1. Introduction
Transportation has long been a cornerstone of economic development and social connectivity. However, it is now one of the leading contributors to anthropogenic greenhouse gas (GHG) emissions worldwide. The transport sector accounts for approximately 24 percent of direct carbon dioxide (CO
2) emissions from fuel combustion, a figure that is expected to rise further due to ongoing urbanization and motorization [
1,
2]. Consequently, decarbonizing transportation has become a critical and urgent challenge for advancing sustainable development and enhancing climate resilience [
3].
In response to this challenge, European countries, particularly Spain, have implemented a series of transformative policies consistent with the objectives of the European Green Deal [
4]. These initiatives promote the integration of vehicle electrification, intelligent mobility systems, fuel efficiency improvements, and renewable energy sources within a unified and sustainable transport framework [
5]. The success of these efforts depends not only on technological innovation but also on the capacity to model and analyze vehicle emissions with precision and detail. This requirement is especially important given the structural heterogeneity of modern vehicle fleets, which leads to complex and often asymmetric emission patterns across various powertrain types, usage conditions, and vehicle designs. Conventional emission modeling tools often struggle to account for such real-world complexity and nonlinearity [
6].
While laboratory-based testing protocols and simulation models provide useful insights under controlled conditions, they frequently fail to capture the nuanced interactions between vehicle attributes and operational environments. Factors such as dynamic driving behavior, road conditions, and drivetrain architecture can generate asymmetric and nonlinear emission responses that traditional models are not equipped to represent. In contrast, machine learning (ML) techniques offer a flexible, data-driven approach that can uncover hidden patterns in high-dimensional datasets. Advances in explainable artificial intelligence (XAI), especially through the application of SHapley Additive exPlanations (SHAPs), have further improved the interpretability of ML models. These developments enable researchers to identify the specific contributions of individual vehicle characteristics to emission outcomes with greater clarity [
7].
Building on this methodological shift, the present study investigates a critical question: how do structural factors drive asymmetric CO2 emission responses across diverse vehicle categories, particularly between conventional internal combustion engine (ICE) vehicles and new energy vehicles (NEVs)? While previous research has applied ML techniques to emission prediction, these studies have rarely accounted for the non-uniform influence of key features such as fuel consumption, vehicle weight, or hybrid drivetrain configuration. This limitation reduces the practical utility of predictive models in supporting the formulation of performance-based emission policies. By leveraging a comprehensive, high-resolution dataset from the Spanish Institute for Diversification and Energy Saving (IDAE), this study aims to develop an explainable ML framework that not only improves predictive accuracy but also reveals underlying emission asymmetries. The findings offer evidence-based insights to inform symmetry-aware transport policies, challenge the validity of uniform regulatory approaches, and provide a more refined foundation for incentive structures, fleet management strategies, and eco-labeling systems.
The dataset includes detailed vehicle-level information, including engine specifications, physical dimensions, fuel consumption rates, and CO2 emission values measured under the Worldwide Harmonized Light Vehicles Test Procedure (WLTP). To account for the technological heterogeneity inherent in modern vehicle fleets, the data are categorized into two distinct groups: conventional ICE vehicles powered by petrol or diesel and NEVs, comprising both hybrid and plug-in hybrid vehicles. A total of five supervised ML algorithms are applied to each vehicle group: Multiple Linear Regression (MLR), Random Forest (RF), Gradient Boosting Machines (GBMs), Support Vector Regression (SVR), and K-Nearest Neighbors (KNNs). Model performance is evaluated using four key metrics, namely R-squared (R2), Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and Mean Absolute Error (MAE), to assess their effectiveness in predicting average WLTP CO2 emissions. Among all models, the RF algorithm consistently demonstrates superior performance, achieving near-perfect R2 scores (greater than 0.99) and minimal prediction errors across both the conventional and hybrid vehicle datasets.
To address the opaque nature often associated with ML models, this study incorporates SHAPs to interpret the contribution of individual features to emission outcomes. Rather than focusing solely on predictive accuracy, this approach facilitates the identification of asymmetric and threshold-based relationships across a wide range of vehicle configurations. The results reveal systematic differences in how structural attributes such as fuel consumption, powertrain architecture, and vehicle mass influence emissions. These asymmetries are particularly evident among hybrid vehicle subtypes and across various weight categories, where emission responses deviate substantially from linear or uniform expectations. By emphasizing these nonlinear patterns, the proposed framework enhances model interpretability. It provides a data-driven foundation for advancing vehicle design practices and regulatory standards in support of sustainable transport objectives.
Building on these insights, this study offers a methodological contribution by integrating high-performance ML models with interpretable frameworks such as SHAPs within the context of sustainability analytics. This integration not only enhances predictive accuracy but also enables the identification of hidden structural patterns, particularly in instances where emission responses deviate from assumed symmetry across vehicle attributes or powertrain types. These insights help bridge the gap between algorithmic precision and policy relevance. Policymakers, urban planners, and vehicle manufacturers can apply the findings to prioritize vehicle categories and design specifications that yield the most substantial emission reductions.
In addition, this study emphasizes the value of publicly accessible vehicle registration and emissions datasets as a foundation for evidence-based environmental policymaking. In contexts such as Spain, where climate targets are evolving rapidly, the incorporation of ML into national monitoring systems can enhance both the granularity and responsiveness of transport policies. By uncovering asymmetries and hidden structures within emission data, these analytical tools support more targeted interventions that align with the real-world behavior of vehicles.
In comparison to the existing literature, this study contributes new knowledge in three key areas. First, it combines explainable ML techniques with symmetry-aware analysis to reveal nonlinear and often overlooked emission behaviors. Second, it differentiates emission responses across various hybrid vehicle subtypes, drawing attention to policy-relevant distinctions between plug-in and diesel hybrid systems. Third, it introduces a replicable and scalable modeling framework based on publicly available data, thereby facilitating the translation of interpretable model outputs into actionable transport policy recommendations. These innovations contribute to the broader literature on sustainable transportation and emission modeling, with implications for both academic research and environmental governance.
The remainder of this paper is structured as follows.
Section 2 reviews the relevant literature on symmetry-aware emissions modeling and ML applications in sustainable transport.
Section 3 describes the dataset, variable selection, and data preprocessing procedures.
Section 4 presents the modeling methodology, including the selected algorithms and the SHAP-based interpretation framework.
Section 5 discusses empirical results and identifies key drivers of emissions across vehicle categories.
Section 6 outlines policy implications and reflects on the observed asymmetries in emission behavior. Finally,
Section 7 concludes the paper.
3. Data and Variables
3.1. Data Collection
The dataset utilized in this study contains detailed information on fuel consumption and CO
2 emissions for new vehicles registered in Spain as of July 2022. Published by the Spanish government’s IDAE, this dataset aims to enable consumers to compare vehicle fuel efficiency and emissions. The dataset comprises 15,753 observations across 24 variables and is publicly available on the Spanish government’s official website.
Table 2 provides a detailed list of the variables:
3.2. Data Exploration and Pre-Processing
Initial data exploration was conducted using descriptive statistics, correlation analysis, and visual inspection to identify potential anomalies, multicollinearity, and structural issues in the dataset. Several steps were made during the pre-processing phase to ensure model robustness and interpretability.
First, vehicles labeled as “Pure electric” were excluded from the analysis, as their operational CO2 emissions are zero and including them would skew the distribution of the emission variable. Next, features that were either irrelevant to the prediction target or posed risks of data leakage were removed. For example, “max_wltp_emissions_gCO2_km” and “min_wltp_emissions_gCO2_km” were excluded, because they are strongly correlated with the target variable “avg_wltp_emissions_gCO2_km” and including them would compromise model validity by introducing circularity.
Variables with excessive missing data (greater than 80%), such as “ev_motor_kW” (electric motor power) and “ev_range_km” (battery range), were also excluded. The high proportion of missing values made reliable imputation unfeasible, and their inclusion would have introduced instability into the training process. The final feature set was selected to balance information richness with data completeness and model integrity.
Moreover, the original dataset included numerous categorical features in string format, which were transformed into binary variables using one-hot encoding. This encoding approach preserved the nominal nature of the categories, avoided introducing artificial ordinal relationships, and ensured compatibility with the ML models used in this study.
3.3. Dataset Partitioning and Feature Engineering
Due to inherent differences in emission profiles between traditional fuel-powered vehicles and NEVs, the dataset was divided into two subsets for targeted analysis: traditional fuel vehicles (Dataset 1) and NEVs (Dataset 2).
Each subset was partitioned into training (80%) and testing (20%) datasets. The training sets facilitated model development by enabling pattern recognition, while the test sets assessed model predictive performance on unseen data, minimizing overfitting risks.
Feature engineering processes included scaling related emission metrics such as “consumption_min_l_100 km”, “consumption_max_l_100 km”, and “avg_wltp_consumption_l_100 km” to mitigate undue influence on model outcomes. Additionally, redundant or irrelevant variables—such as “power_electric_kW” for diesel or petrol vehicles—were systematically excluded to enhance model relevance and efficiency.
Appendix A summarizes key descriptive statistics of selected variables. Notably, the average CO
2 emissions under the WLTP standard were approximately 122 g/km, with a median of 118 g/km. Diesel and petrol engines showed considerable variation in both fuel consumption and emissions. Variables such as vehicle length, weight, and engine displacement also displayed wide ranges, reflecting the wide range of vehicle specifications captured in the dataset.
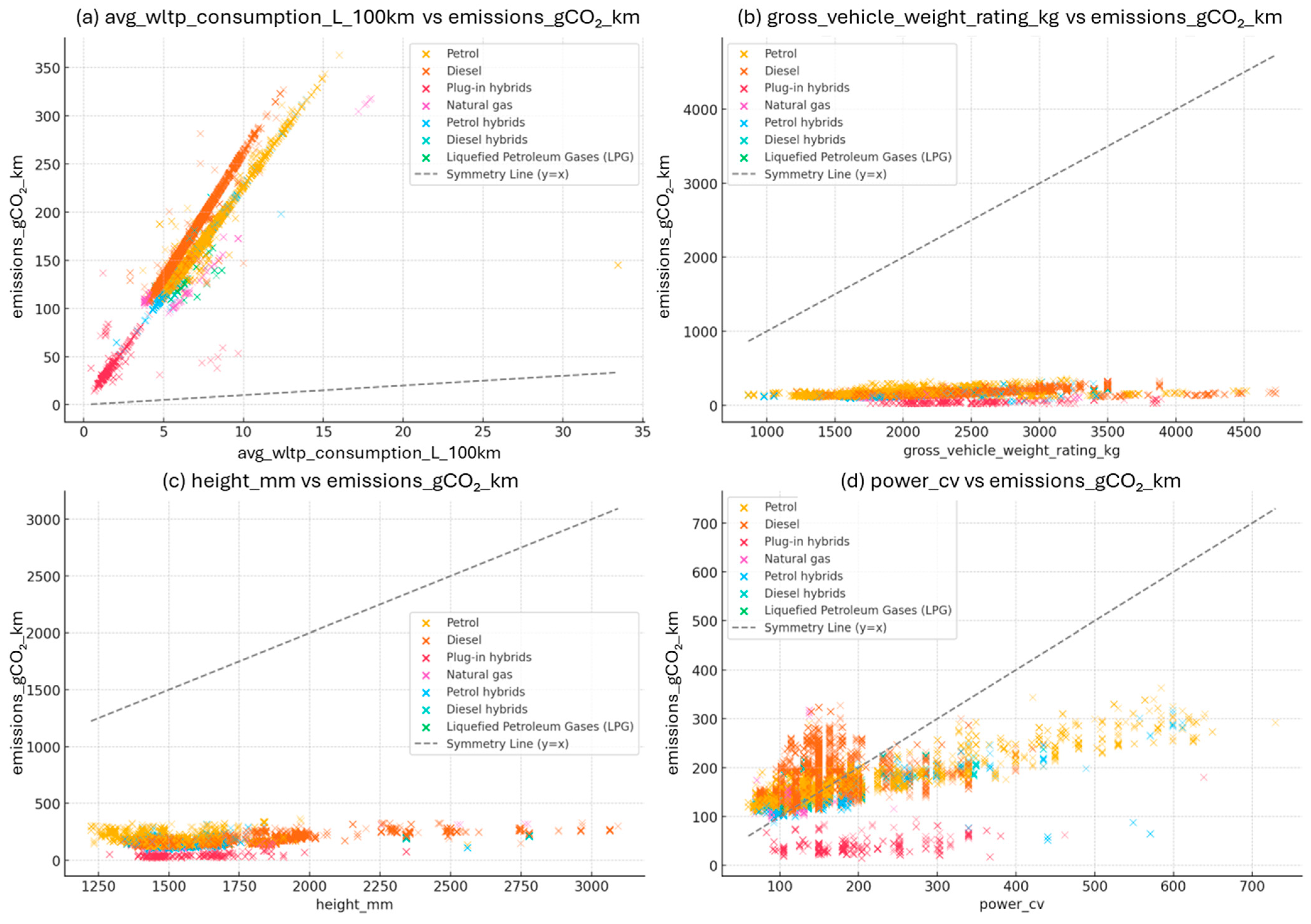
Figure 1 illustrates the associations between selected vehicle attributes and CO
2 emissions, highlighting asymmetric patterns across different engine types. A diagonal reference line (y = x) is included in each subplot to represent hypothetical symmetry; deviations from this line indicate structural or behavioral asymmetries in the underlying data. Panel (a) shows a near-linear correlation between avg_wltp_consumption_l_100 km and emissions; however, the slope and spread varies between petrol and diesel vehicles, implying asymmetric energy conversion efficiencies. Panel (b) reveals that gross vehicle weight rating exerts a nonlinear impact on emissions—vehicles under 1800 kg show limited variation, while heavier vehicles demonstrate a steep increase in emissions, underscoring weight-induced asymmetry. Panel (c) presents vehicle height, where aerodynamic drag effects become increasingly significant beyond 1500 mm, reflecting asymmetrical aerodynamic penalties in taller vehicles. Finally, panel (d) depicts engine power, with asymmetric effects evident across engine categories and power levels; while power generally increases emissions, the rate and magnitude of influence differ notably by engine type.
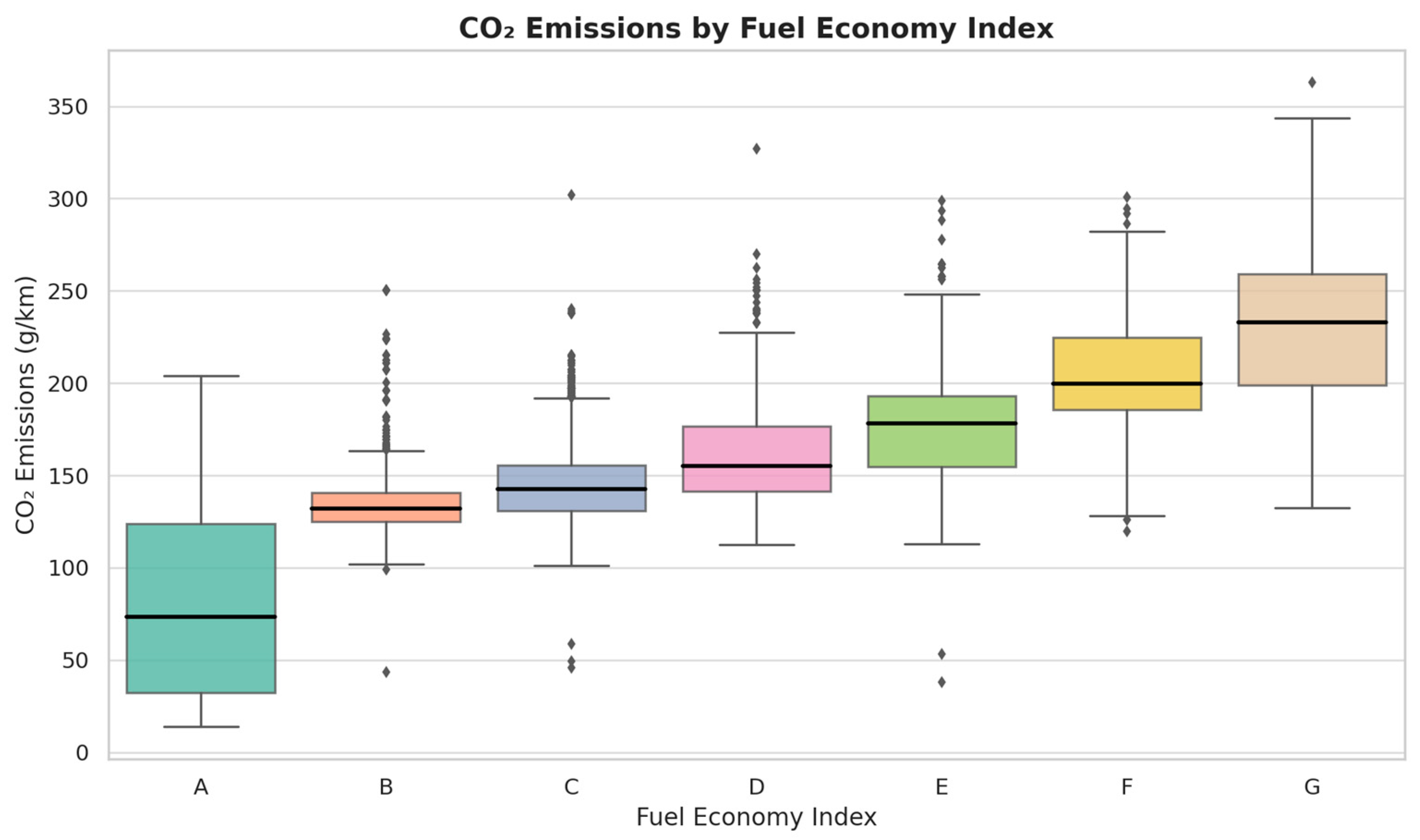
Figure 2 presents the distribution of CO
2 emissions across different fuel economy indices, revealing a form of categorical symmetry. As the rating progresses from A to G, a nearly monotonic increase in median emissions is observed, forming a structurally symmetric profile centered around mid-level categories. This gradient underscores the inverse relationship between fuel efficiency and emissions, supporting the regulatory use of tiered classification systems. Minor asymmetries in dispersion—particularly in extreme categories—highlight the underlying heterogeneity within efficiency classes, inviting further investigation into technological or behavioral factors driving these deviations.
6. Discussion
6.1. Traditional Fuel Vehicles (Dataset 1)
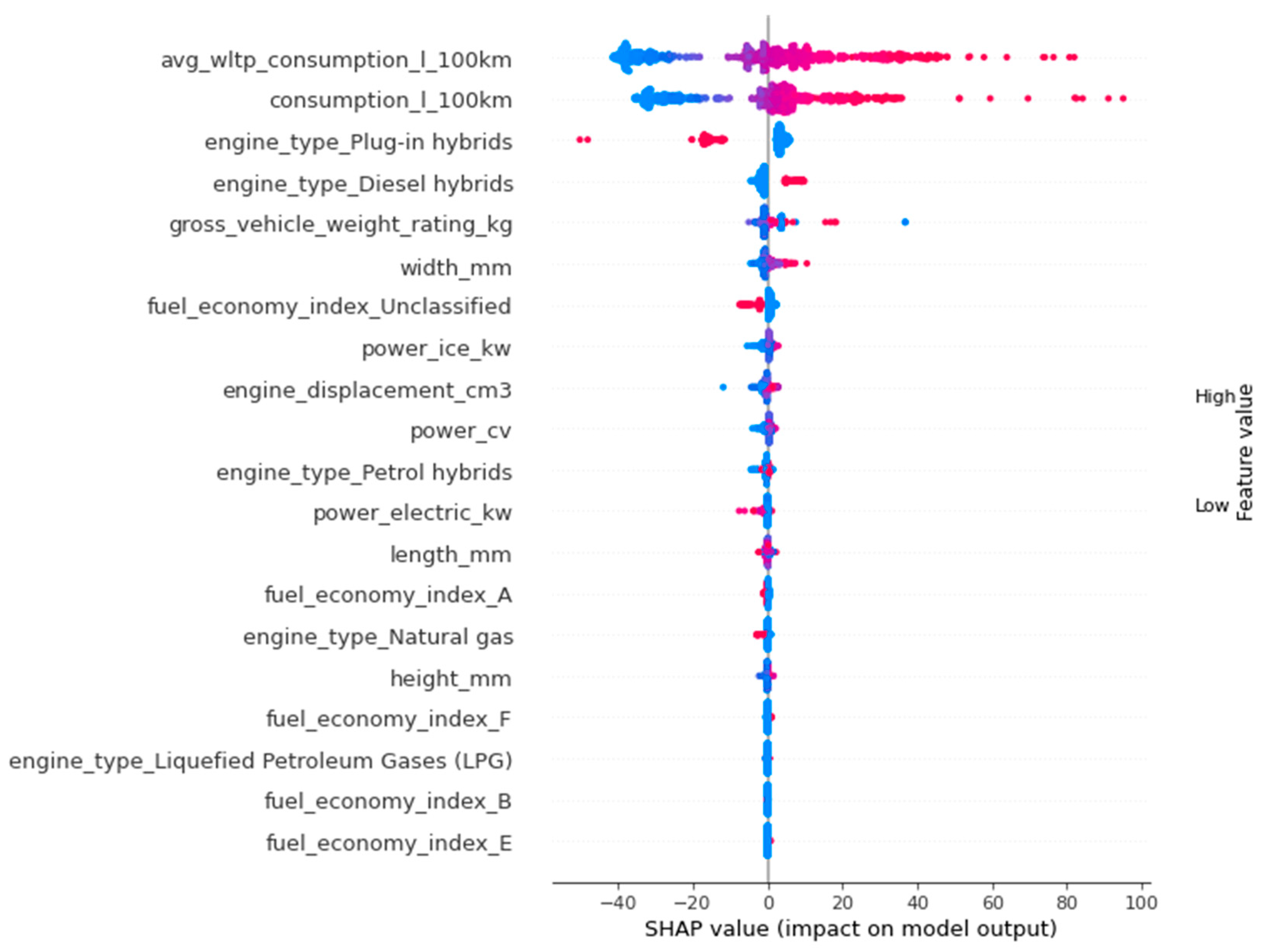
Figure 5 presents SHAP dependence plots for the five most influential features affecting CO
2 emissions in conventional vehicles: consumption_l_100 km, avg_wltp_consumption_l_100 km, engine_type, gross_vehicle_weight_rating_kg (GVWR), and height_mm. These plots offer insights not only into the magnitude of each variable’s contribution but also into its directionality and the presence of nonlinear thresholds. This allows for the identification of structured relationships that may be overlooked by linear models. The emergence of such consistent patterns suggests a relatively symmetric emission response, in which variations in physical attributes result in proportionate and interpretable changes in emission levels.
Fuel consumption per 100 km (consumption_l_100 km) is identified as the most influential predictor. SHAP analysis reveals a distinct breakpoint at approximately 6.5 L/100 km. Below this level, marginal increases in fuel consumption are associated with relatively modest changes in CO2 emissions. However, beyond this point, SHAP values increase sharply, indicating a nonlinear and asymmetric escalation. This threshold likely reflects the compounded inefficiencies present in higher-consumption vehicles. When fuel consumption exceeds 6.5 L/100 km, internal combustion engines tend to operate further from their thermodynamic optimal load, and energy losses due to engine friction, idling, and suboptimal transmission ratios increase disproportionately. Additionally, vehicles in this range often have heavier chassis and less aerodynamic designs, which further elevate CO2 emissions per kilometer. From a regulatory standpoint, this threshold represents a technically grounded inflection point for designing policy instruments. For instance, fuel economy standards or tiered taxation schemes could be structured to increase sharply beyond this level, thereby internalizing the external costs associated with disproportionately high emissions. In contrast to flat thresholds, such an approach more accurately reflects real-world emission behavior and establishes a steeper incentive gradient for efficiency improvements just above the 6.5 L/100 km mark.
Avg_wltp_consumption_l_100 km, which captures standardized fuel use under the WLTP protocol, exhibits a similarly strong and monotonic relationship. As the WLTP test simulates a broad range of driving conditions (e.g., acceleration, idling, and deceleration), this variable serves as a robust proxy for average efficiency. The convergence in SHAP profiles between real-world and standardized consumption measures underscores a structural symmetry in how combustion efficiency translates into carbon output across driving contexts.
The variable engine_type (coded as 0 for diesel and 1 for petrol) provides additional explanatory value. Diesel engines consistently exhibit higher SHAP values, indicating a stronger positive contribution to predicted CO2 emissions. This observation is consistent with engineering evidence: although diesel engines are generally more thermally efficient, they combust fuel with higher carbon density and typically produce greater quantities of CO2, NOx, and PM. While modern diesel vehicles are equipped with after-treatment systems to mitigate these emissions, such technologies are not always sufficient to offset the inherent asymmetries in pollutant output when compared to petrol engines. These findings point to a structural imbalance in emission potential between fuel types, with diesel vehicles exhibiting systematically higher emission contributions.
Gross Vehicle Weight Rating (GVWR) contributes to emissions through its impact on propulsion energy demand. The SHAP plot shows a piecewise effect: below 2500 kg, GVWR has limited influence; beyond this threshold, its contribution increases sharply, indicating a nonlinear amplification of emissions as vehicle mass increases. This effect likely arises from drivetrain inefficiencies, higher rolling resistance and aerodynamic penalties in heavier vehicles. The presence of a distinct threshold again reflects partial symmetry, where structural variables have stable effects up to a point and then diverge.
Height_mm, representing vehicle height, affects emissions through its influence on aerodynamic drag, center of gravity, and suspension design. The SHAP dependence plot shows a general upward trend, with the steepest increase occurring between 1500 mm and 1750 mm. This suggests that this range is particularly critical for aerodynamic inefficiencies. Beyond 2000 mm, SHAP values tend to level off, indicating a saturation effect. This plateau may reflect a diminishing marginal penalty once the vehicle’s shape, load, or function, such as the distinction between SUVs and vans, becomes the dominant factor in aerodynamic performance.
In summary, the SHAP dependence plots reveal a structured and interpretable emissions landscape for conventional vehicles, where most physical and combustion-related features display directionally consistent and often threshold-based effects. This overall symmetry in the relationships between features and emissions supports the application of both linear and ensemble-based machine learning models in this context. It also provides a strong foundation for the development of threshold-sensitive emission policies, eco-design strategies, and targeted public guidance measures.
6.2. Hybrid Vehicles (Dataset 2)
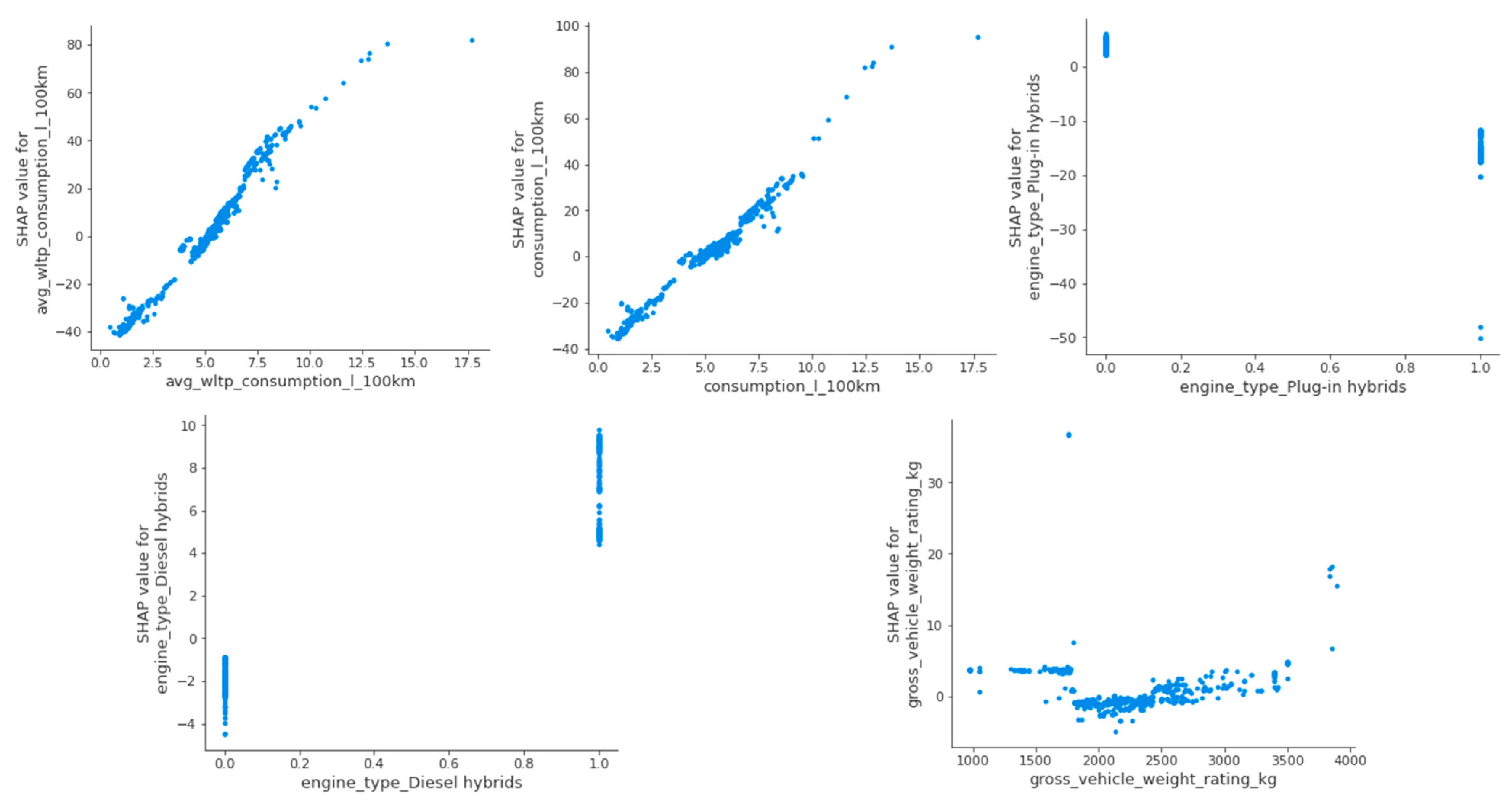
Figure 6 presents SHAP dependence plots for five key variables influencing CO
2 emissions in hybrid and NEVs: avg_wltp_consumption_l_100 km, consumption_l_100 km, engine_type_Plug-in hybrids, engine_type_Diesel hybrids, and gross_vehicle_weight_rating_kg (GVWR). These plots illustrate how electrified powertrains interact with traditional fuel consumption patterns and structural design, revealing notable asymmetries and nonlinearities in emission responses.
Fuel consumption remains the dominant driver of emissions, even in hybrid configurations. Both avg_wltp_consumption_l_100 km and consumption_l_100 km display near-linear and strongly positive SHAP trends, confirming that higher fuel usage results in proportionally greater emissions under both standard and real-world driving conditions. However, in contrast to the case of conventional vehicles, where the SHAP plots indicated a distinct threshold near 6.5 L/100 km, the hybrid vehicle plots exhibit smoother gradients. This suggests a more elastic and less abrupt emission response. The observed pattern reflects the partial substitution effect provided by electric propulsion, which reduces but does not eliminate fuel-based emissions.
The asymmetry between PHEVs and diesel hybrids stems from fundamental differences in powertrain architecture and fuel characteristics. PHEVs are equipped with larger batteries and onboard charging systems, which enable substantial electric-only driving. This feature is particularly effective in urban environments. Their hybrid control strategies are designed to prioritize electric propulsion whenever feasible, often relegating ICE usage to a secondary role. In contrast, most diesel hybrids employ mild or parallel hybrid systems with limited electric range and smaller battery capacities. These vehicles lack plug-in capabilities and rely heavily on the diesel engine, which emits more CO
2 per liter of fuel compared to petrol. Moreover, diesel engines tend to perform inefficiently in stop-and-go traffic conditions, where hybridization offers minimal benefits. These structural and operational limitations account for the higher emissions observed in diesel hybrids relative to PHEVs, despite both being categorized under the general label of “hybrid” vehicles. The findings are consistent with recent studies by Guo et al. (2024) and Alam et al. (2025) and further contribute to the literature by differentiating among hybrid subtypes. This differentiation demonstrates that not all hybrid configurations deliver equivalent environmental benefits [
39,
40].
The SHAP plot for GVWR further supports the observation of conditional asymmetry. For hybrid vehicles weighing less than 1800 kg, vehicle mass exerts minimal influence on CO2 emissions. This suggests that other factors, such as the ratio of battery capacity to engine size and engine control strategies, play a more dominant role. However, beyond this threshold, SHAP values begin to increase, indicating that structural mass becomes more significant in heavier hybrid models. This nonlinear transition points to an inflection zone in which battery expansion and structural reinforcements lead to diminishing returns in emission reduction. This pattern is particularly evident in sport utility vehicles and performance-focused hybrid configurations.
Overall, the SHAP analysis for Dataset 2 reveals a less uniform and more segmented emission landscape compared to traditional fuel vehicles. Fuel consumption remains central, but its effects are moderated by drivetrain design and electric power integration. The divergence in SHAP responses across hybrid types emphasizes the need for drivetrain-aware emission policy, where not all “hybrids” are treated equally. Plug-in hybrids emerge as viable transitional solutions, while diesel hybrids demand closer scrutiny. These findings also reinforce the importance of structural weight management in hybrid vehicle design, especially as energy storage needs increase.
In summary, while conventional vehicles display relatively symmetric and consistent emission responses across key features, hybrid vehicles introduce nonlinearities and asymmetries that challenge the effectiveness of uniform regulatory strategies. These nuanced response patterns highlight the value of explainable machine learning tools in supporting targeted and evidence-based decarbonization pathways for the future of transport systems.
7. Conclusions
This study proposes an interpretable ML framework for predicting CO2 emissions from newly registered vehicles in Spain, incorporating both ICE vehicles and NEVs. Among the five supervised learning algorithms evaluated, ensemble-based models, particularly the Random Forest algorithm, demonstrated the highest levels of predictive accuracy and robustness.
A key contribution of this study is the integration of SHAP to identify asymmetric and threshold-based relationships between vehicle characteristics and CO2 emissions. Fuel consumption emerged as the most dominant and symmetric predictor, with both real-world and standardized measures (consumption_L/100 km and avg_WLTP_consumption_L/100 km) displaying strong positive SHAP responses. Notably, emissions increased disproportionately beyond the 6.5 L/100 km threshold, indicating that regulatory limits on fuel consumption may lead to substantial reductions in emissions.
The results also reveal significant asymmetries across hybrid subtypes. PHEVs consistently exhibited negative SHAP values, confirming their capacity to reduce emissions under typical driving conditions. In contrast, diesel hybrids contributed positively to predicted emissions, suggesting limited environmental benefits despite the presence of hybrid technology. These findings highlight the need for performance-based incentive schemes that account for actual environmental outcomes, rather than relying on technology-neutral classifications.
GVWR exhibited a nonlinear effect on emissions, particularly among hybrid vehicles. While vehicles weighing less than 1800 kg showed relatively stable emission levels, heavier models displayed a clear upward trend. This pattern supports the implementation of weight-sensitive design incentives, such as taxation measures or credits for the use of lightweight materials.
Overall, this study presents a replicable, interpretable, and symmetry-aware approach to vehicle emission modeling. The findings support the development of more nuanced transport policies that move beyond binary classifications, such as ICE versus hybrid, and instead acknowledge the varied emission profiles across different vehicle categories. Tiered emission caps, dynamic registration fees based on predicted emissions, and structurally targeted incentives represent some of the policy instruments that can be informed by this modeling framework.
As countries such as Spain advance toward their 2030 and 2050 climate targets, the application of interpretable artificial intelligence methods in conjunction with high-resolution vehicle-level data offers a promising pathway to bridge the gap between scientific modeling and policy implementation. By capturing both generalizable patterns and asymmetric emission behaviors, this approach contributes meaningfully to sustainable and adaptive transport governance. Beyond national relevance, this research aligns with several United Nations Sustainable Development Goals (SDGs). By enhancing the modeling of vehicle emissions and revealing asymmetric response patterns, the findings support SDG 11 (Sustainable Cities and Communities) through the facilitation of more effective low-emission urban transport planning. The analysis also advances SDG 12 (Responsible Consumption and Production) by enabling better-informed decisions among consumers and manufacturers, grounded in structural efficiency. Most notably, the study supports SDG 13 (Climate Action) by offering policy-relevant insights into targeted decarbonization strategies, particularly through a more nuanced treatment of hybrid vehicle categories and weight-related thresholds. The proposed framework, therefore, serves as a bridge between data-driven innovation and global sustainability objectives.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}