4.2. Performance Evaluation of HoVerNet Optimization Results
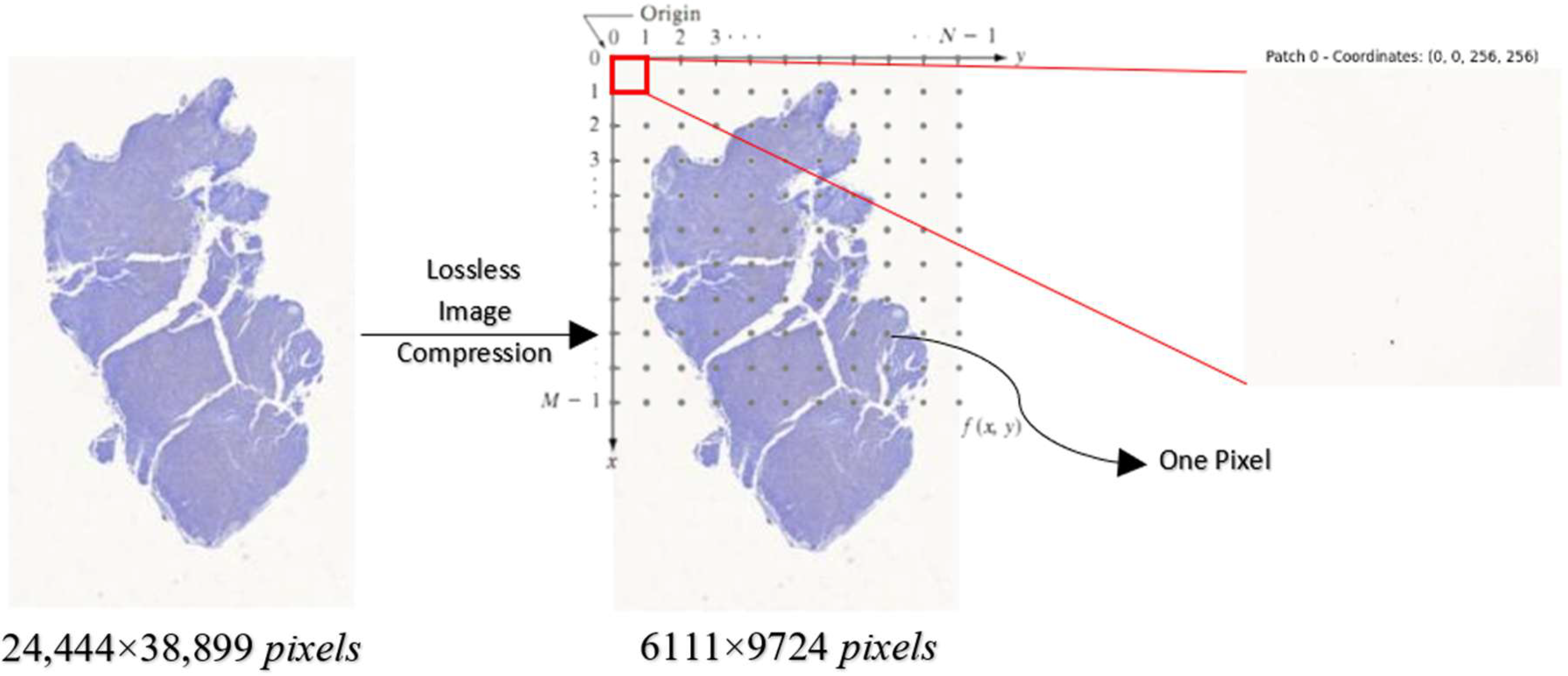
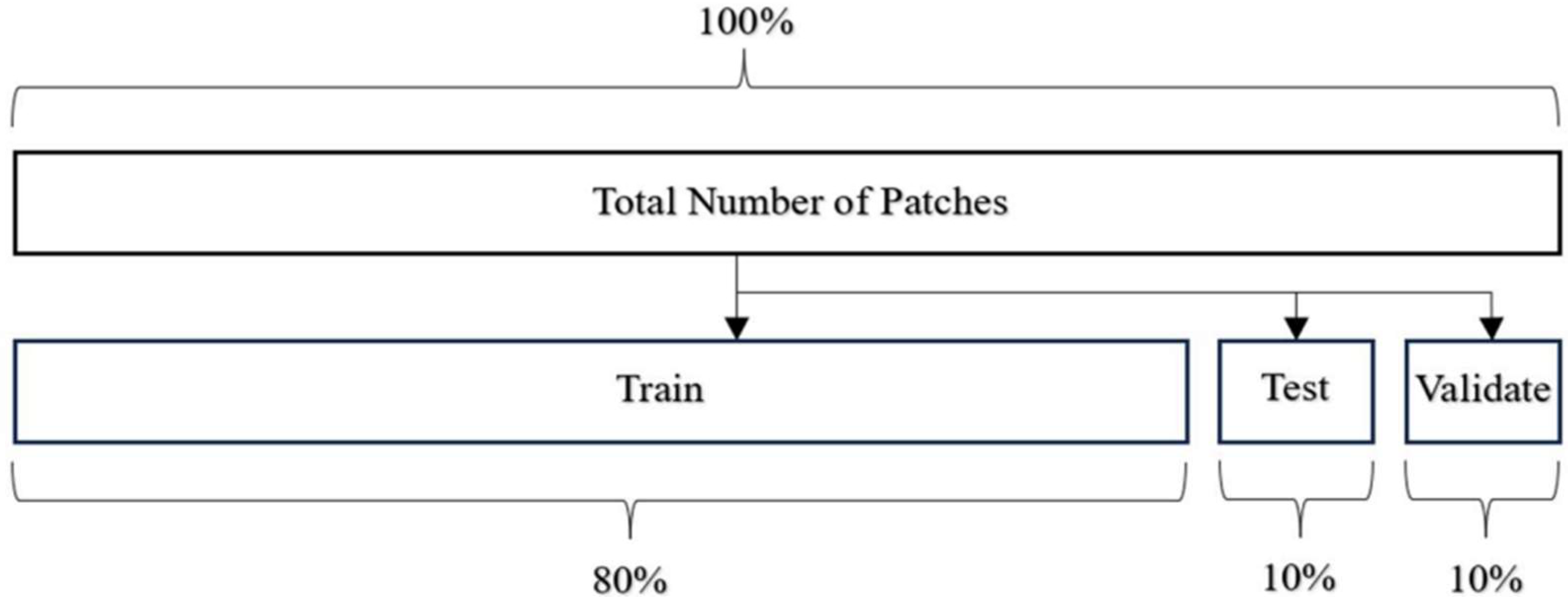
Before feeding the images into HoVerNet and VGG16, the dataset is divided into training, testing, and validation sets (
Table 1).
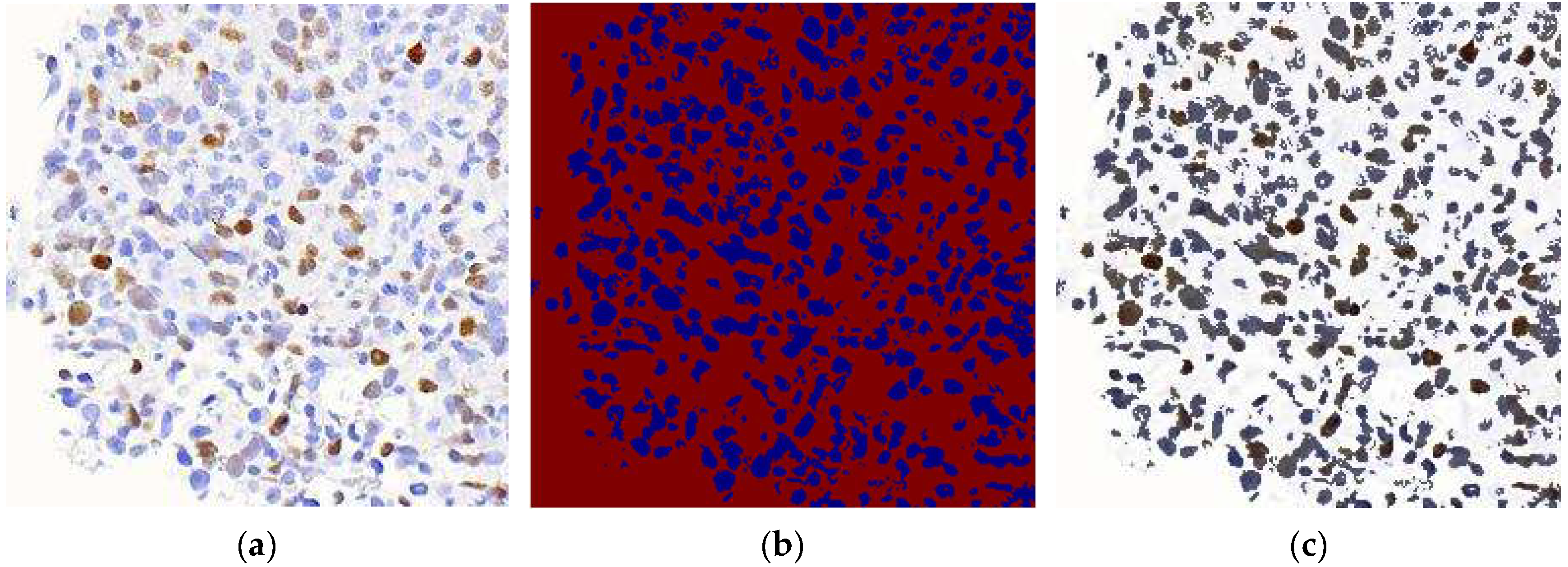
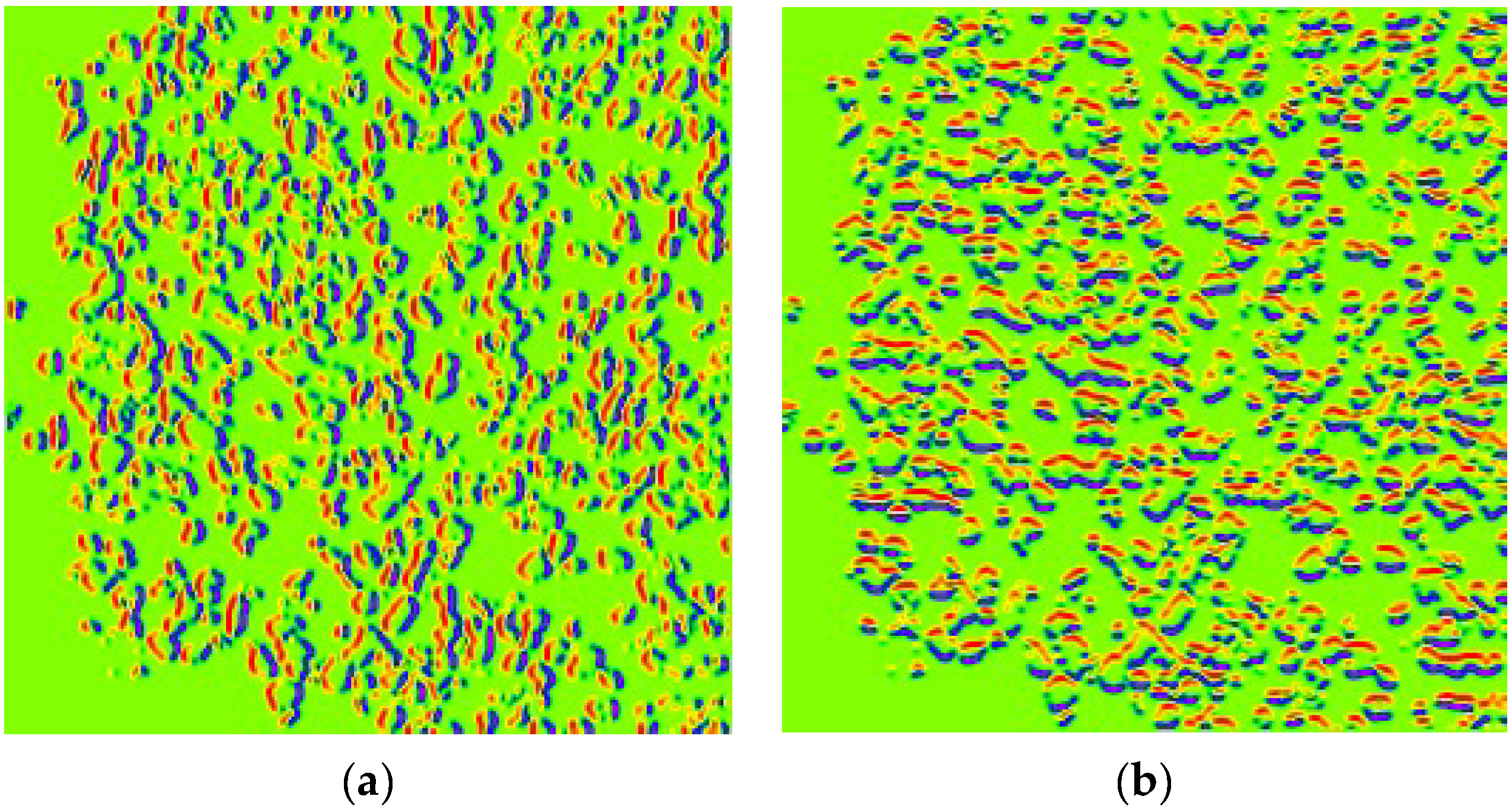
HoVerNet consists of three branches: the ‘Nuclei Pixel Branch,’ the ‘HoVer Branch,’ and the ‘Nuclei Classification Branch.’ The process starts with normalized patched images as input. These images are processed to detect nuclei, producing a binary image where nuclei pixels are set to one value (blue), and non-nuclei pixels are set to another value (red), as shown in
Figure 5b. The output from the ‘Nuclei Pixel Branch’ is then overlaid on the normalized patched image, creating a composite image. In this overlay, the nuclei are distinctly highlighted against the background, making them easier to visually identify and analyze.
The overlay image is then projected onto the horizontal and vertical axes to create horizontal and vertical images, respectively. This process introduces an additional branch called the ‘HoVer Branch’ (
Figure 6). These projections provide useful summaries of the spatial distribution of the nuclei in the image. For example, a horizontal projection provides information on how the nuclei are distributed from top to bottom, while a vertical projection provides information on how they are distributed from left to right.
After defining the architecture, an instance of the HoVerNet model was created and compiled using the Adam optimizer and binary cross-entropy loss function, suitable for binary classification tasks. The model was initially trained for 800 epochs with batch sizes of 32 and 64, following the approach of Wójcik et al. [
4], who reported achieving the highest F1 score of 0.939 for similar tasks.
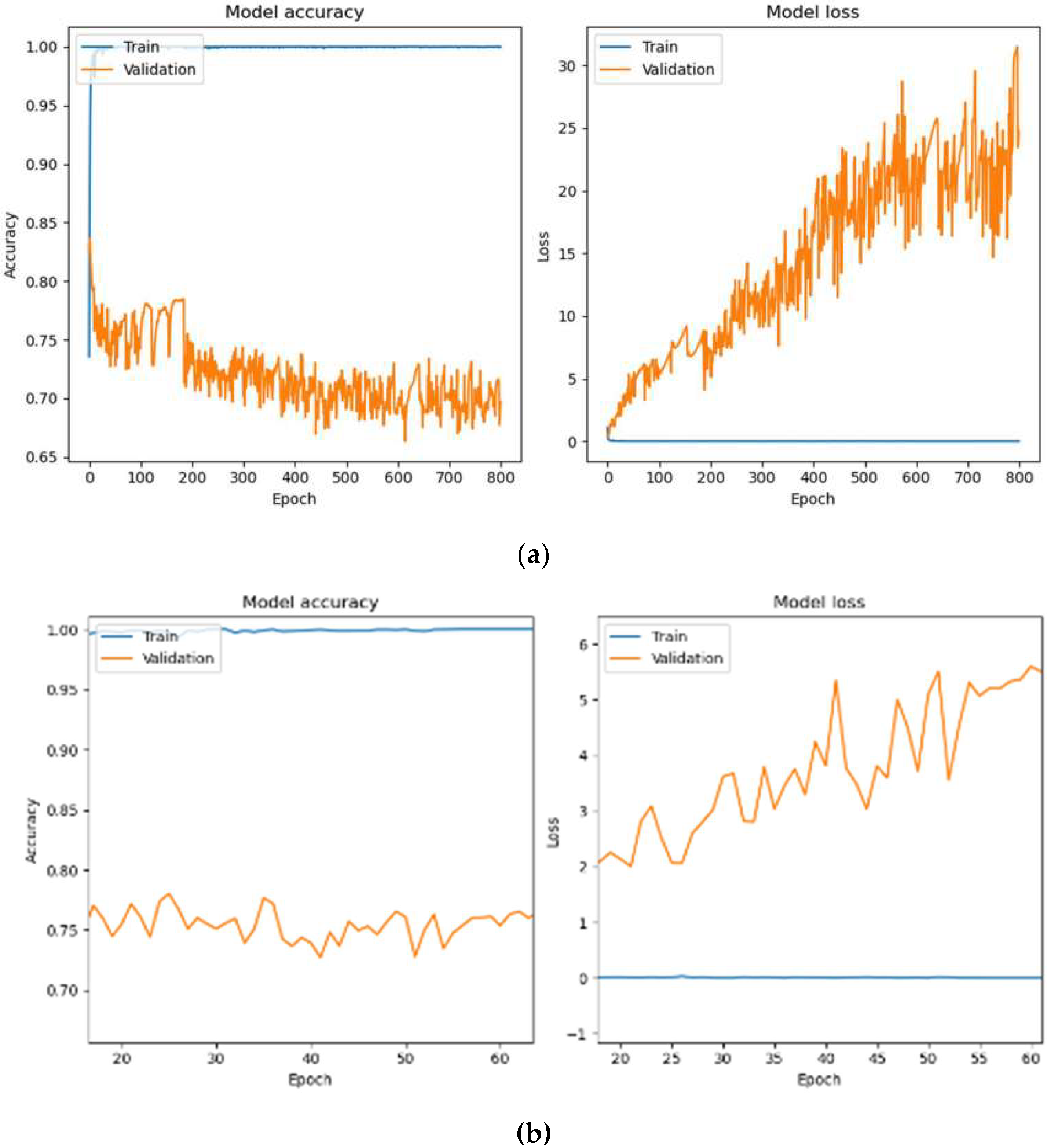
Figure 7a depicts the training process of the HoVerNet model over 800 epochs with a batch size of 32. The model achieved perfect training accuracy of 100% and an exceptionally low training loss of 2.21 × 10
−4. However, validation and testing accuracy were notably lower, at 69.63% and 71.26%, with higher validation and testing losses at 24.7998 and 23.0890, respectively. These results indicate overfitting, as the model performed well on training data but failed to generalize effectively to unseen data.
Figure 7b focuses on the training dynamics for a batch size of 32 over a zoomed-in epoch range of 20–60. While the training accuracy was consistently 100%, validation performance remained unstable, showing fluctuations in accuracy and higher validation losses. This pattern indicates overfitting, as the model was overly tuned to the training data and struggled to generalize to unseen data.
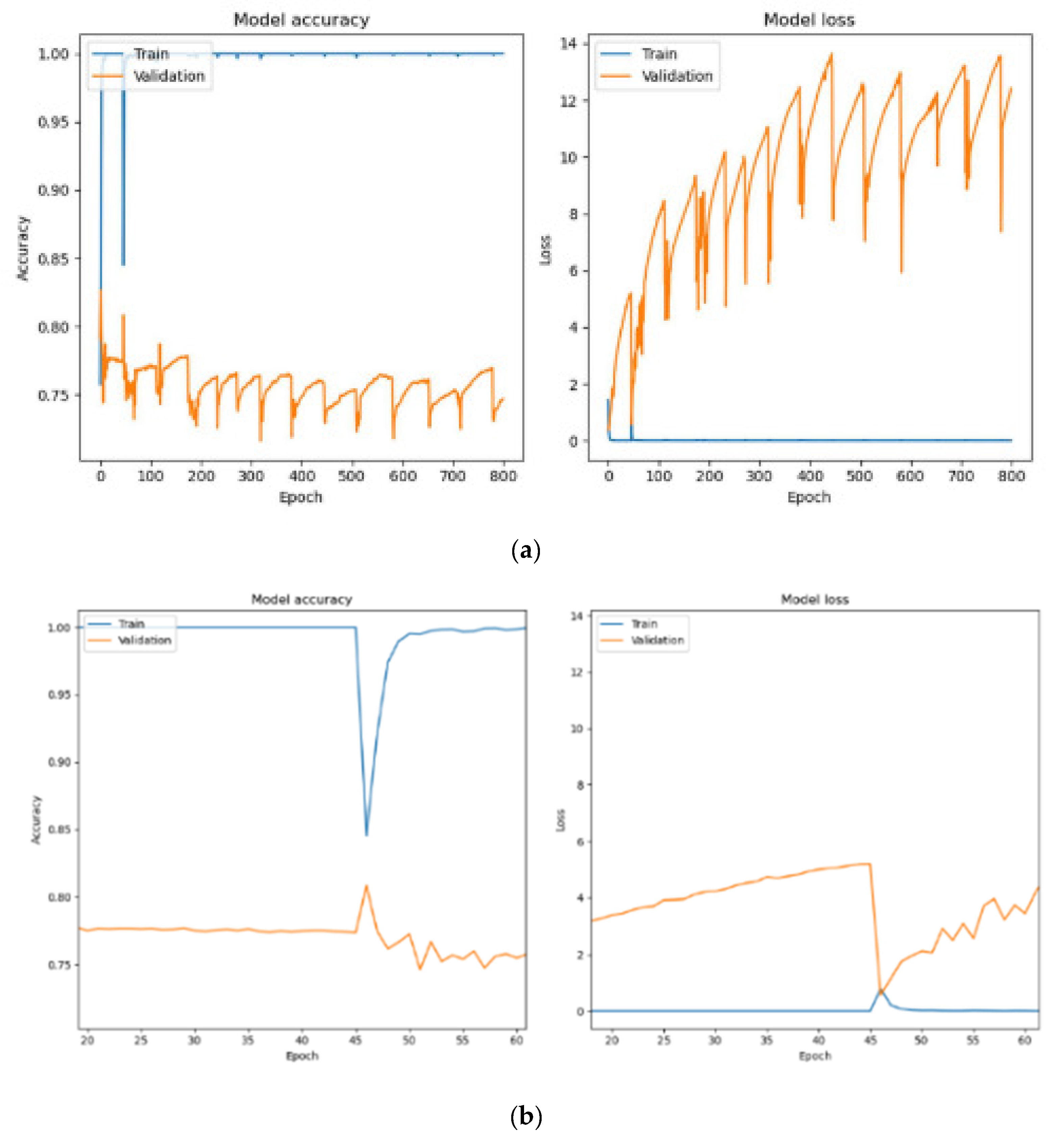
Figure 8a shows the training and validation performance when using a batch size of 64. The model achieved 100% training accuracy, with an even lower training loss of 1.07 × 10
−7. Validation and testing accuracies improved to 74.68% and 75.75%, respectively, with reduced validation losses of 12.4109 and testing loss of 11.9979. The larger batch size resulted in more stable training, with fewer parameter updates per epoch, enabling better generalization to unseen data.
Figure 8b provides a closer analysis of training with a batch size of 64 between epochs 20 and 60. A sharp decline in training accuracy occurred at epoch 45 due to adjustments in model parameters to balance training and validation losses. After this drop, the training accuracy quickly recovered and stabilized at 100%. Validation accuracy showed steady improvement, and validation losses decreased over time, demonstrating the model’s ability to generalize effectively. However, after epoch 45, the accuracy of validation gradually decreases as the epoch increases. This indicates that HoVerNet achieves better performance and generalization when trained for fewer epochs (less than 45).
Further investigation into the optimal number of epochs (15, 20, 25, 30, 35, 45, and 50) aimed to maximize validation and testing accuracies while minimizing losses (
Table 2). For batch size 32, the model reached 100% training accuracy by epoch 35, with validation and testing accuracy peaking at 82.78% and 83.67%, respectively. Beyond this, accuracy declined, indicating overfitting. At epoch 100, training accuracy decreased to 98.72%, with further drops in validation and testing accuracies, suggesting underfitting and potential learning rate issues.
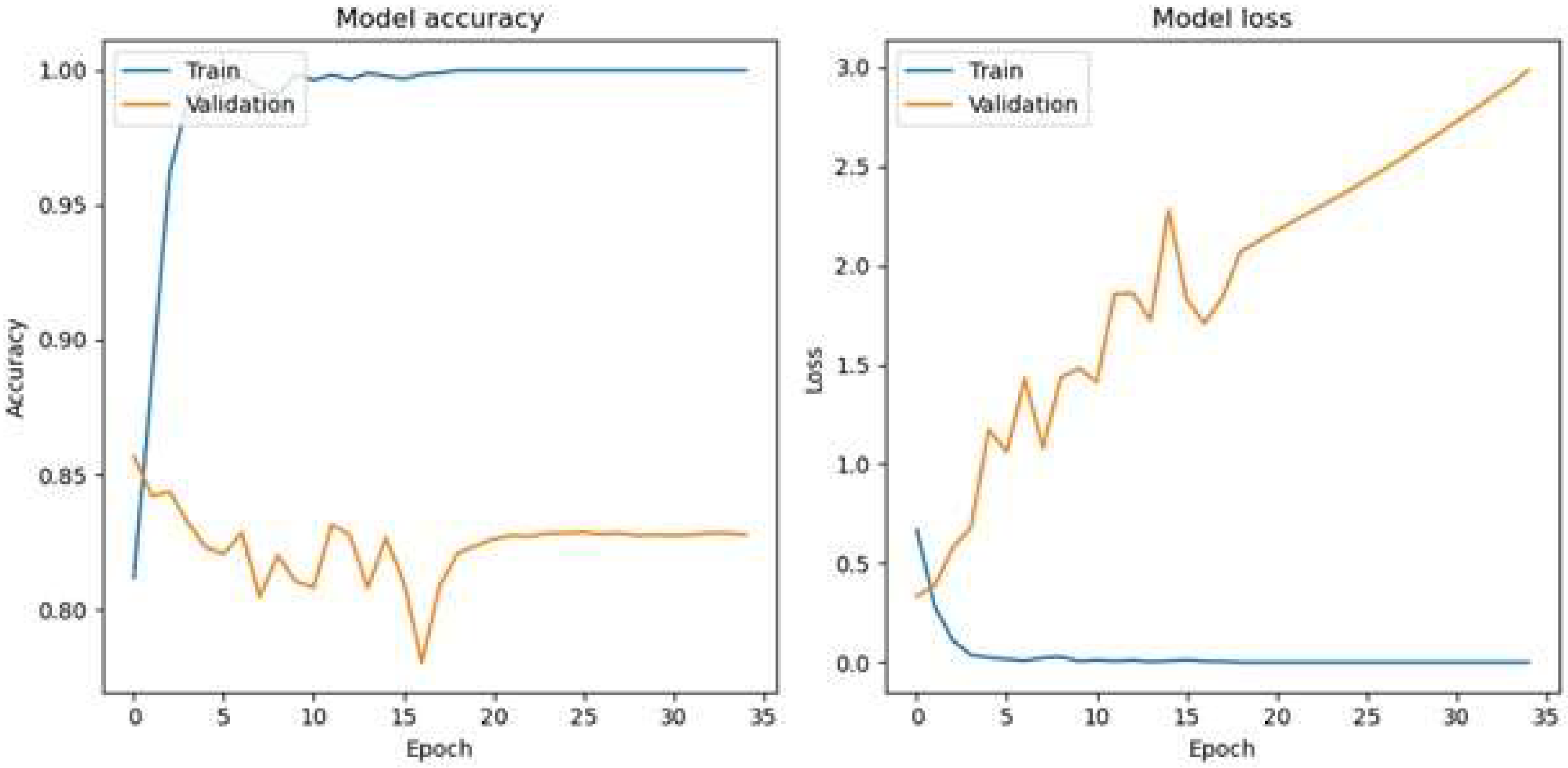
The optimal epoch for a batch size of 32 for the HoVerNet and VGG16 models is 35 (
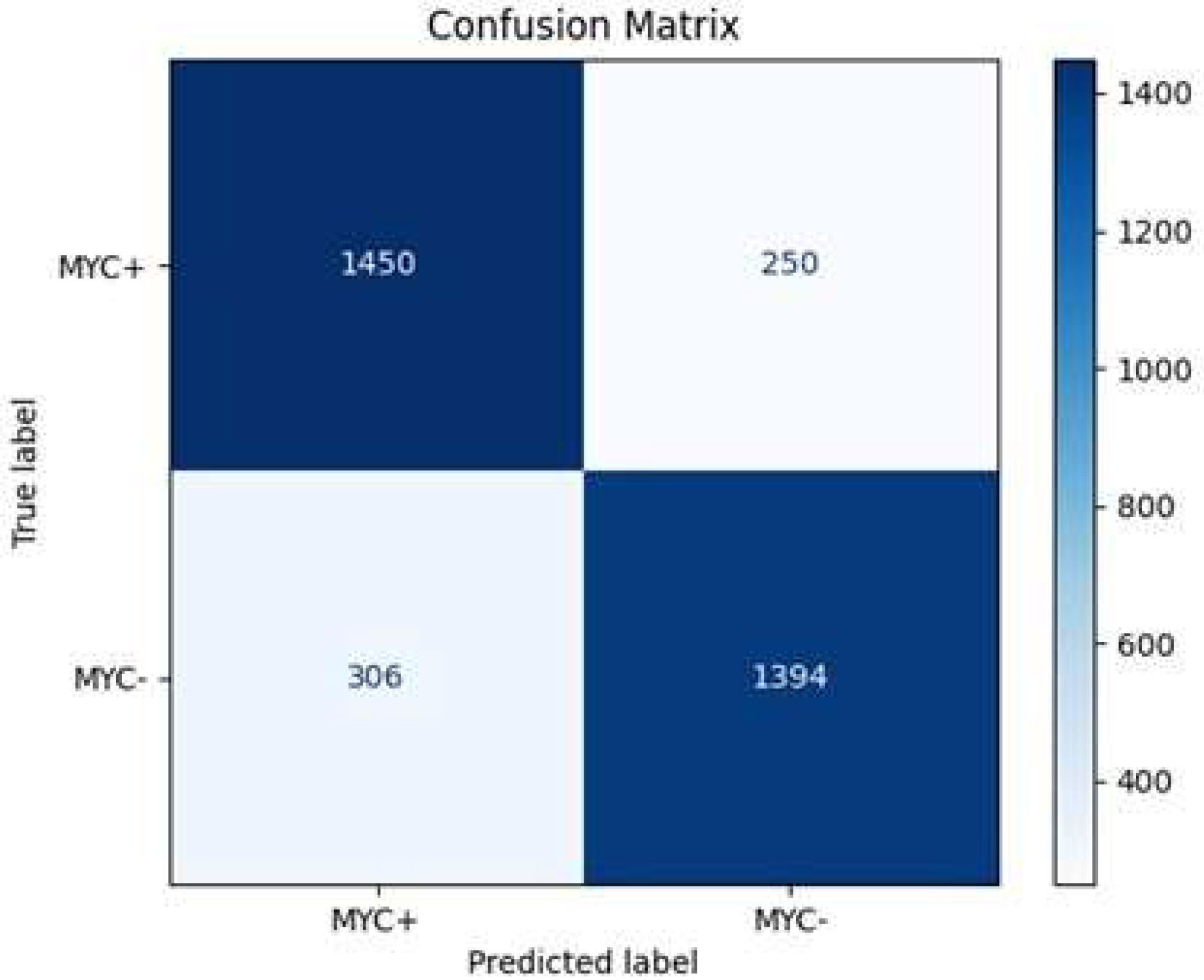
Figure 9), where validation and testing accuracies were highest, balancing effective generalization and minimizing overfitting. This iterative approach allowed for fine-tuning the model’s training dynamics and enhancing its ability to generalize effectively. Based on the confusion matrix in
Figure 10, the HoVerNet model correctly identified 1450 MYC+ instances and 1394 MYC- instances, resulting in a high true positive (TP) and true negative (TN) count. However, it misclassified 250 MYC- instances as MYC+ (FP) and 306 MYC+ instances as MYC- (FN).
Based on
Table 2 and Table 4, VGG16 achieved higher classification accuracy compared to HoVerNet. However, VGG16 is a standard CNN not inherently designed for nuclei segmentation tasks. It performs well in distinguishing image-level classes but lacks the ability to accurately delineate individual nuclei, especially in cases of overlapping structures. In contrast, HoVerNet is specifically optimized for nuclear instance segmentation and classification, making it more adept at handling the complex morphological variations and overlapping nuclei commonly seen in histopathological images of DLBCL. Although its overall accuracy is lower than VGG16, HoVerNet offers superior segmentation granularity and biological interpretability, which are essential for meaningful diagnostic assessment in clinical practice.
These results are tabulated in
Table 3, with an overall accuracy of approximately 85.2%, indicating that the model is effective in its predictions. The precision, which measures the accuracy of positive predictions, is about 85.3%, while the recall, reflecting the model’s ability to identify true positive cases, stands at 82.6%. The specificity, or true negative rate, is 84.8%, highlighting the model’s proficiency in correctly identifying negative instances. Additionally, the F1 score, a balance between precision and recall, is around 83.9%, underscoring the model’s robustness in handling both MYC+ and MYC- classification.
Apart from that, when the Adam optimizer with a batch size of 64 is used, the HoVerNet model achieves a training accuracy of 100% across all epochs (
Table 4), indicating that it has perfectly learned the training dataset. However, this does not translate to the validation and testing sets, where the accuracy is significantly lower, suggesting that the model is overfitting to the training data. In the early epochs, there is a gradual increase in both validation and testing accuracies, peaking at 83.25% and 84.46%, respectively, at epoch 25 (
Figure 11). This could be the model’s sweet spot, where it has learned enough patterns to generalize well to unseen data. Beyond this point, there is a noticeable decline in performance on the validation and testing sets, with the lowest accuracy observed at epoch 100, dropping to 74.79% and 74.53%, respectively. This decline could be due to the model becoming too specialized in the training data features, which do not represent the broader patterns needed for new data.
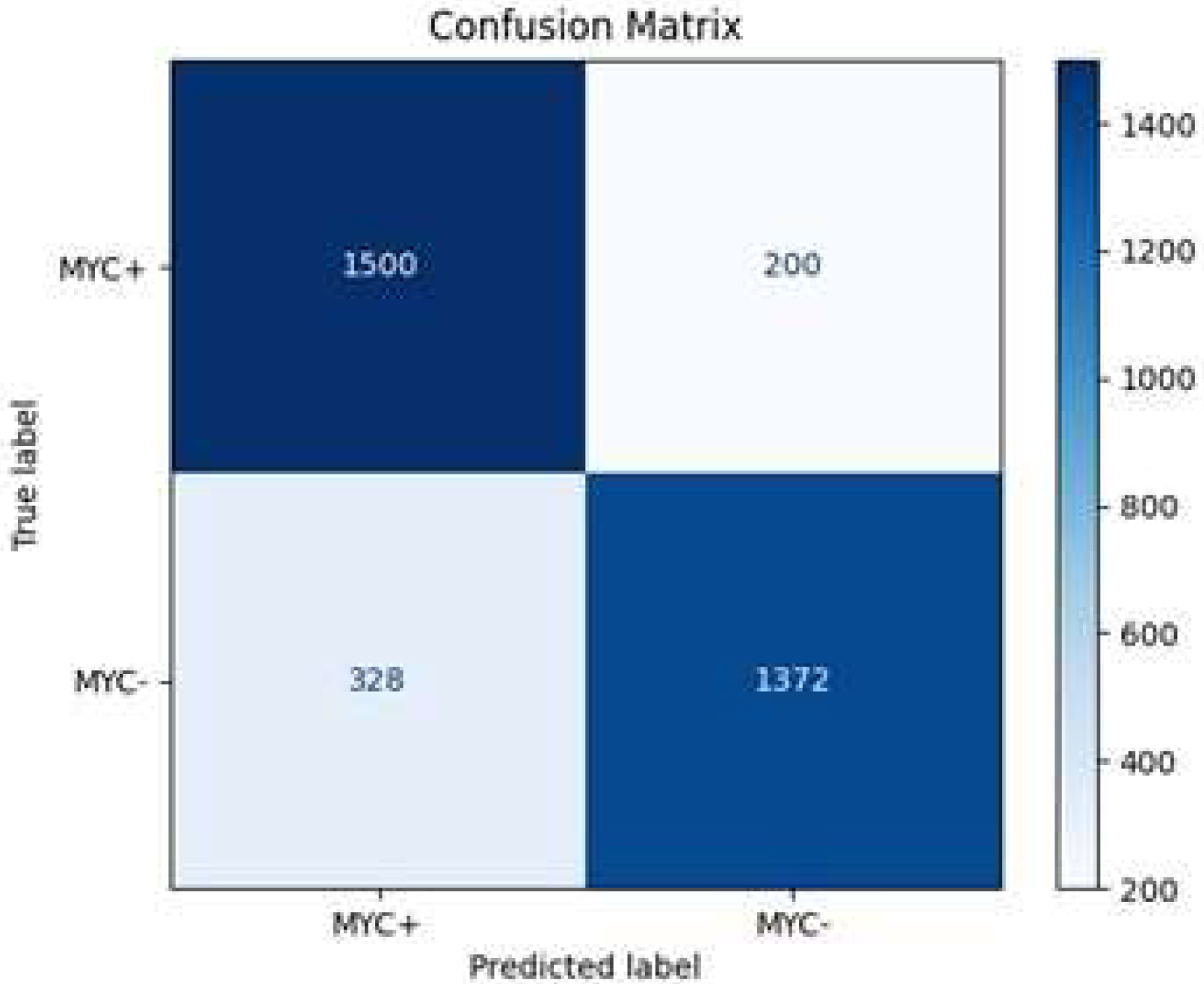
The model correctly identified 1500 MYC+ instances and 1372 MYC- instances, resulting in a high true positive (TP) and true negative (TN) count. However, it misclassified 200 MYC- instances as MYC+ (FP) and 328 MYC+ instances as MYC- (FN) (
Figure 12). These metrics indicate that the model achieves an overall accuracy of approximately 85.5% (
Table 5), demonstrating its reliability in predicting MYC+ and MYC- cases. The precision of 82.1% reflects the model’s accuracy in predicting positive cases, while the recall of 88.2% indicates a high true positive rate. The specificity, at 80.7%, shows the model’s effectiveness in correctly identifying negative cases. The F1 score of 85.1% balances both precision and recall, emphasizing the model’s robustness in classification tasks.
Comparing batch sizes of 32 and 64 shows significant differences in performance metrics and execution times. Although both batch sizes achieve perfect training accuracy, a batch size of 64 yields higher validation and testing accuracy with lower losses, and it reaches these results in fewer epochs (25 vs. 35). Additionally, training time per epoch is slightly shorter for a batch size of 64 (62 s vs. 63 s), and validation and testing times are also faster, taking 7 s compared to 8 s for batch size 32. These findings suggest that a batch size of 64 provides better efficiency and faster convergence.
After model training, the simultaneous nuclei segmentation and classification process is taken. This process is defined as the last branch in HoVerNet, known as the ‘Nuclei Classification Branch.’ HoVerNet contains an encoder-decoder structure that can capture both high-level and low-level features in the images, which helps in accurately segmenting an image. Abnormal cells (positive cells and negative cells) are classified in red while normal cells are classified in green (
Figure 13).
4.4. Graphic User Interface (GUI)
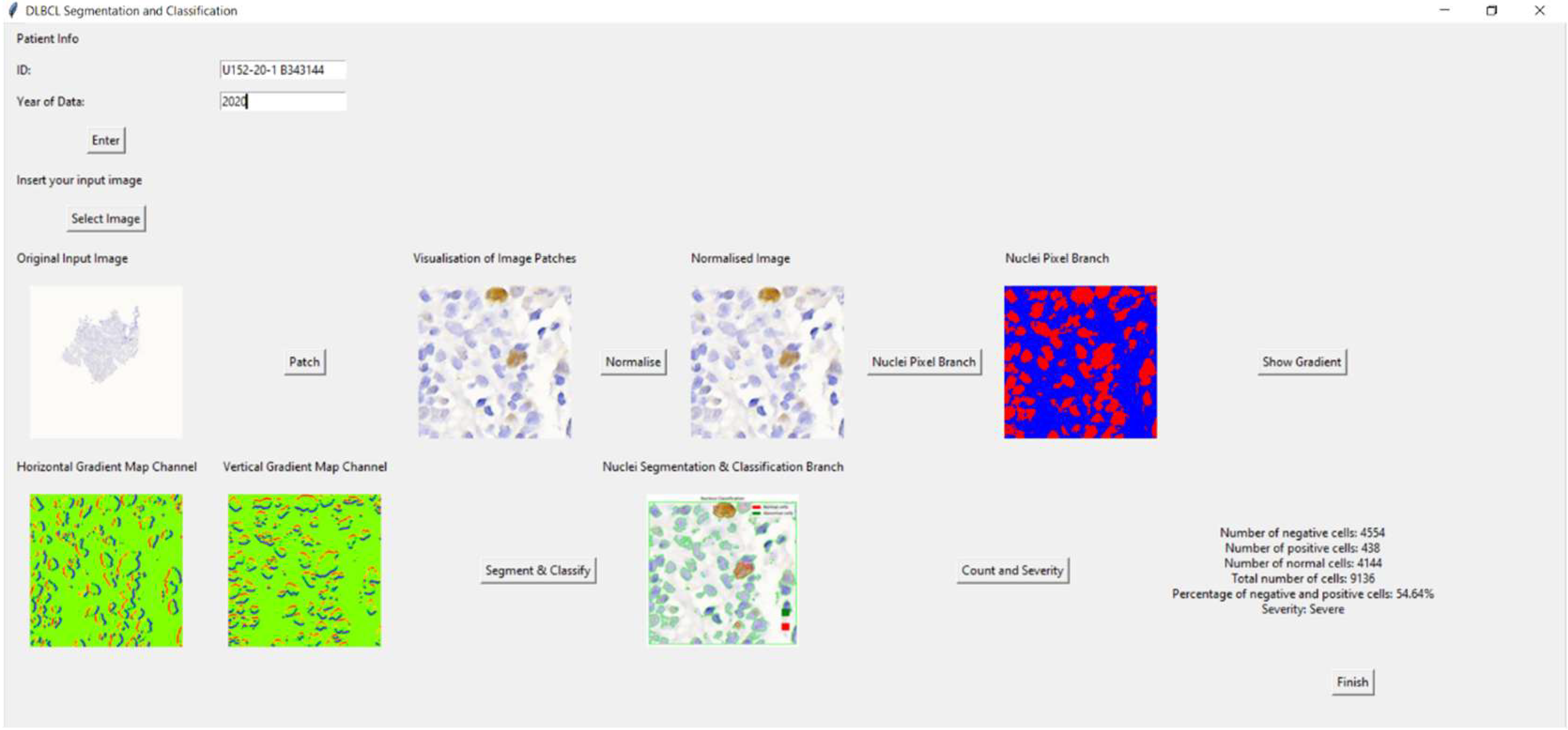
The Tkinter-based application for DLBCL nuclei segmentation and classification allows users to input patient information, upload an image, visualize image patches, and analyze cells. Initially, a main window was created for inputting patient data. If the patient’s ID and year are not filled in, an error message appears. Once an image is selected, it is displayed in the window with an option to view patch images. Users can normalize the image, convert it to grayscale, and create a binary image highlighting the nuclei. Gradient images, showing horizontal and vertical gradients, can also be displayed.
The application further segments and classifies nuclei, enabling cell counting. It calculates the number of negative, positive, and normal cells, their percentages, and the severity based on these percentages. Results are displayed, and a ‘Finish’ button concludes the process, providing a diagnostic tool for medical professionals. This application streamlines the process of analyzing DLBCL nuclei, making it efficient and user-friendly for medical use.
Figure 14 shows the overview of the GUI for DLBCL diagnosis. As an example of the GUI in action, one clinical slide was analyzed through the full pipeline. The system detected 4554 negative cells, 438 positive cells, 4114 normal cells, and a total of 9136 cells. It identified 54.64% as abnormal and classified the case as ‘Severe,’ demonstrating the practical functionality and diagnostic potential of the application.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}