_Su.png)
Hybrid Gaussian Process Regression Models for Accurate Prediction of Carbonation-Induced Steel Corrosion in Cementitious Mortars


Abstract
1. Introduction
1.1. Background and Motivation
1.2. Literature Review
1.3. Research Objectives
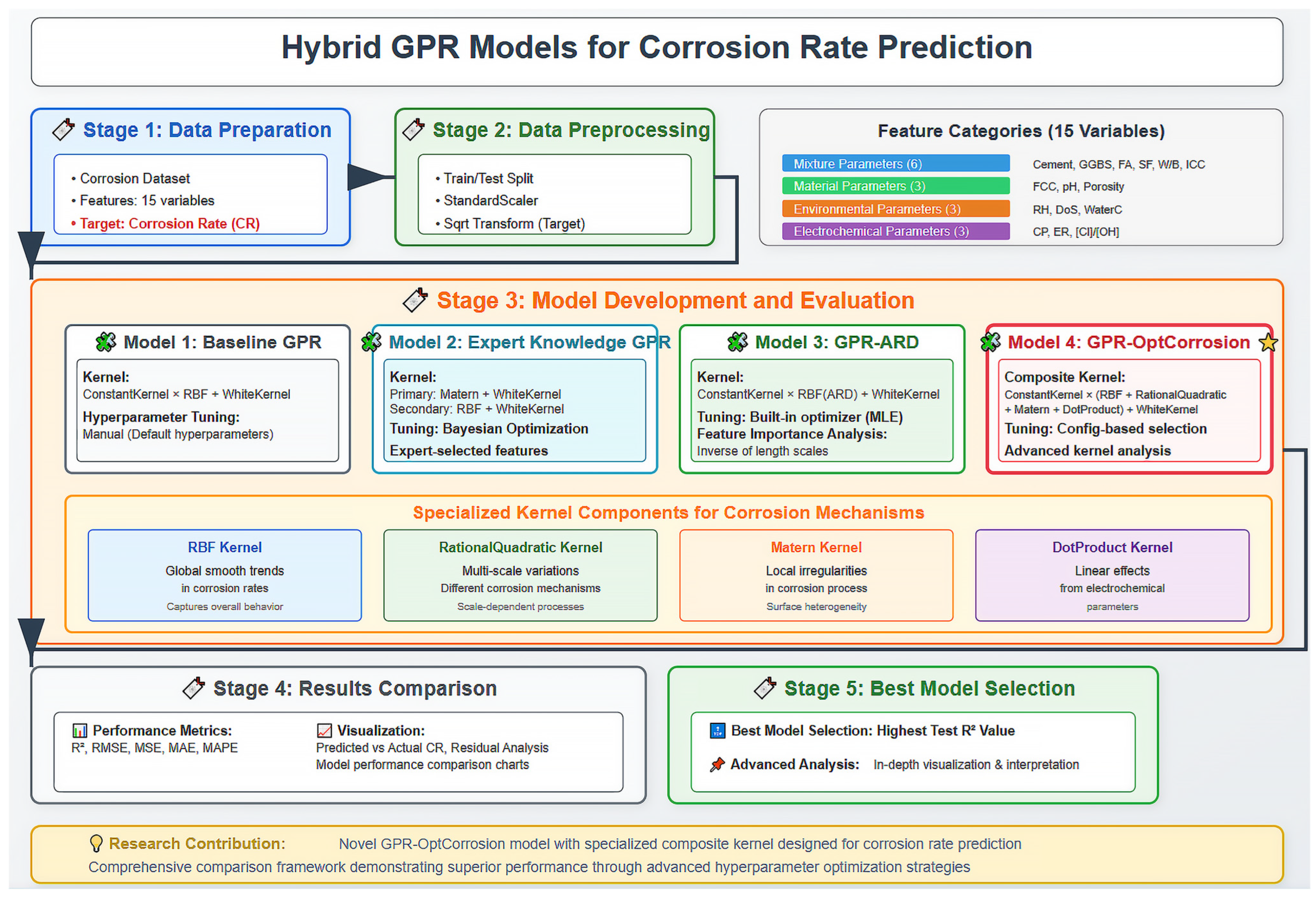
- Development of Domain-Informed GPR Architecture: Create a novel Expert Knowledge GPR model that systematically integrates electrochemical principles with ML capabilities through specialized dual-kernel architecture and feature classification based on mechanistic understanding.
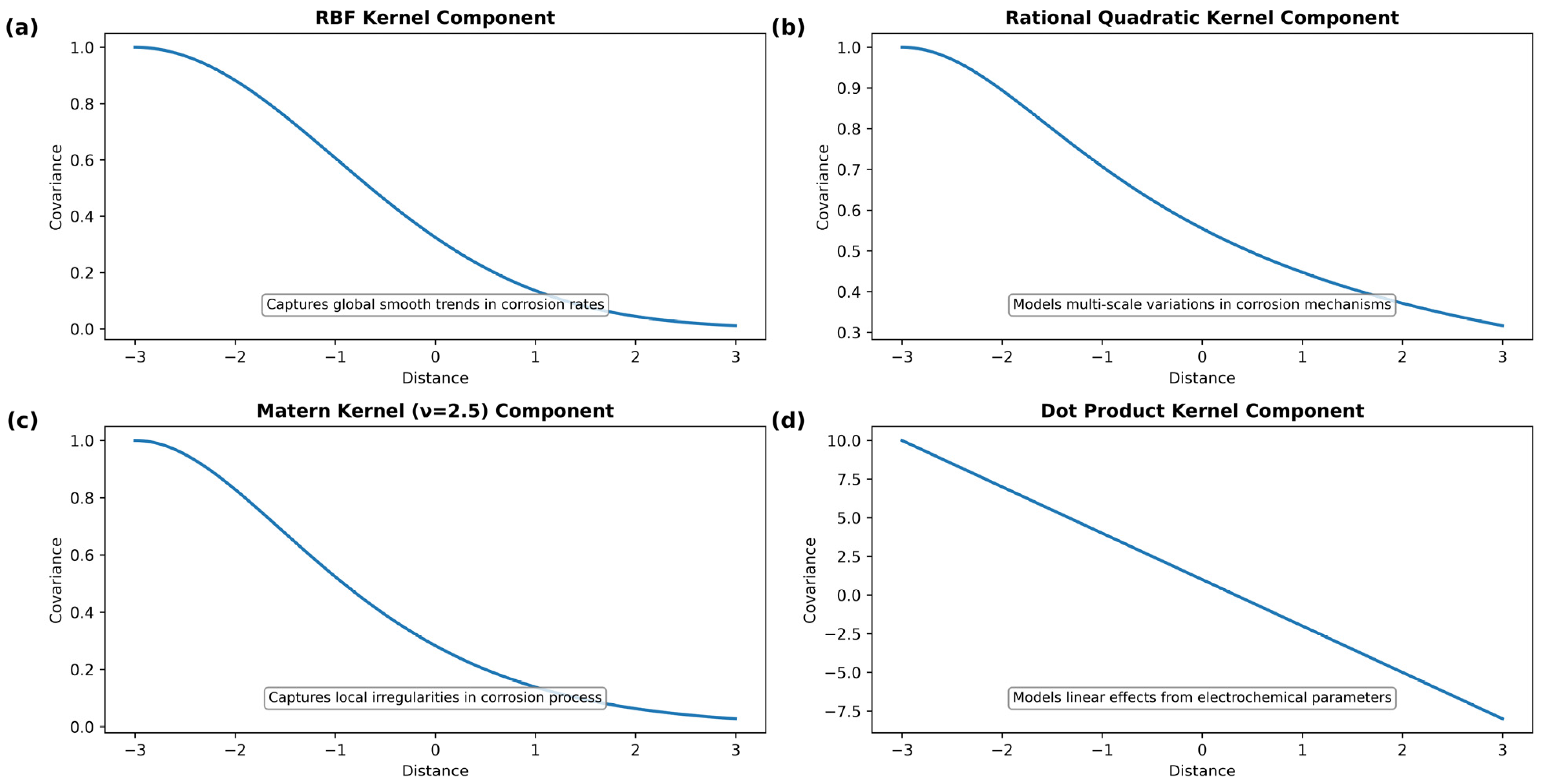
- Advanced Kernel Design for Corrosion Applications: Develop the GPR-OptCorrosion model featuring a specialized composite kernel architecture combining the RBF, RationalQuadratic, Matérn, and DotProduct components to capture multi-scale corrosion phenomena.
- Automatic Feature Relevance Assessment: Implement GPR-ARD methodology to provide quantitative feature importance analysis through ARD, enabling data-driven validation of domain expertise.
- Comprehensive Uncertainty Quantification: Establish a probabilistic prediction framework with inherent uncertainty quantification suitable for risk-informed decision making in corrosion management.
- Systematic Performance Evaluation: Conduct a comprehensive comparison of GPR variants against baseline approaches using multiple performance metrics and statistical validation procedures.
2. Materials and Methods
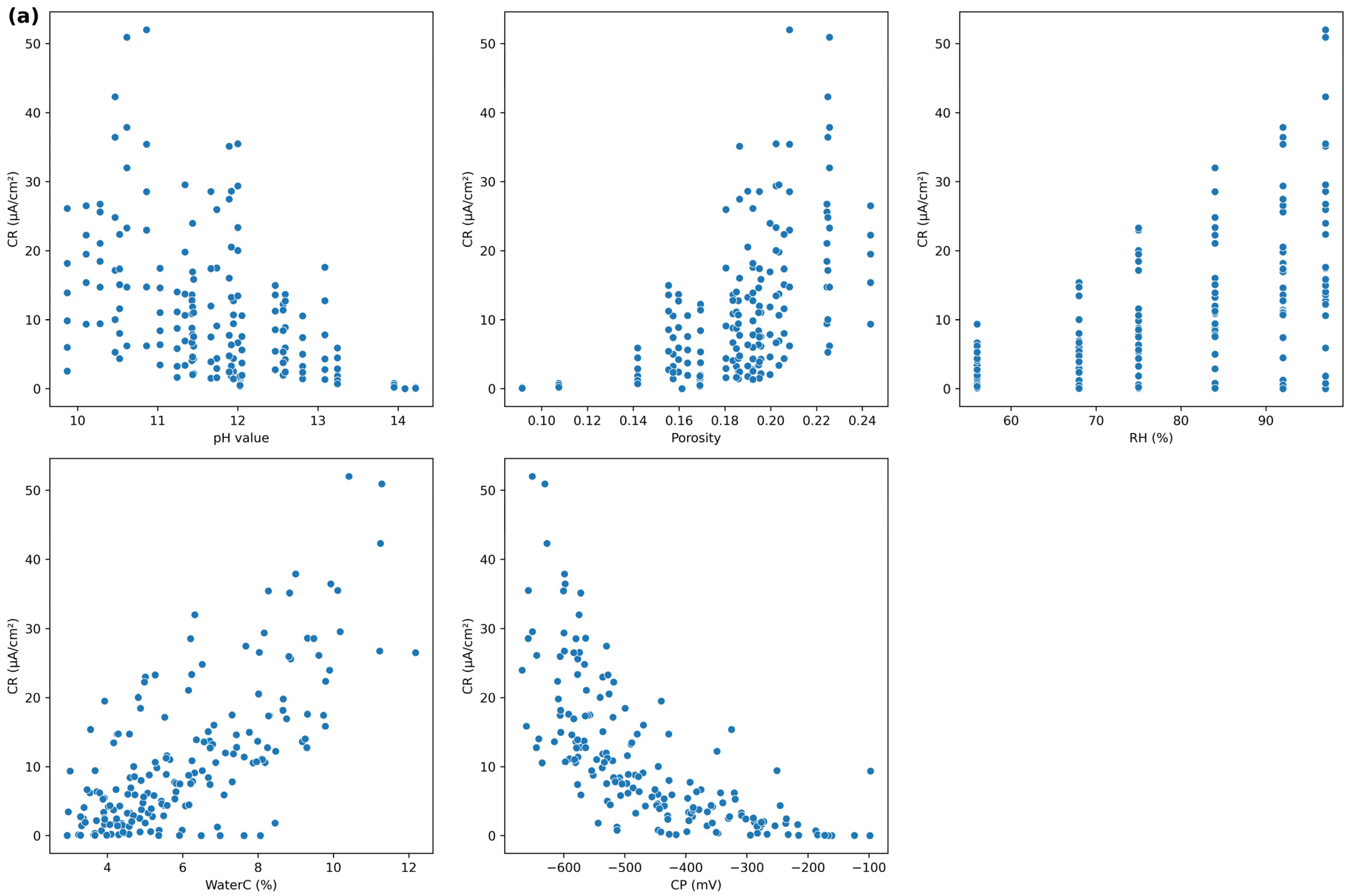
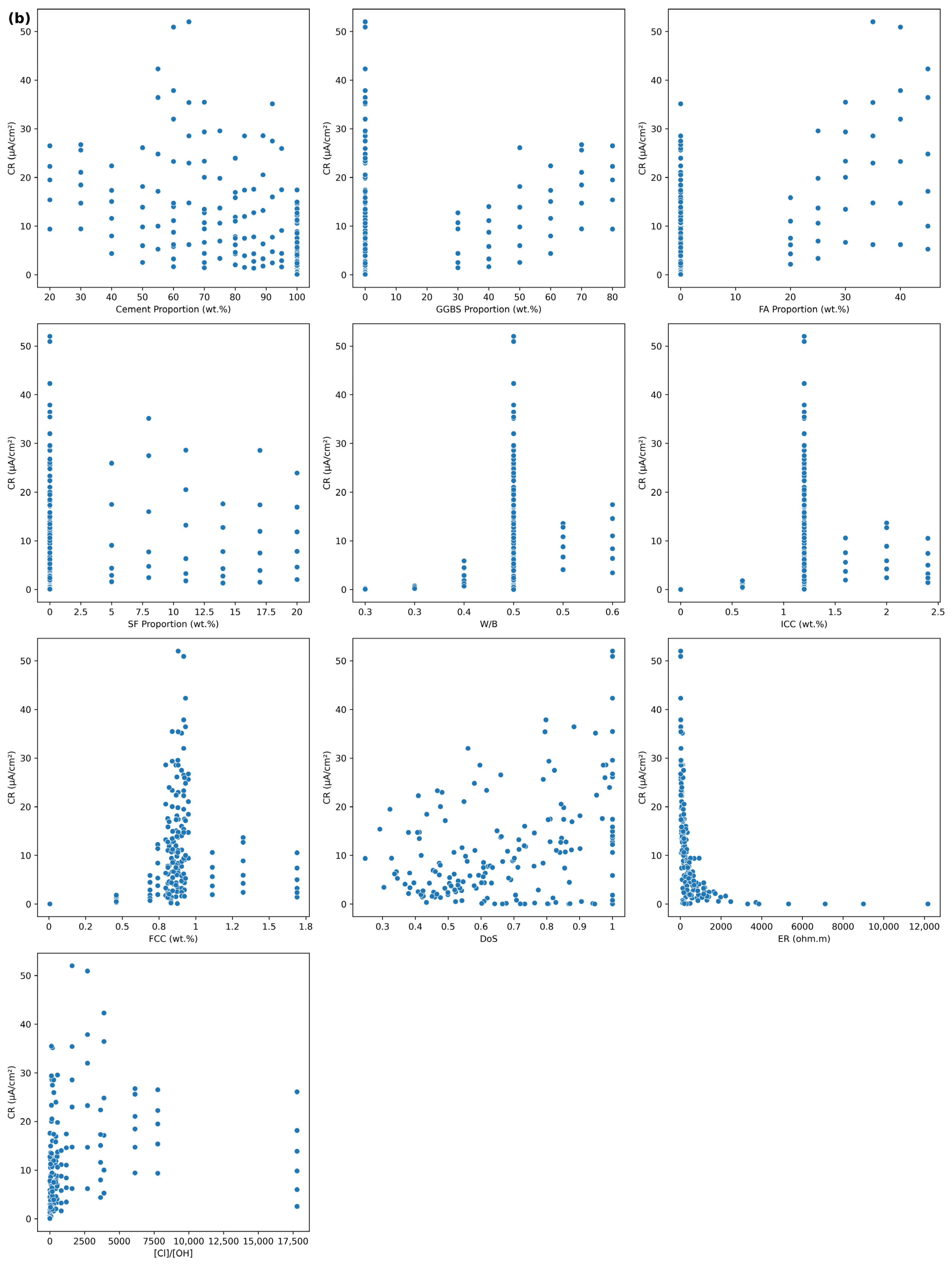
2.1. Experimental Dataset
2.1.1. Data Source and Background
2.1.2. Feature Categorization
2.1.3. Statistical Characteristics
2.2. Data Preprocessing
2.2.1. Dataset Partitioning
2.2.2. Feature Standardization
2.2.3. Target Transformation
2.3. Gaussian Process Regression Framework
2.3.1. Theoretical Foundation
2.3.2. GPR Model Development Strategy
2.4. Performance Evaluation Framework
2.4.1. Performance Assessment Evaluation Metrics
Cross-Validation Strategy
2.4.2. Statistical Testing
2.4.3. Computational Environment
2.5. Baseline Model Comparison
3. Results and Discussion
3.1. Model Performance Comparison
3.1.1. Overall Performance Assessment
3.1.2. Generalization Performance
3.1.3. Computational Efficiency Analysis
3.2. Advanced Model Analysis
3.2.1. Model Performance and Feature Analysis
Expert Knowledge GPR Insights
Feature Importance Revelations
3.2.2. GPR-OptCorrosion Configuration Analysis
3.2.3. Uncertainty Quantification Analysis
3.3. Statistical Validation and Comparative Analysis
3.3.1. Statistical Significance Assessment
3.3.2. Model Selection and Recommendations
4. Implications for Engineering Practice
4.1. Predictive Maintenance Applications
4.2. Design and Construction Considerations
4.3. Research and Development Directions
5. Limitations and Future Work
5.1. Study Limitations
5.2. Future Research Directions
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Baseline GPR Implementation
| Algorithm A1: Gaussian Process Regression |
| Input = Training features X_train, targets y_train, test features X_test, targets y_test Output = Trained model, predictions, uncertainty estimates, performance metrics 1: procedure GPR_Corrosion(X_train, y_train, X_test, y_test) 2: K_const ← ConstantKernel(1.0, bounds=(1 × 10−3, 1 × 103)) 3: K_rbf ← RBF(length_scale=1.0, bounds=(1 × 10−2, 1 × 102)) 4: K_white ← WhiteKernel(noise_level=1 × 10−3, bounds=(1 × 10−5, 1 × 101)) 5: K ← K_const × K_rbf + K_white 6: M ← GaussianProcessRegressor(K, n_restarts_optimizer=10, α=1e-10, normalize_y=true) 7: M.fit(X_train, y_train) 8: ŷ_train, σ_train ← M.predict(X_train, return_std=true) 9: ŷ_test, σ_test ← M.predict(X_test, return_std=true) 10: for each set s ∈ {train, test} do 11: y_true ← y_s 12: y_pred ← ŷ_s 13: R2_s ← calculate_r2(y_true, y_pred) 14: RMSE_s ← √(mean((y_true - y_pred)2)) 15: MAE_s ← mean(|y_true - y_pred|) 16: MAPE_s ← mean(|y_true - y_pred|/|y_true|) 17: MSE_s ← mean((y_true - y_pred)2) 18: end for 19: return M, ŷ_train, ŷ_test, σ_train, σ_test, metrics 20: end procedure |
Appendix A.2. Expert Knowledge GPR Implementation
- Feature Classification and Domain Integration
| Algorithm A2: Expert Knowledge GPR |
| Input = Training features X_train, targets y_train, test features X_test, targets y_test, transform functions, scaler Output = Model ensemble, predictions, performance metrics, model results 1: procedure ExpertKnowledgeGPR(X_train, y_train, X_test, y_test, transform, inverse_transform, scaler) 2: important_features ← ["ER", "CP", "WaterC", "Porosity", "pH"] 3: secondary_features ← [f ∈ X_train.columns | f ∉ important_features] 4: X_train_scaled ← scaler.transform(X_train) 5: X_test_scaled ← scaler.transform(X_test) 6: y_train_transformed ← transform(y_train) 7: primary_indices ← get_indices(important_features, X_train.columns) 8: secondary_indices ← get_indices(secondary_features, X_train.columns) 9: X_train_primary ← X_train_scaled[:, primary_indices] 10: X_train_secondary ← X_train_scaled[:, secondary_indices] 11: X_test_primary ← X_test_scaled[:, primary_indices] 12: X_test_secondary ← X_test_scaled[:, secondary_indices] 13: K_primary_matern ← Matern(length_scale=[1.0] × len(primary_indices), nu=1.5, length_scale_bounds=(1 × 10−3, 1 × 102)) 14: K_primary_white ← WhiteKernel(noise_level=1 × 10−5, noise_level_bounds=(1 × 10−8, 1 × 10−1)) 15: primary_kernel ← K_primary_matern + K_primary_white 16: K_secondary_rbf ← RBF(length_scale=[1.0] × len(secondary_indices), length_scale_bounds=(1 × 10−3, 1 × 102)) 17: K_secondary_white ← WhiteKernel(noise_level=1 × 10−5, noise_level_bounds=(1 × 10−8, 1 × 10−1)) 18: secondary_kernel ← K_secondary_rbf + K_secondary_white 19: primary_model ← optimize_hyperparameters(GPR(primary_kernel), X_train_primary, y_train_transformed, n_iter=20) 20: secondary_model ← optimize_hyperparameters(GPR(secondary_kernel), X_train_secondary, y_train_transformed, n_iter=20) 21: y_train_pred_primary ← primary_model.predict(X_train_primary) 22: y_train_pred_secondary ← secondary_model.predict(X_train_secondary) 23: y_train_pred_combined ← 0.8 × y_train_pred_primary + 0.2 × y_train_pred_secondary 24: y_train_pred ← inverse_transform(y_train_pred_combined) 25: y_test_pred_primary ← primary_model.predict(X_test_primary) 26: y_test_pred_secondary ← secondary_model.predict(X_test_secondary) 27: y_test_pred_combined ← 0.8 × y_test_pred_primary + 0.2 × y_test_pred_secondary 28: y_test_pred ← inverse_transform(y_test_pred_combined) 29: train_metrics ← evaluate_model(y_train, y_train_pred) 30: test_metrics ← evaluate_model(y_test, y_test_pred) 31: results ← create_results_dataframe(train_metrics, test_metrics) 32: raw_metrics ← {train_r2: train_metrics.R2, test_r2: test_metrics.R2, train_rmse: train_metrics.RMSE, test_rmse: test_metrics.RMSE} 33: return {model_name: ‘Expert Knowledge GPR’, y_train_pred: y_train_pred, y_test_pred: y_test_pred, results: results, raw_metrics: raw_metrics} 34: end procedure |
- Dual-Kernel Design
- Optimization and Ensemble Strategy
- Technical Implementation and Computational Efficiency
Appendix A.3. GPR-ARD Implementation
| Algorithm A3: GPR-ARD |
| Input = Training features X_train, targets y_train, test features X_test, targets y_test, transform functions, scaler Output = Trained ARD model, predictions, feature importance rankings, performance metrics 1: procedure GPR_ARD(X_train, y_train, X_test, y_test, transform, inverse_transform, scaler) 2: X_train_scaled ← scaler.transform(X_train) 3: X_test_scaled ← scaler.transform(X_test) 4: y_train_transformed ← transform(y_train) 5: n_features ← X_train_scaled.shape[1] 6: K_const ← ConstantKernel(1.0, bounds=(1 × 10−2, 1 × 102)) 7: K_rbf ← RBF(length_scale = ones(n_features), bounds = (1 × 10−3, 1 × 103)) 8: K_white ← WhiteKernel(noise_level = 1 × 10−5, bounds = (1 × 10−8, 1 × 10−1)) 9: ard_kernel ← K_const × K_rbf + K_white 10: gpr_ard ← GaussianProcessRegressor(kernel = ard_kernel, normalize_y = True, n_restarts_optimizer = 25, random_state = 42) 11: gpr_ard.fit(X_train_scaled, y_train_transformed) 12: length_scales ← gpr_ard.kernel_.k1.k2.length_scale 13: importance_scores ← 1.0/length_scales 14: normalized_importance ← importance_scores/sum(importance_scores) 15: y_train_pred_transformed ← gpr_ard.predict(X_train_scaled) 16: y_test_pred_transformed ← gpr_ard.predict(X_test_scaled) 17: y_train_pred ← inverse_transform(y_train_pred_transformed) 18: y_test_pred ← inverse_transform(y_test_pred_transformed) 19: feature_importance ← create_dataframe(features, length_scales, normalized_importance) 20: metrics ← evaluate_model(y_train, y_train_pred, y_test, y_test_pred) 21: return gpr_ard, y_train_pred, y_test_pred, feature_importance, metrics 22: end procedure |
- Implementation and Optimization
- Advanced Feature Analysis Framework
Appendix A.4. GPR-OptCorrosion Implementation
| Algorithm A4: GPR-OptCorrosion |
| Input = Training features X_train, targets y_train, test features X_test, targets y_test, transform functions, scaler Output = Best trained model, predictions, performance metrics, optimal configuration 1: procedure GPR_OptCorrosion(X_train, y_train, X_test, y_test, transform, inverse_transform, scaler) 2: X_train_scaled ← scaler.transform(X_train) 3: X_test_scaled ← scaler.transform(X_test) 4: y_train_transformed ← transform(y_train) 5: n_features ← X_train_scaled.shape[1] 6: function create_corrosion_kernel(params) 7: rbf_length_scale ← ones(n_features) × params.rbf_length_scale_init 8: K_const ← ConstantKernel(1.0) 9: K_rbf ← RBF(length_scale=rbf_length_scale, bounds=(1 × 10−3, 1 × 103)) 10: K_rq ← RationalQuadratic(length_scale=params.rq_length_scale, alpha=params.rq_alpha, 11: length_scale_bounds=(1 × 10−3, 1 × 103), alpha_bounds=(1 × 10−2, 2.0)) 12: K_matern ← Matern(length_scale=params.matern_length_scale, nu=params.matern_nu, 13: length_scale_bounds=(1 × 10−3, 1 × 103)) 14: K_dot ← DotProduct(sigma_0=params.dot_sigma0, sigma_0_bounds=(1 × 10−3, 1 × 103)) 15: K_white ← WhiteKernel(noise_level=params.noise_level, noise_level_bounds=(1 × 10−10, 1 × 10−2)) 16: return K_const × (K_rbf + K_rq + K_matern + K_dot) + K_white 17: end function 18: configs ← [ 19: {rbf_length_scale_init=1.0, rq_length_scale=1.0, rq_alpha=0.5, matern_length_scale=1.0, matern_nu=1.5, dot_sigma0=1.0, noise_level=1 × 10−5}, 20: {rbf_length_scale_init=2.0, rq_length_scale=2.0, rq_alpha=0.5, matern_length_scale=2.0, matern_nu=2.5, dot_sigma0=1.0, noise_level=1 × 10−5}, 21: {rbf_length_scale_init=1.0, rq_length_scale=1.0, rq_alpha=0.5, matern_length_scale=1.0, matern_nu=0.5, dot_sigma0=1.0, noise_level=1 × 10−5}, 22: {rbf_length_scale_init=1.0, rq_length_scale=1.0, rq_alpha=1.5, matern_length_scale=1.0, matern_nu=1.5, dot_sigma0=1.0, noise_level=1 × 10−5}, 23: {rbf_length_scale_init=1.0, rq_length_scale=1.0, rq_alpha=0.5, matern_length_scale=1.0, matern_nu=1.5, dot_sigma0=3.0, noise_level=1 × 10−5}, 24: {rbf_length_scale_init=0.8, rq_length_scale=1.2, rq_alpha=0.8, matern_length_scale=0.9, matern_nu=1.5, dot_sigma0=2.0, noise_level=1 × 10−6} 25: ] 26: best_model ← null, best_test_r2 ← –∞, best_config ← null 27: best_train_pred ← null, best_test_pred ← null 28: for each config in configs do 29: try 30: kernel ← create_corrosion_kernel(config) 31: model ← GaussianProcessRegressor(kernel=kernel, normalize_y=False, n_restarts_optimizer=10, random_state=42) 32: model.fit(X_train_scaled, y_train_transformed) 33: y_train_pred_transformed ← model.predict(X_train_scaled) 34: y_test_pred_transformed ← model.predict(X_test_scaled) 35: y_train_pred ← inverse_transform(y_train_pred_transformed) 36: y_test_pred ← inverse_transform(y_test_pred_transformed) 37: test_r2 ← calculate_r2(y_test, y_test_pred) 38: if test_r2 > best_test_r2 then 39: best_model ← model, best_test_r2 ← test_r2 40: best_config ← config 41: best_train_pred ← y_train_pred, best_test_pred ← y_test_pred 42: end if 43: catch exception 44: continue to next config 45: end try 46: end for 47: metrics ← evaluate_model(y_train, best_train_pred, y_test, best_test_pred) 48: return best_model, best_train_pred, best_test_pred, metrics, best_config 49: end procedure |
- Composite Kernel Design
- RBF kernels model smooth, diffusion-controlled electrochemical processes for continuous relationships between environmental parameters and corrosion rates;
- RationalQuadratic kernels capture multi-scale variations from atomic-level reactions to macroscopic transport phenomena inherent in concrete systems;
- DotProduct kernels encode linear thermodynamic relationships between driving forces and corrosion kinetics, capturing direct proportionality effects from fundamental thermodynamic relationships.
- Configuration-Based Optimization Strategy
- Implementation and Computational Considerations
- Advanced Analysis Framework
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Kernel | Parameter Tuning | Transformation | Feature Engineering | Uncertainty Quantification |
|---|---|---|---|---|---|
| Baseline GPR | RBF + WhiteKernel | Manual | None | Basic | Basic |
| Expert Knowledge GPR | Matern + RBF | Bayesian Optimization * | Square Root | Expert-guided | Intermediate |
| GPR-ARD | ARD | Built-in optimizer † | Square Root | Automatic | Advanced |
| GPR-OptCorrosion | Multi-kernel | Config-based selection ‡ | Square Root | Comprehensive | Comprehensive |
Appendix C
| Model | Key Parameters | Preprocessing |
|---|---|---|
| SVR (RBF) | C = 1.0, gamma = ‘scale’ | StandardScaler (X,y) |
| SVR (Linear) | C = 1.0, kernel = ‘linear’ | StandardScaler (X,y) |
| Random Forest | n_estimators = 100, random_state = 42 | None |
| ANN (MLP) | hidden_layers = (100,50), max_iter = 1000, early_stopping = True | StandardScaler (X,y) |
| Gradient Boosting | n_estimators = 100, learning_rate = 0.1, max_depth = 3 | None |
| XGBoost | n_estimators = 100, learning_rate = 0.3, max_depth = 6 | None |
| Baseline GPR | Composite kernel, n_restarts = 10, alpha = 1 × 10−10 | None |
References
- Ji, H.; Ye, H. Machine learning prediction of corrosion rate of steel in carbonated cementitious mortars. Cem. Concr. Compos. 2023, 143, 105256. [Google Scholar] [CrossRef]
- Taffese, W.Z.; Sistonen, E. Machine learning for durability and service-life assessment of reinforced concrete structures: Recent advances and future directions. Autom. Constr. 2017, 77, 1–14. [Google Scholar] [CrossRef]
- Elsener, B.; Angst, U. Corrosion of steel in concrete: New challenges. In Encyclopedia of Interfacial Chemistry; Wandelt, K., Ed.; Elsevier: Amsterdam, The Netherlands, 2018; pp. 183–191. [Google Scholar] [CrossRef]
- Yu, Y.; Dong, B.; Gao, W.; Sofi, A. Physics-based stochastic aging corrosion analysis assisted by machine learning. Probab. Eng. Mech. 2022, 69, 103270. [Google Scholar] [CrossRef]
- Stefanoni, M.; Angst, U.; Elsener, B. Corrosion rate of carbon steel in carbonated concrete—A critical review. Cem. Concr. Res. 2018, 103, 35–48. [Google Scholar] [CrossRef]
- Ramirez, D.E.A.; Meira, G.R.; Quattrone, M.; John, V.M. A review on reinforcement corrosion propagation in carbonated concrete–Influence of material and environmental characteristics. Cem. Concr. Compos. 2023, 140, 105085. [Google Scholar] [CrossRef]
- Šavija, B.; Luković, M. Carbonation of cement paste: Understanding, challenges, and opportunities. Constr. Build. Mater. 2016, 117, 285–301. [Google Scholar] [CrossRef]
- Cheng, L.; Maruyama, I. A prediction method for the corrosion rate of steel rebar in carbonated mortar under variable environmental conditions. J. Adv. Concr. Technol. 2023, 21, 611–630. [Google Scholar] [CrossRef]
- Wan, L.S.; Hirata, M.; Oyamoto, T.; Kanda, T.; Tan, K.H. Synergistic Impact of Temperature and Pore Saturation on Corrosion in Carbonated Reinforced Concrete. Case Stud. Constr. Mater. 2025, 22, e04364. [Google Scholar] [CrossRef]
- Yu, B.; Yang, L.; Wu, M.; Li, B. Practical model for predicting corrosion rate of steel reinforcement in concrete structures. Constr. Build. Mater. 2014, 54, 385–401. [Google Scholar] [CrossRef]
- Rodrigues, R.; Gaboreau, S.; Gance, J.; Ignatiadis, I.; Betelu, S. Reinforced concrete structures: A review of corrosion mechanisms and advances in electrical methods for corrosion monitoring. Constr. Build. Mater. 2021, 269, 121240. [Google Scholar] [CrossRef]
- Otieno, M.; Beushausen, H.; Alexander, M. Prediction of corrosion rate in reinforced concrete structures–a critical review and preliminary results. Mater. Corros. 2012, 63, 777–790. [Google Scholar] [CrossRef]
- Jiang, Z.; Li, S.; Fu, C.; Dong, Z.; Zhang, X.; Jin, N.; Xia, T. Macrocell corrosion of steel in concrete under carbonation, internal chloride admixing and accelerated chloride penetration conditions. Materials 2021, 14, 7691. [Google Scholar] [CrossRef]
- Coelho, L.B.; Zhang, D.; Van Ingelgem, Y.; Steckelmacher, D.; Nowé, A.; Terryn, H. Reviewing machine learning of corrosion prediction in a data-oriented perspective. Npj Mater. Degrad. 2022, 6, 8. [Google Scholar] [CrossRef]
- Wang, Z.; Sobey, A.J.; Wang, Y. Corrosion prediction for bulk carrier via data fusion of survey and experimental measurements. Mater. Des. 2021, 208, 109910. [Google Scholar] [CrossRef]
- Yan, L.; Diao, Y.; Gao, K. Analysis of environmental factors affecting the atmospheric corrosion rate of low-alloy steel using random forest-based models. Materials 2020, 13, 3266. [Google Scholar] [CrossRef]
- Chou, J.S.; Ngo, N.T.; Chong, W.K. The use of artificial intelligence combiners for modeling steel pitting risk and corrosion rate. Eng. Appl. Artif. Intell. 2017, 65, 471–483. [Google Scholar] [CrossRef]
- Ji, H.; Tian, Y.; Fu, C.; Ye, H. Transfer learning enables prediction of steel corrosion in concrete under natural environments. Cem. Concr. Compos. 2024, 148, 105488. [Google Scholar] [CrossRef]
- Tian, Z.; Kang, X.; Ji, H.; Ye, H. Quantitative relationship between microstructure of steel-concrete interface and chloride-induced corrosion rate of steel in unsaturated cementitious materials. Cem. Concr. Res. 2025, 188, 107736. [Google Scholar] [CrossRef]
- Hosseinnia, A.; Sichani, M.N.; Alamdari, B.E.; Aghelizadeh, P.; Teimortashlu, A. Machine learning formulation for predicting concrete carbonation depth: A sustainability analysis and optimal mixture design. Structures 2025, 76, 109036. [Google Scholar] [CrossRef]
- Mei, K.; He, Z.; Yi, B.; Lin, X.; Wang, J.; Wang, H.; Liu, J. Study on electrochemical characteristics of reinforced concrete corrosion under the action of carbonation and chloride. Case Stud. Constr. Mater. 2022, 17, e01351. [Google Scholar] [CrossRef]
- Sagar, C.; Chauhan, A.; Sharma, U.K. Synergistic effect of carbonation and cast-in-chlorides on corrosion initiation in reinforced concrete. Structures 2025, 72, 108264. [Google Scholar] [CrossRef]
- Ji, H.; Ye, H. Dataset on carbonation and chloride-induced steel corrosion in cementitious mortars. Data Brief. 2024, 55, 110595. [Google Scholar] [CrossRef] [PubMed]
- Khalaf, A.A.; Kopecskó, K. Modelling of Modulus of Elasticity of Low-Calcium-Based Geopolymer Concrete Using Regression Analysis. Adv. Mater. Sci. Eng. 2022, 2022, 4528264. [Google Scholar] [CrossRef]
- Biswal, U.S.; Dinakar, P. Evaluating corrosion resistance of recycled aggregate concrete integrating ground granulated blast furnace slag. Constr. Build. Mater. 2023, 370, 130676. [Google Scholar] [CrossRef]
- Köliö, A.; Honkanen, M.; Lahdensivu, J.; Vippola, M.; Pentti, M. Corrosion products of carbonation induced corrosion in existing reinforced concrete facades. Cem. Concr. Res. 2015, 78, 200–207. [Google Scholar] [CrossRef]
- De Belie, N.; Bernal, S. Closing Letter of RILEM TC 281-CCC: Carbonation of Concrete with Supplementary Cementitious Materials. RILEM Tech. Lett. 2025, 10, 22–32. [Google Scholar] [CrossRef]
- Guo, R.; Guo, Z.; Yao, G.; Jin, Y.; Liu, Z. Hybrid prediction model for reinforcements’ corrosion stage by multiple nondestructive electrochemical indices. J. Build. Eng. 2024, 82, 108327. [Google Scholar] [CrossRef]
- Keo, S.A.; De Larrard, T.; Duprat, F.; Geoffroy, S. Enhancement of predictive bayesian network model for corrosion alarm of steel reinforcement with uncertainty of NDT measurements. J. Nondestruct. Eval. 2023, 42, 51. [Google Scholar] [CrossRef]
- Du, Z.; Wang, P.; Chen, Z.; Cui, D.; Jin, Z.; Zhang, H. All-solid-state, long term stable, and embedded pH sensor for corrosion monitoring of concrete. J. Build. Eng. 2022, 57, 104978. [Google Scholar] [CrossRef]
- Cheng, L.; Maruyama, I.; Ren, Y. Novel accelerated test method for RH dependency of steel corrosion in carbonated mortar. J. Adv. Concr. Technol. 2021, 19, 207–215. [Google Scholar] [CrossRef]
- Tiwari, A.; Goyal, S.; Luxami, V.; Chakraborty, M.K.; Gundlapalli, P. Evaluation of inhibition efficiency of generic compounds with additional heteroatom in simulated concrete pore solution and migration potential in concrete. J. Build. Eng. 2021, 43, 102490. [Google Scholar] [CrossRef]
- Tiwari, A.K.; Goyal, S.; Luxami, V. Influence of corrosion inhibitors on two different concrete systems under combined chloride and carbonated environment. Structures 2023, 48, 717–735. [Google Scholar] [CrossRef]
- Ji, H.; Lyu, Y.; Tian, Z.; Ye, H. Assessment of corrosion probability of steel in mortars using machine learning. Reliab. Eng. Syst. Saf. 2025, 253, 110535. [Google Scholar] [CrossRef]
- Chang, H. Chloride binding capacity of pastes influenced by carbonation under three conditions. Cem. Concr. Compos. 2017, 84, 1–9. [Google Scholar] [CrossRef]
- Gopinath, R.; Alexander, M.; Beushausen, H. Single-parameter concrete carbonation model for varying environmental exposure conditions. Mater. Struct. 2025, 58, 21. [Google Scholar] [CrossRef]
- Tassos, C.; Sideris, K.K.; Chatzopoulos, A.; Tzanis, E.; Katsiotis, M.S. Influence of the type of cement on the durability of concrete structures exposed to various carbonation environments in Greece: A contribution to the sustainability of structures. Constr. Mater. 2023, 3, 14–35. [Google Scholar] [CrossRef]
- Yoon, I.S.; Chang, C.H. Effect of chloride on electrical resistivity in carbonated and non-carbonated concrete. Appl. Sci. 2020, 10, 6272. [Google Scholar] [CrossRef]
- Zeng, Z.; Ying, G.; Zhang, Y.; Gong, Y.; Mei, Y.; Li, X.; Li, S. Classification of failure modes, bearing capacity, and effective stiffness prediction for corroded RC columns using machine learning algorithm. J. Build. Eng. 2025, 102, 111982. [Google Scholar] [CrossRef]
- Jedidi, M. Carbonation of Concrete: Measurement and Repair. Civ. Eng. Archit. 2024, 12, 3664–3674. [Google Scholar] [CrossRef]
- Dong, W.; Huang, Y.; Lehane, B.; Ma, G. XGBoost algorithm-based prediction of concrete electrical resistivity for structural health monitoring. Autom. Constr. 2020, 114, 103155. [Google Scholar] [CrossRef]
- Cao, L.; Zhang, D.; Li, X.; Fan, Z.; Cao, Y. Prediction of Corrosion Rate in Carbon Dioxide Pipeline Based on KPCA–BP. J. Pipeline Syst. Eng. Pract. 2025, 16, 04025001. [Google Scholar] [CrossRef]
- Jabed, A.; Tusher, M.M.H.; Shuvo, M.S.I.; Imam, A. Corrosion of Steel Rebar in concrete: A review. Corros. Sci. Technol. 2023, 22, 273–286. [Google Scholar] [CrossRef]
- Chen, L.; Su, R.K.L. Effect of high rebar temperature during casting on corrosion in carbonated concrete. Constr. Build. Mater. 2020, 249, 118718. [Google Scholar] [CrossRef]
- Li, G.; Evitts, R.; Boulfiza, M. Interactive effects of moisture, chloride, and carbonation on rebar corrosion in mortar. Constr. Build. Mater. 2024, 440, 137440. [Google Scholar] [CrossRef]
- Poursaee, A.; Angst, U.M. Principles of corrosion of steel in concrete structures. In Corrosion of Steel in Concrete Structures, 2nd ed.; Poursaee, A., Ed.; Woodhead Publishing: Cambridge, UK, 2023; pp. 17–34. [Google Scholar] [CrossRef]


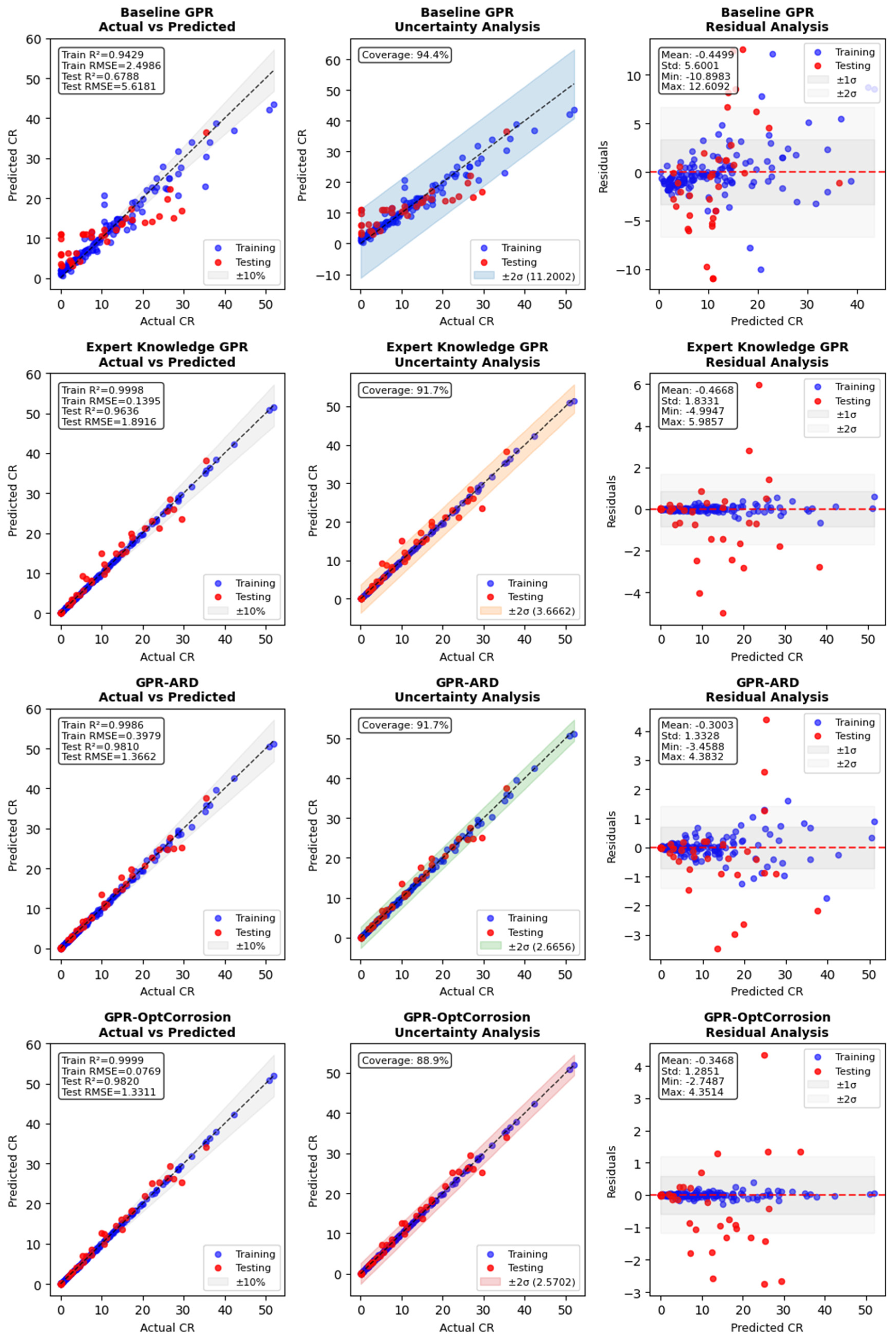
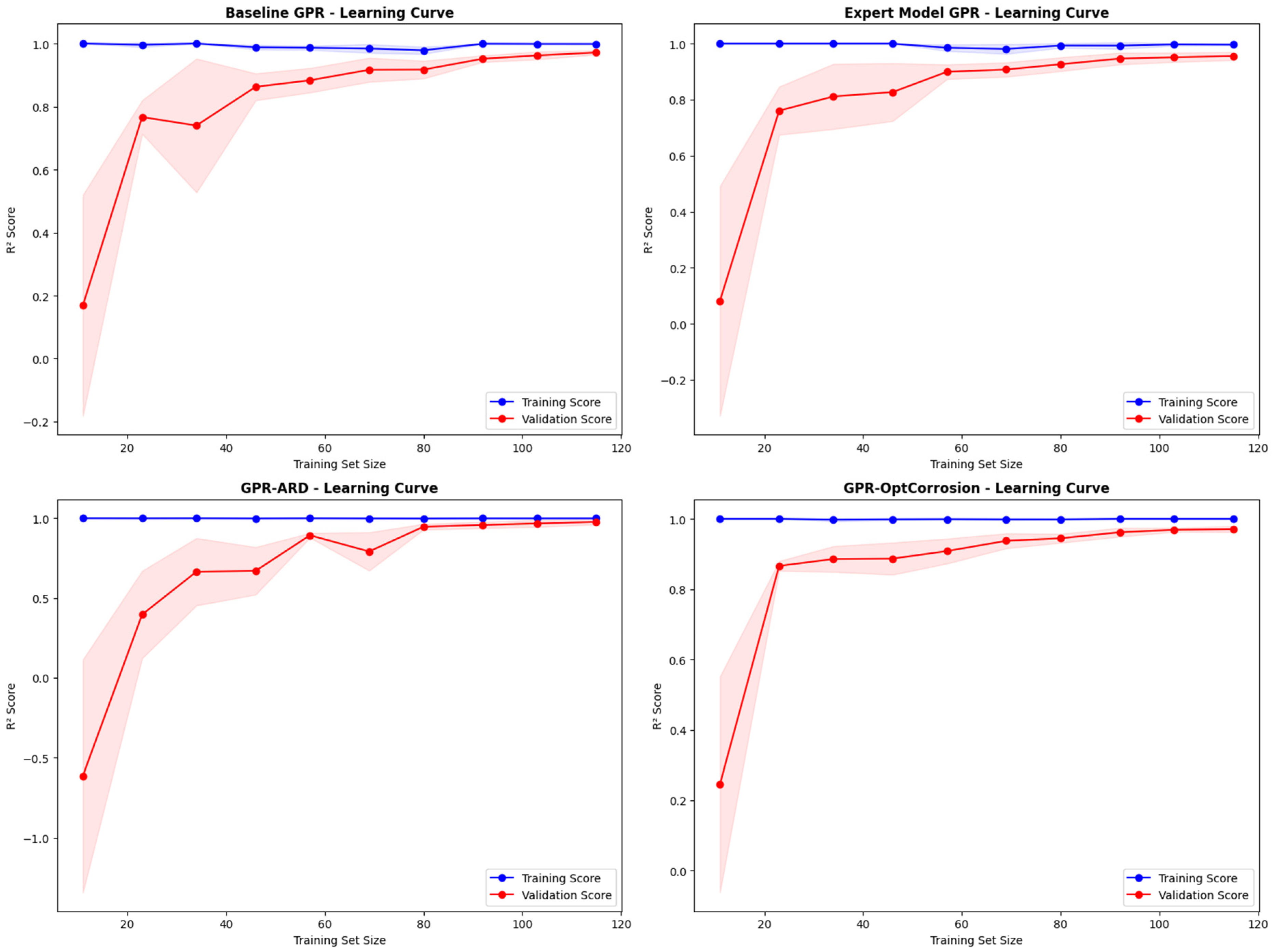
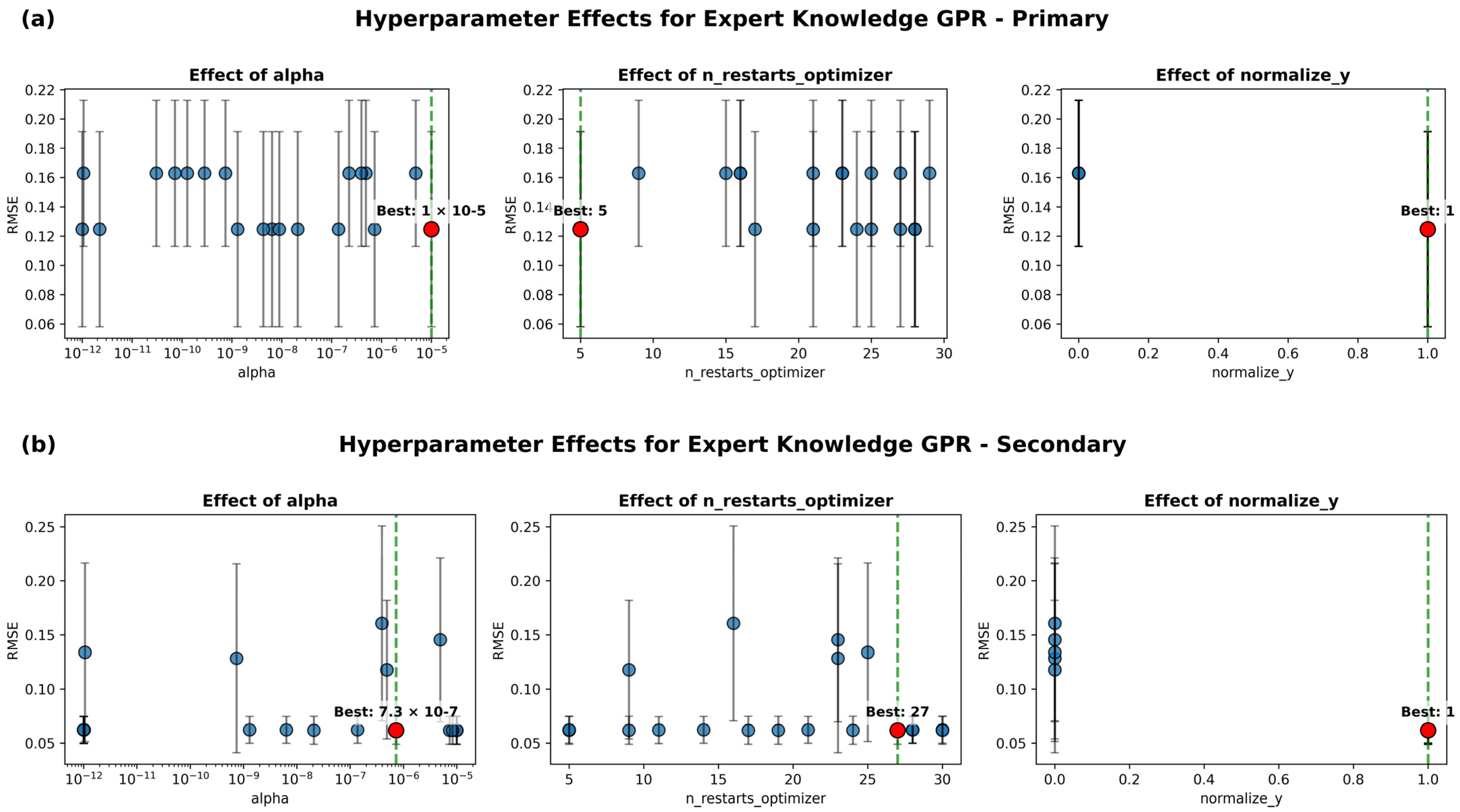
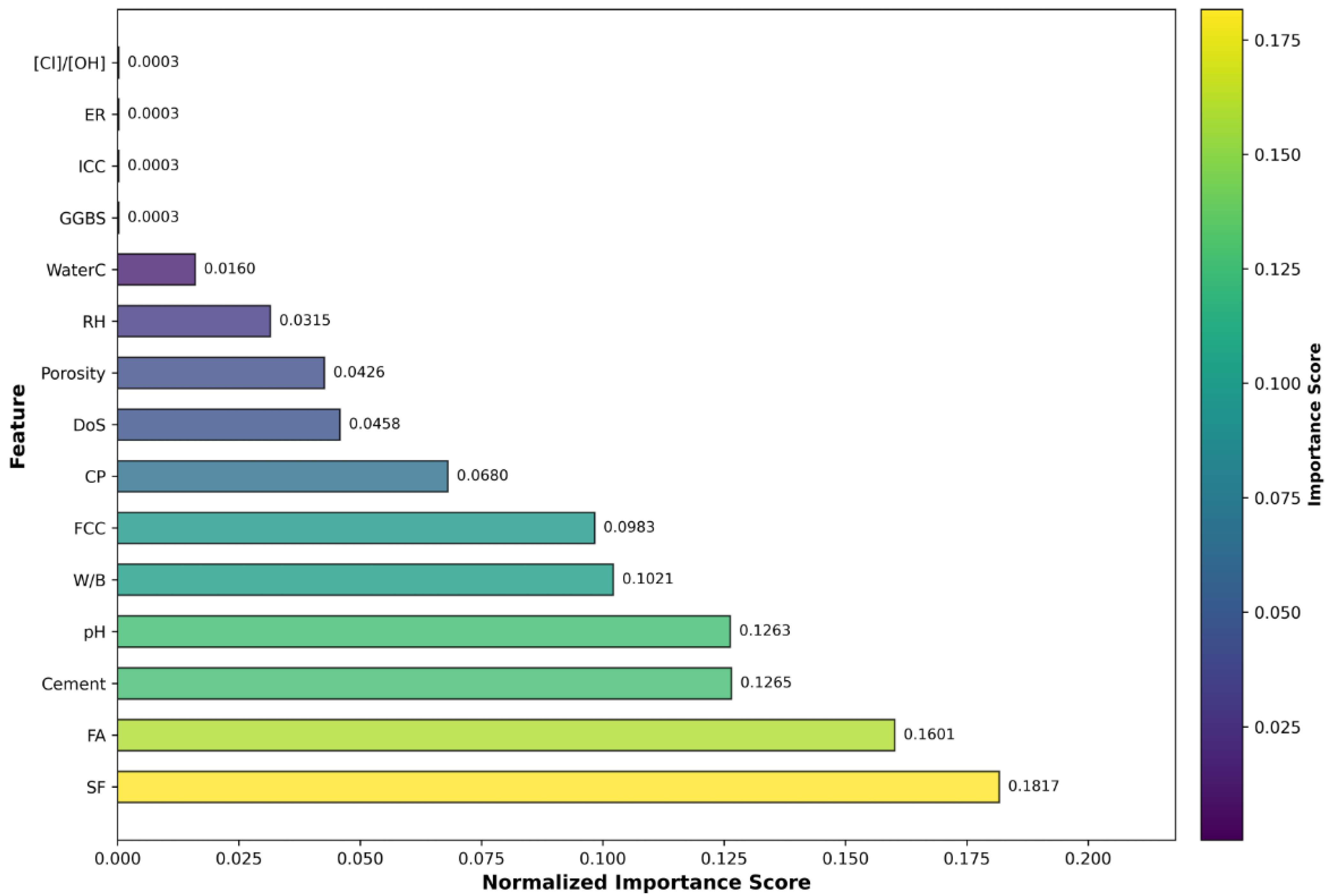
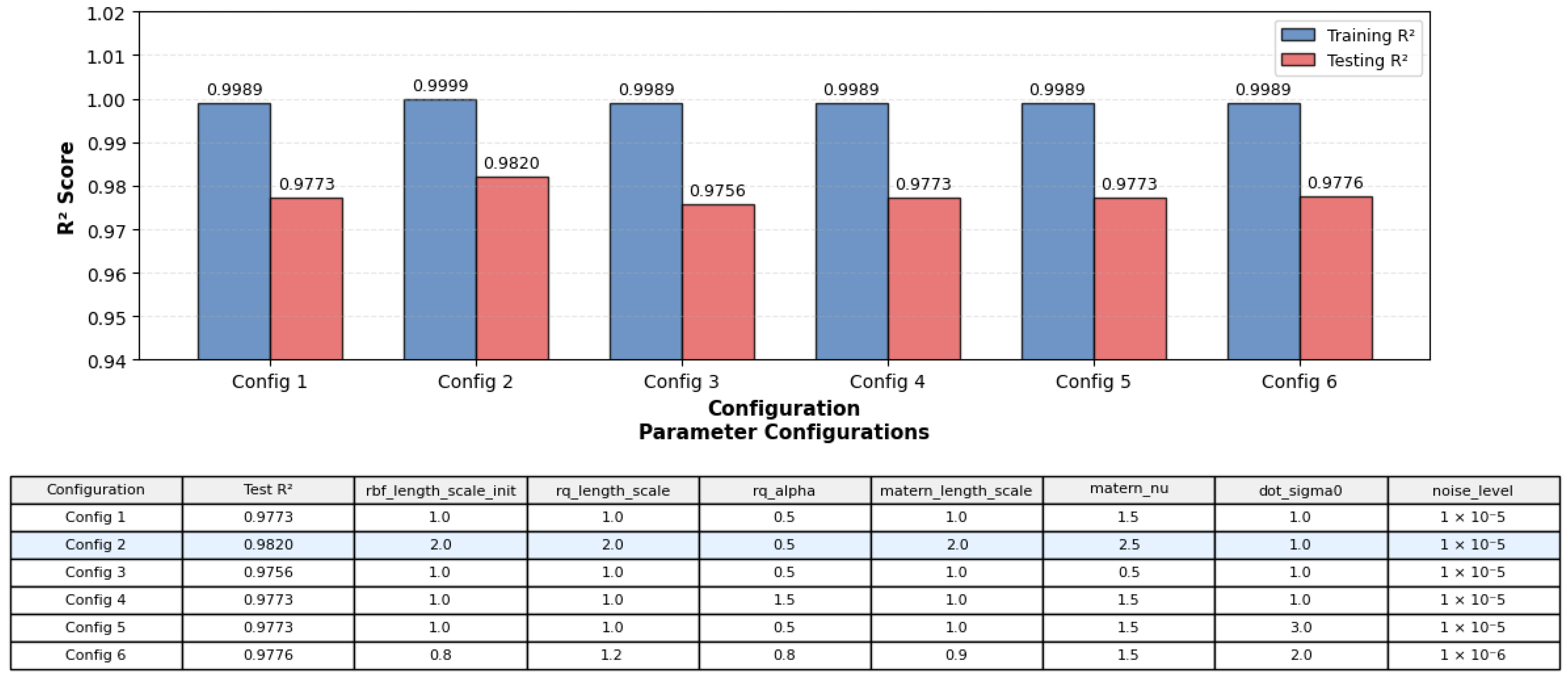
| Model | Model Type | Dataset | R2 | RMSE | MSE | MAE | MAPE | Time (s) | Generalization Gap † |
|---|---|---|---|---|---|---|---|---|---|
| Baseline GPR | Basic GPR | Train | 0.9429 | 2.4986 | 6.2430 | 1.5955 | 3.4403 | 0.0029 | 0.2641 |
| Test | 0.6788 | 5.6181 | 31.5630 | 4.2872 | 67.8656 | 0.0020 | |||
| Expert Knowledge GPR | Advanced | Train | 0.9998 | 0.1395 | 0.0195 | 0.0810 | 0.0110 | 0.0023 | 0.0362 |
| GPR | Test | 0.9636 | 1.8916 | 3.5782 | 1.1844 | 0.1787 | 0.0011 | ||
| GPR-ARD | Advanced | Train | 0.9986 | 0.3979 | 0.1583 | 0.2376 | 0.0300 | 0.0010 | 0.0176 |
| GPR | Test | 0.9810 | 1.3662 | 1.8665 | 0.8063 | 0.0974 | 0.0004 | ||
| GPR-OptCorrosion | Advanced | Train | 0.9999 | 0.0769 | 0.0059 | 0.0494 | 0.0083 | 0.0043 | 0.0179 |
| GPR | Test | 0.9820 | 1.3311 | 1.7718 | 0.8926 | 0.1630 | 0.0016 | ||
| XGBoost | Ensemble | Train | 0.9999 | 0.0010 | 0.0001 | 0.0007 | 0.0018 | 0.2449 | 0.1061 |
| Test | 0.8938 | 3.2297 | 10.4311 | 2.0162 | 0.7185 | 0.0120 | |||
| Gradient | Ensemble | Train | 0.9977 | 0.5043 | 0.2543 | 0.3951 | 0.3098 | 0.1639 | 0.1242 |
| Boosting | Test | 0.8735 | 3.5256 | 12.4301 | 2.3536 | 1.0137 | 0.0020 | ||
| Random Forest | Ensemble | Train | 0.9809 | 1.4453 | 2.0888 | 0.9147 | 0.8101 | 0.2899 | 0.1899 |
| Test | 0.7910 | 4.5315 | 20.5349 | 3.0997 | 3.2321 | 0.0170 | |||
| ANN (MLP) | Neural | Train | 0.9441 | 2.4710 | 6.1061 | 1.5244 | 1.8705 | 0.2049 | 0.1567 |
| Network | Test | 0.7875 | 4.5698 | 20.8828 | 3.0788 | 9.7160 | |||
| SVR (RBF) | Kernel | Train | 0.9149 | 3.0491 | 9.2971 | 1.6920 | 2.1125 | 0.0020 | 0.0959 |
| Method | Test | 0.8191 | 4.2163 | 17.7769 | 2.8778 | 4.0709 | 0.0010 | ||
| SVR (Linear) | Linear | Train | 0.8035 | 4.6351 | 21.4839 | 3.1978 | 12.3060 | 0.0080 | 0.2868 |
| Method | Test | 0.5166 | 6.8919 | 47.4983 | 5.4000 | 34.8412 | 0.0010 |
| Model 1 | Model 2 | p-Value | Significance | Interpretation |
|---|---|---|---|---|
| Baseline GPR | Expert Knowledge GPR | 0.0004 | *** | Highly Significant |
| Baseline GPR | GPR-ARD | 0.0002 | *** | Highly Significant |
| Baseline GPR | GPR-OptCorrosion | 0.0002 | *** | Highly Significant |
| Expert Knowledge GPR | GPR-ARD | 0.0256 | * | Marginally Significant |
| Expert Knowledge GPR | GPR-OptCorrosion | 0.0412 | * | Marginally Significant |
| GPR-ARD | GPR-OptCorrosion | 0.8376 | ns | Not Significant |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saeheaw, T. Hybrid Gaussian Process Regression Models for Accurate Prediction of Carbonation-Induced Steel Corrosion in Cementitious Mortars. Buildings 2025, 15, 2464. https://doi.org/10.3390/buildings15142464
Saeheaw T. Hybrid Gaussian Process Regression Models for Accurate Prediction of Carbonation-Induced Steel Corrosion in Cementitious Mortars. Buildings. 2025; 15(14):2464. https://doi.org/10.3390/buildings15142464
Chicago/Turabian StyleSaeheaw, Teerapun. 2025. "Hybrid Gaussian Process Regression Models for Accurate Prediction of Carbonation-Induced Steel Corrosion in Cementitious Mortars" Buildings 15, no. 14: 2464. https://doi.org/10.3390/buildings15142464
APA StyleSaeheaw, T. (2025). Hybrid Gaussian Process Regression Models for Accurate Prediction of Carbonation-Induced Steel Corrosion in Cementitious Mortars. Buildings, 15(14), 2464. https://doi.org/10.3390/buildings15142464