1. Introduction
The trend toward intelligent shipping has become a focal point in global maritime development, driving significant and rapid reforms toward digitization and intelligence in the maritime industry. As typical reciprocating power machinery, marine diesel engines exhibit complexity and diversity in faults due to the interactions among various systems. These complexities and the intricate causal relationships of faults increase the difficulty of predicting and diagnosing diesel engine malfunctions. The lubrication system of a diesel engine, which reduces wear and promotes cooling, is a critical component in ensuring its safe and stable performance. Therefore, diagnosing lubrication system failures and predicting related alarms play a crucial role in the reliable operation of diesel engines [
1].
Currently, the prevalent monitoring method for marine diesel engine lubrication systems involves reading parameters from external pipelines and setting static alarm thresholds to detect and identify faults. This approach has issues with low accuracy, missed alerts, or false alarms, making it impossible to implement more comprehensive and accurate protection. In order to solve the limitation of fixed thresholds, some diesel engine experts have put forward an improved method based on threshold monitoring. Otero et al. [
2] addressed the shortcomings and limitations of threshold alarms by proposing a solution for designing intelligent alarms. To overcome the limitations of traditional monitoring methods in nuclear power plants, Wu et al. [
3] suggested the introduction of kernel principal component analysis (KPCA) in the online monitoring of nuclear power plant equipment. KPCA can provide more advanced fault warnings than existing threshold monitoring methods. In order to ensure the safe operation of major equipment, domestic and foreign diesel engine manufacturers and researchers have conducted a lot of research in the field of fault diagnosis. The fault diagnosis methods for marine diesel engine lubrication systems can be categorized into methods based on empirical knowledge, analytical models, and intelligent diagnostic methods driven by data [
4].
Methods based on empirical knowledge are currently the most commonly used in engineering applications, typically relying on engineers’ professional knowledge and experience to judge and analyze faults. Streichfuss et al. [
5] proposed a machine monitoring and maintenance management system based on expert systems. The diagnostic system is integrated with a maintenance planning and control system to provide data management free from contradictions and redundancies. Xu et al. [
6] designed a belief rule-based (BRB) expert system for the fault diagnosis of marine diesel engines, which exhibits good accuracy and stability and can effectively identify concurrent faults. Unver et al. [
7] conducted a systematic study of crankcase explosions in two-stroke marine diesel engines using the fault tree analysis method in a fuzzy environment for system reliability and shipping sustainability. However, methods based on empirical knowledge highly depend on human expertise, and their scientific validity and feasibility are subject to scrutiny.
Methods based on analytical models focus on the fault mechanism as the research subject. Krzysztofowicz R. et al. [
8] proposed a Bayesian detection model designed for distributed sensor systems, where each sensor provides a detection probability to the central processor rather than an observation vector or detection decision. Moussa et al. [
9] developed a physical model of the cooling and lubrication system of a marine diesel engine, which prepared an essential database for fault diagnosis and forecasting strategies for diesel engines. Although such methods can detect and diagnose faults, they are limited to scenarios where accurate physical or mathematical models can be established. The lubrication system of diesel engines provides lubrication for the moving parts of the whole machine and it has a complicated relationship with other systems. The accurate mathematical model of the operating fault is often difficult to obtain, which leads to the great limitations of the traditional model-based fault diagnosis method in application.
The large amount of diesel engine running process data acquisition provides good data conditions for the development of a data-driven intelligent diagnosis strategy. Intelligent diagnostic methods driven by data can, to some extent, overcome the shortcomings of the previous two approaches by reducing dependence on models and empirical knowledge. Using diesel engine running data and various data analysis methods, we can find the hidden information in the data. Further, the fault detection is carried out to realize the separation evaluation and decision of the lubrication system. Liu et al. [
10] aimed at the coherent real-time monitoring of bearing status and proposed a gated recurrent unit-based fault monitoring structure to obtain a timely response to and preliminary classification of sudden faults. Ding et al. [
11] considered the non-stationary stochastic characteristics of the current of PV strings and applied the local outlier factor (LOF) to detect faults in the PV system by evaluating the deviation between the observed data and the whole data. Zhao et al. [
12] presented a novel intelligent fault diagnosis method based on an improved extreme learning machine (ELM). Alireza et al. [
13] presented a condition monitoring and combustion fault detection technique for a 12-cylinder 588 KW trainset diesel engine based on vibration signature analysis using a fast Fourier transform, a discrete wavelet transform, and a multilayer perceptron (MLP). Liu et al. [
14] proposed a fault diagnosis method based on fuzzy theory and a multidimensional model, indicating that a SVM (support vector machine) can handle the fuzzy information of fault samples and solve the indivisibility problem of SVM classification. Mariela et al. [
15] used genetic algorithms and a classifier based on random forest (RF) to improve the gear fault detection’s reliability, effectiveness, and accuracy. Li et al. [
16] described and evaluated the application by integrating empirical mode decomposition (EMD), kernel independent component analysis (KICA), Wigner bispectrum, and SVM for the fault diagnosis of marine diesel engines. Zhang et al. [
17] analyzed aero-engine bearing vibration failure caused by low-pressure rotor imbalance and proposed a fault diagnosis model using the XGBoost algorithm. Wang et al. [
18] established a hybrid fault monitoring scheme integrating manifold learning and the isolation forest (IF) to monitor the state of marine diesel engines. Cai et al. [
19] proposed a novel fault detection and diagnostic method for diesel engines by combining rule-based algorithms and Bayesian networks (BNs) or back propagation neural networks (BPNNs). In addition, the influences of decomposed signal layers, sensor noise, and external excitation interference on fault diagnostic performance have been researched.
Although data-driven diagnostic methods can uncover information about the status of diesel lubrication systems, ample training data is a prerequisite for data-driven models to achieve high-precision diagnostic results. Moreover, in practical engineering applications, failures in diesel engine lubrication systems are low-probability events, and it is difficult to promptly detect and collect the data, resulting in a scarcity of fault samples [
20]. As diesel engines operate under high-temperature, high-pressure, and high-velocity conditions over long periods, it is impossible to directly understand the diesel engine’s internal lubrication and cooling conditions through monitoring data, nor is it feasible to monitor fault trends [
21]. How to use the existing oil pipeline monitoring data to monitor the internal dynamic change and fault trend of the lubrication system is the problem that needs to be solved in this paper.
In response to the problems identified with the above methods, this paper proposes a fault detection method for diesel engine lubrication systems based on adaptive dynamic thresholds. The main views and contributions are summarized as follows:
Dynamic parameter relationship inference algorithm: Utilizes the maximal information coefficient (MIC) [
22] to evaluate the correlations among multiple parameters within the diesel engine lubrication system. This approach constructs relational surfaces and identifies critical parameters for more targeted analysis.
Adaptive dynamic threshold construction method: Develops adaptive thresholds for the diesel engine lubrication system under conditions devoid of fault samples. This enables a more precise detection of lubrication system faults, substantially reducing the likelihood of missed detections and false alarms.
Mechanistic study and analysis of lubrication system parameter relationships: Conducts a thorough investigation into the relationships between lubrication system parameters, culminating in proposing a mechanistic model. This model aims to deepen understanding of the system’s operation and enhance diagnostic accuracy.
The structure of this paper is as follows:
Section 2 presents the theoretical framework for the dynamic parameter relationship inference algorithm and the adaptive dynamic threshold method for dynamic parameters;
Section 3 introduces the experimental setup, data collection methods, and the experimental dataset;
Section 4 discusses the experimental results; and the final section presents the conclusions.
2. Adaptive Threshold Fault Diagnosis Method
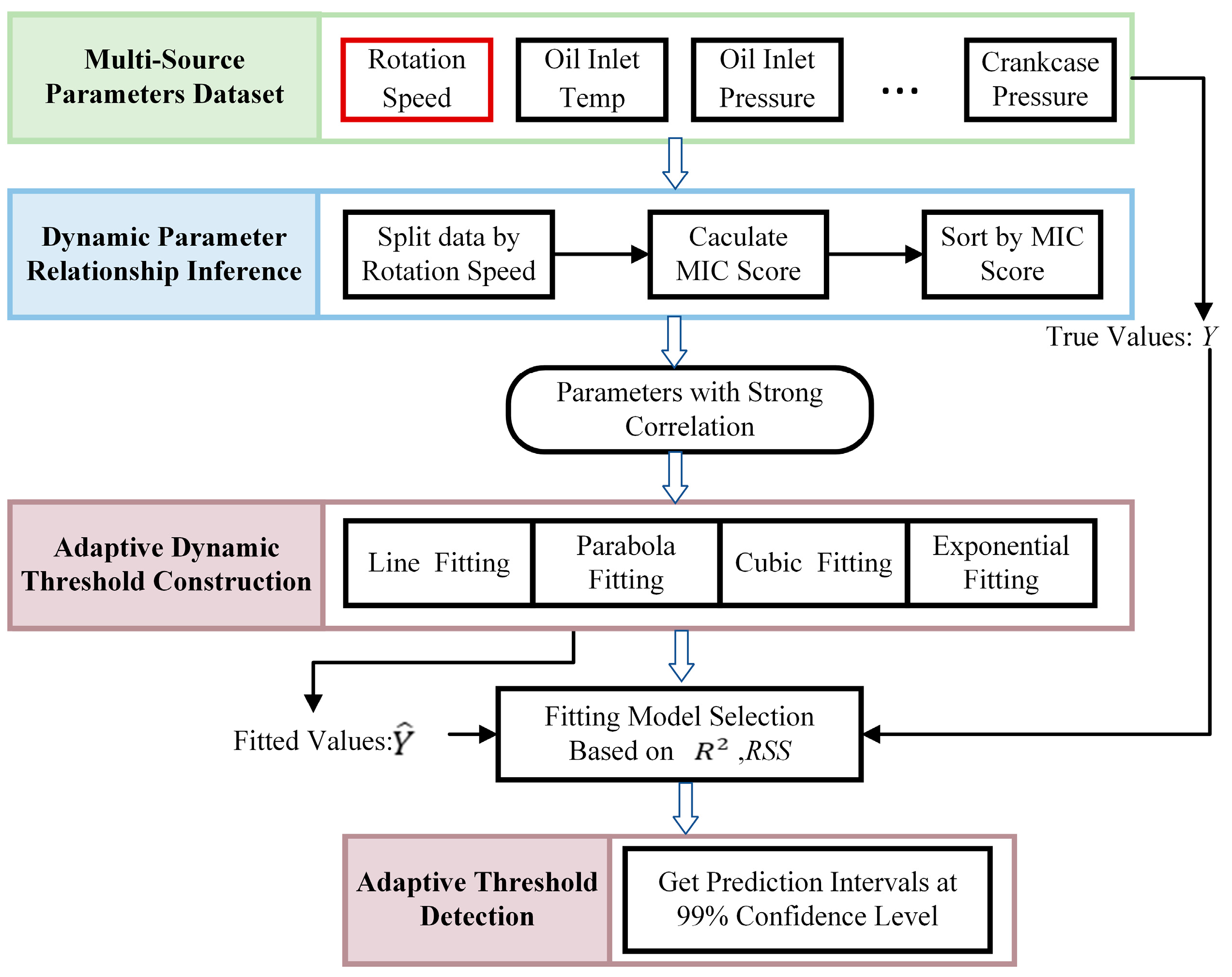
This paper introduces a fault detection algorithm for marine diesel engine lubrication systems, primarily comprising a dynamic parameter relationship inference algorithm and an adaptive dynamic threshold method for dynamic parameters. The dynamic parameter relationship inference algorithm delves into the intricate relationships between sensor data to identify potential patterns and correlations among different parameters under varying conditions. By employing advanced data analytics techniques, this algorithm can sift through large volumes of data to pinpoint critical parameters that significantly influence engine performance and reliability. Once these key parameters have been identified, the algorithm proceeds to construct adaptive thresholds that dynamically adjust in response to changes in engine speed and other relevant factors. This adaptability ensures that the thresholds remain pertinent and practical across a broad spectrum of operational conditions, thereby enhancing fault detection accuracy. The adaptive threshold detection algorithm is specifically designed to locate anomalies within predefined threshold ranges, focusing on trends that deviate from the norm. By analyzing data trends and variations, this algorithm can detect subtle shifts in engine behavior that may indicate the emergence of a fault or a deviation from expected performance levels. The entire algorithm model is shown in
Figure 1.
Specifically, by utilizing a multi-source parameter dataset composed of data from different sensors in the diesel engine lubrication system, we determine the strongly correlated parameters under various operating conditions through mechanism analysis and MIC scoring. We then fit and model a large amount of data for these parameters to identify and establish a current “standard model” with a high degree of fit. The “standard model” under healthy conditions is used as a threshold condition for dynamic threshold fault diagnosis throughout the entire operational life cycle of the diesel engine. Naturally, as the operating time increases and machine performance deteriorates, the “standard model” will also undergo subtle changes.
2.1. Dynamic Parameter Relationship Inference Algorithm
The lubrication system encompasses a great deal of sensor information, typically including temperature signals from various locations, pressure signals, rotational speed signals, oil levels, etc., encompassing approximately 5–15 parameters to offer a comprehensive view of the lubrication system’s status. The challenge lies in extracting valuable information from the interrelations among these diverse parameters and how to synergistically utilize these sensor signals to enhance the utilization efficiency of this sensor information, which holds substantial latent value.
First, a matrix containing all sensor data from the lubrication system is constructed.
In the above equation, denotes the number of sensors measured within the system (such as the diesel engine speed, oil inlet temperature, oil inlet pressure, etc.) and represents the continuous sampling time window length.
2.1.1. Basic Theory of the MIC
The determination of the MIC requires the mutual information metrics among variables to be calculated. Mutual information, a principle from information theory, measures the extent of mutual reliance between two random variables. It is an index of how much information is shared between the variables. A higher mutual information metric indicates a stronger connection between the variables. For two parameters,
and
, their mutual information, represented as
, is established in the following manner:
where
represents the joint probability distribution of
and
and
and
denote the marginal probability distributions of
and
.
Unlike mutual information, the MIC exhibits enhanced sensitivity toward various relational types among variables. It is proficient in recognizing both linear and nonlinear functional relationships, such as those that are exponential or periodic, and identifying non-functional relationships that may involve mixtures or combinations of functional types. The MIC aims to establish a comprehensive metric for gauging similarity across different relationship categories. Rooted in mutual information principles, the MIC operates through an exhaustive search of all possible data grid partitions, aiming to find the partition that maximizes the mutual information. The MIC value can range from 0, indicating an absence of any relationship, to 1, denoting perfect correlation, thereby offering a precise measure of the relationship’s intensity and character between the variables. In practice, the MIC method involves calculating the mutual information for a spectrum of grid partitions to pinpoint the partition that maximizes the mutual information. Specifically, the MIC algorithm assesses various grid dimensions and arrangements for any given dataset, methodically determining the mutual information for each setup. The setup that results in the maximum mutual information is chosen, and its mutual information score is defined as the MIC value.
In a dataset comprising data points with two parameters,
and
, these points are distributed within a two-dimensional space. To analyze these data, an
grid is utilized to partition this space. The frequency of data points falling within a specific row
of the grid is used to estimate the marginal probability
. Similarly, the frequency of data points in a particular column
is used as an estimate for the marginal probability
. Furthermore, the frequency of data points located within a specific cell
of the grid provides an estimate for the joint probability
:
Modifying the methodology and configuration of grid partitioning can produce a spectrum of mutual information values. This variability plays a pivotal role in the computation process of the MIC:
where
represents the scale of the data. The value of the constant
can be set based on experience or scale. The condition
is to limit the size of the grid to divide regions. Dividing by
completes data normalization in different dimensions, ensuring their values fall within the interval 0 to 1.
2.1.2. Dynamic Parameter Relationship Inference Utilizing MIC Ranking
In the maritime industry, ship operators make decisions about the operation of diesel engines based on the factory parameters provided by the manufacturer, the optimum operating conditions, and the ship operating conditions. This decision-making process usually involves running the engine for extended periods at several specific speed ranges, typically including 400 revolutions per minute (rpm), 720 rpm, 840 rpm, and 1000 rpm. These speed ranges are selected to ensure the engines run at the most efficient and economical mode at the vessel’s usual speed.
The data collected can be utilized to meticulously classify various parameters across standard velocities to enhance precision in monitoring and adjust the engine’s operational state. The MIC algorithm determines the mutual information shared among different parameters during this analytical process. This algorithm is adept at quantifying the intensity and the intricacy of the connections between two variables, distinguishing straightforward linear relations and complex nonlinear interactions.
Utilizing the MIC algorithm for analysis enables the quantification and prioritization of parameter correlations, the calculation process is shown in
Table 1. This prioritization facilitates the identification of parameters that exhibit strong interconnections. For parameters demonstrating significant correlations, a more detailed examination will be undertaken. This deeper investigation aims to evaluate the feasibility of implementing adaptive threshold methods on these parameters to optimize engine performance and operational efficiency.
The MIC’s two primary attributes confer substantial benefits on parameter selection.
Generality: Exhibiting broad applicability, the MIC can recognize an extensive range of relationship types, including linear, nonlinear, monotonic, and non-monotonic connections. This wide-ranging applicability permits the inclusive selection of parameters that embody diverse functional relationships, facilitating a comprehensive examination of the correlations among parameters.
Equitability: The MIC maintains a uniform sensitivity to different relationships. This uniformity ensures that irrespective of whether the relationship between variables is linear, curvilinear, or embodies more complex configurations, the MIC can detect it with comparable effectiveness, assuming the relationship possesses adequate strength. Hence, the MIC is adept at identifying the most pertinent and informative parameters.
2.2. Adaptive Dynamic Threshold Construction Method
In this study, we introduce an advanced method known as the dynamic parameter adaptive threshold method, aimed at optimizing the management of parameters closely related to engine performance and safety. This method explicitly targets those parameters found to have high correlations through the analysis with the MIC algorithm. To precisely fit the complex relationships among these parameters, we integrate four different fitting models: the line model, the parabola model, the cubic model, and the exponential model.
Each model fits the relationship between data based on its unique mathematical structure and adaptability. The selection of these models is based on their potential to provide the relatively best-fitting effect under specific conditions, thereby ensuring an accurate mathematical description of the dependencies among parameters. The line model is suitable for describing superficial linear relationships, whereas the parabola and cubic models can capture more complex curvilinear relationships. The exponential model is appropriate for describing relationships that change exponentially with the variation of a particular parameter. The formulas and parameters of each model are shown in
Table 2.
During the parameter estimation process, we employ the least squares method as the primary mathematical tool to determine the optimal values of the model parameters. The least squares method is an optimization technique widely used in linear and nonlinear regression analysis. Its core principle involves minimizing the residual sum of squares (RSS), the sum of the squares of the differences between the model’s predicted and observed values. This function is the sum of the squared differences between the observed values of all data points and the values predicted by the model. The following formula can formally represent it:
where
is the actual observed value of the
ith data point and
is the value predicted by the model corresponding to the same independent variable value.
To evaluate the fitting effectiveness and applicability of these models, we adopted the coefficient of determination
R2(R-squared) as the primary evaluation metric [
23].
R2 (R-squared = SSR/TSS) is the percentage of information in the explainable part of the model, where TSS is the variance inherent in the response variable before regression analysis and SSR is the variance that the regression model can account for. The
value measures the degree of correlation between the model’s predicted values and the actual data, with its value ranging from 0 to 1. An
value closer to 1 indicates a better fit of the model, whereas a value closer to 0 signifies a poorer fit. The RSS metric is an absolute quantity, closely related to the capacity of the dataset, and combined with the relative amount of
R2, it can accurately measure the goodness of fit of the model. By comparing the
values of different models, we can effectively select the model that best suits the current dataset, thereby providing a solid foundation for further analysis and application [
24]:
By constructing adaptive threshold prediction intervals with a 99% confidence level, our primary aim is to establish a credible range for observations, thereby validating whether new data points reside within the normal operational range and whether they suggest the presence of potential faults. This dynamic parameter adaptive threshold setting technique offers a more flexible and precise monitoring strategy for complex systems, significantly enhancing the system’s stability and safety. By adopting this method, we ensure that the selected models can accurately map the dynamic relationships between parameters and build reliable fault diagnosis models without the need for fault data, suitable for real-time system monitoring and fault prediction.
4. Results and Discussion
4.1. Dynamic Parameter Relationship Inference
Based on
Table 3 for Dataset A, it is evident that the critical parameters of the engine’s lubrication system primarily encompass two dimensions: pressure and temperature. The interrelationship between these two dimensions holds significant analytical value. Following the dynamic parameter relationship inference algorithm introduced in
Section 2.1, this study has computed the MIC score between various parameters and the oil inlet temperature for two engines under different rotational speed conditions. The results are displayed as a radar chart, as shown in
Figure 4 below.
The observations indicate that across all engine rotational speed ranges, the oil inlet pressure, the oil pressure after filtering, and the supercharger oil pressure before filtering significantly correlate with the oil inlet temperature. Notably, the geographical proximity of the measurement points for the oil inlet temperature and the oil inlet pressure could contribute to their strong correlation. After conducting an in-depth analysis, it was found that calculating the mean of the MIC values of all parameters with the lubricant inlet temperature across different rotational speeds resulted in the highest overall MIC scores for this parameter combination, as shown in
Table 7. This finding underscores the importance of the lubricant inlet pressure in evaluating engine lubrication system performance and reveals the complexity of interactions among these key parameters under varying operational conditions. Consequently, by comprehensively considering the dynamic correlations between these parameters and the lubricant inlet temperature, we can more accurately understand and predict the performance of the engine’s lubrication system across various working states, thereby providing crucial data support for engine optimization adjustments and fault prevention.
We employed a three-dimensional data visualization method to investigate the operational characteristics of diesel engines and the interactions among their internal parameters in depth. In this approach, the engine’s rotational speed is set as the X-axis and the oil inlet temperature is used as the Y-axis. Three-dimensional fitting surfaces are drawn with the oil inlet pressure and the crankcase pressure as the Z-axis to illustrate the complex interdependencies among these critical parameters and their dynamic behaviors as the rotational speed varies, the parameters of the 3D fitting model are shown in
Table 8.
The analysis results from
Figure 5 show that the three-dimensional surface constructed using speed, oil inlet temperature, and oil inlet pressure exhibits a smoother characteristic than other parameter combinations. This smoothness indicates a tighter and more stable relationship among these parameters, suggesting that the oil inlet pressure is significantly influenced by both the rotational speed and the oil inlet temperature, with this influence demonstrating a certain level of regularity and predictability under different operating conditions. Conversely, when the rotational speed and the oil inlet temperature are combined with the crankcase pressure to construct the surface, the resulting surface exhibits more peaks and irregular fluctuations. These peaks may indicate that the relationship between the crankcase pressure and the other two parameters is more complex, possibly subject to more uncontrollable factors, or that the variations in crankcase pressure do not follow a simple linear or smooth pattern under different rotational speeds and temperature conditions.
4.2. Theoretical Analysis
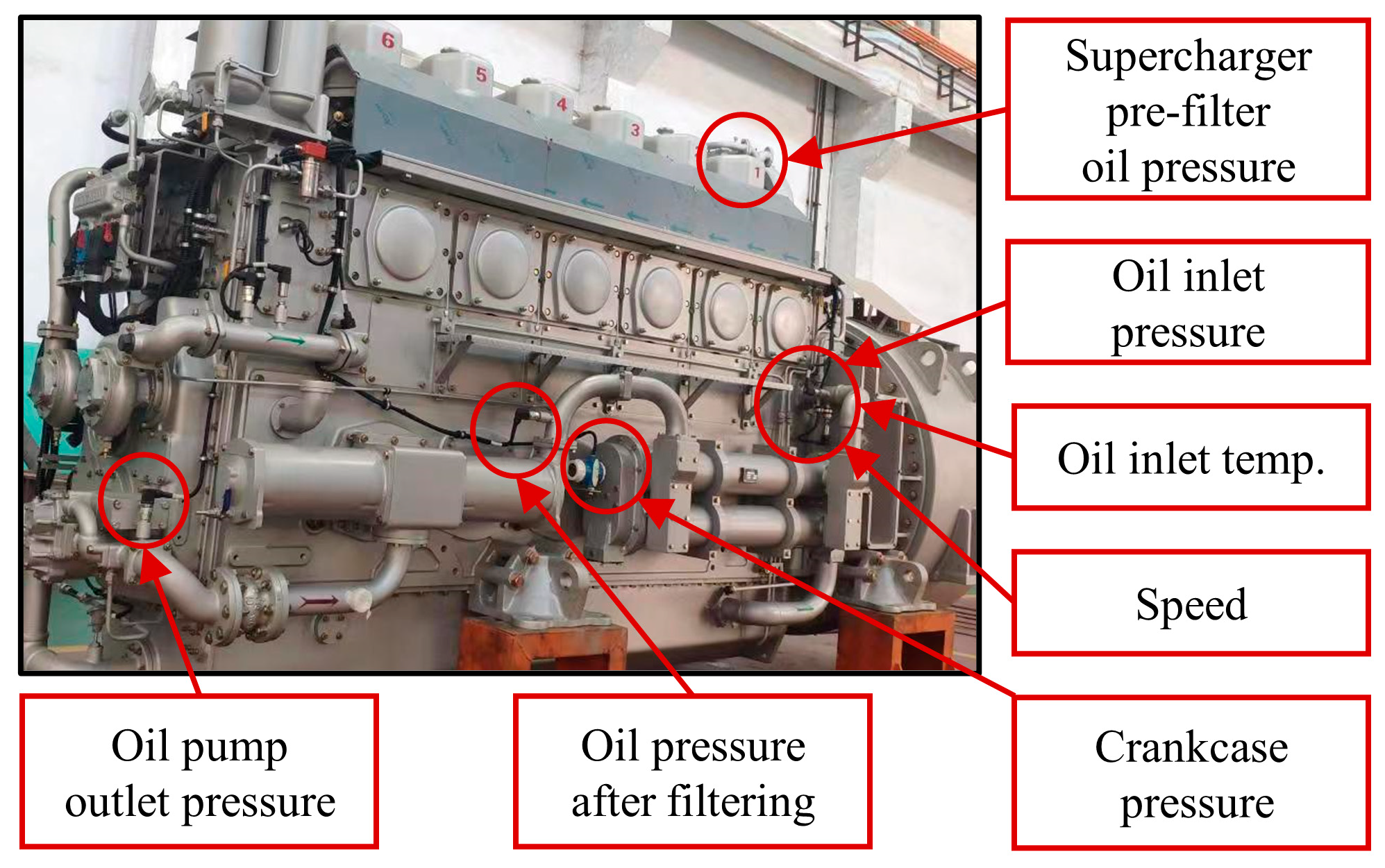
As is widely recognized, the primary function of the lubrication system in a diesel engine is to reduce the wear of components, decrease frictional work, and achieve the cooling and cleaning of the lubricated surfaces. The oil pump raises the lubricating oil to sufficient pressure and forces it to the friction pairs of internal components, ensuring that all the moving friction pairs within the diesel engine are adequately lubricated. Subsequently, the lubricating oil flows back to the oil pan under the force of gravity. The internal moving friction pairs within the lubrication system are not amenable to direct monitoring, and monitoring points are typically arranged on the off-board piping of the engine, as shown in
Figure 6 and
Figure 7 presents the lubrication system sensor measurement points.
Some scholars have managed to detect failures in external components through the monitoring points on the external lubrication piping of engines. This includes detecting leaks in oil pipelines, the wear of oil pumps, and faults in heat exchangers or filters. However, monitoring the internal lubrication conditions of diesel engines remains a significant challenge. Internal lubrication in a diesel engine is a complex system crucial for fault diagnosis. Abnormal wear or high temperatures in internal moving friction pairs can cause considerable damage to the engine. The lubrication state at the friction surfaces depends on the friction pairs’ operational state and the lubricating oil’s viscosity. Appropriate lubricating oil viscosity can produce an oil film thickness that protects the moving parts. Given that current monitoring capabilities are limited to measuring external pipeline temperatures and pressures, this discussion aims to analyze the internal operational state of the diesel engine based on parameters from the external piping of the engine’s oil system.
When the pressure relief valve in the piping is closed, the pressure inside the diesel engine is primarily generated by the flow resistance of the lubricating oil [
25]. Under this condition, it can be assumed that the lubricating oil flows laminarly in the oil passages, adhering to the Hagen–Poiseuille law [
26]:
where
represents the pressure difference between the two ends of the pipe,
is the volumetric flow rate,
is the dynamic viscosity,
is the length of the pipe, and
is the radius of the pipe. When the pipeline structure and the clearance between the friction pairs remain unchanged, it is apparent that variations in the internal pressure of the pipeline are related to the oil flow rate and the oil viscosity. This is more specifically illustrated in
Figure 8.
Firstly, as the diesel engine’s rotational speed, power, and torque increase, calculations from the test bench indicate that 6.49% of the total heat generated by the fuel is carried away by the engine oil, leading to a rise in oil temperature. Engine oil viscosity is highly sensitive to temperature changes. The viscosities of oil at 40 °C, 80 °C, and 88 °C were measured and regressed using the Vogel equation based on the observed temperature–viscosity data, as shown in
Figure 9.
is the temperature and , , and are constants related to the properties of the oil sample.
According to
Figure 9, as the engine oil’s temperature increases, the oil’s viscosity decreases. Consequently, this leads to a reduction in the oil film thickness and oil pressure.
There exists the following relationship between the pump speed and the oil flow rate [
27]:
In the equation, represents the average flow rate, is the pitch circle radius, is the tooth height, is the tooth width, and is the rotational speed.
According to the principles of mechanical design, under standard conditions
where
represents the gear module,
is the number of teeth, and
is the ratio of the tooth width to the module.
Given the constant
, by rearranging the above formula for the average flow rate, the relationship between the rotational speed and the engine oil flow rate can be derived:
The formula shows that the rotational speed and the engine oil flow rate are in direct proportion for a given diesel engine, with all design parameters being constant. As the temperature of the engine oil increases, causing a decrease in density, both factors together can increase the flow rate of the engine oil, ultimately leading to a rise in pressure. It is worth noting that the clearance size of the moving friction pairs also influences the engine oil pressure. The radial clearance of the lubrication system’s friction pairs should be within the range of 0.09 to 0.133 mm. If design errors or assembly mistakes cause the clearance to be outside this reasonable range, there can be significant deviations in engine oil pressure. Overall, the engine’s rotational speed and oil temperature affect the oil pressure value during operation.
4.3. Establish an Adaptive Dynamic Threshold
In this section, we applied the dynamic parameter threshold method introduced in
Section 2.2, focusing on the critical parameters identified earlier: the oil inlet temperature and the oil inlet pressure. For different engine rotational speed positions, we utilized four distinct mathematical models for data fitting: the cubic model, the parabola model, the exponential model, and the line model. By establishing fitting curves for each model, we further calculated the coefficient of determination
and the RSS metrics to assess the fitting effectiveness and select the optimal fitting model.
This process aims to determine which mathematical model most accurately describes the relationship between the oil inlet temperature, the oil inlet pressure, and the engine rotational speed, thereby providing a solid theoretical basis for setting dynamic parameter thresholds. The selection of the optimal model is based on two criteria: the coefficient of determination
reflects the model’s ability to explain the variability of the dependent variable, and the RSS measures the deviation between the model’s predicted values and the actual observed values. High
values and low RSS values indicate good fitting effectiveness, meaning the model can accurately predict the relationship between parameters. The fitting results are organized and displayed in
Table 9.
As shown in
Figure 10, by plotting the four fitting models for a single condition and performing a summary analysis of all the fitting models and fitting accuracy, it was found that after comparing the four models (cubic, parabola, exponential, and line), the cubic fitting model achieved higher coefficients of determination
and lower SSE across all four rotational speed positions for both engines, demonstrating superior fitting performance in almost all cases. This indicates that the cubic model can more accurately capture the complex nonlinear relationship between the oil inlet temperature, the oil inlet pressure, and the engine rotational speed.
To further validate this fitting result’s reliability and predictive accuracy, the next step involves plotting the optimal fitting model graphs for the two engines at various rotational speeds, along with the 99% prediction intervals and residual statistics charts.
Table 10 shows the parameter information of the fitting model.
As can be seen from the
Figure 11 and
Figure 12, although the two diesel engines exhibit similarities in various aspects, there are still subtle differences in the fitted models due to factors such as assembly processes, component quality, or fuel quality. Therefore, there is no absolute standard model for fault diagnosis in the diesel lubrication system. The adaptive threshold diagnosis method we propose is based on the operational characteristics of each diesel engine, enabling self-correction and the evaluation of the model throughout its entire life cycle.
Specifically, across various gear positions, we observed that the oil inlet pressure tends to decrease with an increase in temperature. This trend suggests that the decrease in oil pressure could be due to a reduction in the viscosity of the lubricating oil as its temperature rises. When the dataset is sufficient, the distribution of residuals for the oil inlet pressure conforms to a normal distribution, indicating the adaptability of the model fitting and the consistency of predictions. However, for Engine #2, the residual distribution exhibited an unusual bimodal characteristic under the condition of 1000 RPM due to limited data. Such a bimodal distribution might indicate the presence of two distinct operational modes at this specific rotational speed or reflect some form of systematic bias in the data collection process. These findings underscore the importance of considering the interplay among the rotational speed, the inlet oil temperature, and the inlet oil pressure when conducting engine fault detection.
4.4. Fault Data Validation
To validate the effectiveness of the proposed approach, fault detection was conducted on Dataset B, which contains fault data collected from the lubrication system failure tests described in
Section 3.2. This study’s method was compared with current mainstream fault detection algorithms, covering supervised and unsupervised learning algorithms. The specific supervised learning algorithms compared include the MLP, RF, SVM, and XGBoost models, and the unsupervised learning algorithms include the LOF and IF models.
A notable advantage of this study’s model is that it does not require fault data for the training phase. Therefore, different training data configurations were adopted to fairly evaluate the performance of the supervised learning algorithms, involving training these algorithms with 0.1%, 1%, and 10% of the fault data. This configuration aims to explore the performance of supervised learning algorithms at varying levels of fault data availability and to test the superiority of the method proposed in this paper in fault detection tasks.
According to the method described in this paper, we can utilize data from a healthy state diesel engine to construct an adaptive threshold for the oil inlet pressure at 1000 RPM. The plotting data collected under fault conditions showed that many data points exceeded the established threshold range. This phenomenon validates the practicality of the proposed method in effectively capturing lubrication system faults.
Based on the analysis results presented in
Table 11, for Dataset B, the most significant correlation is observed between the oil inlet pressure and the oil inlet temperature, where the MIC score reached 0.728. Furthermore, as indicated by the data in
Table 12, the optimal model fitting choice is identified as the cubic polynomial model when employing the adaptive dynamic threshold construction method. The model’s
and RSS are 0.88 and 4,725,577, respectively, demonstrating the model’s superior fitting performance and prediction accuracy.
Figure 13 intuitively displays the distribution of the normal and faulty samples and the threshold intervals determined by those above the optimal fitting model. This visual representation reveals the model’s effectiveness in distinguishing between samples in different states and provides a powerful tool and basis for further fault diagnosis and health monitoring. The success of this method lies in its ability to fully utilize data from normal operating conditions by constructing adaptive thresholds to delineate the normal operational range of the system. When a fault occurs, relevant parameters (such as the oil inlet pressure) will exhibit significant deviations from the normal range, triggering a fault alarm. This approach to building thresholds based on health state data is particularly suitable for practical application scenarios where fault data are challenging to obtain or completely absent.
Currently, most domestic medium-speed diesel engine manufacturers use fixed alarm values for threshold monitoring at monitoring points. Each monitoring sensor has its own unique alarm point, unload point, or shutdown point. Based on the fault data in
Figure 13, under the operating condition of 1000 rpm, the oil inlet temperature is approximately 63–67 °C, and the oil inlet pressure is around 600–750 kPa. According to the alarm points, unload points, and shutdown points in
Table 3, the existing fixed threshold monitoring method does not trigger any alerts. However, using the dynamic threshold alarm method proposed in this paper, it is evident that a fault has already occurred within the diesel engine lubrication system. Inspection after disassembly confirmed that the diesel engine has experienced mild bearing wear.
It can be seen from the test parameters in
Table 13 and the data in
Table 14 that the method proposed in this study significantly outperforms the IF and LOF algorithms regarding fault detection performance. Although supervised learning models can achieve high diagnostic accuracy with an abundance of fault samples, their performance in detecting faults dramatically decreases in environments where fault samples are scarce, rendering them inadequate for practical application requirements. Among them, it can be observed that the false positive rate of the supervised learning algorithms is 0. The main reason for this is the issue of data imbalance. During training, the data for healthy conditions significantly outweighs that for fault conditions, causing the model to be more inclined to classify the equipment as being in a healthy state during inference.
4.5. Method Application
During the model fitting process, the confidence interval of the predicted boundary is calculated, which consists of two confidence boundary curves. When the monitoring data points fall within the confidence interval, it indicates that the lubrication system is operating normally. If the total number of monitoring data points exceeds a certain percentage of the confidence interval over a monitoring cycle, the system will issue an alarm.
Just as abnormal blood indicators in humans change with age, we believe that diesel engines also exhibit a weakening of indicators as their life cycle extends. Therefore, the system fitting model needs to change along with the life cycle of the diesel engine. In practical engineering applications, it is essential to dynamically update the fitting model and confidence interval in cycles using the dynamic threshold monitoring method, allowing for the timely observation of faults and trends. Specifically, we first perform self-learning on the data from the diesel engine’s healthy state to fit the current “standard model”. Then, we use the collected short-term, medium-term, and long-term datasets for the diagnostic evaluation of the system. The short-term dataset primarily diagnoses in conjunction with the confidence interval of the “standard model”, the medium-term dataset conducts a trend analysis by comparing the fitted model with the parameters of the “standard model”, and the long-term model focuses on correcting the model after the performance of the “standard model” has weakened.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}