
An Environmental-Adaptability-Improved RatSLAM Method Based on a Biological Vision Model



Abstract
:1. Introduction
2. RatSLAM Model
2.1. Pose Cells
2.2. Local View Cell
2.3. Experience Map
2.4. Effect of Light and Solution
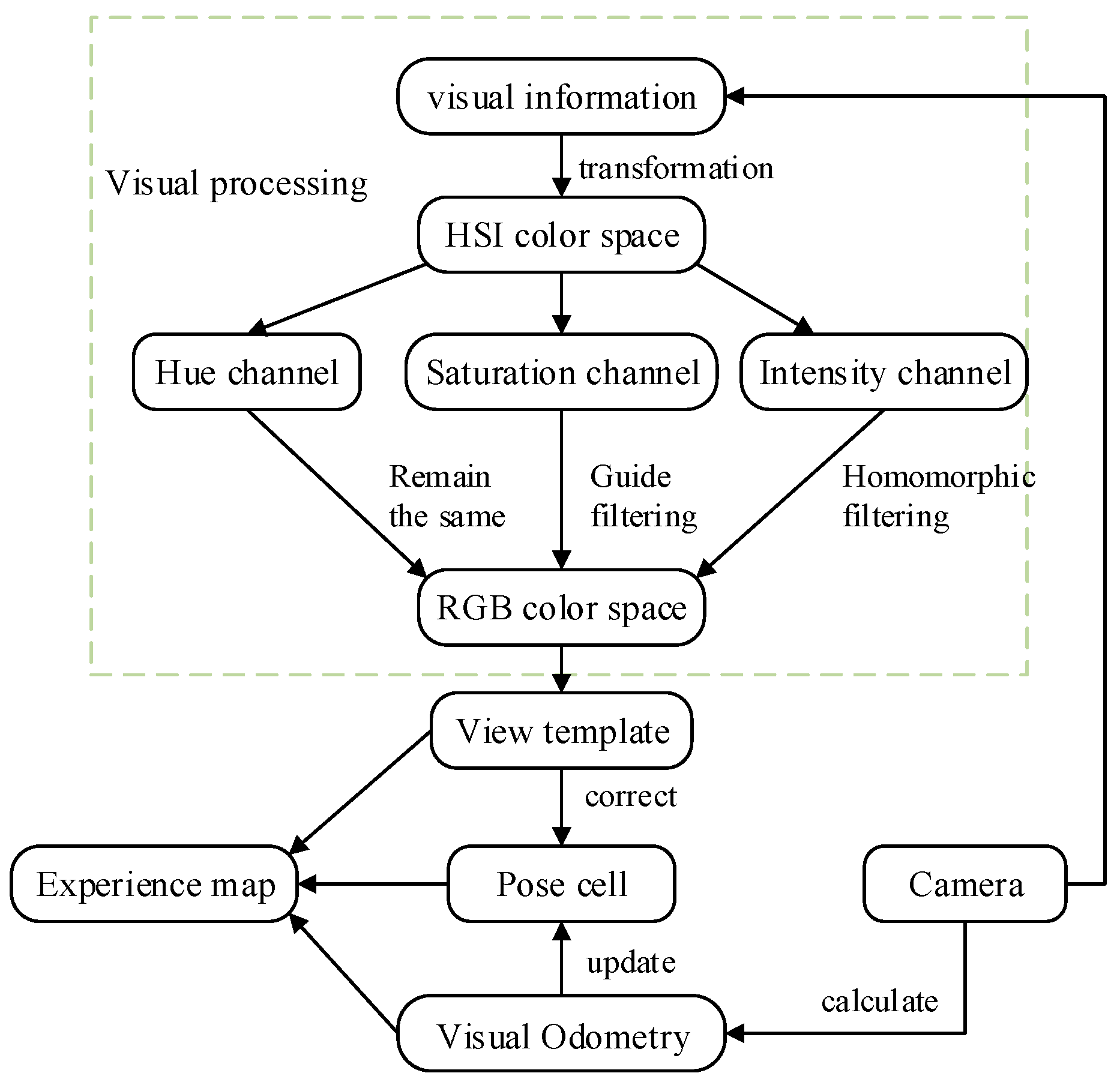
3. RatSLAM with HSI Color Space
3.1. HSI Color Space
3.2. Transformation between HSI Space and RGB Space
3.3. Homomorphic Filtering
3.4. Guided Filter
3.5. The Effect of Biological Vision Modeling
4. Experiments
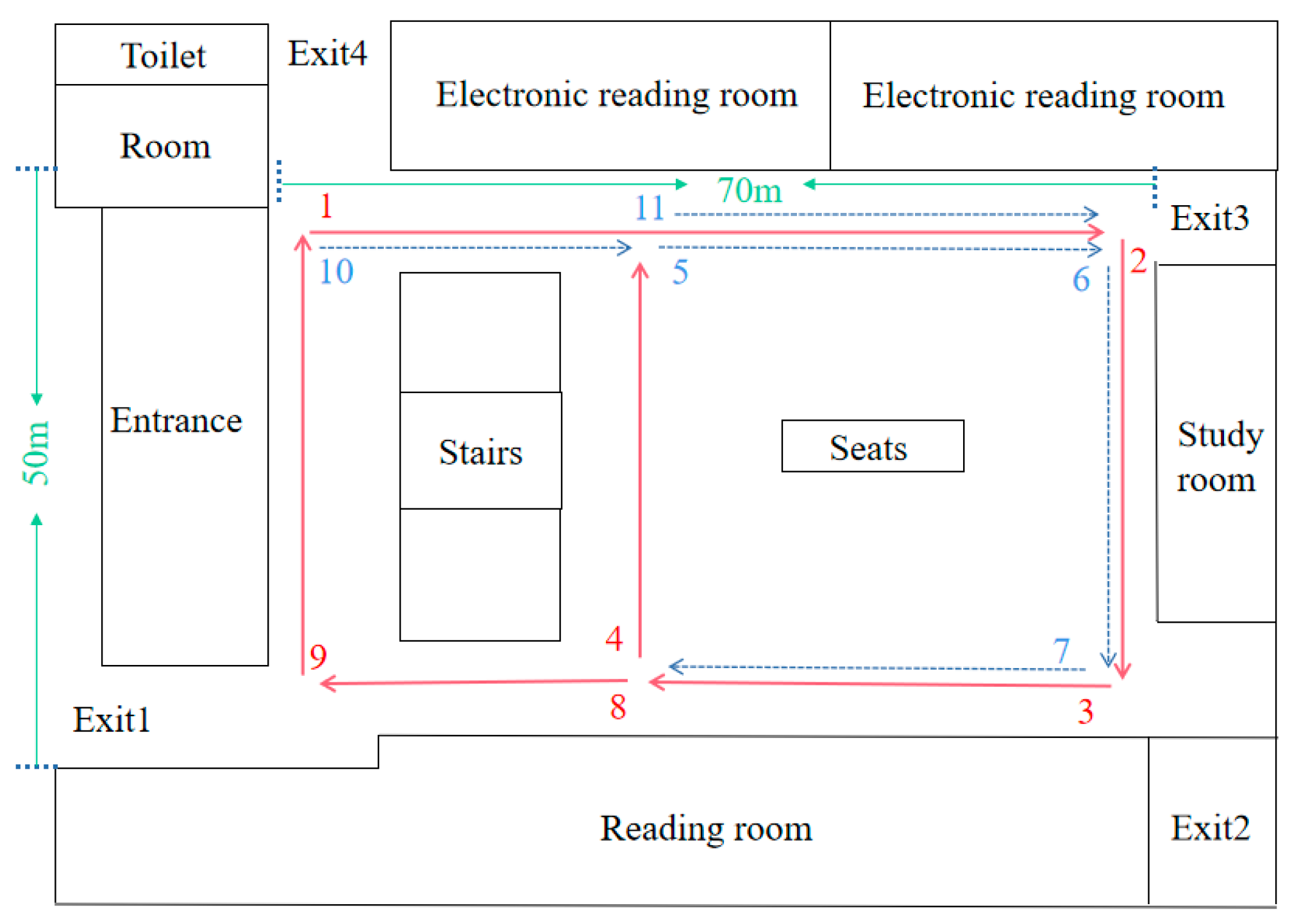
4.1. Experimental Setup
4.1.1. Experimental Equipment
4.1.2. Evaluation Criteria
4.2. Parameter Selection of Filters
4.3. Ablation Studies of Two Modules
4.4. Analysis of Image Similarity and SAD Results
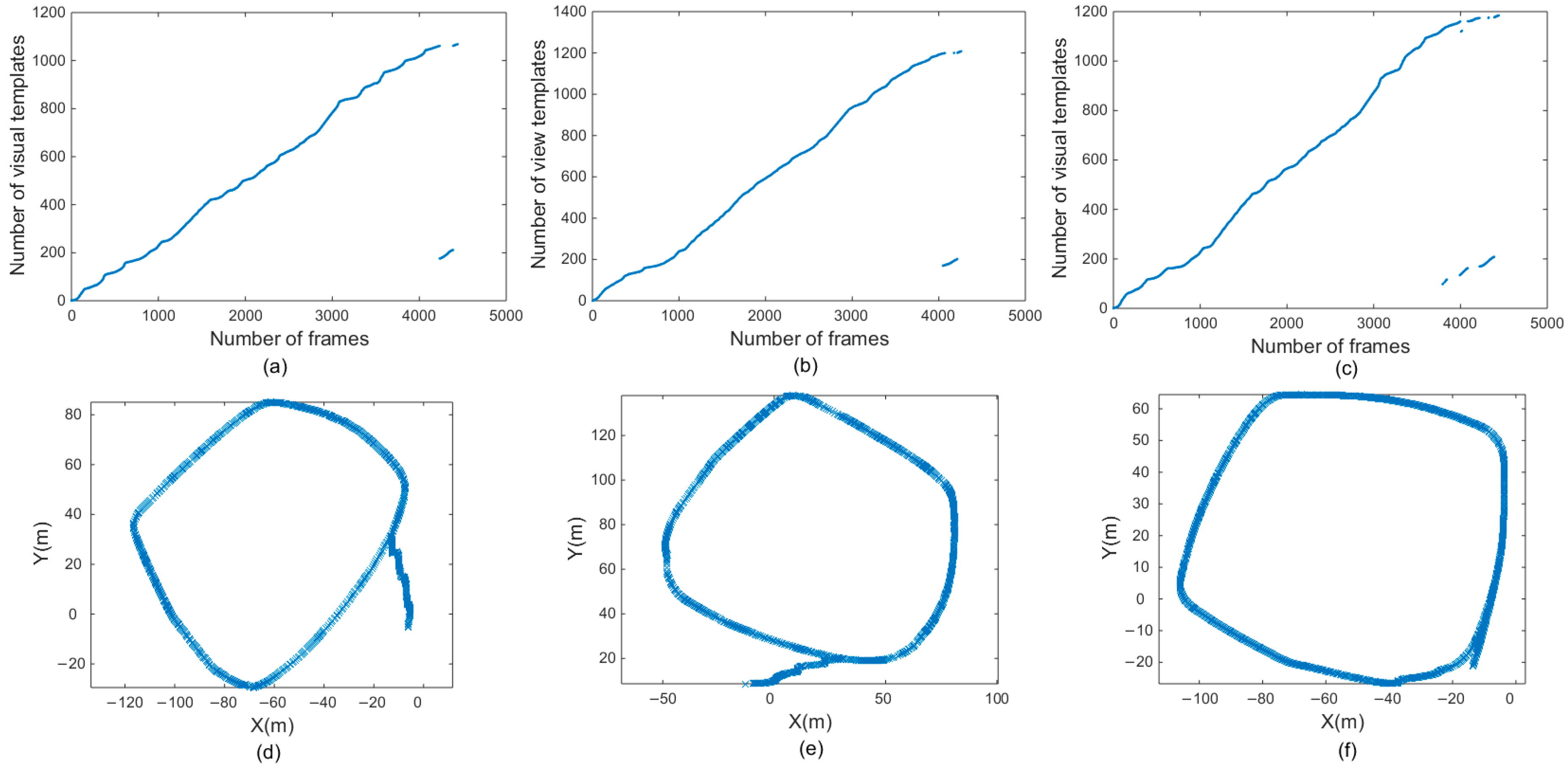
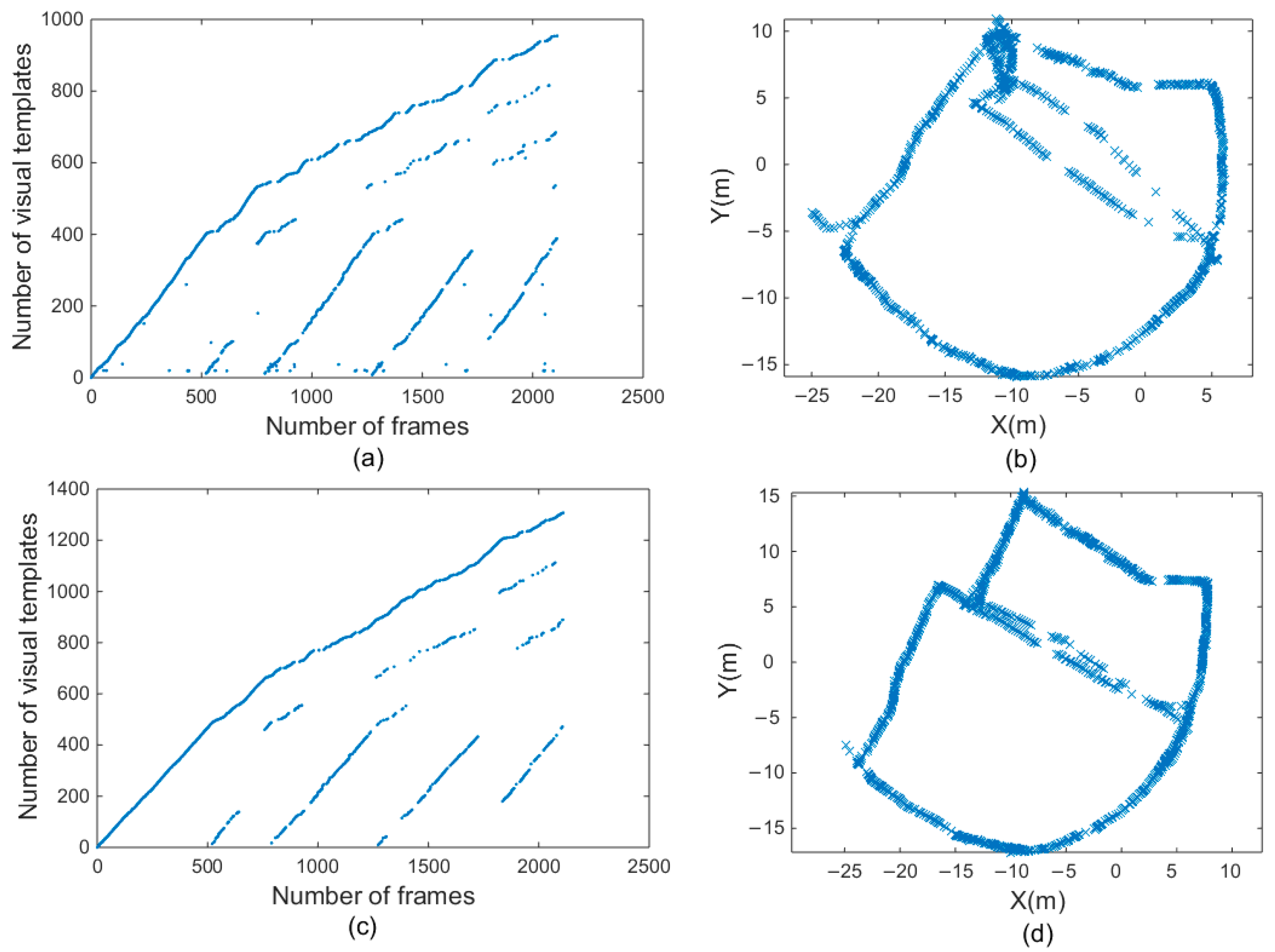
4.5. Analysis of Visual Template and Experience Map
4.5.1. First Scene: Mechanical Building Corridor
4.5.2. Second Scene: Second Floor of the Library Lobby
4.5.3. Third Scene: Jingwen Library and Wenhui Building
4.5.4. Fourth Scene: An Office in the Fusinopolis Building, Singapore
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Milford, J.M.; Wyeth, G.F.; Prasser, D. RatSLAM: A hippocampal model for simultaneous localization and mapping. In Proceedings of the IEEE International Conference on Robotics and Automation, New Orleans, LA, USA, 26 April–1 May 2004. [Google Scholar]
- O’Keefe, J. Place units in the hippocampus of the freely moving rat. Exp. Neurol. 1976, 51, 78–109. [Google Scholar] [CrossRef]
- Taube, J.; Muller, R.; Ranck, J. Head-direction cells recorded from the postsubiculum in freely moving rats. I. Description and quantitative analysis. J. Neurosci. 1990, 10, 420–435. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hafting, T.; Fyhn, M.; Molden, S.; Moser, M.B.; Moser, E.I. Microstructure of a spatial map in the entorhinal cortex. Nature 2005, 436, 801–806. [Google Scholar] [CrossRef] [PubMed]
- Prasser, D.; Milford, M.; Wyeth, G. Outdoor Simultaneous Localisation and Mapping Using RatSLAM. In Field and Service Robotics; Springer: Berlin/Heidelberg, Germany, 2006; Volume 25, pp. 143–154. [Google Scholar]
- Milford, M.J.; Wyeth, G.F. Mapping a Suburb With a Single Camera Using a Biologically Inspired SLAM System. IEEE Trans. Robot. 2008, 24, 1038–1053. [Google Scholar] [CrossRef] [Green Version]
- Milford, M.J.; Schill, F.; Corke, P.; Mahony, R.; Wyeth, G. Aerial SLAM with a single camera using visual expectation. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Milford, M.; Jacobson, A.; Chen, Z.; Wyeth, G. RatSLAM: Using Models of Rodent Hippocampus for Robot Navigation and Beyond. In Robotics Research; Inaba, M., Corke, P., Eds.; Springer: Cham, Switzerland, 2016; Volume 114. [Google Scholar]
- Glover, A.J.; Maddern, W.P.; Milford, M.J.; Wyeth, G.F. FAB-MAP + RatSLAM: Appearance-based SLAM for multiple times of day. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010. [Google Scholar]
- Zhou, S.C.; Yan, R.; Li, J.X.; Chen, Y.K.; Tang, H. A brain-inspired SLAM system based on ORB features. Int. J. Autom. Comput. 2017, 14, 564–575. [Google Scholar] [CrossRef] [Green Version]
- Kazmi, S.A.M.; Mertsching, B. Gist+RatSLAM: An Incremental Bio-inspired Place Recognition Front-End for RatSLAM. In Proceedings of the 9th EAI International Conference on Bio-inspired Information and Communications Technologies (formerly BIONETICS), New York, NY, USA, 1 May 2016. [Google Scholar]
- Tubman, R.; Potgieter, J.; Arif, K.M. Efficient robotic SLAM by fusion of RatSLAM and RGBD-SLAM. In Proceedings of the 23rd International Conference on Mechatronics and Machine Vision in Practice (M2VIP), Nanjing, China, 28–30 November 2017. [Google Scholar]
- Tian, B.; Shim, V.A.; Yuan, M.; Srinivasan, C.; Tang, H.; Li, H. RGB-D based cognitive map building and navigation. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013. [Google Scholar]
- Salman, M.; Pearson, M.J. Advancing whisker based navigation through the implementation of Bio-Inspired whisking strategies. In Proceedings of the 2016 IEEE International Conference on Robotics and Biomimetics (ROBIO), Qingdao, China, 3–7 December 2016. [Google Scholar]
- Milford, M.; McKinnon, D.; Warren, M.; Wyeth, G.; Upcroft, B. Feature-based Visual Odometry and Featureless Place Recognition for SLAM in 2.5 D Environments. In Proceedings of the Australasian Conference on Robotics and Automation, Melbourne, Australia, 7–9 December 2011. [Google Scholar]
- Silveira, L.; Guth, F.; Drews, P., Jr.; Ballester, P.; Machado, M.; Codevilla, F.; Duarte-Filho, N.; Botelho, S. An Open-source Bio-inspired Solution to Underwater SLAM. In Proceedings of the 4th IFAC Workshop on Navigation, Guidance and Control of Underwater Vehicles (NGCUV) 2015, Girona, Spain, 28–30 April 2015; Elsevier: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Ball, D.; Heath, S.; Milford, M.; Wyeth, G.; Wiles, J. A navigating rat animat. In Proceedings of the 12th International Conference on the Synthesis and Simulation of Living Systems, Odense, Denmark, 19–23 August 2010; MIT Press: Cambridge, MA, USA, 2010; pp. 804–811. [Google Scholar]
- Milford, M.; Schulz, R.; Prasser, D.; Wyeth, G.; Wiles, J. Learning spatial concepts from RatSLAM representations. In Robotics and Autonomous Systems; Elsevier: Amsterdam, The Netherlands, 2007; Volume 55, pp. 403–410. [Google Scholar]
- Qin, G.; Xinzhu, S.; Mengyuan, C. Research on Improved RatSLAM Algorithm Based on HSV Image Matching. J. Sichuan Univ. Sci. Eng. 2018, 31, 49–55. [Google Scholar]
- Fan, C.N.; Zhang, F.Y. Homomorphic filtering based illumination normalization method for face recognition. Pattern Recognit. Lett. 2011, 32, 1468–1479. [Google Scholar] [CrossRef]
- Nnolim, U.; Lee, P. Homomorphic Filtering of colour images using a Spatial Filter Kernel in the HSI colour space. In Proceedings of the 2008 IEEE Instrumentation and Measurement Technology Conference, Victoria, BC, Canada, 12–15 May 2008; pp. 1738–1743. [Google Scholar]
- Ball, D.; Heath, S.; Wiles, J.; Wyeth, G.; Corke, P.; Milford, M. OpenRatSLAM: An open source brain-based SLAM system. Auton. Robot. 2013, 34, 149–176. [Google Scholar] [CrossRef]
- Milford, M.J. Robot Navigation from Nature: Simultaneous Localisation, Mapping, and Path Planning Based on Hippocampal Models; Springer Science & Business Media: Berlin, Germania, 2008; Volume 41. [Google Scholar]
- Milford, M. Vision-based place recognition: How low can you go? Int. J. Robot. Res. 2013, 32, 766–789. [Google Scholar] [CrossRef]
- Townes-Anderson, E.; Zhang, N. Synaptic Plasticity and Structural Remodeling of Rod and Cone Cells. In Plasticity in the Visual System; Springer: Boston, MA, USA, 2006. [Google Scholar]
- Dhandra, B.V.; Hegadi, R.; Hangarge, M.; Malemath, V.S. Analysis of Abnormality in Endoscopic images using Combined HSI Color Space and Watershed Segmentation. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR'06), Hong Kong, China, 20–24 August 2006. [Google Scholar]
- Ju, Z.; Chen, J.; Zhou, J. Image segmentation based on the HSI color space and an improved mean shift. In Proceedings of the Information and Communications Technologies (IETICT 2013), Beijing, China, 27–29 April 2013. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 2nd ed.; Prentice Hall: New York, NY, USA, 2003. [Google Scholar]
- Yang, H.; Wang, J. Color Image Contrast Enhancement by Co-occurrence Histogram Equalization and Dark Channel Prior. In Proceedings of the 2010 3rd International Congress on Image and Signal Processing, Yantai, China, 16–18 October 2010. [Google Scholar]
- Blotta, E.; Bouchet, A.; Ballarin, V.; Pastore, J. Enhancement of medical images in HSI color space. J. Phys. Conf. 2011, 332, 012041. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, Z.; Yuan, H.; Shao, S. Single Remote-Sensing Image Dehazing in HSI Color Space. J. Korean Phys. Soc. 2019, 74, 779–784. [Google Scholar] [CrossRef]
- Dong, S.; Ma, J.; Su, Z.; Li, C. Robust circular marker localization under non-uniform illuminations based on homomorphic filtering. Measurement 2020, 170, 108700. [Google Scholar] [CrossRef]
- Delac, K.; Grgic, M.; Kos, T. Sub-Image Homomorphic Filtering Technique for Improving Facial Identification under Difficult Illumination Conditions. In Proceedings of the International Conference on Systems, Signals and Image Processing, Budapest, Hungary, 21–23 September 2006. [Google Scholar]
- Frezza, F.; Galli, A.; Gerosa, G.; Lampariello, P. Characterization of the resonant and coupling parameters of dielectric resonators of NRD-guide filtering devices. In Proceedings of the 1993 IEEE MTT-S International Microwave Symposium Digest, Atlanta, GA, USA, 14–18 June 1993. [Google Scholar]
- Jiang, H.; Zhao, Y.; Gao, J.; Gao, Z. Adaptive pseudo-color enhancement method of weld radiographic images based on HSI color space and self-transformation of pixels. Rev. Sci. Instrum. 2017, 88, 065106. [Google Scholar] [CrossRef] [PubMed]
- Lu, B.; Chen, J.; Zheng, Y.; Wang, J. Tone mapping algorithm of iCAM06 based on guide filtering. Opt. Tech. 2016, 42, 130–135,140. [Google Scholar]
- Biswas, P.; Pramanik, S.; Giri, B.C. Cosine Similarity Measure Based Multi-attribute Decision-making with Trapezoidal Fuzzy Neutrosophic Numbers. Neutrosophic Sets Syst. 2015, 8, 47–56. [Google Scholar]
- Yu, S.; Wu, J.; Xu, H.; Sun, R.; Sun, L. Robustness Improvement of visual templates Matching Based on Frequency-Tuned Model in RatSLAM. Front. Neurorobotics 2020, 14, 568091. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Zhang, C. Optimization design of homomorphic Filter based on Matlab. Appl. Opt. 2010, 4, 584–588. [Google Scholar]
- Ling, G.; Zhang, Q. Image Fusion Method Combining Non-subsampled Contourlet Transform and Guide Filtering. Infrared Technol. 2018, 40, 444–448. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rl | Rh | c | D0 | Information Entropy | Pixel Mean | Pixel Variance |
|---|---|---|---|---|---|---|
| 0.25 | 2 | 1 | 10 | 6.74 | 151.00 | 0.027 |
| 0.5 | 2 | 1 | 10 | 6.87 | 122.49 | 0.032 |
| 0.2 | 4 | 1 | 10 | 6.82 | 154.58 | 0.025 |
| 0.1 | 4 | 2 | 10 | 6.76 | 166.87 | 0.022 |
| 0.1 | 4 | 1.5 | 3 | 6.57 | 170.21 | 0.024 |
| 0.1 | 4 | 1.5 | 5 | 6.70 | 169.47 | 0.023 |
| 0.22 | 4.7 | 1.5 | 10 | 6.83 | 153.09 | 0.026 |
| ε | Information entropy | |||||
| 0.1 | 6.797 | |||||
| 0.8 | 6.804 | |||||
| 5 | 6.804 | |||||
| Filter Used | Information Entropy | Pixel Mean | Pixel Variance |
|---|---|---|---|
| None | 6.728 | 77.60 | 0.11 |
| Guided filter | 6.803 | 77.34 | 0.11 |
| Homomorphic filter | 7.003 | 116.55 | 0.08 |
| The fusion | 7.056 | 116.35 | 0.07 |
| Scene | SAD Result | Cosine Value | |
|---|---|---|---|
| Figure 6a,d | Raw image | 0.337 | 0.893 |
| Image with HSI | 0.325 | 0.901 | |
| Figure 6b,e | Raw image | 0.035 | 0.985 |
| Image with HSI | 0.033 | 0.996 | |
| Figure 6c,f | Raw image | 0.025 | 0.995 |
| Image with HSI | 0.023 | 0.998 | |
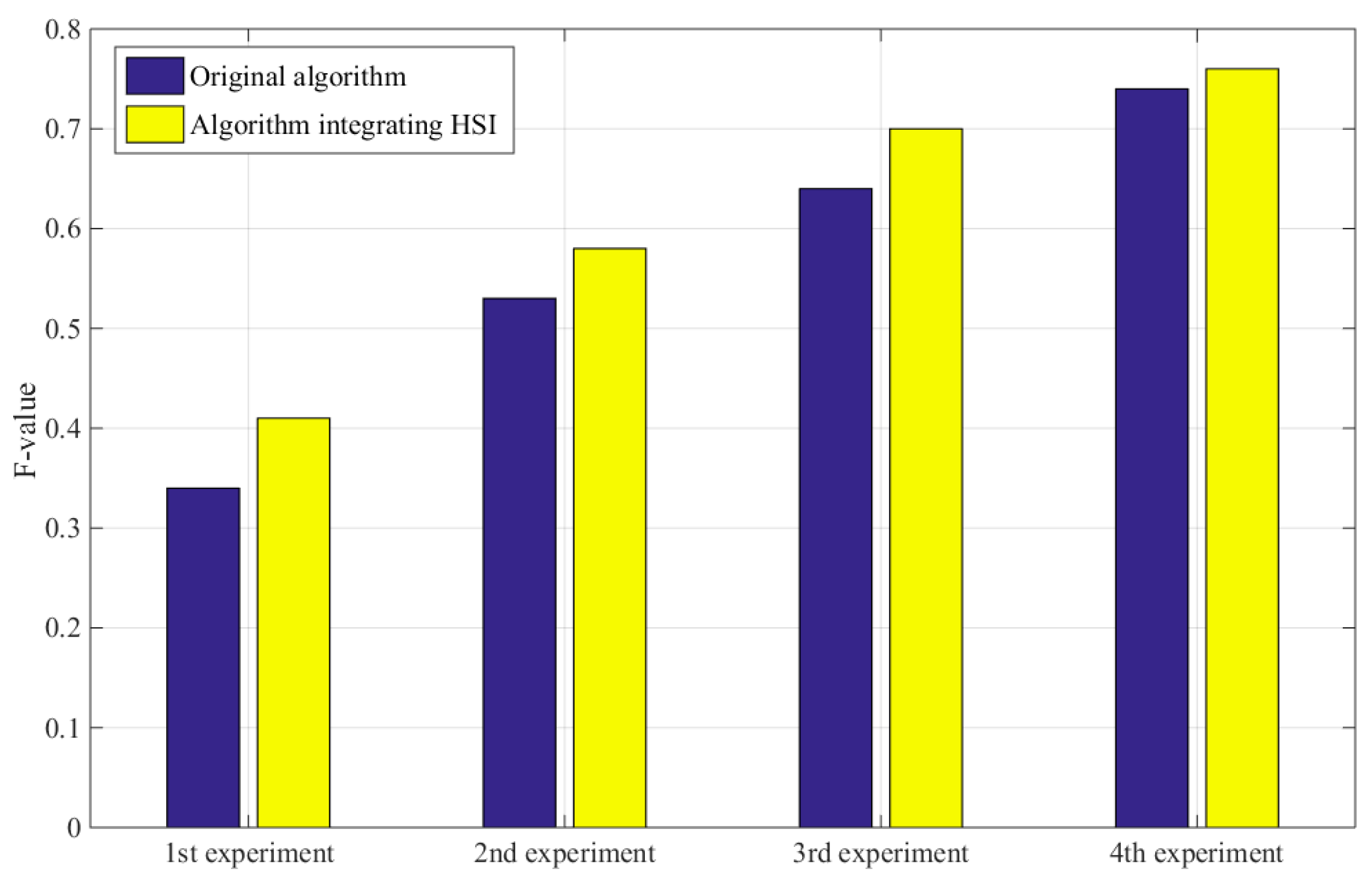
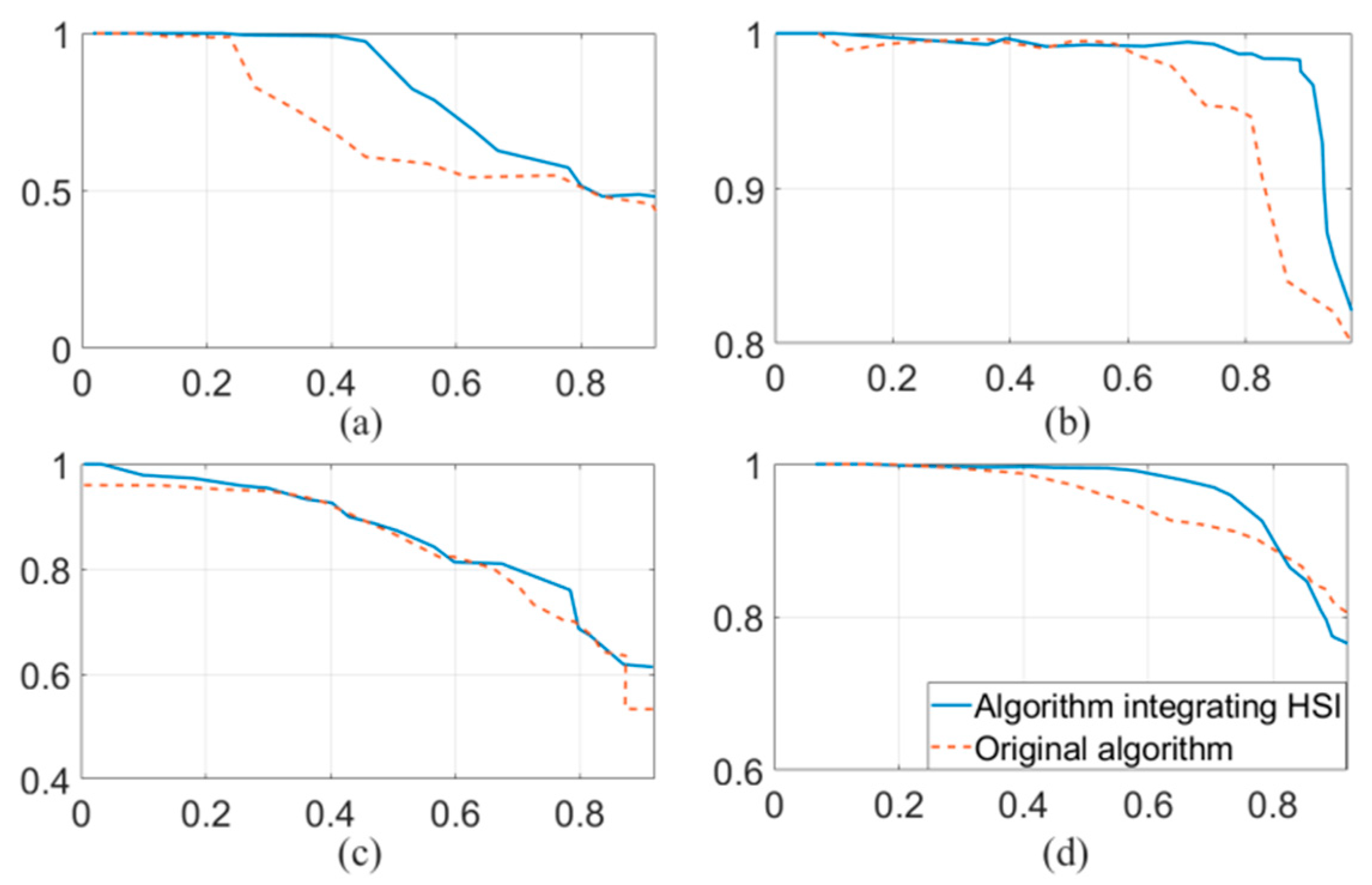
| Scene | Method | TPs | FPs | FNs | Precision | Recall | F Value |
|---|---|---|---|---|---|---|---|
| 1st Scene | Traditional RatSLAM | 154 | 2 | 596 | 98.73% | 20.53% | 0.34 |
| FT model-based | 169 | 1 | 581 | 99.41% | 22.53% | 0.37 | |
| HSI model-based RatSLAM | 194 | 1 | 556 | 99.49% | 25.87% | 0.41 | |
| 2nd Scene | Traditional RatSLAM | 533 | 9 | 916 | 98.34% | 36.78% | 0.53 |
| FT model-based | 548 | 3 | 901 | 99.45% | 37.81% | 0.55 | |
| HSI model-based RatSLAM | 598 | 2 | 851 | 99.67% | 41.27% | 0.58 | |
| 3rd Scene | Traditional RatSLAM | 1631 | 647 | 1169 | 71.59% | 58.25% | 0.64 |
| HSI model-based RatSLAM | 1684 | 207 | 1116 | 89.05% | 60.14% | 0.70 | |
| 4th Scene | Traditional RatSLAM | 874 | 73 | 527 | 92.29% | 62.38% | 0.74 |
| HSI model-based RatSLAM | 896 | 21 | 537 | 97.71% | 62.53% | 0.76 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.; Yu, S.; Chen, L.; Sun, R. An Environmental-Adaptability-Improved RatSLAM Method Based on a Biological Vision Model. Machines 2022, 10, 259. https://doi.org/10.3390/machines10040259
Wu C, Yu S, Chen L, Sun R. An Environmental-Adaptability-Improved RatSLAM Method Based on a Biological Vision Model. Machines. 2022; 10(4):259. https://doi.org/10.3390/machines10040259
Chicago/Turabian StyleWu, Chong, Shumei Yu, Liang Chen, and Rongchuan Sun. 2022. "An Environmental-Adaptability-Improved RatSLAM Method Based on a Biological Vision Model" Machines 10, no. 4: 259. https://doi.org/10.3390/machines10040259
APA StyleWu, C., Yu, S., Chen, L., & Sun, R. (2022). An Environmental-Adaptability-Improved RatSLAM Method Based on a Biological Vision Model. Machines, 10(4), 259. https://doi.org/10.3390/machines10040259