1. Introduction
Structural timber serves as a fundamental building material in modern construction, extensively utilized in load-bearing components such as beams, columns, and trusses due to its favorable strength-to-weight ratio, sustainability, and aesthetic properties [
1]. However, surface defects—including cracks, dead knots, live knots, resin accumulation, decay, and insect damage—significantly deteriorate its mechanical performance, dimensional stability, and long-term structural reliability [
2]. These imperfections create localized stress concentrations, reduce load-carrying capacity, accelerate moisture penetration, and ultimately compromise building integrity, posing substantial safety risks throughout a structure’s service life [
3]. Consequently, developing efficient and accurate defect detection technologies is imperative for ensuring construction safety, extending building lifespan, complying with international timber grading standards [
4,
5], and minimizing material waste in architectural applications.
Conventional inspection methodologies primarily depend on manual visual assessment or rule-based image processing techniques [
6,
7,
8]. Manual inspection suffers from critical limitations: low efficiency (requiring trained specialists), high labor costs, susceptibility to subjective judgment, and inconsistent defect identification—particularly for subtle or morphologically complex flaws [
9]. While automated image processing improves throughput, its reliance on handcrafted feature extractors (e.g., edge detectors, texture filters) proves inadequate for distinguishing defects from intricate wood grain patterns or adapting to the high variability of natural imperfections (e.g., irregular crack propagation, knot clusters) [
10]. These deficiencies hinder reliable quality assurance in construction-grade timber, where undetected defects may propagate into catastrophic structural failures during extreme loading events [
11].
The emergence of deep learning has revolutionized defect detection through its capacity for adaptive feature extraction and high-precision classification [
12,
13]. There mainly exist single-stage and two-stage detection algorithms in the field of target detection [
14]. Two-stage algorithms (e.g., the R-CNN series) first generate candidate frames and then perform feature classification, with high accuracy but large computation and slow speed. A typical representative, Faster R-CNN [
15] improves the detection speed by using a region suggestion network (RPN), but its complex structure is still difficult to meet the real-time demand. The improved algorithm Mask R-CNN adds segmentation branches on the basis of detection [
16], which is suitable for scenarios requiring accurate segmentation such as medical images, but the higher computational complexity further restricts real-time applications. Single-stage detection algorithms directly complete the detection through a single network, which has the advantages of fast speed and real-time performance [
17]. SSD algorithms utilize multi-scale feature maps to detect targets of different sizes [
18], which is suitable for real-time scenarios such as image search [
19]; the YOLO series is known for its balance of speed and accuracy, and YOLOv1 dramatically improves the speed through a regressive detection framework [
20,
21], and the subsequent versions. The performance is continuously strengthened by structural optimization [
22], but there are still defects in small target leakage detection and insufficient adaptability to complex scenes [
23].
In addition to the mainstream target detection algorithms mentioned above, there are also some improved models and methods for specific problems. For example, RetinaNet solves the problem of positive and negative sample imbalance in target detection by introducing the Focal Loss loss function, which significantly improves the detection performance of small objects [
24]. Focal Loss effectively mitigates the problem of category imbalance by reducing the weight of the easy-to-categorize samples and focusing more attention on the difficult-to-categorize samples. EfficientDet, on the other hand, achieves state-of-the-art performance on multiple benchmark datasets through an efficient backbone network and multi-scale feature fusion [
25], but it requires a large amount of computational resources. In addition, Transformer-based target detection models (e.g., DETR) can better handle long-range dependencies by introducing an attention mechanism, which is suitable for target detection in complex scenes [
26]. However, the training process of DETR is more complex, and the inference speed is slow, which limits its wide use in real-time applications [
27]. In addition to object detection frameworks, semantic segmentation models such as DeepLab offer pixel-level defect localization capabilities. By leveraging atrous convolution and spatial pyramid pooling, DeepLab achieves fine-grained segmentation of irregular defects (e.g., crack propagation paths) while maintaining resolution fidelity [
28]. Meanwhile, EfficientNet optimizes computational efficiency through compound scaling of network depth, width, and resolution, enabling high-accuracy defect classification with minimal resource overhead [
29]. These approaches provide complementary solutions for scenarios requiring detailed morphological analysis or edge-device deployment.
In the practical application of structural timber defect detection, the selection of target detection models needs to comprehensively consider the balance of detection accuracy, real-time performance, and computational resources. For example, FastYolo significantly improves the inference speed while ensuring high accuracy by optimizing the model architecture and introducing a lightweighting strategy [
30], which is suitable for use in resource-constrained environments. And the improved models based on YOLOv8, such as LCS-YOLOv8 [
31], further improve the detection accuracy and efficiency by introducing a lightweight feature extraction module and a multi-scale detection head, which is suitable for high-precision target detection tasks. Additionally, some studies have attempted to combine traditional image processing techniques with deep learning to enhance the robustness and adaptability of detection [
32]. For example, Chen et al. [
33] employed HOG features combined with an SVM classifier in wood defect detection, achieving acceptable recall rates under controlled imaging conditions (such as uniform lighting or CT scans). However, this method faces significant limitations in complex-textured scenes: textural interference in knotty regions leads to a substantial increase in false positive rates, while sub-millimeter defects result in significantly higher false negative rates due to insufficient feature extraction compared to conventional defects. This indicates that while deep learning techniques have made significant progress in structural wood defect detection, the path of integrating traditional and deep learning approaches still needs to address such challenges [
34,
35].
This research addresses the critical need for efficient structural wood defect detection in practical production environments. We focus on eight safety-critical surface defects: quartz, live knot, marrow, resin, dead knot, knot with crack, missing knot, and crack. These imperfections present fundamental challenges characterized by multi-scale coexistence complicating hierarchical feature extraction, inter-class similarity hindering accurate defect discrimination, and high morphological diversity requiring precise geometric reconstruction. However, traditional detection technologies often fall short when faced with these challenges.
To enable robust detection, we curated a specialized dataset from the VSB Technical University benchmark, comprising 4000 high-resolution RGB images (2800 × 1024 pixels) with pixel-level annotations. The original pixel values range from 0 to 255 across the three color channels, targeting the aforementioned eight defect classes critical for structural integrity assessment.
Therefore, developing efficient and accurate detection technologies that are suitable for practical deployment and can effectively address the shortcomings of traditional detection technologies in the face of these core challenges is of great practical significance. To this end, we propose WDNET-YOLO, an enhanced framework based on YOLOv8n, which aims to systematically overcome these limitations through three key innovations:
Enhanced RepVGG Backbone: Captures hierarchical defect features through multi-branch structural reparameterization, addressing multi-scale detection challenges [
36].
Efficient Channel Attention: Enhances discriminative feature representation via dynamic channel recalibration, overcoming inter-class similarity limitations [
37].
CARAFE Up-sampling: Preserves morphological details with instance-adaptive kernels, accommodating high geometric variability [
38].
2. Materials and Methods
2.1. YOLOv8
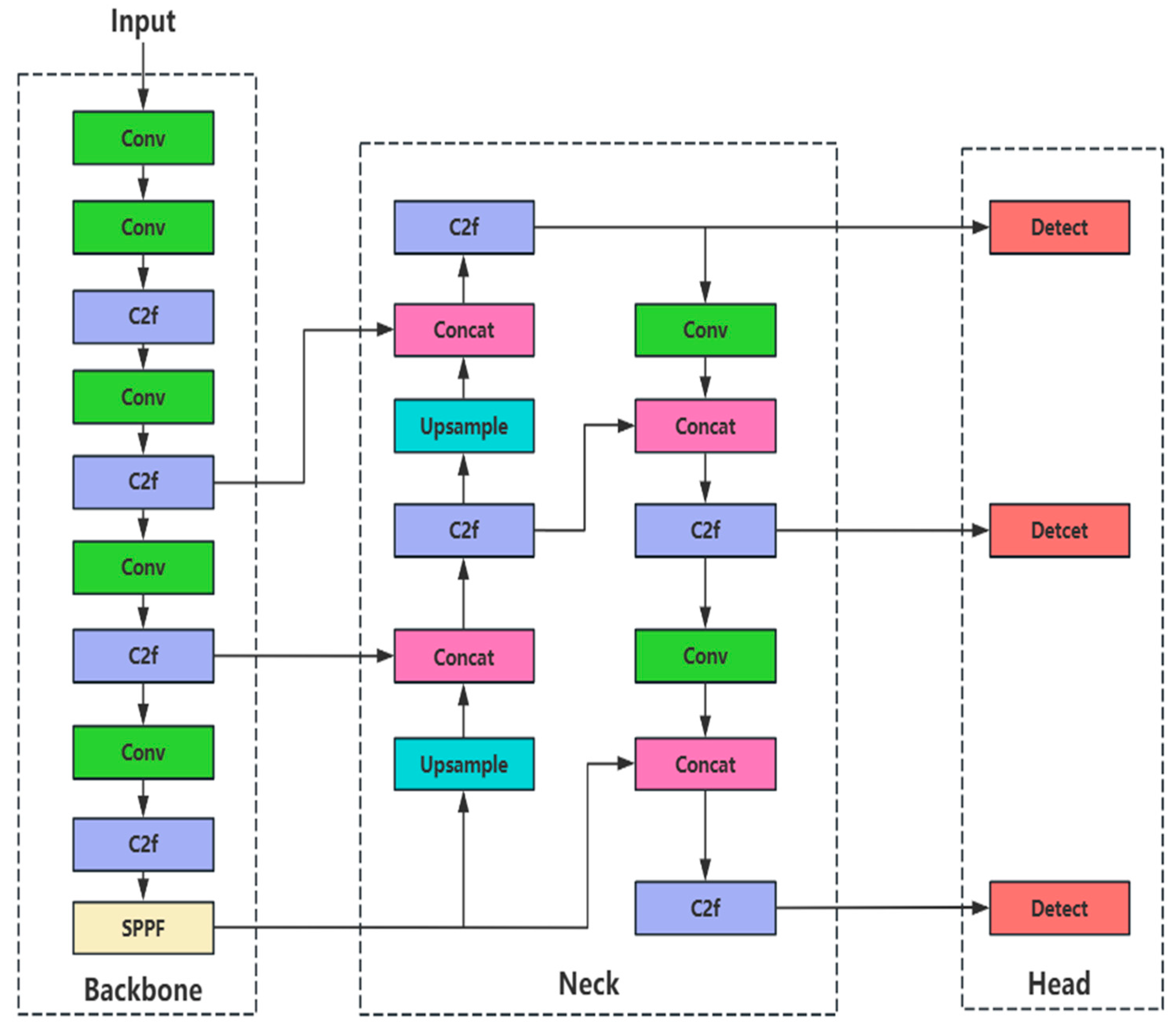
YOLOv8 achieves the synergistic optimization of accuracy and speed in real-time target detection [
39]. As shown in
Figure 1, its architecture consists of a multi-scale feature extraction backbone (Backbone), a feature enhancement network (Neck), and a decoupled detection head (Head). The Backbone network is based on a modified CSPDarknet architecture, using C2f modules instead of the traditional C3 modules [
40]. C2f enhances the sensitivity to small defects (e.g., insect holes) while reducing the number of references by 25% through cross-stage feature interactions with a dual-path design (3 × 3 depth-separable convolution and 1 × 1 cross-channel convolution). The feature enhancement network uses a streamlined version of the PAN-FPN architecture [
41] to fuse multi-resolution features through bidirectional cross-scale connections. Compared to YOLOv5, YOLOv8 removes the redundant up-sampling layer and introduces the C2f module to retain more detailed information. The detection head is decoupled to separate the classification and regression tasks. The classification branch predicts the category probability through the fully connected layer, and the regression branch directly outputs the target location offset. The anchor-free strategy is adopted to avoid the matching bias between the preset anchor frames and the morphological diversity of wood surface defects, which improves the detection flexibility.
2.2. WDNET-YOLO
The YOLOv8 algorithm demonstrates robust performance in detecting standard-sized objects [
42], yet faces significant challenges in structural timber defect inspection scenarios. Construction-grade timber datasets typically contain numerous defects characterized by minute dimensions, high morphological diversity, and substantial visual similarity between critical defect classes such as tension-reducing cracks and compression-weakening knots. Furthermore, multi-scale overlapping defects exacerbate detection complexity, potentially compromising structural safety assessments. To address these construction safety-critical challenges, this study proposes WDNET-YOLO—an enhanced model that achieves superior detection performance through synergistic optimization of the backbone network, channel attention mechanisms, and dynamic context-aware feature fusion.
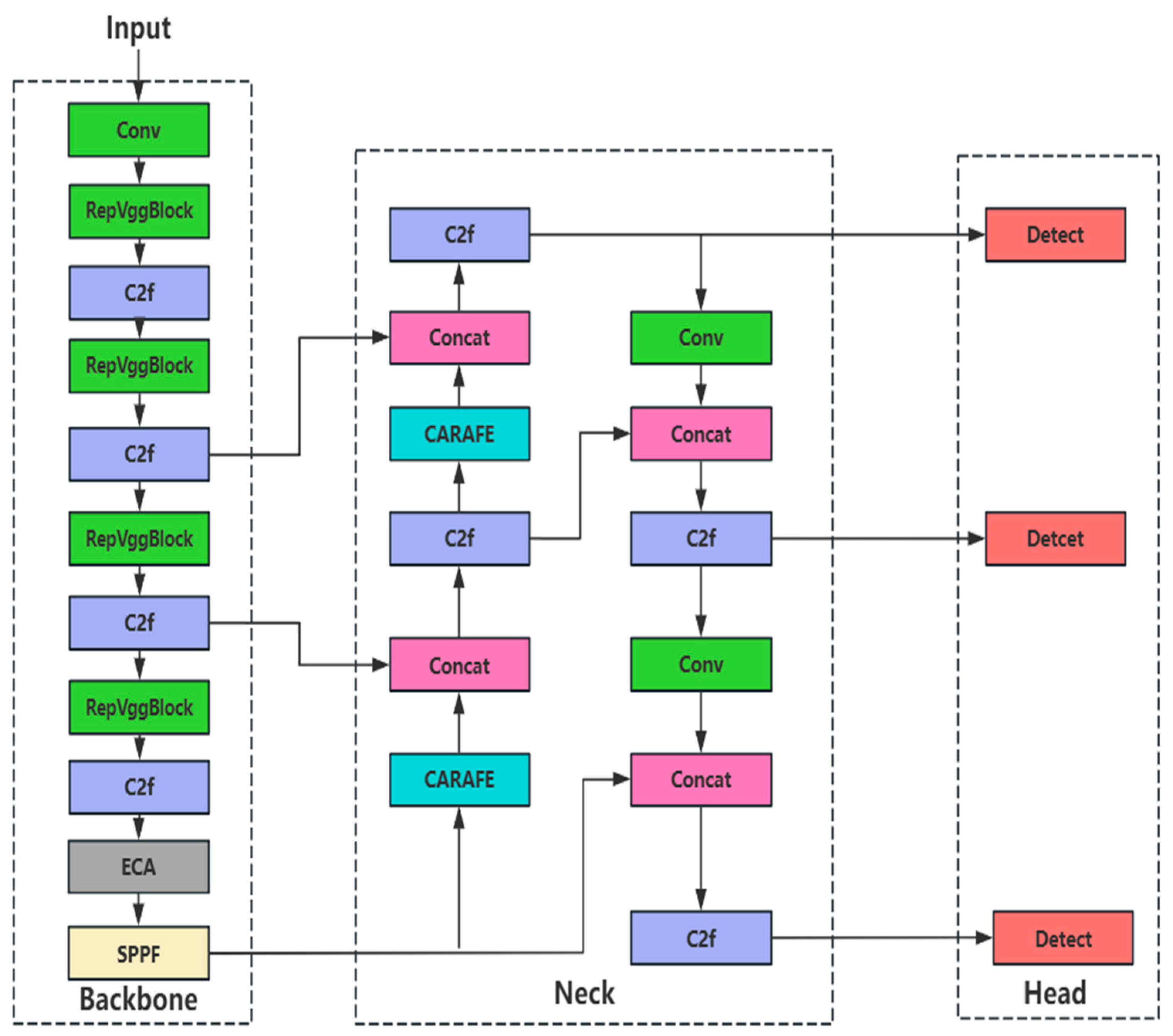
The architecture of the proposed WDNET-YOLO framework is illustrated in
Figure 2. The backbone network is reconfigured using RepVGG modules to implement a multi-branch training strategy that captures hierarchical defect features essential for structural integrity evaluation. During training, the 3 × 3 convolutional branch models global morphological characteristics of safety-critical defects, such as crack propagation patterns in load-bearing beams. Simultaneously, the 1 × 1 convolutional branch enhances cross-channel interactions to distinguish dense knot clusters from background textures—critical for assessing shear resistance in timber joints. The identity mapping branch preserves spatial fidelity while suppressing interference from natural wood grain noise. Batch normalization nonlinearly fuses these multi-branch features, significantly improving sensitivity to multi-scale defects that impact structural performance.
An Efficient Channel Attention (ECA) module is integrated at the terminus of the backbone network to mitigate false detection risks in safety-critical applications. This mechanism extracts channel-wise statistical features through global average pooling, then dynamically recalibrates channel weights using adaptive 1D convolution kernels. By selectively amplifying discriminative features between high-risk defect classes (e.g., cracks compromising tensile strength vs. knots reducing load capacity) while suppressing complex texture interference, the ECA module significantly enhances classification reliability for structural timber components.
Within the feature pyramid network, CARAFE up-sampling combined with C2f modules optimizes morphological sensitivity for construction-grade timber inspection. CARAFE generates content-aware kernels that adaptively reorganize contextual information, preserving critical geometric details such as microcrack initiation points and resin distribution anomalies that indicate material degradation. Concurrently, the C2f module facilitates efficient cross-stage feature interaction, maintaining defect morphology integrity during multi-scale fusion. This dual mechanism substantially enhances detection capabilities for geometrically complex defects affecting long-term structural durability.
The RepVGG backbone provides highly discriminative foundational features for the ECA module’s channel weighting operations, while its global defect modeling capability complements CARAFE’s local detail preservation. ECA suppresses background noise through dynamic channel recalibration, and CARAFE optimizes small-defect retention via context-aware restructuring. Collectively, these components establish a coarse-to-fine defect detection pipeline specifically engineered for automated quality assurance in timber construction, where undetected defects may lead to catastrophic structural failures.
2.3. REPVGG
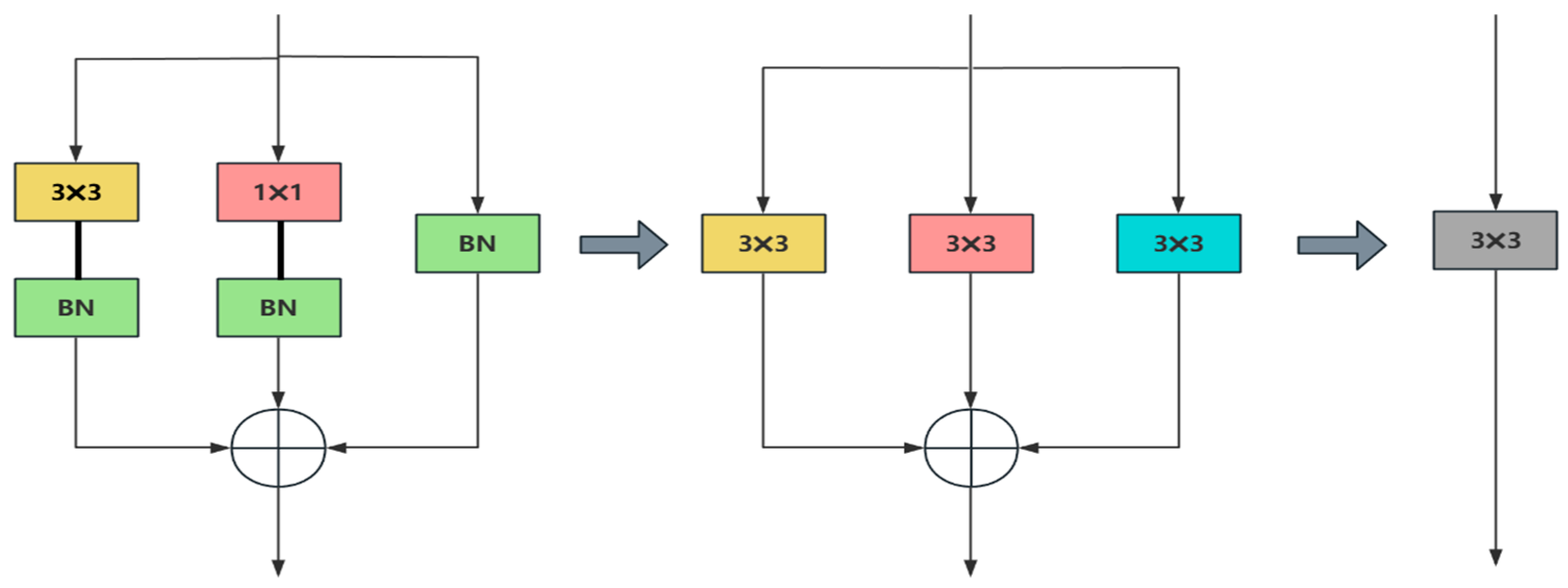
In structural timber defect detection, traditional single-path backbone networks exhibit limited capability in concurrently capturing global defect morphology (e.g., continuous crack propagation in load-bearing beams) and local detail features (e.g., fine boundaries of knots within timber joints). This limitation stems from constrained receptive fields and insufficient feature interactions, resulting in elevated miss rates for safety-critical small-scale defects such as clustered knots and scattered cracks that compromise structural integrity. To address these challenges, our study reconfigures the YOLOv8n backbone using RepVGG modules, implementing a multi-branch collaborative training strategy to enhance multi-scale feature representation for construction-grade timber assessment.
During training, parallel branch structures are deployed: The 3 × 3 convolutional branch models global morphological characteristics of safety-critical defects. The 1 × 1 convolutional branch enhances cross-channel interactions to distinguish dense knot clusters from background textures—critical for assessing shear resistance evaluation. Crucially, the 1 × 1 branch, with its finer receptive field, is particularly adept at capturing localized features from minute defects (e.g., sub-pixel cracks) that may fall below the effective receptive field of the 3 × 3 branch, especially in clustered defect scenarios. An identity branch preserves original feature localization fidelity, providing a baseline representation. Following feature fusion via batch normalization, nonlinear superposition achieves dynamic equilibrium between these complementary feature streams: global context, fine-grained local details, and baseline fidelity. This integration significantly improves detection sensitivity for multi-scale defects, including co-located ones, affecting timber service life. Importantly, the subsequent batch normalization (BN) layer during training plays a key role in harmonizing the contributions of these branches. While the identity mapping inherently carries background texture information (“noise”), the BN layer normalizes the activations across the fused multi-branch features. This normalization, coupled with learnable scale and shift parameters within BN, allows the network to dynamically attenuate the influence of purely noisy identity contributions and amplify the discriminative signals (including those from the 1 × 1 branch) during the nonlinear fusion process. Furthermore, the later ECA module (
Section 2.4) provides an additional mechanism for suppressing irrelevant channel-wise noise, including potential residual noise propagated from the identity branch.
During inference, the multi-branch structure is transformed into a single 3 × 3 convolutional layer through mathematical reparameterization. The weights and biases from each training branch are fused as
where
operation extends the 1 × 1 convolution kernel to 3 × 3 size by zero padding and
is the unit matrix.
As demonstrated in
Figure 3, this design preserves multi-scale feature extraction capabilities through structural reparameterization. The consolidated network accurately models both global fracture morphology and local defect details, essential for predicting residual load capacity in structural timber components.
2.4. ECA
In structural timber defect detection, complex and variable wood texture backgrounds and high inter-class feature similarity (e.g., between tension-reducing cracks and compression-weakening knots, or between different knot types) frequently cause model confusion. This leads to false positives (misidentifying grain as defects) and missed detections (failing to identify genuine flaws obscured by texture), severely compromising the reliability of building safety assessments.
In structural timber defect detection, complex wood texture backgrounds and inter-class feature similarity (e.g., cracks and knots) frequently cause model interference, leading to false positives and missed detections that compromise building safety assessments. While traditional attention mechanisms like CBAM improve feature differentiation through joint channel-spatial modeling, their multi-branch structures introduce computational overhead, and channel attention modules relying on fully connected layers risk information loss through dimension compression. To address these limitations in construction material inspection, we implement the Efficient Channel Attention (ECA) mechanism—a lightweight dynamic channel weighting strategy that enhances defect feature discrimination while minimizing computational complexity for practical timber grading applications.
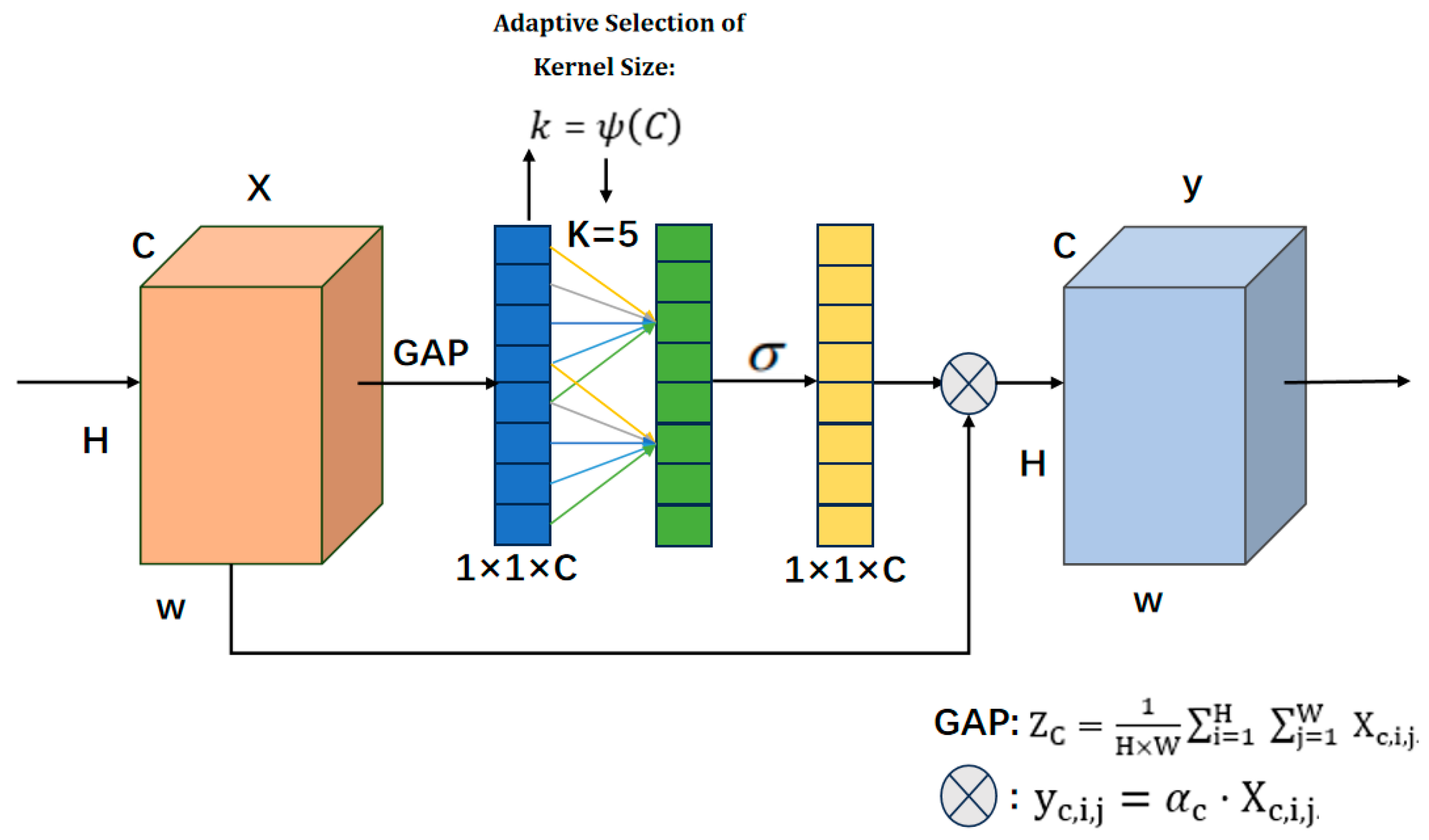
As depicted in
Figure 4, the ECA module operates through the following optimized workflow:
Firstly, the input feature map
to generate channel-level statistical feature vectors compressed along the spatial dimension:
where
characterizes the global context information of the cth channel and provides the basis for subsequent channel weight assignments.
To optimize the efficiency of local cross-channel interactions, the module dynamically adjusts the size of the one-dimensional convolutional kernel k according to the number of channels C, whose dimensions are adaptively generated by a nonlinear function:
where
and
are hyperparameters that guarantee that the
result is odd. Adaptation of feature interaction requirements for different channel dimensions. This design avoids the limitation of fixed kernel dimensions and reduces computational complexity through dynamic kernel adjustment.
Subsequently, a one-dimensional convolution operation is performed on the feature vector
to model the dependencies between neighboring channels:
Nonlinear correlations between channels are captured through local interactions, replacing the parameter redundancy of traditional fully connected layers. The convolution output is normalized to the channel attention weights by a Sigmoid function:
Ultimately, the original feature maps are multiplied channel-by-channel with the weight vectors to achieve dynamic calibration of the feature maps:
This process significantly enhances discrimination between structurally consequential defect classes, such as cracks and knots by amplifying critical channel responses while suppressing wood grain noise, thereby improving reliability in safety-critical timber inspections. This dynamic channel recalibration provides a secondary line of defense against noise interference, including potential residual background texture noise propagated from earlier layers (e.g., the identity branch of RepVGG), further ensuring that discriminative features dominate the representation.
The ECA module introduces minimal computational overhead due to its lightweight design. The 1D adaptive convolution operates on a compressed channel vector Z ∈ RC × 1 × 1, reducing GFLOPs to O (C⋅k), where k ≤ 5 (typically k = 3). For a 640 × 640 input, this corresponds to <0.01 GFLOPs—below the precision threshold of standard deep learning profilers, explaining its negligible impact until combined with CARAFE.
2.5. CARAFE
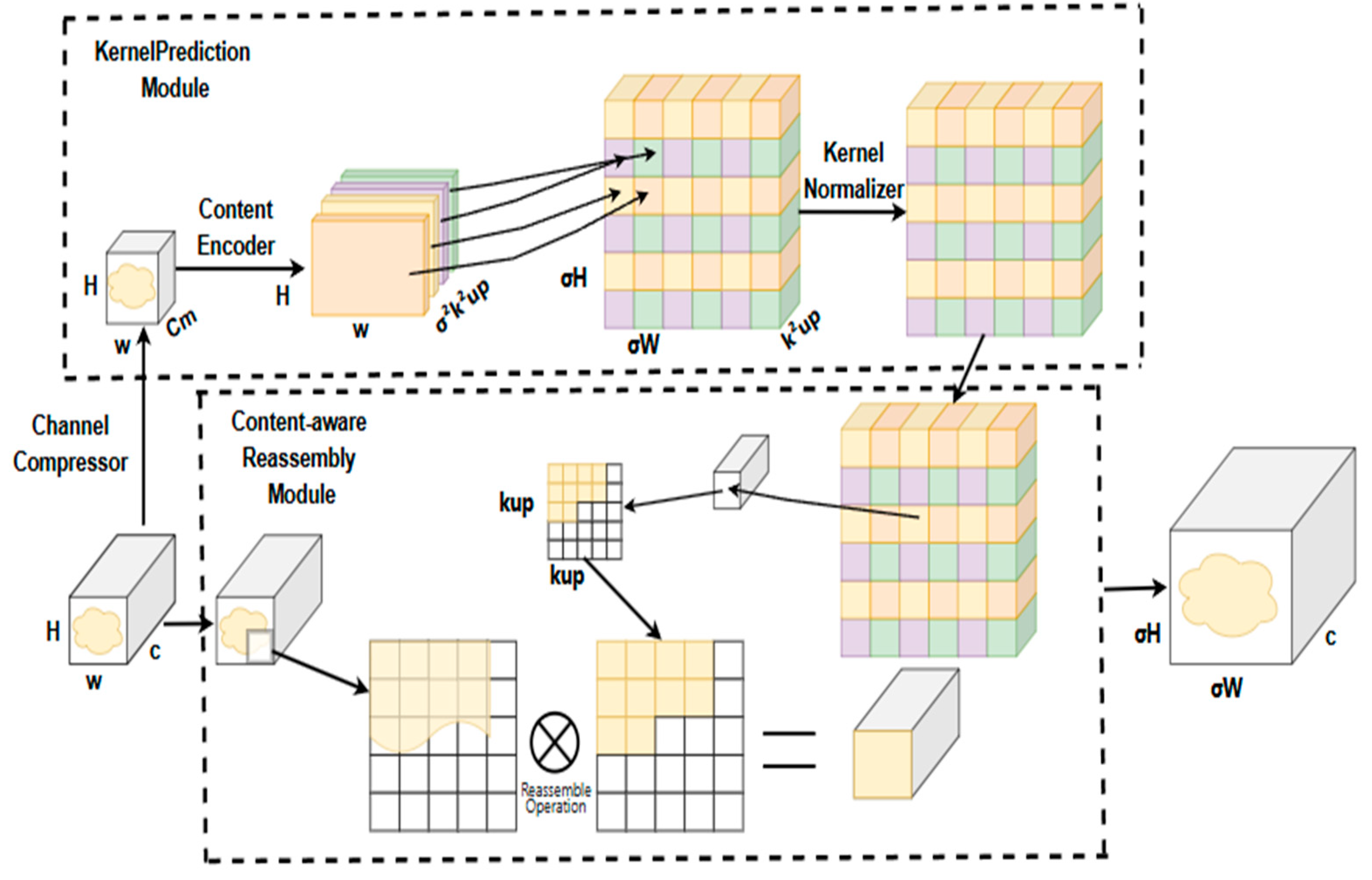
In timber construction quality assurance, accurate detection of surface defects directly determines structural reliability, load-bearing capacity, and building longevity. Morphologically variable defects—such as irregularly propagating cracks (creating unpredictable stress concentrations), complex-textured knots at joint interfaces (reducing effective area), and resin pockets/inhomogeneities (indicating potential zones of weakness or moisture ingress)—pose significant challenges. Traditional up-sampling methods with fixed kernel sizes and limited receptive fields struggle to capture the global context and fine details of these safety-critical imperfections, potentially leading to missed detections or inaccurate sizing. CARAFE overcomes these limitations through a content-aware feature reorganization mechanism that dynamically generates adaptive up-sampling kernels based on input feature maps. This approach enables deep correlation modeling of contextual defect information through localized dot-product operations, significantly expanding receptive fields while enhancing defect semantic representation via nonlinear feature interactions—critical for pinpointing subtle defects in structural timber.
As illustrated in
Figure 5, the CARAFE module comprises two core components essential for construction-grade timber inspection: The Up-sampling Kernel Prediction Module first reduces computational load through channel compression: a 1 × 1 convolution decreases input channels from C to Cm. A kencoder × kencoder convolutional layer then predicts up-sampling kernels with Cm input channels and σ
2k
2up output channels, where kup × kup defines the kernel dimensions (typically 3 × 3) and σ denotes the upscaling factor. These adaptive kernels encode defect-specific contextual patterns vital for structural assessment. The Feature Reorganization Module generates the output feature map (dimensions σH × σW × C) by computing dot products between kup × kup regions centered on input feature map locations and their corresponding predicted kernels. This process is particularly crucial for timber defect detection as it extracts fine-grained features correlating with structural performance—such as microcrack propagation tendencies and resin distribution anomalies affecting moisture resistance—by establishing mappings from output coordinates to input regions. This allows comprehensive utilization of semantic information, substantially improving detection accuracy for safety-critical defects.
Through content-aware reorganization, CARAFE significantly enhances sensitivity to morphologically variable defects that critically impact structural durability and load capacity. By preserving fine geometric details (e.g., microcrack initiation points) and capturing long-range contextual correlations (e.g., the full path of a crack), CARAFE provides more precise defect localization and characterization. This robust solution for automated quality control is vital for preventing catastrophic structural failures under service loads caused by undetected or mischaracterized imperfections.
3. Results and Discussion
3.1. Dataset
Originally comprising 20,275 high-resolution images (2800 × 1024 pixels) documenting ten categories of wood surface imperfections, this resource was rigorously filtered through a three-step protocol: (1) Safety-critical class retention: Only images containing the eight defects most threatening to structural integrity (quartz, live knot, marrow, resin, dead knot, knot with crack, missing knot, and crack) were retained; (2) Quality control: Exclusion of images with motion blur, inconsistent lighting, or ambiguous annotations; and (3) Distribution preservation: The final curated dataset of 4000 images maintains the original defect occurrence ratios observed in the full dataset (
Table 1). This ensures representative sampling while eliminating noise. Data partitioning followed an 8:1:1 ratio for training, validation, and testing.
All images underwent standardized preprocessing to ensure robustness and convergence efficiency. RGB pixel values were normalized to the [0, 1] range through division by 255, a critical step for stabilizing gradient descent during optimization. Defect categories were systematically converted to integer indices via ordinal encoding (0: Quartz, 1: Live knot, 2: Marrow, 3: Resin, 4: Dead knot, 5: Knot with crack, 6: Knot missing, 7: Crack), with bounding box annotations formatted as normalized coordinates (center_x, center_y, width, height) relative to image dimensions. During training, we employed YOLOv8′s augmentation pipeline including mosaic composition, random geometric transformations, and photometric adjustments to enhance model generalization across variable imaging conditions typical in structural timber inspection environments.
3.2. Analysis Environment Configuration and Network Parameters
This analysis was carried out in a standardized training environment, and the hardware configuration, software environment, and model training parameters are shown in
Table 2 and
Table 3. All analyses used the same parameter settings to ensure comparable results.
The hyperparameters were selected based on established practices for YOLO-series models and preliminary grid-search experiments. We adopted SGD with Nesterov momentum due to its proven generalization capability in object detection tasks. Initial learning rate (0.01), momentum (0.937), and weight decay (5 × 10−4) were calibrated through a reduced grid search on 10% of the training data, evaluating mAP50 at epoch 100. We tested learning rates {0.1, 0.01, 0.001}, momentum {0.9, 0.937, 0.98}, and weight decay {1e−3, 5e−4, 1e−4}, selecting values that maximized validation recall. The epoch count (220) was determined via early stopping with a 30-epoch patience threshold on mAP50-95. Comparative tests show that AdamW (lr = 1e−3, weight decay = 0.05) has a faster initial convergence speed, but the final mAP50 is 1.2% lower.
3.3. Evaluation Indicators
This study constructs a quantitative evaluation system from two dimensions: detection accuracy and model complexity. In terms of detection accuracy, precision rate, recall rate, F1 score, and average precision mean are used as the core indexes; in terms of computational efficiency, the number of model parameters is used as the core index, and the formula is as follows:
where
TP denotes the number of correctly detected defective samples, FP is the number of misdetected non-defective samples, and FN corresponds to the number of missed real defective samples. p measures the accuracy of the model in correctly identifying positive class samples, R reflects the completeness of the model in covering real defects, and the F1 score combines the two as a core performance indicator through harmonic averaging. AP is the average precision rate of each defective class, and mAP is the mean of the AP values of all defective categories, where AP values are averaged. The mAP50 and mAP50-95 metrics reported for the YOLOv8n and WDNET-YOLO models are based on the average of five independent training experiments.
3.4. Ablation Analyses
In order to verify the synergistic optimization effect of the improved modules on the structural timber defect detection performance, this study gradually introduces RepVGG, ECA, and CARAFE modules based on the YOLOv8n baseline model, and constructs the ablation analysis. The contribution mechanism of each module is systematically analyzed in terms of detection accuracy (mAP, F1) and computational efficiency (GFLOPs), and the results of the ablation analyses are shown in
Table 4.
All GFLOPs measurements used consistent 640 × 640 inputs. ECA’s near-zero GFLOPs occur because: (1) its global average pooling (H × W1) adds no multiply-add operations and (2) the subsequent 1D convolution on C-dimensional vectors requires only C × k operations (e.g., 0.0002 GFLOPs for C = 512, k = 3), which rounds to 0.0 GFLOPs in standard reporting. CARAFE’s kernel prediction and reorganization operations increase GFLOPs measurably.
The comprehensive multi-round evaluation (
Table 5) confirms the statistically significant reliability of the WDNET-YOLO improvements, achieving a 3.7% increase in mAP50 and a 3.5% increase in mAP50-95. These gains significantly exceed the run-to-run variance by factors of 8.8 for mAP50 and 6.6 for mAP50-95. The results of the paired
t-tests were highly significant (t (4) = 16.5,
p < 0.0001 for mAP50; t (4) = 13.2,
p < 0.0001 for mAP50-95), clearly demonstrating that the observed improvements surpass training noise and represent genuine performance enhancements.
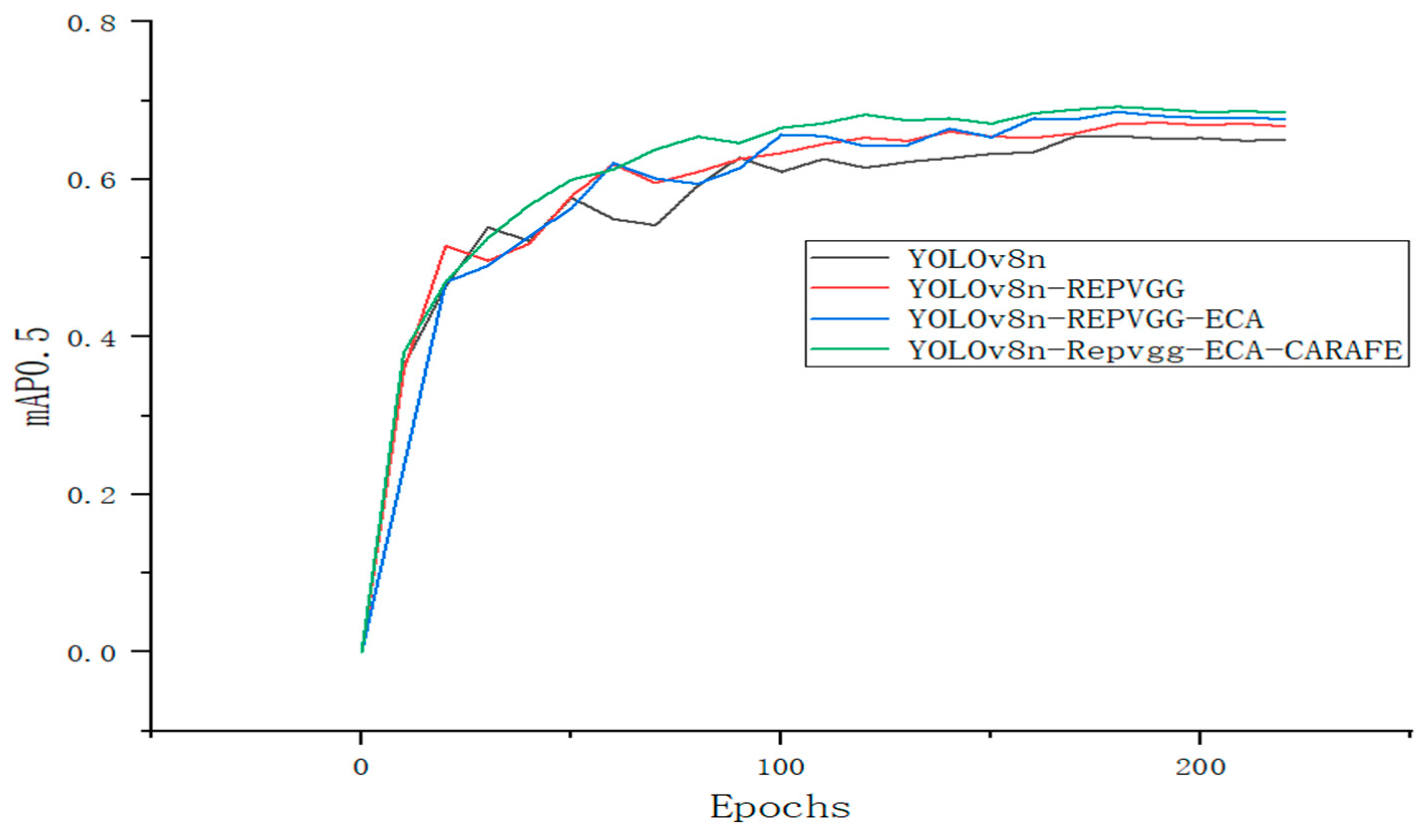
In order to observe the comparison of the results of the ablation analyses more intuitively during the analyses, we plotted the mAP50 results of each model as a visual data plot, as shown in
Figure 6.
Based on the results of the ablation analyses, we found that the RepVGG module, without increasing the number of parameters and computation, elevated mAP50 to 67.2% and mAP95 to 37.5%. After superimposing the ECA channel attention, mAP50 and mAP50-95 further increased to 68.6% and 38.5%, respectively, with F1 reaching 68.8%. Finally, with the introduction of CARAFE dynamic up-sampling, mAP50 and mAP50-95 were significantly increased to 69.2% and 40.2%, respectively, and precision increased by 4.6% to 77.1%. “After the synergistic optimization of the three modules, WDNET-YOLO achieves significant improvements over the YOLOv8n baseline: mAP50 increases by 3.7% (from 65.5% to 69.2%), mAP50-95 increases by 3.5% (from 36.7% to 40.2%), and F1 score increases by 1.5% (from 68.1% to 69.6%). More importantly, this performance improvement was achieved with only a 4.4% increase in the number of parameters (from 3 million to 3.1 million parameters). These results strongly validate the effectiveness of the proposed improvement scheme and demonstrate an excellent balance between detection accuracy and model efficiency.
3.5. Comparative Analyses
In this study, the performance of the proposed WDNET-YOLO model is compared with other mainstream target detection algorithms, and the comparison results are shown in
Table 6.
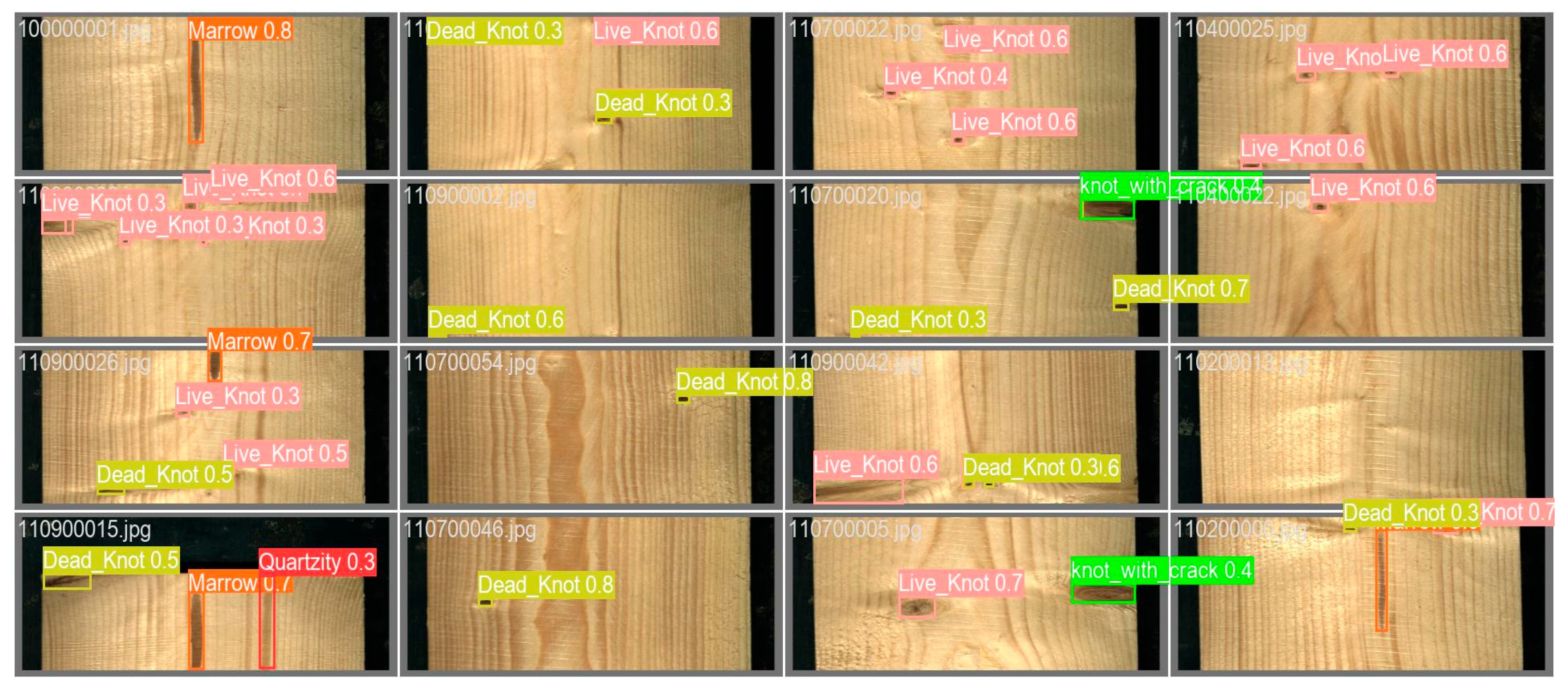
Based on the results of the comparison analyses, we find that WDNET-YOLO performs well in all the metrics, especially in the metrics of mAP50 and mAP95, which reach 0.693 and 0.402, respectively, and are significantly higher than the comparison models such as YOLOv5n, YOLOv10n, and Faster CNN. In addition, WDNET-YOLO maintains good efficiency by having higher accuracy with a more moderate number of parameters and computational complexity. As shown in the comparison chart of detection results in
Figure 7 and
Figure 8, compared with the YOLOv8n baseline model, WDNET-YOLO obtains a much better detection performance without a significant increase in computational effort, thus demonstrating the potential for application in structural timber defect detection tasks.
When the input resolution is reduced from 2800 × 1024 to 640 × 640, microcracks with a width ≤ 5 pixels in the original image are compressed to the sub-pixel scale. The morphological information of such defects may be partially lost. To assess the impact of resolution reduction on sub-pixel-level defects, 136 microcracks with a width ≤ 5 pixels were selected from the dataset. The performance of the three scenarios was compared under unified experimental conditions.
As shown in
Table 7 results, the sensitivity loss due to reduced resolution is negligible: WDNET-YOLO’s recall rate (0.557) at 640 × 640 resolution is 4.7% lower than the original resolution (0.604). This small decrease demonstrates that the WDNET-YOLO model effectively mitigates the loss of sub-pixel morphological information caused by the significant downsampling, maintaining high sensitivity for detecting microcracks even below 5 pixels in the original image. Under the same 640 × 640 input, WDNET-YOLO’s recall rate (0.557) is 3.9% higher than that of YOLOv8n (0.518), demonstrating that its enhanced structure provides substantial optimization for microcrack detection. Future research should explore further improvements in detection capabilities through a high-low resolution collaborative framework.
3.6. Discussion
The results presented in the ablation and comparative analyses demonstrate the effectiveness of the proposed WDNET-YOLO model. This advanced deep learning framework integrates three synergistic innovations into the YOLOv8n architecture specifically to address critical safety challenges in timber construction through high-precision defect detection.
The RepVGG-reconfigured backbone significantly enhances the model’s ability to capture multi-scale defect features critical for structural assessment. This capability is essential for precisely identifying diverse imperfections ranging from minute insect holes (potential initiation points for decay) to large crack propagation patterns (directly threatening load-bearing capacity) in beams and columns, which are critical for assessing structural integrity. The multi-branch design, particularly the synergy between the 1 × 1 branch (capturing fine details like microcracks below the 3 × 3 receptive field) and the 3 × 3 branch (modeling global context), proved crucial in handling clustered defects. The batch-normalization-based fusion mechanism effectively balanced the contributions, preventing overwhelming noise from the identity branch while preserving valuable localization fidelity (
Table 4, RepVGG improves mAP50 by 1.7%). Complementing this, the ECA attention mechanism can dynamically suppress interference caused by complex and variable wood grain textures—the main source of false positives in traditional methods. At the same time, it can selectively amplify distinguishing features between high-risk defect categories (e.g., tension-weakened cracks and compression-weakened knots, live knots and dead knots). If these categories are misclassified, it could lead to catastrophic errors when estimating the load-bearing capacity of wooden components. Further enhancing morphological sensitivity. CARAFE up-sampling with adaptive context reorganization meticulously preserves minute geometric details of safety-critical micro-defects exhibiting high variability. For instance, accurately capturing the width, branching, and termination points of fine cracks is essential for assessing their potential to propagate under load and cause catastrophic fracture. The directly addresses a key durability concern in modern timber construction.
WDNET-YOLO achieves 3.7% higher mAP50 and 3.5% higher mAP50-95 compared to YOLOv8n, while maintaining computational efficiency with only a 4.4% parameter increase. These improvements translate directly to enhanced building safety. Superior detection sensitivity for defects affecting structural durability reduces the risk of undetected flaws compromising performance. Reduced misclassification during material grading prevents improper load capacity estimation. Reliable defect quantification provides robust support for compliance with international timber construction standards. Rigorous ablation and comparative analyses consistently demonstrate WDNET-YOLO’s superiority over mainstream detectors, including YOLOv5n, SSD, and Faster R-CNN, particularly in complex inspection scenarios involving dense knots, fine cracks, and varied resin distributions characteristic of real-world construction-grade timber.
While WDNET-YOLO demonstrates significant advantages, three limitations warrant consideration: validation was performed exclusively on timber specimens under controlled imaging conditions, leaving performance on other construction materials unverified; the current RGB-based approach cannot detect internal defects; and real-time deployment on resource-constrained edge devices requires further optimization despite the model’s parameter efficiency. To address these constraints and enhance practical adoption, future efforts will focus on three interconnected pathways: developing multi-modal fusion techniques combining RGB with ultrasonic sensing for comprehensive defect characterization; optimizing edge deployment through TensorRT quantization for NVIDIA Jetson devices and Raspberry Pi-based portable inspection kits; and validating the framework across steel-concrete composites and engineered bamboo systems.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}