Y. Stiffness-oriented posture optimization in robotic machining applications. Robot. Comput.-Integr. Manuf. 2015, 35, 69–76. [Google Scholar] [CrossRef]
- Lukić, B.; Jovanović, K.; Žlajpah, L.; Petrič, T. Online Cartesian Compliance Shaping of Redundant Robots in Assembly Tasks. Machines 2023, 11, 35. [Google Scholar] [CrossRef]
- Ajoudani, A.; Tsagarakis, N.G.; Bicchi, A. On the role of robot configuration in Cartesian stiffness control. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1010–1016. [Google Scholar]
- Celikag, H.; Sims, N.D.; Ozturk, E. Cartesian Stiffness Optimization for Serial Arm Robots. Procedia CIRP 2018, 77, 566–569. [Google Scholar] [CrossRef]
- Petit, F.; Albu-Schäffer, A. Cartesian impedance control for a variable stiffness robot arm. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 4180–4186. [Google Scholar]
- Petit, F.P. Analysis and Control of Variable Stiffness Robots. Ph.D. Thesis, ETH Zurich, Zürich, Switzerland, 2014. [Google Scholar] [CrossRef]
- Roveda, L. Adaptive interaction controller for compliant robot base applications. IEEE Access 2018, 7, 6553–6561. [Google Scholar] [CrossRef]
- Masinga, P.; Campbell, H.; Trimble, J.A. A framework for human collaborative robots, operations in South African automotive industry. In Proceedings of the 2015 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Singapore, 6–9 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1494–1497. [Google Scholar]
- Kana, S.; Lakshminarayanan, S.; Mohan, D.M.; Campolo, D. Impedance controlled human–robot collaborative tooling for edge chamfering and polishing applications. Robot. Comput.-Integr. Manuf. 2021, 72, 102199. [Google Scholar] [CrossRef]
- Zanchettin, A.M.; Rocco, P.; Robertsson, A.; Johansson, R. Exploiting task redundancy in industrial manipulators during drilling operations. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Cherubini, A.; Passama, R.; Crosnier, A.; Lasnier, A.; Fraisse, P. Collaborative manufacturing with physical human–robot interaction. Robot. Comput.-Integr. Manuf. 2016, 40, 1–13. [Google Scholar] [CrossRef]
- Surgical, I. da Vinci Surgical System. 2013. Available online: http://www.intusurg.com/html/davinci.html (accessed on 3 January 2024).
- Freschi, C.; Ferrari, V.; Melfi, F.; Ferrari, M.; Mosca, F.; Cuschieri, A. Technical review of the da Vinci surgical telemanipulator. Int. J. Med. Robot. Comput. Assist. Surg. 2013, 9, 396–406. [Google Scholar] [CrossRef] [PubMed]
- Burgner-Kahrs, J.; Rucker, D.C.; Choset, H. Continuum robots for medical applications: A survey. IEEE Trans. Robot. 2015, 31, 1261–1280. [Google Scholar] [CrossRef]
- Vijayakumar, S.; D’Souza, A.; Schaal, S. Incremental Online Learning in High Dimensions. Neural Comput. 2005, 17, 2602–2634. [Google Scholar] [CrossRef]
- Kraft, D. A Software Package for Sequential Quadratic Programming; Deutsche Forschungs- und Versuchsanstalt fur Luft- und Raumfahrt Koln: Köln, Germany, 1988; Forschungsbericht, Wiss. Berichtswesen d. DFVLR. [Google Scholar]
- Boggs, P.T.; Tolle, J.W. Sequential quadratic programming for large-scale nonlinear optimization. J. Comput. Appl. Math. 2000, 124, 123–137. [Google Scholar] [CrossRef]
- Chen, Y.; Ding, Y. Posture Optimization in Robotic Flat-End Milling Based on Sequential Quadratic Programming. J. Manuf. Sci. Eng. 2023, 145, 061001. [Google Scholar] [CrossRef]
- Usevitch, N.S.; Hammond, Z.M.; Schwager, M. Locomotion of Linear Actuator Robots Through Kinematic Planning and Nonlinear Optimization. IEEE Trans. Robot. 2020, 36, 1404–1421. [Google Scholar] [CrossRef]
- Mitrovic, D.; Klanke, S.; Vijayakumar, S. Learning impedance control of antagonistic systems based on stochastic optimization principles. Int. J. Robot. Res. 2011, 30, 556–573. [Google Scholar] [CrossRef]
- Schaal, S.; Atkeson, C.; Vijayakumar, S. Scalable Techniques from Nonparametric Statistics for Real Time Robot Learning. Appl. Intell. 2002, 17, 49–60. [Google Scholar] [CrossRef]
- Catalano, M.G.; Grioli, G.; Garabini, M.; Bonomo, F.; Mancini, M.; Tsagarakis, N.; Bicchi, A. VSA-CubeBot: A modular variable stiffness platform for multiple degrees of freedom robots. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 5090–5095. [Google Scholar]
- Lukić, B.Z.; Jovanović, K.M.; Kvaščcev, G.S. Feedforward neural network for controlling qbmove maker pro variable stiffness actuator. In Proceedings of the 2016 13th Symposium on Neural Networks and Applications (NEUREL), Belgrade, Serbia, 22–24 November 2016; pp. 1–4. [Google Scholar]
- Knezevic, N.; Lukic, B.; Jovanovic, K.; Zlajpah, L.; Petric, T. End-effector cartesian stiffness shaping—Sequential least squares programming approach. Serbian J. Electr. Eng. 2021, 18, 1–14. [Google Scholar] [CrossRef]
- Franka Robotics. Available online: https://franka.de (accessed on 15 November 2023).
- Deutschmann, B.; Liu, T.; Dietrich, A.; Ott, C.; Lee, D. A Method to Identify the Nonlinear Stiffness Characteristics of an Elastic Continuum Mechanism. IEEE Robot. Autom. Lett. 2018, 3, 1450–1457. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
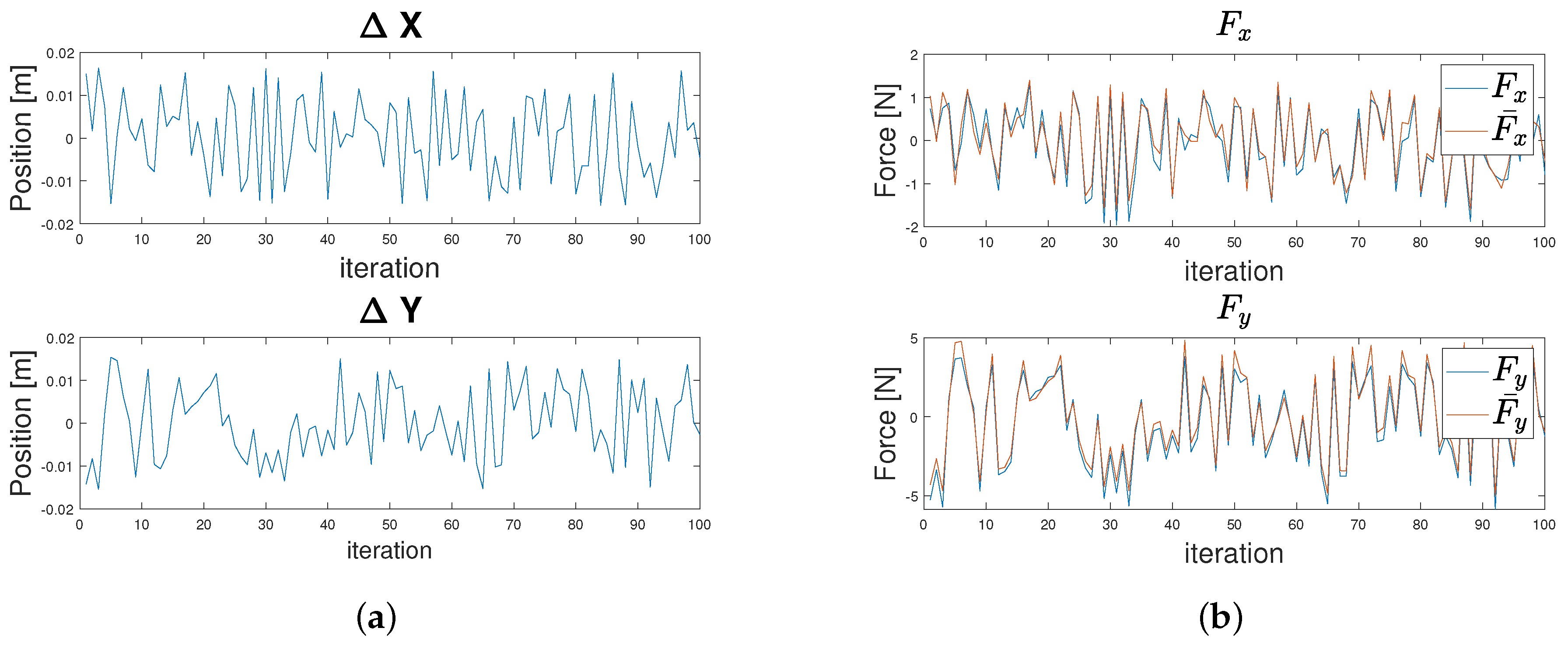{kind=link}
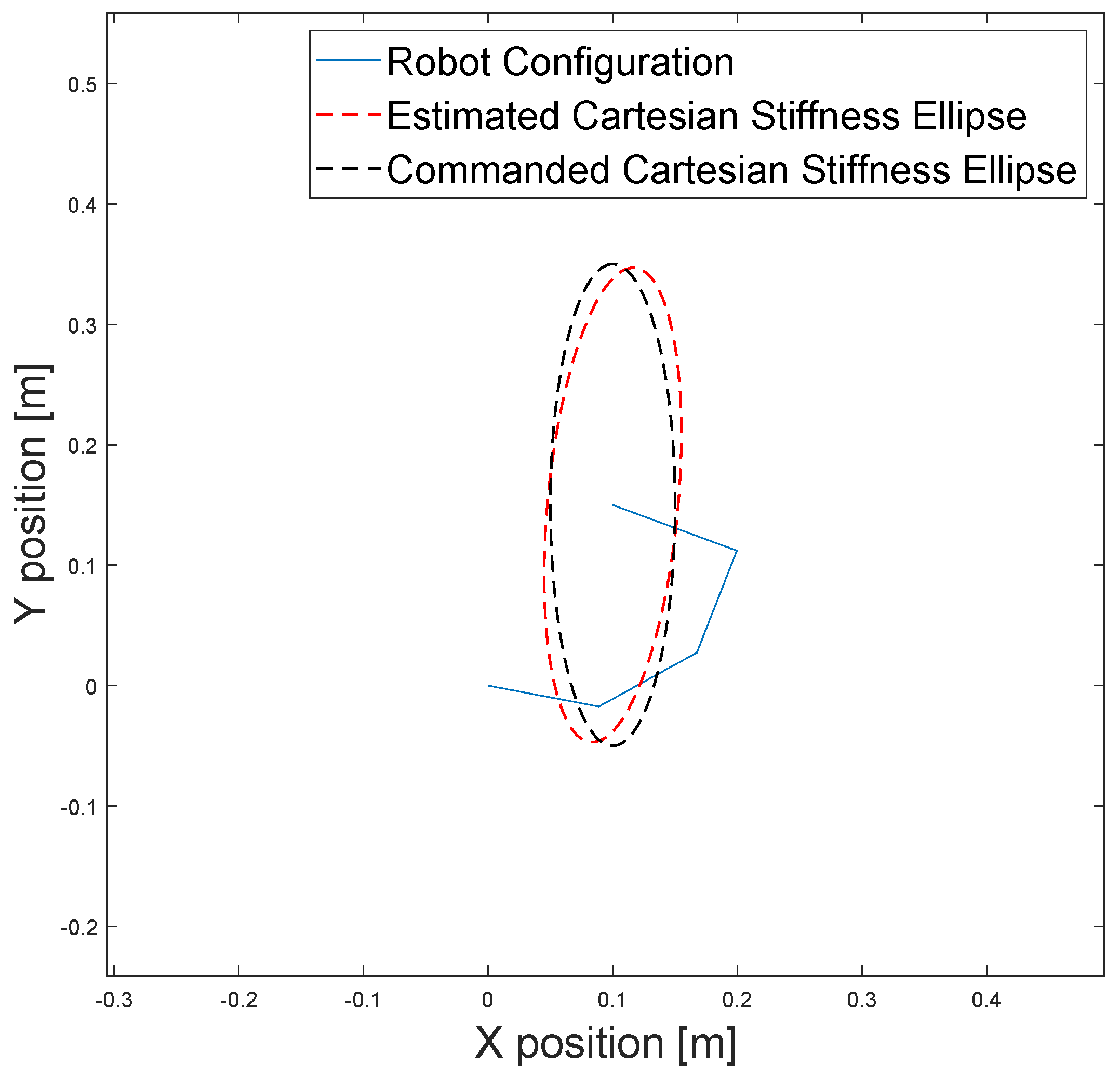{kind=link}
| Sim. | Desired Pos. | Init. Conf. | Res. Stiff. | Res. Conf. | Res. Pos. | Norm Val. | Stiffness: |
|---|---|---|---|---|---|---|---|
| Ach. (Des.) | |||||||
| [m] | [Rad] | [Nm/Rad] | [Rad] | [m] | [N/m] | ||
| 1 | 0.0241 | 1.1472 | 7.1004 | 1.5707 | 0.0241 | 235 | |
| 1.1272 | 0.5348 | −0.8605 | |||||
| 0.3564 | −0.2472 | 3.5427 | 0.9859 | 0.3564 | (235) | ||
| 0.7154 | 0.6301 | 0.2777 | |||||
| 2 | 0.0241 | 0.9472 | 6.7482 | 1.2941 | 0.0241 | 440 | |
| 0.8972 | 1.6680 | −0.2958 | |||||
| 0.3564 | −0.2472 | 4.5738 | 0.5010 | 0.3564 | (440) | ||
| 0.9054 | 2.5607 | 0.7727 | |||||
| 3 | 0.1125 | 1.1472 | 2.0157 | 0.8516 | 0.1125 | 728.08 | |
| 1.1272 | 0.5133 | 0.0298 | |||||
| 0.3198 | 0.0146 | 12.0378 | 1.3616 | 0.3198 | (745) | ||
| −0.8554 | 3.7201 | −1.1421 | |||||
| 4 | 0.1125 | 0.9472 | 5.9942 | 0.9342 | 0.1125 | 1350 | |
| 0.8972 | 2.7714 | −0.2770 | |||||
| 0.3198 | 0.0146 | 9.3229 | 1.5074 | 0.3198 | (1350) | ||
| −0.0783 | 3.1778 | −0.8967 |
| Sim. | Desired Pos. | Init. Conf. | Res. Stiff. | Res. Conf. | Res. Pos. | Norm Val. | Stiffness: |
|---|---|---|---|---|---|---|---|
| Ach. (Des.) | |||||||
| [m] | [Rad] | [Nm/Rad] | [Rad] | [m] | [N/m] | ||
| 1 | 0.0241 | 1.1472 | 12.9489 | 0.9865 | 0.0241 | 60; 350 | |
| 1.1272 | 13 | 0.1284 | |||||
| 0.3564 | −0.2472 | 3.4717 | 0.7027 | 0.3564 | (60; 350) | ||
| 0.7154 | 0.5000 | 0.2841 | |||||
| 2 | 0.0241 | 0.9472 | 12.6546 | 1.5690 | 0.0241 | 75; 2700 | |
| 0.8972 | 12.7370 | 0.3654 | |||||
| 0.3564 | −0.2472 | 8.5553 | −1.2348 | 0.3564 | (75; 2700) | ||
| 0.9054 | 5.0958 | 1.0421 | |||||
| 3 | 0.1125 | 1.1472 | 7.1619 | 1.4837 | 0.1125 | 149.9; 499.9 | |
| 1.1272 | 5.9281 | 0.4001 | |||||
| 0.3198 | 0.0146 | 8.3310 | −0.7289 | 0.3198 | (150; 500) | ||
| −0.8554 | 5.5392 | −0.8127 | |||||
| 4 | 0.2125 | 0.3224 | 12.4952 | 1.4081 | 0.2125 | 500; 200 | |
| 0.0336 | 3.5669 | 0.1878 | |||||
| 0.2198 | 0.3768 | 8.0491 | −1.5175 | 0.2198 | (500; 200) | ||
| 1.3664 | 12.3320 | 0.0554 |
| Sim. | Desired Pos. | A and B | Res. Stiff. | Res. Conf. | Res. Pos. | Norm Val. | Stiffness: |
|---|---|---|---|---|---|---|---|
| Ach. (Des.) | |||||||
| [m] | [Nm/Rad] | [Rad] | [m] | [N/m] | |||
| 1 | 0.1172 | 1 | 13 | 1.5708 | 0.1172 | 243; 874 | |
| 0.5 | −0.4909 | ||||||
| 0.3164 | 1 | 12.99 | −0.7612 | 0.3164 | (330; 850) | ||
| 6.1066 | 1.5040 | ||||||
| 2 | 0.1172 | 1 | 13 | 1.5708 | 0.1172 | 170 | 159; 847 |
| 7.6633 | −0.9172 | ||||||
| 0.3164 | 16 | 13 | 0.0357 | 0.3164 | (330; 850) | ||
| 5.4937 | 1.2859 | ||||||
| 3 | 0.1172 | 16 | 12.9728 | 1.5653 | 0.1172 | 330; 834 | |
| 5.8234 | −0.2659 | ||||||
| 0.3164 | 1 | 0.8217 | −1.0942 | 0.3164 | (330; 850) | ||
| 12.9846 | 1.4461 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Knežević, N.; Petrović, M.; Jovanović, K. Cartesian Stiffness Shaping of Compliant Robots—Incremental Learning and Optimization Based on Sequential Quadratic Programming. Actuators 2024, 13, 32. https://doi.org/10.3390/act13010032
Knežević N, Petrović M, Jovanović K. Cartesian Stiffness Shaping of Compliant Robots—Incremental Learning and Optimization Based on Sequential Quadratic Programming. Actuators. 2024; 13(1):32. https://doi.org/10.3390/act13010032
Chicago/Turabian StyleKnežević, Nikola, Miloš Petrović, and Kosta Jovanović. 2024. "Cartesian Stiffness Shaping of Compliant Robots—Incremental Learning and Optimization Based on Sequential Quadratic Programming" Actuators 13, no. 1: 32. https://doi.org/10.3390/act13010032
APA StyleKnežević, N., Petrović, M., & Jovanović, K. (2024). Cartesian Stiffness Shaping of Compliant Robots—Incremental Learning and Optimization Based on Sequential Quadratic Programming. Actuators, 13(1), 32. https://doi.org/10.3390/act13010032