
Vision-Based Robotic Object Grasping—A Deep Reinforcement Learning Approach

Abstract
:1. Introduction
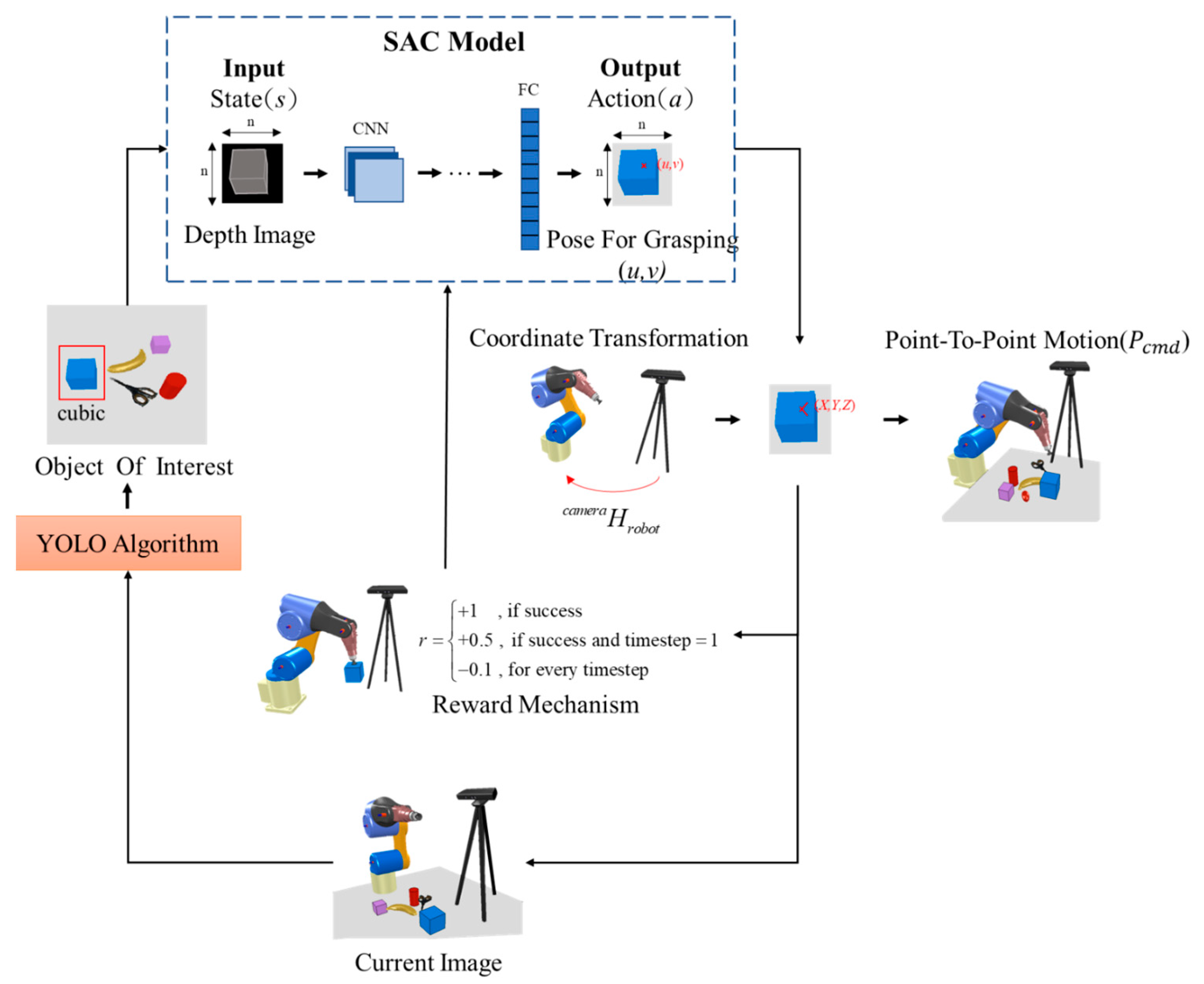
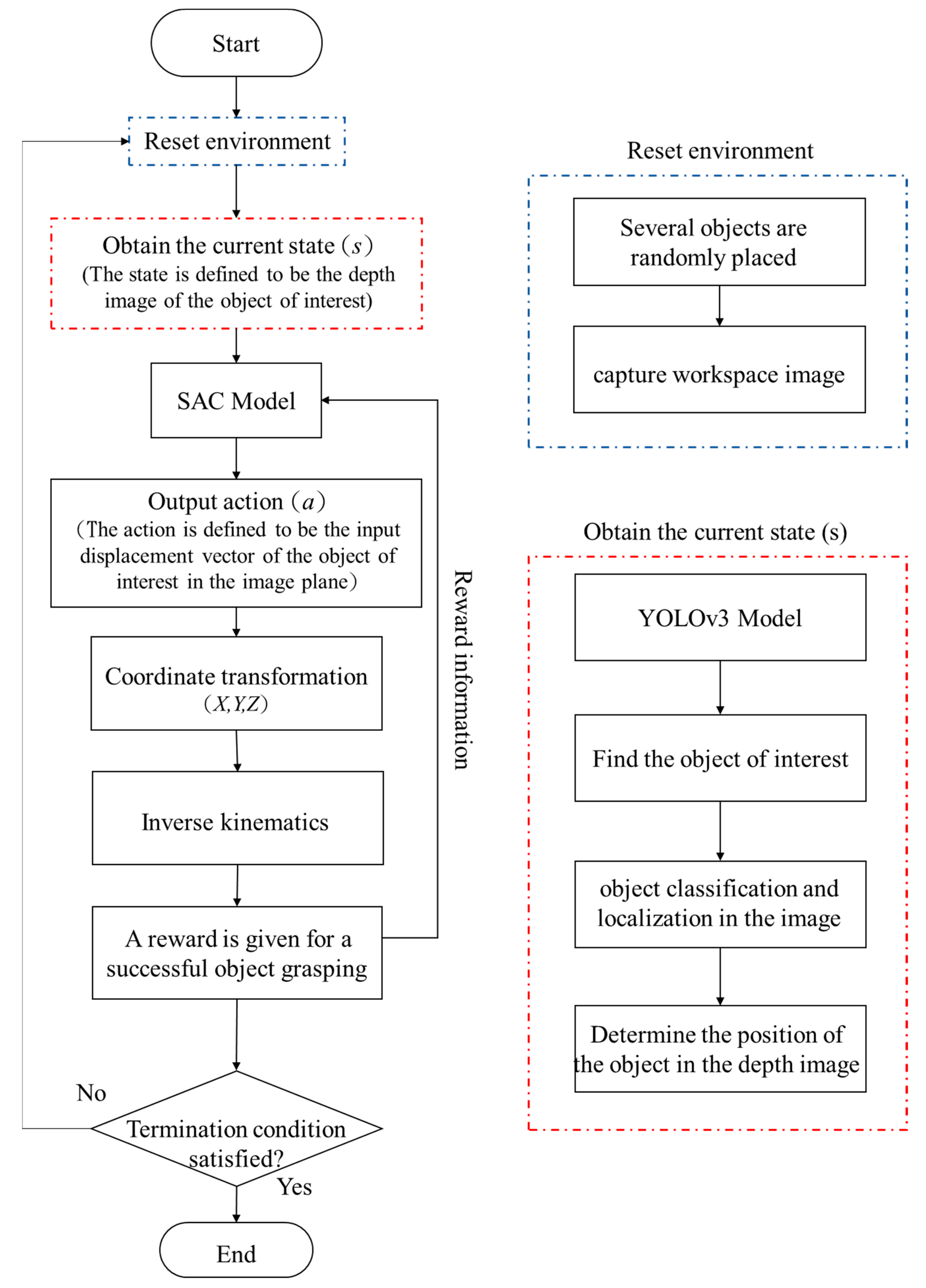
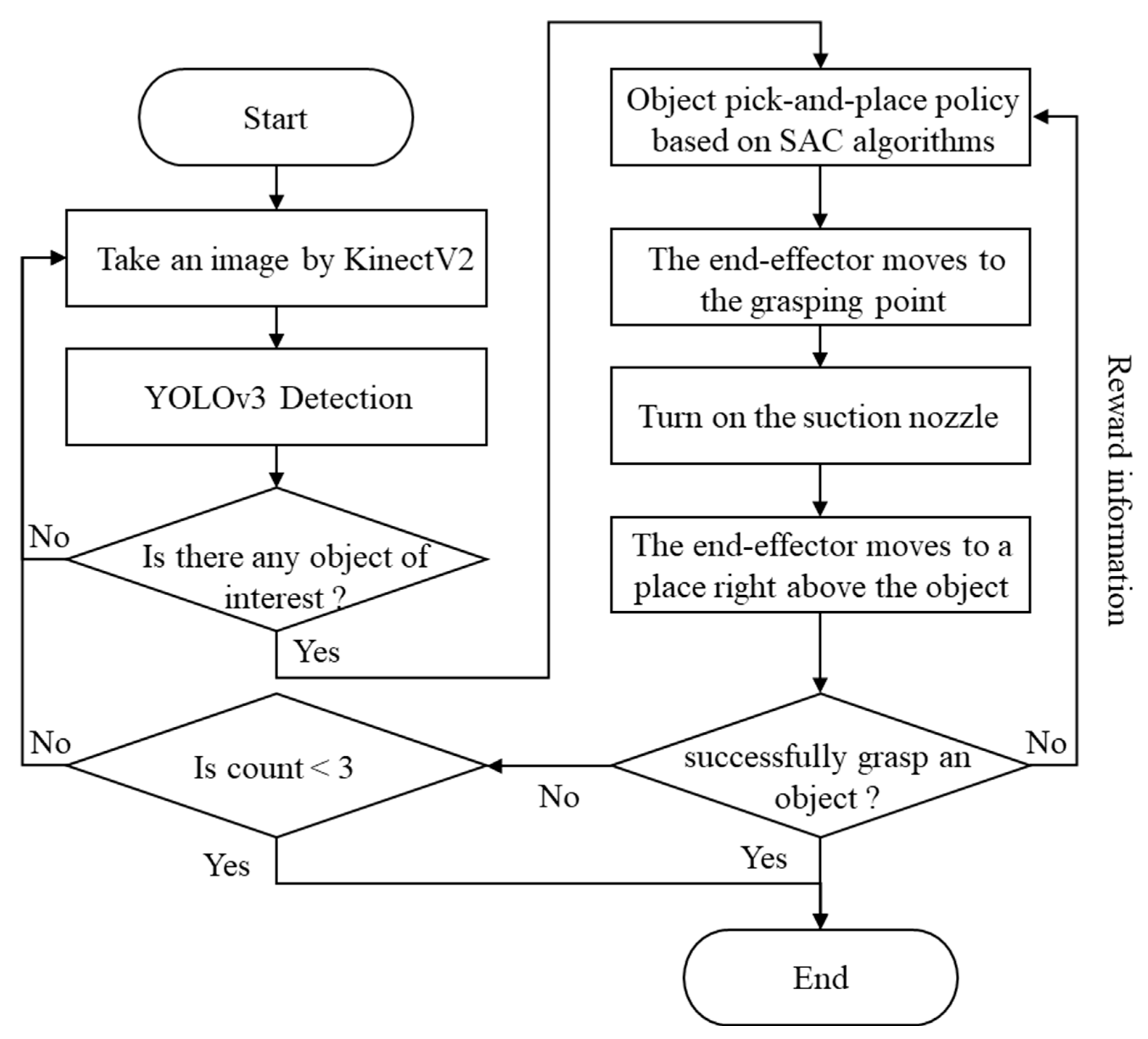
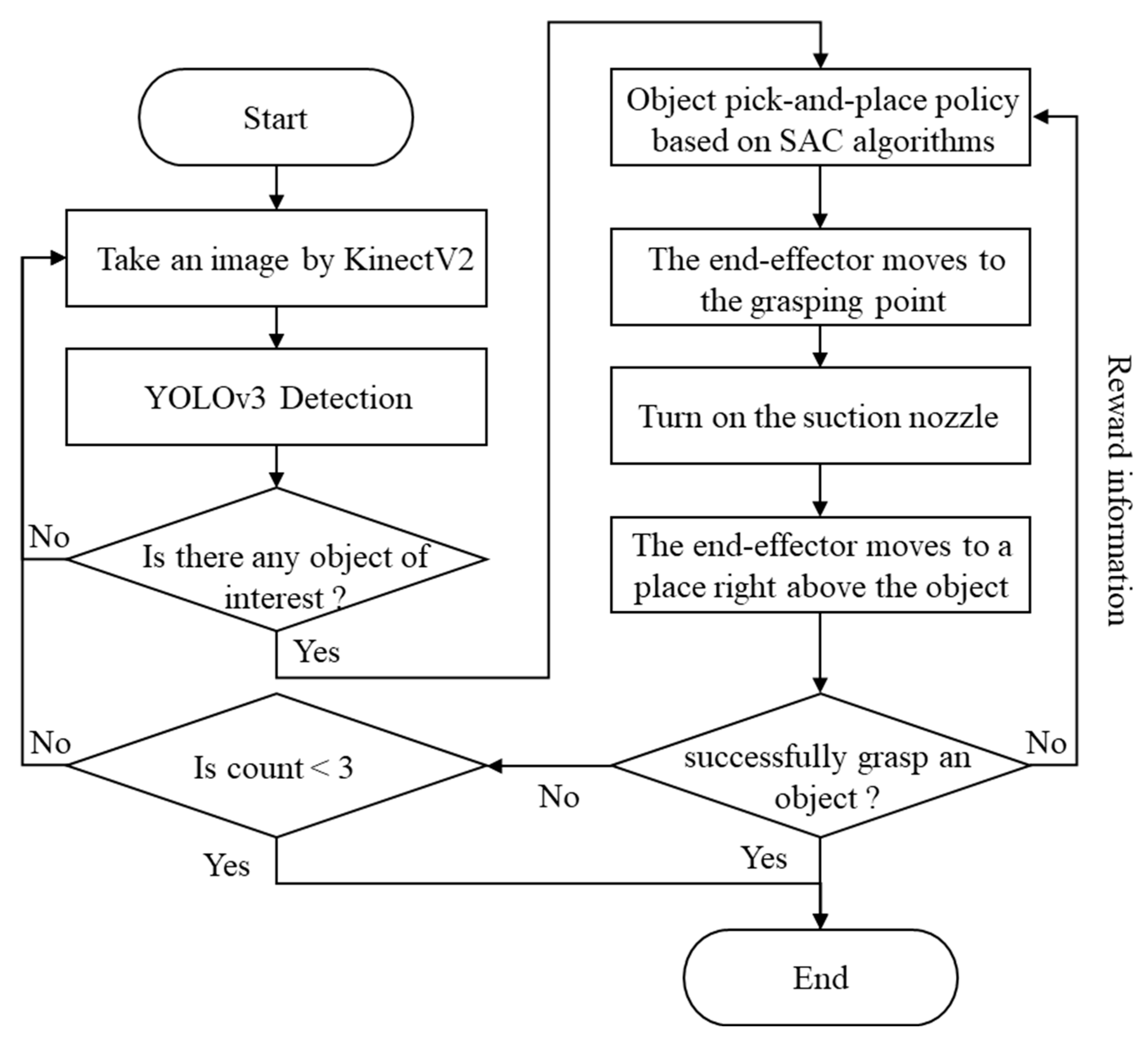
2. Framework
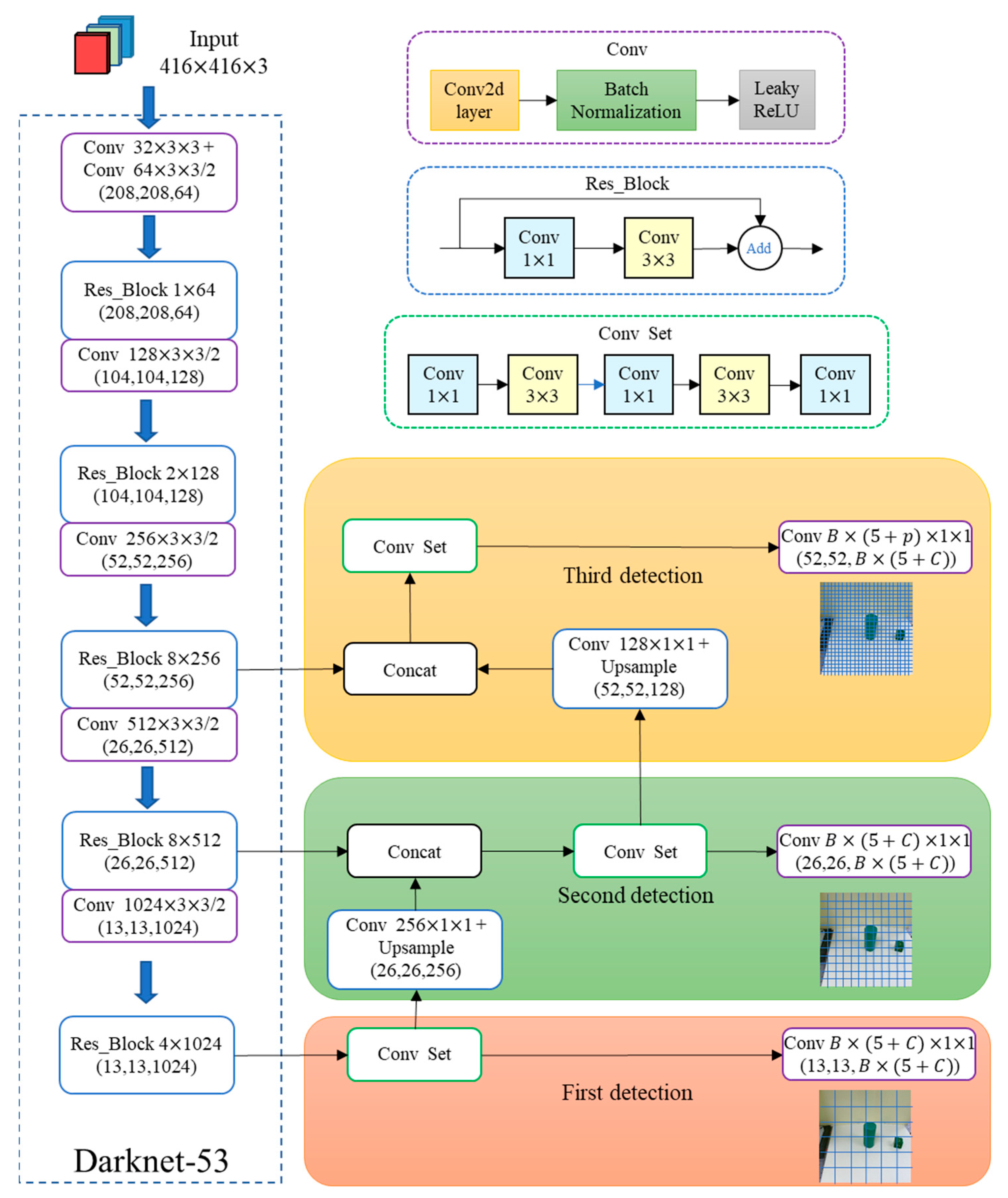
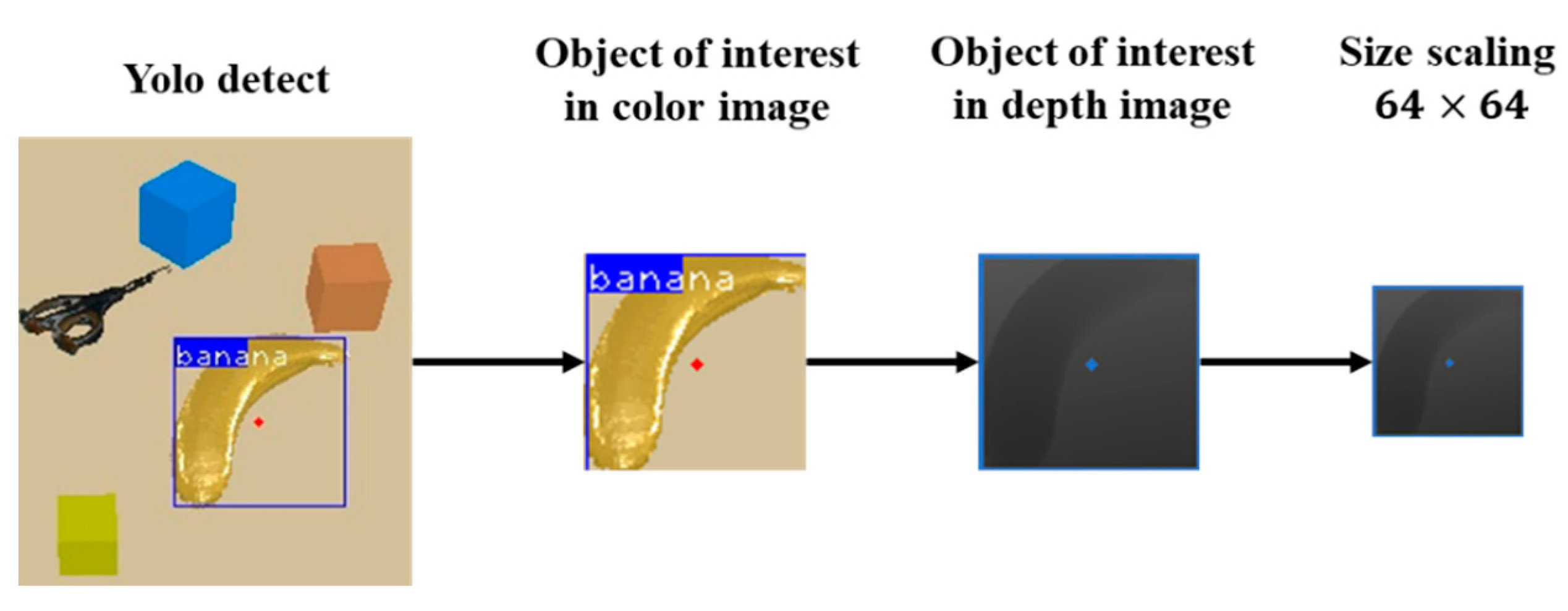
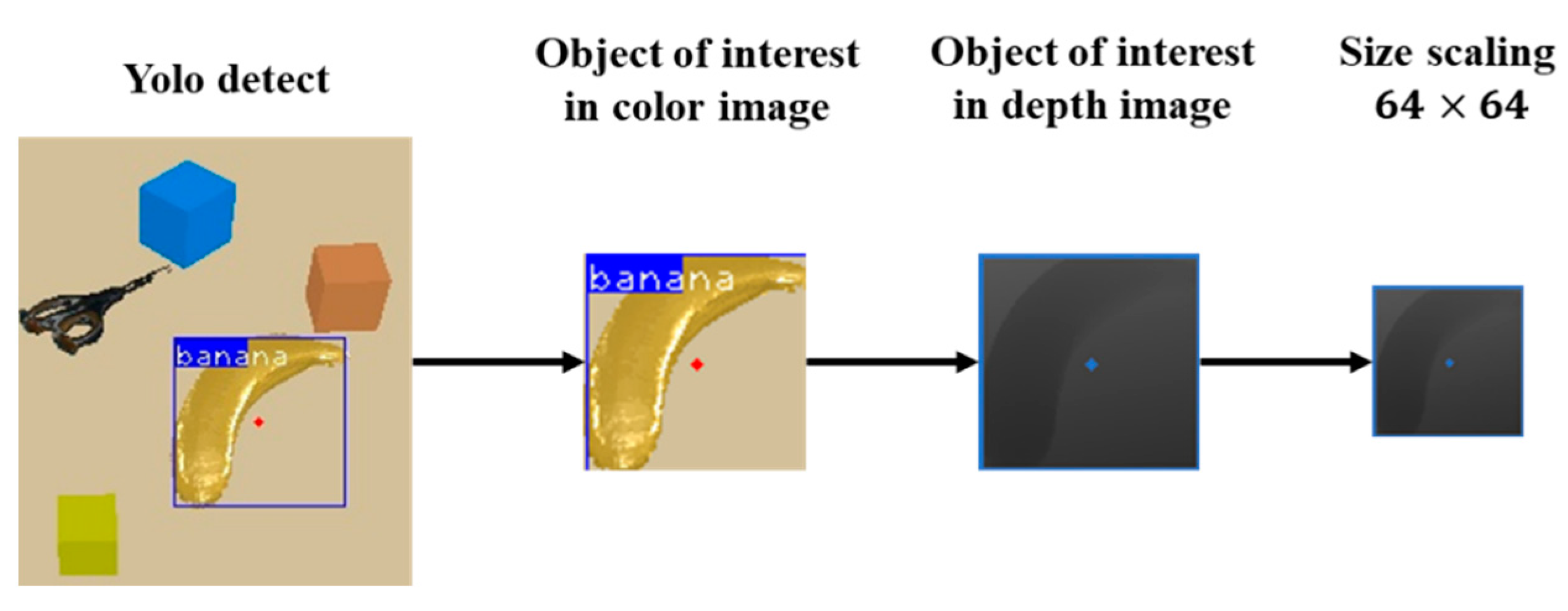
3. Object Recognition and Localization Based on YOLO Algorithms
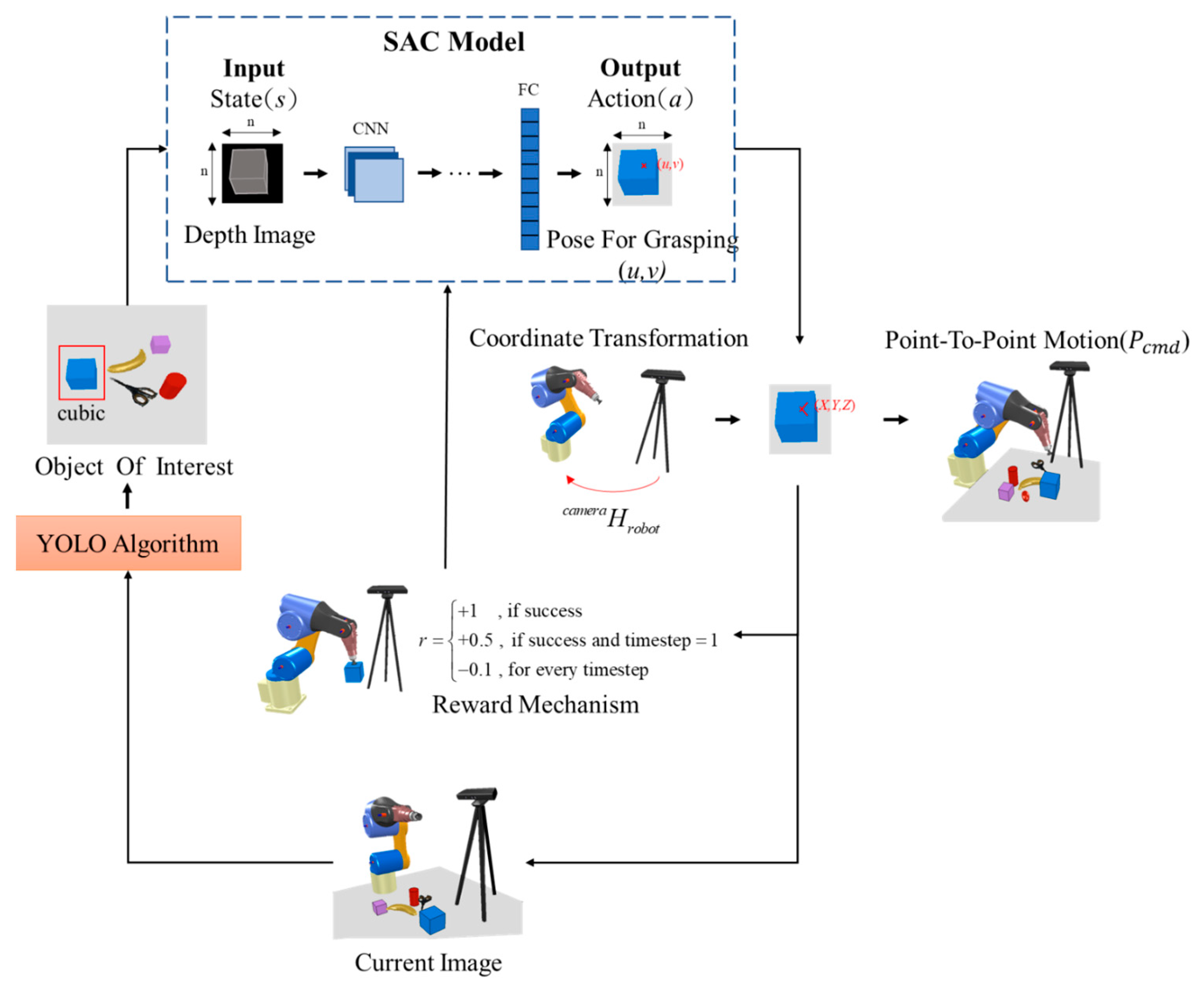
4. Object Pick-and-Place Policy Based on SAC Algorithms
4.1. Policy
4.1.1. State (State s)
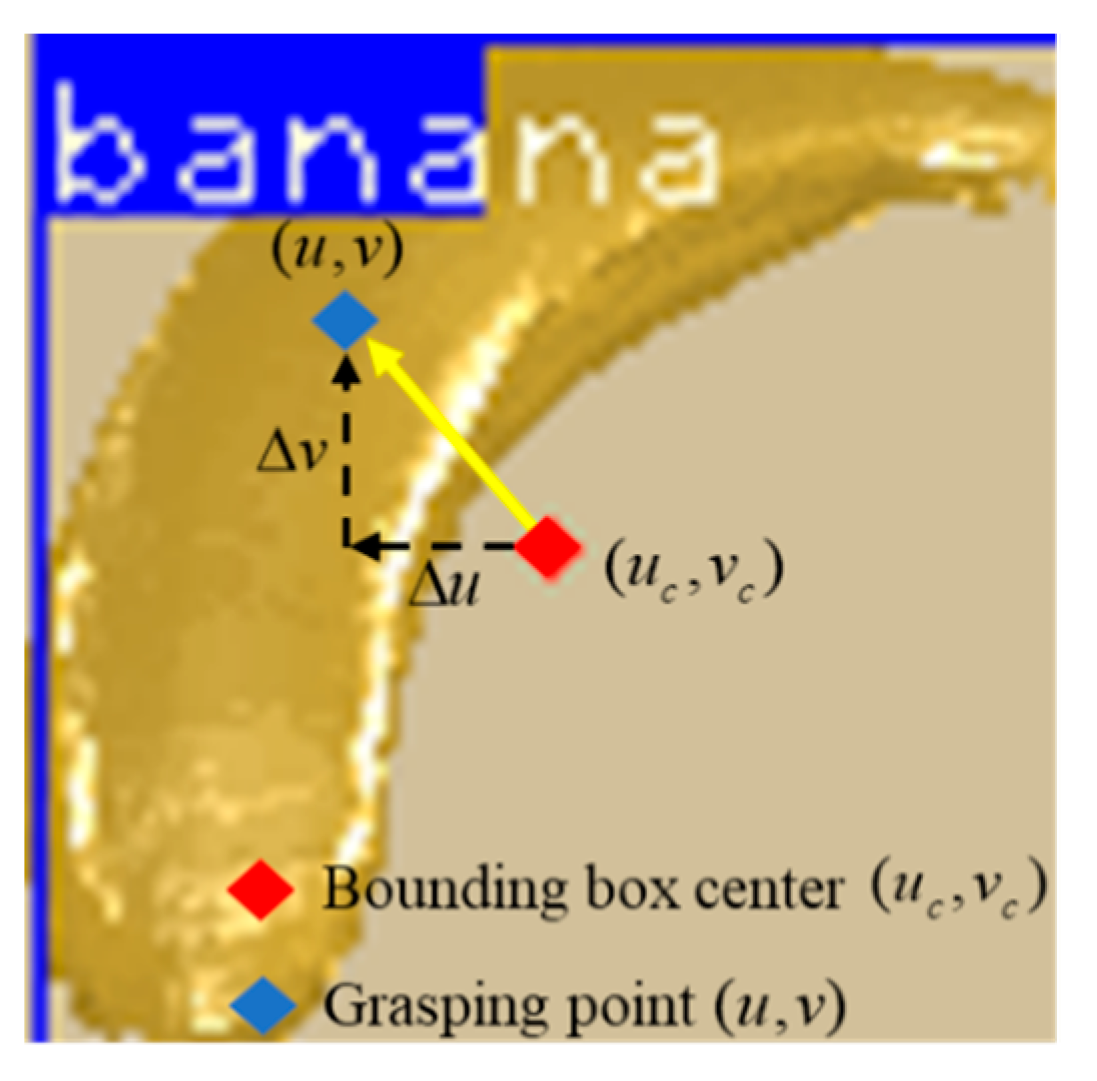
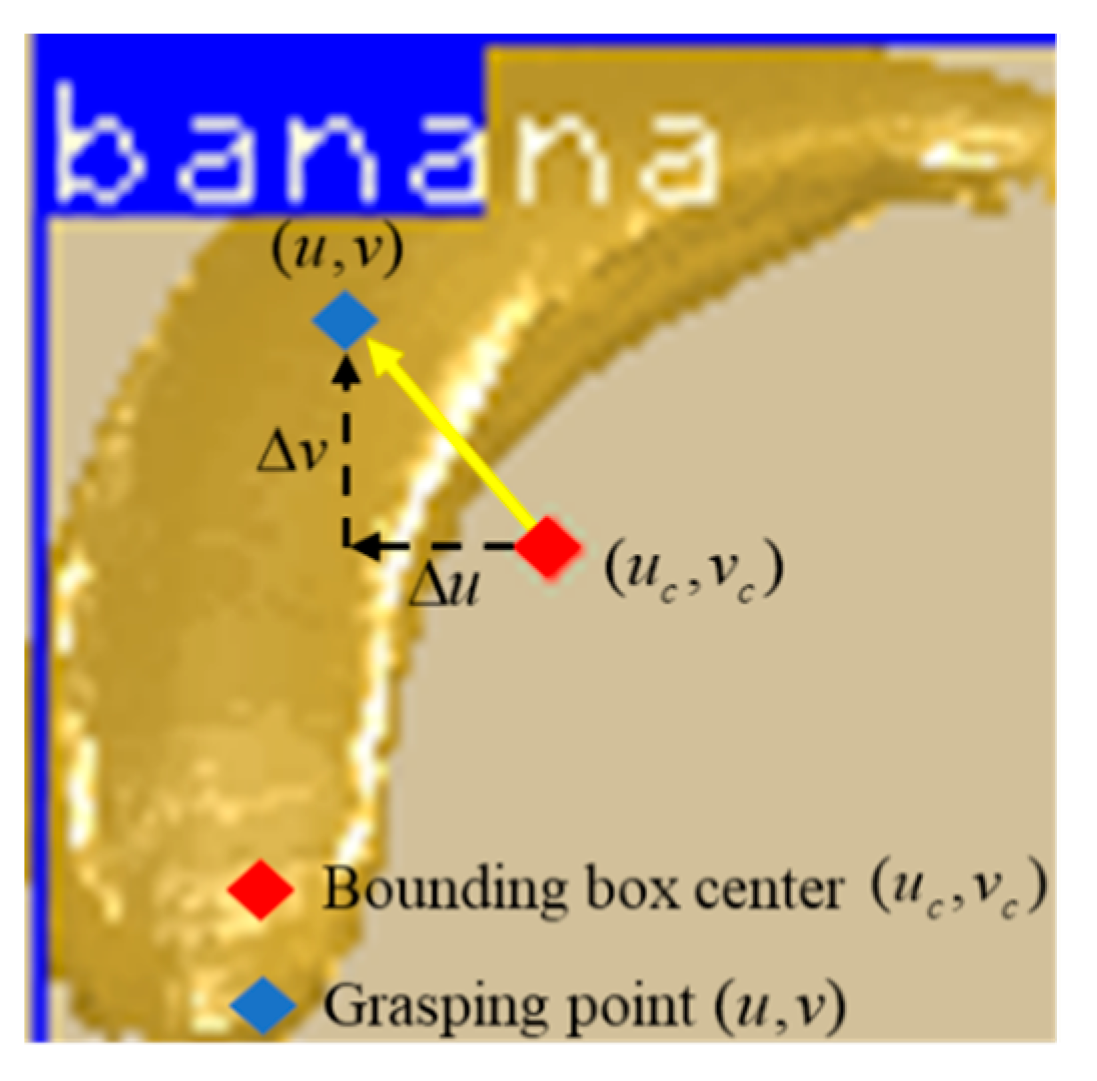
4.1.2. Action (Action a)
4.1.3. Reward (Reward, r)
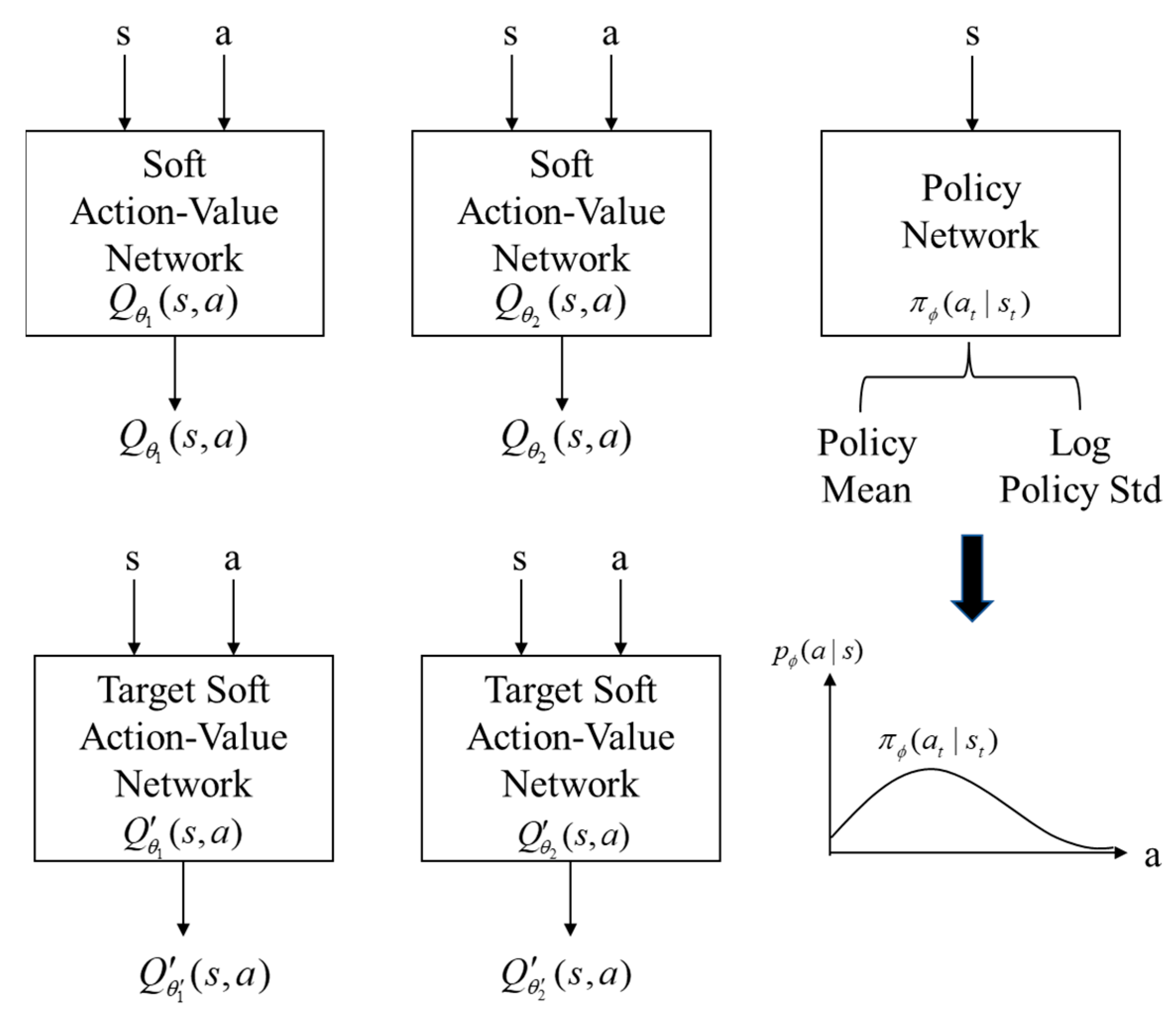
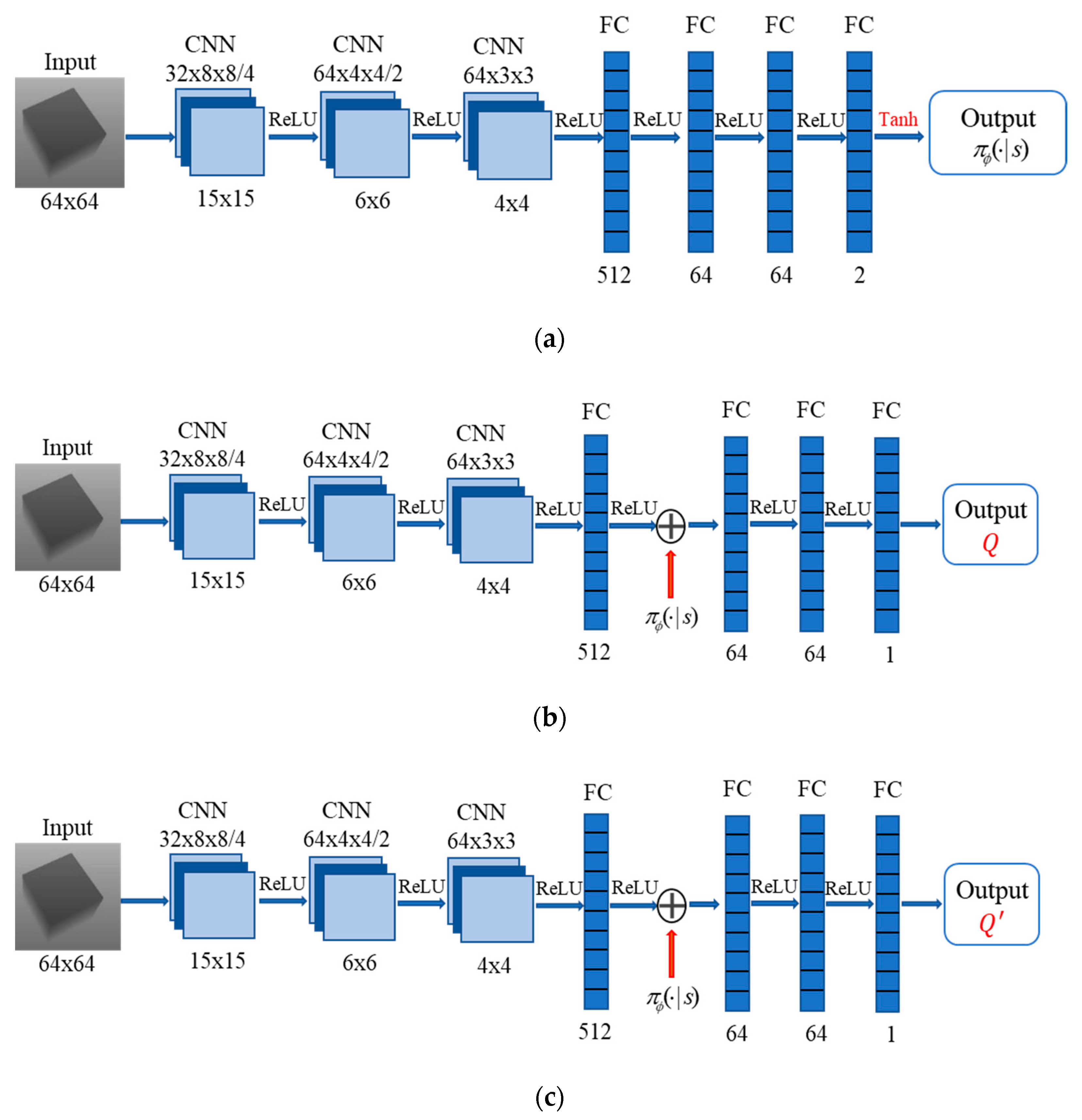
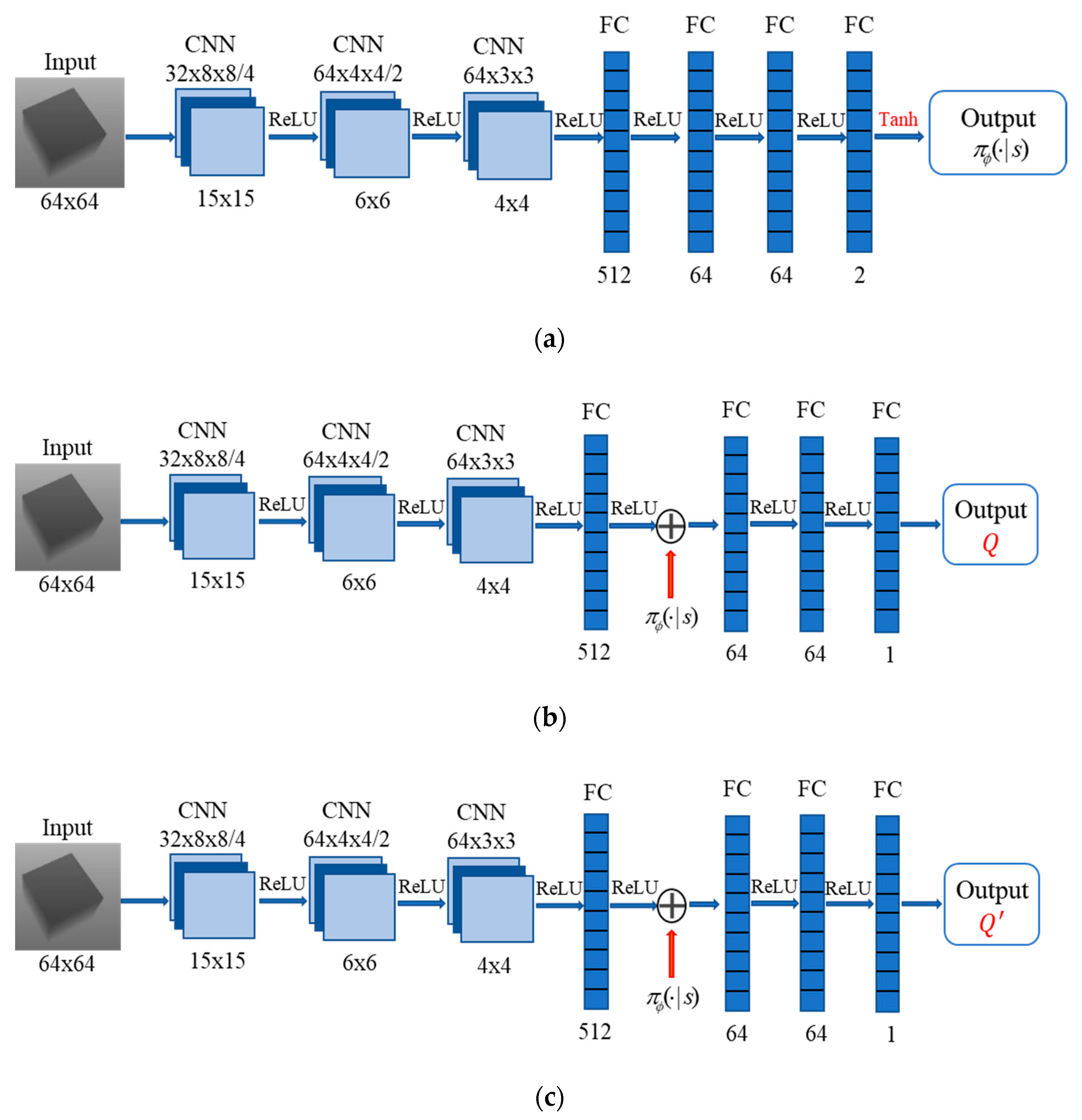
4.2. Architecture Design of SAC Neural Network
5. Experimental Setup and Results
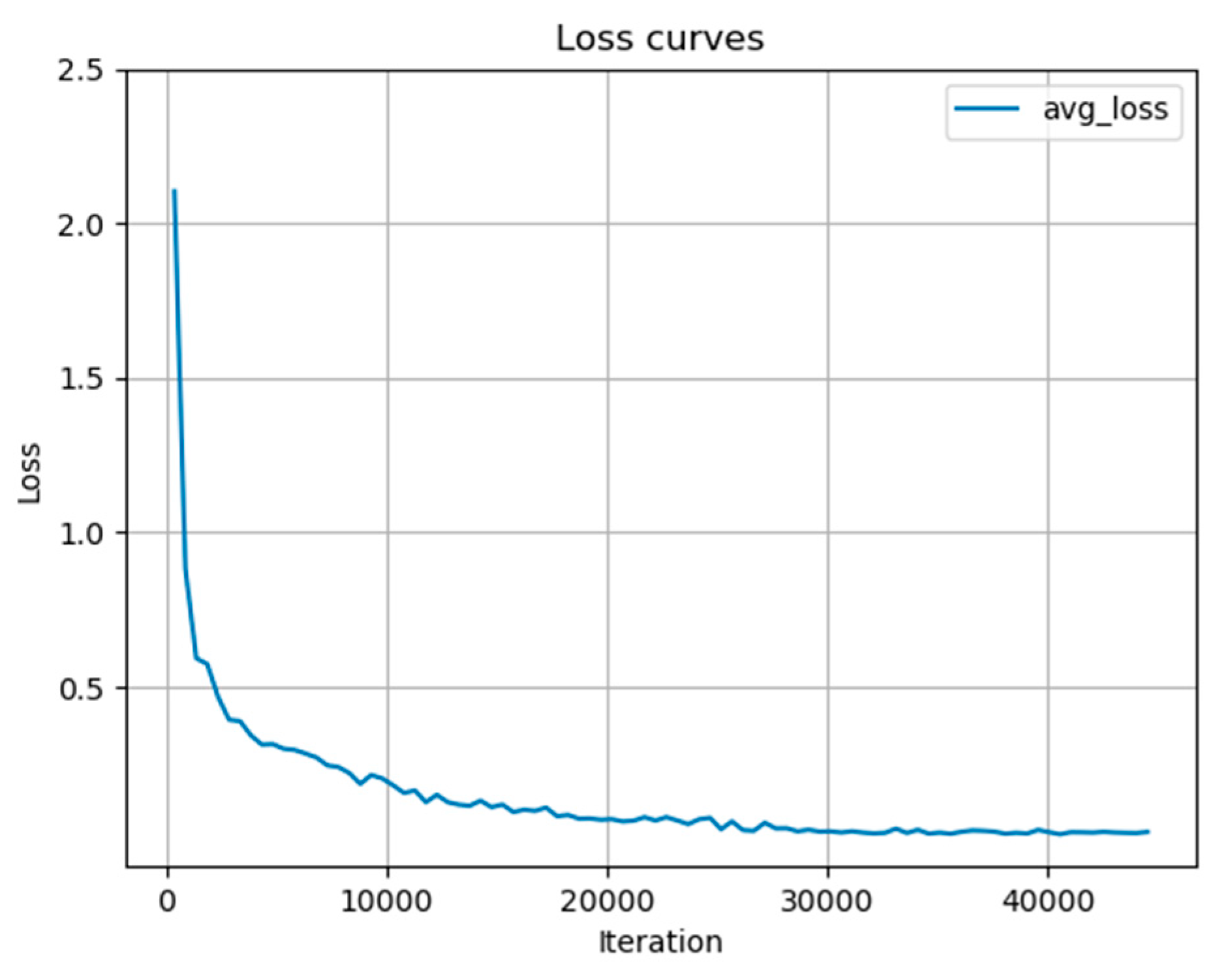
5.1. Training Results of YOLO
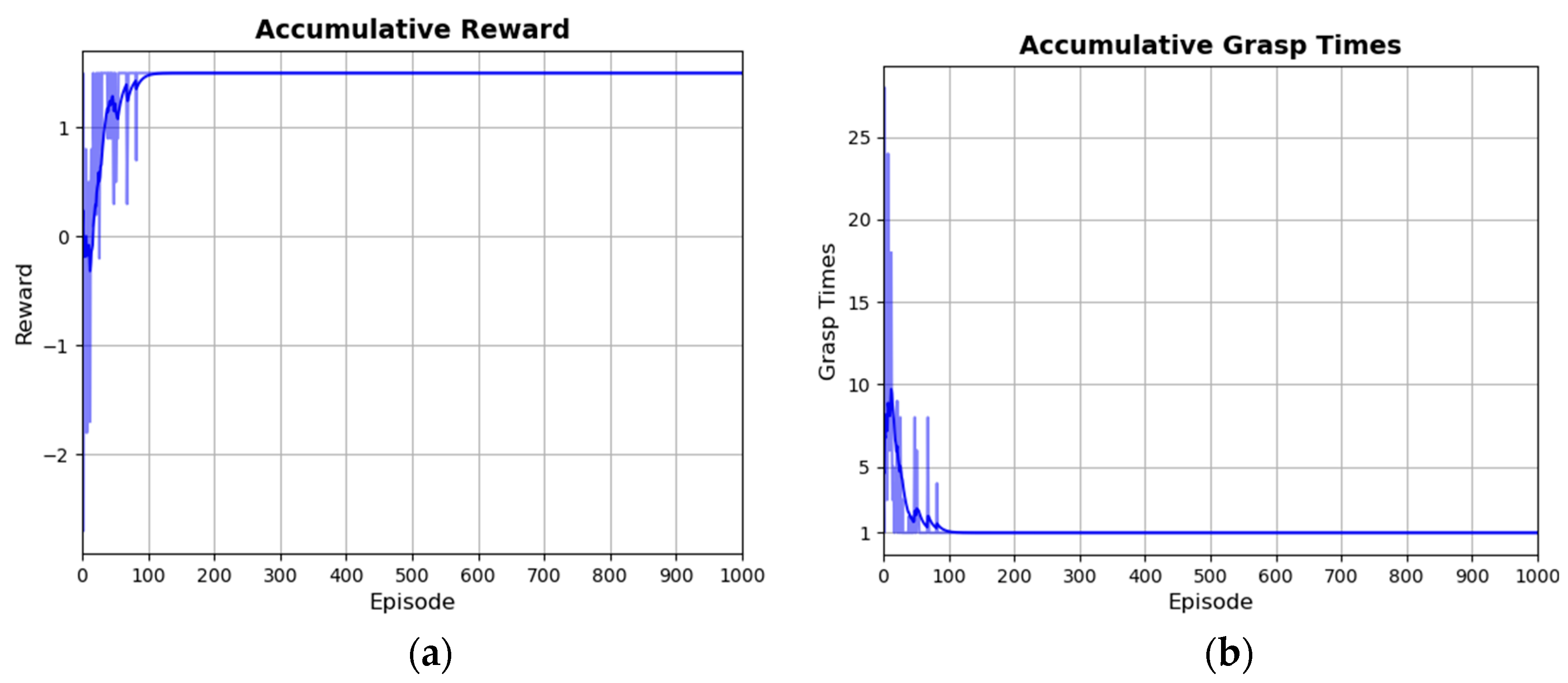
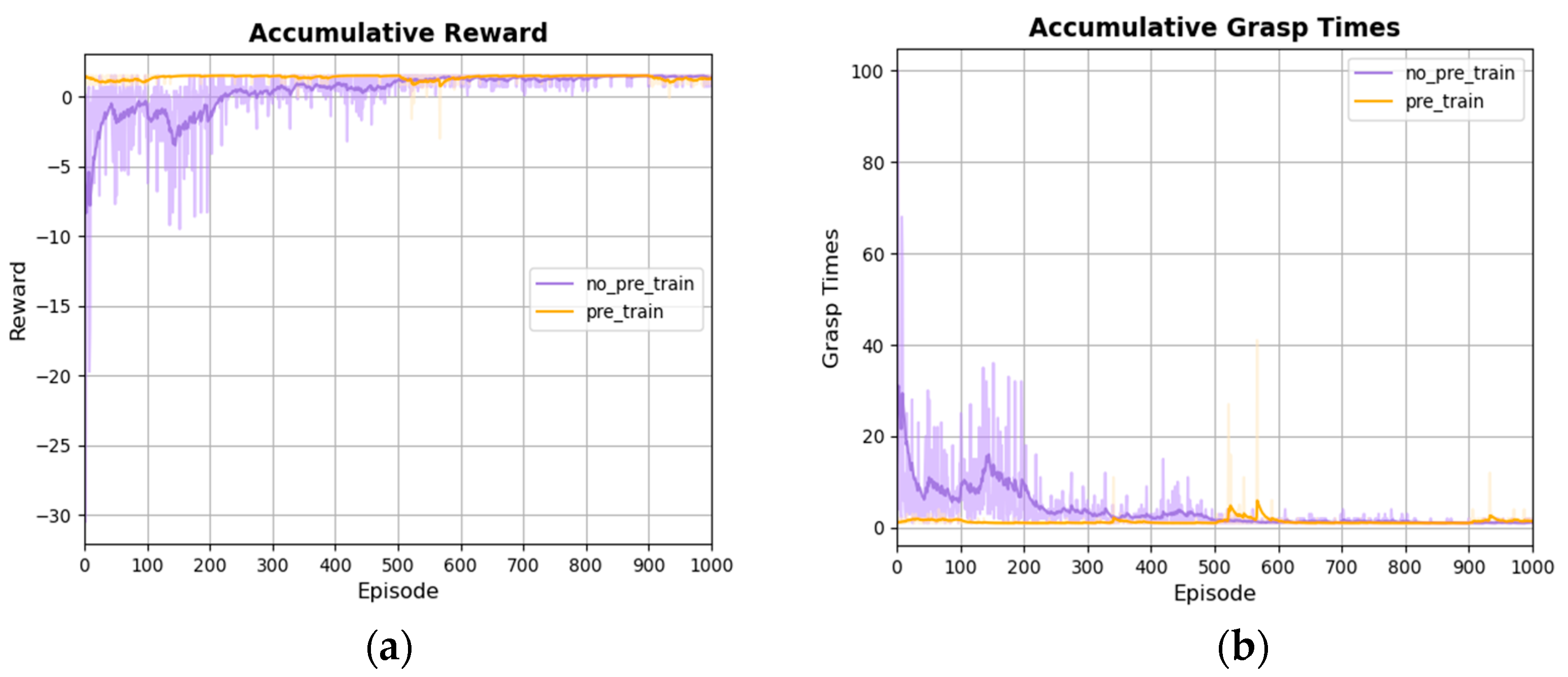
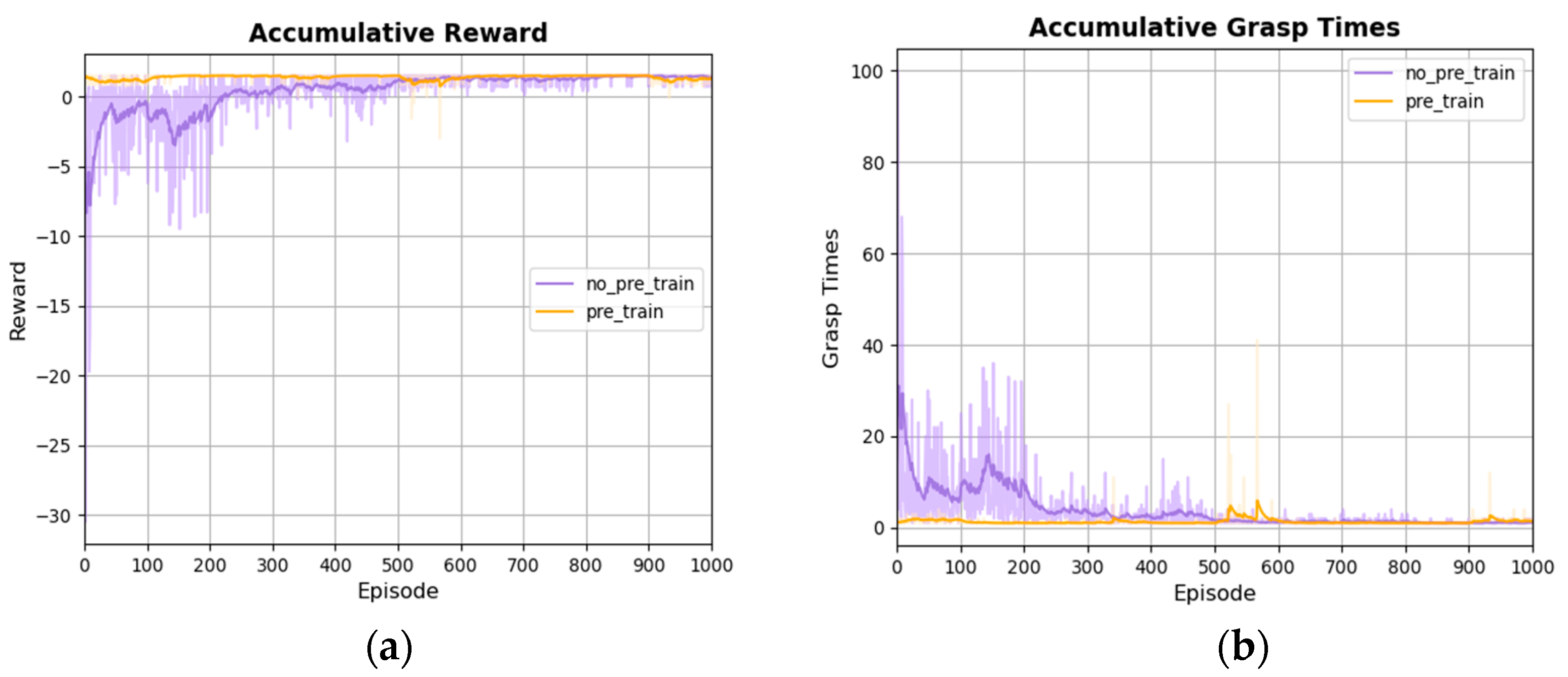
5.2. Training and Simulation Results of Object Grasping Policy Based on SAC
5.3. Object Grasping Using a Real Robot Manipulator
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kyprianou, G.; Doitsidis, L.; Chatzichristofis, S.A. Collaborative Viewpoint Adjusting and Grasping via Deep Reinforcement Learning in Clutter Scenes. Machines 2022, 10, 1135. [Google Scholar] [CrossRef]
- Johns, E.; Leutenegger, S.; Davison, A.J. Deep learning a grasp function for grasping under gripper pose uncertainty. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems, Daejeon, Republic of Korea, 9–14 October 2016; pp. 4461–4468. [Google Scholar] [CrossRef]
- Lenz, I.; Lee, H.; Saxena, A. Deep learning for detecting robotic grasps. Int. J. Robot. Res. 2015, 34, 705–724. [Google Scholar] [CrossRef]
- Pinto, L.; Gupta, A. Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; pp. 3406–3413. [Google Scholar] [CrossRef]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robot. Res. 2018, 37, 421–436. [Google Scholar] [CrossRef]
- Mahler, J.; Pokorny, F.T.; Hou, B.; Roderick, M.; Laskey, M.; Aubry, M.; Kohlhoff, K.; Kröger, T.; Kuffner, J.; Goldberg, K. Dex-Net 1.0: A cloud-based network of 3D objects for robust grasp planning using a multi-armed bandit model with correlated rewards. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; pp. 1957–1964. [Google Scholar] [CrossRef]
- Mahler, J.; Liang, J.; Niyaz, S.; Laskey, M.; Doan, R.; Liu, X.; Ojea, J.A.; Goldberg, K. Dex-Net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics. arXiv 2017, arXiv:1703.09312. [Google Scholar] [CrossRef]
- Mahler, J.; Matl, M.; Liu, X.; Li, A.; Gealy, D.; Goldberg, K. Dex-Net 3.0: Computing robust vacuum suction grasp targets in point clouds using a new analytic model and deep learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation, Brisbane, QLD, Australia, 21–25 May 2018; pp. 5620–5627. [Google Scholar] [CrossRef]
- Mahler, J.; Matl, M.; Satish, V.; Danielczuk, M.; DeRose, B.; McKinley, S.; Goldberg, K. Learning ambidextrous robot grasping policies. Sci. Robot. 2019, 4, eaau4984. [Google Scholar] [CrossRef]
- Zhang, H.; Peeters, J.; Demeester, E.; Kellens, K. A CNN-Based Grasp Planning Method for Random Picking of Unknown Objects with a Vacuum Gripper. J. Intell. Robot. Syst. 2021, 103, 1–19. [Google Scholar] [CrossRef]
- Morrison, D.; Corke, P.; Leitner, J. Learning robust, real-time, reactive robotic grasping. Int. J. Robot. Res. 2020, 39, 183–201. [Google Scholar] [CrossRef]
- Fang, K.; Zhu, Y.; Garg, A.; Kurenkov, A.; Mehta, V.; Li, F.F.; Savarese, S. Learning task-oriented grasping for tool manipulation from simulated self-supervision. Int. J. Robot. Res. 2020, 39, 202–216. [Google Scholar] [CrossRef]
- Ji, X.; Xiong, F.; Kong, W.; Wei, D.; Shen, Z. Grasping Control of a Vision Robot Based on a Deep Attentive Deterministic Policy Gradient. IEEE Access 2021, 10, 867–878. [Google Scholar] [CrossRef]
- Horng, J.R.; Yang, S.Y.; Wang, M.S. Self-Correction for Eye-In-Hand Robotic Grasping Using Action Learning. IEEE Access 2021, 9, 156422–156436. [Google Scholar] [CrossRef]
- Ibarz, J.; Tan, J.; Finn, C.; Kalakrishnan, M.; Pastor, P.; Levine, S. How to train your robot with deep reinforcement learning: Lessons we have learned. Int. J. Robot. Res. 2021, 40, 698–721. [Google Scholar] [CrossRef]
- Gualtieri, M.; Ten Pas, A.; Platt, R. Pick and place without geometric object models. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation, Brisbane, QLD, Australia, 21–25 May 2018; pp. 7433–7440. [Google Scholar] [CrossRef]
- Fujita, Y.; Uenishi, K.; Ummadisingu, A.; Nagarajan, P.; Masuda, S.; Castro, M.Y. Distributed reinforcement learning of targeted grasping with active vision for mobile manipulators. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 9712–9719. [Google Scholar] [CrossRef]
- Zeng, A.; Song, S.; Welker, S.; Lee, J.; Rodriguez, A.; Funkhouser, T. Learning synergies between pushing and grasping with self-supervised deep reinforcement learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018; pp. 4238–4245. [Google Scholar] [CrossRef]
- Deng, Y.; Guo, X.; Wei, Y.; Lu, K.; Fang, B.; Guo, D.; Liu, H.; Sun, F. Deep reinforcement learning for robotic pushing and picking in cluttered environment. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems, Macau, China, 3–8 November 2019; pp. 619–626. [Google Scholar] [CrossRef]
- Kalashnikov, D.; Irpan, A.; Pastor, P.; Ibarz, J.; Herzog, A.; Jang, E.; Quillen, D.; Holly, E.; Kalakrishnan, M.; Vanhoucke, V.; et al. QT-opt: Scalable deep reinforcement learning for vision-based robotic manipulation. arXiv 2018, arXiv:1806.10293. [Google Scholar] [CrossRef]
- Chen, R.; Dai, X.Y. Robotic grasp control policy with target pre-detection based on deep q-learning. In Proceedings of the 2018 3rd International Conference on Robotics and Automation Engineering, Guangzhou, China, 17–19 November 2018; pp. 29–33. [Google Scholar] [CrossRef]
- Chen, Z.; Lin, M.; Jia, Z.; Jian, S. Towards generalization and data efficient learning of deep robotic grasping. arXiv 2020, arXiv:2007.00982. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft actor-critic algorithms and applications. arXiv 2019, arXiv:1812.05905. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Cai, C.; Somani, N.; Nair, S.; Mendoza, D.; Knoll, A. Uncalibrated stereo visual servoing for manipulators using virtual impedance control. In Proceedings of the 13th International Conference on Control Automation Robotics & Vision, Singapore, 10–12 December 2014; pp. 1888–1893. [Google Scholar]
- Peng, X.B.; Andrychowicz, M.; Zaremba, W.; Abbeel, P. Sim-to-Real Transfer of Robotic Control with Dynamics Randomization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Title 2 |
|---|---|
| optimizer | Adam |
| learning rate | 0.001 |
| replay buffer size | 200,000 |
| batch size | 64 |
| discount factor (γ) | 0.99 |
| target smoothing coefficient (τ) | 0.005 |
| entropy temperature parameter (α) | 0.01 |
| Pre_Train (Use Transfer Learning) | No_Pre_Train | Without_YOLO | |
|---|---|---|---|
| Training time | 6443 (s) | 15,076 (s) | 102,580 (s) |
| Number of grasping attempts | 1323 (attempts) | 3635 (attempts) | 38,066 (attempts) |
| Object of Interest | Building Block | Apple | Banana | Orange | Cup |
|---|---|---|---|---|---|
| Rate of successful grasping | 19/20 | 6/10 | 6/10 | 8/10 | 9/10 |
| Object is in the training set | yes | no | yes | no | no |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-L.; Cai, Y.-R.; Cheng, M.-Y. Vision-Based Robotic Object Grasping—A Deep Reinforcement Learning Approach. Machines 2023, 11, 275. https://doi.org/10.3390/machines11020275
Chen Y-L, Cai Y-R, Cheng M-Y. Vision-Based Robotic Object Grasping—A Deep Reinforcement Learning Approach. Machines. 2023; 11(2):275. https://doi.org/10.3390/machines11020275
Chicago/Turabian StyleChen, Ya-Ling, Yan-Rou Cai, and Ming-Yang Cheng. 2023. "Vision-Based Robotic Object Grasping—A Deep Reinforcement Learning Approach" Machines 11, no. 2: 275. https://doi.org/10.3390/machines11020275
APA StyleChen, Y.-L., Cai, Y.-R., & Cheng, M.-Y. (2023). Vision-Based Robotic Object Grasping—A Deep Reinforcement Learning Approach. Machines, 11(2), 275. https://doi.org/10.3390/machines11020275