1. Introduction
Patent drafting serves as the critical bridge between technological achievements and legal rights, directly influencing the scope of protection and the competitive advantage of innovators. This process is highly specialized, requiring not only a deep understanding of the technical domain but also a solid grasp of relevant legal principles. Traditional patent applications are often time-consuming, costly, and demand high standards of drafting quality. These challenges are particularly pronounced in the field of prefabricated integral buildings, where the complexity of technical descriptions and the precision required in claims further complicate the drafting process [
1,
2]. Prefabricated integral buildings (PIBs) are factory-finished volumetric modules, three-dimensional units that arrive on-site with a structural frame, envelope, building-services systems and finishes already integrated, requiring only stacking and mechanical connection. Volumetric modular systems have become a major focus of industrialized construction policy and produce an especially rich corpus of patents on inter-module joints; the combination of detailed 3D descriptions and high document density makes PIB patents an ideal test-bed for evaluating large language model-based validation methods.
The effectiveness of large language models (LLMs) in generating patent documents depends fundamentally on their capacity for accurate semantic understanding and logical coherence, since deficiencies in these aspects frequently manifest as internal inconsistencies and errors in generated texts. To systematically assess these critical capabilities before selecting our primary baseline model, we conducted a targeted error-detection experiment. Specifically, candidate LLMs were tasked with identifying deliberately introduced semantic and logical inconsistencies within a carefully constructed dataset comprising 100 prefabricated building patent text excerpts (containing 300 seeded errors in total).
Precision refers to the proportion of correctly identified errors among all detected errors, recall refers to the proportion of correctly identified errors among all actual errors, and the F1 score represents the harmonic mean of precision and recall. The results of this evaluation, as detailed in
Table 1, indicated that GPT-4o achieved superior performance, obtaining the highest precision (0.90), the highest recall (0.58), and consequently, the best overall F1 score (0.70). These outcomes confirm GPT-4o’s strong ability to consistently interpret complex technical information and maintain logical clarity, thereby justifying its adoption as the central LLM in our subsequent patent-drafting experiments. In addition, ChatGPT’s advanced natural language capabilities can markedly accelerate patent preparation. It can rapidly generate multiple candidate claims and detailed technical descriptions, thereby reducing the time patent professionals spend on drafting and revision [
3,
4]. Second, ChatGPT improves the linguistic quality of patent documents by translating complex technical language into more accessible and accurate patent descriptions, which is crucial for ensuring clarity and professionalism in patent applications [
5]. Recent research shows that ChatGPT outperforms other LLMs in API validation tasks, especially in low-latency, high-precision scenarios [
6]. Moreover, its o3-mini-high variant likewise surpasses competing models in scientific computing, combining top-tier accuracy with the fastest reasoning speed [
7]. Complementing these findings, Jurišević et al. have demonstrated the practical viability of GPT-3.5 in kindergarten energy management, underscoring the growing relevance of LLMs for building-related optimization tasks [
8].
However, despite the numerous advantages that ChatGPT offers, several challenges remain in practical applications. A primary concern is that ChatGPT may not yet fully comprehend intricate technical concepts or adhere strictly to precise legal requirements, potentially resulting in outputs that lack technical depth or legal accuracy [
9,
10,
11]. Additionally, due to the broad and diverse sources of training data, the model may inadvertently introduce biases or omit critical information, which could compromise the fairness and comprehensiveness of patent texts. Moreover, using AI tools such as GPT for patent drafting raises concerns regarding data security and confidentiality. It is essential to safeguard the sensitive information of inventors and enterprises and to ensure compliance with the disclosure regulations stipulated in patent law [
12,
13,
14].
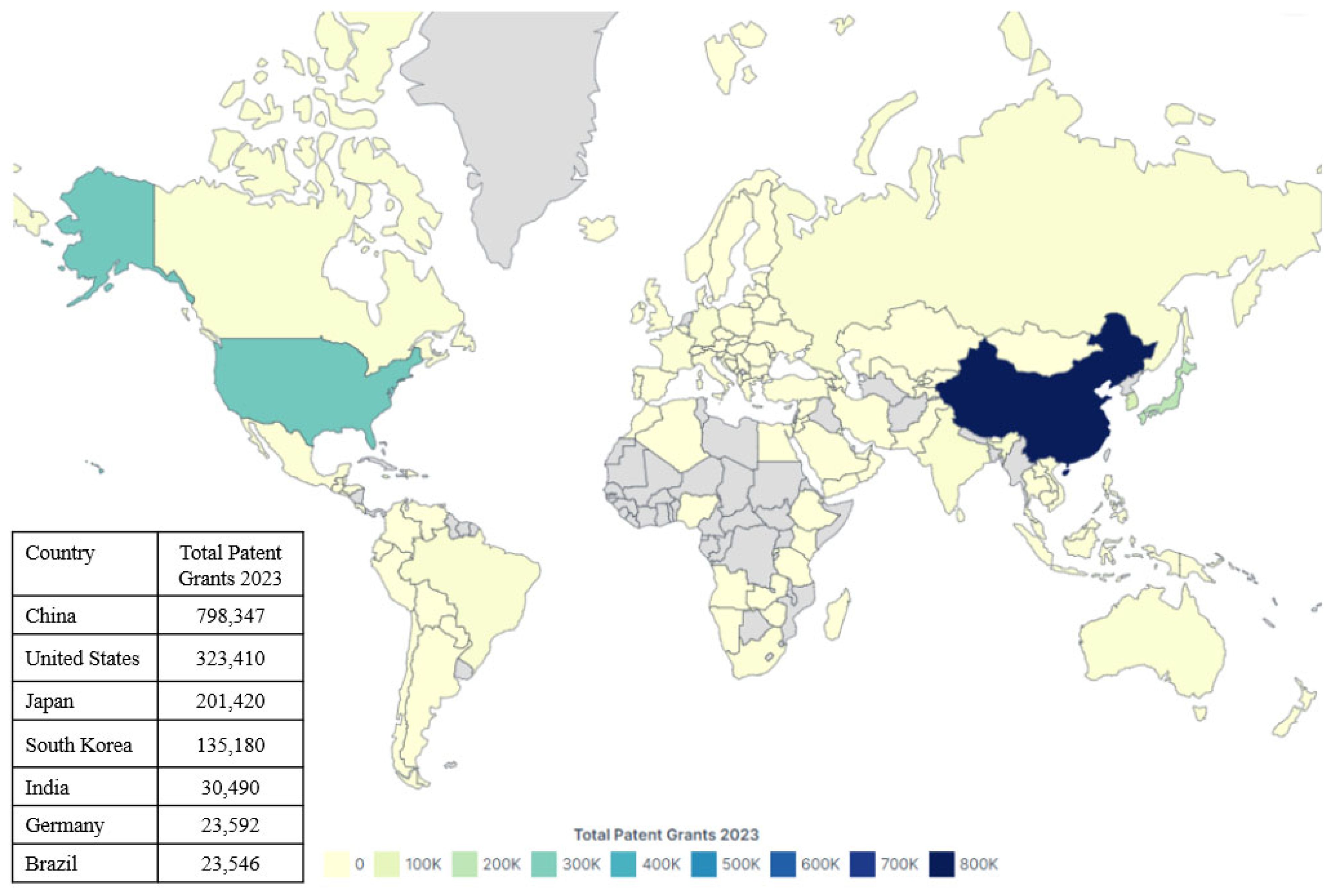
Over the past five years, China has granted more than 2.53 million patents, with an average annual growth rate of 13.4%. In 2023 alone, approximately 798,347 patents were granted in China, as illustrated in
Figure 1.
Figure 2 shows a continuous increase in the number of patents granted per 10,000 R&D personnel, indicating a rise in productivity or innovation output among Chinese researchers and a growing demand for patent filings.
Beyond China, several developed countries have maintained relatively stable patent authorization volumes, with a general trend of steady growth. In contrast, some emerging economies are still in the accumulation phase of patent development, with room for improvement in both the quantity and quality of patent output [
17].
In summary, GPT-4o demonstrates significant potential in generating structured and logically coherent patent texts in the architectural domain, particularly in supporting the drafting of legal and technical documents. The aim of this study is to explore the use of GPT-4o in drafting patent texts for prefabricated integral buildings and to document the model’s performance in generating initial patent drafts, thereby providing guidance for applicants in the patent writing process.
2. Methodology
To comprehensively evaluate the effectiveness of GPT-4o in drafting patents for prefabricated integral buildings, the research methodology was systematically designed combining research strategy, data collection, text generation, and statistical analysis. First, a hybrid framework combining experimental design with expert evaluation was established to ensure both the professionalism and practical applicability of the generated texts. Second, during the data collection phase, representative patent cases from China and Russia were carefully selected. A stepwise input approach was adopted to simulate realistic drafting scenarios, enabling a systematic assessment of the model’s performance under varying input conditions. This stepwise design closely simulates the real-world patent drafting process and ensures that the evaluation comprehensively captures both linguistic quality and technical accuracy.
Building on this foundation, the quality of the generated texts was evaluated through a combination of self-assessment and expert scoring, which served as the basis for the iterative refinement of the generation process. Finally, multiple linear regression analysis was employed to quantitatively analyze the evaluation scores, identify key variables influencing expert assessments, and verify the validity and consistency of the model’s output.
2.1. Research Strategy
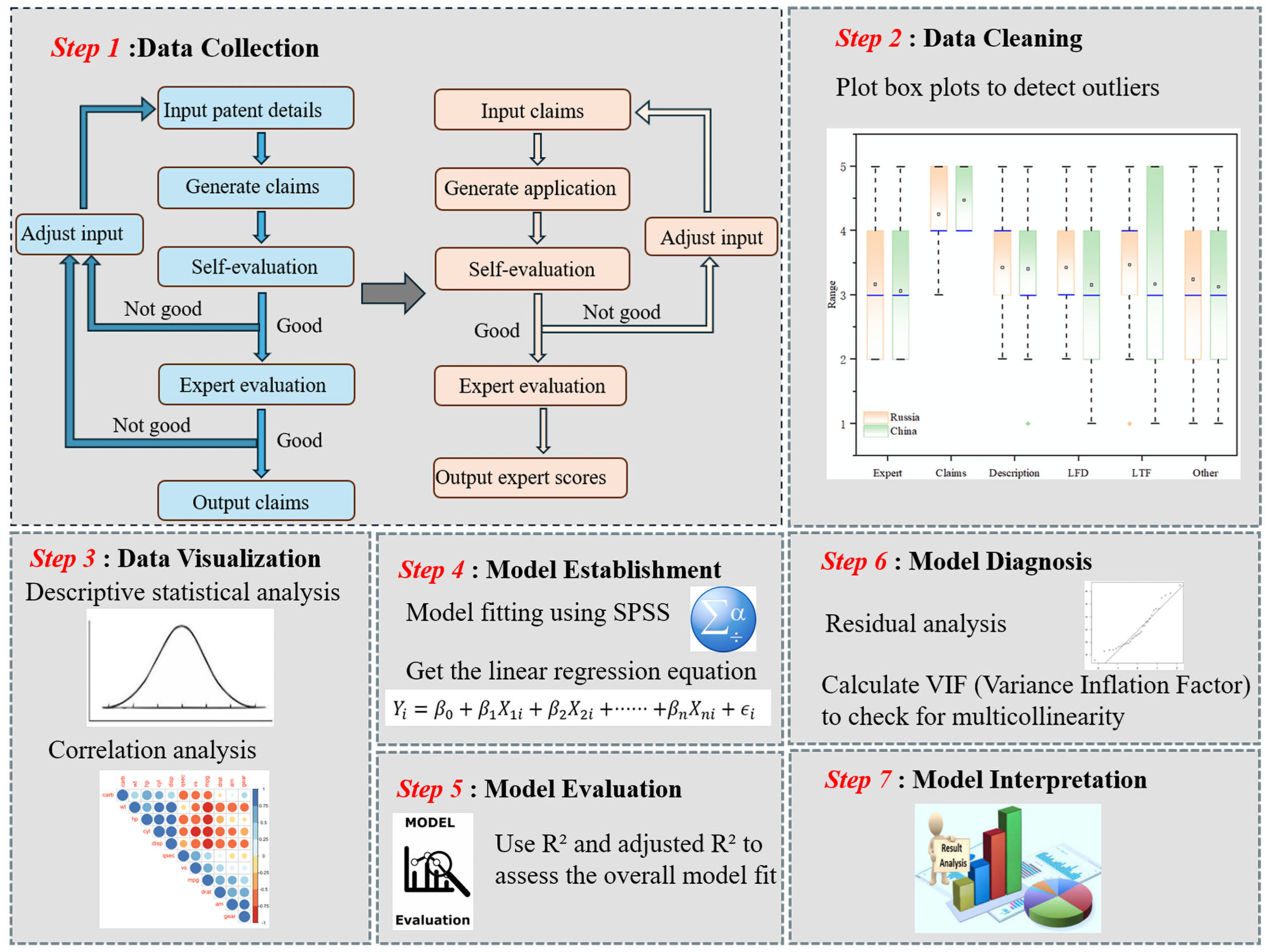
This study adopted a mixed research strategy combining experimental design and expert evaluation to assess the potential of artificial intelligence in the patent drafting process, as illustrated in
Figure 3 Specifically, focus was placed on evaluating the performance of GPT-4o in generating claims for prefabricated integral building technology patents. By comparing the model’s outputs with expert assessments, the study aimed to verify its generation capabilities and linguistic quality under varying levels of input specificity [
18,
19].
The research began by gradually refining the input content to observe GPT-4o’s performance under different input conditions. Interactive adjustments were made based on both system self-assessment and expert evaluation. This strategy was designed to simulate the iterative drafting and optimization process inherent to real-world patent applications, while its mixed-method structure (quantitative probe + qualitative expert review) provides both statistical rigor and practical relevance. With the goal of maximizing the technical accuracy and legal validity of the generated texts while improving drafting efficiency. The inclusion of multiple rounds of self-assessment and expert review ensured the reliability of the findings and their practical relevance in real application contexts [
20]. This strategy ensured that both the drafting logic and expert validation were fully integrated into the experimental workflow.
Through the research strategy, this study aims to conduct an in-depth analysis of GPT-4o’s performance in the patent drafting process, with a focus on evaluating the quality of Claims, Descriptions, Linkage of Features to Disclosure, and Linkage of Text to Figures and Other Text. In addition, the study explores the correlation between the model’s self-assessment capabilities and expert evaluation results, thereby providing both theoretical and practical foundations for the future application of AI-assisted patent drafting.
2.2. Data Collection Methods
The research design centered around a step-by-step experimental procedure aimed at stimulating the real-world patent drafting process. Initially, a total of 230 representative patents were selected from the Google Patents database—115 from Russia and 115 from China—covering key technological innovations in the field. This ensured both the breadth and representativeness of the research sample. For each patent, the title, abstract, and relevant figures were extracted to provide GPT-4o with the initial input, thereby simulating the basic information typically available to patent drafters during the claims drafting stage.
During the experiment, GPT-4o was instructed to generate corresponding patent claims based on the provided abstracts and figures. The model first produced an initial draft, after which a self-evaluation was conducted manually by the research team using a five-level rubric: “Very Bad,” “Bad,” “Fair,” “Good,” and “Very Good.” GPT-4o was not involved in performing the self-evaluation. If the result of the manual self-evaluation did not reach the “Good” level, the input information was incrementally enriched—for example, by supplying basic component descriptions, lists of involved elements, technical details, connection methods, materials used, and their advantages. This iterative process was repeated until the research team rated the output as “Good” or higher. Only those drafts that met this threshold were forwarded to domain experts for external review, ensuring the overall quality and completeness of the generated texts [
21,
22].
The iterative generation process followed a structured prompt refinement strategy aligned with the three evaluation dimensions outlined in
Table 2. The initial prompt provided only the abstract and figure to simulate minimal input. If the resulting draft lacked key components or implementation steps, the next prompt supplemented this information. If the language was vague or the alignment between text and figures was unclear, further refinement addressed terminological precision and structural consistency. When claim boundaries were ambiguous or no embodiment was included, a final prompt was issued to clarify scope and add at least one concrete example. In most cases, two rounds of refinement were sufficient to reach the required “Good” level.
The regional focus on Chinese and Russian patent cases was informed by both methodological and practical considerations. These two jurisdictions represent distinct legal traditions and technical disclosure practices, allowing for a meaningful comparison of GPT-4o’s adaptability to different institutional contexts. Furthermore, the composition of the research team—consisting primarily of Chinese and Russian researchers—ensured strong linguistic and contextual familiarity with both patent systems. This background not only facilitated accurate interpretation of the model outputs but also enabled the effective recruitment of qualified domain experts from both countries, thereby enhancing the reliability of the expert evaluation process.
2.3. Data Analysis Methods
The objective of this study was to evaluate the impact of the quality and terminological standardization of GPT-4o-generated patent texts in the field of prefabricated integral buildings on expert comprehensive evaluations. Based on the 230 collected patent cases, data analysis was conducted using IBM SPSS Statistics 27.0.1 and a multiple linear regression model, which is a statistical method used to assess the relationship between a dependent variable and multiple independent variables [
23,
24].
The data collection involved multidimensional evaluations of each case, with the Expert Comprehensive Evaluation serving as the dependent variable to reflect the overall assessment of the patent texts. The independent variables included Quality of Claims, Quality of Description Text, Linkage of Features to Disclosure, Linkage of Text to Figures, and Other Text. This model enabled us to investigate how each explanatory variable independently influences the experts’ overall evaluation of the patent documents.
Once a claim draft received a “Good” rating from GPT-4o’s self-evaluation, it was submitted to two domain experts specializing in prefabricated integral building technologies for evaluation. These experts were deliberately selected for their highly relevant expertise: one is a professor in construction engineering who has authored dozens of granted patents, and the other is a senior engineer actively engaged in the research and development of prefabricated construction technologies, with extensive experience in patent drafting and examination. If both experts also rated the output as “Good,” the claims were accepted without modification. However, if the expert assessments did not meet expectations, the input information was further refined based on expert feedback, and the generation and evaluation process was repeated accordingly, as outlined in
Table 3. This iterative loop ensured that each generated draft met both the model’s internal standards and the expert validation thresholds before proceeding to the next experimental stage. During this self-evaluation phase, one to two additional regeneration rounds were typically sufficient for a draft to reach a “Good” rating before it was forwarded to the human experts. This phase aimed to verify the acceptability and practical applicability of GPT-4oT-generated texts within a specialized professional context.
Building on the validated claim drafts, GPT-4o was then guided to generate a complete patent application document, including sections such as “Field of Application,” “Description of the Prior Art,” “Statement of the Problem,” and “Disclosure of the Invention (Utility Model).” Experts assessed these outputs based on textual quality, degree of terminological precision, and technical accuracy, using a five-point rating scale (1 to 5), and provided detailed feedback (see
Figure 4).
In our experiments, most patent cases required at least one additional iteration after the initial AI draft before receiving a “Good” rating from the experts, as shown in
Table 4. On average, each patent underwent approximately two rounds of generation and refinement (including the initial attempt) to achieve final expert approval. The generation process similarly followed an iterative loop of self-assessment and expert evaluation to ensure the final document met high standards of quality and professionalism.
First, a descriptive statistical analysis was conducted on the expert evaluation scores to understand the basic characteristics of the data. Specifically, the mean, standard deviation, and score distribution were calculated. The mean represents the central tendency of the overall ratings, while the standard deviation measures the degree of dispersion in the scores [
25]. The formulas for calculating these statistical measures are as follows:
where
denotes the mean,
S represents the standard deviation,
is the expert rating for the
i-th patent, and
n is the sample size (
n = 115).
To assess the correlation between the explanatory variables and the dependent variable, a Pearson correlation analysis was conducted. The resulting correlation matrix illustrated the relationships between each pair of variables, with particular attention paid to their levels of statistical significance. By analyzing the correlation coefficients, we identified potential linear associations between the explanatory variables and the expert evaluation scores [
26].
A multiple linear regression model was then applied to evaluate the influence of each variable on expert ratings. The model is expressed as follows:
where
is the comprehensive evaluation of the
i-th expert,
is constant,
are the quality of claims, quality of description text, and precision of input text,
are the regression coefficients of each explanatory variable, and
is the error term, which represents the impact of other factors not explained by the model.
To evaluate the fitness of the regression model, the adjusted R-squared (
) was used to assess the explanatory power of the model. The values of
were employed to compare model fit across different conditions. In addition, an F-test was conducted to examine the overall significance of the regression model. If the models for both countries were statistically significant at the 0.05 level (
p < 0.05), this indicated that the explanatory variables had a significant overall effect on the dependent variable [
27,
28].
Finally, to verify whether the assumptions of the regression model were satisfied, a residual analysis was performed, including tests for the normality and independence of residuals. The Durbin–Watson statistic indicated that the residuals of both models did not exhibit significant autocorrelation, thus supporting the assumption of independent errors [
29].
3. Results
Descriptive statistics provide the foundation for subsequent statistical analyses and help to reveal differences in variable performance across regions. A higher mean combined with a lower standard deviation typically indicates that the corresponding variable exhibits more consistent and concentrated performance within the sample [
30]. In contrast, a lower mean and higher standard deviation suggest greater variability in evaluations, which may be attributed to sample heterogeneity or inconsistencies in assessment criteria. The following results are presented in a sequential structure: starting with descriptive statistics, followed by correlation analysis, regression modeling, and residual diagnostics. This stepwise approach ensures a clear and logical presentation of the findings.
By comparing the evaluation results of patent documents from Russia and China, we observed that both models received relatively high scores for the Claims section, indicating that the quality of this part was generally perceived as superior. Nevertheless, both countries showed relatively lower performance in expert evaluations related to Other Text components, suggesting room for improvement in those areas. Overall, despite some differences in scoring, the two countries demonstrated similar performance across most evaluation indicators, indicating a degree of consistency in the quality of patent document drafting.
Figure 5 presents the correlation matrix among different sections of the patent applications. Each matrix element represents the correlation coefficient between two variables, ranging from −1.0 (perfect negative correlation) to 1.0 (perfect positive correlation). The color gradient from orange to green reflects the direction and strength of the correlations, where orange indicates positive correlation and green indicates negative correlation, with darker shades representing stronger relationships.
As illustrated in
Figure 6, a notably strong positive correlation is observed between the Description section and expert evaluation in both Russia (r = 0.52) and China (r = 0.56). This suggests that more detailed and comprehensive descriptive content tends to be associated with higher expert appraisal scores. Furthermore, a moderate correlation between Claims and expert evaluations is also evident (Russia: r = 0.40; China: r = 0.47), indicating that the substantive quality of the claims contributes meaningfully to expert assessments. In contrast, structural components such as LFD and LTF exhibit weak or negligible correlations with expert evaluations, underscoring the relatively limited impact of formal layout features on perceived patent quality.
The R
2 values (Russia: 0.647; China: 0.681) in
Table 5 indicate that approximately 64.7% of the variance in expert comprehensive evaluations in Russia and 68.1% in China can be explained by the predictive variables in the model, suggesting a good model fit. The Standard Error of the Estimate was 0.645 for Russia and 0.581 for China, reflecting the average deviation between the predicted and actual values, with the Chinese model exhibiting slightly lower prediction error. The Durbin–Watson statistics (Russia: 1.797; China: 1.786) were both close to 2, indicating that the residuals were independent, and no significant autocorrelation was present in the data.
The model summary is further validated through analysis of variance, confirming the statistical robustness of the regression models.
The results of the analysis of variance (ANOVA) in
Table 6 further confirmed the statistical significance of the models and demonstrated a high level of predictive reliability. The total regression sum of squares was 32.547 for Russia and 31.794 for China, indicating that the variables included in the models effectively accounted for the variance in the dependent variable. The F-values for the two models were 15.658 and 18.844, respectively, with
p < 0.001, suggesting that at least one predictor variable had a significant effect on the dependent variable and thus rejecting the null hypothesis of no relationship. These findings indicate that the models possess strong statistical power in explaining patent evaluation outcomes.
In summary, the regression models, as detailed in
Table 7, demonstrated good fit and explanatory capability, offering valuable insights into how independent variables influence expert comprehensive evaluation.
Based on the regression analysis results, the contribution of each independent variable to the expert evaluations can be quantified through the following formulas:
The analysis results indicated that Claims and Description had the most significant effects (p < 0.001), suggesting that detailed and well-articulated claims and specifications are critical in achieving higher expert evaluations. Additionally, other variables exhibited a significant positive impact in the Russian model (p = 0.007), possibly reflecting a greater emphasis by Russian experts on the completeness and practical relevance of elements such as application fields, objectives, and implementation examples. In contrast, these aspects had a weaker influence in the Chinese model, implying that Chinese experts may place more importance on descriptions of technological innovation and technical detail.
The Linkage of Text to Figures (LTF) showed a significant positive effect in the Chinese model (p = 0.042), indicating that Chinese experts are more attentive to the consistency between figures and textual descriptions and their role in clarifying technical solutions. This effect was not significant in the Russian model, which may be due to a greater focus on textual depth and logical coherence. These differences highlight cultural and evaluative distinctions in patent assessment practices across countries, offering valuable insights into international patent applications.
The variance inflation factors (VIFs) were all close to 1, indicating no serious multicollinearity among the variables, thus ensuring the stability and reliability of the model. Overall, the results underscore the importance of clear claims and comprehensive descriptive documentation in the patent application process, while the influence of other factors was relatively limited [
31].
Table 8 shows that the predicted value ranges and means of the Russian and Chinese models are comparable, indicating similar performance in predicting expert evaluations. The mean residuals are zero, suggesting a good model fit. However, the Chinese model exhibits slightly smaller residual ranges and standard deviations, implying a marginally higher prediction accuracy compared to the Russian model. Both standardized predicted values and residuals fall within the normal distribution range, with no outliers observed, which further confirms the stability of the models. The residual statistics collectively indicate that both regression models are stable and reliable, exhibiting satisfactory predictive performance.
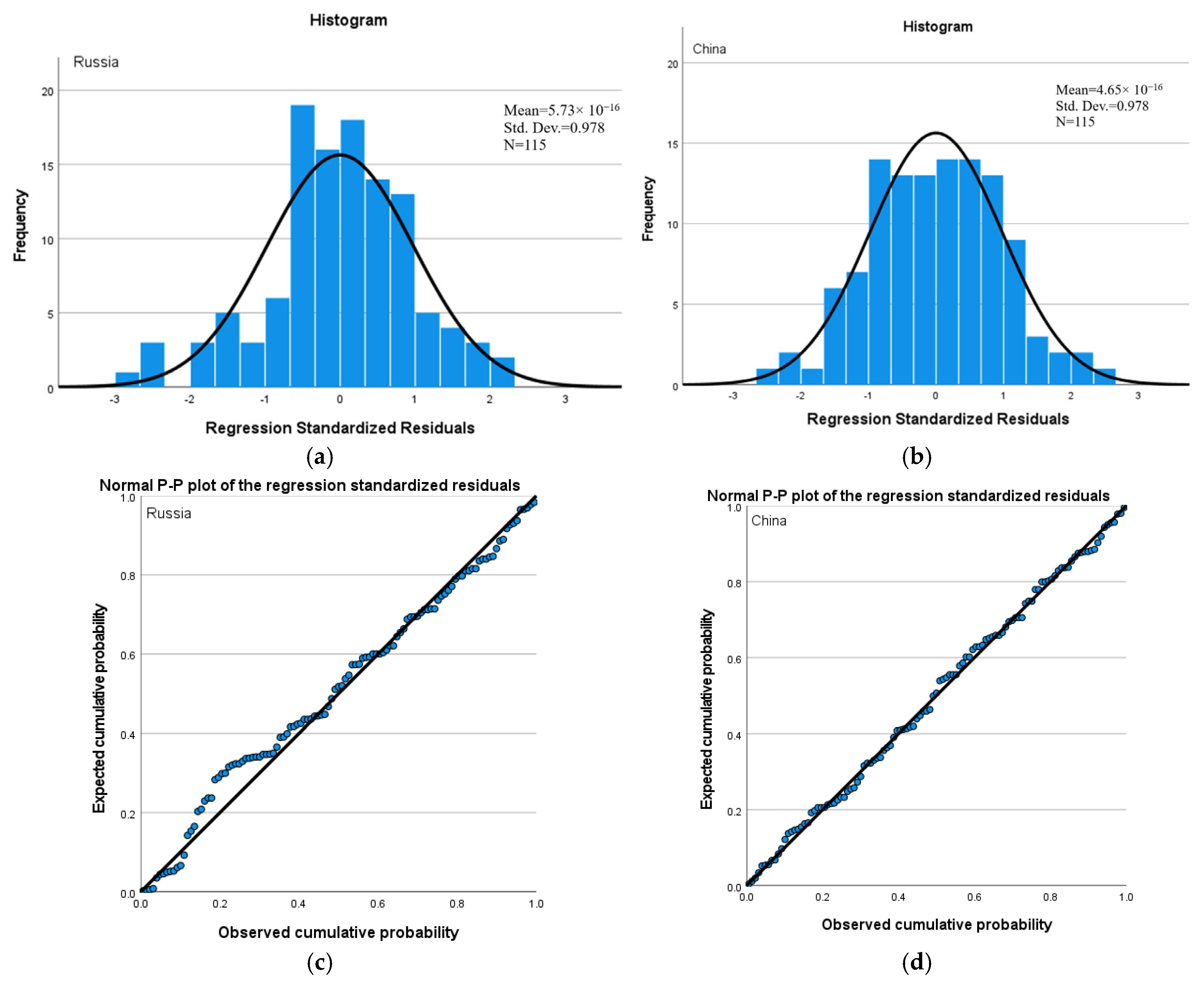
The histogram (
Figure 7a,b) illustrates the distribution of residuals for both models in comparison with the normal distribution. Ideally, if the residuals approximate a normal distribution, this suggests an absence of systematic error in the model. The histograms for both the Russian and Chinese models show that the residuals are generally normally distributed, with only slight deviations. The mean residuals are close to zero, and the standard deviations are near 1, which aligns with the characteristics of a well-fitting regression model.
The normal probability plots (
Figure 7c,d) further confirmed the normality of the residuals. The data points largely align along the reference line (the 45-degree line), with most points closely clustered around the line, especially in the mid-range. This supports the assumption of normal residual distribution, indicating that the observed cumulative probabilities closely match those expected from a theoretical normal distribution. Although a few points deviate slightly from the line, such deviations are not sufficient to challenge the overall assumption of normality for the models [
32,
33,
34].
In summary, the results are consistently presented across descriptive, correlational, and regression analyses, with additional diagnostic evidence reinforcing the statistical reliability of the models.
4. Discussion
This study verified both the potential and limitations of GPT-4o in the context of patent drafting for prefabricated integral buildings. While the model significantly enhanced the efficiency of writing patent claims and descriptive sections, several issues emerged during its application—issues that necessitate further model refinement and the integration of human expert input.
First, GPT-4o demonstrated the ability to generate high-quality claims and technical descriptions, greatly accelerating the early stages of patent preparation. Its natural language processing capabilities were particularly effective in transforming complex technical concepts into accurate and comprehensible language. However, the model still exhibited notable deficiencies in handling intricate technical constructs and domain-specific legal terminology. Notably, several expert reviewers found that some AI-generated drafts lacked concrete technical details, such as stepwise implementation methods or key engineering parameters, underscoring the need for future improvements in the model’s technical specificity.
Specifically, one recurring issue observed during the generation of claims was redundancy in the description of technical outcomes. This redundancy not only lengthened the text unnecessarily but also, in some cases, introduced ambiguity that detracted from the legal precision required in patent documentation. Moreover, the model often proposed multiple similar technical solutions, resulting in vague or overly broad patent scopes; however, patent claims must define distinct and well-delimited innovations. This reflects the current limitations of AI models in maintaining the consistency and uniqueness of technical disclosures.
During manual review, experts frequently noted repetitive phrases and ambiguous language in certain AI-generated drafts, which can undermine both the distinctiveness and legal enforceability of patent claims. To counter these problems, we recommend that future workflows combine automated redundancy/ambiguity checks with expert editing, and leverage model parameter adjustments (e.g., increased penalty for n-gram repetition) to further constrain output. In our study, all drafts were manually checked and edited to minimize such issues prior to expert evaluation.
Another key shortcoming was the lack of detailed descriptions of how the technical solutions are to be implemented. In many cases, the generated text failed to provide clear explanations of practical implementation, thereby reducing the utility and operational clarity of the claims. In patent examinations, detailed disclosure of implementation methods is critical to ensure that the application meets the standards of sufficiency and enablement.
Additionally, the evaluation methodology employed in this study has inherent limitations. While a structured manual self-evaluation was performed by the research team, it must be acknowledged that relying on the same researchers or model developers for evaluating outputs introduces potential subjectivity and bias. In principle, utilizing GPT-4o or any automated system for self-evaluation of its own outputs lacks logical validity, as such an approach is susceptible to systemic biases and limited objectivity. Therefore, we emphasize that our internal ratings primarily served as a filtering and pre-screening mechanism to improve efficiency, whereas the final validation of text quality and legal robustness was exclusively carried out by independent domain experts. Future work should incorporate additional layers of external evaluation—such as automated rating frameworks or assessments by a broader panel of experts—to further enhance the objectivity and reproducibility of the evaluation process.
Moreover, as this study focused only on Chinese and Russian patent data, the findings may not be fully generalizable to other legal and technical systems. Future research should extend the analysis to broader jurisdictions. A key limitation of this study is the regional and technical focus of the patent data used for both model prompting and evaluation. For future research, we believe it is essential to incorporate a wider variety of real-world patents—covering different fields, legal systems, and innovation types—to equip AI models with more comprehensive technical and legal knowledge. Such expansion is critical for generalizing findings and for further advancing the field of AI-driven patent drafting.
These limitations suggest that GPT-4o’s ability to handle technical depth and legal complexity remains constrained. To address these issues, future research may consider the following measures:
(1) Increasing the diversity of training data: Incorporating a broader range of legal texts and technical documents related to patents—especially from different technical fields—can improve the model’s understanding of legal and technical nuances.
(2) Integrating expert-assisted feedback mechanisms: Introducing expert review into the generation workflow can help refine the model output based on human feedback, thereby improving the accuracy and professionalism of the generated text.
(3) Implementing a rigorous text review process: After automated generation, a strict review process should be employed to detect and correct redundancy, inaccuracy, or ambiguity in the output [
35].
(4) Enhancing the evaluation framework: Combining internal screening with independent assessments and transparent criteria can increase the credibility, reproducibility, and academic rigor of future LLM-based patent generation studies.
5. Conclusions
This study conducted an in-depth investigation into the practical application potential of GPT-4o in the patent drafting process within the field of prefabricated integral buildings. The results demonstrated that GPT-4o exhibits notable advantages in generating Claims and Description texts, particularly in terms of linguistic expression, structural organization, and the completeness of technical descriptions. These capabilities highlight the model’s value in improving drafting efficiency and reducing labor costs, making it especially suitable for generating initial drafts and supporting revisions.
However, several critical issues remain in the model’s current implementation. For instance, a high degree of redundancy in the description of technical achievements was observed, which compromises textual conciseness and may blur the boundaries of patent protection. The model also tends to generate multiple similar but insufficiently differentiated technical solutions, leading to reduced novelty and clarity in the patent text. In addition, the lack of detailed descriptions regarding the implementation of technical solutions undermines the practical applicability and sufficiency of disclosure—both of which are essential for patent approval.
To address these issues, this study recommends establishing an expert-driven review mechanism when using GPT-4o to assist in patent drafting. Such a mechanism would ensure that model outputs are scrutinized and refined to meet high standards of legal compliance and technical accuracy. Improving the model’s performance also requires optimizing the structure and quality of training data, particularly by incorporating more diverse and high-quality patent samples, including real-world cases from various fields and technological levels. Furthermore, implementing a rigorous review and feedback process is crucial in enhancing the precision, professionalism, and usability of AI-generated patent documents.
In summary, while ChatGPT is not without limitations, it already demonstrates strong application potential in specific dimensions. With the integration of appropriate human oversight mechanisms and continuous optimization strategies, ChatGPT holds the promise of delivering transformative improvements to the patent drafting workflow.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}