
Compound Uncertainty Quantification and Aggregation for Reliability Assessment in Industrial Maintenance †




Abstract
1. Introduction
2. Literature Review
2.1. Deriving Uncertainty and Risk
2.2. Combining Quantitative and Qualitative Uncertainty
2.2.1. Qualitative Contributions
2.2.2. Correlation and Sensitivity Analysis
2.2.3. Compound Aggregation
2.3. Research Gaps
- Approaches to quantify and aggregate compound uncertainties represented by different distributions, considering dependencies between them, applicable to increasingly complex engineering systems.
- Application of GSA to determine the impact of individual uncertainties on the aggregated total, accounting for compound parameters and significant correlation.
3. Compound Uncertainty Quantification and Aggregation Framework
4. Stepped Implementation and Results of CUQA Framework
4.1. Case Study 1: Heat Exchanger Test Rig
4.2. Case Study 2: Turbofan Engine Degradation
5. Discussion and Conclusions
- Use of the CV to enable effective quantification and aggregation of compound uncertainties represented by different distribution types;
- Assessment of the correlation between compound parameters;
- GSA for dependant compound parameters;
- Intuitive visualisation of results showing the most-significant parameters and dominant sensitivity indices.
- Deriving the uncertainty measure as the CV proved effective for the aggregation of uncertainties represented by different PDFs, but further research into the scaling of geometric against arithmetic standard deviations is required. Aggregating individual CVs by a combination of the propagation of error method for symmetric CVs and the product of asymmetric CVs allowed an aggregated total estimate to be obtained. This can be used to determine how the aggregated uncertainty changes over time.
- Dependencies between compound parameters were not found to impact the aggregated total for the two case studies. However, the influence attributed by individual CVs to the aggregated total was shown to exhibit dependencies that warrant further investigation. Such dependencies may have a significant impact in real-world environments where operating conditions such as atmospheric temperatures or wind speeds impact the accuracy of recorded data or subjective opinion.
- The case studies served to prove the functionality of the CUQA framework, exhibiting uncertainties akin to those faced in operational environments and comparable challenges to UQ. User-defined ideal limits to identify significant correlations between compound parameters enabled the definition of the desired levels of detail for the dependant variables. Stronger dependencies between parameter values will have a greater influence on emergent behaviour in more complex systems.
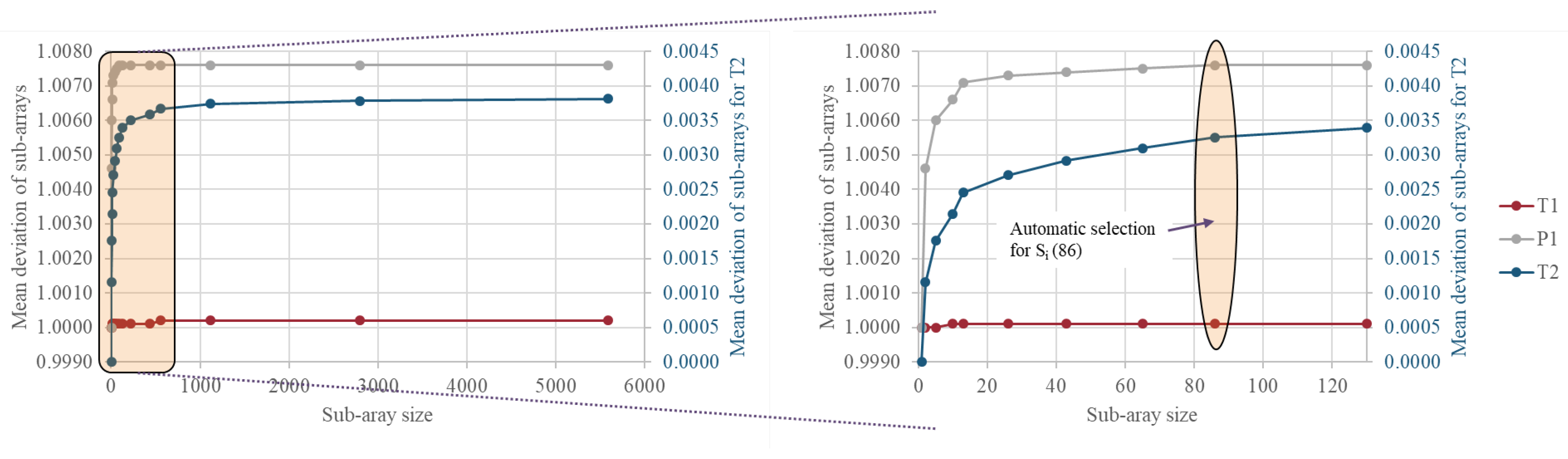
- The GSA method applied by Groen [68] was deemed the best-suited approach for the CUQA framework because it can be implemented with relatively small datasets and illustrated the influence of dependant and independent uncertainties against the aggregated total. Intuitive visualisation of the results at each stage further boosted the framework’s useability and enabled rapid identification of uncertainties outside of acceptable levels and where mitigation may be required.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Heat Exchanger Test Rig

Appendix B. C-MAPSS Turbofan Engine


References
- NASA. Measurement Uncertainty Analysis Principles and Methods; NASA: Washington, DC, USA, 2010.
- Lanza, G.; Viering, B. A novel standard for the experimental estimation of the uncertainty of measurement for micro gear measurements. CIRP Ann. Manuf. Technol. 2011, 60, 543–546. [Google Scholar] [CrossRef]
- Newman, M.E.J. Complex Systems: A Survey. Am. J. Phys. 2011, 79, 800–810. [Google Scholar] [CrossRef]
- Stevens, R. Profiling Complex Systems. In Proceedings of the 2nd Annual IEEE Systems Conference, Montreal, QC, Canada, 7–10 April 2008; pp. 1–6. [Google Scholar] [CrossRef]
- Efthymiou, K.; Mourtzis, D.; Pagoropoulos, A.; Papakostas, N.; Chryssolouris, G. Manufacturing systems complexity analysis methods review. Int. J. Comput. Integr. Manuf. 2016, 29, 1025–1044. [Google Scholar] [CrossRef]
- Helton, J.C.; Davis, F.J. Latin hypercube sampling and the propagation of uncertainty in analyses of complex systems. Reliab. Eng. Syst. Saf. 2003, 81, 23–69. [Google Scholar] [CrossRef]
- Grenyer, A.; Dinmohammadi, F.; Erkoyuncu, J.A.; Zhao, Y.; Roy, R. Current practice and challenges towards handling uncertainty for effective outcomes in maintenance. Procedia CIRP 2019, 86, 282–287. [Google Scholar] [CrossRef]
- MacAulay, G.D.; Giusca, C.L. Assessment of uncertainty in structured surfaces using metrological characteristics. CIRP Ann. Manuf. Technol. 2016, 65, 533–536. [Google Scholar] [CrossRef]
- Dantan, J.; Vincent, J.; Goch, G.; Mathieu, L. Correlation uncertainty—Application to gear conformity. CIRP Ann. Manuf. Technol. 2010, 59, 509–512. [Google Scholar] [CrossRef]
- Shamsi, M.H.; Ali, U.; Mangina, E.; O’donnell, J. A framework for uncertainty quantification in building heat demand simulations using reduced-order grey-box energy models. Appl. Energy 2020, 275, 115141. [Google Scholar] [CrossRef]
- Bentaha, M.L.; Battaïa, O.; Dolgui, A.; Hu, S.J. Dealing with uncertainty in disassembly line design. CIRP Ann. Manuf. Technol. 2014, 63, 21–24. [Google Scholar] [CrossRef]
- Addepalli, S.; Eiroa, D.; Lieotrakool, S.; François, A.-L.; Guisset, J.; Sanjaime, D.; Kazarian, M.; Duda, J.; Roy, R.; Phillips, P. Degradation Study of Heat Exchangers. Procedia CIRP 2015, 38, 137–142. [Google Scholar] [CrossRef]
- Andretta, M. Some Considerations on the Definition of Risk Based on Concepts of Systems Theory and Probability. Risk Anal. 2014, 34, 1184–1195. [Google Scholar] [CrossRef]
- Aven, T. On how to define, understand and describe risk. Reliab. Eng. Syst. Saf. 2010, 95, 623–631. [Google Scholar] [CrossRef]
- Savage, S. The flaw of averages. Harv. Bus. Rev. 2002, 80, 20. [Google Scholar] [CrossRef]
- Krane, H.P.; Johansen, A.; Alstad, R. Exploiting Opportunities in the Uncertainty Management. Procedia Soc. Behav. Sci. 2014, 119, 615–624. [Google Scholar] [CrossRef]
- Perminova, O.; Gustafsson, M.; Wikström, K. Defining uncertainty in projects–a new perspective. Int. J. Proj. Manag. 2008, 26, 73–79. [Google Scholar] [CrossRef]
- Ward, S.; Chapman, C. Transforming project risk management into project uncertainty management. Int. J. Proj. Manag. 2003, 21, 97–105. [Google Scholar] [CrossRef]
- Erkoyuncu, J.A.; Durugbo, C.; Roy, R. Identifying uncertainties for industrial service delivery: A systems approach. Int. J. Prod. Res. 2013, 51, 6295–6315. [Google Scholar] [CrossRef]
- Lequin, R.M. Guide to the Expression of Uncertainty of Measurement: Point/Counterpoint. Clin. Chem. 2004, 50, 977–978. [Google Scholar] [CrossRef]
- Willink, R. A procedure for the evaluation of measurement uncertainty based on moments. Metrologia 2005, 42, 329–343. [Google Scholar] [CrossRef]
- Ratcliffe, C.; Ratcliffe, B. Doubt-Free Uncertainty in Measurement; Springer International Publishing: Cham, Switzerland; Berlin/Heidelberg, Germany, 2015. [Google Scholar] [CrossRef]
- Willink, R. Measurement Uncertainty and Probability; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar] [CrossRef]
- Van Der Sluijs, J.P.; Craye, M.; Funtowicz, S.; Kloprogge, P.; Ravetz, J.; Risbey, J. Combining Quantitative and Qualitative Measures of Uncertainty in Model-Based Environmental Assessment: The NUSAP System. Risk Anal. 2005, 25, 481–492. [Google Scholar] [CrossRef]
- Clarke, D.D.; Vasquez, V.R.; Whiting, W.B.; Greiner, M. Sensitivity and uncertainty analysis of heat-exchanger designs to physical properties estimation. Appl. Therm. Eng. 2001, 21, 993–1017. [Google Scholar] [CrossRef]
- Minkina, W.; Dudzik, S. Infrared Thermography: Errors and Uncertainties; John Wiley and Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Kiureghian, A.; Ditlevsen, O. Aleatoric or Epistemic? Does it matter? Spec. Workshop Risk Accept. Risk Commun. 2009, 31, 105–112. [Google Scholar] [CrossRef]
- Flage, R.; Baraldi, P.; Zio, E.; Aven, T. Probability and Possibility-Based Representations of Uncertainty in Fault Tree Analysis. Risk Anal. 2013, 33, 121–133. [Google Scholar] [CrossRef] [PubMed]
- Soundappan, P.; Nikolaidis, E.; Haftka, R.T.; Grandhi, R.; Canfield, R. Comparison of evidence theory and Bayesian theory for uncertainty modeling. Reliab. Eng. Syst. Saf. 2004, 85, 295–311. [Google Scholar] [CrossRef]
- Chalupnik, M.J.; Wynn, D.C.; Clarkson, P.J. Approaches to mitigate the Impact of Uncertainty in Development Processes. In Proceedings of the 16th International Conference on Engineering Design, Stanford, CA, USA, 24–27 August 2009; pp. 459–470. [Google Scholar]
- Hogan, R. Calculating Effective Degrees of Freedom, ISO Budgets. 2014. Available online: http://www.isobudgets.com/calculating-effective-degrees-of-freedom/ (accessed on 24 August 2017).
- Helton, J.C. Uncertainty and sensitivity analysis in the presence of stochastic and subjective uncertainty. J. Stat. Comput. Simul. 1997, 57, 3–76. [Google Scholar] [CrossRef]
- Helton, J.C.; Johnson, J.D. Quantification of margins and uncertainties: Alternative representations of epistemic uncertainty. Reliab. Eng. Syst. Saf. 2011, 96, 1034–1052. [Google Scholar] [CrossRef]
- Xu, Y.; Reniers, G.; Yang, M.; Yuan, S.; Chen, C. Uncertainties and their treatment in the quantitative risk assessment of domino effects: Classification and review. Process Saf. Environ. Prot. 2023, 172, 971–985. [Google Scholar] [CrossRef]
- Aven, T.; Renn, O. The Role of Quantitative Risk Assessments for Characterizing Risk and Uncertainty and Delineating Appropriate Risk Management Options, with Special Emphasis on Terrorism Risk. Risk Anal. 2009, 29, 587–600. [Google Scholar] [CrossRef]
- Ciroth, A. Quantitative Inventory Uncertainty. Greenh. Gas Protoc. 2013, 2, 89. Available online: https://www.ghgprotocol.org/sites/default/files/ghgp/QuantitativeUncertaintyGuidance.pdf (accessed on 6 April 2019).
- Ellison, S.L.; Williams, A. Quantifying Uncertainty in Analytical Measurement; EURACHEM/CITAC Working Group: Teddington, UK, 2012; Volume 126, Available online: https://www.eurachem.org/index.php/publications/guides/quam (accessed on 25 August 2022).
- Ciroth, A.; Muller, S.; Weidema, B.; Lesage, P. Empirically based uncertainty factors for the pedigree matrix in ecoinvent. Int. J. Life Cycle Assess. 2016, 21, 1338–1348. [Google Scholar] [CrossRef]
- Coleman, H.W.; Steele, W.G. Experimentation, Validation, and Uncertainty Analysis for Engineers; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2009. [Google Scholar] [CrossRef]
- Kloprogge, P.; van der Sluijs, J.P.; Petersen, A.C. A method for the analysis of assumptions in model-based environmental assessments. Environ. Model. Softw. 2011, 26, 289–301. [Google Scholar] [CrossRef]
- Willink, R. An improved procedure for combining Type A and Type B components of measurement uncertainty. Int. J. Metrol. Qual. Eng. 2013, 4, 55–62. [Google Scholar] [CrossRef][Green Version]
- Azene, Y.T.; Roy, R.; Farrugia, D.; Onisa, C.; Mehnen, J.; Trautmann, H. Work roll cooling system design optimisation in presence of uncertainty and constrains. CIRP J. Manuf. Sci. Technol. 2010, 2, 290–298. [Google Scholar] [CrossRef]
- Iman, R.L.; Helton, J.C. An Investigation of Uncertainty and Sensitivity Analysis Techniques for Computer Models. Risk Anal. 1988, 8, 71–90. [Google Scholar] [CrossRef]
- Fleeter, C.M.; Geraci, G.; Schiavazzi, D.E.; Kahn, A.M.; Marsden, A.L. Multilevel and multifidelity uncertainty quantification for cardiovascular hemodynamics. Comput. Methods Appl. Mech. Eng. 2020, 365, 113030. [Google Scholar] [CrossRef]
- Valdez, A.R.; Rocha, B.M.; Chapiro, G.; Santos, R.W.D. Uncertainty quantification and sensitivity analysis for relative permeability models of two-phase flow in porous media. J. Pet. Sci. Eng. 2020, 192, 107297. [Google Scholar] [CrossRef]
- Cardin, M.-A.; Nuttall, W.J.; de Neufville, R.; Dahlgren, J. Extracting Value from Uncertainty: A Methodology for Engineering Systems Design. INCOSE Int. Symp. 2007, 17, 668–682. [Google Scholar] [CrossRef]
- Vasquez, V.R.; Whiting, W.B. Accounting for Both Random Errors and Systematic Errors in Uncertainty Propagation Analysis of Computer Models Involving Experimental Measurements with Monte Carlo Methods. Risk Anal. 2005, 25, 1669–1681. [Google Scholar] [CrossRef]
- Tatara, R.; Lupia, G. Assessing heat exchanger performance data using temperature measurement uncertainty. Int. J. Eng. Sci. Technol. 2012, 3, 1–12. [Google Scholar] [CrossRef]
- Funtowicz, S.O.; Ravetz, J.R. Uncertainty and Quality in Science for Policy; Springer: Dordrecht, The Netherlands, 1990. [Google Scholar] [CrossRef]
- Berner, C.L.; Flage, R. Comparing and integrating the NUSAP notational scheme with an uncertainty based risk perspective. Reliab. Eng. Syst. Saf. 2016, 156, 185–194. [Google Scholar] [CrossRef]
- Erkoyuncu, J.A. Cost Uncertainty Management and Modelling for Industrial Product-Service Systems; Cranfield University: Cranfield, UK, 2011. [Google Scholar]
- Durugbo, C.; Erkoyuncu, J.A.; Tiwari, A.; Alcock, J.R.; Roy, R.; Shehab, E. Data uncertainty assessment and information flow analysis for product-service systems in a library case study. Int. J. Serv. Oper. Inform. 2010, 5, 330. [Google Scholar] [CrossRef]
- Muller, S.; Lesage, P.; Ciroth, A.; Mutel, C.; Weidema, B.P.; Samson, R. The application of the pedigree approach to the distributions foreseen in ecoinvent v3. Int. J. Life Cycle Assess. 2016, 21, 1327–1337. [Google Scholar] [CrossRef]
- Limpert, E.; Stahel, W.A.; Abbt, M. Log-normal Distributions across the Sciences: Keys and Clues. BioScience 2001, 51, 341. [Google Scholar] [CrossRef]
- Smart, C. Bayesian Parametrics: How to Develop a CER with Limited Data and Even Without Data. Int. Cost Estim. Anal. Assoc. 2014, 1, 1–23. [Google Scholar]
- Hochbaum, D.S.; Wagner, M.R. Production cost functions and demand uncertainty effects in price-only contracts. IIE Trans. Inst. Ind. Eng. 2015, 47, 190–202. [Google Scholar] [CrossRef]
- Groen, E.A. An Uncertain Climate: The Value of Uncertainty and Sensitivity Analysis in Environmental Impact Assessment of Food; Wageningen University: Wageningen, The Netherlands, 2016. [Google Scholar] [CrossRef]
- Saltelli, A.; Ratto, M.; Andres, T.; Campolongo, F.; Cariboni, J.; Gatelli, D.; Saisana, M.; Tarantola, S. Global Sensitivity Analysis. In The Primer; John Wiley & Sons, Ltd.: Chichester, UK, 2007. [Google Scholar] [CrossRef]
- Saltelli, A. Sensitivity analysis for importance assessment. Risk Anal. 2002, 22, 579–590. [Google Scholar] [CrossRef]
- Brune, A.J.; West, T.K.; Hosder, S. Uncertainty quantification of planetary entry technologies. Prog. Aerosp. Sci. 2019, 111, 100574. [Google Scholar] [CrossRef]
- Iooss, B.; Lemaître, P. A Review on Global Sensitivity Analysis Methods. In Operations Research/Computer Science Interfaces Series; Dellino, G., Meloni, C., Eds.; Springer: Boston, MA, USA, 2015; pp. 101–122. [Google Scholar] [CrossRef]
- Patelli, E.; Pradlwarter, H.J.; Schuëller, G.I. Global sensitivity of structural variability by random sampling. Comput. Phys. Commun. 2010, 181, 2072–2081. [Google Scholar] [CrossRef]
- Groen, E.A.; Bokkers, E.A.M.; Heijungs, R.; de Boer, I.J.M. Methods for global sensitivity analysis in life cycle assessment. Int. J. Life Cycle Assess. 2017, 22, 1125–1137. [Google Scholar] [CrossRef]
- Saltelli, A.; Bolado, R. An alternative way to compute Fourier amplitude sensitivity test (FAST). Comput. Stat. Data Anal. 1998, 26, 445–460. [Google Scholar] [CrossRef]
- Sobol, I.M. Sensitivity analysis for nonlinear mathematical models, M.V. Keldysh Institute of Applied Mathematics. Russ. Acad. Sci. Mosc. 1993, 1, 407–414. [Google Scholar] [CrossRef]
- DeCarlo, E.C.; Mahadevan, S.; Smarslok, B.P. Efficient global sensitivity analysis with correlated variables. Struct. Multidiscip. Optim. 2018, 58, 2325–2340. [Google Scholar] [CrossRef]
- Xu, C.; Gertner, G.Z. Uncertainty and sensitivity analysis for models with correlated parameters. Reliab. Eng. Syst. Saf. 2008, 93, 1563–1573. [Google Scholar] [CrossRef]
- Groen, E.; Heijungs, R. Ignoring correlation in uncertainty and sensitivity analysis in life cycle assessment: What is the risk? Environ. Impact Assess. Rev. 2017, 62, 98–109. [Google Scholar] [CrossRef]
- Castrup, H. Estimating and Combining Uncertainties. In Proceedings of the 8th Annual ITEA Instrumentation Workshop, Lancaster, CA, USA, 5 May 2004. [Google Scholar]
- Grote, G. Management of Uncertainty: Theory and Application in the Design of Systems and Organisations, Decision Engineering, London; Springer: Zurich, Switzerland, 2009. [Google Scholar]
- Stockton, D.; Wang, Q. Developing cost models by advanced modelling technology, Proceedings of the Institution of Mechanical Engineers. Part B J. Eng. Manuf. 2004, 218, 213–224. [Google Scholar] [CrossRef]
- Limbourg, P.; de Rocquigny, E. Uncertainty analysis using evidence theory–confronting level-1 and level-2 approaches with data availability and computational constraints. Reliab. Eng. Syst. Saf. 2010, 95, 550–564. [Google Scholar] [CrossRef]
- Schwabe, O.; Shehab, E.; Erkoyuncu, J. Uncertainty quantification metrics for whole product life cycle cost estimates in aerospace innovation. J. Prog. Aerosp. Sci. 2015, 77, 1–24. [Google Scholar] [CrossRef]
- Schwabe, O.; Shehab, E.; Erkoyuncu, J.A. A framework for geometric quantification and forecasting of cost uncertainty for aerospace innovations. Prog. Aerosp. Sci. 2016, 84, 29–47. [Google Scholar] [CrossRef]
- Grenyer, A.; Erkoyuncu, J.A.; Addepalli, S.; Zhao, Y. An Uncertainty Quantification and Aggregation Framework for System Performance Assessment in Industrial Maintenance. In Proceedings of the TESConf 2020–9th International Conference on Through-life Engineering Services, Cranfield, UK, 3–4 November 2020. [Google Scholar] [CrossRef]
- Mathworks Documentation, Corrplot, Econometrics Toolbox. 2012. Available online: https://uk.mathworks.com/help/econ/corrplot.html (accessed on 25 August 2022).
- Thulukkanam, K. Heat Exchanger Design Handbook, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar] [CrossRef]
- Langford, E. Quartiles in Elementary Statistics. J. Stat. Educ. 2006, 14, 3. [Google Scholar] [CrossRef]
- Saxena, A.; Goebel, K.; Simon, D.; Eklund, N. Damage propagation modeling for aircraft engine run-to-failure simulation. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008; pp. 1–9. [Google Scholar] [CrossRef]
- Ramasso, E.; Saxena, A. Performance benchmarking and analysis of prognostic methods for CMAPSS datasets. Int. J. Progn. Health Manag. 2014, 5, 1–15. [Google Scholar] [CrossRef]
- Shi, Z.; Chehade, A. A dual-LSTM framework combining change point detection and remaining useful life prediction. Reliab. Eng. Syst. Saf. 2021, 205, 107257. [Google Scholar] [CrossRef]
- Wu, Y.; Yuan, M.; Dong, S.; Lin, L.; Liu, Y. Remaining useful life estimation of engineered systems using vanilla LSTM neural networks. Neurocomputing 2018, 275, 167–179. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distribution | Parameters | Deterministic Value | CV Calculation | |
|---|---|---|---|---|
| Lognormal | : Input dataset : Geometric mean : Geometric Standard Deviation (GSD) | Median: | ||
| Normal | : Input dataset : Arithmetic mean : Arithmetic standard deviation | Mean: | ||
| Uniform | : Input dataset : Minimum value : Maximum value | Mean: | ||
| Triangular | : Input dataset : Minimum value : Maximum value : Most likely value | Most likely value: |
| Component | Specification |
|---|---|
| Oil | Aero shell turbine 500 |
| Pump | Vivoil X2P4702EBBA motorised pump |
| Heater | 3 connected units controlled by 3 switches, temp. indicated by probe |
| Heat exchanger | Jaguar oil cooler, plate-fin type |
| Temperature sensors | Barksdale BTS38GVM0050M1 |
| Pressure sensor | Barksdale BPS38GVM0010B |
| IO-Link master | Pepperl + Fuchs ICE2-8IOL-G65L-V1D |
| Parameter | Reading Type | Reading Interval | Reading Error | |
|---|---|---|---|---|
| T1, sensor, hot fluid temp. into HEx (°C) | Digital | Lognormal | 0.1 °C | ±0.1 °C |
| T2, sensor, hot fluid temp. out of HEx (°C) | Digital | Lognormal | 0.1 °C | ±0.1 °C |
| T3, dial, hot fluid temp. out of HEx (°C) | Analogue | Normal | 5 °C | ±2 °C |
| T4, dial, cold fluid temp. (air blower) (°C) | Analogue | Uniform | 2 °C | ±0.5 °C |
| P1, sensor, hot fluid pressure pre-HEx (bar) | Digital | Lognormal | 0.01 bar | ±0.01 bar |
| P2, dial, hot fluid pressure post-HEx (bar) | Analogue | Uniform | 0.5 bar | ±0.3 bar |
| , volumetric flow rate of hot fluid (L/min) | Analogue | Uniform | 5 L/min | ±2 L/min |
| Score | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Reliability of data | Data are <2 months old and/or recorded by fully calibrated sensor or fully qualified person | Data are <6 months old and/or recorded by fully qualified person, but sensor requires recalibration | Data are <12 months old and/or recorded by experienced person, but sensor requires recalibration | Data are >12 months old and/or recorded by experienced person, sensor accuracy unknown | Age or source of data unknown or >12 months old |
| Basis of estimate | Best-possible data, use of historical field data, validated tools, and independently verified data, given by fully qualified person | Smaller sample of historic data, parametric estimates, internally verified data, some experience in the area | Limited available data, unverified, inexperienced opinions | Incomplete data, small sample, educated guesses, indirect approximate rule of thumb estimate | No experience in the data |
| Reading accuracy | Measurements taken using fully calibrated and accurate equipment: ±0.01 °C, ±0.1 bar | Measurements taken using recently calibrated, but less accurate equipment: ±0.1 °C, ±0.5 bar | Measurements taken using recently calibrated, but less accurate equipment: >±1 °C, >±2 bar | Measurements taken using accurate equipment that may need recalibrating | Measurements taken using un-calibrated and inaccurate equipment |
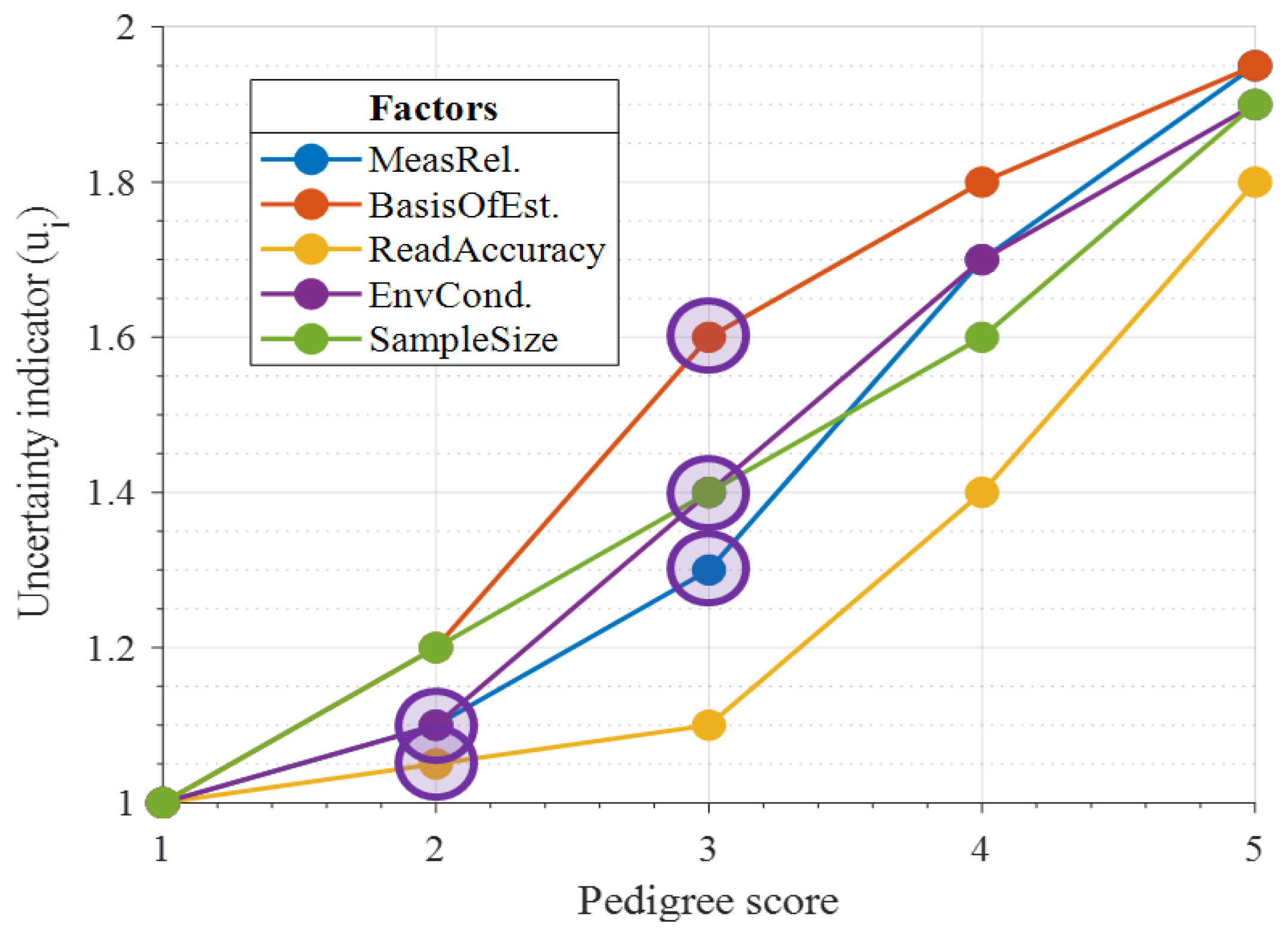
| Environmental conditions | Data recorded under specific consistent conditions or a specified range of conditions from area under study | Data recorded in generally consistent conditions with fluctuations specified | Data recorded in generally consistent conditions, changes not specified | Data recorded in a range of unspecified conditions | Data from unknown or distinctly different areas |
| Mean sample size | >1000 | >100 | >50 | <50 | Unknown |
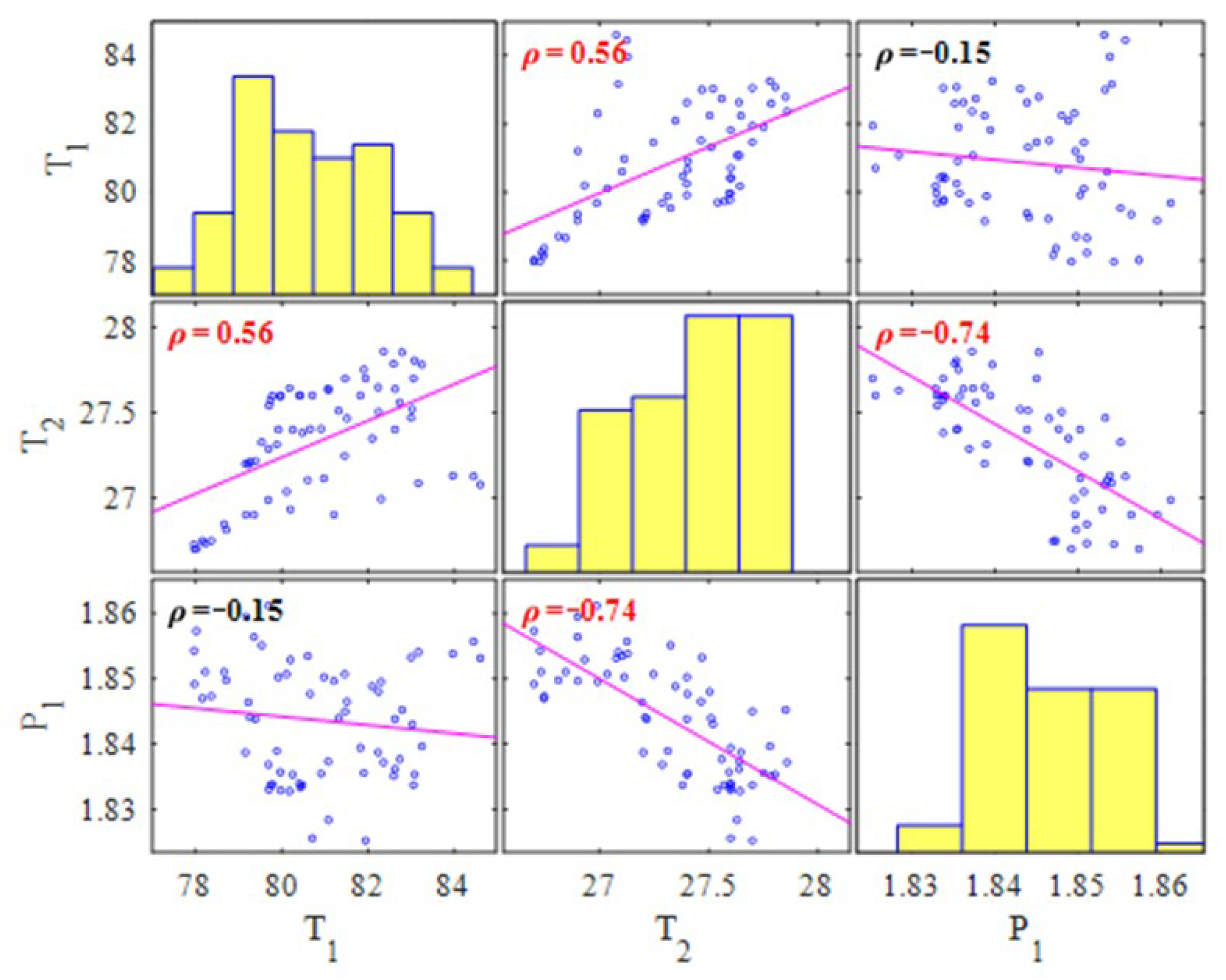
| Parameter | Reading Interval | Reading Error | Distribution | Mean | Standard Deviation | Min | Max | CV |
|---|---|---|---|---|---|---|---|---|
| T1 (°C) | 0.1 °C | ± 0.1 °C | Lognormal | 80.8654 | 1.0209 | 77.9628 | 84.6012 | 0.0207 |
| T2 (°C) | 0.1 °C | ± 0.1 °C | Normal | 27.3305 | 0.3351 | 26.7 | 27.8581 | 0.0123 |
| T3 (°C) | 5.0 °C | ±2.0 °C | Lognormal | 24.6 | 2.881 | 20 | 28 | 0.1171 |
| T4 (°C) | 2.0 °C | ±0.5 °C | Uniform | 21.6 | 0.8944 | 20 | 22 | 0 |
| P1 (bar) | 0.5 bar | ±1.0 bar | Normal | 1.8436 | 0.0088 | 1.8252 | 1.8612 | 0.0048 |
| P2 (bar) | 0.5 bar | ±0.3 bar | Uniform | 0.9 | 0.2236 | 0.5 | 1 | 0 |
| Flow (L/min) | 5 L/min | ±2 L/min | Uniform | 4.9575 | 0.0253 | 4.9343 | 4.9865 | 0 |
| Factor | Distribution | Pedigree Score | Uncertainty Indicator | GSD | CV |
|---|---|---|---|---|---|
| Meas. Relbl. | Lognormal | 2 | 1.1 | 1.0488 | 0.0477 |
| Basis of Est. | Lognormal | 2 | 1.2 | 1.0954 | 0.0914 |
| Read Accuracy | Lognormal | 1 | 1 | 1 | 0 |
| Envir. Cond. | Lognormal | 2 | 1.1 | 1.0488 | 0.0477 |
| Sample Size | Lognormal | 3 | 1.4 | 1.1832 | 0.1694 |
| CV Comb. | CV Agg. | Corr. | CVT | |
|---|---|---|---|---|
| Ln recorded | 0.0207 | 0.2256 | 0.0001 | 0.2593 |
| Ln pedigree | 0.2050 | 0.0011 | ||
| Norm. recorded | 0.1179 | 0.1179 | ||
| Uni. Recorded | 0 |
| Sensor Number | Notation | Description | Unit |
|---|---|---|---|
| 2 | T24 | Total temperature at LPC inlet | °R (Rankine scale) |
| 3 | T30 | Total temperature at HPC inlet | °R |
| 4 | T50 | Total temperature at LPT inlet | °R |
| 7 | P30 | Total pressure at HPC outlet | psi abs. (pounds per square inch, absolute) |
| 8 | Nf | Physical fan speed | rpm (revolutions per minute) |
| 9 | Nc | Physical core speed | rpm |
| 11 | Ps30 | Static pressure at HPC outlet | psi abs. |
| 12 | Phi | Ratio of fuel flow to Ps30 | psi |
| 13 | NRf | Corrected fan speed | rpm |
| 14 | NRc | Corrected core speed | rpm |
| 15 | BPR | Bypass ratio | – |
| 17 | htBleed | Bleed enthalpy | – |
| 20 | W31 | HPT coolant bleed | lbm/s (pound mass per second) |
| 21 | W32 | LPT coolant bleed | lbm/s |
| Score | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Manufacturing and assembly variations | Negligible range of initial wear on components, not contributing to engine efficiency | Minimal range in initial wear on engine components | Notable range in initial wear on engine components, occasional reduction in engine efficiency | Notable range in initial wear on engine components, regular reduction in engine efficiency | High range in initial wear on engine components, high variance in engine efficiency |
| Process noise | Negligible trend in degradation trajectory, no noise | Minor trend in degradation trajectory, minimal noise | Minor trend in degradation trajectory, manageable noise | Significant trend in degradation trajectory, variable noise | Highly contaminated degradation trajectory |
| Measurement noise | Negligible sensor noise, no impact | Minimal sensor noise, minor impact, predictable trend | Notable random complex sensor noise, measurable impact | Significant random complex sensor noise, inaccurate impact measurement | High random complex sensor noise, tangible point estimate unobtainable |
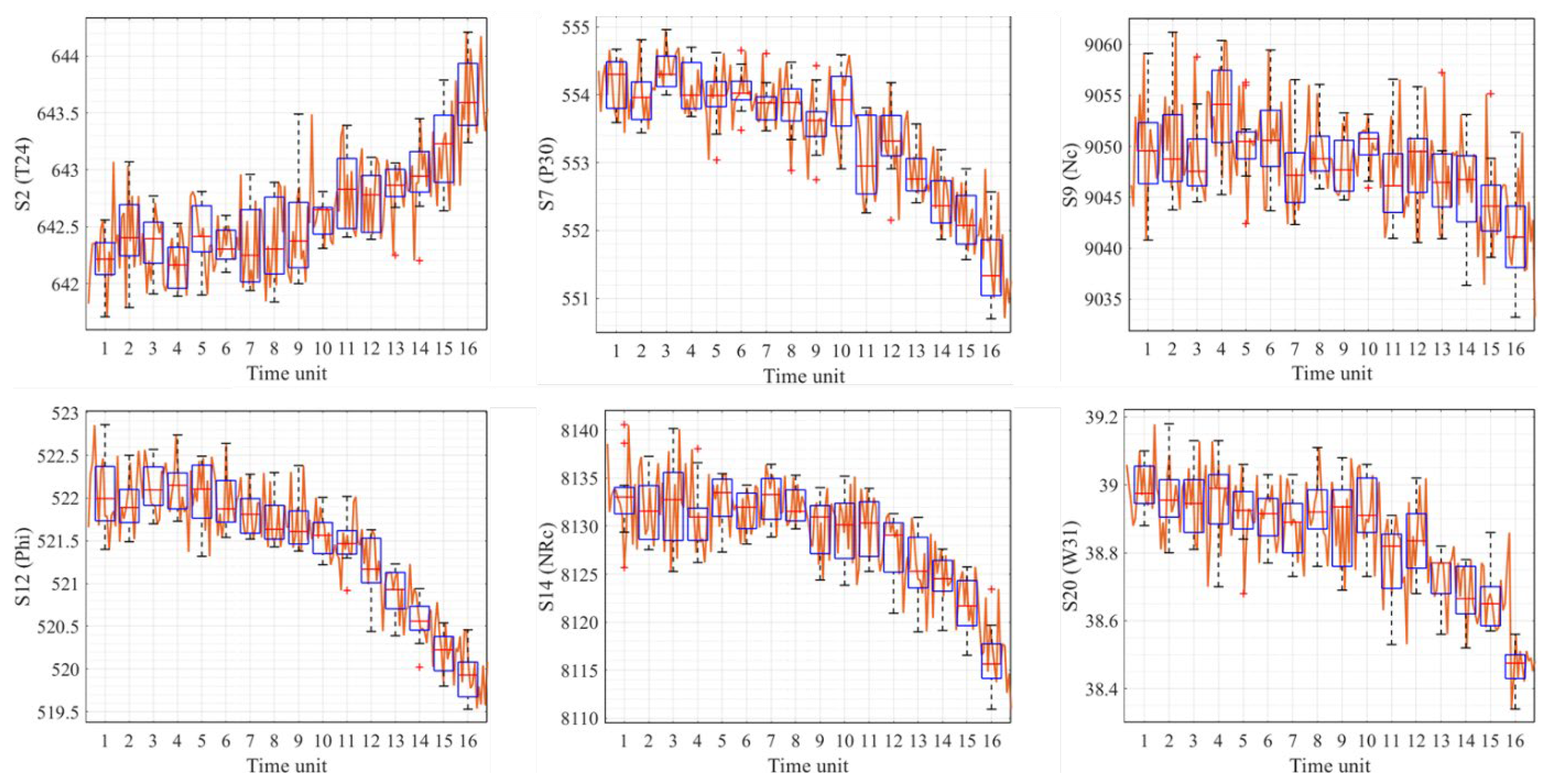
| Parameter | Distribution | Mean | Deviation | Min | Max | CV |
|---|---|---|---|---|---|---|
| S2 (T24) | Lognormal | 642.20 | 1.0004 | 641.71 | 642.56 | 0.0004 |
| S3 (T30) | Lognormal | 1586.85 | 1.0026 | 1581.75 | 1592.32 | 0.0026 |
| S4 (T50) | Lognormal | 1400.76 | 1.0021 | 1394.80 | 1406.22 | 0.0021 |
| S7 (P30) | Lognormal | 554.17 | 1.0007 | 553.59 | 554.67 | 0.0007 |
| S8 (Nf) | Lognormal | 2388.05 | 1.0000 | 2388.00 | 2388.11 | 0.0000 |
| S9 (Nc) | Normal | 9049.55 | 4.9243 | 9040.80 | 9059.13 | 0.0005 |
| S11 (Ps30) | Lognormal | 47.25 | 1.0029 | 47.03 | 47.49 | 0.0029 |
| S12 (Phi) | Lognormal | 522.05 | 1.0008 | 521.40 | 522.86 | 0.0008 |
| S13 (NRf) | Lognormal | 2388.04 | 1.0000 | 2388.01 | 2388.08 | 0.0000 |
| S14 (NRc) | Lognormal | 8133.09 | 1.0005 | 8125.69 | 8140.58 | 0.0005 |
| S15 (BPR) | Lognormal | 8.41 | 1.0027 | 8.37 | 8.43 | 0.0027 |
| S17 (htBleed) | Lognormal | 391.75 | 1.0022 | 390.00 | 393.00 | 0.0022 |
| S20 (W31) | Lognormal | 38.99 | 1.0018 | 38.88 | 39.10 | 0.0018 |
| S21 (W32) | Lognormal | 23.40 | 1.0021 | 23.31 | 23.48 | 0.0021 |
| Factor | Distribution | Pedigree Score | Uncertainty Indicator | GSD | CV |
|---|---|---|---|---|---|
| ManufVariations | Lognormal | 2 | 1.01 | 1.0488 | 0.0477 |
| ProcssNoise | Lognormal | 3 | 1.06 | 1.0954 | 0.0914 |
| MeasurmntNoise | Lognormal | 4 | 1.05 | 1.3038 | 0.2701 |
| CV Comb. | CV Agg. | Corr. | CVT | |
|---|---|---|---|---|
| Ln recorded | 0.00639 | 0.29049 | 2.7168 × 10−7 | 0.2905 |
| Ln pedigree | 0.29042 | |||
| Norm. recorded | 0.000544 | 0.000544 | ||
| Uni. recorded | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grenyer, A.; Erkoyuncu, J.A.; Addepalli, S.; Zhao, Y. Compound Uncertainty Quantification and Aggregation for Reliability Assessment in Industrial Maintenance. Machines 2023, 11, 560. https://doi.org/10.3390/machines11050560
Grenyer A, Erkoyuncu JA, Addepalli S, Zhao Y. Compound Uncertainty Quantification and Aggregation for Reliability Assessment in Industrial Maintenance. Machines. 2023; 11(5):560. https://doi.org/10.3390/machines11050560
Chicago/Turabian StyleGrenyer, Alex, John Ahmet Erkoyuncu, Sri Addepalli, and Yifan Zhao. 2023. "Compound Uncertainty Quantification and Aggregation for Reliability Assessment in Industrial Maintenance" Machines 11, no. 5: 560. https://doi.org/10.3390/machines11050560
APA StyleGrenyer, A., Erkoyuncu, J. A., Addepalli, S., & Zhao, Y. (2023). Compound Uncertainty Quantification and Aggregation for Reliability Assessment in Industrial Maintenance. Machines, 11(5), 560. https://doi.org/10.3390/machines11050560