1. Introduction
Deaf persons are unable to discriminate speech through their ears, and therefore cannot use hearing for communication. Sign language is one communication method for deaf or hearing-impaired people that communicates information through hand gestures and other body actions. However, most hearing people cannot comprehend sign language, which can cause communication difficulties. To solve this issue, hand sign language translation may be able to help deaf or hearing-impaired people communicate with hearing people. There have been many research studies on hand sign translation in a variety of sign languages. However, in order to translate the hand sign, the system needs to know both where the hands are, and what their movements are. To ease this problem, some research studies have utilised cyber-gloves (electronic gloves) to help detect the hand positions [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12]. Other research works have used colour-coded gloves instead of cyber-gloves [
13,
14,
15,
16,
17]. However, signers in these two cases had to wear extra equipment in order for the system to work properly, which might not fit well with daily life. Hence, there has also been other research on freehand (no extra equipment) translation systems. Some of these involved pre-processing the image frames, which included hand segmentation [
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32]. Others only pre-processed the portion of the image with hand parts (only hands were captured in the video data set) [
33,
34,
35,
36,
37]. Other works utilised motion sensors or Kinect [
38,
39,
40] to capture hand movements. The remaining methods were visual-based, without any segmentation, and only used cameras [
41,
42,
43,
44,
45,
46]. Although some of the visual-based methods provided impressively correct classifications, as shown in
Table 1, they still suffered from errors that were caused by similar hand movements that had different finger movements for different words, similar hand gestures for different words, etc.
The above-mentioned methods all suffer from extra equipment usage, pre-processing, segmentation, or a capturing device that might not be practical in daily life. In this paper, we improve the method for Thai sign language translation using Scale Invariant Feature Transform (SIFT) and String Grammar Unsupervised Possibilistic C-Medians (sgUPCMed). The String Grammar Unsupervised Possibilistic C-Medians (sgUPCMed) algorithm is a new string grammar clustering method that is introduced in this paper for the first time. Since fuzzy clustering is able to cluster overlapping data samples and deal with noise or outliers, this method might better cope with the problems outlined above. Moreover, our system does not require hand region detection or hand segmentation for sign language translation. The system only uses a camera to record the movement, without any extra sensors or equipment on the signers. The Scale Invariant Feature Transform method is used to match the test frame with symbols in the signature library. The String Grammar Unsupervised Possibilistic C-Medians (sgUPCMed) algorithm is used for prototype generation, while the fuzzy k-nearest neighbour is utilised as a classifier. Ten isolated Thai sign words are used in our experiments: ‘‘elder’’, ‘‘grandfather’’, ‘‘grandmother’’, ‘‘gratitude’’, ‘‘female’’, ‘‘male’’, ‘‘glad’’, ‘‘thank you’’, ‘‘understand’’, and ‘‘miss’’. The experiments are implemented within signer-dependent, signer semi-dependent, and signer-independent scenarios. The subjects used in the signature library collection for the SIFT algorithm and in the string grammar clustering algorithms for the generation of prototypes are utilised in a subject-dependent case, while the subjects that are only presented in the blind test data set are utilised in a signer-independent case. However, there are two types of signer semi-independent cases. One is when subjects are only in the signature library collection, and the other is when subjects are only in the prototype generation process.
The first experiments were implemented with constraints: subjects were asked to wear a black shirt with long sleeves and stand in front of a dark background. The best system that emerged from these constraints was then implemented on signers in the blind test data set without any constraints, i.e., they were asked to wear a short-sleeve shirt and stand in front of various natural backgrounds. We implemented our proposed system with the RWTH-BOSTON-50 data set, which consists of 31 isolated American Sign Language (ASL) words as well, in order to show the ability of the system with other sign languages. We also compare the results with those from the existing algorithms. The remainder of this paper is organised as follows.
Section 2 explains our proposed system, along with a review of the SIFT method and the String Grammar Unsupervised Possibilistic C-Medians (sgUPCMed) algorithm. The experimental results are shown in
Section 3, and finally, we draw the conclusion in
Section 4.
2. System Description
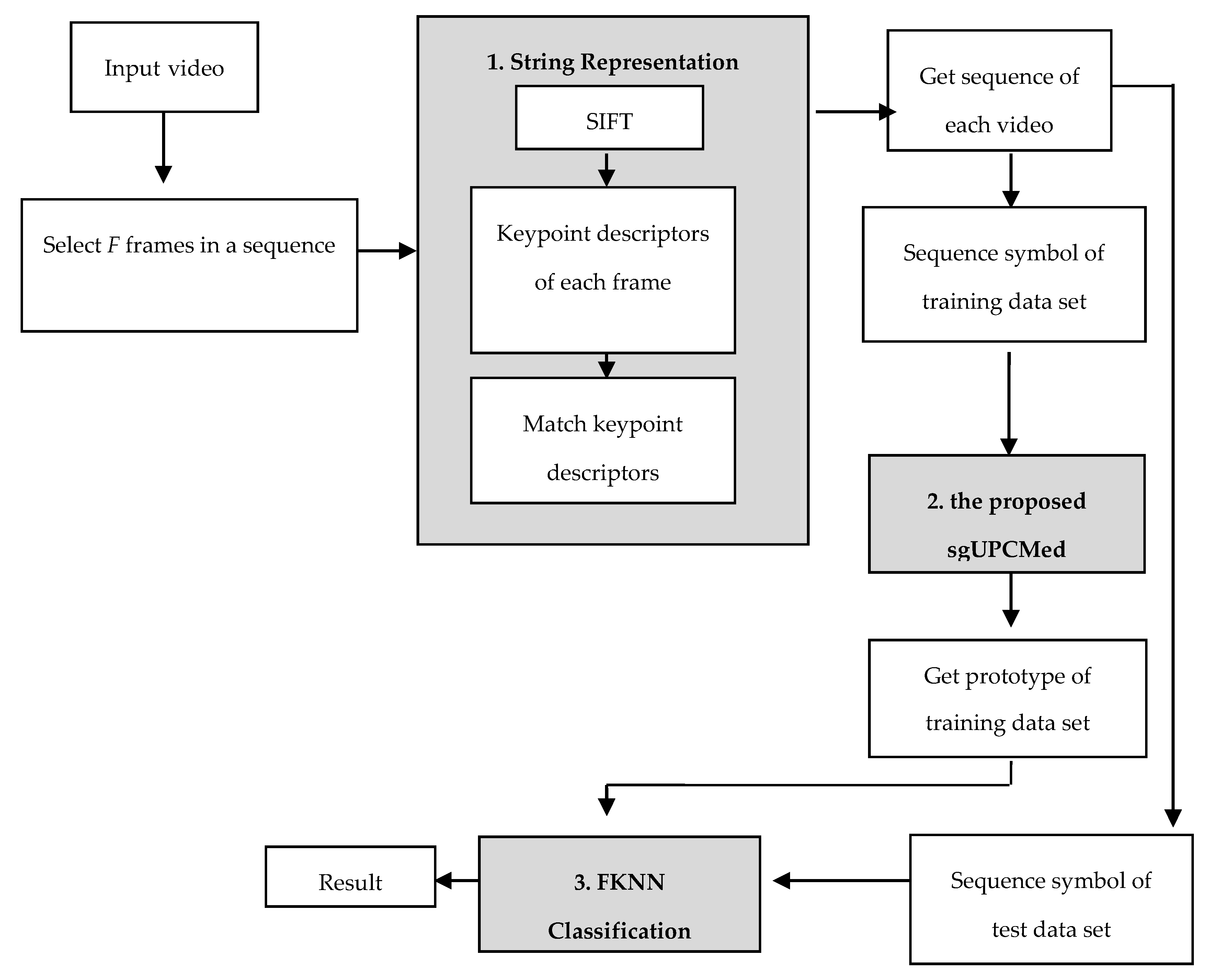
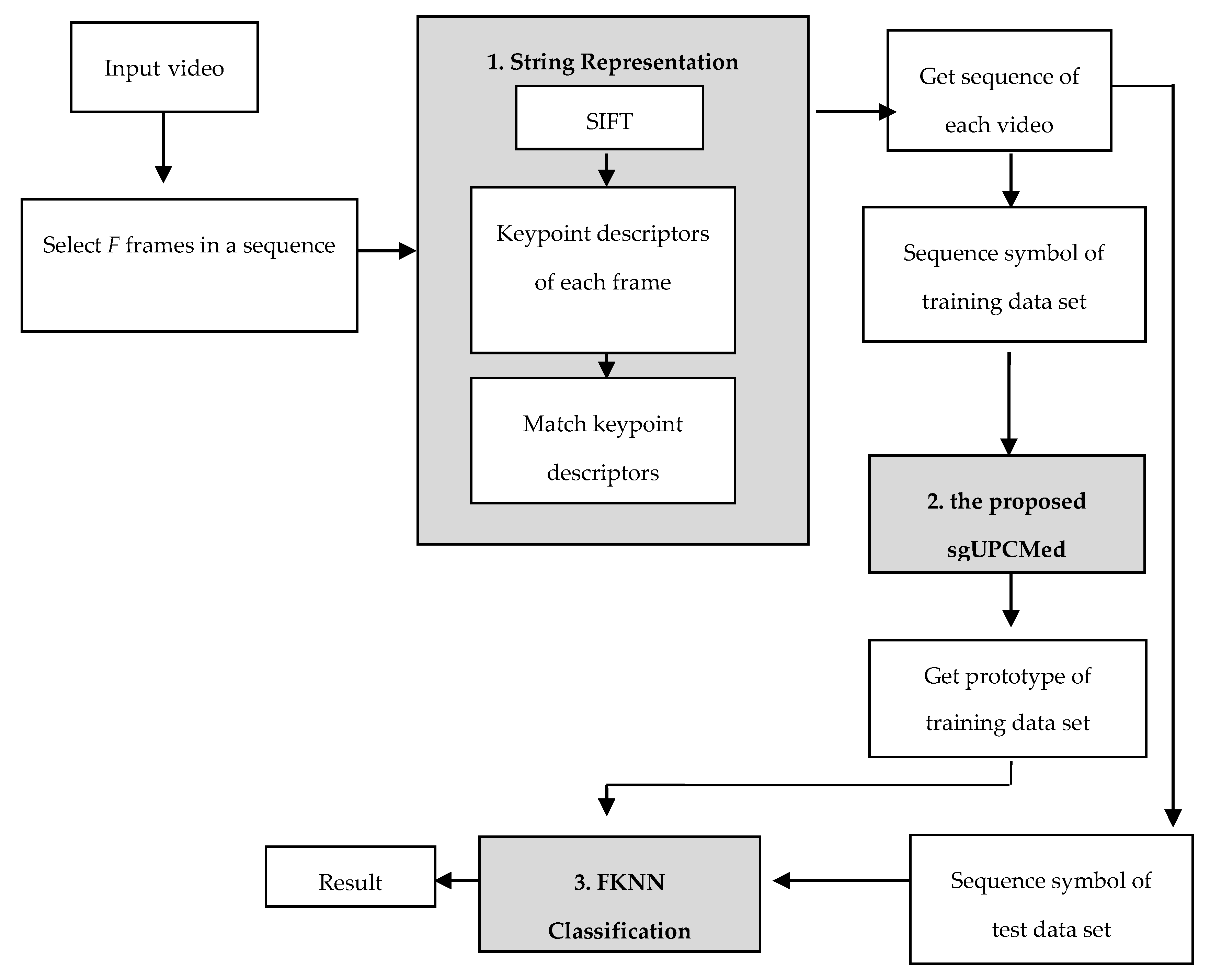
The overview of the proposed Thai Sign Language translation system is shown in
Figure 1. There are three parts to the system: string representation, string grammar clustering, and string grammar classification. In order to create string representation for each video, we first needed to collect 31 hand gestures [
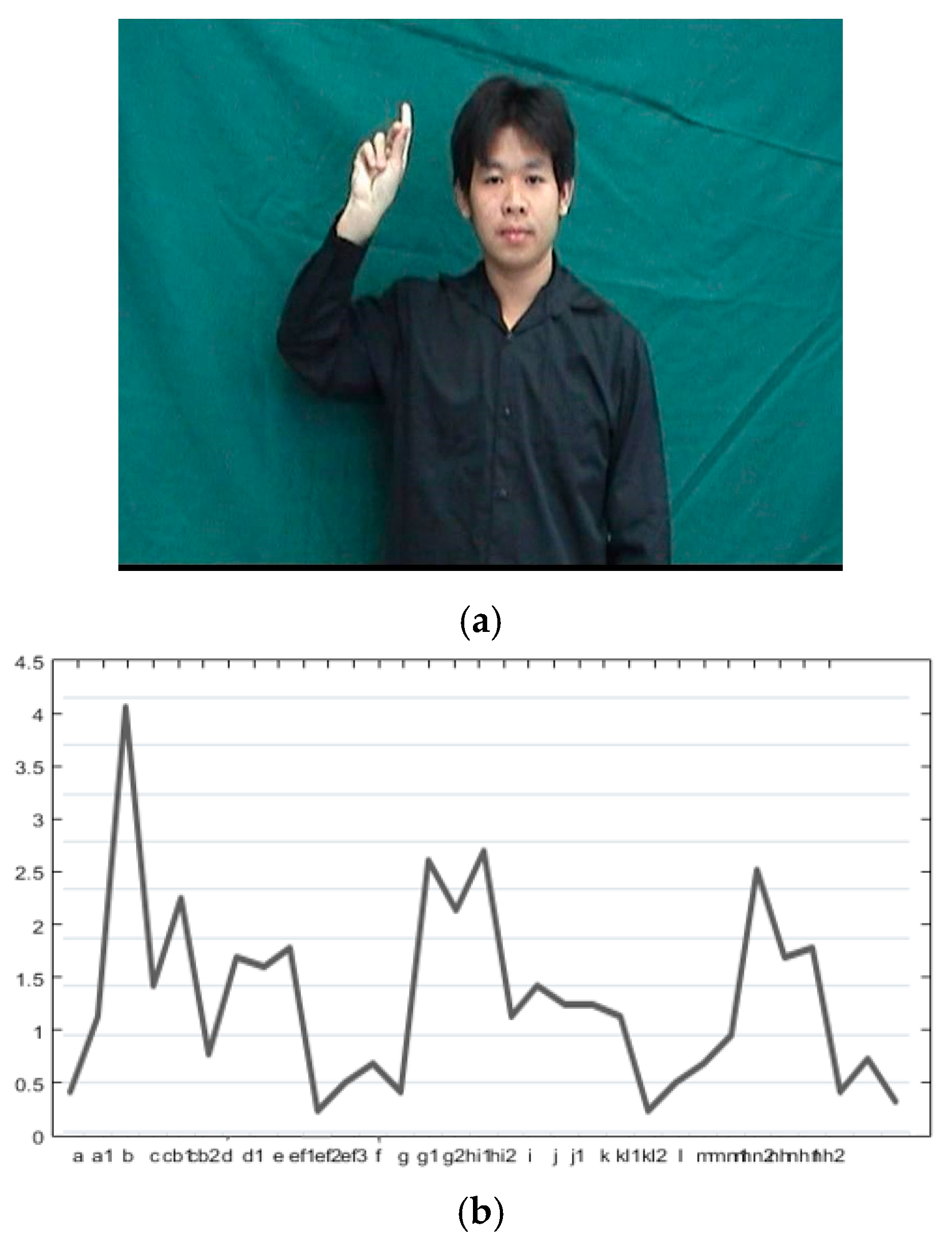
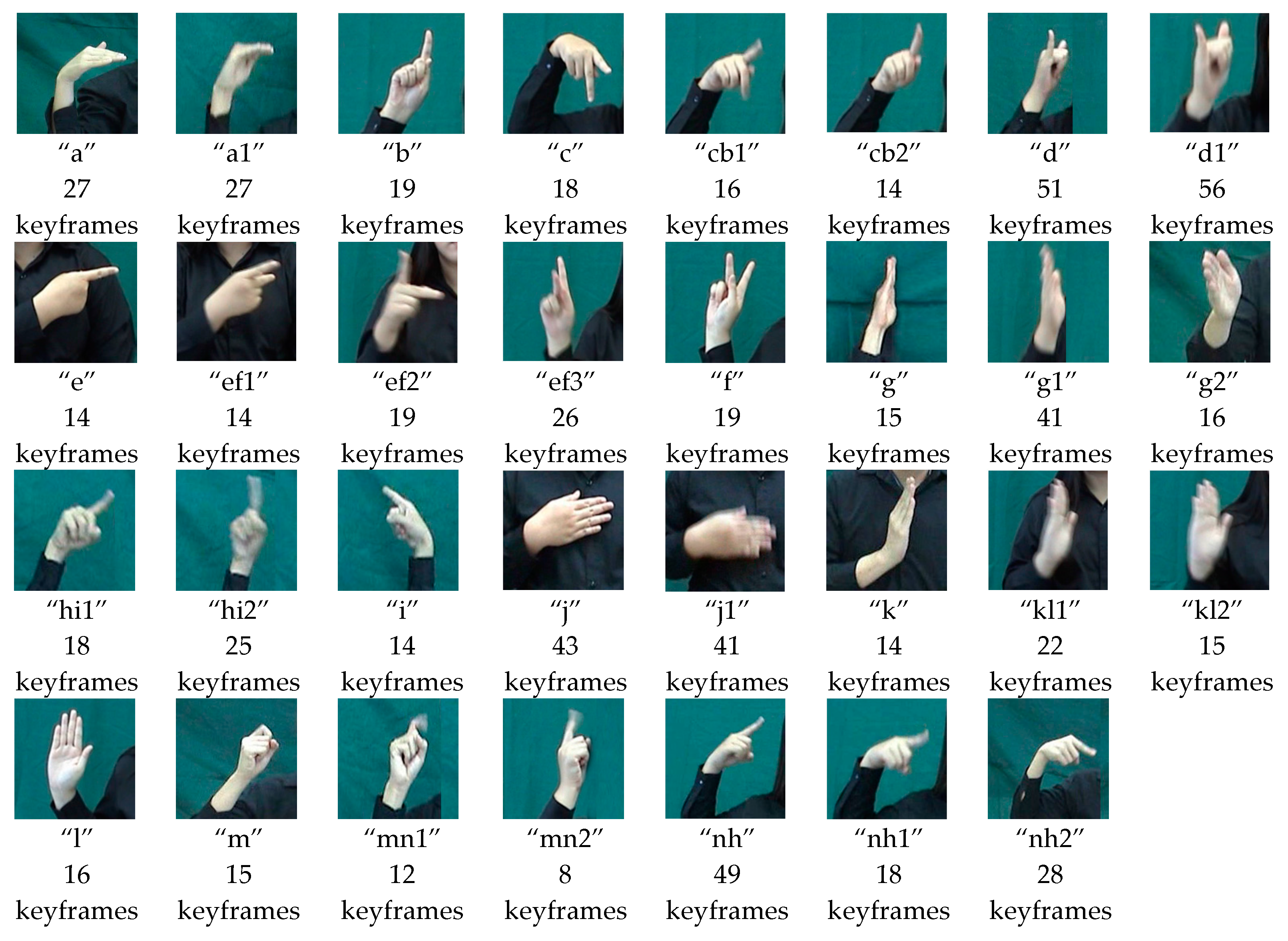
47] from 10 Thai hand sign words. Since fingers shapes, positions, and hand information are needed in the recognition system, we asked five subjects to wear a black shirt with long sleeves and stand in front of a dark background for the hand gesture collection process. Each subject was asked to perform each hand sign several times, and their movements were recorded in the form of video files. Then, we manually selected representative frames (Rframes) of each video file, and created the signature library [
43] from these Rframes as a part of the training process. Each manual Rframe selection only captured a portion of the hand, which measured 190 × 190 pixels. Please note that this hand image is called a keyframe for the sake of simplicity. For each subject, we had 730 keyframes, and there were 3650 keyframes in total. Examples of hand gestures and their corresponding numbers of keyframes in the signature library are shown in
Figure 2.
In the recognising process, we first chose
F image frames with approximately equal spacing from each video sequence to generate a string from the video file. For each image frame, we utilised the Scale Invariant Feature Transform (SIFT) method [
48] to extract interesting points. Then, we created descriptors that matched those in the signature library. Next, we selected a symbol representing that image frame. Finally the whole symbol sequence representing video files was generated. To create a prototype of each Thai hand sign word, we utilised the String Grammar Unsupervised Possibilistic C-Medians (sgUPCMed) algorithm. For the classification process, we utilised a modified version of the fuzzy k-nearest neighbour (FKNN) algorithm [
49] to find the right Thai hand sign word.
Now, let us briefly describe the SIFT algorithm [
48]. This approach is used to detect and describe local features in training images called the keypoint. It is one of the most popular approaches in 2D image-features matching. The SIFT consists of four main steps to generate a keypoint: the detection of scale-space extrema, feature point localisation, orientation assignment, and feature point descriptor. In the detection of scale-space extrema, Gaussian scale-space is constructed. The input image is smoothed with the difference of Gaussian (DoG) function. Scale space is separated into octaves. To create a set of scale-space images, the initial image is repeatedly convolved with Gaussian masks on each octave. The difference between consecutive blur amounts is then output as one octave of the pyramid. The local extrema of difference of Gaussian in scale space are found by comparing an interest pixel to its 26 neighbours in 3 × 3 regions at the current and adjacent scales. The extremum is selected as a keypoint location if the value of the pixel is greater than or less than all of its neighbours. Now, the number of keypoints is less than the number of pixels. However, there are still plenty of points, and many of them are bad points. In the keypoint localisation step, it rejects points with low contrast and points with poor edges. Please note that the number of found keypoints for each image will depend on the characteristics of the image. To assign an orientation, the gradient histogram and a small point around the keypoint based on local image gradient directions are used. The magnitude and direction of the gradient are calculated for all of the pixels in a neighbouring area around the keypoint in the Gaussian-blurred image. A gradient histogram with 36 bins is created in this step. Any peak within 80% of the highest peak is used to create a keypoint with that orientation. Then, a 16 × 16 neighbourhood around the keypoint is found. It is divided into 16 sub-blocks, with the size of 4 × 4. For each sub-block, an eight-bin orientation histogram is created. Each keypoint descriptor is a vector of 128 dimensions that distinctively identifies the neighbourhood around the keypoint.
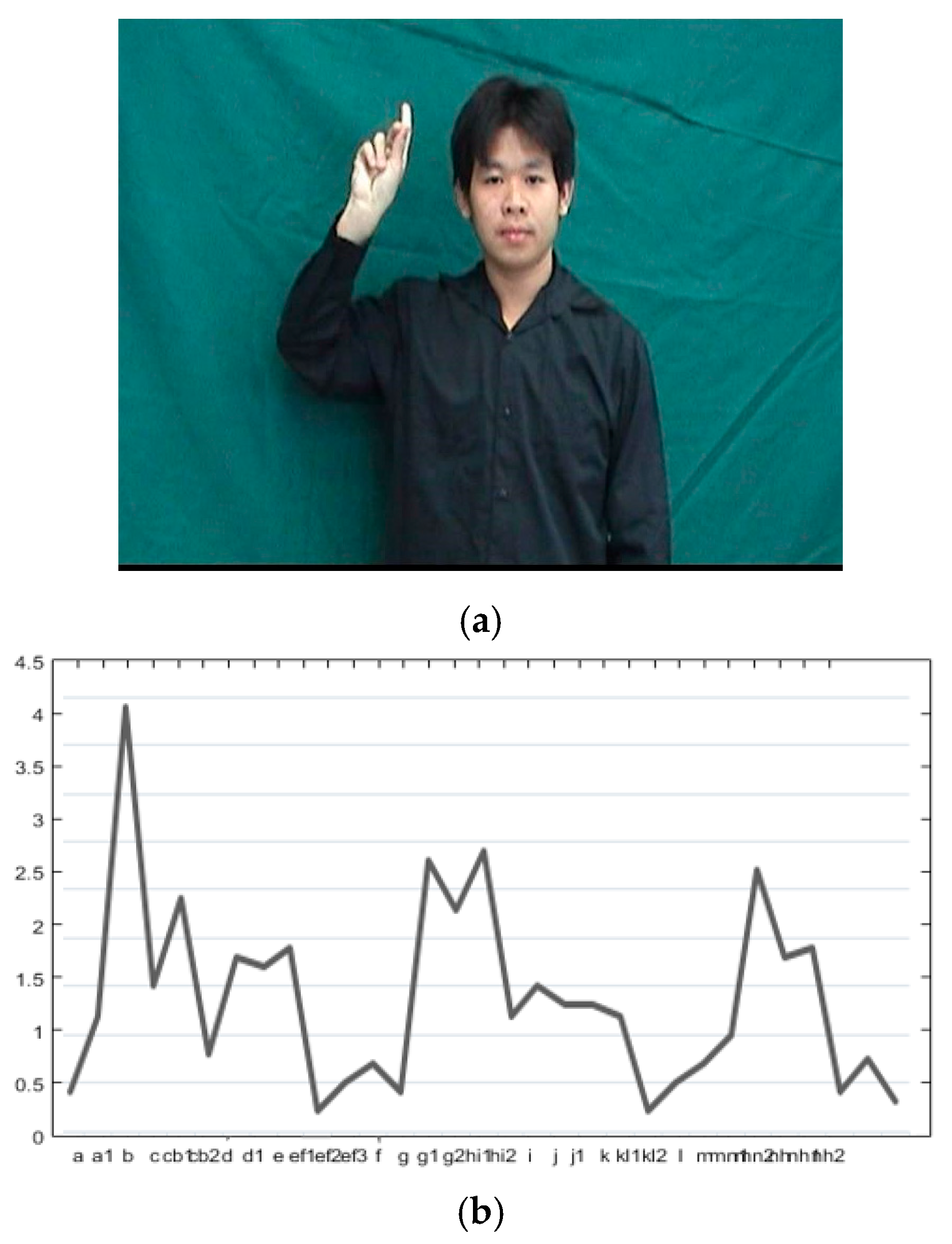
Figure 3a shows the keypoints found in an example keyframe, and examples of keypoint descriptors of three hand gestures are shown in
Figure 3b–d.
The keypoint matching process is performed by comparing the Euclidean distance between the two nearest neighbour keypoint descriptors in the signature library, and the current keypoint descriptor. If the ratio of the smallest distance to the second smallest distance is less than a given threshold, then the two keypoints match. Examples of keypoint matching are shown in
Figure 3e–g. Since the keyframes for each symbol in the signature library may have different numbers of keypoints, to identify the correct symbol for that image frame, the average number of matched keypoints per keyframe (
Avg_Match) [
43] of each symbol is computed as:
An example of this process is shown in
Figure 4. We repeat these steps for
F selected image frames of the video. Then, we obtained the sequence of symbols of each video, and then used this as the sequence of primitives in our string grammar fuzzy clustering algorithms.
In this paper, we propose the String Grammar Unsupervised Possibilistic C-Medians (sgUPCMed) algorithm to find multiprototypes of string data, i.e., Thai hand sign words in this work, from the training data set. We briefly describe the sgUPCMed algorithm here. Let
S = {
s1,
s2, …,
sN} be a set of
N strings. Each string (
sk) is a sequence of symbols (primitives). For example,
sk = (
x1x2…
xl), a string with length
l, where each
xi is a member of a set of defined symbols or primitives. Let
V = (
sc1,
sc2, …,
scc) represent a
C-tuple of string prototypes, each of which characterises one of the
C clusters. Let
U = [
uik]
C×N be a membership value of string
k in cluster
i. Let
T = [
tik]
C×N be a possibilistic value of string
k in cluster
i. Since this is a string calculation, the numeric distance metrics cannot be used in this case. Hence, the distance metric used in the paper is the Levenshtein distance [
50,
51,
52,
53] between string
sj and string prototypes
sci (Lev(
sci,
sj)) (a smallest number of transformations needed to derive one string from the other) between input string
j and cluster prototype
i.
Our String Grammar Unsupervised Possibilistic C-Medians (sgUPCMed) algorithm is a modified version of the unsupervised possibilistic C-medians [
54]. They are based on the same concept. That is, the objective function is based on the fuzzy C-means (FCM) clustering algorithm and two cluster validity indices, i.e., the partition coefficient (PC) and the partition entropy (PE). However, in our case, the feature vectors are not numeric vectors, but strings, and the distance is not the Euclidean distance, but the Levenshtein distance. Hence, the sgUPCMed’s objective function is:
where
uik is the membership value of string
sk belonging to cluster
i,
is the string prototype of cluster
i,
m is the fuzzifier (normally,
m > 1),
β is a positive parameter, and
N is the number of strings. Yang and Wu [
19] defined
β as the sample covariance based on the Euclidean distance. However, our data set is a string data set, and our
β is calculated based on the Levenshtein distance as:
where
Med is the median string of the data set, i.e.,
Theorem 1 (sgUPCMed). If for all i and k, when m, η, k >1, and S contains C < N distinct string data, then Jm,η is minimised only if the update equation of uik is: Proof. The reduced form of Equation (5) with
V fixed for the
kth column of
U is:
From the Lagrange multiplier theorem, the derivative of
Li(
U,
λ) with respect to
uik and setting it to zero leads to:
☐
The fuzzy median string [
55,
56,
57,
58] is utilised as a cluster center update equation because of the utilisation of the Levenshtein distance in our string grammar clustering. Hence, the cluster center
i update equation is:
However, Ref. 56 and 57proved that the modified median string provides a better classification rate than the regular median string. Then, the modified method in [
56,
57,
58] is also modified to calculate the fuzzy median. Let Σ* be the free monoid over the alphabet set Σ and a set of strings
S Σ*. Then, the modified fuzzy median, i.e., an approximation of fuzzy median using edition operations (insertion, deletion, and substitution) over each symbol of the string [
56,
57,
58] will be:
The modified fuzzy median string algorithm of the sgUPCMed isshown in Algorithm 1:
| Algorithm 1. The modified fuzzy median string algorithm of the sgUPCMed. |
| Start with the initial string s. |
| For each position i in the string s |
| 1. Build alternative |
| Substitution: Set z = s. For each symbol a Σ |
| (a) Set z’ to be the result of substituting ith symbol with symbol a. |
| (b) If . |
| then, set z = z’. |
| Deletion: Set y to be the result of deleting the ith symbol of s. |
| Insertion: Set x = s. For each symbol a Σ |
| (a) Set x’ to be the result of adding a at position ith of s. |
| (b) If . |
| then, set x = x’. |
| 2. Choose an alternative |
| Select string s’ from the set of strings {s,x,y,z} from step 1 using |
| . |
| Then, set s = s’. |
Hence, the summary of sgUPCMed algorithm is shown in Algorithm 2.
| Algorithm 2. sgUPCMed algorithm. |
| Store N unlabeled finite strings S = {sk; k = 1, ..., N} |
| Initialise string prototypes for all C classes |
| Set m |
| Compute β using Equation (3) |
| Do { |
| Update membership value using Equation (5) |
| Update center string of each cluster i (sci) using Equations (8) and (9) |
| } Until (stabilise) |
After, the multiprototypes, i.e.,
where
is string prototype
k of class
j, are created. The fuzzy k-nearest neighbour [
48] is utilised as a classifier. The FKNN is similar to the k-nearest neighbour (KNN), except that each data point can belong to multiple classes, with different membership values associated to these classes. For each string
s, the membership value
ui in class
i can be calculated as the following:
where
uij is the membership value of the
jth prototype from class
q (
) in class
i,
c is the number of classes, and
K is the number of nearest neighbours. The decision rule for the test string
s is:
In the experiment, since we know the class that the prototype string represents, we set uiq = 1 for in class q and 0 for all of the other classes. The parameter m is used to determine how heavily the distance is weighted when calculating each neighbour’s contribution to the membership value, and its value is chosen for our experiment as m = 2.
To summarise our algorithm as shown in
Figure 1, we first need to create the multiprototypes training process with the SIFT and the sgUPCMed algorithms. The Levenshtein distance and the FKNN are used to recognise the sign language words. The computational complexity of the training process will be
O(
F·(
ot·m·n + kp + m·n + m·n·b2·kp))
+ O(
F·nS·dl2)
+ O((
l2·N2)
+ (
l2·N2)
+ (
l3·c·|Σ|)), where
m and
n are the width and height of an image,
ot and
kp are the number of octaves and the number of keypoints,
dl is the SIFT descriptor length,
F is the number of video image frames, and
nS is the number of keyframes in the signature library. The remaining parameters are string length (
l) (equals to
F), the number of data samples (
N), the number of clusters (
c), and the alphabet set (Σ). For the recognising process, the computational complexity is
O(
F(
ot·m·n + kp + m·n + m·n·b2·kp))
+ O(
F·nS·dl2)
+ O(
N·(l2 + Nlog
N + K)), where
K is the number of nearest neighbours used.
3. Experimental Results
An experiment data set (training and test video data sets) was collected from 25 subjects at different times of day for several days. Subjects 1–20 were asked to wear a black shirt with long sleeves and stand in front of a dark background. In contrast, subjects 21–25 were asked to wear short sleeves and were in front of various complex natural backgrounds. The data set consisted of 10 hand sign words (classes), i.e., ‘‘elder’’, ‘‘grandfather’’, ‘‘grandmother’’, ‘‘gratitude’’, ‘‘female’’, ‘‘male’’, ‘‘glad’’, ‘‘thank you’’, ‘‘understand’’, and ‘‘miss’’. The number of samples for each hand sign is shown in
Table 2. We first collected the keyframes in the signature library from subjects 1–5. We manually selected a portion of the hand in each frame that measured 190 × 190 pixels. After that, we computed keypoint descriptors for each frame using SIFT, and then stored it in the signature library database. The test videos were recorded for subjects 1–20 (with constraint) and for subjects 21–25 (without any constraints). Each video was decimated, which left only 14 frames. Each frame was matched to a representative symbol in the signature library using SIFT, and the threshold values for the experiment varied between 0.65, 0.7, and 0.75.
Our experiment was divided into three parts, i.e., training with 1a, training with 1a–5a, and training with 1a–15a. There were three groups of blind test: data set 1b–15b, data set 16–20 (used to represent the signer-independent cases), and 21–25 (with various complex natural backgrounds). For all of the training and test data sets, we assigned symbols to each frame in the training data set using the SIFT method. We use multiprototypes created from the sgUPCMed algorithm to classify 10 hand sign words, in which the lengths of each string representation were 14. Afterwards, we created multiprototypes in terms of a sequence of primitives, and the test string was assigned to the word that the closest prototype belonged to, according to the FKNN algorithm with the Levenshtein distance.
We implemented four-fold cross validation on the training set and implemented the sgUPCMed with four, eight, and 12 clusters on each class separately to create multiprototypes for each class. Then, the FKNN with
K = 1, 3, 5, 7 and 9 were implemented as classifiers.
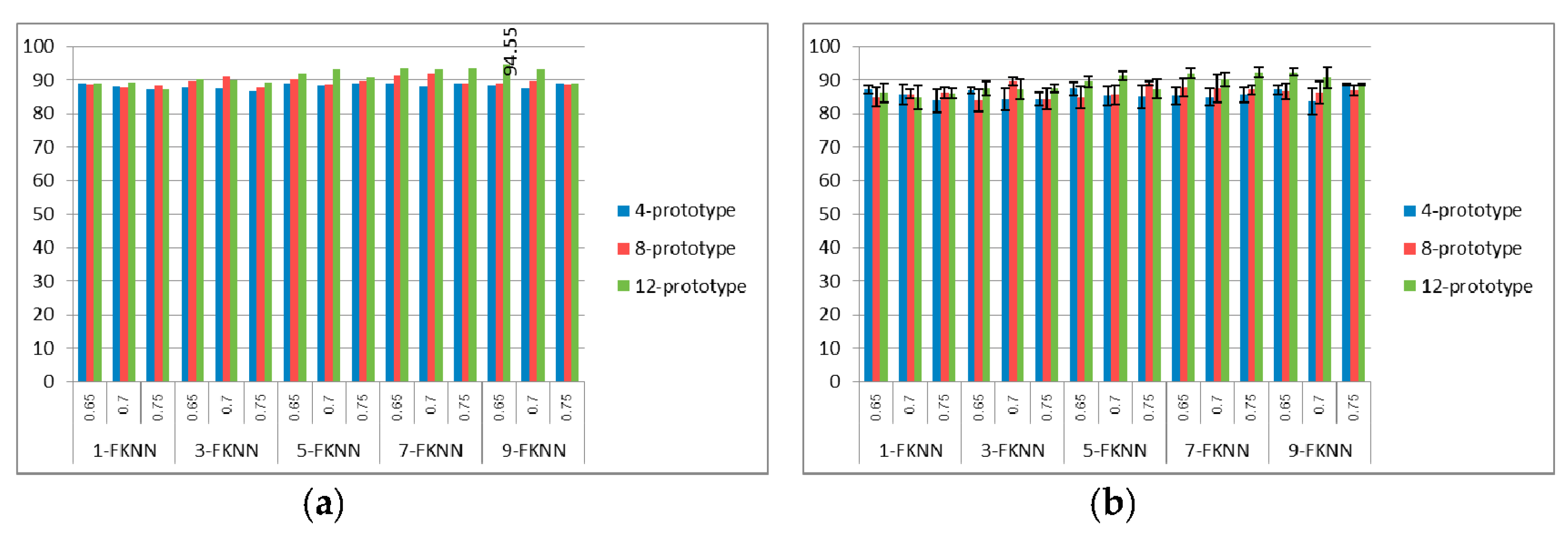
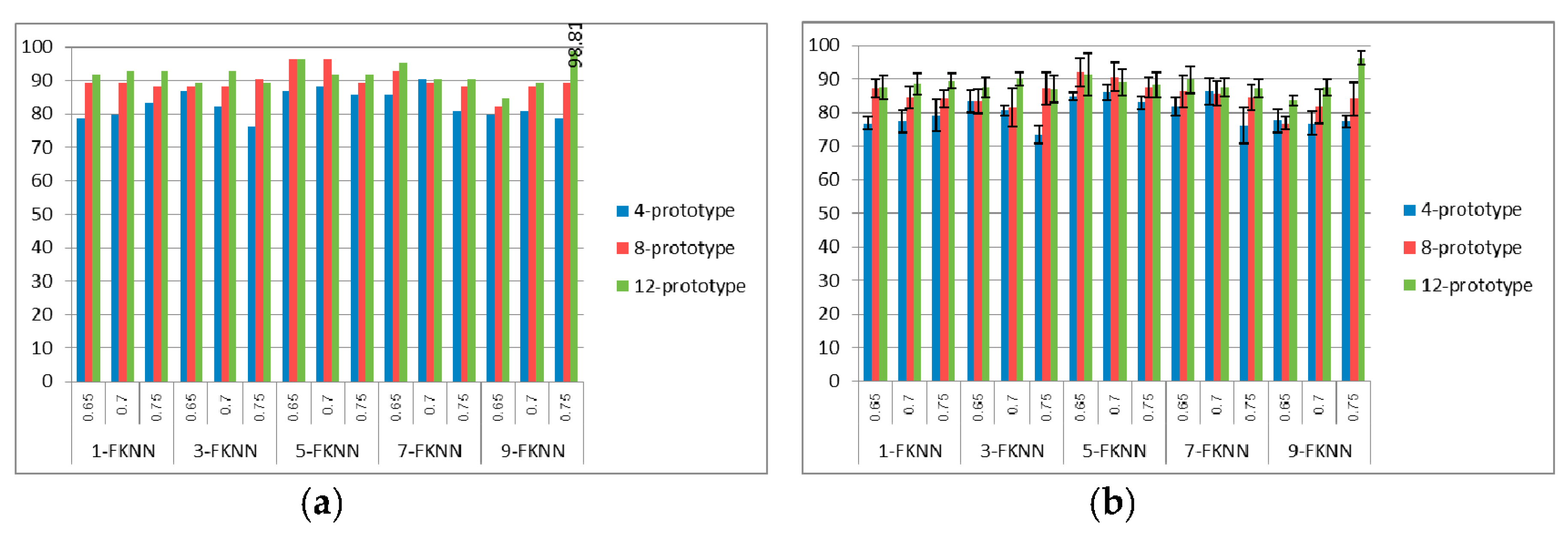
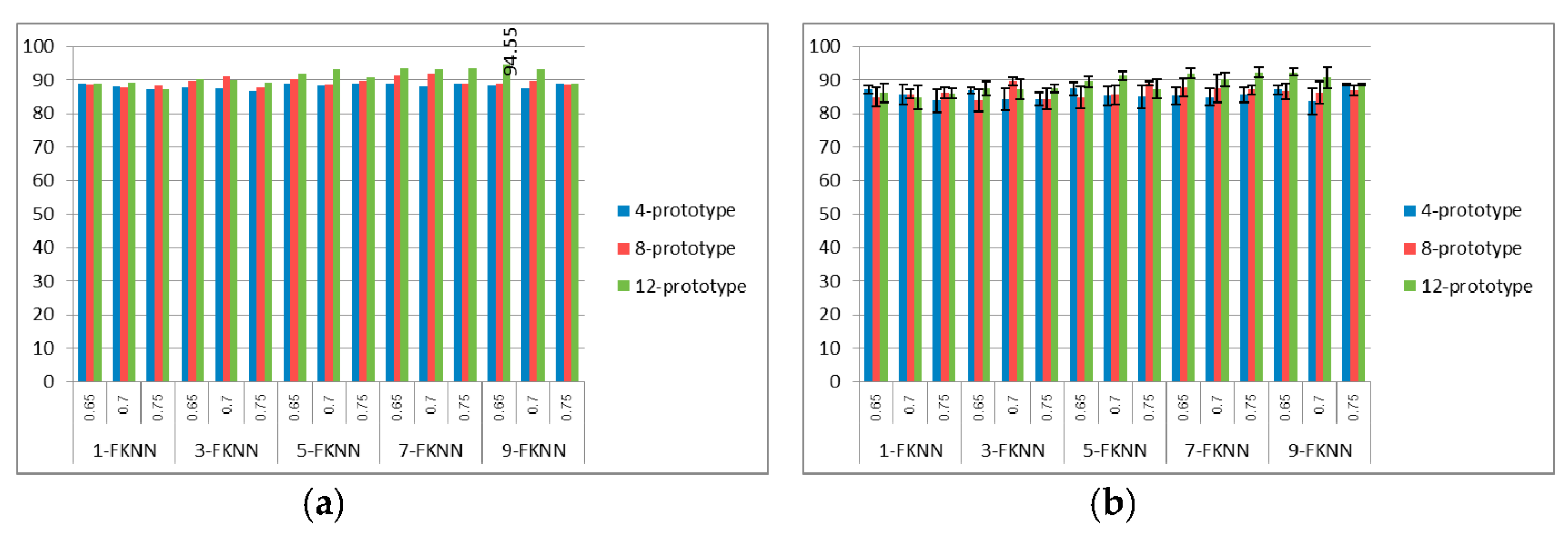
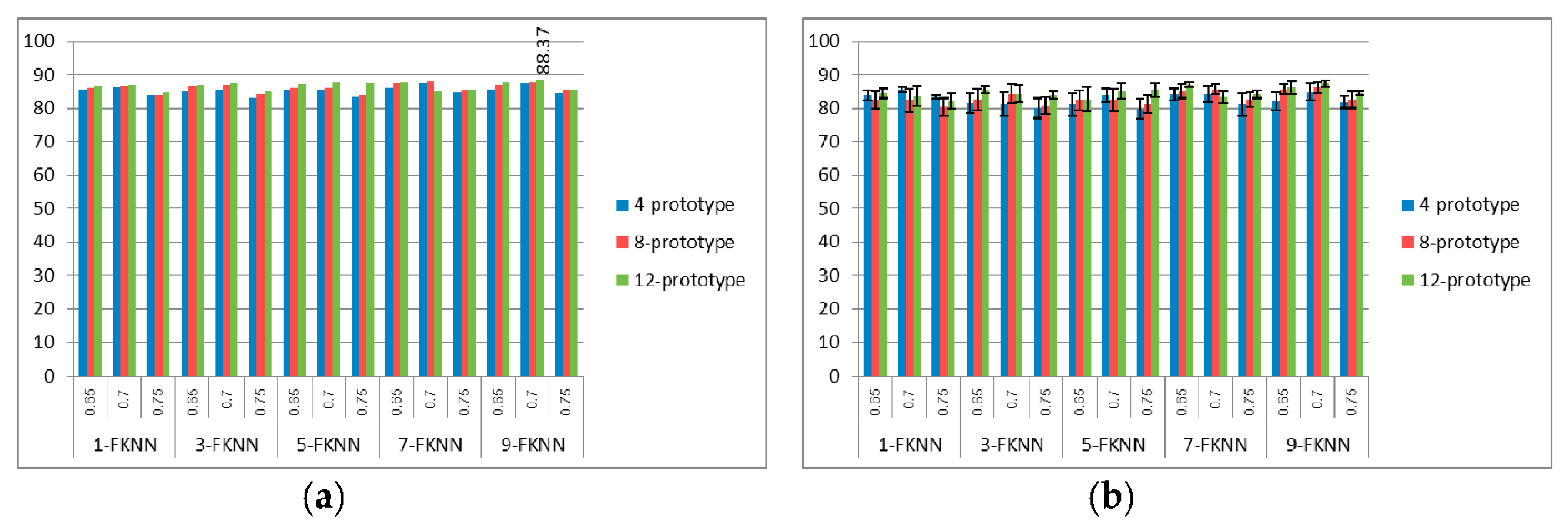
Figure 5,
Figure 6 and
Figure 7 show the best and average correct classification of the validation set of training with 1a, training with 1a–5a, and training with 1a–15a for the FKNN with
K = 1, 3, 5, 7, and 9, respectively. We can see that the best classification rate was at 98.81%, when trained with 1a and 12 prototypes for each class with 0.75 SIFT threshold and
K = 9. Whereas, when trained with 1a–5a, the best classification rate that system provided was at 94.55%, with 12 prototypes, 0.65 SIFT threshold, and
K = 9. For the 1a–15a training data set, we obtained 88.37% correct classification with 12 prototypes, 0.7 SIFT threshold, and
K = 9. From all of the experiments, we can see that if we increase the number of prototypes in the process of string grammar clustering, there is a chance that the classification rates of all of the types of signer will also increase. From the results in
Figure 5,
Figure 6 and
Figure 7, the 12-prototype string grammar clustering with 9-FKNN gave a classification rate that was higher than the other prototypes. Hence, we used 12-prototypes string grammar clustering with 9-FKNN to test the blind test data set, as shown in
Figure 8,
Figure 9,
Figure 10 and
Figure 11.
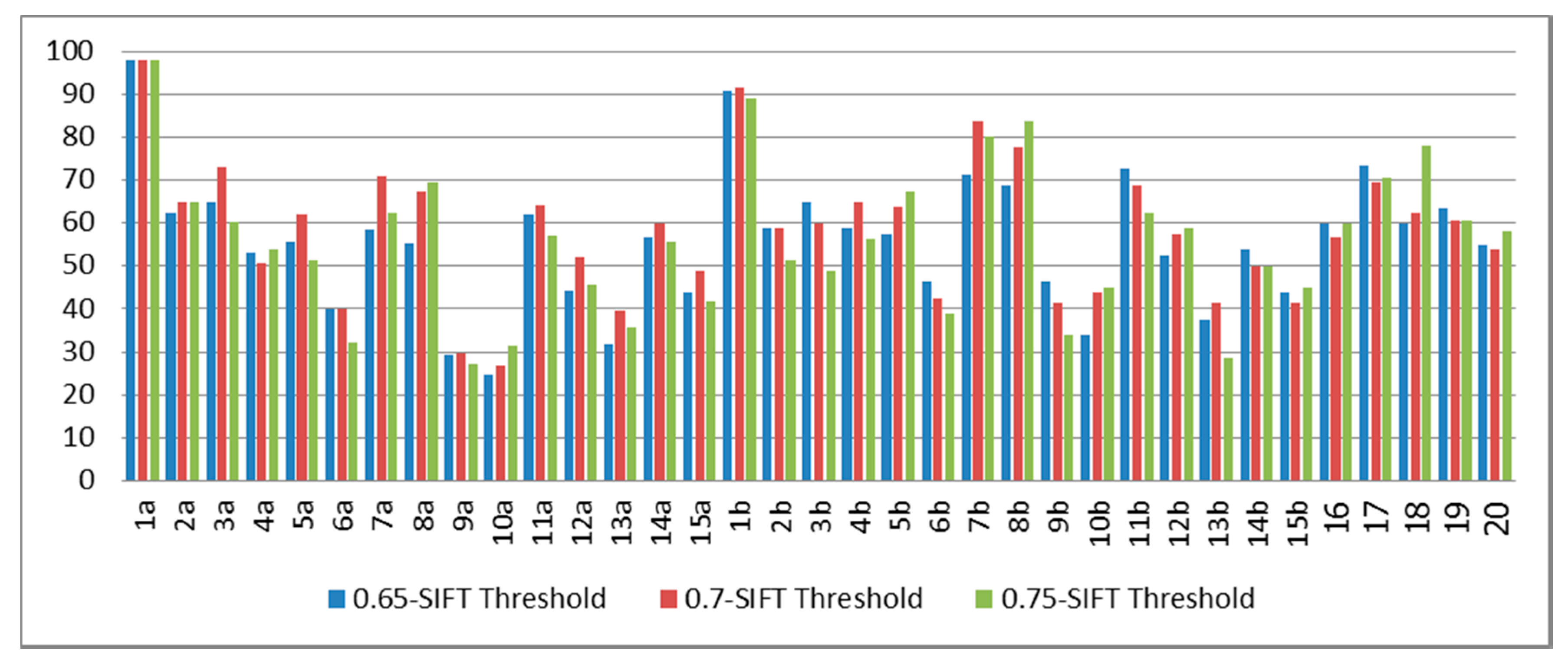
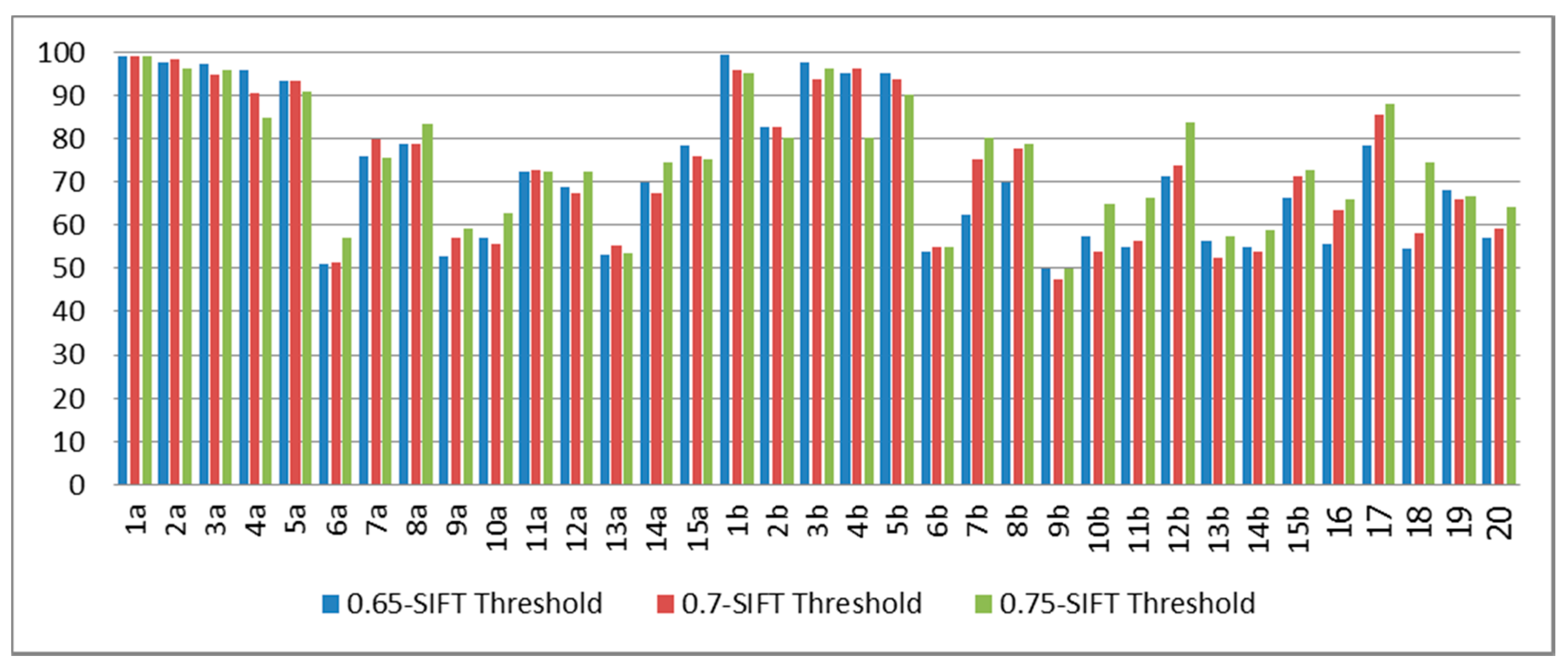
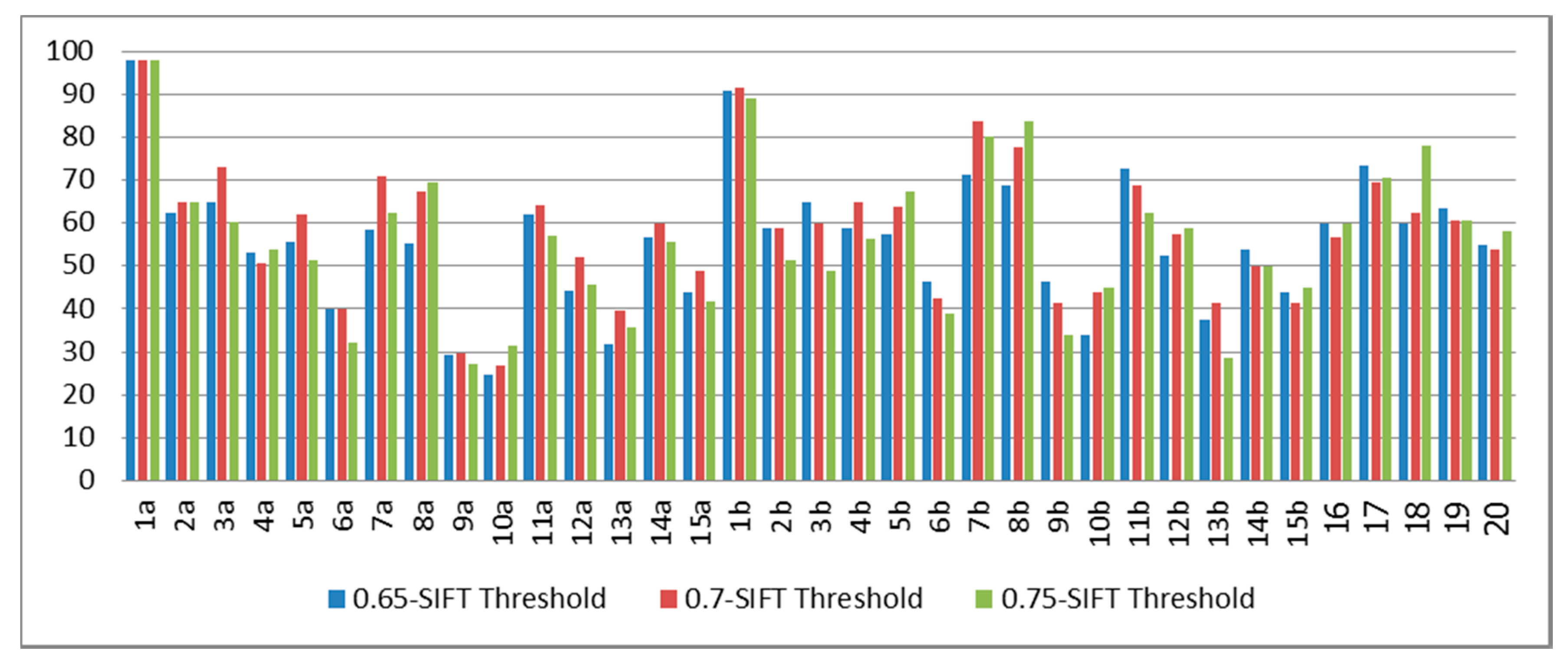
From
Figure 8, the classification rates for 1a and 1b (signer-dependent cases) were 97.92% and 90.56%, respectively, since this system was trained with the first subject. The average classification rate from the signer semi-independent cases (2a–5a and 2b–5b) was approximately 59.50%. Meanwhile, the average classification results from subjects 6a–15a, 6b–15b, and 16–20 (the signer-independent cases) was around 54.32%.
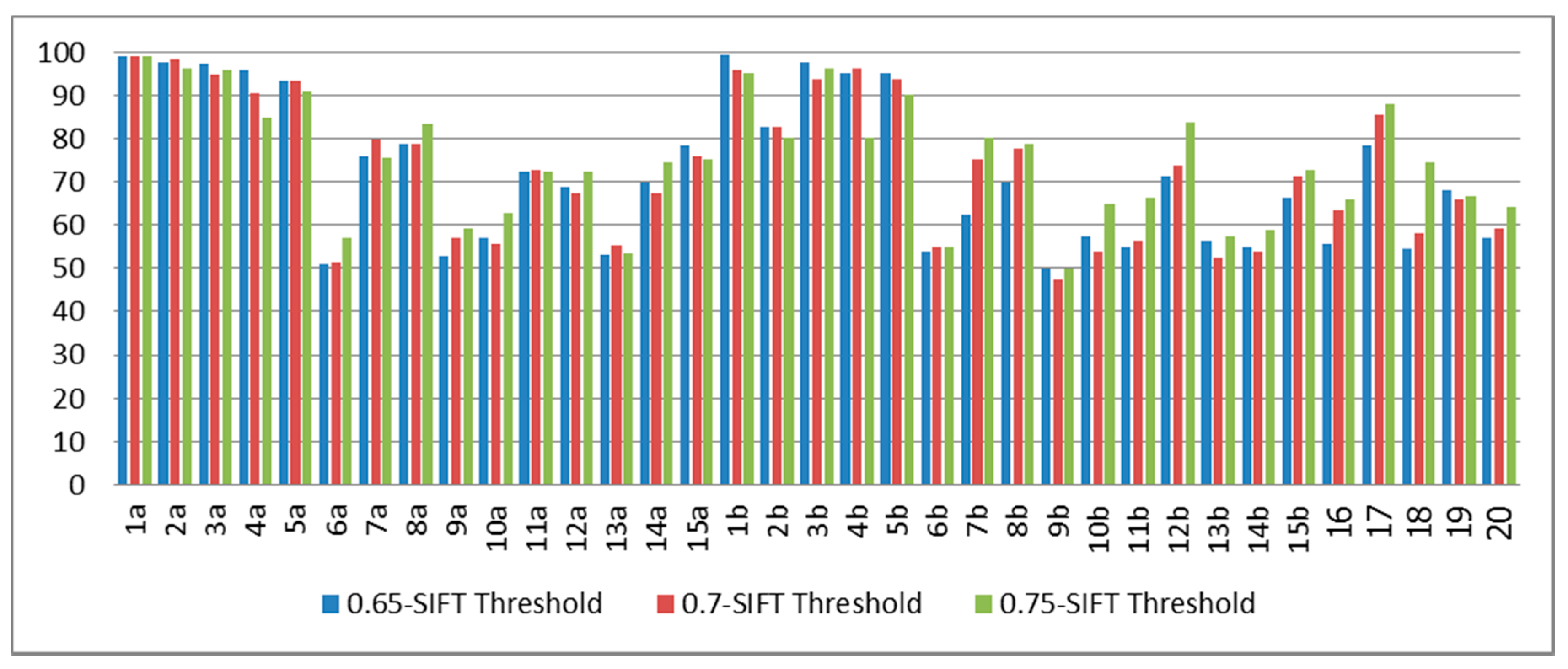
The classification results on the test set when we trained on the data set 1a–5a are shown in
Figure 9. The best average classification rate of the blind test data sets of the signer-dependent cases (subjects 1–5) was around 95.24%. The best average classification rates of the blind test data sets of the signer-independent cases, subjects 6–15 and subjects 16–20, were 67.64% and 71.8%, respectively. Therefore, we can see that the classification rates from all of the types of signer are increased, if we increase the number of signers in the training process of the sgUPCMed method.
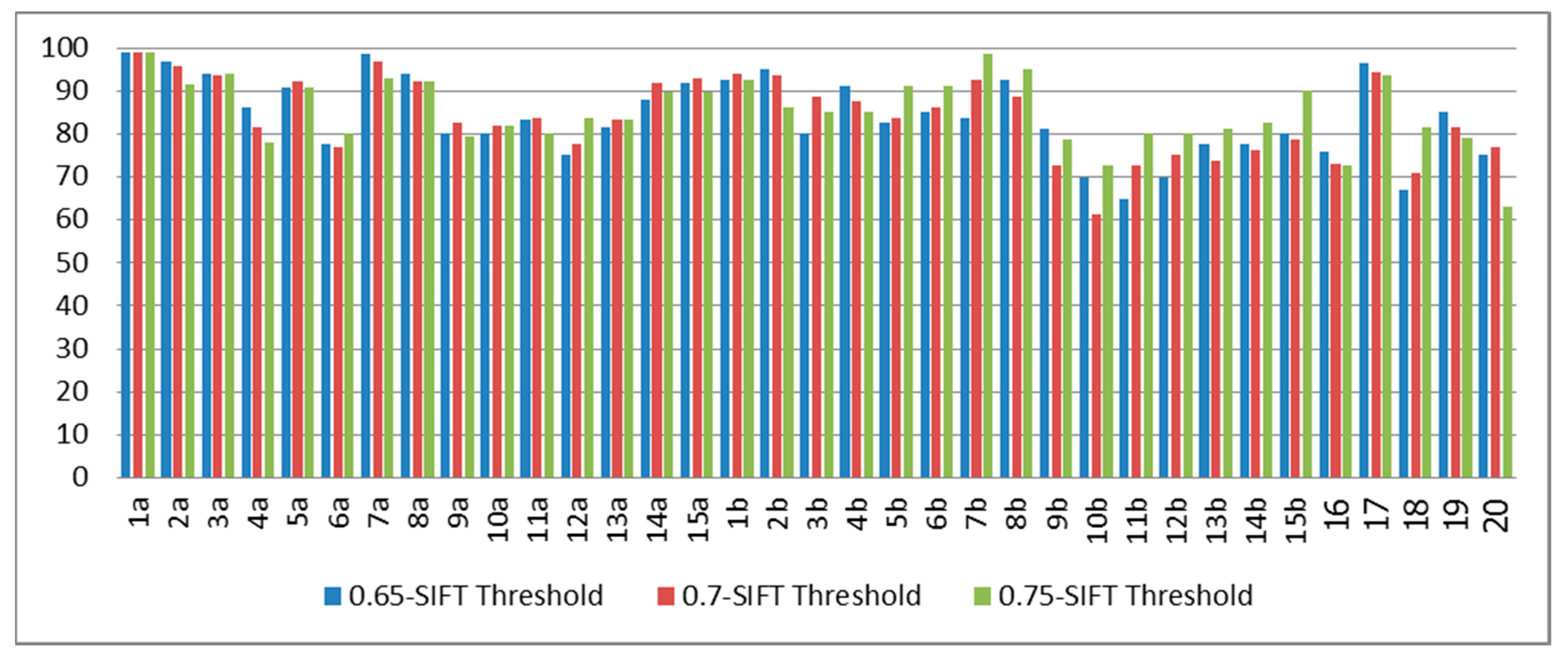
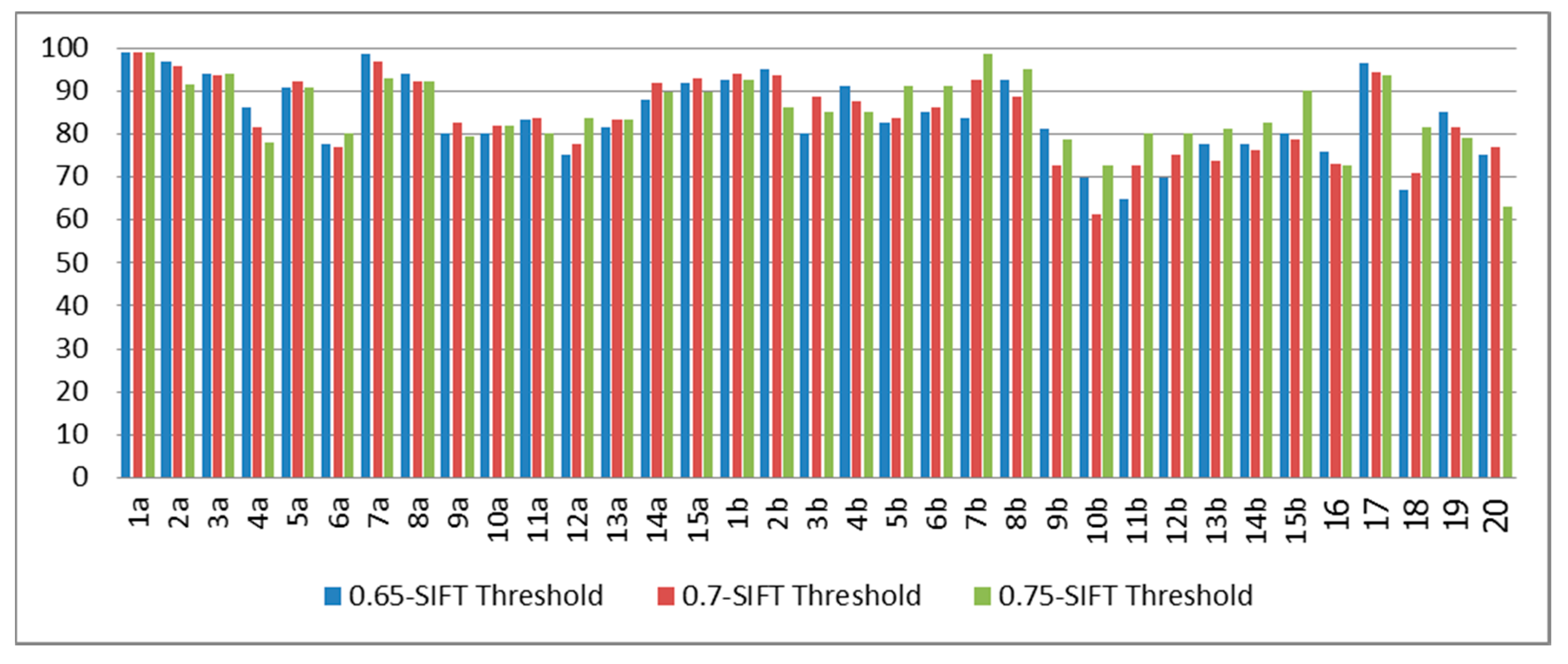
From the blind test results from the training process with 1a–15a, as shown in
Figure 10, we can see that the best average classification rates for the signer-dependent cases (subjects 1–5) was 90.99%, whereas that of the signer semi-dependent cases (subjects 6–15) was 85.14%. Meanwhile, the best average classification rate of the signer-independent cases (subjects 16–20) was 79.90%. Again, the greater the number of training subjects, the more accurate the system.
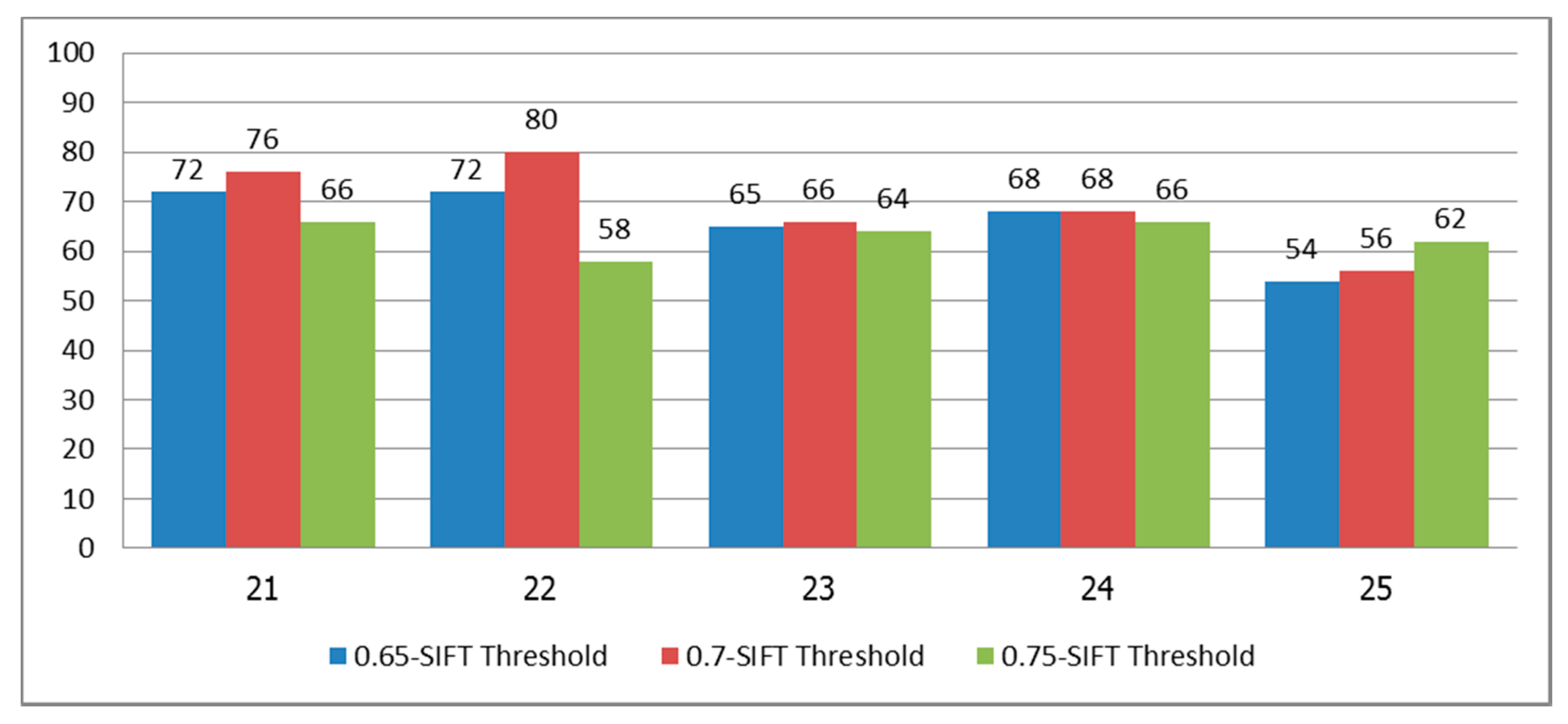
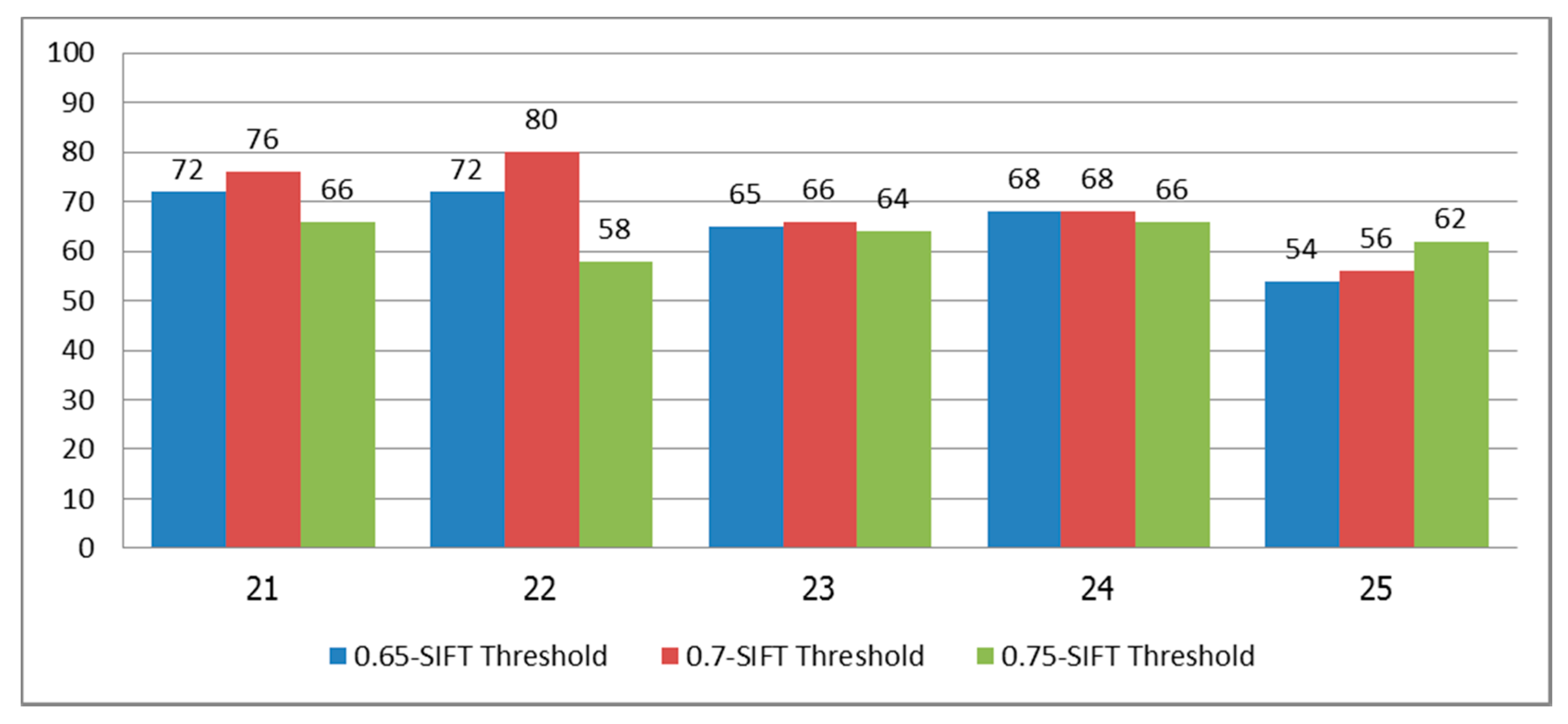
Hence, we selected the system trained with subjects 1a–15a, and tested it on subjects 21–25, who were asked to wear any type of shirt and stand in front of natural backgrounds. Each subject performed each sign five times at any time of day. The classification results are shown in
Figure 11. We can see that the best result for subjects 21–25 were 76% with 0.70 SIFT threshold, 80% with 0.70 SIFT threshold, 66% with 0.70 SIFT threshold, 68% with 0.65 and 0.70 SIFT threshold, and 62% with 0.75 SIFT threshold for the five subjects, respectively. Since the signers of this test set (subjects 21–25) were different signers from the training data set and the signature library, the results of this experiment provided low classification. Furthermore, when we used SIFT with the unconstrained system and complex natural backgrounds, the matched keypoints might be incorrectly matched, as shown
Figure 3g. We can use Equation (1) to find the correct symbol for each test frame, even though it has some mismatched keypoints from the SIFT process. However, our algorithm cannot find the right symbol if there are too many mismatched keypoints.
Now, we compare the performance of our algorithm with the reported classification rate results of the Thai Sign Language (TSL) translation system [
43] using Hidden Markov Model (HMM) on the same data set as shown in
Table 3. We can see that the best results for the signer-dependent, signer semi-dependent and signer-independent cases from the TSL with HMM were 88.60%, 80.55%, and 76.75%, respectively. Whereas those from our proposed algorithms were 90.85%, 85.14%, and 79.90%, respectively. A comparison can be done between this method and the best average of our translation system. Our system yields a pretty good result that is comparable with TSL [
43] in all of the experiments. HMM may create higher misclassification than our method because the HMM model that gives the maximum value is not the right one. Meanwhile, our method not only chooses the maximum one, it also utilises string grammar fuzzy clustering to find the multiprototypes, and after that, the FKNN algorithm will choose the closest string prototypes using the k-nearest neighbours.
In order to consider how this system performs when implemented on other sign languages; we implemented our system on the RWTH-BOSTON-50 data set [
46]. Although this data set has 50 words from three signers, there are 19 words in which the total number of video sequences for each word is around one to three sequences. Hence, we only used the 31 words that have more than three sequences for each word. The details of the words used and the number of sequences and signers performing the words are shown in
Table 4. Hence, for 31 words, there are 437 sequences in total. Again, for this data set, we collected keyframes to create a signature library. Since each signer did not perform the same amount of sequences for each word, the numbers of repetitions selected manually for each keyframe were not the same. There were 81 keyframes; hence, there are 319 keyframes in total in the signature library. An example of keyframes and the corresponding number of keyframes is shown in
Figure 12. In this case, to generate a string for each word, the minimum number of frames of each word is used as the number of symbols
F of the word sequence, because each word contains a different number of frames, as shown in
Table 4. For example, for the word “ARRIVE”, we created a string with a length of seven, whereas for “BOX”, the created string had a length of nine. Again, we chose
F image frames with approximately equal spacing from each video sequence to generate a test string for each word. This shows that our sgUPCMed does not require the strings to have the same length in order to perform the string clustering.
We implemented leave-one-out cross-validation for this data set, meaning that we only selected one sequence for each word to be our validation set, and used all of the other sequences to train our sgUPCMed algorithm. The numbers of prototypes created by our sgUPCMed algorithm were not the same, as shown in
Table 5, because of the different numbers of word repetitions of the data set. We then used FKNN with only one nearest neighbour to find the best word match. The SIFT threshold used in this data set varied from 0.4 to 0.75, with a step size of 0.5. The results from the validation data set and the combined training and validation set are shown in
Table 6. The SIFT threshold used in this data set varied from 0.4 to 0.75, with a step size of 0.5. The best result of the validation set was 88.56%, while the best result of the combined training and validation set was 91.35%.
We compared our results with the existing algorithms to show the performance of our proposed method.
Table 7 and
Table 8 show the performance of the proposed algorithm and that of the existing algorithms on the Thai sign language data set and the RWTH-BOSTON data set, respectively. However, on the RWTH-BOSTON data set, we merely show the performance of different algorithms ([
27,
45,
46]) on the same data set without any comparison analysis, because it could be thought of as an unfair comparison.
Table 8 shows that our result is in the same range (88.56% correct classification rate) of those in [
27,
45,
46] with different experiment settings. Also, it is difficult to directly/indirectly compare our method with the other methods, because the sign languages of other countries are different from Thai Sign Language. Hence, we can only say that our algorithm can be used in different sign languages, not just in Thai Sign Language, and it can provide a reasonable result that is within the same range as the existing algorithms shown in
Table 1. Moreover, in order to implement our proposed algorithm in a different sign language, we need to create a signature library for each sign language, since it is not the same for different sign languages. We also need to train our system according to that separately.
One might also ask about the difference between the proposed method with that in [
42,
43]. The method in [
42] can be used to translate Thai finger-spelling, but not Thai hand sign. The method only uses the SIFT method to find a matching alphabet. If the composed alphabets match with any spelled words, then the system reports that word. The one in [
43] used the SIFT method to extract this feature as in this proposed method. However, it used HMM as a classifier, while we use the sgUPCMed and the FKNN algorithms as our classifiers here. In addition, from
Table 7, our proposed method is better than the results shown in [
43].
One of the advantages of our algorithm is that it provides a good result for recognising isolated sign language words that have similar hand gestures. Examples of Rframes representing the Thai Sign Language words of “grandmother” and “grandfather” are shown in
Figure 13. The symbol sequence of the word “grandmother” is “mmmbbbbbmbbbbb”, while that of the “grandfather” is “mmmmcb2cb2bbbbbbbb”. We can see that these two words have similar hand gestures in the sequence. The blind test recognition rates of “grandmother” and “grandfather” at a SIFT threshold of 0.65 and FKNN with
K = 9 are 72% and 84%, respectively. Examples of frames from “GO” with the symbol sequence of “ooooo1o2” and “SHOULD” with the symbol sequence of “ooo1o2” from the RWTH-BOSTON-50 are shown in
Figure 14. Again, the recognition rates with a SIFT threshold of 0.45 with one nearest neighbour (FKNN) of these “GO” and “SHOULD” are 73.68% and 80%, respectively. These are examples of sign language words with similar hand gesture. However, for the whole data set, there were some other words with similar hand gestures as well. With this condition, our system can still provide a good recognition rate for the whole data set. However, some misclassifications have occurred in our system, which might be the result of some hand gestures that are very similar, yet represent different symbols in the signature library. An example of similar hand gestures for symbols “g”, “g2”, and “k” in Thai Sign Language are shown in
Figure 15. Meanwhile,
Figure 16 shows an example of the similar hand gestures for symbols “t”, “t1”, “v”, and “v3” in RWITH-BOSTON-50. If this occurs for different words, it might cause the system to think that they are the same word.
To implement this system in real time, one might wonder how fast the algorithm will be when implemented online. One of the parameters that might influence the real-time processing is the number of keypoints found on each image frame. The number of minimum, maximum, and average number of keypoints from the Thai Sign Language data set were 56, 153, and 72, respectively. Whereas, those from the RWTH-BOSTON-50 data set were 32, 112, and 41 keypoints, respectively. Of course, the greater the number of keypoints, the slower the algorithm. However, the average recognising processing times of both data sets was approximately one to two seconds per sign word, respectively. This part of the experiment was implemented on a 3.6 GHz Intel Core i7 with 8 GB 2400 MHz DDR4 RAM.
4. Conclusions
In this paper, we improved the dynamic Thai Sign Language translation system with video caption without prior hand region detection and segmentation using the Scale Invariant Feature Transform (SIFT) method and the proposed String Grammar Unsupervised Possibilistic C-Medians (sgUPCMed) algorithm. The SIFT method was used to match test frames with symbols in the signature library, whereas the proposed sgUPCMed algorithm was used to generate multiprototypes for each sign. The fuzzy k-nearest neighbour (FKNN) algorithm was utilised to find the matched sign words. Please note that because of the different signs in various languages, it is necessary to train the system with several SIFT thresholds and several cluster numbers from sgUPCMed in order to find the best SIFT threshold and the best cluster number. Also, the best number of K in the FKNN for the recognising process can be found by trial and error on several testing data sets before using the system in real-time applications. We found that the best result for the blind Thai Sign Language (isolated sign word) data sets of signer-dependent cases was in between 89% and 91% on average, and the average for the signer semi-independent cases (where the same subjects were used in the string grammar clustering) was around 81–85%. Whereas, the best average classification rate of the blind data sets of the signer-independent cases was 77–80%. Moreover, our system could perform translations for each video without the need for any pre-processing techniques, i.e., segmentation and hand detection. The SIFT method provides more informative information of the position, shape, and orientation of the hand and fingers. This allows the system to be able to recognise hand sign words that have similar gestures. However, when we tested our algorithm with the test subject without any constraint on five signers (subjects 21–25), who were asked to stand in front of various complex backgrounds and could wear any shirt, the best correct classification rate in this case was around 70–80% on average.
To prove our generality over sign languages, we also implemented our proposed algorithm with the RWTH-BOSTON-50 data set, which consists of 31 isolated American Sign Language words. The result showed that the sign language word recognition was 88.56% and 91.35% on the validation set only and for both the training and validation sets, respectively. This shows that our algorithm is flexible enough to be implemented on any sign language.
Since the objective function of our sgUPCMed algorithm is based on the validity indices PC and PE as in the Unsupervised Possibilistic C-Means (UPCM), the exponential membership functions were used to describe the degree of belonging. This is an advantage of our system, because the system can detect the outliers (too far from prototypes) of Thai Sign Language by yielding very low or close to zero membership values for those outliers. However, one constraint of the sgUPCMed algorithm was that it sometimes generated coincident clusters when we ran multiprototype clustering. It might generate prototypes with very close locations, because of the relaxing constraint of the columns and rows of the independent possibilistic values.
We also compared our method with the HMM method, and demonstrated that the best classification of our method is better than HMM on all of the experiments. The HMM method may create higher misclassification rates than our method because of the chance that the selected probability-based HMM model is not the actually the best one. Although our system provides better classification rates than previous methods for Thai Sign Language, there are still some issues regarding its performance that we could improve. For instance, the string representation process could be improved by using other features, because the SIFT method could not extract some interesting points from images with complex natural backgrounds. Hence, the classification rates in these cases were low.
Although our system performs very well in translating hand sign, the final goal is to translate continuous sign language. Some research studies are already investigating continuous sign language translation [
59,
60,
61]. Our future plan is to embed our system into a continuous sign language translation system.
One of the disadvantages of the system might be from the transformation from 3D images to 2D images. Our future work will consider including 3D information in the acquisition process of the data set before implementing it into the translation system.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}