1. Introduction
A fingerprint is a type of function that maps a large data string to a value/string with relatively much shorter bit-length. Generally speaking, hash functions [
1] can also be recognized as special fingerprints that are used to identify substantial blocks of data uniquely, while their cryptographic properties are believed to be safe against malicious attacks. Conversely, the Rabin–Karp (KR) fingerprint is another type of function implementing fingerprints using polynomials over a finite field. Such a function is much faster than the hash function and easy to implement.
KR Fingerprint Function. In 1987, Karp and Rabin [
2] defined a fingerprint function as follows:
for a prime modulo
p, a randomly selected integer
, and a string
coded over the finite field
. For the sake of brevity, throughout this paper, we also refer to such a KR fingerprint as a fingerprint.
This fingerprint is very important to string matching, as two identical strings generate the same fingerprints. Given a text string
and a pattern
of string length
ℓ, one straightforward string-matching algorithm computes a fingerprint of a sliding text window of size
ℓ, in
, and compares this fingerprint to the fingerprint of
, marking all the candidate occurrences with fingerprints equaling the pattern’s fingerprint. Clearly, compared with a letter-to-letter matching approach, a fingerprint can improve the string-matching efficiency using relatively shorter values. Based on fingerprints, many schemes have been developed to achieve better performance of string matching [
3,
4,
5] during the last decades. In particular, a study [
4] on exact online string matching has demonstrated how rolling hashes enable sublinear time search in static texts, and subsequent work [
5] presents a low-latency algorithm in real-time streaming string matching. These results underscore the utility of fingerprinting not only in batch processing but also in dynamic, streaming environments, motivating our adoption of the KR fingerprint for privacy-preserving queries.
However, all these methods only work on plaintext and do not ensure any user’s privacy. That is to say, if the file is encrypted or secret shared, one cannot search the keywords over this file using previous methods. Recently, Sharma et al. proposed a secret-shared form of fingerprint, and applied it for keywords search over a secret-shared database [
6]. They symmetrically distribute computational loads between servers using additive sharing, achieving highly efficient keyword queries. In fact, we note that in clouds, a database can be deployed in encryption or secret-share form, for the privacy consideration. This scheme provides protection for both datasets and users’ queries. However, the scheme by Sharma et al. is primarily tailored for privacy-preserving queries over encrypted databases. In many practical applications, the database itself may remain in plaintext while only the query privacy must be protected [
7]. For example, medical records, restaurant sites, product catalogs, and positions in maps are open to everyone, but users’ queries can reveal their hobbies, locations, etc. Hiding access patterns is an important way to protect users’ privacy. Consequently, for such applications, a more efficient scheme needs to be designed.
On the other hand, note that all fingerprint functions map a long string to a short one—the collision does exist. Even in secret-share form, the collision problem still exists for the fingerprint.
For string matching, the collision problem will lead to false positive errors [
8], which indicates the existence of phantom occurrence. Fortunately, differing with the hash function, the probability of a false positive error in the fingerprint function can be precisely analyzed. In order to do a precise query, we also need to reduce such probability.
Motivation: This work specifically addresses privacy-preserving keyword queries over publicly accessible datasets, where the primary privacy concern is the user’s query content rather than the data itself. Current privacy-preserving schemes such as searchable encryption, private information retrieval, or oblivious RAM often incur substantial overhead, especially when only query privacy (not database secrecy) is required. Thus, our research primarily addresses two critical challenges:
Efficiency: achieving privacy-preserving keyword searches without heavy computational or communication burdens;
Accuracy: reducing and precisely quantifying the false positive error inherent in fingerprint-based methods.
To overcome these challenges, we leverage KR fingerprints and distributed point functions (DPF) [
9,
10] to design a highly efficient and secure two-server query scheme, balancing query privacy, efficiency, and accuracy.
Related Work. Our proposed method for enabling private keyword queries on public datasets leverages a novel combination of KR fingerprint and DPF. This approach offers distinct advantages when contrasted with existing private information retrieval (PIR), particularly keyword PIR (kPIR), and oblivious RAM (ORAM) constructions.
PIR schemes, in general, aim to allow users to retrieve data from a server without revealing their query. In this domain, the kPIR scheme is a special case of PIR, and is designed to achieve exact keyword matching. However, this function often needs substantial overhead, especially within single-server PIR frameworks. For instance, Piano [
11] introduced a single-server kPIR scheme, which achieves sublinear online server computation. Nonetheless, it requires clients to download the entire database during a preprocessing phase, which is often impractical for the large-scale datasets targeted in our work. Other single-server kPIR schemes, such as Spiral [
12] and Vectorized Batch PIR [
13], employ advanced cryptographic primitives like lattice-based homomorphic encryption to reduce the communication complexity. But these sophisticated cryptographic tools typically introduce significant computational overhead on the server side. The above kPIR schemes underscore persistent practical challenges, including substantial client-side burdens and intensive server-side computations. Broader general PIR schemes also present various trade-offs. SealPIR [
14] introduces compressed queries and probabilistic batch codes to distribute computation across multiple queries, which reduces communication cost but brings a non-negligible failure probability. More recently, SimplePIR [
15] attains high throughput through Pseudo-Random Function optimizations, but brings a large cost of setup and per-query communication.
ORAM schemes aim to obfuscate data access patterns. Path ORAM [
16] exemplifies a widely recognized approach, employing a relatively simple tree-based construction. Although its simple design is an advantage, this method requires client-side state and multiple server interactions per query, incurring notable communication overhead. Recent works have been aiming to improve the efficiency of communication and computation. Asharov et al. [
17] presented an ORAM scheme achieving a worst-case overhead of logarithmical order of block accesses for any block size, while requiring only constant client storage. Cong et al. [
18] introduced an ORAM scheme based on fully homomorphic encryption (FHE) that is both non-interactive and stateless. Panacea shifts all computation to the server, greatly simplifying the client while leveraging FHE for privacy, though it incurs heavier server-side cryptographic overhead.
Additionally, beyond PIR and ORAM, some works in searchable symmetric encryption (SSE) also focus on hiding access patterns and result patterns. For example, Yuan et al. [
19] propose a dynamic conjunctive SSE scheme that hides the result pattern of keyword pairs while offering forward and backward privacy. Similarly, Shang et al. [
20] introduce obfuscated SSE, which obfuscates both access and search patterns at each query, achieving pattern privacy with lower communication costs than ORAM-based SSE. Although these works provide strong privacy, they often incur higher preprocessing or retrieval latency due to relying on structured encryption or oblivious data structures. In contrast, our scheme targets lightweight, public read-only databases and is based on simple symmetric primitives, which achieve lower communication and computation.
Our scheme departs from prior works by uniquely combining the KR fingerprint with DPF within a symmetric mirror-server architecture to protect query privacy over public databases. Leveraging the compressibility of DPF, we reduce the query domain to communication complexity, where is the security parameter and p is the DPF domain size. Additionally, we formally bound the false positive collision probability inherent in the KR fingerprint. Compared to traditional PIR and ORAM constructions, our scheme not only ensures query privacy but also achieves a more advantageous trade-off between client-side communication and server-side computation.
Organization. The remainder of this paper is structured as follows.
Section 2 reviews preliminaries, including additive shares, distributed point function, our formal security definition, and a previous analysis of fingerprint false positive rates.
Section 3 details the proposed scheme and two illustrative applications. In
Section 4, we present a full security proof alongside a rigorous analysis of the false positive error probability of our scheme.
Section 5 offers both theoretical complexity comparisons and experimental performance results. Finally,
Section 6 concludes the paper.
3. Fingerprint-Based Query
In this section, we provide a detailed description of the proposed scheme based on fingerprint (FP) and DPF and discuss its applicability in two typical-use case scenarios.
3.1. Concrete Construction of the Scheme
Assume that there is a table deployed over clouds, which contains several columns, e.g., name, salary, address, etc. One may want to query whether some keywords exist or not in a certain column. We note that a straightforward way is directly asking the server to return all the keywords appearing in the database and to send such a list to the user, and the user will search by himself. However, this method is a somewhat offline search, and the user should download the keywords list and search on the client side. If there are millions of different keywords, it will bring a large computational and communication overhead to users.
Thus, in this section, we develop a private online query algorithm for public datasets based on the combination of DPF and fingerprint. Our approach utilizes two servers, and each of them stores the same table. We utilize fingerprint to convert the keyword space to number domain, based on which, a DPF query can be developed. Then, this query is additively shared into two parts, which are sent to servers, separately. Servers receive such query and return the result in share form. After that, the user collects these shares and reconstructs the final result. The schematic diagram of users’ query is presented in
Figure 1. The concrete construction of our scheme is Algorithm 1.
| Algorithm 1: Fingerprint-Based Query Scheme |
![Symmetry 17 01227 i001]() |
To better understand the execution of the proposed scheme, we illustrate each step of the above algorithm through a concrete example. For simplicity, we consider a database that has only two columns, i.e., name and salary, presented in
Table 2. The explicit query is stated in the following:
User side: If a user wants to search the keyword “john’’, firstly he chooses parameter
of fingerprint, where
r and
p are defined in
Section 1. Then, a corresponding fingerprint for the name “John’’ is generated, denoted by
. We construct a point function for the range
as follows:
for
After that, based on DPF, we construct the function
and two keys are output,
. The user sent
to server 1 and
to server 2, respectively.
Server side: Servers 1 (or 2) can run the DPF function for all to build a truth table , (). When the servers have the truth table , it can provide 1) count query, the number of matching records; and 2) sum query, the sum of items in other columns corresponding to the matching records. These operations are presented in Algorithms 1 and 2. After that, they can send the results of these algorithms to the user.
User side: Collect the results from server 1 and 2, and perform modular addition between these two results and obtain the final answer.
Comments: We firstly prove the correctness of Algorithm 1. Please notice that is the additive shares of the truth table of . Only if the fingerprint of the name is “john”, servers will obtain the shares of “1”; otherwise they will obtain the shares of “0”. Therefore, when the servers add all these shares in Algorithm 1, the user finally obtains the shares of the count.
We also note that, essentially, the function additively shares the truth table of and compress it to . At the server side, is used to decompress . Compared with the original DPF, we prefer to use to decompress firstly, then the matching operation will become a table lookup operation.
The algorithm compresses arbitrary string keywords into the integer domain . It expresses point queries as key pairs via DPF without transmitting plaintext indexes with a communication cost of bits. The construction combines the compressibility of the fingerprint function and the symmetry of the DPF for privacy queries in a symmetric mirror server architecture.
3.2. Applications of the Proposed Scheme
To demonstrate the practicality and versatility of the proposed scheme, we present two representative application examples in this subsection. The first example, privacy-preserving sum query, is designed to compute the aggregate value associated with a keyword while preserving query privacy. The second example, oblivious download, enables a secure download of a file in an ignorant way. Together, these use cases illustrate the adaptability of our scheme to aggregation and lightweight retrieval tasks.
3.2.1. Privacy-Preserving Sum Query
In many practical scenarios, users are interested not only in the existence of a keyword in the database but also in retrieving aggregate statistics associated with that keyword. For example, in a medical data platform, a researcher may wish to compute the total reported cases of a disease or the cumulative usage of a specific drug, while keeping the query intent confidential.
To support such functionality, we extend the original scheme to a privacy-preserving sum query. Similar to the count query, this approach leverages two non-colluding mirror servers and a pair of DPF keys generated for the fingerprint of the query keyword. However, unlike counting, the servers return the sum of all values associated with the matching keyword, thus enabling privacy-preserving aggregation. The core algorithm of this protocol is described in Algorithm 2. Concretely, the entire protocol consists of three main stages:
| Algorithm 2: Sum Operation For Servers i (). |
![Symmetry 17 01227 i002]() |
User: The user selects fingerprint parameters and computes the KR fingerprint of the query keyword w as . Then, the user invokes the DPF key generation algorithm to obtain the key pair and sends to server 1 and to server 2.
Server : Each server reconstructs its DPF truth table over the domain using the received key . For each row in the dataset, the server computes and checks the corresponding entry in . If the entry is 1, the value is added to the local sum . After processing all records, the server returns to the user.
User: Upon receiving and from both servers, the user computes the final result as . This represents the total sum of values associated with the queried keyword w in the dataset.
The communication cost remains sublinear at
, and the server-side computation involves
symmetric operations and modular additions. As with the count query, the only source of potential inaccuracy stems from fingerprint collisions, which are bounded and analyzed in
Section 4.2. Therefore, the scheme remains secure and practical within acceptable accuracy margins.
This protocol is particularly suited for statistical data aggregation tasks in public platforms, such as opinion trend analysis in social media or cumulative sensor readings in IoT systems, offering high scalability and lightweight deployment.
3.2.2. Oblivious Download
Furthermore, our approach can be applied in another scenario where users are allowed to download files in an oblivious way. Assume that there is a list of files indexed by their filename and the filename is unique. Note that it is not necessary for all the files to have the identical size; see
Table 3.
Table 3 presents a list of files indexed by their filenames and corresponding content. In the oblivious download scenario outlined in the paper, each file on this list features a unique filename and differs in both size and content. Typically stored on the server, these files can be downloaded without disclosing the specific file being requested, owing to the implementation of the DPF.
If a user wants to download one file of a certain filename, he just follows the same line as presented previously: (1) calculate the fingerprint of the desired filename; (2) construct a DPF based on such a fingerprint value, then send the shares its truth table to two servers. Then, the servers do the following operations presented in Algorithm 3.
| Algorithm 3: Oblivious File Downloading from Servers i (). |
![Symmetry 17 01227 i003]() |
Finally, the user only needs to download the shares from servers 1 and 2 then recover the file. The size of the download file is equal to the maximum file size. If the desired file size is smaller, 0 will be padded at the end of the file. This padding ensures all returned files have equal length, preventing the server from inferring the actual file size and thus preserving query privacy. It introduces negligible computational and communication overhead, as padding involves only constant-time operations and a small number of additional bits. Moreover, since the client knows the true length of the desired file in advance, it can safely discard the padded zeros after retrieval without impacting the correctness or usability of the result. Clearly, during this procedure, the servers will never find which file is of interest to the user, since all the files are added together.
4. Analysis of Security and Accuracy
In this section, we will analyze the security of the schemes mentioned in the previous section and provide a theoretical analysis of the error rates of the schemes.
4.1. Security Proof of the Proposed Scheme
In this subsection, we analyze the security of the proposed scheme. Concretely, before presenting the formal security proof, we first reduce the query privacy guarantee of scheme to the core security of the underlying DPF scheme. Specifically, by assuming that the DPF construction is IND-CPA secure, we can conclude that scheme satisfies the query privacy requirement articulated in Definition 1. We capture this result in the following lemma.
Lemma 2. If the underlying distributed point function (DPF) scheme is IND-CPA secure, then the scheme π achieves the query privacy defined in Definition 1.
Proof. We prove the security of the proposed scheme by adopting a standard game-hopping argument, and define two games first:
. In the real game, the user computes the fingerprint and runs . Server () then proceeds with the scheme , producing the real view . By definition, exactly captures the transcript seen by an honest execution of .
. In the simulated game, the simulator does not invoke the DPF functionality. Instead, it takes the leakage function and outputs a uniformly random key and a random shared value . The resulting transcript is the simulated view .
By the IND-CPA security of the DPF scheme and the non-collusion assumption between the mirrored servers, no PPT adversary can distinguish from or from . Hence, and are computationally indistinguishable, which implies that scheme satisfies the query privacy guarantee of Definition 1. □
4.2. Enhancing Robustness and Deployment Flexibility
While our scheme assumes two non-colluding mirror servers, which is commonly adopted in dual-server privacy-preserving frameworks, it is important to discuss strategies for enhancing robustness in case this assumption is violated.
One practical mitigation is to extend the architecture to a threshold-based multi-server model, such as a (t, n)-threshold setup. In this approach, the user splits their query into n DPF key shares and distributes them across n mirror servers. Only if t or more servers collude can the query be reconstructed, offering greater resilience to collusion at the cost of slightly increased communication. Alternatively, Trusted Execution Environments (TEEs) such as Intel SGX can be employed to protect the DPF evaluation process. Under this setting, even if the server itself is untrusted, its enclave can securely execute the fingerprint-based query without leaking sensitive information.
Both of these approaches can be flexibly integrated into our framework as optional extensions, depending on deployment scenarios and the level of trust available. They provide complementary trade-offs between deployment complexity and collusion resistance.
In addition to stronger adversary models, we also consider real-world deployment challenges. Our current scheme assumes fully replicated databases across two mirror servers. This simplifies query processing and minimizes communication. However, in large-scale or geo-distributed environments, full replication may not be practical.
To support such settings, future extensions could incorporate partial replication or erasure coding to enable fault tolerance. The database can be partitioned across multiple servers with overlap, and DPF keys can be directed to query specific partitions. It would require a lightweight scheduling protocol but would retain the core privacy guarantees of our design.
These extensions illustrate how our framework can flexibly adapt to various deployment models and how to balance trade-offs among trust assumptions, system complexity, and robustness.
4.3. False Positive Error Probability
Recall that false positives exist in fingerprint search operations, whose probability can be evaluated using Lemma 1, presented in
Section 2. Note that this probability is different from that of fingerprint collision. If we assume that there are
n fingerprints with each mapping a random value in the range
, we need to reassess the error rate in this case.
Based on Lemma 1, it is clear that the false positive error probability depends on the string length and magnitude of p. Considering that words in the dictionary are typically short, using a larger p can help reduce the error rate. Moreover, to illustrate the false positive probability on a real dataset composed solely of words, we conducted further evaluations on the dictionary set.
Claim 1. Let S be a dictionary of n words, where the average length of these words is l. Assuming that the fingerprint function ϕ is uniformly distributed over , for any word , the expected number of collisions with other words in the set satisfying does not exceed .
Proof. For each string
, define the indicator random variable as follows:
Since
is assumed to be uniformly distributed, according to the Lemma 1, the probability that
equals
is at most
. Thus, the expected value of
,
, is less than
.
By the linearity of expectation, the total expected number of collisions for the word
s in the dataset
S is
This completes the proof. □
Based on Claim 1, we can accurately estimate the error rate of the proposed scheme on a commonly used dictionary dataset. Taking the Merriam-Webster dictionary (
https://www.merriam-webster.com/help/faq-how-many-english-words, accessed on 26 April 2025) as an example—which contains approximately
words with an average word length of 5 [
23]—when a prime number slightly greater than 10 million is chosen for
p, the error rate in this dataset is bounded above by
.
4.4. Analysis of English Word Letter-Pattern Effects on Fingerprint Collision Probability
The character sequences of English words are not random but follow specific letter-pattern structures, such as common letter combinations, prefixes, and suffixes. These linguistic patterns induce correlations among the coefficients of the fingerprint polynomial: words sharing the same morphological root tend to cluster in the hash space, whereas words from different families map more diffusely. Empirical evidence shows that even within the same word family, the actual collision rate typically lies below the worst-case bound of .
Formally, let
u and
v be two distinct English words of length
l, and consider their difference polynomial:
Since
when
, we conclude that the degree of
is less than
l. Under the uniform-random oracle model, the collision probability satisfies
.
Note that English words frequently adhere to consistent spelling patterns, such as beginning with “pre-” or ending in “-ing”, which means that most character positions remain the same across different words, and only a handful of specific positions differ. Consequently, the indices i for which are typically concentrated at these particular locations. Let and . Then effectively becomes a degree-d polynomial, and its collision probability can be tightened to .
This refined bound quantitatively captures how English word letter-patterns reduce collision rates and explains why, in dictionary-like non-uniform distributions, the observed collision probability is substantially lower than the theoretical worst-case .
5. Performance Analysis
In this section, we evaluate the performance of our proposed protocol from two aspects. First, in the view of theoretical analysis, we rigorously contrast the proposed scheme against representative PIR and ORAM schemes in communication and computation costs. Then, in the Experimental Evaluation subsection, we validate these theoretical predictions with experimental measurements.
5.1. Theoretical Comparison
In our scheme, the client invokes the DPF key-generation algorithm to produce two keys of length bits, effectively compressing a p-entry truth table into compact key elements. For each query, the client transmits one DPF key along with the fingerprint parameters r and p, for a total communication cost of bits. Moreover, the client receives from each server a secret share of size bits. On the server side, answering a query requires n calls of the function and n modular additions, resulting in a computational complexity of .
Although our scheme serves a different scenario than traditional PIR and ORAM schemes, we theoretically compare our scheme against representative PIR and ORAM schemes from recent work.
Table 4 summarizes the client communication and server computation complexities of the three schemes. The concrete analysis is given as follows.
In terms of communication, our scheme achieves a sublinear cost of
bits due to the transmission of DPF keys and fingerprint parameters. This makes it particularly well-suited for the large-scale database. By contrast, Vectorized Batch PIR (VB-PIR) [
13] supports parallel retrieval of batch size
k at a communication cost of
bits. Since it utilizes homomorphic encryption to amalgamate multiple queries and reduce per-query bandwidth, its communication overhead scales linearly with
k, limiting its practicality for large batches. Worst-Case Logarithmic ORAM (WCL-ORAM) [
17] hides arbitrary read/write patterns with a communication cost of
bits (where
N is the number of blocks). This scheme adopts multiple accesses and data reshuffles to ensure privacy, but incurs the communication cost that grows logarithmically with the database size.
Regarding server computation, our scheme requires evaluations and modular-add operations over n records. VB-PIR, in contrast, incurs homomorphic encryption operations. The WCL-ORAM scheme performs only block accesses, each corresponding to one symmetric encryption and one symmetric decryption. Since symmetric encryption is vastly more efficient than fully homomorphic encryption operations, WCL-ORAM achieves the best server-side efficiency, and the VB-PIR scheme needs the most computation cost.
Beyond communication and computation complexity, real-world deployment requires a comprehensive evaluation of cryptographic primitives, deployment complexity, and application suitability. To this end,
Table 5 provides an extended comparison between our proposed scheme, a representative PIR scheme (VB-PIR) [
13], and the WCL-ORAM scheme [
17].
Our approach relies on a pair of non-colluding symmetric mirror servers, thereby avoiding the need for expensive primitives, such as fully homomorphic encryption (FHE). This lightweight design makes it particularly well-suited for large-scale, read-only public databases where the content is non-sensitive but query privacy is critical. In contrast, VB-PIR incurs significant overhead due to reliance on FHE, while WCL-ORAM requires maintaining client-side state and recursive access paths, which leads to much higher deployment complexity. Although fingerprint collisions in our scheme may introduce a small probability of false positives, this can be tightly bound through parameter tuning. Our experiments demonstrate that the accuracy consistently exceeds 99% under practical conditions.
In summary, the proposed scheme strikes a favorable balance between accuracy, efficiency, and deployment overhead. It means that our scheme is especially attractive for lightweight and publicly accessible query environments.
5.2. Experimental Evaluation
To evaluate the query performance and accuracy of our scheme, we extracted all English words of lengths 4, 5, 6, 7, and 8 from the Merriam-Webster online dictionary to form the test corpus. For approximately 11,000 seven-letter words, we randomly sampled 2000, 4000, 6000, 8000, and 10,000 entries to create query subsets of varying sizes. The fingerprint parameters were set to
and
10,007, 100,003, 1,000,003, 10,000,019, 100,000,009}. Using these datasets, we quantitatively assessed the efficiency and correctness of the proposed scheme. Furthermore, to compare efficiency, we implemented the baseline Vectorized Batch PIR scheme [
13] under the same hardware and input conditions, and measured its query runtime alongside our proposed method. It is worth noting that while we provide theoretical complexity comparisons with ORAM in
Section 5.1, we exclude ORAM from experimental evaluation. This is because ORAM targets generic access pattern protection, often requiring trusted hardware or recursive constructions, which makes it unsuitable for our focused task of lightweight keyword count queries over public datasets. To ensure a fair and relevant comparison, we concentrate on the PIR-based scheme for experimental benchmarking. Our algorithm ran on Intel Core(TM) i5-10500 3.10 GHz processors and 8 GB of RAM. The analysis of the experiment results is given as follows.
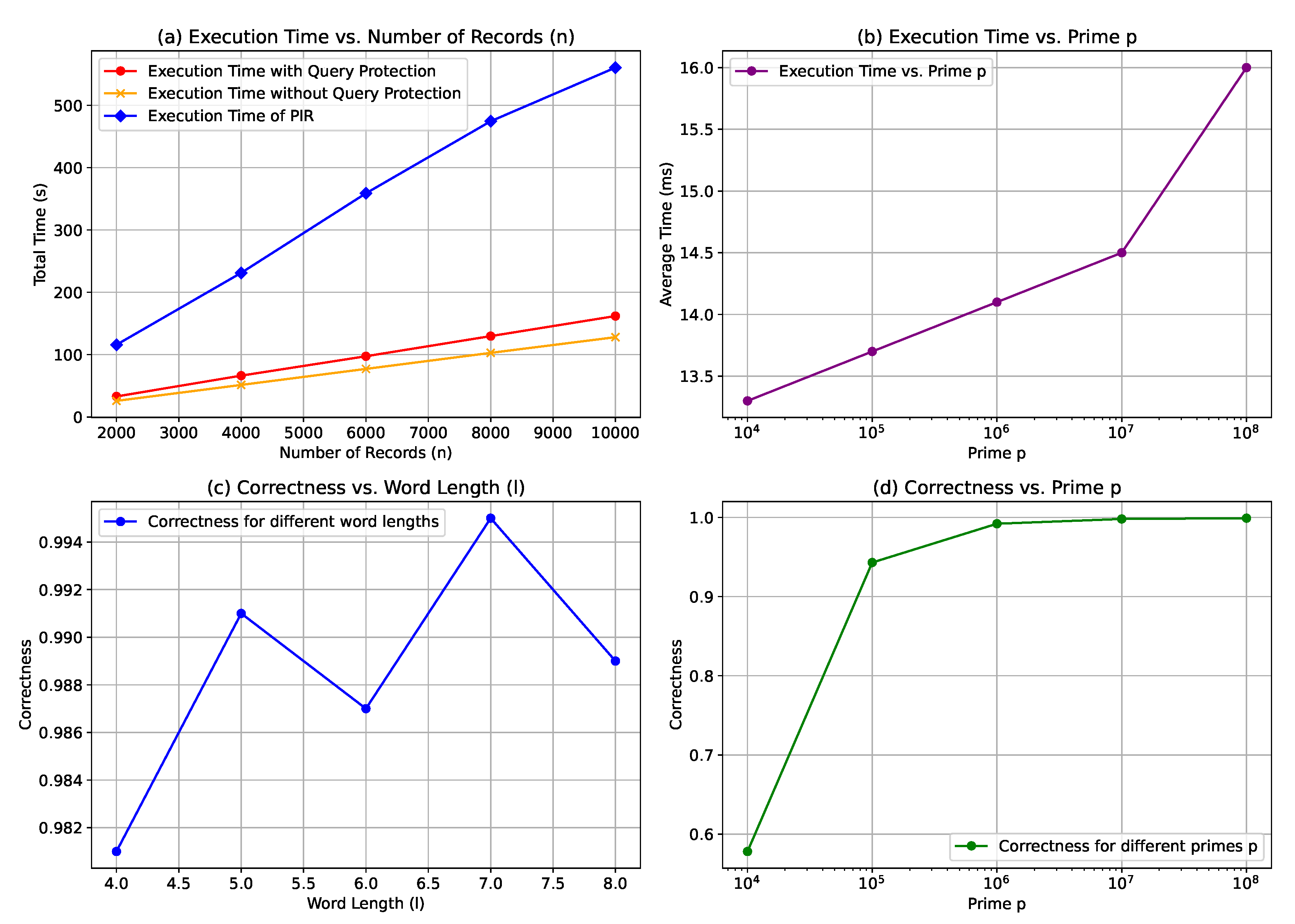
Figure 2 presents the experimental results, comparing accuracy and execution time across different word length
l, modulo
p, and database size
n. The following part provides a detailed analysis of these results.
Database Size
n vs. Execution Time. As the number of records
n increases from 2000 to 10,000, the execution time of our scheme grows linearly from 32.9 s to 161.9 s, which is consistent with the theoretical analysis. We also compare the proposed scheme to the method without query protection, finding that the unprotected version consistently runs about 20% faster at each dataset size. Furthermore, under the same hardware and input settings, the execution time of the PIR scheme increases from 115.8 s to 560.5 s, showing a clear linear trend. In contrast, our scheme completes the same queries with substantially lower runtimes, roughly one-third of the PIR overhead at each scale.
Figure 2a illustrates both the linear growth and the performance gap between the three schemes.
Modulo
p vs. Execution Time. When the fingerprint modulo
p increases from 10,007 to 100,000,009, the average query time rises from 13.3 ms to 16.0 ms. This moderate growth stems from the increasing bit length of
p, which affects the speed of modular multiplication and addition operations. Despite the larger modulus, the overall execution time remains acceptable and does not impact scalability significantly.
Figure 2b presents this trend, which aligns closely with our theoretical predictions.
Word Length
l vs. Accuracy. As shown in
Figure 2c, the accuracy improves with increasing word length. This trend arises because longer words tend to have more distinctive letter patterns, which reduces the chance of fingerprint collisions. Furthermore, English vocabulary is not randomly distributed. For example, common prefixes (e.g., “pre-”, “dis-”) and suffixes (e.g., “-ing”, “-tion”) help distinguish words more effectively in the fingerprint space. This structural bias reduces collision events and thus boosts query correctness.
Figure 2c clearly reflects this pattern.
Modulo
p vs. Accuracy.
Figure 2d shows that, as the modulo
p increases, the correctness rate increases, from 0.578 at
p = 10,007 to 0.999 at
p =100,000,009. Increasing the value of
p significantly improves the correctness rate when the number of records
n is less than
p. When
p is much larger than
n, the correctness rate will stabilize. When
p is much larger than
n, its correct rate will stabilize. This phenomenon verifies the previous analysis that an increase in the modulo
p leads to an increase in the fingerprint hash space and a decrease in the probability of collision. Notably, when
p is only marginally larger than
n, the fingerprint domain becomes densely populated, which leads to an increased chance of collisions. For example, at
p = 10,007
, we observe significantly more false positives, which is reflected in the low accuracy. In contrast, selecting a larger
p (e.g.,
1,000,003) ensures that the fingerprint space is much larger than the number of records, reducing collision rates and pushing the accuracy above
. Therefore, we recommend choosing
p at least one order of magnitude larger than
n in practice. This provides a robust trade-off between computational efficiency and accuracy. Furthermore, we also recommend two practical mitigation strategies for fingerprint collisions. First, adaptively increasing
p can dynamically reduce false positives by enlarging the hash space. Second, if unexpected accuracy degradation is detected, the client can retry the query with a newly sampled random parameter
r, effectively reshaping the fingerprint polynomial and reducing the probability of repeated collisions. Both techniques are lightweight and preserve the privacy guarantees of the scheme, which makes them suitable for real-world deployment.
The above experiments confirm that our scheme achieves high query accuracy while maintaining low computational and communication overhead, making it well-suited for privacy-preserving queries over large read-only databases. Overall, the experimental results are consistent with our theoretical analysis and further demonstrate the applicability and efficiency of the proposed scheme in large-scale database settings.









{kind=link}
{kind=link}