Abstract
Ore hardness plays a critical role in comminution circuits. Ore hardness is usually characterized at sample support in order to populate geometallurgical block models. However, the required attributes are not always available and suffer for lack of temporal resolution. We propose an operational relative-hardness definition and the use of real-time operational data to train a Long Short-Term Memory, a deep neural network architecture, to forecast the upcoming operational relative-hardness. We applied the proposed methodology on two SAG mill datasets, of one year period each. Results show accuracies above 80% on both SAG mills at a short upcoming period of times and around 1% of misclassifications between soft and hard characterization. The proposed application can be extended to any crushing and grinding equipment to forecast categorical attributes that are relevant to downstream processes.
1. Introduction
In mining operations, the primary energy consumer is the comminution system, responsible for more than half of the entire mine consumption [1]. From all pieces of equipment that integrate the comminution circuit, the semi-autogenous grinding mill (SAG) is perhaps the most important in the system. With an aspect ratio of 2:1 (diameter to length), these mills combine impact, attrition and abrasion to reduce the ore size. SAG mills are located at the beginning of the comminution circuits, after a primary crushing stage. Although there are small SAG mills, their size usually ranges from 9.8 × 4.3 to 12.8 × 7.6 m, with a nominal energy demand of 8.2 and 26 MW, respectively [2], which make SAG mills the most relevant energy consumer within the concentrator. Modelling their consumption behaviour supports the operational control and energy demand-side management [3].
Most theoretical and empirical models [4,5,6] demand input feed characteristics, such as hardness, size distribution and inflow rate, SAG characteristics, such as sizing and product size distribution, and operational variables such as bearing pressure, water addition and grinding charge level. Although they are suitable to provide adequate design guidelines, they lack accurate in-situ inference since most assume steady-state and isolation from up and downstream processes. In response, model predictive control, SAG MPC [7], combines those methods with real-time operational information. However, expert knowledge is required to model the SAG mill dynamics properly.
From a geometallurgical perspective, the integration of new predictive methods that account for space and time relationships over real-time attributes has been defined as a fundamental challenge [8,9] in mining operations, particularly in an integrated system such as comminution. In response, data-driven approaches have been proposed ranging from support vector machines [10] and gene expression programming [11] to hybrid models that combine genetic algorithms and neural networks [12] and recurrent neural networks [13]. As data-driven methods are sensitive to the context (available information) and representation (information workflow), the authors have studied the use of several machine learning and deep learning methods in modelling the SAG energy consumption behaviour based only on operational variables [14].
The energy consumed by a SAG mill is related to several factors such as expert operator decisions, charge volume, charge specific gravity and the hardness of the feed material. Knowing the output hardness material becomes relevant for the downstream stage in the primary grinding circuit. Ore hardness can be characterized at sample support by combining the logged geological properties and the result of standardized comminution tests. They can be used to predict the hardness of each block sent to the process. However, these attributes are not always available. In response, a qualitative characterization of the ore hardness processed at time t, relative to the operational hardness of the ore processed at time can be done using only operational variables rather than a set of mineralogical characterizations. This qualitative characterization is referred and here used as operational relative-hardness (ORH).
We take advantage of previous works [14] by knowing that the Long Short-Term Memory (LSTM) [15] outperforms other machine learning and deep learning techniques on inferring the SAG mill energy consumption. Therefore, Section 2 presents the ORH and LSTM models, Section 3 establishes the SAG mill experimental framework, the results of which are presented in Section 4, and conclusions are drawn in Section 5.
2. Model
2.1. Operational Relative-Hardness Criteria
From the several operational parameters that can be captured and associated to SAG mill operations, we consider the energy consumption (EC) and feed tonnage (FT) to build our operational relative-hardness criteria.
{EC,FT is collected over a period of time T using a discretization. By considering the one-step forward time difference of energy consumption (ECECEC) and feed tonnage ( FT = FTFT), a qualitative assessment of the operational relative-hardness can be done. For instance, if the energy consumption is increasing and the feed tonnage is constant, it can be interpreted as an increase in ore hardness relative to the previous period. Similarly, if the feed tonnage is constant and the energy decreases, a decrease in ore hardness relative to the previous period can be assumed. Particularly, when both EC and FT show the same behaviour, the SAG can be either processing ore with medium operational relative-hardness or being filled up or emptied. To avoid misclassification in this last case, the operational relative-hardness is labelled as undefined. Table 1 summarizes the nine combinations of states and the associated operational relative-hardness.

Table 1.
Operational relative-hardness criteria based on one time-step difference of energy consumption and feed tonnage.
The qualitative labelling of EC and FT as increasing, constant or decreasing can be established based on their global distribution over the period T as:
where and represent the standard deviations over the period T of and , respectively, and is a scalar value that modulates the labelling distribution. Note that (i) a value above 1.5 would make the entire definition meaningless since most values would remain as constant, and (ii) the value definition is an external model parameter and can be guided either subjectively or via statistical meaning.
2.2. Long Short-Term Memory
The Long Short-Term Memory (LSTM) [15] neural network architecture belongs to the family of recurrent neural networks in Deep Learning [16]. They are suitable to capture short and long term relationships in temporal datasets. Internally, LSTM applies several combinations of affine transformations, element-wise multiplications and non-linear transfer functions, for which the building blocks are:
- : input vector at time t. Dimension .
- , , : weight matrices for . Dimensions .
- : hidden state at time t. Dimension .
- , , : weight matrices for . Dimensions .
- , , : bias vectors. Dimensions .
- : weight matrix for as output. Dimension .
- : bias vector for output. Dimension .
where m is the number of variables as input, K is the number of output variables, and is the number of hidden units. Let be a temporal window. At each time , the LSTM receives the input , the previous hidden state and previous memory cell . The forget gate is the permissive barrier of the information carried by . The input gate decides the relevance of the information carried by . Note that both and use sigmoid as the activation function over a linear combination of and .
By passing the combination of and through a Tanh function, a candidate memory cell is computed. The final memory cell is computed as a sum of (i) what to forget from the past memory cell as an element-wise multiplication (⊙) between and , and (ii) what to learn from the candidate memory cell as an element-wise multiplication (⊙) between and .
Similar to and the output gate passes through a sigmoid function a linear combination between and . It controls the information passing from the current memory cell to the final hidden state as an element-wise multiplication between and . At the final step , the output is computed as . When dealing with more than one categorical prediction (), as in the present work for ORH forecasting, a softmax function is applied over to obtain the normalized probability distribution, and the category k has a probability of .
An illustrative scheme of the internal connection at time step t inside an LSTM is shown in Figure 1 (left). The ORH prediction has three categories (hard, soft and undefined) and the probability is computed at the last unit, at time step , as shown in the unrolled LSTM in Figure 1 (right).
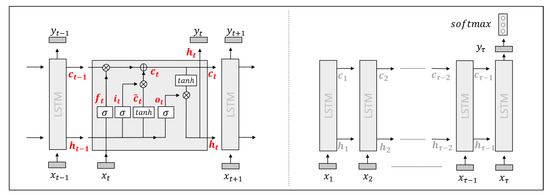
Figure 1.
Schemes. Information flow inside Long Short-Term Memory (LSTM) (left) and unrolled LSTM where the output is computed at the last recurrence (right).
3. Experiment
3.1. Dataset
We used two datasets containing operational data for two independent SAG mills every half hour over a total time of 340 and 331 days, respectively. Each one of the SAG mills receives fresh feed and is connected in an open circuit configuration (SABC-B) where the pebble crusher product is sent to ball mills. At each time t, the dataset contains Feed tonnage (FT) (ton/h), Energy consumption (EC) (kWh), Bearing pressure (BPr) (psi) and Spindle speed (SSp) (rpm). They are split into two main subsets (a validation dataset is not considered since the optimum LSTM architecture to train is drawn from previous work [14]): training and testing (Table 2). This is an arbitrary division, and we seek to have a proportion of ∼50/50, respectively.
Table 2.
Summary statistics over training testing dataset on semi-autogenous grinding mill (SAG) mills.
As it can be seen in Table 2, the predictive methods are trained with the first 50% and tested with the upcoming 50%, without being fed with the previous 50% of historical data.
Note that the comminution properties of the ore, such as or BWi, are not included in the datasets; therefore, the relationship between forecasted ORH and comminution properties is not explored in this work. The results herein presented, however, serve as a basis to examine such a relationship if those properties were known.
3.2. Assumptions
SAG mills are fundamental pieces in comminution circuits. As no information regarding downstream/upstream processes is available, recognizing bottlenecks in the dataset becomes subjective. We assume that SAG mills will potentially show changes from steady-state to under capacity and vice versa along with the dataset. Thus, stationarity of all operational variable distributions is assumed throughout this work, including the ore grindability. It means that the entire dataset belongs to a known and planned combination of ore characteristics (geometallurgical units). By doing so, we limit the applicability of the present models beyond the temporal dataset without a proper training process.
As explained in the problem statement section, we make use of the temporal average over energy consumption and feed tonnage as input for operational hardness prediction. Thus, we assume an additivity property over those variables as their units are kWh and ton/h, respectively, over constant temporal discretization so averaging adjacent data points is mathematically consistent.
In the operation from which the datasets were obtained, the SAG mill liners are replaced every 5–7 months. Since the datasets cover almost a year, we can ensure that the liners were replaced in each SAG mill at least once during the tested period, which may alter the relationship between energy consumption and other operational variables, inducing a discontinuity in the temporal plots. However, since in this work the temporal window for ORH evaluation is eight hours, the local discontinuity associated with liners replacement is not expected to affect the forecast at that time frame. The ORH is related to what was happening in the corresponding mill within the last few hours, and not to the mill behaviour prior to the last replacement of liners.
3.3. Problem Statement
The aim is to forecast the operational relative-hardness. To do so, we need to label the datasets with the associated ORH category at data point. We know from Equation (1) that the ORH labelling process requires as input (i) the one-step forward differences on energy consumption () and feed tonnage (), and (ii) a lambda () value. In addition, we are interested in forecasting the ORH at different time supports.
Since the information is collected every 30 min, the upcoming energy consumption EC and feed tonnage FT at 0.5 h support are denoted simply as EC and FT in reference to EC and FT, respectively. An upcoming EC and FT at 1 h support, EC and FT, are computed by averaging the next two energy consumption, EC and EC, and the two feed tonnage, FT and FT. Similarly, by averaging the upcoming ECs and FTs, different supports can be computed. Let be the time support in hours, which represents the average over a temporal interval of a given duration, then EC and FT are calculated as:
In this experiment, three different supports () are considered: 0.5, 2 and 8 h.
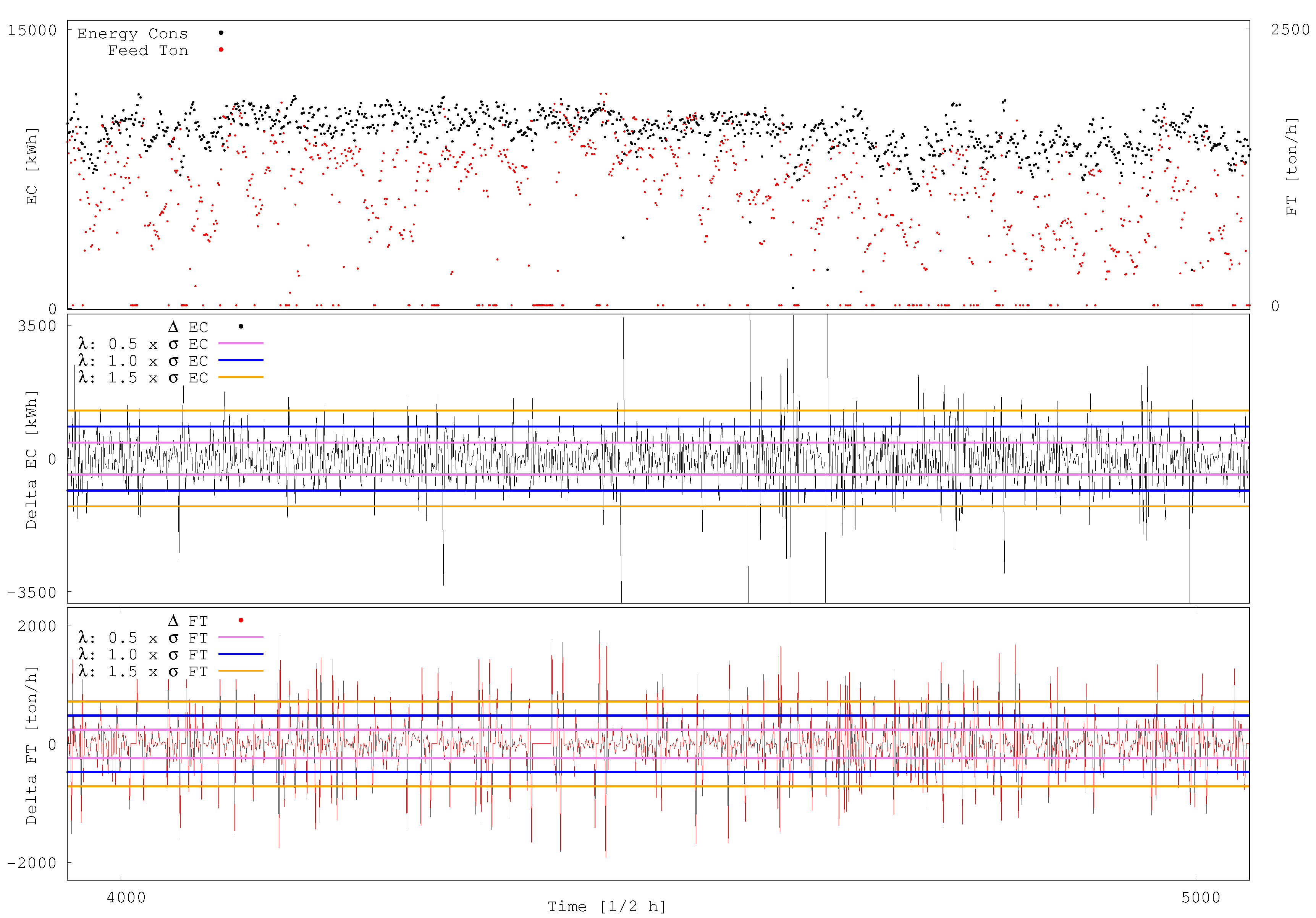
Figure 2 illustrates the ORH criteria using a half-hour time support on SAG mill 1 dataset. From the daily graph of EC and FT at the top, the graph of EC and FT are extracted and presented at the centre and bottom, respectively. Three different bands, corresponding to : 0.5, 1.0 and 1.5, are shown. The values that are above the band are considered as increasing, the ones below it are considered as decreasing and inside as undefined (relatively constant). The corresponding categories for EC and FT are used to define the operational relative-hardness (as in Table 1). It can be seen that, when increases, the proportions of hard and soft instances decrease. Since is an arbitrary parameter, a sensitivity analysis is performed in the range to capture its influence on the resulting LSTM accuracy to suitably learn to predict the ORH at the different time supports.
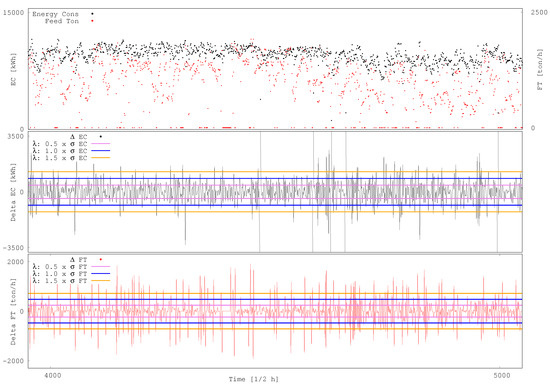
Figure 2.
SAG mill 1. Graphic representation of the relative-hardness inference criteria at 0.5 h time support. Daily graphs of energy consumption and feed tonnage (top), delta of energy consumption (centre), and delta of feed tonnage (bottom).
At each time t the input variables considered to predict ORH are FT, BPr and SSp. To account for trends, and since FT and SSp are operational decisions, the differences FTFT and SSpSSp are also considered as inputs. Therefore, the dataset of predictors and output , at each time support , has samples made by FT, BPr, SSp, FTFT, SSpSSp and . We also tried several other combinations of input variables, but all led to results with lower quality. A temporal window of the previous four hours (previous eight consecutive data points) are used as input for training and testing the LSTM models.
3.4. Preprocessing Dataset
A preprocessing step is performed over the raw datasets to make them suitable for deep neural network training and inference processes. The aim is to make all input attributes fall into certain regions of the non-linear transfer functions via normalization and to be properly coded in categories via one-hot encoding. Thus, we normalize the entire raw dataset with the mean and standard deviation of the training dataset.
Let be one of the five input variables () at time t, its normalized expression is computed as , where and represent the mean and standard deviation of in the training dataset. We normalize the first three attributes of , FT, BPr and SSp while for last two attributes, the differences between the original values FTFT and SSpSSp, are replaced by the differences between the normalized values of FT and SSp.
The known operational relative-hardness at time t () is one-hot encoding such that soft, undefined and hard are encoded as , and , respectively.
3.5. Optimal LSTM Architecture
From the training dataset, sequence of length are extracted to train the LSTM model in order to forecast the operational relative-hardness at next time step , at different time supports. The chosen length is four hours (: 8).
The external hyper-parameter to be optimized on any LSTM architecture is the number of hidden units, . Based on a previous work [14], the optimum number of hidden units was found and here used. They are displayed in Table 3.
Table 3.
Optimal number of hidden units in the LSTM architecture at different time supports [14].
Adam Optimizer is used to train the LSTM with hyper-parameters , and as recommended by [17].
4. Results
Directly from the datasets, the real operational relative-hardness ORH is calculated from Equation (1), varying in the set at each time t and for each time support. On the other hand, a probability vector with soft, undefined and hard ORH states is predicted. By taking the highest probability, the predicted ORH is obtained. Then, a confusion matrix, filled with the number of instances of pairs (RH, RH), is built for each time support and each value. Table 4 summarizes and presents the cases of : 0.5, and , and supports 0.5, 2 and 8 h over the SAG mill 1, while the Table 5 summarizes the same results over the SAG mill 2.
Table 4.
SAG mill 1. Confusion matrices (number of instances) of operational relative-hardness (ORH) predictions using : 0.5, 1.0 and 1.5 at 0.5, 2 and 8 h time supports.
Table 5.
SAG mill 2. Confusion matrices (number of instances) of ORH predictions using : 0.5, 1.0 and 1.5 at 0.5, 2 and 8 h time supports.
The accuracy of the model prediction, ORH, defined as the percentage of right predictions is computed as:
and it represents the percentage of elements in the confusion matrix diagonal. The relative percentage of predictions of each class (rows) is shown in Table 6 for SAG mill 1 and in Table 7 for SAG mill 2.
Table 6.
SAG mill 1. Confusion matrices (percentage) of ORH prediction using : 0.5, 1.0 and 1.5 at 0.5, 2 and 8 h time supports.
Table 7.
SAG mill 2. Confusion matrices (percentage) of ORH prediction using : 0.5, 1.0 and 1.5 at 0.5, 2 and 8 h time supports.
As shown in Table 6 and Table 7 at 0.5 h time support, the LSTM is able to predict with enough confidence the ORH regardless the value of . Nevertheless, as increases, the number of instances of soft and hard ORH decreases improving the final accuracy since the higher the value of , the more data points are classified as undefined. Particularly, for 0.5 h time support, increasing from 0.5 to 1.5 makes real undefined points increase from 4325 to 6577 (from 53.0% to 80.7%) in SAG mill 1 and from 3600 to 6469 (from 45.3% to 81.4%) in SAG mill 2. Therefore, increasing improves accuracy, but the price is resolution. On the other hand, the number of extreme cases () and () is close to zero. This is a great result, since predicting soft hardness when it is actually hard (or vice versa) may induce bad short term decisions on how to operate the SAG mill, along with other downstream decisions.
The percentage of extreme cases (() and ()) using : increases when moving from 0.5 to 8 h time support, on both SAG mills. However, they decrease to a value close to zero when increasing from 0.5 to 1.5, at all time supports. However, LSTM loses accuracy in terms of predicting the relevant cases () and () as soon as the time support increases, on both SAG mills.
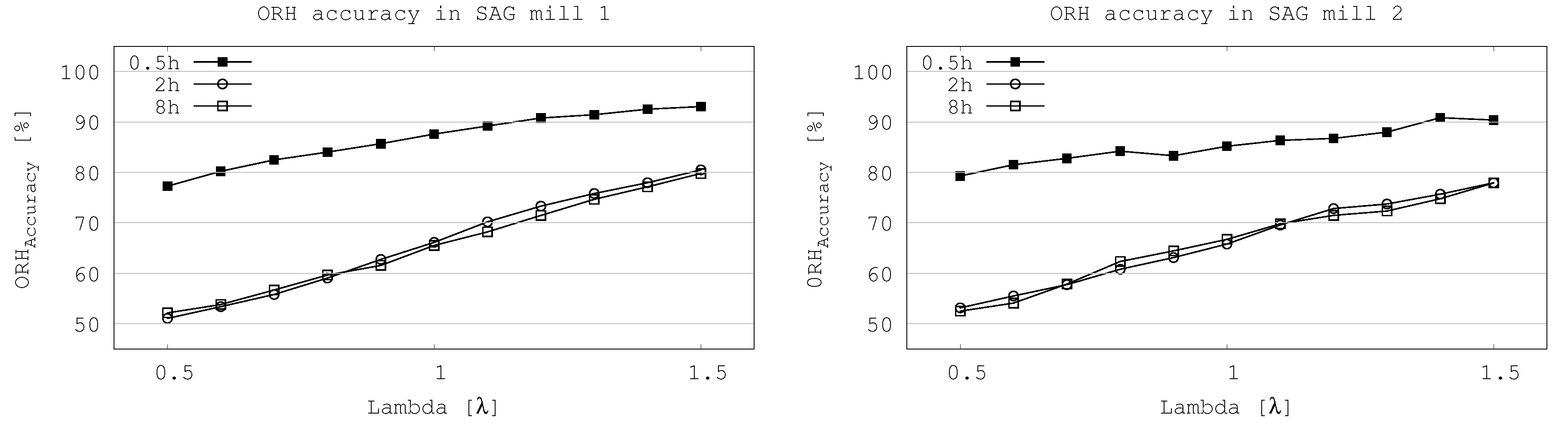
The accuracy graph (Figure 3) shows the sensitivity at all time supports on both SAG mills. The lower accuracy is 51% and is achieved at 2 h time supports with : 0.5 on SAG mill 1. Its accuracy increases to 66% with : 1.0 and 81% with : 1.5. The best results are achieved at 0.5 h time support (same support as the original data) where 77%, 88% and 93% of accuracy are obtained with : 0.5, 1.0 and , respectively on SAG mill 1, and 79%, 85% and 90% of accuracy with : 0.5, 1.0 and on SAG mill 2.
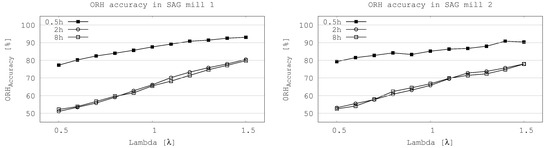
Figure 3.
Accuracy of operational relative-hardness prediction at different time support as function of lambda () on both SAG mills.
5. Conclusions
This work proposes the use of Long Short-Term Memory networks to forecast relative operational hardness in two SAG mills using operational data. We have presented the internal architecture of the deep networks, how to deal with raw operational datasets, and qualitative criteria to estimate the operational hardness of processing material inside the SAG mill based on the consumed energy, feed tonnage and a statistical distribution using a lambda value. Particularly, Long Short-Term Memory models have been trained to predict the operational relative-hardness based only on low-cost and fast acquiring operational information (feed tonnage, spindle speed and bearing pressure).
The LSTM network shows great results on predicting the relative operational hardness at 30 min time support. On SAG mill 1, using a lambda value of 0.5, the obtained accuracy was 77.3% while increasing the lambda to 1.5 led to an increase in accuracy of 93.1%. Similar results were found on the second SAG mill. As the time support increases to two and eight hours, the accuracy drops to around 52% using a lambda value of 0.5 and 78% with a lambda value of 1.5, on both SAG mills.
The inaccuracy of LSTM, when predicting extreme cases such as soft hardness when it is hard and vice-versa, is pretty low. Extreme misclassification is close to 1% at 0.5 h time support on both SAGs regardless of the lambda value. Although it increases to around 20% when increasing the time support using a lambda value of 0.5, it rapidly decreases to around 1% as lambda increases.
Lastly, the proposed application can be extended to any crushing and grinding equipment, under a similar context of real-data acquisition in order to forecast categorical attributes that are relevant to downstream processes.
Author Contributions
Conceptualization, S.A. and W.K.; methodology, S.A.; codes, S.A.; validation, S.A., W.K. and J.M.O.; formal analysis, S.A.; investigation, S.A.; resources, W.K.; data curation, S.A.; writing—original draft preparation, S.A.; visualization, S.A.; supervision, W.K. and J.M.O.; project administration, W.K.; funding acquisition, W.K. and J.M.O. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Natural Sciences and Engineering Council of Canada (NSERC) grant number RGPIN-2017-04200 and RGPAS-2017-507956, and by the Chilean National Commission for Scientific and Technological Research (CONICYT), through CONICYT/PIA Project AFB180004, and the CONICYT/FONDAP Project 15110019.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| LSTM | Long Short-Term Memory |
| ORH | Operational relative-hardness |
| FT | Feed tonnage |
| BPr | Bearing pressure |
| SSp | Spindle speed |
| SAG | Semi-autogenous grinding |
References
- Cochilco. Actualización de Información sobre el Consumo de Energía asociado a la Minería del Cobre al año 2012; COCHILCO: Santiago, Chile, 2013. [Google Scholar]
- Jones, S.M.; Fresko, M. Autogenous and semiautogenous mills 2010 update. In Proceedings of the Fifth International Conference on Autogenous and Semiautogenous Grinding Technology, Vancouver, BC, Canada, 25–28 September 2011. [Google Scholar]
- Ortiz, J.M.; Kracht, W.; Pamparana, G.; Haas, J. Optimization of a SAG mill energy system: Integrating rock hardness, solar irradiation, climate change, and demand-side management. Math. Geosci. 2020, 52, 355–379. [Google Scholar] [CrossRef]
- Jnr, W.V.; Morrell, S. The development of a dynamic model for autogenous and semi-autogenous grinding. Miner. Eng. 1995, 8, 1285–1297. [Google Scholar]
- Morrell, S. A new autogenous and semi-autogenous mill model for scale-up, design and optimisation. Miner. Eng. 2004, 17, 437–445. [Google Scholar] [CrossRef]
- Silva, M.; Casali, A. Modelling SAG milling power and specific energy consumption including the feed percentage of intermediate size particles. Miner. Eng. 2015, 70, 156–161. [Google Scholar] [CrossRef]
- Salazar, J.L.; Valdés-González, H.; Vyhmesiter, E.; Cubillos, F. Model predictive control of semiautogenous mills (sag). Miner. Eng. 2014, 64, 92–96. [Google Scholar] [CrossRef]
- Ortiz, J.; Kracht, W.; Townley, B.; Lois, P.; Cardenas, E.; Miranda, R.; Alvarez, M. Workflows in geometallurgical prediction: Challenges and outlook. In Proceedings of the 17th Annual Conference of the International Association for Mathematical Geosciences IAMG, Freiberg, Germany, 5–13 September 2015. [Google Scholar]
- Van den Boogaart, K.; Tolosana-Delgado, R. Predictive Geometallurgy: An Interdisciplinary Key Challenge for Mathematical Geosciences. In Handbook of Mathematical Geosciences; Springer: Berlin, Germany, 2018; pp. 673–686. [Google Scholar]
- Curilem, M.; Acuña, G.; Cubillos, F.; Vyhmeister, E. Neural networks and support vector machine models applied to energy consumption optimization in semiautogeneous grinding. Chem. Eng. Trans. 2011, 25, 761–766. [Google Scholar]
- Hoseinian, F.S.; Faradonbeh, R.S.; Abdollahzadeh, A.; Rezai, B.; Soltani-Mohammadi, S. Semi-autogenous mill power model development using gene expression programming. Powder Technol. 2017, 308, 61–69. [Google Scholar] [CrossRef]
- Hoseinian, F.S.; Abdollahzadeh, A.; Rezai, B. Semi-autogenous mill power prediction by a hybrid neural genetic algorithm. J. Cent. South Univ. 2018, 25, 151–158. [Google Scholar] [CrossRef]
- Inapakurthi, R.K.; Miriyala, S.S.; Mitra, K. Recurrent Neural Networks based Modelling of Industrial Grinding Operation. Chem. Eng. Sci. 2020, 219, 115585. [Google Scholar] [CrossRef]
- Avalos, S.; Kracht, W.; Ortiz, J.M. Machine learning and deep learning methods in mining operations: A data-driven SAG mill energy consumption prediction application. Min. Metall. Explor. 2020, 37, 1–16. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).