1. Introduction
A vernacular building is a traditional house designed with an architectural style that evolves naturally, adapting to a particular region’s climatic characteristics, culture, and available resources, and is typically constructed by local craftsmen [
1,
2]. One of the prominent features of vernacular architecture is the use of natural materials readily available from the surrounding environment, such as wood for walls and floors and rumbia leaves for roofing [
3,
4]. These materials reflect local wisdom and contribute to passive thermal comfort due to their good heat insulation properties [
5]. The structure of a vernacular building is adapted to the local climate and geographical conditions, commonly taking the form of an elevated stilt house with ventilation holes in the walls and roof to support air circulation [
6]. This design reflects local wisdom and serves the community’s social, cultural, and spiritual functions while enhancing effective thermal quality [
7,
8]. The shape and orientation of the building are typically designed to maximize the natural benefits of the surrounding environment [
9]. In addition, the elevation of the building allows for air circulation beneath the floor, facilitating airflow within the interior spaces [
10,
11]. This condition naturally helps reduce heat buildup and keeps indoor temperatures cool [
12,
13]. This cooling effect is supported by ventilation that allows continuous airflow in and out of the building [
14]. Moreover, the wooden materials used also play an essential role in maintaining thermal conditions due to their ability to absorb heat during the day and release it gradually at night, contributing to a more stable indoor temperature [
15,
16]. The insulating thermal properties of wood make it effective in dampening temperature fluctuations from the environment [
17]. In addition, wood is a natural, renewable material with a lower carbon footprint than modern materials [
18,
19]. The orientation of the building, adjusted according to wind direction and sunlight exposure, is also part of the strategy to improve thermal quality [
20,
21]. By orienting the ventilation toward the prevailing wind direction, the building can help reduce indoor temperatures [
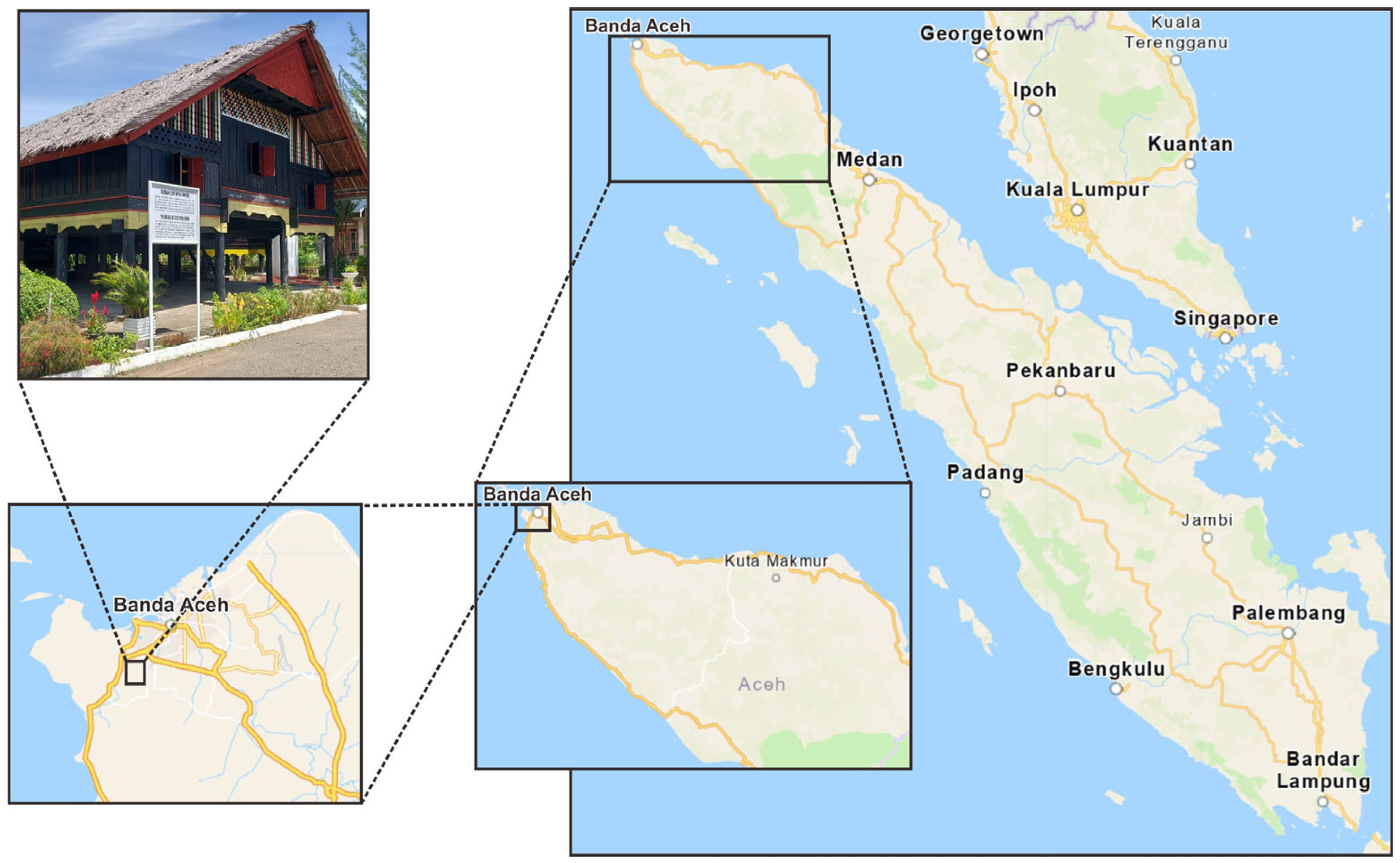
22]. One example of a vernacular building is the Rumoh Aceh in Aceh Province, Indonesia [
23,
24].
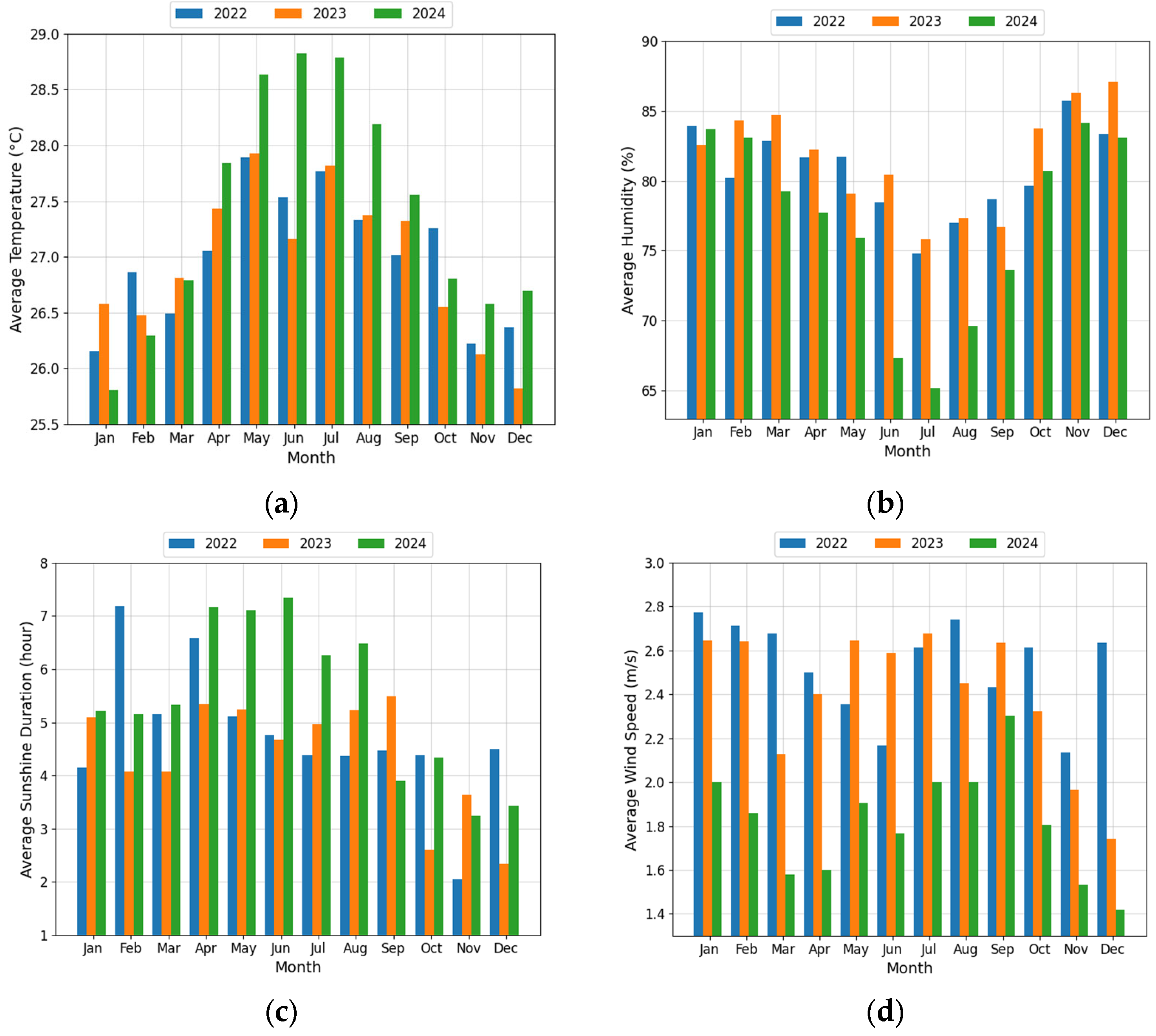
Thermal performance in vernacular building plays a vital role in assessing how effectively these buildings can ensure a comfortable indoor environment. Air temperature, humidity, wind speed, and sunlight exposure significantly influence a building’s thermal behavior. Numerous studies have explored these aspects in vernacular structures across tropical regions. For instance, the study in [
25] examined traditional Malay houses in Penang, Malaysia, and found that their well-designed natural ventilation systems resulted in lower indoor air temperature and humidity than outdoor conditions despite reduced indoor wind speed. Similarly, research in [
26] evaluated the thermal characteristics of vernacular buildings in a hot and humid climate in Bushehr, Iran. It concluded that materials with low thermal conductivity like wood improved indoor thermal quality. Wood, known for its insulating properties, contributed to maintaining stable indoor temperatures. In another case, ref. [
27] investigated traditional buildings in Yazd, Iran, and discovered that their thermal quality was relatively poor, requiring mechanical ventilation to enhance comfort. These findings underscore the importance of architectural design, choice of materials, and ventilation systems in shaping the thermal performance of vernacular buildings. Predictive thermal models are essential to better assess and improve thermal quality.
Thermal prediction models are designed to estimate indoor temperature conditions based on environmental factors and building attributes [
28,
29]. This model makes predictions to enhance occupant comfort, reduce energy consumption, and design more optimal ventilation and cooling systems, particularly in buildings [
30,
31]. Their primary function is to simulate and forecast indoor thermal behavior by analyzing various external variables and structural features. Generally, these models fall into two categories: physical models and data-driven models. Physical models rely on thermodynamic and heat transfer equations to replicate thermal conditions but require detailed architectural and thermal input data [
32,
33]. Although physical models are instrumental in the technical design of modern buildings, their application in the study of vernacular buildings is limited due to the requirement for detailed input variables [
34]. Conversely, data-driven models utilize historical data to identify patterns between environmental parameters and indoor temperatures, offering greater flexibility and efficiency [
35,
36]. This model does not require detailed technical information about the building structure, making it easier to apply to traditional buildings with minimal architectural documentation [
37]. Many studies have explored data-driven approaches to thermal prediction. For example, [
38] used an Adaptive Neuro-Fuzzy Inference System (ANFIS) to predict air temperature in a livestock barn based on six days of environmental data, enabling optimized ventilation control for thermal stability and animal well-being. The model performance results show that the
,
, and
values are 0.182, 0.548%, and 0.997, respectively. In paper [
39], a Nonlinear Autoregressive with External Input (NARX) model was developed to forecast indoor temperatures in a commercial building, aiming to enhance energy efficiency without compromising thermal comfort. The statistical results show that the
and
values are 0.083 and 0.837%, respectively. Additionally, [
40] evaluated the effectiveness of various machine learning methods, such as Autoregressive Exogenous (ARX), Robust Multiple Linear Regression (RMLR), Extreme Learning Machine (ELM), Multilayer Perceptron (MLP), and NARX, combined with traditional approaches to predicting room temperatures in different parts of buildings. The study demonstrated that these predictive models support energy management and contribute to designing more thermally efficient and comfortable indoor environments. The numerical results indicate that the MLP-NARX method is the most accurate indoor temperature prediction, with an average annual
of 0.111. This method outperforms the others due to its ability to capture nonlinear patterns and daily periodicity. The ARX method ranks second with an
of 0.171, followed by RMLR at 0.207, MLP at 0.242, and ELM at 0.286. Consequently, developing data-driven thermal prediction models is a valuable strategy for optimizing building design and enhancing indoor thermal comfort.
Multiple Linear Regression (MLR) is a traditional statistical technique that models the linear relationship between a single dependent variable and multiple independent variables. MLR has been applied in thermal condition prediction, as demonstrated in [
41], where an MLR model was developed to estimate indoor temperature in a mobile container using inputs such as global solar irradiance, ambient temperature, and wind speed. The model achieved relatively high accuracy, reporting an error rate of 7.1%. A key advantage of MLR is its strong interpretability; however, it struggles to capture nonlinear relationships. Artificial Neural Networks (ANNs) have been introduced to address this limitation, as they can learn complex, nonlinear patterns. A related study in [
42] explored using ANN models to predict indoor thermal conditions, including air temperature, humidity, and wind speed, based on building orientation and geographical location. The results of this study indicate that the ANN-based predictive model produced error levels ranging from 0.03 to 1.05, demonstrating the effectiveness of this method in supporting building design oriented toward thermal comfort. Support Vector Regression (SVR), an extension of the Support Vector Machine (SVM) framework tailored for regression problems, has also been investigated in this context. SVR works by finding a predictive function that tolerates minor deviations and can handle nonlinear relationships using kernel functions. In paper [
43], SVR was applied to predict air temperature inside a greenhouse. This approach aimed to address the complexity of the greenhouse temperature system, which is both nonlinear and time-varying. The study results show that the SVR model achieved the best performance, with a maximum relative error of 1.73%, an
of 0.00019, and an
of 0.99945. In comparison, the Backpropagation Neural Network (BPNN) model exhibited a higher error of up to 16.23%, an
of 0.019564, and an
of 0.96425. These findings confirm that the proposed SVR model is more accurate, stable, and effective in representing the actual temperature conditions in the greenhouse. Furthermore, the Generative Adversarial Network (GAN) is a data preprocessing technique capable of generating realistic data that closely resembles the original data, primarily imputing missing data. In paper [
44], GAN was used to enhance the quality of mammographic images through data augmentation. By applying GAN, the dataset used for modeling became more representative. The results of this study demonstrate that applying GAN in the data preprocessing stage significantly enriches the dataset, thereby increasing the prediction model’s accuracy to 100%, compared to only 57.5% without augmentation. Paper [
45] also highlights the critical role of GAN in data augmentation. The study used GAN to generate synthetic data to enrich the existing dataset. The study results indicate that applying GAN data augmentation improved the model’s accuracy from 76.1% to 88.5%. This approach not only successfully addressed data imbalance issues but also enhanced the generalization of the model. In addition, GAN offers advantages over simpler methods such as K-Nearest Neighbor (KNN) or mean substitution. In the mean substitution method, missing data is replaced with a fixed value, which can eliminate natural variability and alter the data distribution. Meanwhile, the KNN method tends to be less effective when dealing with high-dimensional data and requires considerable computational resources [
46,
47]. In contrast to these approaches, GAN can learn and understand the data distribution patterns more deeply through the adversarial mechanism between two networks: the generator and the discriminator. Through this competitive training process, GAN can generate synthetic data that closely resembles the original data, making it more effective in imputing missing data by the actual data distribution characteristics [
48].
This study presents a hybrid method for developing an indoor temperature prediction model tailored to the traditional Rumoh Aceh building, using external environmental variables such as temperature, humidity, sunshine duration, and wind speed. The dataset combines ecological data sourced from the Meteorology, Climatology, and Geophysics Agency with sample measurements taken from four rooms within Rumoh Aceh structures located in Aceh Province, Indonesia. To ensure the dataset’s quality, a data preprocessing stage was conducted using the GAN method as an imputation technique to address the issue of missing data. This process generated synthetic data that closely resembled the original. Next, two primary predictive models, MLR and ANN, were applied, with each model further optimized using the SVR approach. The MLR algorithm was chosen due to its ease of interpreting regression coefficients. It allows the contribution of each variable to room temperature to be directly understood, although only for linear relationships. The ANN algorithm was then adopted to capture complex nonlinear patterns that MLR cannot address. Finally, the SVR approach was applied to reduce the risk of overfitting in models built from limited datasets. The MLR-SVR model combines the interpretability of MLR with the generalization capability of SVR. In contrast, the ANN-SVR model integrates the nonlinear modeling flexibility of ANN with SVR’s predictive precision. The evaluation used statistical metrics to determine the best-performing model with high accuracy, ensuring applicability in real-world conditions. The findings of this study present a practical approach for evaluating thermal performance in vernacular buildings and support architectural planning in designing more comfortable living environments. The main contributions of this paper are as follows:
We propose a study to support passive thermal comfort in the Rumoh Aceh vernacular building by developing a predictive model to estimate indoor thermal conditions based on external environmental variables such as air temperature, humidity, sunshine duration, and wind speed.
We introduce the GAN method in the data preprocessing stage to impute missing data, generating synthetic data that closely resembles the original. This technique enriches the dataset and improves model generalization.
We propose two hybrid approaches: MLR optimized with SVR and ANN optimized with SVR. The goal is to compare model performance and determine the most accurate model for predicting indoor temperature in Rumoh Aceh based on external environmental parameters.
3. Modeling Process
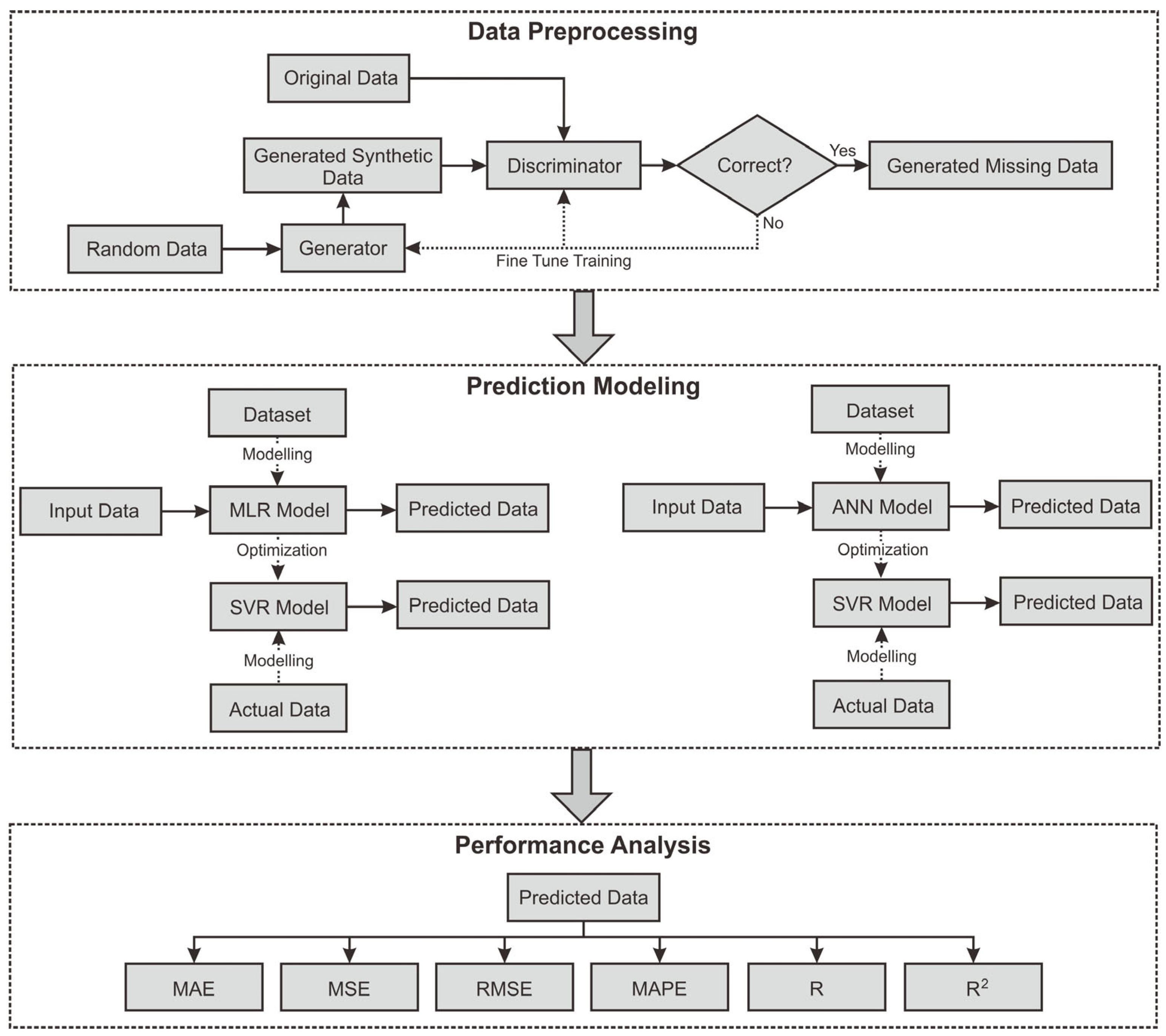
The modeling process in this study is divided into three stages: data preprocessing, prediction modeling, and performance analysis. For a clearer understanding of the predictive modeling methodology, the process diagram is presented in
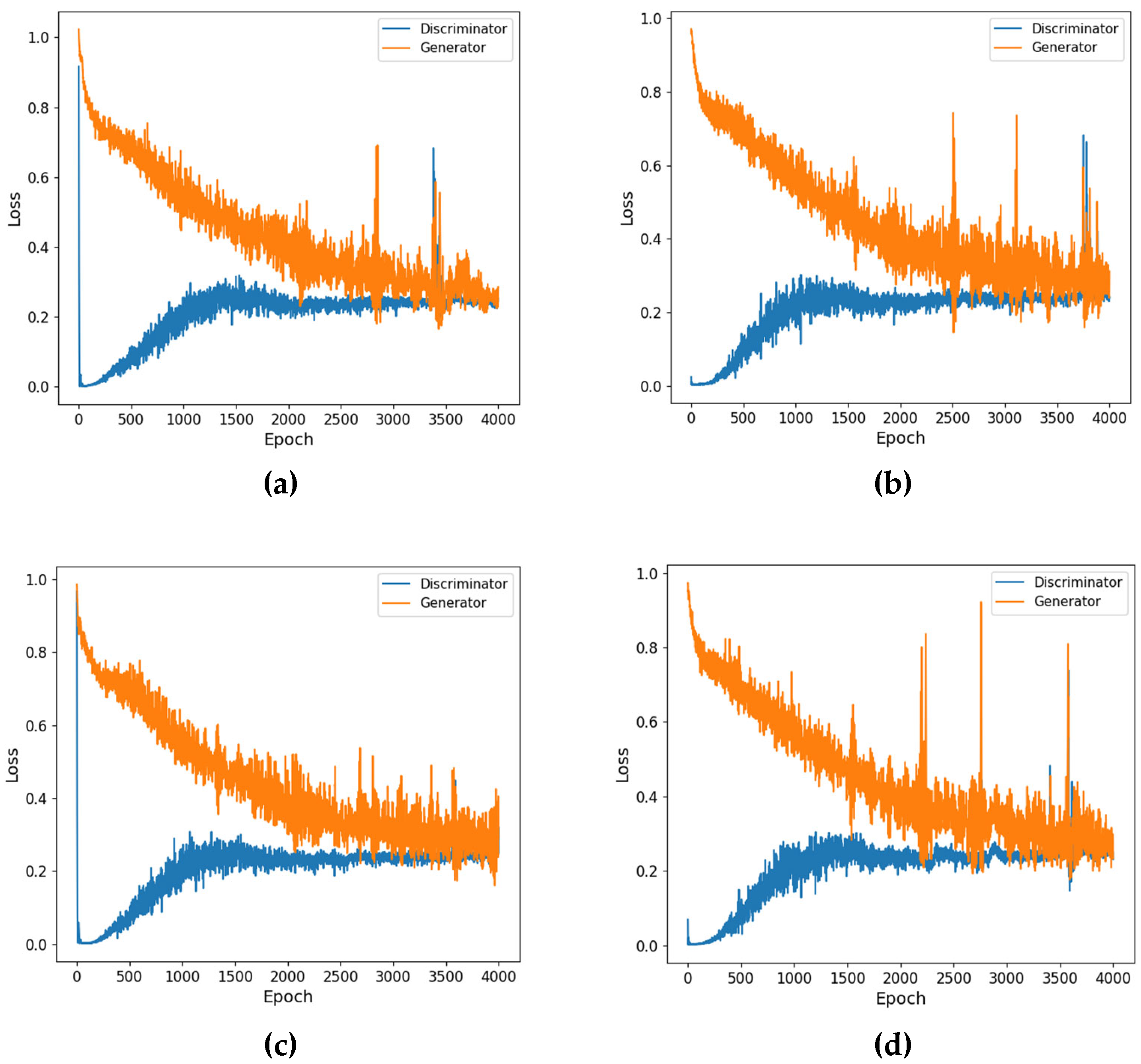
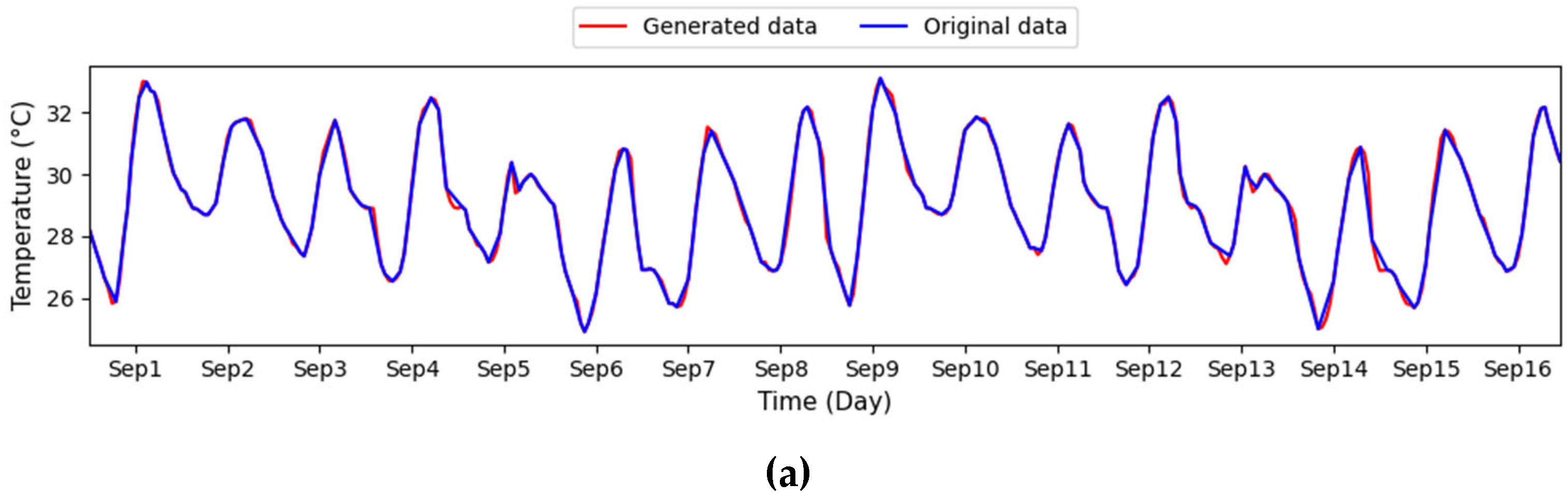
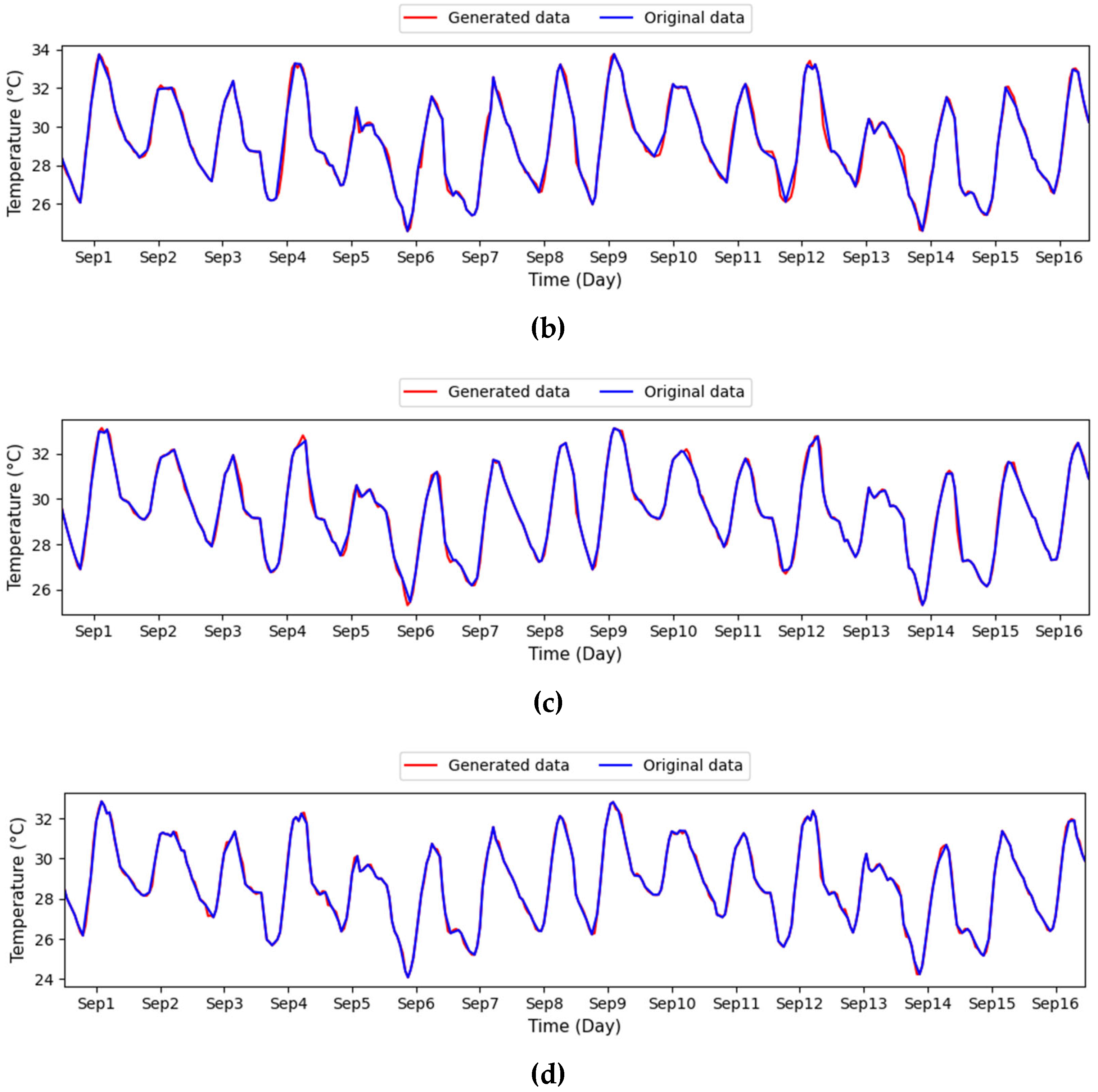
Figure 4. During the data preprocessing stage, a GAN-based method handles missing values within the dataset. The procedure involves inputting real and synthetic data produced by the generator into the discriminator. The GAN framework comprises two core components: the generator, which produces synthetic data resembling actual data, and the discriminator, which evaluates and differentiates between real and generated samples. By fine-tuning between the generator and the discriminator, the algorithm produces synthetic data deemed authentic by the discriminator. These data are then used to fill in the missing parts, resulting in a complete dataset. Next, the dataset is used in the prediction modeling stage, which comprises two models: MLR and ANN. The prediction results from each model are then optimized using an SVR approach. This technique allows the base models to provide an initial understanding of the data, which SVR further refines to improve prediction accuracy. The final stage is performance analysis, where the prediction results are evaluated using various statistical metrics. The evaluation involves an in-depth analysis of each model’s performance in predicting data and assessing the contribution of the GAN-based data imputation process to enhancing predictive model accuracy.
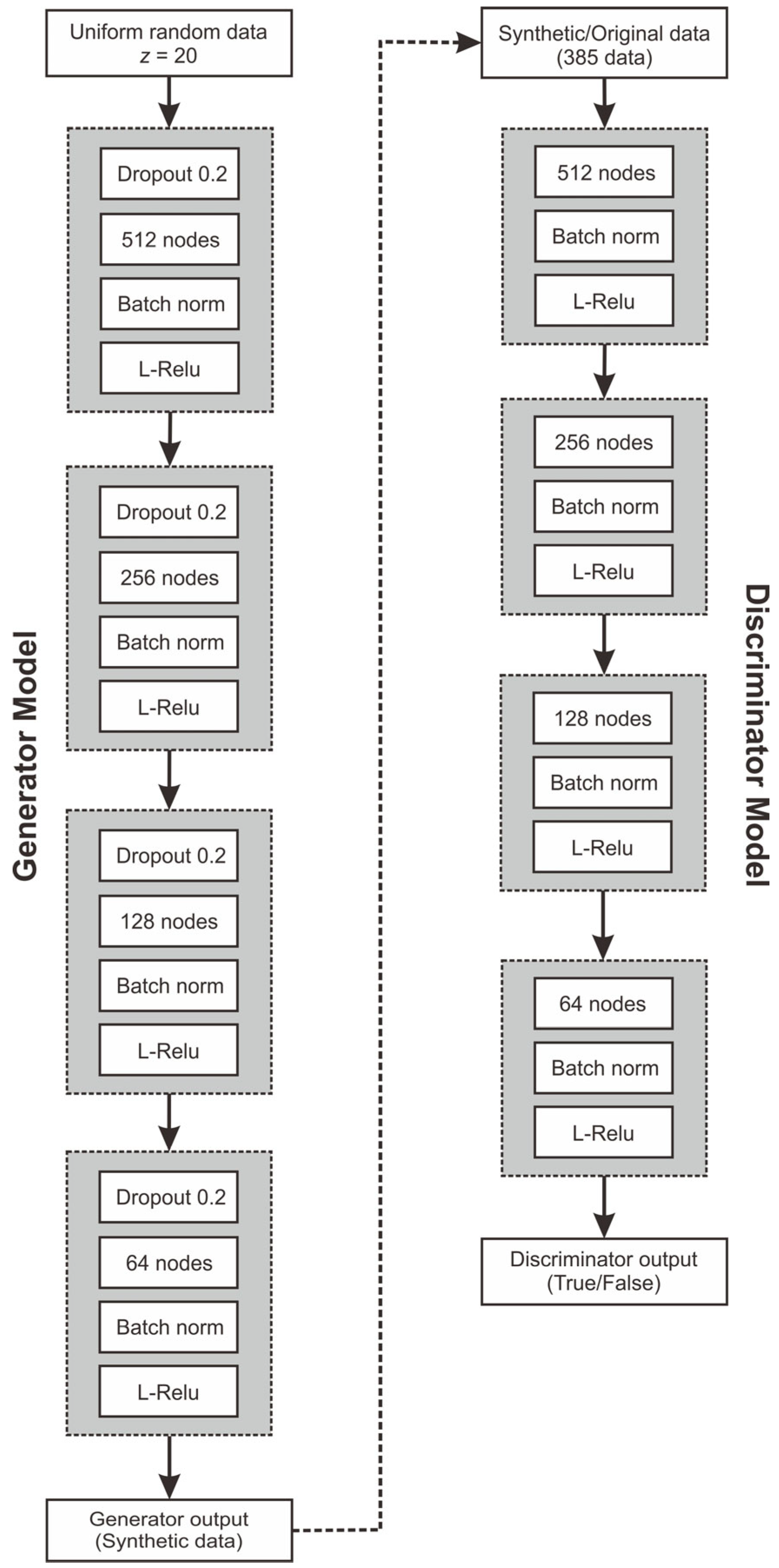
Figure 5 presents the architecture of the GAN, which is composed of two primary components: the generator and the discriminator. The generator takes a 20-dimensional random vector sampled from a uniform distribution and processes it through four layers. Each layer includes a combination of dropout, a defined number of nodes, batch normalization, and an activation function. The generator produces synthetic data to mimic real data fed into the discriminator. The discriminator’s role is to assess whether the input data is genuine or generated. It also features four sequential layers for processing. Training occurs in an adversarial manner: while the generator strives to create increasingly realistic data to fool the discriminator, the discriminator simultaneously enhances its ability to distinguish between real and synthetic inputs.
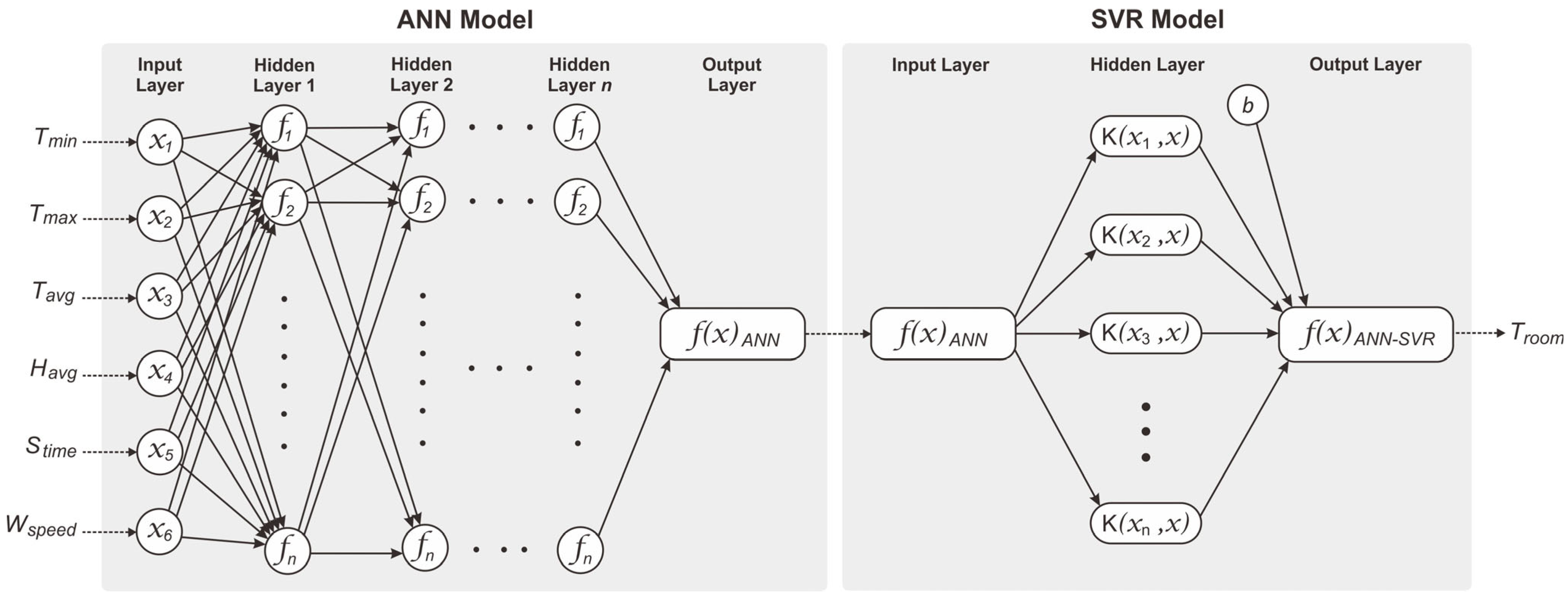
The structure of the MLR model with SVR optimization is shown in
Figure 6. In this model, the initial approach uses MLR, which utilizes six input variables connected to one output room temperature variable through a series of coefficients from
to
. Each input is multiplied by a specific coefficient and summed together with the common intercept (
) to generate the initial prediction data. The coefficient values for each room are presented in
Table 3. Subsequently, the output from the MLR model is further optimized using the SVR approach, as illustrated on the right side of
Figure 6. In this process, the output from the MLR model is used as input for SVR, which maps the input into a higher-dimensional space using a kernel function to minimize prediction error. Key parameters in SVR include the regularization constant (
), kernel parameter (
), error margin (
), number of support vectors (
), and bias value (
). These parameters are adjusted to obtain optimal values, producing more accurate prediction results. The parameter values for each room are shown in
Table 4.
Meanwhile,
Figure 7 displays the architecture of the ANN model refined through the SVR method. The model uses an artificial neural network to learn the nonlinear relationship between six input features and a single output. Its structure comprises four hidden layers, each containing a different number of neurons, and applies the ReLU activation function to enhance training efficiency.
Table 5 describes the network structure, including the number of layers, learning rate, and epochs adjusted for each room. After training, the ANN’s output is further refined using SVR. This step involves projecting the ANN predictions into a higher-dimensional space via a kernel function and determining the optimal hyperplane to boost prediction accuracy. The SVR parameters, shown in
Table 6, are specifically tuned to suit the unique characteristics of each room.
Several strategies were implemented in the model to prevent overfitting. First, the GAN architecture was equipped with dropout and batch normalization layers, preventing the model from relying too heavily on specific neurons. Second, an SVR approach was added to the model’s output. Third, setting the number of epochs and applying early stopping during ANN training helped halt the training process before the model began fitting into the datasets’ noise.
4. Performance Analysis Method
This study seeks to evaluate the performance of the proposed model through metric-based assessment and statistical analysis. The accuracy of the prediction model is measured using several standard metrics, including Mean Absolute Error (
), Mean Squared Error (
), Root Mean Squared Error (
), and Mean Absolute Percentage Error (
).
calculates the average absolute difference between predicted and actual values, indicating the overall error magnitude. Both
and
assess the expected, predicted, and actual variance outcomes. However,
, the square root of
, is more responsive to larger errors, offering a deeper understanding of model accuracy. On the other hand,
represents prediction errors as a percentage of actual values, allowing for relative performance evaluation. The formulas for these metrics are presented below [
83,
84]:
where
denotes the total number of test data points, while
and
represent the actual and predicted values for the
data point, respectively. In addition to the error metrics, statistical indicators such as the correlation coefficient (
) and the coefficient of determination (
) are employed. The correlation coefficient
measures the strength and direction of the linear relationship between two variables. An
value close to 1 suggests a strong positive correlation, meaning both variables tend to increase or decrease together. Conversely, an
value near −1 signifies a strong negative correlation, where an increase in one variable corresponds with a decrease in the other. An
value close to 0 implies a weak or negligible linear relationship. The coefficient of determination
evaluates the regression model’s performance by quantifying the proportion of variance in the dependent variable that the model can explain. The
ranges from 0 to 1, where 0 indicates no explanatory power, and 1 indicates that the model accounts for all observed variance. The corresponding equations for these statistical indicators are provided below [
85]:
Uncertainty analysis using the Monte Carlo method is a statistical technique used to estimate the uncertainty of a system or model’s output by randomly simulating input variations based on known probability distributions. This analysis is conducted by defining a distribution for each input, followed by Monte Carlo sampling, which is expressed as follows [
86]:
where
is the average prediction obtained from all samples,
is the number of Monte Carlo samples, and
is the predicted value using the
sample at data point
. From all the generated predictions, the standard deviation of the output (
) is calculated using the following equation [
87]:
Then, the mean value is calculated using the following equation [
88]:
There are two components of uncertainty: the standard deviation of the model prediction error (
), which is measured using
, and the standard deviation of the prediction resulting from input variability (
). These two components are assumed to be independent, as
originates from the inherent error of the model, while
arises from measurement noise in the input. Therefore, the total prediction uncertainty can be calculated using the following equation [
89]:
If the output distribution approximates a normal distribution, the 95% confidence interval can be expressed as .





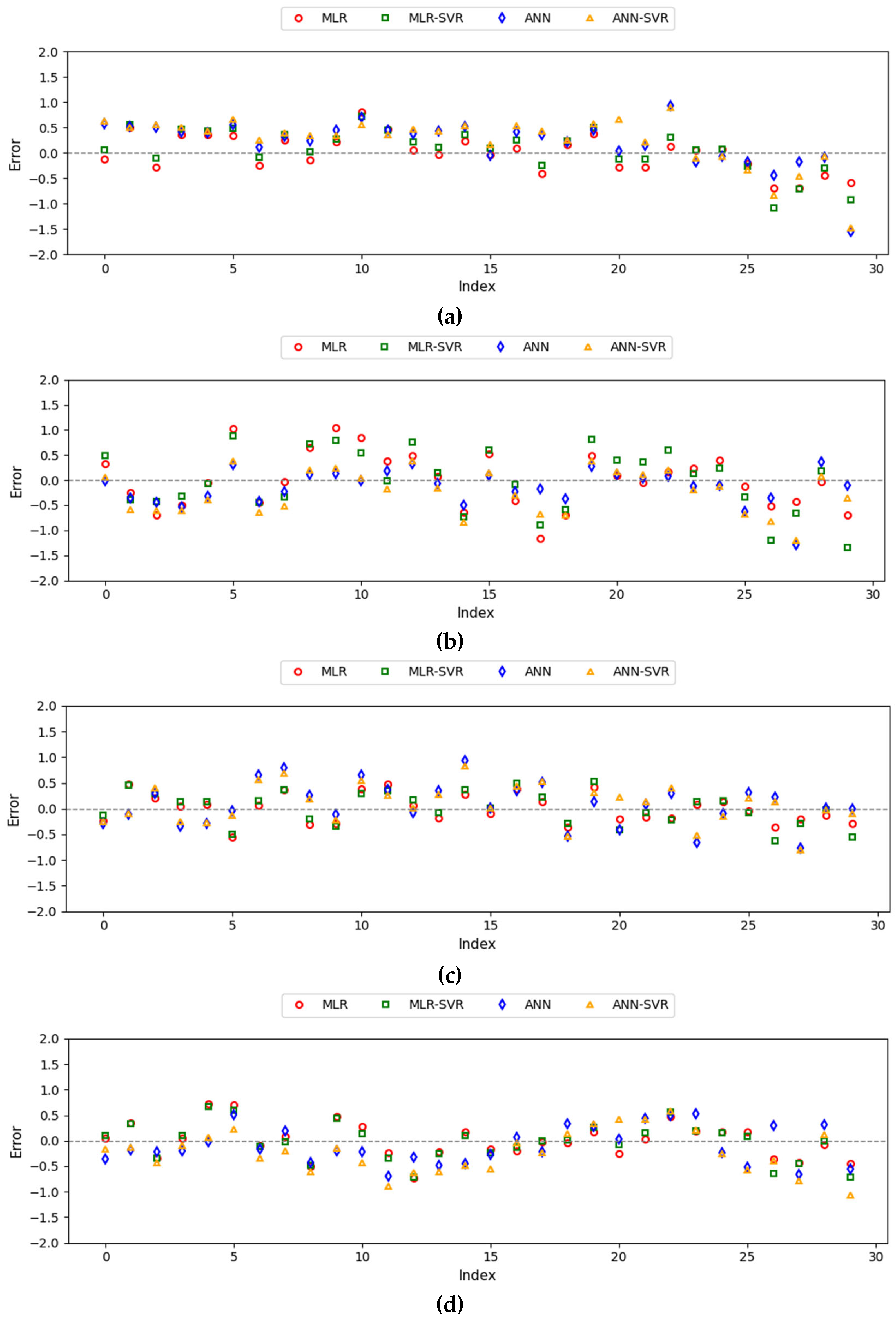
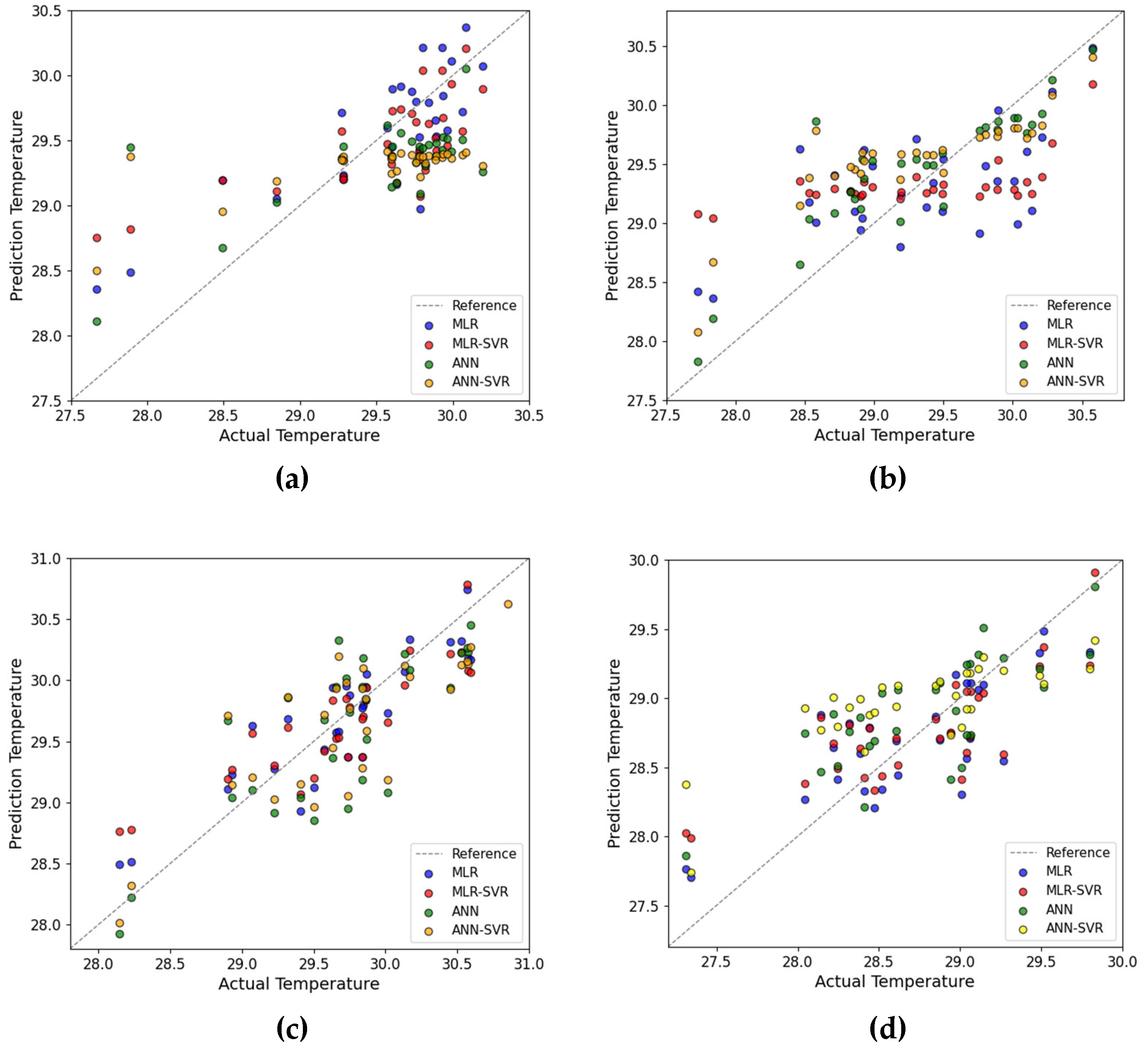
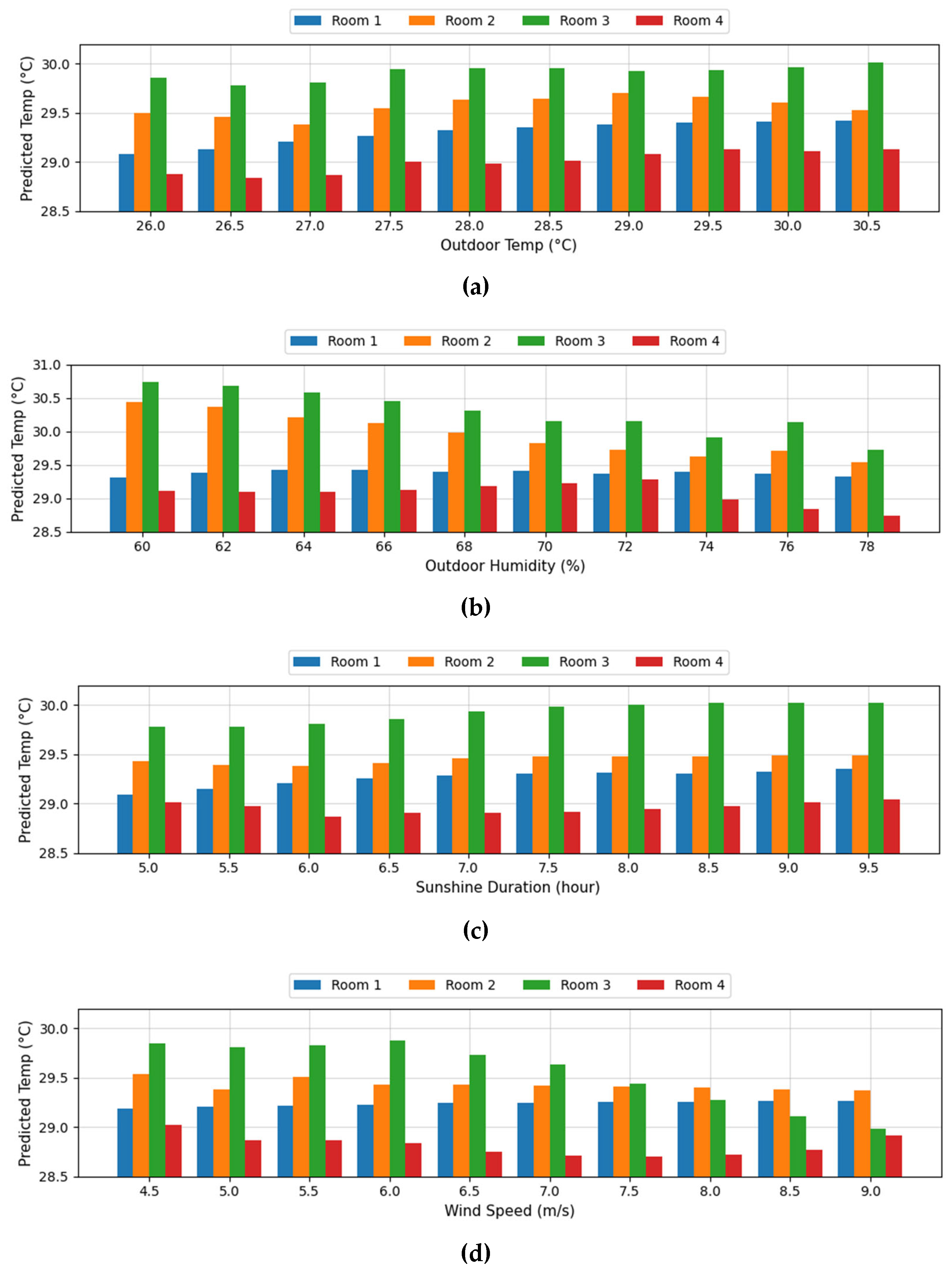

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}