A Hybrid Fuzzy DEA/AHP Methodology for Ranking Units in a Fuzzy Environment

Abstract
:1. Introduction
2. The Methodology
2.1. Construction of Pairwise Comparisons of AHP
2.2. Ranking with AHP
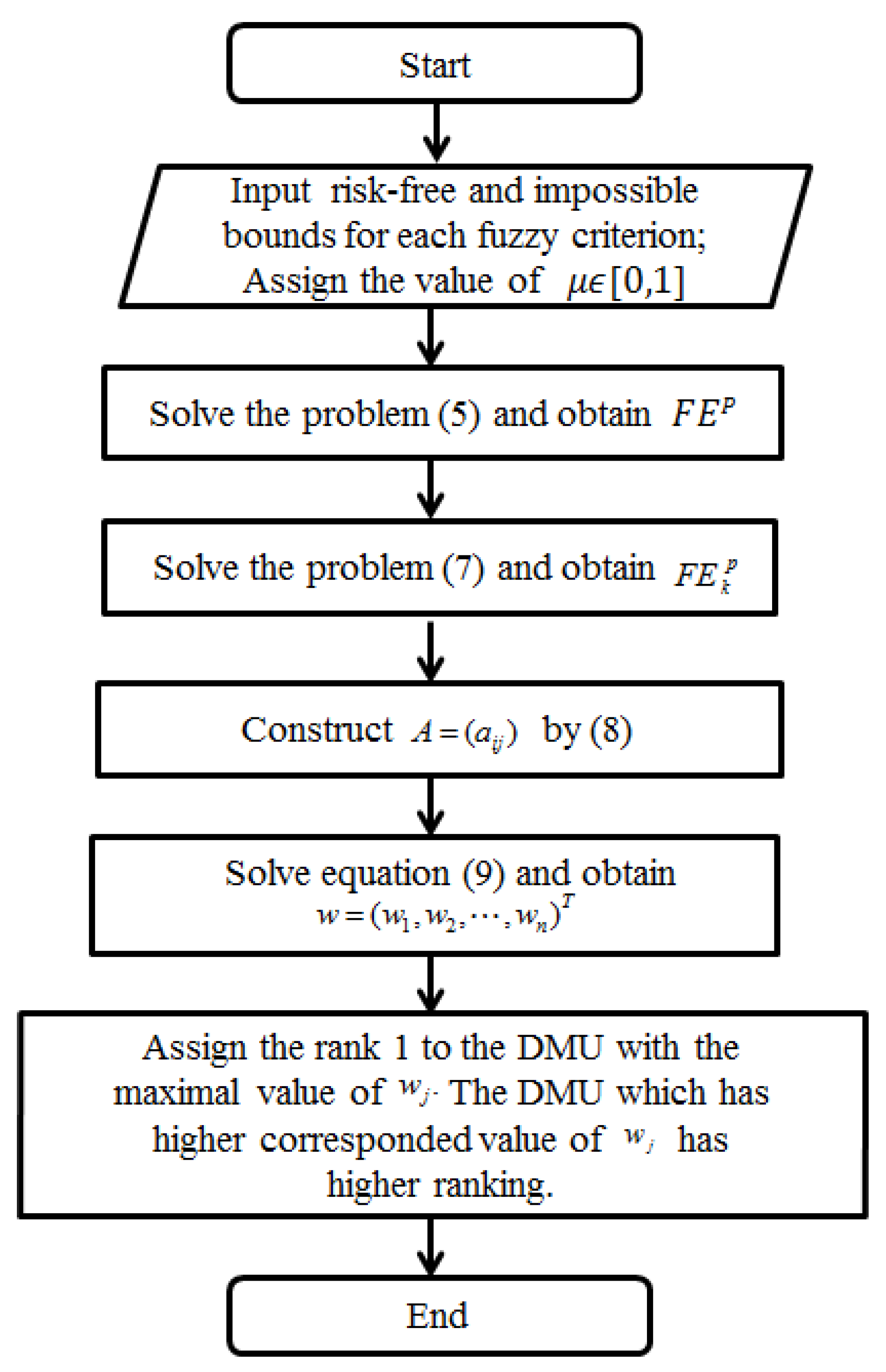
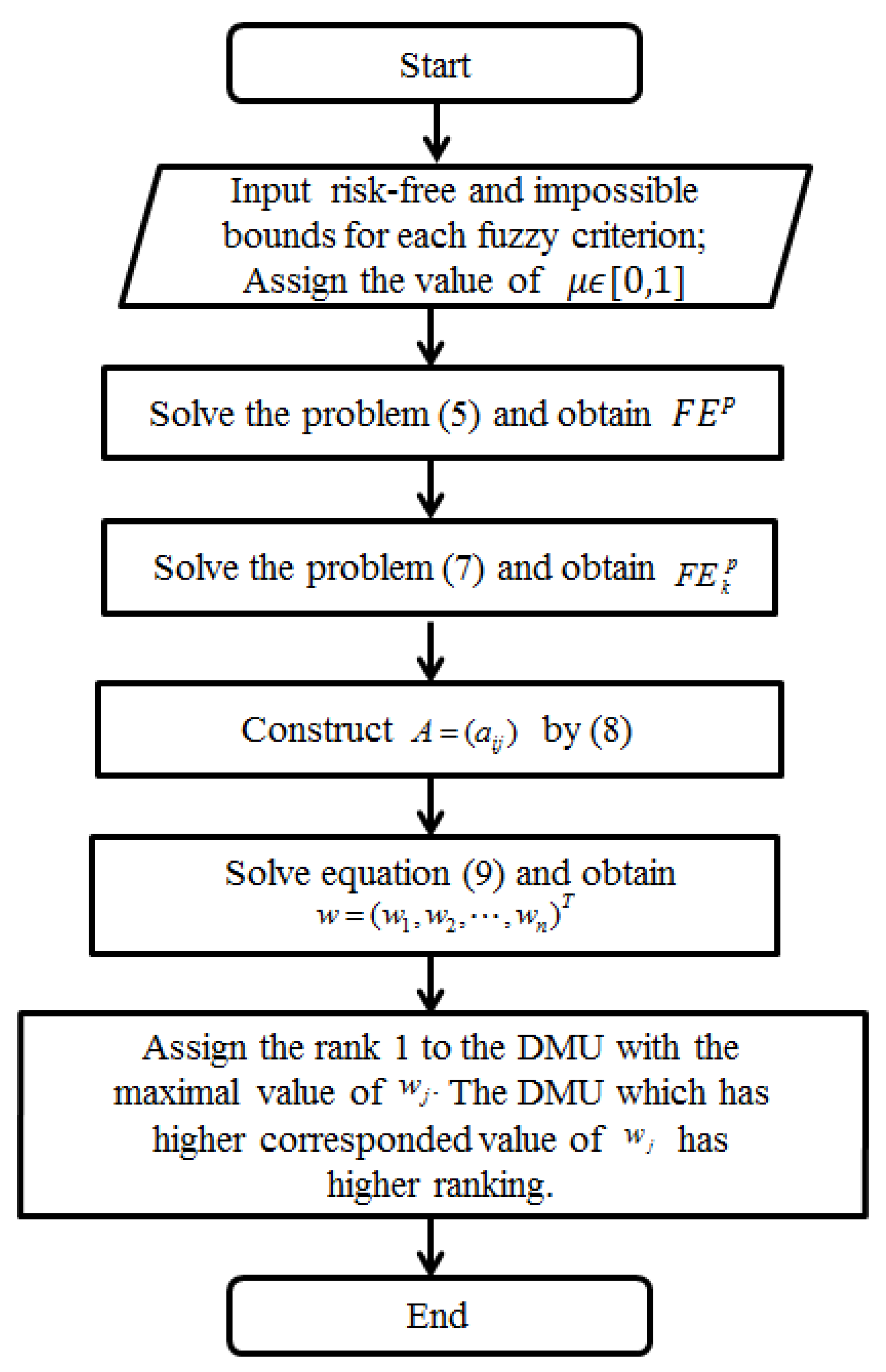
3. An Algorithm and the Validation of the Hybrid Fuzzy DEA/AHP Method
| Algorithm 1: The hybrid fuzzy DEA/AHP ranking method |
|
4. An Illustrated Example on the Facility Layout Design Application
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Saaty, T.L. The Analytic Hierarchy Process: Planning, Priority Setting and Resource Allocation; McGraw-Hill: New York, NY, USA, 1980. [Google Scholar]
- Vaidya, O.S.; Kumar, S. Analytic hierarchy process: An overview of applications. Eur. J. Oper. Res. 2006, 169, 1–29. [Google Scholar] [CrossRef]
- Wang, Y.-M.; Liu, J.; Elhag, T.M.S. An integrated AHP-DEA methodology for bridge risk assessment. Comput. Oper. Res. 2008, 54, 513–525. [Google Scholar] [CrossRef]
- Sinuany-Stern, Z.; Mehrez, A.; Hadad, Y. An AHP/DEA methodology for ranking decision-making units. Int. Trans. Oper. Res. 2000, 7, 109–124. [Google Scholar] [CrossRef]
- Rakhshan, S.A.; Kamyad, A.V.; Effati, S. Ranking decision-making units by using combination of analytical hierarchical process method and Tchebycheff model in data envelopment analysis. Ann. Oper. Res. 2015, 226, 505–525. [Google Scholar] [CrossRef]
- Belton, V.; Vickers, S.P. Demystifying DEA—A visual interactive approach based on multiple criteria analysis. J. Oper. Res. Soc. 1993, 44, 883–896. [Google Scholar]
- Doyle, J.; Green, R. Data envelopment analysis, and multiple criteria decision-making. Omega 1993, 21, 713–715. [Google Scholar] [CrossRef]
- Stewart, T.J. Relationships between data envelopment analysis and multicriteria decision analysis. J. Oper. Res. Soc. 1996, 47, 654–665. [Google Scholar] [CrossRef]
- Ramanathan, R. Data envelopment analysis for weight derivation and aggregation in the analytic hierarchy process. Comput. Oper. Res. 2006, 33, 1289–1307. [Google Scholar] [CrossRef]
- Charnes, A.; Cooper, W.W.; Rhodes, E. Measuring efficiency of decision making units. Eur. J. Oper. Res. 1978, 2, 429–444. [Google Scholar] [CrossRef]
- Seiford, L.M. Data envelopment analysis: The evolution of the state of the art (1978–1995). J. Prod. Anal. 1996, 7, 99–137. [Google Scholar] [CrossRef]
- Friedman, L.; Sinuany-Stern, Z. Combining ranking scales and selecting variables in the DEA context: The case of industrial branches. Comput. Ops. Res. 1998, 25, 781–791. [Google Scholar] [CrossRef]
- Shang, J.; Sueyoshi, T. A unified framework for the selection of a flexible manufacturing system. Eur. J. Oper. Res. 1995, 85, 297–315. [Google Scholar] [CrossRef]
- Alirezaee, M.-R.; Sani, M.R. New analytical hierarchical process/data envelopment analysis methodology for ranking decision-making units. Int. Trans. Oper. Res. 2011, 18, 533–544. [Google Scholar] [CrossRef]
- Precup, R.E.; Preitl, S.; Petriu, E.M.; Tar, J.K.; Tomescu, M.L.; Pozna, C. Generic two-degree-of-freedom linear and fuzzy controllers for integral processes. J. Frankl. Inst. 2009, 346, 980–1003. [Google Scholar] [CrossRef]
- Medina, J.; Ojeda-Aciego, M. Multi-adjoint t-concept lattices. Inf. Sci. 2010, 180, 712–725. [Google Scholar] [CrossRef]
- Nowaková, J.; Prílepok, M.; Snášel, V. Medical image retrieval using vector quantization and fuzzy S-tree. J. Med. Syst. 2017, 41, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Kumar, D.; Jarial, S.K. A hybrid clustering method based on improved artificial bee colony and fuzzy C-Means algorithm. Int. J. Artif. Intell. 2017, 15, 40–60. [Google Scholar]
- Hadi-Vencheh, A.; Mohamadghasemi, A. A fuzzy AHP-DEA approach for multiple criteria ABC inventory classification. Expert Syst. Appl. 2011, 38, 3346–3352. [Google Scholar] [CrossRef]
- Lee, S.K.; Mogi, G.; Li, Z.; Hui, K.S.; Lee, S.K.; Hui, K.N.; Park, S.Y.; Ha, Y.J.; Kim, J.W. Measuring the relative efficiency of hydrogen energy technologies for implementing the hydrogen economy: An integrated fuzzy AHP/DEA approach. Int. J. Hydrog. Energy 2011, 36, 12655–12663. [Google Scholar] [CrossRef]
- Kumar, A.; Shankar, R.; Debnath, R.M. Analyzing customer preference and measuring relative efficiency in telecom sector: A hybrid fuzzy AHP/DEA study. Telemat. Inform. 2015, 32, 447–462. [Google Scholar] [CrossRef]
- Hatami-Marbini, A.; Emrouznejad, A.; Tavana, M. A taxonomy and review of the fuzzy data envelopment analysis literature: Two decades in the making. Eur. J. Oper. Res. 2011, 214, 457–472. [Google Scholar] [CrossRef]
- Lotfi, F.H.; Jahanshahloo, G.R.; Ebrahimnejad, A.; Soltanifar, M.; Mansourzadeh, S.M. Target setting in the general combined-oriented CCR model using an interactive MOLP method. J. Comput. Appl. Math. 2010, 234, 1–9. [Google Scholar] [CrossRef]
- Carlsson, C.; Korhonen, P. A Parametric Approach To Fuzzy Linear Programming. Fuzzy Set Syst. 1986, 20, 17–30. [Google Scholar] [CrossRef]
- Saaty, T.L. Decision-making with the AHP: Why is the principal eigenvector necessary? Eur. J. Oper. Res. 2003, 145, 85–91. [Google Scholar] [CrossRef]
- Saaty, T.L.L.; Vargas, L. Comparison on eigenvalue, logarithmic least squares and least squares methods in estimating ratios. Math. Model. 1984, 5, 209–324. [Google Scholar] [CrossRef]
- Ertay, T.; Ruan, D.; Tuzkaya, U.R. Integrating data envelopment analysis and analytic hierarchy for the facility layout design in manufacturing systems. Inf. Sci. 2006, 176, 237–262. [Google Scholar] [CrossRef]

{kind=link}
| Overview | Advantage | Disadvantage |
|---|---|---|
| Shang and Sueyoshi [13] | This work attempts to fully rank DMUs in DEA utlilizing AHP. | It includes the subjectivity of AHP and the Pareto solutions of DEA. |
| Sinuany-Stern et al. [4] | The AHP pairwise comparisons are generated by running pairwise DEA. Thus, there is no subjective evaluation. | Its ranking is incompatible with traditional model in DEA when there are multiple inputs and outputs. |
| Alirezaee and Sani [14] | This approach overcomes the draw-backs of the AHP/DEA method developed in [4]. | The integrated AHP/DEA models can not reflect the vagueness of human thought while ranking units with multiple fuzzy criteria. |
| Rakhshan et al. [5] | The proposed approach generates the ranking of units which is compatible with traditional DEA ranking. | It has the limitation on dealing with human thoughts with uncertainty in the real-world applications. |
| DMUs | 1 | 2 | 3 | ⋯ | n |
|---|---|---|---|---|---|
| Remove 1 | ∗ | ⋯ | |||
| Remove 2 | ∗ | ⋯ | |||
| ⋮ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| Remove n | ⋯ | ∗ |
| DMU | Inputs | Outputs | ||||
|---|---|---|---|---|---|---|
| 1 | 20,309.56 | 6405 | ||||
| 2 | 20,411.22 | 5393 | ||||
| 3 | 20,280.28 | 5294 | ||||
| 4 | 20,053.20 | 4450 | ||||
| 5 | 19,998.75 | 4370 | ||||
| 6 | 20,193.68 | 4393 | ||||
| 7 | 19,779.73 | 2862 | ||||
| 8 | 19,831.00 | 5473 | ||||
| 9 | 19,608.43 | 5161 | ||||
| 10 | 20,038.10 | 6078 | ||||
| 11 | 20,330.68 | 4516 | ||||
| 12 | 20,155.09 | 3702 | ||||
| 13 | 19,641.86 | 5726 | ||||
| 14 | 20,575.67 | 4639 | ||||
| 15 | 20,687.50 | 5646 | ||||
| 16 | 20,779.75 | 5507 | ||||
| 17 | 19,853.38 | 3912 | ||||
| 18 | 19,853.38 | 5974 |
| DMUs | Fuzzy DEA | Method in [27] | ||||
|---|---|---|---|---|---|---|
| 1 | 0.2419804 (13) | |||||
| 2 | 0.2422704 (4) | |||||
| 3 | 0.2422452 (5) | |||||
| 4 | 0.2350762 (14) | |||||
| 5 | 0.2424019 (1) | |||||
| 6 | 0.2422439 (6) | |||||
| 7 | 0.2421172 (10) | |||||
| 8 | 0.2138516 (17) | |||||
| 9 | 0.2250112 (15) | |||||
| 10 | 0.2423731 (2) | |||||
| 11 | 0.2421616 (7) | |||||
| 12 | 0.2421571 (8) | |||||
| 13 | 0.1945052 (18) | |||||
| 14 | 0.2420896 (12) | |||||
| 15 | 0.2422820 (3) | |||||
| 16 | 0.2421566 (9) | |||||
| 17 | 0.2420933 (11) | |||||
| 18 | 0.2190128 (16) |
| DMUs | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Remove 1 | ∗ | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |||||
| Remove 2 | ∗ | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||||
| Remove 3 | 1 | ∗ | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||||
| Remove 4 | 1 | 1 | ∗ | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |||||
| Remove 5 | 1 | 1 | ∗ | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||||
| Remove 6 | 1 | 1 | 1 | ∗ | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||||
| Remove 7 | 1 | 1 | 1 | 1 | ∗ | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||||
| Remove 8 | 1 | 1 | 1 | 1 | 1 | ∗ | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |||||
| Remove 9 | 1 | 1 | 1 | 1 | 1 | ∗ | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |||||
| Remove 10 | 1 | 1 | 1 | 1 | 1 | ∗ | 1 | 1 | 1 | 1 | 1 | 1 | ||||||
| Remove 11 | 1 | 1 | 1 | 1 | 1 | 1 | ∗ | 1 | 1 | 1 | 1 | 1 | ||||||
| Remove 12 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ∗ | 1 | 1 | 1 | 1 | |||||
| Remove 13 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ∗ | 1 | 1 | 1 | 1 | |||||
| Remove 14 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ∗ | 1 | 1 | 1 | ||||||
| Remove 15 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ∗ | 1 | 1 | ||||||
| Remove 16 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ∗ | 1 | ||||||
| Remove 17 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ∗ | ||||||
| Remove 18 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ∗ |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, C.-K.; Liu, F.-B.; Hu, C.-F. A Hybrid Fuzzy DEA/AHP Methodology for Ranking Units in a Fuzzy Environment. Symmetry 2017, 9, 273. https://doi.org/10.3390/sym9110273
Hu C-K, Liu F-B, Hu C-F. A Hybrid Fuzzy DEA/AHP Methodology for Ranking Units in a Fuzzy Environment. Symmetry. 2017; 9(11):273. https://doi.org/10.3390/sym9110273
Chicago/Turabian StyleHu, Cheng-Kai, Fung-Bao Liu, and Cheng-Feng Hu. 2017. "A Hybrid Fuzzy DEA/AHP Methodology for Ranking Units in a Fuzzy Environment" Symmetry 9, no. 11: 273. https://doi.org/10.3390/sym9110273
APA StyleHu, C.-K., Liu, F.-B., & Hu, C.-F. (2017). A Hybrid Fuzzy DEA/AHP Methodology for Ranking Units in a Fuzzy Environment. Symmetry, 9(11), 273. https://doi.org/10.3390/sym9110273