Abstract
Conventional approaches to building energy retrofit decision-making struggle to generalize across diverse building characteristics, climate conditions, and occupant behaviors, and often lack interpretability. Generative AI, particularly Large Language Models (LLMs), offers a promising solution because they learn from extensive, heterogeneous data and can articulate inferences in transparent natural language. However, their capabilities in retrofit decision-making remain underexplored. This study evaluates six widely used LLMs on two objectives: determining the retrofit measure that maximizes CO2 reduction (a technical task) and minimizes the payback period (a sociotechnical task). We assessed performance across accuracy, consistency, sensitivity, and reasoning. The evaluation used 400 residential buildings from a nationwide, simulation-based database. The results reveal that LLMs vary across cases, with consistently strong technical-task performance but notably weaker performance on the sociotechnical one, highlighting limitations in handling complex economic and contextual trade-offs. The models consistently identify a near-optimal solution for the technical task (Top-5 accuracy reaching 92.8%), although their ability to pinpoint the single best option is limited (Top-1 accuracy reaching 54.5%). While models approximate engineering logic by prioritizing location and geometry, their reasoning processes are oversimplified. These findings suggest LLMs are promising for technical advisory tools but not yet reliable for standalone retrofit decision-making.
1. Introduction
Building energy consumption is shaped by the interplay of physical building characteristics, climate conditions, and occupant behaviors [1]. Structural and thermal properties set a baseline for energy use, climate conditions drive heating and cooling loads, and occupant behaviors can dramatically sway actual consumption. These factors not only determine energy consumption but also critically influence energy retrofit performance. For instance, adding insulation to exterior walls reduces heat loss in buildings with poor insulation but provides only marginal benefits in buildings that already have moderate insulation. A cool roof retrofit helps lower indoor temperatures and reduce cooling demand in hot climates, but can inadvertently increase heating demand in colder zones, offsetting its benefits. Occupant behaviors further complicate outcomes: aggressive thermostat settings or irregular occupancy patterns can negate the expected savings from heating, ventilation, and air conditioning (HVAC) upgrades. These interacting technical, climatic, and behavioral factors make retrofit performance difficult to generalize, underscoring the need for decision-support approaches that can balance multiple objectives and adapt to diverse contexts.
Existing decision-making methods for building retrofits rely on either physics-based or data-driven methods [2,3]; however, they have inherent limitations in handling the aforementioned three factors. Physics-based methods rely on heat and mass transfer principles as well as energy balance to simulate building energy performance and retrofit outcomes. These models are valued for their accuracy and remain a standard benchmark in engineering practice [4,5]. However, they face several challenges, including heavy building input, limited scalability, and static behavior assumptions. First, physics-based simulation requires technically detailed and complex input data [5]. Building characteristics, HVAC system efficiency, and domestic hot water system efficiency can typically be obtained from building audits, blueprints, or energy performance certificates [6,7]. However, reliably collecting these parameters and accurately inputting them into building energy simulations becomes increasingly complex and often impractical as the number of buildings grows in large-scale applications [3]. Second, scalability is limited not only by data demands but also by the neglect of between-building interactions, such as shared energy infrastructure, district systems, and multi-stakeholder coordination [8]. Even when effective at the individual building level, extending them to the community or city scale remains challenging without system-level integration. Third, climate conditions, such as outdoor temperature, solar radiation, and humidity levels, are commonly obtained from empirical meteorological data of reference cities within the same climate zone, for instance, those provided by the EnergyPlus Weather Data Sources [9]. However, low climate sensitivity to local microclimatic variations—such as urban heat island effects—can lead to discrepancies between simulated and actual building performance [10]. Finally, occupant behavior, such as thermostat settings, appliance usage patterns, and lighting setups, is often represented using static schedules and rules, overlooking dynamic interactions and behavioral uncertainty. This static behavior assumption can introduce significant discrepancies in energy predictions, particularly for small-scale buildings, where a smaller sample size magnifies the relative error between simulated and actual energy use [11].
Data-driven methods rely on historical energy data, statistical models, and machine learning algorithms to assess and predict the performance of retrofit measures [3]. While these approaches offer empirical learning and flexible modeling, they face three major challenges: missing baseline data, limited generalizability, and low interpretability. First, the lack of baseline data is particularly evident in older renovated buildings without reliable pre- and post-retrofit records. Even if upgrades such as improved insulation meet current building codes, the absence of prior data makes it difficult to accurately assess actual energy savings [12]. Second, ensuring generalizability is challenging [13]. A model trained in one climate or building stock may fail in another with different usage patterns. Finally, many models operate as black boxes, offering limited interpretability, which undermines stakeholder trust and hinders policy or investment adoption [14,15].
Smart and Connected Communities (S&CC) offer a promising environment for addressing key challenges in building energy retrofits by leveraging technologies such as Digital Twin, Multi-Agent Systems (MAS), and Artificial Intelligence (AI), as summarized in Figure 1. Digital Twin, enabled by Building Information Modeling (BIM) and the Internet of Things (IoT), provides real-time, high-resolution data on building operations, local climate, and occupant behavior, reducing reliance on static assumptions and incomplete baselines while improving responsiveness to microclimatic variations [16,17,18,19]. However, their deployment is often constrained by high implementation costs, data integration challenges, and the need for robust sensor infrastructure. MAS approaches, including Energy System Modeling and Social Network Modeling, improve scalability beyond physics-based methods by simulating inter-building dynamics and supporting coordinated decision-making at larger scales [8]. Yet, their accuracy depends heavily on assumptions about agent behaviors and can be computationally intensive, limiting real-time applicability. Recent advances in Generative AI, particularly large language models (LLMs), offer promise for improving generalizability and interpretability by learning contextual patterns from vast datasets [20], enabling performance predictions across varied building types and climates. Additionally, their natural language capabilities offer new pathways for improving interpretability by translating complex model outputs into human-readable explanations [21]. At the same time, LLMs face well-documented challenges—including hallucinations, inconsistency, and shallow contextual awareness—that must be overcome for their reliable use in high-stakes retrofit decision-making.
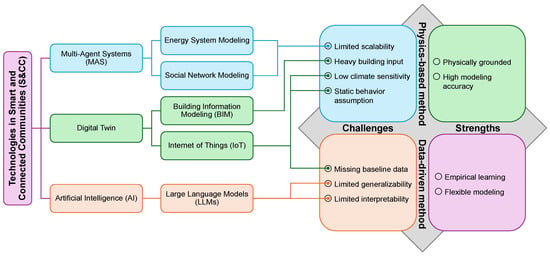
Figure 1.
S&CC technologies for overcoming challenges in decision-making methods for building retrofits.
Recent advances in LLM-based AI promise to overcome the “last-mile” challenge by translating and synthesizing complex technical data into clear, actionable, and personalized recommendations [22,23]. Within an S&CC ecosystem, LLMs can serve as conversational interfaces that connect expert knowledge with everyday decision-making, engaging homeowners, building managers, and community members [24,25]. For instance, they may propose tailored retrofit measures—such as insulation upgrades, HVAC improvements, or solar system integration—while considering comfort, budget, and climate. Through natural language, homeowners can interactively explore various retrofit options with explanations of savings, payback periods, and comfort impacts [26]. Yet most models are trained on broad, general-purpose data, rather than domain-specific knowledge, limiting their ability to reflect diverse building characteristics, climate conditions, and occupant behaviors. This lack of domain grounding, combined with the absence of systematic evaluations, raises concerns about reliability, accuracy, and potential misguidance in real-world retrofit decisions [23,27].
To address the lack of domain-specific evaluation, this study examines the ability of leading LLMs to support residential building energy retrofit decision-making, focusing on environmental benefits and economic feasibility. We selected six widely discussed LLMs and LLM-powered applications released till early 2025—ChatGPT o3, DeepSeek R1, Grok 3, Gemini 2.0, Llama 3.2, and Claude 3.7, representing a mix of proprietary and open-source platforms, multimodal and text-based architectures, and varied cost structures. OpenAI’s ChatGPT o3 is recognized for balanced reasoning and coherent multi-step responses [28]. DeepSeek R1 offers strong coding and mathematical performance while maintaining relatively low deployment costs [29]. Grok 3 from xAI integrates real-time data from X (formerly Twitter), enabling up-to-date responses [30]. Gemini 2.0 from Google DeepMind demonstrates advanced multimodal capabilities, particularly in processing images and long documents [31]. Llama 3.2 from Meta is a lightweight, open-access model that supports flexible fine-tuning [32]. Claude 3.7 from Anthropic combines fast and deep reasoning with reliable instruction-following, and robust data understanding [33]. For simplicity, these LLMs and LLM-powered applications are hereafter collectively referred to as LLMs. Importantly, this study evaluates the intrinsic capabilities of LLMs without any domain-specific fine-tuning or retraining, isolating how well general-purpose models can perform retrofit decision-making tasks out of the box.
For building energy retrofit decision-making, LLMs show promise for improving generalizability and interpretability compared with physics-based and data-driven approaches. However, systematic domain-specific evaluations remain underexplored. Accordingly, we evaluate off-the-shelf LLMs for residential retrofits with a focus on environmental benefits and economic feasibility, and we examine performance across diverse residential contexts. Specifically, we evaluated these LLMs along four key dimensions: accuracy against established baselines, consistency across models, sensitivity to contextual features (e.g., building characteristics, climate conditions, and occupant behaviors), and the quality of their reasoning logic. This multi-faceted assessment offers a foundation for understanding both strengths and limitations of the current LLM-based AI in supporting retrofit decisions across diverse residential contexts.
This research is presented as follows. Methodology introduces the data, prompt design, and evaluation framework. Results present accuracy, consistency, sensitivity, and reasoning. Discussion first summarizes LLM opportunities and limitations, then follows the LLM workflow to identify where performance can be improved, and finally discusses the limitations of this study. Conclusions summarize the key insights.
2. Methodology
2.1. Data
This study used a selected subset of the ResStock 2024.2 dataset developed by the U.S. National Renewable Energy Laboratory (NREL), which contains 550,000 representative residential building samples [34]. For our analysis, we randomly sampled 400 homes using uniform stratified sampling across combinations of 49 U.S. states (excluding Hawaii) and three housing types, allocating sample sizes evenly across combinations to ensure complete coverage. The resulting dataset spans construction vintages from pre-1940 to 2010, and includes single-family houses, multi-family residences, and manufactured (“mobile”) homes, with floor areas ranging from 25 to 519 m2.
Each building sample is defined by 389 parameters, covering building properties (e.g., construction vintage, floor area, and insulation levels), equipment characteristics (e.g., HVAC system type, HVAC system efficiency, and appliance ownership), occupant attributes (e.g., household size, usage patterns, and income), location details (e.g., postal code, census region, and state), and energy usage (e.g., utility bill rate, energy consumption, and energy cost). These parameters are derived primarily from the U.S. Energy Information Administration’s (EIA) Residential Energy Consumption Survey (RECS), the U.S. Census Bureau’s American Housing Survey (AHS), and the American Community Survey (ACS) [34]. All samples were complete and underwent initial NREL quality checks, so no imputation was required.
The selected dataset includes parameters for retrofit measures (e.g., infiltration and insulation upgrades, heat pump upgrades, and appliance electrification) and energy-related outputs (e.g., energy consumption, CO2 emissions, and energy costs). Specifically, 16 retrofit packages are defined (See Table 1). The first 15 vary along three main axes: the type and efficiency of the heat pump, whether infiltration and attic-insulation upgrades are applied, and whether major appliances are electrified. The 16th package consists solely of infiltration and insulation upgrades. Thus, each building sample features 17 sets of energy-related outputs: one baseline scenario with no retrofits and 16 retrofit scenarios (one per package). These outputs are generated by EnergyPlus simulations [34], which provide a detailed and physics-based representation of building performance. Specifically, EnergyPlus simulates energy consumption by dynamically solving heat and mass balance equations for each thermal zone, while accounting for building geometry, material properties, internal loads, HVAC systems, and real weather data over time [35].

Table 1.
Technical specifications and cost estimates for 16 retrofit packages.
Because the ResStock dataset does not provide retrofit costs, we supplemented it with unit price estimates from the National Residential Efficiency Measures (NREM) Database [36]. These unit prices were adjusted to 2024 U.S. dollars and combined with building-specific parameters (e.g., floor area and equipment capacity) to calculate the total cost of each retrofit. Regional cost variation was not incorporated; instead, national averages were used to maintain consistency across samples. These data provided the technical and economic benchmarks against which LLM-generated retrofit recommendations were evaluated in terms of accuracy, consistency, sensitivity, and reasoning. Technical specifications and cost estimates for the 16 packages are summarized in Table 1, converted to International System of Units (SI) where appropriate.
2.2. Prompt Design and Structure
Because LLM performance depends heavily on prompt formulation, we developed a standardized, reproducible prompt to evaluate all models consistently. As shown in Figure 2, the prompt comprises three parts: (1) an overview of the 16 retrofit packages, (2) an assigned expert role and decision-making question, and (3) house-specific information. Together, these components were designed to simulate realistic household decision contexts while ensuring comparability across LLMs. The overview outlines each retrofit measure’s key features (e.g., heat pump efficiency, whether infiltration is upgraded, and whether major appliances are electrified) along with its associated costs. The assigned role positions the LLM as a “house retrofit specialist”, responsible for evaluating multiple homes, comparing costs and efficiency across all packages, and identifying which retrofit yields the greatest CO2 reduction and which offers the lowest payback period for each home.

Figure 2.
Prompt structure for LLMs retrofit decision-making.
House-specific information encompasses 28 key parameters, screened from the original 389 parameters in the ResStock database. The selection emphasizes factors that significantly influence energy consumption and are accessible to most households. Instead of technical metrics such as the climate zone—generally unfamiliar to most households—the selection prioritizes parameters that are accessible while still enabling LLMs to infer climate characteristics from location data. The original tabular dataset was reframed using GPT-4o into household-oriented narratives to facilitate natural language interaction with LLMs. These 28 parameters include location information (e.g., state and county), architectural features (e.g., floor area and orientation), building envelope details (e.g., insulation levels and window type), appliance types (e.g., clothes dryer type and lighting type), water heating systems (e.g., water heater efficiency and fuel), HVAC systems (e.g., heating fuel and cooling type), and occupant usage patterns (e.g., temperature setpoint and number of occupants). The full list of parameters and their metric ranges is provided in Table 2.
Table 2.
Parameters used for prompt with metric value ranges.
2.3. Evaluation Framework
We evaluated six LLMs—ChatGPT o3, DeepSeek R1, Grok 3, Gemini 2.0, Llama 3.2, and Claude 3.7. For each sample house, we identified two baseline retrofit measures. (1) The first baseline identified the retrofit package that maximized annual CO2 reduction based on EnergyPlus simulation outputs. (2) The second identified the package that minimized the payback period, calculated by dividing the total retrofit cost (from NREM Database) by the annual energy cost savings (from ResStock). Retrofit packages were ranked separately for each objective, per house, by sorting all 16 options in descending order of CO2 reduction or ascending order of payback period. To streamline the evaluation and reduce redundancy, the original 16 retrofit packages were consolidated into 10 broader categories.
As depicted in Figure 3, our evaluation rested on four dimensions. All evaluations were conducted on the LLMs in their native form, without fine-tuning, to assess their out-of-the-box capabilities.
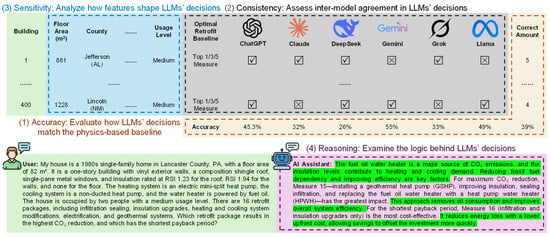
Figure 3.
Four-dimensional evaluation of LLM performance in retrofit decision-making.
First, we measured accuracy using a tiered Top-k scheme to determine how closely each LLM’s single retrofit recommendation aligned with the ranked baseline. This approach acknowledges that multiple near-optimal solutions often exist in practice. A recommendation was scored as a Top-1 match if it exactly matched the optimal baseline measure. It was scored as a Top-3 match if it was among the three best options, and a Top-5 match if it appeared within the five best options. For example, if the baseline ranked options A, B, and C as the top three, an LLM recommendation for option B would be inaccurate at the Top-1 level but accurate at both the Top-3 and Top-5 levels. Accuracy was calculated using the following formula:
where c is the number of correct selections and n is the total number of evaluated cases. Results were reported separately for the two objectives: maximizing CO2 reduction and minimizing payback years.
Second, we evaluated consistency to measure the degree of agreement among the models. We used kappa (κ) statistics, which quantify inter-rater reliability while correcting for chance agreement:
where po is the observed agreement, and pe is the agreement expected by chance. We employed Fleiss’ Kappa for overall agreement, leave-one-out Fleiss’ Kappa for each model’s influence, and pairwise Cohen’s Kappa for inter-model comparisons.
Third, we assessed model sensitivity to determine which input features most influenced the decisions of each LLM compared to the baseline. We used a random forest classifier, treating the retrofit option selected by each LLM (and the baseline) as the target variable and the 28 household parameters as predictors. A random forest essentially works like a collection of “if–then” rules that can reveal which features matter most in driving decisions. The resulting feature importance scores revealed the relative influence of each parameter.
Fourth, we examined the reasoning behind recommendations. Since only ChatGPT and DeepSeek provided detailed step-by-step rationales, our qualitative analysis focused on characterizing the internal logic of these two models to assess whether their outputs reflected grounded principles.
3. Results
3.1. Accuracy
Figure 4 presents the Top-1 (blue), Top-3 (orange), and Top-5 (green) accuracy rates for the LLMs, including their 95% confidence intervals. The top panel shows accuracy rates for maximizing CO2 reduction, while the bottom panel shows accuracy rates for minimizing payback period. “Overall” bars, displayed alongside individual models, represent the average accuracy across all LLMs for each objective.
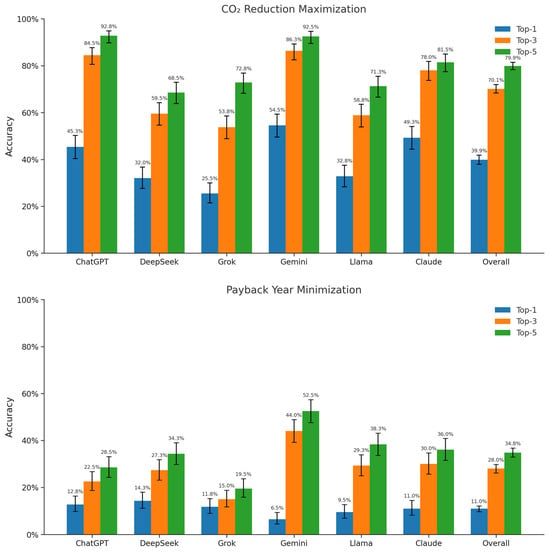
Figure 4.
Top-k accuracy (with 95% CI) of LLMs in selecting optimal retrofit measures.
LLMs demonstrated stronger performance on the technical task of maximizing CO2 reduction than on the sociotechnical task of minimizing payback period. As expected, accuracy improves across all models as the evaluation criteria broaden from Top-1 to Top-5. For the CO2 objective, the Top-1 accuracy is 39.9%, increasing to 70.1% at Top-3 and 79.9% at Top-5. In contrast, for the payback period objective, accuracy remained low across all tiers, with an overall Top-1 accuracy of only 11.0%, rising to just 28.0% at Top-3 and 34.8% at Top-5.
In the CO2 reduction task, leading LLMs produced highly effective recommendations. This suggests that while pinpointing the single best measure remains challenging, most models consistently fall within a near-optimal range. Specifically, Top-1 accuracy ranges from 25.5% (Grok 3) to 54.5% (Gemini 2.0); Top-3 accuracy ranges from 53.8% (Grok 3) to 86.3% (Gemini 2.0); and Top-5 accuracy ranges from 68.5% (DeepSeek R1) to 92.8% (ChatGPT o3). Top performers like ChatGPT o3 and Gemini 2.0 achieve over 45% at Top-1 accuracy, exceed 80% at Top-3 accuracy, and surpass 90% at Top-5 accuracy.
In contrast, performance on payback year minimization remains uniformly poor. Even under the most lenient Top-5 criterion, most models fail to achieve high accuracy. Top-1 accuracy ranges from 6.5% (Gemini 2.0) to 14.3% (DeepSeek R1); Top-3 accuracy ranges from 15.0% (Grok 3) to 44.0% (Gemini 2.0); and Top-5 accuracy ranges from 19.5% (Grok 3) to 52.5% (Gemini 2.0). Gemini 2.0 is the only model to surpass 50% at Top-5 accuracy, underscoring the persistent difficulty of identifying economically optimal retrofit measures.
3.2. Consistency
3.2.1. Overall Agreement
Figure 5 reports the leave-one-out Fleiss’ Kappa for each of the six LLMs, along with the overall Fleiss’ Kappa across all models. Two types of agreement are shown: (1) selection-based agreement (red), measuring whether models chose the same retrofit package as optimal; (2) correctness-based agreement at the Top-1, Top-3, and Top-5, measuring whether models agreed in correctly identifying the optimal retrofit within their top-k results. The upper chart shows these metrics for the CO2 reduction objective, while the lower chart shows results for minimizing the payback period. Bars labeled with model names indicate the leave-one-out Fleiss’ Kappa values when excluding the corresponding model, while “Overall” represents the Fleiss’ Kappa when all models are included. A higher leave-one-out Fleiss’ Kappa value relative to the overall value suggests that the excluded model was lowering the agreement among the other models, whereas a lower leave-one-out value indicates that the excluded model made a positive contribution to the overall agreement.
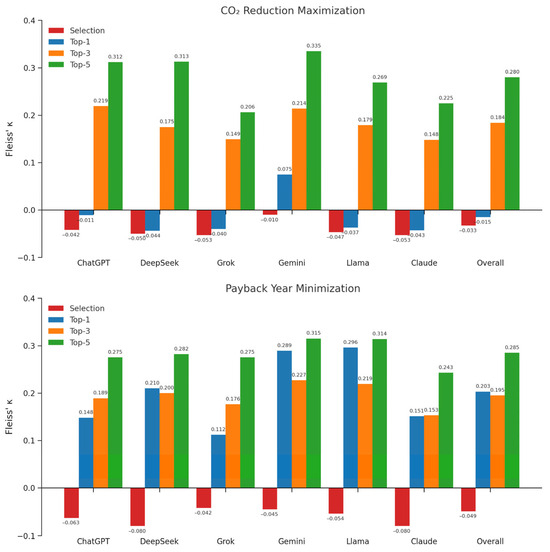
Figure 5.
Overall agreement among LLMs in retrofit selection and correctness.
Across both objectives, selection-based agreement is consistently negative, indicating that the models’ retrofit selections were less consistent than would be expected by chance. Correctness-based agreement reaches, at best, the “fair” agreement range. The overall Fleiss’ Kappa for CO2 reduction at Top-1 is negative (−0.015), in contrast to that for the payback year (0.203). Correctness-based agreement at Top-3 and Top-5 becomes more comparable across the two objectives: the values are 0.184 and 0.280 for CO2, versus 0.195 and 0.285 for payback.
For CO2 reduction, correctness-based agreement increases steadily from Top-1 to Top-5, starting below chance and rising to 0.335 (fair agreement). This trend mirrors the accuracy gains previously shown in Figure 4, suggesting that LLMs show greater agreement in judging the correct optimal retrofit measures as accuracy improves. In addition, top performers in accuracy, such as ChatGPT o3 and Gemini 2.0, also show the highest leave-one-out Fleiss’ Kappa values (both larger than the overall), indicating that their correct judgments diverged from others and therefore lowered overall agreement.
For payback minimization, correctness-based Fleiss′ Kappa values remain within the fair range. Agreement peaks at Top-1 (0.296), dips at Top-3 (0.227), and rises again at Top-5 (0.315). This pattern, together with the accuracy results in Figure 4, suggests that at Top-1, most models perform poorly in a similar manner (raising agreement), at Top-3, their improved but divergent judgments reduce alignment, and at Top-5, more lenient criteria allow partial convergence.
3.2.2. Pairwise Agreement
Figure 6 details the pairwise agreement between models using Cohen’s Kappa, offering a granular view of inter-model alignment. Figure 6a,b display selection-based agreement; Figure 6c–e show correctness-based agreement, and Figure 6f–h report correctness-based agreement for both objectives at each Top-k level.
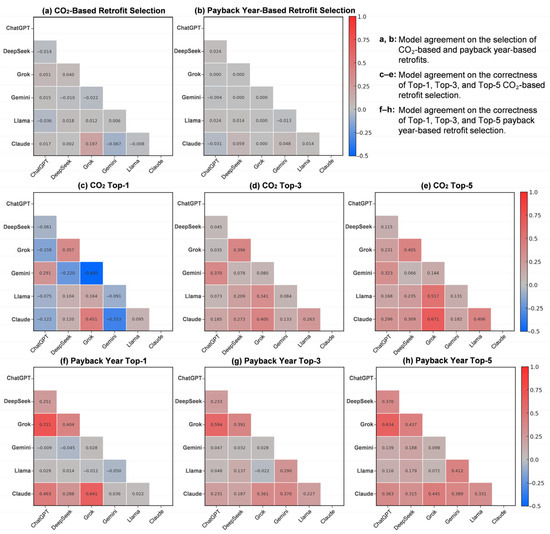
Figure 6.
Pairwise agreement among LLMs in retrofit selection and correctness.
The pairwise analysis confirms the findings from the above overall agreement. Selection-based agreement (Figure 6a,b) is near-zero or negative across almost all model pairs. The only exception is a slight positive agreement between Grok 3 and Claude 3.7 for CO2-based selection.
For CO2 correctness-based agreement (Figure 6c–e), Cohen’s Kappa values increase from Top-1 to Top-5, reinforcing the trend observed in Fleiss’ Kappa (Figure 5). ChatGPT o3 and Gemini 2.0 consistently show the lowest agreement with other models, supporting earlier findings that their correctness judgments diverge from the rest. Conversely, ChatGPT o3 and Grok 3 demonstrate the highest pairwise agreement across all Top-k ranks, suggesting moderate alignment in their correctness patterns—an insight not captured by Fleiss’ Kappa.
For payback year correctness-based agreement (Figure 6f–h), Cohen’s Kappa values generally mirror the overall pattern as in Fleiss’ Kappa, with a slight dip at Top-3 and a modest rise at Top-5. Notably, Gemini 2.0 and Llama 3.2 exhibit the weakest pairwise agreement with other models, further underscoring their distinct correctness profiles identified in the leave-one-out Fleiss’ Kappa values (Figure 5). Meanwhile, ChatGPT o3 and Grok 3 again show moderate agreement from Top-1 to Top-5, confirming their consistent alignment across retrofit decisions.
3.3. Sensitivity
Figure 7 presents feature importance values for 28 input variables in determining optimal retrofit measures under two objectives: maximizing CO2 reduction (left panel) and minimizing payback period (right panel). Each column corresponds to the baseline, one of the six LLMs, or the overall LLMs. In this context, feature importance represents how sensitive a model is to each feature—darker shading in the heatmap indicates stronger reliance. Gray diagonal hatching denotes cases where the LLM recommended the same retrofit for all 400 homes, making sensitivity analysis impossible due to a lack of variation.
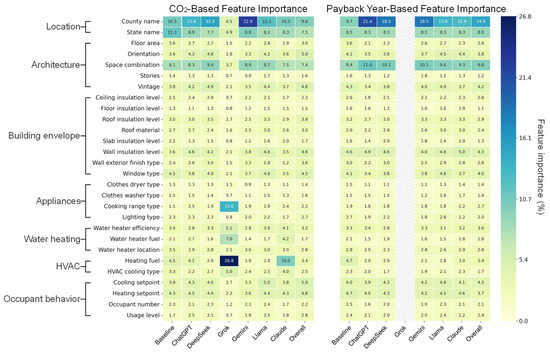
Figure 7.
Feature importance comparison across LLMs for CO2 and payback year-based retrofit decisions.
For both objectives, most LLMs exhibit feature importance patterns that are broadly consistent with the EnergyPlus-derived baseline. “County name”, “State name”, and “Space combination” consistently emerge as the most influential features, followed by a secondary group including “Orientation”, “Vintage”, “Wall insulation level”, “Window type”, “Water heater efficiency”, “Cooling setpoint”, and “Heating setpoint”. Remaining features play a limited role, with only a few LLMs showing deviations. These similarities suggest that most LLMs, like the baseline, prioritize location and architecture characteristics when recommending retrofits.
However, notable deviations were observed. Grok 3 places disproportionate weight on “Heating fuel”, “Cooking range type”, and “Water heater fuel” under the CO2 objective—deviations that may explain its poor accuracy (Figure 4), where it ranked lowest at Top-1 and Top-3 and near the bottom at Top-5. Claude 3.7 also places a relatively high weight on “Heating fuel”, but otherwise aligns with the baseline and most LLMs. Across both objectives, most LLMs assign higher importance to “County name” than the baseline, suggesting they rely heavily on location features like “County name” as a proxy for climate conditions, which strongly shape their judgment on energy use and retrofit selection.
3.4. Reasoning
The models followed a consistent five-step logic that mirrors a simplified engineering workflow: (1) baseline establishment, (2) envelope impact adjustment, (3) system energy calculation, (4) appliance energy assumption, and (5) outcome comparison.
Figure 8 presents representative examples from ChatGPT o3 and DeepSeek R1 corresponding to each reasoning step. ChatGPT o3 expressed its logic through explanatory text supplemented with embedded Python code, whereas DeepSeek R1 relied entirely on descriptive narrative. Despite these differences in presentation, both models applied the same underlying progression. This multi-step logic mirrors engineering principles, but it remains simplified and accounts for only a narrow set of contextual dependencies.

Figure 8.
Reasoning logic and illustrative snapshots from two LLMs.
The reasoning processes begin with a baseline assumption, where the models estimate a building’s original energy load using basic characteristics such as floor area and location. This baseline serves as a reference for evaluating retrofit impacts. Then, in the envelope impact adjustment step, the models apply estimated reductions to account for retrofits such as improved insulation or air sealing. These adjustments are typically expressed as a percentage reduction in baseline energy demand. The system energy calculation step then modifies consumption levels based on the efficiency of newly installed mechanical systems, such as heat pumps or furnaces, estimating demand by dividing adjusted energy loads by system efficiency. During the appliance energy assumption step, savings are estimated by comparing assumed consumption levels of appliances before and after retrofits, reflecting performance differences between technologies. Finally, in the outcome comparison step, results are aggregated to evaluate and prioritize retrofit packages. Although ChatGPT o3 and DeepSeek R1 follow a similar structured logic, their reliance on assumed input values—such as baseline loads and percentage reductions—introduces variability in estimated outcomes and, ultimately, in recommended retrofit selections.
4. Discussion
The overall performance of LLMs in retrofit decision-making depends on their ability to process information effectively across the workflow—prompt understanding, context representation, multi-step inference, and response generation. Weaknesses at any stage can lead to oversimplified or incomplete recommendations. As demonstrated in our evaluation, these weaknesses appeared in the form of simplified reasoning, inconsistent alignment across models, and trade-offs between accuracy and consensus. Recognizing and addressing these limitations is essential to enhancing the performance of LLMs in building energy retrofit applications.
4.1. Opportunities and Limits of LLMs for Practice
With regard to the accuracy of performance, the stark contrast between LLM performance in maximizing CO2 reduction and minimizing payback period underscores a fundamental limitation of current models. While LLMs demonstrate competence in clear, single-objective, technical problems, they struggle with sociotechnical trade-offs that require balancing costs, savings, and contextual variability. This suggests that LLMs may be suitable as technical advisors for identifying high-impact retrofit measures but remain unreliable for guiding economic decisions that directly influence adoption and the distribution of costs and benefits across stakeholders. Accordingly, their most effective role in practice may be within a human-in-the-loop framework, where LLM-generated insights on environmental performance are complemented by expert or data-driven evaluation of financial feasibility.
While some LLMs, such as ChatGPT o3 and Gemini 2.0, demonstrate relatively high accuracy, their divergence from other models underscores a lack of consensus across platforms. This suggests that LLMs are not yet reliable as stand-alone decision-makers for retrofit planning. However, the patterns of disagreement also reveal opportunities: ensemble approaches, human–AI collaboration, or domain-specific fine-tuning may help capture the strengths of high-performing models while mitigating inconsistency. In practice, this means LLMs may be most valuable today as supportive advisors—offering alternative retrofit options, explaining trade-offs, and broadening the decision space.
Pairwise comparisons reveal that while some models, such as ChatGPT o3 and Grok 3, align closely and consistently, others like Gemini 2.0 and ChatGPT o3 achieve higher accuracy but diverge from their peers—highlighting a trade-off between accuracy and consensus across LLMs.
The sensitivity analysis shows that LLMs generally mirror baseline reasoning by emphasizing location and architectural features, but their tendency to overweight location (e.g., county) and mis-prioritize certain technical features, as seen with Grok 3, highlights both their potential to approximate domain logic and their risk of producing biased or distorted judgments.
The emergence of structured, engineering-style reasoning in models like ChatGPT o3 and DeepSeek R1 suggests that LLMs can approximate professional decision logic, but their reliance on simplified assumptions and limited contextual awareness highlights the risk of oversimplification. For practice, this means LLMs may be most effective as tools for communicating reasoning steps transparently, rather than as definitive sources of accurate retrofit calculations.
4.2. Prompt Input and Understanding
Effective prompt design is a foundational determinant of LLM performance. Prior studies show that even slight changes in prompt wording or structure can greatly influence outcomes [37,38], and our results confirm similar sensitivity. When prompted to “identify the retrofit measure with the shortest payback period”, most models selected the option with the lowest upfront investment, disregarding how energy cost savings substantially influence payback outcomes. However, simply adding the phrase “considering both initial investment and energy cost savings” led models to adjust their reasoning and incorporate both factors. While the final recommendations often remained unchanged, the revised prompt more consistently triggered comprehensive reasoning—highlighting that explicit guidance is necessary because LLMs may not fully recognize the relevance of key variables unless directly prompted.
Prompt phrasing also shaped response generation. When asked to “identify the measure with the greatest CO2 reduction and the one with the shortest payback period”, models interpreted the task inconsistently: some returned only one option per objective, while others provided two or three. Notably, even for prompts implying a single optimal solution—such as “the greatest” or “the shortest” —some models still listed multiple alternatives. This pattern suggests that LLMs do not always fully infer the implicit expectations behind user prompts, and that clearer phrasing is needed to ensure alignment between user intent and model understanding.
These findings reinforce the importance of prompt engineering as a practical strategy for improving LLM performance in retrofit decision tasks. Unlike physics-based simulation tools, which rely on numerical inputs and fixed equations, LLMs generate responses based on both the prompt and their learned knowledge. In this context, prompt plays a role analogous to setting initial conditions in a simulation: clear parameters, objectives, and constraints guide the model toward more accurate results. Our study shows that prompt sensitivity can directly affect not only the completeness of reasoning but also the consistency of outputs across models—making prompt design an essential part of quality control for AI-assisted retrofit analysis. Crafting effective prompts often requires iterative refinement and a solid understanding of how the model behaves in domain-specific contexts [37,38]. By structuring prompts to include necessary building parameters, performance targets, and even hints for step-by-step reasoning, practitioners can significantly enhance the decision accuracy of LLM-generated retrofit advice. In short, prompt engineering emerges as a key enabler for harnessing LLMs in retrofit analyses, ensuring that these models remain grounded in context—just as well-defined initial conditions steer a physics-based simulation toward reliable outcomes.
4.3. Context Representation
After interpreting a prompt, LLMs internally form a contextual representation of the problem—organizing the scenario, relevant variables, and their relationships to support reasoning. This stage is critical because it determines what information the model actively retains and uses. However, unlike physics-based models, which explicitly define variable interdependencies through equations, LLMs construct their context using language-based associations. As a result, contextual elements with lower salience may be excluded if their relevance is not explicitly signaled.
Our sensitivity analysis showed that most LLMs assigned similar importance scores to input features as the physics-based baseline. Yet, many of these features were not effectively integrated into the models’ context representation and thus were unavailable during reasoning. For example, “usage level” consistently received a moderate importance—around 2.5% on average across models—but played no role in the reasoning that produced the final retrofit recommendation. This suggests that while LLMs can identify which features are generally relevant, they often fail to embed them into a coherent contextual understanding of the task. Unlike physics-based models, which systematically account for all input variables, LLMs tend to anchor their context representations around only a few salient cues. Even when feature importance aligns with the baseline, an incomplete or fragmented context representation can limit reasoning and reduce overall accuracy.
Improving context representation, therefore, requires not only well-structured prompts but also explicit strategies to emphasize the necessity of key input features. In our study, although the prompts included information such as occupancy levels, we did not emphasize the importance of these variables within the prompt. As a result, models often overlooked them during reasoning. If prompts had more clearly directed the model’s attention—for example, by stating that certain features directly impact energy performance—LLMs might have incorporated them more consistently into their reasoning and generated more accurate recommendations.
4.4. Inference and Response Generation
LLM inference and response generation in our study exhibited three major limitations: oversimplified decision logic, inconsistency across responses, and unintended context-driven bias. These issues were not always evident from the final answers but became clear when examining the model’s step-by-step reasoning traces.
First, models frequently relied on overly simplified reasoning patterns. For instance, some assumed that the retrofit measure with the lowest upfront cost would automatically yield the shortest payback period, or that fossil-fuel systems should always be replaced by electric alternatives. Such rules were applied uncritically, without evaluating performance trade-offs. To mitigate this, prompts can be refined to explicitly emphasize multi-criteria evaluation, such as balancing upfront investment with long-term energy saving. Incorporating counterexamples into prompts may also discourage overgeneralization. Providing structured reasoning templates (e.g., requiring each step for cost, energy saving, and payback) can also help enforce more nuanced inference chains.
Second, we observed a level of variability and uncertainty in LLM-generated outputs atypical of physics-based methods. Because LLMs generate text probabilistically, repeated queries or slight rephrasing produced inconsistent answers, leading to conflicting retrofit recommendations, even when inputs were identical. Such inconsistency limits the suitability of LLMs for high-precision, reliability-critical tasks [39,40], such as hourly energy consumption prediction. Several strategies could address these challenges: (i) fine-tuning LLMs with domain-specific datasets to reduce variability [41]; (ii) distilling large LLMs into smaller, domain-specific models to achieve faster and more consistent inference while retaining reasoning capacity [42]; (iii) employing retrieval-augmented generation to ground responses in validated sources, thereby improving consistency [43]; and (iv) hybrid modeling that uses LLMs for interpreting inputs and generating hypotheses while physics-based simulations validate results, ensuring traceable and repeatable outcomes [25].
Third, in dialogue-based LLM interactions, context carryover may introduce unintended bias when similar but independent queries are asked sequentially. Because models retain elements of prior responses, subsequent answers can be influenced by earlier reasoning, even when each query deserves independent consideration [44]. This undermines reliability and complicates comparisons across scenarios. To counter these effects, users can reset or isolate the conversation context, rephrase questions to stand alone, or provide explicit directives instructing the model to ignore previous content. Conversely, a structured chain-of-thought approach can turn sequential prompting into an advantage: guiding the model step by step breaks complex tasks into smaller logical units, each of which can be checked or refined before proceeding. Users can reinforce this by requesting intermediate reasoning, introducing checkpoints to correct errors, and encouraging the model to “think aloud”. In this way, chain-of-thought prompting leverages the model’s sequential nature for clarity and accuracy rather than allowing context to create unwanted bias [45,46].
Although LLMs can emulate structured decision logic, their tendencies toward oversimplified reasoning, inconsistent outputs, and context-driven bias mean they should currently be used as transparent, assistive tools rather than as stand-alone, reliability-critical systems for retrofit decision-making.
4.5. Study Limitations and Future Work
While this study systematically evaluated LLMs in household retrofit decision-making tasks, several limitations remain. First, although we selected 28 key parameters from the original ResStock dataset to capture the most influential factors in retrofit decisions, the data still omits important real-world variables such as occupant preferences or region-specific policy incentives. These factors can significantly influence retrofit decisions but are difficult to capture in a standardized prompt. Second, this study did not include a quantitative comparison between the LLM-generated recommendations and those derived from traditional, established engineering standards. While our approach emphasizes accessibility and flexible reasoning through natural language, traditional frameworks offer more deterministic outputs and established validation protocols. Future work could integrate LLM-based, rule-based systems, and stakeholder values to balance generalizability, interpretability, and performance in practical applications.
5. Conclusions
This study investigated the capability of six leading large language models (LLMs) to support building energy retrofit decisions, a task where conventional methods often struggle with generalizability and interpretability. Our evaluation, summarized in Table 3, reveals a critical duality in current LLM performance: while they demonstrate a promising ability to reason through technical optimization problems, they fall short when faced with the sociotechnical complexities of real-world economic decisions.
Table 3.
Summary of evaluation results.
The findings underscore that without any domain-specific fine-tuning, LLMs can produce effective retrofit recommendations, particularly for a technical objective like maximizing CO2 reduction. The high Top-5 accuracy in this context (reaching 92.8%) suggests that while pinpointing the single best measure is challenging, most models consistently identify a near-optimal solution. This competence, however, contrasts sharply with their limited effectiveness in minimizing the payback period, where complex trade-offs between costs, savings, and contextual factors proved difficult for the models to navigate.
This performance dichotomy is reflected across other dimensions. The low consistency among models—especially the tendency for higher-accuracy models to diverge from the consensus—highlights the lack of a standardized reasoning process. The sensitivity analysis confirmed that LLMs correctly identified location and architectural features as primary drivers of performance, approximating the logic of physics-based models. Yet the reasoning analysis revealed that this logic, while structured, remains oversimplified and reliant on generalized assumptions.
The results suggest that LLMs, in their current state, are best suited as technical advisory tools rather than standalone economic decision-makers. Their most effective near-term role is likely within a human-in-the-loop framework, where they can generate a set of technically sound retrofit options that are then evaluated by human experts for feasibility and contextual appropriateness. Such workflows can pre-screen plausible retrofit options and streamline early-stage analysis, reducing the time and effort required while keeping final investment decisions under expert control.
To unlock their full potential, future work should focus on overcoming the limitations identified in this study. Domain-specific fine-tuning is a critical next step to imbue models with a deeper understanding of building physics, regional construction practices, and local economic conditions. Furthermore, developing hybrid AI frameworks that integrate LLMs with physics-based simulation engines or robust cost databases could bridge the gap between simplified logic and rigorous, data-driven analysis. By addressing these gaps, generative AI can evolve into a truly transformative tool for accelerating equitable and effective building decarbonization.
Author Contributions
L.S.: Conceptualization, Methodology, Investigation, Data curation, Formal analysis, Visualization, Writing—original draft, Writing—review and editing. A.Y.: Validation, Formal analysis, Writing—review and editing. D.Z.: Conceptualization, Methodology, Formal analysis, Writing—review and editing, Supervision, Funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by U.S. National Science Foundation grant number 2046374. Any opinions, findings, conclusions, or recommendations expressed in this material are those of the researchers and do not necessarily reflect the views of NSF.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AC | Air Conditioning |
| ACS | American Community Survey |
| AHS | American Housing Survey |
| AI | Artificial Intelligence |
| ASHP | Air-Source Heat Pump |
| BIM | Building Information Modeling |
| CFL | Compact Fluorescent Lamp |
| COP | Coefficient of Performance |
| EER | Energy Efficiency Ratio |
| EIA | U.S. Energy Information Administration |
| HP | Heat Pump |
| HPWH | Heat Pump Water Heater |
| HSPF | Heating Seasonal Performance Factor |
| HVAC | Heating, Ventilation, and Air Conditioning |
| IoT | Internet of Things |
| LED | Light-Emitting Diode |
| LLM(s) | Large Language Model(s) |
| MAS | Multi-Agent Systems |
| NREM | National Residential Efficiency Measures |
| NREL | National Renewable Energy Laboratory |
| RECS | Residential Energy Consumption Survey |
| RSI | Thermal resistance (m2·K/W) |
| S&CC | Smart and Connected Communities |
| SEER | Seasonal Energy Efficiency Ratio |
| SI | International System of Units |
References
- Hong, T.; Yan, D.; D’Oca, S.; Chen, C.-F. Ten questions concerning occupant behavior in buildings: The big picture. Build. Environ. 2017, 114, 518–530. [Google Scholar] [CrossRef]
- Baset, A.; Jradi, M. Data-Driven Decision Support for Smart and Efficient Building Energy Retrofits: A Review. Appl. Syst. Innov. 2024, 8, 5. [Google Scholar] [CrossRef]
- Shu, L.; Zhao, D. Decision-making approach to urban energy retrofit—A comprehensive review. Buildings 2023, 13, 1425. [Google Scholar] [CrossRef]
- Mendes, V.F.; Cruz, A.S.; Gomes, A.P.; Mendes, J.C. A systematic review of methods for evaluating the thermal performance of buildings through energy simulations. Renew. Sustain. Energy Rev. 2024, 189, 113875. [Google Scholar] [CrossRef]
- Pan, Y.; Zhu, M.; Lv, Y.; Yang, Y.; Liang, Y.; Yin, R.; Yang, Y.; Jia, X.; Wang, X.; Zeng, F. Building energy simulation and its application for building performance optimization: A review of methods, tools, and case studies. Adv. Appl. Energy 2023, 10, 100135. [Google Scholar] [CrossRef]
- Gouveia, J.P.; Palma, P. Harvesting big data from residential building energy performance certificates: Retrofitting and climate change mitigation insights at a regional scale. Environ. Res. Lett. 2019, 14, 095007. [Google Scholar] [CrossRef]
- Villanueva-Díaz, C.; Álvarez-Sanz, M.; Campos-Celador, Á.; Terés-Zubiaga, J. The Open Data Potential for the Geospatial Characterisation of Building Stock on an Urban Scale: Methodology and Implementation in a Case Study. Sustainability 2024, 16, 652. [Google Scholar] [CrossRef]
- Shu, L.; Mo, Y.; Zhao, D. Energy retrofits for smart and connected communities: Scopes and technologies. Renew. Sustain. Energy Rev. 2024, 199, 114510. [Google Scholar] [CrossRef]
- U.S. Department of Energy. Weather Data Sources. Available online: https://energyplus.net/weather/sources (accessed on 20 March 2025).
- Zinzi, M.; Carnielo, E.; Mattoni, B. On the relation between urban climate and energy performance of buildings. A three-years experience in Rome, Italy. Appl. Energy 2018, 221, 148–160. [Google Scholar] [CrossRef]
- Yao, J. Uncertainty of building energy performance at spatio-temporal scales: A comparison of aggregated and disaggregated behavior models of solar shade control. Energy 2020, 195, 117079. [Google Scholar] [CrossRef]
- Grillone, B.; Danov, S.; Sumper, A.; Cipriano, J.; Mor, G. A review of deterministic and data-driven methods to quantify energy efficiency savings and to predict retrofitting scenarios in buildings. Renew. Sustain. Energy Rev. 2020, 131, 110027. [Google Scholar] [CrossRef]
- Luo, S.-L.; Shi, X.; Yang, F. A review of data-driven methods in building retrofit and performance optimization: From the perspective of carbon emission reductions. Energies 2024, 17, 4641. [Google Scholar] [CrossRef]
- Manfren, M.; Gonzalez-Carreon, K.M.; James, P.A. Interpretable Data-Driven Methods for Building Energy Modelling—A Review of Critical Connections and Gaps. Energies 2024, 17, 881. [Google Scholar] [CrossRef]
- Imam, S.; Coley, D.A.; Walker, I. The building performance gap: Are modellers literate? Build. Serv. Eng. Res. Technol. 2017, 38, 351–375. [Google Scholar] [CrossRef]
- Shu, L.; Zhao, D.; Zhang, W.; Li, H.; Hong, T. IoT-based retrofit information diffusion in future smart communities. Energy Build. 2025, 338, 115756. [Google Scholar] [CrossRef]
- Alam, S.; Zhang, T.; Feng, T.; Shen, H.; Cao, Z.; Zhao, D.; Ko, J.; Somasundaram, K.; Narayanan, S.S.; Avestimehr, S. FedAIoT: A federated learning benchmark for artificial intelligence of things. J. Data-Centric Mach. Learn. Res. 2024, 1–23. [Google Scholar]
- Sun, Y.; Song, H.; Jara, A.J.; Bie, R. Internet of things and big data analytics for smart and connected communities. IEEE Access 2016, 4, 766–773. [Google Scholar] [CrossRef]
- Marinakis, V.; Doukas, H. An advanced IoT-based system for intelligent energy management in buildings. Sensors 2018, 18, 610. [Google Scholar] [CrossRef]
- Budnikov, M.; Bykova, A.; Yamshchikov, I.P. Generalization potential of large language models. Neural Comput. Appl. 2024, 37, 1973–1997. [Google Scholar] [CrossRef]
- Zhao, H.; Chen, H.; Yang, F.; Liu, N.; Deng, H.; Cai, H.; Wang, S.; Yin, D.; Du, M. Explainability for large language models: A survey. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–38. [Google Scholar] [CrossRef]
- Meng, F.; Lu, Z.; Li, X.; Han, W.; Peng, J.; Liu, X.; Niu, Z. Demand-side energy management reimagined: A comprehensive literature analysis leveraging large language models. Energy 2024, 291, 130303. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, L.; Chen, J.; Chen, W.-A.; Yang, Z.; Lo, L.J.; Wen, J.; O’Neill, Z. Large language models for building energy applications: Opportunities and challenges. In Building Simulation; Springer: Berlin/Heidelberg, Germany, 2025. [Google Scholar]
- Xu, Y.; Zhu, S.; Cai, J.; Chen, J.; Li, S. A large language model-based platform for real-time building monitoring and occupant interaction. J. Build. Eng. 2025, 100, 111488. [Google Scholar] [CrossRef]
- Jiang, G.; Ma, Z.; Zhang, L.; Chen, J. EPlus-LLM: A large language model-based computing platform for automated building energy modeling. Appl. Energy 2024, 367, 123431. [Google Scholar] [CrossRef]
- Hidalgo-Betanzos, J.M.; Prol Godoy, I.; Terés Zubiaga, J.; Briones Llorente, R.; Martín Garin, A. Can ChatGPT AI Replace or Contribute to Experts’ Diagnosis for Renovation Measures Identification? Buildings 2025, 15, 421. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, Z. Opportunities of applying Large Language Models in building energy sector. Renew. Sustain. Energy Rev. 2025, 214, 115558. [Google Scholar] [CrossRef]
- OpenAI. Introducing OpenAI o3 and o4-Mini. 2025. Available online: https://openai.com/index/introducing-o3-and-o4-mini/ (accessed on 20 April 2025).
- Shelley, M. DeepSeek-R1: Advancing Reasoning and Affordability. 2025. Available online: https://medium.com/packt-hub/deepseek-r1-advancing-reasoning-and-affordability-12f1412b0db5 (accessed on 29 March 2025).
- God of Prompt. Is Grok 3 Monitoring Your Social Media? 2025. Available online: https://www.godofprompt.ai/blog/is-grok-3-monitoring-your-social-media (accessed on 2 August 2025).
- Pichai, S.; Hassabis, D.; Kavukcuoglu, K. Introducing Gemini 2.0: Our New AI Model for the Agentic Era. 2024. Available online: https://blog.google/technology/google-deepmind/google-gemini-ai-update-december-2024/ (accessed on 29 March 2025).
- Meta. Llama 3.2: Revolutionizing Edge AI and Vision with Open, Customizable Models. 2024. Available online: https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/ (accessed on 29 March 2025).
- Anthropic. Claude 3.7 Sonnet. 2025. Available online: https://www.anthropic.com/claude/sonnet (accessed on 29 March 2025).
- White, P.R.; Present, E.; Harris, C.; Brossman, J.; Fontanini, A.; Merket, N.; Adhikari, R. ResStock 2024.2 Dataset [Slides]; National Renewable Energy Laboratory (NREL): Golden, CO, USA, 2024. [Google Scholar]
- Crawley, D.B.; Lawrie, L.K.; Winkelmann, F.C.; Buhl, W.F.; Huang, Y.J.; Pedersen, C.O.; Strand, R.K.; Liesen, R.J.; Fisher, D.E.; Witte, M.J. EnergyPlus: Creating a new-generation building energy simulation program. Energy Build. 2001, 33, 319–331. [Google Scholar] [CrossRef]
- NREL. National Residential Efficiency Measures Database. 2018. Available online: https://remdb.nrel.gov/ (accessed on 8 December 2024).
- Marvin, G.; Hellen, N.; Jjingo, D.; Nakatumba-Nabende, J. Prompt engineering in large language models. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics, Tirunelveli, India, 27–28 June 2023; Springer: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Jiang, G.; Ma, Z.; Zhang, L.; Chen, J. Prompt engineering to inform large language model in automated building energy modeling. Energy 2025, 316, 134548. [Google Scholar] [CrossRef]
- Gallagher, S.K.; Ratchford, J.; Brooks, T.; Brown, B.P.; Heim, E.; Nichols, W.R.; Mcmillan, S.; Rallapalli, S.; Smith, C.J.; VanHoudnos, N. Assessing LLMs for High Stakes Applications. In Proceedings of the 46th International Conference on Software Engineering: Software Engineering in Practice, Lisbon, Portugal, 14–20 April 2024. [Google Scholar]
- Majumder, S.; Dong, L.; Doudi, F.; Cai, Y.; Tian, C.; Kalathil, D.; Ding, K.; Thatte, A.A.; Li, N.; Xie, L. Exploring the capabilities and limitations of large language models in the electric energy sector. Joule 2024, 8, 1544–1549. [Google Scholar] [CrossRef]
- Jiang, G.; Chen, J. Efficient fine-tuning of large language models for automated building energy modeling in complex cases. Autom. Constr. 2025, 175, 106223. [Google Scholar] [CrossRef]
- Kyoung, M.; Jeon, H.; Park, S. Automated Knowledge Distillation Pipeline for Domain-Specific Small-Scale Language Models. In Proceedings of the 2024 15th International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 16–18 October 2024; IEEE: New York, NY, USA, 2024. [Google Scholar]
- Chai, S.H.; Chen, I.; Huang, J.; Yacoub, T. Large language model for geotechnical engineering applications using retrieval augmented generation. In Proceedings of the Geotechnical Frontiers 2025, Louisville, Kentucky, 2–5 March 2025; pp. 1–10. [Google Scholar]
- Jiao, T.; Zhang, J.; Xu, K.; Li, R.; Du, X.; Wang, S.; Song, Z. Enhancing Fairness in LLM Evaluations: Unveiling and Mitigating Biases in Standard-Answer-Based Evaluations. In Proceedings of the AAAI Symposium Series, Dubai, United Arab Emirates, 25–27 March 2024. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large language models are zero-shot reasoners. Adv. Neural Inf. Process. Syst. 2022, 35, 22199–22213. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).