System Framework for Cardiovascular Disease Prediction Based on Big Data Technology


Abstract
:1. Introduction
2. Methods
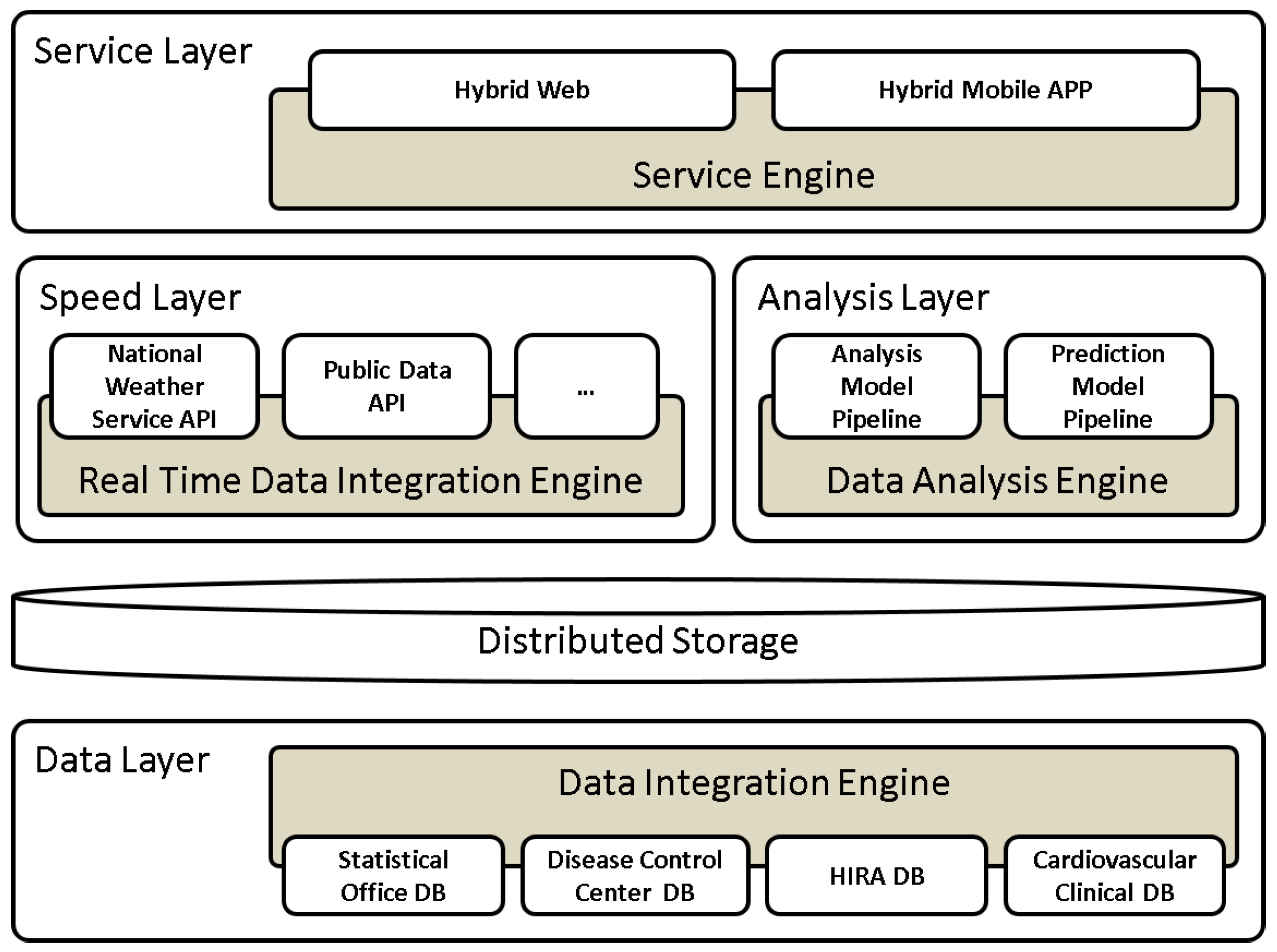
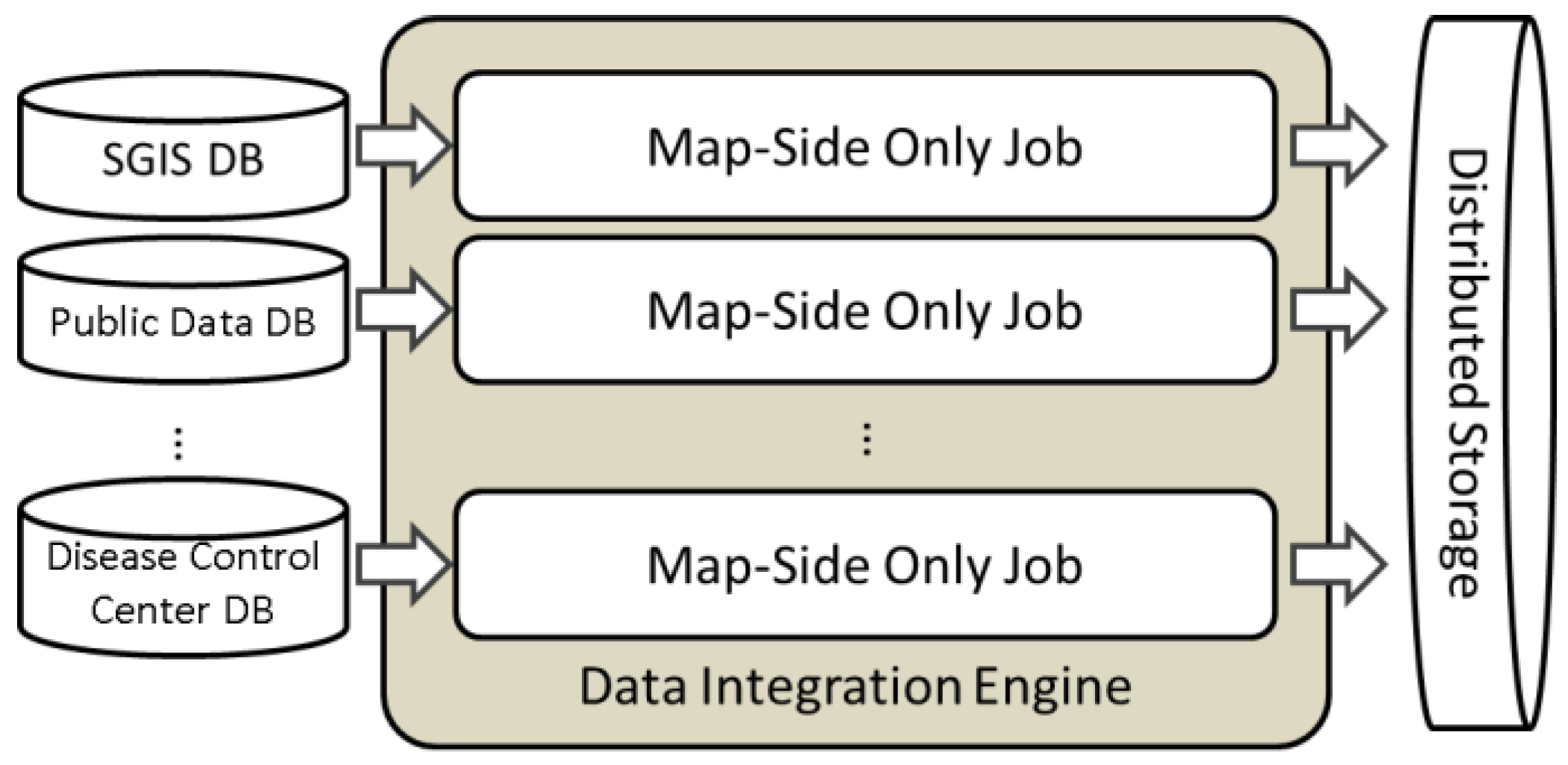
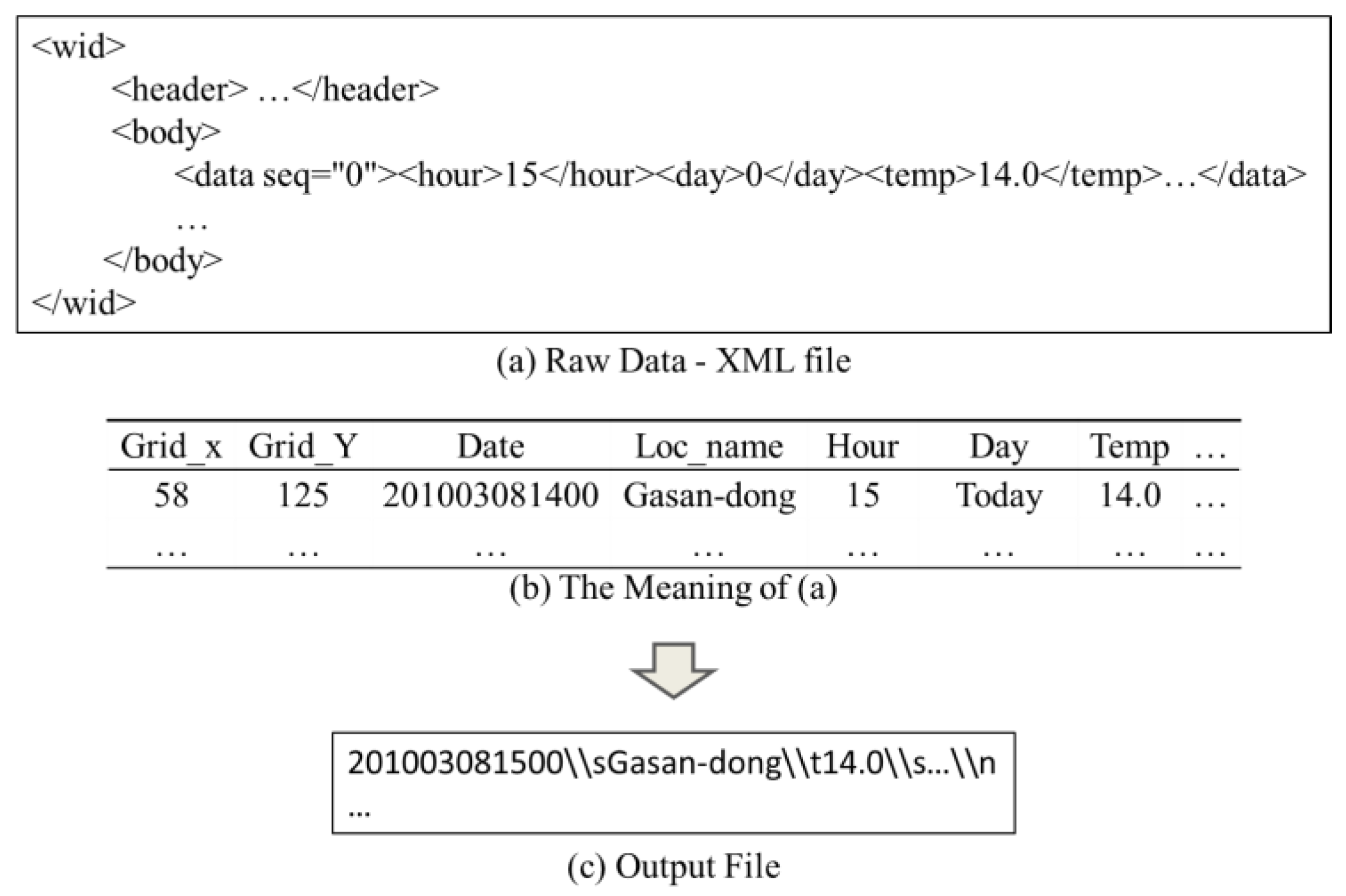
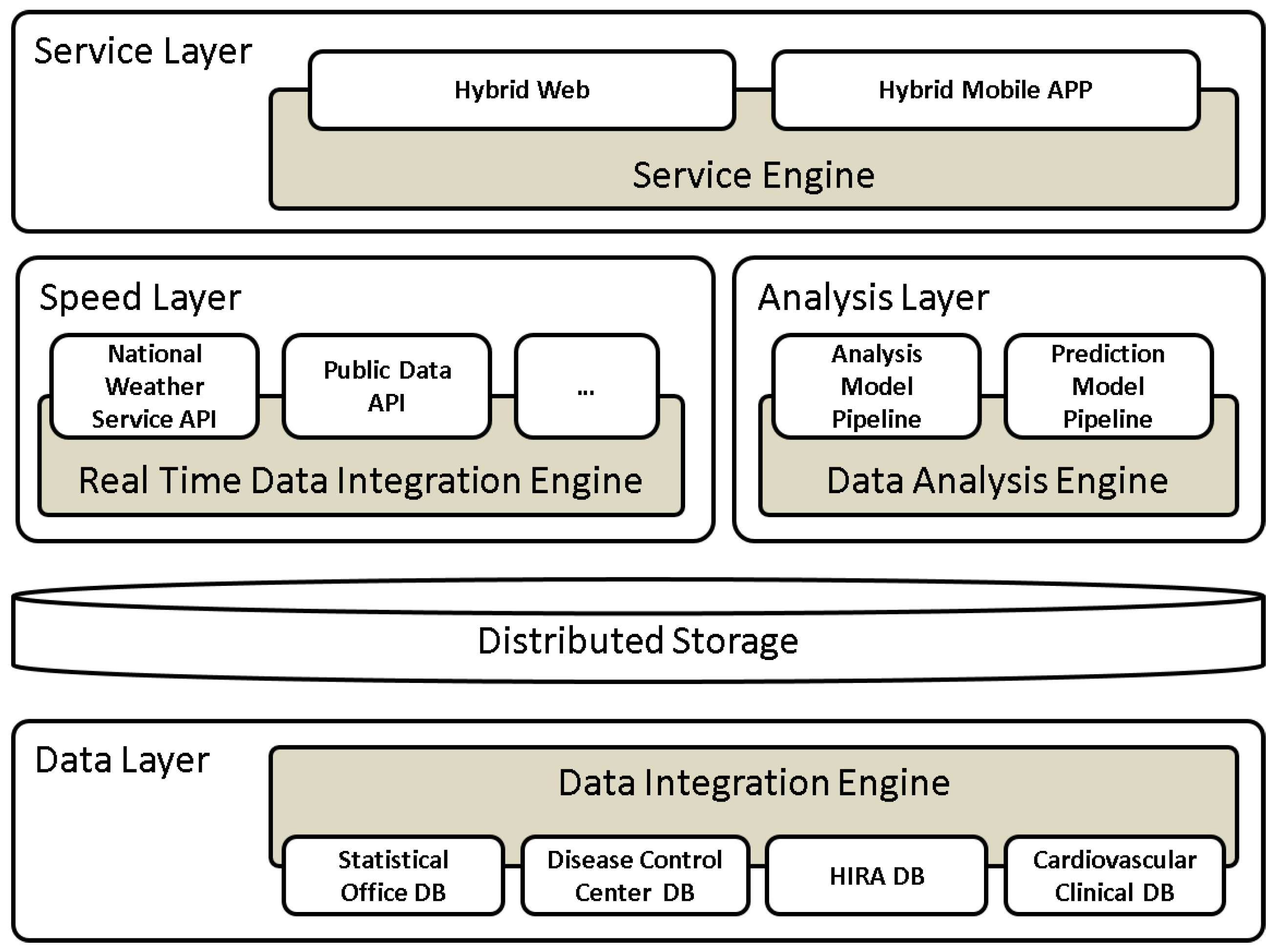
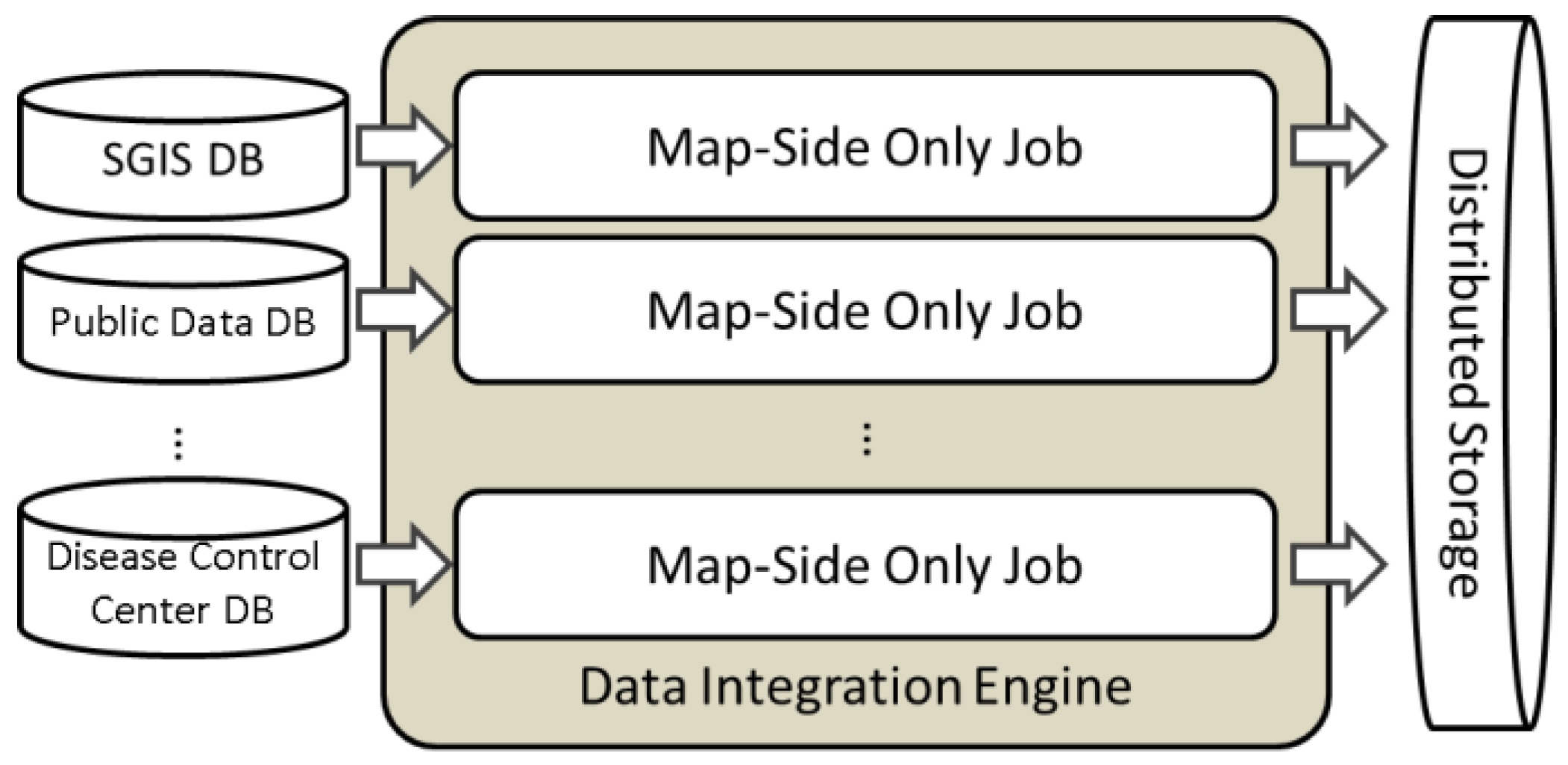
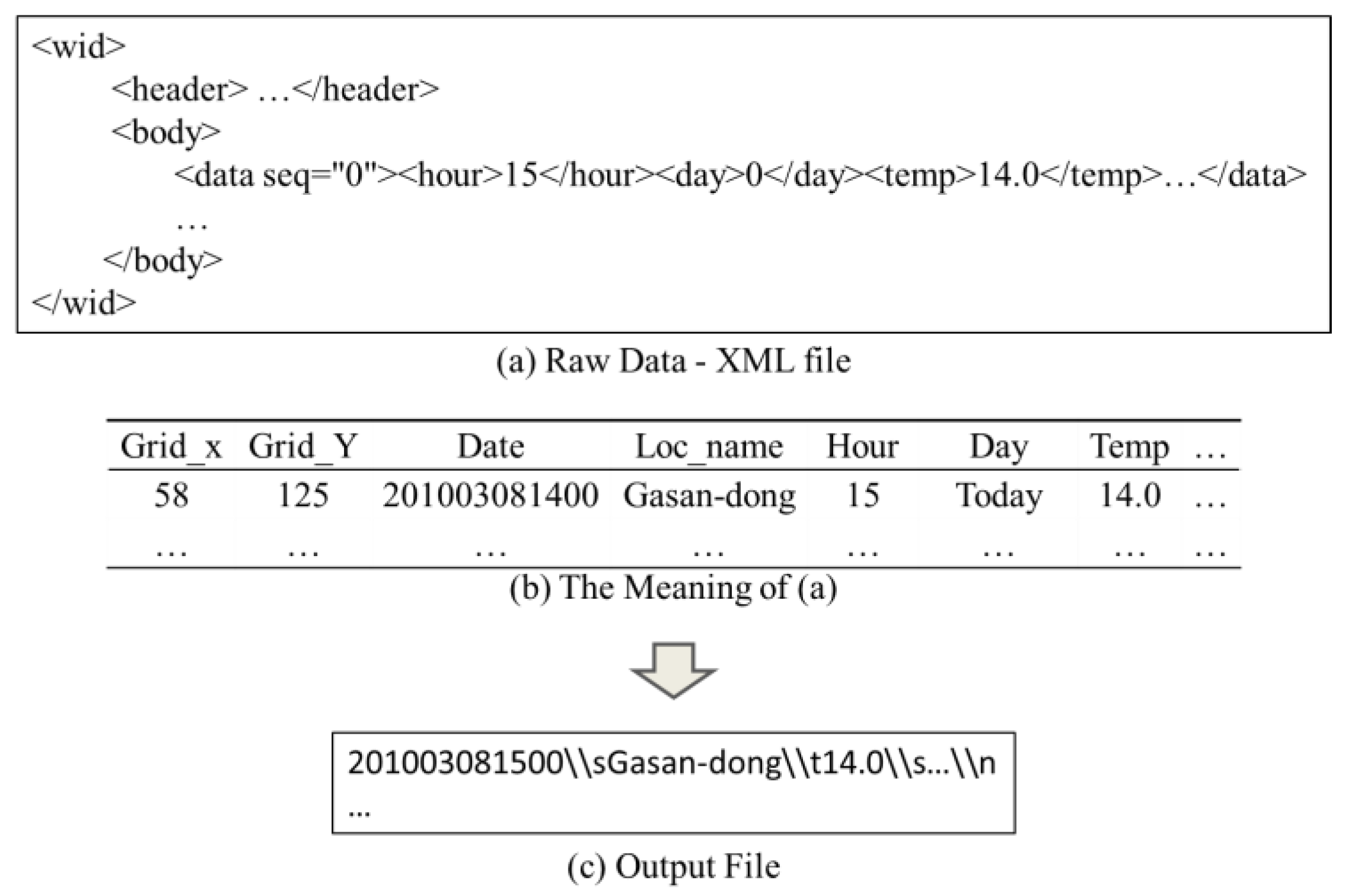
2.1. Data Integration Engine
| Algorithm 1: Preprocessing and Integration |
| 1: class MAPPER 2: method MAP (dbid , record ) 3: .ID 4: .RECORD 5: record (null) 6: for all column record do 7: column Preprocessing (, ) 8: column Integration (, column ) 9: pair ( 10: EMIT (pair(, ), ) |
2.2. Real-Time Data Integration Engine
2.2.1. API Manager
2.2.2. Data Distributer
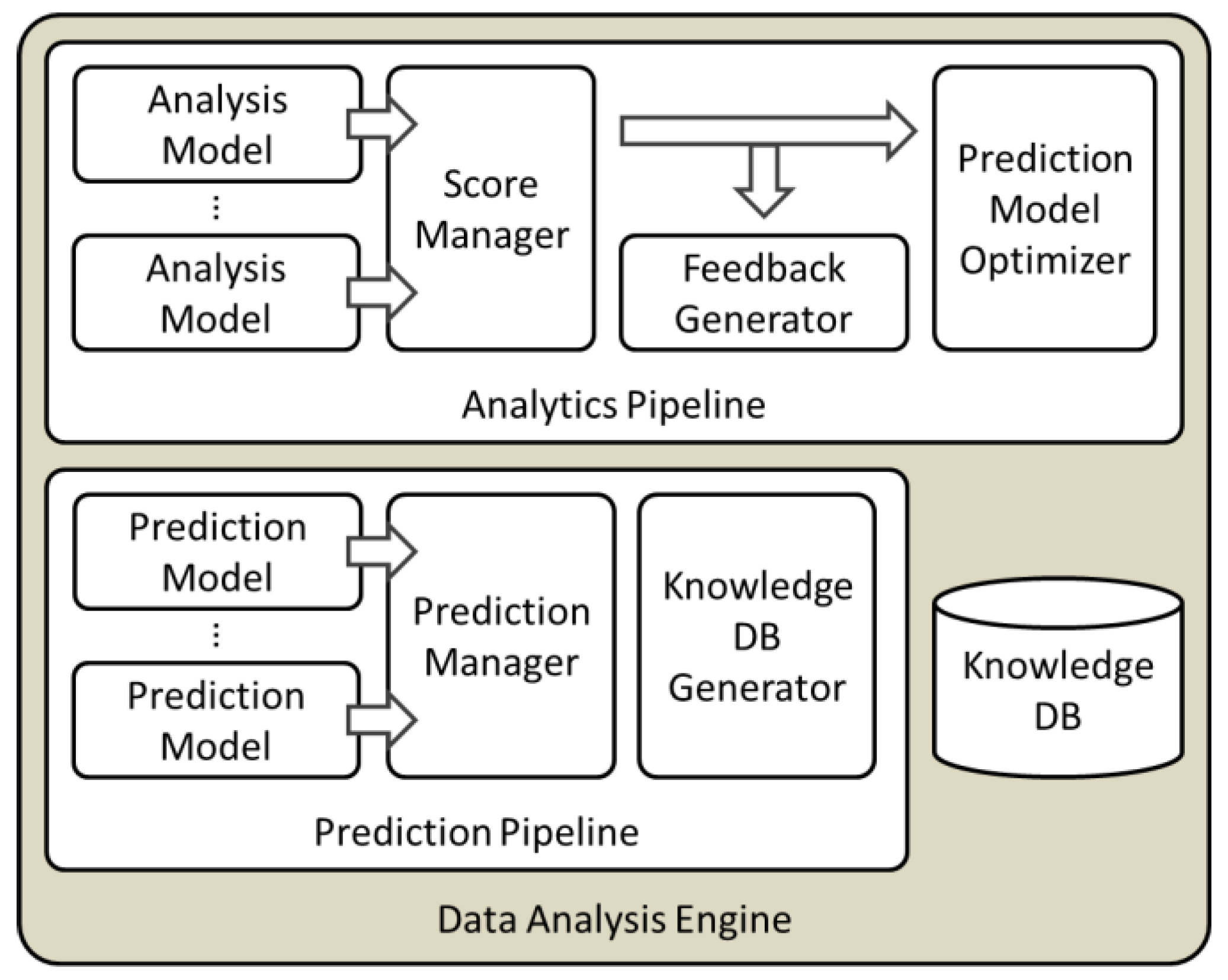
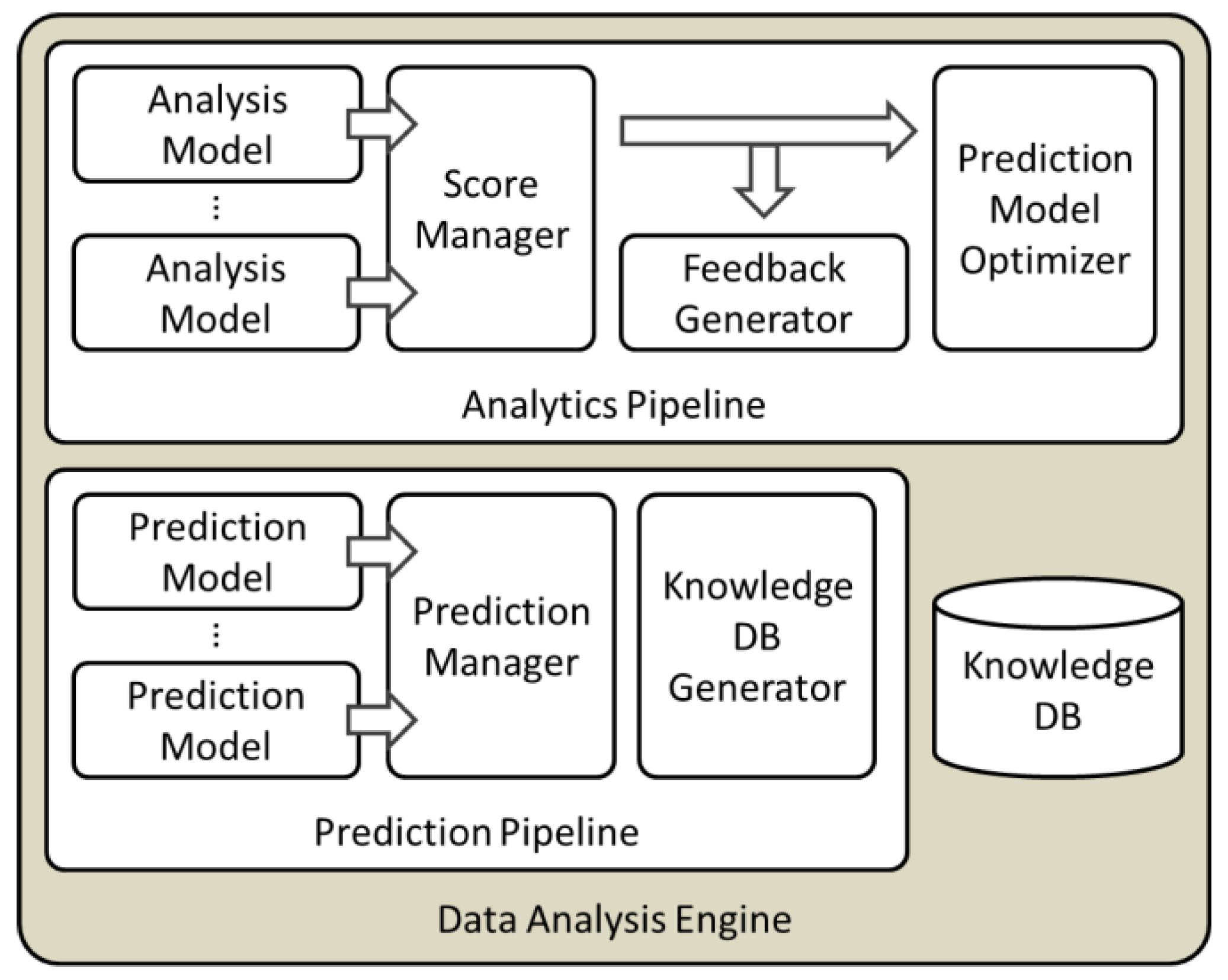
2.3. Data Analysis Engine
2.4. Service Engine
3. Proposed Prediction System Based on Lambda Architecture
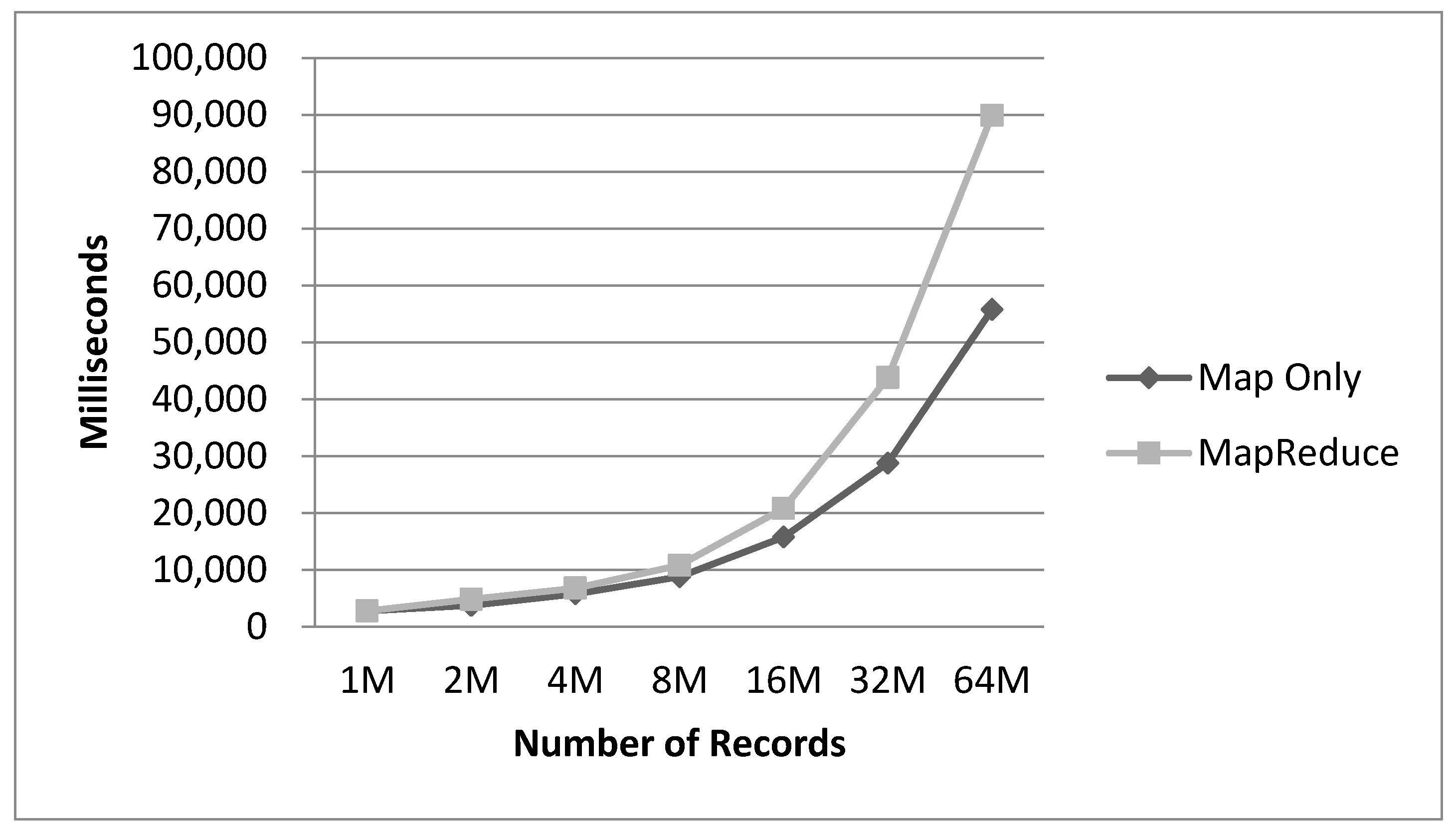
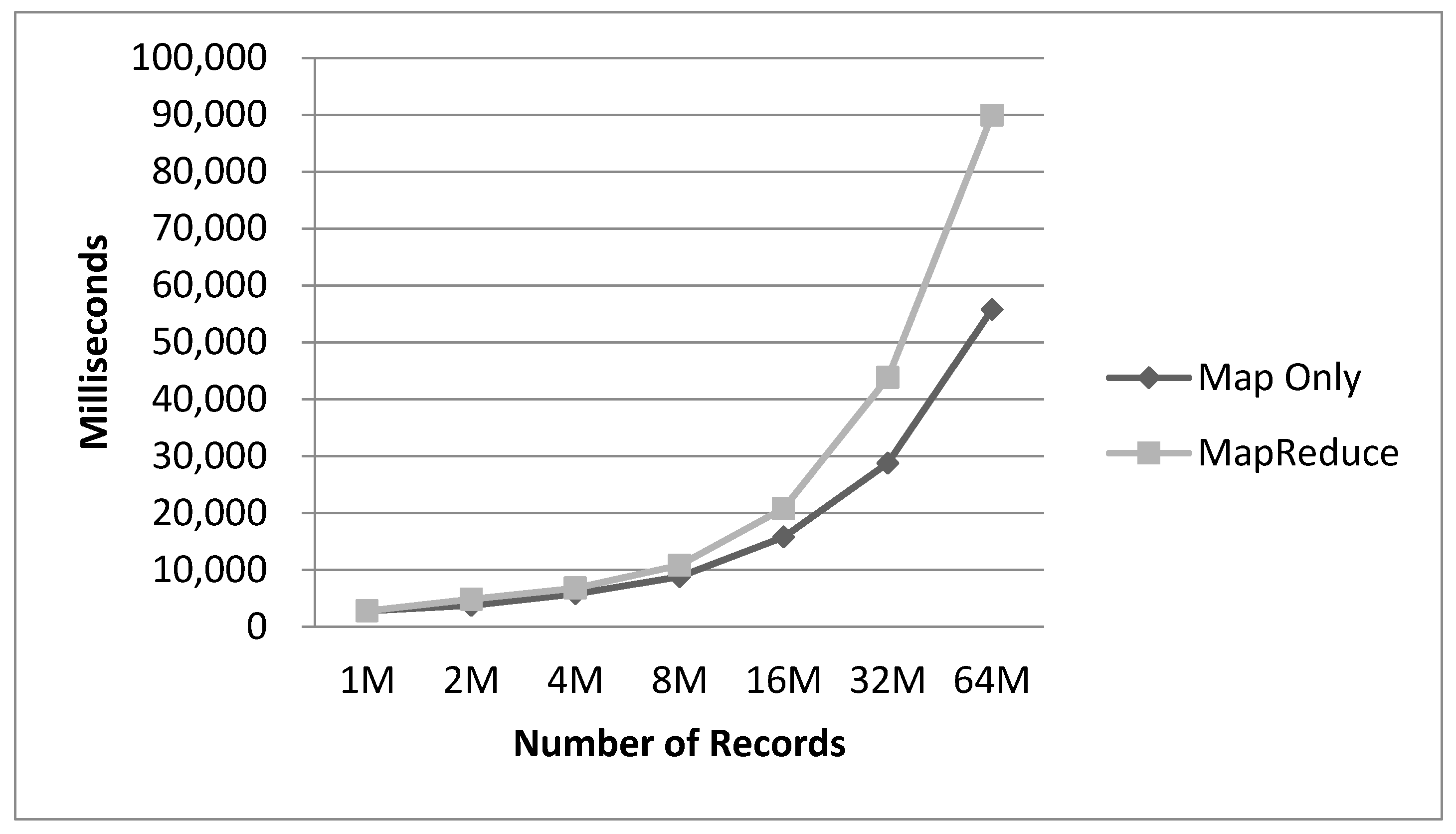
4. Experiment Evaluation
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Myers, V.; Broday, D.M.; Steinberg, D.M.; Drory, Y.; Gerber, Y. Exposure to particulate air pollution and long-term incidence of frailty after myocardial infarction. Ann. Epidemiol. 2013, 23, 395–400. [Google Scholar] [CrossRef] [PubMed]
- Lee, B.J.; Kim, B.; Lee, K. Air pollution exposure and cardiovascular disease. Toxicol. Res. 2014, 30, 71–75. [Google Scholar] [CrossRef] [PubMed]
- Newby, D.E.; Mannucci, P.M.; Tell, G.S.; Baccarelli, A.A.; Brook, R.D.; Donaldson, K.; Forastiere, F.; Franchini, M.; Franco, O.H.; Graham, I.; et al. Expert position paper on air pollution and cardiovascular disease. Eur. Heart J. 2014, 36, 83–93. [Google Scholar] [CrossRef] [PubMed]
- Goggins, W.B.; Chan, E.Y.; Yang, C.Y. Weather, pollution, and acute myocardial infarction in Hong Kong and Taiwan. Int. J. Cardiol. 2013, 168, 243–249. [Google Scholar] [CrossRef] [PubMed]
- Lin, H.; An, Q.; Luo, C.; Pun, V.C.; Chan, C.S.; Tian, L. Gaseous air pollution and acute myocardial infarction mortality in Hong Kong: A time-stratified case-crossover study. Atmos. Environ. 2013, 76, 66–73. [Google Scholar] [CrossRef]
- Medina-Lezama, J.; Morey-Vargas, O.L.; Zea-Díaz, H.; Bolaños-Salazar, J.F.; Corrales-Medina, F.; Cuba-Bustinza, C.; Chirinos-Medina, D.A.; Chirinos, J.A. Prevalence of lifestyle-related cardiovascular risk factors in Peru: The PREVENCION study. Rev. Panam. Salud Publ. Am. J. Public Health 2008, 24, 169–179. [Google Scholar] [CrossRef]
- National Information Board. Personalized Health and Care 2020: Using Data and Technology to Transform Outcomes for Patients and Citizens; HM Government: London, UK, 2014.
- Roski, J.; Bo-Linn, G.W.; Andrews, T.A. Creating value in health care through big data: Opportunities and policy implications. Health Aff. 2014, 33, 1115–1122. [Google Scholar] [CrossRef] [PubMed]
- Salari, N.; Shohaimi, S.; Najafi, F.; Nallappan, M.; Karishnarajah, I. An improved artificial neural network based model for prediction of late onset heart failure. Life Sci. J. 2012, 9, 3684–3689. [Google Scholar]
- Vijayashree, J.; SrimanNarayanaIyengar, N.C. Heart disease prediction system using data mining and hybrid intelligent techniques: A review. Int. J. Bio-Sci. Biotechnol. 2016, 8, 139–148. [Google Scholar] [CrossRef]
- Duan, L.; Tang, C.J.; Dong, G.; Yang, N.; Gou, C. Survey of emerging pattern based contrast mining and applications. J. Comput. Appl. 2012, 32, 304–308. [Google Scholar] [CrossRef]
- Abbes, H.; Gargouri, F. Big data integration: A MongoDB database and modular ontologies based approach. Procedia Comput. Sci. 2016, 96, 446–455. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Eckelman, M.J.; Sherman, J. Environmental impacts of the U.S. health care system and effects on public health. PLoS ONE 2016, 11, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Ministry of Environment. Health Impact Assessment According to Climate Change Linked with Big Data of National Health Insurance; Korea Environment Institute: Chungnam, Korea, 2015. [Google Scholar]
- Tekiner, F.; Keane, J.A. Big data framework. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 1494–1499. [Google Scholar]
- Lambda Architecture. Available online: http://lambda-architecture.net (accessed on 25 November 2017).
- Kiran, M.; Murphy, P.; Monga, I.; Dugan, J.; Baveja, S.S. Lambda architecture for cost-effective batch and speed big data processing. In Proceedings of the 2015 IEEE International Conference on Big Data, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 2785–2792. [Google Scholar]
- Amazon Web Services. Lambda Architecture for Batch and RealTime Processing on AWS with Spark Streaming and Spark SQL; Amazon Web Services Inc.: Seattle, WA, USA, 2015. [Google Scholar]
- Zikopoulos, P.; Eaton, C. Understanding Big Data: Analytics for Enterprise Class Hadoop and Streaming Data; McGraw-Hill Osborne Media: Berkeley, CA, USA, 2011. [Google Scholar]
- Familiar, B.; Barnes, J. Real-time processing using azure stream analytics. In Business in Real-Time Using Azure IoT and Cortana Intelligence Suite; Familiar, B., Barnes, J., Eds.; Apress: New York, NY, USA, 2017; pp. 169–226. [Google Scholar]
- Marcu, O.C.; Tudoran, R.; Nicolae, B.; Costan, A.; Antoniu, G.; Pérez-Hernández, M.S. Exploring shared state in key-value store for window-based multi-pattern streaming analytics. In Proceedings of the 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, Madrid, Spain, 14–17 May 2017; pp. 1044–1052. [Google Scholar]
- Sideris, K.; Nejabati, R.; Simeonidou, D. Seer: Empowering software defined networking with data analytics. In Proceedings of the International Conference on Ubiquitous Computing and Communications and 2016 International Symposium on Cyberspace and Security, Granada, Spain, 14–16 December 2016; pp. 181–188. [Google Scholar]
- Karim, M.R.; Kaysar, M.M. Large Scale Machine Learning with Spark; Packt Publishing: Birmingham, UK, 2016. [Google Scholar]
- Li, B.; Song, M.; Ou, Z.; Haihong, E. Performance comparison and analysis of yarn’s schedulers with stress cases. In Proceedings of the 7th International Conference on Cloud Computing and Big Data, Macau, China, 16–18 November 2016; pp. 93–98. [Google Scholar]
- Dolev, S.; Florissi, P.; Gudes, E.; Sharma, S.; Singer, I. A survey on geographically distributed big-data processing using MapReduce. IEEE Trans. Big Data 2017. [Google Scholar] [CrossRef]
- Rodrigues, R.A.; Lima, L.A.; Goncalves, S.G.; Mialaret, F.S.; Da Chnha, A.M.; Vieira, L.A. Integrating NoSQL, Relational Database, and the Hadoop Ecosystem in an Interdisciplinary Project involving Big Data and Credit Card Transactions. In Information Technology—New Generations, 14th International Conference on Information Technology, Las Vegas, NV, USA, 10–12 April; Springer: New York, NY, USA, 2017; pp. 443–451. [Google Scholar]
- Bagwari, N.; Kumar, O. Indexing optimizations on Hadoop. In Proceedings of the 3rd International Conference on Computational Intelligence & Communication Technology (CICT), Ghaziabad, India, 9–10 February 2017; pp. 1–7. [Google Scholar]
- Kumar, R.; Parasher, B.B.; Gupta, S.; Sharma, Y.; Gupta, N. Apache Hadoop, NoSQL and NewSQL solutions of big data. Int. J. Adv. Found. Res. Sci. Eng. 2014, 1, 28–36. [Google Scholar]
- Gribaudo, M.; Iacono, M.; Kiran, M. A performance modeling framework for lambda architecture based applications. Future Gener. Comput. Syst. 2017. [Google Scholar] [CrossRef]
- Decaneto, A. Design and testing of an active big data architecture for social and crowding emergency management. Politecnico Milano 2017. Available online: http://hdl.handle.net/10589/134427 (accessed on 25 November 2017).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Type | Size | Provider |
|---|---|---|---|
| Climate Data | API File (XML) | 1999~2017 | Korea Meteorological Administration |
| National Health and Nutrition Survey | File (SAV) | 1998~2015 60 files (7 GB) | Korea Centers for Disease Control & Prevention |
| National Core Open Data | API (JSON, XML) File (CSV) | 2000~2017 10 files (7 MB) | National Information Society Agency |
| Health Insurance Statistical Data | API File (XLS) | 2001~2017 10 files (7 MB) | Healthcare Bigdata Hub |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, S.H.; Kim, K.O.; Cha, E.J.; Kim, K.A.; Shon, H.S. System Framework for Cardiovascular Disease Prediction Based on Big Data Technology. Symmetry 2017, 9, 293. https://doi.org/10.3390/sym9120293
Han SH, Kim KO, Cha EJ, Kim KA, Shon HS. System Framework for Cardiovascular Disease Prediction Based on Big Data Technology. Symmetry. 2017; 9(12):293. https://doi.org/10.3390/sym9120293
Chicago/Turabian StyleHan, Sang Hun, Kyoung Ok Kim, Eun Jong Cha, Kyung Ah Kim, and Ho Sun Shon. 2017. "System Framework for Cardiovascular Disease Prediction Based on Big Data Technology" Symmetry 9, no. 12: 293. https://doi.org/10.3390/sym9120293
APA StyleHan, S. H., Kim, K. O., Cha, E. J., Kim, K. A., & Shon, H. S. (2017). System Framework for Cardiovascular Disease Prediction Based on Big Data Technology. Symmetry, 9(12), 293. https://doi.org/10.3390/sym9120293