1. Introduction
Extreme learning machine (ELM) was put forward in 2006 by Huang et al. [
1] as a single-hidden layer feedforward network (SLFN). The hidden layer parameters of ELM are arbitrarily initialized and output weights are determined by utilizing the least squares algorithm. Due to this characteristic, ELM has fast learning speed, better performance and efficient computation cost [
1,
2,
3,
4], and has, as a result, been applied in different areas.
However, ELM suffers from the presence of irrelevant variables in the large and high dimensional real data set [
2,
5]. The unbalanced data set problem occurs in real applications such as text categorization, fault detection, fraud detection, oil-spills detection in satellite images, toxicology, cultural modeling, and medical diagnosis [
6]. Many challenging real problems are characterized by imbalanced training data in which at least one class is under-represented relative to others.
The problem of imbalanced data is often associated with asymmetric costs of misclassifying elements of different classes. In addition, the distribution of the test data set might differ from that of the training samples. Class imbalance happens when the number of samples in one class is much more than that of the other [
7]. The methods aiming to tackle the problem of imbalance can be classified into four groups such as algorithmic based methods, data based methods, cost-sensitive methods and ensembles of classifiers based methods [
8]. In algorithmic based approaches, the minority class classification accuracy is improved by adjusting the weights for each class [
9]. Re-sampling methods can be viewed in the data based approaches where these methods did not improve the classifiers [
10]. The cost-sensitive approaches assign various cost values to training samples of the majority class and the minority class, respectively [
11]. Recently, ensembles based methods have been widely used in classification of imbalanced data sets [
12]. Bagging and boosting methods are the two popular ensemble methods.
The problem of class imbalance has received much attention in the literature [
13]. Synthetic minority over–sampling technique (SMOTE) [
9] is known as the most popular re-sampling method that uses pre-processing for obtaining minority class instances artificially. For each minority class sample, SMOTE creates a new sample on the line joining it to the nearest minority class neighbor. Borderline SMOTE [
14], SMOTE-Boost [
15], and modified SMOTE [
14] are some of the improved variants of the SMOTE algorithm. In addition, an oversampling method was proposed that identifies some minority class samples that are hard to classify [
16]. Another oversampling method was presented that uses bagging with oversampling [
17]. In [
18], authors opted to use double ensemble classifier by combining bagging and boosting. In [
19], authors combined sampling and ensemble techniques to improve the classification performance for skewed data. Another method, namely random under sampling (RUS), was proposed that removes the majority class samples randomly until the training set becomes balanced [
19]. In [
20], authors proposed an ensemble of an support vector machine (SVM) structure with boosting (Boosting-SVM), where the minority class classification accuracy was increased compared to pure SVM. In [
21], a cost sensitive approach was proposed where k-nearest neighbors (k-NN) classifier was adopted. In addition, in [
22], an SVM based cost sensitive approach was proposed for class imbalanced data classification. Decision trees [
23] and logistic regression [
24] based methods were also proposed in order to handle with the imbalanced data classification.
An ELM classifier trained with an imbalanced data set can be biased towards the majority class and obtain a high accuracy on the majority class by compromising minority class accuracy. Weighted ELM (WELM) was employed to alleviate the ELM’s classification deficiency on imbalanced data sets, and which can be seen as one of the cost-proportionate weighted sampling methods [
25]. ELM assigns the same misclassification cost value to all data points such as positive and negative samples in a two-class problem. When the number of negative samples is much larger than that of the number of positive samples or vice versa, assigning the same misclassification cost value to all samples can be seen one of the drawbacks of traditional ELM. A straightforward solution is to obtain misclassification cost values adaptively according to the class distribution, in the form of a weight scheme inversely proportional to the number of samples in the class.
In [
7], the authors proposed a weighted online sequential extreme learning machine (WOS-ELM) algorithm for alleviating the imbalance problem in chunk-by-chunk and one-by-one learning. A weight setting was selected in a computationally efficient way. Weighted Tanimoto extreme learning machine (T-WELM) was used to predict chemical compound biological activity and other data with discrete, binary representation [
26]. In [
27], the authors presented a weight learning machine for a SLFN to recognize handwritten digits. Input and output weights were globally optimized with the batch learning type of least squares. Features were assigned into the prescribed positions. Another weighted ELM algorithm, namely ESOS-ELM, was proposed by Mirza et al. [
28], which was inspired from WOS-ELM. ESOS-ELM aims to handle class imbalance learning (CIL) from a concept-drifting data stream. Another ensemble-based weighted ELM method was proposed by Zhang et al. [
29], where the weight of each base learner in the ensemble is optimized by differential evolution algorithm. In [
30], the authors further improved the re-sampling strategy inside Over-sampling based online bagging (OOB) and Under-sampling based online bagging (UOB) in order to learn class imbalance.
Although much awareness of the imbalance has been raised, many of the key issues remain unresolved and encountered more frequently in massive data sets. How to determine the weight values is key to designing WELM. Different situations such as noises and outlier data should be considered.
The noises and outlier data in a data set can be treated as a kind of indeterminacy. Neutrosophic set (NS) has been successfully applied for indeterminate information processing, and demonstrates advantages to deal with the indeterminacy information of data and is still a technique promoted for data analysis and classification application. NS provides an efficient and accurate way to define imbalance information according to the attributes of the data.
In this study, we present a new weighted ELM scheme using neutrosophic
c-means (NCM) clustering to overcome the ELM’s drawbacks in highly imbalanced data sets. A novel clustering algorithm NCM was proposed for data clustering [
31,
32]. NCM is employed to determine a sample’s belonging, noise, and indeterminacy memberships, and is then used to compute a weight value for that sample [
31,
32,
33]. A weighted ELM is designed using the weights from NCM and utilized for imbalanced data set classification.
The rest of the paper is structured as follows. In
Section 2, a brief history of the theory of ELM and weighted ELM is introduced. In addition,
Section 2 introduces the proposed method.
Section 3 discusses the experiments and comparisons, and conclusions are drawn in
Section 4.
2. Proposed Method
2.1. Extreme Learning Machine
Backpropagation, which is known as gradient-based learning method, suffers from slow convergence speed. In addition, stuck in the local minimum can be seen as another disadvantage of a gradient-based learning algorithm. ELM was proposed by Huang et al. [
1] as an alternative method that overcomes the shortcomings of gradient-based learning methods. The ELM was designed as an SLFN, where the input weights and hidden biases are selected randomly. These weights do not need to be adjusted during the training process. The output weights are determined analytically with Moore–Penrose generalized inverse of the hidden-layer output matrix.
Mathematically speaking, the output of the ELM with
L hidden nodes and activation function g(·) can be written as:
where
is the
jth input data,
is the weight vector,
is the output weight vector,
is the bias of the
jth hidden node and
is the
ith output node and
N shows the number of samples. If ELM learns these
N samples with 0 error, then Equation (
1) can be updated as follows:
where
shows the actual output vector. Equation (
2) can be written compactly as shown in Equation (
3):
where
is the hidden-layer output matrix. Thus, the output weight vector can be calculated analytically with Moore–Penrose generalized inverse of the hidden-layer output matrix as shown in Equation (
4):
where
is the Moore–Penrose generalized inverse of matrix
H.
2.2. Weighted Extreme Learning Machine
Let us consider a training data set belonging to two classes, where and are the class labels. In binary classification, is either or . Then, a diagonal matrix is considered, where each of them is associated with a training sample . The weighting procedure generally assigns larger to , which comes from the minority class.
An optimization problem is employed to maximize the marginal distance and to minimize the weighted cumulative error as:
Furthermore:
where
,
is the error vector and
is the feature mapping vector in the hidden layer with respect to
, and
. By using the Lagrage multiplier and Karush–Kuhn–Tucker theorem, the dual optimization problem can be solved. Thus, hidden layer’s output weight vector
becomes can be derived from Equation (
7) regarding left pseudo-inverse or right pseudo-inverse. When presented data with small size, right pseudo-inverse is recommended because it involves the inverse of an
matrix. Otherwise, left pseudo-inverse is more suitable since it is much easier to compute matrix inversion of size
when
L is much smaller than
N:
In the weighted ELM, the authors adopted two different weighting schemes. In the first one, the weights for the minority and majority classes are calculated as:
and, for the second one, the related weights are calculated as:
The readers may refer to [
25] for detail information about determination of the weights.
2.3. Neutrosophic Weighted Extreme Learning Machine
Weighted ELM assigns the same weight value to all samples in the minority class and another same weight value to all samples in the majority class. Although this procedure works quite well in some imbalanced data sets, assigning the same weight value to all samples in a class may not be a good choice for data sets that have noise and outlier samples. In other words, to deal with noise and outlier data samples in an imbalanced data set, different weight values are needed for each sample in each class that reflects the data point’s significance in its class. Therefore, we present a novel method to determine the significance of each sample in its class. NCM clustering can determine a sample’s belonging, noise and indeterminacy memberships, which can then be used in order to compute a weight value for that sample.
Guo and Sengur [
31] proposed the NCM clustering algorithms based on the neutrosophic set theorem [
34,
35,
36,
37]. In NCM, a new cost function was developed to overcome the weakness of the Fuzzy
c-Means (FCM) method on noise and outlier data points. In the NCM algorithm, two new types of rejection were developed for both noise and outlier rejections. The objective function in NCM is given as follows:
where
m is a constant. For each point
i, the
is the mean of two centers.
,
and
are the membership values belonging to the determinate clusters, boundary regions and noisy data set.
,
,
:
Thus, the related membership functions are calculated as follows:
where
shows the center of cluster
j,
,
, and
are the weight factors and
is a regularization factor which is data dependent [
31]. Under the above definitions, every input sample in each minority and majority class is associated with a triple
,
,
. While the larger
means that the sample belongs to the labeled class with a higher probability, the larger
means that the sample is indeterminate with a higher probability. Finally, the larger
means that the sample is highly probable to be a noise or outlier data.
After clustering procedure is applied in NCM, the weights for each sample of minority and majority classes are obtained as follows:
where
is the ratio of the number of samples in the majority class to the number of the samples in the minority class.
The algorithm of the neutrosophic weighted extreme learning machine (NWELM) is composed of four steps. The first step necessitates applying the NCM algorithm based on the pre-calculated cluster centers, according to the class labels of the input samples. Thus, the T, I and F membership values are determined for the next step. The related weights are calculated from the determined T, I and F membership values in the second step of the algorithm.
In Step 3, the ELM parameters are tuned and samples and weights are fed into the ELM in order to calculate the H matrix. The hidden layer weight vector is calculated according to the H, W and class labels. Finally, the determination of the labels of the test data set is accomplished in the final step of the algorithm (Step 4).
The neutrosophic weighted extreme learning machine (NWELM) algorithm is given as following:
- Input:
Labelled training data set.
- Output:
Predicted class labels.
- Step 1:
Initialize the cluster centers according to the labelled data set and run NCM algorithm in order to obtain the T, I and F value for each data point.
- Step 2:
Compute
and
according to Equations (
18) and (
19).
- Step 3:
Adapt the ELM parameters and run NWELM. Compute H matrix and obtain
according to Equation (
8) or Equation (
9).
- Step 4:
Calculate the labels of test data set based on .
3. Experimental Results
The geometric mean (
) is used to evaluate the performance of the proposed NWELM method. The
is computed as follows:
where
R denotes the recall rate and
,
denotes true-negative and false-positive detections, respectively.
values are in the range of [0–1] and it represents the square root of positive class accuracy and negative class accuracy. The performance evaluation of NWELM classifier is tested on both toy data sets and real data sets, respectively. The five-fold cross-validation method is adopted in the experiments. In the hidden node of the NWELM, the radial basis function (RBF) kernel is considered. A grid search of the trade-off constant
C on {
,
, …,
,
} and the number of hidden nodes
L on {10, 20, …, 990, 2000} was conducted in seeking the optimal result using five-fold cross-validation. For real data sets, a normalization of the input attributes into [
, 1] is considered. In addition, for NCM, the following parameters are chosen such as
,
,
,
respectively, which were obtained by means of trial and error. The
parameter of NCM method is also searched on {
,
, …,
,
}.
3.1. Experiments on Artificial Data Sets
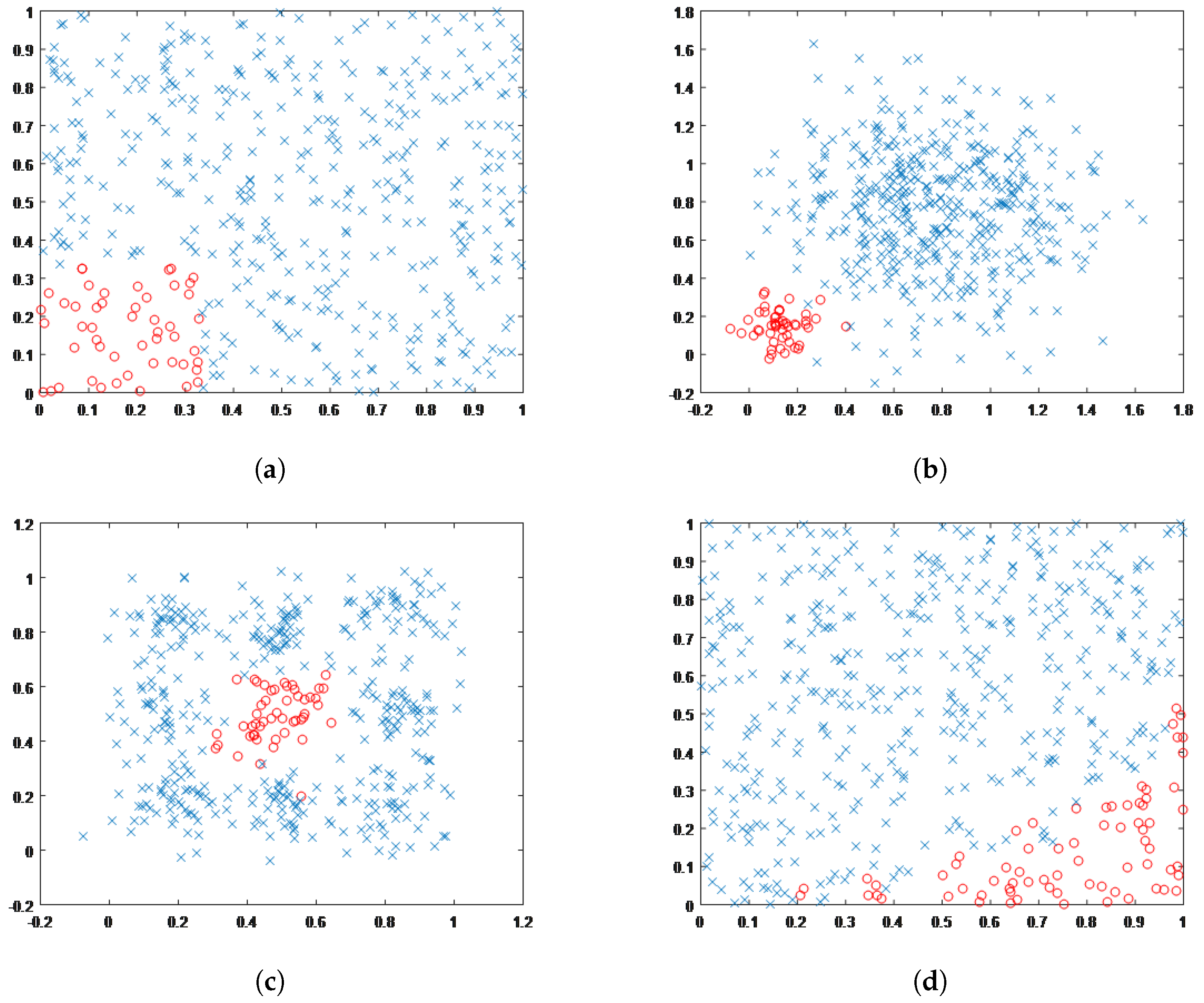
Four two-class artificial imbalance data sets were used to evaluate the classification performance of the proposed NWELM scheme. The illustration of the data sets is shown in
Figure 1 [
38]. The decision boundary between classes is complicated. In
Figure 1a, we illustrate the first artificial data set that follows a uniform distribution. As can be seen, the red circles of
Figure 1a belong to the minority class, with the rest of the data samples shown by blue crosses as the majority class. The second imbalance data set, namely Gaussian-1, is obtained using two Gaussian distributions with a 1:9 ratio of samples as shown in
Figure 1b. While the red circles illustrate the minority class, the blue cross samples show the majority class.
Another Gaussian distribution-based imbalance data set, namely Gaussian-2, is given in
Figure 1c. This data set consists of nine Gaussian distributions with the same number of samples arranged in a
grid. The red circle samples located in the middle belong to the minority class while the blue cross samples belong to the majority class. Finally,
Figure 1d shows the last artificial imbalance data set. It is known as a complex data set because it has a 1:9 ratio of samples for the minority and majority classes.
Table 1 shows the
achieved by the two methods on these four data sets in ten independent runs. For Gaussian-1, Gaussian-2 and the Uniform artificial data sets, the proposed NWELM method yields better results when compared to the weighted ELM scheme; however, for the Complex artificial data sets, the weighted ELM method achieves better results. The better resulting cases are shown in bold text. It is worth mentioning that, for the Gaussian-2 data set, NWELM achieves a higher
across all trials.
3.2. Experiments on Real Data Set
In this section, we test the achievement of the proposed NWELM method on real data sets [
39]. A total of 21 data sets with different numbers of features, training and test samples, and imbalance ratios are shown in
Table 2. The selected data sets can be categorized into two classes according to their imbalance ratios. The first class has the imbalance ratio range of 0 to 0.2 and contains yeast-1-2-8-9_vs_7, abalone9_18, glass-0-1-6_vs_2, vowel0, yeast-0-5-6-7-9_vs_4, page-blocks0, yeast3, ecoli2, new-thyroid1 and the new-thyroid2 data sets.
On the other hand, second class contains the data sets, such as ecoli1, glass-0-1-2-3_vs_4-5-6, vehicle0, vehicle1, haberman, yeast, glass0, iris0, pima, wisconsin and glass1, that have imbalance ratio rates between 0.2 and 1.
The comparison results of the proposed NWELM with the weighted ELM, unweighted ELM and SVM are given in
Table 3. As the weighted ELM method used a different weighting scheme (
,
), in our comparisons, we used the higher
value. As can be seen in
Table 3, the NWELM method yields higher
values for 17 of the imbalanced data sets. For three of the data sets, both methods yield the same
. Just for the page-blocks0 data set, the weighted ELM method yielded better results. It is worth mentioning that the NWELM method achieves 100%
values for four data sets (vowel0, new-thyroid1, new-thyroid2, iris0). In addition, NWELM produced higher
values than SVM for all data sets.
The obtained results were further evaluated by area under curve (AUC) values [
40]. In addition, we compared the proposed method with unweighted ELM, weighted ELM and SVM based on the achieved AUC values as tabulated in
Table 4. As seen in
Table 4, for all examined data sets, our proposal’s AUC values were higher than the compared other methods. For further comparisons of the proposed method with unweighted ELM, weighted ELM and SVM methods appropriately, statistical tests on AUC results were considered. The paired
t-test was chosen [
41]. The paired
t-test results between each compared method and the proposed method for AUC was tabulated in
Table 5 in terms of
p-value. In
Table 5, the results showing a significant advantage to the proposed method were shown in bold–face where
p-values are equal or smaller than 0.05. Therefore, the proposed method performed better than the other methods in 39 tests out of 63 tests when each data set and pairs of methods are considered separately.
Another statistical test, namely the Friedman aligned ranks test, has been applied to compare the obtained results based on AUC values [
42]. This test is a non-parametric test and the Holm method was chosen as the post hoc control method. The significance level was assigned 0.05. The statistics were obtained with the STAC tool [
43] and recorded in
Table 6. According to these results, the highest rank value was obtained by the proposed NWELM method and SVM and WELM rank values were greater than the ELM. In addition, the comparison’s statistics, adjusted
p-values and hypothesis results were given in
Table 6.
We further compared the proposed NWELM method with two ensemble-based weighted ELM methods on 12 data sets [
29]. The obtained results and the average classification
values are recorded in
Table 7. The best classification result for each data set is shown in bold text. A global view on the average classification performance shows that the NWELM yielded the highest average
value against both the ensemble-based weighted ELM methods. In addition, the proposed NWELM method evidently outperforms the other two compared algorithms in terms of
in 10 out of 12 data sets, with the only exceptions being the yeast3 and glass2 data sets.
As can be seen through careful observation, the NWELM method has not significantly improved the performance in terms of the glass1, haberman, yeast1_7 and abalone9_18 data sets, but slightly outperforms both ensemble-based weighted ELM methods.
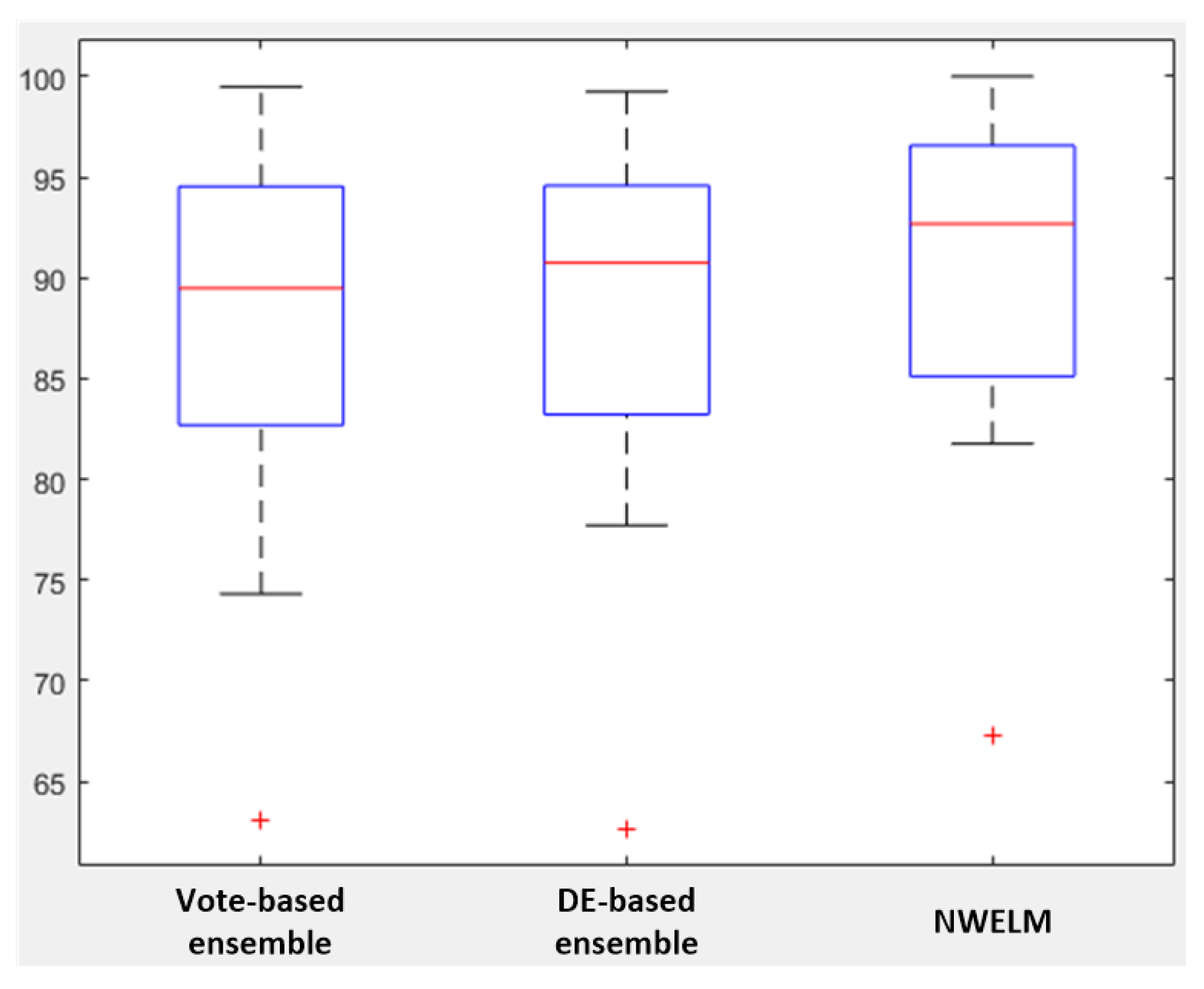
A box plots illustration of the compared methods is shown in
Figure 2. The box generated by the NWELM is shorter than the boxes generated by the compared vote-based ensemble and differential evolution (DE)- based ensemble methods. The dispersion degree of NWELM method is relatively low. It is worth noting that the box plots of all methods consider the
of the haberman data set as an exception. Finally, the box plot determines the proposed NWELM method to be more robust when compared to the ensemble-based weighted ELM methods.







{kind=link}
{kind=link}