
Crack45K: Integration of Vision Transformer with Tubularity Flow Field (TuFF) and Sliding-Window Approach for Crack-Segmentation in Pavement Structures

Abstract
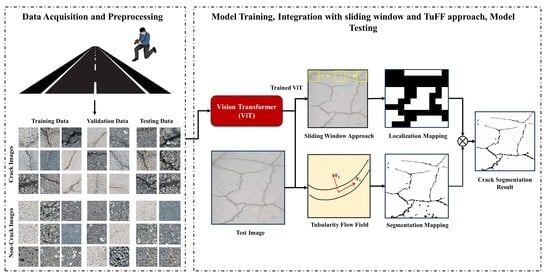
1. Introduction
- The creation of a custom dataset consisting of 45K 224 × 224 pixel images of crack and non-crack diverse pavement surfaces for the crack-detection task;
- The use of ViTs for crack analysis and exploring the feasibility of using self-attention-based networks for crack-image classification. The proposed ViT model is integrated with a sliding window and TuFF algorithm for crack segmentation in pavement surfaces;
- A comparison of the ViT approach with different CNN models on a custom pavement dataset and publicly available concrete dataset (utilized in our earlier work [12]);
- A discussion based on experimental findings that emphasize the significance of ViTs for crack identification in pavement structures. Researchers interested in crack identification and localization using deep-learning methods will find this debate useful.
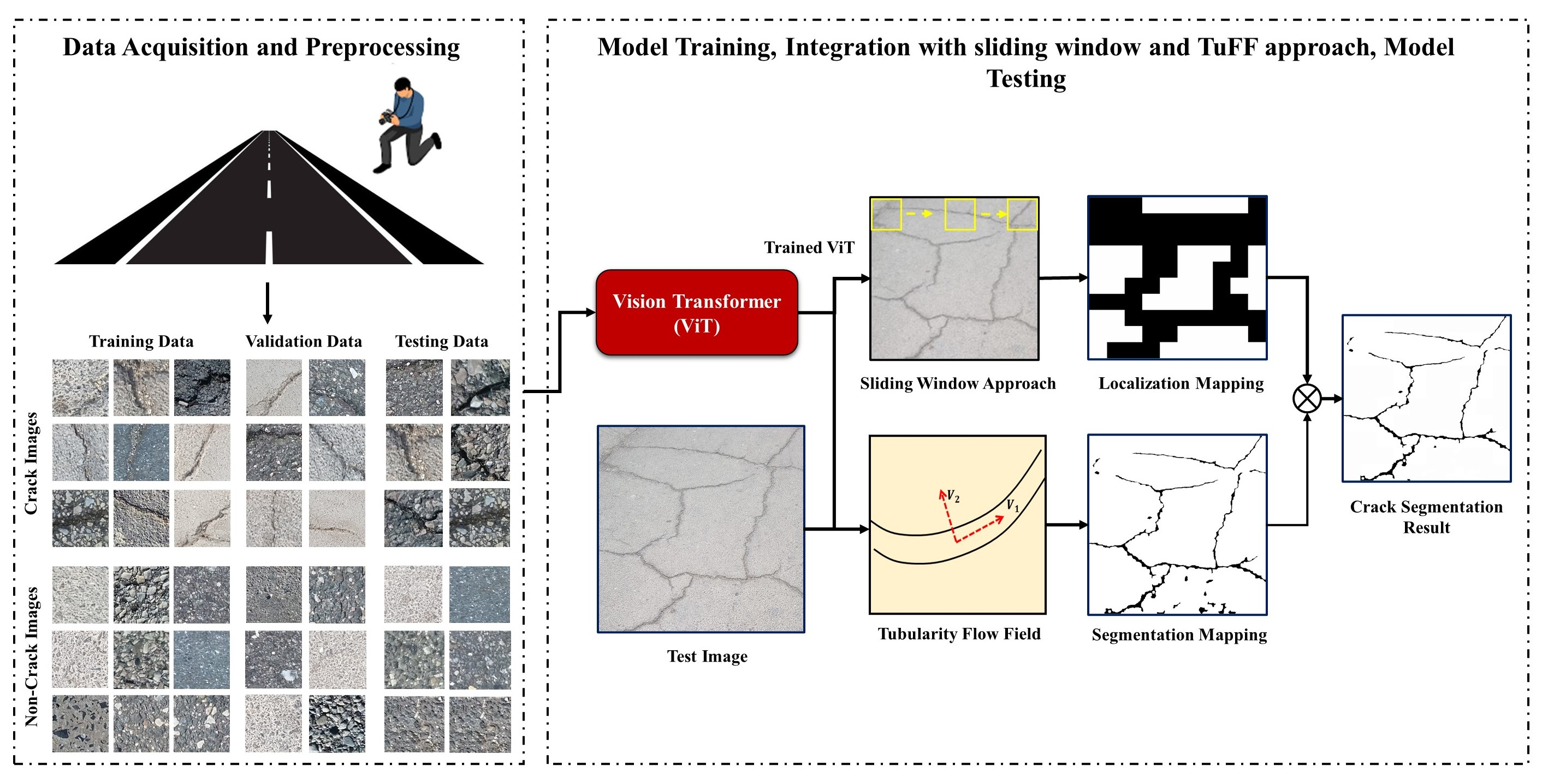
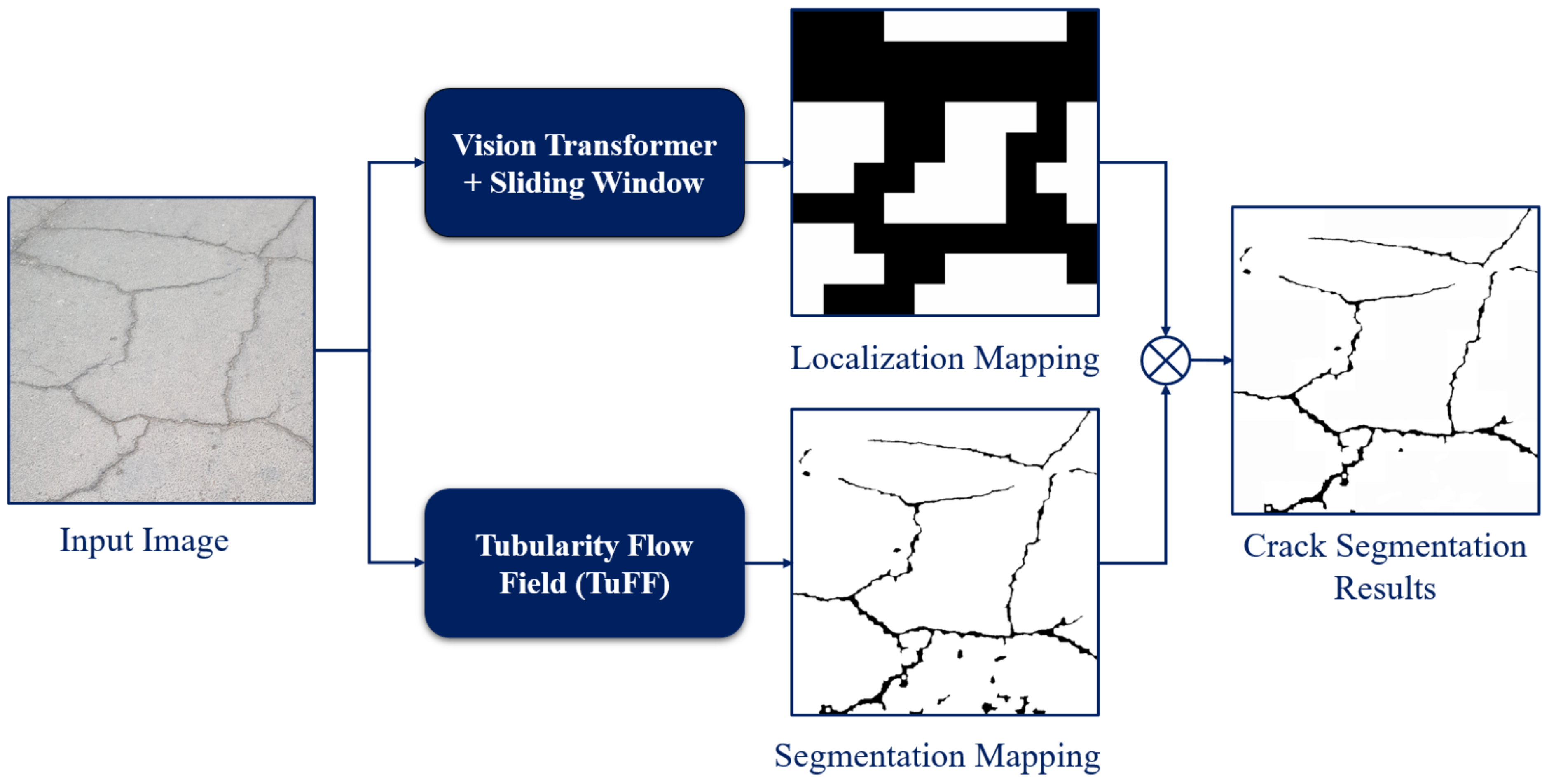
2. Overview of the System
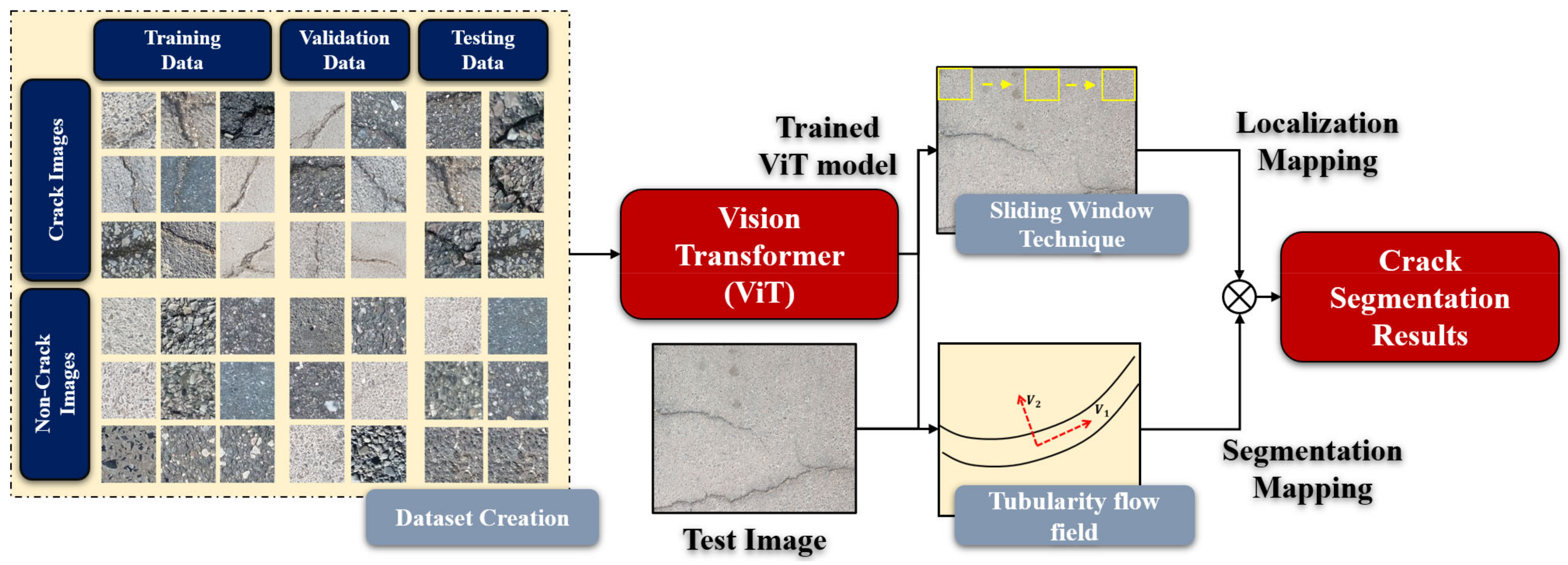
2.1. Database Creation
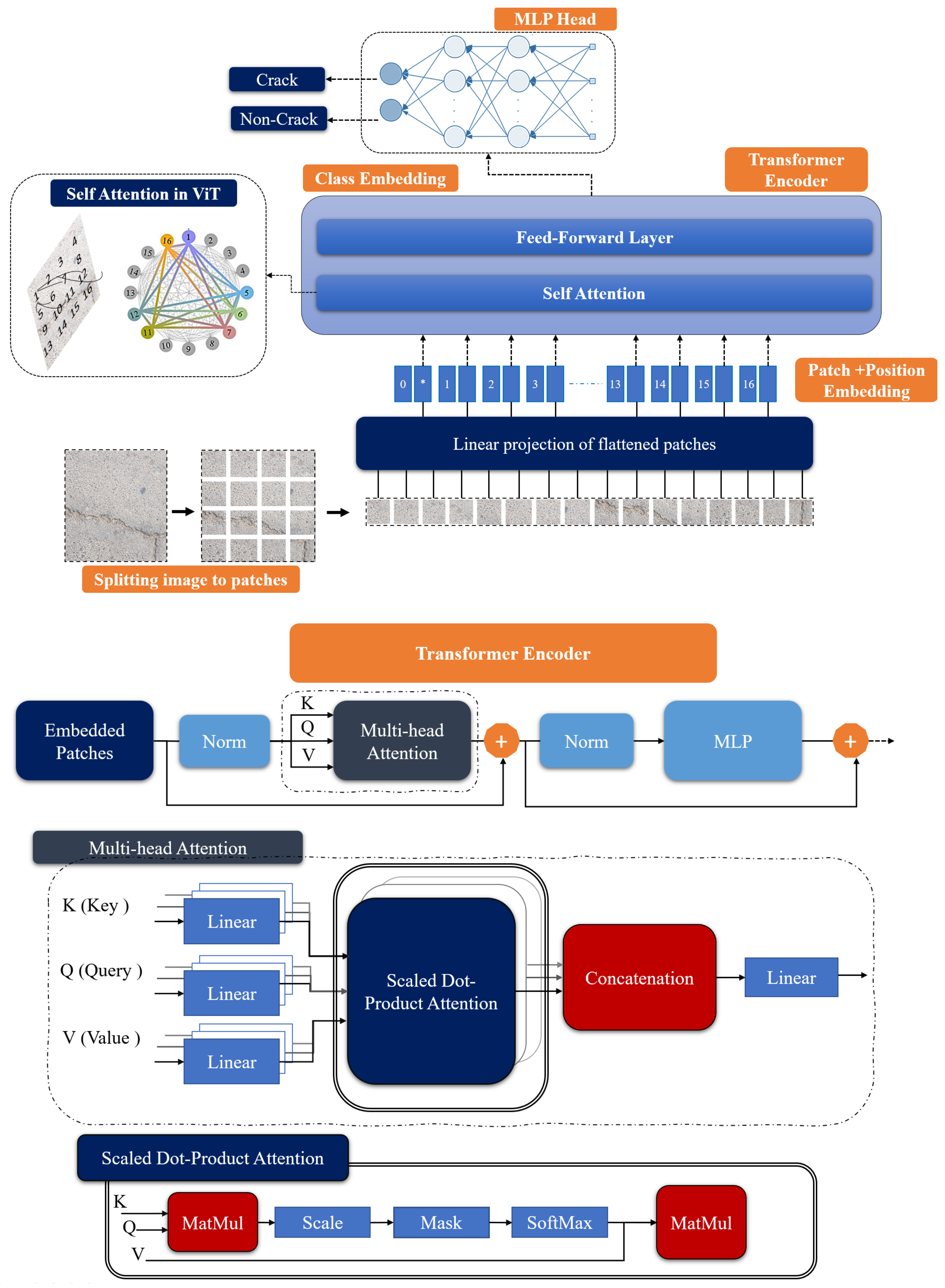
2.2. Vision Transformer (ViT)
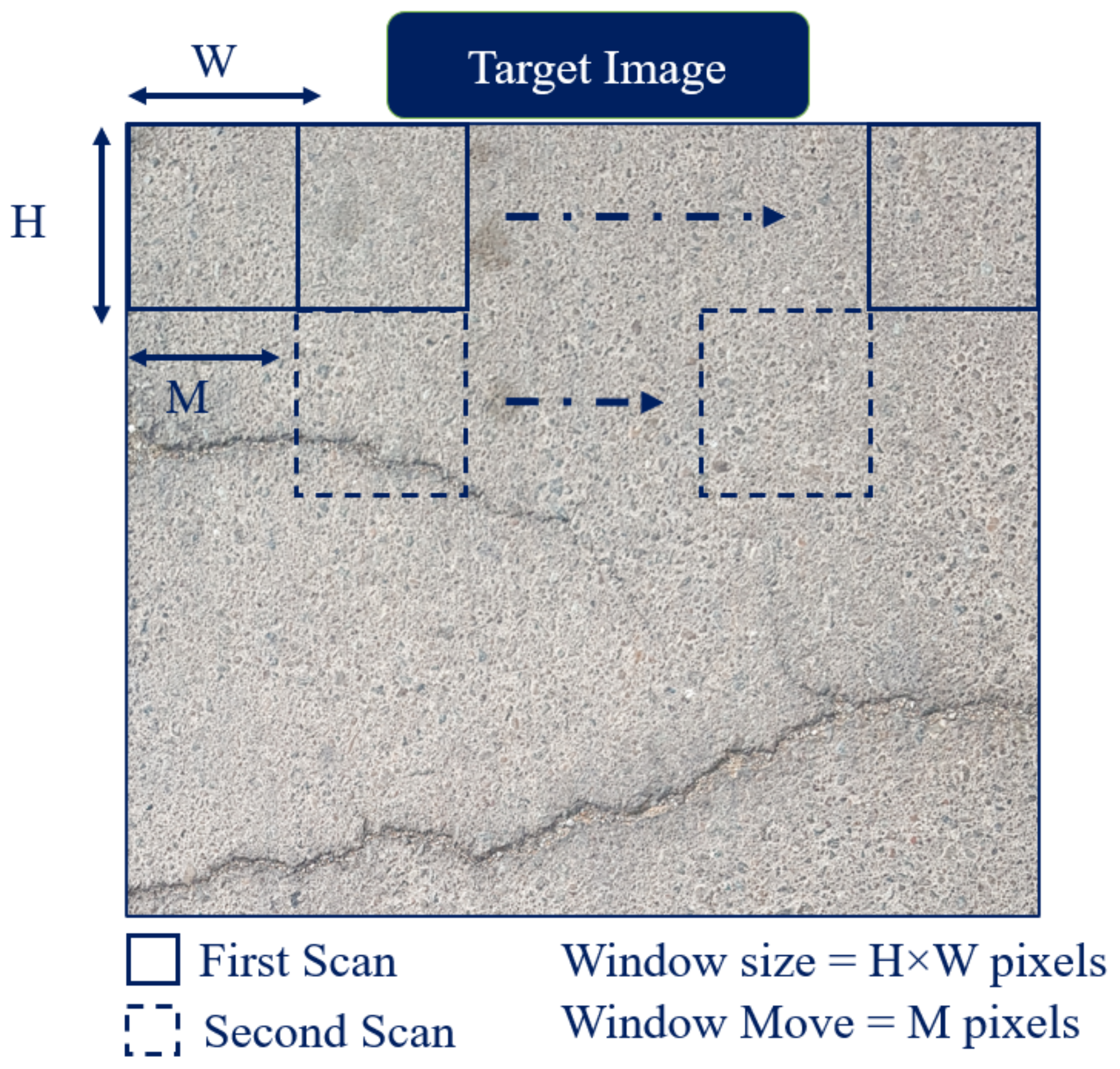
2.3. Sliding-Window Approach
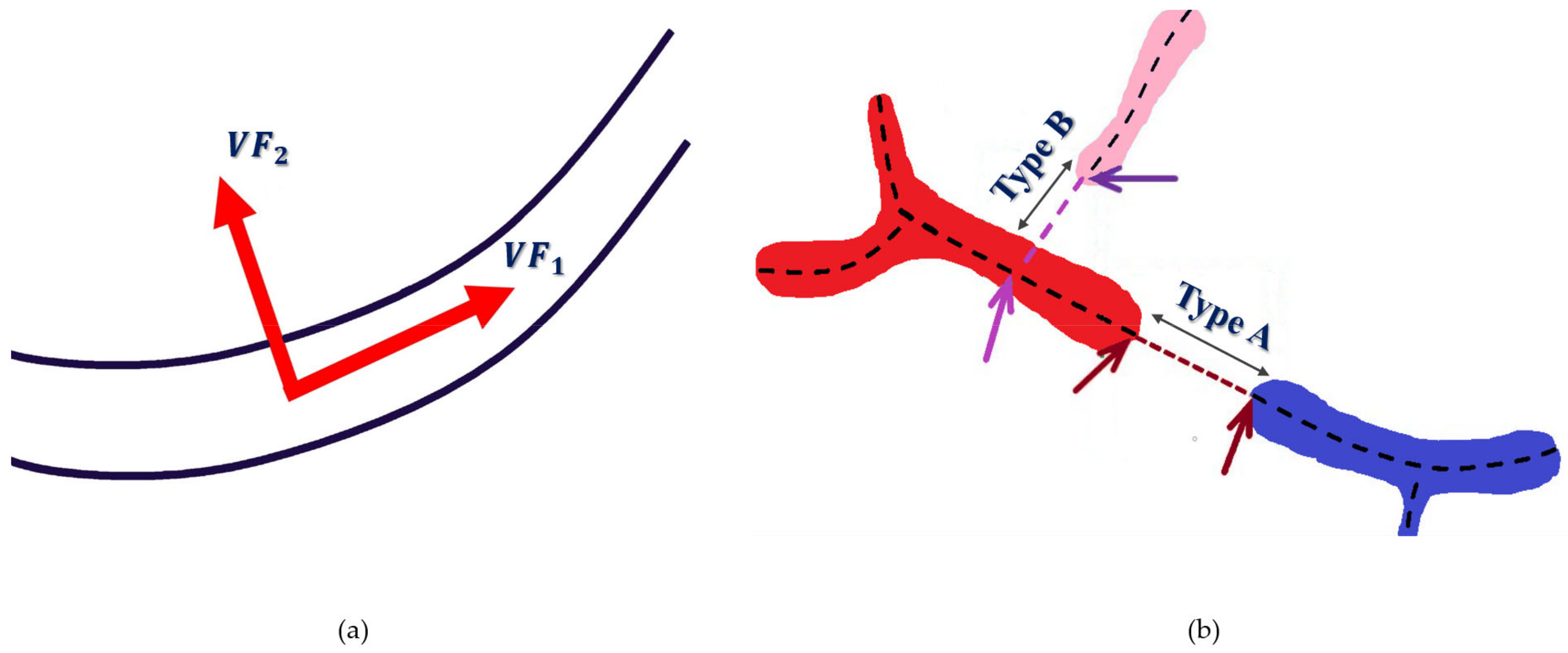
2.4. Tubularity-Flow-Field (TuFF) Algorithm
3. Experiments
3.1. Environmental Setup
3.2. Evaluation Metrics
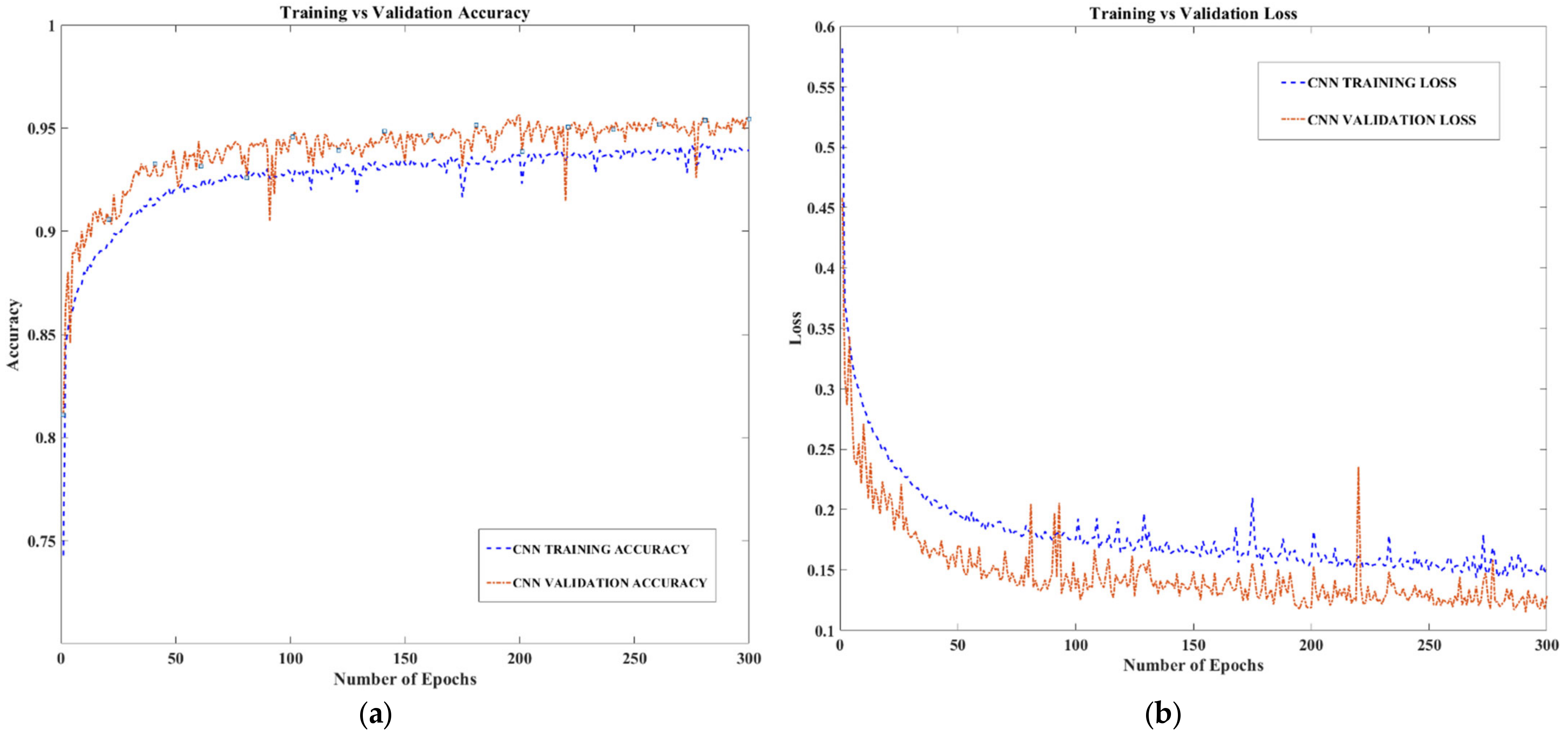
3.3. Classification Results
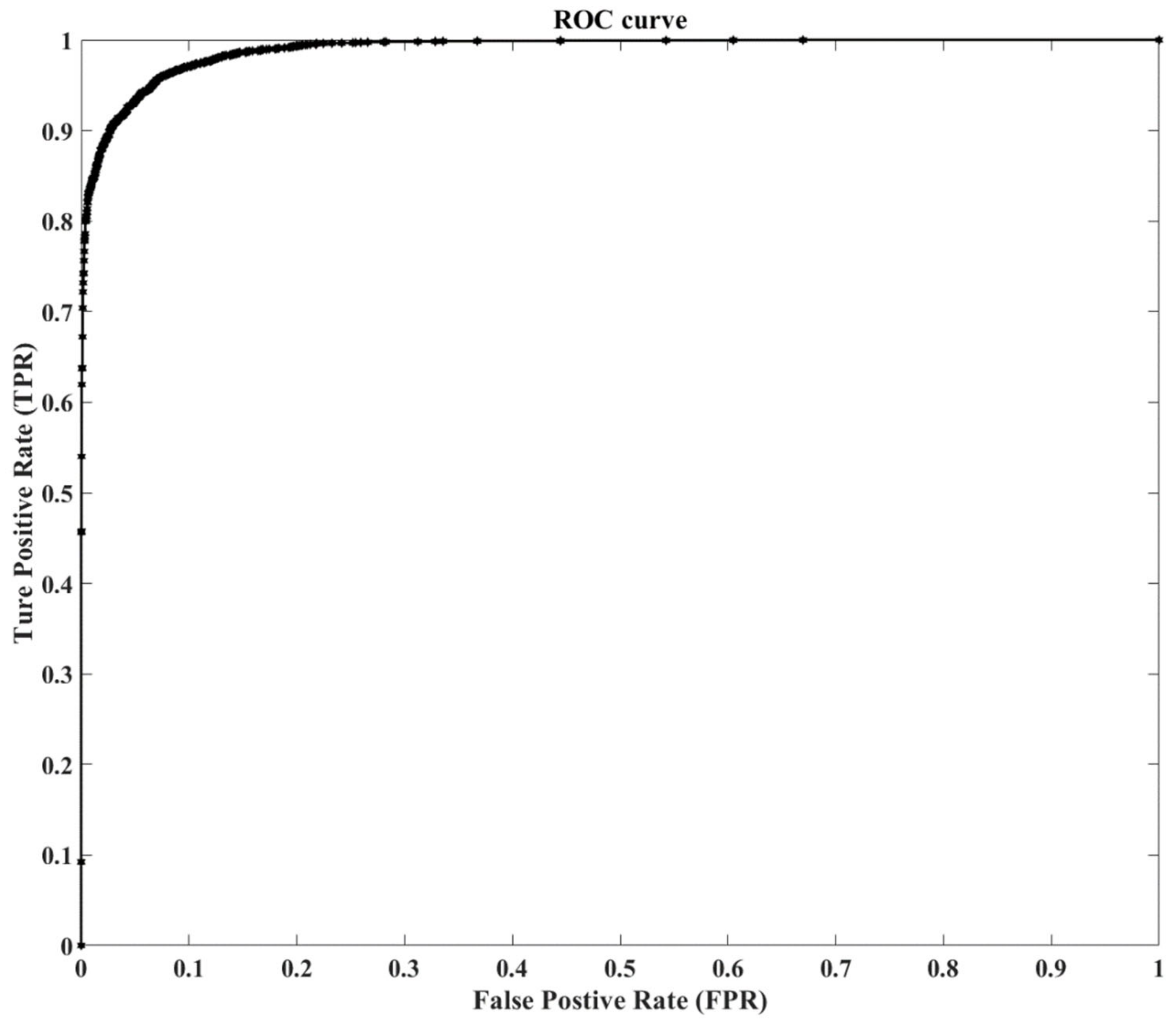
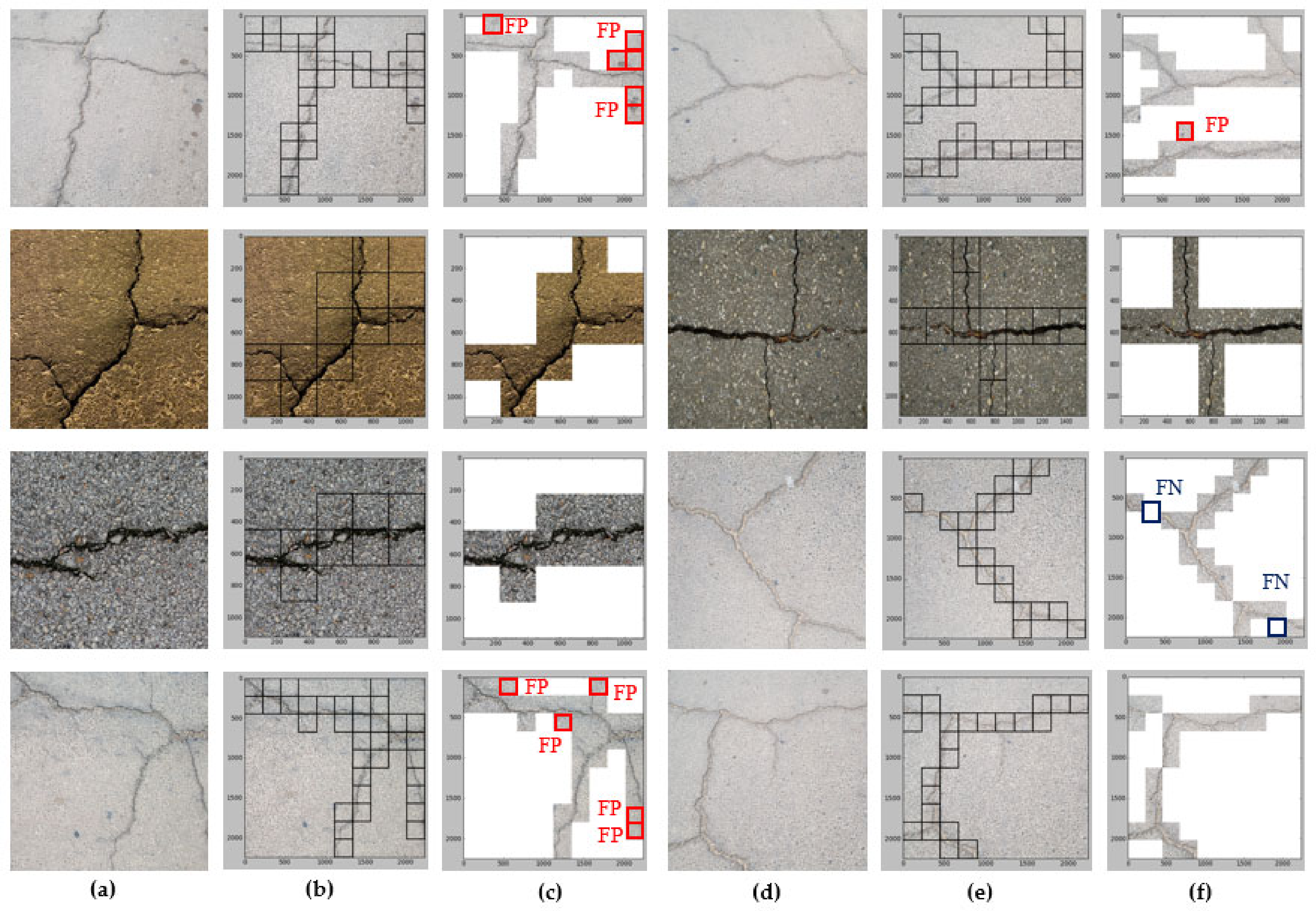
3.4. Localization Results
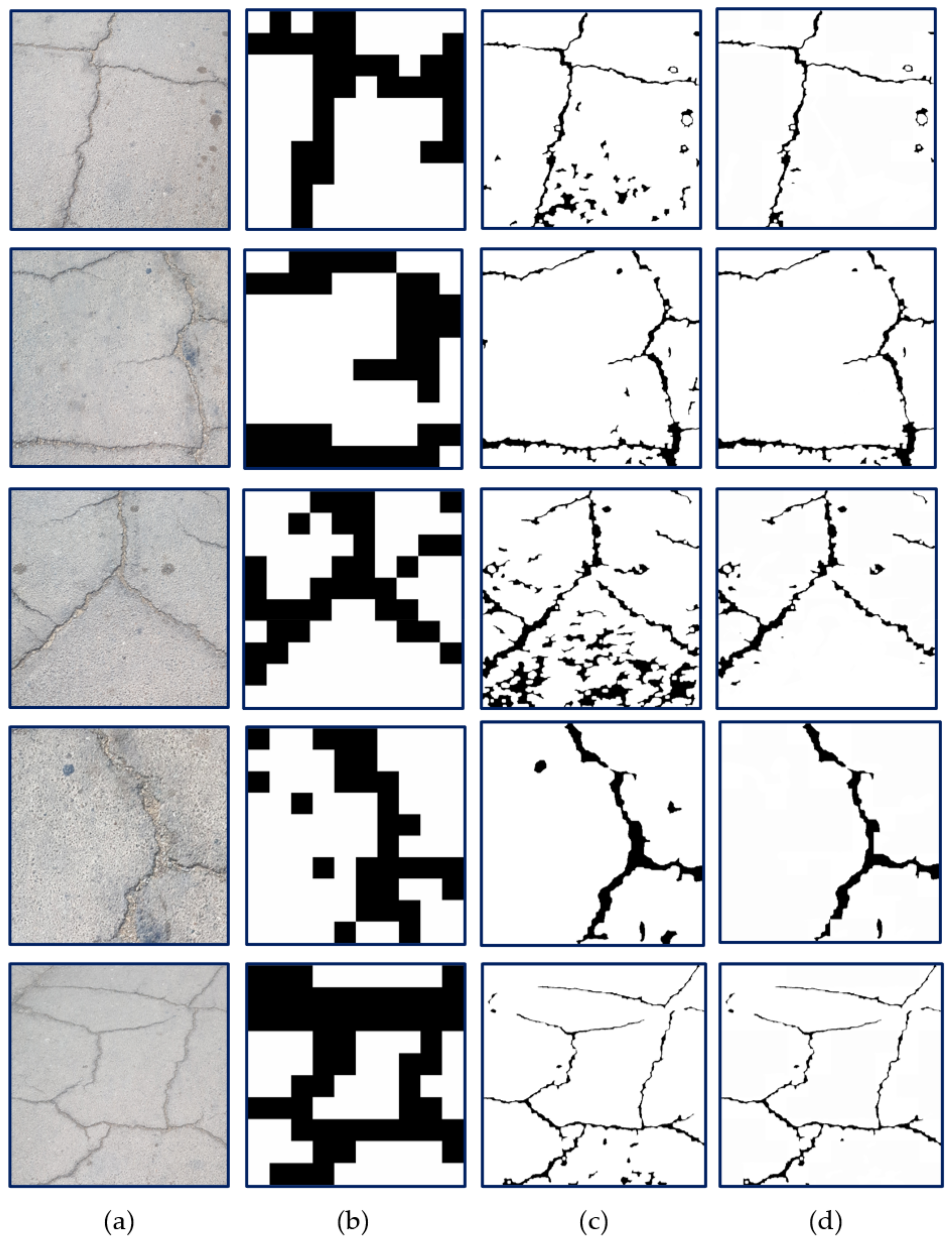
3.5. Segmentation Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of Edge-Detection Techniques for Crack Identification in Bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Kamaliardakani, M.; Sun, L.; Ardakani, M.K. Sealed-Crack Detection Algorithm Using Heuristic Thresholding Approach. J. Comput. Civ. Eng. 2016, 30, 04014110. [Google Scholar] [CrossRef]
- Li, Q.; Zou, Q.; Zhang, D.; Mao, Q. FoSA: F* Seed-growing Approach for crack-line detection from pavement images. Image Vis. Comput. 2011, 29, 861–872. [Google Scholar] [CrossRef]
- Sinha, S.K.; Fieguth, P.W. Morphological segmentation and classification of underground pipe images. Mach. Vis. Appl. 2006, 17, 21. [Google Scholar] [CrossRef]
- Sinha, S.K.; Fieguth, P.W. Automated detection of cracks in buried concrete pipe images. Autom. Constr. 2006, 15, 58–72. [Google Scholar] [CrossRef]
- Chambon, S.; Subirats, P.; Dumoulin, J. Introduction of a wavelet transform based on 2D matched filter in a Markov random field for fine structure extraction: Application on road crack detection. In Image Processing: Machine Vision Applications II, Proceedings of the IS&T/SPIE Electronic Imaging 2009, San Jose, CA, USA, 18–22 January 2009; Niel, K.S., Fofi, D., Eds.; Society of Photo-Optical Instrumentation Engineers: Bellingham, WA, USA, 2009; Volume 7251, pp. 87–98. [Google Scholar] [CrossRef]
- Fujita, Y.; Hamamoto, Y. A robust automatic crack detection method from noisy concrete surfaces. Mach. Vis. Appl. 2011, 22, 245–254. [Google Scholar] [CrossRef]
- Roychowdhury, S.; Diligenti, M.; Gori, M. Regularizing deep networks with prior knowledge: A constraint-based approach. Knowl.-Based Syst. 2021, 222, 106989. [Google Scholar] [CrossRef]
- Spencer, B.F., Jr.; Hoskere, V.; Narazaki, Y. Advances in Computer Vision-Based Civil Infrastructure Inspection and Monitoring. Engineering 2019, 5, 199–222. [Google Scholar] [CrossRef]
- Gomes, G.F.; Mendéz, Y.A.D.; da Silva Lopes Alexandrino, P.; da Cunha, S.S., Jr.; Ancelotti, A.C., Jr. The use of intelligent computational tools for damage detection and identification with an emphasis on composites–A review. Compos. Struct. 2018, 196, 44–54. [Google Scholar] [CrossRef]
- Ali, L.; Alnajjar, F.; Jassmi, H.A.; Gocho, M.; Khan, W.; Serhani, M.A. Performance Evaluation of Deep CNN-Based Crack Detection and Localization Techniques for Concrete Structures. Sensors 2021, 21, 1688. [Google Scholar] [CrossRef] [PubMed]
- Zhang, A.; Wang, K.C.P.; Fei, Y.; Liu, Y.; Tao, S.; Chen, C.; Li, J.Q.; Li, B. Deep Learning–Based Fully Automated Pavement Crack Detection on 3D Asphalt Surfaces with an Improved CrackNet. J. Comput. Civ. Eng. 2018, 32, 04018041. [Google Scholar] [CrossRef]
- Yu, Y.; Samali, B.; Rashidi, M.; Mohammadi, M.; Nguyen, T.N.; Zhang, G. Vision-based concrete crack detection using a hybrid framework considering noise effect. J. Build. Eng. 2022, 61, 105246. [Google Scholar] [CrossRef]
- Mohtasham Khani, M.; Vahidnia, S.; Ghasemzadeh, L.; Ozturk, Y.E.; Yuvalaklioglu, M.; Akin, S.; Ure, N.K. Deep-learning-based crack detection with applications for the structural health monitoring of gas turbines. Struct. Health Monit. 2020, 19, 1440–1452. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuen, K.-V. Review of artificial intelligence-based bridge damage detection. Adv. Mech. Eng. 2022, 14, 16878132221122770. [Google Scholar] [CrossRef]
- Dais, D.; Bal, İ.E.; Smyrou, E.; Sarhosis, V. Automatic crack classification and segmentation on masonry surfaces using convolutional neural networks and transfer learning. Autom. Constr. 2021, 125, 103606. [Google Scholar] [CrossRef]
- Ali, L.; Alnajjar, F.; Khan, W.; Serhani, M.A.; Al Jassmi, H. Bibliometric Analysis and Review of Deep Learning-Based Crack Detection Literature Published between 2010 and 2022. Buildings 2022, 12, 432. [Google Scholar] [CrossRef]
- Park, S.; Bang, S.; Kim, H.; Kim, H. Patch-Based Crack Detection in Black Box Images Using Convolutional Neural Networks. J. Comput. Civ. Eng. 2019, 33, 04019017. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Ali, L.; Valappil, N.K.; Kareem, D.N.A.; John, M.J.; Al Jassmi, H. Pavement Crack Detection and Localization using Convolutional Neural Networks (CNNs). In Proceedings of the 2019 International Conference on Digitization (ICD), Sharjah, United Arab Emirates, 18–19 November 2019; pp. 217–221. [Google Scholar] [CrossRef]
- Ali, L.; Harous, S.; Zaki, N.; Khan, W.; Alnajjar, F.; Al Jassmi, H. Performance Evaluation of different Algorithms for Crack Detection in Concrete Structures. In Proceedings of the 2021 2nd International Conference on Computation, Automation and Knowledge Management (ICCAKM), Dubai, United Arab Emirates, 19–21 January 2021; pp. 53–58. [Google Scholar]
- Ali, L.; Alnajjar, F.; Zaki, N.; Aljassmi, H. Pavement Crack Detection by Convolutional AdaBoost Architecture. In Proceedings of the 8th Zero Energy Mass Custom Home International Conference (ZEMCH 2021), Dubai, United Arab Emirates, 26–28 October 2021; pp. 383–394. [Google Scholar]
- Ali, L.; Sallabi, F.; Khan, W.; Alnajjar, F.; Aljassmi, H. A Deep Learning-Based Multi-Model Ensemble Method for Crack Detection in Concrete Structures: 38th International Symposium on Automation and Robotics in Construction, ISARC 2021. In Proceedings of the 38th International Symposium on Automation and Robotics in Construction, ISARC 2021, Dubai, United Arab Emirates, 2–4 November 2021; pp. 410–418. [Google Scholar]
- Pan, Y.; Zhang, G.; Zhang, L. A spatial-channel hierarchical deep learning network for pixel-level automated crack detection. Autom. Constr. 2020, 119, 103357. [Google Scholar] [CrossRef]
- Dong, Z.; Wang, J.; Cui, B.; Wang, D.; Wang, X. Patch-based weakly supervised semantic segmentation network for crack detection. Constr. Build. Mater. 2020, 258, 120291. [Google Scholar] [CrossRef]
- Zhang, L.; Shen, J.; Zhu, B. A research on an improved Unet-based concrete crack detection algorithm. Struct. Health Monit. 2021, 20, 1864–1879. [Google Scholar] [CrossRef]
- Mei, Q.; Gül, M. Multi-level feature fusion in densely connected deep-learning architecture and depth-first search for crack segmentation on images collected with smartphones. Struct. Health Monit. 2020, 19, 1726–1744. [Google Scholar] [CrossRef]
- Ye, X.-W.; Jin, T.; Chen, P.-Y. Structural crack detection using deep learning–based fully convolutional networks. Adv. Struct. Eng. 2019, 22, 3412–3419. [Google Scholar] [CrossRef]
- Xue, Y.; Li, Y. A Fast Detection Method via Region-Based Fully Convolutional Neural Networks for Shield Tunnel Lining Defects. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 638–654. [Google Scholar] [CrossRef]
- Hoskere, V.; Narazaki, Y.; Hoang, T.A.; Spencer, B.F., Jr. MaDnet: Multi-task semantic segmentation of multiple types of structural materials and damage in images of civil infrastructure. J. Civil. Struct. Health Monit. 2020, 10, 757–773. [Google Scholar] [CrossRef]
- Alipour, M.; Harris, D.K.; Miller, G.R. Robust Pixel-Level Crack Detection Using Deep Fully Convolutional Neural Networks. J. Comput. Civ. Eng. 2019, 33, 04019040. [Google Scholar] [CrossRef]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Islam, M.M.M.; Kim, J.-M. Vision-Based Autonomous Crack Detection of Concrete Structures Using a Fully Convolutional Encoder–Decoder Network. Sensors 2019, 19, 4251. [Google Scholar] [CrossRef]
- Wu, R.-T.; Singla, A.; Jahanshahi, M.R.; Bertino, E.; Ko, B.J.; Verma, D. Pruning deep convolutional neural networks for efficient edge computing in condition assessment of infrastructures. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 774–789. [Google Scholar] [CrossRef]
- Shokri, P.; Shahbazi, M.; Lichti, D.; Nielsen, J. Vision-Based Approaches for Quantifying Cracks in Concrete Structures. In The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences; Paparoditis, N., Mallet, C., Lafarge, F., Remondino, F., Toschi, I., Fuse, T., Eds.; Copernicus GmbH: Göttingen, Germany, 2020; Volume XLIII-B2-2020, pp. 1167–1174. [Google Scholar] [CrossRef]
- Fang, J.; Qu, B.; Yuan, Y. Distribution equalization learning mechanism for road crack detection. Neurocomputing 2021, 424, 193–204. [Google Scholar] [CrossRef]
- Sizyakin, R.; Voronin, V.; Gapon, N.; Pižurica, A. A deep learning approach to crack detection on road surfaces. In Artificial Intelligence and Machine Learning in Defense Applications II, Proceedings of the SPIE Defense + Defence, Online, 21–25 September 2020; Dijk, J., Ed.; Society of Photo-Optical Instrumentation Engineers: Bellingham, WA, USA, 2020; Volume 11543, pp. 128–134. [Google Scholar]
- Andrushia, A.D.; Lubloy, E. Deep learning based thermal crack detection on structural concrete exposed to elevated temperature. Adv. Struct. Eng. 2021, 24, 1896–1909. [Google Scholar] [CrossRef]
- Kanaeva, I.A.; Ivanova, J.A. Road pavement crack detection using deep learning with synthetic data. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1019, 012036. [Google Scholar] [CrossRef]
- Ji, J.; Wu, L.; Chen, Z.; Yu, J.; Lin, P.; Cheng, S. Automated Pixel-Level Surface Crack Detection Using U-Net. In Multi-disciplinary Trends in Artificial Intelligence, Proceedings of the 12th Multi-disciplinary Trends in Artificial Intelligence (MIWAI 2018), Hanoi, Vietnam, 18–20 November 2018; Kaenampornpan, M., Malaka, R., Nguyen, D.D., Schwind, N., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 69–78. [Google Scholar]
- Liu, F.; Wang, L. UNet-Based Model for Crack Detection Integrating Visual Explanations. Construction and Building Materials 2022, 322, 126265. [Google Scholar] [CrossRef]
- Su, H.; Wang, X.; Han, T.; Wang, Z.; Zhao, Z.; Zhang, P. Research on a U-Net Bridge Crack Identification and Feature-Calculation Methods Based on a CBAM Attention Mechanism. Buildings 2022, 12, 1561. [Google Scholar] [CrossRef]
- Asadi Shamsabadi, E.; Xu, C.; Rao, A.S.; Nguyen, T.; Ngo, T.; Dias-da-Costa, D. Vision transformer-based autonomous crack detection on asphalt and concrete surfaces. Autom. Constr. 2022, 140, 104316. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ji, A.; Xue, X.; Wang, Y.; Luo, X.; Xue, W. An integrated approach to automatic pixel-level crack detection and quantification of asphalt pavement. Autom. Constr. 2020, 114, 103176. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 2021. arXiv 2020. [Google Scholar] [CrossRef]
- Mukherjee, S.; Condron, B.; Acton, S.T. Tubularity Flow Field—A Technique for Automatic Neuron Segmentation. IEEE Trans. Image Process. 2015, 24, 374–389. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Acton, S.T. Fast Algorithms for Area Morphology. Digit. Signal Process. 2001, 11, 187–203. [Google Scholar] [CrossRef]
- Hao, M.; Lu, C.; Wang, G.; Wang, W. An Improved Neuron Segmentation Model for Crack Detection—Image Segmentation Model. Cybern. Inf. Technol. 2017, 17, 119–133. [Google Scholar] [CrossRef][Green Version]
- Bazi, Y.; Bashmal, L.; Al Rahhal, M.M.; Al Dayil, R.; Al Ajlan, N. Vision Transformers for Remote Sensing Image Classification. Remote. Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. SDNET2018: An annotated image dataset for non-contact concrete crack detection using deep convolutional neural networks. Data Brief 2018, 21, 1664–1668. [Google Scholar] [CrossRef]
- Özgenel, Ç.F. Concrete Crack Images for Classification. Mendeley Data 2019. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Comparison of deep convolutional neural networks and edge detectors for image-based crack detection in concrete. Constr. Build. Mater. 2018, 186, 1031–1045. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Daniel Zhang, Y.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Słoński, M. A comparison of deep convolutional neural networks for image-based detection of concrete surface cracks. Comput. Assist. Methods Eng. Sci. 2019, 26, 105–112. [Google Scholar] [CrossRef]
- Fang, F.; Li, L.; Gu, Y.; Zhu, H.; Lim, J.-H. A novel hybrid approach for crack detection. Pattern Recognit. 2020, 107, 107474. [Google Scholar] [CrossRef]
- Lu, G.; He, X.; Wang, Q.; Shao, F.; Wang, J.; Zhao, X. MSCNet: A Framework With a Texture Enhancement Mechanism and Feature Aggregation for Crack Detection. IEEE Access 2022, 10, 26127–26139. [Google Scholar] [CrossRef]
- Zheng, Y.; Gao, Y.; Lu, S.; Mosalam, K.M. Multistage semisupervised active learning framework for crack identification, segmentation, and measurement of bridges. Comput.-Aided Civ. Infrastruct. Eng. 2022, 37, 1089–1108. [Google Scholar] [CrossRef]
- Lu, G.; He, X.; Wang, Q.; Shao, F.; Wang, J.; Jiang, Q. Bridge crack detection based on improved single shot multi-box detector. PLoS ONE 2022, 17, e0275538. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the 38th International Conference on Machine Learning (PMLR), Online, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; XU, C.; Wang, Y. Transformer in Transformer. In Advances in Neural Information Processing Systems 34, Proceedings of the 2021 Advances in Neural Information Processing Systems (NeurIPS 2021), Online, 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P.S., Wortman Vaughan, J., Eds.; Curran Associates, Inc.: New York, NY, USA, 2021; Volume 34, pp. 15908–15919. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Surface Type | Dataset | Train Data | Val Data | Test Data | |||
|---|---|---|---|---|---|---|---|
| Crk Patches | NCrk Patches | Crk Patches | NCrk Patches | Crk Patches | Crk Patches | ||
| Pavement | Crack45K | 13.5K | 13.5K | 4.5K | 4.5K | 4.5K | 4.5K |
| Concrete | work [12] | 2520 | 2520 | 840 | 840 | 840 | 840 |
| Concrete | work [12] | 7500 | 7500 | 2500 | 2500 | 2500 | 2500 |
| Model | Model Size | Number of Parameters (Millions) | Patch Size |
|---|---|---|---|
| Customized CNN Model [12] | 10.3 MB | 2.70 | 224 × 224 |
| VGG-16 Model [54] | 528 MB | 138 | 224 × 224 |
| VGG-19 Model [54] | 549 MB | 143.67 | 224 × 224 |
| ResNet-50 Model [55] | 98 MB | 23.78 | 224 × 224 |
| Vision Transformer | 44.0 MB | 11.46 | 224 × 224 |
| Inception-V3 Model [56] | 92 MB | 21.80 | 229 × 229 |
| Models | ||||||||
|---|---|---|---|---|---|---|---|---|
| Dataset Size | Vision Transformer | |||||||
| Confusion Matrices | Val_ACC | Test_ACC | PRE | REC | F score | |||
| 45K | Class | Crk (0) | NCrk (1) | 0.968 | 0.960 | 0.971 | 0.950 | 0.960 |
| Crk (0) | 4410 | 130 | ||||||
| NCrk (1) | 229 | 4231 | ||||||
| Customized CNN Model | ||||||||
| Class | Crk (0) | NCrk (1) | 0.947 | 0.940 | 0.945 | 0.938 | 0.941 | |
| Crk (0) | 4310 | 250 | ||||||
| NCrk (1) | 287 | 4150 | ||||||
| VGG16 Model | ||||||||
| Class | Crk (0) | NCrk (1) | 0.908 | 0.906 | 0.895 | 0.913 | 0.904 | |
| Crk (0) | 3992 | 468 | ||||||
| NCrk (1) | 376 | 4164 | ||||||
| VGG19 Model | ||||||||
| Class | Crk (0) | NCrk (1) | 0.912 | 0.895 | 0.902 | 0.888 | 0.895 | |
| Crk (0) | 4023 | 437 | ||||||
| NCrk (1) | 508 | 4032 | ||||||
| ResNet50 Model | ||||||||
| Class | Crk (0) | NCrk (1) | 0.725 | 0.704 | 0.599 | 0.754 | 0.688 | |
| Crk (0) | 2671 | 1789 | ||||||
| NCrk (1) | 871 | 3669 | ||||||
| InceptionV3 Model | ||||||||
| Class | Crk (0) | NCrk (1) | 0.915 | 0.905 | 0.924 | 0.888 | 0.906 | |
| Crk (0) | 4120 | 340 | ||||||
| NCrk (1) | 518 | 4022 | ||||||
| Models | ||||||||
|---|---|---|---|---|---|---|---|---|
| Dataset Size | Vision Transformer | |||||||
| Confusion Matrices | Val_ACC | Test_ACC | PRE | REC | F score | |||
| 8K | Class | Crk (0) | NCrk (1) | 0.992 | 0.974 | 0.993 | 0.957 | 0.975 |
| Crk (0) | 2459 | 17 | ||||||
| NCrk (1) | 114 | 2411 | ||||||
| Customized CNN Model | ||||||||
| Class | Crk (0) | NCrk (1) | 0.967 | 0.958 | 0.993 | 0.930 | 0.960 | |
| Crk (0) | 2449 | 16 | ||||||
| NCrk (1) | 192 | 2343 | ||||||
| VGG16 Model [12] | ||||||||
| Class | Crk (0) | NCrk (1) | 0.987 | 0.986 | 0.976 | 0.996 | 0.986 | |
| Crk (0) | 2396 | 69 | ||||||
| NCrk (1) | 128 | 2407 | ||||||
| VGG19 Model | ||||||||
| Class | Crk (0) | NCrk (1) | 0.960 | 0.960 | 0.972 | 0.949 | 0.960 | |
| Crk (0) | 2396 | 69 | ||||||
| NCrk (1) | 128 | 2407 | ||||||
| ResNet50 Model | ||||||||
| Class | Crk (0) | NCrk (1) | 0.923 | 0.916 | 0.868 | 0.979 | 0.920 | |
| Crk (0) | 2433 | 369 | ||||||
| NCrk (1) | 50 | 2148 | ||||||
| InceptionV3 Model | ||||||||
| Class | Crk (0) | NCrk (1) | 0.985 | 0.982 | 0.972 | 0.992 | 0.982 | |
| Crk (0) | 2463 | 71 | ||||||
| NCrk (1) | 18 | 2448 | ||||||
| Model | Patch Inference-Time (Sec) | Entire Image Inference-Time 2240 ∗ 2240 (Sec) |
|---|---|---|
| Customized CNN Model | 0.0048 | 0.480 |
| Vision Transformer | 0.0380 | 3.800 |
| Inception-V3 Model [26] | 0.0385 | 3.850 |
| ResNet-50 Model [27] | 0.0662 | 6.620 |
| VGG-16 Model [25] | 0.1995 | 19.95 |
| VGG-19 Model [25] | 0.2093 | 20.93 |
| Work | Dataset | Algorithm | NOE | NOI | ACC | PREC | REC | F1 |
|---|---|---|---|---|---|---|---|---|
| [59] | SDNET [57] | DCNN | 30 | 18K | 0.970 | NA | NA | 0.800 |
| [60] | CCIC [58] | DCNN | <20 | 1000K | NA | 0.869 | 0.925 | 0.896 |
| [61] | SDNET [57] | DCNN | 100 | 5.2K | 0.85 | NA | NA | NA |
| [62] | SDNET [57] + CCIC [58,59] | DCNN | 20 | 184K | NA | 0.184 | 0.943 | 0.307 |
| [63] | SDNET [57] + CCIC [58] | MSCNet [63] | 300 | 30K | 0.927 | 0.935 | 0.942 | 0.938 |
| [65] | SDNET [57] + CCIC [58] | ISSD | 400 | 30K | 0.915 | 0.905 | 0.911 | 0.908 |
| [64] | SDNET [57] + CCIC [58] | SE-Inception-ResNet-18 | 100 | 3K | 0.948 | 0.979 | 0.916 | 0.946 |
| [12] | SDNET [57] + CCIC [58] | Custom CNN | 20 | 25K | 0.967 | 0.997 | 0.850 | 0.918 |
| Ours | SDNET [57] + CCIC [58] | Vision Transformer | 20 | 25K | 0.974 | 0.993 | 0.955 | 0.974 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, L.; Jassmi, H.A.; Khan, W.; Alnajjar, F. Crack45K: Integration of Vision Transformer with Tubularity Flow Field (TuFF) and Sliding-Window Approach for Crack-Segmentation in Pavement Structures. Buildings 2023, 13, 55. https://doi.org/10.3390/buildings13010055
Ali L, Jassmi HA, Khan W, Alnajjar F. Crack45K: Integration of Vision Transformer with Tubularity Flow Field (TuFF) and Sliding-Window Approach for Crack-Segmentation in Pavement Structures. Buildings. 2023; 13(1):55. https://doi.org/10.3390/buildings13010055
Chicago/Turabian StyleAli, Luqman, Hamad Al Jassmi, Wasif Khan, and Fady Alnajjar. 2023. "Crack45K: Integration of Vision Transformer with Tubularity Flow Field (TuFF) and Sliding-Window Approach for Crack-Segmentation in Pavement Structures" Buildings 13, no. 1: 55. https://doi.org/10.3390/buildings13010055
APA StyleAli, L., Jassmi, H. A., Khan, W., & Alnajjar, F. (2023). Crack45K: Integration of Vision Transformer with Tubularity Flow Field (TuFF) and Sliding-Window Approach for Crack-Segmentation in Pavement Structures. Buildings, 13(1), 55. https://doi.org/10.3390/buildings13010055