
Building Surface Crack Detection Using Deep Learning Technology

Abstract
1. Introduction
2. Related Work
2.1. Current Status of Surface Crack Detection
2.2. Deep Learning Technology Used for Crack Detection
3. Method
3.1. Overview of CNN-Based Crack Detection Framework
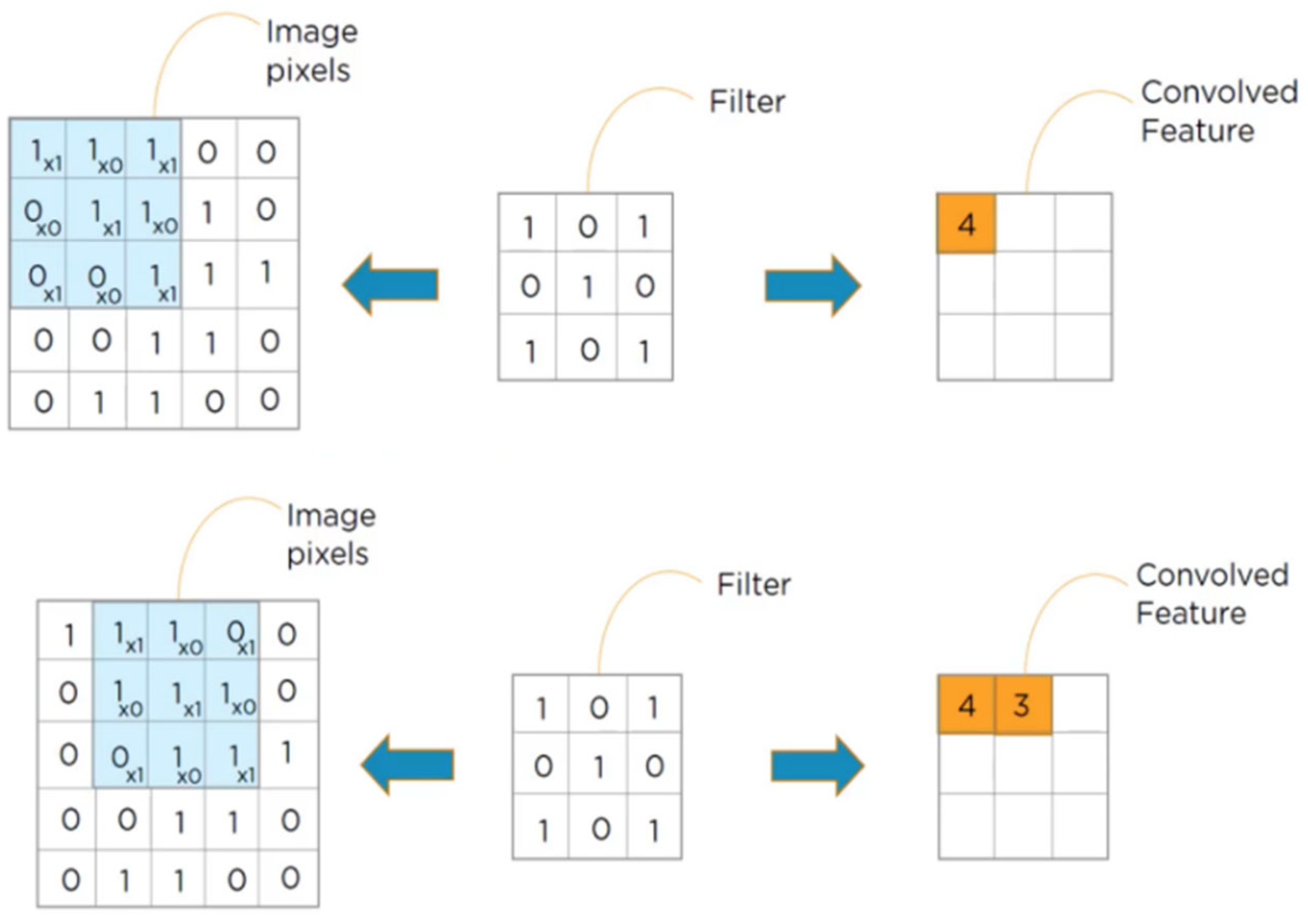
3.2. Convolutional Layer
3.3. ReLU Layer
3.4. Max Pooling Layer
3.5. Fully Connected Layer
3.6. Hidden Layers
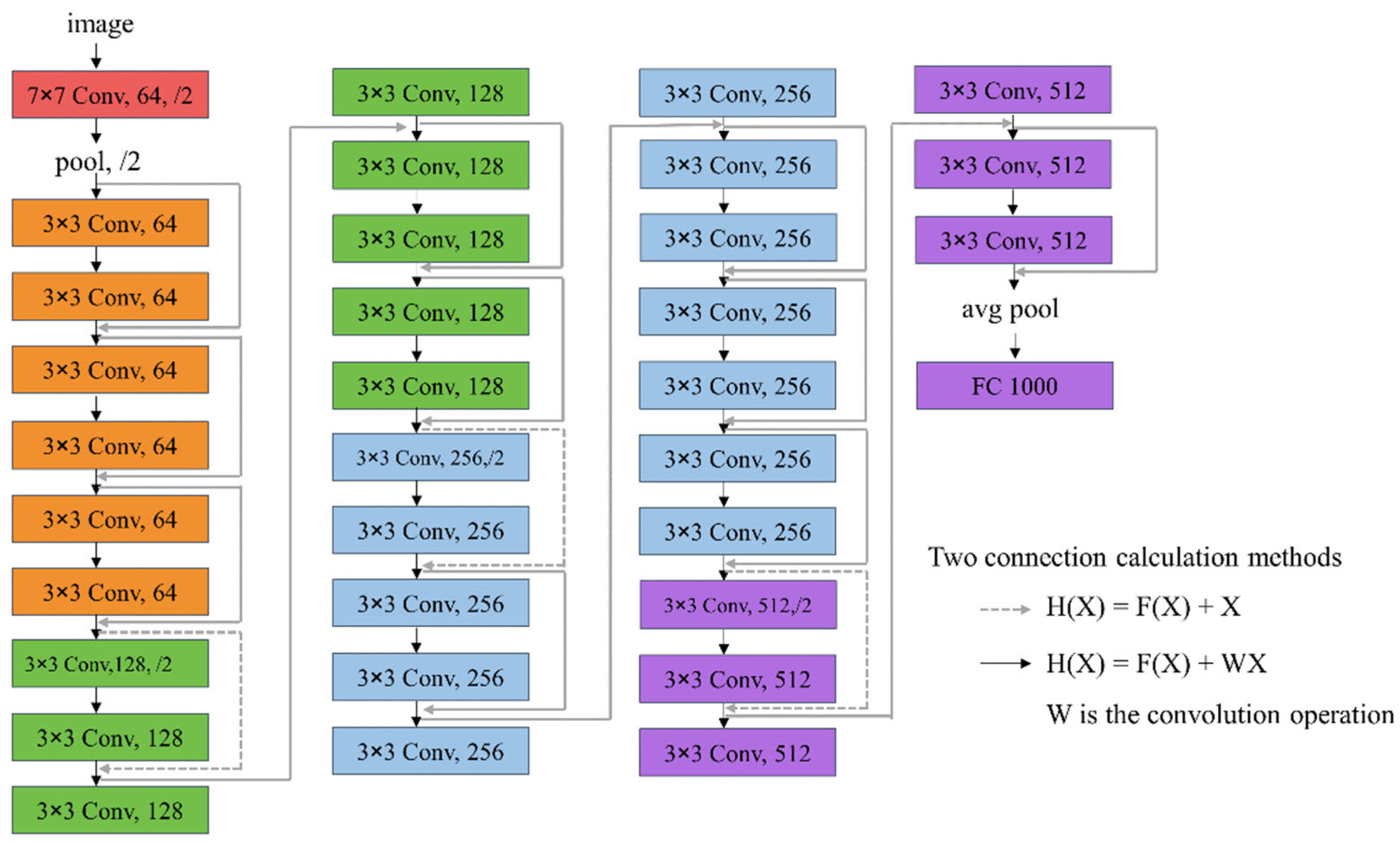
3.7. Deep Residual Learning
3.8. Network Structure
4. Experiment
4.1. Experiment Setting
4.2. Experiment Preparation
4.3. Experiment Result
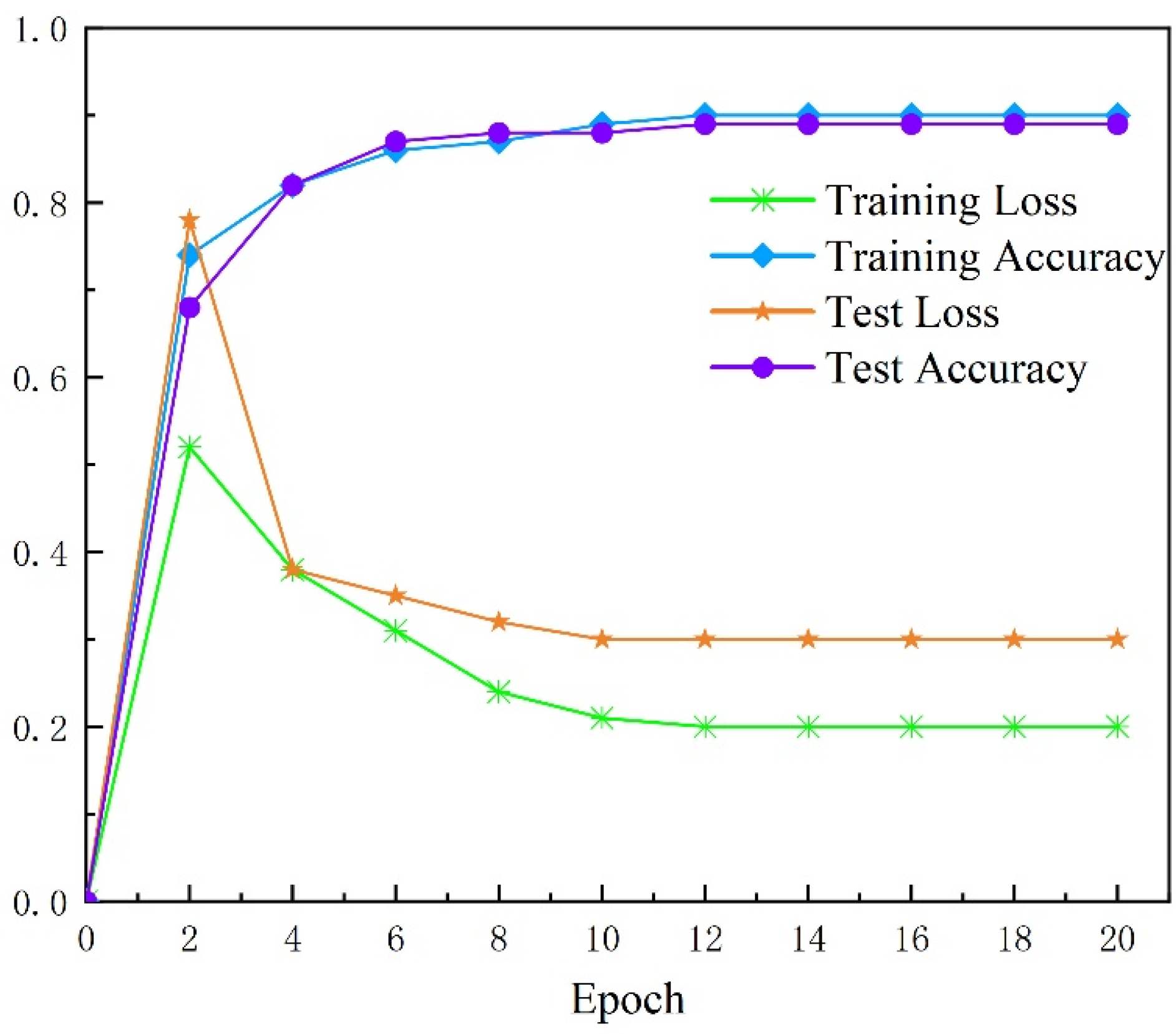
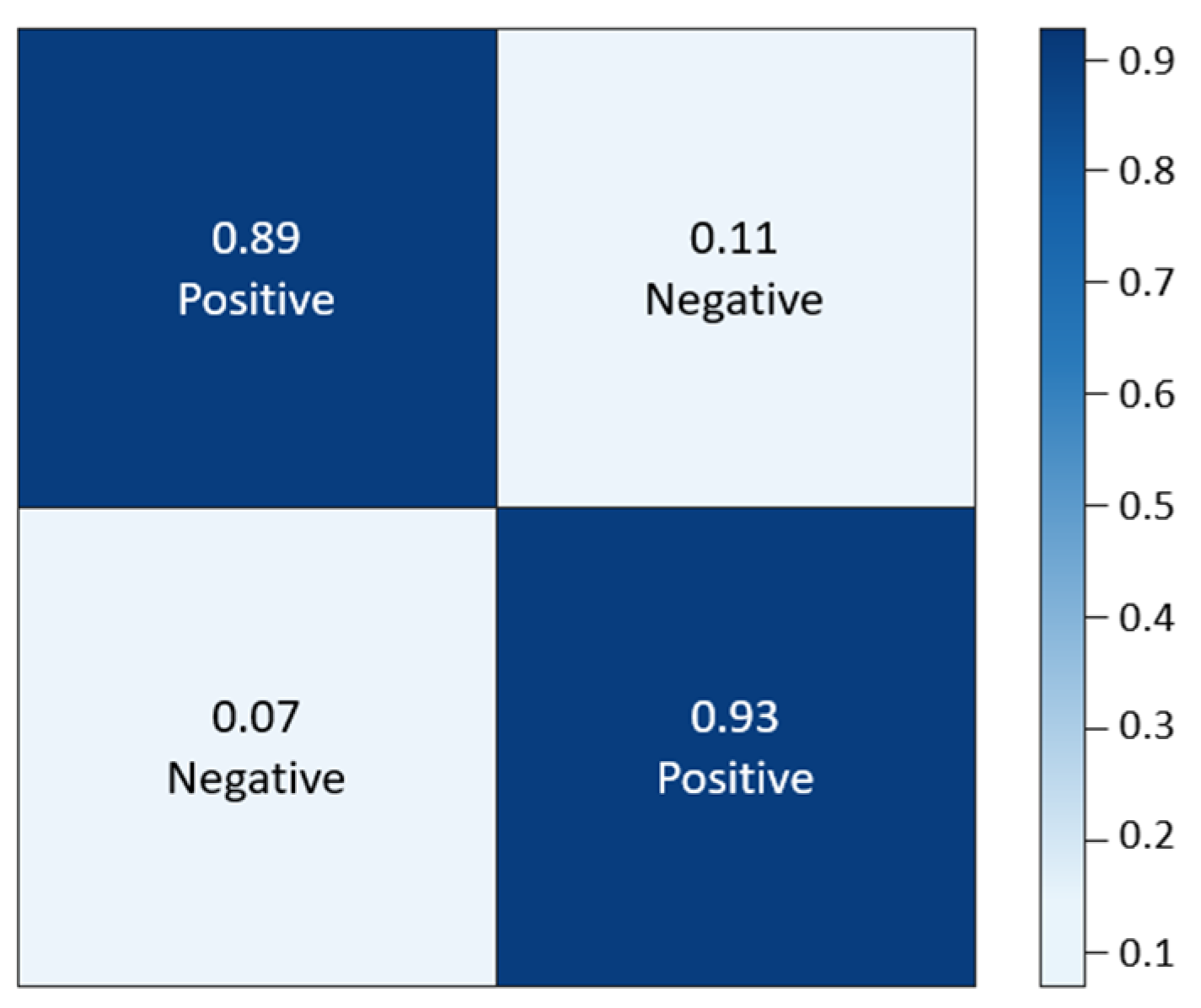
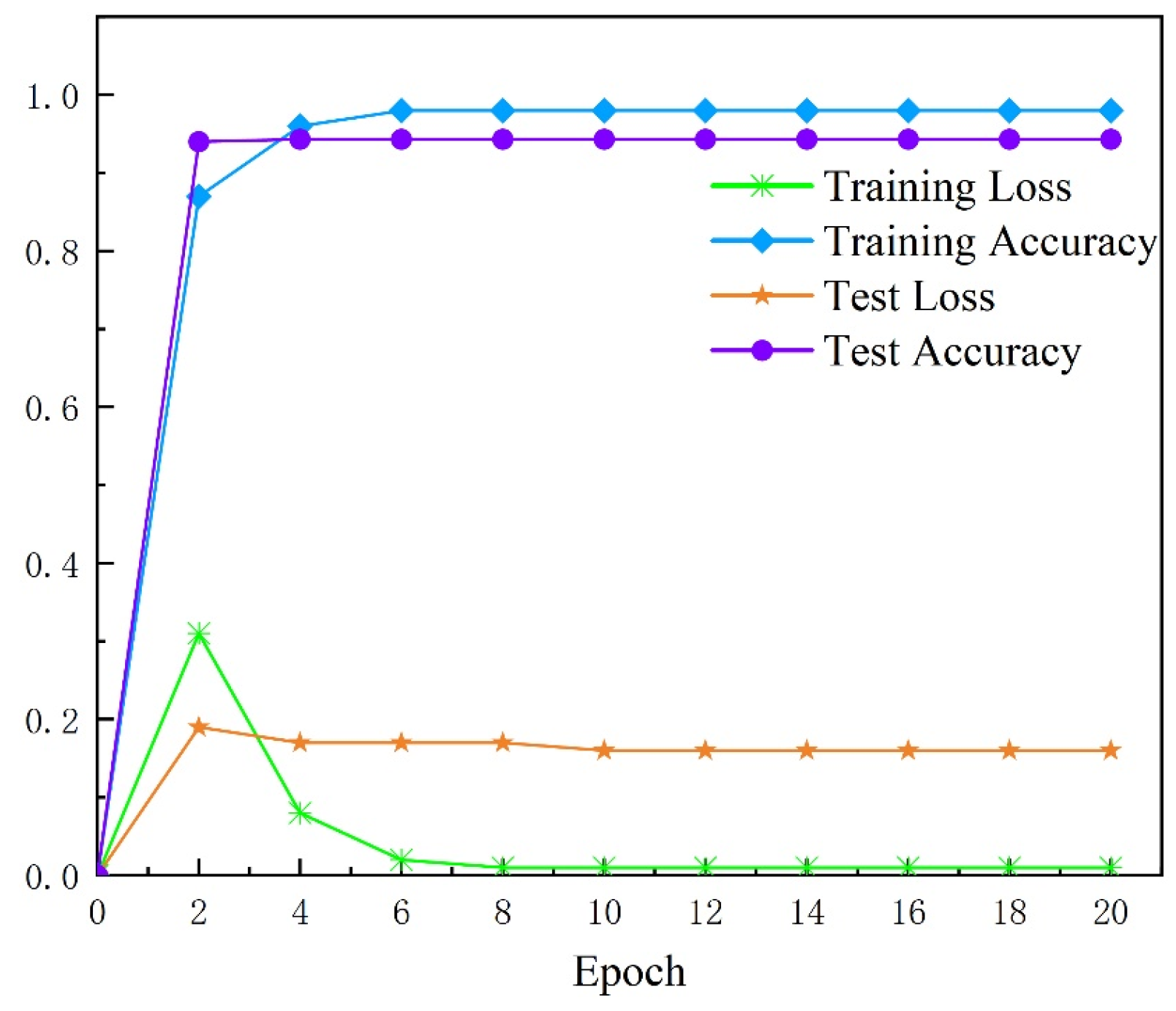
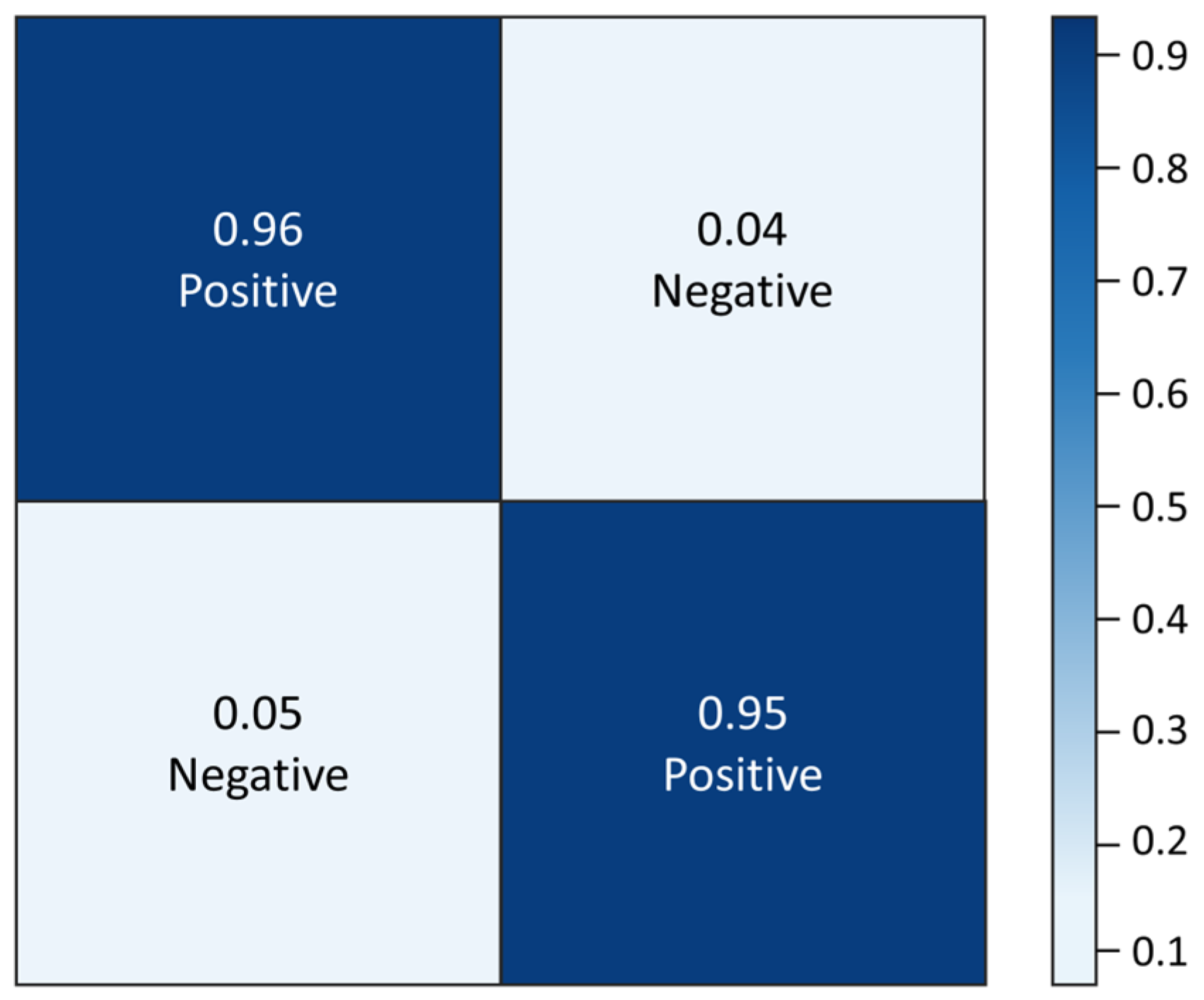
4.3.1. Evaluation of the Result with Basic CNN with Image Augmentation
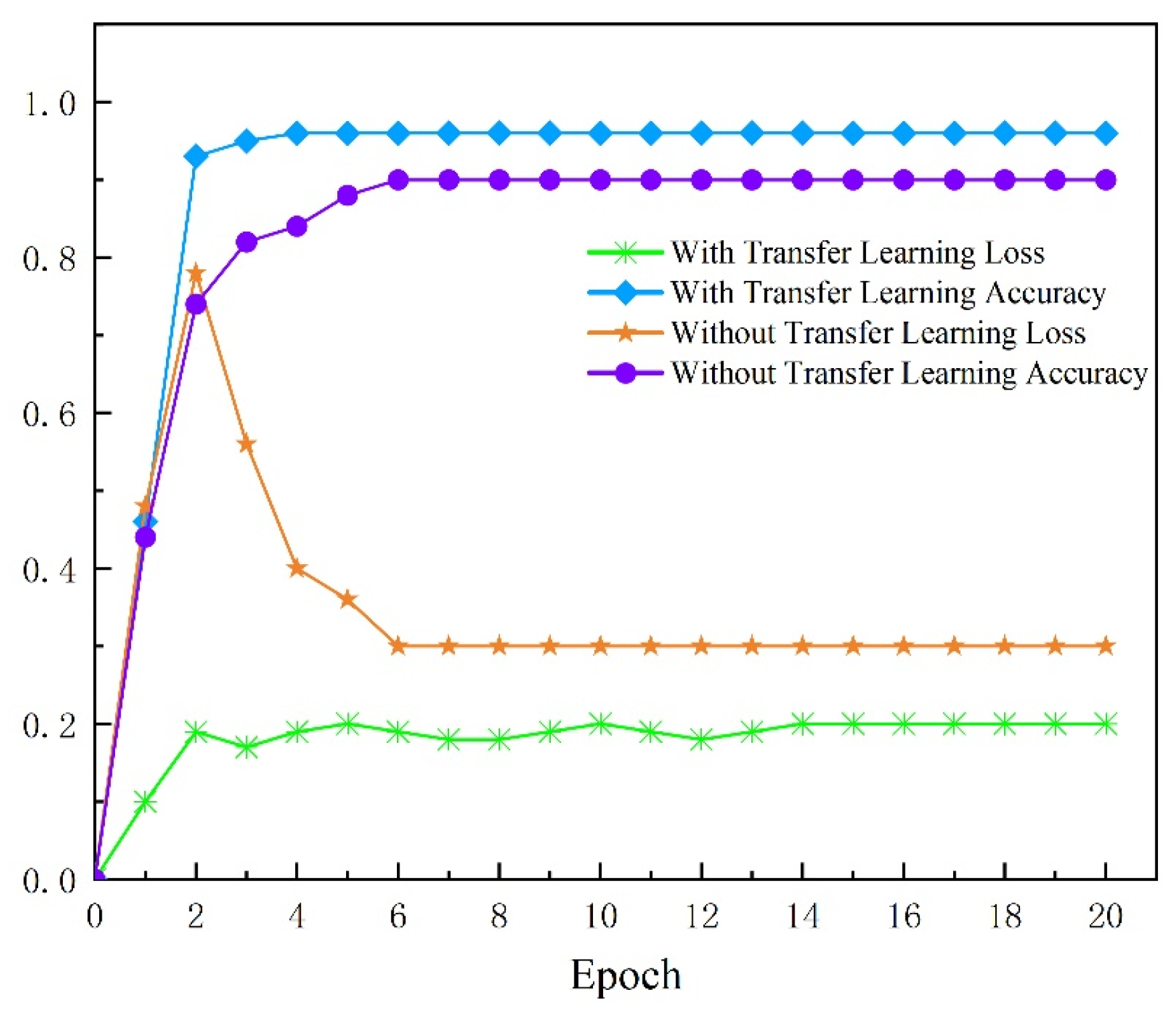
4.3.2. Evaluation of the Result with Transfer Learning
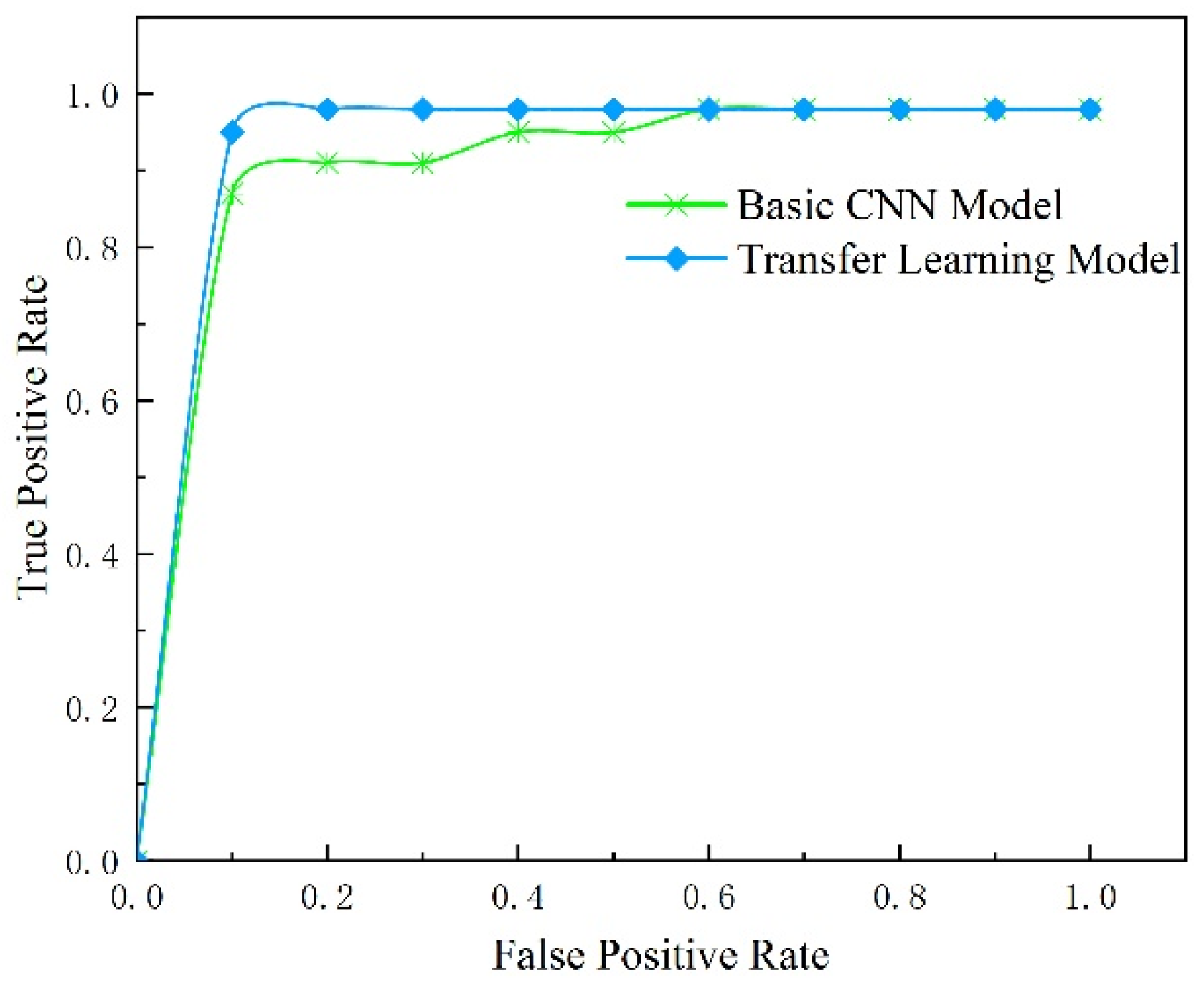
4.3.3. Comparison of Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tan, Y.; Li, G.; Cai, R.; Ma, J.; Wang, M. Mapping and modelling defect data from UAV captured images to BIM for building external wall inspection. Autom. Constr. 2022, 139, 104284. [Google Scholar] [CrossRef]
- Xie, X.; Liu, C.H.; Leung, D.Y. Impact of building facades and ground heating on wind flow and pollutant transport in street canyons. Atmos. Environ. 2007, 41, 9030–9049. [Google Scholar] [CrossRef]
- Moghtadernejad, S.; Chouinard, L.E.; Mirza, M.S. Design strategies using multi-criteria decision-making tools to enhance the performance of building façades. J. Build. Eng. 2020, 30, 101274. [Google Scholar] [CrossRef]
- Shugar, D.H.; Jacquemart, M.; Shean, D.; Bhushan, S.; Upadhyay, K.; Sattar, A.; Schwanghart, W.; McBride, S.; De Vries, M.V.W.; Mergili, M.; et al. A massive rock and ice avalanche caused the 2021 disaster at Chamoli, Indian Himalaya. Science 2021, 373, 300–306. [Google Scholar] [CrossRef] [PubMed]
- Dang, L.M.; Wang, H.; Li, Y.; Nguyen, L.Q.; Nguyen, T.N.; Song, H.K.; Moon, H. Deep learning-based masonry crack segmentation and real-life crack length measurement. Constr. Build. Mater. 2022, 359, 129438. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Yang, C.; Chen, J.; Li, Z.; Huang, Y. Structural Crack Detection and Recognition Based on Deep Learning. Appl. Sci. 2021, 11, 2868. [Google Scholar] [CrossRef]
- Golding, V.P.; Gharineiat, Z.; Munawar, H.S.; Ullah, F. Crack Detection in Concrete Structures Using Deep Learning. Sustainability 2022, 14, 8117. [Google Scholar] [CrossRef]
- Druķis, P.; Gaile, L.; Pakrastiņš, L. Inspection of Public Buildings Based on Risk Assessment. Procedia Eng. 2017, 172, 247–255. [Google Scholar] [CrossRef]
- Yang, Y.; Chaoyue, W.; Xiaoyu, G.; Jianchun, L. A novel deep learning-based method for damage identification of smart building structures. Struct. Health Monit. 2019, 18, 143–163. [Google Scholar]
- He, Y.; Chen, H.; Liu, D.; Zhang, L. A framework of structural damage detection for civil structures using fast fourier transform and deep convolutional neural networks. Appl. Sci. 2021, 11, 9345. [Google Scholar] [CrossRef]
- Chen, F.; Jahanshahi, M.R. NB-CNN: Deep Learning-Based Crack Detection Using Convolutional Neural Network and Naive Bayes Data Fusion. IEEE Trans. Ind. Electron. 2018, 65, 4392–4400. [Google Scholar] [CrossRef]
- Li, R.; Yuan, Y.; Zhang, W.; Yuan, Y. Unified vision-based methodology for simultaneous concrete defect detection and geolocalization. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 527–544. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Kim, B.; Yuvaraj, N.; Sri Preethaa, K.R.; Arun Pandian, R. Surface crack detection using deep learning with shallow CNN architecture for enhanced computation. Neural Comput. Appl. 2021, 33, 9289–9305. [Google Scholar] [CrossRef]
- Katsigiannis, S.; Seyedzadeh, S.; Agapiou, A.; Ramzan, N. Deep learning for crack detection on masonry façades using limited data and transfer learning. J. Build. Eng. 2023, 76, 107105. [Google Scholar] [CrossRef]
- Lee, K.; Hong, G.; Sael, L.; Lee, S.; Kim, H.Y. MultiDefectNet: Multi-class defect detection of building façade based on deep convolutional neural network. Sustainability 2020, 12, 9785. [Google Scholar] [CrossRef]
- Chen, K.; Reichard, G.; Xu, X.; Akanmu, A. Automated crack segmentation in close-range building façade inspection images using deep learning techniques. J. Build. Eng. 2021, 43, 102913. [Google Scholar] [CrossRef]
- Karen, S.; Andrew, Z. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kaiming, H.; Xiangyu, Z.; Shaoqing, R.; Jian, S. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Cao, V.D.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar]
- Alex, K.; Ilya, S.; Geoffrey, E.H. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar]
- He, J.; Li, L.; Xu, J. ReLU deep neural networks from the hierarchical basis perspective. Comput. Math. Appl. 2022, 120, 105–114. [Google Scholar] [CrossRef]
- Christian, S.; Vincent, V.; Sergey, I.; Jonathon, S.; Zbigniew, W. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Christian, S.; Wei, L.; Yangqing, J.; Pierre, S.; Scott, E.R.; Dragomir, A.; Dumitru, E.; Vincent, V.; Andrew, R. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Tarkhan, A.; Simon, N. An online framework for survival analysis: Reframing Cox proportional hazards model for large data sets and neural networks. Biostatistics 2022, kxac039. [Google Scholar] [CrossRef]
- Pedro, D. A few useful things to know about machine learning. Commun. ACM 2012, 55, 78–87. [Google Scholar]
- Kaiming, H.; Xiangyu, Z.; Shaoqing, R.; Jian, S. Identity Mappings in Deep Residual Networks. arXiv 2016, arXiv:1603.05027. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Positive | Negative | Total | |
|---|---|---|---|
| Training | 1505 | 1341 | 2846 |
| Testing | 385 | 369 | 754 |
| Total | 1890 | 1710 | 3600 |
| Network | Labels | IoU (%) | DSC (%) | SEN (%) | SPE (%) | |
|---|---|---|---|---|---|---|
| Original | Refined | |||||
| SegNet | √ | 67.23 | 79.13 | 82.31 | 99.74 | |
| Attention-UNet | √ | 70.38 | 82.13 | 85.51 | 99.78 | |
| UNet | √ | 68.98 | 79.57 | 83.38 | 99.74 | |
| DeepLabV3+ | √ | 72.43 | 82.94 | 85.08 | 99.79 | |
| MDS-UNet | √ | 99.13 | 99.99 | 99.99 | 100.00 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Zhu, Z.; Lin, Z.; Zhou, Y. Building Surface Crack Detection Using Deep Learning Technology. Buildings 2023, 13, 1814. https://doi.org/10.3390/buildings13071814
Chen Y, Zhu Z, Lin Z, Zhou Y. Building Surface Crack Detection Using Deep Learning Technology. Buildings. 2023; 13(7):1814. https://doi.org/10.3390/buildings13071814
Chicago/Turabian StyleChen, Yulong, Zilong Zhu, Zhijie Lin, and Youmei Zhou. 2023. "Building Surface Crack Detection Using Deep Learning Technology" Buildings 13, no. 7: 1814. https://doi.org/10.3390/buildings13071814
APA StyleChen, Y., Zhu, Z., Lin, Z., & Zhou, Y. (2023). Building Surface Crack Detection Using Deep Learning Technology. Buildings, 13(7), 1814. https://doi.org/10.3390/buildings13071814