Physicochemical Foundations of Life that Direct Evolution: Chance and Natural Selection are not Evolutionary Driving Forces


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
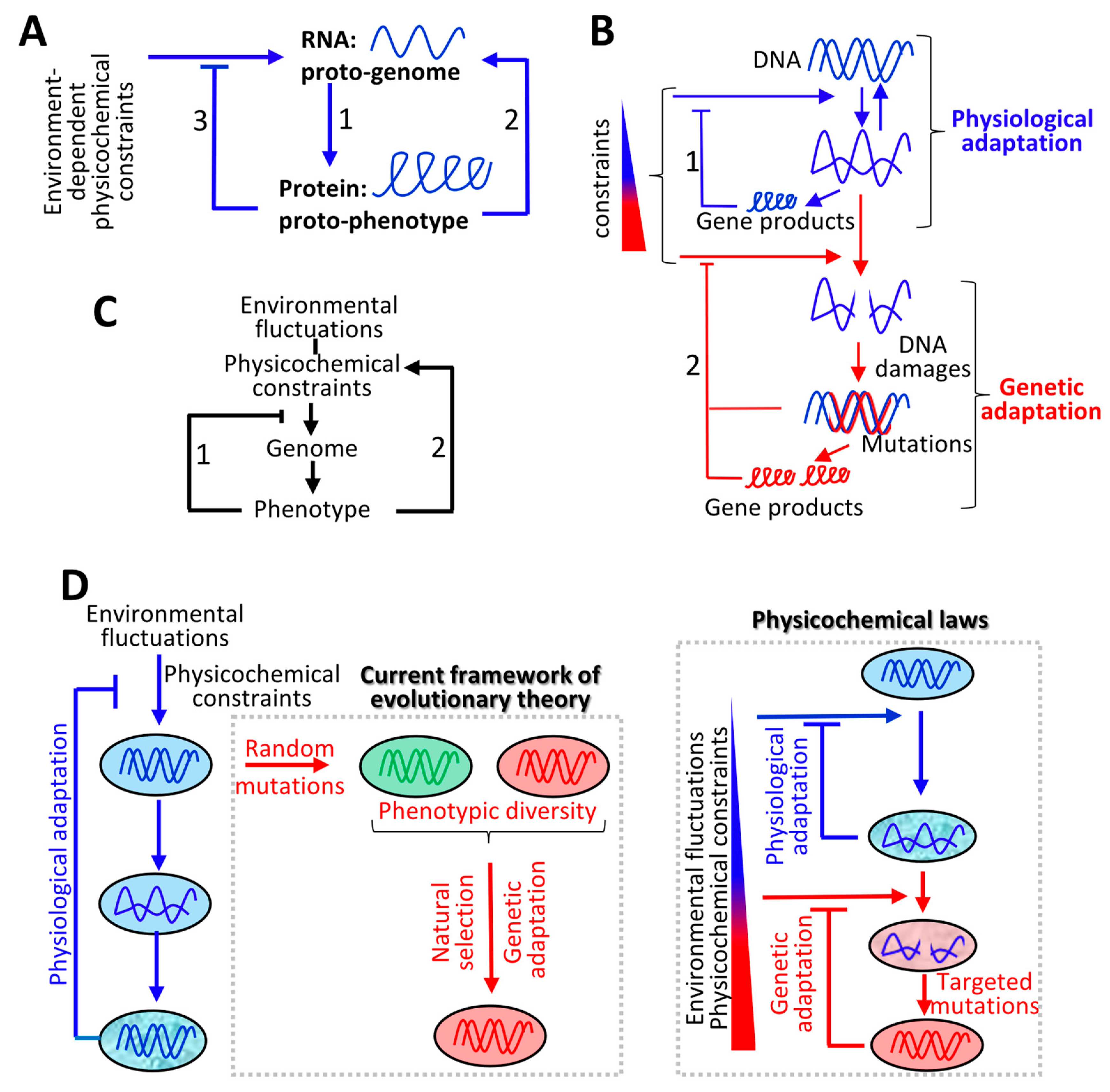
2. Overview
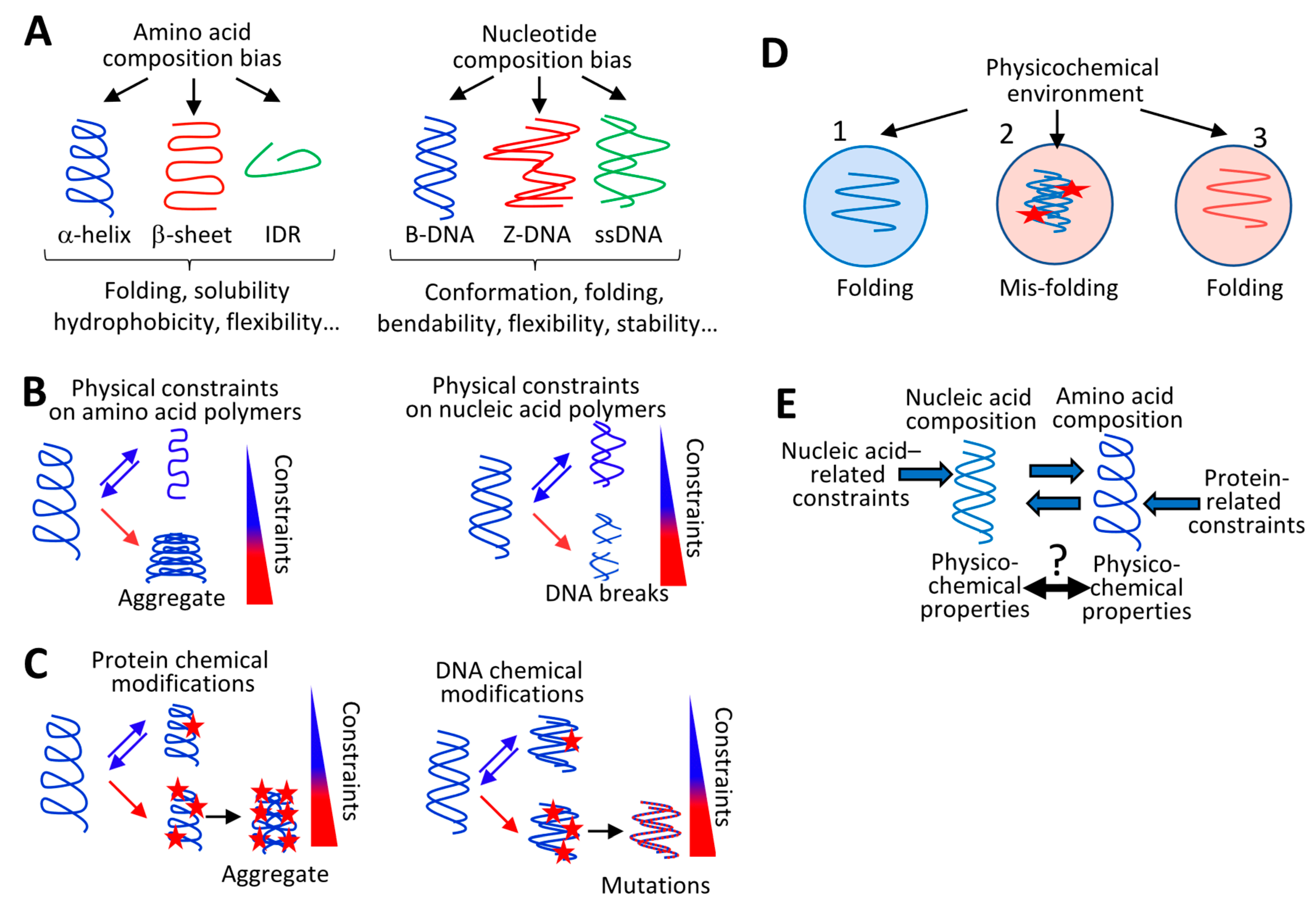
3. Environment-Dependent Physicochemical Constraints on Nucleic and Amino Acid Polymer Composition
3.1. Physicochemical Constraints on Protein Composition
3.2. Physicochemical Constraints on Nucleic Acid Polymer Composition
3.3. Interdependency between the Physicochemical Properties of Nucleic Acid Polymers and their Cognate Amino Acid Polymers
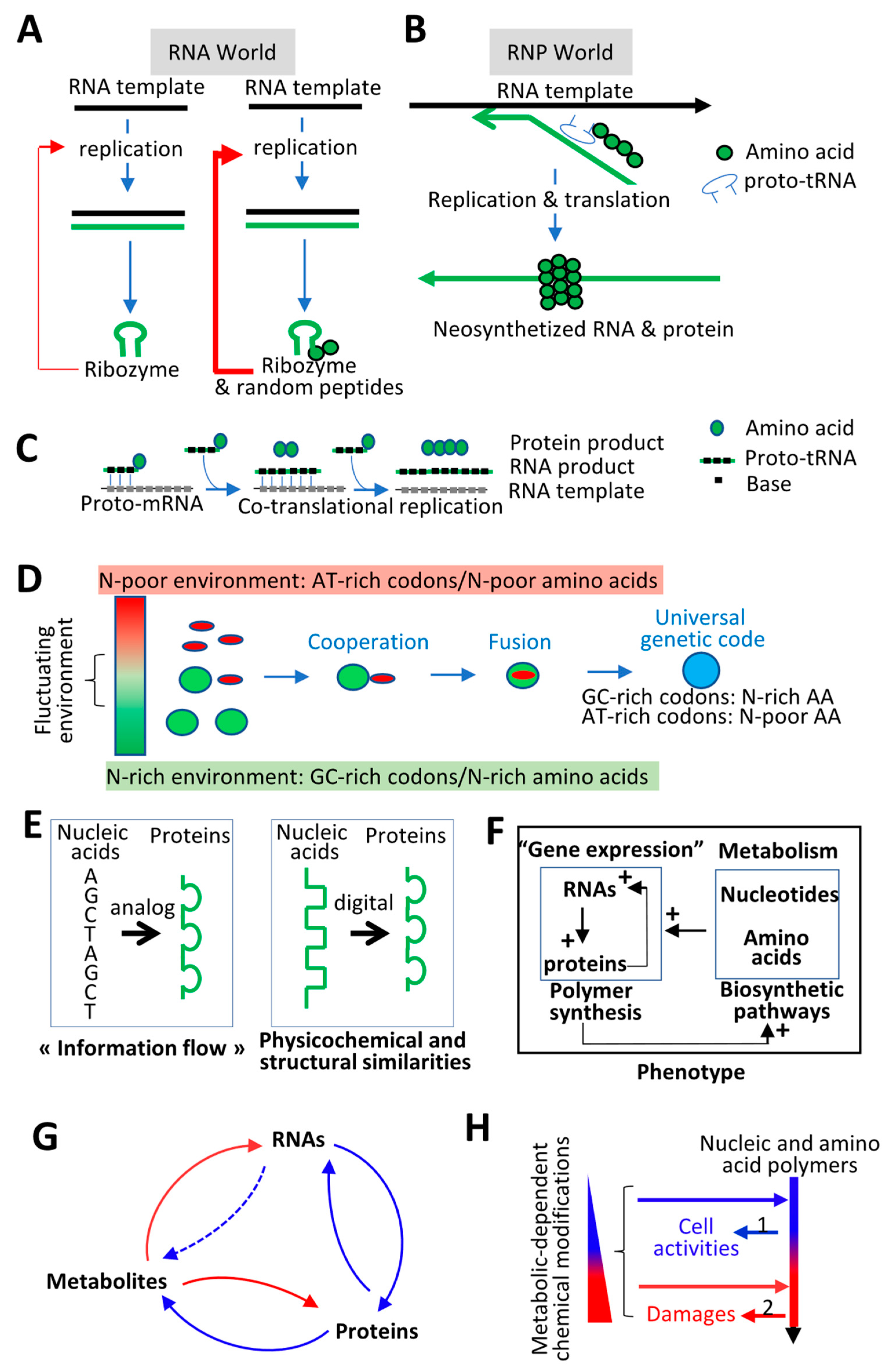
4. Molecular Origin of Life and Evolution of the Genetic Code: Defining Evolutionary Driving Forces
4.1. Molecular Origin of Life: Interdependency between RNAs and Proteins
4.2. Evolution of the Genetic Code: Co-Adaptation of Nucleic Acid Polymers and their Encoded Proteins to the Same Fundamental Physicochemical Parameters
4.3. Feedforward and Feedback Loops between Gene Products and their Products (i.e., Metabolites)
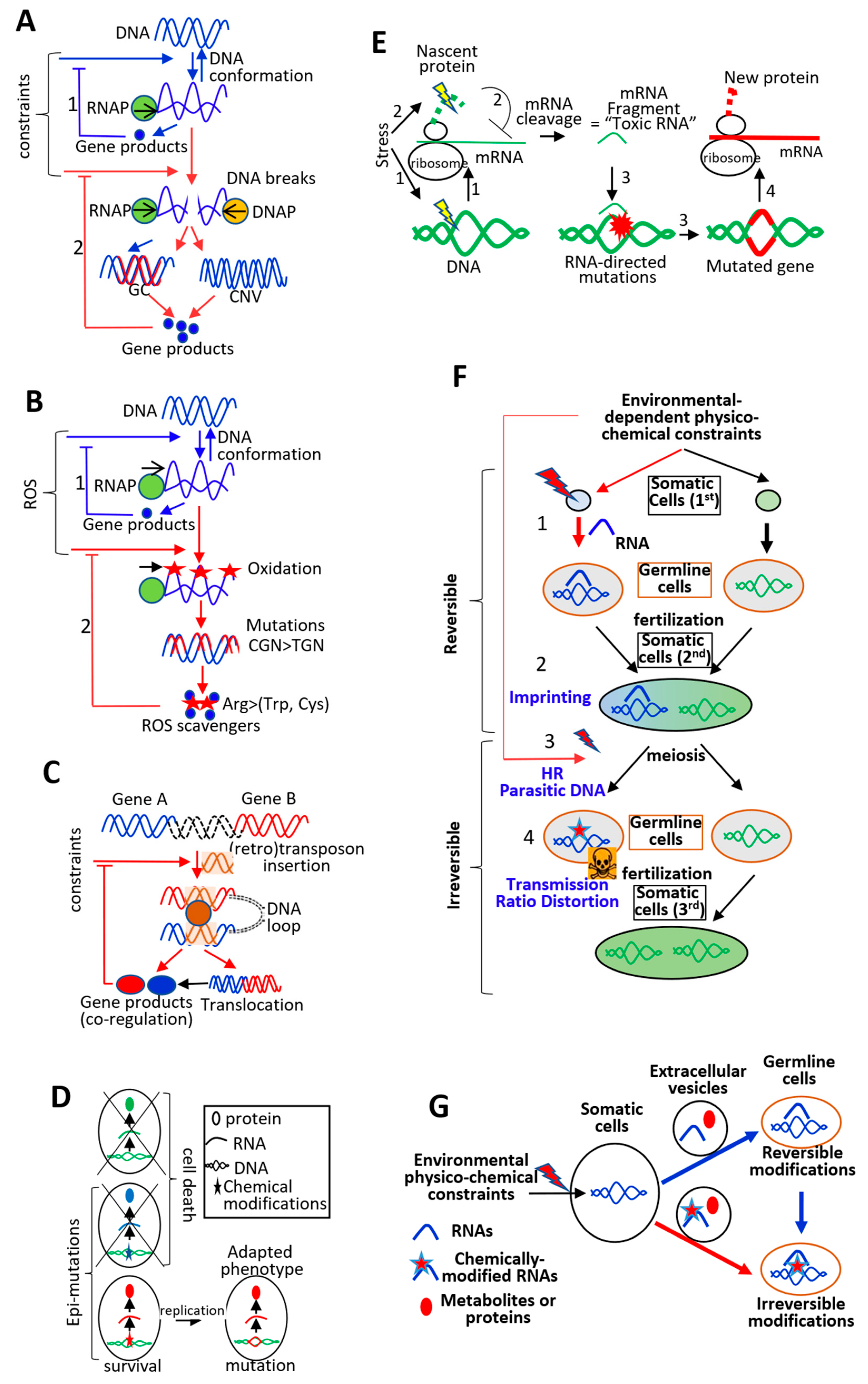
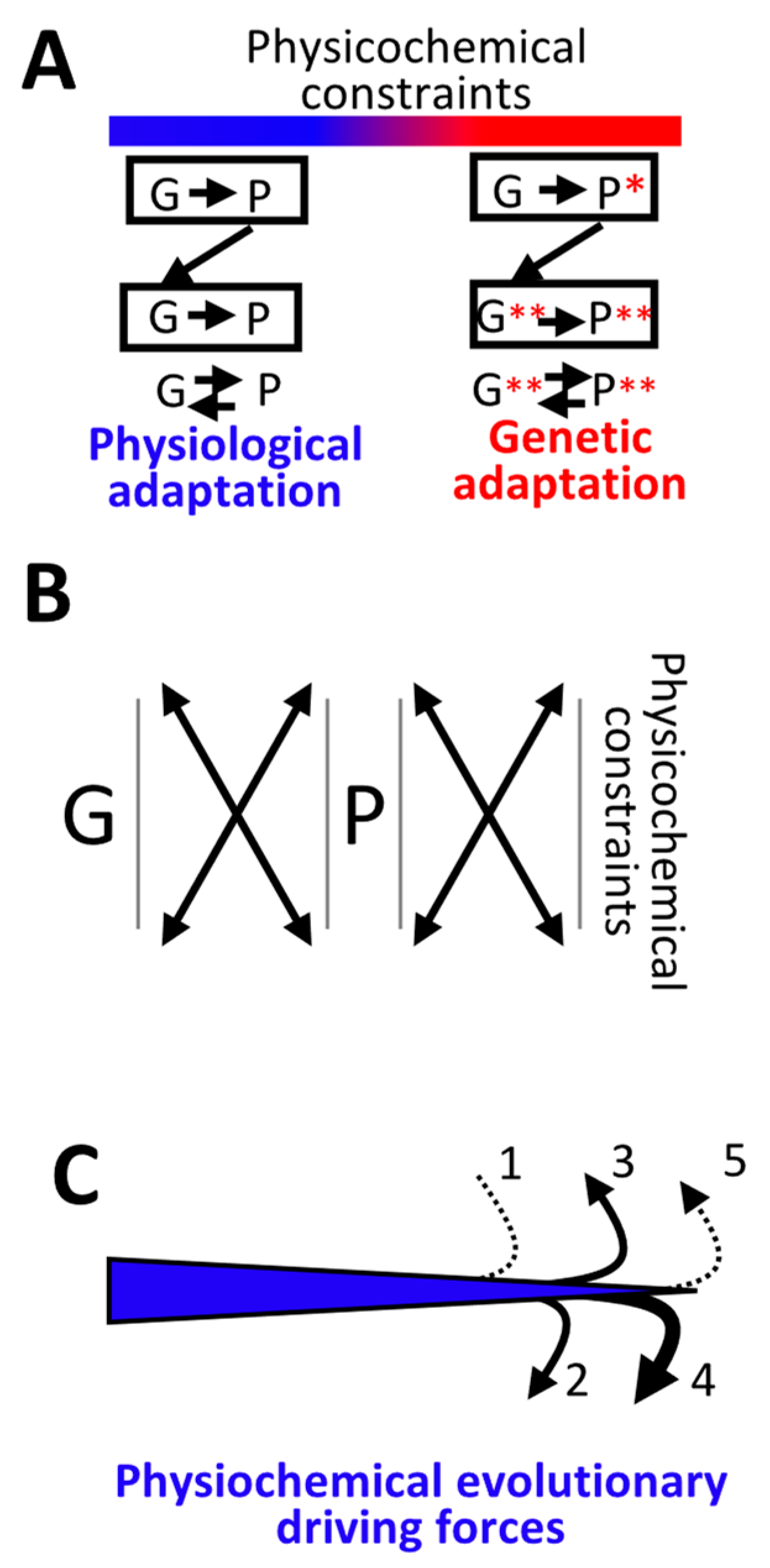
5. Continuum between Physiological and Genetic Adaptation
5.1. Genetic Adaptation Directed by Transcription: Transcription-Replication Conflicts
5.2. Genetic Adaptation Directed by Transcription: Role of ssDNA Formation and DNA Folding
5.3. Physiological Adaptation Facilitates Genetic Adaptation: Role of RNAs
5.4. Somatic Physiological Adaptation and Germline Genetic Adaptation: Role of RNAs
6. Interplay between Environment-Dependent and Cell-Dependent Physicochemical Constraints and the Emergence of Complex Phenotypes
6.1. From Molecular Innovations to Emergence of New Properties at Multiple Scales of Life Organization: Metabolic Activities and Cell Organization
6.2. From Adaptation to a Diversity of Environment-Dependent Constraints, to Side Effects: Genome Organization, Epigenetics, and Multicellularity
6.3. From Diversity to Complexity: Interplay between Germline Cell DNA and Somatic Cell Phenotype
7. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Genome Physical Organization: From Gene Expression Regulation to Gene Product Functions
Appendix A.2. The Genetic Code is not a Cipher but the Result of an Evolutionary Process Directed by Physicochemical Laws
Appendix A.3. Meiosis
References
- Koonin, E.V. The Origin at 150: Is a new evolutionary synthesis in sight? Trends Genet. 2009, 25, 473–475. [Google Scholar] [CrossRef]
- Noble, D.; Jablonka, E.; Joyner, M.J.; Muller, G.B.; Omholt, S.W. Evolution evolves: Physiology returns to centre stage. J. Physiol. 2014, 592, 2237–2244. [Google Scholar] [CrossRef] [PubMed]
- Laland, K.; Uller, T.; Feldman, M.; Sterelny, K.; Muller, G.B.; Moczek, A.; Jablonka, E.; Odling-Smee, J.; Wray, G.A.; Hoekstra, H.E.; et al. Does evolutionary theory need a rethink? Nature 2014, 514, 161–164. [Google Scholar] [CrossRef] [PubMed]
- Lynch, M.; Ackerman, M.S.; Gout, J.F.; Long, H.; Sung, W.; Thomas, W.K.; Foster, P.L. Genetic drift, selection and the evolution of the mutation rate. Nat. Rev. Genet. 2016, 17, 704–714. [Google Scholar] [CrossRef] [PubMed]
- Tomkova, M.; Schuster-Bockler, B. DNA Modifications: Naturally More Error Prone? Trends Genet. 2018, 34, 627–638. [Google Scholar] [CrossRef] [PubMed]
- Makova, K.D.; Hardison, R.C. The effects of chromatin organization on variation in mutation rates in the genome. Nat. Rev. Genet. 2015, 16, 213–223. [Google Scholar] [CrossRef] [PubMed]
- Tomkova, M.; Tomek, J.; Kriaucionis, S.; Schuster-Bockler, B. Mutational signature distribution varies with DNA replication timing and strand asymmetry. Genome Biol. 2018, 19, 129. [Google Scholar] [CrossRef]
- Boulikas, T. Evolutionary consequences of nonrandom damage and repair of chromatin domains. J. Mol. Evol. 1992, 35, 156–180. [Google Scholar] [CrossRef]
- Stamatoyannopoulos, J.A.; Adzhubei, I.; Thurman, R.E.; Kryukov, G.V.; Mirkin, S.M.; Sunyaev, S.R. Human mutation rate associated with DNA replication timing. Nat. Genet. 2009, 41, 393–395. [Google Scholar] [CrossRef]
- Rahbari, R.; Wuster, A.; Lindsay, S.J.; Hardwick, R.J.; Alexandrov, L.B.; Turki, S.A.; Dominiczak, A.; Morris, A.; Porteous, D.; Smith, B.; et al. Timing, rates and spectra of human germline mutation. Nat. Genet. 2016, 48, 126–133. [Google Scholar] [CrossRef]
- Danchin, E.; Pocheville, A. Inheritance is where physiology meets evolution. J. Physiol. 2014, 592, 2307–2317. [Google Scholar] [CrossRef] [PubMed]
- Yona, A.H.; Frumkin, I.; Pilpel, Y. A relay race on the evolutionary adaptation spectrum. Cell 2015, 163, 549–559. [Google Scholar] [CrossRef] [PubMed]
- Noble, R.; Noble, D. Was the Watchmaker Blind? Or Was She One-Eyed? Biology 2017, 6, 47. [Google Scholar] [CrossRef] [PubMed]
- Booker, T.R.; Jackson, B.C.; Keightley, P.D. Detecting positive selection in the genome. BMC Biol. 2017, 15, 98. [Google Scholar] [CrossRef]
- Wideman, J.G.; Novick, A.; Munoz-Gomez, S.A.; Doolittle, W.F. Neutral evolution of cellular phenotypes. Curr. Opin. Genet. Dev. 2019, 58–59, 87–94. [Google Scholar] [CrossRef]
- Lanfear, R.; Kokko, H.; Eyre-Walker, A. Population size and the rate of evolution. Trends Ecol. Evol. 2014, 29, 33–41. [Google Scholar] [CrossRef]
- Barrett, R.D.; Hoekstra, H.E. Molecular spandrels: Tests of adaptation at the genetic level. Nat. Rev. Genet. 2011, 12, 767–780. [Google Scholar] [CrossRef]
- Darwin, C. On the Origin of Species; John Murray: London, UK, 1859. [Google Scholar]
- Echave, J.; Wilke, C.O. Biophysical Models of Protein Evolution: Understanding the Patterns of Evolutionary Sequence Divergence. Annu. Rev. Biophys. 2017, 46, 85–103. [Google Scholar] [CrossRef]
- Reed, C.J.; Lewis, H.; Trejo, E.; Winston, V.; Evilia, C. Protein adaptations in archaeal extremophiles. Archaea 2013, 2013, 373275. [Google Scholar] [CrossRef]
- Harmel, R.; Fiedler, D. Features and regulation of non-enzymatic post-translational modifications. Nat. Chem. Biol. 2018, 14, 244–252. [Google Scholar] [CrossRef]
- Panda, A.; Ghosh, T.C. Prevalent structural disorder carries signature of prokaryotic adaptation to oxic atmosphere. Gene 2014, 548, 134–141. [Google Scholar] [CrossRef] [PubMed]
- Elser, J.J.; Acquisti, C.; Kumar, S. Stoichiogenomics: The evolutionary ecology of macromolecular elemental composition. Trends Ecol. Evol. 2011, 26, 38–44. [Google Scholar] [CrossRef] [PubMed]
- Bragg, J.G.; Thomas, D.; Baudouin-Cornu, P. Variation among species in proteomic sulphur content is related to environmental conditions. Proc. Biol. Sci. 2006, 273, 1293–1300. [Google Scholar] [CrossRef] [PubMed]
- Vinogradov, A.E. DNA helix: The importance of being GC-rich. Nucleic Acids Res. 2003, 31, 1838–1844. [Google Scholar] [CrossRef] [PubMed]
- Harteis, S.; Schneider, S. Making the bend: DNA tertiary structure and protein-DNA interactions. Int. J. Mol. Sci. 2014, 15, 12335–12363. [Google Scholar] [CrossRef] [PubMed]
- Dans, P.D.; Faustino, I.; Battistini, F.; Zakrzewska, K.; Lavery, R.; Orozco, M. Unraveling the sequence-dependent polymorphic behavior of d(CpG) steps in B-DNA. Nucleic Acids Res. 2014, 42, 11304–11320. [Google Scholar] [CrossRef]
- Goncearenco, A.; Ma, B.G.; Berezovsky, I.N. Molecular mechanisms of adaptation emerging from the physics and evolution of nucleic acids and proteins. Nucleic Acids Res. 2014, 42, 2879–2892. [Google Scholar] [CrossRef]
- Versteeg, R.; van Schaik, B.D.; van Batenburg, M.F.; Roos, M.; Monajemi, R.; Caron, H.; Bussemaker, H.J.; van Kampen, A.H. The human transcriptome map reveals extremes in gene density, intron length, GC content, and repeat pattern for domains of highly and weakly expressed genes. Genome Res. 2003, 13, 1998–2004. [Google Scholar] [CrossRef]
- Urrutia, A.O.; Hurst, L.D. The signature of selection mediated by expression on human genes. Genome Res. 2003, 13, 2260–2264. [Google Scholar] [CrossRef]
- Reymer, A.; Zakrzewska, K.; Lavery, R. Sequence-dependent response of DNA to torsional stress: A potential biological regulation mechanism. Nucleic Acids Res. 2018, 46, 1684–1694. [Google Scholar] [CrossRef]
- Chen, K.; Zhao, B.S.; He, C. Nucleic Acid Modifications in Regulation of Gene Expression. Cell Chem. Biol. 2016, 23, 74–85. [Google Scholar] [CrossRef] [PubMed]
- Olinski, R.; Gackowski, D.; Cooke, M.S. Endogenously generated DNA nucleobase modifications source, and significance as possible biomarkers of malignant transformation risk, and role in anticancer therapy. Biochim. Biophys. Acta Rev. Cancer 2018, 1869, 29–41. [Google Scholar] [CrossRef] [PubMed]
- Tubbs, A.; Nussenzweig, A. Endogenous DNA Damage as a Source of Genomic Instability in Cancer. Cell 2017, 168, 644–656. [Google Scholar] [CrossRef] [PubMed]
- Reichenberger, E.R.; Rosen, G.; Hershberg, U.; Hershberg, R. Prokaryotic nucleotide composition is shaped by both phylogeny and the environment. Genome Biol. Evol. 2015, 7, 1380–1389. [Google Scholar] [CrossRef]
- Seward, E.A.; Kelly, S. Dietary nitrogen alters codon bias and genome composition in parasitic microorganisms. Genome Biol. 2016, 17, 226. [Google Scholar] [CrossRef]
- Kelly, S. The Amount of Nitrogen Used for Photosynthesis Modulates Molecular Evolution in Plants. Mol. Biol. Evol. 2018, 35, 1616–1625. [Google Scholar] [CrossRef]
- Smarda, P.; Hejcman, M.; Brezinova, A.; Horova, L.; Steigerova, H.; Zedek, F.; Bures, P.; Hejcmanova, P.; Schellberg, J. Effect of phosphorus availability on the selection of species with different ploidy levels and genome sizes in a long-term grassland fertilization experiment. New Phytol. 2013, 200, 911–921. [Google Scholar] [CrossRef]
- Hunt, R.C.; Simhadri, V.L.; Iandoli, M.; Sauna, Z.E.; Kimchi-Sarfaty, C. Exposing synonymous mutations. Trends Genet. 2014, 30, 308–321. [Google Scholar] [CrossRef]
- Quintales, L.; Soriano, I.; Vazquez, E.; Segurado, M.; Antequera, F. A species-specific nucleosomal signature defines a periodic distribution of amino acids in proteins. Open Biol. 2015, 5, 140218. [Google Scholar] [CrossRef]
- Babbitt, G.A.; Alawad, M.A.; Schulze, K.V.; Hudson, A.O. Synonymous codon bias and functional constraint on GC3-related DNA backbone dynamics in the prokaryotic nucleoid. Nucleic Acids Res. 2014, 42, 10915–10926. [Google Scholar] [CrossRef]
- Bailey, S.F.; Hinz, A.; Kassen, R. Adaptive synonymous mutations in an experimentally evolved Pseudomonas fluorescens population. Nat. Commun. 2014, 5, 4076. [Google Scholar] [CrossRef] [PubMed]
- Taylor, F.J.; Coates, D. The code within the codons. Biosystems 1989, 22, 177–187. [Google Scholar] [CrossRef]
- Woese, C.R.; Dugre, D.H.; Saxinger, W.C.; Dugre, S.A. The molecular basis for the genetic code. Proc. Natl. Acad. Sci. USA 1966, 55, 966–974. [Google Scholar] [CrossRef] [PubMed]
- Prilusky, J.; Bibi, E. Studying membrane proteins through the eyes of the genetic code revealed a strong uracil bias in their coding mRNAs. Proc. Natl. Acad. Sci. USA 2009, 106, 6662–6666. [Google Scholar] [CrossRef]
- Panda, A.; Podder, S.; Chakraborty, S.; Ghosh, T.C. GC-made protein disorder sheds new light on vertebrate evolution. Genomics 2014, 104, 530–537. [Google Scholar] [CrossRef]
- Brbic, M.; Warnecke, T.; Krisko, A.; Supek, F. Global Shifts in Genome and Proteome Composition Are Very Tightly Coupled. Genome Biol. Evol. 2015, 7, 1519–1532. [Google Scholar] [CrossRef]
- Goncearenco, A.; Berezovsky, I.N. The fundamental tradeoff in genomes and proteomes of prokaryotes established by the genetic code, codon entropy, and physics of nucleic acids and proteins. Biol. Direct 2014, 9, 29. [Google Scholar] [CrossRef]
- Warnecke, T.; Weber, C.C.; Hurst, L.D. Why there is more to protein evolution than protein function: Splicing, nucleosomes and dual-coding sequence. Biochem. Soc. Trans. 2009, 37, 756–761. [Google Scholar] [CrossRef]
- Fontrodona, N.; Aube, F.; Claude, J.B.; Polveche, H.; Lemaire, S.; Tranchevent, L.C.; Modolo, L.; Mortreux, F.; Bourgeois, C.F.; Auboeuf, D. Interplay between coding and exonic splicing regulatory sequences. Genome Res. 2019, 29, 711–722. [Google Scholar] [CrossRef]
- Faure, G.; Ogurtsov, A.Y.; Shabalina, S.A.; Koonin, E.V. Adaptation of mRNA structure to control protein folding. RNA Biol. 2017, 14, 1649–1654. [Google Scholar] [CrossRef] [PubMed]
- Brunak, S.; Engelbrecht, J. Protein structure and the sequential structure of mRNA: Alpha-helix and beta-sheet signals at the nucleotide level. Proteins 1996, 25, 237–252. [Google Scholar] [CrossRef]
- Trifonov, E.N.; Volkovich, Z.; Frenkel, Z.M. Multiple levels of meaning in DNA sequences, and one more. Ann. N. Y. Acad. Sci. 2012, 1267, 35–38. [Google Scholar] [CrossRef] [PubMed]
- Ponce de Leon, M.; de Miranda, A.B.; Alvarez-Valin, F.; Carels, N. The Purine Bias of Coding Sequences is Determined by Physicochemical Constraints on Proteins. Bioinform. Biol. Insights 2014, 8, 93–108. [Google Scholar] [CrossRef] [PubMed]
- Tagami, S.; Attwater, J.; Holliger, P. Simple peptides derived from the ribosomal core potentiate RNA polymerase ribozyme function. Nat. Chem. 2017, 9, 325–332. [Google Scholar] [CrossRef]
- Kun, A.; Radvanyi, A. The evolution of the genetic code: Impasses and challenges. Biosystems 2018, 164, 217–225. [Google Scholar] [CrossRef]
- Koonin, E.V.; Novozhilov, A.S. Origin and Evolution of the Universal Genetic Code. Annu. Rev. Genet. 2017, 51, 45–62. [Google Scholar] [CrossRef]
- Gulik, P.T. On the Origin of Sequence. Life 2015, 5, 1629–1637. [Google Scholar] [CrossRef]
- Grosjean, H.; Westhof, E. An integrated, structure- and energy-based view of the genetic code. Nucleic Acids Res. 2016, 44, 8020–8040. [Google Scholar] [CrossRef]
- Szostak, J.W. On the origin of life. Medicina 2016, 76, 199–203. [Google Scholar]
- Usui, K.; Ichihashi, N.; Yomo, T. A design principle for a single-stranded RNA genome that replicates with less double-strand formation. Nucleic Acids Res. 2015, 43, 8033–8043. [Google Scholar] [CrossRef]
- Bansho, Y.; Ichihashi, N.; Kazuta, Y.; Matsuura, T.; Suzuki, H.; Yomo, T. Importance of parasite RNA species repression for prolonged translation-coupled RNA self-replication. Chem. Biol. 2012, 19, 478–487. [Google Scholar] [CrossRef]
- Eigen, M.; Biebricher, C.K.; Gebinoga, M.; Gardiner, W.C. The hypercycle. Coupling of RNA and protein biosynthesis in the infection cycle of an RNA bacteriophage. Biochemistry 1991, 30, 11005–11018. [Google Scholar] [CrossRef]
- Carter, C.W., Jr.; Wills, P.R. Interdependence, Reflexivity, Fidelity, Impedance Matching, and the Evolution of Genetic Coding. Mol. Biol. Evol. 2018, 35, 269–286. [Google Scholar] [CrossRef] [PubMed]
- Saad, N. A ribonucleopeptide world at the origin of life: Co-evolution of RNA. J. Syst. Evol. 2018, 56, 1–13. [Google Scholar] [CrossRef]
- Francis, B.R. The Hypothesis that the Genetic Code Originated in Coupled Synthesis of Proteins and the Evolutionary Predecessors of Nucleic Acids in Primitive Cells. Life 2015, 5, 467–505. [Google Scholar] [CrossRef] [PubMed]
- Gounaris, Y. An evolutionary theory based on a protein-mRNA co-synthesis hypothesis. J. Biol. Res. Thessalon. 2011, 15, 3–16. [Google Scholar]
- Gordon, K.H. Were RNA replication and translation directly coupled in the RNA (+protein?) World? J. Theor. Biol. 1995, 173, 179–193. [Google Scholar] [CrossRef]
- Zamft, B.; Bintu, L.; Ishibashi, T.; Bustamante, C. Nascent RNA structure modulates the transcriptional dynamics of RNA polymerases. Proc. Natl. Acad. Sci. USA 2012, 109, 8948–8953. [Google Scholar] [CrossRef]
- Chen, X.; Yang, J.R.; Zhang, J. Nascent RNA folding mitigates transcription-associated mutagenesis. Genome Res. 2016, 26, 50–59. [Google Scholar] [CrossRef]
- Proshkin, S.; Rahmouni, A.R.; Mironov, A.; Nudler, E. Cooperation between translating ribosomes and RNA polymerase in transcription elongation. Science 2010, 328, 504–508. [Google Scholar] [CrossRef]
- Auboeuf, D. Alternative mRNA processing sites decrease genetic variability while increasing functional diversity. Transcription 2018, 9, 75–87. [Google Scholar] [CrossRef] [PubMed]
- Morgens, D.W. The protein invasion: A broad review on the origin of the translational system. J. Mol. Evol. 2013, 77, 185–196. [Google Scholar] [CrossRef] [PubMed]
- Altstein, A.D. The progene hypothesis: The nucleoprotein world and how life began. Biol. Direct 2015, 10, 67. [Google Scholar] [CrossRef] [PubMed]
- Sutherland, J.D.; Blackburn, J.M. Killing two birds with one stone: A chemically plausible scheme for linked nucleic acid replication and coded peptide synthesis. Chem. Biol. 1997, 4, 481–488. [Google Scholar] [CrossRef][Green Version]
- Attwater, J.; Raguram, A.; Morgunov, A.S.; Gianni, E.; Holliger, P. Ribozyme-catalysed RNA synthesis using triplet building blocks. Elife 2018, 7. [Google Scholar] [CrossRef] [PubMed]
- Maizels, N.; Weiner, A.M. Phylogeny from function: Evidence from the molecular fossil record that tRNA originated in replication, not translation. Proc. Natl. Acad. Sci. USA 1994, 91, 6729–6734. [Google Scholar] [CrossRef]
- Zeldovich, K.B.; Berezovsky, I.N.; Shakhnovich, E.I. Protein and DNA sequence determinants of thermophilic adaptation. PLoS Comput. Biol. 2007, 3, e5. [Google Scholar] [CrossRef]
- Lemaire, S.; Fontrodona, N.; Aube, F.; Claude, J.B.; Polveche, H.; Modolo, L.; Bourgeois, C.F.; Mortreux, F.; Auboeuf, D. Characterizing the interplay between gene nucleotide composition bias and splicing. Genome Biol. 2019, 20, 259. [Google Scholar] [CrossRef]
- Granold, M.; Hajieva, P.; Tosa, M.I.; Irimie, F.D.; Moosmann, B. Modern diversification of the amino acid repertoire driven by oxygen. Proc. Natl. Acad. Sci. USA 2018, 115, 41–46. [Google Scholar] [CrossRef]
- Chowdhury, K.; Kumar, S.; Sharma, T.; Sharma, A.; Bhagat, M.; Kamai, A.; Ford, B.M.; Asthana, S.; Mandal, C.C. Presence of a consensus DNA motif at nearby DNA sequence of the mutation susceptible CG nucleotides. Gene 2018, 639, 85–95. [Google Scholar] [CrossRef]
- Szpiech, Z.A.; Strauli, N.B.; White, K.A.; Ruiz, D.G.; Jacobson, M.P.; Barber, D.L.; Hernandez, R.D. Prominent features of the amino acid mutation landscape in cancer. PLoS ONE 2017, 12, e0183273. [Google Scholar] [CrossRef] [PubMed]
- Tsuber, V.; Kadamov, Y.; Brautigam, L.; Berglund, U.W.; Helleday, T. Mutations in Cancer Cause Gain of Cysteine, Histidine, and Tryptophan at the Expense of a Net Loss of Arginine on the Proteome Level. Biomolecules 2017, 7, 49. [Google Scholar] [CrossRef] [PubMed]
- Son, H.; Kang, H.; Kim, H.S.; Kim, S. Somatic mutation driven codon transition bias in human cancer. Sci. Rep. 2017, 7, 14204. [Google Scholar] [CrossRef] [PubMed]
- Tan, H.; Bao, J.; Zhou, X. Genome-wide mutational spectra analysis reveals significant cancer-specific heterogeneity. Sci. Rep. 2015, 5, 12566. [Google Scholar] [CrossRef]
- Suarez-Villagran, M.Y.; Azevedo, R.B.R.; Miller, J.H., Jr. Influence of Electron-Holes on DNA Sequence-Specific Mutation Rates. Genome Biol. Evol. 2018, 10, 1039–1047. [Google Scholar] [CrossRef]
- Bender, A.; Hajieva, P.; Moosmann, B. Adaptive antioxidant methionine accumulation in respiratory chain complexes explains the use of a deviant genetic code in mitochondria. Proc. Natl. Acad. Sci. USA 2008, 105, 16496–16501. [Google Scholar] [CrossRef]
- Vetsigian, K.; Woese, C.; Goldenfeld, N. Collective evolution and the genetic code. Proc. Natl. Acad. Sci. USA 2006, 103, 10696–10701. [Google Scholar] [CrossRef]
- Hlevnjak, M.; Polyansky, A.A.; Zagrovic, B. Sequence signatures of direct complementarity between mRNAs and cognate proteins on multiple levels. Nucleic Acids Res. 2012, 40, 8874–8882. [Google Scholar] [CrossRef]
- Polyansky, A.A.; Zagrovic, B. Evidence of direct complementary interactions between messenger RNAs and their cognate proteins. Nucleic Acids Res. 2013, 41, 8434–8443. [Google Scholar] [CrossRef]
- Zagrovic, B.; Bartonek, L.; Polyansky, A.A. RNA-protein interactions in an unstructured context. FEBS Lett. 2018, 592, 2901–2916. [Google Scholar] [CrossRef]
- Cadena-Nava, R.D.; Comas-Garcia, M.; Garmann, R.F.; Rao, A.L.; Knobler, C.M.; Gelbart, W.M. Self-assembly of viral capsid protein and RNA molecules of different sizes: Requirement for a specific high protein/RNA mass ratio. J. Virol. 2012, 86, 3318–3326. [Google Scholar] [CrossRef] [PubMed]
- Wong, J.T.; Ng, S.K.; Mat, W.K.; Hu, T.; Xue, H. Coevolution Theory of the Genetic Code at Age Forty: Pathway to Translation and Synthetic Life. Life 2016, 6, 12. [Google Scholar] [CrossRef] [PubMed]
- Di Giulio, M. The aminoacyl-tRNA synthetases had only a marginal role in the origin of the organization of the genetic code: Evidence in favor of the coevolution theory. J. Theor. Biol. 2017, 432, 14–24. [Google Scholar] [CrossRef] [PubMed]
- Copley, S.D.; Smith, E.; Morowitz, H.J. A mechanism for the association of amino acids with their codons and the origin of the genetic code. Proc. Natl. Acad. Sci. USA 2005, 102, 4442–4447. [Google Scholar] [CrossRef] [PubMed]
- van der Knaap, J.A.; Verrijzer, C.P. Undercover: Gene control by metabolites and metabolic enzymes. Genes Dev. 2016, 30, 2345–2369. [Google Scholar] [CrossRef]
- Schvartzman, J.M.; Thompson, C.B.; Finley, L.W.S. Metabolic regulation of chromatin modifications and gene expression. J. Cell Biol. 2018, 217, 2247–2259. [Google Scholar] [CrossRef]
- Reid, M.A.; Dai, Z.; Locasale, J.W. The impact of cellular metabolism on chromatin dynamics and epigenetics. Nat. Cell Biol. 2017, 19, 1298–1306. [Google Scholar] [CrossRef]
- Varela, F.G.; Maturana, H.R.; Uribe, R. Autopoiesis: The organization of living systems, its characterization and a model. Biosystems 1974, 5, 187–196. [Google Scholar] [CrossRef]
- Maturana, H.; Varela, F. The Tree of Knowledge; Shambhala Publications: Boston, MA, USA, 1998. [Google Scholar]
- Eigen, M. Selforganization of matter and the evolution of biological macromolecules. Naturwissenschaften 1971, 58, 465–523. [Google Scholar] [CrossRef]
- Eigen, M.; Schuster, P. Stages of emerging life—Five principles of early organization. J. Mol. Evol. 1982, 19, 47–61. [Google Scholar] [CrossRef]
- Cairns, J.; Overbaugh, J.; Miller, S. The origin of mutants. Nature 1988, 335, 142–145. [Google Scholar] [CrossRef]
- Wright, B.E. A biochemical mechanism for nonrandom mutations and evolution. J. Bacteriol. 2000, 182, 2993–3001. [Google Scholar] [CrossRef]
- Correa, R.; Thornton, P.C.; Rosenberg, S.M.; Hastings, P.J. Oxygen and RNA in stress-induced mutation. Curr. Genet. 2018, 64, 769–776. [Google Scholar] [CrossRef]
- Sebastian, R.; Oberdoerffer, P. Transcription-associated events affecting genomic integrity. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2017, 372. [Google Scholar] [CrossRef]
- Wang, G.; Vasquez, K.M. Effects of Replication and Transcription on DNA Structure-Related Genetic Instability. Genes 2017, 8, 17. [Google Scholar] [CrossRef]
- Merrikh, H. Spatial and Temporal Control of Evolution through Replication-Transcription Conflicts. Trends Microbiol. 2017, 25, 515–521. [Google Scholar] [CrossRef]
- Chen, Y.H.; Keegan, S.; Kahli, M.; Tonzi, P.; Fenyo, D.; Huang, T.T.; Smith, D.J. Transcription shapes DNA replication initiation and termination in human cells. Nat. Struct. Mol. Biol. 2019, 26, 67–77. [Google Scholar] [CrossRef]
- Duret, L.; Galtier, N. Biased gene conversion and the evolution of mammalian genomic landscapes. Annu. Rev. Genom. Hum. Genet. 2009, 10, 285–311. [Google Scholar] [CrossRef]
- Long, H.; Sung, W.; Kucukyildirim, S.; Williams, E.; Miller, S.F.; Guo, W.; Patterson, C.; Gregory, C.; Strauss, C.; Stone, C.; et al. Evolutionary determinants of genome-wide nucleotide composition. Nat. Ecol. Evol. 2018, 2, 237–240. [Google Scholar] [CrossRef]
- Pozzoli, U.; Menozzi, G.; Fumagalli, M.; Cereda, M.; Comi, G.P.; Cagliani, R.; Bresolin, N.; Sironi, M. Both selective and neutral processes drive GC content evolution in the human genome. BMC Evol. Biol. 2008, 8, 99. [Google Scholar] [CrossRef]
- Kudla, G.; Helwak, A.; Lipinski, L. Gene conversion and GC-content evolution in mammalian Hsp70. Mol. Biol. Evol. 2004, 21, 1438–1444. [Google Scholar] [CrossRef] [PubMed]
- Yin, Y.; Yang, L.; Zheng, G.; Gu, C.; Yi, C.; He, C.; Gao, Y.Q.; Zhao, X.S. Dynamics of spontaneous flipping of a mismatched base in DNA duplex. Proc. Natl. Acad. Sci. USA 2014, 111, 8043–8048. [Google Scholar] [CrossRef] [PubMed]
- Sankar, T.S.; Wastuwidyaningtyas, B.D.; Dong, Y.; Lewis, S.A.; Wang, J.D. The nature of mutations induced by replication-transcription collisions. Nature 2016, 535, 178–181. [Google Scholar] [CrossRef] [PubMed]
- Sueoka, N. Wide intra-genomic G+C heterogeneity in human and chicken is mainly due to strand-symmetric directional mutation pressures: dGTP-oxidation and symmetric cytosine-deamination hypotheses. Gene 2002, 300, 141–154. [Google Scholar] [CrossRef]
- Chen, C.L.; Rappailles, A.; Duquenne, L.; Huvet, M.; Guilbaud, G.; Farinelli, L.; Audit, B.; d’Aubenton-Carafa, Y.; Arneodo, A.; Hyrien, O.; et al. Impact of replication timing on non-CpG and CpG substitution rates in mammalian genomes. Genome Res. 2010, 20, 447–457. [Google Scholar] [CrossRef] [PubMed]
- Kenigsberg, E.; Yehuda, Y.; Marjavaara, L.; Keszthelyi, A.; Chabes, A.; Tanay, A.; Simon, I. The mutation spectrum in genomic late replication domains shapes mammalian GC content. Nucleic Acids Res. 2016, 44, 4222–4232. [Google Scholar] [CrossRef] [PubMed]
- Gul, I.S.; Staal, J.; Hulpiau, P.; De Keuckelaere, E.; Kamm, K.; Deroo, T.; Sanders, E.; Staes, K.; Driege, Y.; Saeys, Y.; et al. GC Content of Early Metazoan Genes and Its Impact on Gene Expression Levels in Mammalian Cell Lines. Genome Biol. Evol. 2018, 10, 909–917. [Google Scholar] [CrossRef]
- Rao, Y.S.; Wang, Z.F.; Chai, X.W.; Wu, G.Z.; Zhou, M.; Nie, Q.H.; Zhang, X.Q. Selection for the compactness of highly expressed genes in Gallus gallus. Biol. Direct 2010, 5, 35. [Google Scholar] [CrossRef]
- Tilgner, H.; Knowles, D.G.; Johnson, R.; Davis, C.A.; Chakrabortty, S.; Djebali, S.; Curado, J.; Snyder, M.; Gingeras, T.R.; Guigo, R. Deep sequencing of subcellular RNA fractions shows splicing to be predominantly co-transcriptional in the human genome but inefficient for lncRNAs. Genome Res. 2012, 22, 1616–1625. [Google Scholar] [CrossRef]
- Quandt, E.M.; Traverse, C.C.; Ochman, H. Local genic base composition impacts protein production and cellular fitness. PeerJ 2018, 6, e4286. [Google Scholar] [CrossRef]
- Gorochowski, T.E.; Ignatova, Z.; Bovenberg, R.A.; Roubos, J.A. Trade-offs between tRNA abundance and mRNA secondary structure support smoothing of translation elongation rate. Nucleic Acids Res. 2015, 43, 3022–3032. [Google Scholar] [CrossRef]
- Kudla, G.; Murray, A.W.; Tollervey, D.; Plotkin, J.B. Coding-sequence determinants of gene expression in Escherichia coli. Science 2009, 324, 255–258. [Google Scholar] [CrossRef] [PubMed]
- Rao, Y.; Wang, Z.; Chai, X.; Nie, Q.; Zhang, X. Hydrophobicity and aromaticity are primary factors shaping variation in amino acid usage of chicken proteome. PLoS ONE 2014, 9, e110381. [Google Scholar] [CrossRef]
- Du, M.Z.; Zhang, C.; Wang, H.; Liu, S.; Wei, W.; Guo, F.B. The GC Content as a Main Factor Shaping the Amino Acid Usage During Bacterial Evolution Process. Front. Microbiol. 2018, 9, 2948. [Google Scholar] [CrossRef] [PubMed]
- Gao, N.; Lu, G.; Lercher, M.J.; Chen, W.H. Selection for energy efficiency drives strand-biased gene distribution in prokaryotes. Sci. Rep. 2017, 7, 10572. [Google Scholar] [CrossRef] [PubMed]
- Hull, R.M.; Cruz, C.; Jack, C.V.; Houseley, J. Environmental change drives accelerated adaptation through stimulated copy number variation. PLoS Biol. 2017, 15, e2001333. [Google Scholar] [CrossRef] [PubMed]
- Ambriz-Avina, V.; Yasbin, R.E.; Robleto, E.A.; Pedraza-Reyes, M. Role of Base Excision Repair (BER) in Transcription-associated Mutagenesis of Nutritionally Stressed Nongrowing Bacillus subtilis Cell Subpopulations. Curr. Microbiol. 2016, 73, 721–726. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Shewaramani, S.; Finn, T.J.; Leahy, S.C.; Kassen, R.; Rainey, P.B.; Moon, C.D. Anaerobically Grown Escherichia coli Has an Enhanced Mutation Rate and Distinct Mutational Spectra. PLoS Genet. 2017, 13, e1006570. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, J. Yeast Spontaneous Mutation Rate and Spectrum Vary with Environment. Curr. Biol. 2019, 29, 1584–1591.e3. [Google Scholar] [CrossRef]
- Maharjan, R.P.; Ferenci, T. A shifting mutational landscape in 6 nutritional states: Stress-induced mutagenesis as a series of distinct stress input-mutation output relationships. PLoS Biol. 2017, 15, e2001477. [Google Scholar] [CrossRef]
- Chu, X.L.; Zhang, B.W.; Zhang, Q.G.; Zhu, B.R.; Lin, K.; Zhang, D.Y. Temperature responses of mutation rate and mutational spectrum in an Escherichia coli strain and the correlation with metabolic rate. BMC Evol. Biol. 2018, 18, 126. [Google Scholar] [CrossRef] [PubMed]
- Matsuba, C.; Ostrow, D.G.; Salomon, M.P.; Tolani, A.; Baer, C.F. Temperature, stress and spontaneous mutation in Caenorhabditis briggsae and Caenorhabditis elegans. Biol Lett. 2013, 9, 20120334. [Google Scholar] [CrossRef] [PubMed]
- Rogozin, I.B.; Pavlov, Y.I.; Goncearenco, A.; De, S.; Lada, A.G.; Poliakov, E.; Panchenko, A.R.; Cooper, D.N. Mutational signatures and mutable motifs in cancer genomes. Brief. Bioinform. 2018, 19, 1085–1101. [Google Scholar] [CrossRef] [PubMed]
- White, K.A.; Ruiz, D.G.; Szpiech, Z.A.; Strauli, N.B.; Hernandez, R.D.; Jacobson, M.P.; Barber, D.L. Cancer-associated arginine-to-histidine mutations confer a gain in pH sensing to mutant proteins. Sci. Signal. 2017, 10. [Google Scholar] [CrossRef] [PubMed]
- Saier, M.H., Jr.; Kukita, C.; Zhang, Z. Transposon-mediated directed mutation in bacteria and eukaryotes. Front. Biosci. (Landmark Ed.) 2017, 22, 1458–1468. [Google Scholar] [CrossRef]
- Newman, A.G.; Bessa, P.; Tarabykin, V.; Singh, P.B. Activity-DEPendent Transposition. EMBO Rep. 2017, 18, 346–348. [Google Scholar] [CrossRef]
- Vandecraen, J.; Monsieurs, P.; Mergeay, M.; Leys, N.; Aertsen, A.; Van Houdt, R. Zinc-Induced Transposition of Insertion Sequence Elements Contributes to Increased Adaptability of Cupriavidus metallidurans. Front. Microbiol. 2016, 7, 359. [Google Scholar] [CrossRef]
- Grandbastien, M.A. LTR retrotransposons, handy hitchhikers of plant regulation and stress response. Biochim. Biophys. Acta 2015, 1849, 403–416. [Google Scholar] [CrossRef]
- Miousse, I.R.; Chalbot, M.C.; Lumen, A.; Ferguson, A.; Kavouras, I.G.; Koturbash, I. Response of transposable elements to environmental stressors. Mutat. Res. Rev. Mutat. Res. 2015, 765, 19–39. [Google Scholar] [CrossRef]
- Rada-Iglesias, A.; Grosveld, F.G.; Papantonis, A. Forces driving the three-dimensional folding of eukaryotic genomes. Mol. Syst. Biol. 2018, 14, e8214. [Google Scholar] [CrossRef]
- Meyer, S.; Reverchon, S.; Nasser, W.; Muskhelishvili, G. Chromosomal organization of transcription: In a nutshell. Curr. Genet. 2018, 64, 555–565. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.H.; Forman-Kay, J.D.; Chan, H.S. Theories for Sequence-Dependent Phase Behaviors of Biomolecular Condensates. Biochemistry 2018, 57, 2499–2508. [Google Scholar] [CrossRef] [PubMed]
- Erdel, F.; Rippe, K. Formation of Chromatin Subcompartments by Phase Separation. Biophys. J. 2018, 114, 2262–2270. [Google Scholar] [CrossRef]
- Rieder, D.; Trajanoski, Z.; McNally, J.G. Transcription factories. Front. Genet. 2012, 3, 221. [Google Scholar] [CrossRef] [PubMed]
- Gu, Z.; Jin, K.; Crabbe, M.J.C.; Zhang, Y.; Liu, X.; Huang, Y.; Hua, M.; Nan, P.; Zhang, Z.; Zhong, Y. Enrichment analysis of Alu elements with different spatial chromatin proximity in the human genome. Protein Cell 2016, 7, 250–266. [Google Scholar] [CrossRef]
- Sundaram, V.; Cheng, Y.; Ma, Z.; Li, D.; Xing, X.; Edge, P.; Snyder, M.P.; Wang, T. Widespread contribution of transposable elements to the innovation of gene regulatory networks. Genome Res. 2014, 24, 1963–1976. [Google Scholar] [CrossRef]
- Puc, J.; Aggarwal, A.K.; Rosenfeld, M.G. Physiological functions of programmed DNA breaks in signal-induced transcription. Nat. Rev. Mol. Cell Biol. 2017, 18, 471–476. [Google Scholar] [CrossRef]
- Kaiser, V.B.; Semple, C.A. Chromatin loop anchors are associated with genome instability in cancer and recombination hotspots in the germline. Genome Biol. 2018, 19, 101. [Google Scholar] [CrossRef]
- Schwer, B.; Wei, P.C.; Chang, A.N.; Kao, J.; Du, Z.; Meyers, R.M.; Alt, F.W. Transcription-associated processes cause DNA double-strand breaks and translocations in neural stem/progenitor cells. Proc. Natl. Acad. Sci. USA 2016, 113, 2258–2263. [Google Scholar] [CrossRef]
- Roychowdhury, T.; Abyzov, A. Chromatin organization modulates the origin of heritable structural variations in human genome. Nucleic Acids Res. 2019, 47, 2766–2777. [Google Scholar] [CrossRef]
- Mellor, J.; Woloszczuk, R.; Howe, F.S. The Interleaved Genome. Trends Genet. 2016, 32, 57–71. [Google Scholar] [CrossRef] [PubMed]
- Hurst, L.D.; Pal, C.; Lercher, M.J. The evolutionary dynamics of eukaryotic gene order. Nat. Rev. Genet. 2004, 5, 299–310. [Google Scholar] [CrossRef] [PubMed]
- Yin, Y.; Zhang, H.; Olman, V.; Xu, Y. Genomic arrangement of bacterial operons is constrained by biological pathways encoded in the genome. Proc. Natl. Acad. Sci. USA 2010, 107, 6310–6315. [Google Scholar] [CrossRef]
- Nutzmann, H.W.; Huang, A.; Osbourn, A. Plant metabolic clusters—From genetics to genomics. New Phytol. 2016, 211, 771–789. [Google Scholar] [CrossRef]
- Gordon, A.J.; Satory, D.; Halliday, J.A.; Herman, C. Lost in transcription: Transient errors in information transfer. Curr. Opin. Microbiol. 2015, 24, 80–87. [Google Scholar] [CrossRef] [PubMed]
- Bradley, C.C.; Gordon, A.J.E.; Halliday, J.A.; Herman, C. Transcription fidelity: New paradigms in epigenetic inheritance, genome instability and disease. DNA Repair 2019, 81, 102652. [Google Scholar] [CrossRef] [PubMed]
- Reid-Bayliss, K.S.; Loeb, L.A. Accurate RNA consensus sequencing for high-fidelity detection of transcriptional mutagenesis-induced epimutations. Proc. Natl. Acad. Sci. USA 2017, 114, 9415–9420. [Google Scholar] [CrossRef]
- Xu, L.; Wang, W.; Chong, J.; Shin, J.H.; Xu, J.; Wang, D. RNA polymerase II transcriptional fidelity control and its functional interplay with DNA modifications. Crit. Rev. Biochem. Mol. Biol. 2015, 50, 503–519. [Google Scholar] [CrossRef]
- Morreall, J.; Kim, A.; Liu, Y.; Degtyareva, N.; Weiss, B.; Doetsch, P.W. Evidence for Retromutagenesis as a Mechanism for Adaptive Mutation in Escherichia coli. PLoS Genet. 2015, 11, e1005477. [Google Scholar] [CrossRef][Green Version]
- Sekowska, A.; Wendel, S.; Fischer, E.C.; Norholm, M.H.H.; Danchin, A. Generation of mutation hotspots in ageing bacterial colonies. Sci. Rep. 2016, 6, 2. [Google Scholar] [CrossRef]
- Williamson, A.K.; Zhu, Z.; Yuan, Z.M. Epigenetic mechanisms behind cellular sensitivity to DNA damage. Cell Stress 2018, 2, 176–180. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez-Perez, A.; Sabarinathan, R.; Lopez-Bigas, N. Local Determinants of the Mutational Landscape of the Human Genome. Cell 2019, 177, 101–114. [Google Scholar] [CrossRef] [PubMed]
- Elfman, J.; Li, H. Chimeric RNA in Cancer and Stem Cell Differentiation. Stem Cells Int. 2018, 2018, 3178789. [Google Scholar] [CrossRef] [PubMed]
- Keskin, H.; Shen, Y.; Huang, F.; Patel, M.; Yang, T.; Ashley, K.; Mazin, A.V.; Storici, F. Transcript-RNA-templated DNA recombination and repair. Nature 2014, 515, 436–439. [Google Scholar] [CrossRef]
- Yang, Y.G.; Qi, Y. RNA-directed repair of DNA double-strand breaks. DNA Repair 2015, 32, 82–85. [Google Scholar] [CrossRef]
- Shapiro, J.A. Living Organisms Author Their Read-Write Genomes in Evolution. Biology 2017, 6, 42. [Google Scholar] [CrossRef]
- Khanduja, J.S.; Calvo, I.A.; Joh, R.I.; Hill, I.T.; Motamedi, M. Nuclear Noncoding RNAs and Genome Stability. Mol. Cell 2016, 63, 7–20. [Google Scholar] [CrossRef]
- Auboeuf, D. Putative RNA-Directed Adaptive Mutations in Cancer Evolution. Transcription 2016, 7, 164–187. [Google Scholar] [CrossRef]
- Auboeuf, D. Genome evolution is driven by gene expression-generated biophysical constraints through RNA-directed genetic variation: A hypothesis. Bioessays 2017, 39. [Google Scholar] [CrossRef]
- Ibrahim, F.; Maragkakis, M.; Alexiou, P.; Mourelatos, Z. Ribothrypsis, a novel process of canonical mRNA decay, mediates ribosome-phased mRNA endonucleolysis. Nat. Struct. Mol. Biol. 2018, 25, 302–310. [Google Scholar] [CrossRef]
- Ikeuchi, K.; Izawa, T.; Inada, T. Recent Progress on the Molecular Mechanism of Quality Controls Induced by Ribosome Stalling. Front. Genet. 2018, 9, 743. [Google Scholar] [CrossRef] [PubMed]
- Karimi, J.; Goodarzi, M.T.; Tavilani, H.; Khodadadi, I.; Amiri, I. Increased receptor for advanced glycation end products in spermatozoa of diabetic men and its association with sperm nuclear DNA fragmentation. Andrologia 2012, 44, 280–286. [Google Scholar] [CrossRef] [PubMed]
- Sies, H. Strategies of antioxidant defense. Eur. J. Biochem. 1993, 215, 213–219. [Google Scholar] [CrossRef] [PubMed]
- Sales, V.M.; Ferguson-Smith, A.C.; Patti, M.E. Epigenetic Mechanisms of Transmission of Metabolic Disease across Generations. Cell Metab. 2017, 25, 559–571. [Google Scholar] [CrossRef]
- Vanhees, K.; Vonhogen, I.G.; van Schooten, F.J.; Godschalk, R.W. You are what you eat, and so are your children: The impact of micronutrients on the epigenetic programming of offspring. Cell. Mol. Life Sci. 2014, 71, 271–285. [Google Scholar] [CrossRef]
- da Silveira, J.C.; de Avila, A.; Garrett, H.L.; Bruemmer, J.E.; Winger, Q.A.; Bouma, G.J. Cell-secreted vesicles containing microRNAs as regulators of gamete maturation. J. Endocrinol. 2018, 236, R15–R27. [Google Scholar] [CrossRef]
- Chen, Q.; Yan, M.; Cao, Z.; Li, X.; Zhang, Y.; Shi, J.; Feng, G.H.; Peng, H.; Zhang, X.; Zhang, Y.; et al. Sperm tsRNAs contribute to intergenerational inheritance of an acquired metabolic disorder. Science 2016, 351, 397–400. [Google Scholar] [CrossRef]
- Chen, Q.; Yan, W.; Duan, E. Epigenetic inheritance of acquired traits through sperm RNAs and sperm RNA modifications. Nat. Rev. Genet. 2016, 17, 733–743. [Google Scholar] [CrossRef]
- Danchin, E.; Pocheville, A.; Huneman, P. Early in life effects and heredity: Reconciling neo-Darwinism with neo-Lamarckism under the banner of the inclusive evolutionary synthesis. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2019, 374, 20180113. [Google Scholar] [CrossRef]
- Klosin, A.; Lehner, B. Mechanisms, timescales and principles of trans-generational epigenetic inheritance in animals. Curr. Opin. Genet. Dev. 2016, 36, 41–49. [Google Scholar] [CrossRef]
- Horsthemke, B. A critical view on transgenerational epigenetic inheritance in humans. Nat. Commun. 2018, 9, 2973. [Google Scholar] [CrossRef] [PubMed]
- Monk, D.; Mackay, D.J.G.; Eggermann, T.; Maher, E.R.; Riccio, A. Genomic imprinting disorders: Lessons on how genome, epigenome and environment interact. Nat. Rev. Genet. 2019, 20, 235–248. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhang, X.; Shi, J.; Tuorto, F.; Li, X.; Liu, Y.; Liebers, R.; Zhang, L.; Qu, Y.; Qian, J.; et al. Dnmt2 mediates intergenerational transmission of paternally acquired metabolic disorders through sperm small non-coding RNAs. Nat. Cell. Biol. 2018, 20, 535–540. [Google Scholar] [CrossRef] [PubMed]
- Hollick, J.B. Paramutation and related phenomena in diverse species. Nat. Rev. Genet. 2017, 18, 5–23. [Google Scholar] [CrossRef]
- Bernstein, H.; Bernstein, C.; Michod, R.E. Meiosis as an Evolutionary Adaptation for DNA Repair. In DNA Repair; Inna Kruman, IntechOpen: London, UK, 2011. [Google Scholar] [CrossRef]
- Horandl, E.; Speijer, D. How oxygen gave rise to eukaryotic sex. Proc. Biol. Sci. 2018, 285. [Google Scholar] [CrossRef]
- Poljsak, B.; Milisav, I.; Lampe, T.; Ostan, I. Reproductive benefit of oxidative damage: An oxidative stress “malevolence”? Oxidative Med. Cell. Longev. 2011, 2011, 760978. [Google Scholar] [CrossRef]
- Immler, S.; Otto, S.P. The Evolutionary Consequences of Selection at the Haploid Gametic Stage. Am. Nat. 2018, 192, 241–249. [Google Scholar] [CrossRef]
- Fishman, L.; McIntosh, M. Standard Deviations: The Biological Bases of Transmission Ratio Distortion. Annu. Rev. Genet. 2019, 53, 347–372. [Google Scholar] [CrossRef]
- Tock, A.J.; Henderson, I.R. Hotspots for Initiation of Meiotic Recombination. Front. Genet. 2018, 9, 521. [Google Scholar] [CrossRef]
- Brachet, E.; Sommermeyer, V.; Borde, V. Interplay between modifications of chromatin and meiotic recombination hotspots. Biol. Cell 2012, 104, 51–69. [Google Scholar] [CrossRef]
- Acuna-Hidalgo, R.; Veltman, J.A.; Hoischen, A. New insights into the generation and role of de novo mutations in health and disease. Genome Biol. 2016, 17, 241. [Google Scholar] [CrossRef] [PubMed]
- Goldmann, J.M.; Wong, W.S.; Pinelli, M.; Farrah, T.; Bodian, D.; Stittrich, A.B.; Glusman, G.; Vissers, L.E.; Hoischen, A.; Roach, J.C.; et al. Parent-of-origin-specific signatures of de novo mutations. Nat. Genet. 2016, 48, 935–939. [Google Scholar] [CrossRef] [PubMed]
- Michaelson, J.J.; Shi, Y.; Gujral, M.; Zheng, H.; Malhotra, D.; Jin, X.; Jian, M.; Liu, G.; Greer, D.; Bhandari, A.; et al. Whole-genome sequencing in autism identifies hot spots for de novo germline mutation. Cell 2012, 151, 1431–1442. [Google Scholar] [CrossRef] [PubMed]
- Skinner, M.K.; Guerrero-Bosagna, C.; Haque, M.M. Environmentally induced epigenetic transgenerational inheritance of sperm epimutations promote genetic mutations. Epigenetics 2015, 10, 762–771. [Google Scholar] [CrossRef] [PubMed]
- Guerrero-Bosagna, C.; Morisson, M.; Liaubet, L.; Rodenburg, T.B.; de Haas, E.N.; Kostal, L.; Pitel, F. Transgenerational epigenetic inheritance in birds. Environ. Epigenet. 2018, 4, dvy008. [Google Scholar] [CrossRef] [PubMed]
- Wurdinger, T.; Gatson, N.N.; Balaj, L.; Kaur, B.; Breakefield, X.O.; Pegtel, D.M. Extracellular vesicles and their convergence with viral pathways. Adv. Virol. 2012, 2012, 767694. [Google Scholar] [CrossRef]
- Koonin, E.V. Evolution of RNA- and DNA-guided antivirus defense systems in prokaryotes and eukaryotes: Common ancestry vs convergence. Biol. Direct 2017, 12, 5. [Google Scholar] [CrossRef]
- Durdevic, Z.; Schaefer, M. Dnmt2 methyltransferases and immunity: An ancient overlooked connection between nucleotide modification and host defense? Bioessays 2013, 35, 1044–1049. [Google Scholar] [CrossRef]
- Rechavi, O. Guest list or black list: Heritable small RNAs as immunogenic memories. Trends Cell Biol. 2014, 24, 212–220. [Google Scholar] [CrossRef][Green Version]
- Zheng, Y.; Lorenzo, C.; Beal, P.A. DNA editing in DNA/RNA hybrids by adenosine deaminases that act on RNA. Nucleic Acids Res. 2017, 45, 3369–3377. [Google Scholar] [CrossRef]
- Zhang, X.; Cozen, A.E.; Liu, Y.; Chen, Q.; Lowe, T.M. Small RNA Modifications: Integral to Function and Disease. Trends Mol. Med. 2016, 22, 1025–1034. [Google Scholar] [CrossRef] [PubMed]
- Linster, C.L.; Van Schaftingen, E.; Hanson, A.D. Metabolite damage and its repair or pre-emption. Nat. Chem. Biol. 2013, 9, 72–80. [Google Scholar] [CrossRef] [PubMed]
- Mulkidjanian, A.Y.; Junge, W. On the origin of photosynthesis as inferred from sequence analysis. Photosynth. Res. 1997, 51, 27–42. [Google Scholar] [CrossRef]
- Wolstencroft, R.D.; Raven, J.A. Photosynthesis: Likelihood of Occurrence and Possibility of Detection on Earth-like Planets. Icarus 2002, 157, 535–548. [Google Scholar] [CrossRef]
- Michaelian, K.; Simeonov, A. Fundamental molecules of life are pigments which arose and co-evolved as a response to the thermodynamic imperative of dissipating the prevailing solar spectrum. Biogeosciences 2015, 12, 4913–4937. [Google Scholar] [CrossRef]
- Degli Esposti, M.; Mentel, M.; Martin, W.; Sousa, F.L. Oxygen Reductases in Alphaproteobacterial Genomes: Physiological Evolution From Low to High Oxygen Environments. Front. Microbiol. 2019, 10, 499. [Google Scholar] [CrossRef]
- Muller, M.; Mentel, M.; van Hellemond, J.J.; Henze, K.; Woehle, C.; Gould, S.B.; Yu, R.Y.; van der Giezen, M.; Tielens, A.G.; Martin, W.F. Biochemistry and evolution of anaerobic energy metabolism in eukaryotes. Microbiol. Mol. Biol. Rev. 2012, 76, 444–495. [Google Scholar] [CrossRef]
- Forte, E.; Borisov, V.B.; Falabella, M.; Colaco, H.G.; Tinajero-Trejo, M.; Poole, R.K.; Vicente, J.B.; Sarti, P.; Giuffre, A. The Terminal Oxidase Cytochrome bd Promotes Sulfide-resistant Bacterial Respiration and Growth. Sci. Rep. 2016, 6, 23788. [Google Scholar] [CrossRef]
- Margulis, L.; Chapman, M.; Guerrero, R.; Hall, J. The last eukaryotic common ancestor (LECA): Acquisition of cytoskeletal motility from aerotolerant spirochetes in the Proterozoic Eon. Proc. Natl. Acad. Sci. USA 2006, 103, 13080–13085. [Google Scholar] [CrossRef]
- Kurland, C.G.; Andersson, S.G. Origin and evolution of the mitochondrial proteome. Microbiol. Mol. Biol. Rev. 2000, 64, 786–820. [Google Scholar] [CrossRef]
- Speijer, D. Alternating terminal electron-acceptors at the basis of symbiogenesis: How oxygen ignited eukaryotic evolution. Bioessays 2017, 39. [Google Scholar] [CrossRef] [PubMed]
- Raymond, J.; Segre, D. The effect of oxygen on biochemical networks and the evolution of complex life. Science 2006, 311, 1764–1767. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.Y.; Kong, D.X.; Qin, T.; Li, X.; Caetano-Anolles, G.; Zhang, H.Y. The impact of oxygen on metabolic evolution: A chemoinformatic investigation. PLoS Comput. Biol. 2012, 8, e1002426. [Google Scholar] [CrossRef] [PubMed]
- Desmond, E.; Gribaldo, S. Phylogenomics of sterol synthesis: Insights into the origin, evolution, and diversity of a key eukaryotic feature. Genome Biol. Evol. 2009, 1, 364–381. [Google Scholar] [CrossRef]
- Zhang, X.; Barraza, K.M.; Beauchamp, J.L. Cholesterol provides nonsacrificial protection of membrane lipids from chemical damage at air-water interface. Proc. Natl. Acad. Sci. USA 2018, 115, 3255–3260. [Google Scholar] [CrossRef]
- Galea, A.M.; Brown, A.J. Special relationship between sterols and oxygen: Were sterols an adaptation to aerobic life? Free Radic. Biol. Med. 2009, 47, 880–889. [Google Scholar] [CrossRef]
- Deng, Y.; Almsherqi, Z.A. Evolution of cubic membranes as antioxidant defence system. Interface Focus 2015, 5, 20150012. [Google Scholar] [CrossRef]
- Lambowitz, A.M.; Belfort, M. Mobile Bacterial Group II Introns at the Crux of Eukaryotic Evolution. Microbiol. Spectr. 2015, 3, MDNA3-0050-2014. [Google Scholar] [CrossRef]
- de Lange, T. A loopy view of telomere evolution. Front. Genet. 2015, 6, 321. [Google Scholar] [CrossRef]
- Coros, C.J.; Piazza, C.L.; Chalamcharla, V.R.; Belfort, M. A mutant screen reveals RNase E as a silencer of group II intron retromobility in Escherichia coli. RNA 2008, 14, 2634–2644. [Google Scholar] [CrossRef]
- Belfort, M. Mobile self-splicing introns and inteins as environmental sensors. Curr. Opin. Microbiol. 2017, 38, 51–58. [Google Scholar] [CrossRef] [PubMed]
- Friedman, K.; Heller, A. On the Non-Uniform Distribution of Guanine in Introns of Human Genes: Possible Protection of Exons against Oxidation by Proximal Intron Poly-G Sequences. J. Phys. Chem. B 2001, 105, 11859–11865. [Google Scholar] [CrossRef]
- Amit, M.; Donyo, M.; Hollander, D.; Goren, A.; Kim, E.; Gelfman, S.; Lev-Maor, G.; Burstein, D.; Schwartz, S.; Postolsky, B.; et al. Differential GC content between exons and introns establishes distinct strategies of splice-site recognition. Cell Rep. 2012, 1, 543–556. [Google Scholar] [CrossRef] [PubMed]
- Enright, H.; Miller, W.J.; Hays, R.; Floyd, R.A.; Hebbel, R.P. Preferential targeting of oxidative base damage to internucleosomal DNA. Carcinogenesis 1996, 17, 1175–1177. [Google Scholar] [CrossRef] [PubMed]
- Colangeli, R.; Haq, A.; Arcus, V.L.; Summers, E.; Magliozzo, R.S.; McBride, A.; Mitra, A.K.; Radjainia, M.; Khajo, A.; Jacobs, W.R., Jr.; et al. The multifunctional histone-like protein Lsr2 protects mycobacteria against reactive oxygen intermediates. Proc. Natl. Acad. Sci. USA 2009, 106, 4414–4418. [Google Scholar] [CrossRef] [PubMed]
- Speijer, D. Birth of the eukaryotes by a set of reactive innovations: New insights force us to relinquish gradual models. Bioessays 2015, 37, 1268–1276. [Google Scholar] [CrossRef]
- Ljungman, M.; Hanawalt, P.C. Efficient protection against oxidative DNA damage in chromatin. Mol. Carcinog. 1992, 5, 264–269. [Google Scholar] [CrossRef]
- Cannan, W.J.; Tsang, B.P.; Wallace, S.S.; Pederson, D.S. Nucleosomes suppress the formation of double-strand DNA breaks during attempted base excision repair of clustered oxidative damages. J. Biol. Chem. 2014, 289, 19881–19893. [Google Scholar] [CrossRef]
- D’Souza, G.; Shitut, S.; Preussger, D.; Yousif, G.; Waschina, S.; Kost, C. Ecology and evolution of metabolic cross-feeding interactions in bacteria. Nat. Prod. Rep. 2018, 35, 455–488. [Google Scholar] [CrossRef]
- Jeltsch, A. Oxygen, epigenetic signaling, and the evolution of early life. Trends Biochem. Sci. 2013, 38, 172–176. [Google Scholar] [CrossRef]
- Drinnenberg, I.A.; Berger, F.; Elsasser, S.J.; Andersen, P.R.; Ausio, J.; Bickmore, W.A.; Blackwell, A.R.; Erwin, D.H.; Gahan, J.M.; Gaut, B.S.; et al. EvoChromo: Towards a synthesis of chromatin biology and evolution. Development 2019, 146. [Google Scholar] [CrossRef] [PubMed]
- Aravind, L.; Burroughs, A.M.; Zhang, D.; Iyer, L.M. Protein and DNA modifications: Evolutionary imprints of bacterial biochemical diversification and geochemistry on the provenance of eukaryotic epigenetics. Cold Spring Harb. Perspect. Biol. 2014, 6, a016063. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Wahl, M.E.; Murray, A.W. Multicellularity makes somatic differentiation evolutionarily stable. Proc. Natl. Acad. Sci. USA 2016, 113, 8362–8367. [Google Scholar] [CrossRef]
- Goldsby, H.J.; Knoester, D.B.; Ofria, C.; Kerr, B. The evolutionary origin of somatic cells under the dirty work hypothesis. PLoS Biol. 2014, 12, e1001858. [Google Scholar] [CrossRef] [PubMed]
- Blagojevic, D.P.; Grubor-Lajsic, G.N.; Spasic, M.B. Cold defence responses: The role of oxidative stress. Front. Biosci. (Schol. Ed.) 2011, 3, 416–427. [Google Scholar] [CrossRef] [PubMed]
- Speijer, D. Being right on Q: Shaping eukaryotic evolution. Biochem. J. 2016, 473, 4103–4127. [Google Scholar] [CrossRef][Green Version]
- Oelkrug, R.; Goetze, N.; Meyer, C.W.; Jastroch, M. Antioxidant properties of UCP1 are evolutionarily conserved in mammals and buffer mitochondrial reactive oxygen species. Free Radic. Biol. Med. 2014, 77, 210–216. [Google Scholar] [CrossRef]
- Rowland, L.A.; Bal, N.C.; Periasamy, M. The role of skeletal-muscle-based thermogenic mechanisms in vertebrate endothermy. Biol. Rev. Camb. Philos. Soc. 2015, 90, 1279–1297. [Google Scholar] [CrossRef]
- Nowack, J.; Giroud, S.; Arnold, W.; Ruf, T. Muscle Non-shivering Thermogenesis and Its Role in the Evolution of Endothermy. Front. Physiol. 2017, 8, 889. [Google Scholar] [CrossRef]
- Newman, S.A. Form and function remixed: Developmental physiology in the evolution of vertebrate body plans. J. Physiol. 2014, 592, 2403–2412. [Google Scholar] [CrossRef]
- Newman, S.A.; Mezentseva, N.V.; Badyaev, A.V. Gene loss, thermogenesis, and the origin of birds. Ann. N. Y. Acad. Sci. 2013, 1289, 36–47. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.; Dong, H.; Becker, A.S.; Dapito, D.H.; Modica, S.; Grandl, G.; Opitz, L.; Efthymiou, V.; Straub, L.G.; Sarker, G.; et al. Cold-induced epigenetic programming of the sperm enhances brown adipose tissue activity in the offspring. Nat. Med. 2018, 24, 1372–1383. [Google Scholar] [CrossRef] [PubMed]
- Koonin, E.V. Splendor and misery of adaptation, or the importance of neutral null for understanding evolution. BMC Biol. 2016, 14, 114. [Google Scholar] [CrossRef] [PubMed]
- Il’icheva, I.A.; Khodikov, M.V.; Poptsova, M.S.; Nechipurenko, D.Y.; Nechipurenko, Y.D.; Grokhovsky, S.L. Structural features of DNA that determine RNA polymerase II core promoter. BMC Genom. 2016, 17, 973. [Google Scholar] [CrossRef]
- Todolli, S.; Perez, P.J.; Clauvelin, N.; Olson, W.K. Contributions of Sequence to the Higher-Order Structures of DNA. Biophys. J. 2017, 112, 416–426. [Google Scholar] [CrossRef]
- Travers, A.; Muskhelishvili, G. DNA structure and function. FEBS J. 2015, 282, 2279–2295. [Google Scholar] [CrossRef]
- Ramirez, F.; Bhardwaj, V.; Arrigoni, L.; Lam, K.C.; Gruning, B.A.; Villaveces, J.; Habermann, B.; Akhtar, A.; Manke, T. High-resolution TADs reveal DNA sequences underlying genome organization in flies. Nat. Commun. 2018, 9, 189. [Google Scholar] [CrossRef]
- Jabbari, K.; Bernardi, G. An Isochore Framework Underlies Chromatin Architecture. PLoS ONE 2017, 12, e0168023. [Google Scholar] [CrossRef]
- Lian, S.; Liu, T.; Jing, S.; Yuan, H.; Zhang, Z.; Cheng, L. Intrachromosomal colocalization strengthens co-expression, co-modification and evolutionary conservation of neighboring genes. BMC Genom. 2018, 19, 455. [Google Scholar] [CrossRef]
- Bessiere, C.; Taha, M.; Petitprez, F.; Vandel, J.; Marin, J.M.; Brehelin, L.; Lebre, S.; Lecellier, C.H. Probing instructions for expression regulation in gene nucleotide compositions. PLoS Comput. Biol. 2018, 14, e1005921. [Google Scholar] [CrossRef]
- Yin, H.; Wang, G.; Ma, L.; Yi, S.V.; Zhang, Z. What Signatures Dominantly Associate with Gene Age? Genome Biol. Evol. 2016, 8, 3083–3089. [Google Scholar] [CrossRef] [PubMed]
- Fuertes, M.A.; Rodrigo, J.R.; Alonso, C. Do Intron and Coding Sequences of Some Human-Mouse Orthologs Evolve as a Single Unit? J. Mol. Evol. 2016, 82, 247–250. [Google Scholar] [CrossRef] [PubMed]
- Polyansky, A.A.; Hlevnjak, M.; Zagrovic, B. Analogue encoding of physicochemical properties of proteins in their cognate messenger RNAs. Nat. Commun. 2013, 4, 2784. [Google Scholar] [CrossRef] [PubMed]
- Keene, J.D. RNA regulons: Coordination of post-transcriptional events. Nat. Rev. Genet. 2007, 8, 533–543. [Google Scholar] [CrossRef] [PubMed]
- Cascarina, S.M.; Ross, E.D. Proteome-scale relationships between local amino acid composition and protein fates and functions. PLoS Comput. Biol. 2018, 14, e1006256. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Tang, H. The physical characteristics of human proteins in different biological functions. PLoS ONE 2017, 12, e0176234. [Google Scholar] [CrossRef]
- Karathia, H.; Kingsford, C.; Girvan, M.; Hannenhalli, S. A pathway-centric view of spatial proximity in the 3D nucleome across cell lines. Sci. Rep. 2016, 6, 39279. [Google Scholar] [CrossRef] [PubMed]
- Paz, A.; Frenkel, S.; Snir, S.; Kirzhner, V.; Korol, A.B. Implications of human genome structural heterogeneity: Functionally related genes tend to reside in organizationally similar genomic regions. BMC Genom. 2014, 15, 252. [Google Scholar] [CrossRef]
- Tsochatzidou, M.; Malliarou, M.; Papanikolaou, N.; Roca, J.; Nikolaou, C. Genome urbanization: Clusters of topologically co-regulated genes delineate functional compartments in the genome of Saccharomyces cerevisiae. Nucleic Acids Res. 2017, 45, 5818–5828. [Google Scholar] [CrossRef]
- Hlevnjak, M.; Zagrovic, B. Malleable nature of mRNA-protein compositional complementarity and its functional significance. Nucleic Acids Res. 2015, 43, 3012–3021. [Google Scholar] [CrossRef][Green Version]
- Nahalka, J. Protein-RNA recognition: Cracking the code. J. Theor. Biol. 2014, 343, 9–15. [Google Scholar] [CrossRef] [PubMed]
- Biro, J.C. Coding nucleic acids are chaperons for protein folding: A novel theory of protein folding. Gene 2013, 515, 249–257. [Google Scholar] [CrossRef] [PubMed]
- Yarus, M. The Genetic Code and RNA-Amino Acid Affinities. Life 2017, 7, 13. [Google Scholar] [CrossRef] [PubMed]
- de Ruiter, A.; Zagrovic, B. Absolute binding-free energies between standard RNA/DNA nucleobases and amino-acid sidechain analogs in different environments. Nucleic Acids Res. 2015, 43, 708–718. [Google Scholar] [CrossRef]
- Root-Bernstein, R.; Root-Bernstein, M. The ribosome as a missing link in prebiotic evolution II: Ribosomes encode ribosomal proteins that bind to common regions of their own mRNAs and rRNAs. J. Theor. Biol. 2016, 397, 115–127. [Google Scholar] [CrossRef]
- Aldana-Gonzalez, M.; Cocho, G.; Larralde, H.; Martinez-Mekler, G. Translocation properties of primitive molecular machines and their relevance to the structure of the genetic code. J. Theor. Biol. 2003, 220, 27–45. [Google Scholar] [CrossRef][Green Version]
- Babbitt, G.A.; Coppola, E.E.; Mortensen, J.S.; Ekeren, P.X.; Viola, C.; Goldblatt, D.; Hudson, A.O. Triplet-Based Codon Organization Optimizes the Impact of Synonymous Mutation on Nucleic Acid Molecular Dynamics. J. Mol. Evol. 2018, 86, 91–102. [Google Scholar] [CrossRef]
- Taghavi, A.; van der Schoot, P.; Berryman, J.T. DNA partitions into triplets under tension in the presence of organic cations, with sequence evolutionary age predicting the stability of the triplet phase. Q. Rev. Biophys. 2017, 50, e15. [Google Scholar] [CrossRef]
- Goldshtein, M.; Lukatsky, D.B. Specificity-Determining DNA Triplet Code for Positioning of Human Preinitiation Complex. Biophys. J. 2017, 112, 2047–2050. [Google Scholar] [CrossRef][Green Version]
- Lukacisin, M.; Landon, M.; Jajoo, R. Sequence-specific thermodynamic properties of nucleic acids influence both transcriptional pausing and backtracking in yeast. PLoS ONE 2017, 12, e0174066. [Google Scholar] [CrossRef]
- Trotta, E. Selection on codon bias in yeast: A transcriptional hypothesis. Nucleic Acids Res. 2013, 41, 9382–9395. [Google Scholar] [CrossRef]
- Dai, Z.; Dai, X. Gene expression divergence is coupled to evolution of DNA structure in coding regions. PLoS Comput. Biol. 2011, 7, e1002275. [Google Scholar] [CrossRef]
- Bosaeus, N.; Reymer, A.; Beke-Somfai, T.; Brown, T.; Takahashi, M.; Wittung-Stafshede, P.; Rocha, S.; Norden, B. A stretched conformation of DNA with a biological role? Q. Rev. Biophys. 2017, 50, e11. [Google Scholar] [CrossRef] [PubMed]
- Rokas, A. The origins of multicellularity and the early history of the genetic toolkit for animal development. Annu. Rev. Genet. 2008, 42, 235–251. [Google Scholar] [CrossRef]
- Michod, R.E. Evolution of individuality during the transition from unicellular to multicellular life. Proc. Natl. Acad. Sci. USA 2007, 104 (Suppl. 1), 8613–8618. [Google Scholar] [CrossRef]
- Kaiser, D. Building a multicellular organism. Annu. Rev. Genet. 2001, 35, 103–123. [Google Scholar] [CrossRef]
- Kupiec, J.J. A Darwinian theory for the origin of cellular differentiation. Mol. Gen. Genet. 1997, 255, 201–208. [Google Scholar] [CrossRef]






© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Auboeuf, D. Physicochemical Foundations of Life that Direct Evolution: Chance and Natural Selection are not Evolutionary Driving Forces. Life 2020, 10, 7. https://doi.org/10.3390/life10020007
Auboeuf D. Physicochemical Foundations of Life that Direct Evolution: Chance and Natural Selection are not Evolutionary Driving Forces. Life. 2020; 10(2):7. https://doi.org/10.3390/life10020007
Chicago/Turabian StyleAuboeuf, Didier. 2020. "Physicochemical Foundations of Life that Direct Evolution: Chance and Natural Selection are not Evolutionary Driving Forces" Life 10, no. 2: 7. https://doi.org/10.3390/life10020007
APA StyleAuboeuf, D. (2020). Physicochemical Foundations of Life that Direct Evolution: Chance and Natural Selection are not Evolutionary Driving Forces. Life, 10(2), 7. https://doi.org/10.3390/life10020007