In order to implement the reinforcement learning approach into an ATL process, the tape laying system developed in the HyFiVe project and in particular the infrared-based heating system are introduced in
Section 2.1.
Section 2.2 describes the structure of the used reinforcement learning algorithm.
Section 2.3 contains the rewarding strategy and the exploration strategy to implement the algorithm as a temperature controller.
Section 2.4 finally describes the execution of the training.
2.2. Design of the Learning Temperature Controller
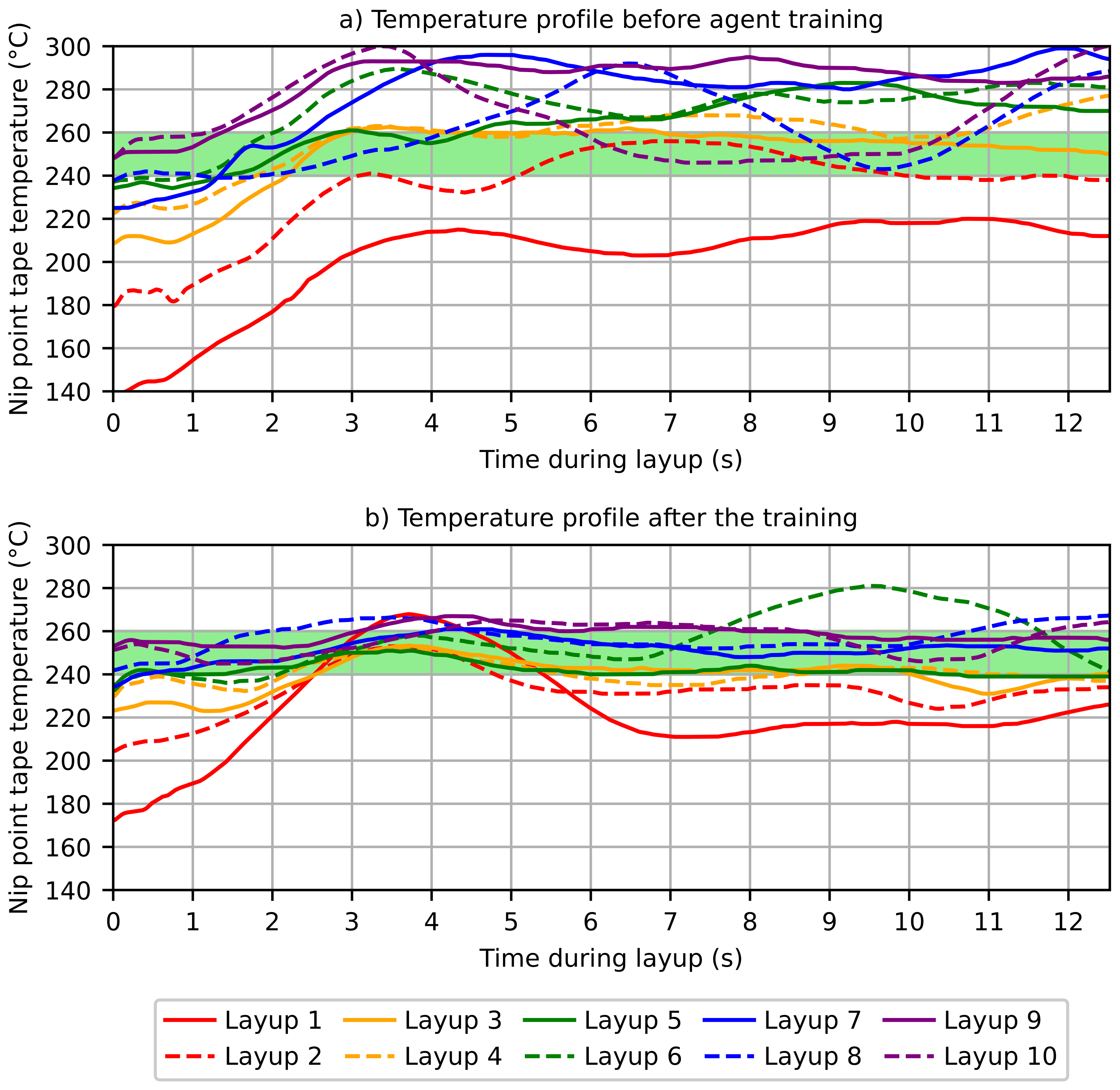
To achieve a constantly high quality of the ATL process, it is important to keep the target temperature at the nip point within a predefined thermal tolerance window. In order to learn the heating behaviour of the endeffector and discrete environmental conditions, a learning temperature controller based on a reinforcement learning approach is proposed. Reinforcement learning is based on software agents that try to find the best possible path to solve a problem in an environment. For this purpose, they read the state of the environment (state) and select an action to adapt to the environment (action) based on their learned knowledge. After execution of the action and the subsequent change of the environment based on this action, the state is read again (next state). The evaluation of the action on the basis of the change in the environment is carried out by a reward strategy. The reward (R) is expressed by a numerical value [
17].
In the context of reinforcement learning, the exploration-exploitation-dilemma plays an important role. This describes the conflict between the selection of an optimal result for the current problem or the knowledge extension by consideration of other environmental conditions under acceptance of a current sub-optimal solution [
17]. An exploration strategy is used to solve this dilemma. The basic structure of the chosen algorithm is explained in this chapter. The reward and exploration strategy are described in the
Section 2.3.
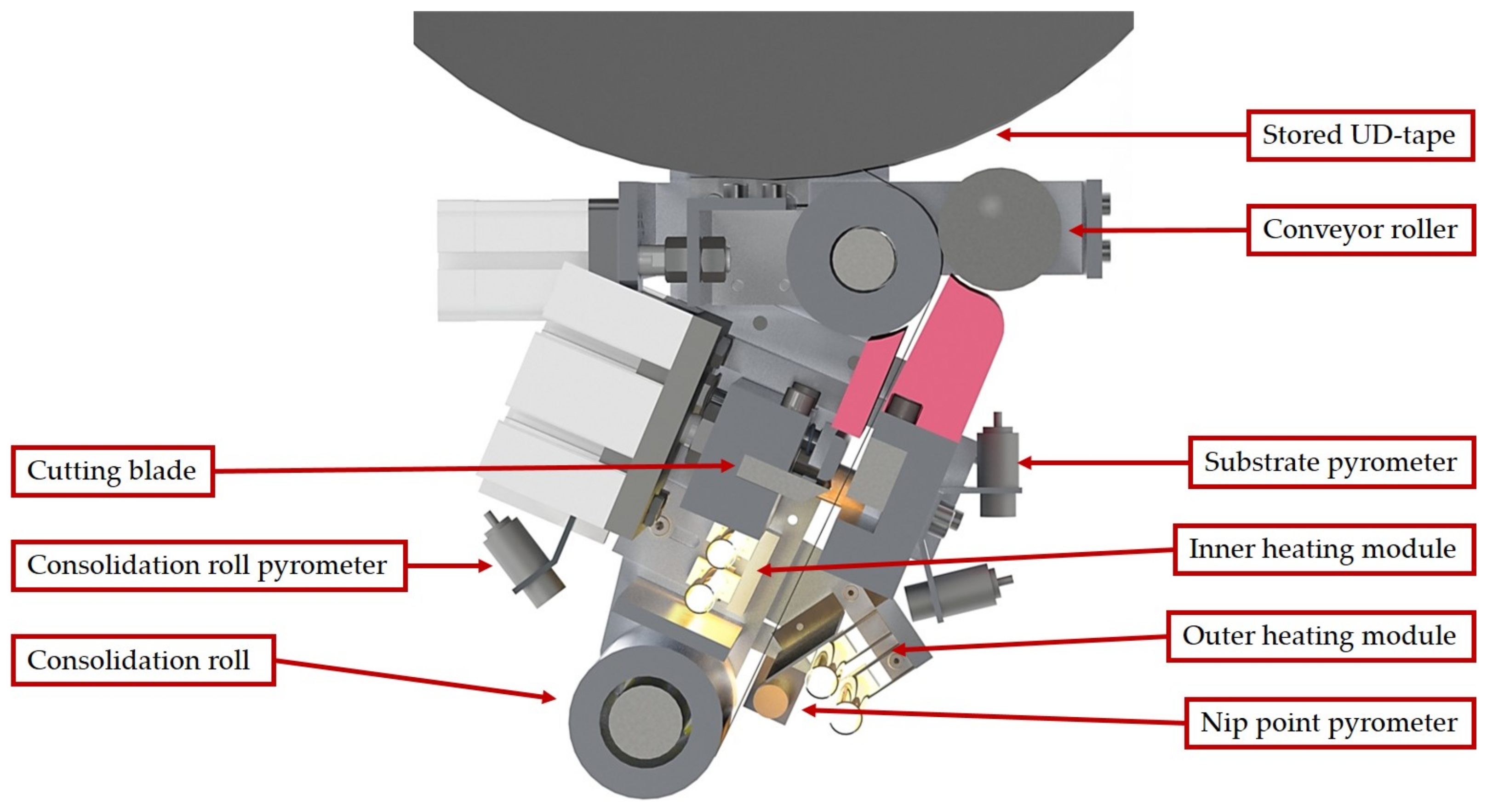
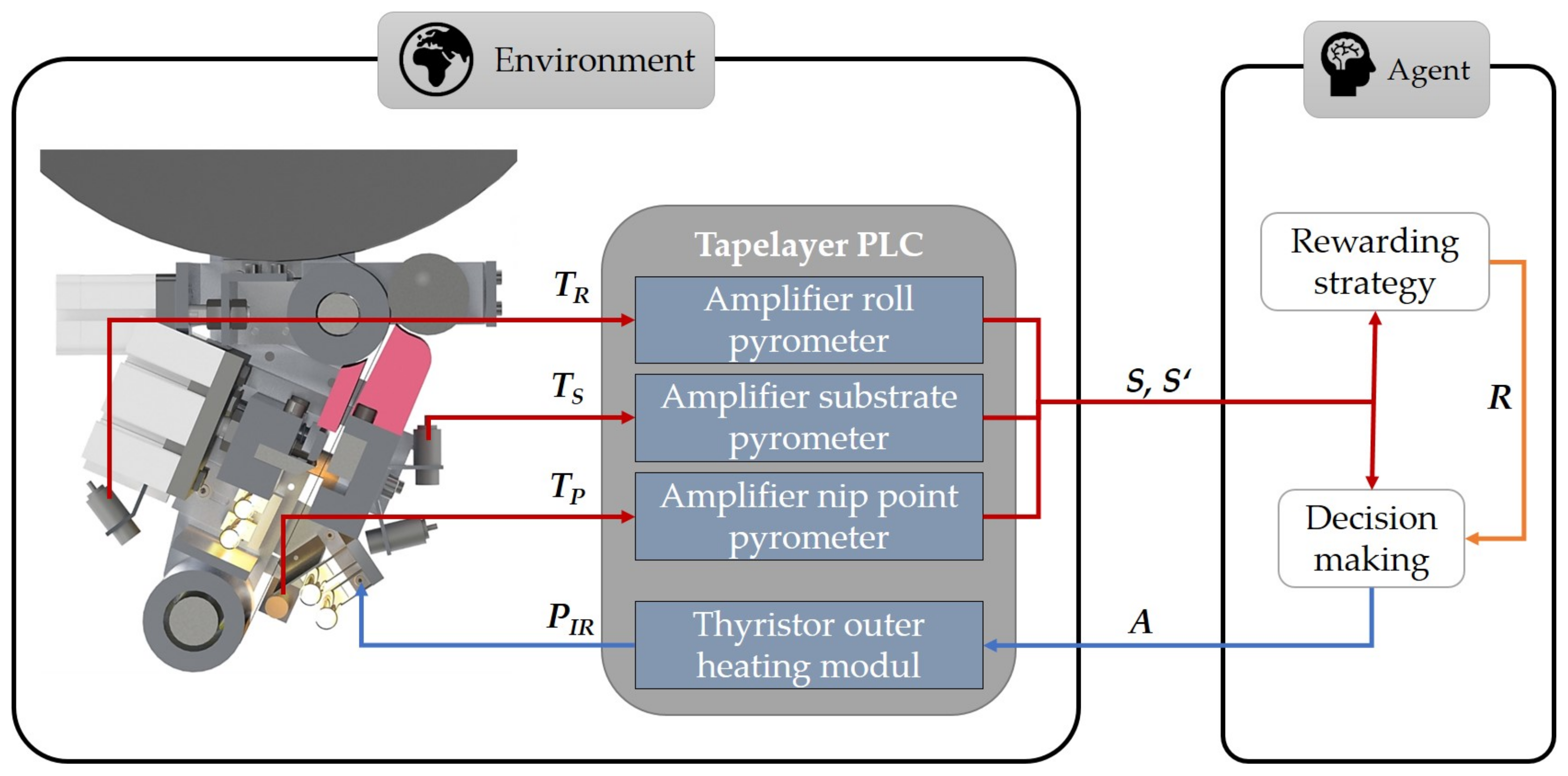
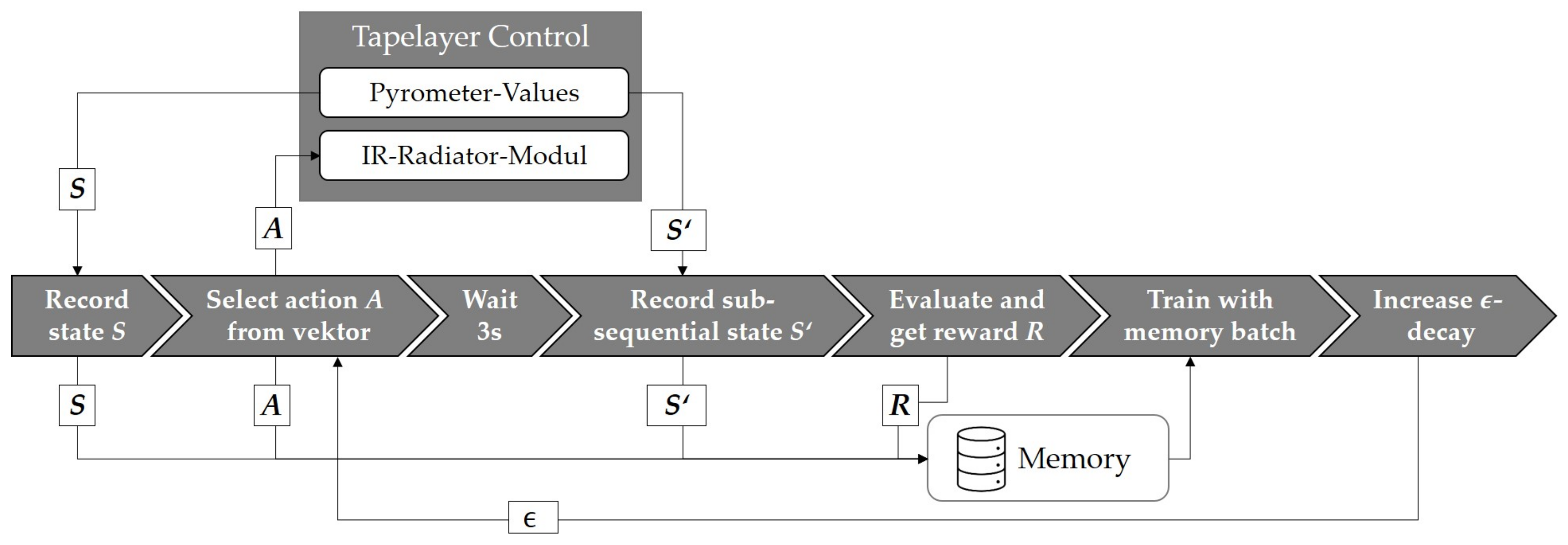
One of the main tasks of the agent is the recording of the state of the environment
S. In addition to the tape temperature at the nip point
(target variable), the recording consists of the main variables influencing the tape described above: The roll temperature
and the substrate temperature
. The temperature is recorded by the pyrometers as real temperature in °C. In order to smooth the volatile temperature curve of the pyrometers for better processing, the temperature data is passed through a mean average filter with 25 values. Based on its current policy, the agent selects an action
A with the goal of maximizing the reward. For this purpose, the agent tries to minimize the difference between the measured and the target temperature. The action available to the agent is the power setting of the front infrared module
. According to the installed thyristors, the action size is a percentage of the total power (0–100%) with a high resolution. The action is transmitted via an interface to the thyristors, which set the new value. Then the agent checks the system state again
and receives a reward
R based on the impact of its action. The vector of state, action, reward and next state is stored by the agent and used to optimize its policy. This procedure is continued iteratively over the entire layup process (episode) (
Figure 3).
Due to the high-resolution state and action space, both can be considered quasi-continuous in practice. An algorithm which is designed for such cases is the deep deterministic policy gradient algorithm (DDPG). Like all Actor-Critic algorithms, the DDPG consists of two artificial neural networks (ANN), the Actor network and the Critic network. In the DDPG, the Actor network takes the decision of the action based on the state vector. The Critic network determines the Q value based on the selected action and the state vector. The DDPG belongs to the off-policy algorithms, which allows it to reuse already generated data. Therefore, it stores recorded experiences (
) in a replay buffer and uses them for later optimization. To increase stability during learning, the DDPG further uses target networks for both networks, which are time-shifted copies of the original networks [
18]. To deal with the continuous action and state space, a DDPG software agent is used to control the temperature in the ATL process described above. The network structures were programmed according to the original publication by Lillicrap [
18] with two hidden layers each with 400 and 300 neurons. The layers are connected via a rectified linear unit (ReLU) activation function. In order to meet the special requirements of the control of the radiator power, however, a sigmoid activation function was used for the output layer of the actor network, which gives out values between 0 and 1. The structures of the implemented actor and critic networks are shown in
Table 1.
The programming environment Python 3.8 and the data-science library pytorch were used for implementation. The interface between the DDPG implementation and the machine PLC was realized via the pyADS library. The algorithm used is basically capable of solving the problem and learning the relationship between the system temperatures and the power setting of the infrared module. For the successful execution of the learning process, however, a reward strategy is necessary, which evaluates the action decisions of the agent. Furthermore, an exploration strategy is needed to quickly adapt the agent to an optimal solution. Both strategies are described in the following.
2.3. Design of Rewarding and Exploration Strategy
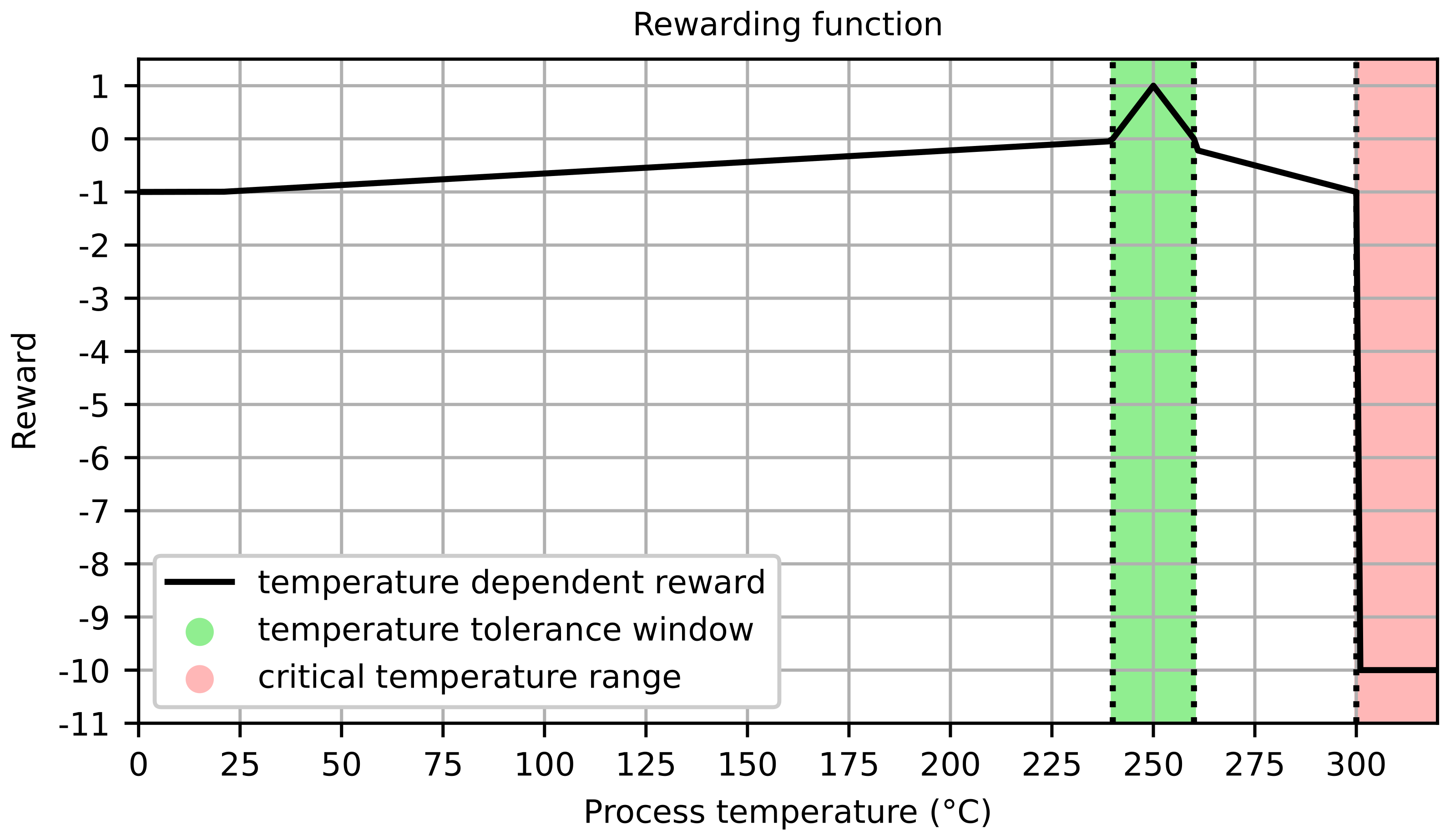
In order to perform the learning process successfully, both a reward and an exploration strategy are needed. Using the reward strategy, the software agent learns its policy and can evaluate the ranges in which it should maintain the target temperature. At the same time, the agent can develop aversions against harmful temperature ranges. The main goal of the controller is to keep the process temperature
constantly within the thermal tolerance window at any point in the process. Therefore, it is reasonable to make the reward dependent on the difference between the actual process temperature and the target temperature
. The target temperature is set to 250 °C for the processing temperature of the tape, since this temperature has proven to be effective in previous experiments for the used tape. A tolerance range
of ± 10 °C is defined around this target temperature. No significant changes in process performance were observed with variations in this temperature range. Furthermore, above the maximum temperature
of 300 °C, the degeneration of the matrix material is intolerable and the system shuts down. According to this temperature zone, the agent receives a reward depending on the difference between process and target temperature (
Figure 4).
A positive reward is given to the agent when the temperature is kept within the tolerance range. The maximum reward is given when the target temperature is reached. Outside the tolerance zone, the reward falls linearly, with a higher degree of punishment in the higher temperature range as the material is more degenerated. A particularly high punishment of −10 is given when
is reached or exceeded to instill in the agent a high aversion to this temperature range. The room temperature of 20 °C is set as the lowest temperature limit. The reward is thus calculated from:
In order to solve the agent’s problem of reaching an optimal solution as quickly as possible and to equally explore the solution space in a meaningful way, exploration strategies are needed. The DDPG algorithm used here already provides a certain exploration strategy called Ohnstein-Uhlenbeck (OU) process, which generates a random noise based on the last used values. Thereby, the agent also considers the solution spaces around its optimal solution. This forces the agent to explore the solution space immediately around its optimal solution. This reduces the risk of being stuck in local optima. The amount of noise is determined by the hyperparameters of the OU process according to the original publication by Lillicrap [
18].
However, since the agent only observes its immediate environment through the OU process, teaching the agent at the beginning would lead to many failed attempts and increase the required teaching time. Since learning in the real process is time- and material-consuming, another strategy must be found that enables faster learning. The advantage of such a strategy is that the process has already been controlled by an open loop controller. Therefore, it is feasible to provide the “knowledge”, that is already stored in the controller to the agent, so that the agent can benefit from this knowledge. This can shorten the start-up time of the agent immensely. In their work, Silver et al. [
19] present an approach for a so-called “Expert Exploration”. Here, the algorithm learns based on a previously imperfect solution. The agent selects from three actions. These include the previous policy of the existing solution, a random value and the proposed solution of the agent. The probabilities of the selection of the three solutions are determined by the hyperparameters
and
.
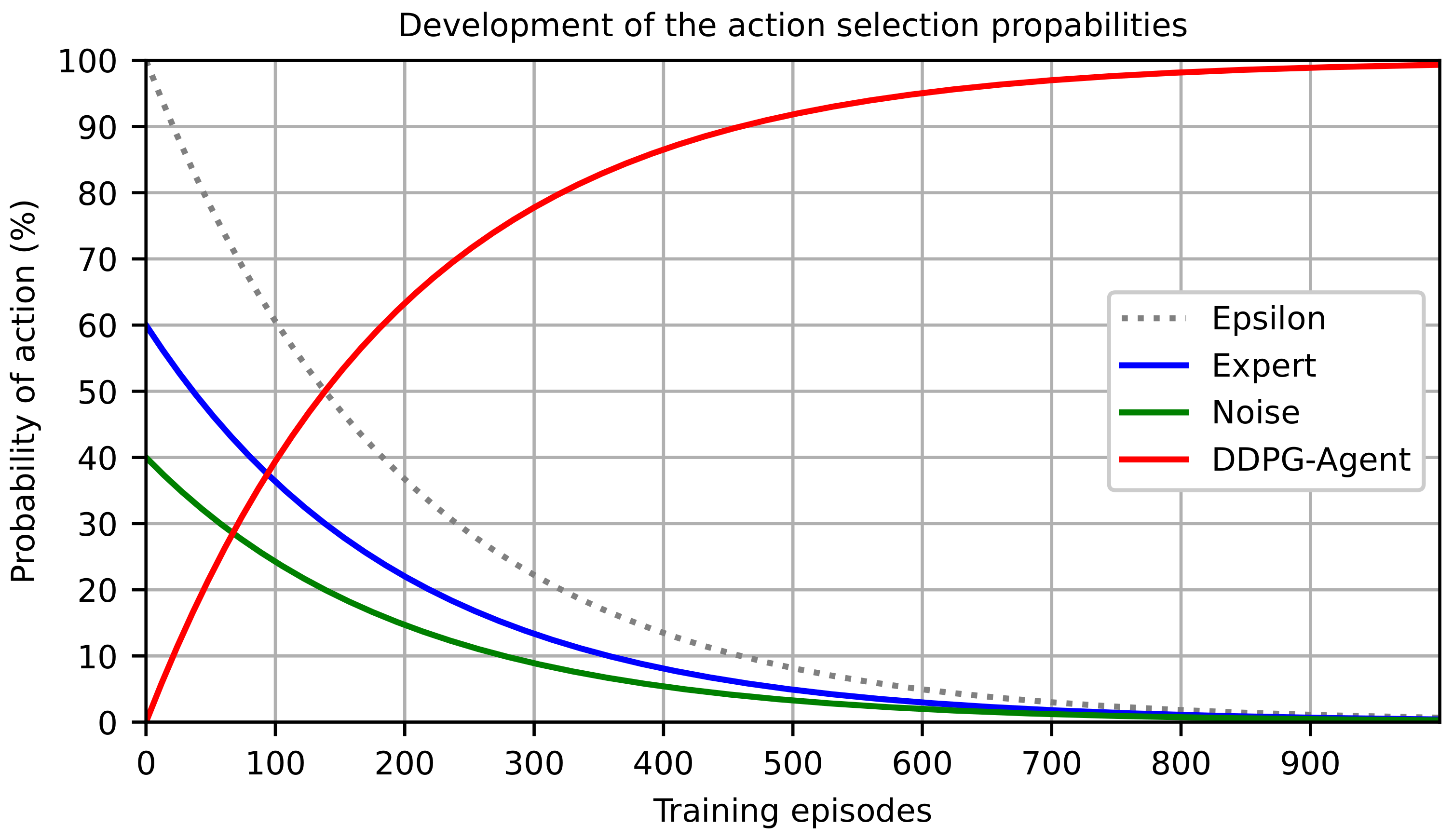
The probability of choosing the agent’s action is calculated by 1 −
. It is initially very low so that the agent can learn from the previous policy and increases with continuous training episodes.
describes the ratio of the probability of the previous policy (expert) with
and the coincidence with
in relation to
. For the DDPG-based temperature control strategy for the proposed ATL process, the procedure is adapted. The previous policy is represented by the previous open-loop temperature control. Here, a continuous value of 60% of the maximum power is set as output. Good results could be achieved with this value in previous tests. The noise is taken over by the OU process. For the adjustment of the
value over time, an epsilon decay method is used with an acceptance factor of 0.995. For
, 0.6 is chosen. The expert-exploration-process was designed for this case for a total number of 1,000 episodes to support the agent by the expert also beyond the experimental series. The progression of probabilities over training episodes is shown in
Figure 5.
By means of the expert exploration process, the agent quickly reaches the level of the expert during the open-loop power control of the infrared radiator module and continues to improve thereafter. This can reduce the number of required training sections and thus the material and energy consumption.
The last step in integrating the software agent into the tape creation process is to set the system dead time. Since the environment only adapts to the change caused by the agent’s action with a certain inertia, direct observation of the environment is not helpful. A defined delay time between execution of the selected action by the agent and recording the next state of the environment must be implemented. Due to the inertia of the system, a too short delay would lead to incorrectly recorded end temperatures of the tape. The agent would therefore learn the wrong correlations. A too long delay decreases the possible reaction speed of the agent.
This time is significantly affected by the infrared system of the tape layer. On the one hand, the filament of the infrared emitters needs a certain time to reach a new stable filament temperature. On the other hand, the local offset of the impact zone of the infrared radiation and the measurement by the pyrometer leads to a delay on the heat transport to the measuring zone, which is directly dependent on the traversing speed. Furthermore, the average-mean filters used for smoothing the pyrometer signals also influence a temporal offset which is, however, negligible in this case. First attempts with a direct reward of the agent at its action led to a strongly fluctuating behavior of the system. After some preliminary tests, in which action and next state of the agent were observed, a waiting time of 3 s turned out to be beneficial for the learning behavior for the subsequent experiments.
With the rewarding and exploration strategy, fast and effective learning of the agent is possible. By means of expert exploration, the agent can also benefit from previous knowledge of the process. The system dead time also helps to evaluate the effects of the agent action in a stable way. The design of the agent can thus be integrated into the ATL process.
2.4. Training of the DDPG Algorithm
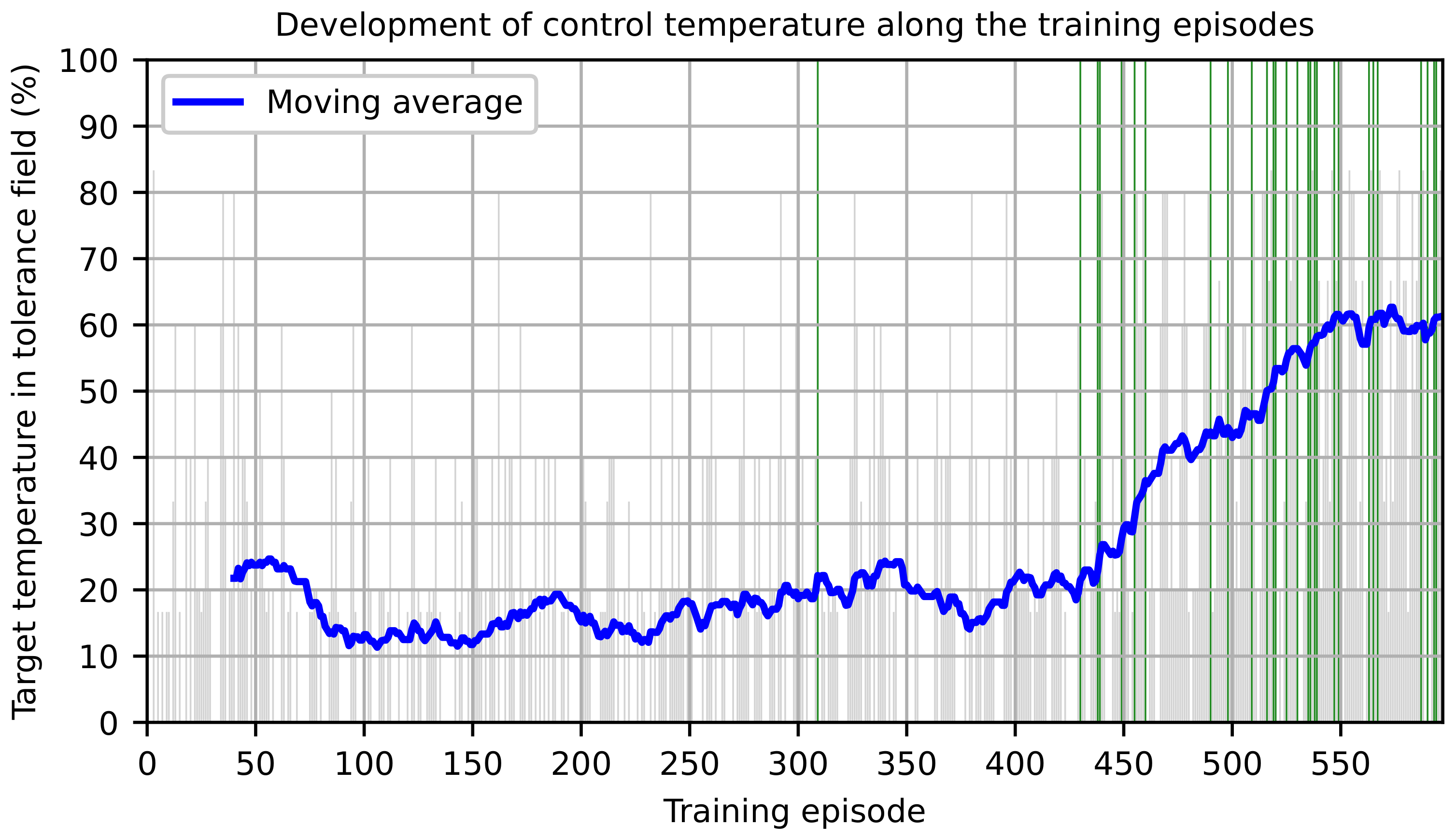
The agent was trained according to a defined iteration process. The python-implemented agent is connected to the Beckhoff PLC using the pyADS interface, which coordinates the thyristors for the power setting of the infrared emitters and the data recording of the pyrometers. For the data generation, tapes were automatically deposited on a flat surface consisting of a steel sheet and a thermal insulation layer.
The state consists of the temperature values of the three pyrometers for nip point, roll and substrate temperature. After selecting the action, the corresponding power values are transmitted to the IR emitters. The agent waits for 3 s until the environment shows a reaction to the action and then determines the next state. Based on this, it receives the corresponding reward. The data set of state, action, reward and next state is stored in the replay buffer. After the transition, the agent trains its 4 networks with a mini-batch of 64 data, which is randomly selected from the replay buffer. Finally, the epsilon decay is increased by one episode. The iteration process is shown in
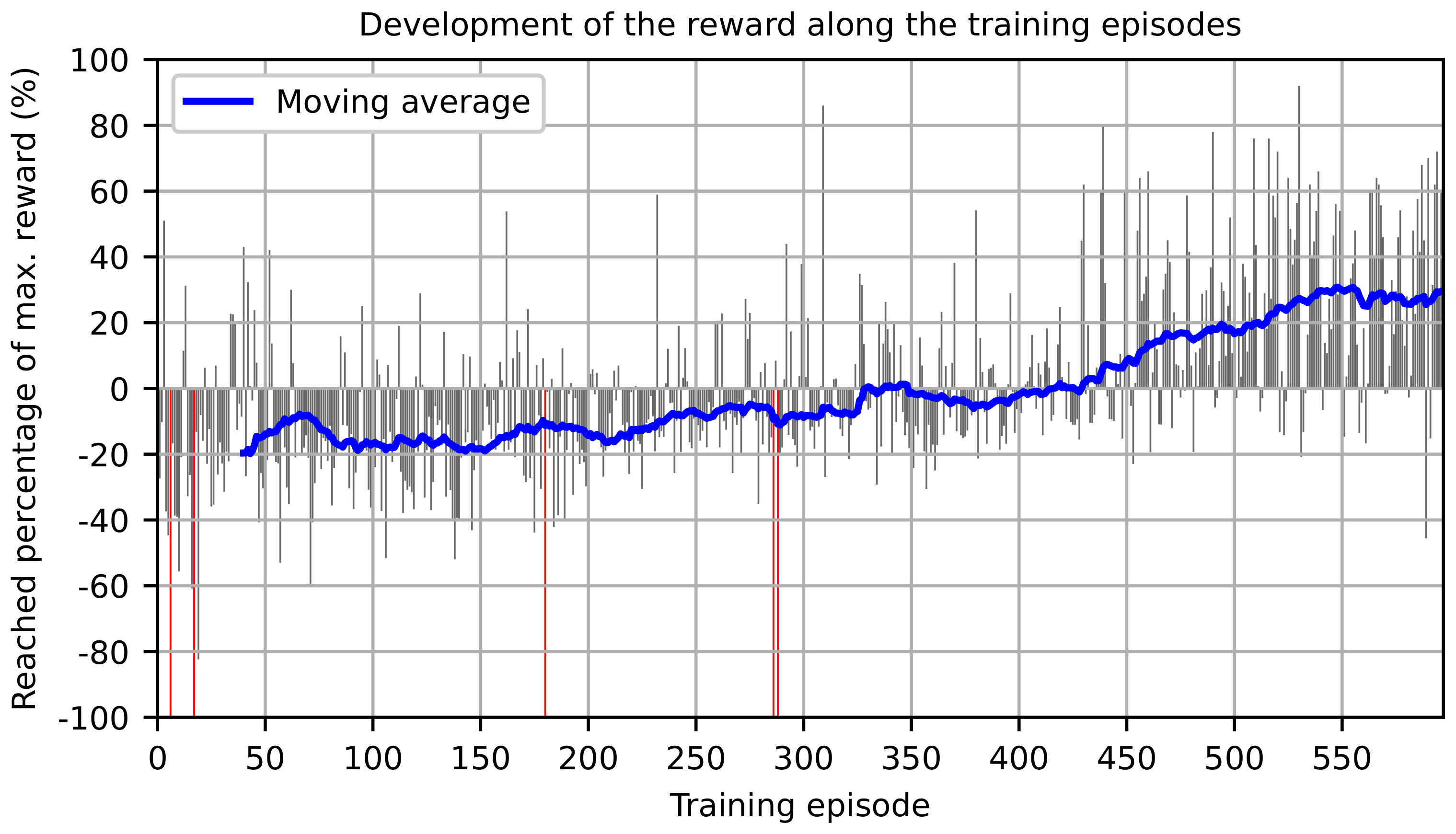
Figure 6. A layup length of 400 mm was chosen with a process speed of 20 mm s
−1 for each episode. According to the layup duration and the processing time of each iteration, a data set of 5–6 control iterations results per layup depending on the speed of the interface. A total layup length of 239 m was specified for the training, resulting in 597 layup iterations.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}