Abstract
Existing non-intrusive load monitoring (NILM) methods predominantly rely on centralized models, which introduce privacy vulnerabilities and lack scalability in large industrial park scenarios equipped with distributed energy resources. To address this issue, a Federated Temporal Pattern-based NILM framework (FedTP-NILM) is proposed. It aims to ensure data privacy while enabling efficient load monitoring in distributed and heterogeneous environments, thereby extending the applicability of NILM technology in large-scale industrial park scenarios. First, a federated aggregation method is proposed, which integrates the FedYogi optimization algorithm with a secret sharing mechanism to enable the secure aggregation of local data. Second, a pyramid neural network architecture is presented to capture complex temporal dependencies in load identification tasks. It integrates temporal encoding, pooling, and decoding modules, along with an enhanced feature extractor, to better learn and distinguish multi-scale temporal patterns. In addition, a hybrid data augmentation strategy is proposed to expand the distribution range of samples by adding noise and linear mixing. Finally, experimental results validate the effectiveness of the proposed federated learning framework, demonstrating superior performance in both distributed energy device identification and privacy preservation.
1. Introduction
Within the framework of the carbon emission reduction goals and the advancement of intelligent energy systems, large industrial parks are accelerating the deployment of distributed energy resources such as photovoltaic and wind power [1,2,3]. Consequently, their load consumption patterns exhibit greater volatility and complexity. Given that traditional load monitoring methods fall short in meeting the requirements of non-intrusiveness, high precision, and privacy preservation, non-intrusive load monitoring is increasingly recognized as a key technology for achieving refined load management in large-scale industrial parks [4,5,6].
NILM methods are generally divided into two main categories: unsupervised learning and supervised learning. Unsupervised learning techniques, such as clustering, dimensionality reduction, and autoencoders, are used to automatically discover load behavior patterns [7]. In [8], a one-dimensional convolutional autoencoder was presented to extract features from time-series data, and the K-means clustering algorithm was proposed to classify different load events. Reference [9] extended the traditional hidden Markov model (HMM) by allowing multiple independent Markov chains to jointly influence the power sequence decomposition. Although unsupervised approaches offer strong adaptability and scalability without labeled data, they still face significant challenges in load identification accuracy and model interpretability.
Supervised learning relies on large amounts of labeled data for model training. Common approaches include traditional machine learning methods such as support vector machines (SVMs) and random forests [10,11]. These methods require relatively less training data and offer strong interpretability, but they struggle to handle complex data and lack scalability. A more prominent branch of supervised learning involves deep learning models based on deep neural networks (DNNs), which are capable of effectively processing high-dimensional and complex data [12,13]. Deep learning has become the most representative architecture applied to NILM. Reference [14] evaluated the mainstream deep learning models for NILM and highlighted the need to optimize aspects such as data dependency, real-time performance, and interpretability at the application level. In [15], a lightweight optimization method based on pre-training pruning was proposed to improve the computational efficiency of deep learning models. Reference [16] incorporated attribution maps as a regularization prior during training in deep neural network models, thereby improving both performance and interpretability. In [17], multi-feature auxiliary inputs were integrated into a denoising autoencoder (DAE) model to enhance feature representation capabilities. Reference [18] proposed a deep convolutional network (DCN) model combined with wavelet scattering transform, achieving more efficient and generalizable load disaggregation. Deep learning architectures in NILM research are becoming increasingly diverse, and their disaggregation accuracy has significantly improved compared to traditional methods. However, most existing models currently rely on centralized data training. Centralized training requires the aggregation of data from multiple parties, which raises concerns about privacy leakage and communication overhead.
Federated learning has emerged as an effective collaborative learning paradigm for privacy-preserving model training across decentralized data sources [19,20,21], offering a promising alternative to centralized NILM approaches that raise significant privacy concerns in industrial settings. However, most existing FL-based NILM methods still struggle to cope with the high heterogeneity of non-IID data across clients, which leads to reduced model generalizability and unstable training. At the same time, they often lack robust mechanisms to prevent gradient leakage, where sensitive information can still be inferred from shared model updates [22,23]. These limitations pose serious challenges for applying NILM in large-scale industrial parks with diverse energy infrastructures and complex load behaviors.
To address the aforementioned challenges, this study focuses on large-scale industrial park scenarios with integrated distributed energy resources, targeting industrial and commercial electricity loads and local renewable energy generation. It addresses key technical challenges in such environments, including privacy preservation, data heterogeneity, and multi-scale load identification. To this end, a federated time pattern-based framework, FedTP-NILM, is proposed for distributed load disaggregation. This framework enables intelligent and privacy-preserving NILM across distributed and multi-region environments, aiming to meet the practical technical demands of large-scale industrial energy consumption systems. The main contributions of this study include the following aspects:
- A federated aggregation approach is proposed to achieve secure and efficient aggregation across multiple clients. It integrates the FedYogi optimization algorithm with a secret sharing scheme to address the problems of data heterogeneity and privacy leakage.
- A pyramid neural network is presented to capture complex temporal dependencies in load identification. The network learns and distinguishes multi-scale temporal patterns through an enhanced feature extraction mechanism.
- A hybrid data augmentation strategy is built to improve model generalization and robustness. The strategy introduces controlled perturbations through noise injection and rearranged segments via linear mixing to broaden the sample distribution.
The remainder of this paper is organized as follows. Section 2 introduces related work on the FedTP-NILM framework. Section 3 presents an overview of the proposed FedTP-NILM architecture. Section 4 describes the experimental procedure and analyzes the results. Finally, Section 5 concludes the study.
2. Problem Description
Non-intrusive load monitoring is widely used for identifying energy usage patterns without installing sensors on individual devices [14]. In large-scale industrial parks, NILM technology significantly contributes to energy efficiency management, demand response implementation, and accurate accounting for energy market transactions. However, its application faces several technical challenges:
- (1)
- Industrial environments involve diverse and fluctuating loads due to the integration of distributed energy sources like solar and wind. These complex patterns make it difficult for traditional models to generalize across different clients or regions.
- (2)
- The data from different industrial sites are highly heterogeneous and non-IID, influenced by equipment types, processes, and schedules. This makes centralized training less effective and prone to overfitting.
- (3)
- Energy data may reveal sensitive business information, which are often subject to strict privacy regulations. As a result, centralized data processing is either discouraged or prohibited. This regulatory environment makes privacy-compliant research no longer optional but essential.
To address these practical challenges, NILM models need to ensure not only accuracy but also robust privacy protection and distributed training capabilities. Federated learning emerges as a highly suitable solution by enabling multiple distributed nodes to perform local training and collaboratively aggregate into a global model. A common horizontal federated learning framework is shown in Figure 1. This approach effectively utilizes limited local data, enhancing generalization across heterogeneous scenarios. Through optimized aggregation algorithms, federated learning significantly mitigates data consistency issues, improving convergence stability and overall model performance in complex industrial environments. Additionally, federated learning inherently supports privacy preservation, as only model parameters or gradients, not the raw data, are shared among nodes. This mechanism satisfies privacy protection requirements imposed by regulatory bodies, effectively mitigating risks associated with sensitive information leakage.
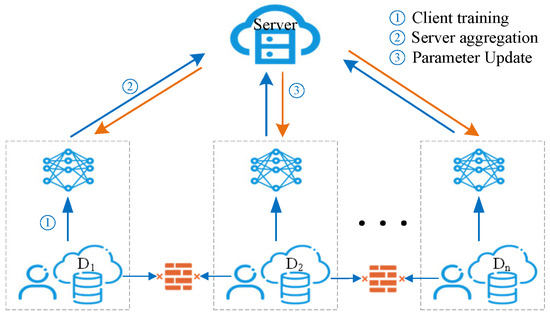
Figure 1.
Horizontal federated learning architecture.
These factors highlight the necessity and appropriateness of the proposed FedTP-NILM framework, which is specifically designed to manage data heterogeneity, ensure regulatory compliance on privacy, and deliver stable, high-performance NILM solutions for complex industrial scenarios.
To train and evaluate NILM models under realistic industrial scenarios, we employ a simulation-based approach using the IES-134 integrated energy system (self-developed simulation platform, developed at Northeastern University, Shenyang, China). This system models interconnected electricity, heat, gas, and cooling networks, and generates time-series load data that reflect complex interactions among distributed energy resources and consumer behavior. This simulation platform provides a practical basis for validating the FedTP-NILM framework.
3. FedTP-NILM Framework
3.1. Review of FedTP-NILM
The FedTP-NILM framework is a distributed, privacy-preserving non-intrusive load monitoring system that integrates federated learning with time-series pattern recognition to optimize the NILM task. The FedTP-NILM framework is shown in Figure 2, which consists of two core layers: the client training layer and the server aggregation layer.
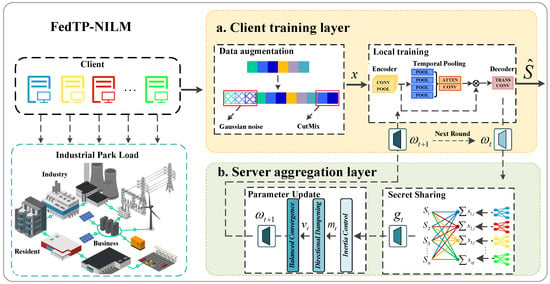
Figure 2.
FedTP-NILM framework diagram.
- Client Training Layer. In this layer, the client executes the hybrid data augmentation strategy and trains the local model. On each client, the collected data is preprocessed and transformed into a time-series format suitable for training. The local model is trained using data associated with the client. FedTP-NILM employs privacy-enhancing mechanisms and secure aggregation protocols to prevent access to private data between clients. After local updates, clients upload model parameters to the server for weighted aggregation, triggering the next round of federated training.
- Server Aggregation Layer. In this layer, the server receives the aggregated gradient fragments, updates the global gradient through the FedYogi optimization method, and distributes the updated gradient parameters to each client for the next round of training. After each round of gradient aggregation, the global model is used to evaluate the unified validation set or various typical load data, monitor the performance of federated learning training in real time, and determine whether the model has reached the convergence standard.
As illustrated in Figure 2, the input to the model is a total power time series , where is the number of input channels and T denotes the sequence length including boundaries. The model generates the activation status for each device type at every time step, represented as . The output channel corresponds to the number of device types to be predicted simultaneously—in this case, three types of energy node devices. For each device type c, the output indicates the predicted ON-state probability at time step t. By applying both a threshold function and a state duration rule, the final prediction is given by
where denotes the threshold used to determine the state of device c, and denote the minimum duration constraints for the ON and OFF states, respectively; and PostProcess represents a segment-pruning algorithm that enforces the minimum duration rule.
3.2. Security Aggregation Strategy
Each client computes its local gradient based on the current model parameters , and applies additive secret sharing to split it into n random shares. For client i, the gradient vector is split as , where denotes the share that client i sends to client j, and each individual share carries no meaningful information. Then, each client j aggregates the shares it receives from all clients to obtain a local sum: . Finally, the server collects all aggregated shares , and computes the global gradient update as . This process ensures that the original gradient of any individual client cannot be reconstructed by other clients or the server, thereby preserving privacy. The polymerization process is shown in Figure 3.
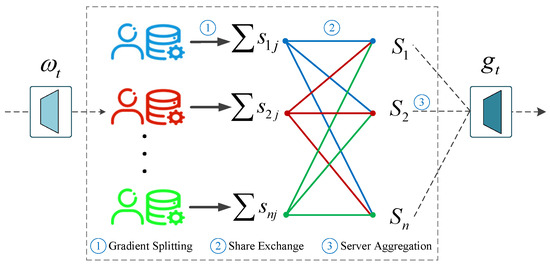
Figure 3.
Secret sharing process for exchanging gradient fragments.
Only partial gradient fragments are exchanged, making it infeasible to reconstruct the parameters of any client from a single share. This decentralized exchange mechanism preserves inter-client privacy, as no individual party possesses sufficient information to infer the data of another client. Furthermore, the server only receives aggregated updates, which prevents the reconstruction or inference of the model parameters of any specific client. Consequently, all raw training data remains strictly local on each client device throughout the learning process, thereby maximizing data confidentiality and ensuring compliance with privacy-preserving principles.
To address the heterogeneity of the distributed load energy data, the FedTP framework adopts the FedYogi optimization algorithm for global parameter aggregation. FedYogi, an improved variant of FedAdam, is specifically designed to enhance convergence stability in federated learning environments with non-IID data [24]. FedAdam incorporates first- and second-order moment estimations to guide parameter updates using the Adam optimizer. Building upon this, FedYogi introduces direction-adaptive adjustments to the second-order moment, thereby reducing gradient oscillations and improving the robustness of global model updates. Given t training rounds, the global model momentum and the update rule for the global parameters are defined as follows:
where denotes the aggregated gradients from the clients; denotes the first-order momentum; denotes the second-order moment; denotes the learning rate; and denotes a small constant added for numerical stability to prevent division by zero.
3.3. Hybrid Data Augmentation Strategies
Deep learning models typically require large amounts of training data to achieve strong generalization [14]. In distributed energy datasets, labeled node power consumption patterns are often limited and lack richness. Training directly on such limited or imbalanced datasets can easily lead to model overfitting, making it difficult to identify the noise and anomalies present in real-world power consumption data [25,26].
To address the limited diversity and imbalance in distributed energy datasets, particularly in federated learning scenarios characterized by significant local data heterogeneity, a hybrid data augmentation strategy is proposed. This strategy aims to enhance model robustness against unseen variations and improve the generalization ability across clients. Specifically, two complementary techniques are integrated: (1) Gaussian noise injection, which simulates real-world sensor perturbations and grid fluctuations to improve tolerance to noise; and (2) CutMix-based linear segment mixing, which rearranges and fuses segments from the different samples to simulate temporal transitions and expand the effective feature space.
Gaussian noise is employed to simulate realistic disturbances such as sensor drift, electromagnetic interference, and small-scale fluctuations in load signals. It can be mathematically expressed as , where is the mean of the Gaussian distribution, representing the central tendency of the noise, and is the variance, which determines the spread or intensity of the perturbation. These perturbations help the model learn to distinguish genuine load transitions from transient anomalies, improving its robustness to noise-prone or low-quality data commonly encountered in industrial NILM deployments.
The CutMix-based linear mixing strategy generates hybrid samples by combining segments from different time-series windows. While CutMix is primarily applied in image classification, numerous studies have demonstrated its effectiveness in stabilizing and boosting performance in classification tasks involving data sequences [25]. The resulting augmented sample is created through a weighted combination of two original samples, expressed as , where and are two different input samples, and is a mixing coefficient drawn from a Beta distribution . The parameter controls the mixing ratio, enabling the generation of intermediate representations near class boundaries. This process increases the diversity of temporal patterns and introduces ambiguous cases near decision boundaries, enabling the model to learn smoother activation transitions and more discriminative representations of load changes.
3.4. Client Training Model
In NILM tasks, device activation states are often influenced by temporal context and frequency variations. By aggregating features at multiple scales, the pyramid neural network architecture in FedTP-NILM effectively models both long-term dependencies and transient variations in time-series signals. To strengthen the temporal representation capability of the model, a self-attention mechanism is integrated, allowing for the better identification of critical time-dependent patterns. As shown in Figure 4, the model comprises three main components: a temporal encoding layer, a temporal pooling layer, and a transposed convolution decoding layer.
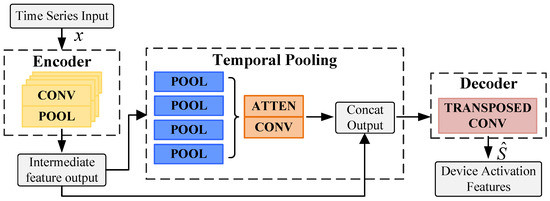
Figure 4.
Pyramid-like neural network model.
- Temporal Encoding Layer. This layer primarily serves to extract fine-grained features from local temporal segments and establish long-range dependencies, thereby providing rich contextual information for subsequent load classification. The encoder performs feature extraction on the input time series data using a stacked structure composed of convolutional filters and max-pooling layers. While sacrificing some temporal resolution, it enables the extraction of more abstract and hierarchical representations from the signal. The encoding module uses the ReLU activation function to introduce nonlinearity and combines it with the BatchNorm1d layer for batch normalization to stabilize the training process.
- Temporal Pooling Layer. This layer performs temporal downsampling to compress redundant information and extract key trend variations. It consists of four pooling modules, each reducing the temporal resolution of the encoded features. By aggregating multi-resolution features from the encoder output, the layer generates supplementary inputs for the decoder. Additionally, these modules capture the dependencies between different time steps and global context information through self-attention mechanism. Finally, features are upsampled via linear interpolation to match the temporal resolution of the encoder. These global contextual features are concatenated with fine-grained encoder outputs to form a unified multi-scale representation, which facilitates the model to extract local and global dynamic patterns from load curves at different temporal perspectives.
- Transposed Convolution Decoding Layer. This layer reconstructs the temporal resolution of the output sequence while preserving the learned feature representations. Using transposed convolution operations, it upsamples the feature maps to gradually restore the original sequence length. The decoder combines the coarse-grained features from the temporal pooling layer and the fine-grained features from the encoder through concatenation. The fused features are refined through a sequence of transposed convolutions, batch normalization, and ReLU activations to reconstruct the high-resolution output. Finally, the decoder outputs a time-aligned sequence of activation probabilities indicating the ON/OFF status of each device.
4. Experimental Setup
4.1. Dataset Settings
The experimental data in this study are generated using our self-developed IES-134 simulation system, which models realistic load behaviors in industrial scenarios. This system adopts a surrogate model-based multi-objective optimization framework, allowing the efficient and flexible generation of diverse power consumption patterns. Such frameworks have been widely applied in engineering domains such as structural design, aerospace systems, and energy modeling [27,28,29]. These methods help improve simulation efficiency while maintaining model fidelity and provide a theoretical foundation for the construction of systems such as IES-134. IES-134 simulates distributed energy scenarios and generates an open dataset comprising four interconnected subnetworks: electricity, gas, thermal, and cooling. Its power node topology is shown in Figure 5.
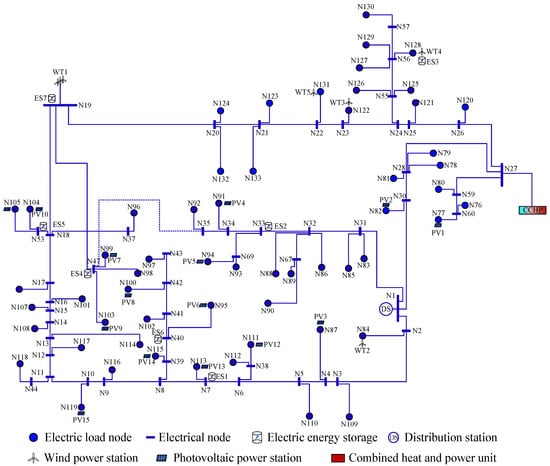
Figure 5.
IES-134 power node system topology.
The public distributed energy dataset generated by the power grid system covers grid load consumption data from January to December 2023, including abnormal data under extreme weather conditions and equipment failure scenarios. With a sampling interval of one hour, the dataset is well-suited for long-term load forecasting applications. While the low sampling frequency reduces computational complexity, it may also compromise the monitoring accuracy.
A single region within the IES-134 simulation is regarded as an individual client in the proposed federated NILM framework, and multiple simulation datasets represent the data distributions of different regions, thereby constructing a multi-client NILM federated training scenario. The photovoltaic and wind power stations in the system are deployed at load nodes such as industry, commerce, and data centers. Three of these nodes are selected as the targets for load monitoring, with their labels defined as: commercial power consumption with PV generation, charging station power consumption with PV generation, and commercial power consumption with wind generation. These correspond to nodes N103, N119, and N122 in the IES-134 system.
4.2. Evaluation Metrics
The study employs five evaluation metrics to assess the performance of the binary classification model in the FedTP-NILM framework. The terms , , , and refer to the core components of the confusion matrix: true positive, true negative, false positive, and false negative, respectively. Based on these values, evaluation metrics such as accuracy, precision, recall, and F1-score are defined. The formulations of these metrics are as follows:
These metrics are widely accepted in NILM research and enable a balanced evaluation of classification performance, especially when imbalanced data are involved [14]. Reference [26] emphasizes that using only accuracy can be misleading in the case of class imbalance, making precision and recall more reliable metrics for evaluation. Reference [30] conducted a comparative analysis of ML models and evaluated them using accuracy, precision, recall, and F1 to highlight performance differences under imbalanced class distributions [31] adopted the F1-score to assess the balance between detecting appliance activations and avoiding false alarms, demonstrating its effectiveness in multi-label NILM classification tasks.
In addition, in order to evaluate the stability of the model, the standard deviation of the multiple evaluation indicators is calculated, and a stability indicator is defined as follows:
where M is the number of experiments, represents the performance metric, is the mean value of these metrics, denotes the average standard deviation of the performance metric for the i-th device, and is the maximum average standard deviation among all models in the comparison group.
4.3. Training Process and Results
Within the proposed framework, distributed energy nodes are treated as monitoring devices, and the model is formulated as a classification task to detect the activation status of the designated equipment. A node is considered to be in an active state when the absorbed power exceeds a predefined threshold. Compared to regression or other model configurations, classification models may sacrifice some precision but offer easier implementation and faster response times. The relevant thresholds set during data preprocessing are listed in Table 1. These power consumption thresholds have practical significance; different threshold settings can serve distinct purposes in energy optimization or anomaly detection. Given that the sampling interval is one hour and that power curves typically exhibit minimal fluctuation during downward transitions, the shutdown duration threshold is set to a single time step in the experiment. In contrast, the activation duration threshold is more strictly enforced to ensure the accurate recognition of active states.

Table 1.
Related threshold information settings.
The federated learning experiment was conducted using data from five distributed node simulations. After unified preprocessing, the data were partitioned into training, validation, and testing time windows according to a specified ratio. To simulate clients in the federated learning framework, the distributed datasets from multiple node simulations were sequentially assigned to different clients, while ensuring data independence during the partitioning process. The data distribution of the selected samples is listed in Table 2. Each client generates training samples using a sliding window mechanism on the dataset, where each sample depends on the power state transitions of the main meter and the target electrical devices within a continuous time interval.
Table 2.
Distribution of federated datasets.
Each local dataset is associated with an independent training model, and the loss information is recorded throughout the training process. The Adam optimizer used for training includes a regularization term to prevent overfitting. The learning rate scheduling and optimal model saving are conducted based on changes in validation loss. The test loss does not influence model parameters during training; it is used solely to monitor the generalization capability of the model across training epochs. Therefore, each client uses the same test dataset, which is distinct from the training data.
Network parameters are optimized using the Adam optimizer, with an initial learning rate set to , and the L2 regularization coefficient is set to to mitigate overfitting. Training employs a ReduceLROnPlateau scheduler to adjust the learning rate in response to validation loss. Upon the completion of training, each client extracts all parameter tensors with gradients from the current model. These gradients are then processed via a secret sharing mechanism before being transmitted to the server for aggregation.
Figure 6a shows the convergence curves of the training loss, validation loss, and test loss during the local model training process. Figure 6b illustrates the training loss curves from multiple clients in the aggregated model. For both types of models trained, convergence can be achieved around epoch 200, and both the validation and test losses exhibit minimal variation. This consistent loss behavior suggests that that the model progressively reaches optimal performance during training.
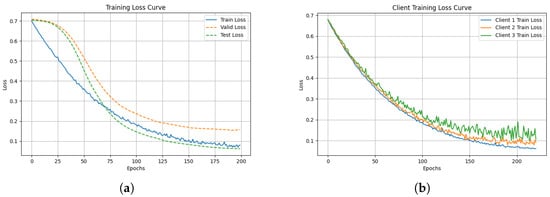
Figure 6.
The loss function of the training model converges in both individual and federated environments. (a) Local model training results. (b) Multi-client federated learning training results.
4.4. Performance Evaluation
The study evaluates the models used in the FedTP-NILM framework and their performance enhancement schemes. Table 3 presents two types of models: the local training model and the federated aggregation model. The local training model uses distributed energy data from a single node simulation only, representing a single client unable to aggregate data for training. The federated aggregation model trains on distributed data from multiple node simulations, allowing data sharing among parties via a central server. The results show the average score Meanand standard deviation std over five independent runs on the test set, quantifying the performance variability of the model across different runs.
Table 3.
Performance comparison of trained models in individual and federated environments.
By systematically comparing the client evaluation performance of the local training model and the federated aggregation model, this study analyzes the impact of the federated learning framework on model training effectiveness, thereby assessing the feasibility of the proposed scheme. Experimental results demonstrate that, on the distributed energy dataset, the monitoring performance of node devices generally achieves high scores, with the federated model outperforming the local model overall. Notably, the recognition precision at energy nodes N103 and N122 improved by 6.64% and 8.92%, respectively, which fully validates the significant advantages of federated learning in scenarios with limited data volume or insufficient local model capacity.
The proposed FedTP-NILM framework, by jointly training data from multiple regions, exhibits strong generalization ability and performance gains from cross-node information fusion. Regarding the standard deviation of the results, the federated model demonstrates higher stability for some metrics. This is especially true for photovoltaic nodes. In these nodes, the standard deviation values of multiple indicators are lower compared to those from the local model. This indicates smaller prediction fluctuations across training rounds or data subsets. It also suggests better consistency in the performance of the federated model.
For wind turbine node N122, due to the larger inherent data fluctuations, the overall standard deviation of model outputs is higher; however, the federated model still demonstrates a stronger fitting ability for complex load characteristics. The recognition performance and stability of photovoltaic nodes generally surpass the performance of wind turbine nodes. This difference is related to the periodicity and regularity found in the input data for photovoltaic nodes. Such characteristics make it easier for the model to learn the patterns of load variation. Wind power nodes are more influenced by factors such as wind speed, resulting in high data volatility. Local models find it difficult to accurately capture these patterns, whereas federated models improve recognition robustness through cross-node information sharing.
4.5. Ablation Experiments
To evaluate the performance contributions of data augmentation and the self-attention module in the FedTP-NILM framework, ablation experiments were conducted. The three following comparison schemes were designed: (1) FedTP-NILM: Framework with both data augmentation and the self-attention module. (2) No Augmentation: FedTP-NILM without the data augmentation component, used to evaluate the role of noise injection and linear mixing in improving generalization and handling non-IID data. (3) No Self-Attention: FedTP-NILM with the self-attention module removed, used to assess the mechanism’s contribution to temporal dependency modeling. All schemes were trained and evaluated under identical experimental conditions to ensure the comparability of the results.
Figure 7 presents a comparison of the performance metrics for the three model variants across the energy device nodes N103, N119, and N122. The full FedTP-NILM consistently achieves the best performance across all metrics, validating the effectiveness and synergy of the data augmentation strategy and self-attention mechanism.
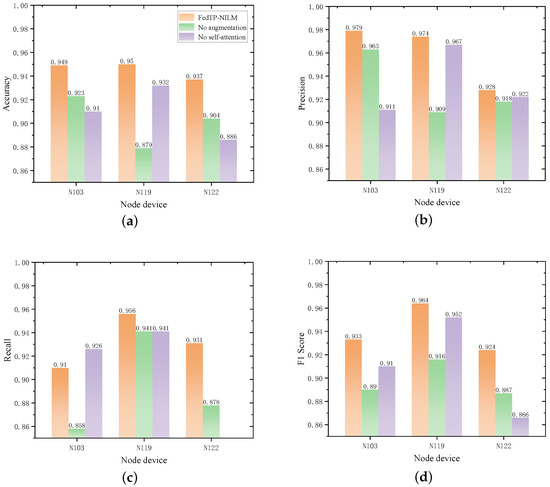
Figure 7.
Ablation experiment performance comparison chart. (a) Accuracy comparison; (b) Precision comparison; (c) Recall comparison; (d) F1 Score comparison.
For the photovoltaic nodes N103 and N119, the removal of data augmentation led to a significant decrease in recall, with reductions of 5.2 percent for N103 and 4.8 percent for N119, accompanied by a notable drop in F1 scores. This confirms that the hybrid augmentation strategy is vital for capturing weak load events and mitigating data imbalance under federated conditions.
The exclusion of the self-attention module leads to a more pronounced degradation across Accuracy and F1 scores. For instance, at node N122, the F1 score dropped from 0.924 to 0.866, and Recall declined by over 8 percentage points. This demonstrates that self-attention plays a key role in learning long-term temporal structures and modeling complex load patterns.
From the analysis of these results, it can be concluded that the data augmentation module enhances the generalization ability of the model and increases its sensitivity to weak load events. Meanwhile, the self-attention module strengthens the modeling of temporal structures and improves the expression of deep features. Together, these improvements enhance the robustness and adaptability of the FedTP-NILM framework in federated learning environments.
4.6. Comparison of Different Models
Additionally, to comprehensively evaluate the effectiveness of the proposed FedTP-NILM framework in load identification tasks, three deep learning models were selected for performance comparison: FedDL [32], ELECTRIcity [33] and ITCN-Attack [34]. All three models were implemented within the FedTP-NILM framework, maintaining consistent data splits and federated settings to ensure a fair comparison of the performance of different feature extraction structures. The results are presented in Table 4.
Table 4.
Performance comparison of different neural network models under FedTP-NILM.
Figure 8 presents the performance comparison of various models in the benchmark experiments. Overall, the baseline model under the FedTP-NILM framework consistently outperforms the three other structures in terms of stability and adaptability to complex scenarios. However, it is noteworthy that although all models are implemented within the unified FedTP-NILM framework with consistent data splits and federated configurations, differences in architectural design and parameter settings within the framework may still impact training effectiveness and final performance. For example, the LSTM model, due to its sequential dependency design, is more sensitive to gradient stability and long-sequence modeling, making it less effective at extracting key features from multi-source heterogeneous load signals. The Transformer architecture, although capable of global modeling, is prone to overfitting or underfitting in energy device nodes with limited training data (e.g., N122). The performance of a model structure is closely related to its parameter adaptability and module integration for specific tasks. In contrast, the FedTP-NILM framework is better tailored to the characteristics of federated learning, particularly in scenarios involving non-IID data and substantial client heterogeneity, making it more practical and forward-looking.
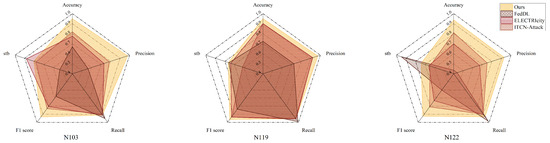
Figure 8.
Comparison of NILM performance under different network models. The references shown in the figure are cited in the format of author and year, e.g., (Zhou et al., 2022 [32]), (Sykiotis et al., 2022 [33]), and (Li et al., 2024 [34]). All referenced works are fully cited in the main text.
5. Conclusions
This study has proposed FedTP-NILM framework to enhance privacy protection and improve load detection accuracy in NILM. First, a federated aggregation method has been proposed to achieve secure and efficient collaborative learning across multiple clients by integrating FedYogi optimization and a secret sharing scheme. Next, a pyramid neural network has been presented to improve multi-dimensional temporal pattern recognition through enhanced feature extraction. A hybrid data augmentation strategy has been built to expand the training data distribution by adding controlled noise and reorganizing data segments. Finally, the proposed framework has been verified to be effective by node data of IES-134 system simulation. Experimental results have shown that this method achieves high accuracy in load recognition. Specifically, the F1 score exceeded 0.92 across all monitoring nodes, indicating a strong balance between precision and recall.
Author Contributions
Conceptualization, C.Z. (Chi Zhang); Data curation, C.Z. (Chi Zhang), B.L., X.H., and Z.Z.; Funding acquisition, B.L. and X.H.; Investigation, B.L. and C.Z. (Chenghao Zhou); Methodology, C.Z. (Chi Zhang) and B.L.; Supervision, X.H. and Z.J.; Validation, Z.Z.; Writing—original draft, C.Z. (Chi Zhang); Writing—review and editing, C.Z. (Chi Zhang), B.L., Z.Z., and C.Z. (Chenghao Zhou). All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 62303103, and Grant 62373089, in part by the Fundamental Research Funds for the Central Universities in China under Grant N25ZJL020, in part by the Natural Science Foundation of Liaoning Province under Grant 2023-BSBA-140, and in part by the Scientific Research Project of Liaoning Provincial Department of Education under Grant JYTQN2023161.
Data Availability Statement
The data presented in this study are available upon request from the corresponding author.
Conflicts of Interest
The authors declare no competing interest. The author Biqi Liu was employed by the company State Grid Liaoning Information and Communication Company. There is no conflict of interest between any of the authors and the company.
References
- Liu, Z.; Huang, B.; Hu, X.; Du, P.; Sun, Q. Blockchain-based renewable energy trading using information entropy theory. IEEE Trans. Netw. Sci. Eng. 2024, 11, 5564–5575. [Google Scholar] [CrossRef]
- Gao, H.; Jin, T.; Feng, C.; Li, C.; Chen, Q.; Kang, C. Review of virtual power plant operations: Resource coordination and multidimensional interaction. Appl. Energy 2024, 357, 122284. [Google Scholar] [CrossRef]
- Mourtzis, D.; Angelopoulos, J. Reactive power optimization based on the application of an improved particle swarm optimization algorithm. Machines 2023, 11, 724. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, H.; Ma, D.; Wang, R. A tnGAN-based leak detection method for pipeline network considering incomplete sensor data. IEEE Trans. Instrum. Meas. 2021, 70, 3510610. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, H.; Ma, D.; Wang, R.; Tu, P. Small leak location for intelligent pipeline system via action-dependent heuristic dynamic programming. IEEE Trans. Ind. Electron. 2022, 69, 11723–11732. [Google Scholar] [CrossRef]
- Gao, H.; Jin, T.; Zheng, K.; Ahn, S.J.; Kang, C. Dynamic construction and enhanced control of VPPs considering trade matching in IoT-based local energy system. IEEE Internet Things J. 2024, 11, 24523–24537. [Google Scholar] [CrossRef]
- Tanoni, G.; Principi, E.; Squartini, S. Non-intrusive load monitoring in industrial settings: A systematic review. Renew. Sustain. Energy Rev. 2024, 202, 114703. [Google Scholar] [CrossRef]
- Munoz, O.; Ruelas, A.; Rosales-Escobedo, P.F.; Ibarra-Esquer, J.E.; Reyes-Zamora, R.A.; Acuna, A.; Suastegui, A. Design and implementation of an automatic and self-adaptive NILM system using unsupervised learning and an IoT platform. Electr. Power Syst. Res. 2025, 241, 111376. [Google Scholar] [CrossRef]
- Kumar, P.; Abhyankar, A.R. A time efficient factorial hidden Markov model-based approach for non-intrusive load monitoring. IEEE Trans. Smart Grid 2023, 14, 3627–3639. [Google Scholar] [CrossRef]
- Jung, G.; Kim, G.Y.; Ahn, S.H. Sub-Nyquist harmonic current component extraction using band pass filters for NILM. Int. J. Precis. Eng. Manuf.-Green Technol. 2025. [Google Scholar]
- Lu, L.; Kang, J.-S.; Yu, M. Event detection based on robust random cut forest algorithm for non-intrusive load monitoring. J. Mod. Power Syst. Clean Energy 2024, 12, 2019–2029. [Google Scholar] [CrossRef]
- Schroeder, A.; McClure, P.; Thulasiraman, P. Anomaly detection in operational technology systems using non-intrusive load monitoring based on supervised learning. In Proceedings of the 2024 IEEE International Conference on Cyber Security and Resilience (CSR), London, UK, 29–31 July 2024; pp. 1–6. [Google Scholar]
- Han, K.; Wang, W.; Guo, J. Research on a bearing fault diagnosis method based on a CNN-LSTM-GRU model. Machines 2024, 12, 927. [Google Scholar] [CrossRef]
- Rafiq, H.; Manandhar, P.; Rodriguez-Ubinas, E.; Qureshi, O.A.; Palpanas, T. A review of current methods and challenges of advanced deep learning-based non-intrusive load monitoring (NILM) in residential context. Energy Build. 2024, 305, 113890. [Google Scholar] [CrossRef]
- Athanasoulias, S.; Sykiotis, S.; Kaselimi, M.; Doulamis, A.; Doulamis, N.; Ipiotis, N. OPT-NILM: An Iterative Prior-to-Full-Training Pruning Approach for Cost-Effective User Side Energy Disaggregation. IEEE Trans. Consum. Electron. 2023, 70, 4435–4446. [Google Scholar] [CrossRef]
- Batic, D.; Stankovic, V.; Stankovic, L. XNILMBoost: Explainability-informed load disaggregation training enhancement using attribution priors. Eng. Appl. Artif. Intell. 2025, 141, 109766. [Google Scholar] [CrossRef]
- Pu, Z.; Huang, Y.; Weng, M.; Meng, Y.; Zhao, Y.; He, G. Enhancing non-intrusive load monitoring with weather and calendar feature integration in DAE. Front. Energy Res. 2024, 12, 1361916. [Google Scholar] [CrossRef]
- de Aguiar, E.L.; da Silva Nolasco, L.; Lazzaretti, A.E.; Pipa, D.R.; Lopes, H.S. ST-NILM: A wavelet scattering-based architecture for feature extraction and multilabel classification in NILM signals. IEEE Sens. J. 2024, 24, 10540–10550. [Google Scholar] [CrossRef]
- Liu, B.; Lv, N.; Guo, Y.; Li, Y. Recent advances on federated learning: A systematic survey. Neurocomputing 2024, 565, 128019. [Google Scholar] [CrossRef]
- Yang, W.; Yu, G. Federated multi-model transfer learning-based fault diagnosis with peer-to-peer network for wind turbine cluster. Machines 2022, 10, 972. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, J.; Wang, Z. Bearing faulty prediction method based on federated transfer learning and knowledge distillation. Machines 2022, 10, 376. [Google Scholar] [CrossRef]
- Wang, H.; Si, C.; Liu, G.; Zhao, J.; Wen, F.; Xue, Y. Fed-NILM: A federated learning-based non-intrusive load monitoring method for privacy-protection. Energy Convers. Econ. 2022, 3, 51–60. [Google Scholar] [CrossRef]
- Hudson, N.; Hossain, M.J.; Hosseinzadeh, M.; Khamfroush, H.; Rahnamay-Naeini, M.; Ghani, N. A framework for edge intelligent smart distribution grids via federated learning. In Proceedings of the 2021 International Conference on Computer Communications and Networks (ICCCN), Athens, Greece, 19–22 July 2021; pp. 1–9. [Google Scholar]
- Riedel, P.; Reichert, M.; Von Schwerin, R.; Hafner, A.; Schaudt, D.; Singh, G. Performance analysis of federated learning algorithms for multilingual protest news detection using pre-trained DistilBERT and BERT. IEEE Access 2023, 11, 134009–134022. [Google Scholar] [CrossRef]
- Guo, P.; Yang, H.; Sano, A. Empirical study of mix-based data augmentation methods in physiological time series data. In Proceedings of the 2023 IEEE 11th International Conference on Healthcare Informatics (ICHI), Houston, TX, USA, 26–29 June 2023; IEEE: New York, NY, USA, 2023; pp. 206–213. [Google Scholar]
- Chen, T.; Yuan, Y.; Gao, J.; Guo, S.; Yang, P. Non-intrusive load monitoring based on time-enhanced multidimensional feature visualization. Sci. Rep. 2025, 15, 4800. [Google Scholar] [CrossRef]
- Díaz-Manríquez, A.; Toscano, G.; Barron-Zambrano, J.H.; Tello-Leal, E. A review of surrogate assisted multiobjective evolutionary algorithms. Comput. Intell. Neurosci. 2016, 2016, 9420460. [Google Scholar] [CrossRef]
- Zhu, H.; Li, D.; Nie, H.; Wei, X.; Wei, Y. Multiobjective optimization of a staggered-rotor octocopter design based on a surrogate model. Aerosp. Sci. Technol. 2023, 139, 108387. [Google Scholar] [CrossRef]
- Araújo, G.R.; Gomes, R.; Gomes, M.G.; Guedes, M.C.; Ferrão, P. Surrogate models for efficient multi-objective optimization of building performance. Energies 2023, 16, 4030. [Google Scholar] [CrossRef]
- Shabbir, N.; Vassiljeva, K.; Nourollahi Hokmabad, H.; Husev, O.; Petlenkov, E.; Belikov, J. Comparative analysis of machine learning techniques for non-intrusive load monitoring. Electronics 2024, 13, 1420. [Google Scholar] [CrossRef]
- da Silva Nolasco, L.; Lazzaretti, A.E.; Mulinari, B.M. DeepDFML-NILM: A new CNN-based architecture for detection, feature extraction and multi-label classification in NILM signals. IEEE Sens. J. 2021, 22, 501–509. [Google Scholar] [CrossRef]
- Zhou, X.; Feng, J.; Wang, J.; Pan, J. Privacy-preserving household load forecasting based on non-intrusive load monitoring: A federated deep learning approach. PeerJ Comput. Sci. 2022, 8, e1049. [Google Scholar] [CrossRef] [PubMed]
- Sykiotis, S.; Kaselimi, M.; Doulamis, A.; Doulamis, N. Electricity: An efficient transformer for non-intrusive load monitoring. Sensors 2022, 22, 2926. [Google Scholar] [CrossRef] [PubMed]
- Li, D.; Yang, Q.; Zhang, F.; Wang, Y.; Qian, Y.; An, D. Research on Privacy Issues in Smart Metering System: An Improved TCN-Based NILM Attack Method and Practical DRL-Based Rechargeable Battery Assisted Privacy Preserving Method. IEEE Trans. Autom. Sci. Eng. 2024, 21, 2882–2899. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).