

Robotic Positioning Accuracy Enhancement via Memory Red Billed Blue Magpie Optimizer and Adaptive Momentum PSO Tuned Graph Neural Network



Abstract
1. Introduction
- (a)
- A memory-enhanced RBMO algorithm is proposed to accurately identify geometric errors in robot kinematic calibration, improving absolute positioning accuracy.
- (b)
- An adaptive momentum PSO is designed to optimize the GNN model, enabling effective compensation of nonlinear and time-varying non-geometric error.
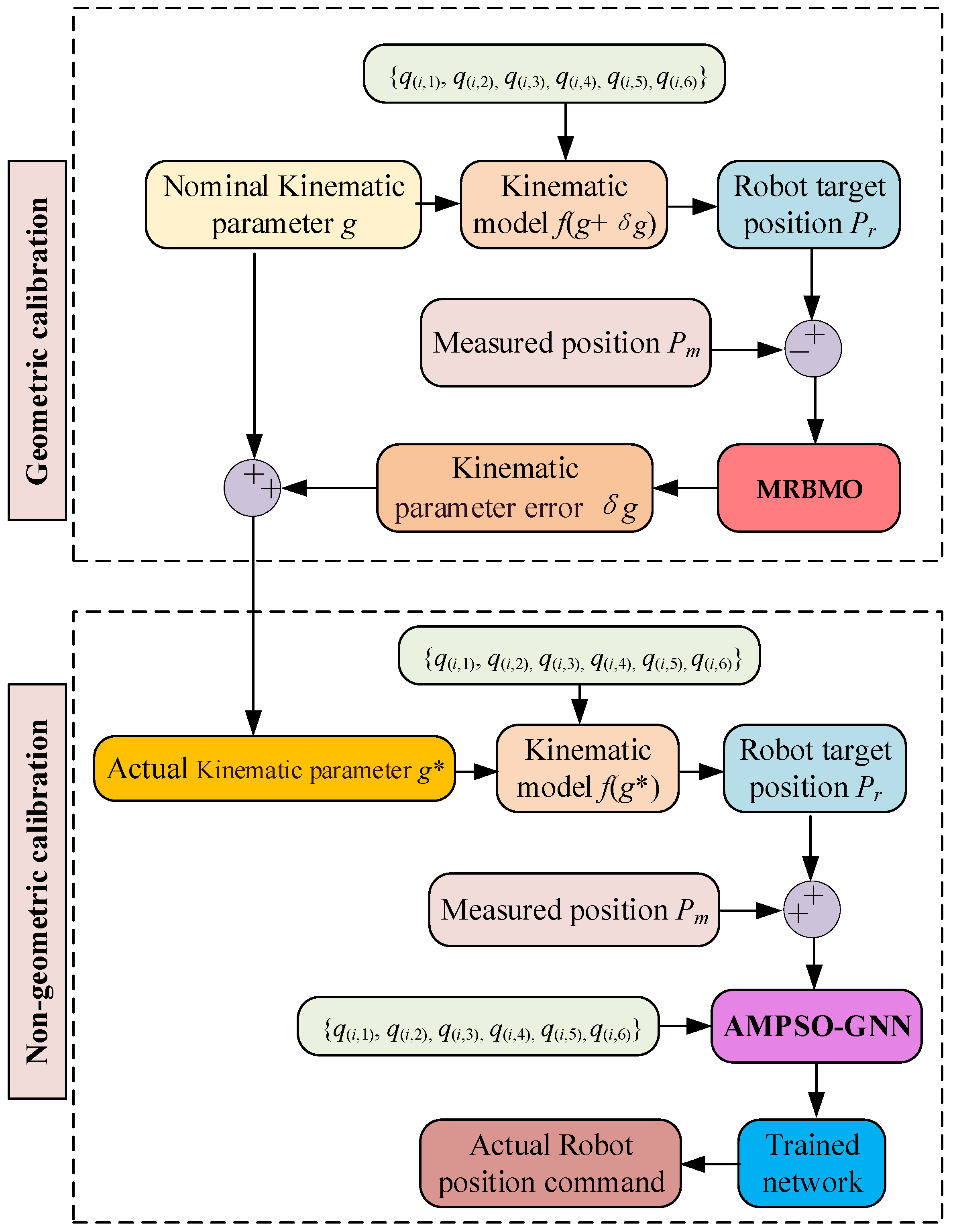
2. Kinematic Model of the Robot
3. Robot Geometric Error Calibration
3.1. Loss Function
3.2. Red Billed Blue Magpie Optimizer
3.3. Memory Based Red Billed Blue Magpie Optimizer
| Algorithm 1: MRBMO-GPI | |
| Input: x0, {q(i,1), q(i,2), q(i,3), q(i,4), q(i,5), q(i,6)}, {L1, L2, L3, L4, L5, L6} Objective function f(⋅), Search space boundaries Xmin, Xmax, Population size N, maximum iteration K, k = 1 | |
| 1. | Initialize population X∈RN×D with random values with in [Xmin, Xmax] |
| 2. | Set Pbest←X, Pbest_fit(i)←∞ for all i |
| 3. | Evaluate fitness of each individual f(x(i,:)), update Pbest(i,:) and global best xfood |
| 4. | while k ≤ K do |
| 5. | for i = 1 to N |
| 6. | |
| 7. | |
| 8. | Select a random reference rs ∈ [1, N] |
| 9. | if rand < ϵ |
| 10. | |
| 11. | else |
| 12. | |
| 13. | end if |
| 14. | Update position: xk+1(i,:) = xk(i,:) + dir⋅rand + 0.3⋅(Pbest(i,:) − xk(i,:)) |
| 15. | Apply boundary check |
| 16. | Evaluate new fitness, update Pbest(i,:) if improved |
| 17. | Update global best xfood if improved |
| 18. | end for |
| 19. | Compute control factor: CF = (1 − k/K)(2k/K) |
| 20. | for i = 1 to N |
| 21. | Update with memory-guided prey attack: xk+1(i,:)= xfood + CF⋅(group_mean − xk(i,:))⋅randn + 0.3⋅(Pbest(i,:) − xk(i,:)) |
| 22. | Apply boundary check |
| 23. | Evaluate and update Pbest and xfood |
| 24. | end for |
| 25. | Increment iteration k = k + 1 |
| 26. | end while |
| Return δg←xfood, ΔP←f(xfood) | |
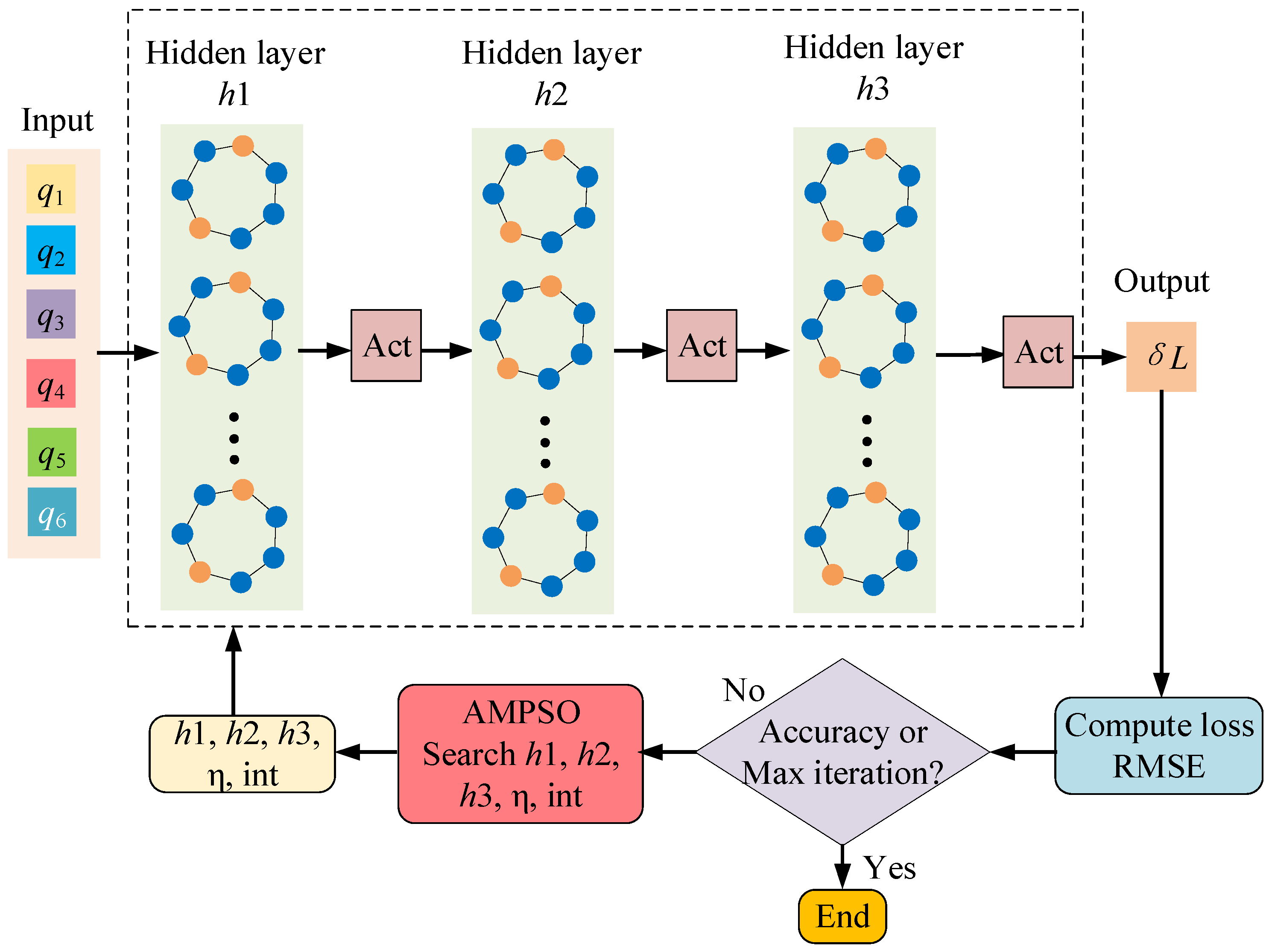
4. Nongeometric Calibration
| Algorithm 2: AMPSO-GNN-NGPI | |
| Input: Training data {qtrain, δLtrain}and testing data {qtest, δLtest} | |
| 1. | Initialize Population size N, particle dimension D = 6 |
| 2. | Maximum iterations T |
| 3. | PSO parameters: wmax, wmin, c1, c2; |
| 4. | Momentum parameters: mmax, mmin, λ, ζ |
| 5. | Initialize X0 = Xmin + (Xmax − Xmin)·rand(N,D); V0 = Vmin + (Vmax − Vmin)·rand(N,D) |
| 6. | For i = 1 to N |
| 7. | →(h1, h2, h3, η, act, init) |
| 8. | Construct a fGNN |
| 9. | = fGNN(qtrain, θ), ytest = fGNN(qtest, θ) |
| 10. | ) |
| 11. | |
| 12. | |
| 13. | end for |
| 14. | }) |
| 15. | For t = 1 to T |
| 16. | Compute wᵗ = wmax − (wmax − wmin) × (t/T) |
| 17. | }) |
| 18. | + ζ)) |
| 19. | For i = 1 to N |
| 20. | )] |
| 21. | |
| 22. | ∈ [xmin, xmax] |
| 23. | →(h1, h2, h3, η, act, init) |
| 24. | Build and train GNN with decoded structure on {qtrain, δLtrain} |
| 25. | ) |
| 26. | |
| 27. | If frmse (pᵢ) < frmsef(g), then update g←pᵢ |
| 28. | end for |
| 29. | end for |
| 30. | Return optimal solution g* = g and corresponding fitness frmse(g*) |
5. Evaluation Results and Comparative Analysis
5.1. Implementation Details
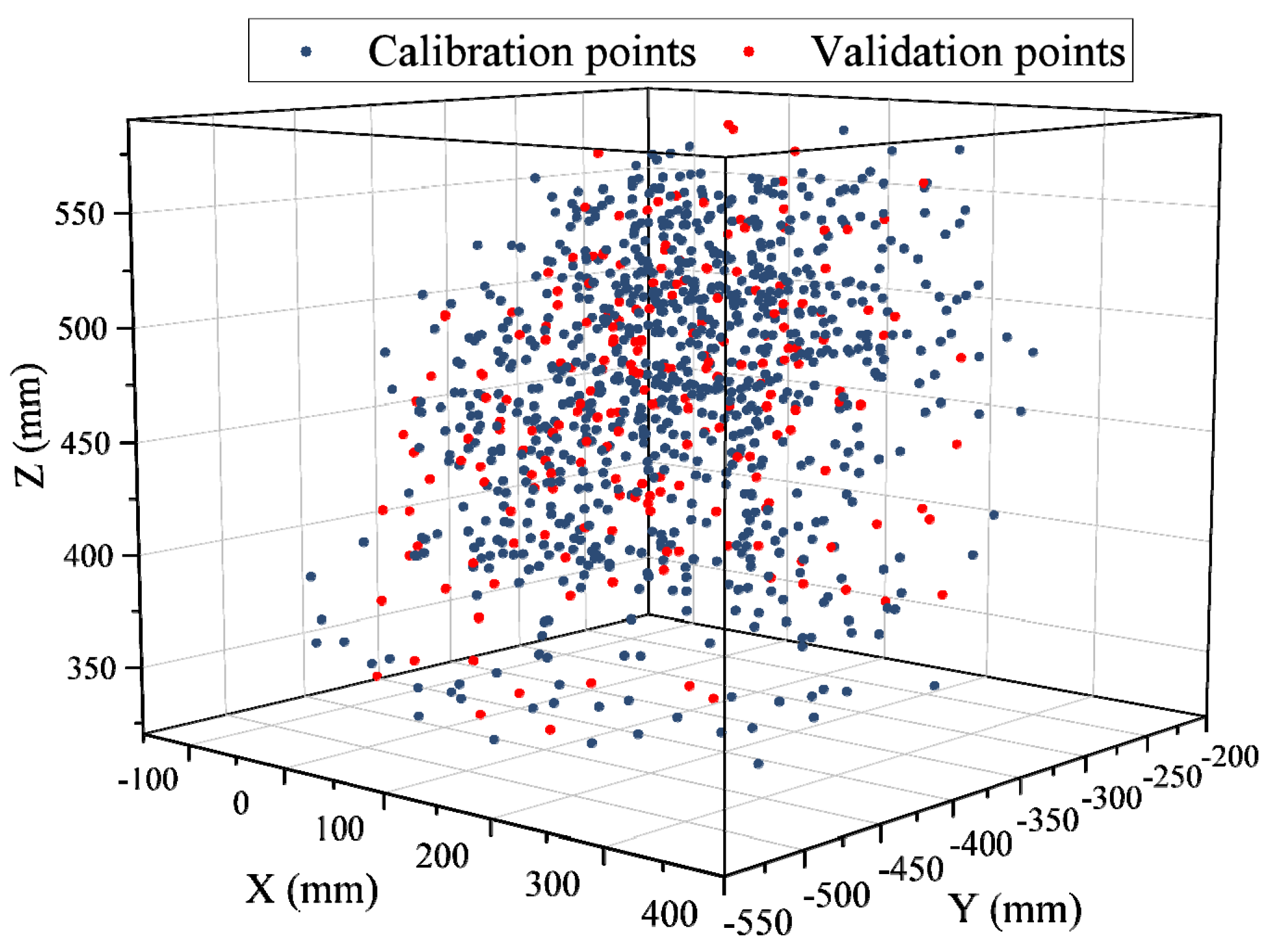
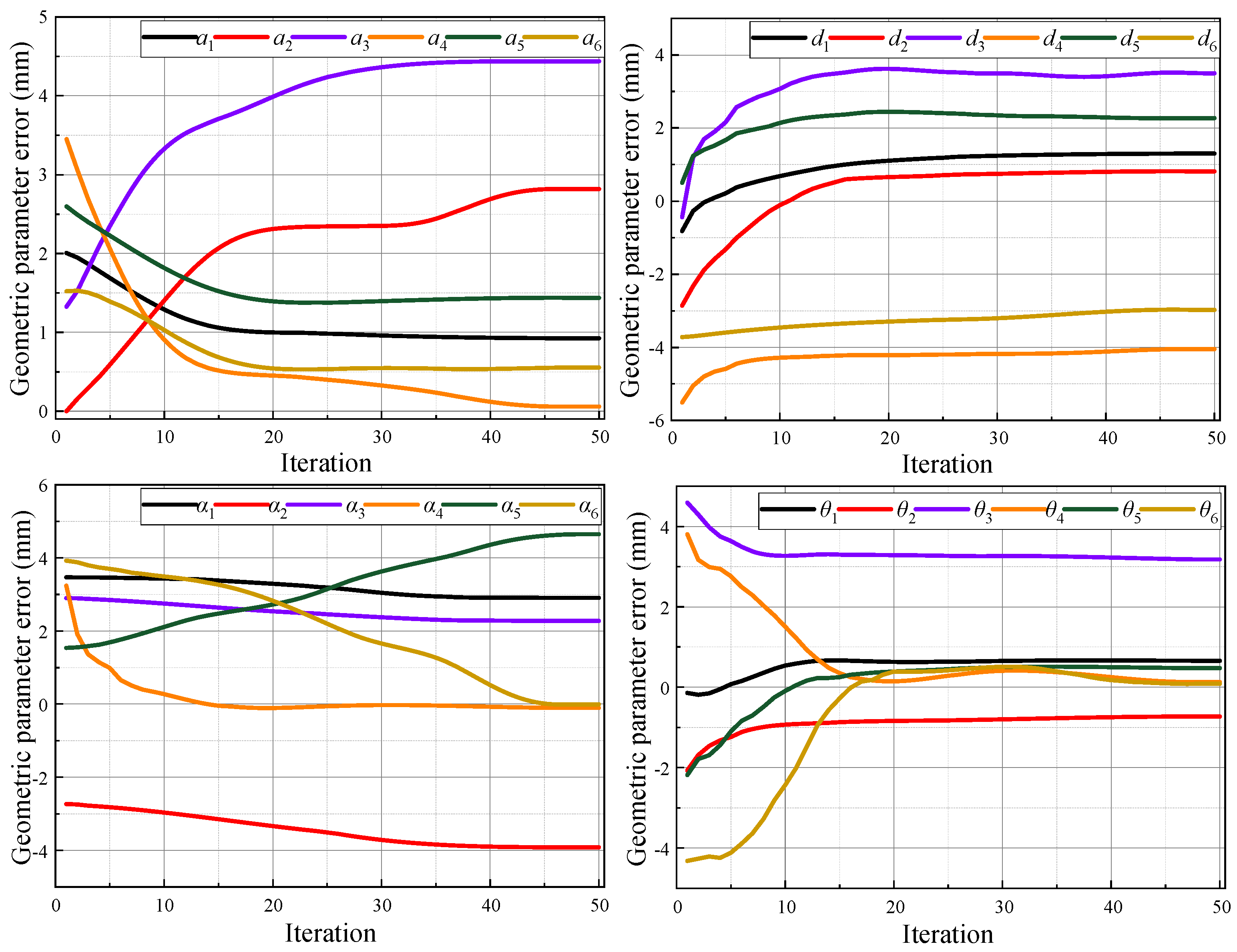
5.2. Experimental Verification of Geometric Parameter Calibration
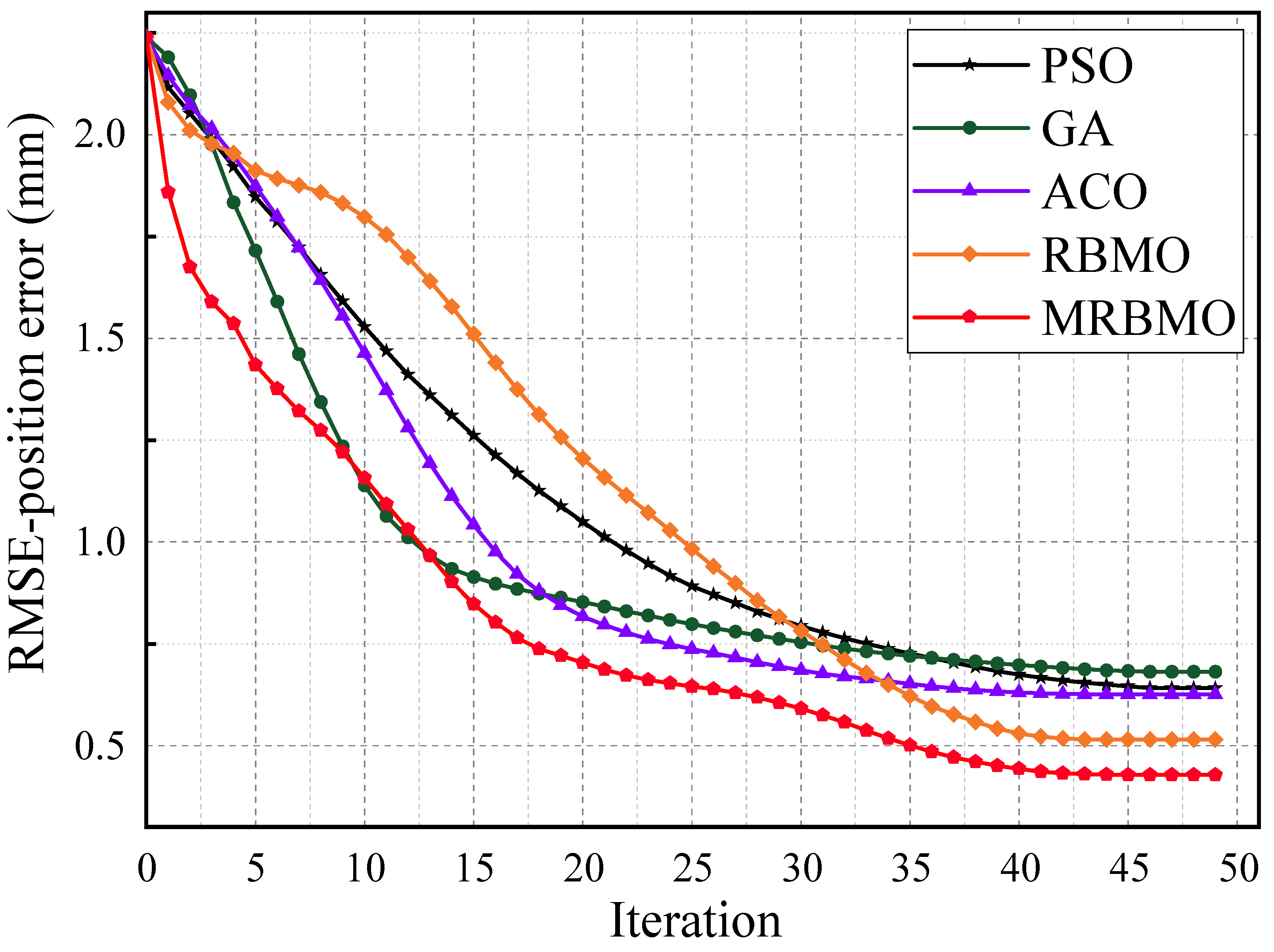
5.2.1. Comparative Method Validation
5.2.2. Result Analysis and Discussion

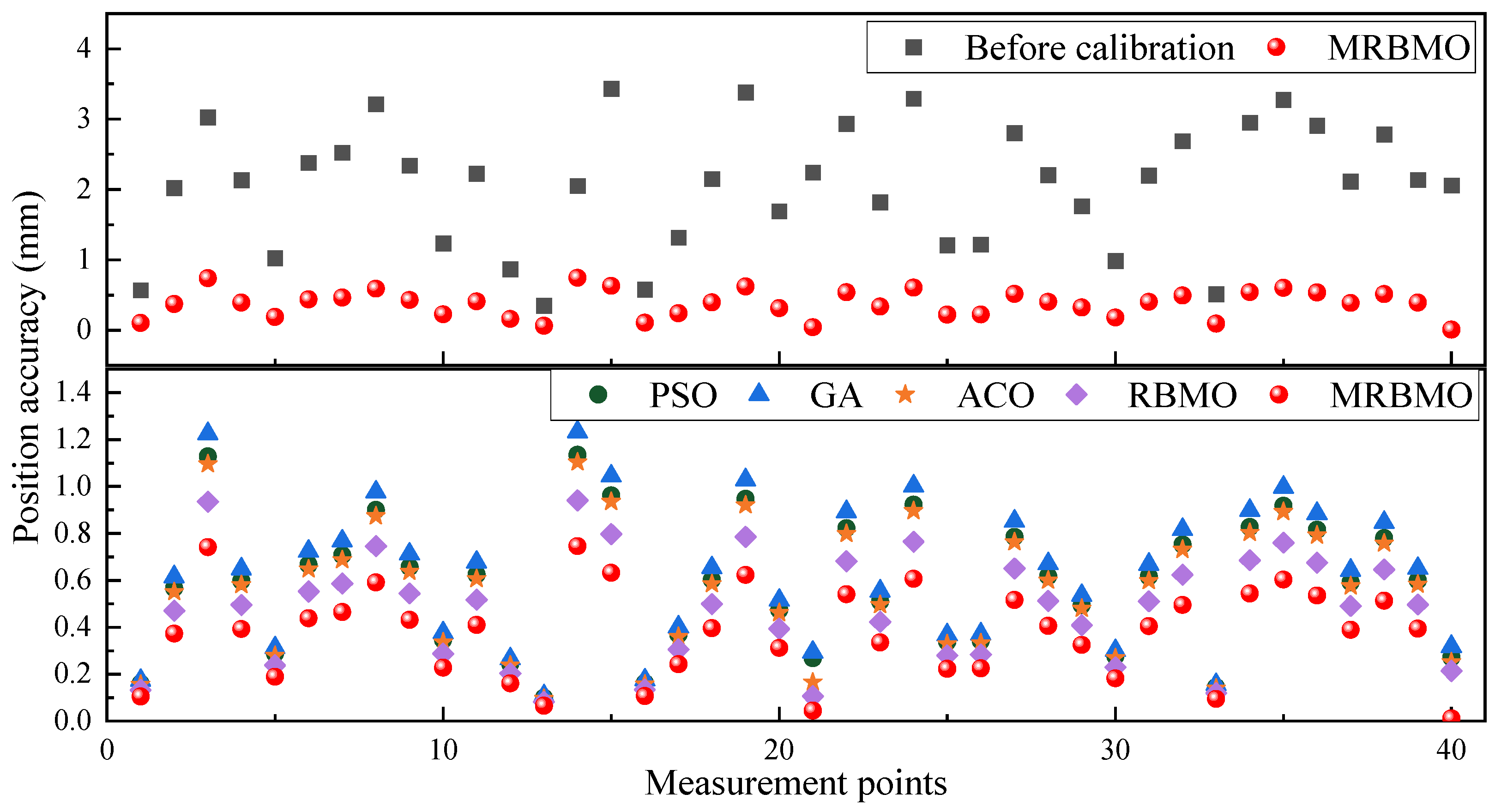
5.3. Experimental Validation of Non-Geometric Calibration

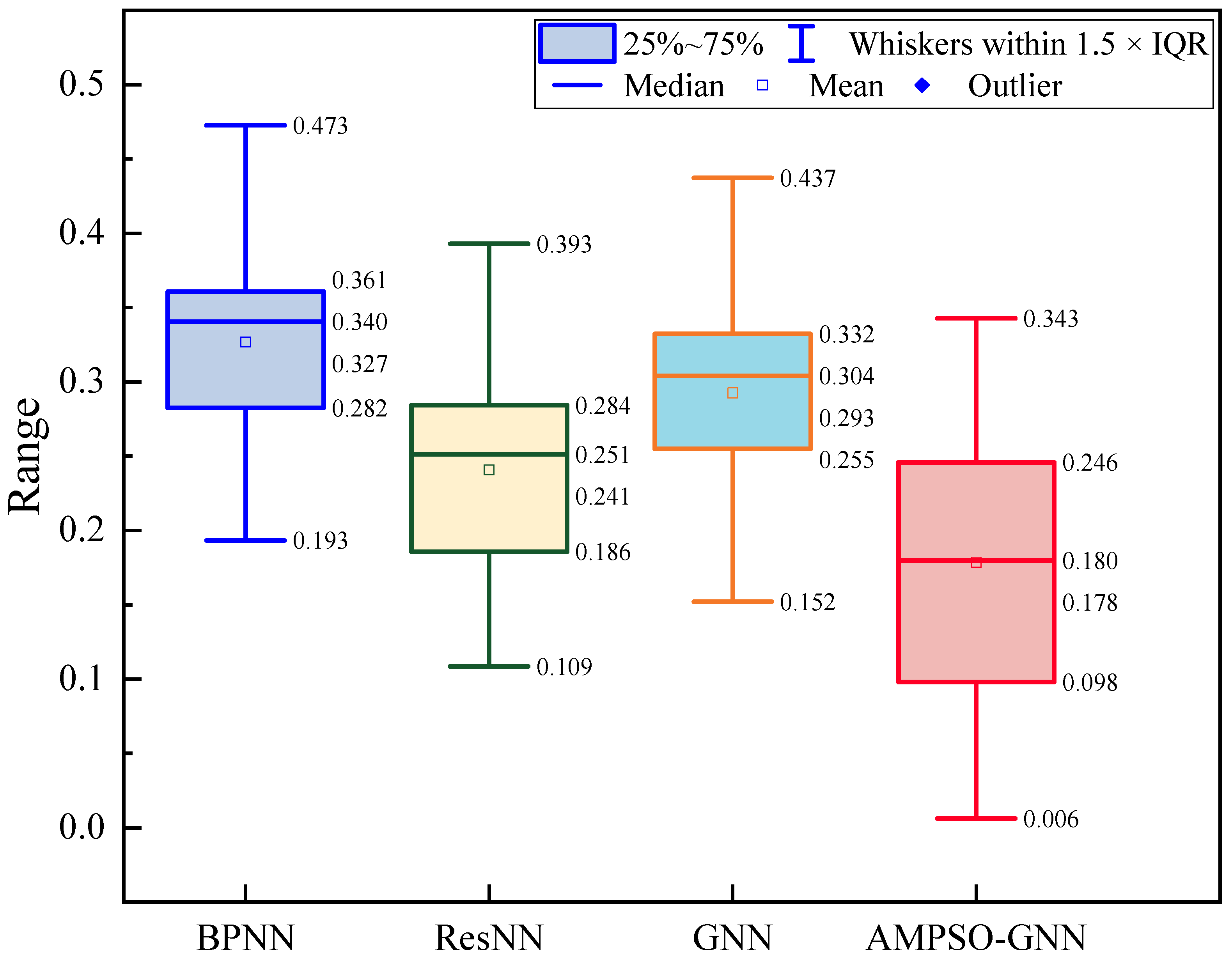
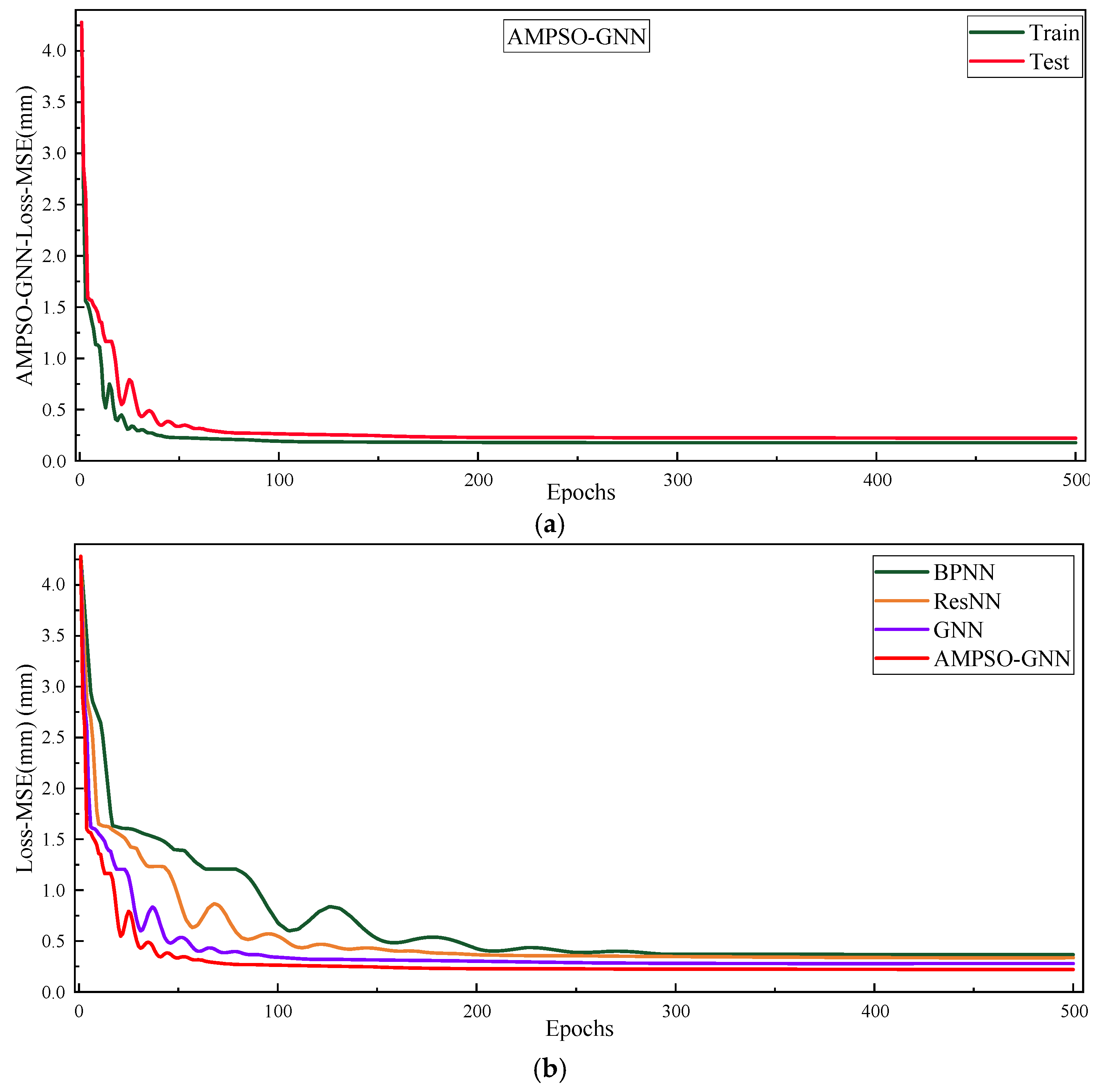
5.4. Overall Positioning Accuracy Improvement Comparison
- (1)
- Before Calibration (uncalibrated),
- (2)
- After Geometric Calibration using MRBMO, and
- (3)
- After Full Calibration combining MRBMO and AMPSO-GNN.

6. Conclusions
- (a)
- The proposed MRBMO algorithm effectively enhances geometric parameter calibration accuracy by incorporating memory-based guidance into the search process. Compared to conventional optimization methods such as PSO, GA, ACO, and RBMO, MRBMO achieves better convergence and higher identification precision.
- (b)
- The proposed AMPSO-GNN model significantly outperforms conventional learning-based approaches in compensating non-geometric errors. Compared to BPNN, ResNN, and GNN, AMPSO-GNN achieves lower RMSE, reduced error variability, and faster convergence. These improvements are attributed to the adaptive momentum PSO’s capability to fine-tune GNN hyperparameters, leading to enhanced learning efficiency and generalization ability.
- (c)
- The combination of MRBMO for geometric calibration and AMPSO-GNN for non-geometric compensation enables a significant improvement in robot positioning accuracy. The two-stage strategy ensures that both systematic kinematic deviations and complex residual errors are effectively addressed, resulting in consistent error suppression across measurement points.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dehghani, M.; McKenzie, R.A.; Irani, R.A.; Ahmadi, M. Robot-mounted sensing and local calibration for high-accuracy manufacturing. Robot. Comput.-Integr. Manuf. 2023, 79, 102429. [Google Scholar] [CrossRef]
- Deng, Y.; Hou, X.; Li, B.; Wang, J.; Zhang, Y. A novel method for improving optical component smoothing quality in robotic smoothing systems by compensating path errors. Opt. Express 2023, 31, 30359–30378. [Google Scholar] [CrossRef]
- Maghami, A.; Imbert, A.; Côté, G.; Monsarrat, B.; Birglen, L.; Khoshdarregi, M. Calibration of multi-robot cooperative systems using deep neural networks. J. Intell. Robot. Syst. 2023, 107, 55. [Google Scholar] [CrossRef]
- Gao, G.; Zhao, J.; Na, J. Decoupling of kinematic parameter identification for articulated arm coordinate measuring machines. IEEE Access 2018, 6, 50433–50442. [Google Scholar] [CrossRef]
- Haring, M.; Grøtli, E.I.; Riemer-Sørensen, S.; Seel, K.; Hanssen, K.G. A Levenberg–Marquardt algorithm for sparse identification of dynamical systems. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9323–9336. [Google Scholar] [CrossRef]
- Deng, Y.; Hou, X.; Li, B.; Wang, J.; Zhang, Y. A highly powerful calibration method for robotic smoothing system calibration via using adaptive residual extended Kalman filter. Robot. Comput.-Integr. Manuf. 2024, 86, 102660. [Google Scholar] [CrossRef]
- Chen, X.; Zhan, Q. The kinematic calibration of a drilling robot with optimal measurement configurations based on an improved multi-objective PSO algorithm. Int. J. Precis. Eng. Manuf. 2021, 22, 1537–1549. [Google Scholar] [CrossRef]
- Toquica, J.S.; Motta, J.M.S.T. A novel approach for robot calibration based on measurement sub-regions with comparative validation. Int. J. Adv. Manuf. Technol. 2024, 131, 3995–4008. [Google Scholar] [CrossRef]
- Cao, H.Q.; Nguyen, H.X.; Tran, T.N.C.; Tran, H.N.; Jeon, J.W. A robot calibration method using a neural network based on a butterfly and flower pollination algorithm. IEEE Trans. Ind. Electron. 2021, 69, 3865–3875. [Google Scholar] [CrossRef]
- Kong, Y.; Yang, L.; Chen, C.; Zhu, X.; Li, D.; Guan, Q.; Du, G. Online kinematic calibration of robot manipulator based on neural network. Measurement 2024, 238, 115281. [Google Scholar] [CrossRef]
- Chen, D.; Wang, T.; Yuan, P.; Sun, N.; Tang, H. A positional error compensation method for industrial robots combining error similarity and radial basis function neural network. Meas. Sci. Technol. 2019, 30, 125010. [Google Scholar] [CrossRef]
- Mon, Y.J. Tikhonov-Tuned Sliding Neural Network Decoupling Control for an Inverted Pendulum. Electronics 2023, 12, 4415. [Google Scholar] [CrossRef]
- Mon, Y.J. Fuzzy PDC-Based LQR Sliding Neural Network Control for Two-Wheeled Self-Balancing Cart. Electronics 2025, 14, 1842. [Google Scholar] [CrossRef]
- Pan, J.; Qu, L.; Peng, K. Deep residual neural-network-based robot joint fault diagnosis method. Sci. Rep. 2022, 12, 17158. [Google Scholar] [CrossRef]
- Guo, J.; Nguyen, H.T.; Liu, C.; Cheah, C.C. Convolutional neural network-based robot control for an eye-in-hand camera. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 4764–4775. [Google Scholar] [CrossRef]
- Zhou, Y.; Xiao, J.; Zhou, Y.; Loianno, G. Multi-robot collaborative perception with graph neural networks. IEEE Robot. Autom. Lett. 2022, 7, 2289–2296. [Google Scholar] [CrossRef]
- Fu, S.; Li, K.; Huang, H.; Ma, C.; Fan, Q.; Zhu, Y. Red-billed blue magpie optimizer: A novel metaheuristic algorithm for 2D/3D UAV path planning and engineering design problems. Artif. Intell. Rev. 2024, 57, 134. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [PubMed]
- Feng, A.; Zhou, Y.; Zhang, R.; Zhao, W.; Li, Z.; Zhu, M. A novel kinematic calibration method for robot based on the Levenberg–Marquardt and improved Marine Predators algorithm. Measurement 2025, 243, 116125. [Google Scholar] [CrossRef]
- Jiang, X.; Zhang, D.; Wang, H. Positioning error calibration of six-axis robot based on sub-identification space. Int. J. Adv. Manuf. Technol. 2024, 130, 5693–5707. [Google Scholar] [CrossRef]
- Wang, K. Application of genetic algorithms to robot kinematics calibration. Int. J. Syst. Sci. 2009, 40, 147–153. [Google Scholar] [CrossRef]
- Wang, X.; Xie, L.; Jiang, M.; He, K.; Chen, Y. Kinematic calibration and feedforward control of a heavy-load manipulator using parameters optimization by an ant colony algorithm. Robotica 2024, 42, 728–756. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approaches | Strengths | Weaknesses |
|---|---|---|
| Least squares [4] | The least squares algorithm with regularization improves numerical stability and is effective for identifying kinematic errors in over-constrained parallel kinematic mechanisms. It works well with linearized models and has been validated by both simulation and experiments. | This method is sensitive to outliers and depends on the accuracy of the model. It performs poorly for highly nonlinear systems and requires careful tuning of the regularization parameter. |
| Levenberg-Marquardt [5] | The LM algorithm offers fast convergence and improved numerical stability, making it suitable for solving nonlinear least squares problems in robotic calibration under noise and constraints. | Despite its efficiency, the LM algorithm is prone to truncation errors and may face difficulty in escaping local minima, especially when the initial guess is far from the true solution. |
| Filtering-based methods [6] | Filtering-based methods are widely used in robot calibration for their ability to handle dynamic, uncertain, and nonlinear environments. They enable accurate state and parameter estimation under noise by combining system models with measurement feedback. For example, EKF handles Gaussian noise with real-time efficiency, while PF is effective in non-Gaussian and highly nonlinear cases. | These methods rely heavily on accurate initial values and model assumptions. EKF may suffer from linearization (truncation) errors, and PF is sensitive to the prior distribution and can be computationally intensive. |
| Maximum Likelihood Estimation [8] | Maximum likelihood estimation offers strong convergence properties and high calibration accuracy. It is particularly effective for modeling complex kinematic errors and is more flexible than traditional least squares methods, with better adaptability to iterative optimization frameworks. | Maximum likelihood estimation requires an accurate system model and high-quality measurement data. It can be computationally intensive due to iterative parameter estimation, and its effectiveness may decline when the model structure is poorly defined or the data are noisy. |
| Evolutionary computation methods [7] | Evolutionary algorithms like GA, PSO, and DE are robust for nonlinear, multi-modal calibration problems. They do not require gradient information and have strong global search ability, making them effective under noisy or complex conditions. | These methods can be computationally expensive and slow to converge. Their performance depends on parameter tuning, and results may vary due to randomness, requiring multiple runs or post-validation. |
| Approaches | Advantages | Disadvantages |
|---|---|---|
| BP Neural Network [3,9,10] | BP neural networks are easy to implement and capable of approximating complex nonlinear mappings between joint states and non-geometric errors. Their simplicity and wide applicability make them a common baseline model in robotic error compensation. | They often suffer from slow convergence and are prone to getting stuck in local minima. Performance is sensitive to network structure and hyperparameter settings, limiting scalability for complex systems. |
| RBF Neural Network [11] | RBF networks train quickly and are highly effective for modeling localized error patterns due to their strong interpolation capabilities. They are suitable for smooth, low-dimensional compensation tasks. | Their performance depends heavily on the choice of centers and spread parameters. They are less effective in high-dimensional or highly dynamic environments and can struggle with generalization. |
| Residual Neural Network [14] | ResNet structures overcome vanishing gradients through skip connections, enabling deeper models to accurately learn complex nonlinear relationships. They are particularly effective for modeling high-dimensional, multi-source error data. | They require large datasets and greater computational resources. The increased architectural complexity makes them more difficult to train and tune in practical robotic systems. |
| Convolutional Neural Network [15] | CNNs are excellent at extracting spatial features from structured data such as thermal fields or deformation maps. They are effective for modeling spatially varying errors and capturing local patterns. | CNNs are not ideal for low-dimensional input data like joint angles. Training requires large datasets and computing power, and their use is limited in systems lacking image-like inputs. |
| Graph Neural Network [16] | GNNs can naturally model the topological and spatial relationships in robot kinematic chains, making them well-suited for capturing complex joint dependencies. They offer strong generalization across configurations. | GNNs are more difficult to design and implement due to the need for graph construction and message-passing mechanisms. Their application in industrial calibration is still emerging and lacks standardized practices. |
| Nominal Parameter | Identified Parameter | |||||||
|---|---|---|---|---|---|---|---|---|
| Joint | a (mm) | d (mm) | α (°) | θ (°) | a (mm) | d (mm) | α (°) | θ (°) |
| 1 | 0 | 290 | −90 | 0 | 0.926 | 291.301 | −87.093 | 0.659 |
| 2 | 270 | 0 | 0 | −90 | 272.816 | 0.815 | −3.918 | −90.728 |
| 3 | 70 | 0 | −90 | 0 | 74.440 | 3.498 | −87.721 | 3.176 |
| 4 | 0 | 302 | 90 | 0 | 0.058 | 297.752 | 89.898 | 0.126 |
| 5 | 0 | 0 | −90 | 0 | 1.436 | 2.269 | −85.345 | 0.474 |
| 6 | 0 | 72 | 0 | 0 | 0.555 | 69.024 | −0.006 | 0.088 |
| Metric | Before | PSO | GA | ACO | RBMO | MRBMO |
|---|---|---|---|---|---|---|
| RMSE (mm) | 2.240 | 0.642 | 0.681 | 0.625 | 0.515 | 0.428 |
| Std(mm) | 2.030 | 0.543 | 0.594 | 0.520 | 0.438 | 0.391 |
| Max(mm) | 3.520 | 1.410 | 1.583 | 1.467 | 1.312 | 1.126 |
| Time(s) | / | 75.146 | 92.851 | 108.215 | 70.512 | 82.148 |
| Comparison | R+ | R− | p-Value * |
|---|---|---|---|
| MRBMO vs. PSO | 45 | 0 | 0.002 |
| MRBMO vs. GA | 45 | 0 | 0.002 |
| MRBMO vs. ACO | 45 | 0 | 0.002 |
| MRBMO vs. RBMO | 45 | 0 | 0.002 |
| BP | ResNN | GNN | AMPSO-GNN | ||
|---|---|---|---|---|---|
| Network structure | (6, 30, 30, 30, 1) | (6, 30, 30, 30,1) | (6, 30, 30, 30, 1) | 3 hidden Layers | |
| Metric | RMSE (mm) | 0.354 | 0.275 | 0.321 | 0.220 |
| Std (mm) | 0.315 | 0.245 | 0.285 | 0.196 | |
| Max (mm) | 0.625 | 0.486 | 0.567 | 0.389 | |
| Calibration Stage | RMSE (mm) | Std (mm) | Max (mm) |
|---|---|---|---|
| Before Calibration | 2.240 | 2.030 | 3.520 |
| After Geometric | 0.428 | 0.391 | 1.126 |
| After Full (MRBMO + AMPSO − GNN) | 0.220 | 0.196 | 0.389 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Huang, X.; Deng, Y.; Xiao, C.; Li, Z. Robotic Positioning Accuracy Enhancement via Memory Red Billed Blue Magpie Optimizer and Adaptive Momentum PSO Tuned Graph Neural Network. Machines 2025, 13, 526. https://doi.org/10.3390/machines13060526
Liu J, Huang X, Deng Y, Xiao C, Li Z. Robotic Positioning Accuracy Enhancement via Memory Red Billed Blue Magpie Optimizer and Adaptive Momentum PSO Tuned Graph Neural Network. Machines. 2025; 13(6):526. https://doi.org/10.3390/machines13060526
Chicago/Turabian StyleLiu, Jian, Xiaona Huang, Yonghong Deng, Canjun Xiao, and Zhibin Li. 2025. "Robotic Positioning Accuracy Enhancement via Memory Red Billed Blue Magpie Optimizer and Adaptive Momentum PSO Tuned Graph Neural Network" Machines 13, no. 6: 526. https://doi.org/10.3390/machines13060526
APA StyleLiu, J., Huang, X., Deng, Y., Xiao, C., & Li, Z. (2025). Robotic Positioning Accuracy Enhancement via Memory Red Billed Blue Magpie Optimizer and Adaptive Momentum PSO Tuned Graph Neural Network. Machines, 13(6), 526. https://doi.org/10.3390/machines13060526