1. Introduction
Construction cost estimation is one of the most fundamental construction management tasks, intending to determine the total construction cost of projects before construction commences. It provides the base for cost management and control during the construction stage. Construction cost estimation typically involves several procedures [
1], such as (1) developing construction methods, (2) establishing work breakdown structure (WBS), (3) take-off quantities for construction work packages in WBS, (4) calculating direct cost based on quantities and unit price of each work packages, and (5) determining the total construction cost by adding overhead, profit, and contingencies. However, these steps demand substantial manual efforts and are challenging to be fully automated. The reason for this partially arises from the fact that construction cost estimation is a knowledge-intensive process and estimation knowledge is missing from current computer systems. For example, knowledge and experience of cost estimators are required to interpret the construction specifications to establish the WBS. The quantity take-off (QTO) step also demands manual judgments and involvements of estimators in analyzing work descriptions of the WBS cost items to determine their quantities accordingly. Construction-oriented QTO herein is defined as determining the quantity amount of construction cost items or work packages. As each cost item is associated with a specific construction crew and production rate, their unit cost regarding labor, material, and equipment varies. As such, each cost item is defined with a clear work scope through its unique work description. The work descriptions provide the basis for estimators in construction-oriented QTO and cost estimation.
Work descriptions are the textual information describing the nature and scope of work packages and construction tasks to deliver construction projects. Typical information of work descriptions includes construction material, construction method, product features such as locations and sizes, and accessories required. Construction-oriented QTO has to be determined in accordance with work descriptions of cost items. Work descriptions provide essential information regarding product and construction methods and are usually expressed using a collection of construction vocabulary, which are semi-structured and separated by commas. For example, a work description for a cost item of walls is ‘
Wall framing, studs, 2″ × 4″, 8′ high wall, pneumatic’ [
2]. This description informs cost estimators to take off the total length of studs hosted by walls that are made of 2″
× 4″ studs, with a height of 8′, functioning as structural walls, and framed using a pneumatic nailing gun. Accordingly, the quantity for this cost item should be derived for building elements with the proper product features, namely, (1) quantity unit: length in the linear foot, (2) building material: lumber stud, (3) building element: wall, (4) material size: 2″
× 4″ for studs, (5) building element feature: wall height of 8′, and (6) building element feature: structural usage. Such information could guide estimators to extract the quantities of related building elements from the design document.
The traditional QTO is a tedious manual process that is subject to human error [
3]. For example, substantive manual efforts from estimators are required to interpret the work descriptions manually in the traditional QTO. Different estimators may end up with different quantities results, even though they use the same work descriptions for cost items. The knowledge-based automation in QTO has been proven to be capable of addressing such identified issues. It can eliminate the manual measurement process, resulting in enhanced efficiency. Therefore, the knowledge-based automated QTO is required to address current issues in manual QTO. There is a need to extract desired information from work descriptions for automated construction-oriented QTO and construction cost estimation.
Although plenty of research has been devoted to NLP-based text analysis and information extraction in the construction industry, most of the existing literature primarily focuses on information extraction from inspection reports and construction specifications, consisting of natural language sentences. In contrast, work descriptions are a collection of construction vocabulary separated by commas and are not expressed with natural language sentence structure. At times, the collection of words for work descriptions has different sequential orders, i.e., unstructured data. For example, the work descriptions of wood framing activities for walls and floors are “Wall framing, studs, 2″ × 4″, 8′ high wall” and “2″ × 6″ rafters, roof framing, to 4 in 12 pitch”, respectively. Such variation in work descriptions imposes challenges in automated IE. In addition, the association of the desired information, such as building element/material and size, is difficult to identify, as the size can be either material size or building element size. These challenges affect the performance of the existing IE model. An automated approach that extracts the desired information from work descriptions for the purpose of construction-oriented QTO is lacking.
To fill this gap, this research developed an integrated approach for automatically extracting required information from the work description of cost items. Theoretically, the proposed approach contributed to the body of knowledge by integrating HMM and formalized labeling rules for automatically processing work item descriptions. This approach achieves the integration of named entity recognition (NER) and IE rules, leading to a better performance in terms of precision, i.e., the F1 score. It lays a foundation for automated QTO and cost estimation. The practical contributions of the presented research are two-fold, including (1) increased automation by reducing massive manual efforts in the QTO process and (2) enhanced accuracy of information extraction and interpretation through eliminating manual subjective interpretation of work descriptions, especially for junior estimators. With that, the extracted information could be used to query a given BIM model to automatically extract the desired quantity and achieve the mapping between cost items and the BIM model in the future. The NER-rule-based approach for automatic information extraction is developed in this research as the first step in automated cost estimation. It also lays a foundation for automated QTO and cost estimation and sheds light on artificial intelligence (AI) applications for smart construction.
The remainder of this paper is organized as follows. In
Section 2, previous research regarding NLP application in construction is reviewed to clarify the research gap. Subsequently, the research methodology is illustrated in
Section 3 in detail.
Section 4 presents the case study, as well as their results. The final section concludes the paper, highlighting the research contribution.
3. Research Methodology
To address these limitations, this research explores various NER models and rule-based methods to extract the product and process information from work descriptions for QTO. It is worth noting that NER is an IE task, where desired entities are identified from unstructured text and assigned with predefined labels [
19]. This research addresses IE as a sequence labeling problem through a novel NER-based framework. The proposed sequence labeling framework can classify all target entities related to a given source entity in the cost item’s work descriptions into predefined labels, such as construction material, construction method, function, size, sub-component of building elements, etc. The proposed framework achieves the integration of ML-based IE, rule-based approach, and active learning for IE from work descriptions, which reduces the label efforts and rule development while improving the IE performance, such as precision.
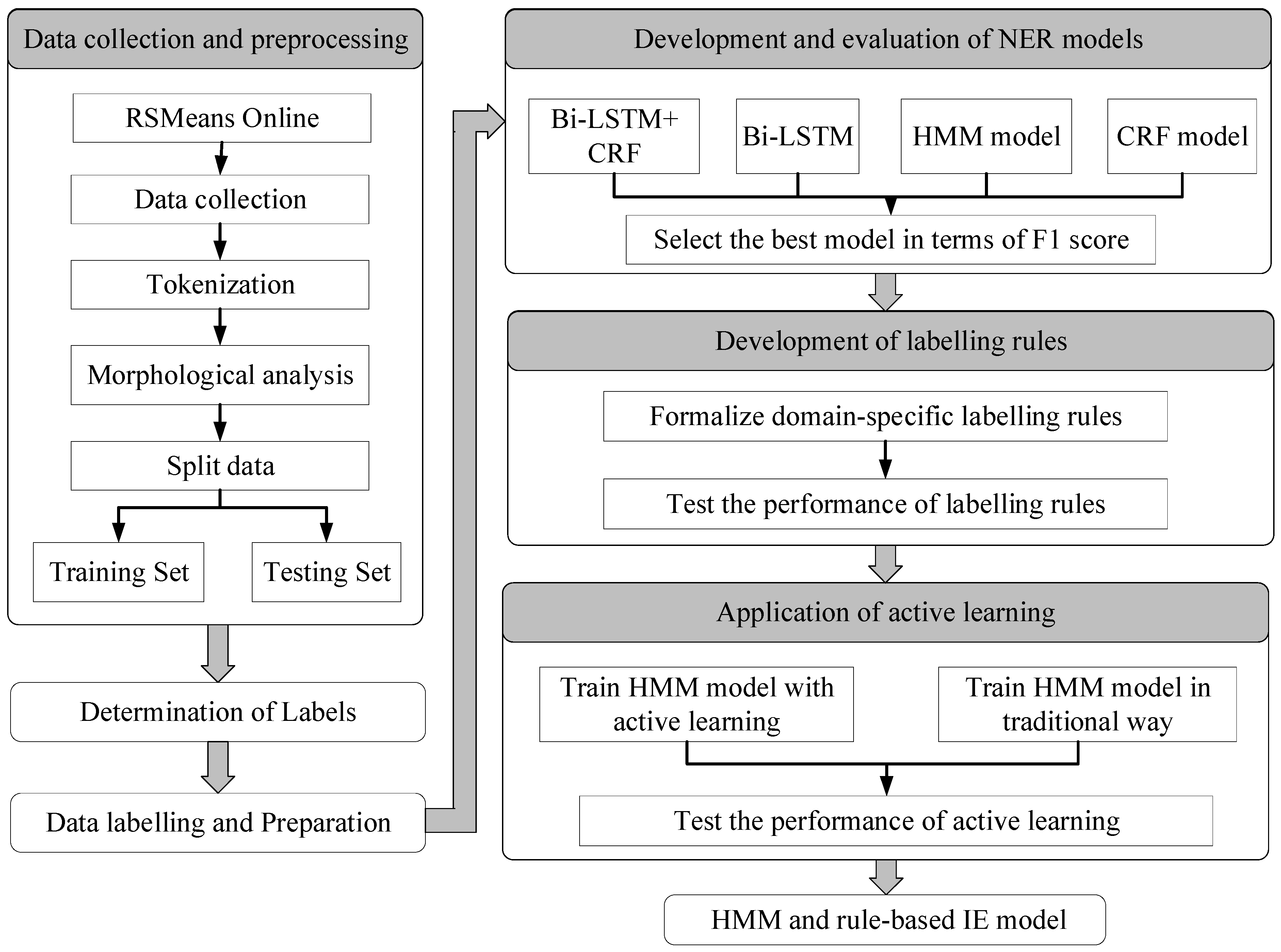
Figure 1 illustrates the research methodology. It consists of seven steps, namely, (1) data collection and preprocessing, where the authors collected cost items and retrieved the corresponding description from the construction cost database (i.e., RSMeans Online); (2) identification of labels, which is intended to determine what sort of information should be extracted for the purpose of construction-oriented QTO; (3) data labeling and preparation, which prepare training data and testing data for ML-based sequence labeling; (4) development and performance evaluation of NER algorithms, where four NER algorithms are developed and evaluated quantitatively in terms of F1 score; (5) formalization of sequence labeling rules, which function as prior knowledge to improve the performance of ML-based NER models; and (6) application of active learning to train the selected NER model (i.e., HMM), which reduces manual efforts spent on data labeling. Each of these steps is described in detail in the following sub-sections.
3.1. Data Collection and Preprocessing
Construction work packages or cost items are the basic units used to estimate the direct cost for construction projects. Each work package in cost databases has its description. For example, RSMeans online consists of thousands of cost items for construction estimation, and each item is associated with a unique description. Items in other cost databases, including the in-house database of contractors, also offer work descriptions. RSMeans online was selected in this study as it is the most widely used commercial cost database in North America [
29] and uses Construction Specifications Institute (CSI) MasterFormat to manage all cost item data for all types of construction, such as steel, concrete, wood, and so forth. It should be noted that the proposed method is also applicable to cost items in other sources. This research mainly focuses on the wood and concrete work, and the case study in this research is a wood framing building with a concrete basement. Therefore, typical cost items for wood buildings are selected in the data collection.
Figure 2 shows several examples of RSMeans cost items. As shown in
Figure 2, each work package has unique line lumber and work description. Intuitively, the textual description of work packages is structured so that it should be much easier to extract the desired information from the work description than natural language statements. However, the descriptions of cost items are unstructured data. For example, the item “061110182680,
Wood framing, joists, 2″ × 6″” is under the item category “Joist framing”, which is a sub-category of “Framing with Dimensional, Engineered or Composite Lumber”. Ideally, the textual description of item “061110182680” should contain information related to its categories. However, the item ”061110182680” is described as “
Wood framing, joists, 2″ × 6″”, while “Framing with Dimensional, Engineered or Composite Lumber” is missing from its work description. In addition, the cost items within the same category have different description patterns. For example, the items of “061110182680” and “061110182700” are from the same category, “Joist framing”. However, the item “061110182680” is described as “
Wood framing, joists, 2″ × 6″” while the item “061110182700” is described as “
2″ × 8″”
wood joist, framing”. Their work descriptions are expressed in a different pattern. As such, the NLP-NER is required to analyze such textual data.
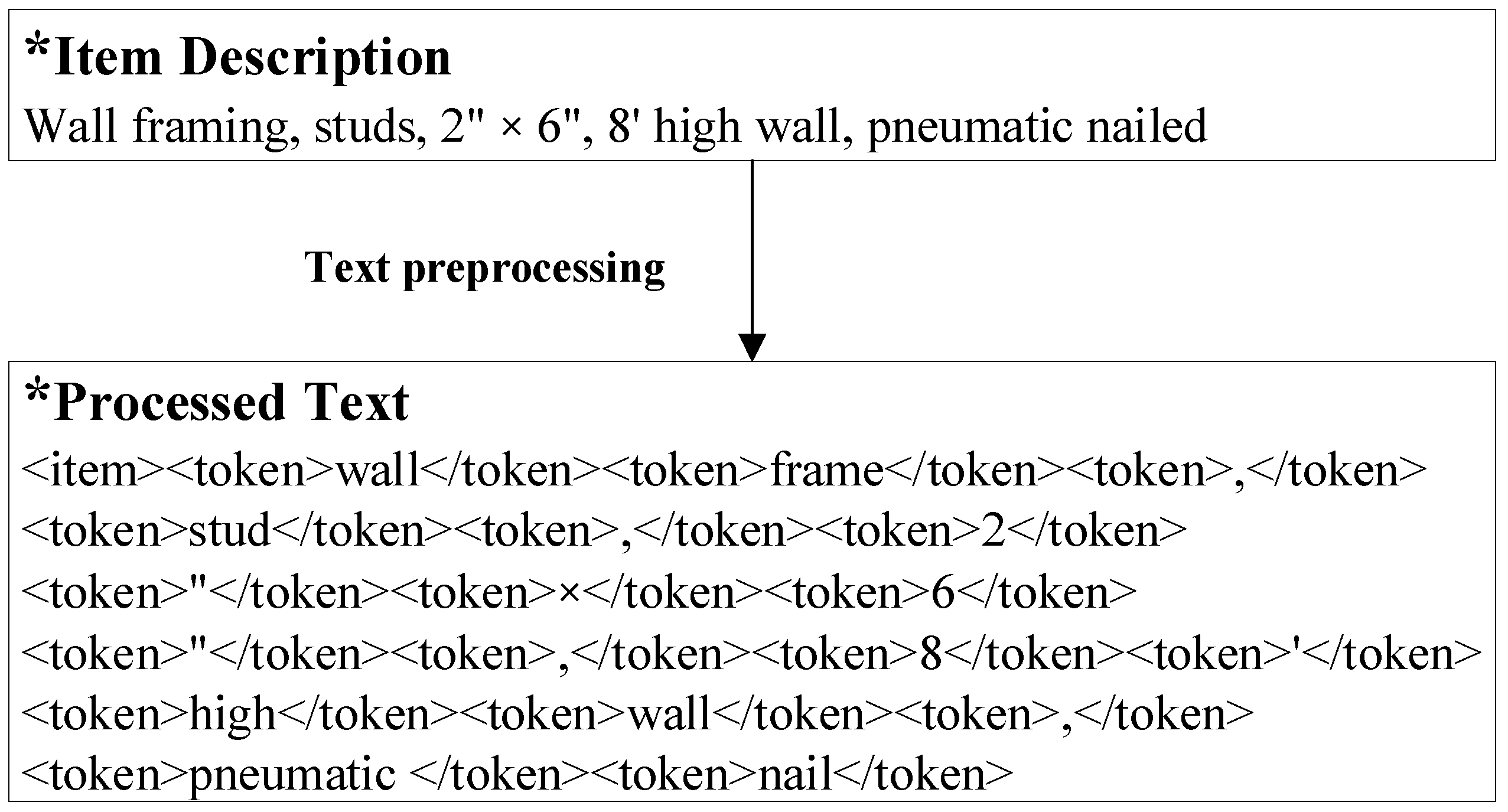
In the initial stage of IE from work descriptions, the preprocessing is conducted to transform the obtained text data into a clean and computer-processable format. Several NLP techniques were employed, such as tokenization and morphological analysis. For example, tokenization was used to separate the text into several tokens for feature representation. Generally, the ‘word’ is a chunk of alphabetical characters separated by space marks, and it is the most commonly used unit in text analysis. Punctuation was also regarded as a token to separate sentences in this study. Following this, morphological analysis (MA) was conducted to identify the different forms of a word and map it to its standard form. MA converts various nonstandard forms of a word (e.g., plural form of the noun) to its lexical form (e.g., the singular form of the noun).
Figure 3 presents one illustrative example of text preprocessing. For example, “frames” and “framing” are all mapped to their lexical form “frame”, as shown in
Figure 3.
3.2. Identification of Predefined Labels
This research addresses information extraction as a sequence labeling problem through NER models. That is, cost parameters are extracted by assigning their proper predefined labels. The predefined labels of tokens should be determined based on the specific need of the targeted application. For example, the labels can be defined as organization and person, provided that such information is of particular interest. In this research, the desired information is the construction method and product-related features that could be used to query a given BIM model for quantities. Consequently, labels are defined to describe (1) construction activity, (2) construction material, (3) building component, (4) measurement unit, and (5) additional information (e.g., work scope). The description of each category is summarized in
Table 1. For example, such labels as material name, type of building element, type of element part, size of building element, function of building element, and material characteristics are defined to describe product-related features.
3.3. Data Labeling and Preparation of Training and Testing Data
Typically, the NER technique demands manually annotated data to train the ML-based NER models that could be used to classify and label new data/parameters. As such, this step is to prepare work description data and manually label item descriptions. The retrieved dataset was split into two datasets: a training set (80%) and a testing set (20%). The training set was used to train the developed ML-based NER models, while the testing dataset was used to evaluate the performance of the developed algorithms. Each token in preprocessed data is annotated manually after determining token labels.
Figure 4 shows one example of the annotated work description. As shown in
Figure 4, “Wall Frame” is annotated as “TBE”, “Stud” is labeled as “TEP”, “
2″ × 6″” is annotated as “SEP”, and “8′ high” is labeled as “SBE”, and “pneumatic nailed” is given a label of “CM”.
3.4. Development and Evaluation of NER Models
Several NER algorithms have been proven to be effective for various construction applications, including (1) Hidden Markov model (HMM) [
30], (2) Conditional Random Field (CRF) [
31], (3) Bidirectional-Long Short-Term Memory (Bi-LSTM) [
32], and (4) Bi-LSTM+CRF [
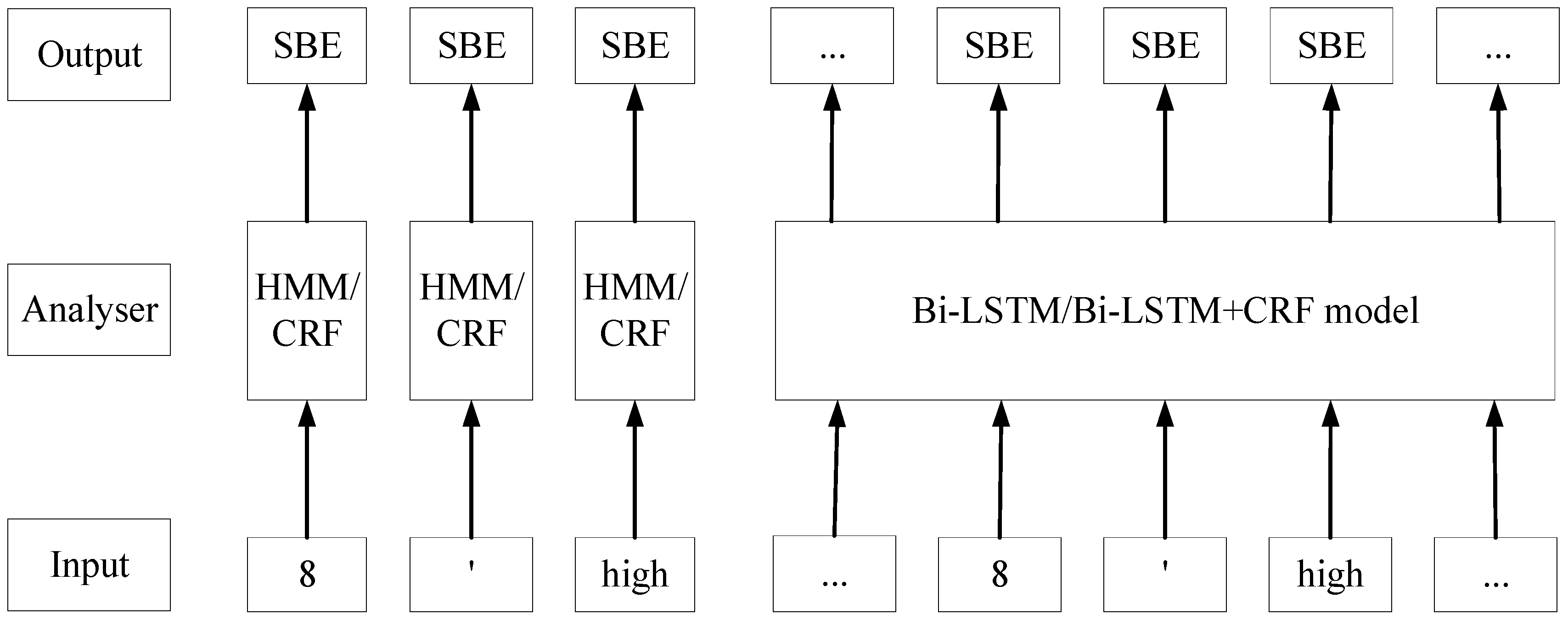
33]. However, there is no evidence indicating that one of them outperforms than others. These algorithms were adopted in this research and were trained based on the retrieved data. As shown in
Figure 5, the NER models take a sequence of tokens as inputs and predict corresponding labels. For example, “8′ high” are labeled by NER models as “SBE”, “SBE”, and “SBE”. The conceptual labeling processes of these four models are briefly shown in
Figure 5. As shown in
Figure 5, HMM and CRF models label every token independently; on the contrary, Bi-LSTM and Bi-LSTM+CRF models can classify all the tokens in a sequence as a whole, capitalizing on the Recurrent Neural Network (RNN).
3.4.1. Feature Engineering
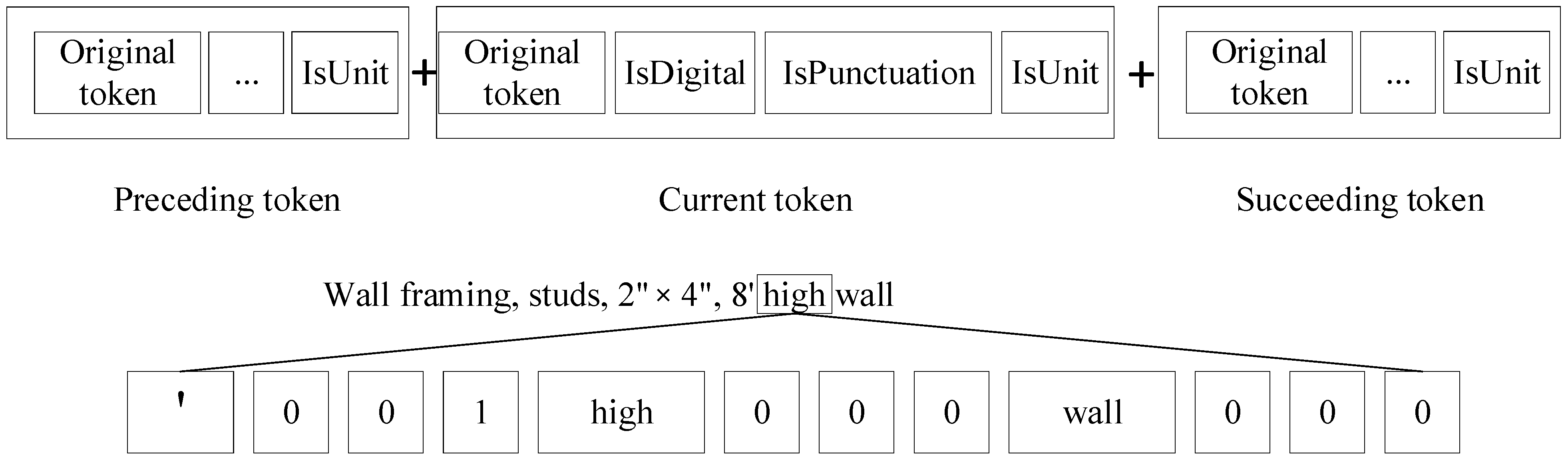
This study employed different strategies of feature representation for each NER model. The HMM algorithm uses the original word to represent each token in a sentence due to its simplicity. In terms of the CRF algorithm, the authors proposed a new feature representation, i.e., adding syntactic features to express each token in a sentence. A context window of size one is used to capture features of its surrounding tokens to enrich the information contained in the token feature.
Figure 6 illustrates the feature vectors for the CRF model. As shown in
Figure 6, the generated d feature is a 1 × 12 feature vector. The added features consist of syntactic and semantic features. The syntactic features contain “isDigital” and “isPunctuation”. The semantic feature is “isUnit” and can be recognized based on the developed dictionary by comparing the token with each word in the dictionary. The common units in the domain of construction are included in the Unit Dictionary, such as “‘”, “S.Y.”, “HP”, and “ga”. The token “high” in item description “
Wall framing, studs, 2″ × 4″, 8′ high wall” is transformed into vector [‘, 0, 0, 1, high, 0, 0, 0, wall, 0, 0, 0]. The feature vector indicates that the current token is “high”. Its preceding token is “‘”, while its succeeding token is “high”. Moreover, its previous token is a unit.
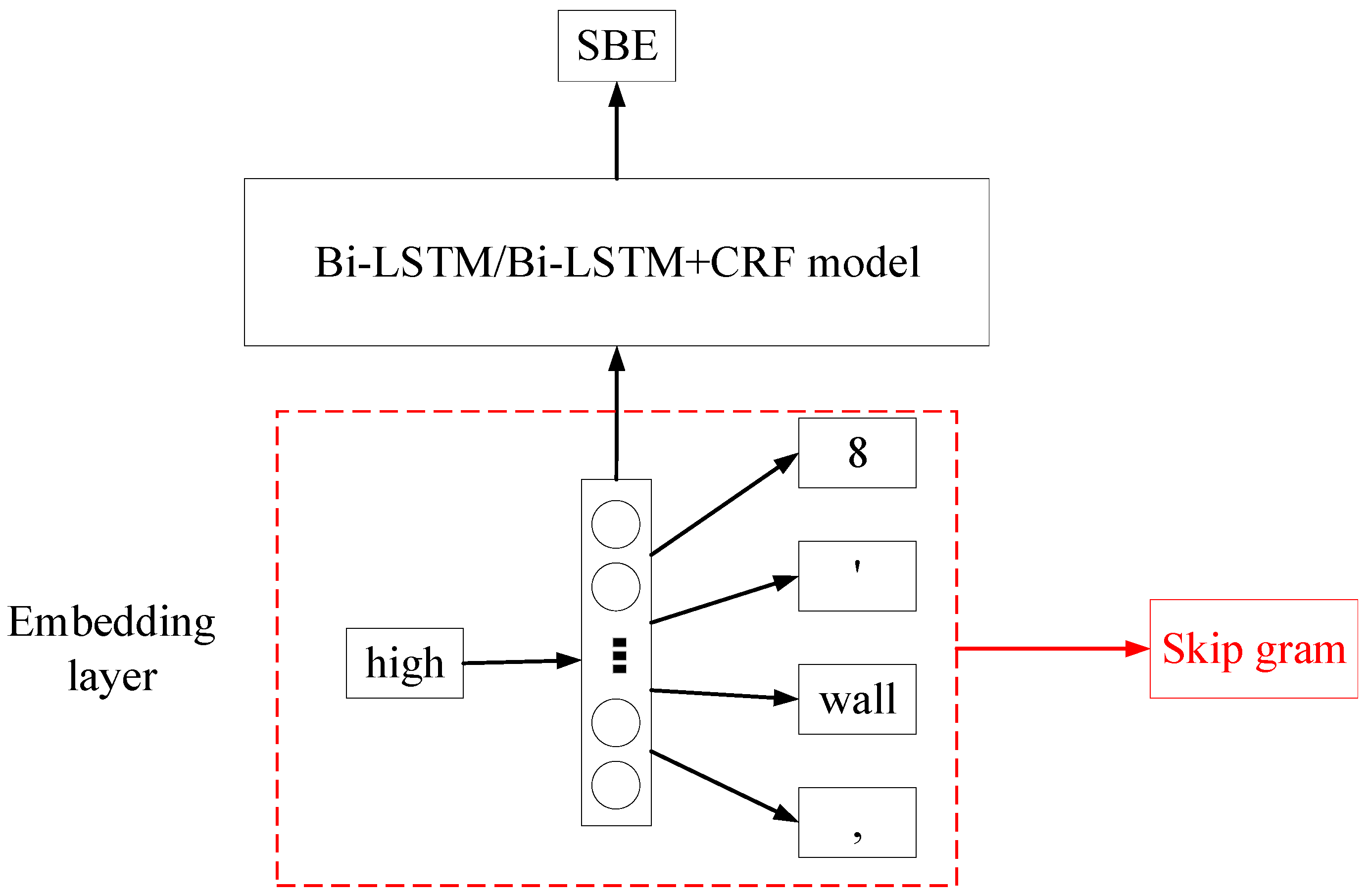
As for the BiLSTM and BiLSTM+CRF models, the authors employed word embedding to transform textual descriptions of cost items into numerical data so that these two models could take the whole description as the input. The Word2vec method represents a token as a numerical vector, assuming that the meaning of a token can be inferred by its neighbors. Since a piece of item description is a sequence of tokens, a line item is consequently represented as a matrix by the word embedding method. The matrix size is L × d, where L is the number of tokens in the item description and d is the length of a token vector. The word embedding is presented in
Figure 7. As shown in the figure, the token “high” was processed in the embedding layer before being fed into the NER model. The skip-gram Word2vec model is a two-layer ANN (Artificial Neural Network). This simple ANN model takes a token as input and returns surrounding words of the target word. After training this model with all samples, weights of the hidden layer have fitted with the training data so that the trained model can predict the context of a given token in samples. Therefore, the hidden layer of the trained ANN model was employed to represent the input token. In this study, the dimension of word vectors, which is also the hidden unit of the skip gram’s layer, was set as 140. In addition, the maximum length of the padded sequences was specified as 60 in Bi-LSTM/Bi-LSTM+CRF model, considering the max size of samples in the collected data.
3.4.2. Model Development
The algorithm selected for HMM model is Viterbi algorithm due to its efficiency in decoding the NER label state sequences [
34]. The algorithm in the CRF model is determined as ‘lbfgs’, which is the abbreviation of “Limited-memory Broyden–Fletcher–Goldfarb–Shanno algorithm” because of its significant outperformance than GIS and other gradient-based algorithms regarding convergence rate [
35]. Then, the number of max iterations was set as 100. The BiLSTM model consists of four layers: (1) embedding layer, (2) bidirectional LSTM (also known as the first LSTM layer), (3) LSTM layer, and (4) time-distributed layer. The embedding layer has been described thoroughly in the last section. The maximum length of the padded sequences was specified as 60 in Bi-LSTM/Bi-LSTM+CRF model, considering the max length of samples in collected data. In training the BiLSTM model, the batch size is set as two because of the limited training data size. In addition, verbose and epochs are determined to 1 and 1 after tuning hyperparameters. Bi-LSTM+CRF model adds a CRF layer to the bidirectional LSTM model. Therefore, the detailed configuration is the same as the previous two models.
3.4.3. Model Evaluation
Three performance metrics are widely used to evaluate the NER models [
36], including (1) precision, (2) recall, and (3) F1 score. Precision refers to the ratio of the number of correctly labeled tokens over the total number of tokens. The recall is calculated by dividing the number of correctly labeled tokens by the number of tokens with the same label in the ground truth dataset. On the contrary, the F1 score is the harmonic mean of precision and recall so that it outperforms others in terms of imbalanced class distribution [
36]. It is used to measure the performance of the proposed NER-based methods. The performance of these four algorithms is discussed later in the “Case Study” section.
3.5. Sequence Labeling Rules Based on Expert Knowledge
As described earlier, two approaches are typically used for information extraction: (1) ruled-based methods and (2) ML-based methods [
11]. ML-based methods eliminate manual effort in rule development by automatically extracting implicit rules (i.e., training the model) from training data. However, ML-based methods suffer from labeling training data and lower prediction accuracy [
11,
37]. The sequence labeling rules were developed by authors and integrated with ML algorithms described in the previous sub-sections. The formalized sequence labeling rules are summarized in
Table 2. For example, rule #1 specifies that when the current token is labeled as “SBE”/“SHBE”/“FBE”, its preceding tokens should contain “TBE” tokens. The entities of “SBE” or “SHBE” provides additional information for tokens with “TBE”. For example, detailed information of building elements is always specified after the tokens “Type of Building Element”. Similarly, the authors formalized rule #2, because information of “Design feature” is used to describe the building element or element part. Rule #3 indicates that information of “SBE”/“SEP”/”DF” usually contains a cardinal digit. Furthermore, Rule #4 shows that a cardinal digit followed by a unit token is an entity of SBE, SEP, or DF. For example, “
2″ × 4″” in item description “
Wall framing, studs, 2″ × 4″, 8′ high wall” is labeled as “SEP”, while it contains two cardinal digits and two-unit tokens. It should be noted that the developed rules served as a checker on the results obtained by ML models and cannot work independently.
Figure 8 provides one example of how the sequence labeling rules work with ML-based NER algorithms. Generally, the ML-based NER model returns a sequence of predicted probabilities of different labels, and the predicted label is the one with the highest probability. Afterward, the developed sequence labeling rules are applied to check the prediction results. As shown in
Figure 8, “8′” is labeled as “FBE”, which conflicts with sequencing rules. Then, the labeling result with a lower probability will be checked until the proposed labeling rules are satisfied.
3.6. Active Learning
ML-based NER requires human annotators to label a large amount of training data. Such labeling is exceptionally costly and time-consuming [
23]. To address such limitations, this study employed the strategy of active learning to minimize the volume of training data, thereby reducing manual labeling efforts. Active learning is to select and learn the most informative-to-learn instances to reduce labeling efforts. In other words, active learning intervenes the selection of the training data for the developed NER model to increase the overall efficiency. Essentially, active learning allows the selection of the most valuable data as input of ML algorithms. For example, ‘
10″ × 10″ wood column framing, heavy mill timber, structural grade, 1500f’ and ‘
12″ × 12″ wood column framing, heavy mill timber, structural grade, 1500f’ are similar cost items [
2]. If the former has been used in the training set, the trained model is expected to label the latter accurately. Active learning, thus, will not feed these two similar items into the training set, thereby reducing the cost spent on labeling data.
Figure 9 depicts how active learning works in the proposed NER-based framework. In the traditional method, all the training data are labeled by the human annotator and fed into NER models. In contrast, the training data are inputted to the active learner before being labeled in the scenario of active learning. The active learner evaluates and sorts these unlabeled data in terms of their impact on model training so that the most valuable data selected by the active learner can be fed into the NER model. As a result, there is no need for the human labeler to annotate invaluable data, thereby reducing the manual efforts to label training data. It is important to note that active learning is not intended to improve the performance of the model. It is used to reduce the manual efforts in preparing the training data. Its strategy is to enable the employed model to reach the best performance with minimal training data in the most efficient manner.
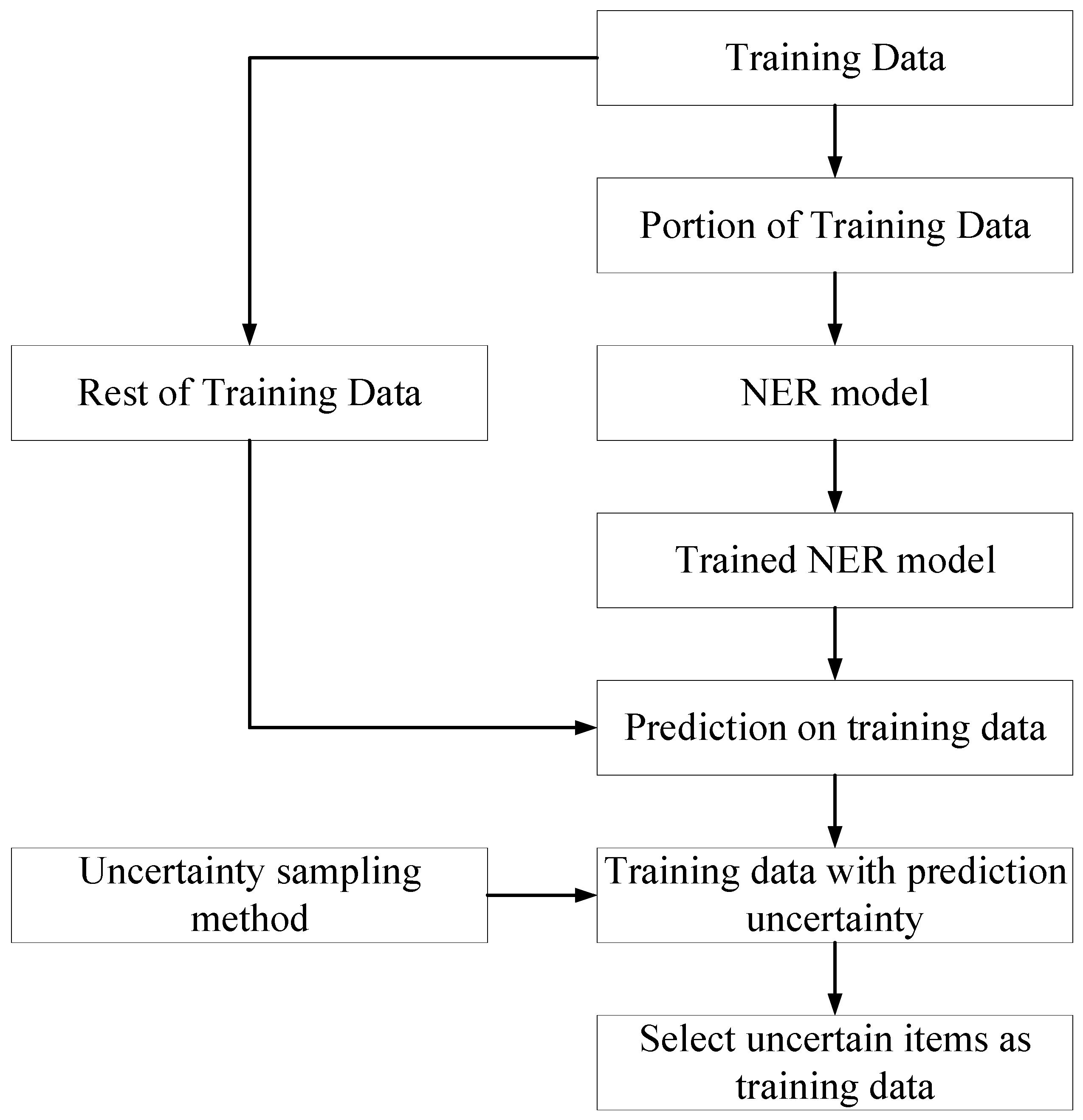
Uncertainty sampling is a strategy for identifying unlabeled items that the developed ML model cannot predict confidently. It means that only items with low certainty are selected as the training data. It was adopted by the authors because the developed NER returns the sequence of probabilities that could be used to calculate the uncertainty of the prediction.
Figure 10 displays the workflow of the uncertainty sampling method, which functions as an active learner to select training data. Initially, a small portion of the training data is randomly selected from the training data and labeled by the human annotator. Then, these labeled data were fed into the developed NER model. Subsequently, the trained NER model was employed to predict the rest of the training data. Afterward, the uncertainty sampling method is utilized to calculate the uncertainty of the rest of the training samples based on the NER model prediction results. Eventually, the samples with the highest uncertainty are selected as the training data. The prediction uncertainty of the NER model on a piece of work description is quantified by counting the arithmetic average of the uncertainty of every token in the work description of a cost item, employing Equation (1) [
23]. The entropy for each token (i.e., uncertainty) is measured using Equation (2).
where
denotes the entropy of cost item description,
represents the entropy of tokens,
N denotes the number of total tokens in a given cost item, and
is the categorical label of the token.
To test the performance of active learning, two NER models were trained in different strategies. The first one was implemented in the traditional environment. The second one employed active learning. A comparative analysis between two experiments was conducted to quantify the performance of active learning on the developed NER method and presented in the “Case Study” section. In the evaluation of the performance of the active learning method, the involved labeling effort is an important aspect. In this research, the manual annotation effort spent on every cost item is assumed to be equivalent. The human labeling effort is measured based on the size of the required training data.
5. Conclusions
Intending to automate construction-oriented QTO, this research developed an NER-based information extraction method that extracts information from the work descriptions of cost items. Four NER algorithms, namely (1) HMM, (2) CRF, (3) Bi-LSTM, and (4) Bi-LSTM+CRF, were tested. The results revealed that HMM outperforms others in terms of the F1 score. As such, it was selected to implement the NER-based IE model. Moreover, this study integrated the HMM and manually developed labeling rules. The strategy of active learning was adopted to reduce the number of training data and human labeling efforts. The experimental results showed that the developed NER model (i.e., active learning-based HMM model) could extract the cost parameters from the work item description with satisfactory performance. With the assistance of developed labeling rules, the performance of the ML-based NER model was improved by 3%. The active learning approach could reach the performance of the traditional method with a significantly reduced size of training data, thereby reducing costs for human labeling.
This research contributed to the body of knowledge by the NLP-based IE model integrating HMM and formalized labeling rules that automatically process work descriptions and lay a foundation for automated QTO and cost estimation. This research indicated that HMM algorithm is the most suitable algorithm for IE from the textual description of cost items compared other three common NER algorithms. The integration of HMM and formalized labeling rules has improved accuracy by 89% in NER. In addition, active learning strategies reduced by 26% the labeling efforts for the case study. The represented approach can extract cost parameters from work descriptions, laying a foundation for automated QTO.



 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}