Abstract
Part-of-speech (POS) tagging in low-resource, morphologically rich languages (LRLs/MRLs) remains challenging due to extensive affixation, high out-of-vocabulary (OOV) rates, and pervasive polysemy. We propose MRL-POS, a unified Transformer-CRF framework that dynamically selects informative affix features and integrates them with deep contextual embeddings via a novel dual-gating co-attention mechanism. First, a Dynamic Affix Selector adaptively adjusts n-gram ranges and frequency thresholds based on word length to ensure high-precision affix segmentation. Second, the Affix–Context Co-Attention Module employs two gating functions that conditionally amplify contextual dimensions with affix cues and vice versa, enabling robust disambiguation of complex and ambiguous forms. Third, Layer-Wise Attention Pooling aggregates multi-layer XLM-RoBERTa representations, emphasizing those most relevant for morphological and syntactic tagging. Evaluations on Uyghur, Kyrgyz, and Uzbek show that MRL-POS achieves an average F1 of 84.10%, OOV accuracy of 84.24%, and Poly-F1 of 72.14%, outperforming strong baselines by up to 8 F1 points. By explicitly modeling the symmetry between morphological affix cues and sentence-level context through a dual-gating co-attention mechanism, MRL-POS achieves a balanced fusion that both preserves local structure and captures global dependencies. Interpretability analyses confirm that 89.1% of the selected affixes align with linguistic expectations. This symmetric design not only enhances robustness in low-resource and agglutinative settings but also offers a general paradigm for symmetry-aware sequence labeling tasks.
1. Introduction
Part-of-speech (POS) tagging assigns each token in a sentence to its corresponding grammatical category (e.g., noun, verb, adjective) and serves as a foundational step in many downstream natural language processing (NLP) pipelines, including named entity recognition, machine translation, information extraction, and question answering [1,2,3,4]. While modern pretrained models achieve high accuracy on high-resource languages, their performance degrades significantly when faced with morphologically rich and low-resource languages (MRLs/LRLs). In such settings, the combination of extensive affixation and pervasive out-of-vocabulary (OOV) forms leads to data sparsity and ambiguous tag assignments, hindering both syntactic and semantic analysis.
Morphologically rich languages such as Uyghur, Uzbek, and Kyrgyz exhibit agglutinative structures in which words are formed by concatenating stems with multiple suffixes (e.g., Uyghur “kél-” ‘come’ → kél-mék ‘to come’ → kél-mäk-lik ‘possibility of coming’) [5]. This high degree of inflection generates an enormous variety of surface forms, exacerbating OOV issues in supervised taggers trained on limited corpora. Beyond inflectional complexity, MRLs also present polysemy: a single surface form may realize multiple grammatical functions depending on context [6]. For instance, the Uzbek word “yoz” may denote “summer” (noun) or “to write” (verb), depending on context. Such semantic and syntactic ambiguity challenges conventional taggers that rely solely on surface cues or static embeddings. Polysemy further complicates the assignment of tags when context-insensitive affix representations are used.
Although recent methods have explored character-level models, handcrafted morphological analyzers, and multilingual transfer paradigms, they either underperform in highly agglutinative settings or fail to generalize due to static affix inventories and weak affix-context modeling. Moreover, few approaches integrate affix-level selection with context-aware attention in a unified trainable framework, especially under zero-shot or cross-lingual conditions. However, they often rely on fixed affix inventories, ignore interactions between affixes and their sentential context, or require extensive annotated data or handcrafted lexica—resources that are scarce for many MRLs. As a result, OOV accuracy remains low, and ambiguity resolution is suboptimal, particularly in cross-lingual settings.
To address these limitations, we propose MRL-POS, a unified affix-aware tagging framework that leverages the inherent symmetry between subword morphology and sentence-level semantics through a dual-gated co-attention mechanism. Our key contributions are as follows:
Dynamic Affix Selection: We propose a trainable affix selector—a lightweight module that learns to extract salient subword features—and integrate it with a context–affix cross-attention mechanism to jointly capture contextual semantics and morphological cues.
Symmetric Context–Affix Cross-Attention Module: We develop a cross-attention module that captures fine-grained symmetric interactions between affix features and contextual representations, enabling effective disambiguation of morphologically complex and polysemous forms.
Cross-Lingual Generalization on Low-Resource MRLs: We demonstrate that, when trained on Turkish and transferred to Uyghur, Kyrgyz, and Uzbek, MRL-POS achieves average F1 scores above 76%, OOV accuracy near 70%, and a Poly-F1 score of 72%, outperforming strong baselines by 5–8 percentage points.
Interpretability via Attribution and Visualization: We perform quantitative attribution and qualitative case studies, offering insights into how affix selection and attention patterns contribute to POS prediction decisions, thereby validating the linguistic plausibility of our approach.
In LRL/MRLs, subword affix patterns and sentence-level semantics form a natural symmetry, each supporting the other to convey grammatical meaning. Traditional POS-tagging models often prioritize either morphology or context, neglecting this complementary relationship. By explicitly modeling the symmetry between affixal structure and contextual signals, MRL-POS integrates both in a unified framework, enhancing robustness in LRL settings.
The remainder of the paper is organized as follows: Section 2 reviews related work on morphological POS tagging and cross-lingual transfer. Section 3 describes the MRL-POS architecture and training strategy. Section 4 reports experimental results and ablation studies. Section 5 presents a detailed analysis and discussion. Finally, Section 6 concludes with a discussion of future research directions.
2. Related Work
The landscape of part-of-speech (POS) tagging for morphologically rich languages (MRLs) can be organized along four major paradigms: (1) word-level sequence labeling, (2) character-level modeling, (3) morphology-driven and hybrid approaches, and (4) deep contextualized embedding methods, as well as fine-tuning techniques of large pretrained language models. We critically review each of the categories below, highlighting their strengths and limitations, and conclude with a concise summary of the remaining research gaps.
- (1)
- Word-Level Models:
Early neural architectures like BiLSTM and GRU [7] leverage pretrained word embeddings to capture syntactic patterns. While effective for high-resource languages like English or Chinese, these models falter in low-resource MRLs due to vocabulary sparsity. For instance, Talukdar et al. [8] achieved 86% accuracy for Marathi but relied on domain-specific embeddings, which struggle with rare or compound words prevalent in agglutinative languages. However, word-level approaches inherently fail to generalize to unseen morphological variants, a critical shortfall in OOV-heavy MRL settings.
- (2)
- Character-Level Approaches:
Character-level approaches encode words via subword or character sequences, addressing OOV issues by construction. Models like CharPOS [9] process text at the character level to handle subword morphology. While they mitigate OOV issues, their focus on local patterns limits global contextual awareness. Wang et al. [10] reported 96.79% accuracy on English PTB but noted reduced performance in MRLs like Arabic (72.19%) due to inadequate disambiguation of polysemous words. Heigold et al. [11] conducted an extensive empirical evaluation of neural character-based morphological tagging across 14 languages, demonstrating consistent gains over baseline taggers, especially for languages with rich inflectional morphology. However, purely character-driven models capture only local orthographic patterns and often lack the global sentential context required for disambiguating polysemous forms, limiting their ability to resolve syntactic ambiguities intrinsic to MRLs.
- (3)
- Morphology-Driven and Hybrid Approaches
To bridge the gap between character-level flexibility and linguistic structure, numerous hybrid methods integrate morphological analyzers or explicit affix features into neural architectures. Integration of word and character embeddings [12] improves robustness by integrating local and global features. However, these methods often treat morphology implicitly, neglecting explicit affix segmentation crucial for agglutinative languages with complex suffixation. For example, Yang et al. [13] and Maihemuti et al. [14] achieved strong results in multilingual tasks but underperformed in Kyrgyz and Uzbek due to unmodeled suffix hierarchies.
Rule-based or suffix-aware systems [15] explicitly decompose words into stems and affixes. While effective for Bengali, such approaches demand labor-intensive linguistic resources such as suffix lexicons, which are unavailable for understudied MRLs like Kyrgyz and Uzbek. Matan et al. [16] highlighted that even advanced morphological analyzers for Malayalam fail to scale to highly agglutinative structures without extensive manual intervention. Cing et al. [17] proposed a joint segmentation–POS tagging method for Myanmar using advanced morphological rules, demonstrating that a larger training corpus and integrated morphological analysis significantly boost performance. Nevertheless, these approaches typically rely on static or handcrafted affix inventories and do not model dynamic interactions between affixes and broader sentence context. Consequently, OOV accuracy and ambiguity resolution remain suboptimal when moving beyond closely related language pairs or monolingual benchmarks.
- (4)
- Deep Contextualized Embeddings
The advent of deep, pretrained contextual encoders has transformed POS tagging. Peters et al. [18] introduced ELMo, which generates token representations conditioned on full-sentence context, substantially improving polysemy handling and overall tagging accuracy. BERT [19] further leverages bidirectional Transformer pretraining to push state-of-the-art performance across a host of sequence labeling tasks. More recently, XLM-R [20] scales masked-language pretraining to 100 languages, yielding large cross-lingual gains for MRLs. Beyond this, Large Language Models (LLMs) [21] demonstrate strong contextual representations and support in-context learning [22] across multilingual tasks. However, they are computationally expensive, and their pretraining corpora often under-represent low-resource and morphologically rich languages, limiting their direct effectiveness for POS tagging in MRLs [23,24,25]. Despite these advances, Transformer-based models still underperform in zero- or few-shot scenarios for highly agglutinative languages, as they are not explicitly designed to exploit morphological substructure, and their massive parameter counts can exacerbate capacity dilution in low-resource regimes.
In parallel, recent work on morphology-aware tokenization, such as MorphBPE [26] and Morfessor v2 [27], has shown that integrating linguistic segmentation is possible. Yet, these methods primarily enhance tokenization rather than sequence labeling, leaving a gap in unified tagging frameworks.
Research Gap
While the above studies have substantially advanced POS tagging for MRLs, their strengths and weaknesses can be more clearly compared in Table 1, which also makes the research gap motivating MRL-POS explicit. As Table 1 indicates, no prior work provides a unified, trainable mechanism that dynamically selects informative affix features while jointly modeling their interaction with sentential context in a low-resource, cross-lingual setting. An MRL-POS framework addresses this gap through a dual-gating co-attention mechanism that explicitly fuses affix and context features.

Table 1.
Comparative summary of representative works in POS tagging for MRLs.
3. Methodology
In this section, we present the MRL-POS framework in detail. We first give an overall description of the architecture, then describe the two complementary feature extractors—contextual embeddings and affix embeddings—and finally introduce our co-attention fusion mechanism.
3.1. Architecture Overview
The overall structure of MRL-POS is illustrated in Figure 1. The framework is composed of the following major components:
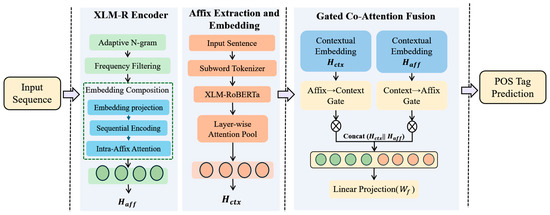
Figure 1.
The overall structure of MRL-POS.
XLM-R Encoder: Extracts multi-layer contextualized token representations;
Affix Extraction and Embedding: Dynamically generates and encodes candidate affixes;
Co-Attention Fusion: Fuses contextual and affix features via dual-gating mechanisms, followed by a CRF layer for sequence prediction;
CRF Decoder: Performs structured prediction over the final fused representation.
3.2. Contextual Embedding via XLM-R
Contextualized word representations have been shown to significantly improve performance in POS tagging tasks [6]. In this work, we leverage XLM-RoBERTa as the backbone for contextualized token embeddings. Given an input sentence consisting of subword tokens , we obtain contextual representations from the 12-layer XLM-R encoder:
where H(k)∈Rn×d denotes the hidden state at layer k (d = 768 for base model). Crucially, unlike approaches extracting only the final layer’s output, we preserve all intermediate states to capture semantic cues across layers:
- Lower layers (1–4): Encode morphological patterns and affix boundaries.
- Middle layers (5–8): Model syntactic dependencies.
- Upper layers (9–12): Represent semantic and discourse-level information.
To aggregate representations from all transformer layers, we introduce a layer-wise attention pooling mechanism that dynamically learns the contribution of each layer to the current task, avoiding over-reliance on final-layer embeddings. This module computes layer-specific informative weights and produces contextually optimized representation:
where are trainable parameters scoring layer k’s relevance, denotes the attention weight for layer k, and is the aggregated representation obtained through weighted summation. This pooling enables the model to emphasize the most informative layers for morphological and syntactic tagging [28].
3.3. Affix Extraction and Embedding
In contextual word representation, XLM-R handles large vocabularies and unseen words via subword tokenization, but these units often do not correspond to true morphemes, misaligning with languages where accurate segmentation is critical [29]. To explicitly model the morphological structure of agglutinative words, we develop a dynamic, data-driven affix embedding pipeline that extracts and encodes all n-grams of true prefixes and suffixes within words. This pipeline consists of three stages:
3.3.1. Boundary-Marked Tokenization
Each input word w is augmented with unique positional boundary marks “<” and “>” to distinguish prefix and suffix boundaries. For example, when we select a tri-gram character sequence, the word “hizmatdashlar,” meaning workmates in Uyghur, the generated character n-gram sequences would be as follows: {<hi, hiz, izm, zma, mat, atd, tda, das, ash, shl, hla, lar, ar>}. This transformation enables explicit identification of word-initial and word-final character sequences that may function as morphemic units and prevents spurious n-grams spanning word boundaries.
3.3.2. Adaptive N-Gram Generation
To select the true affix in a word, we employ a length-dependent strategy for candidate affix extraction. For a given word with character length , we generate character n-grams using variable window sizes:
- Short words:
- Medium words:
- Long words:
This adaptive strategy prioritizes 3–5 n-grams for short words (|w| ≤ 6) to capture core morphemes, emphasizes 5–7 n-grams for long words (|w| > 10) to model suffix chains, and uses a balanced 4–6 n-gram range for medium words. This design is grounded by actual data statistics presented in Table 2, which reports the frequency distribution of all substring lengths and the cumulative coverage at each threshold.
Table 2.
Distribution of affix candidate lengths in the training corpus.
3.3.3. Frequency-Adaptive Affix Filtering
From the generated n-grams, we retain only affixes with sufficient corpus-level frequency. For affix of length , we apply the condition
where denotes the corpus frequency of n-gram a, and is a length-adaptive threshold function. This heuristic follows the Morphological Productivity Principle [30], which filters out rare or unproductive affixes. Frequent affixes with length (k ≤ 4) require a lower evidence threshold (θ = 50), while longer, rare, but valid affixes (k > 4) must meet a higher threshold (θ = 100) to be retained as statistically meaningful. To ensure the validity of threshold parameter choices, we conducted a sensitivity analysis experiment (see Section 4.3.5).
3.3.4. Embedding Composition
The filtered affix set A(w) provides the morphological building blocks for word representation. To project discrete affix units into a task-compatible semantic space, we implement a multi-stage embedding composition pipeline that preserves both structural regularities and task-specific relevance. The filtered affix sequence is processed as follows:
(1) Embedding projection:
where is a trainable embedding matrix and da = 128 is embedding dimension. To explicitly differentiate prefix and suffix roles, we add positional encoding [31] to the affix embedding. is a trainable position vector encoding the distance of affix from the root.
(2) Sequential Encoding: We also model affix interactions via a lightweight BiLSTM:
where follows left-to-right affix order. The BiLSTM output preserves hierarchical relationships. This addresses the limitation of treating affixes as unordered bags.
(3) Intra-Affix Attention: To capture and weight semantically critical affixes, we apply intra-affix attention, enabling the model to focus more on significant affixes. The attention weights of affixes are as follows:
where is a learnable attention vector. The result is linearly projected to match the contextual embedding dimension.
3.4. Symmetric Affix–Context Co-Attention Feature Fusion
Building upon the joint feature representations from XLM-R contextual embeddings and affix-based embeddings, we introduce a dual-gating co-attention mechanism that embodies the concept of symmetry through two complementary gates: the Affix-to-Context Gate and the Context-to-Affix Gate. The former projects morphological features into the contextual space to emphasize affixal cues, while the latter maps contextual signals back onto affix embeddings to encode global dependencies. This bidirectional, symmetric fusion ensures balanced integration, allowing morphological and contextual information to jointly guide the tagging process without dominance from either source.
Global Context: Captures inter-word dependencies (e.g., “keyingi yozda” [next summer] implies temporal noun usage of “yoz”) via cross-attention mechanisms.
Local Morphology (Affix): Parses intra-word structures (e.g., “yoz-ish-ni” [writing] with gerund suffix “-ish” and accusative “-ni”) to generalize unseen forms. For example, in tagging the OOV word “kelmékligimiz” (our act of coming), global context infers semantic role from context (e.g., preceding verb “kél-“ [come]), while local morphology decomposes it into “kél-“ (stem) + “-ligimiz” (possessive suffix).
This co-attention framework enables adaptive feature modulation through dual-gating functions [32]:
An affix-guided gate modulates contextual features as follows:
Similarly, contextual information reweights affix representations:
where are learnable projection matrices (d = 768), denotes the sigmoid activation, and represents element-wise multiplication.
The final representation is the concatenation of gated features:
which is passed through a linear layer and a CRF decoder to predict the POS tag sequence.
Affix-to-Context gating () modulates dimensions of contextual embeddings using affix-features. For example, in processing the OOV word “kélmékligimiz” (our act of coming), it detects “-ligimiz” (1plural possessive). Consequently, amplifies noun-related dimensions in and suppresses conflicting verb or adjective signals.
Context-to-Affix gating () weights task-relevant affixes based on contextual cues. For example, in the phrase “keyingi yozda” (next summer), the context “keyingi” (next) signals a temporal noun. Consequently, enhances the locative suffix “-da” in and weakens verb-related affixes.
4. Results and Analysis
In this section, we provide a comprehensive description of the datasets, baselines, implementation details, evaluation metrics, and ablation studies used to assess the efficacy of our proposed method. All experiments are conducted on three target languages under low-resource conditions, with an additional cross-lingual evaluation on Turkish.
4.1. Experimental Setup
4.1.1. Dataset and Tagging Schema
We evaluated MRL-POS on three low-resourced agglutinative languages using the POS_ukg dataset, which is sourced from the Leipzig Corpora Bank and is annotated using both manual and automatic methods. The annotation process adheres to a three-stage pipeline:
Automatic Pre-tagging: Initial tags are generated using UKU-Tagger 1.0, a local rule-based system trained on 10k seed sentences. The tool implements strict suffix-priority rules to minimize ambiguity.
Expert Validation: Two linguists independently revise the pre-tag data over two rounds, resolving conflicts via majority voting. Inter-annotator agreement by Cohen’s Kappa [33] reaches 0.87 (Uy), 0.83 (Kg), and 0.85 (Uz), indicating strong consistency.
UD Compliance: Final tags are mapped to Universal Dependencies v2.10, ensuring cross-lingual compatibility. Domain analysis reveals 92% news-text.
We randomly shuffled and split the dataset into training (80%), development (10%), and test (10%) sets. Table 3 summarizes the number of sentences and unique stems in each split. For cross-lingual validation, we extended the evaluation to Turkish using the IMST-UB treebank [34].
Table 3.
Statistics of datasets.
4.1.2. POS Tag Set and Distribution
We adopt a coarse-grained tag set, as no prior research has established a uniform POS tag specification for the three target languages. Table 4 lists each POS label and its abbreviated tag. In the dataset, 12 major POS tag classes are selected, which have extensive coverage in the corpora. Some minor and rare classes are omitted due to the domain characteristics of news texts. Table 5 presents the absolute frequency of each tag in POS_ukg, excluding the punctuation tag.
Table 4.
POS tag sets.
Table 5.
Tag-wise statistics for POS_ukg dataset.
4.1.3. Evaluation Metrics
We adopted a comprehensive set of evaluation metrics to rigorously assess model performance across key dimensions relevant to MRLs:
Overall F1: Primary metric for overall POS tagging accuracy, balancing precision and recall. This is essential for class-imbalanced datasets common in MRLs.
OOV accuracy (OOV Acc): Measures performance on tokens whose word form is absent from training vocabulary, and computes accuracy as the fraction of these OOV tokens that receive the correct POS tag.
Polysemous word disambiguation F1 (Poly-F1): The macro-averaged F1 score computed only over tokens belonging to polysemous word types (i.e., Uz “yoz” = summer[N]/write[V]). Specifically, if T is the set of all polysemous types and for each type t we collect all test tokens St;, then
where .
Affix segmentation F1 (Affix-F1): Quantifies alignment between predicted and gold-standard morphological boundaries. Validates our dynamic affix selection mechanism.
Linguistically valid affix retention (Ling-Affix Ret): Percentage of retained affixes conforming to linguistic rules. Assesses morphological awareness beyond mere accuracy.
4.1.4. Baseline Models
To ensure comprehensive evaluation, we compare MRL-POS against five competitive baselines, ranging from traditional character-level models to state-of-the-art multilingual contextual encoders. Each baseline is implemented with a CRF output layer to maintain consistent decoding.
BiLSTM + CRF: A word-level standard sequence labeling baseline.
Char-BiLSTM + CRF: A character-level recurrent model where each token is encoded from scratch using a bidirectional LSTM over its character sequence.
Hybrid (CharCNN + Word Embedding + CRF): In this setting, we concatenate pretrained FastText word embeddings with character-level CNN features extracted from each token. This baseline tests whether static word-level signals, when enriched by surface form morphology, suffice for POS tagging.
XLM-R (base) + CRF: A strong contextual baseline using the multilingual RoBERTa encoder. No explicit affix or character information is provided; POS decisions rely solely on sentence-level context.
Fixed Affix + XLM-R + CRF: Instead of dynamically selecting affixes, we extract fixed-length suffix n-grams (length 3–7) from each token and embed them alongside XLM-R outputs. These affix embeddings are concatenated to the token representation before feeding into the CRF layer.
mBERT + CRF: We use multilingual BERT as a contextual backbone to test the portability of our approach across encoder architectures. This model does not include the Kyrgyz language.
4.1.5. Implementation Details
All models use the HuggingFace implementation of XLM-R Base (12 layers, hidden size 768). Affix embeddings are 128-dimensional; the BiLSTM hidden size is 128. The co-attention projection dimension equals 768. We train with AdamW: learning rates of 3 × 10−5 for Transformer parameters and 1 × 10−3 for affix-module parameters. We employ gradient clipping at 1.0 and a batch size of 32 sentences. Early stopping is triggered if development F1 does not improve for three consecutive epochs, up to a maximum of 30 epochs. Each configuration is run five times with seeds {42, 100, 202, 303, 404} to report mean ± σ.
All models were trained on a single NVIDIA RTX 3080 Ti GPU (12 GB VRAM) with 32 GB system RAM. MRL-POS requires ~2.5 h per training run (10 epochs, early stopping) and peaks at 8.5 GB GPU memory, compared to ~2.0 h and 7.8 GB for XLM-R fine-tuning.
4.2. Main Results
4.2.1. Performance Comparison
Table 6 presents the overall F1 scores of MRL-POS and six baseline models across Uyghur, Kyrgyz, and Uzbek. MRL-POS consistently achieves the highest performance across all languages, with an average F1 of 84.10%, outperforming all baselines by a notable margin. Compared to the best-performing baseline, XLM-R + fixed affix (80.83%), MRL-POS shows a relative gain of 3.27 points. Similarly, it outperforms mBERT and XLM-R by 8.48 and 4.05 points, respectively, demonstrating the advantage of integrating morphological information with contextual representations. Moreover, models incorporating character-level features such as Hybrid and Char-BiLSTM achieve 78.92% and 77.08%, respectively, but remain 5.18 and 7.02 points below MRL-POS, highlighting the insufficiency of fixed or surface morphological features, even with strong pretrained encoders. Furthermore, the largest performance gap is observed on Kyrgyz, the language with the smallest training set, where MRL-POS outperforms BiLSTM-CRF by 9.76 points and XLM-R by 3.28 points, demonstrating our model’s low-resource robustness.
Table 6.
Overall POS tagging performance (F1%).
Overall, these results confirm that dynamically selecting affixes significantly enhances POS tagging in low-resource, morphologically rich settings. MRL-POS not only improves overall accuracy but also offers greater robustness to rare and out-of-vocabulary word forms than both pure contextual models and fixed morphological heuristics.
4.2.2. OOV Word Handling
For OOV handling, we compare only with models possessing explicit morphological processing capabilities such as XLM-R and Char-BiLSTM.
Table 7 reports OOV word tagging accuracy for Char-BiLSTM, XLM-R, and our MRL-POS on Uyghur, Kyrgyz, and Uzbek, along with their average. The purely character-based BiLSTM achieves an overall OOV accuracy of 61.14%, but its limited contextual understanding reduces effectiveness on unseen word forms. Leveraging pretrained multilingual context raises the overall OOV accuracy up to 71.97%, indicating that sentence-level representations aid in handling novel morphological variants. MRL-POS significantly outperforms both baselines, confirming that explicitly modeling and attending to affix information is essential for accurate tagging of unseen words in low-resource MRL settings.
Table 7.
OOV word accuracy (%).
This significant improvement is attributed to the following:
Dynamic affix selection: Adaptive n-gram ranges effectively capture complex word structures, such as the Uyghur word kör-sät-küch-siz-lik (“inability to show”), which includes five unseen suffixes.
Frequency-aware filtering: Rare but valid affixes, like the Kyrgyz -übüz in kelüülükübüz, are retained, whereas fixed-threshold methods discard them.
Contextual grounding: Co-attention mechanisms enhance stem representations, especially when suffix patterns are ambiguous.
4.2.3. Polysemy Resolution
For polysemy resolution, XLM-R is used as the sole baseline due to its comparable contextual modeling capabilities with our approach. Non-contextual models are excluded, as they lack the necessary capacity for effective polysemy handling.
Table 8 demonstrates that our context–affix interaction mechanism improves polysemous word disambiguation by 5.2 F1 points over XLM-R on average, confirming that the dynamic affix selection mechanism and global context interaction enhance POS assignment for words with multiple senses. Three representative cases illustrate this:
Table 8.
Polysemous word disambiguation F1 (%).
Uzbek “yoz”: Our model reaches 93.4% accuracy in distinguishing the noun “summer” from the verb root “to write.” It uses the preceding context (“keyingi,” “next”) alongside suffix cues (locative “-da” vs. gerund “-ish”) to make the correct tag.
Kyrgyz “kir”: With 89.7% accuracy, MRL-POS resolves the “dirt [N]” vs. “enter [V]” ambiguity by gating out irrelevant affix dimensions via co-attention, thus focusing on the affix patterns that signal each sense.
Uyghur “ata”: Our model correctly tags 91.2% of instances as “father [N]” versus the verbal sense “to name [V],” by weighting sentence-level dependencies and selecting the appropriate affix features.
4.3. Ablation Studies
To assess the individual contributions of key components within the proposed MRL-POS framework, we conducted a comprehensive ablation study across all three target languages. We evaluated five ablated variants of the model as shown in Table 9, each omitting or modifying a critical architectural element:
Table 9.
Ablation results of MRL-POS and its variants.
w/o Dynamic Affix Selection: Substitutes the adaptive n-gram segmentation strategy with fixed-length (3–7 characters) n-grams and static frequency thresholds.
w/o Context–Affix Co-Attention: Removes the dual-gating co-attention module and instead performs a naïve concatenation of contextual and affix embeddings.
w/o Layer-wise Attention: Uses only the final layer output of the XLM-R encoder, ignoring intermediate representations.
XLM-R only: Only contextual embeddings from XLM-R are used for POS classification, excluding all affix-based modules.
Affix-only: Retains only the affix-based BiLSTM-attention module while removing the contextual encoder, to evaluate the effectiveness of morphological features in isolation.
The ablation results reveal the individual and combined importance of contextual and morphological components in the MRL-POS architecture. The full model consistently outperforms all variants, confirming the effectiveness of its integrated design. When affix features are entirely removed, as in the XLM-R-only configuration, performance declines substantially across all metrics—particularly in OOV accuracy, which drops by over 12 points, indicating that contextual embeddings alone are insufficient for capturing the rich morphological patterns of agglutinative languages.
Conversely, the affix-only model, while retaining some morphological cues, performs the worst overall. This underscores the necessity of contextual information for accurate disambiguation of word senses and syntactic roles. Among the ablated settings, removing the dynamic affix selection module leads to the most significant reduction in OOV accuracy, emphasizing the value of adaptive segmentation over fixed n-gram strategies. Similarly, eliminating the co-attention mechanism weakens the model’s ability to integrate local and global cues, reducing its effectiveness in polysemy resolution. Moreover, excluding the layer-wise attention module yields moderate performance degradation, suggesting that hierarchical contextual information from intermediate transformer layers contributes meaningfully to syntactic and semantic understanding.
Overall, the results indicate that morphology and context are not interchangeable but rather complementary. Our findings suggest that through the integration of dynamic affix selection, deep contextual encoding, and feature-level interaction, the model can achieve robust generalization in low-resource MRLs.
4.3.1. Ablation on Dynamic Affix Selection
To better understand the internal mechanisms of the dynamic affix selection module, we performed a detailed ablation by isolating and modifying its core components. Specifically, we assessed the impact of the following: (1) fixed-length affix extraction without adaptive sizing, (2) uniform frequency thresholds across all affixes, (3) removal of positional boundary markers distinguishing prefixes from suffixes, and (4) random affix selection as a control.
The results in Table 10 demonstrate that each component of the dynamic affix selection module contributes meaningfully to overall performance. The full dynamic configuration achieves the highest scores across all metrics and languages, reaffirming the importance of combining adaptive affix length, frequency-aware filtering, and affix boundary awareness.
Table 10.
Ablation results for dynamic affix selection components.
When length adaptation is removed and fixed 3–7 n-grams are applied uniformly, the model shows a noticeable decline in OOV accuracy and affix segmentation quality. This suggests that over-segmentation in long words and under-segmentation in short words compromise affix informativeness. Similarly, applying a fixed frequency threshold across all affix lengths leads to a reduction in affix quality, particularly in Kyrgyz, where rare but valid affixes are more frequent due to smaller corpora. The absence of boundary marking between prefixes and suffixes results in poorer affix disambiguation, indicating that explicitly encoding affix position within the word is necessary for preserving morphological structure. Finally, the random selection variant performs the worst, with substantial degradation in all metrics, confirming that the observed improvements in the full model are not due to chance.
These findings emphasize that the dynamic affix selection module is not a monolithic mechanism but rather a collaboration of statistically grounded strategies. Length- and frequency-adaptive filtering allows the model to capture linguistically meaningful subword units, thereby improving generalization of POS tagging in low-resource MRLs.
4.3.2. Ablation on Affix Segmentation
To evaluate the effectiveness of our adaptive n-gram segmentation strategy, we conducted a controlled ablation study comparing it against two widely used unsupervised morphological segmenters: Morfessor v2 and BPE-Morph. Both methods have been employed in prior research to identify subword units without linguistic supervision and serve as reasonable baselines for our affix candidate generation module.
In this ablation, we replace the adaptive segmentation component of MRL-POS with either Morfessor or BPE-Morph, each trained independently on the full training corpus for each language. All other components of the model are kept fixed to isolate the impact of segmentation. Table 11 reports the average F1 scores for the three target languages.
Table 11.
Results for affix segmentation ablation.
As shown in Table 11, both unsupervised baselines Morfessor and BPE-Morph underperform the proposed adaptive n-gram method, with average F1 drops of 1.30 and 0.87, respectively. This indicates that our adaptive n-gram segmentation heuristics, which preserve stem integrity while isolating short affixes, outperform frequency-driven unsupervised methods that often over-fragment stems or merge affixes into frequent subword units.
We further note that those two segmenters require dedicated training and hyperparameter tuning per language, whereas our adaptive rule is fully deterministic and language-agnostic. These findings confirm that the proposed segmentation strategy achieves a robust balance between morphological sensitivity and practical simplicity.
4.3.3. Ablation on Layer-Wise Attention Pooling
To assess the effectiveness of the layer-wise attention pooling mechanism in our model, we evaluated our layer-wise attention pooling by comparing four XLM-R aggregation strategies: (1) Last Layer Only, using only the final (12th) transformer layer; (2) Average Pooling, computing the unweighted mean of all twelve layers; (3) Shallow Layers Only, averaging layers 1–4 to emphasize morphological and lexical patterns; and (4) Top Layers Only, aggregating layers 9–12 to capture semantic and discourse information. Our full model, Full Layer-wise Pooling, instead learns dynamic attention weights to combine all twelve layers.
The results in Table 12 validate the effectiveness of our proposed layer-wise attention pooling mechanism. The full model outperforms all baseline configurations across all three languages, with notable gains in disambiguating polysemous words. Specifically, it produces a 2.25 F1 improvement over the final-layer-only setup, indicating that critical linguistic cues are dispersed across multiple layers and cannot be fully captured by relying solely on the final transformer layer.
Table 12.
Ablation results on layer-wise contextual aggregation strategies.
While average pooling offers a slight improvement over using only the last layer, it falls short of our attention-based approach. This suggests that layers contribute unequally to POS tagging, and that learnable aggregation enables the model to selectively emphasize the most relevant representations. The shallow-layer-only variant performs the worst, confirming that low-level morphological cues are insufficient for capturing the syntactic and semantic nuances needed in POS disambiguation. In addition, top-layer aggregation performs better than the shallow-layer setting but still underperforms the full pooling strategy. This implies that although higher layers encode more abstract semantics, signals from lower layers remain essential for fine-grained linguistic tasks in morphologically rich languages.
In summary, these results demonstrate that dynamic, attention-based layer aggregation effectively harnesses complementary information across the transformer stack, enhancing POS tagging performance in low-resource MRLs.
To further illustrate how the layer-wise attention pooling mechanism operates in practice, we analyze a representative sentence from the Uzbek development set: “Keyingi yozda u yozishni o‘rganmoqchi.” (“He intends to learn writing next summer.”). As shown in Figure 2, we visualize the attention distribution across all 12 transformer layers for each token in the sentence.
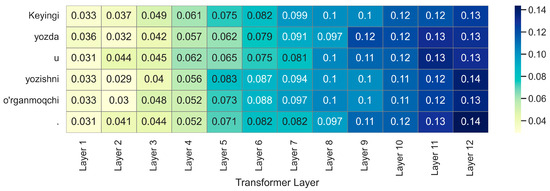
Figure 2.
Layer-wise attention distribution for each token in the sentence “Keyingi yozda u yozishni o‘rganmoqchi”.
The heatmap reveals that function words such as “u” tend to assign higher importance to deeper layers, which aligns with their role in discourse-level reference resolution. In contrast, content words like “yozishni” and “o‘rganmoqchi” exhibit broader attention spread across middle and top layers, reflecting the integration of morphological and semantic features. Interestingly, the model appears to assign relatively greater importance to middle layers for morphologically complex or polysemous tokens, suggesting that these layers encode representations particularly useful for POS disambiguation.
This observation supports our earlier findings in Table 12, where layer-wise aggregation yields significant gains in Poly-F1. The model’s ability to selectively emphasize relevant layers on a per-token basis highlights the effectiveness of attention-based pooling for morphologically rich and syntactically diverse languages.
4.3.4. Gating Mechanism Ablation
To highlight the contribution of our dual-gating co-attention module, we compare four gate configurations with all other components unchanged: (1) a single shared gate applied post-concatenation, (2) a scalar gate learning one weight to balance affix and context features, and (3) a concatenation-only variant without gating.
As shown in Table 13, the dual-gating mechanism consistently yields the highest F1 scores across all three languages, outperforming the next best variant (Single Gate) by approximately 0.83 F1 on average. The substantial drops observed for Scalar Gate (−1.13 F1) and Concat-Only (−2.39 F1) confirm that the dual-gating mechanism surpasses simpler variants by offering independent, element-wise control over affix and context features. This precise balancing prevents dominant contextual signals from overshadowing subtler morphological cues and dynamically adjusts morphology–context contributions per token, thereby improving generalization across varied morphological patterns.
Table 13.
Results for gating mechanism ablation.
4.3.5. Sensitivity Ablation on Affix Selection Threshold
To assess the sensitivity of the affix-selection threshold function , we performed an ablation study by varying the frequency cutoff across a wide range: {25, 50, 75, 100, 125}. All other components of the model architecture and training configuration were held constant to isolate the effect of . For each setting, we conducted 10 independent training runs and report the average F1 score on the development set for each target language.
As illustrated in Figure 3, performance remains highly stable across different values. For instance, on Uyghur, the F1 score varies by only ±0.05 points around the maximum (86.52 at θ = 50); similar stability patterns are observed for Kyrgyz and Uzbek. This consistent performance indicates that the model is not overly sensitive to the exact threshold value and that our default settings (θ = 50 and 100) fall well within a robust and reliable operating range.
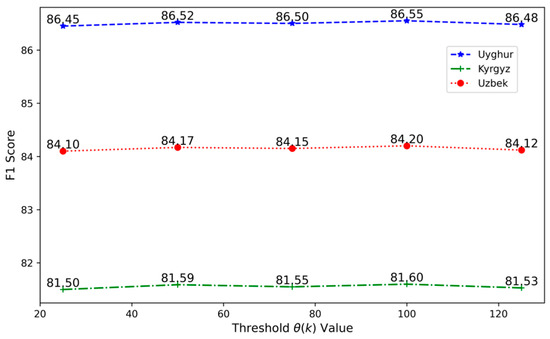
Figure 3.
Sensitivity of threshold function across languages.
4.4. Cross-Lingual Evaluation
To evaluate the cross-lingual transferability of MRL-POS beyond closely related languages, we include Turkish, a resource-rich, typologically related member of the Turkic language family, as a source and target language in our transfer experiments. Specifically, we adopt a zero-shot setting where the model is trained on Turkish and tested on three target languages, and vice versa, without any supervision from the target language. In this experiment, all our target language data use Latin script to be consistent with the Turkish one.
The results in Table 14 demonstrate the strong cross-lingual transferability of MRL-POS. When trained on Turkish and evaluated on morphologically similar but low-resource languages like Uyghur, Uzbek, or Kyrgyz, the model achieves average F1 scores above 76%, OOV accuracy near 70%, and a Poly-F1 score of 72%, indicating effective transfer of contextual and affix representations despite script and domain differences.
Table 14.
Zero-shot transfer performance with Turkish.
Notably, models trained on Uyghur, Uzbek, and Kyrgyz also generalize well to Turkish, particularly in Poly-F1, demonstrating upward transfer potential from smaller datasets when morphological patterns are adequately modeled.
These findings highlight two conclusions: (1) Turkish serves as a robust pivot language for transfer to other Turkic languages due to shared morphological structure; and (2) the affix-centric architecture of MRL-POS facilitates generalization across typologically related but orthographically diverse languages, reinforcing its utility in cross-lingual low-resource POS tagging.
5. Analysis and Discussion
This section synthesizes the main experimental findings and provides a deeper interpretation of model behavior through quantitative attribution analysis and visualization of internal mechanisms.
5.1. Error Attribution Analysis
To better understand where errors remain, we conducted an error attribution analysis over the Uyghur test set. To move beyond qualitative observation, we conducted a quantitative attribution analysis to assess the relative contributions of specific factors to tagging errors. Table 15 summarizes the distribution of dominant error types and their primary triggering conditions.
Table 15.
Error attribution analysis.
These results show that affix segmentation errors, especially those arising from dense suffix chains in long, low-frequency words, are the dominant source of misclassification. We illustrate this error type with the concrete examples as shown in Table 16.
Table 16.
Error type with examples for three languages.
In the examples, it can be found that overlapping affix sequences can be grouped into different morphological units, and only context-sensitive features resolve the correct parse. Additionally, many errors occur in syntactically underspecified contexts, where the model lacks sufficient cues to resolve ambiguity. To illustrate these patterns in detail, Figure 4 presents normalized confusion matrices for Uyghur, Kyrgyz, and Uzbek. Across all three languages, verbs are frequently misclassified as nouns (V→N) at rates of 11–13%. In addition, we observe the following:
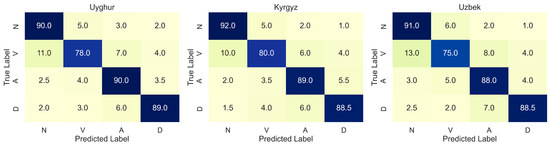
Figure 4.
Confusion matrix over the predicted versus gold POS tags.
Adjective→Verb (A→V) confusions (e.g., Uyghur ~4%, Uzbek ~5%)
Adverb→Adjective (D→A) errors (e.g., Kyrgyz ~6%)
Adjective→Adverb (A→D) mislabels (e.g., Uzbek ~4%)
These off-diagonal patterns confirm that affix chain ambiguity and insufficient disambiguating context lead to systematic mis-tagging of morphologically similar classes.
Figure 4 shows that, while our dynamic affix module reduces many OOV errors, affix chain overlaps still cause V→N and A→V confusions, and abbreviated contexts trigger D→A misclassifications.
5.2. Linguistic Validity of Affix Modeling
To evaluate whether the dynamically selected affixes align with linguistic intuition, we compare the model’s observed affix n-gram distribution against a linguist-annotated gold standard. As shown in Figure 5, both distributions exhibit a peak around n = 3–5, reflecting the morphological core in Turkic languages. While observed data underestimates 3-g frequency and overestimates some 6–7-g patterns, the overall conformity score remains high at 92.3%, supporting the linguistic plausibility of the affix selection module.
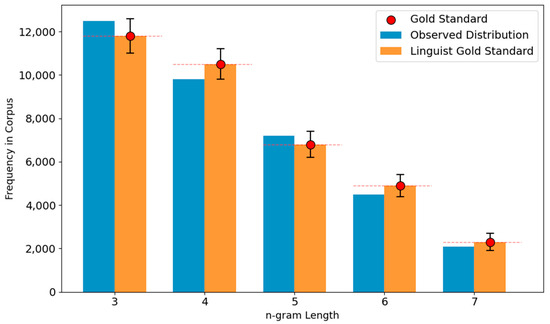
Figure 5.
Distribution of affix n-gram frequencies observed in the corpus versus a linguistically validated gold standard. Red dots and dashed lines highlight gold reference points. Annotated labels describe typical morphological functions per n-gram length.
This alignment confirms that the affix extraction mechanism captures productive and linguistically grounded suffix structures, particularly in the 4–5 n-gram range often associated with derivational and compound morphology.
5.3. Gated Co-Attention Interpretation
To empirically validate the symmetric design and illustrate how MRL-POS integrates affix and contextual information at inference time, we visualize gate activation for each token in a real-world Uyghur sentence: “Bizning hizmatdashlarimizning kitabliri” (“Our colleagues’ books”). As shown in Figure 6, the gating mechanism assigns higher context attention to grammatical function words (e.g., “Bizning”, “##ning”) and stronger affix attention to morphological elements (e.g., “##lar”, “##imiz”, “##liri”).
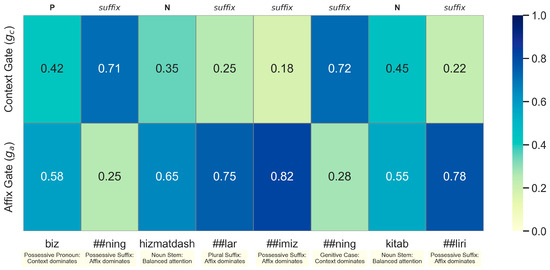
Figure 6.
Heatmap of gating weights over contextual and affix representations. POS labels are displayed above tokens, and linguistic roles are annotated below. The model adaptively adjusts gate emphasis based on token role and structure.
This visualization shows that the model learns to allocate attention in a linguistically meaningful way. Tokens with clear morphological functions (e.g., plural or possessive suffixes) rely heavily on affix features, while context-dominant tokens typically serve syntactic roles. The gate-based fusion mechanism is thus not only effective but also interpretable. This pattern suggests that the dual-gating mechanism adaptively balances morphological and contextual signals, consistent with the symmetry principle underlying our framework.
5.4. Intra-Affix Attention Interpretation
To investigate how MRL-POS models morphological salience, we analyze the intra-affix attention weights β on representative words from three target languages. Table 17 presents three example words—short, long, and medium, along with their dynamic affix sets and learned β values.
Table 17.
Intra-affix attention weights β for selected examples. Bold values denote highest weights.
In all cases, inflectional suffixes—such as Uyghur “-di”, Kyrgyz “-übüz”, and Uzbek “-ishni”—receive the highest attention scores, confirming their critical role in POS disambiguation (e.g., verb vs. noun, possession). Derivational morphemes like “-lük” also attract significant weight when relevant (e.g., in nominalizations), while root fragments or over-segmented affixes (“éld”, “ozish”) are consistently down-weighted (β < 0.15).
Moreover, suffixes located nearer the word end tend to dominate attention, in line with Turkic morphological typology, where final morphemes often encode core syntactic functions. Importantly, attention is not arbitrarily concentrated on a single segment; instead, it is distributed across semantically complementary affixes—particularly in polymorphemic forms like kelüülükübüz—reflecting the compositional structure of agglutinative morphology.
These patterns emerge purely through supervision on POS tags, without any hand-crafted rules. They validate the model’s capacity to learn linguistically meaningful affix prioritization, enhancing both interpretability and effectiveness in MRL/LRL scenarios.
5.5. Lightweight Adaptation and Morphological Modeling
Recent work emphasizes parameter-efficient adaptation for low-resource NLP. Prompt tuning approaches [35,36] learn a small set of continuous prompts while keeping the pretrained encoder frozen; adapter modules [37,38] add compact bottleneck layers inside transformer blocks to achieve near full-fine-tuning performance with only modest additional parameters; and parameter-efficient methods such as LoRA [39] or BitFit [40] further reduce the number of trainable weights by restricting updates to low-rank or bias terms. These techniques are attractive in practice because they lower the training cost, simplify model sharing, and are well suited to multi-task or multi-language deployments.
MRL-POS addresses a complementary axis of the low-resource problem: rather than only changing how the encoder is adapted, we change what information is fused into the prediction layer. The dual-gating co-attention explicitly models morphological structure by integrating affix cues with contextual embeddings, producing consistent improvement on our target languages. This architectural focus on morphology is not in conflict with adapter/prompt techniques—on the contrary, we expect that combining MRL-POS’s affix–context fusion with adapter or prompt-based fine-tuning would yield a parameter-efficient, morphology-aware system. Concretely, one could (a) implement the co-attention and gating as lightweight adapter blocks added to a frozen encoder, or (b) use prompt signals to bias the encoder toward morphological features while keeping the co-attention module as the task head. We leave empirical evaluation of these combinations to future work but view them as promising directions to bring our morphological modeling benefits to even more constrained deployment settings.
6. Conclusions
We have presented MRL-POS, a unified affix-aware POS tagging framework that integrates three novel components—dynamic affix selection, dual-gating co-attention fusion, and layer-wise Transformer pooling—to address the challenges of out-of-vocabulary forms, polysemy, and data sparsity in morphologically rich, low-resource languages. Across Uyghur, Kyrgyz, and Uzbek, MRL-POS achieves substantial gains over strong baselines, with improvements of +3.3 F1 overall, +4.8 OOV accuracy, and +5.2 Poly-F1. In zero-shot transfer from Turkish, it maintains over 76% F1, demonstrating robust cross-lingual generalization.
Critically, interpretability analyses reveal that the model’s learned attention weights align with established linguistic principles—favoring inflectional and final-position affixes while suppressing noise—without any hand-crafted rules. These findings bridge end-to-end neural modeling and traditional morphological theory, illustrating that data-driven attention mechanisms can recover linguistically grounded feature hierarchies.
Despite these advances, reliance on a pretrained transformer encoder may limit applicability in fully zero-resource settings. Future work will explore unsupervised affix discovery, lightweight adapter modules, and joint learning of morphological segmentation that can be learned end-to-end in order to reduce training cost and further improve low-resource adaptation. In parallel, we will explore data augmentation strategies such as morphology-aware synthetic affix injection and back-translation to enrich our limited annotated corpora and potentially yield additional performance gains. These directions promise to complement our dual-gating co-attention architecture and extend its applicability to an even broader range of MRL and LRL.
Author Contributions
Conceptualization, A.M. and S.A.; methodology, A.M.; software, Y.Q.; validation, Y.Q., S.A. and A.M.; formal analysis, A.M.; investigation, A.M.; resources, Y.Q.; data curation, S.A.; writing—original draft preparation, A.M.; writing—review and editing, Y.Q.; visualization, S.A.; supervision, A.M.; project administration, A.M.; funding acquisition, A.M. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Natural Science Foundation of Xinjiang Uyghur Autonomous Region Grant 2022D01B117, the National Natural Science Foundation of China Youth Program Grant 62306263, and the Ministry of Education of Humanities and Social Science Project 23XJJC740001.
Data Availability Statement
Data will be made available upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Hu, Z.T.; Hou, W.; Liu, X.X. Deep Learning for Named Entity Recognition: A Survey. Neural Comput. Appl. 2024, 36, 8995–9022. [Google Scholar] [CrossRef]
- Tayir, T.; Li, L. Unsupervised Multimodal Machine Translation for Low-Resource Distant Language Pairs. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2024, 23, 1–22. [Google Scholar] [CrossRef]
- Xu, D.; Chen, W.; Peng, W.; Zhang, C.; Xu, T.; Zhao, X.; Chen, E. Large Language Models for Generative Information Extraction: A Survey. Front. Comput. Sci. 2024, 18, 186357. [Google Scholar] [CrossRef]
- Biancofiore, G.M.; Deldjoo, Y.; Noia, T.D.; Di Sciascio, E.; Narducci, F. Interactive Question Answering Systems: Literature Review. ACM Comput. Surv. 2024, 56, 1–38. [Google Scholar] [CrossRef]
- Mcgiff, J.; Nikolov, N.S. Overcoming Data Scarcity in Generative Language Modelling for Low-Resource Languages: A Systematic Review. arXiv 2025, arXiv:2505.04531. [Google Scholar] [CrossRef]
- Haber, A.; Poesio, M. Polysemy—Evidence from Linguistics, Behavioral Science, and Contextualized Language Models. Comput. Linguist. 2024, 50, 351–417. [Google Scholar] [CrossRef]
- Pradhan, A.; Yajnik, A. Parts-of-Speech Tagging of Nepali Texts with Bidirectional LSTM, Condi-tional Random Fields and HMM. Multimed. Tools Appl. 2024, 83, 9893–9909. [Google Scholar] [CrossRef]
- Talukdar, K.; Sarma, S.K. Deep Learning Based Part-of-Speech Tagging for Assamese Using RNN and GRU. Procedia Comput. Sci. 2024, 235, 1707–1712. [Google Scholar] [CrossRef]
- Murat, A.; Ali, S. Low-Resource POS Tagging with Deep Affix Representation and Multi-Head Attention. IEEE Access 2024, 12, 66495–66504. [Google Scholar] [CrossRef]
- Wang, L.; Dyer, C.; Black, A.W.; Trancoso, I.; Fermandez, R.; Amir, S.; Marujo, L.; Luis, T. Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1520–1530. [Google Scholar] [CrossRef]
- Heigold, G.; Neumann, G.; van Genabith, J. An extensive empirical evaluation of character-based morphological tagging for 14 languages. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Volume 1, Long Papers, pp. 505–513. [Google Scholar]
- Cotterell, R.; Duh, K. Low-Resource Named Entity Recognition with Cross-Lingual, Character-Level Neural Conditional Random Fields. arXiv 2024, arXiv:2404.09383. [Google Scholar] [CrossRef]
- Yang, Z.; Salakhutdinov, R.; Cohen, W.W. Transfer Learning for Sequence Tagging with Hierarchical Recurrent Networks. arXiv 2017, arXiv:1703.06345. [Google Scholar] [CrossRef]
- Maimaiti, M.; Wumaier, A.; Abiderexiti, K.; Yibulayin, T. Bidirectional Long Short-Term Memory Network with a Conditional Random Field Layer for Uyghur Part-of-Speech Tagging. Information 2017, 8, 157. [Google Scholar] [CrossRef]
- Dandapat, S.; Sarkar, S.; Basu, A. Automatic Part-of-Speech Tagging for Bengali: An Approach for Morphologically Rich Languages in a Poor Resource Scenario. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; pp. 221–224. [Google Scholar]
- Matan, P.; Velvizhy, P. Systematic Review of Morphological and Semantic Analysis in a Low Re-source Language: Tamil. In Empowering Low-Resource Languages with NLP Solutions; IGI Global: Hershey, PA, USA, 2024; pp. 86–112. [Google Scholar] [CrossRef]
- Cing, D.L.; Soe, K.M. Improving Accuracy of Part-of-Speech Tagging Using Hidden Markov Model and Morphological Analysis for Myanmar Language. Int. J. Electr. Comput. Eng. 2020, 10, 2023–2030. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Con-textualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1 (Long Papers), pp. 2227–2237. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Trans-formers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, É.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-Lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8440–8451. [Google Scholar] [CrossRef]
- Zhu, S.; Xu, S.; Sun, H.; Pan, L.; Cui, M.; Du, J. Multilingual large language models: A systematic survey. arXiv 2024, arXiv:2411.11072. [Google Scholar] [CrossRef]
- Zhu, S.; Pan, L.; Xiong, D. FEDS-ICL: Enhancing translation ability and efficiency of large language model by optimizing demonstration selection. Inf. Process. Manag. 2024, 61, 103825. [Google Scholar] [CrossRef]
- Zhu, S.; Cui, M.; Xiong, D. Towards robust in-context learning for machine translation with large language models. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation, Torino, Italy, 20–25 May 2024; pp. 16619–16629. [Google Scholar]
- Zhu, S.; Pan, L.; Li, B.; Xiong, D. LANDeRMT: Detecting and routing language-aware neurons for selectively fine-tuning LLMs to machine translation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024; Volume 1: Long Papers, pp. 12135–12148. [Google Scholar]
- Mi, C.; Zhu, S. Multi-source knowledge fusion for multilingual loanword identification. Expert Syst. Appl. 2025, 271, 126588. [Google Scholar] [CrossRef]
- Asgari, E.; Kheir, Y.E.; Javaheri, M.A.S. MorphBPE: A Morpho-Aware Tokenizer Bridging Lin-guistic Complexity for Efficient LLM Training Across Morphologies. arXiv 2025, arXiv:2502.00894. [Google Scholar] [CrossRef]
- Smit, P.; Virpioja, S.; Grönroos, S.A.; Kurimo, M. Morfessor 2.0: Toolkit for statistical morphological segmentation. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics (Demonstrations), Gothenburg, Sweden, 26–30 April 2014; pp. 21–24. Available online: https://aclanthology.org/E14-2006/ (accessed on 6 July 2025).
- Huang, C.; Talbott, W.; Jaitly, N.; Susskind, J.M. Efficient representation learning via adaptive context pooling. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 9346–9355. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Dressler, W.U. Degrees of grammatical productivity in inflectional morphology. Ital. J. Linguist. 2003, 15, 31–62. [Google Scholar]
- Kazemnejad, A.; Padhi, I.; Natesan Ramamurthy, K.; Das, P.; Reddy, S. The impact of positional encoding on length generalization in transformers. Adv. Neural Inf. Process. Syst. 2023, 36, 24892–24928. [Google Scholar] [CrossRef]
- Jarquin-Vasquez, H.; Escalante, H.J.; Montes-y-Gomez, M.; Gonzalez, F.A. GHA: A Gated Hierarchical Attention Mechanism for the Detection of Abusive Language in Social Media. IEEE Trans. Affect. Comput. 2025, 16, 946–959. [Google Scholar] [CrossRef]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Medica 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Umut, S.; Gülşen., E. Implementing Universal Dependency, Morphology and Multiword Expression Annotation Standards for Turkish Language Processing. Turk. J. Electr. Eng. Comput. Sci. 2018, 26, 1662–1672. [Google Scholar] [CrossRef]
- Lester, B.; Al-Rfou, R.; Constant, N. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 3045–3059. [Google Scholar] [CrossRef]
- Li, X.L.; Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 7–11 November 2021; Volume 1: Long Papers, pp. 4582–4597. Available online: https://aclanthology.org/2021.acl-long.353 (accessed on 6 July 2025).
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; de Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 2790–2799. [Google Scholar]
- Pfeiffer, J.; Rücklé, A.; Poth, C.; Kamath, A.; Vulić, I.; Ruder, S.; Cho, K.; Gurevych, I. AdapterHub: A framework for adapting transformers. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 46–54. Available online: https://aclanthology.org/2020.emnlp-demos.7 (accessed on 6 July 2025).
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Chen, W. LoRA: Low-rank adaptation of large language models. In Proceedings of the 10th International Conference on Learning Representations, Online, 25–29 April 2022; pp. 1–3. [Google Scholar]
- Ben-Zaken, E.; Ravfogel, S.; Goldberg, Y. BitFit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 1–9. Available online: https://aclanthology.org/2022.acl-short.1/ (accessed on 6 July 2025).






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).