4.1. Datasets and Evaluation Metrics
Building upon and extending the pioneering work of [
26], this study focuses on two critical domains—news and scientific literature—for comprehensive evaluation of RE models. Three representative benchmark datasets were systematically selected for assessment: GDS [
9], SemEval-2010 Task 8 [
10], and KBP37 [
11]. The detailed data statistics are shown in
Table 2.
GDS [
9] dataset is a RE corpus combining manual annotation with distant supervision (DS), constructed through expert fine-grained labeling and knowledge base-aligned web data expansion, with multi-stage filtering to ensure data quality.
SemEval-2010 Task 8 (SemEval) [
10], originally developed for the 2010 International Workshop on Semantic Evaluation, has become a benchmark resource that has significantly advanced the field of RE. This carefully annotated corpus has inspired numerous cutting-edge methodological advances [
19,
20,
23,
24], significantly contributing to the advancement of the field.
KBP37 [
11] dataset is an improved version of the MIML-RE dataset originally introduced by Gabor Angeli et al. [
27]. It was constructed by integrating documents from the 2010 and 2013 KBP evaluations, with additional annotations derived from July 2013 Wikipedia data used as supplementary corpora.
Evaluation Metrics. Consistent with the evaluation protocol used in DILUIE, macro-average and micro-average F1-scores are adopted as the primary evaluation metrics across all three datasets in our experiments. The macro-average F1-score evaluates performance by calculating the F1-score independently for each relation class and then averaging them, which provides a balanced view regardless of class distribution. In contrast, the micro-average F1-score aggregates the contributions of all classes to compute the average performance, thus placing more emphasis on frequent relation types. By reporting both metrics, we aim to provide a comprehensive assessment of model performance across both common and rare relation types.
4.2. Experimental Settings
To comprehensively evaluate the performance of language models with different scales on the relation extraction task, two representative variants from the Qwen2.5 series, namely Qwen2.5-3B-Instruct and Qwen2.5-7B-Instruct, were selected as the base models for experimentation. All experiments were conducted on a single NVIDIA A100 GPU server with 40 GB of memory.
The hyperparameters were kept consistent across all three datasets. Detailed parameter settings during the training process are provided, which were largely aligned with those reported in [
28]. To ensure optimal performance on datasets of varying sizes, the number of training epochs and the checkpoint-saving intervals were adjusted accordingly.
In the direct inference stage, the design of the prompt templates played a crucial role, as it directly influenced the model’s understanding of the task and the quality of the inferred results. A general prompt template was carefully designed and is detailed in
Table 3. In our inference experiments, two types of prompts were used for comparison. The primary distinction between them lies in the inclusion or exclusion of relational descriptions. Specifically, the first prompt only contained a basic task instruction along with the input data, aiming to guide the model in performing relation extraction purely based on the textual input. In contrast, the second prompt extended the first by incorporating additional relational description information. This setup was intended to investigate the impact of explicit relation descriptions on the model’s reasoning ability. By comparing the outputs generated under the two different prompt settings, insights were gained into the role of relation descriptions in enhancing extraction performance, thereby providing guidance for future prompt engineering efforts.
During the fine-tuning stage, the design of direct tuning templates plays a critical role in enhancing model performance. Taking the GDS dataset as a case study, a dedicated direct fine-tuning template was designed, as shown in
Table 4. This template includes specific formatting requirements for the input data, explicit task instructions, and the expected format of the output. Such a standardized template design allows the model to better capture the relational patterns and features embedded within the GDS dataset during training. The model processes input data in accordance with the defined template and progressively updates its parameters to improve its performance on the relation extraction task. Moreover, the adoption of a unified fine-tuning template contributes to the reproducibility and comparability of experiments, enabling consistent evaluations across varying experimental settings and facilitating reliable comparative analyses.
4.4. Experimental Results Analysis of Relation Label Refinement Strategy
In this section, a thorough analysis of the experimental results of large language models on the relation extraction task is presented. Using the GDS dataset as a case study, we conducted experiments based on standardized prompt templates, comparing model performance with and without relation label correction. The results are shown in
Table 5.
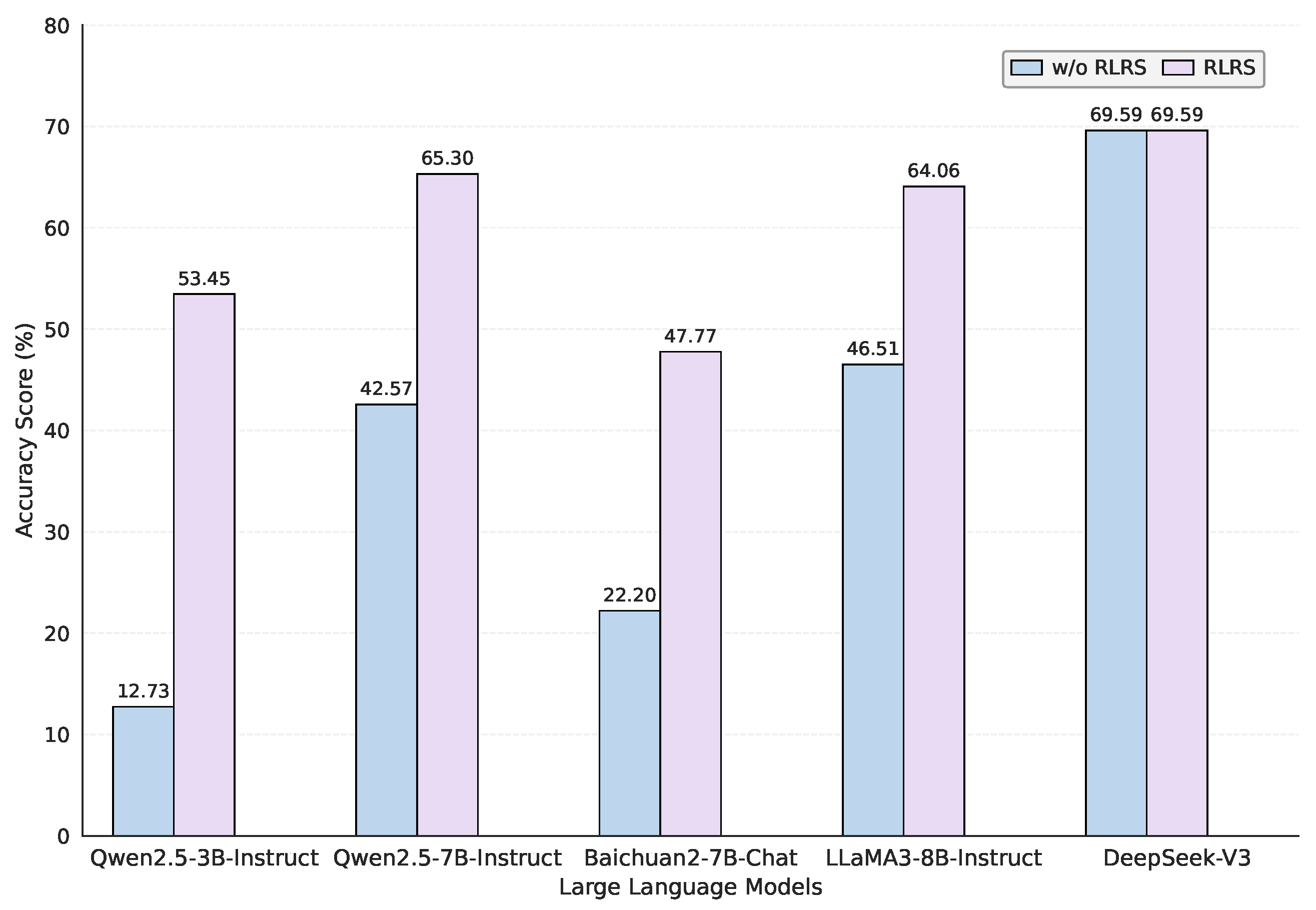
Several key findings can be drawn from these results: Model performance without correction is highly correlated with model size. In the absence of relation label correction, a clear correlation between the number of model parameters and prediction accuracy was observed. Generally, models with fewer parameters exhibited poorer performance. This trend was particularly evident within the same model family. For instance, the Qwen2.5-7B-Instruct model achieved 29.84% higher accuracy than its smaller counterpart, Qwen2.5-3B-Instruct, indicating that increasing parameter size within a reasonable range can substantially enhance relation extraction capabilities.
The Baichuan2-7B-Chat model underperformed compared to peers. Notably, the Baichuan2-7B-Chat model demonstrated weaker performance than other models of similar scale. Further analysis suggests that the predictions of this model may have been affected by significant noise fluctuations, resulting in instability during evaluation and ultimately impairing its overall accuracy.
Relation label refinement significantly improves model performance. After applying RLRS, all models exhibited consistent improvements in prediction accuracy. For example, the Qwen2.5-3B-Instruct model achieved an accuracy gain of approximately 40.72%. This substantial increase strongly supports the effectiveness of the proposed correction strategy, which helps rectify errors in model outputs, leading to more reliable results in practical applications.
DeepSeek-V3 model performance and comparative analysis. The DeepSeek-V3 model, with a total parameter count of 671 billion, achieved the highest accuracy across all experiments. Interestingly, this model showed little difference in performance between corrected and uncorrected outputs. This can be attributed to its large parameter scale, which endows it with a strong capacity to understand task-specific semantics, thereby diminishing the marginal benefit of correction.
However, the computational cost of such a large model must also be considered. Due to its size, DeepSeek-V3 requires significantly more inference time than smaller models. To illustrate this, we compared the prediction accuracy and inference latency of Qwen2.5-7B-Instruct and DeepSeek-V3 under the corrected condition, as shown in
Table 6. Although Qwen2.5-7B-Instruct exhibited a 4.29% lower accuracy than DeepSeek-V3, its inference speed was several times faster, offering a compelling trade-off between performance and efficiency.
Based on the above experimental results, it can be concluded that, in practical application scenarios where time efficiency and computational resources are limited, smaller models can be effectively optimized through techniques such as relation label correction. Although the performance of smaller models may be relatively weak without correction, their predictive accuracy can be significantly improved through well-designed correction strategies. Moreover, their faster inference speed can better meet the real-world requirements for time-sensitive applications. Therefore, it is advisable to select models and optimization strategies according to specific needs and resource constraints in order to achieve efficient and accurate RE.
Building upon the relation label correction strategy, relation descriptions were further introduced and evaluated on the GDS, SemEval, and KBP37 datasets. The corresponding results are presented in
Table 7. A thorough analysis of these results leads to the following findings:
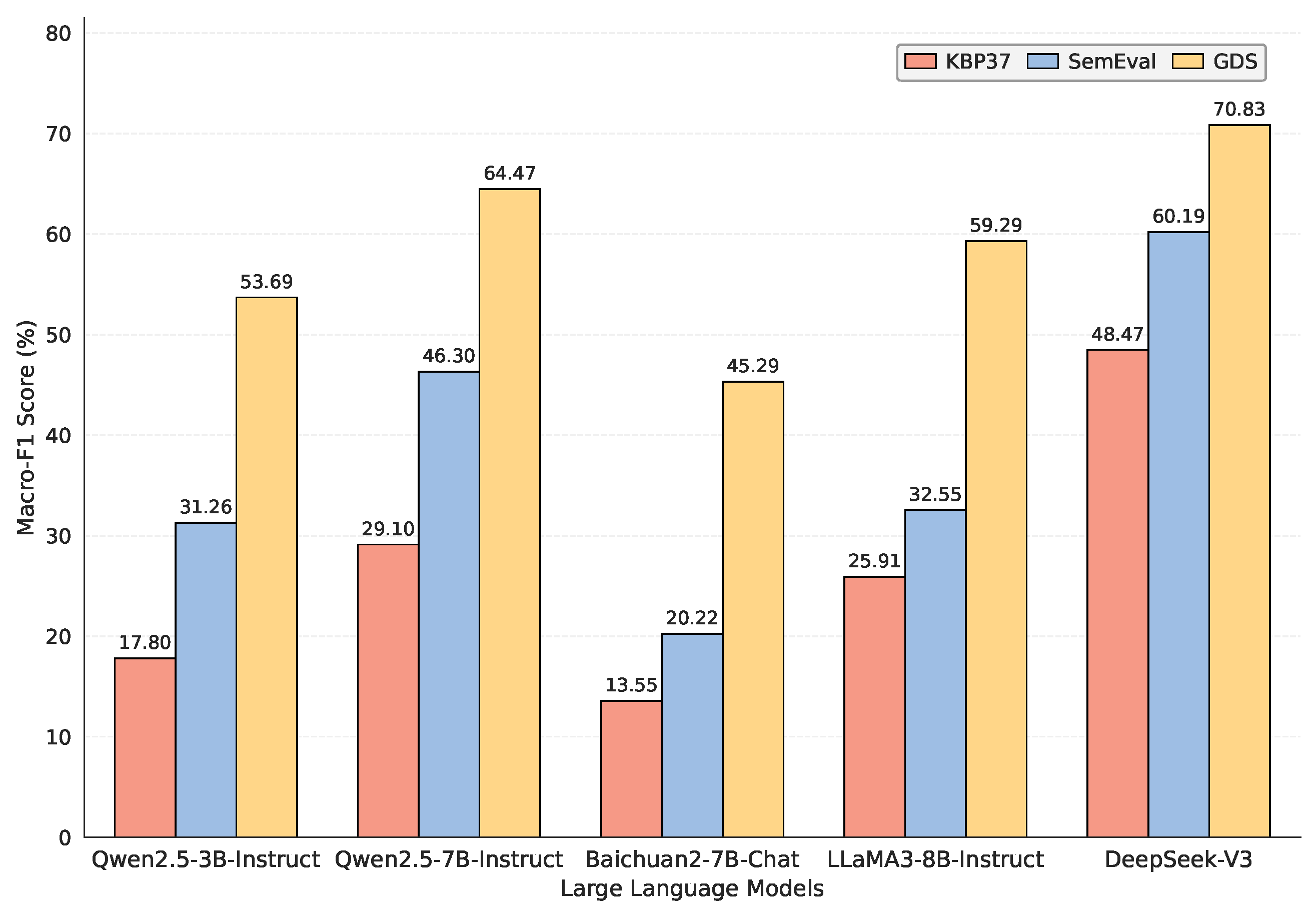
Impact of Relation Descriptions on Model Performance. The incorporation of relation descriptions generally led to performance improvements across all three datasets. For instance, the F1-scores of the Qwen2.5-7B-Instruct model increased by 1.57%, 11.45%, and 1.39% on GDS, SemEval, and KBP37, respectively. Similarly, the Qwen2.5-3B-Instruct model exhibited F1-score improvements of 1.19% and 7.73% on GDS and SemEval, respectively. However, on KBP37, the F1-score of the Qwen2.5-3B-Instruct model dropped slightly from 17.80% to 16.09%, possibly due to the limited model capacity and the resulting susceptibility to noise during prediction. Comparable fluctuations were also observed with Baichuan2-7B-Chat and LLaMA3-8B-Instruct on KBP37, which may be attributed to their limited compatibility with structured relation prompts. These observations indicate that while model size is an important factor, the integration of relation descriptions can enhance relation extraction performance in most cases.
Comparison of Models with Similar Parameter Scales. Under the condition of incorporating relation descriptions, a comparative evaluation was conducted among models with similar parameter sizes, including Baichuan2-7B-Chat, LLaMA3-8B-Instruct, and Qwen2.5-7B-Instruct. The Qwen2.5-7B-Instruct model outperformed Baichuan2-7B-Chat by 18.57%, 52.06%, and 24.74% on the GDS, SemEval, and KBP37 datasets, respectively. Compared with LLaMA3-8B-Instruct, Qwen2.5-7B-Instruct achieved improvements of 4.09%, 11.32%, and 7.68% on the same datasets. These results demonstrate that the Qwen2.5-7B-Instruct model possesses superior capability in understanding and extracting relations.
Balancing Performance and Cost. Although DeepSeek-V3 achieved the best performance across all three datasets, its large parameter scale leads to significantly higher inference latency. Thus, relation label correction strategies and prompt engineering techniques are preferred for smaller models to compensate for their limited reasoning capacity. These findings suggest that architectural design choices may outweigh the benefits of sheer model size. In practice, it is essential to strike a balance between performance and computational cost by selecting suitable models and optimization strategies.
4.5. Overall Advantages and Dataset-Specific Analysis
While considerable performance gains were achieved through correction strategies and prompt optimizations, there remains room for further improvement. To this end, the CARME framework was proposed and applied to the GDS, SemEval, and KBP37 datasets. The results, shown in
Table 8, consistently demonstrate that the CARME framework achieves performance gains over existing baselines. Specifically, the CRE-LLM results were re-implemented using the Qwen2.5-7B-Instruct model, while CARME
3B and CARME
7B refer to models fine-tuned on Qwen2.5-3B and Qwen2.5-7B-Instruct, respectively. Based on the results reported in
Table 8, further insights into the model improvements can be drawn.
Superior Overall Performance.
The CARME7B model achieved state-of-the-art performance, obtaining the highest macro-average F1-scores of 87.12%, 88.51%, and 71.49% on the GDS, SemEval, and KBP37 datasets, respectively. Similarly, the highest micro-average F1-scores of 85.91%, 87.45%, and 69.31% were attained on the same datasets. Notably, in comparison to the previous best-performing baseline, CRE-LLM, macro-average F1-scores improved by 5.59%, 1.81%, and 1.17% across the three datasets. Corresponding micro-average F1-score improvements were 5.46%, 1.70%, and 1.06%. These results clearly demonstrate that the proposed model outperformed existing methods in relation extraction tasks.
Datasets-Specific Improvements.
GDS Dataset: Both variants of the CARME framework significantly outperformed the previous best results reported by DILUIE. Specifically, CARME7B yielded an increase of 2.95 percentage points in both macro- and micro-average F1-scores, indicating the effectiveness of the CARME framework in capturing relation patterns specific to the GDS dataset.
SemEval Dataset: On top of the strong baseline performance of CRE-LLM, CARME7B further improved micro- and macro-average F1-scores by 1.70% and 1.81%, respectively. This demonstrates the CARME framework’s ability to consistently enhance model performance and improve extraction accuracy on the SemEval dataset.
KBP37 Dataset: On the challenging KBP37 dataset, CARME7B established a new performance benchmark with a macro-average F1-score of 71.49%, representing a 1.17% gain over CRE-LLM. This highlights the robustness and effectiveness of the CARME framework in handling complex datasets.
Architectural Advantages. Despite the trainable parameters accounting for less than 0.0331% of the full model parameters (e.g., in Qwen2.5-7B-Instruct), a significant performance improvement was achieved after integrating both document-level and sentence-level contextual enhancement signals. The performance improvements achieved by the CARME framework can be attributed to the following key factors:
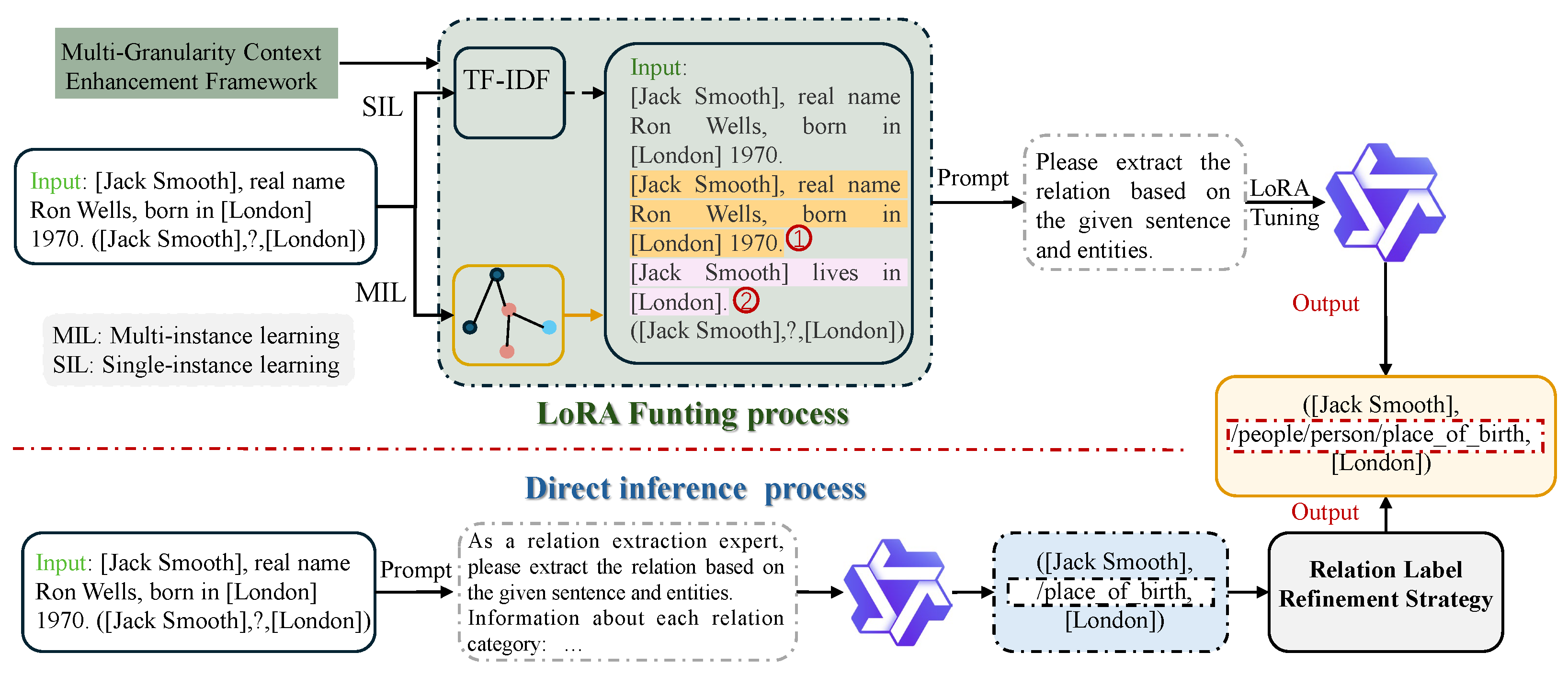
Multi-Granularity and Multi-Level Context Modeling: By integrating document-level features via GraphRAG and sentence-level signals via TF-IDF, the framework captures both local and global relation patterns, thereby providing richer contextual information for relation extraction.
Dynamic Relation Correction: The proposed label refinement strategy effectively addresses noise in the initial predictions of LLMs, thereby improving the overall accuracy of relation extraction.
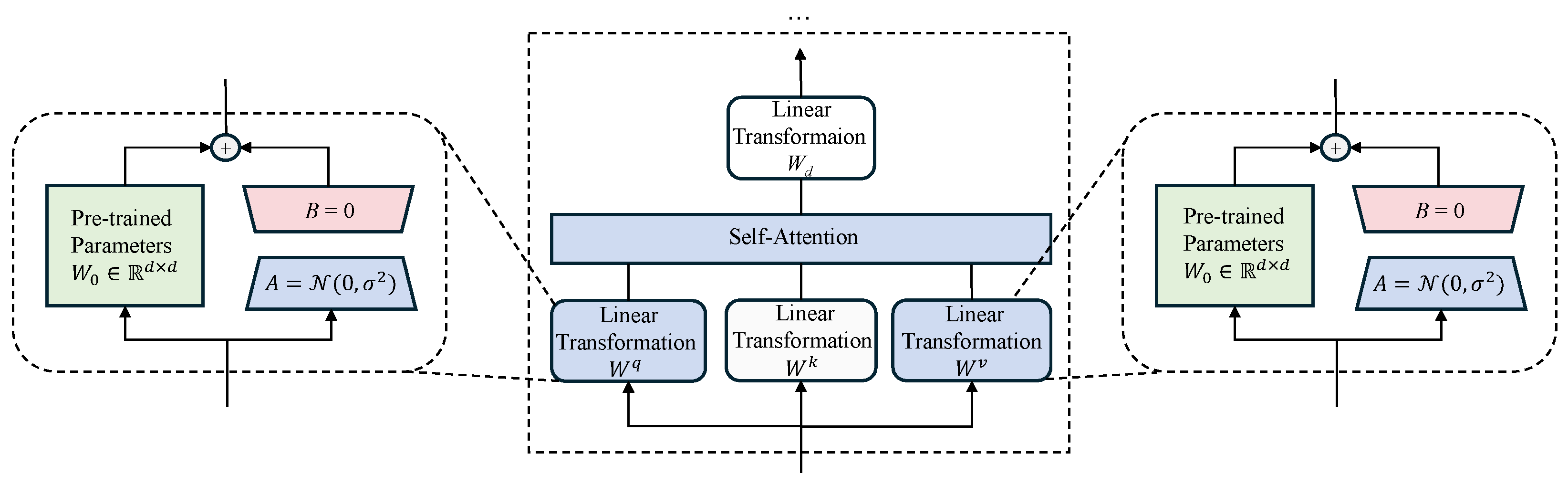
Parameter-Efficient Adaptation: Leveraging the LoRA fine-tuning technique enables the optimization of relation extraction performance while preserving the knowledge encoded in pre-trained models, making it feasible to achieve high performance under limited computational resources.
Despite utilizing 57% fewer parameters compared to CARME7B, the CARME3B model delivered comparable performance, with only a 1.9% difference in F1-score. Both CARME variants demonstrated particularly strong performance on GDS for complex, long-range relations, with an average improvement of 6.3% over the baseline. These findings suggest that in practical applications, appropriate CARME variants can be selected based on resource availability and performance requirements to achieve a balance between efficiency and effectiveness.
4.6. Analysis of Differences in Experimental Results
Following the overall performance evaluation of the model, a more detailed analysis was conducted on the precision, recall, and F1-score across different relation categories within the GDS, SemEval, and KBP37 datasets. The results of this analysis are presented in
Table 9,
Table 10,
Table 11, respectively. By examining the model’s performance on individual relation types, we aim to obtain a more comprehensive understanding of its behavior and identify areas that may benefit from targeted optimization.
GDS Dataset. As shown in
Table 9, the model exhibited considerable variation in precision across different relation types within the GDS dataset. For instance, the relation
/people/deceased_person/place_of_death achieved a precision of 86.66%, a recall of 91.44%, and an F1-score of 88.98%, indicating strong performance in identifying this type of relation. In contrast, the
/education/education/institution relation attained slightly lower values, with a precision of 83.79%, recall of 87.11%, and F1-score of 85.42%, though still within an acceptable performance range. However, for the unknown relation type
NA, the model yielded a precision of only 74.10%, a recall of 66.45%, and an F1-score of 70.06%, which were substantially lower than those of the well-defined relation categories.
SemEval Dataset. A similar trend was observed in the SemEval dataset, as illustrated in
Table 10. Among all relation types,
Cause-Effect demonstrated the highest performance, with a precision of 95.96%, recall of 94.21%, and F1-score of 95.08%, suggesting that the model was particularly effective at recognizing this type of relation. In contrast, the
Other category, which encompasses a broad range of ambiguous or less-defined relationships, exhibited significantly lower performance, with a precision of 71.66%, recall of 67.40%, and F1-score of 69.47%. These results highlight the model’s limited capacity to handle vague or heterogeneous relation types.
KBP37 Dataset. The performance distribution across relation categories in the KBP37 dataset, shown in
Table 11, followed a comparable pattern. The
title_of_person relation achieved strong results, with a precision of 95.20%, recall of 86.86%, and F1-score of 90.84%, indicating reliable recognition by the model. Conversely, for the
NA relation, the model attained only 57.23% precision, 42.48% recall, and 48.77% F1-score, demonstrating significant performance degradation compared to the defined relations.
Based on the above analysis across all three datasets, it is evident that the CARME model consistently performs worse on unknown or ambiguous relation types, such as NA in GDS and KBP37, or Other in SemEval. The presence of such relation categories increases the complexity and uncertainty of the RE task. The model’s low accuracy on these types may adversely affect the overall extraction performance and limit its generalization and practical applicability.
Therefore, improving the model’s capability to identify unknown relation types remains a key direction for future work. Several potential strategies can be explored, such as enhancing the model architecture to better capture uncertainty and ambiguity, incorporating richer contextual information to facilitate deeper semantic understanding, or employing transfer learning techniques to leverage knowledge from related tasks. Through these efforts, it is expected that the model’s performance on unknown relations can be significantly improved, thereby boosting the overall effectiveness of RE systems in real-world applications.
As shown in
Table 8, the multi-granularity and multi-level context enhancement module proposed in this study demonstrates significant effectiveness on distant supervision datasets. A preliminary analysis of the GDS dataset reveals (as shown in
Table 12) that approximately 70% of the test instances benefit from the rich contextual information provided by GraphRAG, which contributes significantly to the observed performance improvements.
Ablation experiments conducted on the Qwen2.5-7B-Instruct model show that removing the two types of contexts constructed by GraphRAG and TF-IDF results in a decrease in the experimental performance of the GDS dataset by 4.72% and 0.83%, respectively. However, the improvements on the SemEval and KBP37 datasets are not as significant as those on GDS, this can primarily be attributed to two factors: first, the higher proportion of single-instance samples reduces the effectiveness of context modeling, as shown in the table above; and second, the relatively smaller test set size may introduce greater variability in the evaluation results. These findings suggest that our method is particularly suitable for datasets like GDS, which are derived from distant supervision and contain rich multi-instance structures.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}