
An Image-Based Steel Rebar Size Estimation and Counting Method Using a Convolutional Neural Network Combined with Homography


Abstract
:1. Introduction
2. Related Works
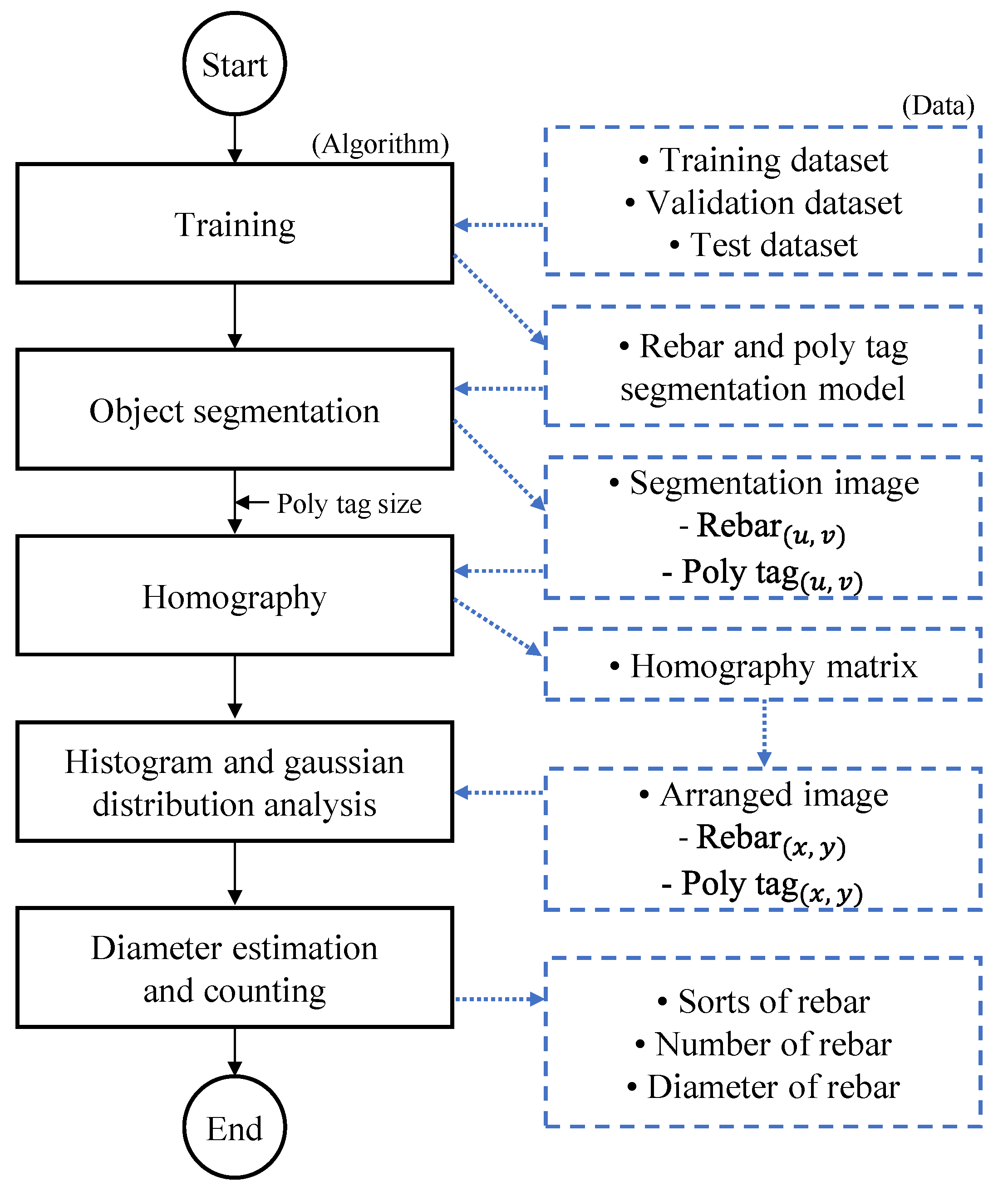
3. Estimation of the Size and Counting the Number of Steel Rebars
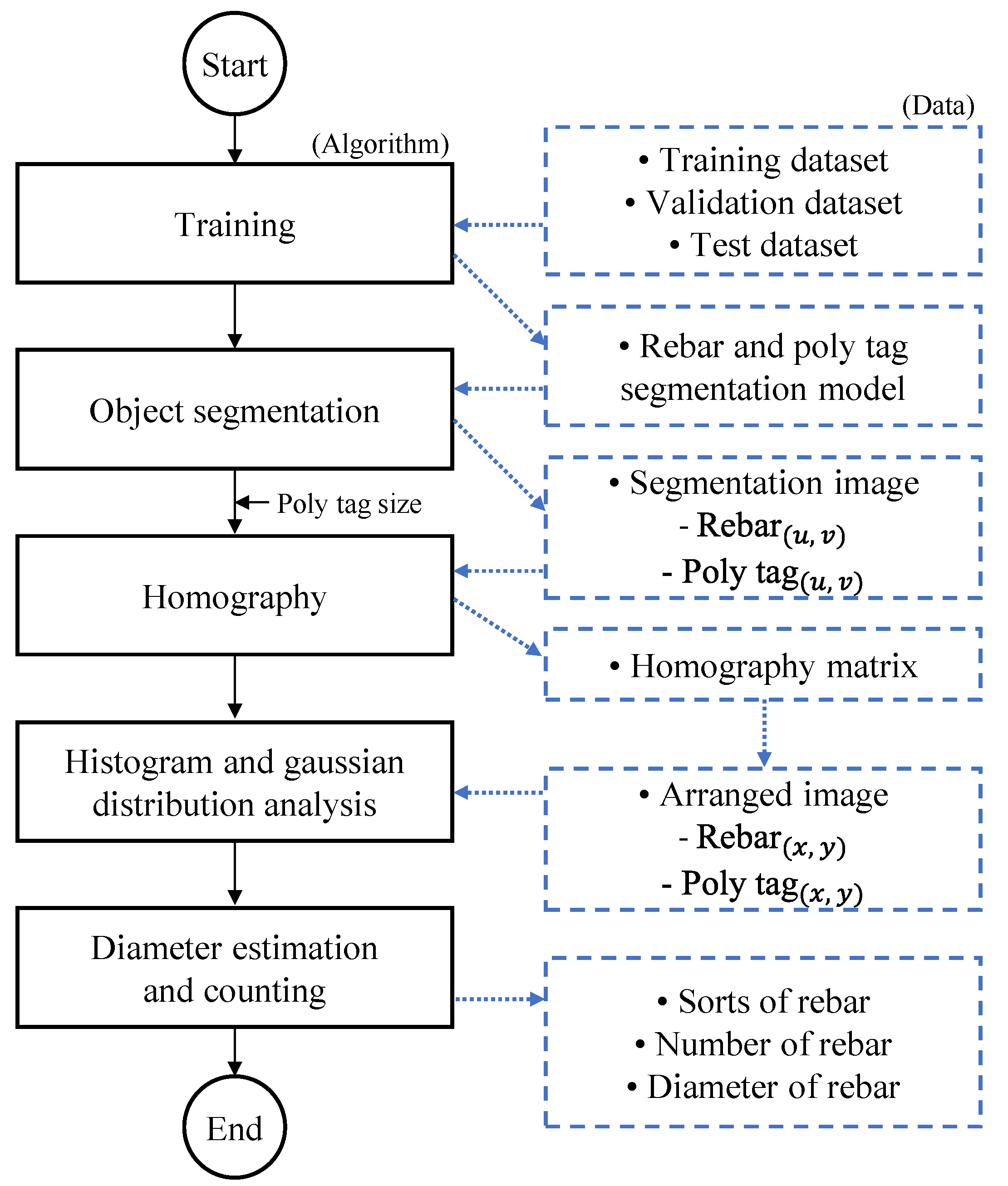
3.1. Research Method
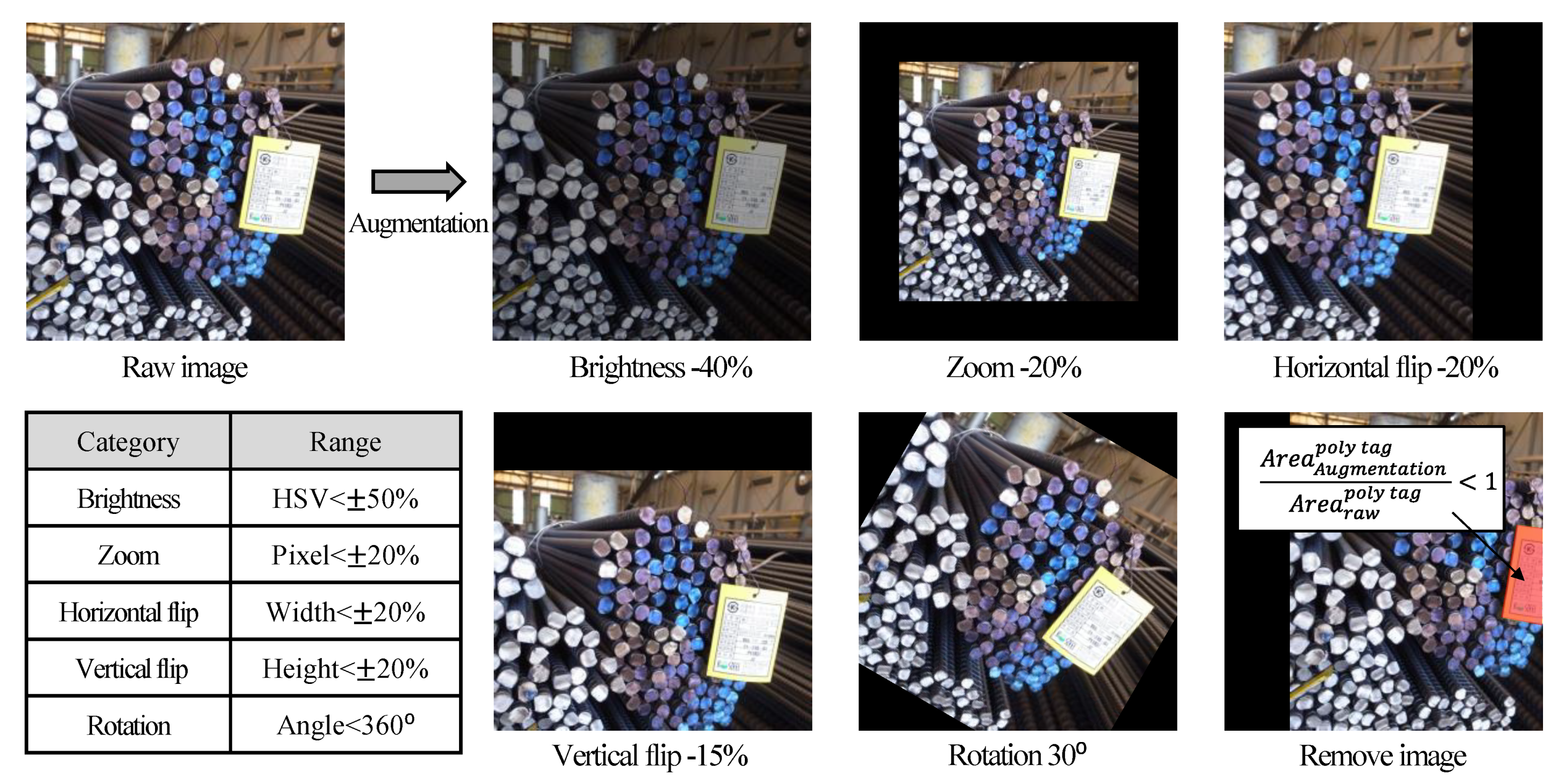
3.2. Image Acquisition for Instance Segmentation
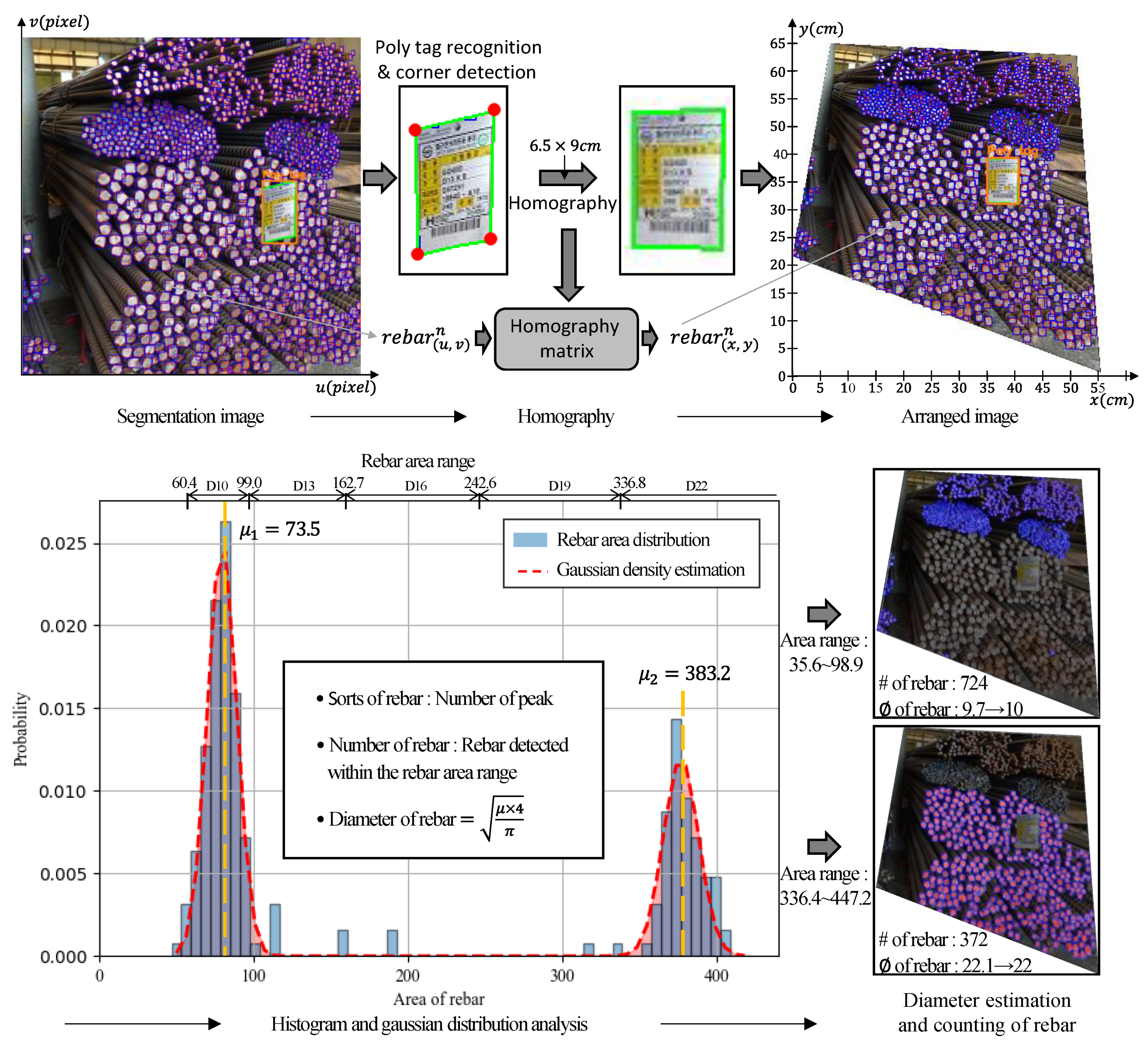
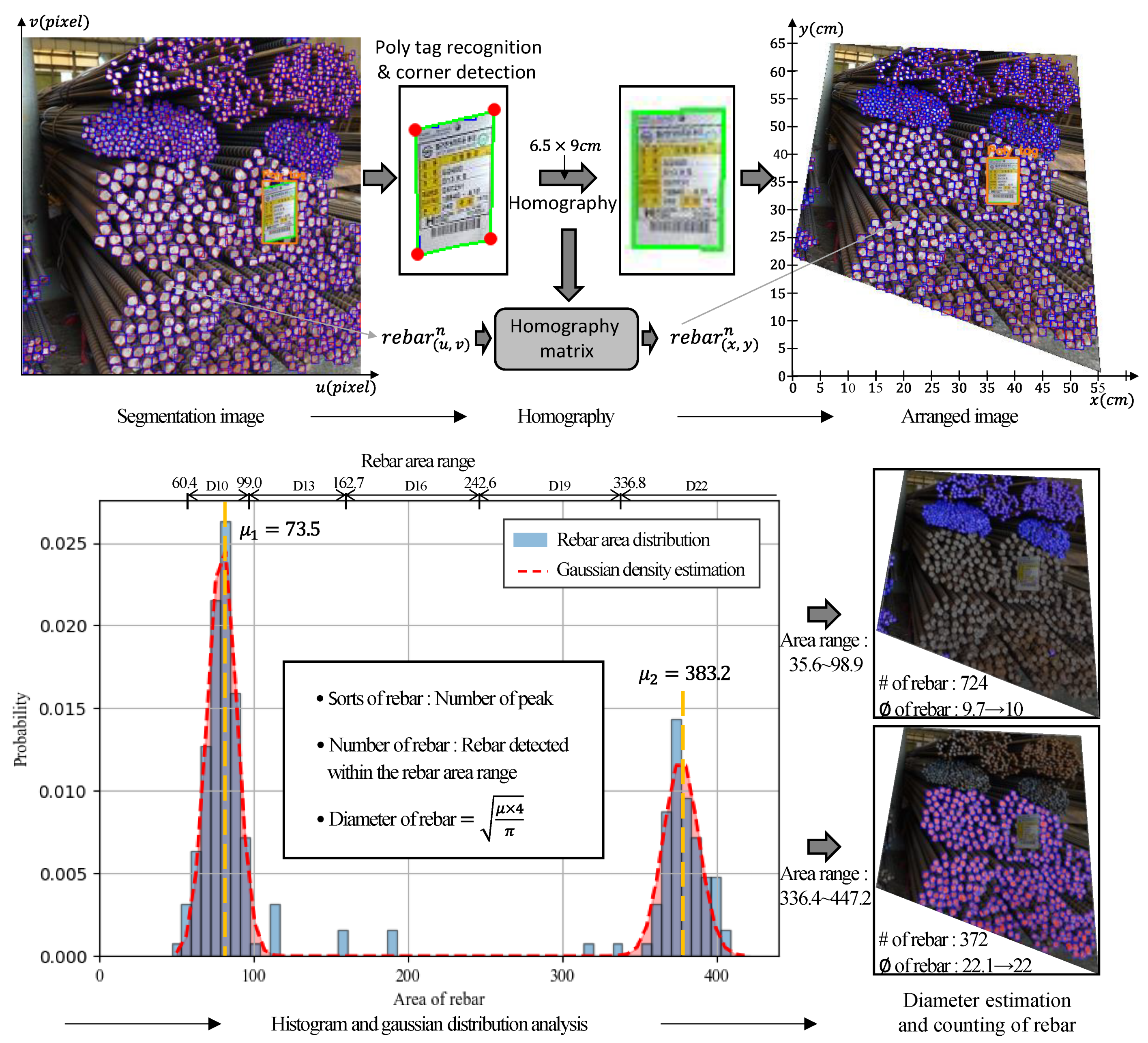
3.3. Rebar Size Estimation Using Homography
4. Results
4.1. Training and Evaluation
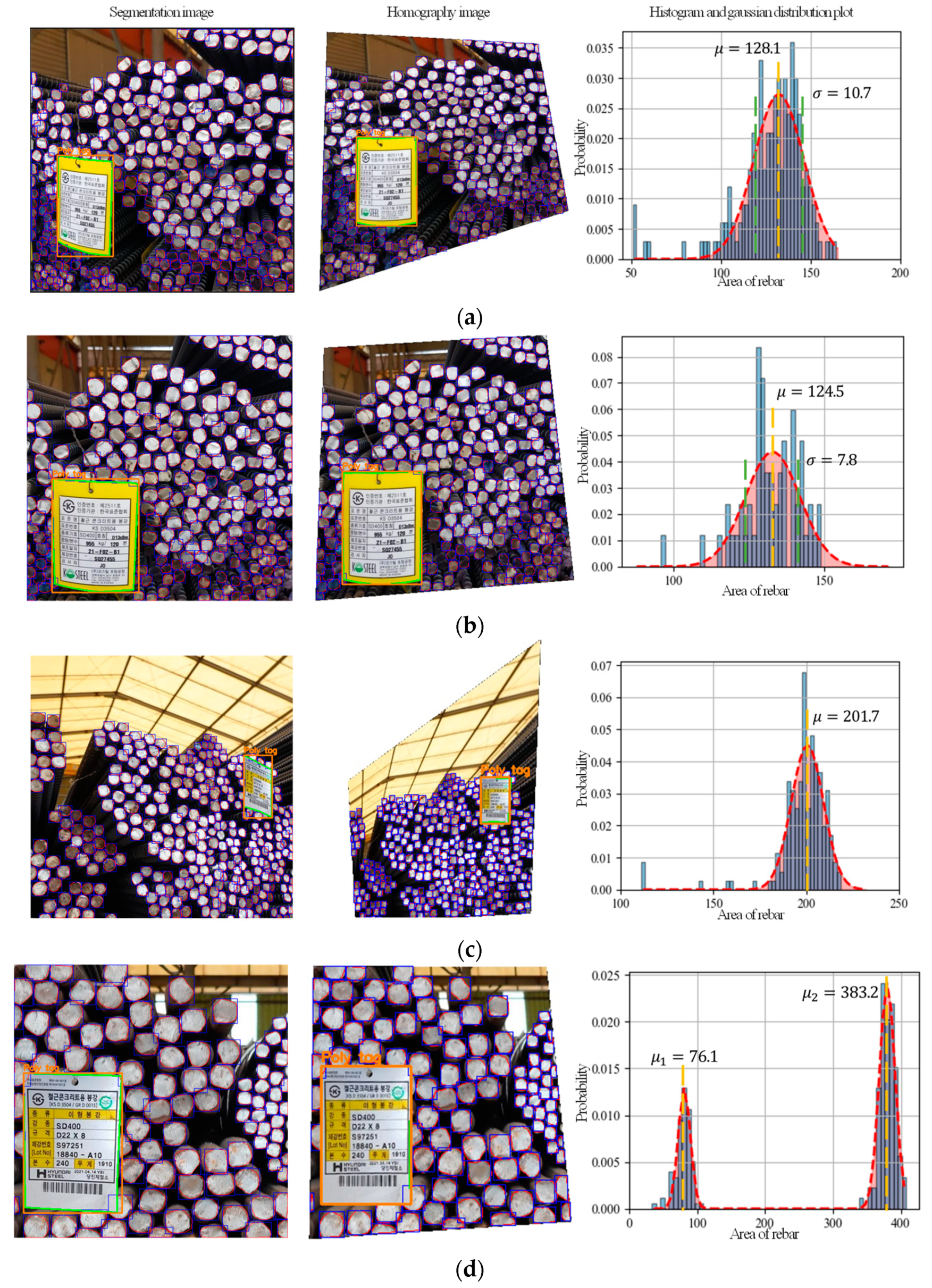
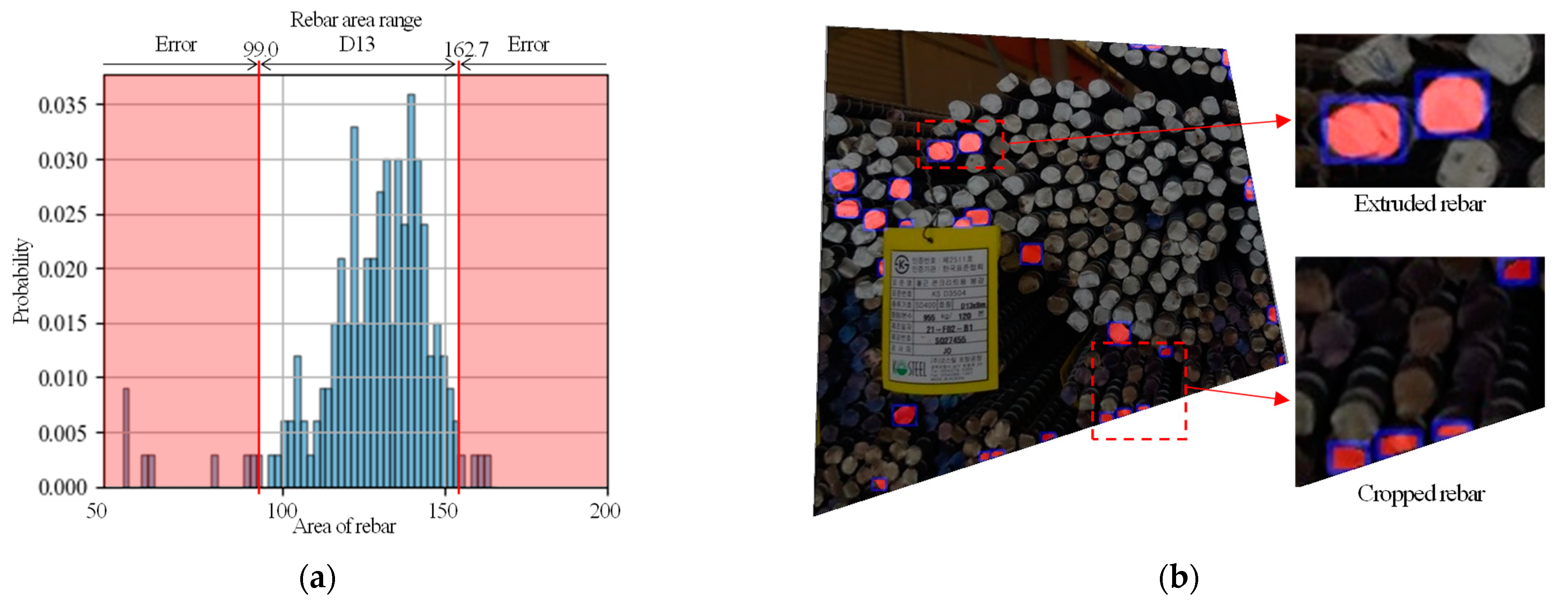
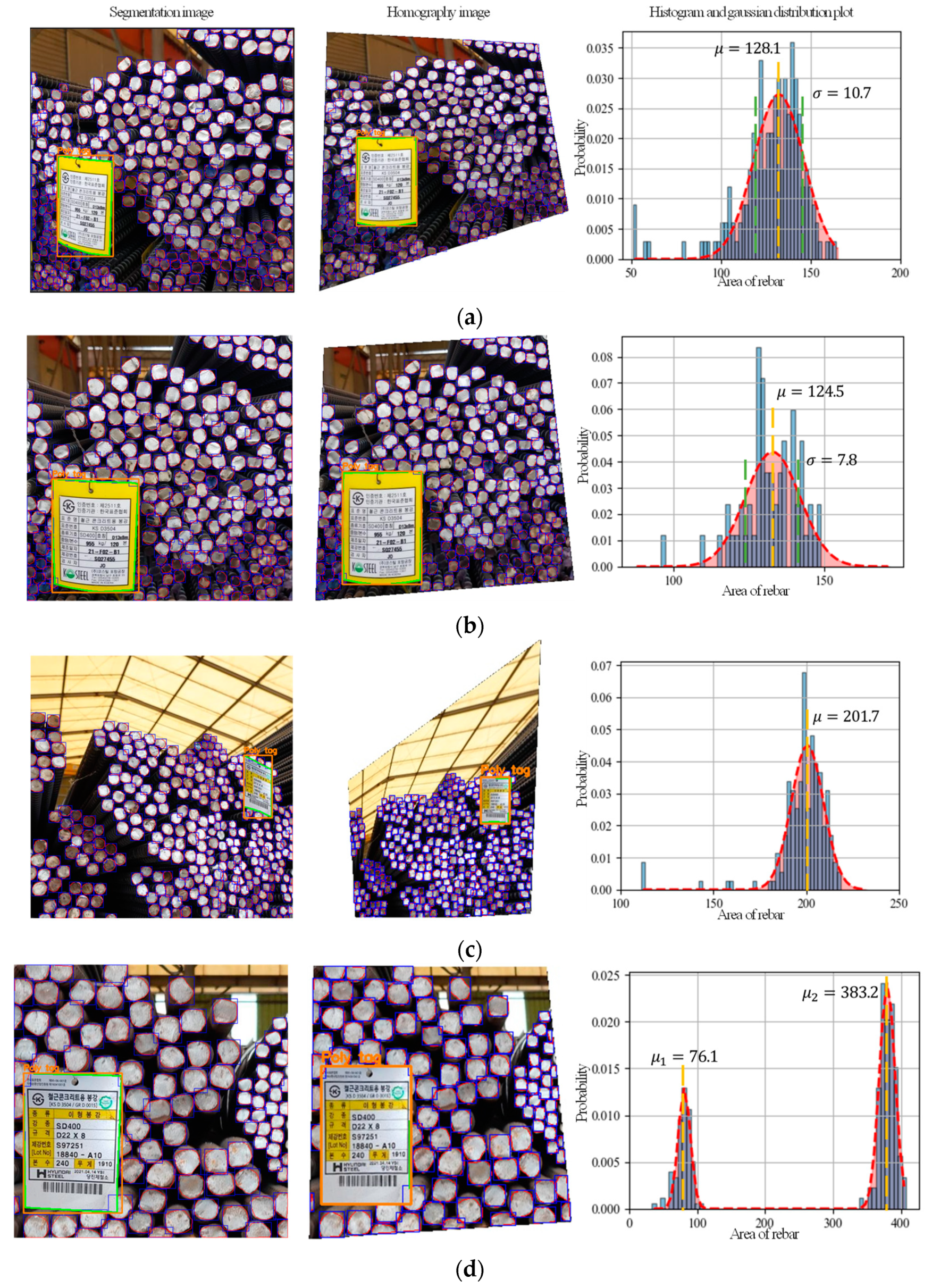
4.2. Rebar Size Estimation and Counting Results
5. Conclusions
- The proposed method, a CNN model combined with homography, can estimate the size and count the number of steel rebars in an image quickly and accurately, and the method can be applied to real construction sites to manage the stock of steel rebars efficiently.
- The application of a homography image by corner detection for poly tags as well as a histogram and Gaussian distribution plot can be used to effectively estimate the size and count the number of steel rebars from images with different perspectives.
- In this study, 622 images taken at various angles and that include a total of 182,522 steel rebars were manually labeled to create the dataset. Data augmentation was carried out to create 4668 images for the training dataset. Based on the training dataset, YOLACT-based steel bar size estimation and a counting model with a Box and Mask of over 30 mAP was generated to satisfy the aim of this study.
- The test results show that the maximum error rate for estimating the size and counting the number of steel rebars in an image was 3.1% and 9.6%, respectively. Most of the errors shown in this study were caused by images of steel rebars whose edges were cut off or that suffered from uneven indentation.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- MacGregor, J.G.; Wight, J.K. Reinforced Concrete: Mechanics and Design, 6th ed.; Prentice Hall Upper: Saddle River, NJ, USA, 1997; Volume 3. [Google Scholar]
- Na, S.; Paik, I. Application of Thermal Image Data to Detect Rebar Corrosion in Concrete Structures. Appl. Sci. 2019, 9, 4700. [Google Scholar] [CrossRef] [Green Version]
- Kmiecik, P.; Kamiński, M. Modelling of reinforced concrete structures and composite structures with concrete strength degradation taken into consideration. Arch. Civ. Mech. Eng. 2011, 11, 623–636. [Google Scholar] [CrossRef]
- Kaming, P.F.; Olomolaiye, P.O.; Holt, G.; Harris, F.C. Factors influencing construction time and cost overruns on high-rise projects in Indonesia. Constr. Manag. Econ. 1997, 15, 83–94. [Google Scholar] [CrossRef]
- Duggal, S.K. Building Materials; Routledge: London, UK, 2017. [Google Scholar]
- Kodur, V.; Harmathy, T. Properties of building materials. In SFPE Handbook of Fire Protection Engineering; Springer: Cham, Switzerland, 2016; pp. 277–324. [Google Scholar]
- Allen, E.; Iano, J. Fundamentals of Building Construction: Materials and Methods; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Kim, M.-K.; Thedja, J.P.P.; Chi, H.-L.; Lee, D.-E. Automated rebar diameter classification using point cloud data based machine learning. Autom. Constr. 2021, 122, 103476. [Google Scholar] [CrossRef]
- Zhang, D.; Xie, Z.; Wang, C. Bar Section Image Enhancement and Positioning Method in On-Line Steel Bar Counting and Automatic Separating System. In Proceedings of the 2008 Congress on Image and Signal Processing, Washington, DC, USA, 27–30 May 2008; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2008; Volume 2, pp. 319–323. [Google Scholar]
- Zhu, Y.; Tang, C.; Liu, H.; Huang, P. End-Face Localization and Segmentation of Steel Bar Based on Convolution Neural Network. IEEE Access 2020, 8, 74679–74690. [Google Scholar] [CrossRef]
- Ying, X.; Wei, X.; Pei-Xin, Y.; Qing-Da, H.; Chang-Hai, C. Research on an Automatic Counting Method for Steel Bars’ Image. In Proceedings of the 2010 International Conference on Electrical and Control Engineering, Washington, DC, USA, 25–27 June 2010; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2010; pp. 1644–1647. [Google Scholar]
- Hernández-Ruiz, A.; Martínez-Nieto, J.A.; Buldain-Pérez, J.D. Steel Bar Counting from Images with Machine Learning. Electronics 2021, 10, 402. [Google Scholar] [CrossRef]
- Xia, Y.; Shi, X.; Song, G.; Geng, Q.; Liu, Y. Towards improving quality of video-based vehicle counting method for traffic flow estimation. Signal Process. 2016, 120, 672–681. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Patel, V.M. A survey of recent advances in CNN-based single image crowd counting and density estimation. Pattern Recognit. Lett. 2018, 107, 3–16. [Google Scholar] [CrossRef] [Green Version]
- Sun, M.; Wang, Y.; Li, T.; Lv, J.; Wu, J. Vehicle counting in crowded scenes with multi-channel and multi-task convolutional neural networks. J. Vis. Commun. Image Represent. 2017, 49, 412–419. [Google Scholar] [CrossRef]
- Shen, J.; Xiong, X.; Xue, Z.; Bian, Y. A convolutional neural-network-based pedestrian counting model for various crowded scenes. Comput. Aided Civ. Infrastruct. Eng. 2019, 34, 897–914. [Google Scholar] [CrossRef]
- Asadi, P.; Gindy, M.; Alvarez, M. A Machine Learning Based Approach for Automatic Rebar Detection and Quantification of Deterioration in Concrete Bridge Deck Ground Penetrating Radar B-scan Images. KSCE J. Civ. Eng. 2019, 23, 2618–2627. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, H.; Yang, L.; Liu, S.; Cao, X. Deep People Counting in Extremely Dense Crowds. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1299–1302. [Google Scholar]
- Miikkulainen, R.; Liang, J.; Meyerson, E.; Rawal, A.; Fink, D.; Francon, O.; Raju, B.; Shahrzad, H.; Navruzyan, A.; Duffy, N.; et al. Evolving Deep Neural Networks. In Artificial Intelligence in the Age of Neural Networks and Brain Computing; Elsevier: Amsterdam, The Netherlands, 2019; pp. 293–312. [Google Scholar]
- Sam, D.B.; Surya, S.; Babu, R.V. Switching Convolutional Neural Network for Crowd Counting. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4031–4039. [Google Scholar]
- Ilyas, N.; Shahzad, A.; Kim, K. Convolutional-Neural Network-Based Image Crowd Counting: Review, Categorization, Analysis, and Performance Evaluation. Sensors 2019, 20, 43. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Zhang, X.; Chen, D. CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar]
- Gomaa, A.; Abdelwahab, M.M.; Abo-Zahhad, M.; Minematsu, T.; Taniguchi, R.-I. Robust Vehicle Detection and Counting Algorithm Employing a Convolution Neural Network and Optical Flow. Sensors 2019, 19, 4588. [Google Scholar] [CrossRef] [Green Version]
- Khaki, S.; Safaei, N.; Pham, H.; Wang, L. Wheatnet: A lightweight convolutional neural network for high-throughput image-based wheat head detection and counting. arXiv 2021, arXiv:2103.09408. [Google Scholar]
- Walach, E.; Wolf, L. Learning to count with CNN boosting. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Abdelwahab, M.A. Accurate Vehicle Counting Approach Based on Deep Neural Networks. In Proceedings of the 2019 International Conference on Innovative Trends in Computer Engineering (ITCE), Aswan, Egypt, 2–4 February 2019; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Chung, J.; Kim, G.; Sohn, K. Transferability of a Convolutional Neural Network (CNN) to Measure Traffic Density. Electronics 2021, 10, 1189. [Google Scholar] [CrossRef]
- Fan, Z.; Lu, J.; Qiu, B.; Jiang, T.; An, K.; Josephraj, A.N.; Wei, C. Automated steel bar counting and center localization with convolutional neural networks. arXiv 2019, arXiv:1906.00891. [Google Scholar]
- Li, Y.; Lu, Y.; Chen, J. A deep learning approach for real-time rebar counting on the construction site based on YOLOv3 detector. Autom. Constr. 2021, 124, 103602. [Google Scholar] [CrossRef]
- Dubrofsky, E. Homography Estimation. Diplomová Práce; Univerzita Britské Kolumbie: Vancouver, BC, Canada, 2009; Volume 5, Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.186.5926&rep=rep1&type=pdf (accessed on 1 September 2021).
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Deep image homography estimation. arXiv 2016, arXiv:1606.03798. [Google Scholar]
- Sukthankar, R.; Stockton, R.G.; Mullin, M.D. Smarter presentations: Exploiting homography in camera-projector systems. In Proceedings of the Eighth IEEE International Conference on Computer Vision, ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2002. [Google Scholar]
- Benhimane, S.; Malis, E. Homography-based 2D Visual Tracking and Servoing. Int. J. Robot. Res. 2007, 26, 661–676. [Google Scholar] [CrossRef]
- Malis, E.; Vargas, M. Deeper Understanding of the Homography Decomposition for Vision-Based Control. INRIA. 2007. Available online: https://hal.inria.fr/inria-00174036/ (accessed on 1 September 2021).
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C.; Back, A.D. Face recognition: A convolutional neural-network approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, X.; Zhao, C.; Pan, W. Towards accurate binary convolutional neural network. arXiv 2017, arXiv:1711.11294. [Google Scholar]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A Database and Web-Based Tool for Image Annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Korea Agency for Technology and Standards. KS D 3504: 2021 Steel Bars for Concrete Reinforcement; Korea Standards and Certifications: Seoul, Korea, 2021. [Google Scholar]
- International Organization for Standardization. ISO 3534-1:2006 Statistics–Vocabulary and Symbols—Part 1: General Statistical Terms and Terms Used in Probability; International Organization for Standardization: Geneva, Switzerland, 2016. [Google Scholar]
- ASTM Standards. ASTM A615/A615M-20: Standard Specification for Deformed and Plain Carbon-Steel Bars for Concrete Reinforcement; ASTM Standards: West Conshohocken, PA, USA, 2020. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-Time Instance Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
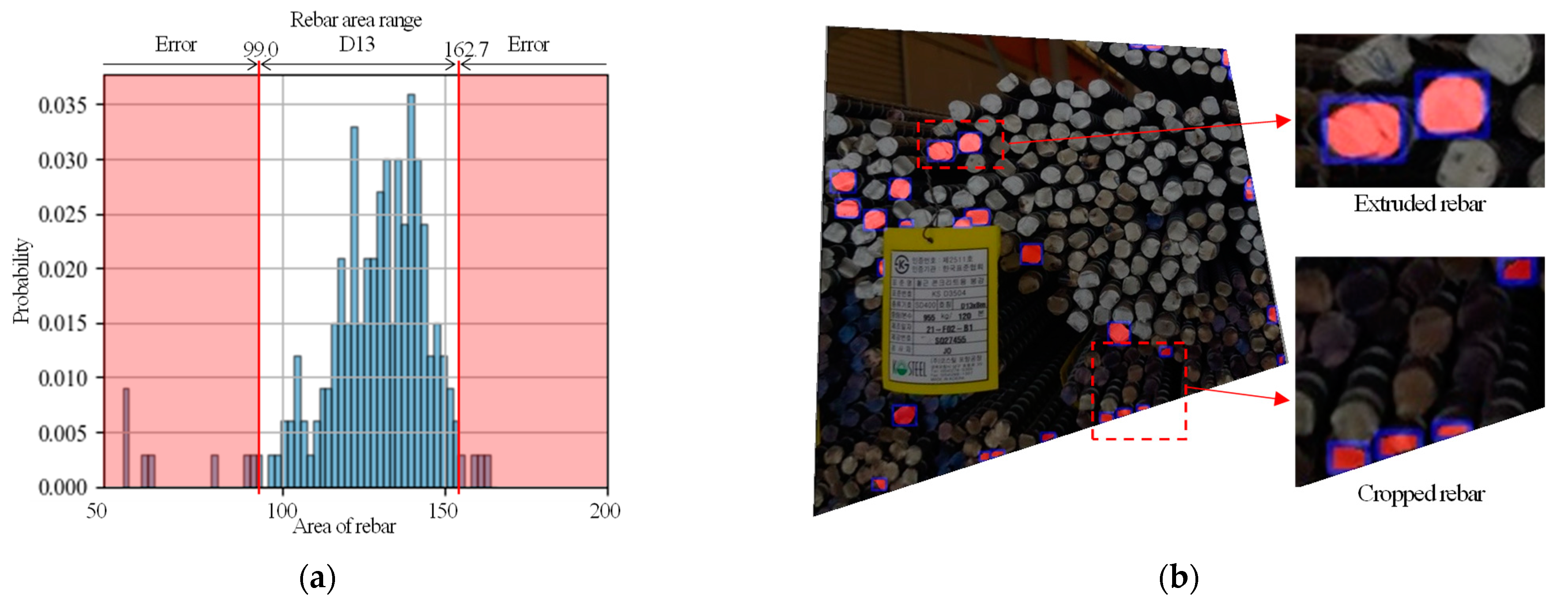{kind=link}
{kind=link}
| Type | Nominal Diameter (mm) | Nominal Cross Section Area (mm2) | Estimated Area (mm2, Proposed) | |
|---|---|---|---|---|
| D10 | 9.53 | 71.33 | Min | 60.4 |
| Max | 99.0 | |||
| D13 | 12.7 | 126.7 | Min | 99.0 |
| Max | 162.6 | |||
| D16 | 15.9 | 198.6 | Min | 162.6 |
| Max | 242.5 | |||
| D19 | 19.1 | 286.5 | Min | 242.5 |
| Max | 336.8 | |||
| D22 | 22.2 | 387.1 | Min | 336.8 |
| Max | 446.9 | |||
| D25 | 25.4 | 506.7 | Min | 449.9 |
| Max | 576.2 | |||
| Iteration | All | 0.50 | 0.55 | 0.60 | 0.65 | 0.70 | 0.75 | 0.80 | 0.85 | 0.90 | 0.95 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 500 | Box | 19.86 | 38.10 | 60.51 | 26.30 | 23.30 | 18.95 | 15.67 | 11.60 | 11.42 | 6.24 | 2.48 |
| Mask | 20.36 | 40.59 | 25.77 | 22.20 | 18.13 | 15.57 | 13.40 | 8.62 | 8.32 | 1.79 | 0.61 | |
| 1000 | Box | 32.53 | 53.61 | 46.80 | 40.17 | 32.86 | 26.69 | 20.35 | 16.57 | 16.09 | 8.10 | 5.29 |
| Mask | 31.98 | 58.38 | 42.17 | 35.12 | 27.25 | 21.63 | 18.87 | 12.86 | 11.56 | 2.33 | 0.83 | |
| 5000 | Box | 33.24 | 55.74 | 48.06 | 40.40 | 33.88 | 28.10 | 20.98 | 17.26 | 16.58 | 8.53 | 5.56 |
| Mask | 32.73 | 59.30 | 42.47 | 35.63 | 28.38 | 22.53 | 19.45 | 13.40 | 12.17 | 2.43 | 0.87 | |
| 10,000 | Box | 33.21 | 56.32 | 48.53 | 41.05 | 34.22 | 28.67 | 21.19 | 17.61 | 16.75 | 8.70 | 5.62 |
| Mask | 32.83 | 59.21 | 42.37 | 35.31 | 28.96 | 22.76 | 19.65 | 13.67 | 12.29 | 2.45 | 0.88 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, Y.; Heo, S.; Han, S.; Kim, J.; Na, S. An Image-Based Steel Rebar Size Estimation and Counting Method Using a Convolutional Neural Network Combined with Homography. Buildings 2021, 11, 463. https://doi.org/10.3390/buildings11100463
Shin Y, Heo S, Han S, Kim J, Na S. An Image-Based Steel Rebar Size Estimation and Counting Method Using a Convolutional Neural Network Combined with Homography. Buildings. 2021; 11(10):463. https://doi.org/10.3390/buildings11100463
Chicago/Turabian StyleShin, Yoonsoo, Sekojae Heo, Sehee Han, Junhee Kim, and Seunguk Na. 2021. "An Image-Based Steel Rebar Size Estimation and Counting Method Using a Convolutional Neural Network Combined with Homography" Buildings 11, no. 10: 463. https://doi.org/10.3390/buildings11100463
APA StyleShin, Y., Heo, S., Han, S., Kim, J., & Na, S. (2021). An Image-Based Steel Rebar Size Estimation and Counting Method Using a Convolutional Neural Network Combined with Homography. Buildings, 11(10), 463. https://doi.org/10.3390/buildings11100463