
A POCS Algorithm Based on Text Features for the Reconstruction of Document Images at Super-Resolution

Abstract
:1. Introduction
2. Methodology
2.1. Classical Image Super-Resolution Reconstruction Algorithm
2.1.1. Establishment of Degraded Model
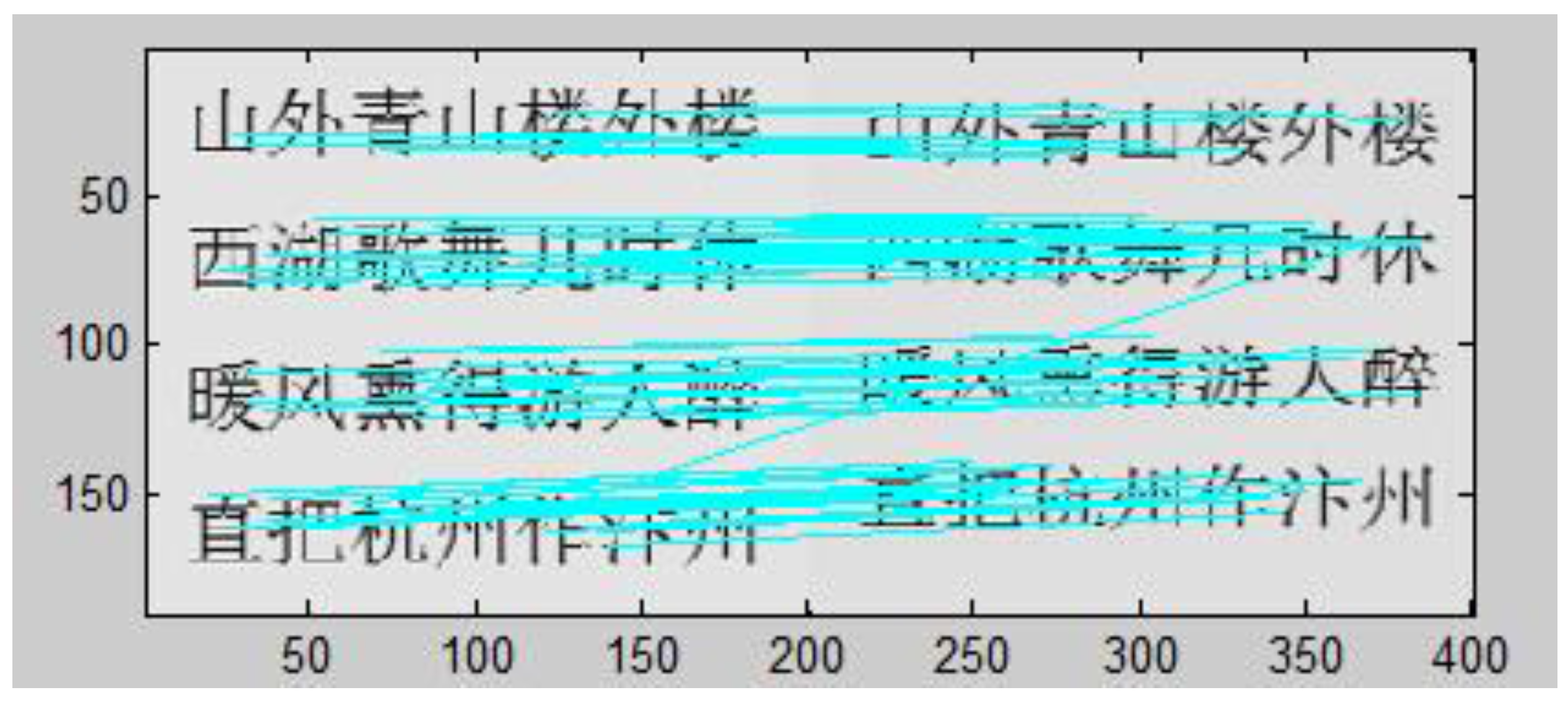
2.1.2. Image Registration Based on SIFT Algorithm
- Construct a scale space
- Detect extreme points in the scale space
- Locate the extreme points accurately
- Determine the main direction of key points
- Find the descriptors of key points
2.1.3. Image Reconstruction Based on the POCS Algorithm
2.2. A POCS Algorithm Based on Text Feature
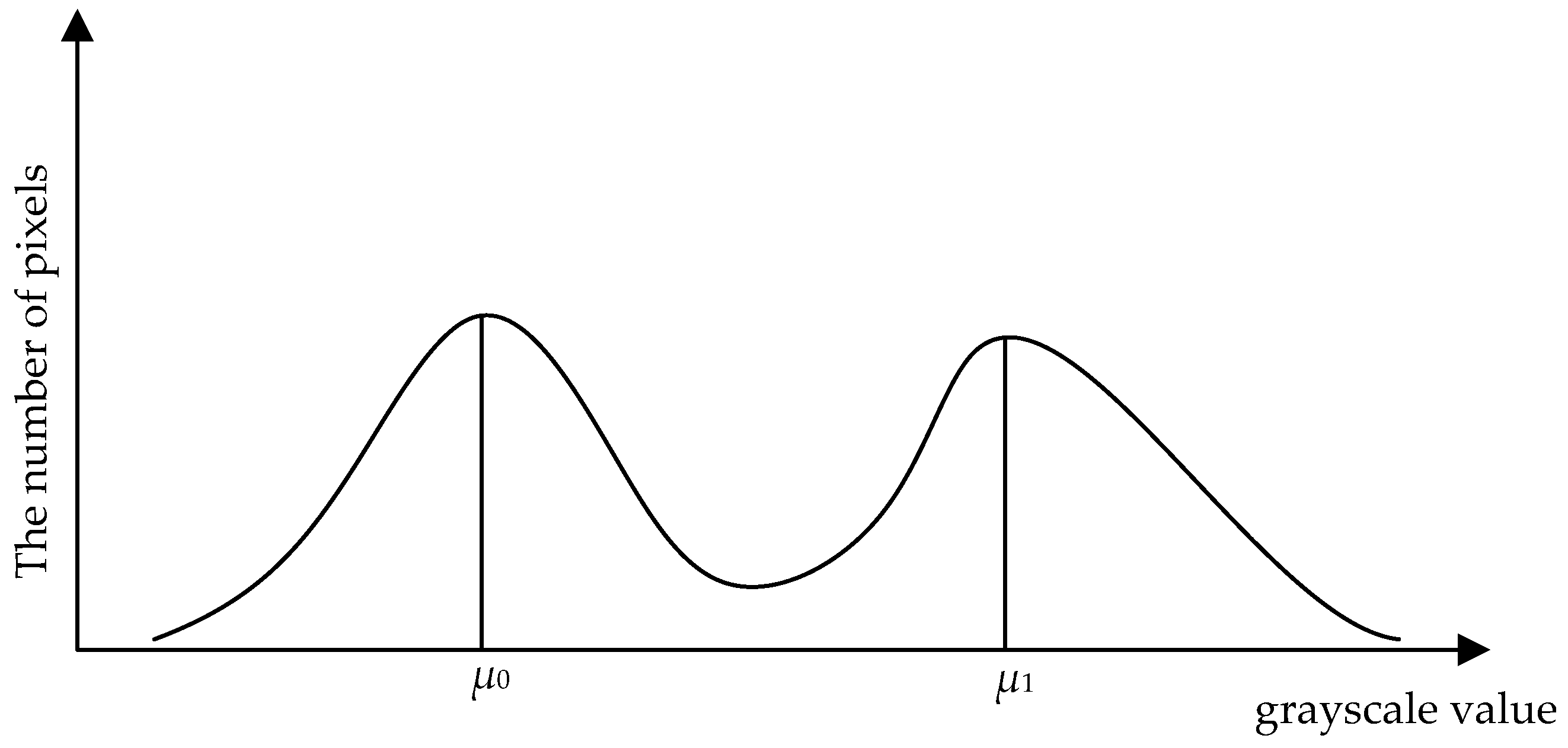
2.2.1. Features of Document Images
2.2.2. Text Features Based on the POCS Algorithm
- Formula (8) is added to the constraint conditions as an a priori function. The initial estimation is repeatedly revised based on it until the results meet the reconstruction conditions.
- In the original POCS algorithm, the image reduction formula is as follows:
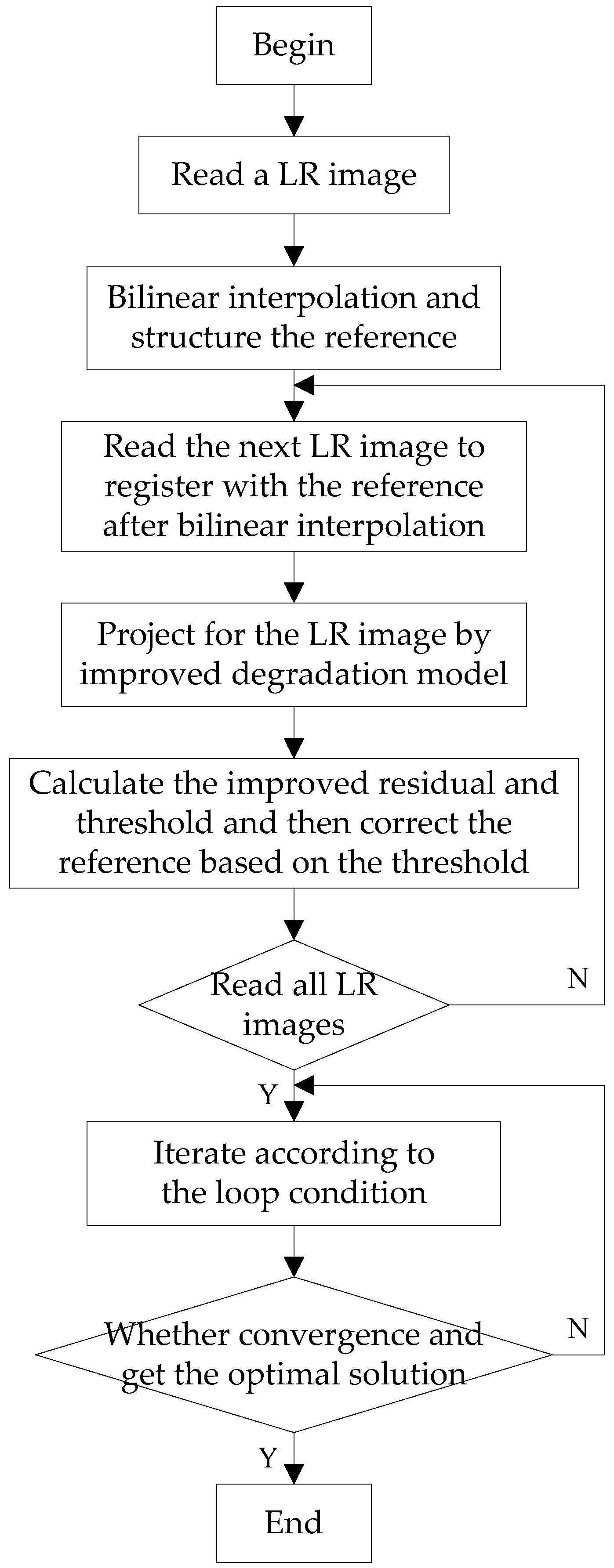
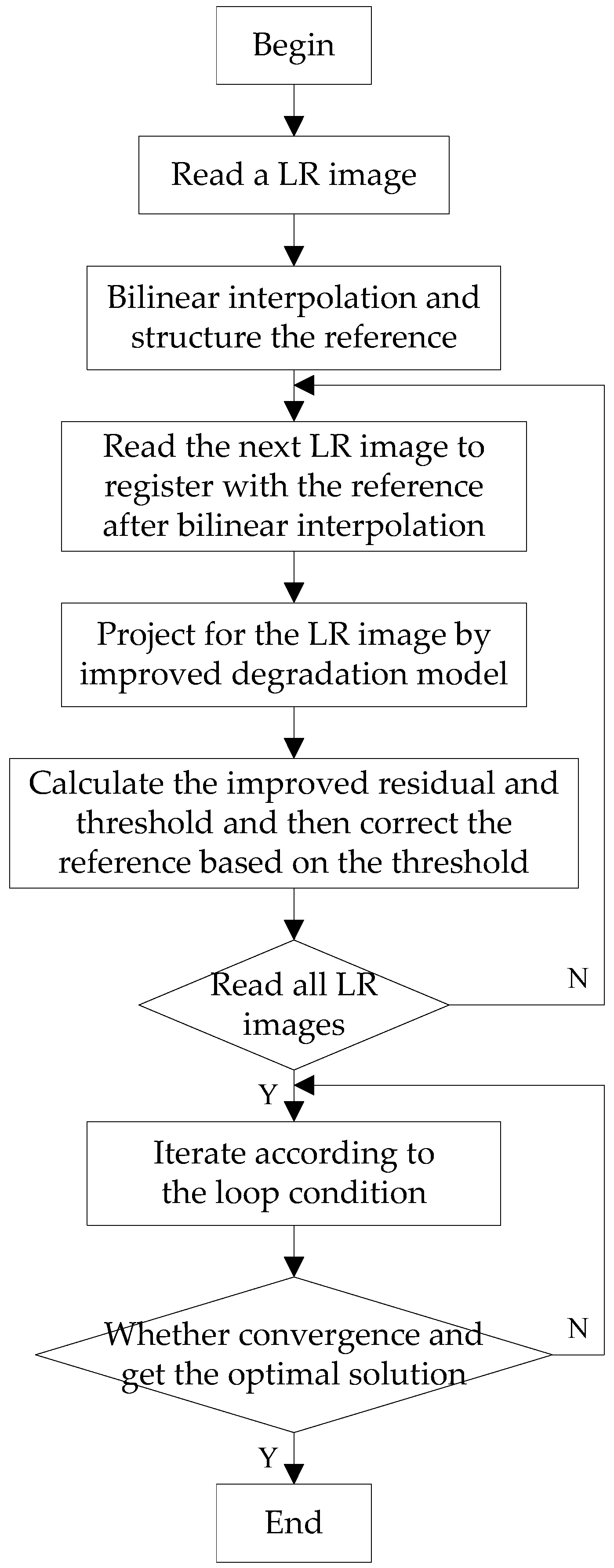
2.2.3. Algorithm Implementation
- Read an LR image and make a bilinear interpolation of it. The interpolation multiplier is a multiple of the desired improved resolution, then this interpolated image was selected as a reference frame. Let the initial estimate be and the threshold value be .
- Read the remaining LR frames to register with the reference frame after bilinear interpolation, and estimate the motion between each frame and the reference frame to produce the registration mapping parameters.
- Define the convex set C of the sequences and calculate the residual r values to correct the reference frame.
- According to the data consistency constraint, the operator P was calculated, and the relationship between r and was assessed to correct .
- The cycle end condition was set to . If the conditions are met, then , and the loop ends. Otherwise, let , and return to the step 3 until meets the convergence conditions. Then is the eligible solution of the algorithm.
3. Analysis of Experimental Results
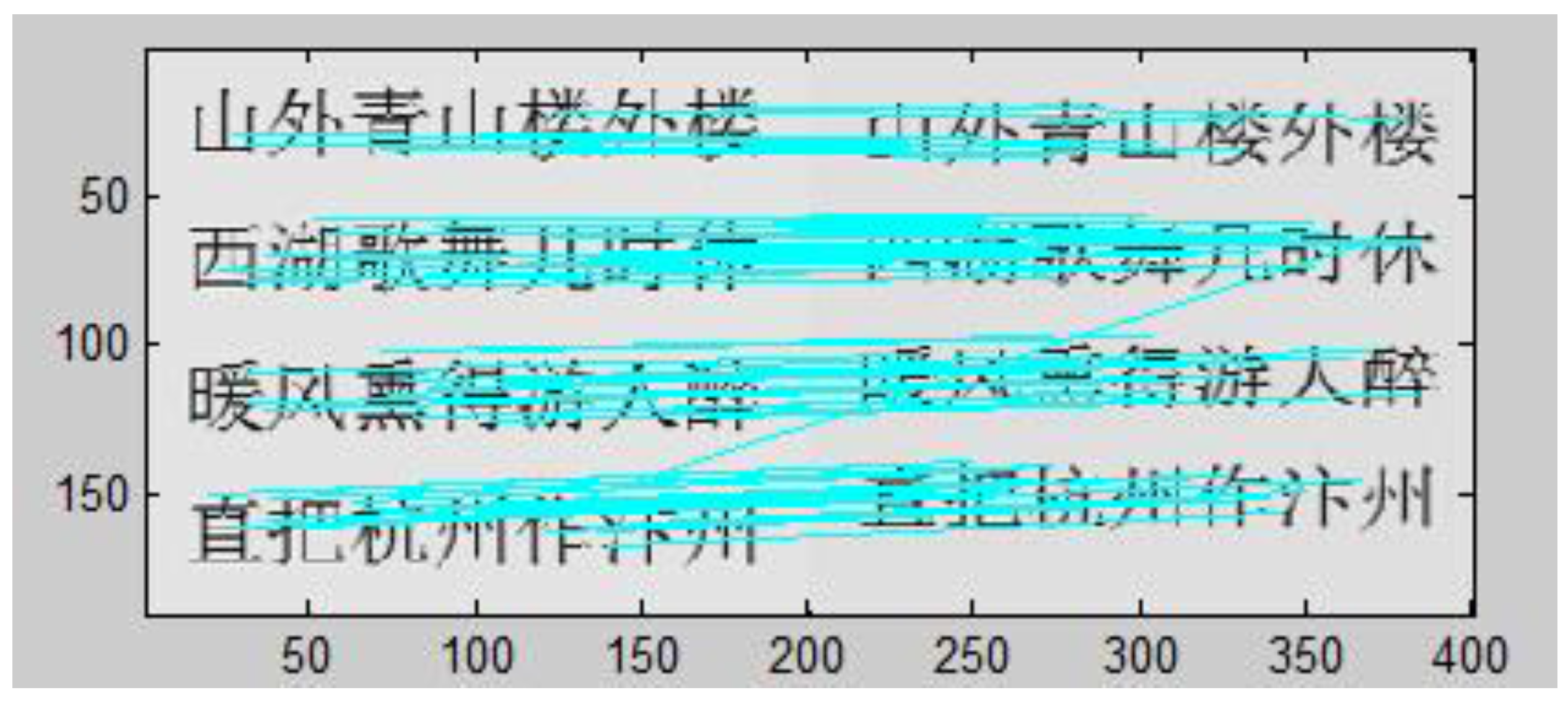
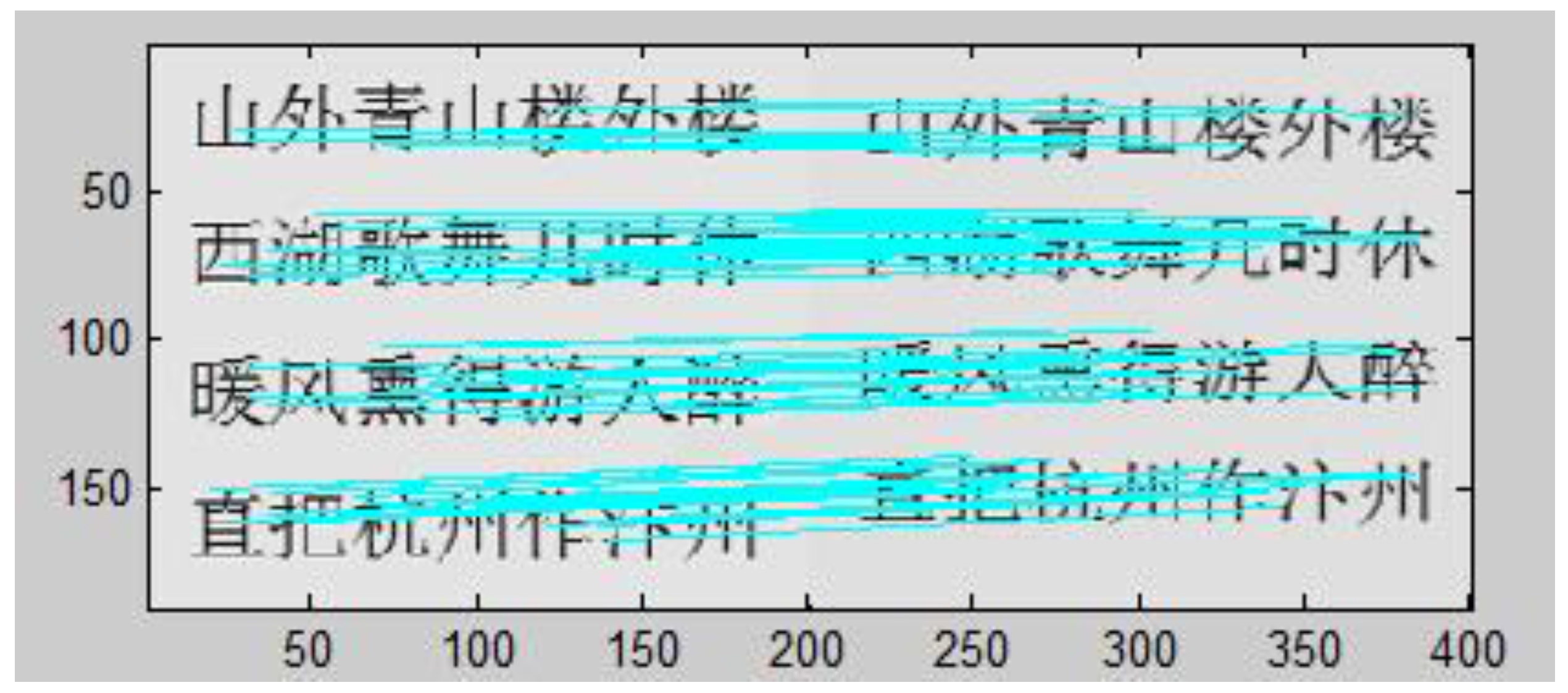
3.1. Registration with the Optimized SIFT Operator
3.2. Reconstructed Results and Analysis
3.2.1. The Reconstructed Result of an LR Image Which Is Generated by Simulation
3.2.2. Reconstruction of Ancient Books and Ancient Inscriptions Taken by Camera
3.2.3. Reconstruction Quality Evaluation
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Tsai, R.Y.; Huang, T.S. Multi frame image restoration and registration. Adv. Comput. Vis. Image Process. 1984, 1, 101–106. [Google Scholar]
- Chen, Y.; Jin, W.; Wang, L.X.; Liu, C. Robust Multiframe Super-resolution reconstruction based on regularization. Comput. Symp. 2010, 10, 408–413. [Google Scholar]
- Kato, T.; Hino, H.; Murata, N. Multi-frame image super resolution based on sparse coding. Neural Netw. 2015, 66, 64–78. [Google Scholar] [CrossRef] [PubMed]
- Panda, S.S.; Jena, G.; Sahu, S.K. Image Super Resolution Reconstruction Using Iterative Adaptive Regularization Method and Genetic Algorithm. Indian J. Med. Res. 2015, 60, 19–27. [Google Scholar]
- Fan, W.; Sun, J.; Minagawa, A.; Hotta, Y. Local consistency constrained adaptive neighbor embedding for text image super-resolution. In Proceedings of the 10th IAPR International Workshop on Document Analysis System (DAS), Gold Coast, Australia, 27–29 March 2012; pp. 90–94.
- Kumar, V.; Bansal, A.; Tulsiyan, G.H.; Mishra, A.; Namboodiri, A. Sparse document image coding for restoration. In Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR), Washington, DC, USA, 25–28 August 2013; pp. 713–717.
- Abedi, A.; Kabir, E. Stroke width-based directional total variation regularisation for document image super resolution. IET Image Process. 2016, 10, 158–166. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Stark, H.; Oskoui, P. High Resolution Image Recovery from Image-plane Arrays Using Convex Projections. Opt. Soc. Am. J. 1989, 6, 1715–1726. [Google Scholar] [CrossRef]
- Xu, H.; Miao, H.; Yang, C.; Xiong, C. Research on super-resolution based on an improved POCS algorithm. In Proceedings of the SPIE—The International Society for Optical Engineering, International Conference on Optical and Photonic Engineering (icOPEN 2015), Singapore, Singapore, 14–16 April 2015; Volume 9524.
- Al-Anizy, M.H. Super Resolution Image from Low Resolution of Sequenced Frames—Text Image and Image-Based on POCS. J. Al-Nahrain Univ. 2012, 15, 138–141. [Google Scholar]
- He, Y.; Yap, K.H.; Chen, L.; Chau, L.P. A soft map framework for blind super-resolution image reconstruction. Image Vis. Comput. 2009, 27, 364–373. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm Types | Characteristic Points | Matching Points | Matching Points | Time Spent on Matching (s) | The Correct Matching Rate (%) | |
|---|---|---|---|---|---|---|
| n1 | n2 | |||||
| Original algorithm | 220 | 227 | 184 | 7 | 1.795 | 96 |
| Improved algorithm | 220 | 227 | 180 | 1 | 1.763 | 99 |
| Algorithm Types | PSNR/dB | MOS | The Execution Time/s | The Memory Occupation/KB |
|---|---|---|---|---|
| Original POCS | 23.29 | 3.302 | 7.319 | 2464.00 |
| the method in [11] | 23.57 | 3.534 | 7.434 | 2934.00 |
| the method in [12] | 24.31 | 3.708 | 7.327 | 2585.00 |
| Improved POCS | 24.68 | 4.149 | 7.323 | 2324.00 |
| Algorithm Types | PSNR/dB | MOS | The Execution Time/s | The Memory Occupation/KB |
|---|---|---|---|---|
| Original POCS | 36.97 | 3.452 | 10.371 | 3173.00 |
| the method in [11] | 37.34 | 3.598 | 11.453 | 3528.00 |
| the method in [12] | 38.16 | 3.974 | 11.185 | 3259.00 |
| Improved POCS | 38.23 | 4.079 | 10.548 | 3194.00 |
| Algorithm Types | PSNR/dB | MOS | The Execution Time/s | The Memory Occupation/KB |
|---|---|---|---|---|
| Original POCS | 37.98 | 3.548 | 11.079 | 3279.00 |
| the method in [11] | 38.03 | 3.746 | 11.855 | 3371.00 |
| the method in [12] | 38.74 | 4.032 | 11.273 | 3284.00 |
| Improved POCS | 38.82 | 4.214 | 11.143 | 3281.00 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, F.; Xu, Y.; Zhang, M.; Zhang, L. A POCS Algorithm Based on Text Features for the Reconstruction of Document Images at Super-Resolution. Symmetry 2016, 8, 102. https://doi.org/10.3390/sym8100102
Liang F, Xu Y, Zhang M, Zhang L. A POCS Algorithm Based on Text Features for the Reconstruction of Document Images at Super-Resolution. Symmetry. 2016; 8(10):102. https://doi.org/10.3390/sym8100102
Chicago/Turabian StyleLiang, Fengmei, Yajun Xu, Mengxia Zhang, and Liyuan Zhang. 2016. "A POCS Algorithm Based on Text Features for the Reconstruction of Document Images at Super-Resolution" Symmetry 8, no. 10: 102. https://doi.org/10.3390/sym8100102
APA StyleLiang, F., Xu, Y., Zhang, M., & Zhang, L. (2016). A POCS Algorithm Based on Text Features for the Reconstruction of Document Images at Super-Resolution. Symmetry, 8(10), 102. https://doi.org/10.3390/sym8100102