
Reducing the Dimensions of the Stochastic Programming Problems of Metallurgical Design Procedures


Abstract
:1. Introduction
2. Methods
2.1. Modern Design of Experiments (MDoE)
2.2. Supervised Machine Learning (SML)
2.3. Global Sensitivity Analysis (GSA)
2.4. Generic Framework to Reduce the Uncertainty Space
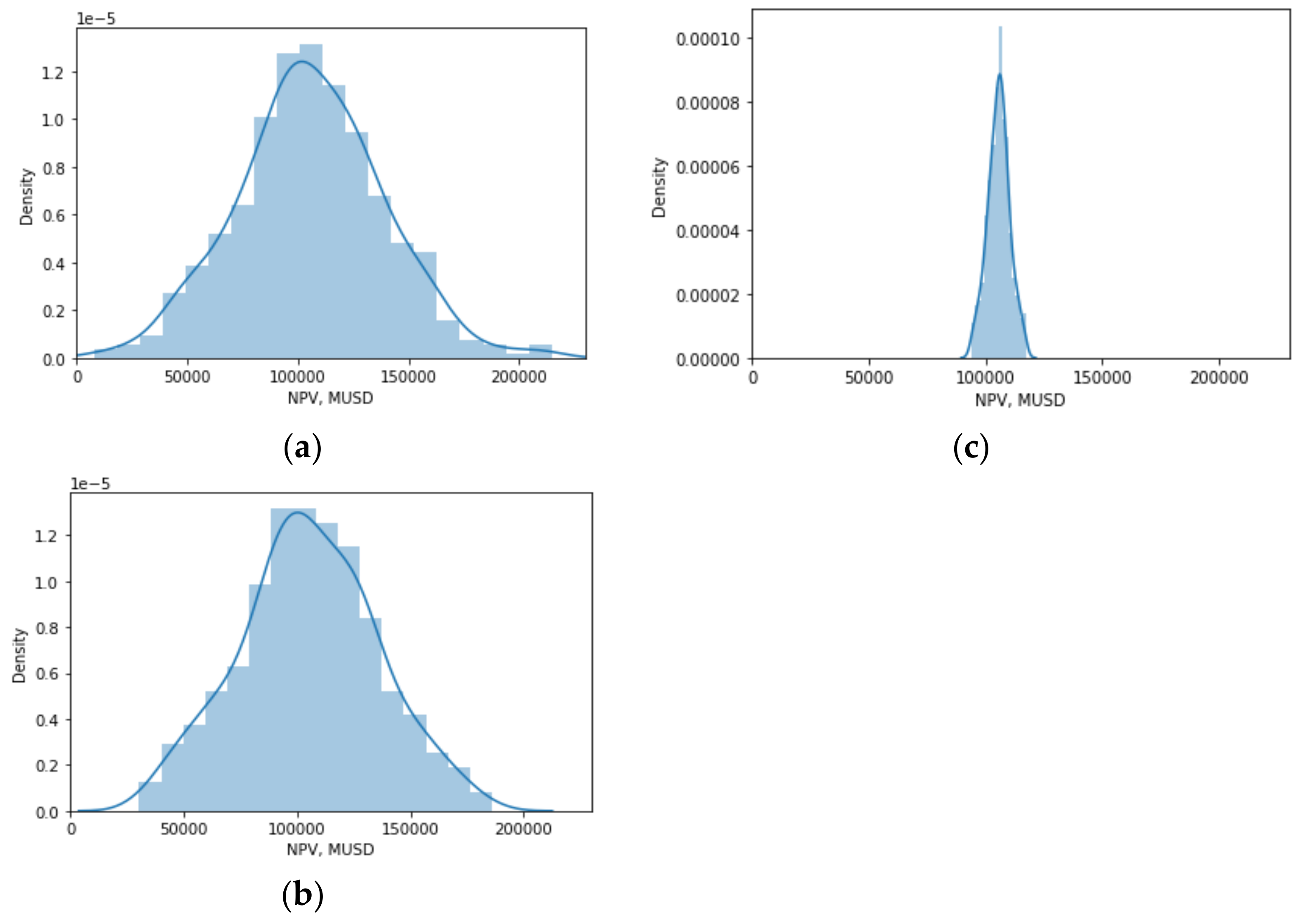
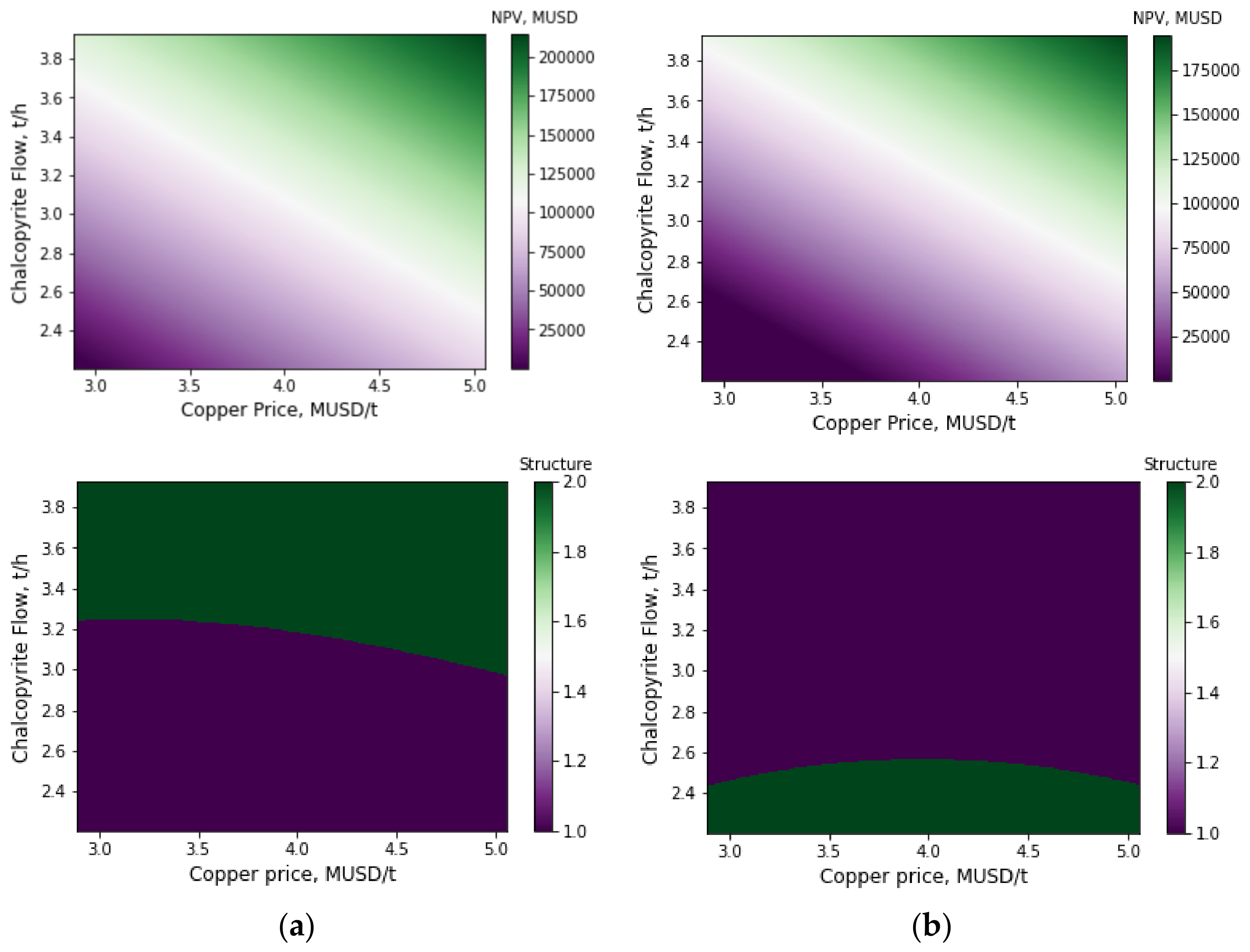
3. Applications
4. Conclusions
Supplementary Materials
Funding
Conflicts of Interest
References
- Calisaya, D.A.; López-Valdivieso, A.; de la Cruz, M.H.; Gálvez, E.E.; Cisternas, L.A. A strategy for the identification of optimal flotation circuits. Miner. Eng. 2016, 96, 157–167. [Google Scholar] [CrossRef]
- Sassi, K.M.; Mujtaba, I.M. Effective design of reverse osmosis based desalination process considering wide range of salinity and seawater temperature. Desalination 2012, 306, 8–16. [Google Scholar] [CrossRef]
- Herrera-León, S.; Lucay, F.A.; Cisternas, L.A.; Kraslawski, A. Applying a multi-objective optimization approach in designing water supply systems for mining industries. The case of Chile. J. Clean. Prod. 2019, 210, 994–1004. [Google Scholar] [CrossRef]
- Hernández, I.F.; Ordóñez, J.I.; Robles, P.A.; Gálvez, E.D.; Cisternas, L.A. A Methodology for Design and Operation of Heap Leaching Systems. Miner. Process. Extr. Metall. Rev. 2017, 38, 180–192. [Google Scholar] [CrossRef]
- Gálvez, E.D.; Vega, C.A.; Swaney, R.E.; Cisternas, L.A. Design of solvent extraction circuit schemes. Hydrometallurgy 2004, 74, 19–38. [Google Scholar] [CrossRef]
- Sahinidis, N.V. Optimization under uncertainty: State-of-the-art and opportunities. In Computers and Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Jamett, N.; Cisternas, L.A.; Vielma, J.P. Solution strategies to the stochastic design of mineral flotation plants. Chem. Eng. Sci. 2015, 134, 850–860. [Google Scholar] [CrossRef] [Green Version]
- Liang, Y.; He, D.; Su, X.; Wang, F. Fuzzy distributional robust optimization for flotation circuit configurations based on uncertainty theories. Miner. Eng. 2020, 156, 106433. [Google Scholar] [CrossRef]
- Liang, Y.; He, D.; Wang, Q.; Lu, X. Fuzzy distributional chance-constrained programming for handling stochastic and epistemic uncertainties during flotation processes. Chem. Eng. Res. Des. 2020, 164, 248–260. [Google Scholar] [CrossRef]
- Cisternas, L.A.; Jamett, N.; Gálvez, E.D. Approximate recovery values for each stage are sufficient to select the concentration circuit structures. Miner. Eng. 2015, 83, 175–184. [Google Scholar] [CrossRef]
- Acosta-Flores, R.; Lucay, F.A.; Gálvez, E.D.; Cisternas, L.A. The effect of regrinding on the design of flotation circuits. Miner. Eng. 2020, 156, 106524. [Google Scholar] [CrossRef]
- Lucay, F.; Mellado, M.E.; Cisternas, L.A.; Gálvez, E.D. Sensitivity analysis of separation circuits. Int. J. Miner. Process. 2012, 110–111, 30–45. [Google Scholar] [CrossRef]
- Sepúlveda, F.D.; Cisternas, L.A.; Gálvez, E.D. The use of global sensitivity analysis for improving processes: Applications to mineral processing. Comput. Chem. Eng. 2014, 66, 221–232. [Google Scholar] [CrossRef]
- Sutton, R.R.S. Generalization in Reinforcement Learning: Successful Examples Using Sparse Coarse Coding. In Advances in Neural Information Processing Systems 8; MIT Press: Cambridge, MA, USA, 1996; pp. 1038–1044. [Google Scholar]
- Vollmer, N.I.; Al, R.; Sin, G. Benchmarking of Surrogate Models for the Conceptual Process Design of Biorefineries. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2021; Volume 50, pp. 475–480. [Google Scholar]
- Pedrozo, H.A.; Rodriguez Reartes, S.B.; Chen, Q.; Diaz, M.S.; Grossmann, I.E. Surrogate-model based MILP for the optimal design of ethylene production from shale gas. Comput. Chem. Eng. 2020, 141, 107015. [Google Scholar] [CrossRef]
- Jones, M.; Forero-Hernandez, H.; Zubov, A.; Sarup, B.; Sin, G. Superstructure Optimization of Oleochemical Processes with Surrogate Models. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2018; Volume 44, pp. 277–282. [Google Scholar]
- Xia, Z.; Wang, S.; Zhou, L.; Dai, Y.; Dang, Y.; Ji, X. Surrogate-assisted optimization of refinery hydrogen networks with hydrogen sulfide removal. J. Clean. Prod. 2021, 310, 127477. [Google Scholar] [CrossRef]
- Ning, C.; You, F. Optimization under uncertainty in the era of big data and deep learning: When machine learning meets mathematical programming. Comput. Chem. Eng. 2019, 125, 434–448. [Google Scholar] [CrossRef] [Green Version]
- Azzi, S. Surrogate Modelig of Stochastic Simulators. Ph.D. Thesis, Institut Polytechnique de Paris, Palaiseau, France, 4 June 2020. [Google Scholar]
- Kim, S.H.; Boukouvala, F. Machine learning-based surrogate modeling for data-driven optimization: A comparison of subset selection for regression techniques. Optim. Lett. 2020, 14, 989–1010. [Google Scholar] [CrossRef]
- Asher, M.J.; Croke, B.F.W.; Jakeman, A.J.; Peeters, L.J.M. A review of surrogate models and their application to groundwater modeling. Water Resour. Res. 2015, 51, 5957–5973. [Google Scholar] [CrossRef]
- Sun, X.Y.; Gong, D.; Li, S. Classification and regression-based surrogate model-assisted interactive genetic algorithm with individual’s fuzzy fitness. In Proceedings of the 11th Annual Genetic and Evolutionary Computation Conference, GECCO-2009, Montreal, QC, Canada, 8–12 July 2009; pp. 907–914. [Google Scholar]
- Gianey, H.K.; Choudhary, R. Comprehensive Review on Supervised Machine Learning Algorithms. In Proceedings of the 2017 International Conference on Machine Learning and Data Science, MLDS 2017, Noida, India, 14–15 December 2017; Volume 2018, pp. 38–43. [Google Scholar]
- Saltelli, A. Making best use of model evaluations to compute sensitivity indices. Comput. Phys. Commun. 2002, 145, 280–297. [Google Scholar] [CrossRef]
- Lucay, F.A.; Cisternas, L.A.; Gálvez, E.D. An LS-SVM classifier based methodology for avoiding unwanted responses in processes under uncertainties. Comput. Chem. Eng. 2020, 138, 106860. [Google Scholar] [CrossRef]
- Cisternas, L.A.; Lucay, F.; Gálvez, E.D. Effect of the objective function in the design of concentration plants. Miner. Eng. 2014, 63, 16–24. [Google Scholar] [CrossRef]
- Yianatos, J.B.; Henríquez, F.D. Short-cut method for flotation rates modelling of industrial flotation banks. Miner. Eng. 2006, 19, 1336–1340. [Google Scholar] [CrossRef]
- Komer, B.; Bergstra, J.; Eliasmith, C. Hyperopt-Sklearn: Automatic Hyperparameter Configuration for Scikit-Learn. In Proceedings of the 13th Python in Science Conference, Austin, TX, USA, 6–12 July 2014; pp. 32–37. [Google Scholar]
- Bashir, D.; Montañez, G.D.; Sehra, S.; Segura, P.S.; Lauw, J. An Information-Theoretic Perspective on Overfitting and Underfitting. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Chanberra, Australia, 29–30 November; pp. 347–358.
- Seasholtz, M.B.; Kowalski, B. The parsimony principle applied to multivariate calibration. Anal. Chim. Acta 1993, 277, 165–177. [Google Scholar] [CrossRef]
- Pianosi, F.; Beven, K.; Freer, J.; Hall, J.W.; Rougier, J.; Stephenson, D.B.; Wagener, T. Sensitivity analysis of environmental models: A systematic review with practical workflow. Environ. Model. Softw. 2016, 79, 214–232. [Google Scholar] [CrossRef]
- Ballantyne, G.R.; Powell, M.S.; Tiang, M. Proportion of energy attributable to comminution. In Proceedings of the 1th Australasian Institute of Mining and Metallurgy Mill Operator’s Conference, Hobart, Australia, 29–31 October 2012; pp. 25–30. [Google Scholar]
- Silva, M.; Casali, A. Modelling SAG milling power and specific energy consumption including the feed percentage of intermediate size particles. Miner. Eng. 2015, 70, 156–161. [Google Scholar] [CrossRef]

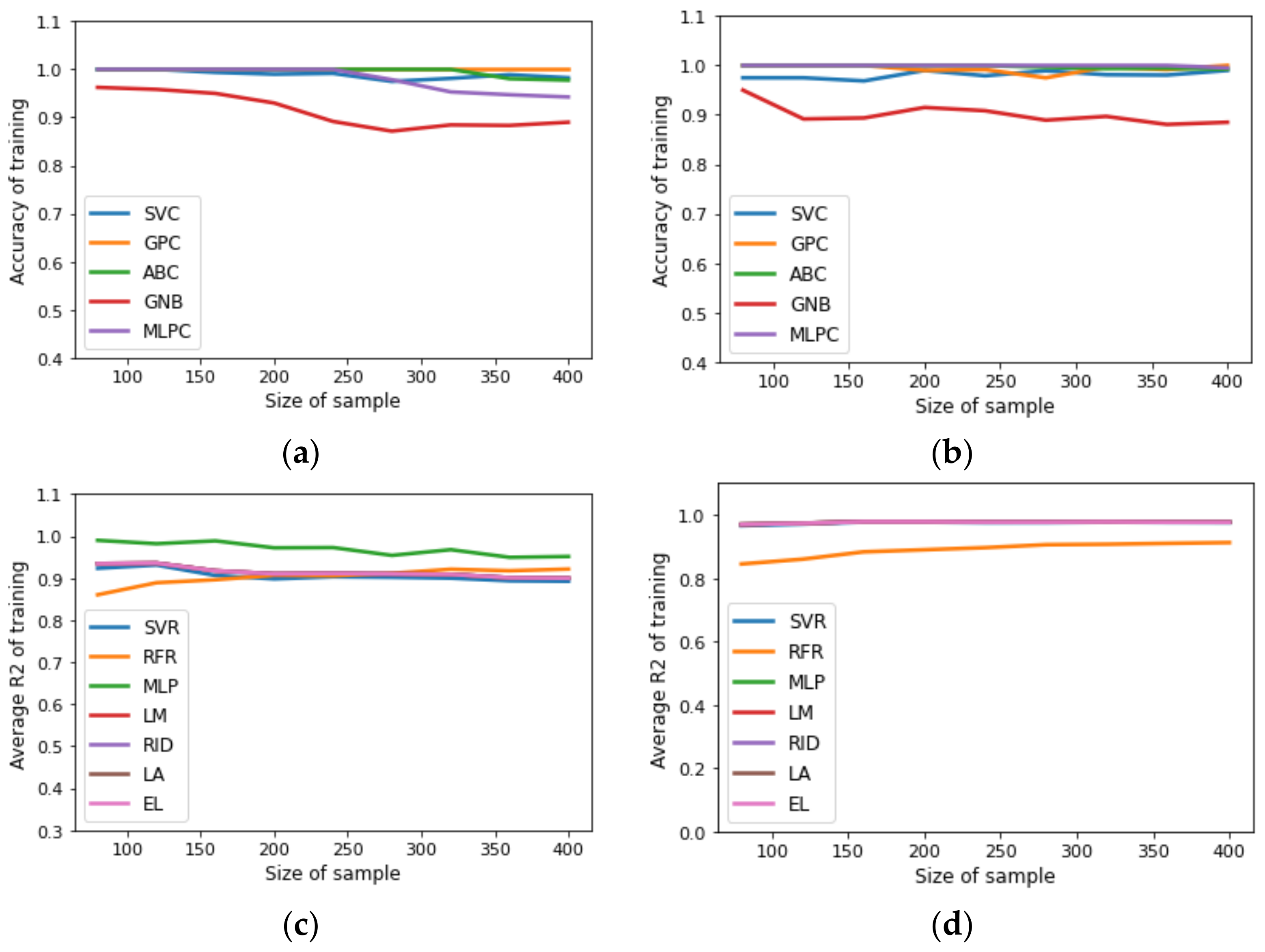
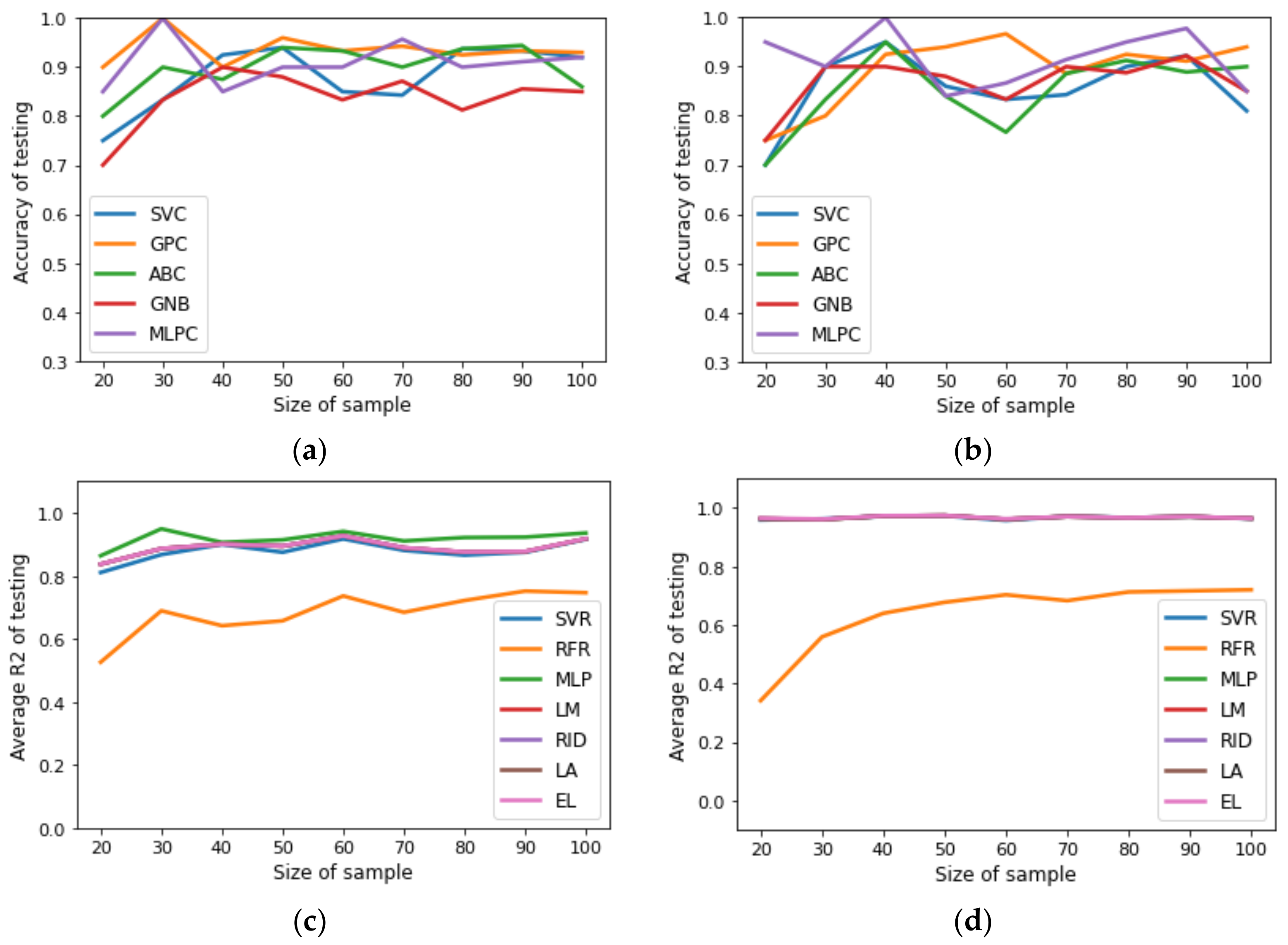
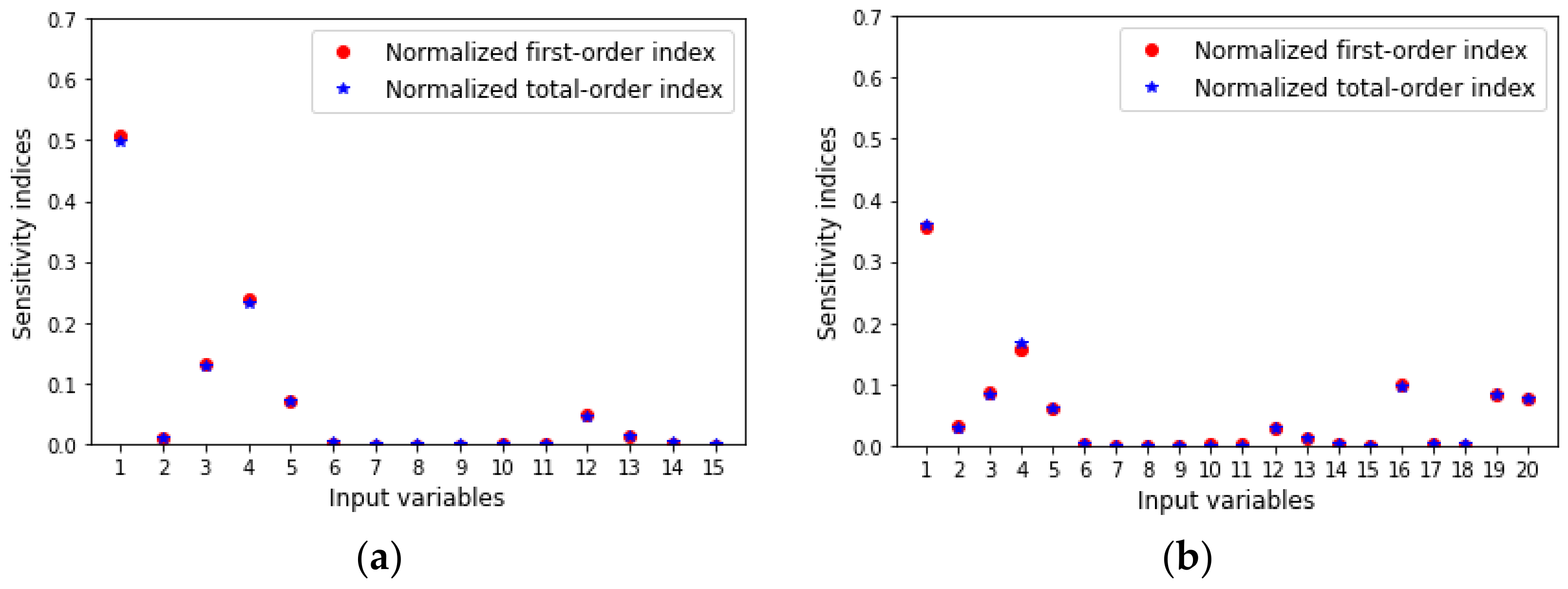
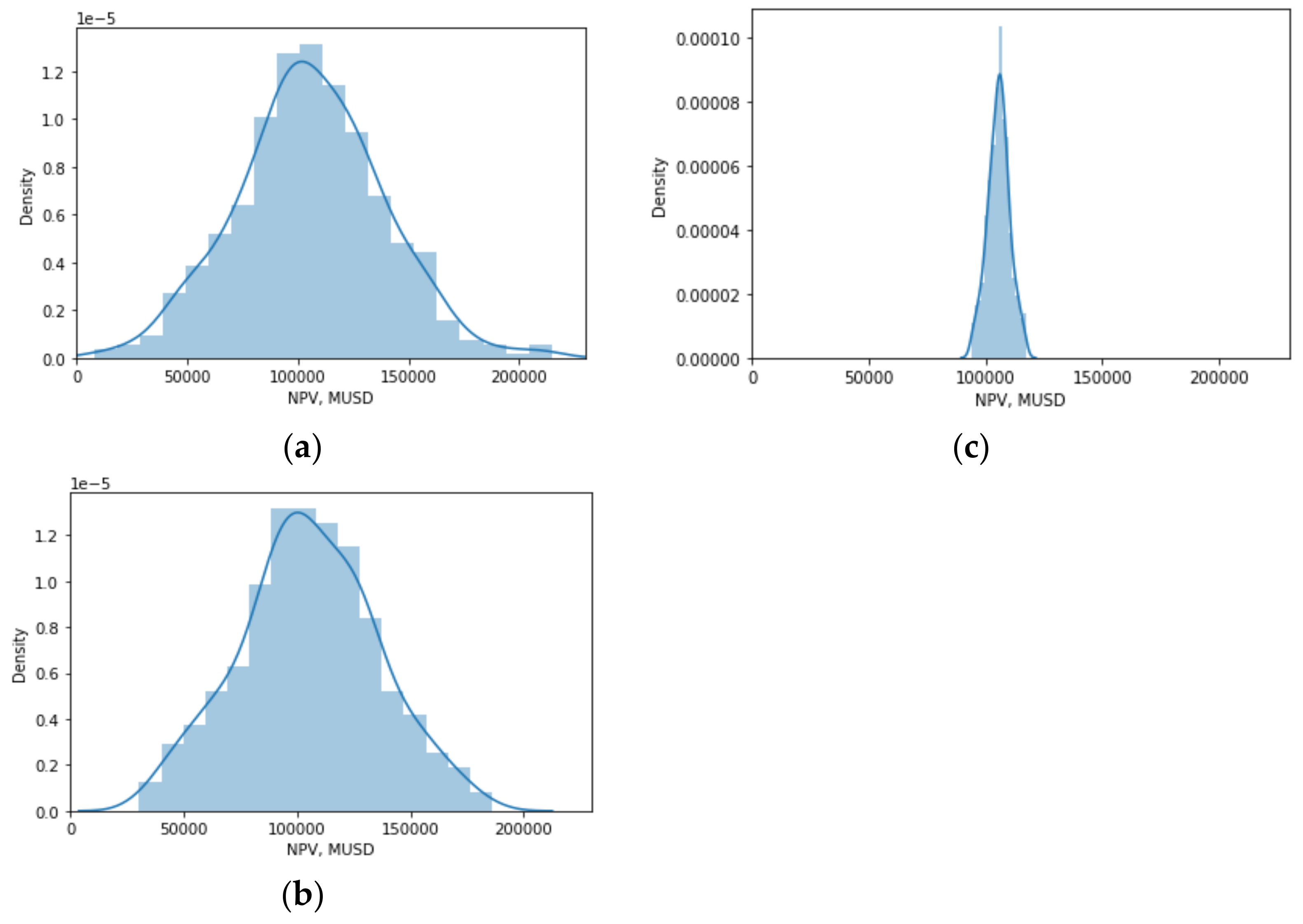
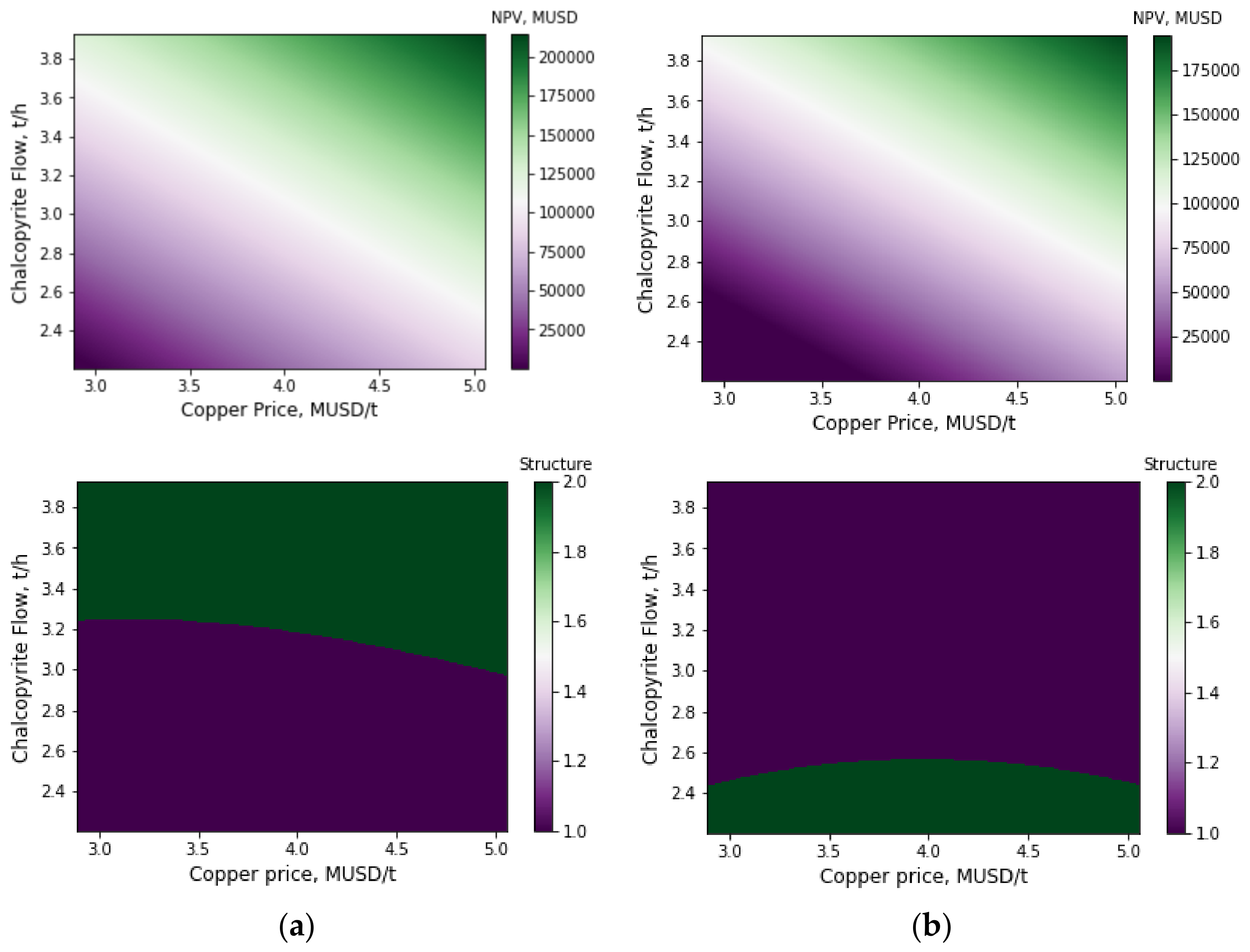

{kind=link}
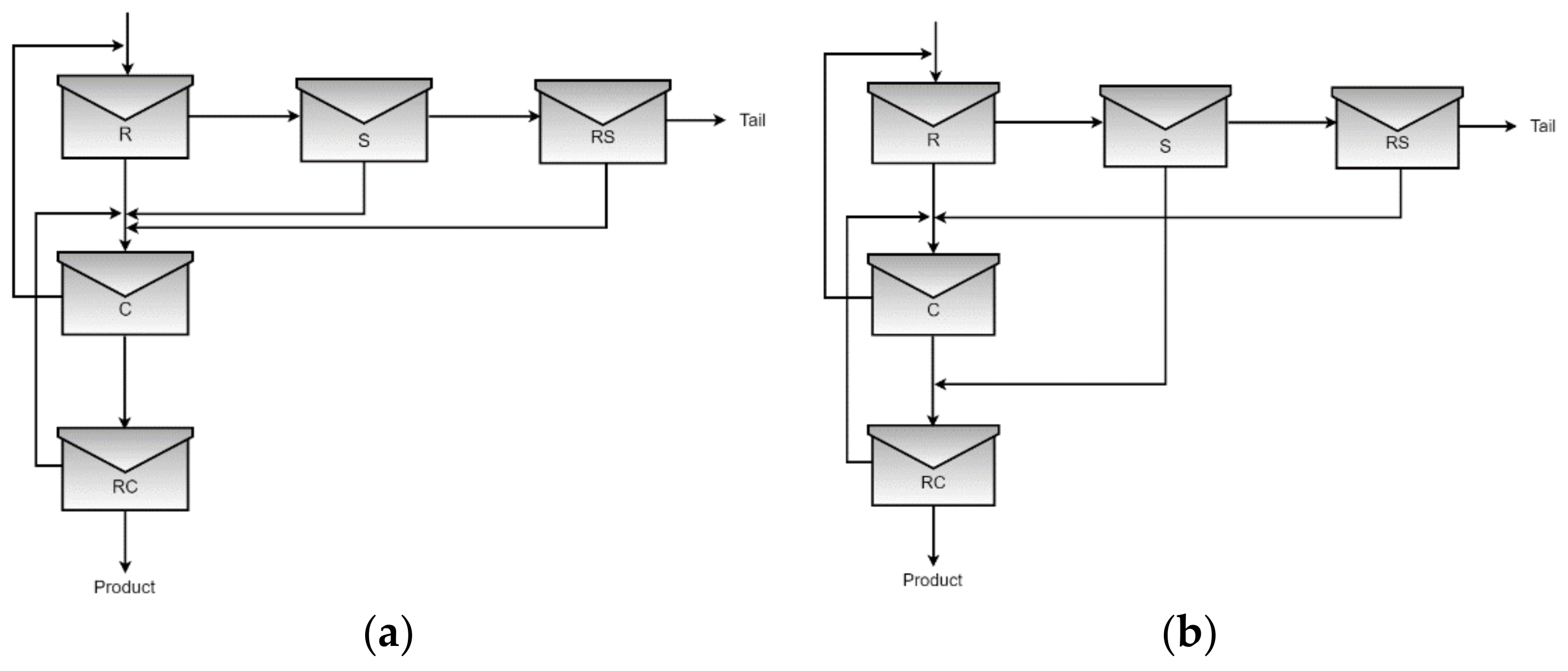
{kind=link}
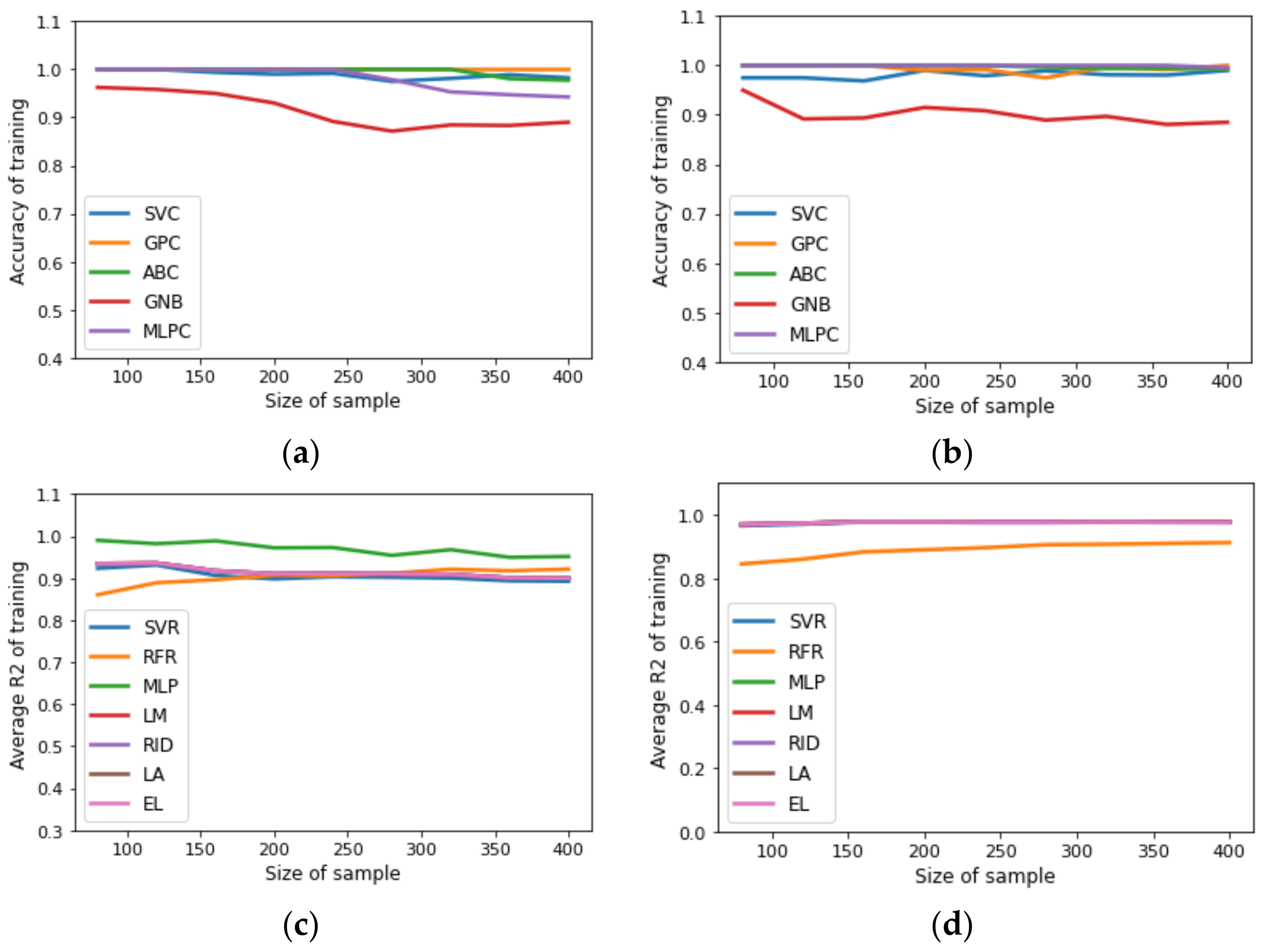
{kind=link}
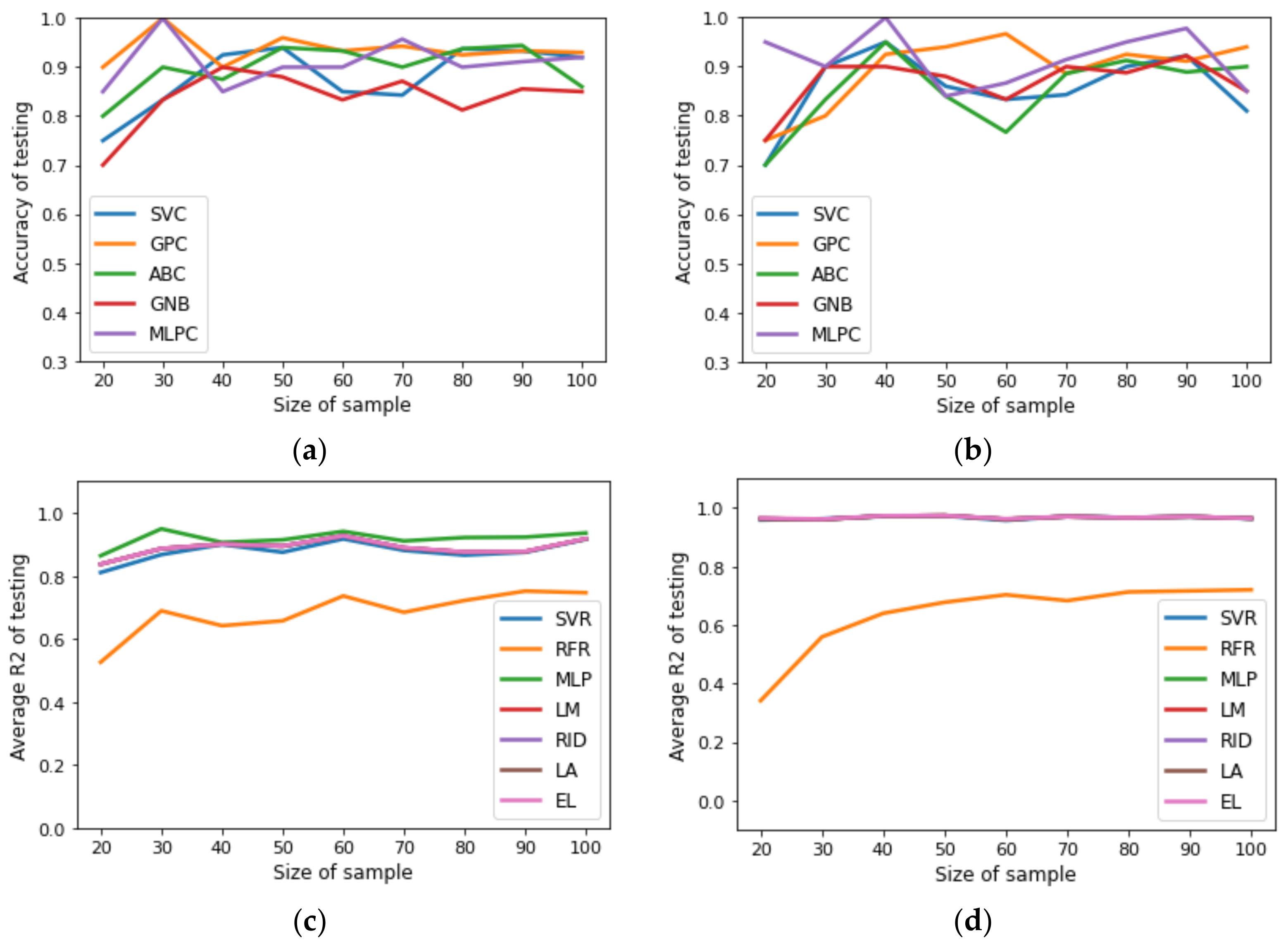
{kind=link}
{kind=link}
{kind=link}
| Input Variable | Standard Condition | Uncertainty |
|---|---|---|
| Copper price (1) | 4 MUSD/t | [4,0.3] |
| Kilowatt-hours (2) | 0.0002 MUSD | [0.0002,0.00002] |
| Cost of mine-crushing-grinding per ton of ore fed to plant (3) | 0.003 MUSD/t | [0.003,0.0004] |
| Chalcopyrite fast mass flux fed (4) | 3 t/h, | [3,0.3] |
| Chalcopyrite slow mass flux fed (5) | 2 t/h | [2,0.3] |
| Chalcocite fast mass flux fed (6) | 1 t/h | [1,0.1] |
| Chalcocite slow mass flux fed (7) | 1 t/h | [0.4,0.04] |
| Pyrite fast mass flux fed (8) | 5 t/h | [5,0.2] |
| Pyrite slow mass flux fed (9) | 3.5 t/h | [3.5,0.3] |
| Quartz mass flux fed (10) | 150 t/h | [150,3] |
| Gangue mass flux fed (11) | 300 t/h | [300,3] |
| Chalcopyrite fast copper grade fed (12) | 34% | [0.34.0.01] |
| Chalcopyrite slow copper grade fed (13) | 25% | [0.25,0.01] |
| Chalcocite fast copper grade fed (14) | 18% | [0.18,0.01] |
| Chalcocite slow copper grade fed (15) | 10% | [0.1,0.01] |
| Number of cells in the rougher stage (16) | 5 | [3,10] |
| Number of cells in the cleaner stage (17) | 5 | [3,10] |
| Number of cells in the recleaner stage (18) | 5 | [3,10] |
| Number of cells in the scavenger stage (19) | 5 | [3,10] |
| Number of cells in the rescavenger stage (20) | 5 | [3,10] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lucay, F.A. Reducing the Dimensions of the Stochastic Programming Problems of Metallurgical Design Procedures. Minerals 2021, 11, 1302. https://doi.org/10.3390/min11121302
Lucay FA. Reducing the Dimensions of the Stochastic Programming Problems of Metallurgical Design Procedures. Minerals. 2021; 11(12):1302. https://doi.org/10.3390/min11121302
Chicago/Turabian StyleLucay, Freddy A. 2021. "Reducing the Dimensions of the Stochastic Programming Problems of Metallurgical Design Procedures" Minerals 11, no. 12: 1302. https://doi.org/10.3390/min11121302
APA StyleLucay, F. A. (2021). Reducing the Dimensions of the Stochastic Programming Problems of Metallurgical Design Procedures. Minerals, 11(12), 1302. https://doi.org/10.3390/min11121302