
Deep Learning Optimized Dictionary Learning and Its Application in Eliminating Strong Magnetotelluric Noise

 ,
, 
 , ,
, ,
Abstract
:1. Introduction
2. Methods and Algorithms
2.1. Implementation of Adaptive Sparse Decomposition
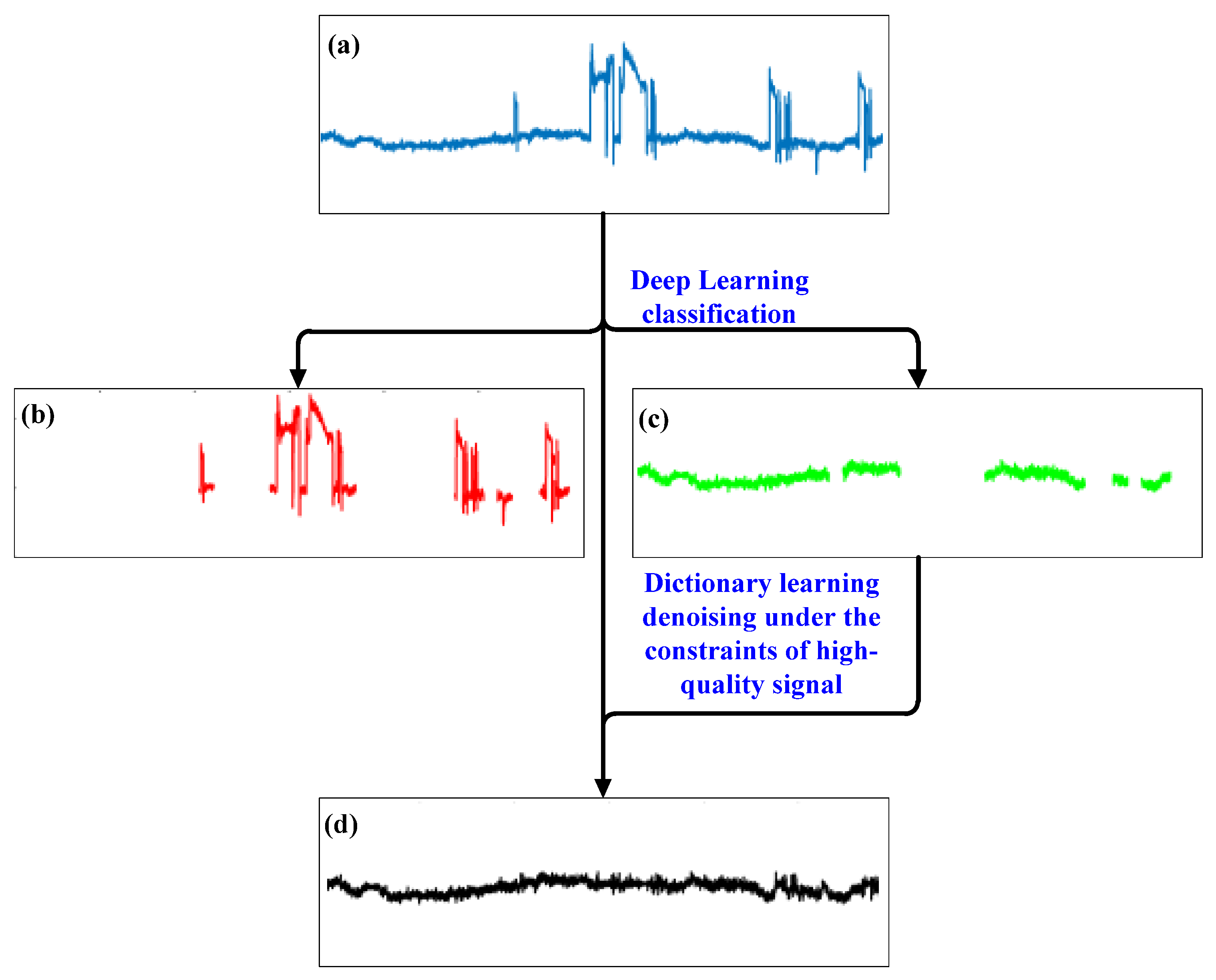
2.2. Method Flow
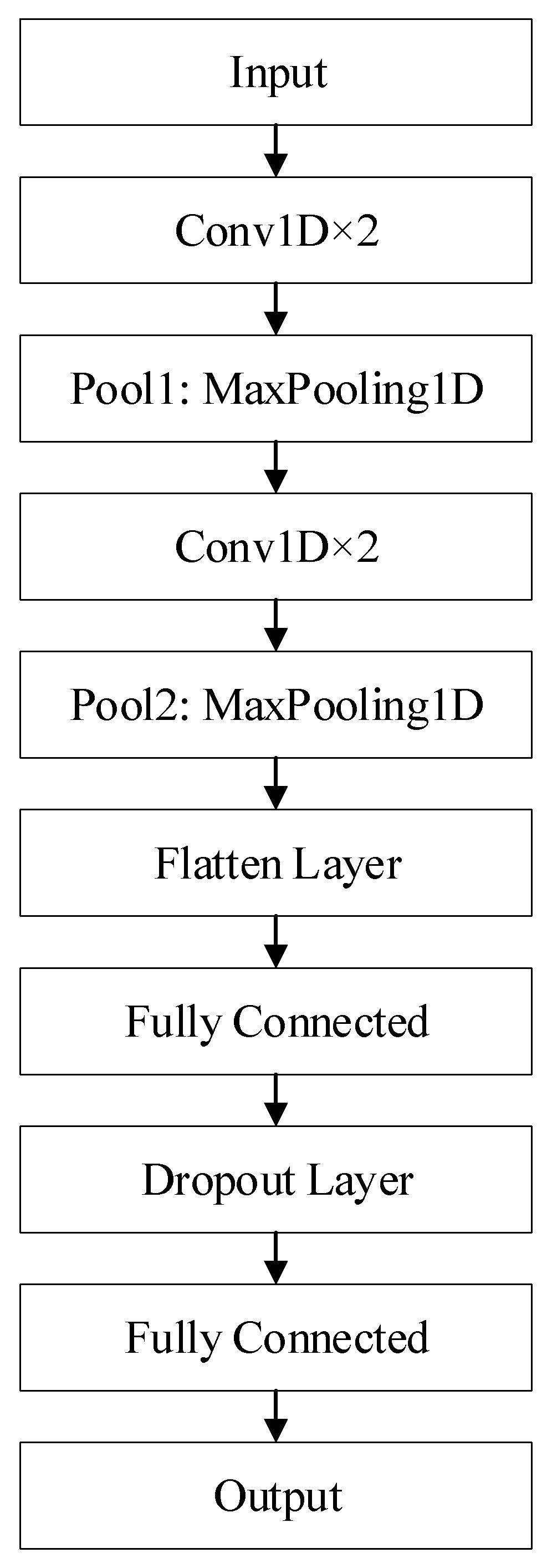
2.3. Deep Conventional Neural Networks (CNN)
2.4. K-SVD Dictionary Learning
3. Model Training and Simulation
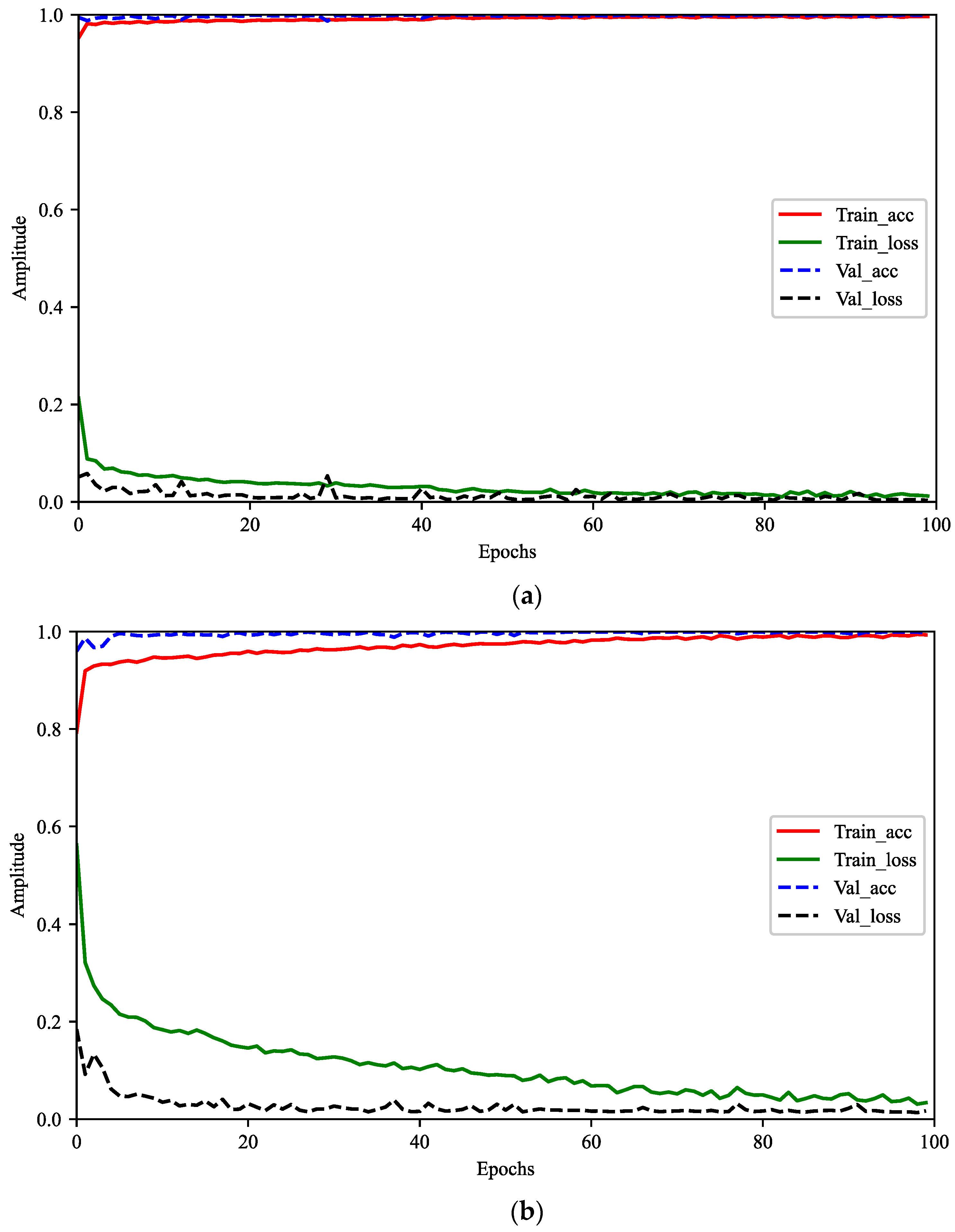
3.1. Sample Labeling and Model Training
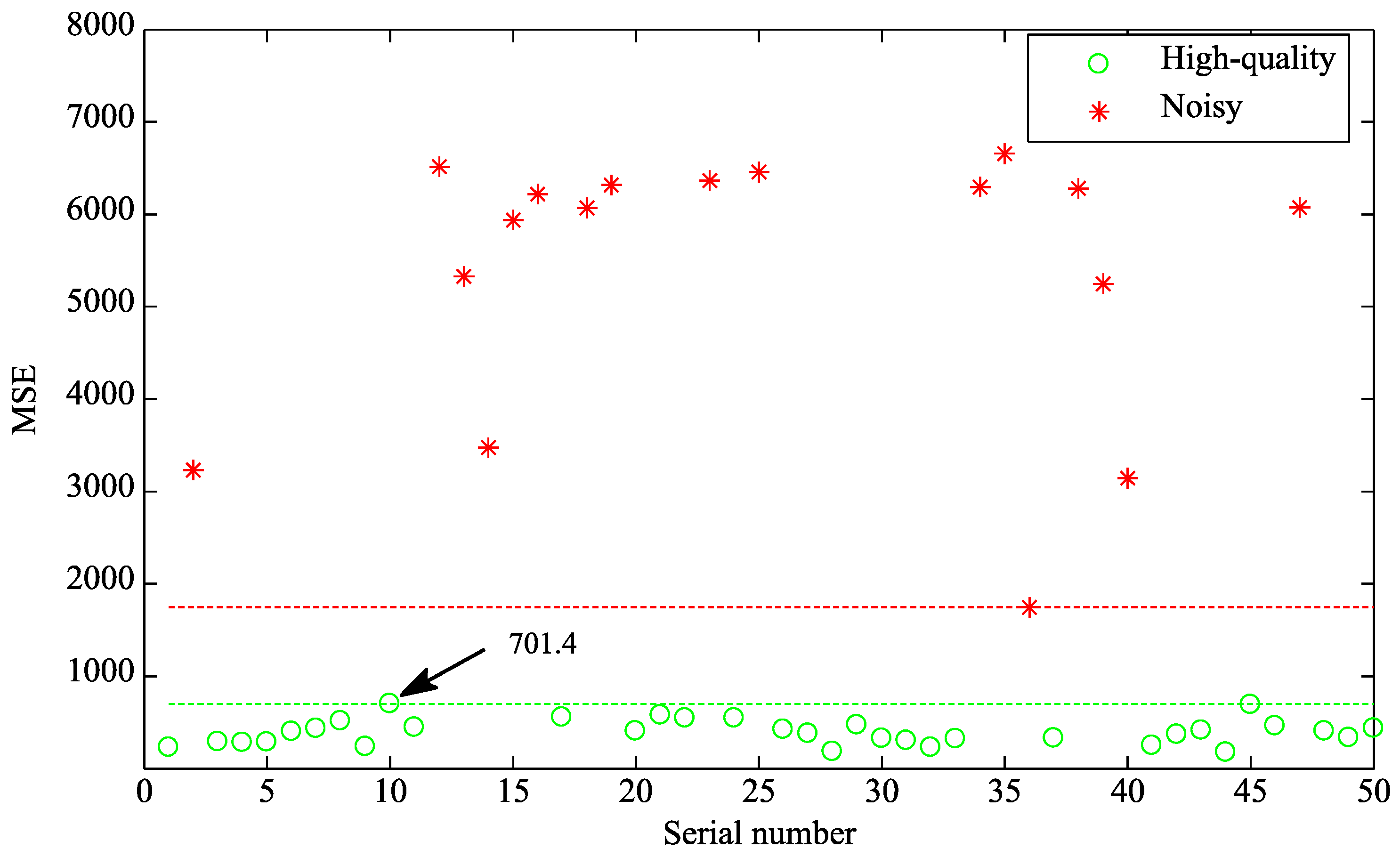
3.2. Simulation
4. Case Analysis
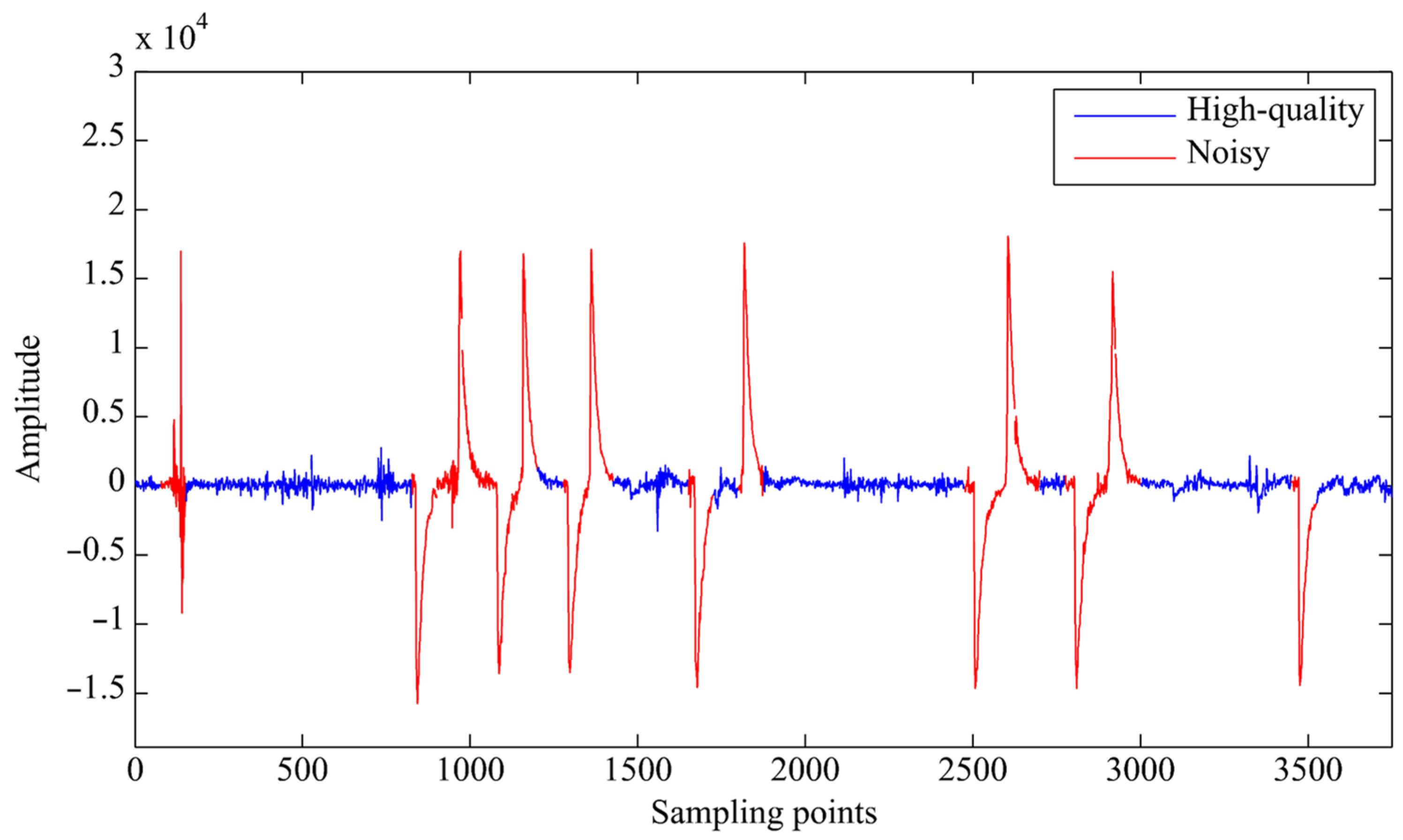
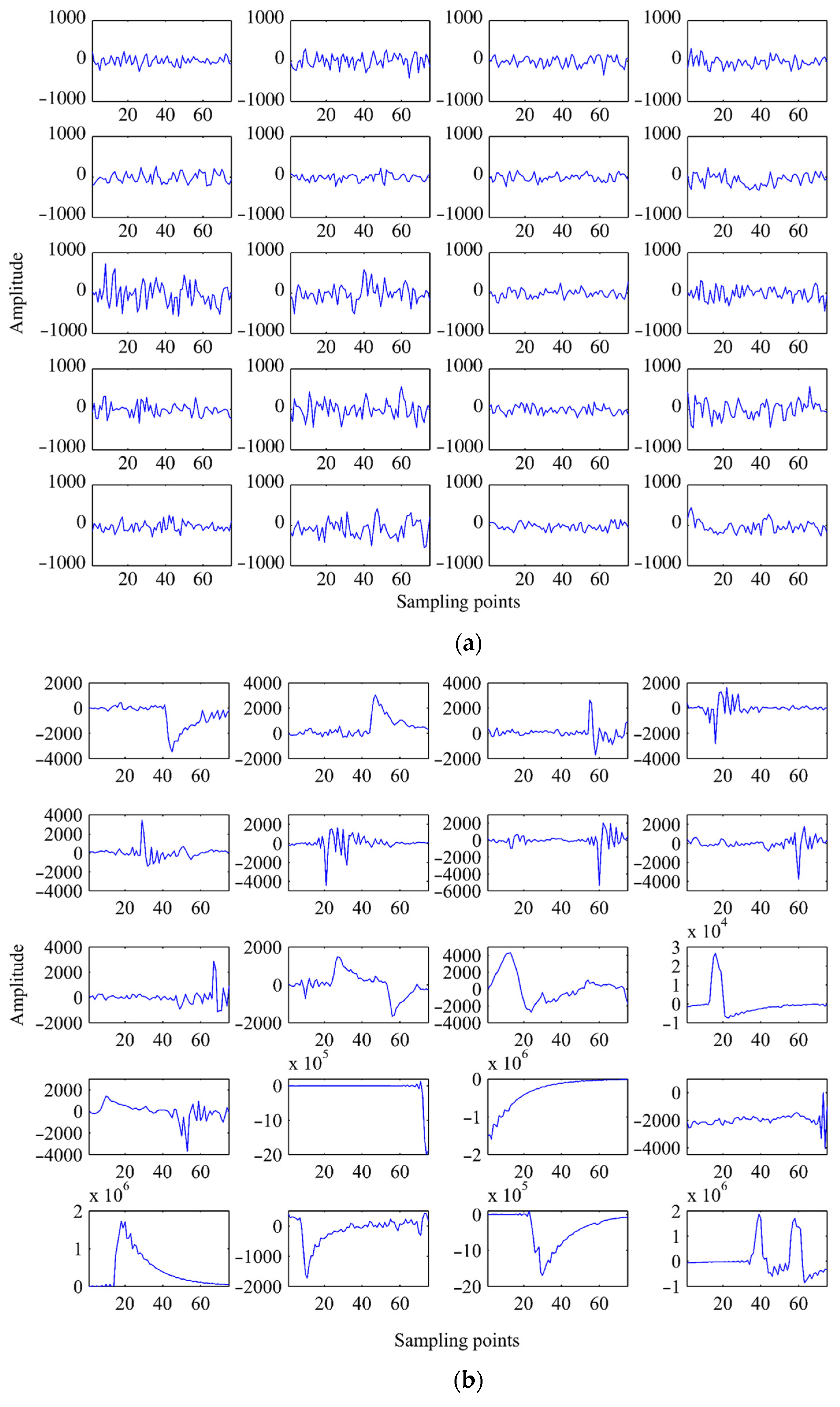
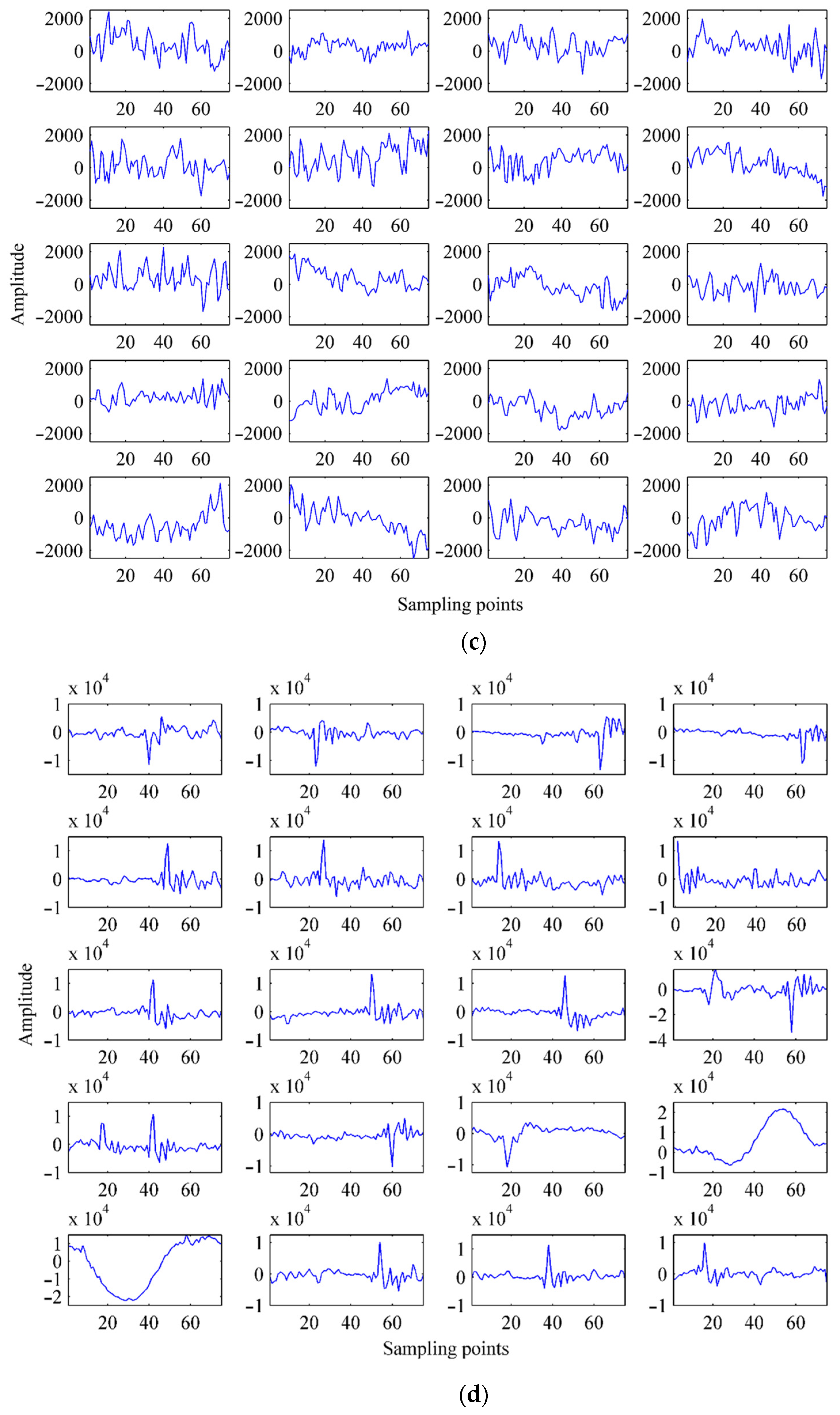
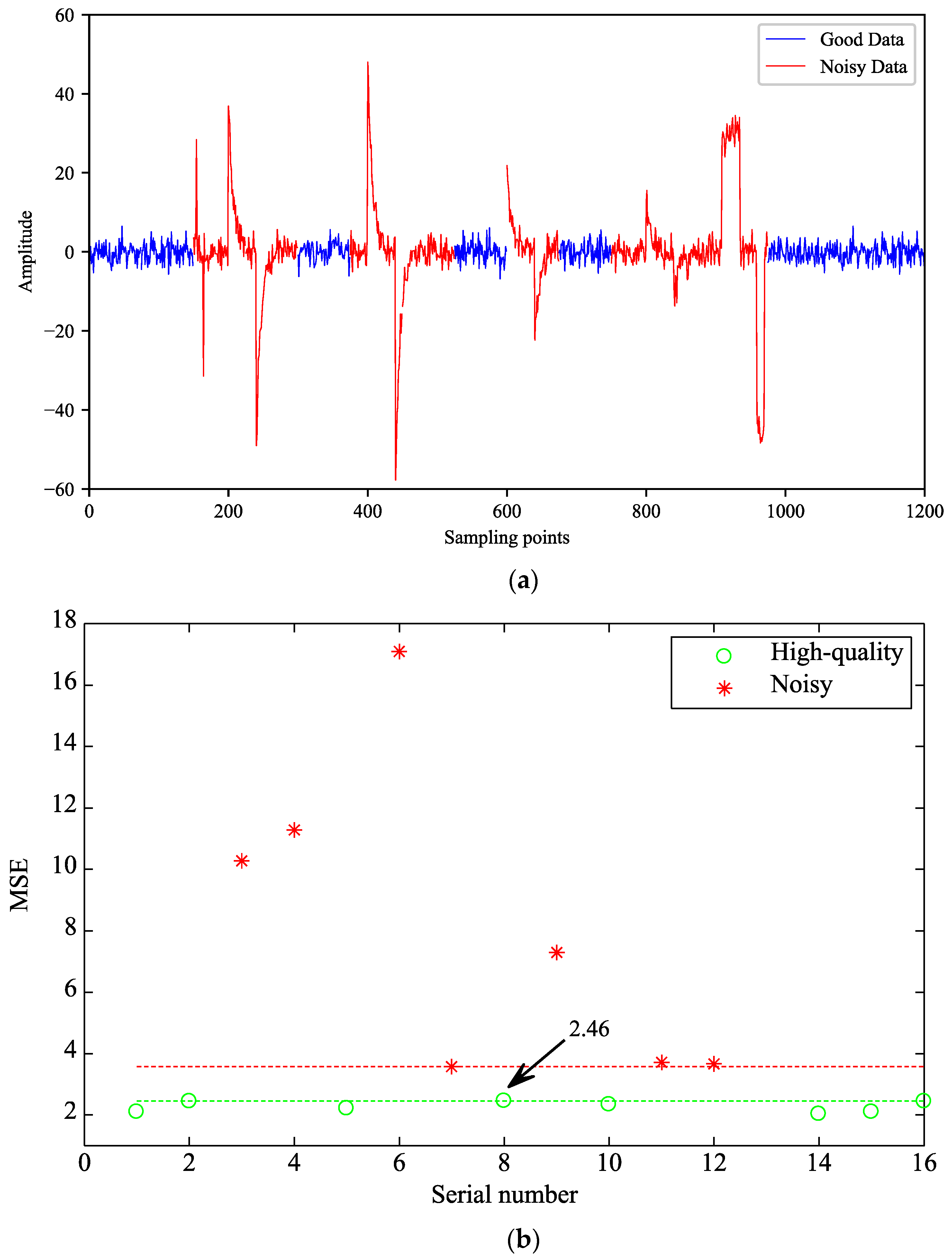
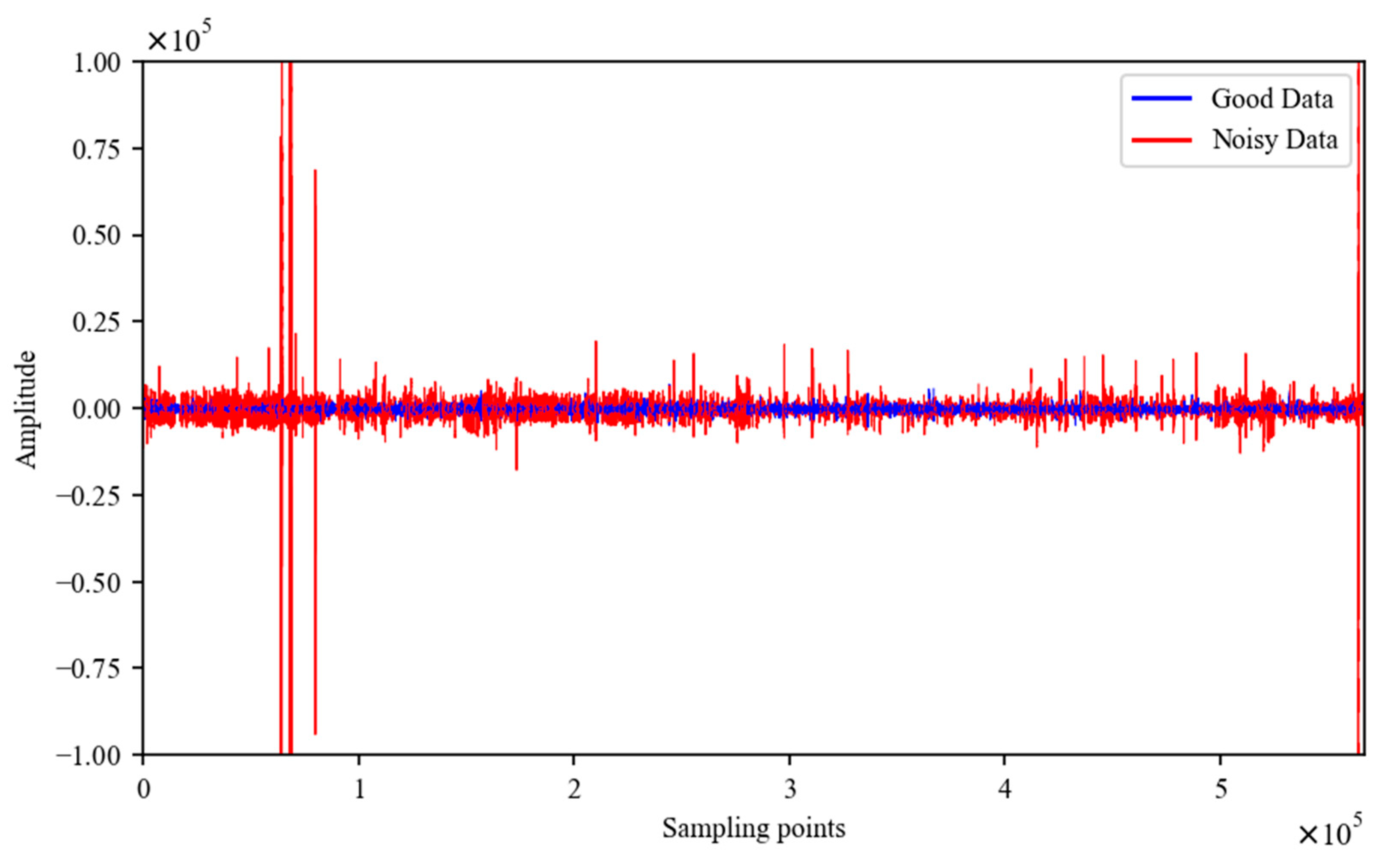
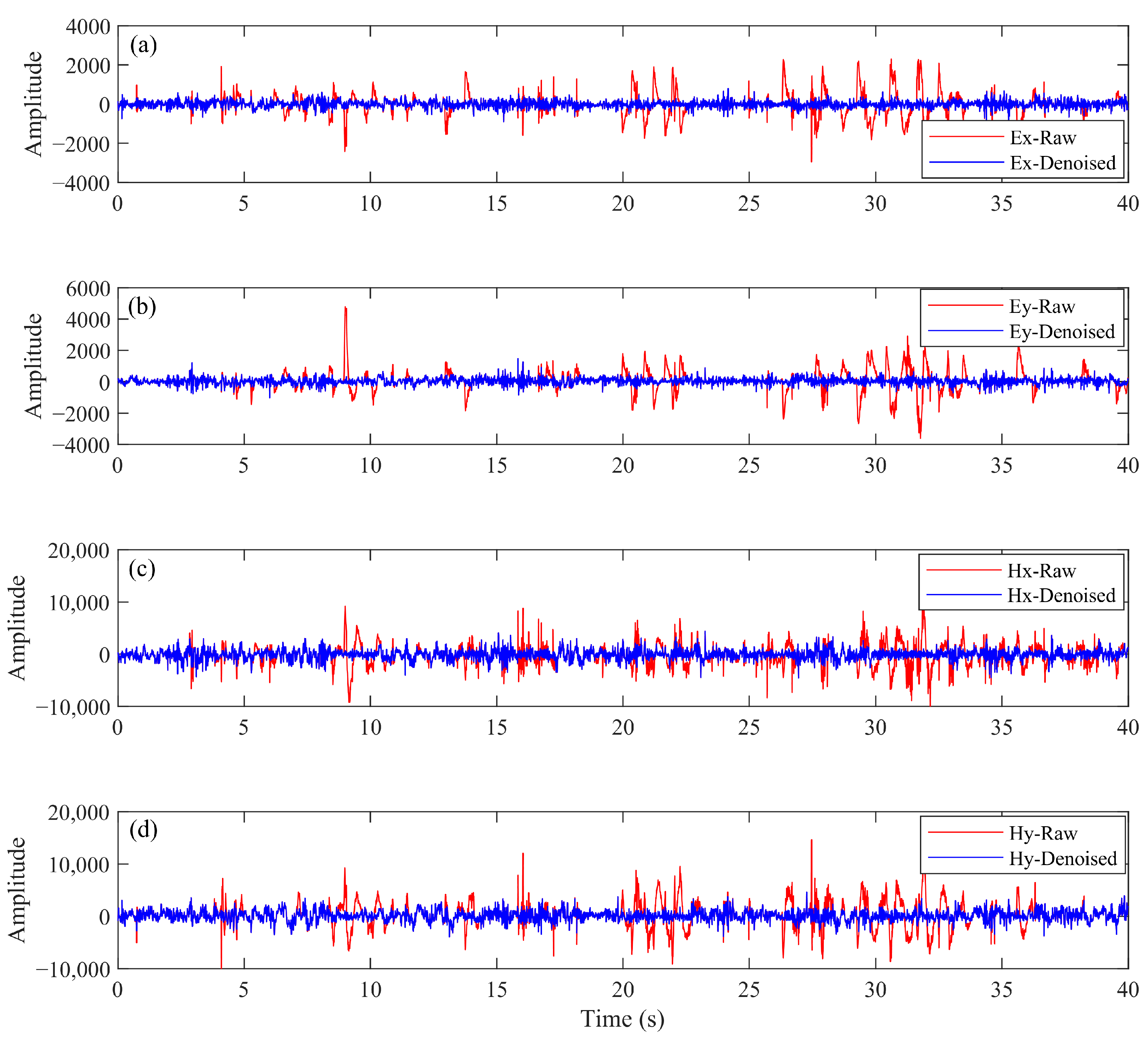
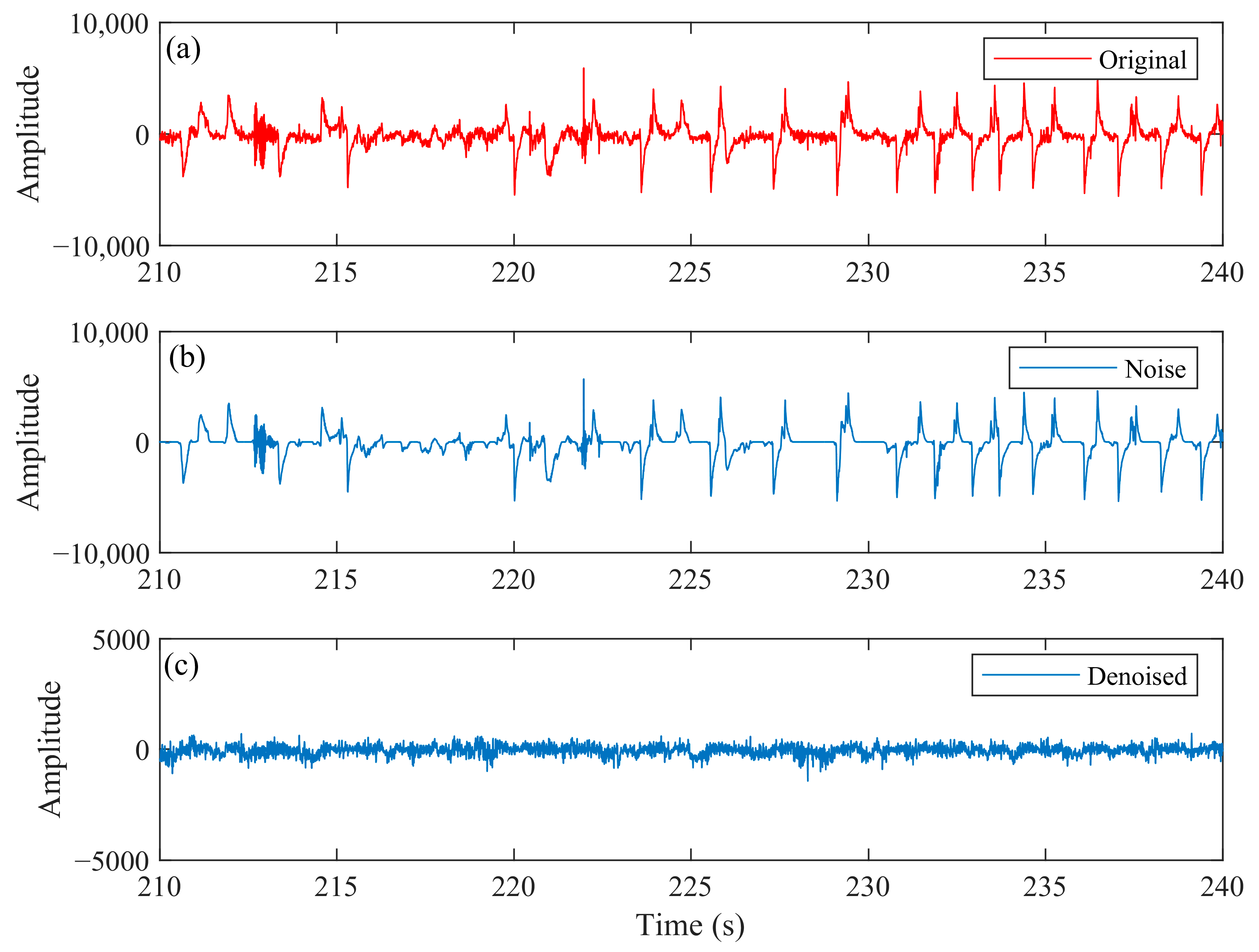
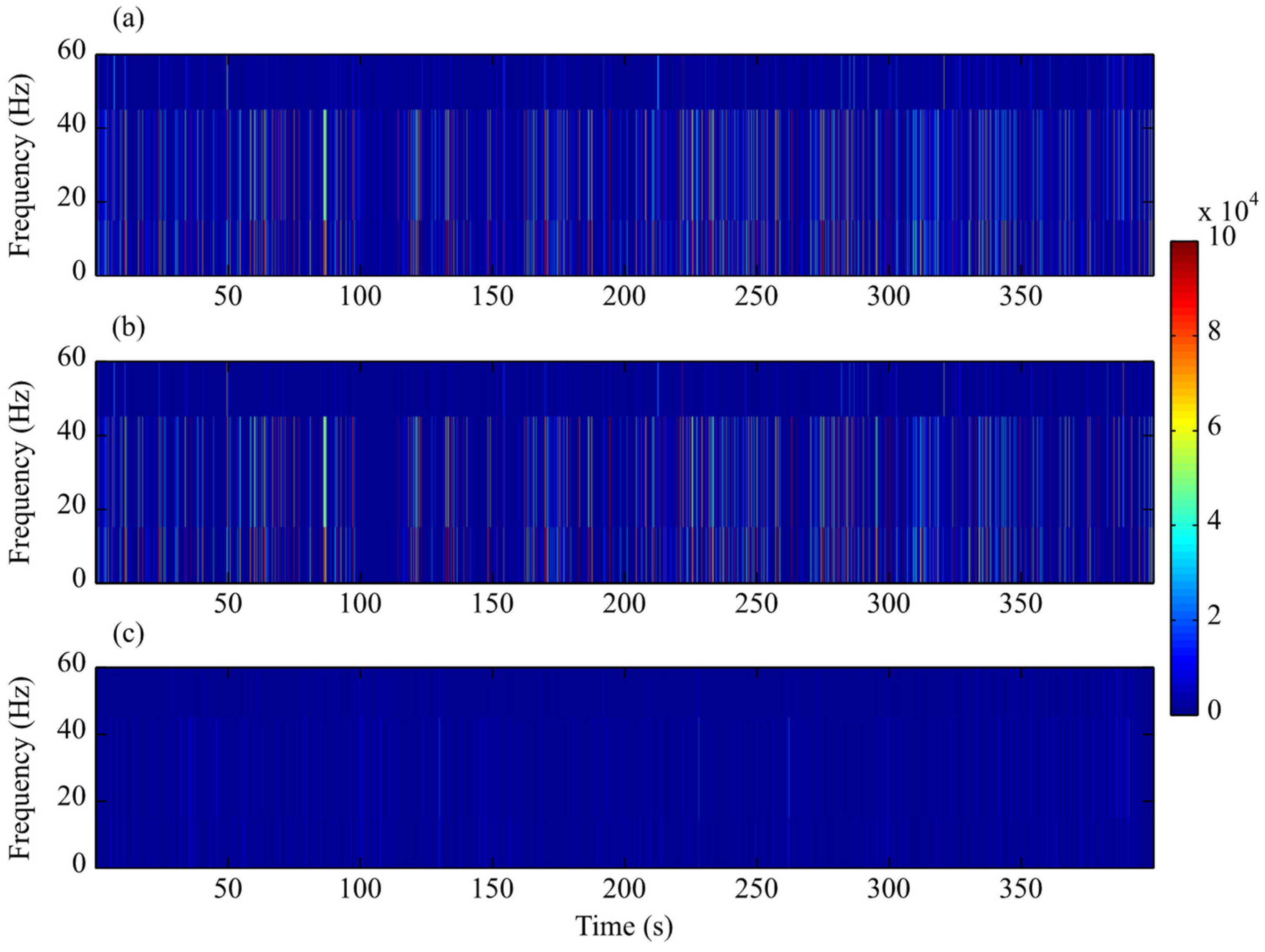
4.1. Time-Series Analysis
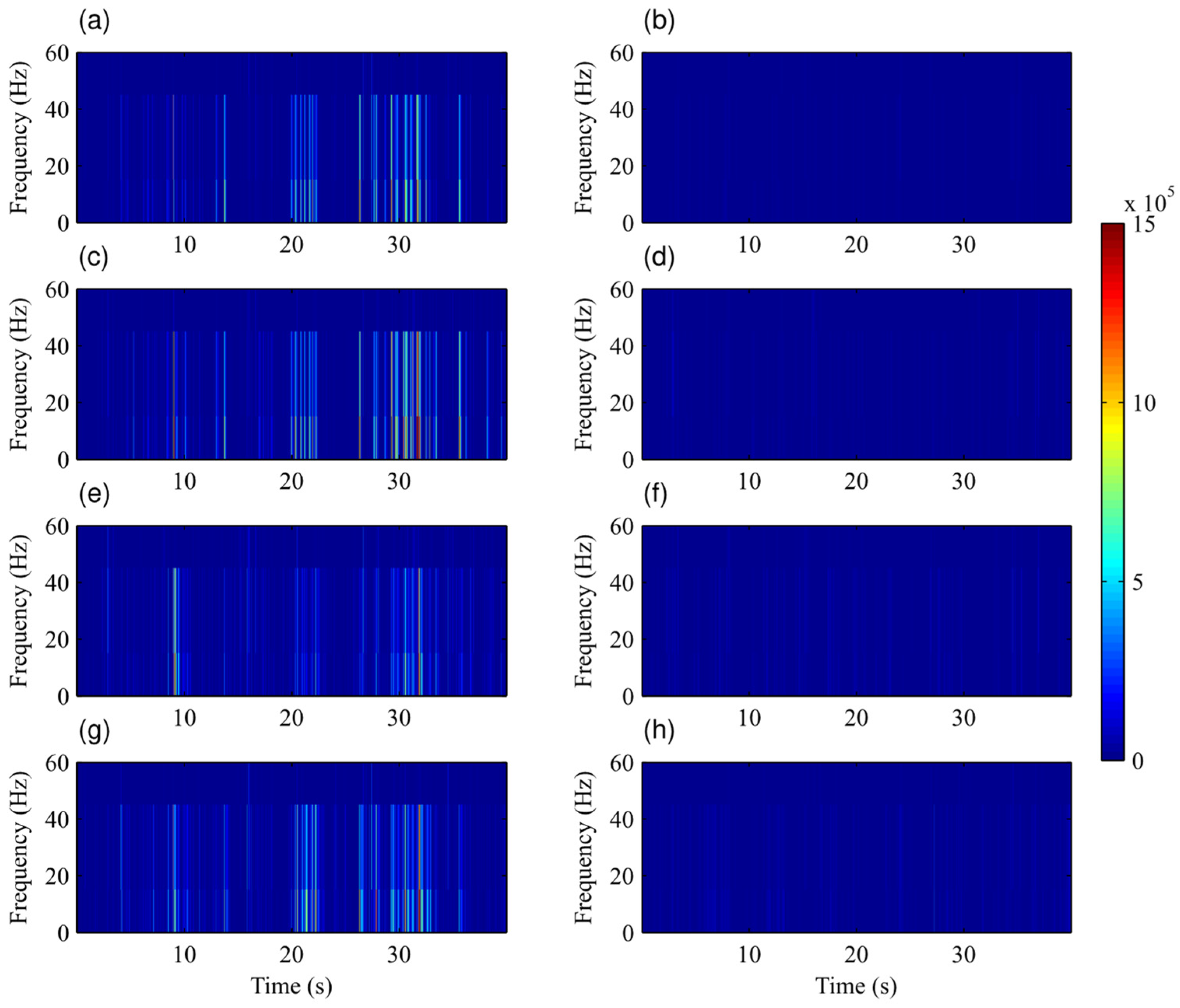
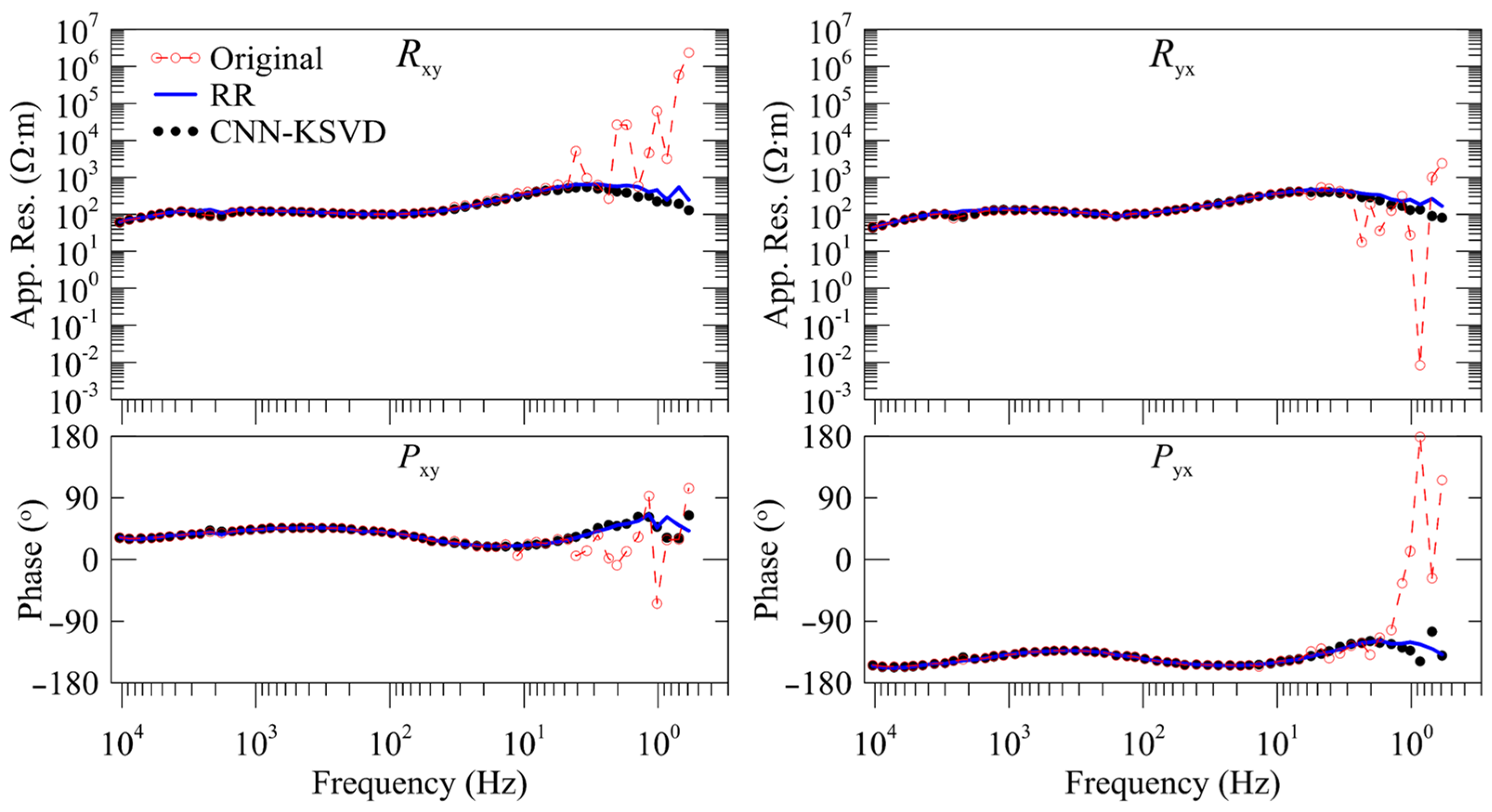
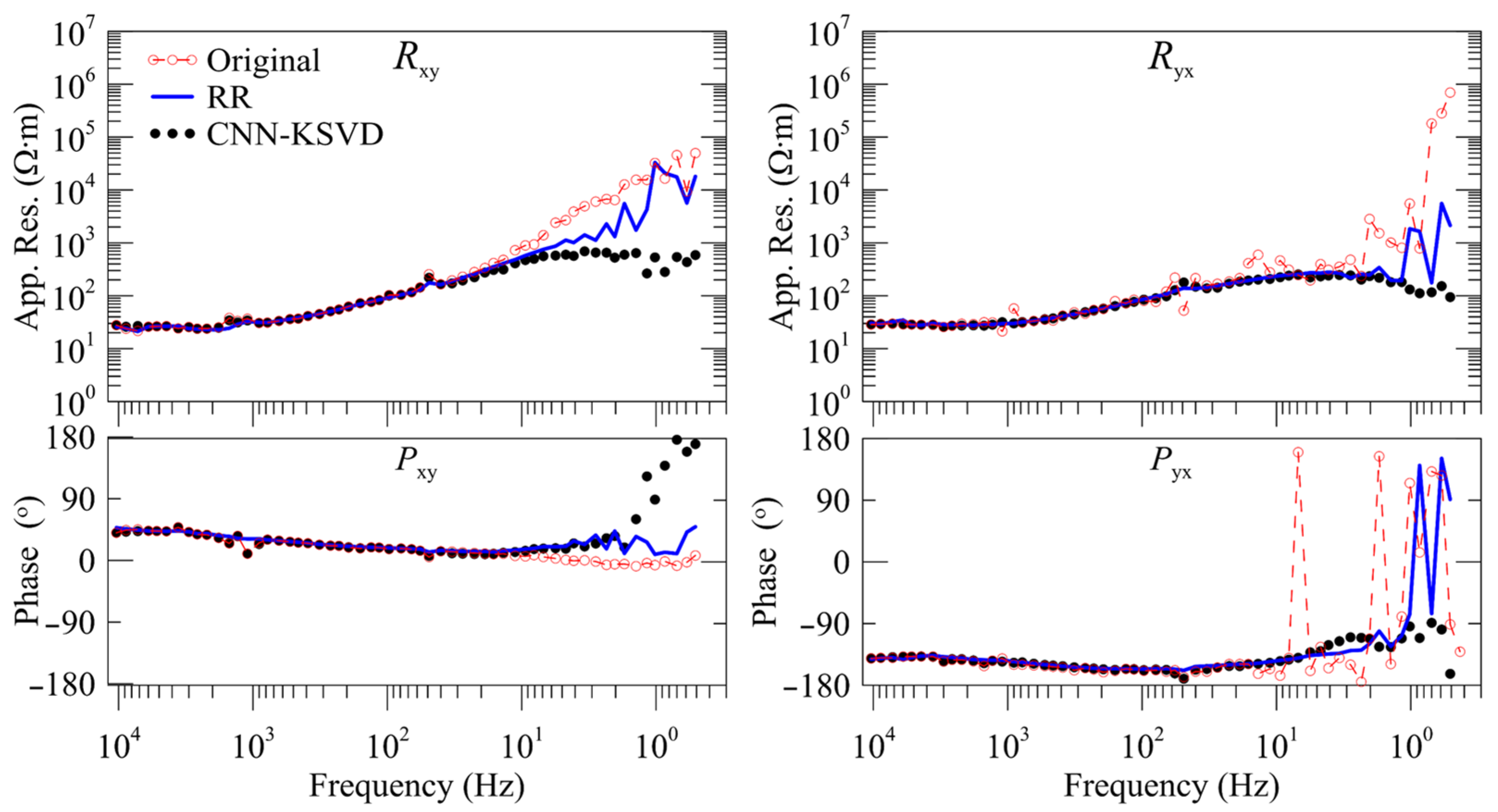
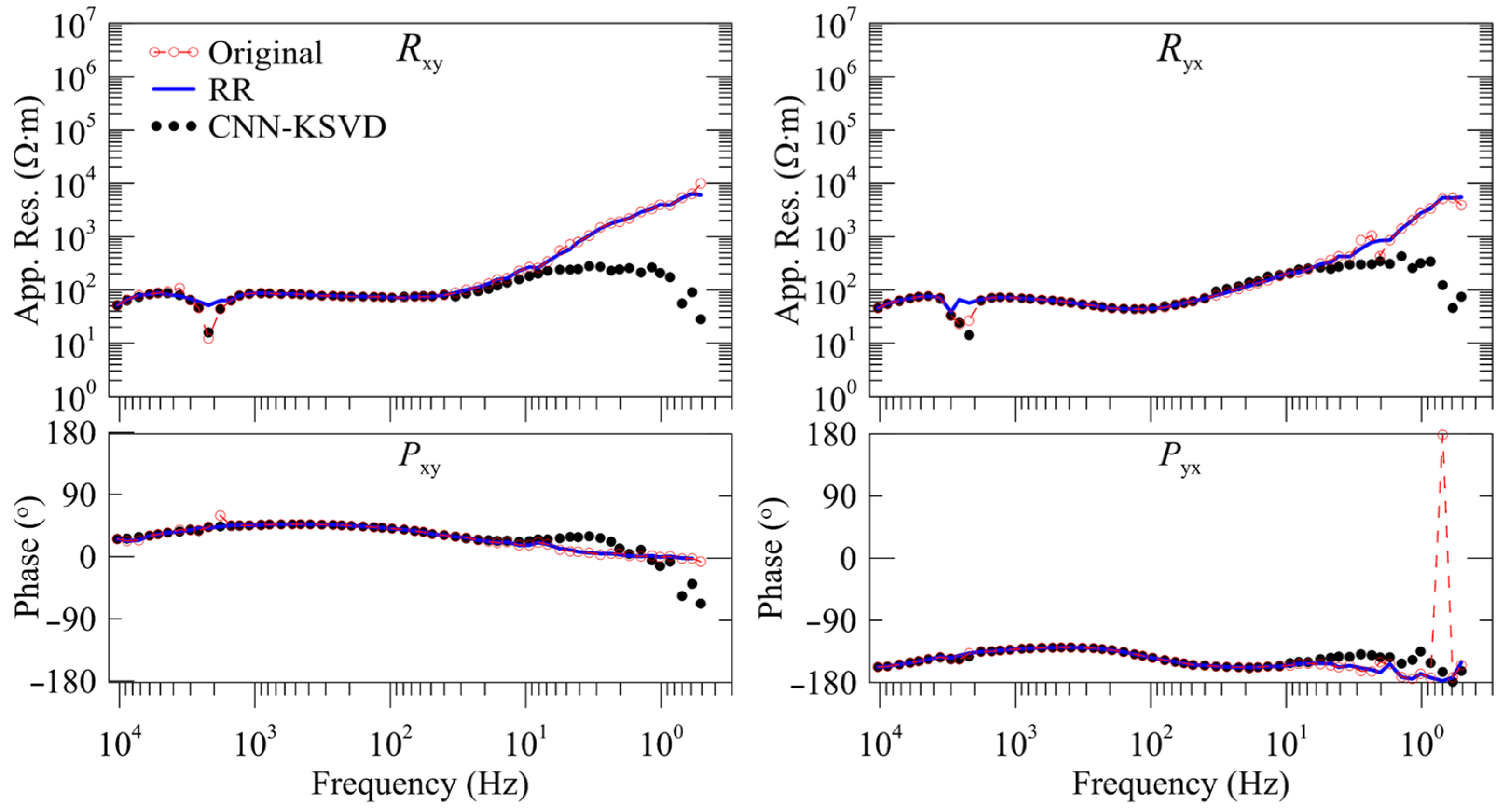
4.2. MT Response Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tikhonov, A.N. On determining electrical characteristics of the deep layers of the Earth’s crus. Dokl. Akad. Nauk 1950, 73, 295–297. [Google Scholar]
- Cagniard, L. Basic theory of the magnetotelluric method of geophysical prospecting. Geophysics 1953, 18, 605–635. [Google Scholar] [CrossRef]
- Yu, N.; Unsworth, M.; Wang, X.; Li, D.; Wang, E.; Li, R.; Hu, Y.; Cai, X. New insights into crustal and mantle flow beneath the Red River Fault zone and adjacent areas on the southern margin of the Tibetan Plateau revealed by a 3D magnetotelluric study. J. Geophys. Res. Solid Earth 2020, 125, e2020JB019396. [Google Scholar] [CrossRef]
- Li, R.H.; Yu, N.; Wang, X.B.; Liu, Y.; Cai, Z.K.; Wang, E.C. Model-Based Synthetic Geoelectric Sampling for Magnetotelluric Inversion With Deep Neural Networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4500514. [Google Scholar] [CrossRef]
- Xu, Y.X.; Zhang, Y.; Yang, B.; Bao, X.W. Phanerozoic evolution of lithospheric structures of the North China Craton. Geophys. Res. Lett. 2022, 49, e2022GL098341. [Google Scholar] [CrossRef]
- Simpson, F.; Bahr, K. Practical Magnetotellurics; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Jiang, F.; Chen, X.B.; Unsworth, M.J.; Cai, J.T.; Han, B.; Wang, L.F.; Dong, Z.Y.; Cui, T.F.; Zhan, Y.; Zhao, G.Z.; et al. Mechanism for the uplift of Gongga Shan in the southeastern Tibetan Plateau constrained by 3D magnetotelluric data. Geophys. Res. Lett. 2022, 49, e2021GL097394. [Google Scholar] [CrossRef]
- Giuseppe, M.G.D.; Troiano, A.; Patella, D. Separation of plain wave and near field contributions in Magnetotelluric time series: A useful criterion emerged during the Campi Flegrei (Italy) prospecting. J. Appl. Geophys. 2018, 156, 55–66. [Google Scholar] [CrossRef]
- Gamble, T.D.; Goubau, W.M.; Clarke, J. Magnetotellurics with a remote magnetic reference. Geophysics 1979, 44, 53–68. [Google Scholar] [CrossRef]
- Egbert, G.D.; Booker, J.R. Robust estimation of geomagnetic transfer functions. Geophys. J. Inter. 1986, 87, 173–194. [Google Scholar] [CrossRef]
- Egbert, G.D. Robust multiple-station magnetotelluric data processing. Geophys. J. Int. 1997, 130, 475–496. [Google Scholar] [CrossRef]
- Trad, D.O.; Travassos, J.M. Wavelet filtering of magnetotelluric data. Geophysics 2000, 65, 482–491. [Google Scholar] [CrossRef]
- Neukirch, M.; Garcia, X. Nonstationary magnetotelluric data processing with instantaneous parameter. J. Geophys. Res. Solid Earth 2014, 199, 1634–1654. [Google Scholar] [CrossRef]
- Li, G.; Liu, X.; Tang, J.; Deng, J.; Hu, S.; Zhou, C.; Chen, C.; Tang, W. Improved shift-invariant sparse coding for noise attenuation of magnetotelluric data. Earth Planets Space 2020, 72, 15. [Google Scholar] [CrossRef]
- Li, G.; Liu, X.; Tang, J.; Li, J.; Ren, Z.; Chen, C. De-noising low-frequency magnetotelluric data using mathematical morphology filtering and sparse representation. J. Appl. Geophys. 2020, 172, 103919. [Google Scholar] [CrossRef]
- Li, J.; Liu, X.Q.; Li, G.; Tang, J.T. Magnetotelluric Noise Suppression Based on Impulsive Atoms and NPSO-OMP Algorithm. Pure Appl. Geophys. 2020, 177, 5275–5297. [Google Scholar] [CrossRef]
- Zhou, R.; Han, J.T.; Guo, Z.Y.; Li, T.L. De-Noising of Magnetotelluric Signals by Discrete Wavelet Transform and SVD Decomposition. Remote Sens. 2021, 13, 4932. [Google Scholar] [CrossRef]
- Cai, J.H. A combinatorial filtering method for magnetotelluric data series with strong interference. Arab. J. Geosci. 2016, 9, 628. [Google Scholar]
- Li, G.; Xiao, X.; Tang, J.T.; Li, J.; Zhu, H.J.; Zhou, C.; Yan, F.B. Near-source noise suppression of AMT by compressive sensing and mathematical morphology filtering. Appl. Geophys. 2017, 14, 581–589. [Google Scholar] [CrossRef]
- Li, J.; Peng, Y.Q.; Tang, J.T.; Li, Y. Denoising of magnetotelluric data using K-SVD dictionary training. Geophys. Prospect. 2021, 69, 448–473. [Google Scholar] [CrossRef]
- Xue, S.Y.; Yin, C.C.; Su, Y.; Liu, Y.H.; Wang, Y.; Liu, C.H.; Xiong, B.; Sun, H.F. Airborne electromagnetic data denoising based on dictionary learning. Appl. Geophys. 2020, 17, 306–313. [Google Scholar] [CrossRef]
- Li, G.; He, Z.; Tang, J.T.; Deng, J.Z.; Liu, X.; Zhu, H.J. Dictionary learning and shift-invariant sparse coding denoising for controlled-source electromagnetic data combined with complementary ensemble empirical mode decomposition. Geophysics 2021, 86, E185–E198. [Google Scholar] [CrossRef]
- Zhang, P.; Pan, X.; Liu, J. Denoising Marine Controlled Source Electromagnetic Data Based on Dictionary Learning. Minerals 2022, 12, 682. [Google Scholar] [CrossRef]
- Jiang, Z.J.; Mallants, D.; Peeters, L.; Gao, L.; Mariethoz, G. High-resolution palaeovalley classification from airborne electromagnetic imaging and deep neural network training using digital elevation model data. Hydrol. Earth Syst. Sci. 2019, 23, 2561–2580. [Google Scholar] [CrossRef]
- Li, J.F.; Liu, Y.H.; Yin, C.C.; Ren, X.Y.; Su, Y. Fast imaging of time-domain airborne EM data using deep learning technology. Geophysics 2020, 85, E163–E170. [Google Scholar] [CrossRef]
- Moghadas, D. One-dimensional deep learning inversion of electromagnetic induction data using convolutional neural network. Geophys. J. Int. 2020, 222, 247–259. [Google Scholar] [CrossRef]
- Wu, X.; Xue, G.; He, Y.; Xue, J. Removal of the Multisource Noise in Airborne Electromagnetic Data Based on Deep Learning. Geophysics 2020, 85, B207–B222. [Google Scholar] [CrossRef]
- Wu, S.H.; Huang, Q.H.; Zhao, L. De-noising of transient electromagnetic data Based on the long short-term memory-autoencoder. Geophys. J. Int. 2021, 224, 669–681. [Google Scholar] [CrossRef]
- Zhang, L.; Ren, Z.Y.; Xiao, X.; Tang, J.T.; Li, G. Identification and Suppression of Magnetotelluric Noise via a Deep Residual Network. Minerals 2022, 12, 766. [Google Scholar] [CrossRef]
- Li, J.; Zhang, X.; Gong, J.; Tang, J.; Ren, Z.; Li, G.; Deng, Y.; Cai, J. Signal-noise identification of magnetotelluric signals using fractal-entropy and clustering algorithm for targeted de-noising. Fractals 2018, 26, 1840011. [Google Scholar] [CrossRef]
- Manoj, C.; Nagarajan, N. The application of artificial neural networks to magnetotelluric time-series analysis. Geophys. J. Int. 2003, 153, 409–423. [Google Scholar] [CrossRef]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar]
- Olshausen, B.A.; Field, D.J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607–609. [Google Scholar] [CrossRef] [PubMed]
- Engan, K.; Aase, S.O.; Husoy, J.H. Method of optimal directions for frame design. In Proceedings of the 1999 IEEE International Conference on Acoustics Speech, and Signal Processing, Phoenix, AZ, USA, 15–19 March 1999; pp. 2443–2446. [Google Scholar]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Tang, J.T.; Zhou, C.; Wang, X.Y.; Xiao, X.; Lu, Q.T. Deep electrical structure and geological significance of Tongling ore district. Tectonophysics 2013, 606, 78–96. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
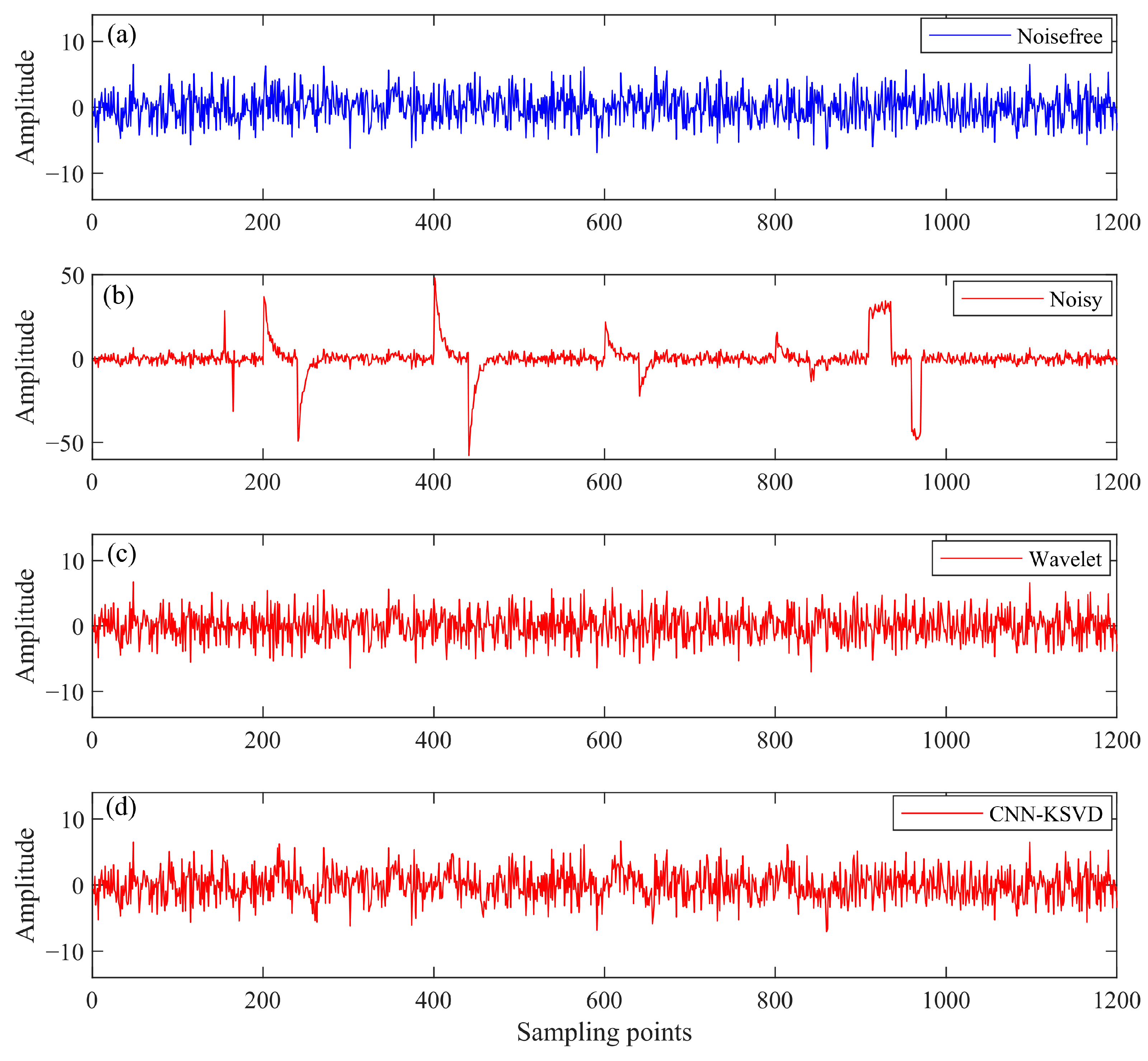
| Methods | SNR | MSE | NCC | RE |
|---|---|---|---|---|
| Noisy | −11.6127 | 8.6797 | 0.2366 | 3.8075 |
| Wavelet | 5.9044 | 1.1552 | 0.8673 | 0.5067 |
| CNN-KSVD | 8.2648 | 0.8803 | 0.9251 | 0.3862 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Gu, X.; Ren, Z.; Wu, Q.; Liu, X.; Zhang, L.; Xiao, D.; Zhou, C. Deep Learning Optimized Dictionary Learning and Its Application in Eliminating Strong Magnetotelluric Noise. Minerals 2022, 12, 1012. https://doi.org/10.3390/min12081012
Li G, Gu X, Ren Z, Wu Q, Liu X, Zhang L, Xiao D, Zhou C. Deep Learning Optimized Dictionary Learning and Its Application in Eliminating Strong Magnetotelluric Noise. Minerals. 2022; 12(8):1012. https://doi.org/10.3390/min12081012
Chicago/Turabian StyleLi, Guang, Xianjie Gu, Zhengyong Ren, Qihong Wu, Xiaoqiong Liu, Liang Zhang, Donghan Xiao, and Cong Zhou. 2022. "Deep Learning Optimized Dictionary Learning and Its Application in Eliminating Strong Magnetotelluric Noise" Minerals 12, no. 8: 1012. https://doi.org/10.3390/min12081012
APA StyleLi, G., Gu, X., Ren, Z., Wu, Q., Liu, X., Zhang, L., Xiao, D., & Zhou, C. (2022). Deep Learning Optimized Dictionary Learning and Its Application in Eliminating Strong Magnetotelluric Noise. Minerals, 12(8), 1012. https://doi.org/10.3390/min12081012