1. Introduction
Prognostics for a system or a process focuses on predicting the remaining useful life (RUL), and the presence of incipient failures within a foreseeable horizon. It is a critical function of prognostics and health management (PHM) systems that utilize results from diagnostics and prognostics modules to monitor the severity of faults and the overall trajectory for a system’s state of health. This type of knowledge, acquired or predicted, facilitates management decisions and actions related to maintenance, logistics, and personnel [
1,
2]. In the literature, diagnostics and prognostics are typically combined within a condition-based monitoring (CBM) module where various model-based, data-driven, and hybrid methods have been proposed. The choice and implementation of a CBM program are dependent on the nature of the system, associated critical components, how each problem is framed, and the depth and coverage of expert knowledge to be incorporated into solving them [
3].
Cluster analysis or clustering focuses on identifying major groups in data such that data in the same group has more similarity than data from a different group [
4,
5]. As a result, it partitions a single set of data into several subsets so the system can zoom into each subset as a sub-problem. It is a commonly used method in CBM applications as a pre-processing step to reduce complexity and noise in the data to “divide, conquer and simplify” otherwise very complex problems. Clustering is an unsupervised task because there are no truth values or labels. To this end, clustering is distinctly different from other popular methods in CBM, such as “classification”, where the truth or label information is assumed to be available. Clustering methods, such as fuzzy c-means (FCM) [
6], k-means clustering [
7], and mountain clustering [
8], are a few of the most popular algorithms, and they have been widely applied for exploratory data mining and visualization, object detection, novelty detection, and knowledge discovery in a wide range of applications. Among these methods, DBSCAN [
9] received a lot of attention recently due to its performance, flexibility, and the ability to represent large amounts of data where the clusters may not necessarily be represented by exactly the same set of features, and the number of clusters may not have to be specified. Online evolving clustering (OEC), a relatively new class of clustering methods, enables the adaptation in both their structure and parameters [
10,
11,
12,
13,
14]. Due to the added capability of performing incremental modifications to the model, it is well suited for data with indefinite length (or data streams). In [
15] it was reported that its performance is on par with a physics-based model for complex systems.
With the advances in machine learning, and the access to large-scale datasets shared across the academia and industry sectors, there has been an acceleration in the development of new techniques. In [
16], challenges in data alignment and noise reduction mechanisms were addressed with ARMA graph convolution, adversarial adaptation, and multi-layer multi-kernel local maximum mean discrepancy (ML-LMMD). To address the increasingly common issues associated with multi-sensors and uncertainty quantification in the predicted RUL information, Ref. [
17] proposed a gated graph convolutional network (GCCN) which simultaneously models the temporal and spatial dependencies in the data. A graphical neural network combines the capability and learning mechanisms of modern neural networks for diagnostics and prognostics progressions and maintains learned knowledge/state representations [
18]. Probabilistic approaches, such as Bayesian networks with recurrent mechanisms, have been improved for generic RUL problems, where uncertainties from different sources are handled by separate layers in the network [
19]. Attention mechanisms were designed and implemented for semi-supervised fault detection by exploiting dependencies between similar data and neighboring nodes in the network in an effort to deal with imperfect information that arise due to natural signal variation under different working conditions and controls for different planned tasks [
20]. In [
21], a hybrid robust convolutional autoencoder (HRCAE) and a parallel convolutional distribution fitting (PCDF) module was constructed to conduct unsupervised anomaly detection of machine tools under a noisy environment when labels of data may not be available most of the time. To deal with frame-based inputs where repetitions and variable length of data and similar inputs have been addressed with dynamic time warping and PCA [
22]. In [
23] two novel neural network variants were proposed, namely the growing neural network (GNN) and a variable sequence LSTM for the diagnosis, prognosis, and health monitoring framework. The domain application was on an aerospace industry where the accuracy of predicted results have implications to ensure safe and successful completion of planned flight tasks, and the models improved management of repair and maintenance costs.
In the work of [
23], the common practice of transfer learning in certain ML domains (i.e., natural language processing) have been surveyed with limited references to CBM applications. The authors break down the tasks into three methods, as follows: model and parameter transfer, feature matching, and adversarial adaptation with examples on machinery diagnostics and prognostics. For the consistently increasing complexity of modern-day industrial systems, Ref. [
24] emphasized the need for a comprehensive integrated health monitoring (IHM) system using the vehicle as an example of the type of systems of systems that are rapidly growing in complexity. Traditionally, the OEM’s focus is mainly on the improvement of diagnostics capabilities with key sub-systems, but the trend is now heading toward a more integrated approach and accurate prognostics information. This is due to the demand from the customers, as well as from the OEMs, due to the significance of these tools for discovering the emerging quality issues and quantifying the associated warranty costs. Hybrid approaches that incorporate multiple RUL learning and prediction mechanisms continue to be investigated to improve the final model’s capability to generalize information to balance between robustness and accuracy for extremely challenging problems, such as RUL estimation of modern lithium-ion batteries [
25].
For human behaviors and early detection of medical conditions, steady progress was made with relatively recent ML architectures. Deep structured models, such as EEGNet and DeepconNet, were investigated and were shown to yield high precision results for autism spectrum disorder (ASD) with EEG signals in a transfer learning setting [
26]. Researchers have also investigated, from the healthcare system and practitioner’s perspective, the implications of AIML-aided diagnosis and prognosis in practice, as well as their educational impacts on the society [
27]. Furthermore, as large-scale data collection becomes more prevalent, the sheer volume of data poses significant challenges in all phases of machine learning-based systems and data-driven operations. In [
28] the latest advances in few-shot learning (FSL) are studied to facilitate learning from a few samples with prior knowledge. In [
29], the team focused on similar issues with applying online learning methodologies, where feature extraction and subsequent model learning were performed online, meaning it goes through a few data points (flow through the data stream) at a time to greatly reduce the computational footprint.
In this paper, the focus is on the prognostics applications of a mutual information-based Gustafson–Kessel-like clustering algorithm (MIRGKL) embedded with local approximation functions. This work is inspired by an online evolving clustering (OEC) algorithm originated from an extended version of the Gustafson–Kessel (GK) clustering algorithm [
10]. The MIRGKL applies the mutual information formulation to the Mahalanobis distance to produce a conservative assessment of the similarity calculations between objects. With the filtered version of the similarity measure, choices are made between cluster maintenance actions, including the creation of a new cluster, merging of existing clusters, or update of an existing cluster. Degradation information of a system is typically made available much less frequently but is necessary to train cluster-specific degradation (survival) models according to a cluster assignment. In the case when the cluster assignment and degradation information are asynchronous, inferred degradation information needs to be estimated, such that the learning of cluster-specific degradation function takes place subsequently right after cluster assignment. The modifiable cluster-specific degradation model is based on the linearized version of the well-known Weibull survival function that can be learned in real-time. Note that while we do not put emphasis on insignificant clusters (i.e., small population and/or low utilization), the frequencies of their occurrences are related to novel emerging patterns and, therefore, may be of interest for diagnostics purposes for mission critical systems [
30,
31]. Treating prognostics as a function learning and prediction problem makes it well suited for various methods that are designed for this purpose. Bundling with an evolving clustering method allows such a learning-based system to start from scratch, initiate RUL predictions early due to the lower data requirement, and to leverage modern incremental training to keep track of newly available data with a small footprint on the computational requirement. Other state of the art tools for tackling similar problems (RUL estimation) as a function approximation problem include support vector regression [
32], Kalman filter [
33], and deep neural networks [
34]. In addition, decision trees and tree-based methodologies, due to their flexibility to incorporate a mixture of related variables, ease of interpretation for predictive purposes, and robustness in performance, continue to be one of the most applied method for many real-world applications [
35,
36].
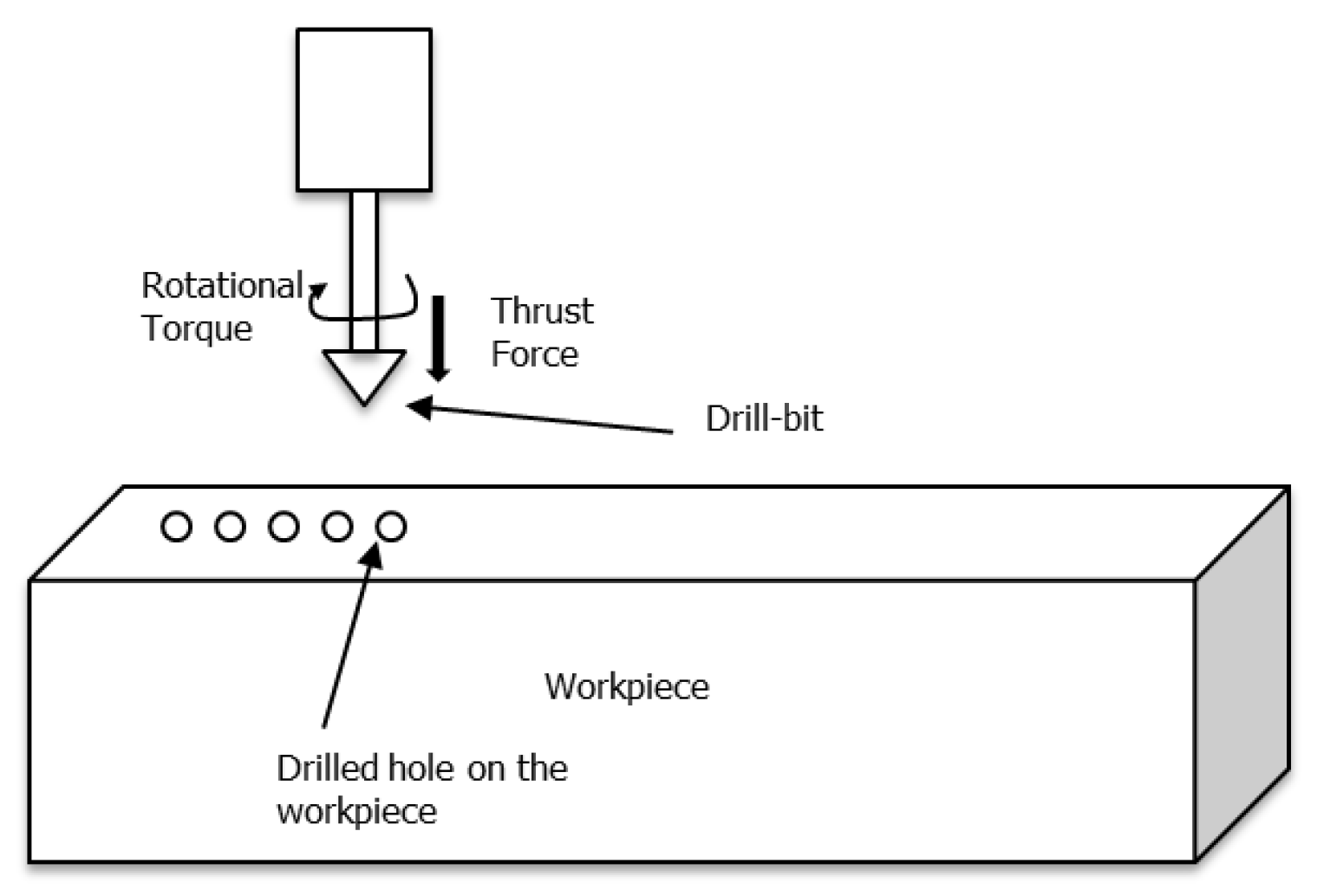
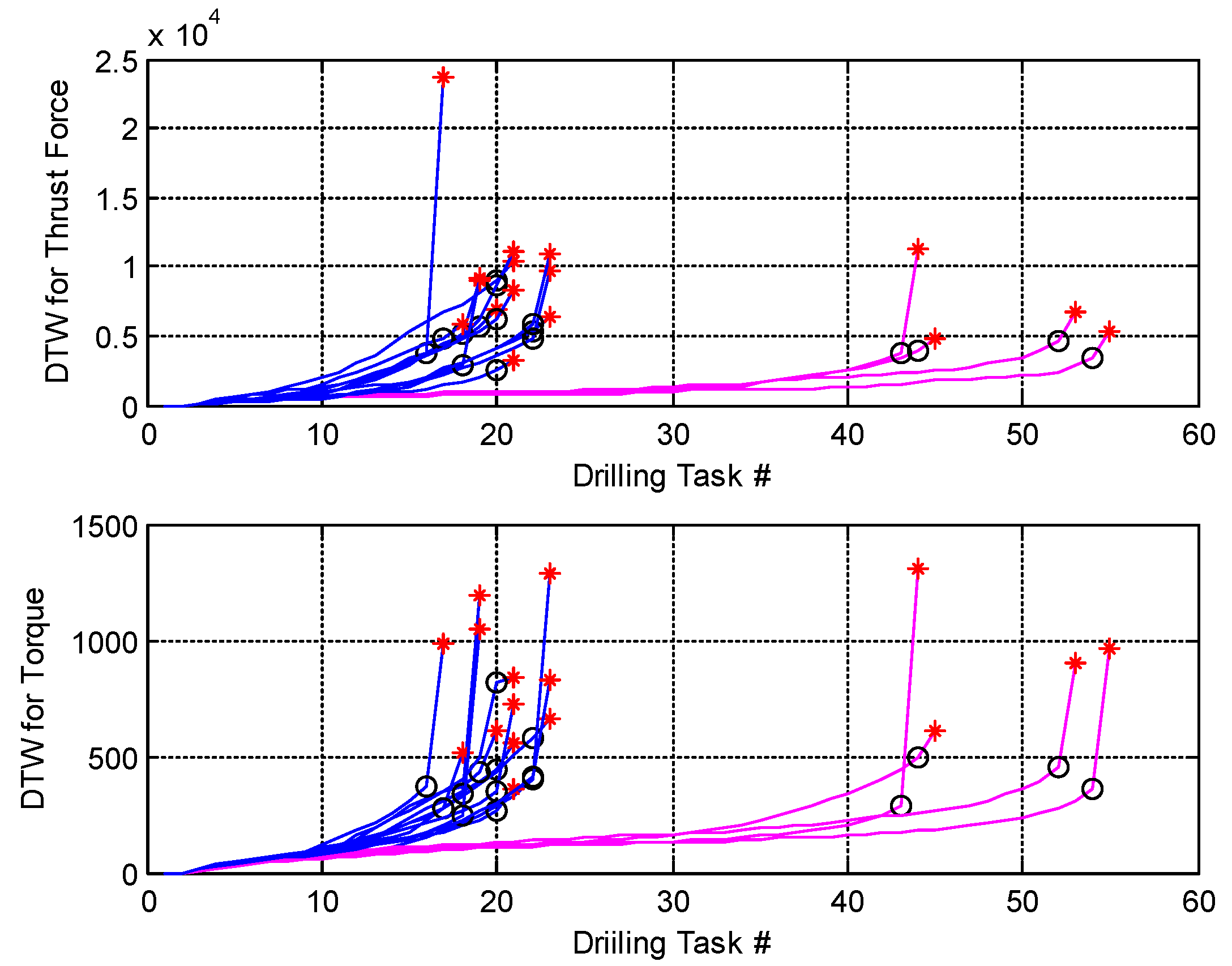
As in most diagnostics and prognostics problems, the signal processing and feature extraction procedure comes from the physical understanding of the problem. To demonstrate the effect of the proposed generic prognostics method, we kept feature extraction at very high levels. For the drill-bit example, we mainly rely on the dynamic time warping (DTW) algorithm to process signal profiles (as a while) acquired during the drilling process with varying lengths. For brake wear monitoring, a more generic descriptive statistics in the form of pre-defined fixed interval distributions is used to summarize the drive content as the primary features. After signal processing and feature processing, MIRGKL with local functions are applied for prognostics purpose.
Therefore, the goal of the research is to develop a generic data-driven algorithm that automatically learns to perform prognostics tasks through the dynamic construction of multiple local (cluster-specific) degradation models and to apply the appropriate model to predict the remaining RUL of a machine or subcomponent. With the advancement in sensing and computer hardware (cloud), we aim at using this research for further development of common and generic learning and computer modules as the essential part of a larger CBM ecosystem.
The rest of the paper is organized as follows.
Section 2 formally introduces the MIRGKL clustering algorithm with the proposed addition of cluster-specific degradation functions.
Section 3 demonstrates the application of the proposed prognostics algorithm on two real-world examples, namely (i) a drill-bit life prediction, and (ii) brake pad wear prediction. Finally,
Section 4 summarizes the results and discusses directions for future research.
2. Method: Clustering with Embedded Local Functions
This section formally introduces the proposed OEC-based prognostics method. To this end, we first describe the mutual information-based recursive Gustafson–Kessel-like (MIRGKL) algorithm [
37], which was inspired by [
10,
38]. Building on MIRGKL, we develop a new method called MIRGKL-plus, where each cluster is embedded with a cluster-specific local function that may be adapted through an asynchronously observed signal. In the case of a typical prognostics problem, this signal is a generic degradation signal or its normalized version that is indicative of the remaining useful life of a system. The purpose and rationale of having a local function in place is multi-faceted, as follows:
- -
Using generic cluster-specific local functions represents decomposing the overall more sophisticated function as a combination of several simpler functions. Each (cluster-specific) local function is learned from a set of similar data points (that belonged to the same cluster) and, therefore, represents the localized behaviors of the overall space. At the predictions phase, it follows the same logic where a given data point’s RUL prediction will be originated from one of the clusters that is most similar to it;
- -
Using multiple cluster-specific local functions reduces the complexity of having one governing function that may be much more complicated where the explicit formulation may not be available. Since the choices of local functions are usually simple linear function or generic distributions, using them to approximate a localized phenomenon (represented by data belong to a single cluster) may be more appropriate because of the increased inter-cluster data similarity.
The authors chose the Weibull function for both of the examples in the paper due to its flexibility to capture varying curvatures in a monotonic decreasing curve (i.e., RUL). More details about this choice can be found in
Section 2.2. For other applications, where different considerations and general domain knowledge might be different, the local function can be replaced with other types of functions or models (i.e., a neural network) as long as the recursion procedure is in place to support that. When compared with neural network-based approaches [
16,
18,
20,
21], the proposed method differs in the following perspectives:
- -
The proposed approach applies a “divide and conquer” principle through the combination of evolving clustering and local function approximation. We are assuming that the clustering mechanism untangles the original overall RUL problem into smaller but simpler ones and allows each location function to capture them individually. The local Weibull function is mainly chosen for the RUL type of problem; if the function of interest (problem domain specific) has fundamentally different properties, this choice needs to be revisited.
- -
The proposed approach can start from scratch and is in online learning mode from the beginning, which requires few samples, similar to few-shot learning (FSL) in the neural networks. For RUL problems where labeled data is abundant and the user is expecting extremely high non-linearity and noise in the data, one should consider higher capacity learning machines architectures [
18,
20,
21,
23], as well as the additional system design considerations mentioned in [
24].
2.1. Mutual Information-Based Gustafson-Kessel-Like (MIRGKL) Clustering Algorithm
In MIRGKL, the measure of similarities is estimated using mutual information-based formulation where a mixture distribution is obtained through combining the two distributions, and their similarities are the primary interest at the moment. One can also understand this as we are putting equal weights on two alternative ways of computing similarities. Example similarities include common measures, such as Euclidean distances or cosine similarities.
In (1),
and
represent the subject distributions and
is the mixture distribution where its descriptive statistics can be obtained from the appropriate sampling theory. The default descriptive statistics in MIRGKL include the mean and covariance matrix, namely
,
∑1,
, and
∑2 for the two subject distributions, and
and
∑M for the mixture distribution. After the mixture distribution is obtained, a bounded and symmetric similarity measure can be formulated as (2) and (3), where
DMD represents the use of the original Mahalanobis distance as the similarity measure where ellipsoidal shaped clusters with different centroids and varying orientations are formed in the multi-dimensional space.
where
and
is the original Mahalanobis Distance:
The same similarity measure calculation is applied in cluster maintenance decisions related to cluster creation and cluster merging with the different thresholds
and
. The
n denotes dimensionality, and
βC (for cluster creation) and
βM (for cluster merging) are different probability thresholds based on Chi-square statistics.
As a result, the first step of MIRGKL involves using (1) to (3) to obtain the similarities between the current data and existing cluster(s). If the current database is empty, the first cluster is created with the initial data. After the first step, the threshold in (4) is evaluated with the closest cluster (minimum of similarities between current data and all clusters) and, if the criterion is met, i.e., step 2-a, the closest cluster is considered the winning cluster and receives an update based on the current data; otherwise, one should consider the creation of a new cluster started with the current data. This is considered as step 2-b. After step 2-a or 2-b, the parameter (if it followed 2-a) or structure (if 2-b) of the overall cluster has been modified; as a result, in step 3 we use (1)–(3) to calculate the similarities between the updated (from 2-a) or newly created (from 2-b) cluster to all other clusters and evaluate whether merging should take place with (5). It is possible to iteratively continue such a process until (5) is not violated. In MIRGKL in its current form, such an operation is not yet being considered.
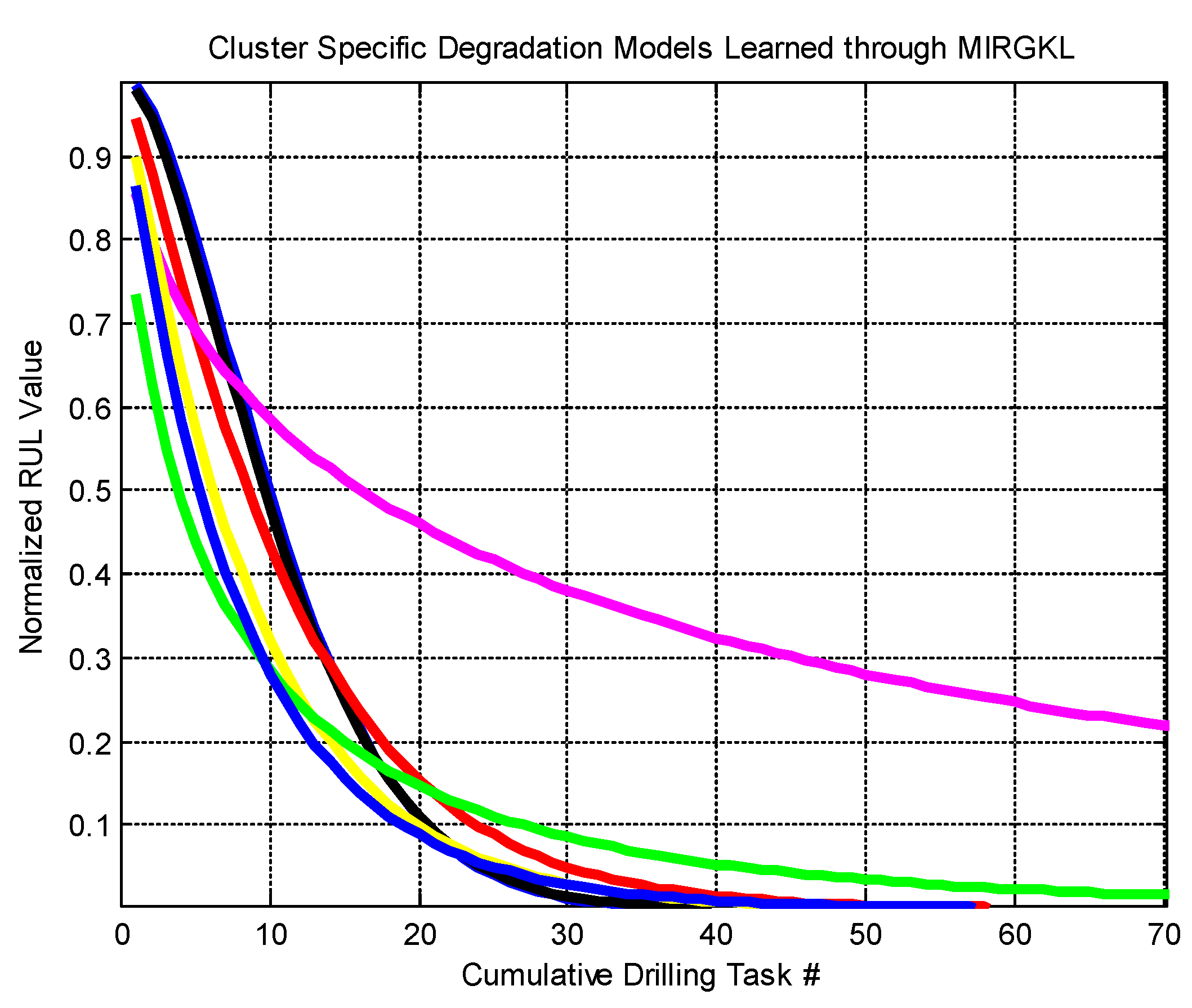
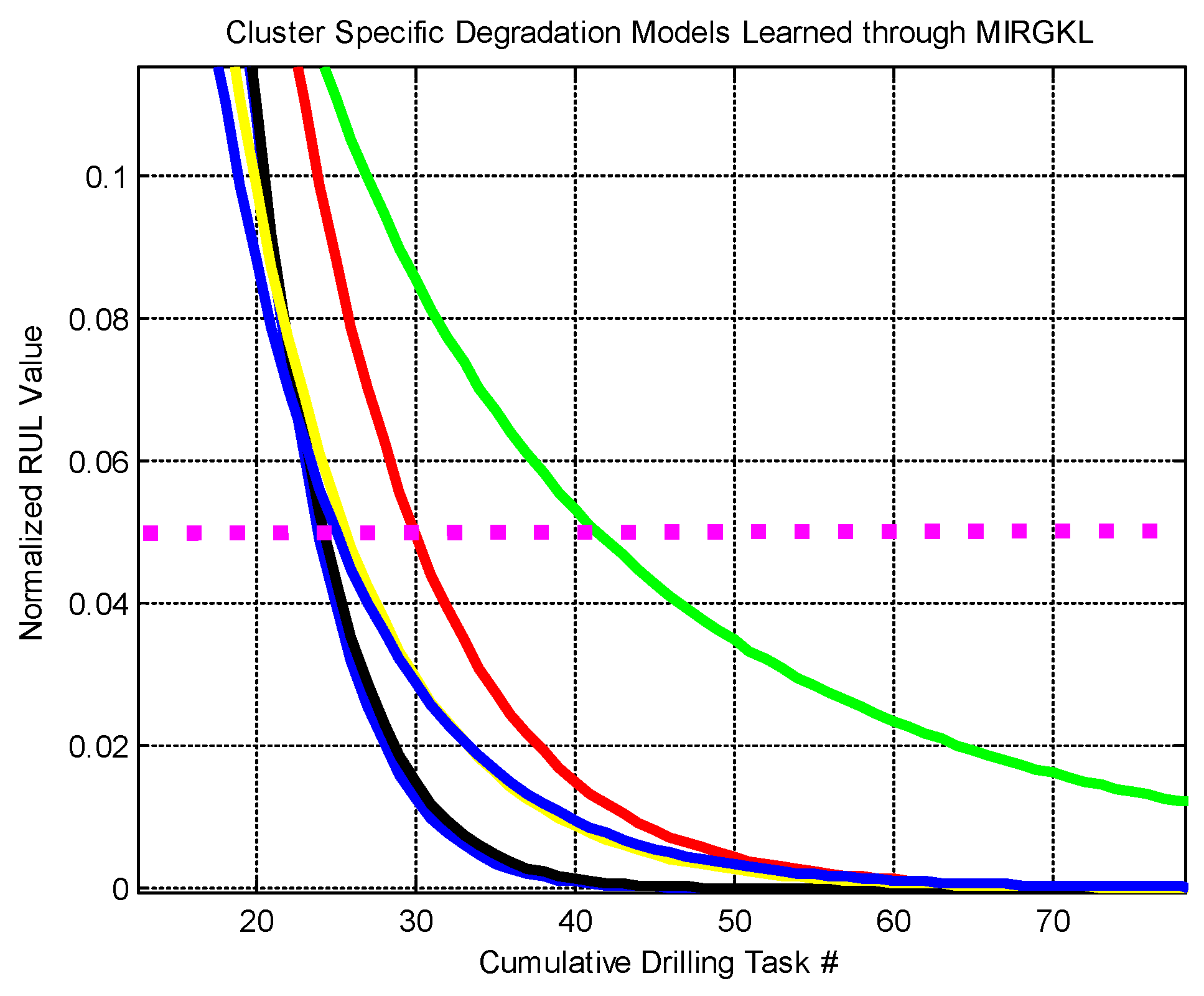
2.2. Clusters Embedded with Weibull Survival (Degradation) Functions
Clusters produced from MIRGKL encapsulate major operating conditions as clusters that receives most of data in the information stream. These can be naturally extended as function approximators with each cluster attached with its own local function. This type of scheme naturally fits the notion of constructing a knowledge base consisting of a set of IF–THEN rules over data streams of indefinite length [
38,
39,
40,
41]. It can also be viewed as an ensemble modeling approach that may enable case-based reasoning and predictions where the most well suited rule(s) or model(s) is (are) activated to perform predictive tasks. In the absence of a good analytical model and in cases where multiple significantly different degradation modes may exist, it represents a class of data-driven and online adaptable models that can effectively extract knowledge regarding dominating degradation patterns in a sparse format. In this paper, we refer to degradation as the process whereby the system’s performance and health status reduces from its nominal value (i.e., 1 or 100%) monotonically with usage. It is closely related to the definition of remaining useful life (RUL) that represents the remainder lifespan on the usage horizon.
A hazard function (HZF) represents the operation of a population of devices and can be viewed to have three distinct phases including (A) infant mortality (burn-in), (B) random failure, and (C) wear-out period [
42]. The HZF takes the following form:
where
f(
t) is the failure distribution function and
F(
t) is the cumulative failure distribution. We chose the Weibull distribution due to its flexibility to deal with accelerated, constant, and decelerated degradation phases which are typical for any degradation phenomenon. Furthermore, it can be linearized so the learning process can be implemented efficiently with batch or online approximation. First proposed by (Weibull, 1951), the Weibull probability distribution defines a random variable x representing “time-to-failure” (TTF) to produce a distribution of failure rates proportional to the power of time. In Weibull distribution,
k, the shape parameter, when smaller than 1, represents the cases where failure rate decreases over time; when it is equal to 1, it represents cases for a constant failure rate and, when it is larger than 1, it represents cases where failure rate increases with time.
Weibull distribution has been widely applied in studies of reliability, failure, and fatality analysis, in engineering and biological studies [
43,
44,
45,
46,
47]. It has been found to be a practical representation of a HZF with a generic bathtub shape (covering common and distinct failure phases), due to its high flexibility and the relationship of its statistical moments to the interpretation of failure rates. Its complementary cumulative distribution function is related to the modeling of the survival probability. The probability distribution function, f, cumulative distribution function, F, and the complementary of F are shown in (7)–(9).
The CDF of Weibull distribution is often associated with modeling of a hazard function, as follows:
The complementary CDF of Weibull is often associated with modeling of a survival function, S(.), as follows:
Linearization of (9) as shown in (10) makes the recursive local function updates feasible with recursive least square or Kalman filtering. This proposed implementation agrees with MIRGKL’s recursive processing of the datastream in situations when online operation is preferable due to constraints on data buffering and computational resources.
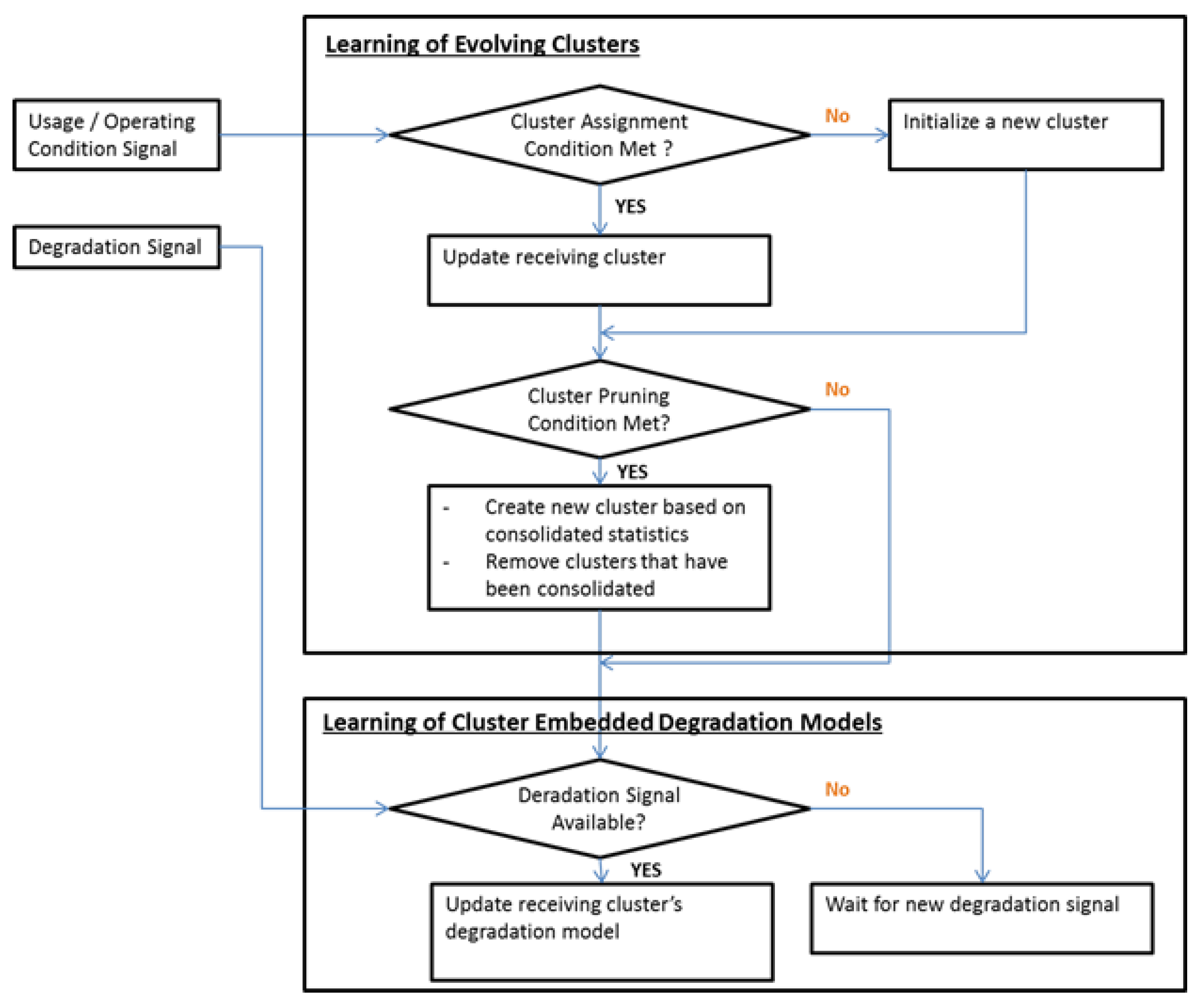
In
Scheme 1, the overall integrated method’s major procedures are summarized. It is broken down into two parts. The upper part A of the flowchart focuses on the identification of the usage and operation condition through the MIRGKL clustering algorithm (cluster assignment or creation). The lower part B of the flowchart deals with the learning of cluster-specific degradation models. At the prediction phase, after a cluster has been assigned, the corresponding cluster’s local degradation function will be applied to make a prediction.
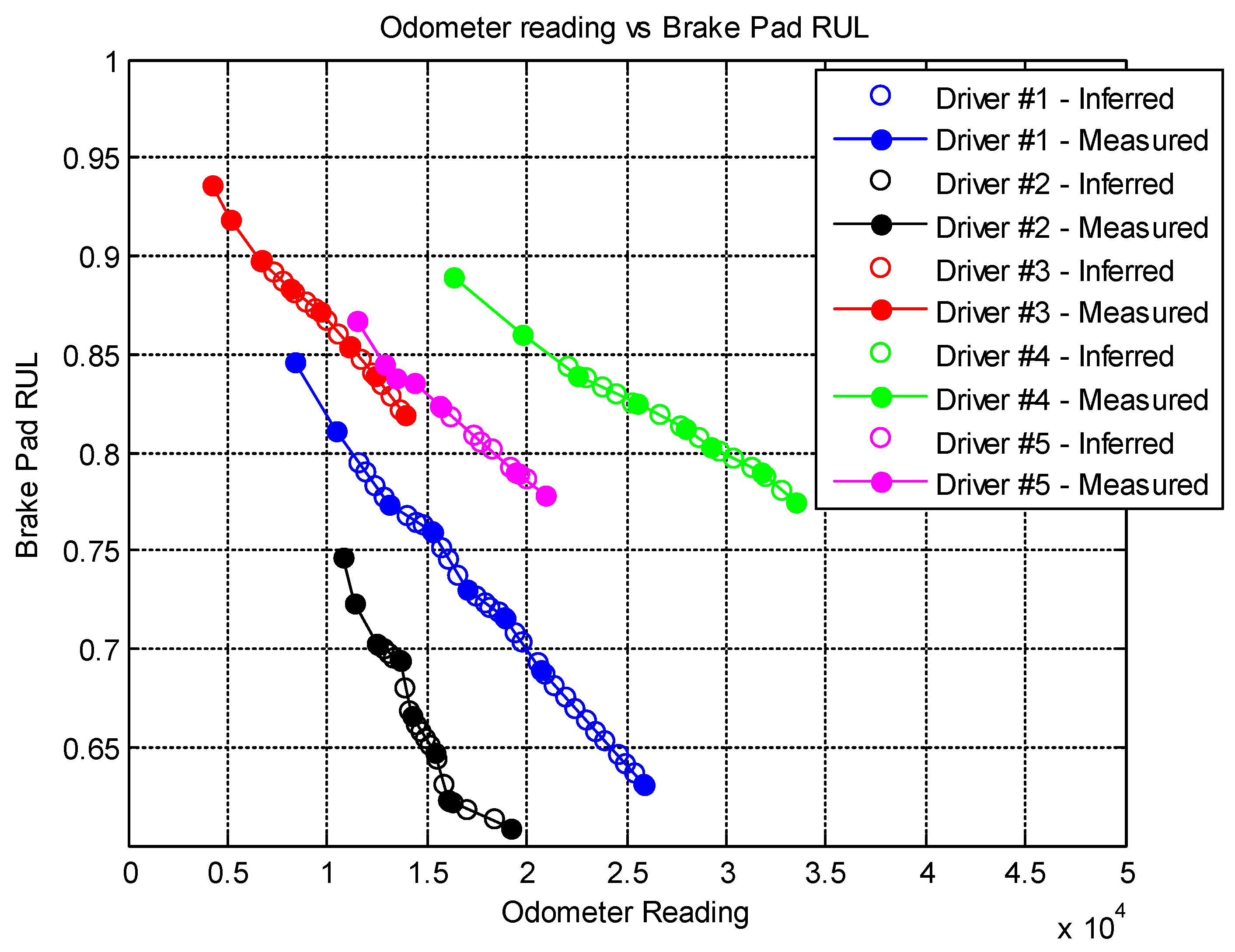
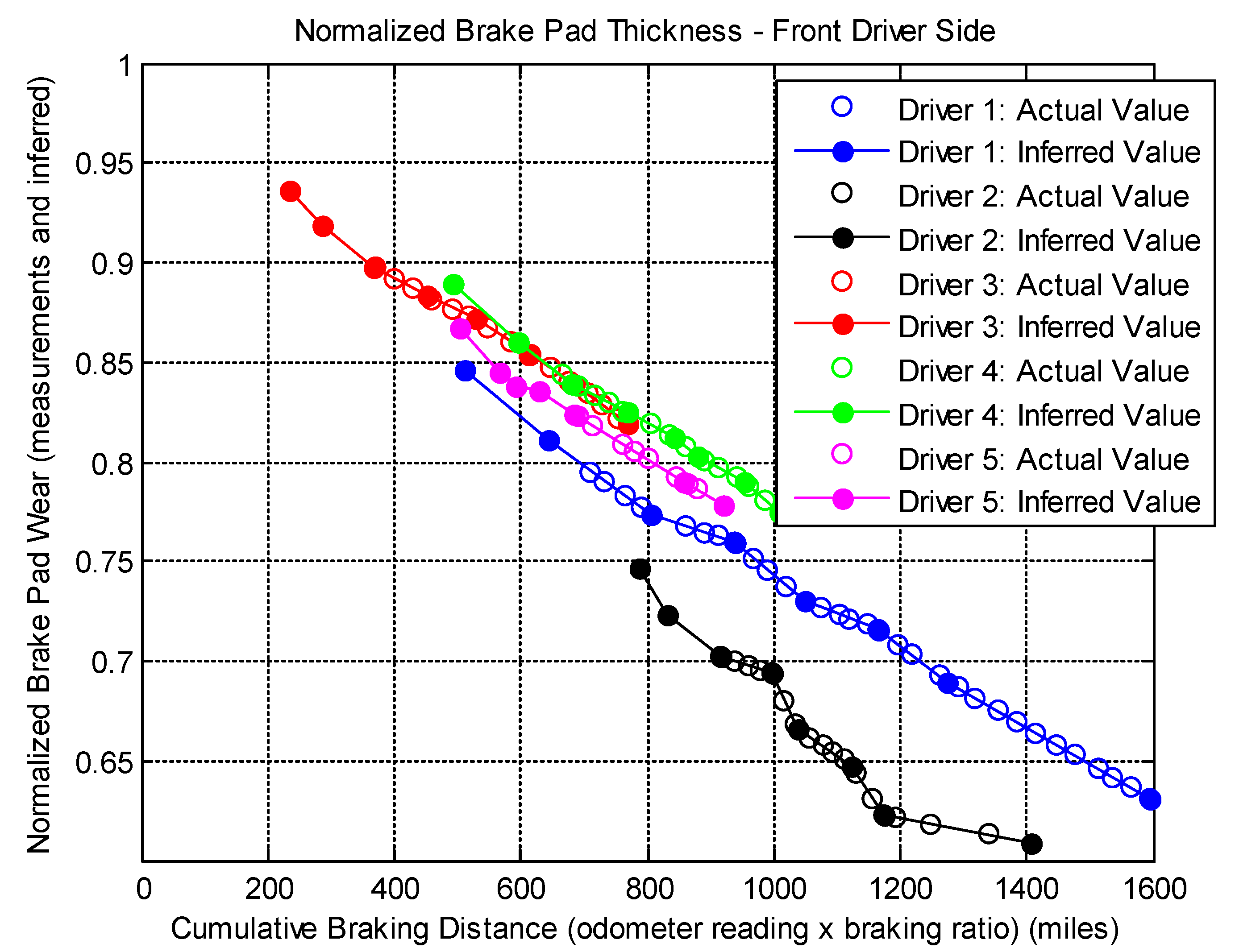
For most systems, data required for part A are typically more readily available for control and generic processing monitoring purposes. For a machine with rotational parts, they could include things, such as the RPM readings or loadings and may include temperature information from a thermocouple. From these measured signals, statistical, model-based, or expert experience-based features can be calculated. When combined with other state information, such as the on/off status or predefined operation modes, conditional usage patterns can be extracted, and trends can be obtained separately for each known state. Such predefined states can be understood as an alternative to the clusters identified by the MIRGKL algorithm. When such predefined major operating conditions are absent, unsupervised clustering algorithms, such as MIRGKL, becomes useful to identify them through continuous monitoring. In addition, if predefined operational states of the machine is available, MIRGKL can still be helpful in identifying different sub-modes for each known states if desirable (i.e., the presence of multiple/nonlinear modes of degradation). One example of such a case would be from historical data, where there may exist multiple failure patterns within the same predefined operational state, indicating that the underlying failure path may be multi-modal.
2.3. Learning Multiple Degradation Paths with MIRGKL-Plus
The lower part B of
Scheme 1 separates the learning procedure of cluster-specific local models from A. Unlike part A of the flowchart, the degradation signal in part B is often not available without some definition of the progression of degradation being defined and measured with additional sensor(s) or estimation. Different alternatives exist as to obtaining indirectly inferred degradation signals. For example, the survival probability within a predefined time window can be computed from machine maintenance records where operation time to failure (OTTF) and time to repair (TTR) information are available. Another example to infer degradation information would be to expect a brand-new part or machine (inspected) to have zero or close to zero degradation. Inferred degradation would increase dramatically (i.e. over a pre-specified failure limit) when the part or machine is determined to be non-functional for its designated task. In real-world problems, intermediate degradation levels are typically determined with scheduled measurements and estimations to produce quantifiable measures of the well-being of the system that can be physically interpreted.
Because A and B of
Scheme 1 are highly asynchronous, the training in part B can be either inactive or create inferred degradation information through interpolation in an effort to facilitate the learning process (requires buffering of the clustering assignment history information). Depending on how the degradation data is obtained, part B would most likely be executed in a delayed fashion with a log of cluster assignments and local models, e.g., if RUL is applied as the degradation signal and such information is unavailable until EOL (end-of-life) has been confirmed. In this situation, part B would not be executed until occurrence of an EOL event.
4. Conclusions
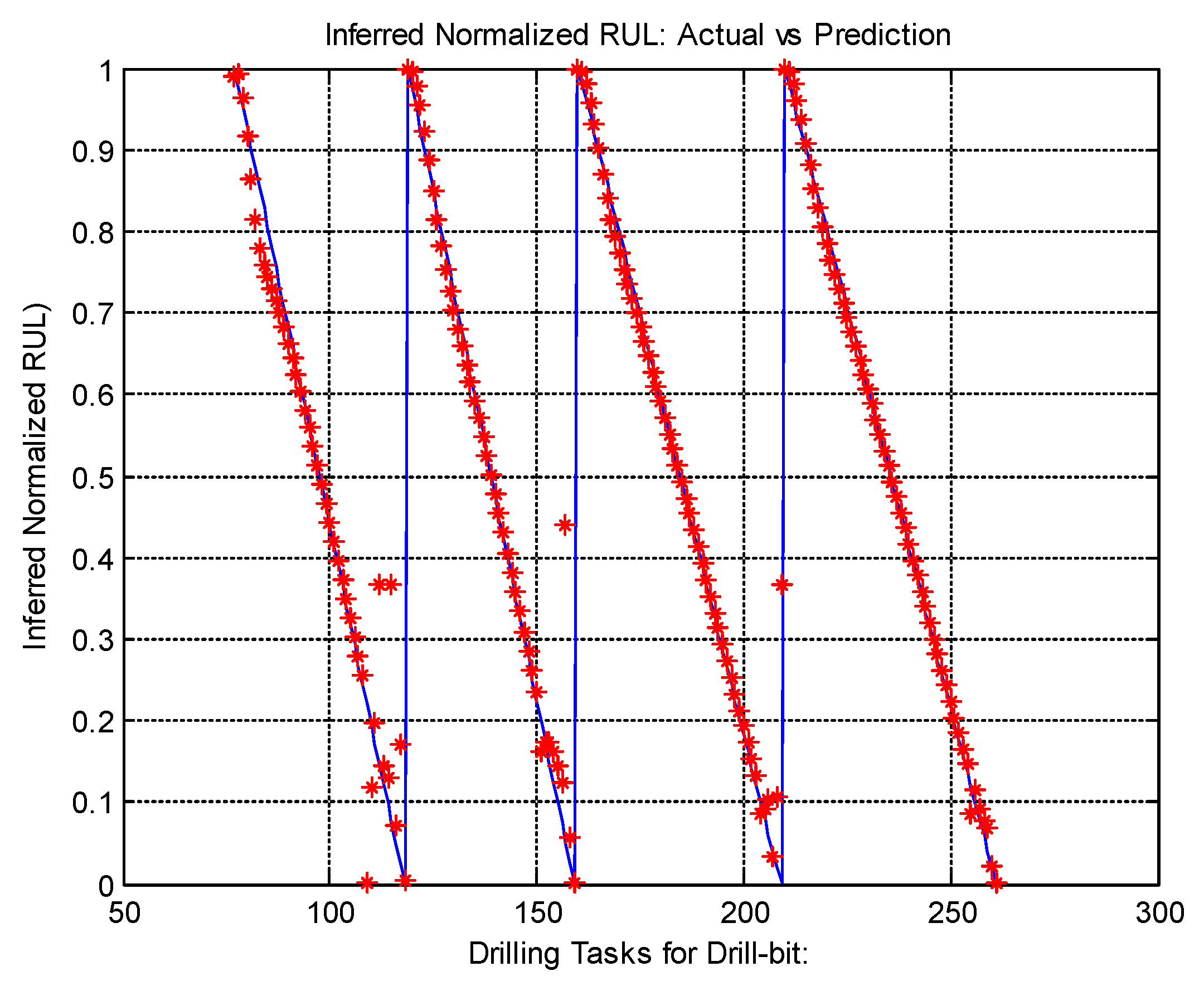
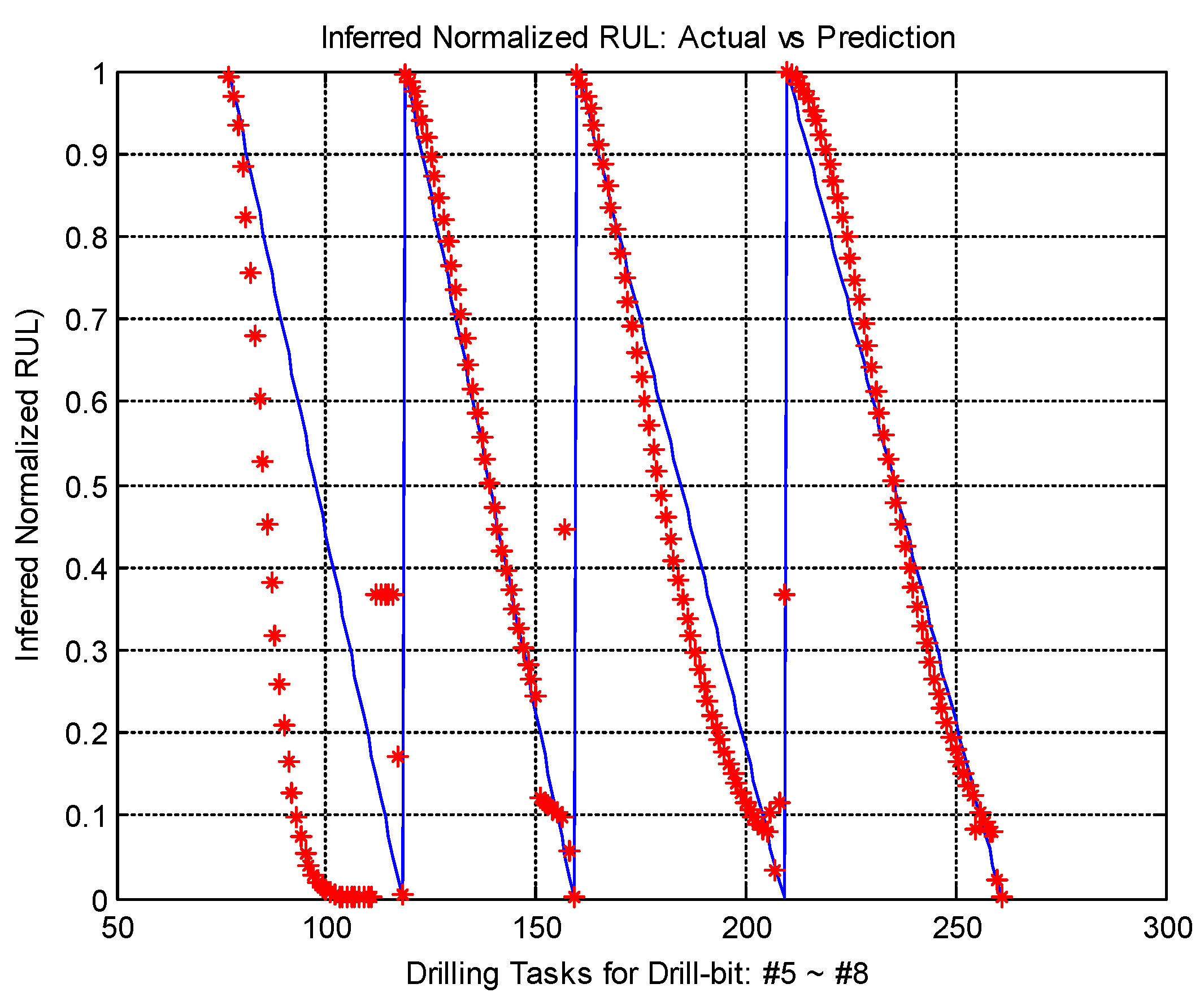
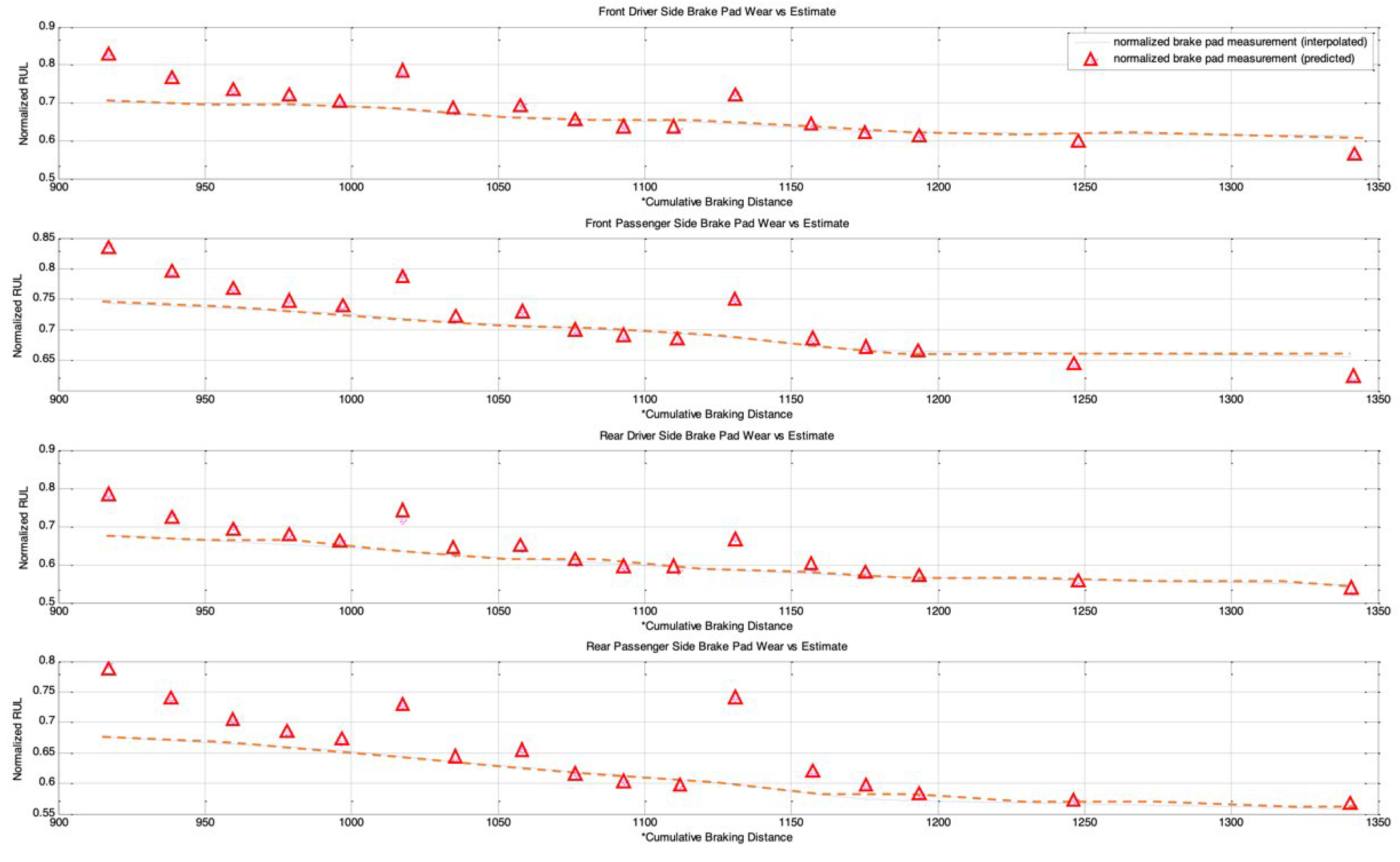
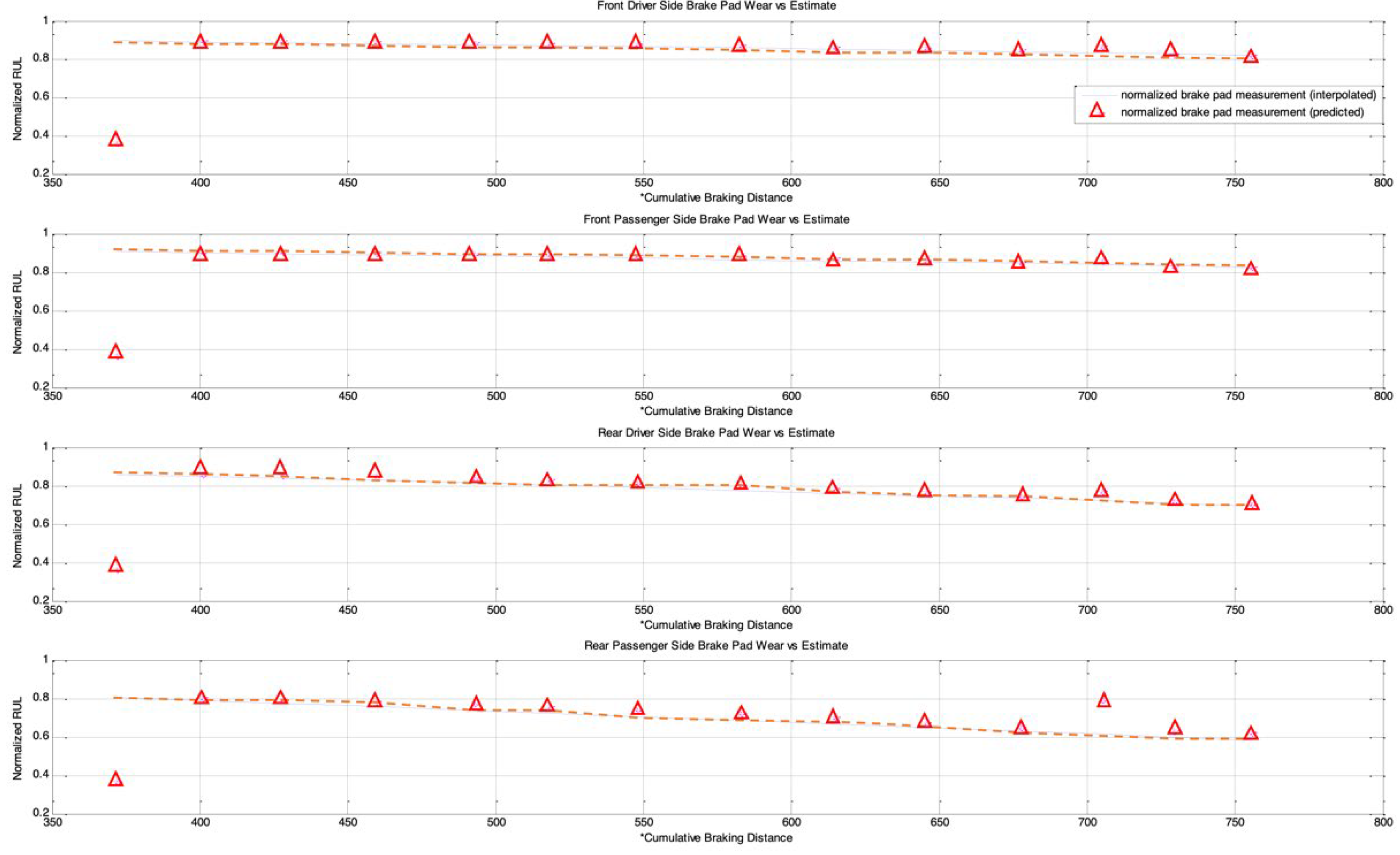
In this paper, we introduced a novel MIRGKL-plus method (MIRGLK embedded with local functions) for the prognostics of common RUL problems. We demonstrate the effectiveness of the proposed prognostic framework with the same generic local function formulation through extensive experiments with two different applications. First, the drill-bit data was obtained in a controlled experimental setting with similar brand-new conditions to determine if the number of successful drilling tasks for different drill-bits could be predicted. Second, the brake wear data was obtained from a fleet of vehicles in the field with variable initial states to determine if the brake wear could be predicted for different vehicles with different usages and driving styles. For prognostic purposes, they present significant challenges that can be summarized as follows: (1) Physical representation of the system with high enough precision for a prognostics purpose is difficult to obtain. From this perspective, we wanted to see if different simplified local models can effectively perform the learning and prediction tasks; (2) Large piece-to-piece variations cannot be well explained or tracked once experiments have been completed and with different initial states. From this perspective, we wanted to see if the proposed evolving cluster approach result in meaningful number of clusters that effectively generalizes population-level variations and behaviors; (3) Multiple underlying degradation modes may be present; (4) During the life of each test subject, the models have access to limited and infrequent observability to determine the actual degradation level. Case studies demonstrated that the proposed prognostic model was able to address the aforementioned problems and provide accurate prognostic predictions.
Both case studies clearly demonstrated the applicability of an evolving clustering algorithm to systems of the same type under somewhat different usage patterns. The proposed model effectively separates the data streams into groups (clusters) where different degradation patterns can be extracted for RUL prediction purposes. We have also proposed the use of limited degradation information that arrives at a different rate when compared to the generic signals. This is achieved with the use of clustering results coupled with linear interpolation and normalization of the operation limits of the crucial system parameter. Aligned normalized degradation through inference allows cluster-specific local models to be updated along with the update procedure of the overall clustering process. In the brake wear example, one thing to note is that the degradation (inferred normalized brake thickness) has to be presented in a meaningful horizon (cumulative braking distance) in order to observe and obtain meaningful results. Even though some drivers may exhibit a similar rate of wear in the horizon of cumulative braking distance, the final odometer value is where the limit may differ significantly due to their differences in braking/driving ratios, which is an aggregate of individual driving content and behavior.
Future research on the evolving clustering method and applications to investigate will be focused on the following:
- A.
Improvement to MIRGKL clustering algorithm.
- B.
Applications to user and behavior prognostics;
- C.
Transfer learning and federated learning to improve cold/initial start issues.
For direction A, the focus will be to further devise and develop the MIRGKL algorithms, as this is key to its application not only for RUL estimation but also as a tool for auto-labeling data streams with partial labels. For B, in user related applications, we foresee that this method can be applicable to the extraction and learning of user preferences and intents and their progression during different usage horizons. One example would be a driver’s intent to take a break from driving or to refill the vehicle. This type of learning and prediction process can be facilitated with a similar hypothesis and interpolation procedure to the one shown in
Section 3.2, with limited need to engage users to create the labels themselves all the time, which can be viewed as inconvenient and intrusive. Direction C points out an important aspect of leveraging many users’ data to create and update a base model, as suggested in federated learning [
57]. Because MIRGKL-plus is inherently a linear combiner model, similar computes can be performed without losing its original interpretability and, if the choice of the local model is also linear, we would expect the combined model to be fairly stable. Having a base model has several implications for ML models. First of all, it can help to alleviate the cold start issues common in all ML methods. Similar to few-shot learning, a system can have all users start out with an average preference and behavior model to evolve with user’s own data over time. Secondly, for applications that have safety implications, the base model may need to be the acting model all the time, meaning that it will be the updated “base” but not the personal version of the model to be active for each user.




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}