
Benchmark of Electricity Consumption Forecasting Methodologies Applied to Industrial Kitchens




Abstract
1. Introduction
2. State of the Art
2.1. Electricity Management in Industrial Kitchens
2.2. Electricity Consumption Forecasting
2.3. Summary
3. Materials and Methods
3.1. Forecasting Algorithms
3.1.1. Prophet
3.1.2. Random Forest
3.1.3. Long Short-Term Memory Deep Neural Network
3.2. Dataset
Data Preprocessing
3.3. Performance Evaluation Methodology
3.3.1. Training and Testing Procedures
3.3.2. Performance Metrics
4. Results and Discussion
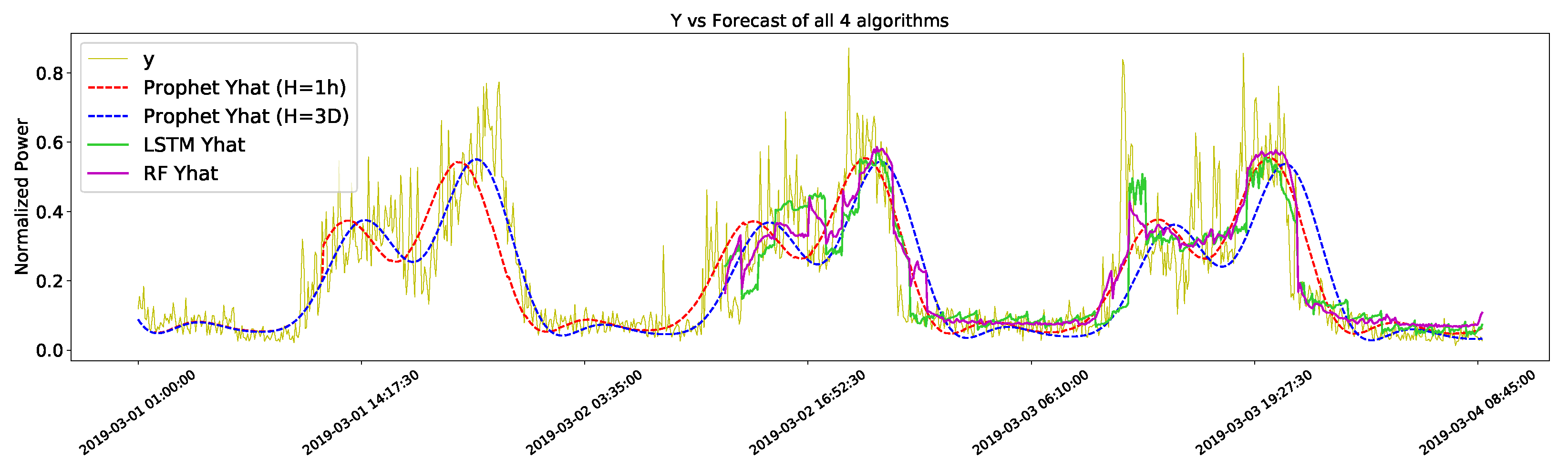
4.1. Virtual Aggregate Forecast
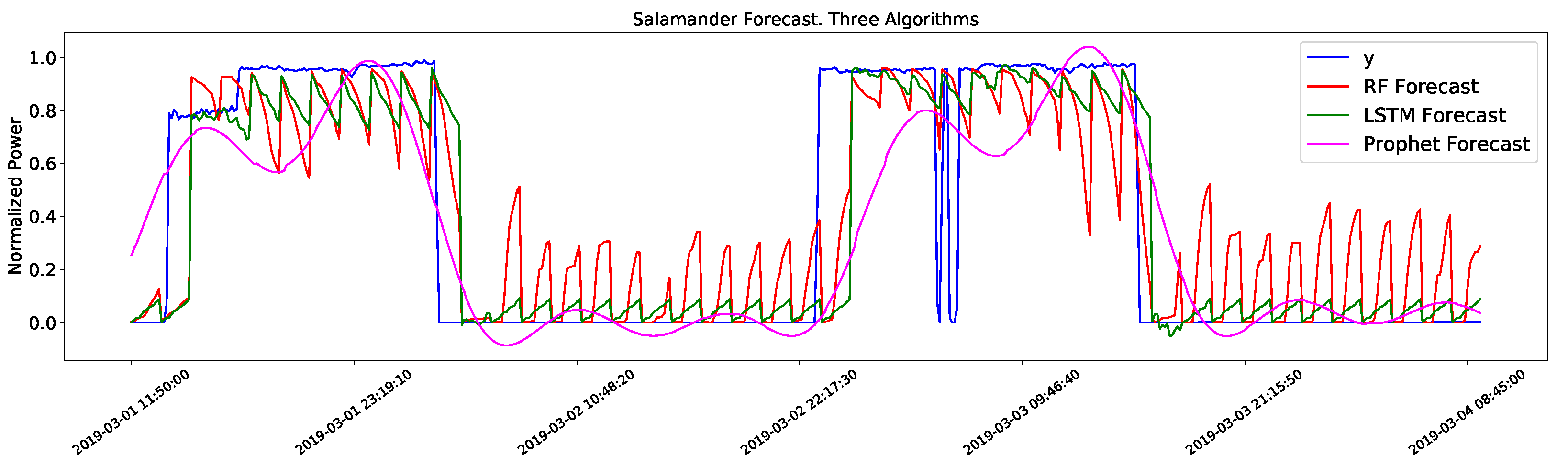
4.2. Individual Appliances Forecast
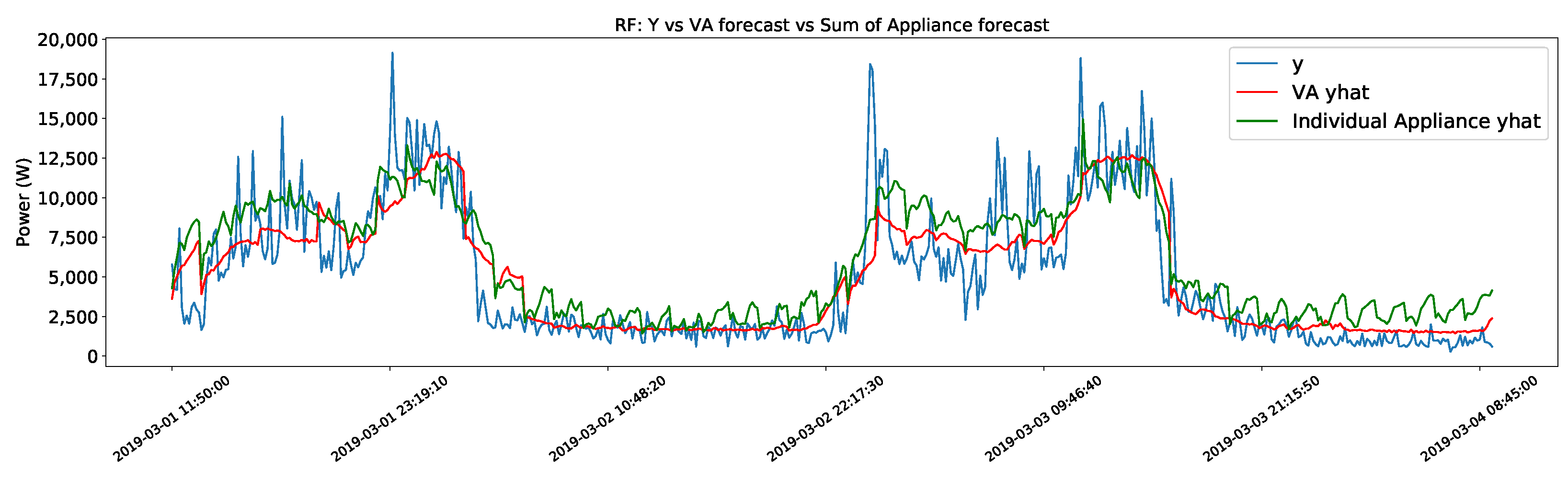
4.3. Virtual Aggregate Forecast vs. Sum of Individual Loads Forecast
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AE | Auto Encoder |
| ARIMA | Auto Regressive Integrated Moving Average |
| DL | Deep Learning |
| DT | Decision Tree |
| IK | Industrial Kitchen |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| ML | Machine Learning |
| MLP | Multi Layer Perceptron |
| NRMSE | Normalized Root Mean Squared Error |
| RES | Renewable Energy Sources |
| RF | Random Forest |
| RMSE | Root Mean Squared Error |
| RNN | Recurrent Neural Network |
| SVM | Support Vector Machine |
| VA | Virtual Aggregate |
References
- IEA. Electricity Market Report-January 2022; Technical Report; IEA: Paris, France, 2022.
- Mudie, S. Energy Benchmarking in UK Commercial Kitchens. Build. Serv. Eng. Res. Technol. 2016, 37, 205–219. [Google Scholar] [CrossRef]
- Mudie, S.; Essah, E.A.; Grandison, A.; Felgate, R. Electricity Use in the Commercial Kitchen. Int. J.-Low-Carbon Technol. 2013, 11, 66–74. [Google Scholar] [CrossRef]
- AEA. Sector Guide Industrial Energy Efficiency Accelerator Contract Catering Sector; Technical Report AEA/R/ED56877; DEFRA and Carbon Trust: Oxfordshire, UK, 2012. [Google Scholar]
- Laib, O.; Khadir, M.T.; Mihaylova, L. Toward Efficient Energy Systems Based on Natural Gas Consumption Prediction with LSTM Recurrent Neural Networks. Energy 2019, 177, 530–542. [Google Scholar] [CrossRef]
- Higgins-Desbiolles, F.; Moskwa, E.; Wijesinghe, G. How Sustainable Is Sustainable Hospitality Research? A Review of Sustainable Restaurant Literature from 1991 to 2015. Curr. Issues Tour. 2019, 22, 1551–1580. [Google Scholar] [CrossRef]
- Mudie, S.; Vadhati, M. Low Energy Catering Strategy: Insights from a Novel Carbon-Energy Calculator. Energy Procedia 2017, 123, 212–219. [Google Scholar] [CrossRef]
- Fernandes, F.; Morais, H.; Vale, Z. Near real-time management of appliances, distributed generation and electric vehicles for demand response participation. Integr.-Comput.-Aided Eng. 2022, 29, 313–332. [Google Scholar] [CrossRef]
- Ye, Y.; Lei, X.; Lerond, J.; Zhang, J.; Brock, E.T. A Case Study about Energy and Cost Impacts for Different Community Scenarios Using a Community-Scale Building Energy Modeling Tool. Buildings 2022, 12, 1549. [Google Scholar] [CrossRef]
- Aldaouab, I.; Daniels, M.; Hallinan, K. Microgrid Cost Optimization for a Mixed-Use Building. In Proceedings of the 2017 IEEE Texas Power and Energy Conference (TPEC), Station, TX, USA, 9–10 February 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Aldaouab, I.; Daniels, M. Microgrid Battery and Thermal Storage for Improved Renewable Penetration and Curtailment. In Proceedings of the 2017 International Energy and Sustainability Conference (IESC), Farmingdale, NJ, USA, 19–20 October 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Bourdeau, M.; Zhai, X.Q.; Nefzaoui, E.; Guo, X.; Chatellier, P. Modeling and Forecasting Building Energy Consumption: A Review of Data-Driven Techniques. Sustain. Cities Soc. 2019, 48, 101533. [Google Scholar] [CrossRef]
- Newsham, G.R.; Birt, B.J. Building-Level Occupancy Data to Improve ARIMA-based Electricity Use Forecasts. In Proceedings of the 2nd ACM Workshop on Embedded Sensing Systems for Energy-Efficiency in Building-BuildSys’10, Zurich, Switzerland, 2 November 2010; ACM Press: New York, NY, USA, 2010; p. 13. [Google Scholar] [CrossRef]
- Yun, K.; Luck, R.; Mago, P.J.; Cho, H. Building Hourly Thermal Load Prediction Using an Indexed ARX Model. Energy Build. 2021, 54, 225–233. [Google Scholar] [CrossRef]
- Taylor, S.J.; Letham, B. Forecasting at Scale. Am. Stat. 2018, 72, 37–45. [Google Scholar] [CrossRef]
- Bashir, T.; Haoyong, C.; Tahir, M.F.; Liqiang, Z. Short Term Electricity Load Forecasting Using Hybrid Prophet-LSTM Model Optimized by BPNN. Energy Rep. 2022, 8, 1678–1686. [Google Scholar] [CrossRef]
- Shohan, M.J.A.; Faruque, M.O.; Foo, S.Y. Forecasting of Electric Load Using a Hybrid LSTM-Neural Prophet Model. Energies 2022, 15, 2158. [Google Scholar] [CrossRef]
- Vasudevan, N.; Venkatraman, V.; Ramkumar, A.; Sheela, A. Real-Time Day Ahead Energy Management for Smart Home Using Machine Learning Algorithm. J. Intell. Fuzzy Syst. 2021, 41, 5665–5676. [Google Scholar] [CrossRef]
- Almazrouee, A.I.; Almeshal, A.M.; Almutairi, A.S.; Alenezi, M.R.; Alhajeri, S.N. Long-Term Forecasting of Electrical Loads in Kuwait Using Prophet and Holt–Winters Models. Appl. Sci. 2020, 10, 5627. [Google Scholar] [CrossRef]
- Paudel, S.; Elmitri, M.; Couturier, S.; Nguyen, P.H.; Kamphuis, R.; Lacarrière, B.; Le Corre, O. A Relevant Data Selection Method for Energy Consumption Prediction of Low Energy Building Based on Support Vector Machine. Energy Build. 2017, 138, 240–256. [Google Scholar] [CrossRef]
- Massana, J.; Pous, C.; Burgas, L.; Melendez, J.; Colomer, J. Short-Term Load Forecasting in a Non-Residential Building Contrasting Models and Attributes. Energy Build. 2015, 92, 322–330. [Google Scholar] [CrossRef]
- Tso, G.K.; Yau, K.K. Predicting Electricity Energy Consumption: A Comparison of Regression Analysis, Decision Tree and Neural Networks. Energy 2007, 32, 1761–1768. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Tsanas, A.; Xifara, A. Accurate Quantitative Estimation of Energy Performance of Residential Buildings Using Statistical Machine Learning Tools. Energy Build. 2012, 49, 560–567. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, Y.; Zeng, R.; Srinivasan, R.S.; Ahrentzen, S. Random Forest Based Hourly Building Energy Prediction. Energy Build. 2018, 171, 11–25. [Google Scholar] [CrossRef]
- Runge, J.; Zmeureanu, R. A Review of Deep Learning Techniques for Forecasting Energy Use in Buildings. Energies 2021, 14, 608. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-Term Residential Load Forecasting Based on LSTM Recurrent Neural Network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Wang, Z.; Hong, T.; Piette, M.A. Building Thermal Load Prediction through Shallow Machine Learning and Deep Learning. Appl. Energy 2020, 263, 114683. [Google Scholar] [CrossRef]
- Yong, Z.; Xiu, Y.; Chen, F.; Pengfei, C.; Binchao, C.; Taijie, L. Short-Term Building Load Forecasting Based on Similar Day Selection and LSTM Network. In Proceedings of the 2018 2nd IEEE Conference on Energy Internet and Energy System Integration (EI2), Beijing, China, 20–22 October 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Braga, L.; Braga, A.; Braga, C. On the characterization and monitoring of building energy demand using statistical process control methodologies. Energy Build. 2013, 65, 205–219. [Google Scholar] [CrossRef]
- Grillone, B.; Mor, G.; Danov, S.; Cipriano, J.; Lazzari, F.; Sumper, A. Baseline Energy Use Modeling and Characterization in Tertiary Buildings Using an Interpretable Bayesian Linear Regression Methodology. Energies 2021, 14, 5556. [Google Scholar] [CrossRef]
- Ahmad, T.; Zhang, H.; Yan, B. A review on renewable energy and electricity requirement forecasting models for smart grid and buildings. Sustain. Cities Soc. 2020, 55, 102052. [Google Scholar] [CrossRef]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. In Ensemble Machine Learning; Zhang, C., Ma, Y., Eds.; Springer: New York, NY, USA, 2012; pp. 157–175. [Google Scholar] [CrossRef]
- Van Houdt, G.; Mosquera, C.; Nápoles, G. A Review on the Long Short-Term Memory Model. Artif. Intell. Rev. 2020, 53, 5929–5955. [Google Scholar] [CrossRef]
- Pereira, L. FIKElectricity: A Electricity Consumption Dataset from Three Restaurant Kitchens in Portugal. Available online: https://accounts.osf.io/login?service=https://osf.io/k3g8n/ (accessed on 22 January 2021).
- Chai, T.; Draxler, R.R. Root Mean Square Error (RMSE) or Mean Absolute Error (MAE)?—Arguments against Avoiding RMSE in the Literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Pinto, T.; Morais, H.; Corchado, J.M. Adaptive entropy-based learning with dynamic artificial neural network. Neurocomputing 2019, 338, 432–440. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Max Power (W) | Avg. Power (W) | Null Samples | |
|---|---|---|---|
| Blast Chiller | 5331 | 215 | 8056 (1.88%) |
| Infrared Lights | 1133 | 211 | 147 (0.03%) |
| Dish Washer | 4456 | 480 | 1949 (0.45%) |
| Glass Washer | 1885 | 43 | 4 (0.001%) |
| Convection Oven 1 | 8797 | 386 | 7044 (1.64%) |
| Convection Oven 2 | 8337 | 382 | 7344 (1.71%) |
| Salamander 1 | 3148 | 944 | 5995 (1.4%) |
| Salamander 2 | 3182 | 526 | 6819 (1.59%) |
| Dual Fryer | 5222 | 219 | 2619 (0.61%) |
| Freezer | 1319 | 577 | 7936 (1.85%) |
| Ice Machine | 421 | 143 | 7433 (1.73%) |
| Mise en Place | 854 | 219 | 8073 (1.88%) |
| Garde Manger 1 | 1278 | 180 | 8232 (1.92%) |
| Garde Manger 2 | 418 | 70 | 8075 (1.88) |
| Refrigerator—Drinks | 623 | 145 | 17 (0.004%) |
| Refrigerator—Fish | 3709 | 96 | 107 (0.02%) |
| Refrigerator—Meat | 1274 | 132 | 54 (0.01%) |
| Refrigerator—Vegetables | 897 | 99 | 146 (0.03%) |
| Prophet (H = 3D) | Prophet (H = 1 h) | RF | LSTM | |
|---|---|---|---|---|
| RMSE | 0.10 | 0.12 | 0.10 | 0.11 |
| MAE | 0.073 | 0.068 | 0.066 | 0.066 |
| Prophet (H = 3D) | Prophet (H = 1 h) | RF | LSTM | |
|---|---|---|---|---|
| Blast Chiller | 0.20 | 0.17 | 0.15 | 0.17 |
| Infrared Lights | 0.31 | 0.26 | 0.24 | 0.25 |
| Dish Washer | 0.20 | 0.19 | 0.20 | 0.21 |
| Glass Washer | 0.06 | 0.05 | 0.0002 | 0.005 |
| Convection Oven 1 | 0.14 | 0.13 | 0.14 | 0.14 |
| Convection Oven 2 | 0.13 | 0.13 | 0.15 | 0.13 |
| Salamander 1 | 0.34 | 0.25 | 0.25 | 0.22 |
| Salamander 2 | 0.24 | 0.21 | 0.15 | 0.17 |
| Dual Fryer | 0.08 | 0.08 | 0.08 | 0.08 |
| Freezer | 0.28 | 0.12 | 0.097 | 0.10 |
| Ice Machine | 0.31 | 0.31 | 0.29 | 0.31 |
| Mise en Place | 0.34 | 0.33 | 0.26 | 0.28 |
| Garde Manger 1 | 0.18 | 0.18 | 0.16 | 0.17 |
| Garde Manger 2 | 0.19 | 0.19 | 0.18 | 0.19 |
| Refrigerator—Drinks | 0.32 | 0.32 | 0.27 | 0.29 |
| Refrigerator—Fish | 0.21 | 0.21 | 0.23 | 0.22 |
| Refrigerator—Meat | 0.21 | 0.21 | 0.22 | 0.22 |
| Refrigerator—Vegetables | 0.18 | 0.18 | 0.17 | 0.17 |
| RMSE | MAE | |
|---|---|---|
| Prophet (H = 1 h)-Virtual Aggregate | 2290 | 1499 |
| Prophet (H = 1 h)-Individual Appliances | 2287 | 1507 |
| RF—Virtual Aggregate | 2230 | 1507 |
| RF—Individual Appliances | 2520 | 1998 |
| LSTM—Virtual Aggregate | 2461 | 1564 |
| LSTM—Individual Appliances | 2630 | 1961 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amantegui, J.; Morais, H.; Pereira, L. Benchmark of Electricity Consumption Forecasting Methodologies Applied to Industrial Kitchens. Buildings 2022, 12, 2231. https://doi.org/10.3390/buildings12122231
Amantegui J, Morais H, Pereira L. Benchmark of Electricity Consumption Forecasting Methodologies Applied to Industrial Kitchens. Buildings. 2022; 12(12):2231. https://doi.org/10.3390/buildings12122231
Chicago/Turabian StyleAmantegui, Jorge, Hugo Morais, and Lucas Pereira. 2022. "Benchmark of Electricity Consumption Forecasting Methodologies Applied to Industrial Kitchens" Buildings 12, no. 12: 2231. https://doi.org/10.3390/buildings12122231
APA StyleAmantegui, J., Morais, H., & Pereira, L. (2022). Benchmark of Electricity Consumption Forecasting Methodologies Applied to Industrial Kitchens. Buildings, 12(12), 2231. https://doi.org/10.3390/buildings12122231